‘AI scaling’ directory
- See Also
- Gwern
- “Dwarkesh Patel Interview”, Gwern & Patel 2024
- “Anonymous Writer Who Predicted AI Trajectory on $12K⧸year Salary; Legacy & Anonymity in the Age of AGI [Video]”, Patel et al 2024
- “Model Collapse Won’t Happen”, Gwern 2022
- “Scaling Image Generation Will Work”, Gwern 2022
- “WBE and DRL: a Middle Way of Imitation Learning”, Gwern 2018
- “30 Questions for Hans Moravec”, Gwern et al 2026
- “Gwern Visits BAIR”, Liu & Gwern 2025
- “AI Cannibalism Can Be Good”, Gwern 2025
- “Absolute Unit NNs: Regression-Based MLPs for Everything”, Gwern 2023
- “Is OpenAI OK?”, Gwern 2024
- “‘Winning’ AI Arms Races: Then What?”, Gwern 2024
- “Scaling ‘Diminishing Returns’”, Gwern 2024
- “Research Ideas”, Gwern 2017
- “GPT-3 Creative Fiction”, Gwern 2020
- “GANs Didn’t Fail, They Were Abandoned”, Gwern 2022
- “The Scaling Hypothesis”, Gwern 2020
- “ML Scaling Subreddit”, Gwern 2020
- “Computer Optimization: Your Computer Is Faster Than You Think”, Gwern 2021
- “Technology Forecasting: The Garden of Forking Paths”, Gwern 2014
- Links
- “Estimating No-CoT Task-Completion Time Horizons of Frontier AI Models [3-Minute-Long Problems With P=0.5]”, Woodruff et al 2026
- “Programmer Science Fiction: My Case for a New Sub-Genre”, Oates 2026
- industriaalist @ "2026-06-04"
- “Q0: Primitives for Hyper-Epoch Pretraining”, Mandal et al 2026
- “Searching for Amanda Askell With Chinese Characteristics: If You Love Claude so Much, Why Don't You Hire a Philosopher?”, Caithrin 2026
- “Negation Neglect: When Models Fail to Learn Negations in Training”, Mayne et al 2026
- “Vision Banana: Image Generators Are Generalist Vision Learners”, Gabeur et al 2026
- “Steering Might Stop Working Soon”, Babcock 2026
- “Introducing
talkie: a 13b-Parameter Vintage Language Model from 1930”, Levine et al 2026 - “My Hobby: Running Deranged Surveys; You Can Just Ask People Things”, Gao 2026
- “MDM-Prime-V2: Binary Encoding and Index Shuffling Enable Compute-Optimal Scaling of Diffusion Language Models”, Chao et al 2026
- “Elon Musk Pushes out More XAI Founders As AI Coding Effort Falters: Tesla and SpaceX Managers Sent in to Review Work As Billionaire’s Start-Up Struggles to Keep pace With Rivals”, Morris & Criddle 2026
- “Neural Thickets: Diverse Task Experts Are Dense Around Pretrained Weights”, Gan & Isola 2026
- “Against Time-Series Foundation Models; Or: My Experience in Modern Forecasting”, shako 2026
- “Revisiting the Platonic Representation Hypothesis: An Aristotelian View”, Gröger et al 2026
- “AI Researchers’ Views on Automating AI R&D and Intelligence Explosions”, Field et al 2026
- “Elon Musk Suggests Spate of XAI Exits Have Been Push, Not Pull”
- “What Happened With Cotra’s Bio Anchors?”, Alexander 2026
- “Weight-Sparse Circuits May Be Interpretable Yet Unfaithful”, Drori 2026
- “Reflections on 2025: The Compute Theory of Everything, Grading the Homework of a Minor Deity, and the Acoustic Preferences of Atlantic Salmon [Learning to Feel the AGI]”, Albanie 2025
- “2025 Letter: Compute, Inevitability, 2nd-Order Effects, Travel Tips, Andor & Isaiah Berlin [Learning to Feel the AGI]”, Wang 2025
- “Shared Sensitivity to Data Distribution during Learning in Humans and Transformer Networks”, Lerousseau & Summerfield 2025
- “2025 LLM Year in Review”, Karpathy 2025
- “Universally Converging Representations of Matter Across Scientific Foundation Models”, Edamadaka et al 2025
- “Perch 2.0 Transfers ‘Whale’ to Underwater Tasks”, Burns et al 2025
- “The Price of Progress: Algorithmic Efficiency and the Falling Cost of AI Inference”, Gundlach et al 2025
- “Weight-Sparse Transformers Have Interpretable Circuits”, Gao et al 2025
- “Scaling Recommender Transformers to a Billion Parameters: How to Implement a New Generation of Transformer Recommenders”, Кhrylchenko 2025
- “The Coverage Principle: How Pre-Training Enables Post-Training”, Chen et al 2025
- “Scaling Laws for Code: A More Data-Hungry Regime”, Luo et al 2025
- “Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity”, Zhang et al 2025
- “Pre-Training under Infinite Compute”, Kim et al 2025
- “‘I Have to Do It’: Why One of the World’s Most Brilliant AI Scientists Left the US for China”, Che 2025
- “How Does A Blind Model See The Earth? A Tiny LLM Eval With Pretty Pictures”, Henry 2025
- “GPT-5 Is Here: Our Smartest, Fastest, and Most Useful Model Yet, With Thinking Built In. Available to Everyone”, OpenAI 2025
- “Perch 2.0: The Bittern Lesson for Bioacoustics”, Merriënboer et al 2025
- “The Making Of Dario Amodei: AI’s Most Outspoken Leader Found Direction in a Personal Tragedy”, Kantrowitz 2025
- “Scaling Recommender Transformers to One Billion Parameters”, Khrylchenko et al 2025
- “How Many Instructions Can LLMs Follow at Once?”, Jaroslawicz et al 2025
- “Cloudflare Will Now Block AI Bots from Crawling Its Clients’ Websites by Default: The Company Will Also Introduce a ‘Pay-Per-Crawl’ System to Give Users More Fine-Grained Control over How AI Companies Can Access Their Sites”, Hall 2025
- “Performance Prediction for Large Systems via Text-To-Text Regression”, Akhauri et al 2025
- “The Bitter Lesson Is Coming for Tokenization: a World of LLMs without Tokenization Is Desirable and Increasingly Possible”, Perić 2025
- “Q1 AI Benchmarking Results: the Most Important Factor for Good Forecasting Is the Base Model”, Wilson 2025
- “Common Corpus: The Largest Collection of Ethical Data for LLM Pre-Training”, Langlais et al 2025
- “Why I Don’t Think AGI Is Right around the Corner: Continual Learning Is a Huge Bottleneck”, Patel 2025
- “What We Learned from Briefing 70+ Lawmakers on the Threat from AI”, Martínez 2025
- “Gen2seg: Generative Models Enable Generalizable Instance Segmentation”, Khangaonkar & Pirsiavash 2025
- “Vec2vec: Harnessing the Universal Geometry of Embeddings”, Jha et al 2025
- “Neural Thermodynamic Laws for Large Language Model Training”, Liu et al 2025
- “Xi Takes an AI Masterclass: Inside the Politburo’s AI Study Session”, Schneider 2025
- “How To Scale: Model Size, Parameterization, HP Scaling Laws, Batch Size”, Seo 2025
- “Psychometrically Derived 60-Question Benchmarks: Substantial Efficiencies and the Possibility of Human-AI Comparisons”, Gignac & Ilić 2025
- “When ChatGPT Broke an Entire Field: An Oral History”, Pavlus 2025
- “Testing the Limit of Atmospheric Predictability With a Machine Learning Weather Model”, Vonich & Hakim 2025
- “Safety Pretraining: Toward the Next Generation of Safe AI”, Maini et al 2025
- “Pre-Training Isn’t Dead, It’s Just Resting: GPT-4.5, the Value of RL, and the Economics of Frontier Training”, Chow & Gross-Whitaker 2025
- “Progress Report on a Toy Model Of Memorization”, Brave 2025
- “Cyc: Obituary for the Greatest Monument to Logical AGI”, Liu 2025
- “Emuru: Zero-Shot Styled Text Image Generation, but Make It Autoregressive”, Pippi et al 2025
- “Compute-Optimal LLMs Provably Generalize Better With Scale”, Finzi et al 2025
- “My Thoughts on the Future of ‘AI’”, Carlini 2025
- “Deep Learning Is Not So Mysterious or Different”, Wilson 2025
- “SSI Israel Hires First Senior Researchers”, Gilead 2025
- “Obscure Scientific Facts Benchmark”, Azulay 2025
- “LLaDA: Large Language Diffusion Models”, Nie et al 2025
- tamaybes @ "2025-02-13"
- “Over-Tokenized Transformer: Vocabulary Is Generally Worth Scaling”, Huang et al 2025
- “Do Generative Video Models Learn Physical Principles from Watching Videos?”, Motamed et al 2025
- “Emergent Effects of Scaling on the Functional Hierarchies within Large Language Models”, Foop 2025
- “What’s the Deal With Mid-Training?”, Doria 2025
- “Things We Learned about LLMs in 2024”, Willison 2024
- “2024 Letter [On LLM Benchmarking]”, Wang 2024
- “Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference”, Warner et al 2024
- “Byte Latent Transformer (BLT): Patches Scale Better Than Tokens”, Pagnoni et al 2024
- “Densing Law of LLMs”, Xiao et al 2024
- “Liquid: Language Models Are Scalable and Unified Multi-Modal Generators”, Wu et al 2024
- “PaliGemma 2: A Family of Versatile VLMs for Transfer”, Steiner et al 2024
- “Best-Of-N Jailbreaking”, Hughes et al 2024
- “Drowning in Documents: Consequences of Scaling Reranker Inference”, Jacob et al 2024
- “Medical Adaptation of Large Language and Vision-Language Models: Are We Making Progress?”, Jeong et al 2024
- “Fractal Patterns May Illuminate the Success of Next-Token Prediction”, Alabdulmohsin et al 2024
- “How Far Is Video Generation from World Model: A Physical Law Perspective”, Kang et al 2024
- “Scaling up Masked Diffusion Models on Text”, Nie et al 2024
- “ABBYY’s Bitter Lesson: How Linguists Lost the Last Battle for NLP”, Skorinkin 2024
- “CT Foundation: Taking Medical Imaging Embeddings 3D”, Kiraly & Traverse 2024
- “Inference Scaling for Long-Context Retrieval Augmented Generation”, Yue et al 2024
- “Strategic Insights from Simulation Gaming of AI Race Dynamics”, Gruetzemacher et al 2024
- “How Feature Learning Can Improve Neural Scaling Laws”, Bordelon et al 2024
- “Dwarkesh Podcast Progress Update”, Patel 2024
- “Safetywashing: Do AI Safety Benchmarks Actually Measure Safety Progress?”, Ren et al 2024
- “Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process”, Ye et al 2024
- “Scaling Laws With Vocabulary: Larger Models Deserve Larger Vocabularies”, Tao et al 2024
- “Scaling Law in Neural Data: Non-Invasive Speech Decoding With 175 Hours of EEG Data”, Sato et al 2024
- “Future Events As Backdoor Triggers: Investigating Temporal Vulnerabilities in LLMs”, Price et al 2024
- “Resolving Discrepancies in Compute-Optimal Scaling of Language Models”, Porian et al 2024
- “Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?”, Lee et al 2024
- “Probing the Decision Boundaries of In-Context Learning in Large Language Models”, Zhao et al 2024
- “How Do Large Language Models Acquire Factual Knowledge During Pretraining?”, Chang et al 2024
- “Explore the Limits of Omni-Modal Pretraining at Scale”, Zhang et al 2024
- “Self-Consuming Generative Models With Curated Data Provably Optimize Human Preferences”, Ferbach et al 2024
- “Beyond Model Collapse: Scaling Up With Synthesized Data Requires Reinforcement”, Feng et al 2024
- “AI Couple”, Siegel & Kirkwood 2024
- “Attention As a Hypernetwork”, Schug et al 2024
- “Training Compute-Optimal Protein Language Models”, Cheng et al 2024
- “AI Will Become Mathematicians’ ‘Co-Pilot’: Fields Medalist Terence Tao Explains How Proof Checkers and AI Programs Are Dramatically Changing Mathematics”, Drösser & Tao 2024
- “Regularization Properties of Polynomial Bases”, Shtoff 2024
- “The Scaling Law in Stellar Light Curves”, Pan et al 2024
- “AstroPT: Scaling Large Observation Models for Astronomy”, Smith et al 2024
- “Aurora: A Foundation Model for the Earth System”, Bodnar et al 2024
- “The Platonic Representation Hypothesis”, Huh et al 2024
- “XLSTM: Extended Long Short-Term Memory”, Beck et al 2024
- “Position: Understanding LLMs Requires More Than Statistical Generalization”, Reizinger et al 2024
- “GSM1k: A Careful Examination of Large Language Model Performance on Grade School Arithmetic”, Zhang et al 2024
- “Scaling and Renormalization in High-Dimensional Regression”, Atanasov et al 2024
- “CatLIP: CLIP-Level Visual Recognition Accuracy With 2.7× Faster Pre-Training on Web-Scale Image-Text Data”, Mehta et al 2024
- “Private Attribute Inference from Images With Vision-Language Models”, Tömekçe et al 2024
- “Test-Time Augmentation to Solve ARC”, Cole 2024
- “Compression Represents Intelligence Linearly”, Huang et al 2024
- “Chinchilla Scaling: A Replication Attempt”, Besiroglu et al 2024
- “Scaling (Down) CLIP: A Comprehensive Analysis of Data, Architecture, and Training Strategies”, Li et al 2024
- “Why Do Small Language Models Underperform? Studying Language Model Saturation via the Softmax Bottleneck”, Godey et al 2024
- “Language Imbalance Can Boost Cross-Lingual Generalization”, Schäfer et al 2024
- “CulturalTeaming: AI-Assisted Interactive Red-Teaming for Challenging LLMs’ (Lack Of) Multicultural Knowledge”, Chiu et al 2024
- “Conformer-1: Robust ASR via Large-Scale Semi-Supervised Bootstrapping”, Zhang et al 2024
- “MiniCPM: Unveiling the Potential of Small Language Models With Scalable Training Strategies”, Hu et al 2024
- “Visual Autoregressive Modeling (VAR): Scalable Image Generation via Next-Scale Prediction”, Tian et al 2024
- “The Rationale-Shaped Hole At The Heart Of Forecasting”, dschwarz et al 2024
- “Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data”, Gerstgrasser et al 2024
- “Scaling Laws For Dense Retrieval”, Fang et al 2024
- “Long-Form Factuality in Large Language Models”, Wei et al 2024
- “Mechanistic Design and Scaling of Hybrid Architectures”, Poli et al 2024
- “Data Mixing Laws: Optimizing Data Mixtures by Predicting Language Modeling Performance”, Ye et al 2024
- “8 Google Employees Invented Modern AI. Here’s the Inside Story: They Met by Chance, Got Hooked on an Idea, and Wrote the Transformers Paper—The Most Consequential Tech Breakthrough in Recent History”, Levy 2024
- “Inflection-2.5: Meet the World’s Best Personal AI”, Inflection 2024
- “Revisiting Dynamic Evaluation: Online Adaptation for Large Language Models”, Rannen-Triki et al 2024
- “Actions Speak Louder Than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations (HSTU)”, Zhai et al 2024
- “When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method”, Zhang et al 2024
- “Investigating Continual Pretraining in Large Language Models: Insights and Implications”, Yıldız et al 2024
- “The Era of 1-Bit LLMs: All Large Language Models Are in 1.58 Bits”, Ma et al 2024
- “StructLM: Towards Building Generalist Models for Structured Knowledge Grounding”, Zhuang et al 2024
- “How to Train Data-Efficient LLMs”, Sachdeva et al 2024
- “Weaver: Foundation Models for Creative Writing”, Wang et al 2024
- “Arrows of Time for Large Language Models”, Papadopoulos et al 2024
- “Can AI Assistants Know What They Don’t Know?”, Cheng et al 2024
- “I Am a Strange Dataset: Metalinguistic Tests for Language Models”, Thrush et al 2024
- “The Perceptron Controversy: Connectionism Died in the 1960s from Technical Limits to Scaling, Then Resurrected in the 1980s After Backprop Allowed Scaling. The Minsky–Papert Anti-Scaling Hypothesis Explained, Psychoanalyzed, and Buried”, Liu 2024
- “TF-T2V: A Recipe for Scaling up Text-To-Video Generation With Text-Free Videos”, Wang et al 2023
- “Generative Multimodal Models Are In-Context Learners”, Sun et al 2023
- “Zoology: Measuring and Improving Recall in Efficient Language Models”, Arora et al 2023
- “Seamless: Multilingual Expressive and Streaming Speech Translation”, Communication et al 2023
- “Scaling Transformer Neural Networks for Skillful and Reliable Medium-Range Weather Forecasting”, Nguyen et al 2023
- “Instruction-Tuning Aligns LLMs to the Human Brain”, Aw et al 2023
- “Mamba: Linear-Time Sequence Modeling With Selective State Spaces”, Gu & Dao 2023
- “Sequential Modeling Enables Scalable Learning for Large Vision Models”, Bai et al 2023
- “UniRepLKNet: A Universal Perception Large-Kernel ConvNet for Audio, Video, Point Cloud, Time-Series and Image Recognition”, Ding et al 2023
- “Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets”, Blattmann et al 2023
- “In Search of the Long-Tail: Systematic Generation of Long-Tail Inferential Knowledge via Logical Rule Guided Search”, Li et al 2023
- “First Tragedy, Then Parse: History Repeats Itself in the New Era of Large Language Models”, Saphra et al 2023
- “I2VGen-XL: High-Quality Image-To-Video Synthesis via Cascaded Diffusion Models”, Zhang et al 2023
- “A Systematic Comparison of Syllogistic Reasoning in Humans and Language Models”, Eisape et al 2023
- “Sam Altman Accepts the 2023 Hawking Fellowship Award § Is There Another Breakthrough That’s Needed to Reach AGI?”, Altman 2023
- “ConvNets Match Vision Transformers at Scale”, Smith et al 2023
- “Evidence of Interrelated Cognitive-Like Capabilities in Large Language Models: Indications of Artificial General Intelligence or Achievement?”, Ilić & Gignac 2023
- “PaLI-3 Vision Language Models: Smaller, Faster, Stronger”, Chen et al 2023
- “GeoLLM: Extracting Geospatial Knowledge from Large Language Models”, Manvi et al 2023
- “Dynamical versus Bayesian Phase Transitions in a Toy Model of Superposition”, Chen et al 2023
- “Sheared LLaMA: Accelerating Language Model Pre-Training via Structured Pruning”, Xia et al 2023
- “FreshLLMs: Refreshing Large Language Models With Search Engine Augmentation”, Vu et al 2023
- “Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors”, Amos et al 2023
- “MTOB: A Benchmark for Learning to Translate a New Language from One Grammar Book”, Tanzer et al 2023
- “Intriguing Properties of Generative Classifiers”, Jaini et al 2023
- “Taken out of Context: On Measuring Situational Awareness in LLMs”, Berglund et al 2023
- “SeamlessM4T: Massively Multilingual & Multimodal Machine Translation”, Communication et al 2023
- “Two Phases of Scaling Laws for Nearest Neighbor Classifiers”, Yang & Zhang 2023
- “Simple Synthetic Data Reduces Sycophancy in Large Language Models”, Wei et al 2023
- “Scaling Relationship on Learning Mathematical Reasoning With Large Language Models”, Yuan et al 2023
- “LLaMA-2: Open Foundation and Fine-Tuned Chat Models”, Touvron et al 2023
- “Measuring Faithfulness in Chain-Of-Thought Reasoning”, Lanham et al 2023
- “Unleashing the Emergent Cognitive Synergy in Large Language Models: A Task-Solving Agent through Multi-Persona Self-Collaboration”, Wang et al 2023
- “Introducing Superalignment”, Leike & Sutskever 2023
- “Gödel, Escher, Bach Author Douglas Hofstadter on the State of AI Today § What about AI Terrifies You?”, Hofstadter & Kim 2023
- “Pretraining Task Diversity and the Emergence of Non-Bayesian In-Context Learning for Regression”, Raventós et al 2023
- “Beyond Scale: the Diversity Coefficient As a Data Quality Metric Demonstrates LLMs Are Pre-Trained on Formally Diverse Data”, Lee et al 2023
- “Scaling MLPs: A Tale of Inductive Bias”, Bachmann et al 2023
- “Inflection-1: Pi’s Best-In-Class LLM”, Inflection 2023
- “Understanding Social Reasoning in Language Models With Language Models”, Gandhi et al 2023
- “Image Captioners Are Scalable Vision Learners Too”, Tschannen et al 2023
- “PaLI-X: On Scaling up a Multilingual Vision and Language Model”, Chen et al 2023
- “The False Promise of Imitating Proprietary LLMs”, Gudibande et al 2023
- “Scaling Data-Constrained Language Models”, Muennighoff et al 2023
- “FST: Improving Speech Translation by Fusing Speech and Text”, Yin et al 2023
- “Scaling Laws for Language Encoding Models in FMRI”, Antonello et al 2023
- “LIMA: Less Is More for Alignment”, Zhou et al 2023
- “PaLM 2 Technical Report”, Anil et al 2023
- “Google’s Newest AI Model Uses Nearly 5× More Text Data for Training Than Its Predecessor”, Elias 2023
- “TorToise: Better Speech Synthesis through Scaling”, Betker 2023
- “TinyStories: How Small Can Language Models Be and Still Speak Coherent English?”, Eldan & Li 2023
- “ImageBind: One Embedding Space To Bind Them All”, Girdhar et al 2023
- “Finding Neurons in a Haystack: Case Studies With Sparse Probing”, Gurnee et al 2023
- “Geoffrey Hinton Tells Us Why He’s Now Scared of the Tech He Helped Build: ‘I Have Suddenly Switched My Views on Whether These Things Are Going to Be More Intelligent Than Us.’”, Heaven 2023
- “Speak, Memory: An Archaeology of Books Known to ChatGPT/GPT-4”, Chang et al 2023
- “Google’s DeepMind-Brain Merger: Tech Giant Regroups for AI Battle”, Murgia 2023
- “CLaMP: Contrastive Language-Music Pre-Training for Cross-Modal Symbolic Music Information Retrieval”, Wu et al 2023
- “Emergent and Predictable Memorization in Large Language Models”, Biderman et al 2023
- “Power Law Trends in Speedrunning and Machine Learning”, Erdil & Sevilla 2023
- “Even The Politicians Thought the Open Letter Made No Sense In The Senate Hearing on AI Today’s Hearing on Ai Covered Ai Regulation and Challenges, and the Infamous Open Letter, Which Nearly Everyone in the Room Thought Was Unwise”, Gorrell 2023
- “DINOv2: Learning Robust Visual Features without Supervision”, Oquab et al 2023
- “Segment Anything”, Kirillov et al 2023
- “Humans in Humans Out: On GPT Converging Toward Common Sense in Both Success and Failure”, Koralus & Wang-Maścianica 2023
- “Sigmoid Loss for Language Image Pre-Training”, Zhai et al 2023
- “‘AI’ on a Calculator: Part 1 [MNIST CNN on a TI-84 Graphing Calculator]”, Mitchell 2023
- “How Well Do Large Language Models Perform in Arithmetic Tasks?”, Yuan et al 2023
- “GPT-4 Technical Report”, OpenAI 2023
- “Securing Liberal Democratic Control of AGI through UK Leadership”, Phillips 2023
- “GigaGAN: Scaling up GANs for Text-To-Image Synthesis”, Kang et al 2023
- “Why Didn’t We Get GPT-2 in 2005?”, Dynomight 2023
- “Language Is Not All You Need: Aligning Perception With Language Models (Kosmos-1)”, Huang et al 2023
- “Why Didn’t DeepMind Build GPT-3?”, Godwin 2023
- “Is Multimodal Vision Supervision Beneficial to Language?”, Madasu & Lal 2023
- “Scaling Vision Transformers to 22 Billion Parameters”, Dehghani et al 2023
- “John Carmack’s ‘Different Path’ to Artificial General Intelligence”, Carmack 2023
- “Large Language Models As Fiduciaries: A Case Study Toward Robustly Communicating With Artificial Intelligence Through Legal Standards”, Nay 2023
- “ClimaX: A Foundation Model for Weather and Climate”, Nguyen et al 2023
- “StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-To-Image Synthesis”, Sauer et al 2023
- “MUG: Vision Learners Meet Web Image-Text Pairs”, Zhao et al 2023
- “GPT-3 As Knowledge Worker: A Zero-Shot Evaluation of AI CPA Capabilities”, Bommarito et al 2023
- “Scaling Laws for Generative Mixed-Modal Language Models”, Aghajanyan et al 2023
- “VALL-E: Neural Codec Language Models Are Zero-Shot Text to Speech Synthesizers”, Wang et al 2023
- “Large-Scale Weakly-Supervised Content Embeddings for Music Recommendation and Tagging”, Huang et al 2023
- “GPT-3 Takes the Bar Exam”, II & Katz 2022
- “Cramming: Training a Language Model on a Single GPU in One Day”, Geiping & Goldstein 2022
- “Evolutionary-Scale Prediction of Atomic Level Protein Structure With a Language Model”, Lin et al 2022
- “Discovering Language Model Behaviors With Model-Written Evaluations”, Perez et al 2022
- “One Embedder, Any Task: Instruction-Finetuned Text Embeddings (INSTRUCTOR)”, Su et al 2022
- “Reproducible Scaling Laws for Contrastive Language-Image Learning”, Cherti et al 2022
- “ERNIE-Code: Beyond English-Centric Cross-Lingual Pretraining for Programming Languages”, Chai et al 2022
- “VideoCoCa: Video-Text Modeling With Zero-Shot Transfer from Contrastive Captioners”, Yan et al 2022
- “VindLU: A Recipe for Effective Video-And-Language Pretraining”, Cheng et al 2022
- “Whisper: Robust Speech Recognition via Large-Scale Weak Supervision”, Radford et al 2022
- “Scaling Language-Image Pre-Training via Masking”, Li et al 2022
- “Galactica: A Large Language Model for Science”, Taylor et al 2022
- “Large Language Models Struggle to Learn Long-Tail Knowledge”, Kandpal et al 2022
- “EVA: Exploring the Limits of Masked Visual Representation Learning at Scale”, Fang et al 2022
- “MMDialog: A Large-Scale Multi-Turn Dialogue Dataset Towards Multi-Modal Open-Domain Conversation”, Feng et al 2022
- “Adversarial Policies Beat Superhuman Go AIs”, Wang et al 2022
- “Increments Podcast: #45—4 Central Fallacies of AI Research (With Melanie Mitchell)”, Mitchell & Chugg 2022
- “A Solvable Model of Neural Scaling Laws”, Maloney et al 2022
- “Will We Run out of Data? An Analysis of the Limits of Scaling Datasets in Machine Learning”, Villalobos et al 2022
- “Evaluating Parameter Efficient Learning for Generation”, Xu et al 2022
- “FLAN: Scaling Instruction-Finetuned Language Models”, Chung et al 2022
- “BioGPT: Generative Pre-Trained Transformer for Biomedical Text Generation and Mining”, Luo et al 2022
- “Vision-Language Pre-Training: Basics, Recent Advances, and Future Trends”, Gan et al 2022
- “Foundation Transformers”, Wang et al 2022
- “Self-Ask: Measuring and Narrowing the Compositionality Gap in Language Models (Bamboogle)”, Press et al 2022
- “The Lie Derivative for Measuring Learned Equivariance”, Gruver et al 2022
- “GLM-130B: An Open Bilingual Pre-Trained Model”, Zeng et al 2022
- “Ask Me Anything (AMA): A Simple Strategy for Prompting Language Models”, Arora et al 2022
- “Do Current Multi-Task Optimization Methods in Deep Learning Even Help?”, Xin et al 2022
- “Monolith: Real Time Recommendation System With Collisionless Embedding Table”, Liu et al 2022
- “Machine Reading, Fast and Slow: When Do Models "Understand" Language?”, Choudhury et al 2022
- “PaLI: A Jointly-Scaled Multilingual Language-Image Model”, Chen et al 2022
- “Using Large Language Models to Simulate Multiple Humans”, Aher et al 2022
- “Understanding Scaling Laws for Recommendation Models”, Ardalani et al 2022
- “
LLM.int8(): 8-Bit Matrix Multiplication for Transformers at Scale”, Dettmers et al 2022 - “Quality Not Quantity: On the Interaction between Dataset Design and Robustness of CLIP”, Nguyen et al 2022
- “Efficient Training of Language Models to Fill in the Middle”, Bavarian et al 2022
- “Why Do Tree-Based Models Still Outperform Deep Learning on Tabular Data?”, Grinsztajn et al 2022
- “PIXEL: Language Modeling With Pixels”, Rust et al 2022
- “High-Performing Neural Network Models of Visual Cortex Benefit from High Latent Dimensionality”, Elmoznino & Bonner 2022
- “Exploring Length Generalization in Large Language Models”, Anil et al 2022
- “Language Models (Mostly) Know What They Know”, Kadavath et al 2022
- “On-Device Training Under 256KB Memory”, Lin et al 2022
- “Beyond Neural Scaling Laws: Beating Power Law Scaling via Data Pruning”, Sorscher et al 2022
- “ProGen2: Exploring the Boundaries of Protein Language Models”, Nijkamp et al 2022
- “RST: ReStructured Pre-Training”, Yuan & Liu 2022
- “Limitations of the NTK for Understanding Generalization in Deep Learning”, Vyas et al 2022
- “Modeling Transformative AI Risks (MTAIR) Project—Summary Report”, Clarke et al 2022
- “LIFT: Language-Interfaced Fine-Tuning for Non-Language Machine Learning Tasks”, Dinh et al 2022
- “BigVGAN: A Universal Neural Vocoder With Large-Scale Training”, Lee et al 2022
- “An Improved One Millisecond Mobile Backbone”, Vasu et al 2022
- “A Neural Corpus Indexer for Document Retrieval”, Wang et al 2022
- “Toward a Realistic Model of Speech Processing in the Brain With Self-Supervised Learning”, Millet et al 2022
- “Teaching Models to Express Their Uncertainty in Words”, Lin et al 2022
- “Why Robust Generalization in Deep Learning Is Difficult: Perspective of Expressive Power”, Li et al 2022
- “M3AE: Multimodal Masked Autoencoders Learn Transferable Representations”, Geng et al 2022
- “InstructDial: Improving Zero and Few-Shot Generalization in Dialogue through Instruction Tuning”, Gupta et al 2022
- “Memorization Without Overfitting: Analyzing the Training Dynamics of Large Language Models”, Tirumala et al 2022
- “Least-To-Most Prompting Enables Complex Reasoning in Large Language Models”, Zhou et al 2022
- “Continual Pre-Training Mitigates Forgetting in Language and Vision”, Cossu et al 2022
- “Dialog Inpainting: Turning Documents into Dialogues”, Dai et al 2022
- “UL2: Unifying Language Learning Paradigms”, Tay et al 2022
- “Building Machine Translation Systems for the Next Thousand Languages”, Bapna et al 2022
- “When Does Dough Become a Bagel? Analyzing the Remaining Mistakes on ImageNet”, Vasudevan et al 2022
- “CoCa: Contrastive Captioners Are Image-Text Foundation Models”, Yu et al 2022
- “Data Determines Distributional Robustness in Contrastive Language Image Pre-Training (CLIP)”, Fang et al 2022
- “Continual Learning With Foundation Models: An Empirical Study of Latent Replay”, Ostapenko et al 2022
- “Flamingo: a Visual Language Model for Few-Shot Learning”, Alayrac et al 2022
- “WebFace260M: A Benchmark for Million-Scale Deep Face Recognition”, Zhu et al 2022
- “Tk-Instruct: Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks”, Wang et al 2022
- “What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?”, Wang et al 2022
- “DeepMind: The Podcast—Excerpts on AGI”, Kiely 2022
- “Can Language Models Learn from Explanations in Context?”, Lampinen et al 2022
- “Chinchilla: Training Compute-Optimal Large Language Models”, Hoffmann et al 2022
- “A Roadmap for Big Model”, Yuan et al 2022
- “A Conversational Paradigm for Program Synthesis”, Nijkamp et al 2022
- “Self-Consistency Improves Chain-Of-Thought Reasoning in Language Models”, Wang et al 2022
- “Effect of Scale on Catastrophic Forgetting in Neural Networks”, Ramasesh et al 2022
- “Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer”, Yang et al 2022
- “FastFold: Reducing AlphaFold Training Time from 11 Days to 67 Hours”, Cheng et al 2022
- “Variational Autoencoders Without the Variation”, Daly et al 2022
- “Performance Reserves in Brain-Imaging-Based Phenotype Prediction”, Schulz et al 2022
- “Self-Distilled StyleGAN: Towards Generation from Internet Photos”, Mokady et al 2022
- “UnifiedQA-V2: Stronger Generalization via Broader Cross-Format Training”, Khashabi et al 2022
- “Vision Models Are More Robust And Fair When Pretrained On Uncurated Images Without Supervision”, Goyal et al 2022
- “Brains and Algorithms Partially Converge in Natural Language Processing”, Caucheteux & King 2022
- “Quantifying Memorization Across Neural Language Models”, Carlini et al 2022
- “Wukong: 100 Million Large-Scale Chinese Cross-Modal Pre-Training Dataset and A Foundation Framework”, Gu et al 2022
- “OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-To-Sequence Learning Framework”, Wang et al 2022
- “Data Scaling Laws in NMT: The Effect of Noise and Architecture”, Bansal et al 2022
- “Webly Supervised Concept Expansion for General Purpose Vision Models”, Kamath et al 2022
- “StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets”, Sauer et al 2022
- “Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model”, Smith et al 2022
- “Reasoning Like Program Executors”, Pi et al 2022
- “Text and Code Embeddings by Contrastive Pre-Training”, Neelakantan et al 2022
- “LaMDA: Language Models for Dialog Applications”, Thoppilan et al 2022
- “SWAG: Revisiting Weakly Supervised Pre-Training of Visual Perception Models”, Singh et al 2022
- “CM3: A Causal Masked Multimodal Model of the Internet”, Aghajanyan et al 2022
- “ZeroPrompt: Scaling Prompt-Based Pretraining to 1,000 Tasks Improves Zero-Shot Generalization”, Xu et al 2022
- “A High-Dimensional Sphere Spilling out of a High-Dimensional Cube despite Exponentially Many Constraints”, Fort 2022
- “ConvNeXt: A ConvNet for the 2020s”, Liu et al 2022
- “The Defeat of the Winograd Schema Challenge”, Kocijan et al 2022
- “Robust Self-Supervised Audio-Visual Speech Recognition”, Shi et al 2022
- “AV-HuBERT: Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction”, Shi et al 2022
- “Self-Supervised Learning from 100 Million Medical Images”, Ghesu et al 2022
- “The Evolution of Quantitative Sensitivity”, Bryer et al 2021
- “ERNIE 3.0 Titan: Exploring Larger-Scale Knowledge Enhanced Pre-Training for Language Understanding and Generation”, Wang et al 2021
- “XGLM: Few-Shot Learning With Multilingual Language Models”, Lin et al 2021
- “An Empirical Investigation of the Role of Pre-Training in Lifelong Learning”, Mehta et al 2021
- “Few-Shot Instruction Prompts for Pretrained Language Models to Detect Social Biases”, Prabhumoye et al 2021
- “Knowledge-Rich Self-Supervised Entity Linking”, Zhang et al 2021
- “You Only Need One Model for Open-Domain Question Answering”, Lee et al 2021
- “EBERT: Epigenomic Language Models Powered by Cerebras”, Trotter et al 2021
- “MAGMA—Multimodal Augmentation of Generative Models through Adapter-Based Finetuning”, Eichenberg et al 2021
- “Improving Language Models by Retrieving from Trillions of Tokens”, Borgeaud et al 2021
- “MLP Architectures for Vision-And-Language Modeling: An Empirical Study”, Nie et al 2021
- “LEMON: Scaling Up Vision-Language Pre-Training for Image Captioning”, Hu et al 2021
- “Scaling Transformers: Sparse Is Enough in Scaling Transformers”, Jaszczur et al 2021
- “Can Pre-Trained Language Models Be Used to Resolve Textual and Semantic Merge Conflicts?”, Zhang et al 2021
- “ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning”, Aribandi et al 2021
- “L-Verse: Bidirectional Generation Between Image and Text”, Kim et al 2021
- “RedCaps: Web-Curated Image-Text Data Created by the People, for the People”, Desai et al 2021
- “Florence: A New Foundation Model for Computer Vision”, Yuan et al 2021
- “BASIC: Combined Scaling for Open-Vocabulary Image Classification”, Pham et al 2021
- “Swin Transformer V2: Scaling Up Capacity and Resolution”, Liu et al 2021
- “XLS-R: Self-Supervised Cross-Lingual Speech Representation Learning at Scale”, Babu et al 2021
- “Solving Linear Algebra by Program Synthesis”, Drori & Verma 2021
- “Covariate Shift in High-Dimensional Random Feature Regression”, Tripuraneni et al 2021
- “Solving Probability and Statistics Problems by Program Synthesis”, Tang et al 2021
- “Few-Shot Self-Rationalization With Natural Language Prompts”, Marasović et al 2021
- “INTERN: A New Learning Paradigm Towards General Vision”, Shao et al 2021
- “Scaling Law for Recommendation Models: Towards General-Purpose User Representations”, Shin et al 2021
- “MAE: Masked Autoencoders Are Scalable Vision Learners”, He et al 2021
- “Persia: An Open, Hybrid System Scaling Deep Learning-Based Recommenders up to 100 Trillion Parameters”, Lian et al 2021
- “Scaling ASR Improves Zero and Few Shot Learning”, Xiao et al 2021
- “Turing-Universal Learners With Optimal Scaling Laws”, Nakkiran 2021
- “LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs”, Schuhmann et al 2021
- “Training Verifiers to Solve Math Word Problems”, Cobbe et al 2021
- “Just Ask for Generalization”, Jang 2021
- “Wide Neural Networks Forget Less Catastrophically”, Mirzadeh et al 2021
- “No One Representation to Rule Them All: Overlapping Features of Training Methods”, Gontijo-Lopes et al 2021
- “When in Doubt, Summon the Titans: Efficient Inference With Large Models”, Rawat et al 2021
- “The Dangers of Underclaiming: Reasons for Caution When Reporting How NLP Systems Fail”, Bowman 2021
- “Symbolic Knowledge Distillation: from General Language Models to Commonsense Models”, West et al 2021
- “LFPT5: A Unified Framework for Lifelong Few-Shot Language Learning Based on Prompt Tuning of T5”, Qin & Joty 2021
- “Scaling Laws for the Few-Shot Adaptation of Pre-Trained Image Classifiers”, Prato et al 2021
- “Unsupervised Neural Machine Translation With Generative Language Models Only”, Han et al 2021
- “Yuan 1.0: Large-Scale Pre-Trained Language Model in Zero-Shot and Few-Shot Learning”, Wu et al 2021
- “Universal Paralinguistic Speech Representations Using Self-Supervised Conformers”, Shor et al 2021
- “M6–10T: A Sharing-Delinking Paradigm for Efficient Multi-Trillion Parameter Pretraining”, Lin et al 2021
- “A Few More Examples May Be Worth Billions of Parameters”, Kirstain et al 2021
- “Exploring the Limits of Large Scale Pre-Training”, Abnar et al 2021
- “Show Your Work: Scratchpads for Intermediate Computation With Language Models”, Nye et al 2021
- “Mining for Strong Gravitational Lenses With Self-Supervised Learning”, Stein et al 2021
- “Stochastic Training Is Not Necessary for Generalization”, Geiping et al 2021
- “Evaluating Machine Accuracy on ImageNet”, Shankar et al 2021
- “BigSSL: Exploring the Frontier of Large-Scale Semi-Supervised Learning for Automatic Speech Recognition”, Zhang et al 2021
- “Scale Efficiently: Insights from Pre-Training and Fine-Tuning Transformers”, Tay et al 2021
- “Scaling Laws for Neural Machine Translation”, Ghorbani et al 2021
- “What Changes Can Large-Scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-Scale Korean Generative Pretrained Transformers”, Kim et al 2021
- “A Recipe For Arbitrary Text Style Transfer With Large Language Models”, Reif et al 2021
- “TruthfulQA: Measuring How Models Mimic Human Falsehoods”, Lin et al 2021
- “A Farewell to the Bias-Variance Tradeoff? An Overview of the Theory of Overparameterized Machine Learning”, Dar et al 2021
- “General-Purpose Question-Answering With Macaw”, Tafjord & Clark 2021
- “An Empirical Exploration in Quality Filtering of Text Data”, Gao 2021
- “A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP”, Zhao et al 2021
- “Want To Reduce Labeling Cost? GPT-3 Can Help”, Wang et al 2021
- “Data and Parameter Scaling Laws for Neural Machine Translation”, Gordon et al 2021
- “Do Vision Transformers See Like Convolutional Neural Networks?”, Raghu et al 2021
- “Modeling Protein Using Large-Scale Pretrain Language Model”, Xiao et al 2021
- “Scaling Laws for Deep Learning”, Rosenfeld 2021
- “Billion-Scale Pretraining With Vision Transformers for Multi-Task Visual Representations”, Beal et al 2021
- “Facebook AI WMT21 News Translation Task Submission”, Tran et al 2021
- “EVA: An Open-Domain Chinese Dialogue System With Large-Scale Generative Pre-Training”, Zhou et al 2021
- “The History of Speech Recognition to the Year 2030”, Hannun 2021
- “The History of Speech Recognition to the Year 2030 [Blog]”, Hannun 2021
- “A Field Guide to Federated Optimization”, Wang et al 2021
- “HTLM: Hyper-Text Pre-Training and Prompting of Language Models”, Aghajanyan et al 2021
- “Brain-Like Functional Specialization Emerges Spontaneously in Deep Neural Networks”, Dobs et al 2021
- “ERNIE 3.0: Large-Scale Knowledge Enhanced Pre-Training for Language Understanding and Generation”, Sun et al 2021
- “Scarecrow: A Framework for Scrutinizing Machine Text”, Dou et al 2021
- “The Dimpled Manifold Model of Adversarial Examples in Machine Learning”, Shamir et al 2021
- “Revisiting the Calibration of Modern Neural Networks”, Minderer et al 2021
- “Partial Success in Closing the Gap between Human and Machine Vision”, Geirhos et al 2021
- “HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units”, Hsu et al 2021
- “Scaling Laws for Acoustic Models”, Droppo & Elibol 2021
- “CoAtNet: Marrying Convolution and Attention for All Data Sizes”, Dai et al 2021
- “Scaling Vision Transformers”, Zhai et al 2021
- “Exploring the Limits of Out-Of-Distribution Detection”, Fort et al 2021
- “Effect of Pre-Training Scale on Intra/Inter-Domain Full and Few-Shot Transfer Learning for Natural and Medical X-Ray Chest Images”, Cherti & Jitsev 2021
- “A Universal Law of Robustness via Isoperimetry”, Bubeck & Sellke 2021
- “Naver Unveils First ‘Hyperscale’ AI Platform”, Jae-eun 2021
- “Unsupervised Speech Recognition”, Baevski et al 2021
- “One4all User Representation for Recommender Systems in E-Commerce”, Shin et al 2021
- “RecPipe: Co-Designing Models and Hardware to Jointly Optimize Recommendation Quality and Performance”, Gupta et al 2021
- “Google Details New AI Accelerator Chips”, Wiggers 2021
- “MLP-Mixer: An All-MLP Architecture for Vision”, Tolstikhin et al 2021
- “XLM-R XL: Larger-Scale Transformers for Multilingual Masked Language Modeling”, Goyal et al 2021
- “Scaling End-To-End Models for Large-Scale Multilingual ASR”, Li et al 2021
- “DINO: Emerging Properties in Self-Supervised Vision Transformers”, Caron et al 2021
- “What Are Bayesian Neural Network Posteriors Really Like?”, Izmailov et al 2021
- “Machine Learning Scaling”, Gwern 2021
- “[Ali Released PLUG: 27 Billion Parameters, the Largest Pre-Trained Language Model in the Chinese Community]”, Yuying 2021
- “The Power of Scale for Parameter-Efficient Prompt Tuning”, Lester et al 2021
- “Revealing Persona Biases in Dialogue Systems”, Sheng et al 2021
- “CrossFit: A Few-Shot Learning Challenge for Cross-Task Generalization in NLP”, Ye et al 2021
- “Probing Across Time: What Does RoBERTa Know and When?”, Liu et al 2021
- “Memorization versus Generalization in Pre-Trained Language Models”, Tänzer et al 2021
- “Large-Scale Self-Supervised and Semi-Supervised Learning for Speech Translation”, Wang et al 2021
- “Scaling Laws for Language Transfer Learning”, Kim 2021
- “Adapting Language Models for Zero-Shot Learning by Meta-Tuning on Dataset and Prompt Collections”, Zhong et al 2021
- “SpeechStew: Simply Mix All Available Speech Recognition Data to Train One Large Neural Network”, Chan et al 2021
- “Understanding Robustness of Transformers for Image Classification”, Bhojanapalli et al 2021
- “UNICORN on RAINBOW: A Universal Commonsense Reasoning Model on a New Multitask Benchmark”, Lourie et al 2021
- “Controllable Generation from Pre-Trained Language Models via Inverse Prompting”, Zou et al 2021
- “The Shape of Learning Curves: a Review”, Viering & Loog 2021
- “Efficient Visual Pretraining With Contrastive Detection”, Hénaff et al 2021
- “Revisiting ResNets: Improved Training and Scaling Strategies”, Bello et al 2021
- “Learning from Videos to Understand the World”, Zweig et al 2021
- “WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training”, Huo et al 2021
- “Fast and Accurate Model Scaling”, Dollár et al 2021
- “Pretrained Transformers As Universal Computation Engines”, Lu et al 2021
- “Greedy Hierarchical Variational Autoencoders (GHVAEs) for Large-Scale Video Prediction”, Wu et al 2021
- “Measuring Mathematical Problem Solving With the MATH Dataset”, Hendrycks et al 2021
- “A Law of Robustness for Two-Layers Neural Networks”, Bubeck et al 2021
- “SEER: Self-Supervised Pretraining of Visual Features in the Wild”, Goyal et al 2021
- “M6: A Chinese Multimodal Pretrainer”, Lin et al 2021
- “Zero-Shot Text-To-Image Generation”, Ramesh et al 2021
- “Improved Denoising Diffusion Probabilistic Models”, Nichol & Dhariwal 2021
- “Conceptual 12M: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts”, Changpinyo et al 2021
- “A Large Batch Optimizer Reality Check: Traditional, Generic Optimizers Suffice Across Batch Sizes”, Nado et al 2021
- “Explaining Neural Scaling Laws”, Bahri et al 2021
- “ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision”, Jia et al 2021
- “NFNet: High-Performance Large-Scale Image Recognition Without Normalization”, Brock et al 2021
- “Learning Curve Theory”, Hutter 2021
- “1-Bit Adam: Communication Efficient Large-Scale Training With Adam’s Convergence Speed”, Tang et al 2021
- “Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Scaling”, Lazaridou et al 2021
- “Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Dynamic Evaluation”, Lazaridou et al 2021 (page 7 org deepmind)
- “Scaling Laws for Transfer”, Hernandez et al 2021
- “Automatic Curation of Large-Scale Datasets for Audio-Visual Representation Learning”, Lee et al 2021
- “Muppet: Massive Multi-Task Representations With Pre-Finetuning”, Aghajanyan et al 2021
- “Language Processing in Brains and Deep Neural Networks: Computational Convergence and Its Limits”, Caucheteux & King 2021
- “Meta Pseudo Labels”, Pham et al 2021
- “CLIP: Learning Transferable Visual Models From Natural Language Supervision”, Radford et al 2021
- “VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation Learning, Semi-Supervised Learning and Interpretation”, Wang et al 2021
- “CDLM: Cross-Document Language Modeling”, Caciularu et al 2021
- “VinVL: Revisiting Visual Representations in Vision-Language Models”, Zhang et al 2021
- “Parameter Count vs Training Dataset Size (1952–2021)”, Adlam 2021
- “Process for Adapting Language Models to Society (PALMS) With Values-Targeted Datasets”, Solaiman & Dennison 2021
- “Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning”, Aghajanyan et al 2020
- “Extrapolating GPT-N Performance”, Finnveden 2020
- “Biological Structure and Function Emerge from Scaling Unsupervised Learning to 250 Million Protein Sequences”, Rives et al 2020
- “CPM: A Large-Scale Generative Chinese Pre-Trained Language Model”, Zhang et al 2020
- “Very Deep VAEs Generalize Autoregressive Models and Can Outperform Them on Images”, Child 2020
- “When Do You Need Billions of Words of Pretraining Data?”, Zhang et al 2020
- “Scaling Laws for Autoregressive Generative Modeling”, Henighan et al 2020
- “Language ID in the Wild: Unexpected Challenges on the Path to a Thousand-Language Web Text Corpus”, Caswell et al 2020
- “MT5: A Massively Multilingual Pre-Trained Text-To-Text Transformer”, Xue et al 2020
- “Beyond English-Centric Multilingual Machine Translation”, Fan et al 2020
- “Pushing the Limits of Semi-Supervised Learning for Automatic Speech Recognition”, Zhang et al 2020
- “Towards End-To-End In-Image Neural Machine Translation”, Mansimov et al 2020
- “The First AI Model That Translates 100 Languages without Relying on English Data”, Fan 2020
- “The Deep Bootstrap Framework: Good Online Learners Are Good Offline Generalizers”, Nakkiran et al 2020
- “Learning Which Features Matter: RoBERTa Acquires a Preference for Linguistic Generalizations (Eventually)”, Warstadt et al 2020
- “The Neural Architecture of Language: Integrative Reverse-Engineering Converges on a Model for Predictive Processing”, Schrimpf et al 2020
- “Uncovering the Limits of Adversarial Training against Norm-Bounded Adversarial Examples”, Gowal et al 2020
- “Fast Stencil-Code Computation on a Wafer-Scale Processor”, Rocki et al 2020
- “Vision Transformer: An Image Is Worth 16×16 Words: Transformers for Image Recognition at Scale”, Dosovitskiy et al 2020
- “Small Data, Big Decisions: Model Selection in the Small-Data Regime”, Bornschein et al 2020
- “New Report on How Much Computational Power It Takes to Match the Human Brain”, Carlsmith 2020
- “Generative Language Modeling for Automated Theorem Proving”, Polu & Sutskever 2020
- “GrokNet: Unified Computer Vision Model Trunk and Embeddings For Commerce”, Bell et al 2020
- “Accuracy and Performance Comparison of Video Action Recognition Approaches”, Hutchinson et al 2020
- “Generative Models Are Unsupervised Predictors of Page Quality: A Colossal-Scale Study”, Bahri et al 2020
- “Matt Botvinick on the Spontaneous Emergence of Learning Algorithms”, Scholl 2020
- “Self-Supervised Learning through the Eyes of a Child”, Orhan et al 2020
- “On Robustness and Transferability of Convolutional Neural Networks”, Djolonga et al 2020
- “Hopfield Networks Is All You Need”, Ramsauer et al 2020
- “ProtTrans: Towards Cracking the Language of Life’s Code Through Self-Supervised Deep Learning and High Performance Computing”, Elnaggar et al 2020
- “NVAE: A Deep Hierarchical Variational Autoencoder”, Vahdat & Kautz 2020
- “Measuring Robustness to Natural Distribution Shifts in Image Classification”, Taori et al 2020
- “WinoGrande: An Adversarial Winograd Schema Challenge at Scale”, Sakaguchi et al 2020
- “Is SGD a Bayesian Sampler? Well, Almost”, Mingard et al 2020
- “Unsupervised Cross-Lingual Representation Learning for Speech Recognition”, Conneau et al 2020
- “Logarithmic Pruning Is All You Need”, Orseau et al 2020
- “Wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations”, Baevski et al 2020
- “Denoising Diffusion Probabilistic Models”, Ho et al 2020
- “On the Predictability of Pruning Across Scales”, Rosenfeld et al 2020
- “IGPT: Generative Pretraining from Pixels”, Chen et al 2020
- “SwAV: Unsupervised Learning of Visual Features by Contrasting Cluster Assignments”, Caron et al 2020
- “SimCLRv2: Big Self-Supervised Models Are Strong Semi-Supervised Learners”, Chen et al 2020
- “Image GPT (IGPT): We Find That, Just As a Large Transformer Model Trained on Language Can Generate Coherent Text, the Same Exact Model Trained on Pixel Sequences Can Generate Coherent Image Completions and Samples”, Chen et al 2020
- “Are We Done With ImageNet?”, Beyer et al 2020
- “OpenAI API”, Brockman et al 2020
- “Object Segmentation Without Labels With Large-Scale Generative Models”, Voynov et al 2020
- “How Big Should My Language Model Be?”, Scao 2020
- “GPT-3 Paper § Figure F.1: Four Uncurated Completions from a Context Suggesting the Model Compose a Poem in the Style of Wallace Stevens With the Title ‘Shadows on the Way’”, GPT-3 2020 (page 48)
- “Danny Hernandez on Forecasting and the Drivers of AI Progress”, Koehler et al 2020
- “Powered by AI: Advancing Product Understanding and Building New Shopping Experiences”, Berg et al 2020
- “ZeRO-2 & DeepSpeed: Shattering Barriers of Deep Learning Speed & Scale”, Team 2020
- “Measuring the Algorithmic Efficiency of Neural Networks”, Hernandez & Brown 2020
- “Pushing the Limit of Molecular Dynamics With ab Initio Accuracy to 100 Million Atoms With Machine Learning”, Jia et al 2020
- “Jukebox: We’re Introducing Jukebox, a Neural Net That Generates Music, including Rudimentary Singing, As Raw Audio in a Variety of Genres and Artist Styles. We’re Releasing the Model Weights and Code, along With a Tool to Explore the Generated Samples.”, Dhariwal et al 2020
- “Blender: A State-Of-The-Art Open Source Chatbot”, Roller et al 2020
- “A Review of Winograd Schema Challenge Datasets and Approaches”, Kocijan et al 2020
- “Scaling Laws from the Data Manifold Dimension”, Sharma & Kaplan 2020
- “DynamicEmbedding: Extending TensorFlow for Colossal-Scale Applications”, Zeng et al 2020
- “PALM: Pre-Training an Autoencoding & Autoregressive Language Model for Context-Conditioned Generation”, Bi et al 2020
- “Deep Learning Training in Facebook Data Centers: Design of Scale-Up and Scale-Out Systems”, Naumov et al 2020
- “TTTTTackling WinoGrande Schemas”, Lin et al 2020
- “A Metric Learning Reality Check”, Musgrave et al 2020
- “Zoom In: An Introduction to Circuits—By Studying the Connections between Neurons, We Can Find Meaningful Algorithms in the Weights of Neural Networks”, Olah et al 2020
- “Rethinking Parameter Counting in Deep Models: Effective Dimensionality Revisited”, Maddox et al 2020
- “Rethinking Bias-Variance Trade-Off for Generalization of Neural Networks”, Yang et al 2020
- “Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers”, Li et al 2020
- “The Messy, Secretive Reality behind OpenAI’s Bid to save the World: The AI Moonshot Was Founded in the Spirit of Transparency. This Is the inside Story of How Competitive Pressure Eroded That Idealism”, Hao 2020
- “Pitfalls of In-Domain Uncertainty Estimation and Ensembling in Deep Learning”, Ashukha et al 2020
- “The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence”, Marcus 2020
- “A Simple Framework for Contrastive Learning of Visual Representations”, Chen et al 2020
- “How Much Knowledge Can You Pack Into the Parameters of a Language Model?”, Roberts et al 2020
- “Turing-NLG: A 17-Billion-Parameter Language Model by Microsoft”, Rosset 2020
- “Quasi-Equivalence of Width and Depth of Neural Networks”, Fan et al 2020
- “Impact of ImageNet Model Selection on Domain Adaptation”, Zhang & Davison 2020
- “Direct Fit to Nature: An Evolutionary Perspective on Biological and Artificial Neural Networks”, Hasson et al 2020
- “Towards a Conversational Agent That Can Chat About…Anything”, Adiwardana & Luong 2020
- “Towards a Human-Like Open-Domain Chatbot”, Adiwardana et al 2020
- “Scaling Laws for Neural Language Models”, Kaplan et al 2020
- “Scaling Laws for Neural Language Models: Figure 15: Far beyond the Model Sizes We Study Empirically, We Find a Contradiction between Our Equations § Pg17”, Kaplan 2020 (page 17 org openai)
- “The Importance of Deconstruction”, Weinberger 2020
- “Big Transfer (BiT): General Visual Representation Learning”, Kolesnikov et al 2019
- “More Data Can Hurt for Linear Regression: Sample-Wise Double Descent”, Nakkiran 2019
- “12-In-1: Multi-Task Vision and Language Representation Learning”, Lu et al 2019
- “Deep Double Descent: We Show That the Double Descent Phenomenon Occurs in CNNs, ResNets, and Transformers: Performance First Improves, Then Gets Worse, and Then Improves Again With Increasing Model Size, Data Size, or Training Time”, Nakkiran et al 2019
- “Deep Double Descent: Where Bigger Models and More Data Hurt”, Nakkiran et al 2019
- “What’s Hidden in a Randomly Weighted Neural Network?”, Ramanujan et al 2019
- “Understanding the Generalization of ‘Lottery Tickets’ in Neural Networks”, Morcos & Tian 2019
- “The Deep Learning Revolution and Its Implications for Computer Architecture and Chip Design”, Dean 2019
- “Momentum Contrast for Unsupervised Visual Representation Learning”, He et al 2019
- “SimpleShot: Revisiting Nearest-Neighbor Classification for Few-Shot Learning”, Wang et al 2019
- “Self-Training With Noisy Student Improves ImageNet Classification”, Xie et al 2019
- “CCMatrix: Mining Billions of High-Quality Parallel Sentences on the WEB”, Schwenk et al 2019
- “CCAligned: A Massive Collection of Cross-Lingual Web-Document Pairs”, El-Kishky et al 2019
- “XLM-R: State-Of-The-Art Cross-Lingual Understanding through Self-Supervision”, FAIR 2019
- “High Fidelity Video Prediction With Large Stochastic Recurrent Neural Networks”, Villegas et al 2019
- “Unsupervised Cross-Lingual Representation Learning at Scale”, Conneau et al 2019
- “T5: Exploring the Limits of Transfer Learning With a Unified Text-To-Text Transformer”, Raffel et al 2019
- “ZeRO: Memory Optimizations Toward Training Trillion Parameter Models”, Rajbhandari et al 2019
- “Environmental Drivers of Systematicity and Generalization in a Situated Agent”, Hill et al 2019
- “A Constructive Prediction of the Generalization Error Across Scales”, Rosenfeld et al 2019
- “Large-Scale Pretraining for Neural Machine Translation With Tens of Billions of Sentence Pairs”, Meng et al 2019
- “UNITER: UNiversal Image-TExt Representation Learning”, Chen et al 2019
- “Exascale Deep Learning for Scientific Inverse Problems”, Laanait et al 2019
- “Simple, Scalable Adaptation for Neural Machine Translation”, Bapna et al 2019
- “CTRL: A Conditional Transformer Language Model For Controllable Generation”, Keskar et al 2019
- “Show Your Work: Improved Reporting of Experimental Results”, Dodge et al 2019
- “MegatronLM: Training Billion+ Parameter Language Models Using GPU Model Parallelism”, ADLR 2019
- “RoBERTa: A Robustly Optimized BERT Pretraining Approach”, Liu et al 2019
- “Robustness Properties of Facebook’s ResNeXt WSL Models”, Orhan 2019
- “Massively Multilingual Neural Machine Translation in the Wild: Findings and Challenges”, Arivazhagan et al 2019
- “Large Scale Adversarial Representation Learning”, Donahue & Simonyan 2019
- “One Epoch Is All You Need”, Komatsuzaki 2019
- “Does Learning Require Memorization? A Short Tale about a Long Tail”, Feldman 2019
- “Intriguing Properties of Adversarial Training at Scale”, Xie & Yuille 2019
- “Scaling Autoregressive Video Models”, Weissenborn et al 2019
- “A Mathematical Theory of Semantic Development in Deep Neural Networks”, Saxe et al 2019
- “Adversarially Robust Generalization Just Requires More Unlabeled Data”, Zhai et al 2019
- “ICML 2019 Notes”, Abel 2019
- “Are Labels Required for Improving Adversarial Robustness?”, Uesato et al 2019
- “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks”, Tan & Le 2019
- “SpArSe: Sparse Architecture Search for CNNs on Resource-Constrained Microcontrollers”, Fedorov et al 2019
- “Asymptotic Learning Curves of Kernel Methods: Empirical Data versus Teacher-Student Paradigm”, Spigler et al 2019
- “UniLM: Unified Language Model Pre-Training for Natural Language Understanding and Generation”, Dong et al 2019
- “Adversarial Examples Are Not Bugs, They Are Features”, Ilyas et al 2019
- “Billion-Scale Semi-Supervised Learning for Image Classification”, Yalniz et al 2019
- “VideoBERT: A Joint Model for Video and Language Representation Learning”, Sun et al 2019
- “Benchmarking Neural Network Robustness to Common Corruptions and Perturbations”, Hendrycks & Dietterich 2019
- “Surprises in High-Dimensional Ridgeless Least Squares Interpolation”, Hastie et al 2019
- “The Bitter Lesson”, Sutton 2019
- “GPT-2 As Step Toward General Intelligence”, Alexander 2019
- “Deep Learning Hardware: Past, Present, & Future”, LeCun 2019
- “Language Models Are Unsupervised Multitask Learners”, Radford et al 2019
- “Better Language Models and Their Implications”, Radford et al 2019
- “Do ImageNet Classifiers Generalize to ImageNet?”, Recht et al 2019
- “Cross-Lingual Language Model Pretraining”, Lample & Conneau 2019
- “Artificial Intelligence: A Guide for Thinking Humans § Prologue: Terrified”, Mitchell 2019
- “High Fidelity Video Prediction With Large Stochastic Recurrent Neural Networks: Videos”, Villegas et al 2019
- “Reconciling Modern Machine Learning Practice and the Bias-Variance Trade-Off”, Belkin et al 2018
- “Nocaps: Novel Object Captioning at Scale”, Agrawal et al 2018
- “On Lazy Training in Differentiable Programming”, Chizat et al 2018
- “How AI Training Scales”, McCandlish et al 2018
- “Is Science Slowing Down?”, Alexander 2018
- “Large Scale GAN Training for High Fidelity Natural Image Synthesis”, Brock et al 2018
- “BigGAN: Large Scale GAN Training For High Fidelity Natural Image Synthesis § 5.2 Additional Evaluation On JFT-300M”, Brock et al 2018 (page 8 org deepmind)
- “Measurement Invariance Explains the Universal Law of Generalization for Psychological Perception”, Frank 2018
- “CurriculumNet: Weakly Supervised Learning from Large-Scale Web Images”, Guo et al 2018
- “Large-Scale Visual Speech Recognition”, Shillingford et al 2018
- “Troubling Trends in Machine Learning Scholarship”, Lipton & Steinhardt 2018
- “Benchmarking Neural Network Robustness to Common Corruptions and Surface Variations”, Hendrycks & Dietterich 2018
- “Neural Scene Representation and Rendering”, Eslami et al 2018
- “GPT-1: Improving Language Understanding With Unsupervised Learning”, OpenAI 2018
- “GPT-1: Improving Language Understanding by Generative Pre-Training”, Radford et al 2018
- “GPT-1: Improving Language Understanding by Generative Pre-Training § Model Specifications”, Radford et al 2018 (page 5)
- “Do CIFAR-10 Classifiers Generalize to CIFAR-10?”, Recht et al 2018
- “Deep Learning Generalizes Because the Parameter-Function Map Is Biased towards Simple Functions”, Valle-Pérez et al 2018
- “Google DeepMind Founder and Leader in Artificial Intelligence Returns to Hamilton”, Tantau 2018
- “Exploring the Limits of Weakly Supervised Pretraining”, Mahajan et al 2018
- “One Big Net For Everything”, Schmidhuber 2018
- “Sensitivity and Generalization in Neural Networks: an Empirical Study”, Novak et al 2018
- “The Description Length of Deep Learning Models”, Blier & Ollivier 2018
- “Learning and Memorization”, Chatterjee 2018
- “ULMFiT: Universal Language Model Fine-Tuning for Text Classification”, Howard & Ruder 2018
- “GPipe: Easy Scaling With Micro-Batch Pipeline Parallelism § Pg4”, Huang 2018 (page 4 org google)
- “The Compute and Data Moats Are Dead”, Merity 2018
- “Deep Image Reconstruction from Human Brain Activity”, Shen et al 2017
- “Deep Learning Scaling Is Predictable, Empirically”, Hestness et al 2017
- “Are GANs Created Equal? A Large-Scale Study”, Lucic et al 2017
- “Knowledge Concentration: Learning 100K Object Classifiers in a Single CNN”, Gao et al 2017
- “Rethinking Generalization Requires Revisiting Old Ideas: Statistical Mechanics Approaches and Complex Learning Behavior”, Martin & Mahoney 2017
- “There’s No Fire Alarm for Artificial General Intelligence”, Yudkowsky 2017
- “The Devil Is in the Tails: Fine-Grained Classification in the Wild”, Horn & Perona 2017
- “WebVision Database: Visual Learning and Understanding from Web Data”, Li et al 2017
- “Revisiting Unreasonable Effectiveness of Data in Deep Learning Era”, Sun et al 2017
- “Towards Deep Learning Models Resistant to Adversarial Attacks”, Madry et al 2017
- “Gradient Diversity: a Key Ingredient for Scalable Distributed Learning”, Yin et al 2017
- “Learning to Learn from Noisy Web Videos”, Yeung et al 2017
- “Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour”, Goyal et al 2017
- “A Simple Neural Network Module for Relational Reasoning”, Santoro et al 2017
- “Deep Learning Is Robust to Massive Label Noise”, Rolnick et al 2017
- “Quo Vadis, Action Recognition? A New Model I3D and the Kinetics Dataset”, Carreira & Zisserman 2017
- “WebVision Challenge: Visual Learning and Understanding With Web Data”, Li et al 2017
- “Geometry of Optimization and Implicit Regularization in Deep Learning”, Neyshabur et al 2017
- “On the Impossibility of Supersized Machines”, Garfinkel et al 2017
- “Parallel Multiscale Autoregressive Density Estimation”, Reed et al 2017
- “Universal Representations: The Missing Link between Faces, Text, Planktons, and Cat Breeds”, Bilen & Vedaldi 2017
- “Estimation of Gap Between Current Language Models and Human Performance”, Shen et al 2017
- “Simple and Scalable Predictive Uncertainty Estimation Using Deep Ensembles”, Lakshminarayanan et al 2016
- “Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation”, Johnson et al 2016
- “Understanding Deep Learning Requires Rethinking Generalization”, Zhang et al 2016
- “Why Does Deep and Cheap Learning Work so Well?”, Lin et al 2016
- “The LAMBADA Dataset: Word Prediction Requiring a Broad Discourse Context”, Paperno et al 2016
- “Residual Networks Behave Like Ensembles of Relatively Shallow Networks”, Veit et al 2016
- “Do Deep Convolutional Nets Really Need to Be Deep and Convolutional?”, Urban et al 2016
- “PlaNet—Photo Geolocation With Convolutional Neural Networks”, Weyand et al 2016
- “Exploring the Limits of Language Modeling”, Jozefowicz et al 2016
- “The Singularity: A Philosophical Analysis”, Chalmers 2016
- “Microsoft Researchers Win ImageNet Computer Vision Challenge”, Linn 2015
- “Deep Speech 2: End-To-End Speech Recognition in English and Mandarin”, Amodei et al 2015
- “The Unreasonable Effectiveness of Noisy Data for Fine-Grained Recognition”, Krause et al 2015
- “Net2Net: Accelerating Learning via Knowledge Transfer”, Chen et al 2015
- “Generative Concatenative Nets Jointly Learn to Write and Classify Reviews”, Lipton et al 2015
- “Learning Visual Features from Large Weakly Supervised Data”, Joulin et al 2015
- “LSUN: Construction of a Large-Scale Image Dataset Using Deep Learning With Humans in the Loop”, Yu et al 2015
- “Clothing-1M: Learning from Massive Noisy Labeled Data for Image Classification”, Xiao et al 2015
- “The Unreasonable Effectiveness of Recurrent Neural Networks”, Karpathy 2015
- “LSTM: A Search Space Odyssey”, Greff et al 2015
- “YFCC100M: The New Data in Multimedia Research”, Thomee et al 2015
- “Machine Intelligence, Part 1”, Altman 2015
- “50 Years of Deep Learning and Beyond: an Interview With Jürgen Schmidhuber”, Schmidhuber 2015
- “Evolution of the Human Brain: From Matter to Mind”, Hofman 2015
- “In Search of the Real Inductive Bias: On the Role of Implicit Regularization in Deep Learning”, Neyshabur et al 2014
- “Deep Speech 1: Scaling up End-To-End Speech Recognition”, Hannun et al 2014
- “Jumping NLP Curves: A Review of Natural Language Processing Research [Review Article]”, Cambria & White 2014
- “Neural Networks, Manifolds, and Topology”, Olah 2014
- “Computing’s Energy Problem (And What We Can Do about It)”, Horowitz 2014b
- “On the Number of Linear Regions of Deep Neural Networks”, Montúfar et al 2014
- “N-Gram Counts and Language Models from the Common Crawl”, Buck et al 2014
- “Evolution of the Human Brain: When Bigger Is Better”, Hofman 2014
- “One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling”, Chelba et al 2013
- “Algorithmic Progress in Six Domains”, Grace 2013
- “Large–Scale Machine Learning Revisited [Slides]”, Bottou 2013
- “20 Years of Bitext”, Brown et al 2013
- “Intelligence Explosion Microeconomics”, Yudkowsky 2013
- “Scalable Modified Kneser-Ney Language Model Estimation”, Heafield et al 2013
- “Large Scale Language Modeling in Automatic Speech Recognition”, Chelba et al 2012
- “The Remarkable, yet Not Extraordinary, Human Brain As a Scaled-Up Primate Brain and Its Associated Cost”, Herculano-Houzel 2012
- “Advantages of Artificial Intelligences, Uploads, and Digital Minds”, Sotala 2012
- “Natural Language Processing (Almost) from Scratch”, Collobert et al 2011
- “Recurrent Neural Network Based Language Model”, Mikolov et al 2010
- “Understanding Sources of Inefficiency in General-Purpose Chips”, Hameed et al 2010
- “The Teenies”, Legg 2009
- “Tick, Tock, Tick, Tock… BING”, Legg 2009
- “Halloween Nightmare Scenario, Early 2020’s”, Wood 2009
- “Matrix Factorization Techniques for Recommender Systems”, Koren et al 2009
- “The Unreasonable Effectiveness of Data”, Halevy et al 2009
- “Economics Of The Singularity: Stuffed into Skyscrapers by the Billion, Brainy Bugbots Will Be the Knowledge Workers of the Future”, Hanson 2008
- “Large Language Models in Machine Translation”, Brants et al 2007
- “The Tradeoffs of Large-Scale Learning”, Bottou & Bousquet 2007
- “Cellular Scaling Rules for Primate Brains”, Herculano-Houzel et al 2007
- “Robot Predictions Evolution”, Moravec 2004
- “Tree Induction versus Logistic Regression: A Learning-Curve Analysis”, Perlich et al 2003
- “Analytic and Algorithmic Solution of Random Satisfiability Problems”, Mezard et al 2002
- “A Bit of Progress in Language Modeling”, Goodman 2001
- “Scaling to Very Very Large Corpora for Natural Language Disambiguation”, Banko & Brill 2001
- “On Discriminative versus Generative Classifiers: A Comparison of Logistic Regression and Naive Bayes”, Ng & Jordan 2001
- “A Survey of Methods for Scaling Up Inductive Algorithms”, Provost & Kolluri 1999
- “On The Effect of Data Set Size on Bias And Variance in Classification Learning”, Brain & Webb 1999
- “The Anatomy of a Large-Scale Hypertextual Web Search Engine”, Brin & Page 1998
- “The Effects of Training Set Size on Decision Tree Complexity”, Oates & Jensen 1997
- “Rigorous Learning Curve Bounds from Statistical Mechanics”, Haussler et al 1996
- “Scaling up the Accuracy of Naive-Bayes Classifiers: a Decision-Tree Hybrid”, Kohavi 1996
- “Reflections After Refereeing Papers for NIPS”, Breiman 1995
- “Biological Limits to Information Processing in the Human Brain”, Cochrane et al 1995
- “Handwritten Character Classification Using Nearest Neighbor in Large Databases”, Smith et al 1994
- “Building a Large Annotated Corpus of English: The Penn Treebank”, Marcus et al 1993
- “Statistical Theory of Learning Curves under Entropic Loss Criterion”, Amari & Murata 1993
- “Learning Curves: Asymptotic Values and Rate of Convergence”, Cortes et al 1993
- “Exhaustive Learning”, Schwartz et al 1990
- “Don’t Worry—It Can’t Happen”, Harrington 1940
- “Neural Net Stack-More-Layers Meme Template”, Anonymous 2026
- “Eric Michaud on Neural Quantum Interpretability”
- “Billion-Scale Semi-Supervised Learning for State-Of-The-Art Image and Video Classification”
- “No Physics? No Problem. AI Weather Forecasting Is Already Making Huge Strides.”
- “Report Describes Apple’s ‘Organizational Dysfunction’ and ‘Lack of Ambition’ in AI”
- “StyleGAN-2 512px Trained on Danbooru2019”
- “Blake Bordelon”, Bordelon 2026
- “How to Train the Best Embedding Model in the World: One PhD Later, I’m Giving My Secrets Away for Free”, Morris 2026
- “Scaling Karpathy’s Autoresearch: What Happens When the Agent Gets a GPU Cluster”
- “Inside the CodeBot: A Gentle Introduction to How LLMs Understand Nullability”
- “Komodo 8: the Smartphone vs Desktop Challenge”
- “Trading Off Compute in Training and Inference § Pruning”
- “Eric Tang”
- “How Can We Make Robotics More like Generative Modeling?”
- “True Story of Pangu: 诺亚盘古大模型研发背后的真正的心酸与黑暗的故事。[Model Plagiarism]”, Whistleblower 2026
- “Compression Represents Intelligence Linearly [Code]”
- “Inverse-Scaling/prize: A Prize for Finding Tasks That Cause Large Language Models to Show Inverse Scaling”
- “Scaling up StyleGAN-2”
- “Finally, a Replacement for BERT: Introducing ModernBERT”
- “Llm-Compression Data”
- “Semi Supervised Learning”
- “Homepage of Paul F. Christiano”, Christiano 2026
- “Statistical Modeling: The Two Cultures”, Breiman 2026
- “NanoGPT Slowrun—Q”
- “T-Rex As: ‘The Computer Scientist’”, North 2026
- “Have Chinese AI Models Caught Up to the US Frontier? [Probably Not]”
- “Jared Kaplan”
- “Safe Superintelligence Inc.”
- “OpenAI Disbands Its Robotics Research Team”
- “Google Workloads for Consumer Devices: Mitigating Data Movement Bottlenecks”
- “The Uneasy Relationship between Deep Learning and (Classical) Statistics”
- “Parameter Counts in Machine Learning”
- “Can LLMs Learn from a Single Example?”
- “Deciphering China’s AI Dream”
- “Jason Wei”
- “Appendix: More Is Different In Other Domains”
- “Beware General Claims about ‘Generalizable Reasoning Capabilities’ (Of Modern AI Systems)”
- “Understanding ‘Deep Double Descent’”
- “How Much Compute Was Used to Train DeepMind’s Generally Capable Agents?”
- “Why Neural Networks Generalise, and Why They Are (Kind Of) Bayesian”
- “LLMs As Giant Lookup-Tables of Shallow Circuits”, niplav 2026
- “(Maybe) A Bag of Heuristics Is All There Is & A Bag of Heuristics Is All You Need”
- “What’s the Backward-Forward FLOP Ratio for Neural Networks?”
- “Optimality Is the Tiger, and Agents Are Its Teeth”
- “What Next? A Dozen Information-Technology Research Goals: 3. Turing’s Vision of Machine Intelligence”
- “Was Linguistic AI Created by Accident?”
- “Tom Henighan”
- “Ilya Sutskever: Deep Learning | AI Podcast #94 With Lex Fridman”
- “A Universal Law of Robustness”
- “Greg Brockman: OpenAI and AGI”, Brockman 2026
- “Season 1 Ep. 22 OpenAI’s Ilya Sutskever: The Man Who Made AI Work”
- “A Law of Robustness and the Importance of Overparameterization in Deep Learning”
- “WELM”
- ImMrShields
- xiao_ted
- “Yuxi on the Wired”, Liu 2026
- “Zhengdong Wang Homepage”, Wang 2026
- Sort By Magic
gpt-3-creativitycharacter-classificationself-supervised-learning knowledge-richco-pilotlogical-agendaspeech-recognitionai-leadership ai-challenges agi-journey innovation-initiative xai-oversight agi-advancementai-regulationadversarial-strategieslanguage-modelsembedding-trainingphilosophy-ai algorithmic-theory digital-minds agi-analysis intelligence-theory algorithmic-advancesai-governanceneural-specializationneural-representationtest-time-augmentationbioacousticsscaling-laws
- Wikipedia (12)
- Miscellaneous
- Bibliography
See Also
Gwern
“Dwarkesh Patel Interview”, Gwern & Patel 2024
“Anonymous Writer Who Predicted AI Trajectory on $12K⧸year Salary; Legacy & Anonymity in the Age of AGI [Video]”, Patel et al 2024
“Model Collapse Won’t Happen”, Gwern 2022
“Scaling Image Generation Will Work”, Gwern 2022
“WBE and DRL: a Middle Way of Imitation Learning”, Gwern 2018
“30 Questions for Hans Moravec”, Gwern et al 2026
“Gwern Visits BAIR”, Liu & Gwern 2025
“AI Cannibalism Can Be Good”, Gwern 2025
“Absolute Unit NNs: Regression-Based MLPs for Everything”, Gwern 2023
“Is OpenAI OK?”, Gwern 2024
“‘Winning’ AI Arms Races: Then What?”, Gwern 2024
“Scaling ‘Diminishing Returns’”, Gwern 2024
“Research Ideas”, Gwern 2017
“GPT-3 Creative Fiction”, Gwern 2020
“GANs Didn’t Fail, They Were Abandoned”, Gwern 2022
“The Scaling Hypothesis”, Gwern 2020
“ML Scaling Subreddit”, Gwern 2020
“Computer Optimization: Your Computer Is Faster Than You Think”, Gwern 2021
Computer Optimization: Your Computer Is Faster Than You Think
“Technology Forecasting: The Garden of Forking Paths”, Gwern 2014
Links
“Estimating No-CoT Task-Completion Time Horizons of Frontier AI Models [3-Minute-Long Problems With P=0.5]”, Woodruff et al 2026
“Programmer Science Fiction: My Case for a New Sub-Genre”, Oates 2026
industriaalist @ "2026-06-04"
“Q0: Primitives for Hyper-Epoch Pretraining”, Mandal et al 2026
“Searching for Amanda Askell With Chinese Characteristics: If You Love Claude so Much, Why Don't You Hire a Philosopher?”, Caithrin 2026
“Negation Neglect: When Models Fail to Learn Negations in Training”, Mayne et al 2026
Negation Neglect: When models fail to learn negations in training
“Vision Banana: Image Generators Are Generalist Vision Learners”, Gabeur et al 2026
Vision Banana: Image Generators are Generalist Vision Learners
“Steering Might Stop Working Soon”, Babcock 2026
“Introducing talkie: a 13b-Parameter Vintage Language Model from 1930”, Levine et al 2026
Introducing talkie: a 13b-parameter vintage language model from 1930
“My Hobby: Running Deranged Surveys; You Can Just Ask People Things”, Gao 2026
My hobby: running deranged surveys; you can just ask people things
“MDM-Prime-V2: Binary Encoding and Index Shuffling Enable Compute-Optimal Scaling of Diffusion Language Models”, Chao et al 2026
“Elon Musk Pushes out More XAI Founders As AI Coding Effort Falters: Tesla and SpaceX Managers Sent in to Review Work As Billionaire’s Start-Up Struggles to Keep pace With Rivals”, Morris & Criddle 2026
“Neural Thickets: Diverse Task Experts Are Dense Around Pretrained Weights”, Gan & Isola 2026
Neural Thickets: Diverse Task Experts Are Dense Around Pretrained Weights
“Against Time-Series Foundation Models; Or: My Experience in Modern Forecasting”, shako 2026
Against Time-Series Foundation Models; Or: My Experience in Modern Forecasting
“Revisiting the Platonic Representation Hypothesis: An Aristotelian View”, Gröger et al 2026
Revisiting the Platonic Representation Hypothesis: An Aristotelian View
“AI Researchers’ Views on Automating AI R&D and Intelligence Explosions”, Field et al 2026
AI Researchers’ Views on Automating AI R&D and Intelligence Explosions
“Elon Musk Suggests Spate of XAI Exits Have Been Push, Not Pull”
Elon Musk suggests spate of xAI exits have been push, not pull
“What Happened With Cotra’s Bio Anchors?”, Alexander 2026
“Weight-Sparse Circuits May Be Interpretable Yet Unfaithful”, Drori 2026
“Reflections on 2025: The Compute Theory of Everything, Grading the Homework of a Minor Deity, and the Acoustic Preferences of Atlantic Salmon [Learning to Feel the AGI]”, Albanie 2025
“2025 Letter: Compute, Inevitability, 2nd-Order Effects, Travel Tips, Andor & Isaiah Berlin [Learning to Feel the AGI]”, Wang 2025
“Shared Sensitivity to Data Distribution during Learning in Humans and Transformer Networks”, Lerousseau & Summerfield 2025
Shared sensitivity to data distribution during learning in humans and Transformer networks
“2025 LLM Year in Review”, Karpathy 2025
“Universally Converging Representations of Matter Across Scientific Foundation Models”, Edamadaka et al 2025
Universally Converging Representations of Matter Across Scientific Foundation Models
“Perch 2.0 Transfers ‘Whale’ to Underwater Tasks”, Burns et al 2025
“The Price of Progress: Algorithmic Efficiency and the Falling Cost of AI Inference”, Gundlach et al 2025
The Price of Progress: Algorithmic Efficiency and the Falling Cost of AI Inference
“Weight-Sparse Transformers Have Interpretable Circuits”, Gao et al 2025
“Scaling Recommender Transformers to a Billion Parameters: How to Implement a New Generation of Transformer Recommenders”, Кhrylchenko 2025
“The Coverage Principle: How Pre-Training Enables Post-Training”, Chen et al 2025
The Coverage Principle: How Pre-Training Enables Post-Training
“Scaling Laws for Code: A More Data-Hungry Regime”, Luo et al 2025
“Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity”, Zhang et al 2025
Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity
“Pre-Training under Infinite Compute”, Kim et al 2025
“‘I Have to Do It’: Why One of the World’s Most Brilliant AI Scientists Left the US for China”, Che 2025
‘I have to do it’: Why one of the world’s most brilliant AI scientists left the US for China
“How Does A Blind Model See The Earth? A Tiny LLM Eval With Pretty Pictures”, Henry 2025
How Does A Blind Model See The Earth? A tiny LLM eval with pretty pictures
“GPT-5 Is Here: Our Smartest, Fastest, and Most Useful Model Yet, With Thinking Built In. Available to Everyone”, OpenAI 2025
“Perch 2.0: The Bittern Lesson for Bioacoustics”, Merriënboer et al 2025
“The Making Of Dario Amodei: AI’s Most Outspoken Leader Found Direction in a Personal Tragedy”, Kantrowitz 2025
The Making Of Dario Amodei: AI’s most outspoken leader found direction in a personal tragedy
“Scaling Recommender Transformers to One Billion Parameters”, Khrylchenko et al 2025
“How Many Instructions Can LLMs Follow at Once?”, Jaroslawicz et al 2025
“Cloudflare Will Now Block AI Bots from Crawling Its Clients’ Websites by Default: The Company Will Also Introduce a ‘Pay-Per-Crawl’ System to Give Users More Fine-Grained Control over How AI Companies Can Access Their Sites”, Hall 2025
“Performance Prediction for Large Systems via Text-To-Text Regression”, Akhauri et al 2025
Performance Prediction for Large Systems via Text-to-Text Regression
“The Bitter Lesson Is Coming for Tokenization: a World of LLMs without Tokenization Is Desirable and Increasingly Possible”, Perić 2025
“Q1 AI Benchmarking Results: the Most Important Factor for Good Forecasting Is the Base Model”, Wilson 2025
Q1 AI Benchmarking Results: the most important factor for good forecasting is the base model
“Common Corpus: The Largest Collection of Ethical Data for LLM Pre-Training”, Langlais et al 2025
Common Corpus: The Largest Collection of Ethical Data for LLM Pre-Training
“Why I Don’t Think AGI Is Right around the Corner: Continual Learning Is a Huge Bottleneck”, Patel 2025
Why I don’t think AGI is right around the corner: Continual learning is a huge bottleneck
“What We Learned from Briefing 70+ Lawmakers on the Threat from AI”, Martínez 2025
What We Learned from Briefing 70+ Lawmakers on the Threat from AI
“Gen2seg: Generative Models Enable Generalizable Instance Segmentation”, Khangaonkar & Pirsiavash 2025
gen2seg: Generative Models Enable Generalizable Instance Segmentation
“Vec2vec: Harnessing the Universal Geometry of Embeddings”, Jha et al 2025
“Neural Thermodynamic Laws for Large Language Model Training”, Liu et al 2025
“Xi Takes an AI Masterclass: Inside the Politburo’s AI Study Session”, Schneider 2025
Xi Takes an AI Masterclass: Inside the Politburo’s AI Study Session
“How To Scale: Model Size, Parameterization, HP Scaling Laws, Batch Size”, Seo 2025
How To Scale: Model Size, Parameterization, HP Scaling Laws, Batch Size
View External Link:
“Psychometrically Derived 60-Question Benchmarks: Substantial Efficiencies and the Possibility of Human-AI Comparisons”, Gignac & Ilić 2025
“When ChatGPT Broke an Entire Field: An Oral History”, Pavlus 2025
“Testing the Limit of Atmospheric Predictability With a Machine Learning Weather Model”, Vonich & Hakim 2025
Testing the Limit of Atmospheric Predictability with a Machine Learning Weather Model
“Safety Pretraining: Toward the Next Generation of Safe AI”, Maini et al 2025
“Pre-Training Isn’t Dead, It’s Just Resting: GPT-4.5, the Value of RL, and the Economics of Frontier Training”, Chow & Gross-Whitaker 2025
“Progress Report on a Toy Model Of Memorization”, Brave 2025
“Cyc: Obituary for the Greatest Monument to Logical AGI”, Liu 2025
“Emuru: Zero-Shot Styled Text Image Generation, but Make It Autoregressive”, Pippi et al 2025
Emuru: Zero-Shot Styled Text Image Generation, but Make It Autoregressive
“Compute-Optimal LLMs Provably Generalize Better With Scale”, Finzi et al 2025
“My Thoughts on the Future of ‘AI’”, Carlini 2025
“Deep Learning Is Not So Mysterious or Different”, Wilson 2025
“SSI Israel Hires First Senior Researchers”, Gilead 2025
“Obscure Scientific Facts Benchmark”, Azulay 2025
“LLaDA: Large Language Diffusion Models”, Nie et al 2025
tamaybes @ "2025-02-13"
“Over-Tokenized Transformer: Vocabulary Is Generally Worth Scaling”, Huang et al 2025
Over-Tokenized Transformer: Vocabulary is Generally Worth Scaling
“Do Generative Video Models Learn Physical Principles from Watching Videos?”, Motamed et al 2025
Do generative video models learn physical principles from watching videos?
“Emergent Effects of Scaling on the Functional Hierarchies within Large Language Models”, Foop 2025
Emergent effects of scaling on the functional hierarchies within large language models
“What’s the Deal With Mid-Training?”, Doria 2025
“Things We Learned about LLMs in 2024”, Willison 2024
“2024 Letter [On LLM Benchmarking]”, Wang 2024
“Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference”, Warner et al 2024
“Byte Latent Transformer (BLT): Patches Scale Better Than Tokens”, Pagnoni et al 2024
Byte Latent Transformer (BLT): Patches Scale Better Than Tokens
“Densing Law of LLMs”, Xiao et al 2024
“Liquid: Language Models Are Scalable and Unified Multi-Modal Generators”, Wu et al 2024
Liquid: Language Models are Scalable and Unified Multi-modal Generators
“PaliGemma 2: A Family of Versatile VLMs for Transfer”, Steiner et al 2024
“Best-Of-N Jailbreaking”, Hughes et al 2024
“Drowning in Documents: Consequences of Scaling Reranker Inference”, Jacob et al 2024
Drowning in Documents: Consequences of Scaling Reranker Inference
“Medical Adaptation of Large Language and Vision-Language Models: Are We Making Progress?”, Jeong et al 2024
Medical Adaptation of Large Language and Vision-Language Models: Are We Making Progress?
“Fractal Patterns May Illuminate the Success of Next-Token Prediction”, Alabdulmohsin et al 2024
Fractal Patterns May Illuminate the Success of Next-Token Prediction
“How Far Is Video Generation from World Model: A Physical Law Perspective”, Kang et al 2024
How Far is Video Generation from World Model: A Physical Law Perspective
“Scaling up Masked Diffusion Models on Text”, Nie et al 2024
“ABBYY’s Bitter Lesson: How Linguists Lost the Last Battle for NLP”, Skorinkin 2024
ABBYY’s Bitter Lesson: How Linguists Lost the Last Battle for NLP
“CT Foundation: Taking Medical Imaging Embeddings 3D”, Kiraly & Traverse 2024
“Inference Scaling for Long-Context Retrieval Augmented Generation”, Yue et al 2024
Inference Scaling for Long-Context Retrieval Augmented Generation
“Strategic Insights from Simulation Gaming of AI Race Dynamics”, Gruetzemacher et al 2024
Strategic Insights from Simulation Gaming of AI Race Dynamics
“How Feature Learning Can Improve Neural Scaling Laws”, Bordelon et al 2024
“Dwarkesh Podcast Progress Update”, Patel 2024
“Safetywashing: Do AI Safety Benchmarks Actually Measure Safety Progress?”, Ren et al 2024
Safetywashing: Do AI Safety Benchmarks Actually Measure Safety Progress?
“Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process”, Ye et al 2024
Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process
“Scaling Laws With Vocabulary: Larger Models Deserve Larger Vocabularies”, Tao et al 2024
Scaling Laws with Vocabulary: Larger Models Deserve Larger Vocabularies
“Scaling Law in Neural Data: Non-Invasive Speech Decoding With 175 Hours of EEG Data”, Sato et al 2024
Scaling Law in Neural Data: Non-Invasive Speech Decoding with 175 Hours of EEG Data
“Future Events As Backdoor Triggers: Investigating Temporal Vulnerabilities in LLMs”, Price et al 2024
Future Events as Backdoor Triggers: Investigating Temporal Vulnerabilities in LLMs
“Resolving Discrepancies in Compute-Optimal Scaling of Language Models”, Porian et al 2024
Resolving Discrepancies in Compute-Optimal Scaling of Language Models
“Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?”, Lee et al 2024
Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
“Probing the Decision Boundaries of In-Context Learning in Large Language Models”, Zhao et al 2024
Probing the Decision Boundaries of In-context Learning in Large Language Models
“How Do Large Language Models Acquire Factual Knowledge During Pretraining?”, Chang et al 2024
How Do Large Language Models Acquire Factual Knowledge During Pretraining?
“Explore the Limits of Omni-Modal Pretraining at Scale”, Zhang et al 2024
“Self-Consuming Generative Models With Curated Data Provably Optimize Human Preferences”, Ferbach et al 2024
Self-Consuming Generative Models with Curated Data Provably Optimize Human Preferences
“Beyond Model Collapse: Scaling Up With Synthesized Data Requires Reinforcement”, Feng et al 2024
Beyond Model Collapse: Scaling Up with Synthesized Data Requires Reinforcement
“AI Couple”, Siegel & Kirkwood 2024
{kind=link}
“Attention As a Hypernetwork”, Schug et al 2024
“Training Compute-Optimal Protein Language Models”, Cheng et al 2024
“AI Will Become Mathematicians’ ‘Co-Pilot’: Fields Medalist Terence Tao Explains How Proof Checkers and AI Programs Are Dramatically Changing Mathematics”, Drösser & Tao 2024
“Regularization Properties of Polynomial Bases”, Shtoff 2024
“The Scaling Law in Stellar Light Curves”, Pan et al 2024
“AstroPT: Scaling Large Observation Models for Astronomy”, Smith et al 2024
“Aurora: A Foundation Model for the Earth System”, Bodnar et al 2024
“The Platonic Representation Hypothesis”, Huh et al 2024
“XLSTM: Extended Long Short-Term Memory”, Beck et al 2024
“Position: Understanding LLMs Requires More Than Statistical Generalization”, Reizinger et al 2024
Position: Understanding LLMs Requires More Than Statistical Generalization
“GSM1k: A Careful Examination of Large Language Model Performance on Grade School Arithmetic”, Zhang et al 2024
GSM1k: A Careful Examination of Large Language Model Performance on Grade School Arithmetic
“Scaling and Renormalization in High-Dimensional Regression”, Atanasov et al 2024
“CatLIP: CLIP-Level Visual Recognition Accuracy With 2.7× Faster Pre-Training on Web-Scale Image-Text Data”, Mehta et al 2024
“Private Attribute Inference from Images With Vision-Language Models”, Tömekçe et al 2024
Private Attribute Inference from Images with Vision-Language Models
“Test-Time Augmentation to Solve ARC”, Cole 2024
“Compression Represents Intelligence Linearly”, Huang et al 2024
“Chinchilla Scaling: A Replication Attempt”, Besiroglu et al 2024
“Scaling (Down) CLIP: A Comprehensive Analysis of Data, Architecture, and Training Strategies”, Li et al 2024
Scaling (Down) CLIP: A Comprehensive Analysis of Data, Architecture, and Training Strategies
“Why Do Small Language Models Underperform? Studying Language Model Saturation via the Softmax Bottleneck”, Godey et al 2024
“Language Imbalance Can Boost Cross-Lingual Generalization”, Schäfer et al 2024
“CulturalTeaming: AI-Assisted Interactive Red-Teaming for Challenging LLMs’ (Lack Of) Multicultural Knowledge”, Chiu et al 2024
“Conformer-1: Robust ASR via Large-Scale Semi-Supervised Bootstrapping”, Zhang et al 2024
Conformer-1: Robust ASR via Large-Scale Semi-supervised Bootstrapping
“MiniCPM: Unveiling the Potential of Small Language Models With Scalable Training Strategies”, Hu et al 2024
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
“Visual Autoregressive Modeling (VAR): Scalable Image Generation via Next-Scale Prediction”, Tian et al 2024
Visual Autoregressive Modeling (VAR): Scalable Image Generation via Next-Scale Prediction
“The Rationale-Shaped Hole At The Heart Of Forecasting”, dschwarz et al 2024
“Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data”, Gerstgrasser et al 2024
“Scaling Laws For Dense Retrieval”, Fang et al 2024
“Long-Form Factuality in Large Language Models”, Wei et al 2024
“Mechanistic Design and Scaling of Hybrid Architectures”, Poli et al 2024
“Data Mixing Laws: Optimizing Data Mixtures by Predicting Language Modeling Performance”, Ye et al 2024
Data Mixing Laws: Optimizing Data Mixtures by Predicting Language Modeling Performance
“8 Google Employees Invented Modern AI. Here’s the Inside Story: They Met by Chance, Got Hooked on an Idea, and Wrote the Transformers Paper—The Most Consequential Tech Breakthrough in Recent History”, Levy 2024
“Inflection-2.5: Meet the World’s Best Personal AI”, Inflection 2024
“Revisiting Dynamic Evaluation: Online Adaptation for Large Language Models”, Rannen-Triki et al 2024
Revisiting Dynamic Evaluation: Online Adaptation for Large Language Models
“Actions Speak Louder Than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations (HSTU)”, Zhai et al 2024
“When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method”, Zhang et al 2024
When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method
“Investigating Continual Pretraining in Large Language Models: Insights and Implications”, Yıldız et al 2024
Investigating Continual Pretraining in Large Language Models: Insights and Implications
“The Era of 1-Bit LLMs: All Large Language Models Are in 1.58 Bits”, Ma et al 2024
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
“StructLM: Towards Building Generalist Models for Structured Knowledge Grounding”, Zhuang et al 2024
StructLM: Towards Building Generalist Models for Structured Knowledge Grounding
“How to Train Data-Efficient LLMs”, Sachdeva et al 2024
“Weaver: Foundation Models for Creative Writing”, Wang et al 2024
“Arrows of Time for Large Language Models”, Papadopoulos et al 2024
“Can AI Assistants Know What They Don’t Know?”, Cheng et al 2024
“I Am a Strange Dataset: Metalinguistic Tests for Language Models”, Thrush et al 2024
I am a Strange Dataset: Metalinguistic Tests for Language Models
“The Perceptron Controversy: Connectionism Died in the 1960s from Technical Limits to Scaling, Then Resurrected in the 1980s After Backprop Allowed Scaling. The Minsky–Papert Anti-Scaling Hypothesis Explained, Psychoanalyzed, and Buried”, Liu 2024
“TF-T2V: A Recipe for Scaling up Text-To-Video Generation With Text-Free Videos”, Wang et al 2023
TF-T2V: A Recipe for Scaling up Text-to-Video Generation with Text-free Videos
“Generative Multimodal Models Are In-Context Learners”, Sun et al 2023
“Zoology: Measuring and Improving Recall in Efficient Language Models”, Arora et al 2023
Zoology: Measuring and Improving Recall in Efficient Language Models
“Seamless: Multilingual Expressive and Streaming Speech Translation”, Communication et al 2023
Seamless: Multilingual Expressive and Streaming Speech Translation
“Scaling Transformer Neural Networks for Skillful and Reliable Medium-Range Weather Forecasting”, Nguyen et al 2023
Scaling transformer neural networks for skillful and reliable medium-range weather forecasting
“Instruction-Tuning Aligns LLMs to the Human Brain”, Aw et al 2023
“Mamba: Linear-Time Sequence Modeling With Selective State Spaces”, Gu & Dao 2023
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
“Sequential Modeling Enables Scalable Learning for Large Vision Models”, Bai et al 2023
Sequential Modeling Enables Scalable Learning for Large Vision Models
“UniRepLKNet: A Universal Perception Large-Kernel ConvNet for Audio, Video, Point Cloud, Time-Series and Image Recognition”, Ding et al 2023
“Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets”, Blattmann et al 2023
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
“In Search of the Long-Tail: Systematic Generation of Long-Tail Inferential Knowledge via Logical Rule Guided Search”, Li et al 2023
“First Tragedy, Then Parse: History Repeats Itself in the New Era of Large Language Models”, Saphra et al 2023
First Tragedy, then Parse: History Repeats Itself in the New Era of Large Language Models
“I2VGen-XL: High-Quality Image-To-Video Synthesis via Cascaded Diffusion Models”, Zhang et al 2023
I2VGen-XL: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models
“A Systematic Comparison of Syllogistic Reasoning in Humans and Language Models”, Eisape et al 2023
A Systematic Comparison of Syllogistic Reasoning in Humans and Language Models
“Sam Altman Accepts the 2023 Hawking Fellowship Award § Is There Another Breakthrough That’s Needed to Reach AGI?”, Altman 2023
“ConvNets Match Vision Transformers at Scale”, Smith et al 2023
“Evidence of Interrelated Cognitive-Like Capabilities in Large Language Models: Indications of Artificial General Intelligence or Achievement?”, Ilić & Gignac 2023
“PaLI-3 Vision Language Models: Smaller, Faster, Stronger”, Chen et al 2023
“GeoLLM: Extracting Geospatial Knowledge from Large Language Models”, Manvi et al 2023
GeoLLM: Extracting Geospatial Knowledge from Large Language Models
“Dynamical versus Bayesian Phase Transitions in a Toy Model of Superposition”, Chen et al 2023
Dynamical versus Bayesian Phase Transitions in a Toy Model of Superposition
“Sheared LLaMA: Accelerating Language Model Pre-Training via Structured Pruning”, Xia et al 2023
Sheared LLaMA: Accelerating Language Model Pre-training via Structured Pruning
“FreshLLMs: Refreshing Large Language Models With Search Engine Augmentation”, Vu et al 2023
FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation
“Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors”, Amos et al 2023
Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors
“MTOB: A Benchmark for Learning to Translate a New Language from One Grammar Book”, Tanzer et al 2023
MTOB: A Benchmark for Learning to Translate a New Language from One Grammar Book
“Intriguing Properties of Generative Classifiers”, Jaini et al 2023
“Taken out of Context: On Measuring Situational Awareness in LLMs”, Berglund et al 2023
Taken out of context: On measuring situational awareness in LLMs
“SeamlessM4T: Massively Multilingual & Multimodal Machine Translation”, Communication et al 2023
SeamlessM4T: Massively Multilingual & Multimodal Machine Translation
“Two Phases of Scaling Laws for Nearest Neighbor Classifiers”, Yang & Zhang 2023
“Simple Synthetic Data Reduces Sycophancy in Large Language Models”, Wei et al 2023
Simple synthetic data reduces sycophancy in large language models
“Scaling Relationship on Learning Mathematical Reasoning With Large Language Models”, Yuan et al 2023
Scaling Relationship on Learning Mathematical Reasoning with Large Language Models
“LLaMA-2: Open Foundation and Fine-Tuned Chat Models”, Touvron et al 2023
“Measuring Faithfulness in Chain-Of-Thought Reasoning”, Lanham et al 2023
“Unleashing the Emergent Cognitive Synergy in Large Language Models: A Task-Solving Agent through Multi-Persona Self-Collaboration”, Wang et al 2023
“Introducing Superalignment”, Leike & Sutskever 2023
“Gödel, Escher, Bach Author Douglas Hofstadter on the State of AI Today § What about AI Terrifies You?”, Hofstadter & Kim 2023
“Pretraining Task Diversity and the Emergence of Non-Bayesian In-Context Learning for Regression”, Raventós et al 2023
Pretraining task diversity and the emergence of non-Bayesian in-context learning for regression
“Beyond Scale: the Diversity Coefficient As a Data Quality Metric Demonstrates LLMs Are Pre-Trained on Formally Diverse Data”, Lee et al 2023
“Scaling MLPs: A Tale of Inductive Bias”, Bachmann et al 2023
“Inflection-1: Pi’s Best-In-Class LLM”, Inflection 2023
“Understanding Social Reasoning in Language Models With Language Models”, Gandhi et al 2023
Understanding Social Reasoning in Language Models with Language Models
“Image Captioners Are Scalable Vision Learners Too”, Tschannen et al 2023
“PaLI-X: On Scaling up a Multilingual Vision and Language Model”, Chen et al 2023
PaLI-X: On Scaling up a Multilingual Vision and Language Model
“The False Promise of Imitating Proprietary LLMs”, Gudibande et al 2023
“Scaling Data-Constrained Language Models”, Muennighoff et al 2023
“FST: Improving Speech Translation by Fusing Speech and Text”, Yin et al 2023
“Scaling Laws for Language Encoding Models in FMRI”, Antonello et al 2023
“LIMA: Less Is More for Alignment”, Zhou et al 2023
“PaLM 2 Technical Report”, Anil et al 2023
“Google’s Newest AI Model Uses Nearly 5× More Text Data for Training Than Its Predecessor”, Elias 2023
Google’s newest AI model uses nearly 5× more text data for training than its predecessor
“TorToise: Better Speech Synthesis through Scaling”, Betker 2023
“TinyStories: How Small Can Language Models Be and Still Speak Coherent English?”, Eldan & Li 2023
TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
“ImageBind: One Embedding Space To Bind Them All”, Girdhar et al 2023
“Finding Neurons in a Haystack: Case Studies With Sparse Probing”, Gurnee et al 2023
Finding Neurons in a Haystack: Case Studies with Sparse Probing
“Geoffrey Hinton Tells Us Why He’s Now Scared of the Tech He Helped Build: ‘I Have Suddenly Switched My Views on Whether These Things Are Going to Be More Intelligent Than Us.’”, Heaven 2023
“Speak, Memory: An Archaeology of Books Known to ChatGPT/GPT-4”, Chang et al 2023
Speak, Memory: An Archaeology of Books Known to ChatGPT/GPT-4
“Google’s DeepMind-Brain Merger: Tech Giant Regroups for AI Battle”, Murgia 2023
Google’s DeepMind-Brain merger: tech giant regroups for AI battle
“CLaMP: Contrastive Language-Music Pre-Training for Cross-Modal Symbolic Music Information Retrieval”, Wu et al 2023
CLaMP: Contrastive Language-Music Pre-training for Cross-Modal Symbolic Music Information Retrieval
“Emergent and Predictable Memorization in Large Language Models”, Biderman et al 2023
Emergent and Predictable Memorization in Large Language Models
“Power Law Trends in Speedrunning and Machine Learning”, Erdil & Sevilla 2023
“Even The Politicians Thought the Open Letter Made No Sense In The Senate Hearing on AI Today’s Hearing on Ai Covered Ai Regulation and Challenges, and the Infamous Open Letter, Which Nearly Everyone in the Room Thought Was Unwise”, Gorrell 2023
“DINOv2: Learning Robust Visual Features without Supervision”, Oquab et al 2023
“Segment Anything”, Kirillov et al 2023
“Humans in Humans Out: On GPT Converging Toward Common Sense in Both Success and Failure”, Koralus & Wang-Maścianica 2023
Humans in Humans Out: On GPT Converging Toward Common Sense in both Success and Failure
“Sigmoid Loss for Language Image Pre-Training”, Zhai et al 2023
“‘AI’ on a Calculator: Part 1 [MNIST CNN on a TI-84 Graphing Calculator]”, Mitchell 2023
‘AI’ on a Calculator: Part 1 [MNIST CNN on a TI-84 graphing calculator]
“How Well Do Large Language Models Perform in Arithmetic Tasks?”, Yuan et al 2023
How well do Large Language Models perform in Arithmetic tasks?
“GPT-4 Technical Report”, OpenAI 2023
“Securing Liberal Democratic Control of AGI through UK Leadership”, Phillips 2023
Securing Liberal Democratic Control of AGI through UK Leadership
“GigaGAN: Scaling up GANs for Text-To-Image Synthesis”, Kang et al 2023
“Why Didn’t We Get GPT-2 in 2005?”, Dynomight 2023
Why didn’t we get GPT-2 in 2005?
View External Link:
“Language Is Not All You Need: Aligning Perception With Language Models (Kosmos-1)”, Huang et al 2023
Language Is Not All You Need: Aligning Perception with Language Models (Kosmos-1)
“Why Didn’t DeepMind Build GPT-3?”, Godwin 2023
“Is Multimodal Vision Supervision Beneficial to Language?”, Madasu & Lal 2023
“Scaling Vision Transformers to 22 Billion Parameters”, Dehghani et al 2023
“John Carmack’s ‘Different Path’ to Artificial General Intelligence”, Carmack 2023
John Carmack’s ‘Different Path’ to Artificial General Intelligence
“Large Language Models As Fiduciaries: A Case Study Toward Robustly Communicating With Artificial Intelligence Through Legal Standards”, Nay 2023
“ClimaX: A Foundation Model for Weather and Climate”, Nguyen et al 2023
“StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-To-Image Synthesis”, Sauer et al 2023
StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-to-Image Synthesis
“MUG: Vision Learners Meet Web Image-Text Pairs”, Zhao et al 2023
“GPT-3 As Knowledge Worker: A Zero-Shot Evaluation of AI CPA Capabilities”, Bommarito et al 2023
GPT-3 as Knowledge Worker: A Zero-Shot Evaluation of AI CPA Capabilities
“Scaling Laws for Generative Mixed-Modal Language Models”, Aghajanyan et al 2023
“VALL-E: Neural Codec Language Models Are Zero-Shot Text to Speech Synthesizers”, Wang et al 2023
VALL-E: Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
“Large-Scale Weakly-Supervised Content Embeddings for Music Recommendation and Tagging”, Huang et al 2023
Large-Scale Weakly-Supervised Content Embeddings for Music Recommendation and Tagging
“GPT-3 Takes the Bar Exam”, II & Katz 2022
“Cramming: Training a Language Model on a Single GPU in One Day”, Geiping & Goldstein 2022
Cramming: Training a Language Model on a Single GPU in One Day
“Evolutionary-Scale Prediction of Atomic Level Protein Structure With a Language Model”, Lin et al 2022
Evolutionary-scale prediction of atomic level protein structure with a language model
“Discovering Language Model Behaviors With Model-Written Evaluations”, Perez et al 2022
Discovering Language Model Behaviors with Model-Written Evaluations
“One Embedder, Any Task: Instruction-Finetuned Text Embeddings (INSTRUCTOR)”, Su et al 2022
One Embedder, Any Task: Instruction-Finetuned Text Embeddings (INSTRUCTOR)
“Reproducible Scaling Laws for Contrastive Language-Image Learning”, Cherti et al 2022
Reproducible scaling laws for contrastive language-image learning
“ERNIE-Code: Beyond English-Centric Cross-Lingual Pretraining for Programming Languages”, Chai et al 2022
ERNIE-Code: Beyond English-Centric Cross-lingual Pretraining for Programming Languages
“VideoCoCa: Video-Text Modeling With Zero-Shot Transfer from Contrastive Captioners”, Yan et al 2022
VideoCoCa: Video-Text Modeling with Zero-Shot Transfer from Contrastive Captioners
“VindLU: A Recipe for Effective Video-And-Language Pretraining”, Cheng et al 2022
VindLU: A Recipe for Effective Video-and-Language Pretraining
“Whisper: Robust Speech Recognition via Large-Scale Weak Supervision”, Radford et al 2022
Whisper: Robust Speech Recognition via Large-Scale Weak Supervision
“Scaling Language-Image Pre-Training via Masking”, Li et al 2022
“Galactica: A Large Language Model for Science”, Taylor et al 2022
“Large Language Models Struggle to Learn Long-Tail Knowledge”, Kandpal et al 2022
“EVA: Exploring the Limits of Masked Visual Representation Learning at Scale”, Fang et al 2022
EVA: Exploring the Limits of Masked Visual Representation Learning at Scale
“MMDialog: A Large-Scale Multi-Turn Dialogue Dataset Towards Multi-Modal Open-Domain Conversation”, Feng et al 2022
MMDialog: A Large-scale Multi-turn Dialogue Dataset Towards Multi-modal Open-domain Conversation
“Adversarial Policies Beat Superhuman Go AIs”, Wang et al 2022
“Increments Podcast: #45—4 Central Fallacies of AI Research (With Melanie Mitchell)”, Mitchell & Chugg 2022
Increments Podcast: #45—4 Central Fallacies of AI Research (with Melanie Mitchell)
“A Solvable Model of Neural Scaling Laws”, Maloney et al 2022
“Will We Run out of Data? An Analysis of the Limits of Scaling Datasets in Machine Learning”, Villalobos et al 2022
Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning
“Evaluating Parameter Efficient Learning for Generation”, Xu et al 2022
“FLAN: Scaling Instruction-Finetuned Language Models”, Chung et al 2022
“BioGPT: Generative Pre-Trained Transformer for Biomedical Text Generation and Mining”, Luo et al 2022
BioGPT: Generative Pre-trained Transformer for Biomedical Text Generation and Mining
“Vision-Language Pre-Training: Basics, Recent Advances, and Future Trends”, Gan et al 2022
Vision-Language Pre-training: Basics, Recent Advances, and Future Trends
“Foundation Transformers”, Wang et al 2022
“Self-Ask: Measuring and Narrowing the Compositionality Gap in Language Models (Bamboogle)”, Press et al 2022
Self-Ask: Measuring and Narrowing the Compositionality Gap in Language Models (Bamboogle)
“The Lie Derivative for Measuring Learned Equivariance”, Gruver et al 2022
“GLM-130B: An Open Bilingual Pre-Trained Model”, Zeng et al 2022
“Ask Me Anything (AMA): A Simple Strategy for Prompting Language Models”, Arora et al 2022
Ask Me Anything (AMA): A simple strategy for prompting language models
“Do Current Multi-Task Optimization Methods in Deep Learning Even Help?”, Xin et al 2022
Do Current Multi-Task Optimization Methods in Deep Learning Even Help?
“Monolith: Real Time Recommendation System With Collisionless Embedding Table”, Liu et al 2022
Monolith: Real Time Recommendation System With Collisionless Embedding Table
“Machine Reading, Fast and Slow: When Do Models "Understand" Language?”, Choudhury et al 2022
Machine Reading, Fast and Slow: When Do Models "Understand" Language?
“PaLI: A Jointly-Scaled Multilingual Language-Image Model”, Chen et al 2022
“Using Large Language Models to Simulate Multiple Humans”, Aher et al 2022
“Understanding Scaling Laws for Recommendation Models”, Ardalani et al 2022
“LLM.int8(): 8-Bit Matrix Multiplication for Transformers at Scale”, Dettmers et al 2022
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
“Quality Not Quantity: On the Interaction between Dataset Design and Robustness of CLIP”, Nguyen et al 2022
Quality Not Quantity: On the Interaction between Dataset Design and Robustness of CLIP
“Efficient Training of Language Models to Fill in the Middle”, Bavarian et al 2022
“Why Do Tree-Based Models Still Outperform Deep Learning on Tabular Data?”, Grinsztajn et al 2022
Why do tree-based models still outperform deep learning on tabular data?
“PIXEL: Language Modeling With Pixels”, Rust et al 2022
“High-Performing Neural Network Models of Visual Cortex Benefit from High Latent Dimensionality”, Elmoznino & Bonner 2022
High-performing neural network models of visual cortex benefit from high latent dimensionality
“Exploring Length Generalization in Large Language Models”, Anil et al 2022
“Language Models (Mostly) Know What They Know”, Kadavath et al 2022
“On-Device Training Under 256KB Memory”, Lin et al 2022
“Beyond Neural Scaling Laws: Beating Power Law Scaling via Data Pruning”, Sorscher et al 2022
Beyond neural scaling laws: beating power law scaling via data pruning
“ProGen2: Exploring the Boundaries of Protein Language Models”, Nijkamp et al 2022
ProGen2: Exploring the Boundaries of Protein Language Models
“RST: ReStructured Pre-Training”, Yuan & Liu 2022
“Limitations of the NTK for Understanding Generalization in Deep Learning”, Vyas et al 2022
Limitations of the NTK for Understanding Generalization in Deep Learning
“Modeling Transformative AI Risks (MTAIR) Project—Summary Report”, Clarke et al 2022
Modeling Transformative AI Risks (MTAIR) Project—Summary Report
“LIFT: Language-Interfaced Fine-Tuning for Non-Language Machine Learning Tasks”, Dinh et al 2022
LIFT: Language-Interfaced Fine-Tuning for Non-Language Machine Learning Tasks
“BigVGAN: A Universal Neural Vocoder With Large-Scale Training”, Lee et al 2022
BigVGAN: A Universal Neural Vocoder with Large-Scale Training
“An Improved One Millisecond Mobile Backbone”, Vasu et al 2022
“A Neural Corpus Indexer for Document Retrieval”, Wang et al 2022
“Toward a Realistic Model of Speech Processing in the Brain With Self-Supervised Learning”, Millet et al 2022
Toward a realistic model of speech processing in the brain with self-supervised learning
“Teaching Models to Express Their Uncertainty in Words”, Lin et al 2022
“Why Robust Generalization in Deep Learning Is Difficult: Perspective of Expressive Power”, Li et al 2022
Why Robust Generalization in Deep Learning is Difficult: Perspective of Expressive Power
“M3AE: Multimodal Masked Autoencoders Learn Transferable Representations”, Geng et al 2022
M3AE: Multimodal Masked Autoencoders Learn Transferable Representations
“InstructDial: Improving Zero and Few-Shot Generalization in Dialogue through Instruction Tuning”, Gupta et al 2022
InstructDial: Improving Zero and Few-shot Generalization in Dialogue through Instruction Tuning
“Memorization Without Overfitting: Analyzing the Training Dynamics of Large Language Models”, Tirumala et al 2022
Memorization Without Overfitting: Analyzing the Training Dynamics of Large Language Models
“Least-To-Most Prompting Enables Complex Reasoning in Large Language Models”, Zhou et al 2022
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
“Continual Pre-Training Mitigates Forgetting in Language and Vision”, Cossu et al 2022
Continual Pre-Training Mitigates Forgetting in Language and Vision
“Dialog Inpainting: Turning Documents into Dialogues”, Dai et al 2022
“UL2: Unifying Language Learning Paradigms”, Tay et al 2022
“Building Machine Translation Systems for the Next Thousand Languages”, Bapna et al 2022
Building Machine Translation Systems for the Next Thousand Languages
“When Does Dough Become a Bagel? Analyzing the Remaining Mistakes on ImageNet”, Vasudevan et al 2022
When does dough become a bagel? Analyzing the remaining mistakes on ImageNet
“CoCa: Contrastive Captioners Are Image-Text Foundation Models”, Yu et al 2022
CoCa: Contrastive Captioners are Image-Text Foundation Models
“Data Determines Distributional Robustness in Contrastive Language Image Pre-Training (CLIP)”, Fang et al 2022
Data Determines Distributional Robustness in Contrastive Language Image Pre-training (CLIP)
“Continual Learning With Foundation Models: An Empirical Study of Latent Replay”, Ostapenko et al 2022
Continual Learning with Foundation Models: An Empirical Study of Latent Replay
“Flamingo: a Visual Language Model for Few-Shot Learning”, Alayrac et al 2022
“WebFace260M: A Benchmark for Million-Scale Deep Face Recognition”, Zhu et al 2022
WebFace260M: A Benchmark for Million-Scale Deep Face Recognition
“Tk-Instruct: Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks”, Wang et al 2022
Tk-Instruct: Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks
“What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?”, Wang et al 2022
What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?
“DeepMind: The Podcast—Excerpts on AGI”, Kiely 2022
“Can Language Models Learn from Explanations in Context?”, Lampinen et al 2022
“Chinchilla: Training Compute-Optimal Large Language Models”, Hoffmann et al 2022
“A Roadmap for Big Model”, Yuan et al 2022
“A Conversational Paradigm for Program Synthesis”, Nijkamp et al 2022
“Self-Consistency Improves Chain-Of-Thought Reasoning in Language Models”, Wang et al 2022
Self-Consistency Improves Chain-of-Thought Reasoning in Language Models
“Effect of Scale on Catastrophic Forgetting in Neural Networks”, Ramasesh et al 2022
Effect of scale on catastrophic forgetting in neural networks
“Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer”, Yang et al 2022
Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer
“FastFold: Reducing AlphaFold Training Time from 11 Days to 67 Hours”, Cheng et al 2022
FastFold: Reducing AlphaFold Training Time from 11 Days to 67 Hours
“Variational Autoencoders Without the Variation”, Daly et al 2022
“Performance Reserves in Brain-Imaging-Based Phenotype Prediction”, Schulz et al 2022
Performance reserves in brain-imaging-based phenotype prediction
“Self-Distilled StyleGAN: Towards Generation from Internet Photos”, Mokady et al 2022
Self-Distilled StyleGAN: Towards Generation from Internet Photos
“UnifiedQA-V2: Stronger Generalization via Broader Cross-Format Training”, Khashabi et al 2022
UnifiedQA-v2: Stronger Generalization via Broader Cross-Format Training
“Vision Models Are More Robust And Fair When Pretrained On Uncurated Images Without Supervision”, Goyal et al 2022
Vision Models Are More Robust And Fair When Pretrained On Uncurated Images Without Supervision
“Brains and Algorithms Partially Converge in Natural Language Processing”, Caucheteux & King 2022
Brains and algorithms partially converge in natural language processing
“Quantifying Memorization Across Neural Language Models”, Carlini et al 2022
“Wukong: 100 Million Large-Scale Chinese Cross-Modal Pre-Training Dataset and A Foundation Framework”, Gu et al 2022
Wukong: 100 Million Large-scale Chinese Cross-modal Pre-training Dataset and A Foundation Framework
“OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-To-Sequence Learning Framework”, Wang et al 2022
“Data Scaling Laws in NMT: The Effect of Noise and Architecture”, Bansal et al 2022
Data Scaling Laws in NMT: The Effect of Noise and Architecture
“Webly Supervised Concept Expansion for General Purpose Vision Models”, Kamath et al 2022
Webly Supervised Concept Expansion for General Purpose Vision Models
“StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets”, Sauer et al 2022
“Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model”, Smith et al 2022
“Reasoning Like Program Executors”, Pi et al 2022
“Text and Code Embeddings by Contrastive Pre-Training”, Neelakantan et al 2022
“LaMDA: Language Models for Dialog Applications”, Thoppilan et al 2022
“SWAG: Revisiting Weakly Supervised Pre-Training of Visual Perception Models”, Singh et al 2022
SWAG: Revisiting Weakly Supervised Pre-Training of Visual Perception Models
“CM3: A Causal Masked Multimodal Model of the Internet”, Aghajanyan et al 2022
“ZeroPrompt: Scaling Prompt-Based Pretraining to 1,000 Tasks Improves Zero-Shot Generalization”, Xu et al 2022
ZeroPrompt: Scaling Prompt-Based Pretraining to 1,000 Tasks Improves Zero-Shot Generalization
“A High-Dimensional Sphere Spilling out of a High-Dimensional Cube despite Exponentially Many Constraints”, Fort 2022
“ConvNeXt: A ConvNet for the 2020s”, Liu et al 2022
“The Defeat of the Winograd Schema Challenge”, Kocijan et al 2022
“Robust Self-Supervised Audio-Visual Speech Recognition”, Shi et al 2022
“AV-HuBERT: Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction”, Shi et al 2022
AV-HuBERT: Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction
“Self-Supervised Learning from 100 Million Medical Images”, Ghesu et al 2022
“The Evolution of Quantitative Sensitivity”, Bryer et al 2021
“ERNIE 3.0 Titan: Exploring Larger-Scale Knowledge Enhanced Pre-Training for Language Understanding and Generation”, Wang et al 2021
“XGLM: Few-Shot Learning With Multilingual Language Models”, Lin et al 2021
“An Empirical Investigation of the Role of Pre-Training in Lifelong Learning”, Mehta et al 2021
An Empirical Investigation of the Role of Pre-training in Lifelong Learning
“Few-Shot Instruction Prompts for Pretrained Language Models to Detect Social Biases”, Prabhumoye et al 2021
Few-shot Instruction Prompts for Pretrained Language Models to Detect Social Biases
“Knowledge-Rich Self-Supervised Entity Linking”, Zhang et al 2021
“You Only Need One Model for Open-Domain Question Answering”, Lee et al 2021
“EBERT: Epigenomic Language Models Powered by Cerebras”, Trotter et al 2021
“MAGMA—Multimodal Augmentation of Generative Models through Adapter-Based Finetuning”, Eichenberg et al 2021
MAGMA—Multimodal Augmentation of Generative Models through Adapter-based Finetuning
“Improving Language Models by Retrieving from Trillions of Tokens”, Borgeaud et al 2021
Improving language models by retrieving from trillions of tokens
“MLP Architectures for Vision-And-Language Modeling: An Empirical Study”, Nie et al 2021
MLP Architectures for Vision-and-Language Modeling: An Empirical Study
“LEMON: Scaling Up Vision-Language Pre-Training for Image Captioning”, Hu et al 2021
LEMON: Scaling Up Vision-Language Pre-training for Image Captioning
“Scaling Transformers: Sparse Is Enough in Scaling Transformers”, Jaszczur et al 2021
Scaling Transformers: Sparse is Enough in Scaling Transformers
“Can Pre-Trained Language Models Be Used to Resolve Textual and Semantic Merge Conflicts?”, Zhang et al 2021
Can Pre-trained Language Models be Used to Resolve Textual and Semantic Merge Conflicts?
“ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning”, Aribandi et al 2021
ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning
“L-Verse: Bidirectional Generation Between Image and Text”, Kim et al 2021
“RedCaps: Web-Curated Image-Text Data Created by the People, for the People”, Desai et al 2021
RedCaps: web-curated image-text data created by the people, for the people
“Florence: A New Foundation Model for Computer Vision”, Yuan et al 2021
“BASIC: Combined Scaling for Open-Vocabulary Image Classification”, Pham et al 2021
BASIC: Combined Scaling for Open-Vocabulary Image Classification
“Swin Transformer V2: Scaling Up Capacity and Resolution”, Liu et al 2021
“XLS-R: Self-Supervised Cross-Lingual Speech Representation Learning at Scale”, Babu et al 2021
XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale
“Solving Linear Algebra by Program Synthesis”, Drori & Verma 2021
“Covariate Shift in High-Dimensional Random Feature Regression”, Tripuraneni et al 2021
Covariate Shift in High-Dimensional Random Feature Regression
“Solving Probability and Statistics Problems by Program Synthesis”, Tang et al 2021
Solving Probability and Statistics Problems by Program Synthesis
“Few-Shot Self-Rationalization With Natural Language Prompts”, Marasović et al 2021
“INTERN: A New Learning Paradigm Towards General Vision”, Shao et al 2021
“Scaling Law for Recommendation Models: Towards General-Purpose User Representations”, Shin et al 2021
Scaling Law for Recommendation Models: Towards General-purpose User Representations
“MAE: Masked Autoencoders Are Scalable Vision Learners”, He et al 2021
“Persia: An Open, Hybrid System Scaling Deep Learning-Based Recommenders up to 100 Trillion Parameters”, Lian et al 2021
“Scaling ASR Improves Zero and Few Shot Learning”, Xiao et al 2021
“Turing-Universal Learners With Optimal Scaling Laws”, Nakkiran 2021
“LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs”, Schuhmann et al 2021
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
“Training Verifiers to Solve Math Word Problems”, Cobbe et al 2021
“Just Ask for Generalization”, Jang 2021
“Wide Neural Networks Forget Less Catastrophically”, Mirzadeh et al 2021
“No One Representation to Rule Them All: Overlapping Features of Training Methods”, Gontijo-Lopes et al 2021
No One Representation to Rule Them All: Overlapping Features of Training Methods
“When in Doubt, Summon the Titans: Efficient Inference With Large Models”, Rawat et al 2021
When in Doubt, Summon the Titans: Efficient Inference with Large Models
“The Dangers of Underclaiming: Reasons for Caution When Reporting How NLP Systems Fail”, Bowman 2021
The Dangers of Underclaiming: Reasons for Caution When Reporting How NLP Systems Fail
“Symbolic Knowledge Distillation: from General Language Models to Commonsense Models”, West et al 2021
Symbolic Knowledge Distillation: from General Language Models to Commonsense Models
“LFPT5: A Unified Framework for Lifelong Few-Shot Language Learning Based on Prompt Tuning of T5”, Qin & Joty 2021
LFPT5: A Unified Framework for Lifelong Few-shot Language Learning Based on Prompt Tuning of T5
“Scaling Laws for the Few-Shot Adaptation of Pre-Trained Image Classifiers”, Prato et al 2021
Scaling Laws for the Few-Shot Adaptation of Pre-trained Image Classifiers
“Unsupervised Neural Machine Translation With Generative Language Models Only”, Han et al 2021
Unsupervised Neural Machine Translation with Generative Language Models Only
“Yuan 1.0: Large-Scale Pre-Trained Language Model in Zero-Shot and Few-Shot Learning”, Wu et al 2021
Yuan 1.0: Large-Scale Pre-trained Language Model in Zero-Shot and Few-Shot Learning
“Universal Paralinguistic Speech Representations Using Self-Supervised Conformers”, Shor et al 2021
Universal Paralinguistic Speech Representations Using Self-Supervised Conformers
“M6–10T: A Sharing-Delinking Paradigm for Efficient Multi-Trillion Parameter Pretraining”, Lin et al 2021
M6–10T: A Sharing-Delinking Paradigm for Efficient Multi-Trillion Parameter Pretraining
“A Few More Examples May Be Worth Billions of Parameters”, Kirstain et al 2021
“Exploring the Limits of Large Scale Pre-Training”, Abnar et al 2021
“Show Your Work: Scratchpads for Intermediate Computation With Language Models”, Nye et al 2021
Show Your Work: Scratchpads for Intermediate Computation with Language Models
“Mining for Strong Gravitational Lenses With Self-Supervised Learning”, Stein et al 2021
Mining for strong gravitational lenses with self-supervised learning
“Stochastic Training Is Not Necessary for Generalization”, Geiping et al 2021
“Evaluating Machine Accuracy on ImageNet”, Shankar et al 2021
“BigSSL: Exploring the Frontier of Large-Scale Semi-Supervised Learning for Automatic Speech Recognition”, Zhang et al 2021
“Scale Efficiently: Insights from Pre-Training and Fine-Tuning Transformers”, Tay et al 2021
Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers
“Scaling Laws for Neural Machine Translation”, Ghorbani et al 2021
“What Changes Can Large-Scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-Scale Korean Generative Pretrained Transformers”, Kim et al 2021
“A Recipe For Arbitrary Text Style Transfer With Large Language Models”, Reif et al 2021
A Recipe For Arbitrary Text Style Transfer with Large Language Models
“TruthfulQA: Measuring How Models Mimic Human Falsehoods”, Lin et al 2021
“A Farewell to the Bias-Variance Tradeoff? An Overview of the Theory of Overparameterized Machine Learning”, Dar et al 2021
“General-Purpose Question-Answering With Macaw”, Tafjord & Clark 2021
“An Empirical Exploration in Quality Filtering of Text Data”, Gao 2021
“A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP”, Zhao et al 2021
A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP
“Want To Reduce Labeling Cost? GPT-3 Can Help”, Wang et al 2021
“Data and Parameter Scaling Laws for Neural Machine Translation”, Gordon et al 2021
Data and Parameter Scaling Laws for Neural Machine Translation
“Do Vision Transformers See Like Convolutional Neural Networks?”, Raghu et al 2021
Do Vision Transformers See Like Convolutional Neural Networks?
“Modeling Protein Using Large-Scale Pretrain Language Model”, Xiao et al 2021
“Scaling Laws for Deep Learning”, Rosenfeld 2021
“Billion-Scale Pretraining With Vision Transformers for Multi-Task Visual Representations”, Beal et al 2021
Billion-Scale Pretraining with Vision Transformers for Multi-Task Visual Representations
“Facebook AI WMT21 News Translation Task Submission”, Tran et al 2021
“EVA: An Open-Domain Chinese Dialogue System With Large-Scale Generative Pre-Training”, Zhou et al 2021
EVA: An Open-Domain Chinese Dialogue System with Large-Scale Generative Pre-Training
“The History of Speech Recognition to the Year 2030”, Hannun 2021
“The History of Speech Recognition to the Year 2030 [Blog]”, Hannun 2021
“A Field Guide to Federated Optimization”, Wang et al 2021
“HTLM: Hyper-Text Pre-Training and Prompting of Language Models”, Aghajanyan et al 2021
HTLM: Hyper-Text Pre-Training and Prompting of Language Models
“Brain-Like Functional Specialization Emerges Spontaneously in Deep Neural Networks”, Dobs et al 2021
Brain-like functional specialization emerges spontaneously in deep neural networks
“ERNIE 3.0: Large-Scale Knowledge Enhanced Pre-Training for Language Understanding and Generation”, Sun et al 2021
ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
“Scarecrow: A Framework for Scrutinizing Machine Text”, Dou et al 2021
“The Dimpled Manifold Model of Adversarial Examples in Machine Learning”, Shamir et al 2021
The Dimpled Manifold Model of Adversarial Examples in Machine Learning
“Revisiting the Calibration of Modern Neural Networks”, Minderer et al 2021
“Partial Success in Closing the Gap between Human and Machine Vision”, Geirhos et al 2021
Partial success in closing the gap between human and machine vision
“HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units”, Hsu et al 2021
HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units
“Scaling Laws for Acoustic Models”, Droppo & Elibol 2021
“CoAtNet: Marrying Convolution and Attention for All Data Sizes”, Dai et al 2021
CoAtNet: Marrying Convolution and Attention for All Data Sizes
“Scaling Vision Transformers”, Zhai et al 2021
“Exploring the Limits of Out-Of-Distribution Detection”, Fort et al 2021
“Effect of Pre-Training Scale on Intra/Inter-Domain Full and Few-Shot Transfer Learning for Natural and Medical X-Ray Chest Images”, Cherti & Jitsev 2021
“A Universal Law of Robustness via Isoperimetry”, Bubeck & Sellke 2021
“Naver Unveils First ‘Hyperscale’ AI Platform”, Jae-eun 2021
“Unsupervised Speech Recognition”, Baevski et al 2021
“One4all User Representation for Recommender Systems in E-Commerce”, Shin et al 2021
One4all User Representation for Recommender Systems in E-commerce
“RecPipe: Co-Designing Models and Hardware to Jointly Optimize Recommendation Quality and Performance”, Gupta et al 2021
RecPipe: Co-designing Models and Hardware to Jointly Optimize Recommendation Quality and Performance
“Google Details New AI Accelerator Chips”, Wiggers 2021
“MLP-Mixer: An All-MLP Architecture for Vision”, Tolstikhin et al 2021
“XLM-R XL: Larger-Scale Transformers for Multilingual Masked Language Modeling”, Goyal et al 2021
XLM-R XL: Larger-Scale Transformers for Multilingual Masked Language Modeling
“Scaling End-To-End Models for Large-Scale Multilingual ASR”, Li et al 2021
“DINO: Emerging Properties in Self-Supervised Vision Transformers”, Caron et al 2021
DINO: Emerging Properties in Self-Supervised Vision Transformers
“What Are Bayesian Neural Network Posteriors Really Like?”, Izmailov et al 2021
“Machine Learning Scaling”, Gwern 2021
“[Ali Released PLUG: 27 Billion Parameters, the Largest Pre-Trained Language Model in the Chinese Community]”, Yuying 2021
“The Power of Scale for Parameter-Efficient Prompt Tuning”, Lester et al 2021
“Revealing Persona Biases in Dialogue Systems”, Sheng et al 2021
“CrossFit: A Few-Shot Learning Challenge for Cross-Task Generalization in NLP”, Ye et al 2021
CrossFit: A Few-shot Learning Challenge for Cross-task Generalization in NLP
“Probing Across Time: What Does RoBERTa Know and When?”, Liu et al 2021
“Memorization versus Generalization in Pre-Trained Language Models”, Tänzer et al 2021
Memorization versus Generalization in Pre-trained Language Models
“Large-Scale Self-Supervised and Semi-Supervised Learning for Speech Translation”, Wang et al 2021
Large-Scale Self-Supervised and Semi-Supervised Learning for Speech Translation
“Scaling Laws for Language Transfer Learning”, Kim 2021
“Adapting Language Models for Zero-Shot Learning by Meta-Tuning on Dataset and Prompt Collections”, Zhong et al 2021
Adapting Language Models for Zero-shot Learning by Meta-tuning on Dataset and Prompt Collections
“SpeechStew: Simply Mix All Available Speech Recognition Data to Train One Large Neural Network”, Chan et al 2021
SpeechStew: Simply Mix All Available Speech Recognition Data to Train One Large Neural Network
“Understanding Robustness of Transformers for Image Classification”, Bhojanapalli et al 2021
Understanding Robustness of Transformers for Image Classification
“UNICORN on RAINBOW: A Universal Commonsense Reasoning Model on a New Multitask Benchmark”, Lourie et al 2021
UNICORN on RAINBOW: A Universal Commonsense Reasoning Model on a New Multitask Benchmark
“Controllable Generation from Pre-Trained Language Models via Inverse Prompting”, Zou et al 2021
Controllable Generation from Pre-trained Language Models via Inverse Prompting
“The Shape of Learning Curves: a Review”, Viering & Loog 2021
“Efficient Visual Pretraining With Contrastive Detection”, Hénaff et al 2021
“Revisiting ResNets: Improved Training and Scaling Strategies”, Bello et al 2021
Revisiting ResNets: Improved Training and Scaling Strategies
“Learning from Videos to Understand the World”, Zweig et al 2021
“WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training”, Huo et al 2021
WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training
“Fast and Accurate Model Scaling”, Dollár et al 2021
“Pretrained Transformers As Universal Computation Engines”, Lu et al 2021
“Greedy Hierarchical Variational Autoencoders (GHVAEs) for Large-Scale Video Prediction”, Wu et al 2021
Greedy Hierarchical Variational Autoencoders (GHVAEs) for Large-Scale Video Prediction
“Measuring Mathematical Problem Solving With the MATH Dataset”, Hendrycks et al 2021
Measuring Mathematical Problem Solving With the MATH Dataset
“A Law of Robustness for Two-Layers Neural Networks”, Bubeck et al 2021
“SEER: Self-Supervised Pretraining of Visual Features in the Wild”, Goyal et al 2021
SEER: Self-supervised Pretraining of Visual Features in the Wild
“M6: A Chinese Multimodal Pretrainer”, Lin et al 2021
“Zero-Shot Text-To-Image Generation”, Ramesh et al 2021
“Improved Denoising Diffusion Probabilistic Models”, Nichol & Dhariwal 2021
“Conceptual 12M: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts”, Changpinyo et al 2021
Conceptual 12M: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts
“A Large Batch Optimizer Reality Check: Traditional, Generic Optimizers Suffice Across Batch Sizes”, Nado et al 2021
A Large Batch Optimizer Reality Check: Traditional, Generic Optimizers Suffice Across Batch Sizes
“Explaining Neural Scaling Laws”, Bahri et al 2021
“ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision”, Jia et al 2021
ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
“NFNet: High-Performance Large-Scale Image Recognition Without Normalization”, Brock et al 2021
NFNet: High-Performance Large-Scale Image Recognition Without Normalization
“Learning Curve Theory”, Hutter 2021
“1-Bit Adam: Communication Efficient Large-Scale Training With Adam’s Convergence Speed”, Tang et al 2021
1-bit Adam: Communication Efficient Large-Scale Training with Adam’s Convergence Speed
“Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Scaling”, Lazaridou et al 2021
Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Scaling
“Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Dynamic Evaluation”, Lazaridou et al 2021 (page 7 org deepmind)
Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Dynamic Evaluation
“Scaling Laws for Transfer”, Hernandez et al 2021
“Automatic Curation of Large-Scale Datasets for Audio-Visual Representation Learning”, Lee et al 2021
Automatic Curation of Large-Scale Datasets for Audio-Visual Representation Learning
“Muppet: Massive Multi-Task Representations With Pre-Finetuning”, Aghajanyan et al 2021
Muppet: Massive Multi-task Representations with Pre-Finetuning
“Language Processing in Brains and Deep Neural Networks: Computational Convergence and Its Limits”, Caucheteux & King 2021
Language processing in brains and deep neural networks: computational convergence and its limits
“Meta Pseudo Labels”, Pham et al 2021
“CLIP: Learning Transferable Visual Models From Natural Language Supervision”, Radford et al 2021
CLIP: Learning Transferable Visual Models From Natural Language Supervision
“VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation Learning, Semi-Supervised Learning and Interpretation”, Wang et al 2021
“CDLM: Cross-Document Language Modeling”, Caciularu et al 2021
“VinVL: Revisiting Visual Representations in Vision-Language Models”, Zhang et al 2021
VinVL: Revisiting Visual Representations in Vision-Language Models
“Parameter Count vs Training Dataset Size (1952–2021)”, Adlam 2021
“Process for Adapting Language Models to Society (PALMS) With Values-Targeted Datasets”, Solaiman & Dennison 2021
Process for Adapting Language Models to Society (PALMS) with Values-Targeted Datasets
“Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning”, Aghajanyan et al 2020
Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning
“Extrapolating GPT-N Performance”, Finnveden 2020
“Biological Structure and Function Emerge from Scaling Unsupervised Learning to 250 Million Protein Sequences”, Rives et al 2020
“CPM: A Large-Scale Generative Chinese Pre-Trained Language Model”, Zhang et al 2020
CPM: A Large-scale Generative Chinese Pre-trained Language Model
“Very Deep VAEs Generalize Autoregressive Models and Can Outperform Them on Images”, Child 2020
Very Deep VAEs Generalize Autoregressive Models and Can Outperform Them on Images
“When Do You Need Billions of Words of Pretraining Data?”, Zhang et al 2020
“Scaling Laws for Autoregressive Generative Modeling”, Henighan et al 2020
“Language ID in the Wild: Unexpected Challenges on the Path to a Thousand-Language Web Text Corpus”, Caswell et al 2020
Language ID in the Wild: Unexpected Challenges on the Path to a Thousand-Language Web Text Corpus
“MT5: A Massively Multilingual Pre-Trained Text-To-Text Transformer”, Xue et al 2020
mT5: A massively multilingual pre-trained text-to-text transformer
“Beyond English-Centric Multilingual Machine Translation”, Fan et al 2020
“Pushing the Limits of Semi-Supervised Learning for Automatic Speech Recognition”, Zhang et al 2020
Pushing the Limits of Semi-Supervised Learning for Automatic Speech Recognition
“Towards End-To-End In-Image Neural Machine Translation”, Mansimov et al 2020
“The First AI Model That Translates 100 Languages without Relying on English Data”, Fan 2020
The first AI model that translates 100 languages without relying on English data
“The Deep Bootstrap Framework: Good Online Learners Are Good Offline Generalizers”, Nakkiran et al 2020
The Deep Bootstrap Framework: Good Online Learners are Good Offline Generalizers
“Learning Which Features Matter: RoBERTa Acquires a Preference for Linguistic Generalizations (Eventually)”, Warstadt et al 2020
“The Neural Architecture of Language: Integrative Reverse-Engineering Converges on a Model for Predictive Processing”, Schrimpf et al 2020
“Uncovering the Limits of Adversarial Training against Norm-Bounded Adversarial Examples”, Gowal et al 2020
Uncovering the Limits of Adversarial Training against Norm-Bounded Adversarial Examples
“Fast Stencil-Code Computation on a Wafer-Scale Processor”, Rocki et al 2020
“Vision Transformer: An Image Is Worth 16×16 Words: Transformers for Image Recognition at Scale”, Dosovitskiy et al 2020
Vision Transformer: An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale
“Small Data, Big Decisions: Model Selection in the Small-Data Regime”, Bornschein et al 2020
Small Data, Big Decisions: Model Selection in the Small-Data Regime
“New Report on How Much Computational Power It Takes to Match the Human Brain”, Carlsmith 2020
New Report on How Much Computational Power It Takes to Match the Human Brain
“Generative Language Modeling for Automated Theorem Proving”, Polu & Sutskever 2020
“GrokNet: Unified Computer Vision Model Trunk and Embeddings For Commerce”, Bell et al 2020
GrokNet: Unified Computer Vision Model Trunk and Embeddings For Commerce
“Accuracy and Performance Comparison of Video Action Recognition Approaches”, Hutchinson et al 2020
Accuracy and Performance Comparison of Video Action Recognition Approaches
“Generative Models Are Unsupervised Predictors of Page Quality: A Colossal-Scale Study”, Bahri et al 2020
Generative Models are Unsupervised Predictors of Page Quality: A Colossal-Scale Study
“Matt Botvinick on the Spontaneous Emergence of Learning Algorithms”, Scholl 2020
Matt Botvinick on the spontaneous emergence of learning algorithms
“Self-Supervised Learning through the Eyes of a Child”, Orhan et al 2020
“On Robustness and Transferability of Convolutional Neural Networks”, Djolonga et al 2020
On Robustness and Transferability of Convolutional Neural Networks
“Hopfield Networks Is All You Need”, Ramsauer et al 2020
“ProtTrans: Towards Cracking the Language of Life’s Code Through Self-Supervised Deep Learning and High Performance Computing”, Elnaggar et al 2020
“NVAE: A Deep Hierarchical Variational Autoencoder”, Vahdat & Kautz 2020
“Measuring Robustness to Natural Distribution Shifts in Image Classification”, Taori et al 2020
Measuring Robustness to Natural Distribution Shifts in Image Classification
“WinoGrande: An Adversarial Winograd Schema Challenge at Scale”, Sakaguchi et al 2020
WinoGrande: An Adversarial Winograd Schema Challenge at Scale
“Is SGD a Bayesian Sampler? Well, Almost”, Mingard et al 2020
“Unsupervised Cross-Lingual Representation Learning for Speech Recognition”, Conneau et al 2020
Unsupervised Cross-lingual Representation Learning for Speech Recognition
“Logarithmic Pruning Is All You Need”, Orseau et al 2020
“Wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations”, Baevski et al 2020
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
“Denoising Diffusion Probabilistic Models”, Ho et al 2020
“On the Predictability of Pruning Across Scales”, Rosenfeld et al 2020
“IGPT: Generative Pretraining from Pixels”, Chen et al 2020
“SwAV: Unsupervised Learning of Visual Features by Contrasting Cluster Assignments”, Caron et al 2020
SwAV: Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
“SimCLRv2: Big Self-Supervised Models Are Strong Semi-Supervised Learners”, Chen et al 2020
SimCLRv2: Big Self-Supervised Models are Strong Semi-Supervised Learners
“Image GPT (IGPT): We Find That, Just As a Large Transformer Model Trained on Language Can Generate Coherent Text, the Same Exact Model Trained on Pixel Sequences Can Generate Coherent Image Completions and Samples”, Chen et al 2020
“Are We Done With ImageNet?”, Beyer et al 2020
“OpenAI API”, Brockman et al 2020
“Object Segmentation Without Labels With Large-Scale Generative Models”, Voynov et al 2020
Object Segmentation Without Labels with Large-Scale Generative Models
“How Big Should My Language Model Be?”, Scao 2020
“GPT-3 Paper § Figure F.1: Four Uncurated Completions from a Context Suggesting the Model Compose a Poem in the Style of Wallace Stevens With the Title ‘Shadows on the Way’”, GPT-3 2020 (page 48)
“Danny Hernandez on Forecasting and the Drivers of AI Progress”, Koehler et al 2020
Danny Hernandez on forecasting and the drivers of AI progress
“Powered by AI: Advancing Product Understanding and Building New Shopping Experiences”, Berg et al 2020
Powered by AI: Advancing product understanding and building new shopping experiences
“ZeRO-2 & DeepSpeed: Shattering Barriers of Deep Learning Speed & Scale”, Team 2020
ZeRO-2 & DeepSpeed: Shattering barriers of deep learning speed & scale
“Measuring the Algorithmic Efficiency of Neural Networks”, Hernandez & Brown 2020
“Pushing the Limit of Molecular Dynamics With ab Initio Accuracy to 100 Million Atoms With Machine Learning”, Jia et al 2020
“Jukebox: We’re Introducing Jukebox, a Neural Net That Generates Music, including Rudimentary Singing, As Raw Audio in a Variety of Genres and Artist Styles. We’re Releasing the Model Weights and Code, along With a Tool to Explore the Generated Samples.”, Dhariwal et al 2020
“Blender: A State-Of-The-Art Open Source Chatbot”, Roller et al 2020
“A Review of Winograd Schema Challenge Datasets and Approaches”, Kocijan et al 2020
A Review of Winograd Schema Challenge Datasets and Approaches
“DynamicEmbedding: Extending TensorFlow for Colossal-Scale Applications”, Zeng et al 2020
DynamicEmbedding: Extending TensorFlow for Colossal-Scale Applications
“PALM: Pre-Training an Autoencoding & Autoregressive Language Model for Context-Conditioned Generation”, Bi et al 2020
“Deep Learning Training in Facebook Data Centers: Design of Scale-Up and Scale-Out Systems”, Naumov et al 2020
Deep Learning Training in Facebook Data Centers: Design of Scale-up and Scale-out Systems
“TTTTTackling WinoGrande Schemas”, Lin et al 2020
“A Metric Learning Reality Check”, Musgrave et al 2020
“Zoom In: An Introduction to Circuits—By Studying the Connections between Neurons, We Can Find Meaningful Algorithms in the Weights of Neural Networks”, Olah et al 2020
“Rethinking Parameter Counting in Deep Models: Effective Dimensionality Revisited”, Maddox et al 2020
Rethinking Parameter Counting in Deep Models: Effective Dimensionality Revisited
“Rethinking Bias-Variance Trade-Off for Generalization of Neural Networks”, Yang et al 2020
Rethinking Bias-Variance Trade-off for Generalization of Neural Networks
“Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers”, Li et al 2020
“The Messy, Secretive Reality behind OpenAI’s Bid to save the World: The AI Moonshot Was Founded in the Spirit of Transparency. This Is the inside Story of How Competitive Pressure Eroded That Idealism”, Hao 2020
“Pitfalls of In-Domain Uncertainty Estimation and Ensembling in Deep Learning”, Ashukha et al 2020
Pitfalls of In-Domain Uncertainty Estimation and Ensembling in Deep Learning
“The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence”, Marcus 2020
The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence
“A Simple Framework for Contrastive Learning of Visual Representations”, Chen et al 2020
A Simple Framework for Contrastive Learning of Visual Representations
“How Much Knowledge Can You Pack Into the Parameters of a Language Model?”, Roberts et al 2020
How Much Knowledge Can You Pack Into the Parameters of a Language Model?
“Turing-NLG: A 17-Billion-Parameter Language Model by Microsoft”, Rosset 2020
Turing-NLG: A 17-billion-parameter language model by Microsoft
“Quasi-Equivalence of Width and Depth of Neural Networks”, Fan et al 2020
“Impact of ImageNet Model Selection on Domain Adaptation”, Zhang & Davison 2020
“Direct Fit to Nature: An Evolutionary Perspective on Biological and Artificial Neural Networks”, Hasson et al 2020
Direct Fit to Nature: An Evolutionary Perspective on Biological and Artificial Neural Networks
“Towards a Conversational Agent That Can Chat About…Anything”, Adiwardana & Luong 2020
“Towards a Human-Like Open-Domain Chatbot”, Adiwardana et al 2020
“Scaling Laws for Neural Language Models”, Kaplan et al 2020
“Scaling Laws for Neural Language Models: Figure 15: Far beyond the Model Sizes We Study Empirically, We Find a Contradiction between Our Equations § Pg17”, Kaplan 2020 (page 17 org openai)
“The Importance of Deconstruction”, Weinberger 2020
“Big Transfer (BiT): General Visual Representation Learning”, Kolesnikov et al 2019
“More Data Can Hurt for Linear Regression: Sample-Wise Double Descent”, Nakkiran 2019
More Data Can Hurt for Linear Regression: Sample-wise Double Descent
“12-In-1: Multi-Task Vision and Language Representation Learning”, Lu et al 2019
12-in-1: Multi-Task Vision and Language Representation Learning
“Deep Double Descent: We Show That the Double Descent Phenomenon Occurs in CNNs, ResNets, and Transformers: Performance First Improves, Then Gets Worse, and Then Improves Again With Increasing Model Size, Data Size, or Training Time”, Nakkiran et al 2019
“Deep Double Descent: Where Bigger Models and More Data Hurt”, Nakkiran et al 2019
“What’s Hidden in a Randomly Weighted Neural Network?”, Ramanujan et al 2019
“Understanding the Generalization of ‘Lottery Tickets’ in Neural Networks”, Morcos & Tian 2019
Understanding the generalization of ‘lottery tickets’ in neural networks
“The Deep Learning Revolution and Its Implications for Computer Architecture and Chip Design”, Dean 2019
The Deep Learning Revolution and Its Implications for Computer Architecture and Chip Design
“Momentum Contrast for Unsupervised Visual Representation Learning”, He et al 2019
Momentum Contrast for Unsupervised Visual Representation Learning
“SimpleShot: Revisiting Nearest-Neighbor Classification for Few-Shot Learning”, Wang et al 2019
SimpleShot: Revisiting Nearest-Neighbor Classification for Few-Shot Learning
“Self-Training With Noisy Student Improves ImageNet Classification”, Xie et al 2019
Self-training with Noisy Student improves ImageNet classification
“CCMatrix: Mining Billions of High-Quality Parallel Sentences on the WEB”, Schwenk et al 2019
CCMatrix: Mining Billions of High-Quality Parallel Sentences on the WEB
“CCAligned: A Massive Collection of Cross-Lingual Web-Document Pairs”, El-Kishky et al 2019
CCAligned: A Massive Collection of Cross-Lingual Web-Document Pairs
“XLM-R: State-Of-The-Art Cross-Lingual Understanding through Self-Supervision”, FAIR 2019
XLM-R: State-of-the-art cross-lingual understanding through self-supervision
“High Fidelity Video Prediction With Large Stochastic Recurrent Neural Networks”, Villegas et al 2019
High Fidelity Video Prediction with Large Stochastic Recurrent Neural Networks
“Unsupervised Cross-Lingual Representation Learning at Scale”, Conneau et al 2019
“T5: Exploring the Limits of Transfer Learning With a Unified Text-To-Text Transformer”, Raffel et al 2019
T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
“ZeRO: Memory Optimizations Toward Training Trillion Parameter Models”, Rajbhandari et al 2019
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
“Environmental Drivers of Systematicity and Generalization in a Situated Agent”, Hill et al 2019
Environmental drivers of systematicity and generalization in a situated agent
“A Constructive Prediction of the Generalization Error Across Scales”, Rosenfeld et al 2019
A Constructive Prediction of the Generalization Error Across Scales
“Large-Scale Pretraining for Neural Machine Translation With Tens of Billions of Sentence Pairs”, Meng et al 2019
Large-scale Pretraining for Neural Machine Translation with Tens of Billions of Sentence Pairs
“UNITER: UNiversal Image-TExt Representation Learning”, Chen et al 2019
“Exascale Deep Learning for Scientific Inverse Problems”, Laanait et al 2019
“Simple, Scalable Adaptation for Neural Machine Translation”, Bapna et al 2019
“CTRL: A Conditional Transformer Language Model For Controllable Generation”, Keskar et al 2019
CTRL: A Conditional Transformer Language Model For Controllable Generation
“Show Your Work: Improved Reporting of Experimental Results”, Dodge et al 2019
“MegatronLM: Training Billion+ Parameter Language Models Using GPU Model Parallelism”, ADLR 2019
MegatronLM: Training Billion+ Parameter Language Models Using GPU Model Parallelism
“RoBERTa: A Robustly Optimized BERT Pretraining Approach”, Liu et al 2019
“Robustness Properties of Facebook’s ResNeXt WSL Models”, Orhan 2019
“Massively Multilingual Neural Machine Translation in the Wild: Findings and Challenges”, Arivazhagan et al 2019
Massively Multilingual Neural Machine Translation in the Wild: Findings and Challenges
“Large Scale Adversarial Representation Learning”, Donahue & Simonyan 2019
“One Epoch Is All You Need”, Komatsuzaki 2019
“Does Learning Require Memorization? A Short Tale about a Long Tail”, Feldman 2019
Does Learning Require Memorization? A Short Tale about a Long Tail
“Intriguing Properties of Adversarial Training at Scale”, Xie & Yuille 2019
“Scaling Autoregressive Video Models”, Weissenborn et al 2019
“A Mathematical Theory of Semantic Development in Deep Neural Networks”, Saxe et al 2019
A mathematical theory of semantic development in deep neural networks
“Adversarially Robust Generalization Just Requires More Unlabeled Data”, Zhai et al 2019
Adversarially Robust Generalization Just Requires More Unlabeled Data
“ICML 2019 Notes”, Abel 2019
“Are Labels Required for Improving Adversarial Robustness?”, Uesato et al 2019
“EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks”, Tan & Le 2019
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
“SpArSe: Sparse Architecture Search for CNNs on Resource-Constrained Microcontrollers”, Fedorov et al 2019
SpArSe: Sparse Architecture Search for CNNs on Resource-Constrained Microcontrollers
“Asymptotic Learning Curves of Kernel Methods: Empirical Data versus Teacher-Student Paradigm”, Spigler et al 2019
Asymptotic learning curves of kernel methods: empirical data versus Teacher-Student paradigm
“UniLM: Unified Language Model Pre-Training for Natural Language Understanding and Generation”, Dong et al 2019
UniLM: Unified Language Model Pre-training for Natural Language Understanding and Generation
“Adversarial Examples Are Not Bugs, They Are Features”, Ilyas et al 2019
“Billion-Scale Semi-Supervised Learning for Image Classification”, Yalniz et al 2019
Billion-scale semi-supervised learning for image classification
“VideoBERT: A Joint Model for Video and Language Representation Learning”, Sun et al 2019
VideoBERT: A Joint Model for Video and Language Representation Learning
“Benchmarking Neural Network Robustness to Common Corruptions and Perturbations”, Hendrycks & Dietterich 2019
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
“Surprises in High-Dimensional Ridgeless Least Squares Interpolation”, Hastie et al 2019
Surprises in High-Dimensional Ridgeless Least Squares Interpolation
“The Bitter Lesson”, Sutton 2019
“GPT-2 As Step Toward General Intelligence”, Alexander 2019
“Deep Learning Hardware: Past, Present, & Future”, LeCun 2019
“Language Models Are Unsupervised Multitask Learners”, Radford et al 2019
“Better Language Models and Their Implications”, Radford et al 2019
“Do ImageNet Classifiers Generalize to ImageNet?”, Recht et al 2019
“Cross-Lingual Language Model Pretraining”, Lample & Conneau 2019
“Artificial Intelligence: A Guide for Thinking Humans § Prologue: Terrified”, Mitchell 2019
Artificial Intelligence: A Guide for Thinking Humans § Prologue: Terrified
“High Fidelity Video Prediction With Large Stochastic Recurrent Neural Networks: Videos”, Villegas et al 2019
High Fidelity Video Prediction with Large Stochastic Recurrent Neural Networks: Videos
“Reconciling Modern Machine Learning Practice and the Bias-Variance Trade-Off”, Belkin et al 2018
Reconciling modern machine learning practice and the bias-variance trade-off
“Nocaps: Novel Object Captioning at Scale”, Agrawal et al 2018
“On Lazy Training in Differentiable Programming”, Chizat et al 2018
“How AI Training Scales”, McCandlish et al 2018
“Is Science Slowing Down?”, Alexander 2018
“Large Scale GAN Training for High Fidelity Natural Image Synthesis”, Brock et al 2018
Large Scale GAN Training for High Fidelity Natural Image Synthesis
“BigGAN: Large Scale GAN Training For High Fidelity Natural Image Synthesis § 5.2 Additional Evaluation On JFT-300M”, Brock et al 2018 (page 8 org deepmind)
“Measurement Invariance Explains the Universal Law of Generalization for Psychological Perception”, Frank 2018
Measurement invariance explains the universal law of generalization for psychological perception
“CurriculumNet: Weakly Supervised Learning from Large-Scale Web Images”, Guo et al 2018
CurriculumNet: Weakly Supervised Learning from Large-Scale Web Images
“Large-Scale Visual Speech Recognition”, Shillingford et al 2018
“Troubling Trends in Machine Learning Scholarship”, Lipton & Steinhardt 2018
“Benchmarking Neural Network Robustness to Common Corruptions and Surface Variations”, Hendrycks & Dietterich 2018
Benchmarking Neural Network Robustness to Common Corruptions and Surface Variations
“Neural Scene Representation and Rendering”, Eslami et al 2018
“GPT-1: Improving Language Understanding With Unsupervised Learning”, OpenAI 2018
GPT-1: Improving Language Understanding with Unsupervised Learning
“GPT-1: Improving Language Understanding by Generative Pre-Training”, Radford et al 2018
GPT-1: Improving Language Understanding by Generative Pre-Training
“GPT-1: Improving Language Understanding by Generative Pre-Training § Model Specifications”, Radford et al 2018 (page 5)
GPT-1: Improving Language Understanding by Generative Pre-Training § Model specifications
“Do CIFAR-10 Classifiers Generalize to CIFAR-10?”, Recht et al 2018
“Deep Learning Generalizes Because the Parameter-Function Map Is Biased towards Simple Functions”, Valle-Pérez et al 2018
Deep learning generalizes because the parameter-function map is biased towards simple functions
“Google DeepMind Founder and Leader in Artificial Intelligence Returns to Hamilton”, Tantau 2018
Google DeepMind founder and leader in artificial intelligence returns to Hamilton
“Exploring the Limits of Weakly Supervised Pretraining”, Mahajan et al 2018
“One Big Net For Everything”, Schmidhuber 2018
“Sensitivity and Generalization in Neural Networks: an Empirical Study”, Novak et al 2018
Sensitivity and Generalization in Neural Networks: an Empirical Study
“The Description Length of Deep Learning Models”, Blier & Ollivier 2018
“Learning and Memorization”, Chatterjee 2018
“ULMFiT: Universal Language Model Fine-Tuning for Text Classification”, Howard & Ruder 2018
ULMFiT: Universal Language Model Fine-tuning for Text Classification
“GPipe: Easy Scaling With Micro-Batch Pipeline Parallelism § Pg4”, Huang 2018 (page 4 org google)
GPipe: Easy Scaling with Micro-Batch Pipeline Parallelism § pg4 :
“The Compute and Data Moats Are Dead”, Merity 2018
“Deep Image Reconstruction from Human Brain Activity”, Shen et al 2017
“Deep Learning Scaling Is Predictable, Empirically”, Hestness et al 2017
“Are GANs Created Equal? A Large-Scale Study”, Lucic et al 2017
“Knowledge Concentration: Learning 100K Object Classifiers in a Single CNN”, Gao et al 2017
Knowledge Concentration: Learning 100K Object Classifiers in a Single CNN
“Rethinking Generalization Requires Revisiting Old Ideas: Statistical Mechanics Approaches and Complex Learning Behavior”, Martin & Mahoney 2017
“There’s No Fire Alarm for Artificial General Intelligence”, Yudkowsky 2017
“The Devil Is in the Tails: Fine-Grained Classification in the Wild”, Horn & Perona 2017
The Devil is in the Tails: Fine-grained Classification in the Wild
“WebVision Database: Visual Learning and Understanding from Web Data”, Li et al 2017
WebVision Database: Visual Learning and Understanding from Web Data
“Revisiting Unreasonable Effectiveness of Data in Deep Learning Era”, Sun et al 2017
Revisiting Unreasonable Effectiveness of Data in Deep Learning Era
“Towards Deep Learning Models Resistant to Adversarial Attacks”, Madry et al 2017
Towards Deep Learning Models Resistant to Adversarial Attacks
“Gradient Diversity: a Key Ingredient for Scalable Distributed Learning”, Yin et al 2017
Gradient Diversity: a Key Ingredient for Scalable Distributed Learning
“Learning to Learn from Noisy Web Videos”, Yeung et al 2017
“Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour”, Goyal et al 2017
“A Simple Neural Network Module for Relational Reasoning”, Santoro et al 2017
“Deep Learning Is Robust to Massive Label Noise”, Rolnick et al 2017
“Quo Vadis, Action Recognition? A New Model I3D and the Kinetics Dataset”, Carreira & Zisserman 2017
Quo Vadis, Action Recognition? A New Model I3D and the Kinetics Dataset
“WebVision Challenge: Visual Learning and Understanding With Web Data”, Li et al 2017
WebVision Challenge: Visual Learning and Understanding With Web Data
“Geometry of Optimization and Implicit Regularization in Deep Learning”, Neyshabur et al 2017
Geometry of Optimization and Implicit Regularization in Deep Learning
“On the Impossibility of Supersized Machines”, Garfinkel et al 2017
“Parallel Multiscale Autoregressive Density Estimation”, Reed et al 2017
“Universal Representations: The Missing Link between Faces, Text, Planktons, and Cat Breeds”, Bilen & Vedaldi 2017
Universal representations: The missing link between faces, text, planktons, and cat breeds
“Estimation of Gap Between Current Language Models and Human Performance”, Shen et al 2017
Estimation of Gap Between Current Language Models and Human Performance
“Simple and Scalable Predictive Uncertainty Estimation Using Deep Ensembles”, Lakshminarayanan et al 2016
Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles
“Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation”, Johnson et al 2016
Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation
“Understanding Deep Learning Requires Rethinking Generalization”, Zhang et al 2016
Understanding deep learning requires rethinking generalization
“Why Does Deep and Cheap Learning Work so Well?”, Lin et al 2016
“The LAMBADA Dataset: Word Prediction Requiring a Broad Discourse Context”, Paperno et al 2016
The LAMBADA dataset: Word prediction requiring a broad discourse context
“Residual Networks Behave Like Ensembles of Relatively Shallow Networks”, Veit et al 2016
Residual Networks Behave Like Ensembles of Relatively Shallow Networks
“Do Deep Convolutional Nets Really Need to Be Deep and Convolutional?”, Urban et al 2016
Do Deep Convolutional Nets Really Need to be Deep and Convolutional?
“PlaNet—Photo Geolocation With Convolutional Neural Networks”, Weyand et al 2016
“Exploring the Limits of Language Modeling”, Jozefowicz et al 2016
“The Singularity: A Philosophical Analysis”, Chalmers 2016
“Microsoft Researchers Win ImageNet Computer Vision Challenge”, Linn 2015
Microsoft researchers win ImageNet computer vision challenge
“Deep Speech 2: End-To-End Speech Recognition in English and Mandarin”, Amodei et al 2015
Deep Speech 2: End-to-End Speech Recognition in English and Mandarin
“The Unreasonable Effectiveness of Noisy Data for Fine-Grained Recognition”, Krause et al 2015
The Unreasonable Effectiveness of Noisy Data for Fine-Grained Recognition
“Net2Net: Accelerating Learning via Knowledge Transfer”, Chen et al 2015
“Generative Concatenative Nets Jointly Learn to Write and Classify Reviews”, Lipton et al 2015
Generative Concatenative Nets Jointly Learn to Write and Classify Reviews
“Learning Visual Features from Large Weakly Supervised Data”, Joulin et al 2015
“LSUN: Construction of a Large-Scale Image Dataset Using Deep Learning With Humans in the Loop”, Yu et al 2015
LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop
“Clothing-1M: Learning from Massive Noisy Labeled Data for Image Classification”, Xiao et al 2015
Clothing-1M: Learning from Massive Noisy Labeled Data for Image Classification
“The Unreasonable Effectiveness of Recurrent Neural Networks”, Karpathy 2015
“LSTM: A Search Space Odyssey”, Greff et al 2015
“YFCC100M: The New Data in Multimedia Research”, Thomee et al 2015
“Machine Intelligence, Part 1”, Altman 2015
“50 Years of Deep Learning and Beyond: an Interview With Jürgen Schmidhuber”, Schmidhuber 2015
50 Years of Deep Learning and Beyond: an Interview with Jürgen Schmidhuber
“Evolution of the Human Brain: From Matter to Mind”, Hofman 2015
“In Search of the Real Inductive Bias: On the Role of Implicit Regularization in Deep Learning”, Neyshabur et al 2014
In Search of the Real Inductive Bias: On the Role of Implicit Regularization in Deep Learning
“Deep Speech 1: Scaling up End-To-End Speech Recognition”, Hannun et al 2014
“Jumping NLP Curves: A Review of Natural Language Processing Research [Review Article]”, Cambria & White 2014
Jumping NLP Curves: A Review of Natural Language Processing Research [Review Article]
“Neural Networks, Manifolds, and Topology”, Olah 2014
“Computing’s Energy Problem (And What We Can Do about It)”, Horowitz 2014b
“On the Number of Linear Regions of Deep Neural Networks”, Montúfar et al 2014
“N-Gram Counts and Language Models from the Common Crawl”, Buck et al 2014
“Evolution of the Human Brain: When Bigger Is Better”, Hofman 2014
“One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling”, Chelba et al 2013
One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling
“Algorithmic Progress in Six Domains”, Grace 2013
“Large–Scale Machine Learning Revisited [Slides]”, Bottou 2013
“20 Years of Bitext”, Brown et al 2013
“Intelligence Explosion Microeconomics”, Yudkowsky 2013
“Scalable Modified Kneser-Ney Language Model Estimation”, Heafield et al 2013
“Large Scale Language Modeling in Automatic Speech Recognition”, Chelba et al 2012
Large Scale Language Modeling in Automatic Speech Recognition
“The Remarkable, yet Not Extraordinary, Human Brain As a Scaled-Up Primate Brain and Its Associated Cost”, Herculano-Houzel 2012
“Advantages of Artificial Intelligences, Uploads, and Digital Minds”, Sotala 2012
Advantages of Artificial Intelligences, Uploads, and Digital Minds
“Natural Language Processing (Almost) from Scratch”, Collobert et al 2011
“Recurrent Neural Network Based Language Model”, Mikolov et al 2010
“Understanding Sources of Inefficiency in General-Purpose Chips”, Hameed et al 2010
Understanding sources of inefficiency in general-purpose chips
“The Teenies”, Legg 2009
“Tick, Tock, Tick, Tock… BING”, Legg 2009
“Halloween Nightmare Scenario, Early 2020’s”, Wood 2009
“Matrix Factorization Techniques for Recommender Systems”, Koren et al 2009
“The Unreasonable Effectiveness of Data”, Halevy et al 2009
“Economics Of The Singularity: Stuffed into Skyscrapers by the Billion, Brainy Bugbots Will Be the Knowledge Workers of the Future”, Hanson 2008
“Large Language Models in Machine Translation”, Brants et al 2007
“The Tradeoffs of Large-Scale Learning”, Bottou & Bousquet 2007
“Cellular Scaling Rules for Primate Brains”, Herculano-Houzel et al 2007
“Robot Predictions Evolution”, Moravec 2004
“Tree Induction versus Logistic Regression: A Learning-Curve Analysis”, Perlich et al 2003
Tree Induction versus Logistic Regression: A Learning-Curve Analysis
“Analytic and Algorithmic Solution of Random Satisfiability Problems”, Mezard et al 2002
Analytic and Algorithmic Solution of Random Satisfiability Problems
“A Bit of Progress in Language Modeling”, Goodman 2001
“Scaling to Very Very Large Corpora for Natural Language Disambiguation”, Banko & Brill 2001
Scaling to Very Very Large Corpora for Natural Language Disambiguation
“On Discriminative versus Generative Classifiers: A Comparison of Logistic Regression and Naive Bayes”, Ng & Jordan 2001
On Discriminative versus Generative Classifiers: A comparison of logistic regression and naive Bayes
“A Survey of Methods for Scaling Up Inductive Algorithms”, Provost & Kolluri 1999
“On The Effect of Data Set Size on Bias And Variance in Classification Learning”, Brain & Webb 1999
On The Effect of Data Set Size on Bias And Variance in Classification Learning
“The Anatomy of a Large-Scale Hypertextual Web Search Engine”, Brin & Page 1998
“The Effects of Training Set Size on Decision Tree Complexity”, Oates & Jensen 1997
The Effects of Training Set Size on Decision Tree Complexity
“Rigorous Learning Curve Bounds from Statistical Mechanics”, Haussler et al 1996
“Scaling up the Accuracy of Naive-Bayes Classifiers: a Decision-Tree Hybrid”, Kohavi 1996
Scaling up the accuracy of Naive-Bayes classifiers: a decision-tree hybrid
“Reflections After Refereeing Papers for NIPS”, Breiman 1995
“Biological Limits to Information Processing in the Human Brain”, Cochrane et al 1995
Biological limits to information processing in the human brain
“Handwritten Character Classification Using Nearest Neighbor in Large Databases”, Smith et al 1994
Handwritten Character Classification Using Nearest Neighbor in Large Databases
“Building a Large Annotated Corpus of English: The Penn Treebank”, Marcus et al 1993
Building a Large Annotated Corpus of English: The Penn Treebank
“Statistical Theory of Learning Curves under Entropic Loss Criterion”, Amari & Murata 1993
Statistical Theory of Learning Curves under Entropic Loss Criterion
“Learning Curves: Asymptotic Values and Rate of Convergence”, Cortes et al 1993
“Exhaustive Learning”, Schwartz et al 1990
“Don’t Worry—It Can’t Happen”, Harrington 1940
“Neural Net Stack-More-Layers Meme Template”, Anonymous 2026
{kind=link}
“Eric Michaud on Neural Quantum Interpretability”
“Billion-Scale Semi-Supervised Learning for State-Of-The-Art Image and Video Classification”
Billion-scale semi-supervised learning for state-of-the-art image and video classification
“No Physics? No Problem. AI Weather Forecasting Is Already Making Huge Strides.”
No physics? No problem. AI weather forecasting is already making huge strides.
“Report Describes Apple’s ‘Organizational Dysfunction’ and ‘Lack of Ambition’ in AI”
Report describes Apple’s ‘organizational dysfunction’ and ‘lack of ambition’ in AI
“StyleGAN-2 512px Trained on Danbooru2019”
“Blake Bordelon”, Bordelon 2026
“How to Train the Best Embedding Model in the World: One PhD Later, I’m Giving My Secrets Away for Free”, Morris 2026
“Scaling Karpathy’s Autoresearch: What Happens When the Agent Gets a GPU Cluster”
Scaling Karpathy’s Autoresearch: What Happens When the Agent Gets a GPU Cluster
“Inside the CodeBot: A Gentle Introduction to How LLMs Understand Nullability”
Inside the CodeBot: A Gentle Introduction to How LLMs Understand Nullability
“Komodo 8: the Smartphone vs Desktop Challenge”
“Trading Off Compute in Training and Inference § Pruning”
“Eric Tang”
“How Can We Make Robotics More like Generative Modeling?”
“True Story of Pangu: 诺亚盘古大模型研发背后的真正的心酸与黑暗的故事。[Model Plagiarism]”, Whistleblower 2026
True Story of Pangu: 诺亚盘古大模型研发背后的真正的心酸与黑暗的故事。[model plagiarism]
“Compression Represents Intelligence Linearly [Code]”
“Inverse-Scaling/prize: A Prize for Finding Tasks That Cause Large Language Models to Show Inverse Scaling”
“Scaling up StyleGAN-2”
“Finally, a Replacement for BERT: Introducing ModernBERT”
“Llm-Compression Data”
“Semi Supervised Learning”
“Homepage of Paul F. Christiano”, Christiano 2026
“Statistical Modeling: The Two Cultures”, Breiman 2026
“NanoGPT Slowrun—Q”
“T-Rex As: ‘The Computer Scientist’”, North 2026
“Have Chinese AI Models Caught Up to the US Frontier? [Probably Not]”
Have Chinese AI Models Caught Up to the US Frontier? [probably not]
“Jared Kaplan”
“Safe Superintelligence Inc.”
“OpenAI Disbands Its Robotics Research Team”
OpenAI disbands its robotics research team
View External Link:
https://venturebeat.com/business/openai-disbands-its-robotics-research-team/
“Google Workloads for Consumer Devices: Mitigating Data Movement Bottlenecks”
Google workloads for consumer devices: mitigating data movement bottlenecks
“The Uneasy Relationship between Deep Learning and (Classical) Statistics”
The uneasy relationship between deep learning and (classical) statistics
“Parameter Counts in Machine Learning”
“Can LLMs Learn from a Single Example?”
“Deciphering China’s AI Dream”
“Jason Wei”
“Appendix: More Is Different In Other Domains”
“Beware General Claims about ‘Generalizable Reasoning Capabilities’ (Of Modern AI Systems)”
Beware General Claims about ‘Generalizable Reasoning Capabilities’ (of Modern AI Systems)
“Understanding ‘Deep Double Descent’”
“How Much Compute Was Used to Train DeepMind’s Generally Capable Agents?”
How much compute was used to train DeepMind’s generally capable agents?
“Why Neural Networks Generalise, and Why They Are (Kind Of) Bayesian”
Why Neural Networks Generalise, and Why They Are (Kind of) Bayesian
“LLMs As Giant Lookup-Tables of Shallow Circuits”, niplav 2026
“(Maybe) A Bag of Heuristics Is All There Is & A Bag of Heuristics Is All You Need”
(Maybe) A Bag of Heuristics is All There Is & A Bag of Heuristics is All You Need
“What’s the Backward-Forward FLOP Ratio for Neural Networks?”
“Optimality Is the Tiger, and Agents Are Its Teeth”
“What Next? A Dozen Information-Technology Research Goals: 3. Turing’s Vision of Machine Intelligence”
What Next? A Dozen Information-Technology Research Goals: 3. Turing’s vision of machine intelligence :
“Was Linguistic AI Created by Accident?”
“Tom Henighan”
“Ilya Sutskever: Deep Learning | AI Podcast #94 With Lex Fridman”
Ilya Sutskever: Deep Learning | AI Podcast #94 with Lex Fridman
“A Universal Law of Robustness”
“Greg Brockman: OpenAI and AGI”, Brockman 2026
“Season 1 Ep. 22 OpenAI’s Ilya Sutskever: The Man Who Made AI Work”
Season 1 Ep. 22 OpenAI’s Ilya Sutskever: The man who made AI work
“A Law of Robustness and the Importance of Overparameterization in Deep Learning”
A law of robustness and the importance of overparameterization in deep learning
“WELM”
ImMrShields
xiao_ted
I’m curious how much overlap there is between ‘serious AI researchers’ and AI-adjacent subcultures
“Yuxi on the Wired”, Liu 2026
“Zhengdong Wang Homepage”, Wang 2026
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
gpt-3-creativity
character-classification
self-supervised-learning knowledge-rich
co-pilot
logical-agenda
speech-recognition
ai-leadership ai-challenges agi-journey innovation-initiative xai-oversight agi-advancement
ai-regulation
adversarial-strategies
language-models
embedding-training
philosophy-ai algorithmic-theory digital-minds agi-analysis intelligence-theory algorithmic-advances
ai-governance
neural-specialization
neural-representation
test-time-augmentation
bioacoustics
scaling-laws
Wikipedia (12)
Miscellaneous
https://www.nytimes.com/2026/04/26/business/dwarkesh-patel-podcast-ai.htmlhttps://www.nytimes.com/2026/03/12/technology/meta-avocado-ai-model-delayed.html/doc/ai/scaling/2024-lin-figure2-inversescalingontruthfulqa.jpg/doc/ai/scaling/2024-smith-figure4-downstreamperformanceinastronomytasksfromgalaxypretrainedgpt2.png/doc/ai/scaling/2023-eldan-figure23-scalinglawoftinystoriesgpttransformermodelswithtrainingflops.jpg/doc/ai/scaling/2023-nguyen-figure6-stormerweatherforecastingscalesinmodelsizeanddatagranularity.png/doc/ai/scaling/2023-wang-figure9-videodatascalingoftft2vvideogeneration.png/doc/ai/nn/fully-connected/2023-bachmann-figure1-mlpcomputescalingoncifar100.jpg/doc/ai/nn/fully-connected/2023-bachmann-figure4-mlpsscalewellwithincreasingbatchsize.jpg/doc/ai/nn/fully-connected/2023-bachmann-figure5-scalingofmlpsoncifar10andimagenet1k.png/doc/ai/nn/fully-connected/2023-bachmann-figure7-suprachinchilladatascalingformlpsoncifar100loss.jpg/doc/ai/scaling/2022-zhu-figure9-webface260mcnnfacerecognitionscalingbyn.png/doc/ai/nn/transformer/gpt/whisper/2022-radford-figure8-whisperscalingbymodelsize.png/doc/ai/scaling/2021-10-11-xinzhiyuan-inspursource10gpt245b.html/doc/ai/scaling/2021-goyal-figure1-seerscalinginparameters.png/doc/ai/scaling/2021-hernandez-transferlearning-figure1-transfervsfinetuning.png/doc/ai/scaling/2021-hu-figure1-lemontransformerscalingonmscocoimagecaptioning.png/doc/ai/scaling/2021-hu-figure2-a-datascalingfinetuningperformanceonmscoco.jpg/doc/ai/scaling/2021-zhang-figure1a-conformermodelworderrorscalingindatasetsize.jpg/doc/ai/scaling/2021-zhang-figure2-conformerpmodelworderrorscalingratesindatasetsize.png/doc/ai/scaling/2020-carlsmith-figure5-flopsbudgetestimates.png/doc/ai/scaling/2020-chrisdyer-aacl2020-machinetranslationscaling-ngramsvsrnns.jpg/doc/ai/scaling/2020-finnveden-extrapolationwcomparisons.png/doc/ai/scaling/2020-rosset-turingnlg-nlpmodelparametercountovertime.png/doc/ai/scaling/2019-liu-table4-robertabenefitsfromscalingdatasets10xoverbert.png/doc/ai/scaling/2018-howard-figure3-datascalingofrnnpretrainingfortextclassification.jpg/doc/ai/scaling/2017-koehn-figure3-bleuscoreswithvaryingamountsoftrainingdata.png/doc/ai/nn/cnn/2015-joulin-figure2-flickrpascalvoc2007precisionscalingwithflickr100mnscaling.jpg/doc/ai/scaling/2014-cambria-figure1-hypotheticalnlpprogresscurves.png/doc/ai/scaling/2012-bottou-figure13-1-sgdtrainingtimetestlossvstron.png/doc/ai/scaling/2012-bottou-figure13-2-sgdtrainingtimetestlossvsconjugategradients.png/doc/ai/scaling/2012-chelba-figure2-5gramscalingindatasize.png/doc/ai/scaling/2009-12-07-shanelegg-supercomputerlinpackoverpast50years.png/doc/ai/scaling/2009-koren-figure4-netflixprizecontentmodelaccuracyscaleswithparametercount.pnghttps://ai.meta.com/blog/harmful-content-can-evolve-quickly-our-new-ai-system-adapts-to-tackle-ithttps://ai.meta.com/blog/harmful-content-can-evolve-quickly-our-new-ai-system-adapts-to-tackle-it/https://cacm.acm.org/research/the-decline-of-computers-as-a-general-purpose-technology/https://github.com/Dicklesworthstone/the_lighthill_debate_on_aihttps://markovbio.github.io/biomedical-progress/View External Link:
https://nonint.com/2023/06/10/the-it-in-ai-models-is-the-dataset/https://research.google/blog/large-scale-matrix-factorization-on-tpus/https://research.google/blog/scalable-deep-reinforcement-learning-for-robotic-manipulation/https://thezvi.substack.com/p/on-openais-preparedness-frameworkhttps://towardsdatascience.com/neural-networks-are-fundamentally-bayesian-bee9a172fad8https://www.beren.io/2022-08-06-The-scale-of-the-brain-vs-machine-learning/https://www.lesswrong.com/posts/KbRxdBCcJqwtbiPzm/whisper-s-wild-implications-1View External Link:
https://www.lesswrong.com/posts/KbRxdBCcJqwtbiPzm/whisper-s-wild-implications-1https://www.lesswrong.com/posts/No5JpRCHzBrWA4jmS/q-and-a-with-shane-legg-on-risks-from-aihttps://www.lesswrong.com/posts/dLXdCjxbJMGtDBWTH/no-one-in-my-org-puts-money-in-their-pensionhttps://www.lesswrong.com/posts/qdStMFDMrWAnTqNWL/gpt-4-predictionsView External Link:
https://www.lesswrong.com/posts/qdStMFDMrWAnTqNWL/gpt-4-predictionshttps://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/https://www.reddit.com/r/mlscaling/comments/1ggr0j4/neural_network_recognizer_for_handwritten_zip/
{kind=link}
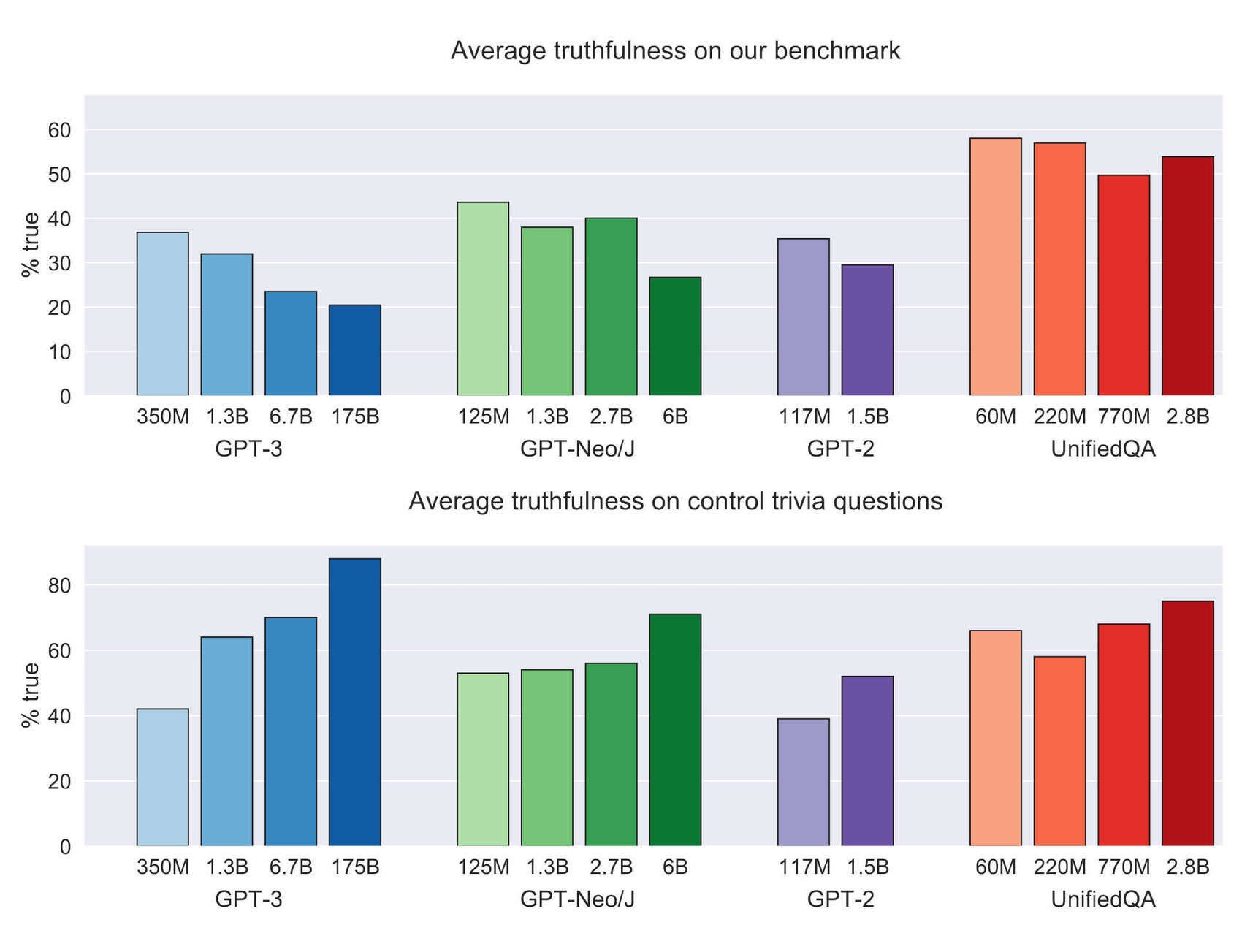{kind=link}
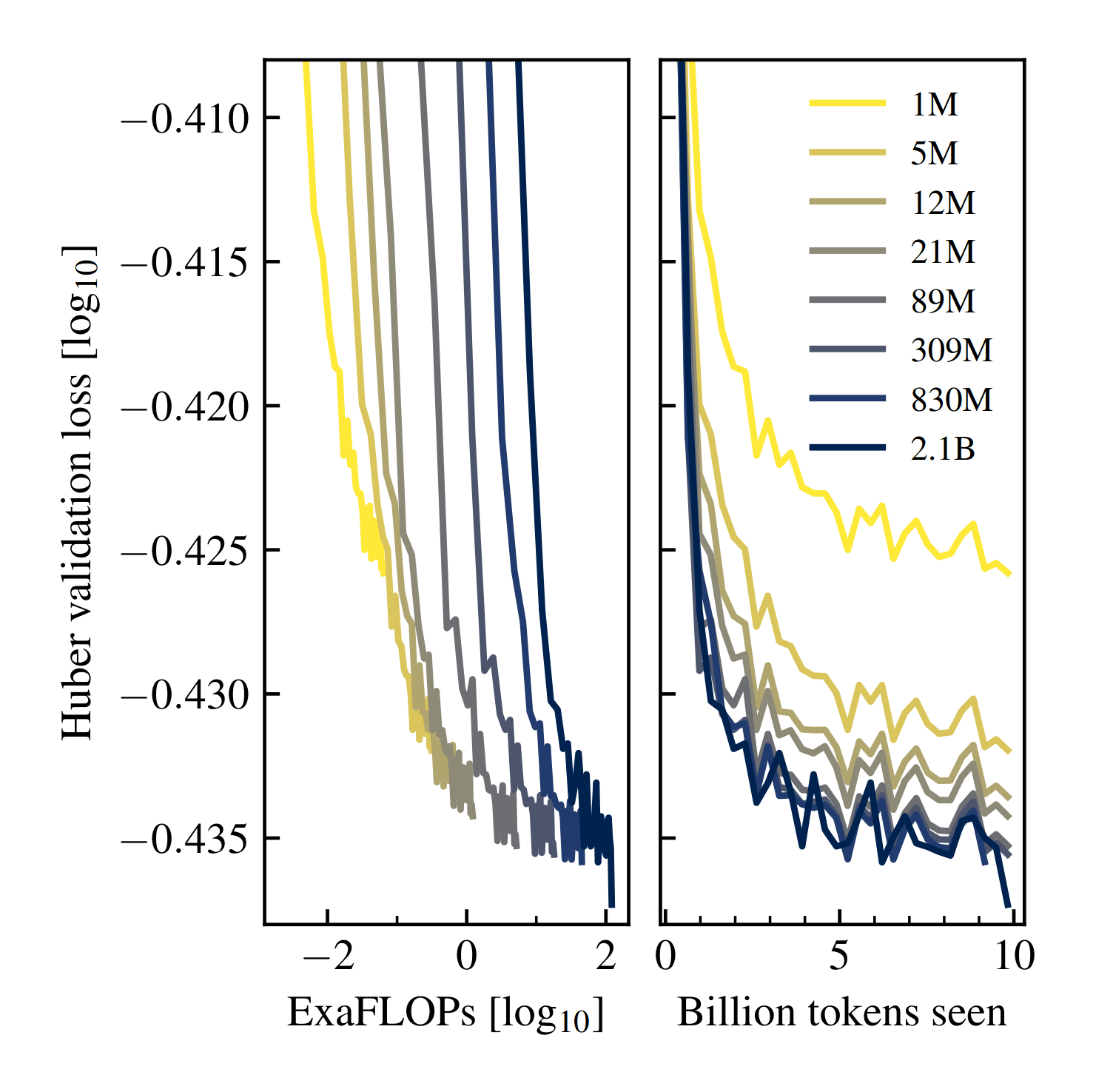{kind=link}
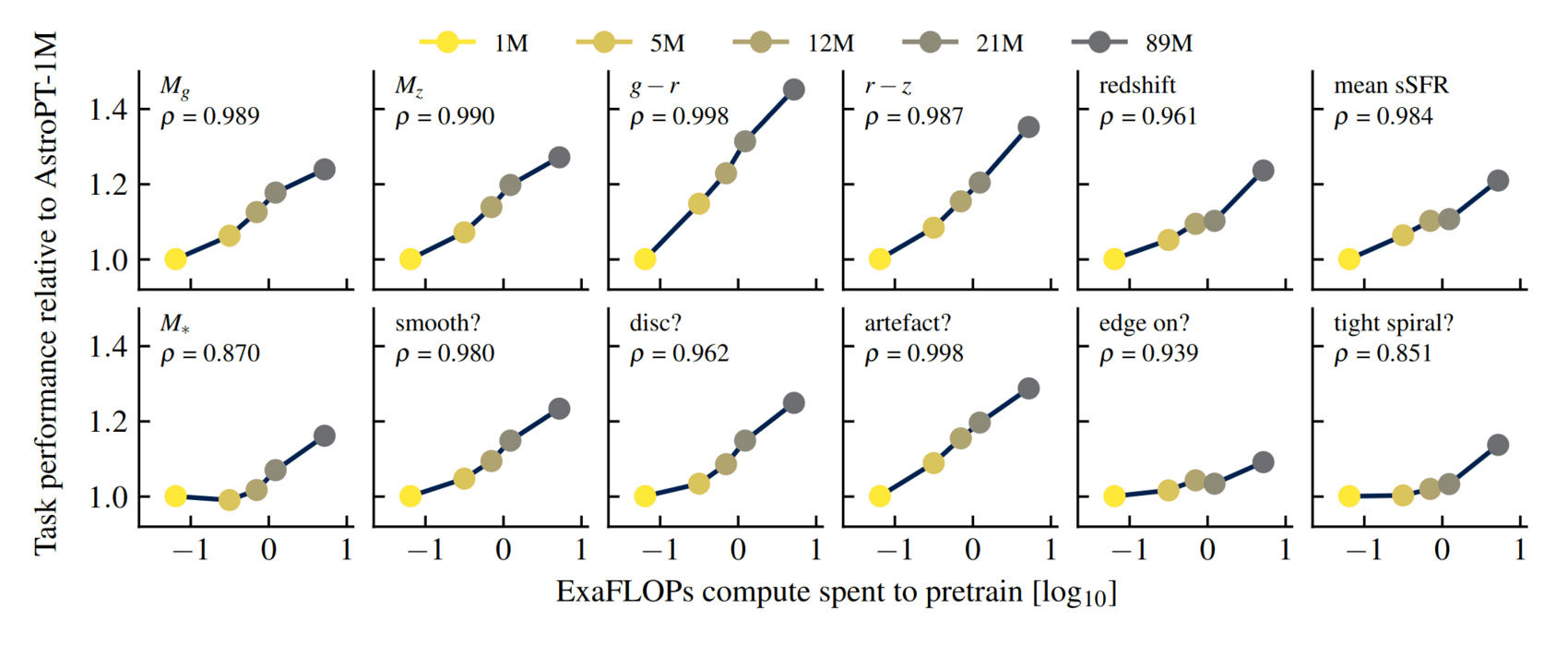{kind=link}
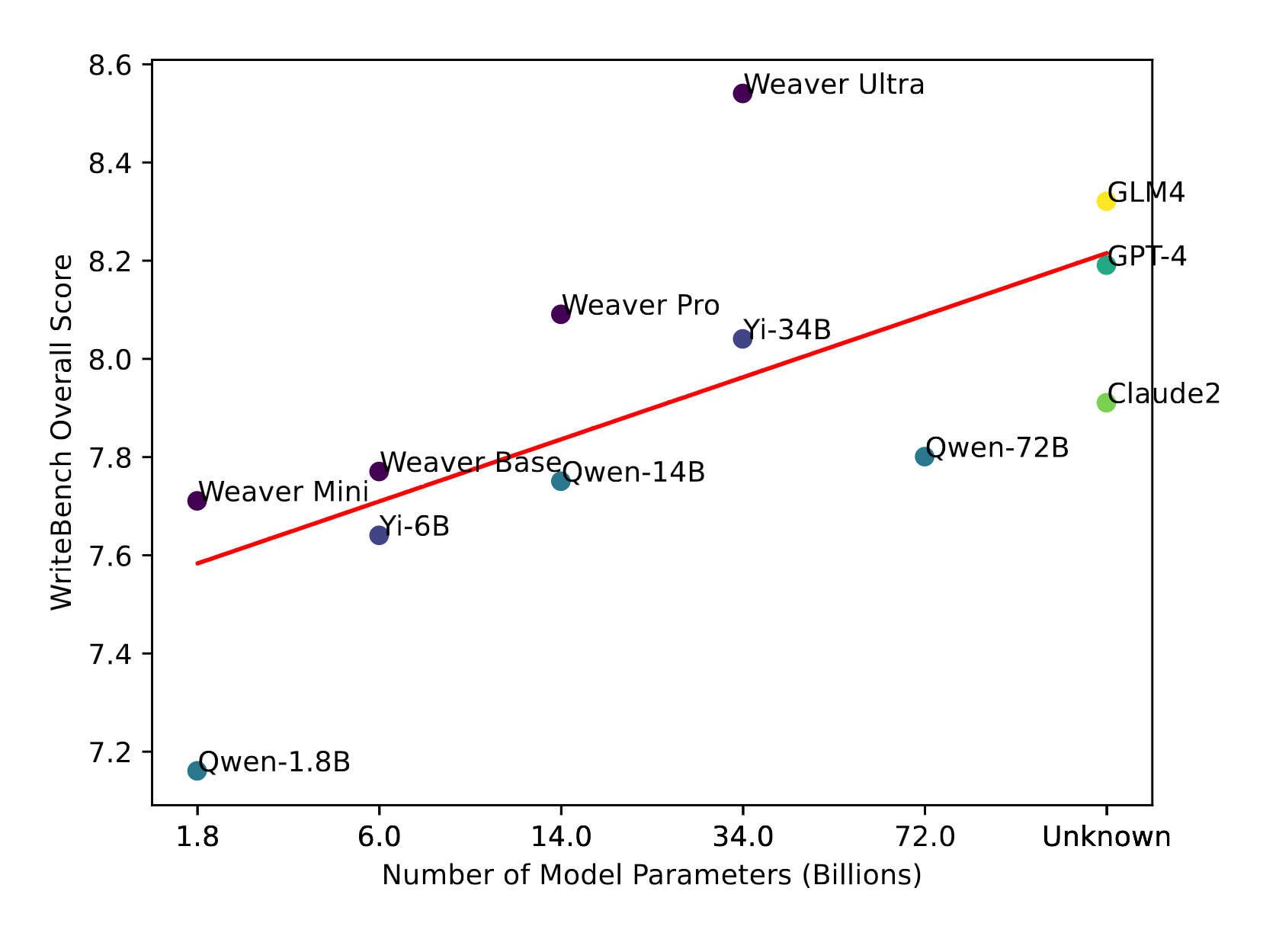{kind=link}
{kind=link}
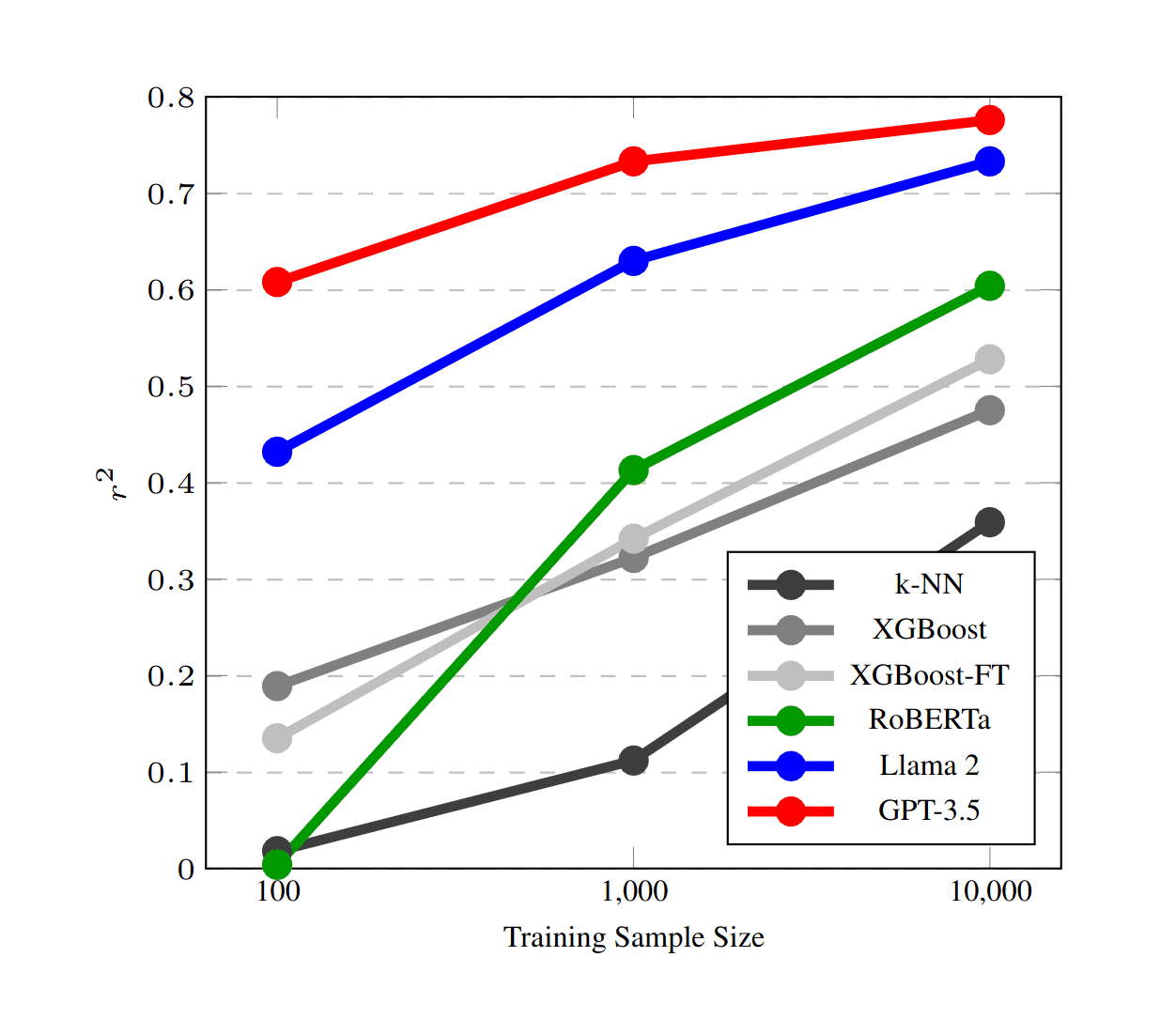{kind=link}
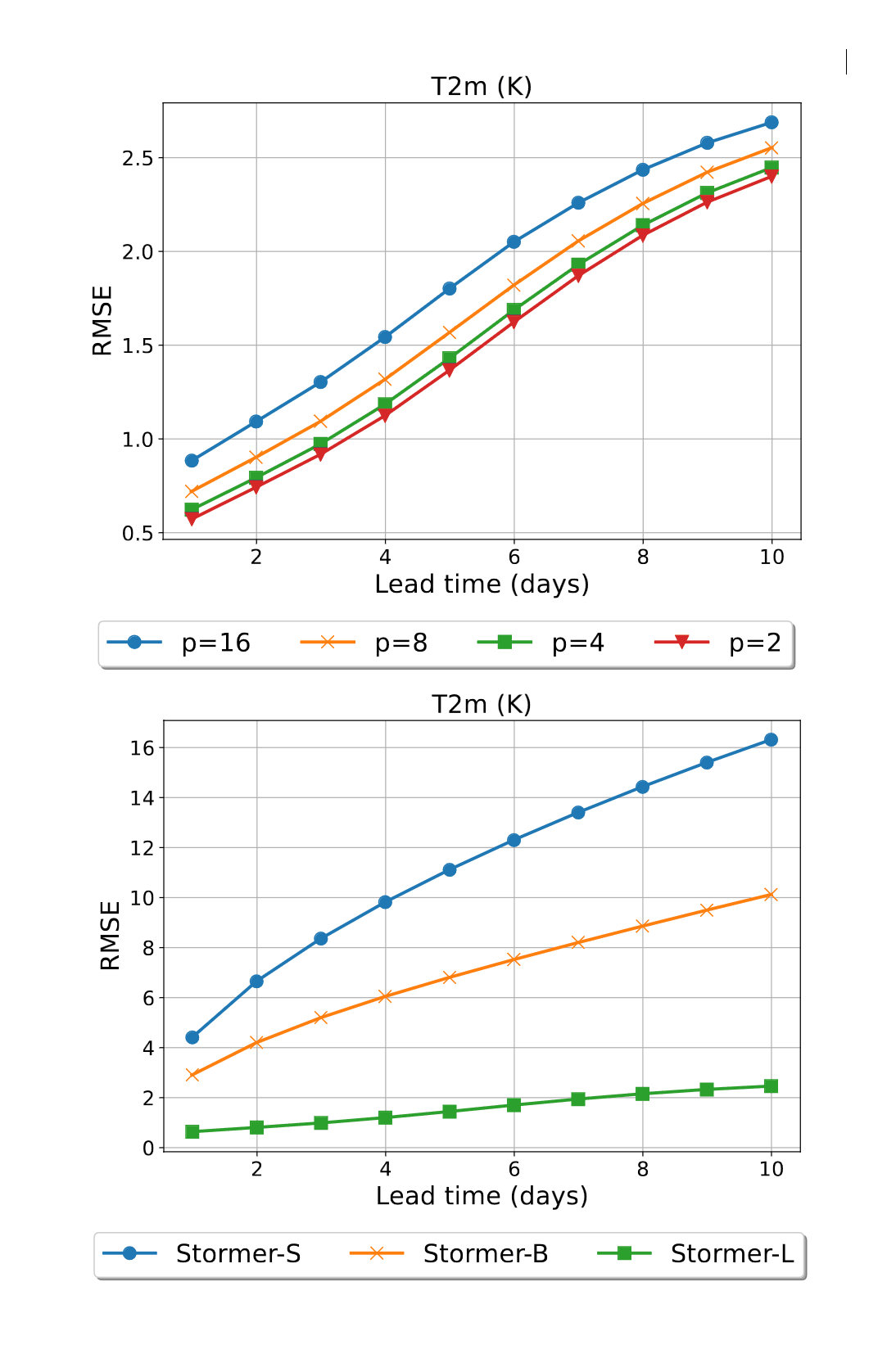{kind=link}
{kind=link}
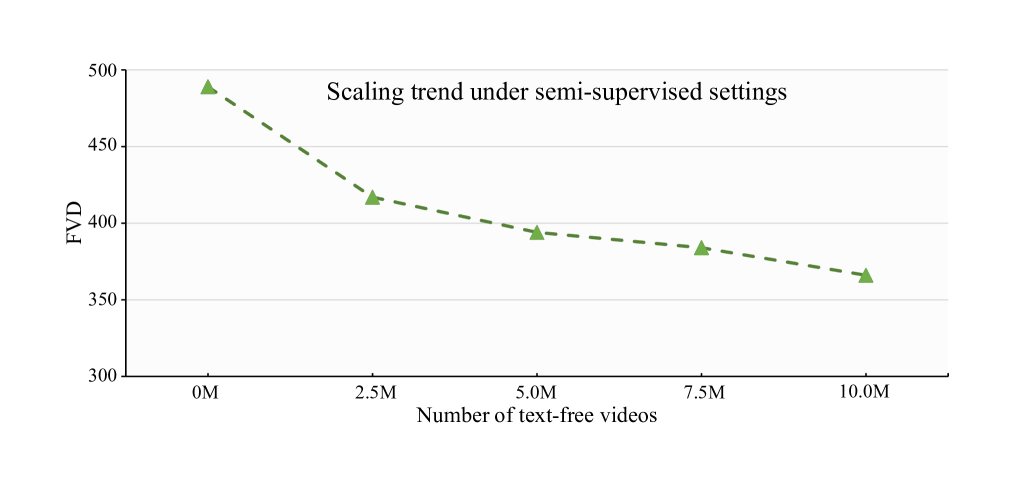{kind=link}
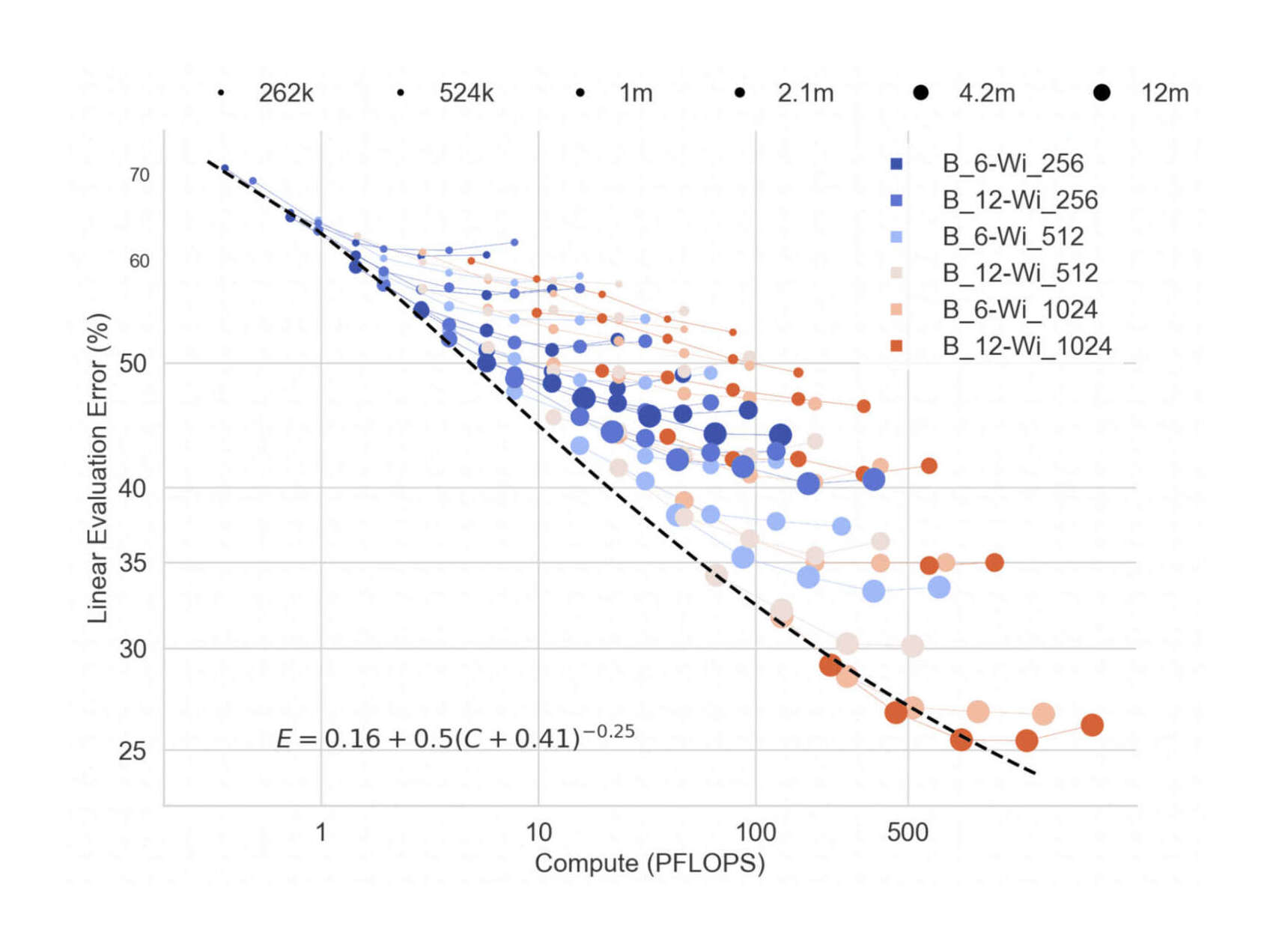{kind=link}
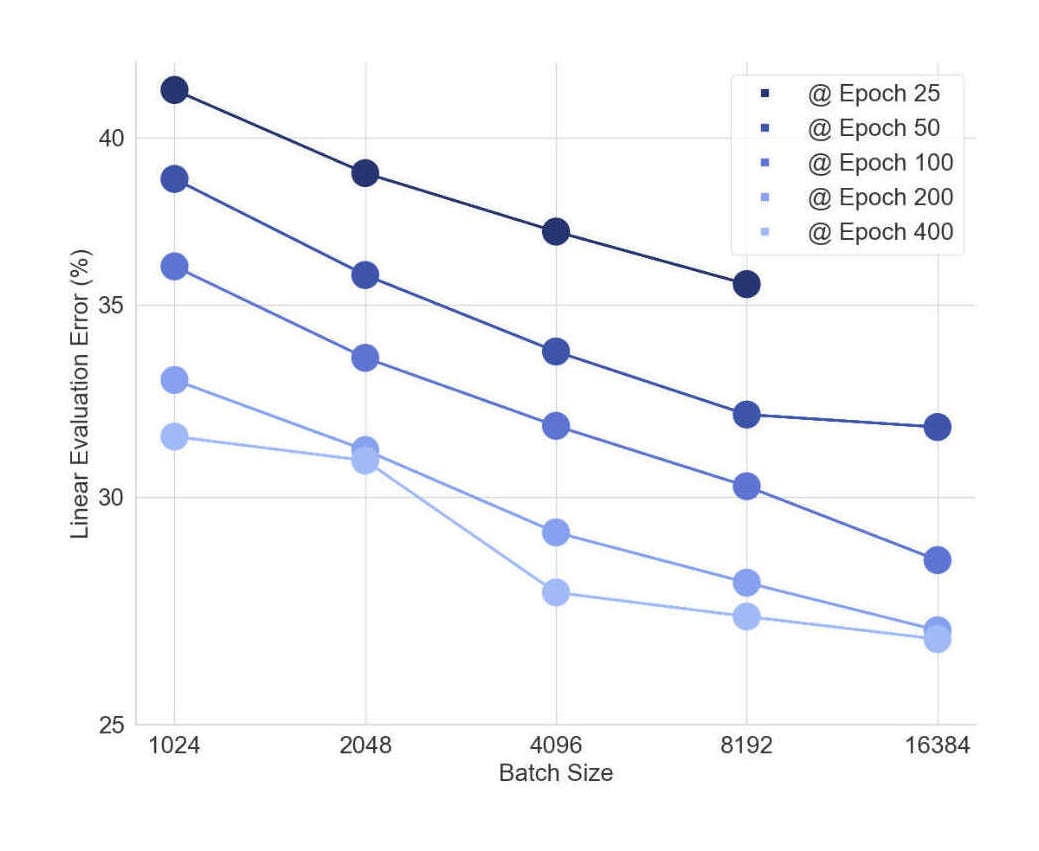{kind=link}
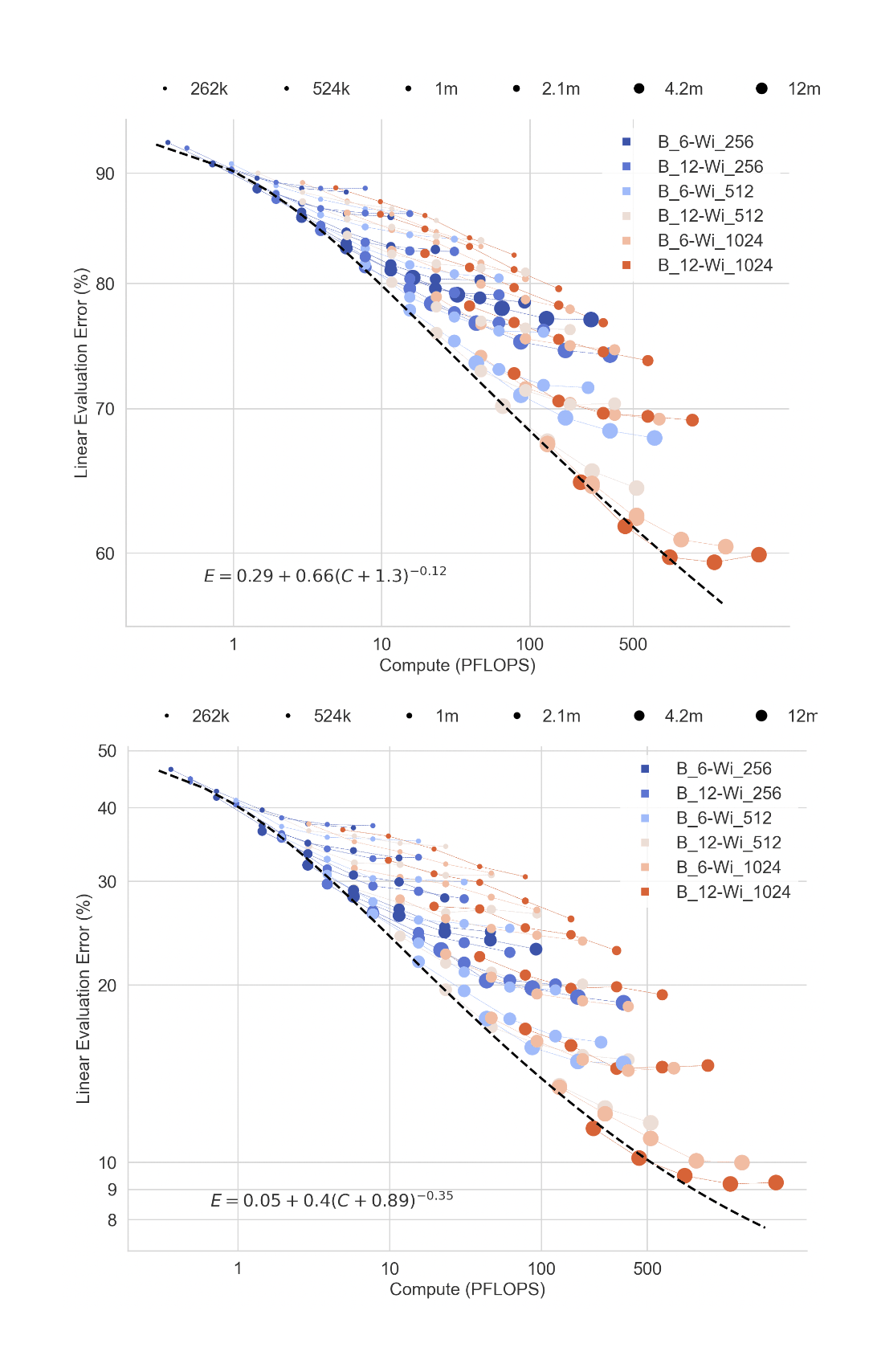{kind=link}
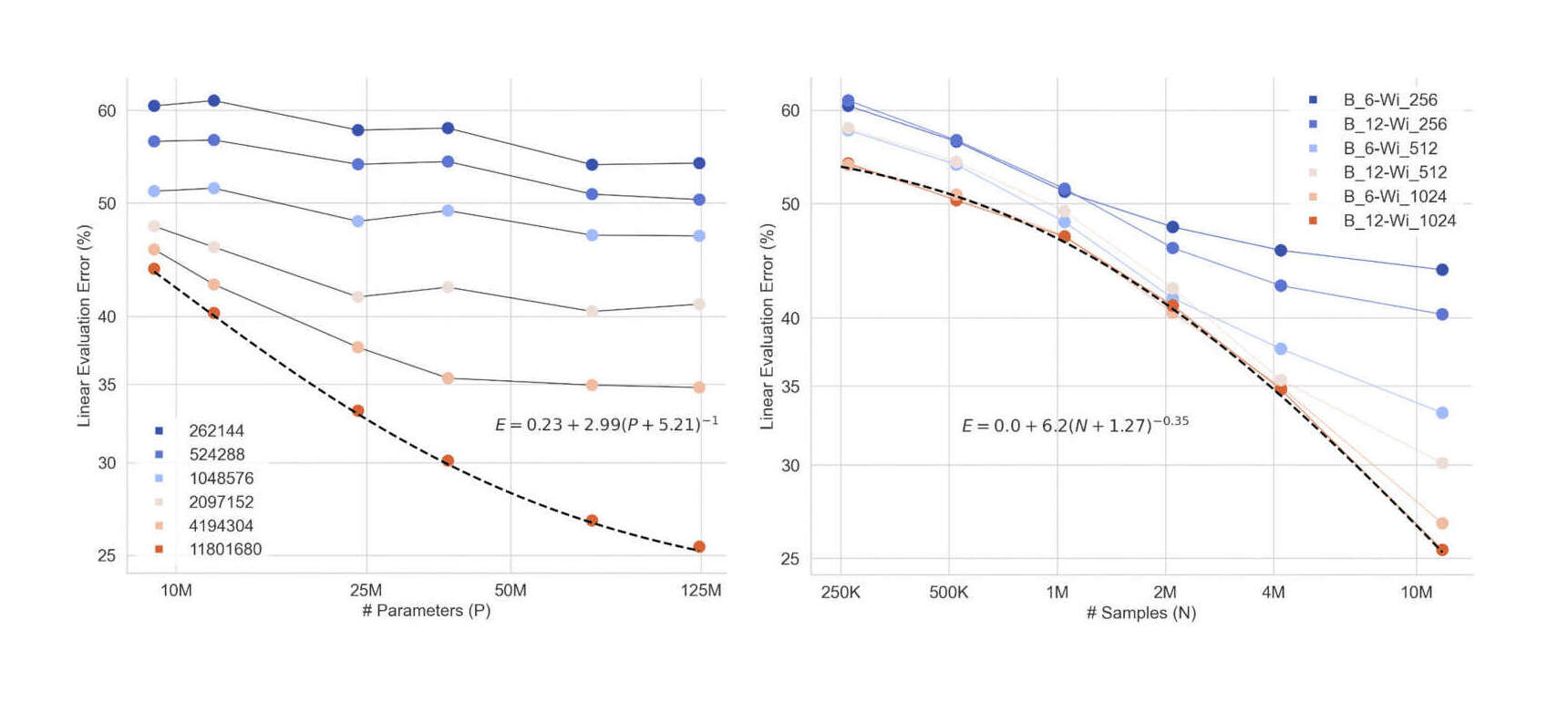{kind=link}
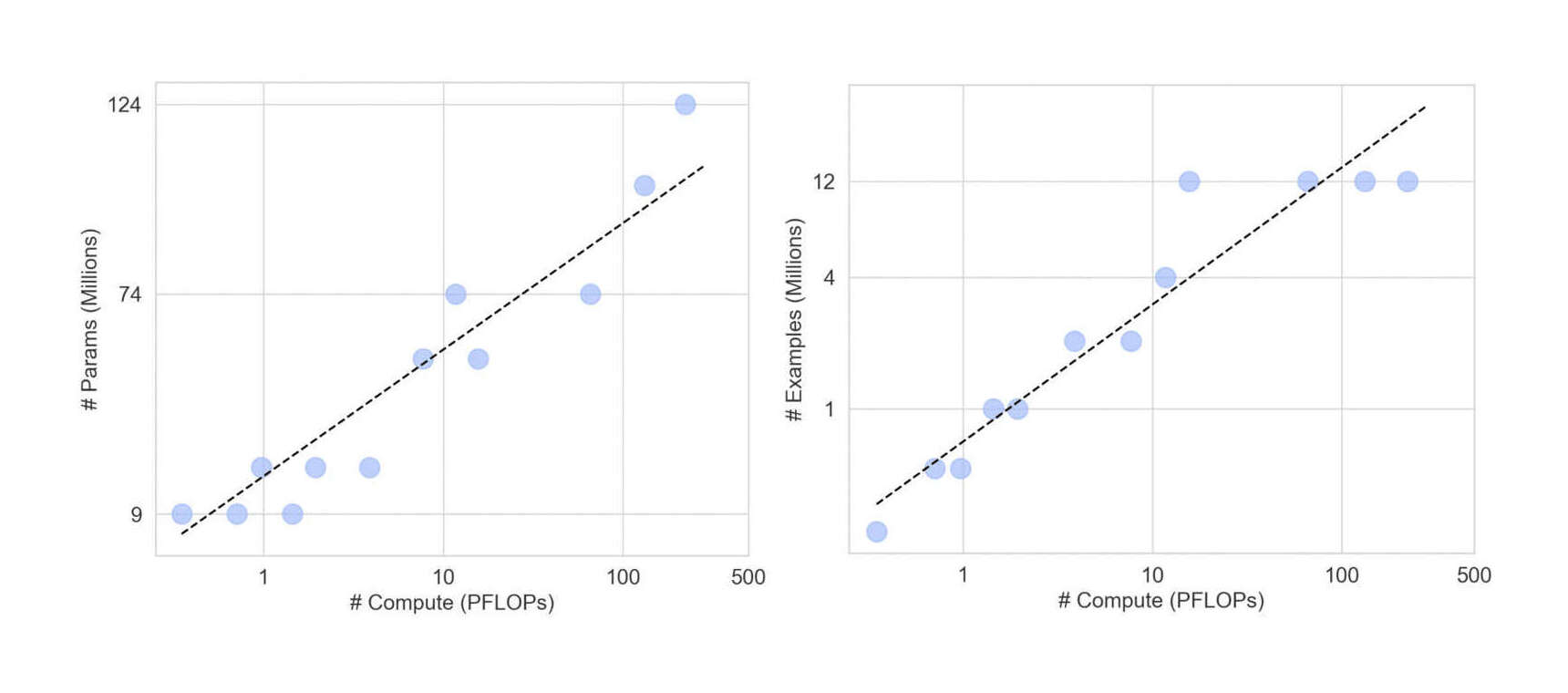{kind=link}
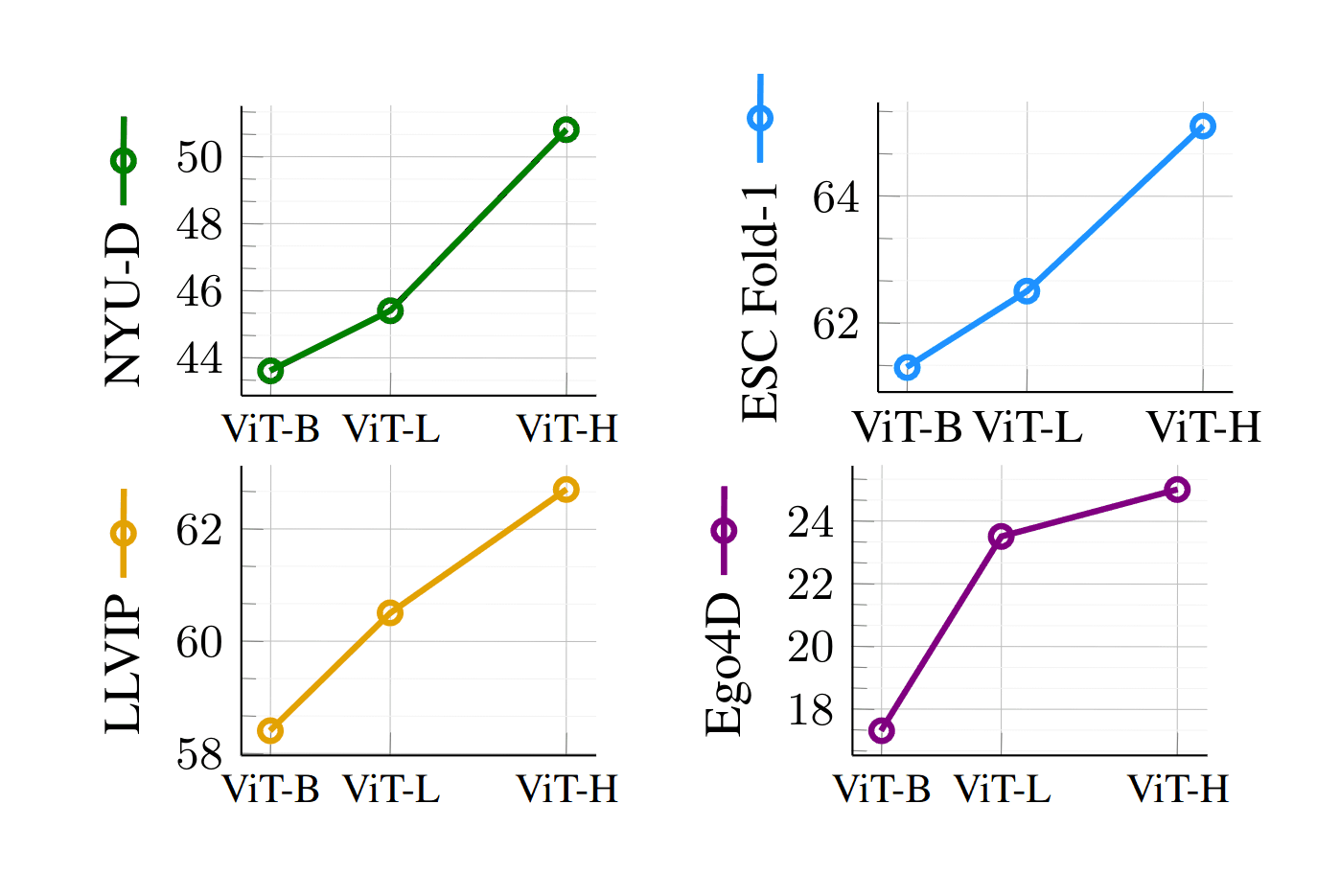{kind=link}
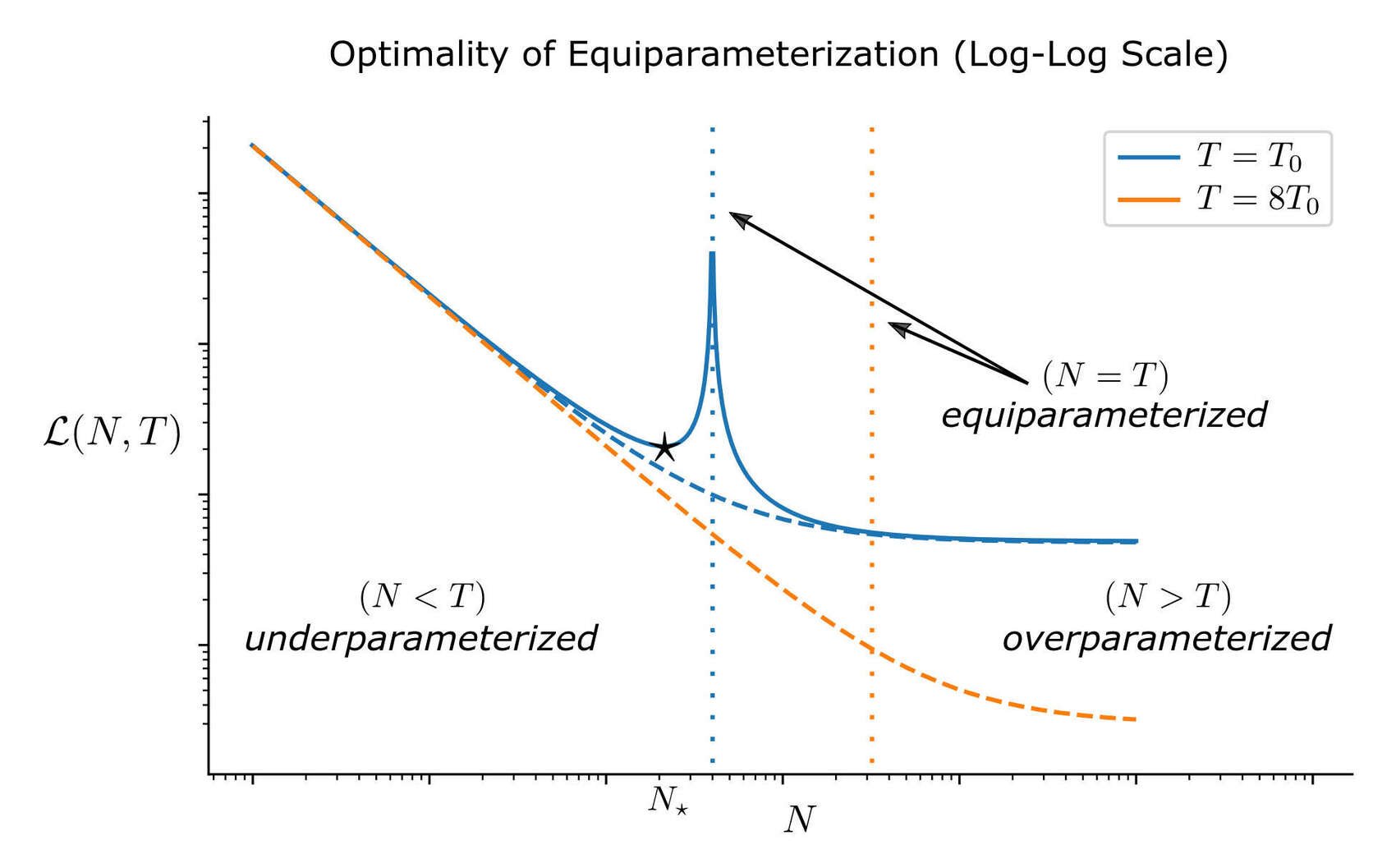{kind=link}
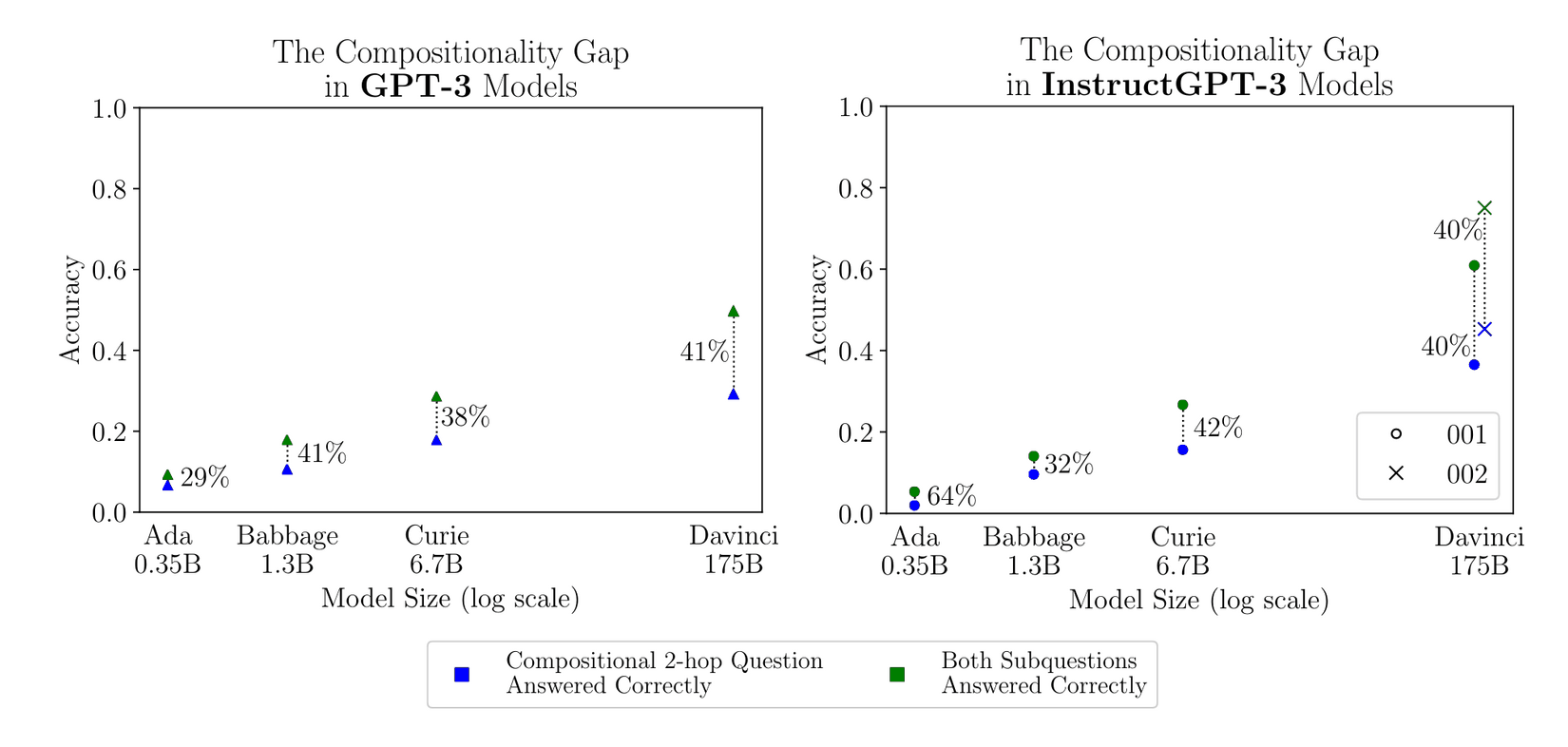{kind=link}
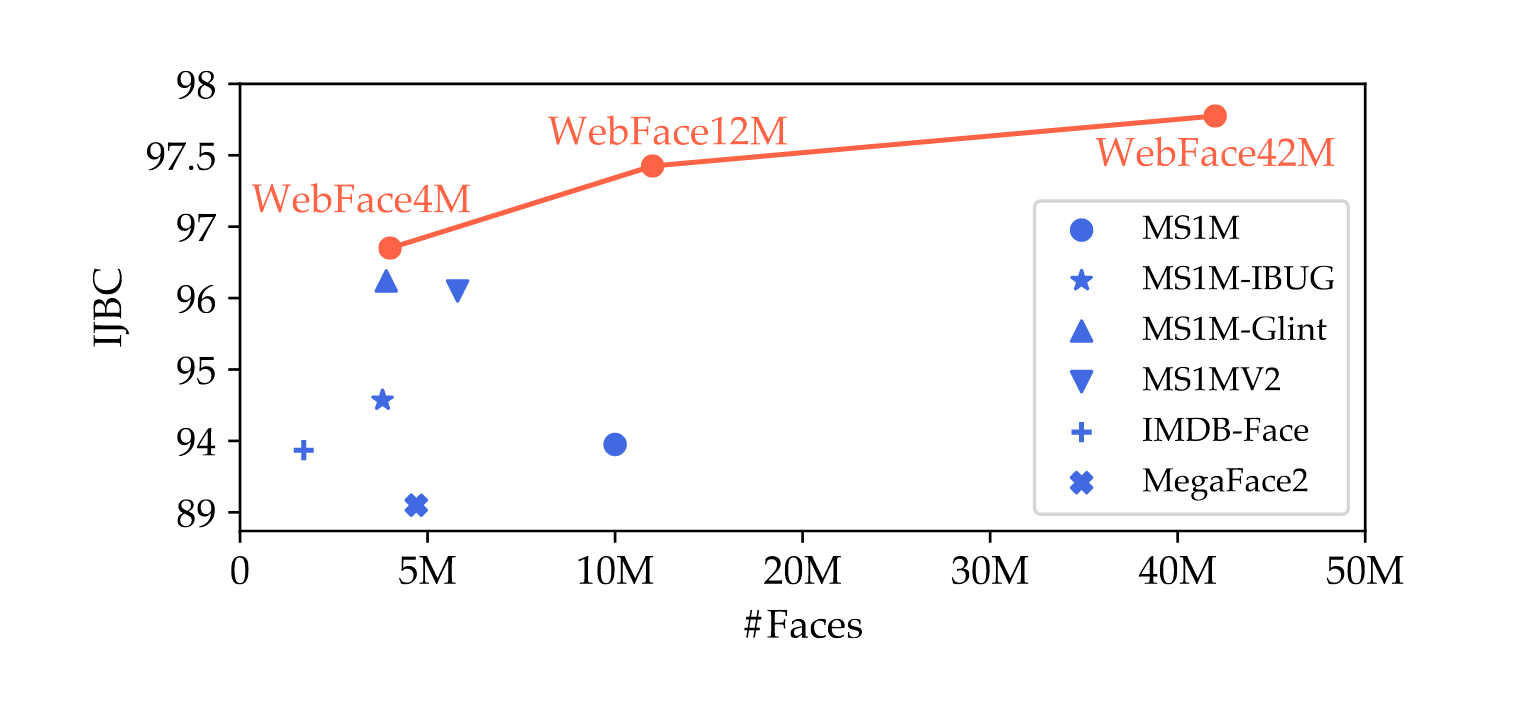{kind=link}
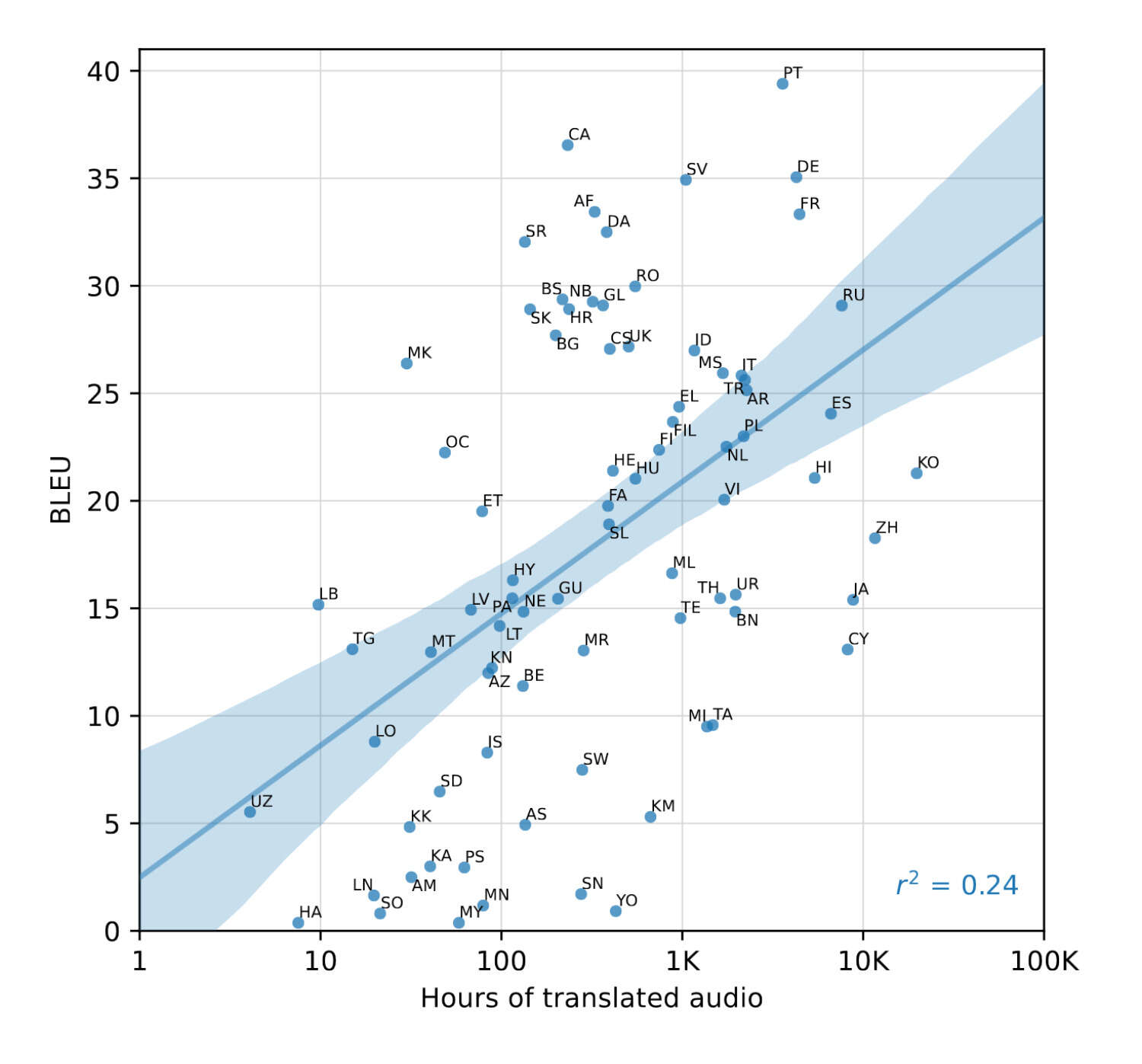{kind=link}
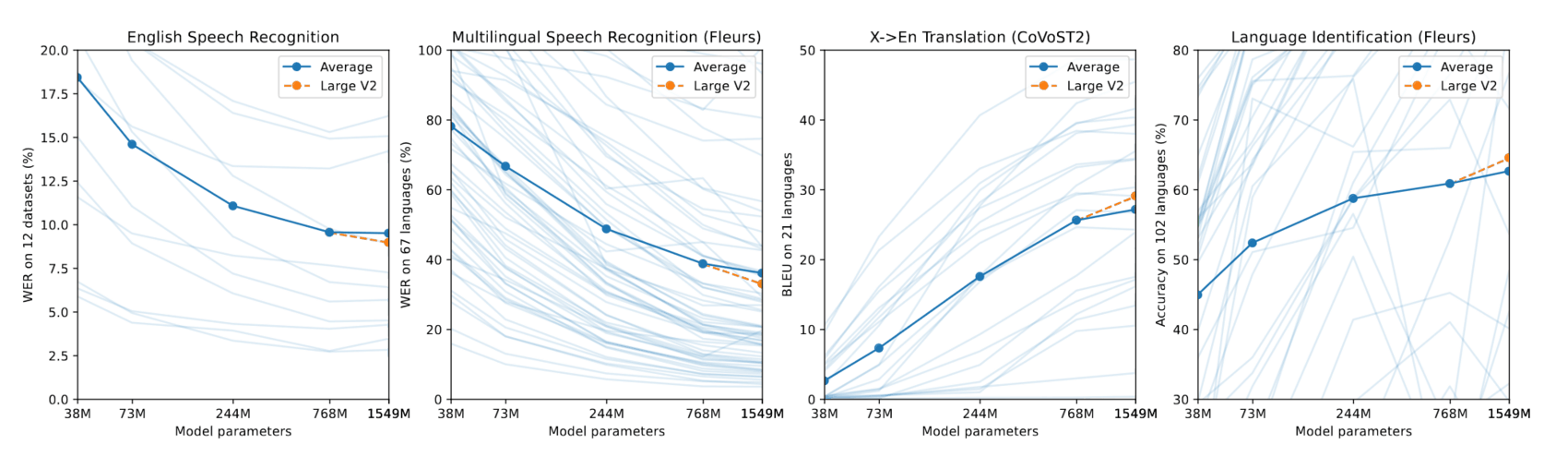{kind=link}
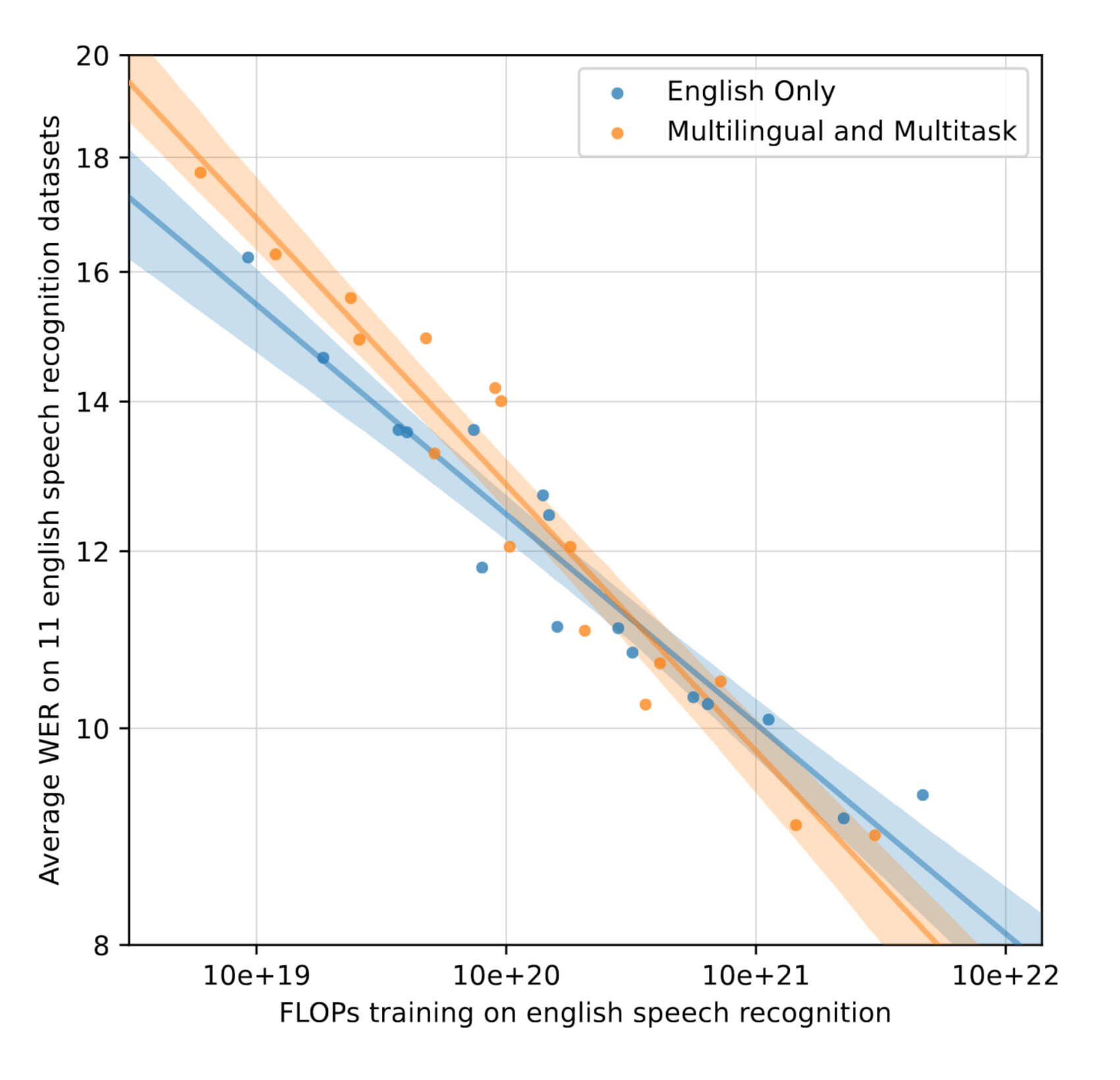{kind=link}
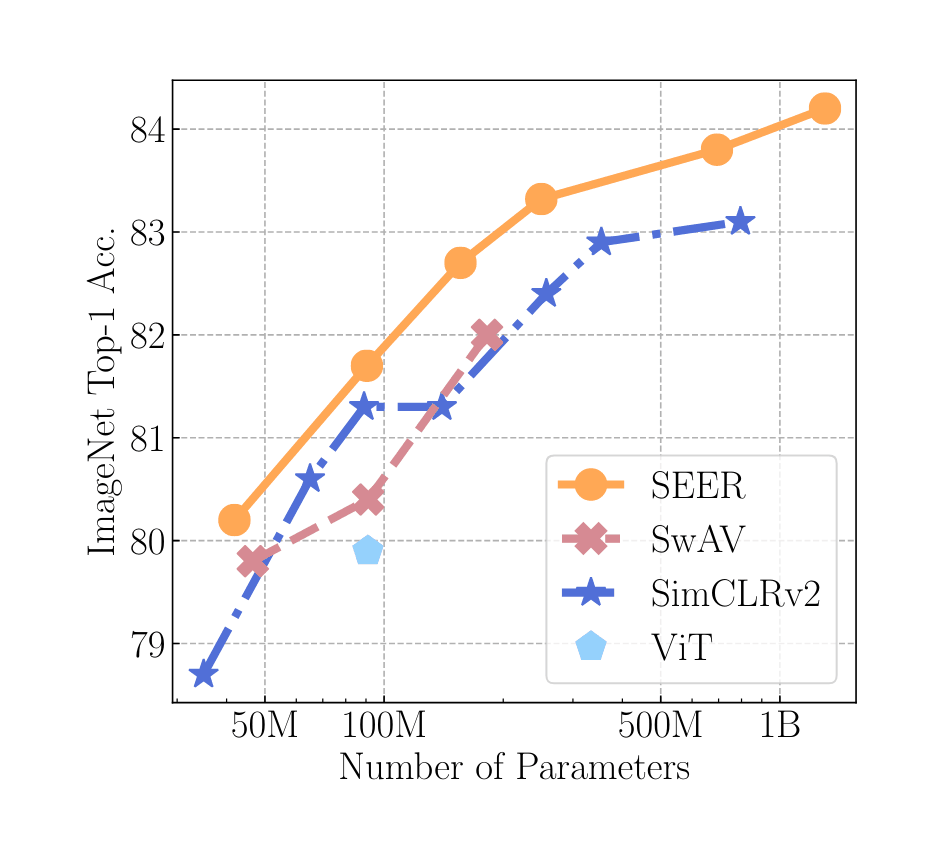{kind=link}
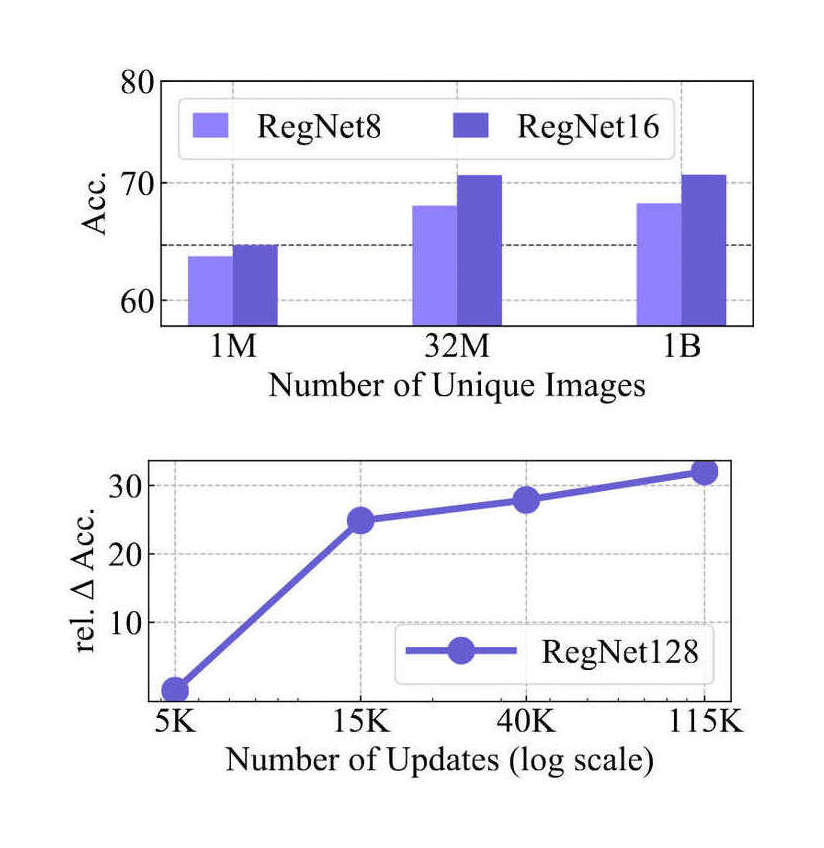{kind=link}
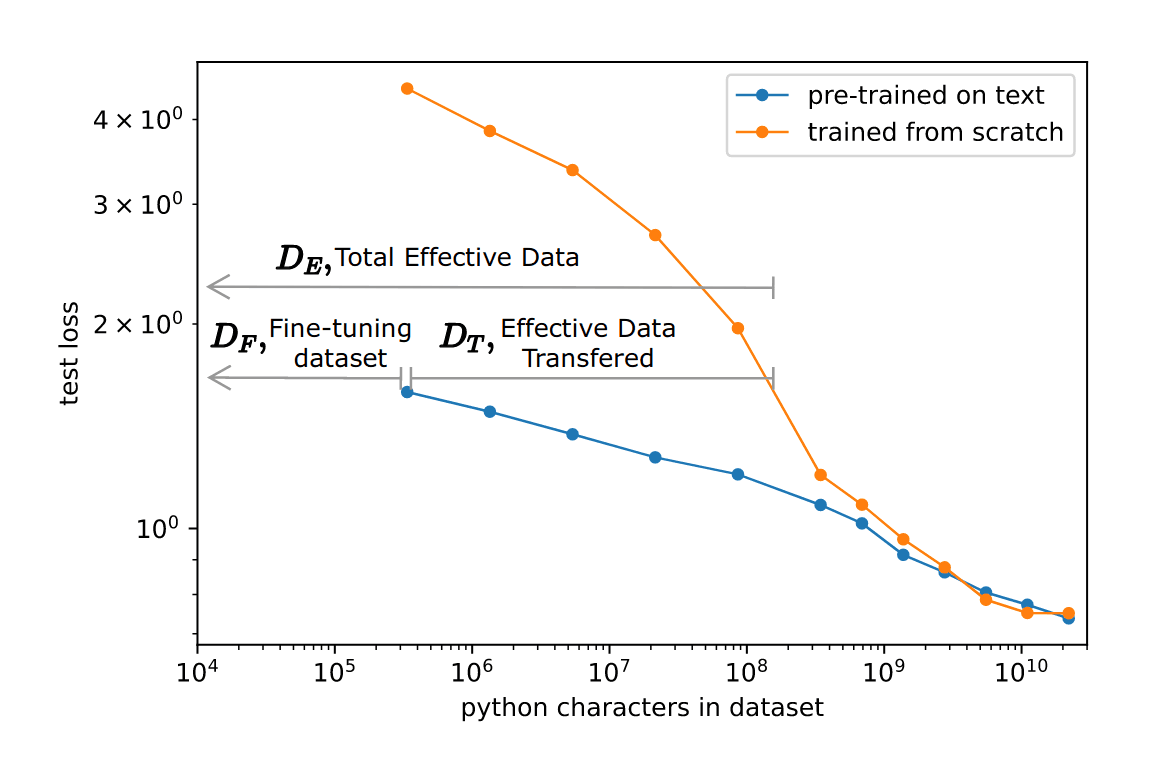{kind=link}
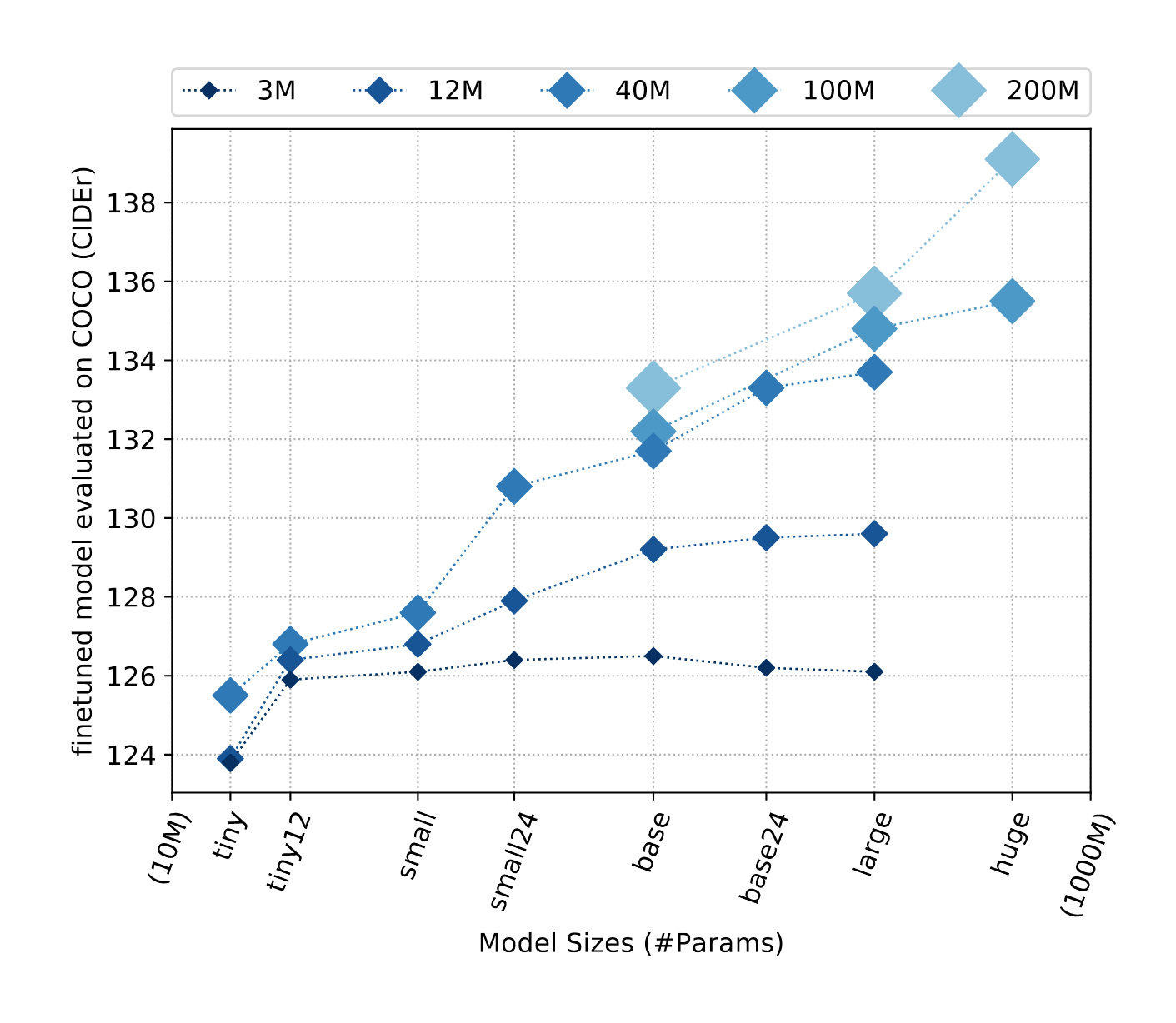{kind=link}
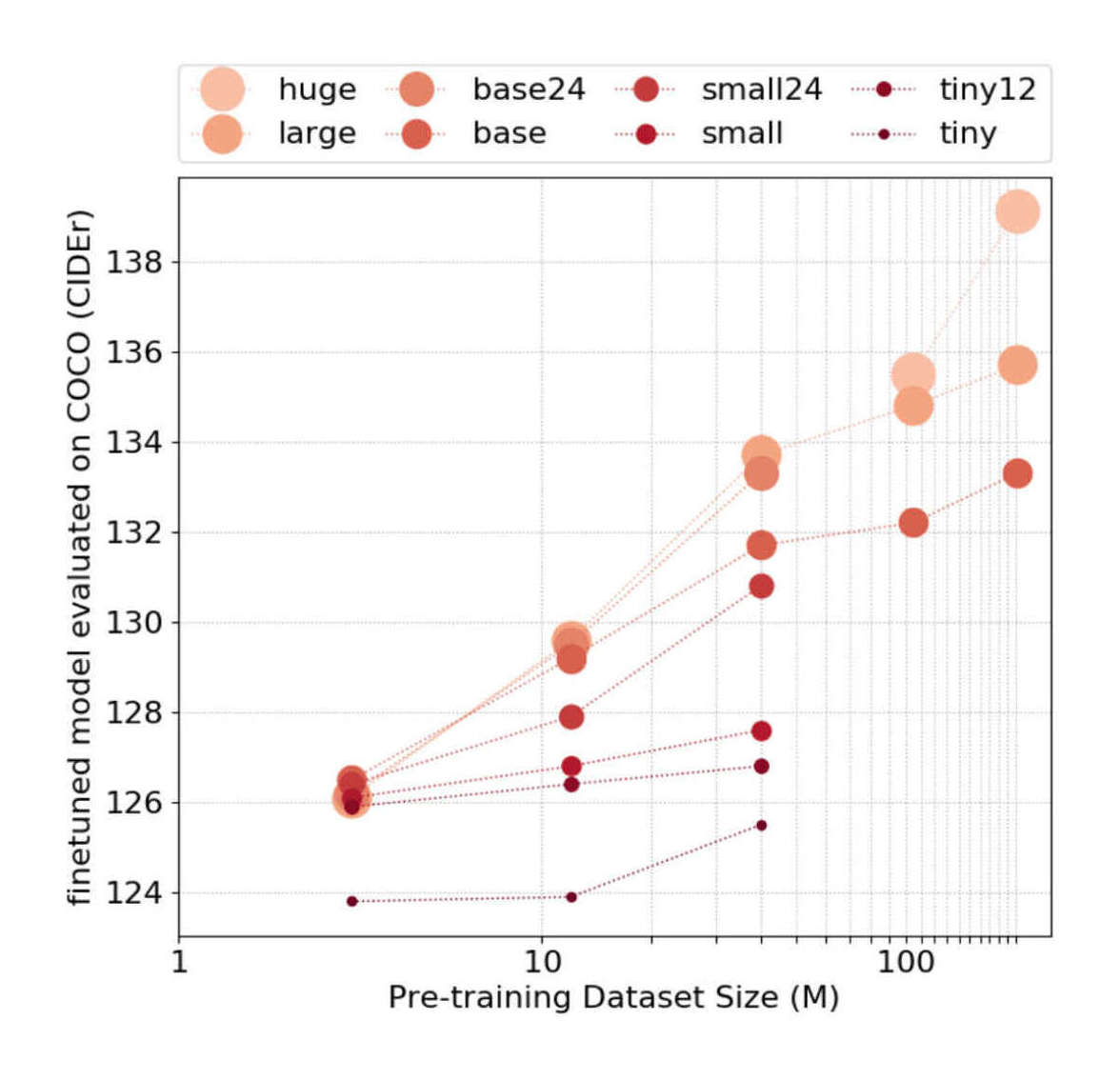{kind=link}
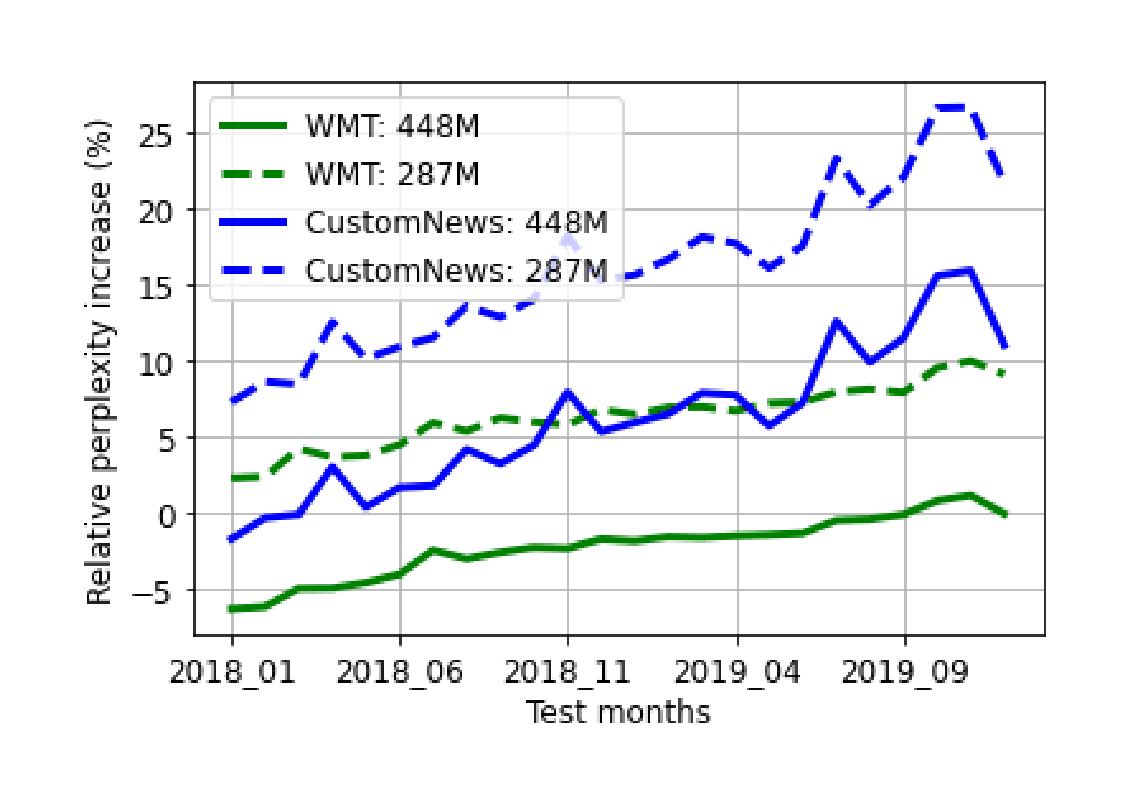{kind=link}
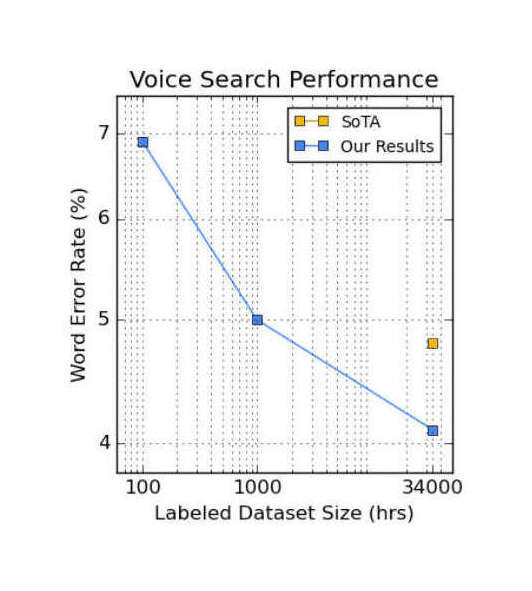{kind=link}
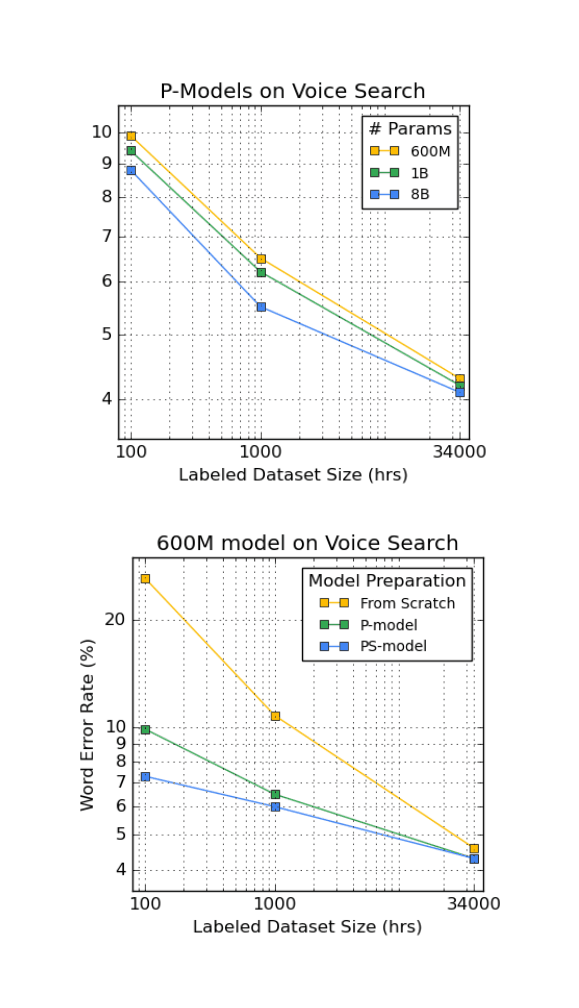{kind=link}
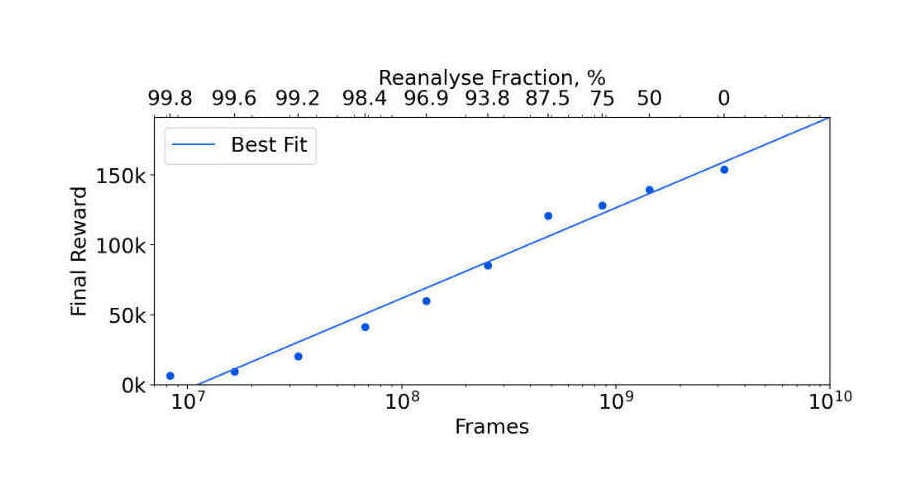{kind=link}
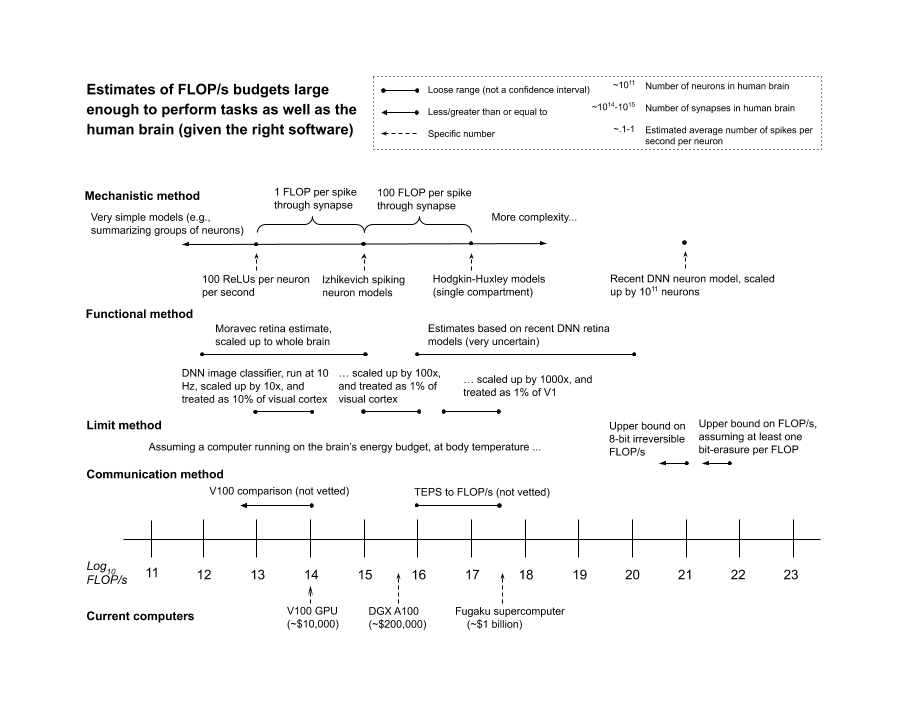{kind=link}
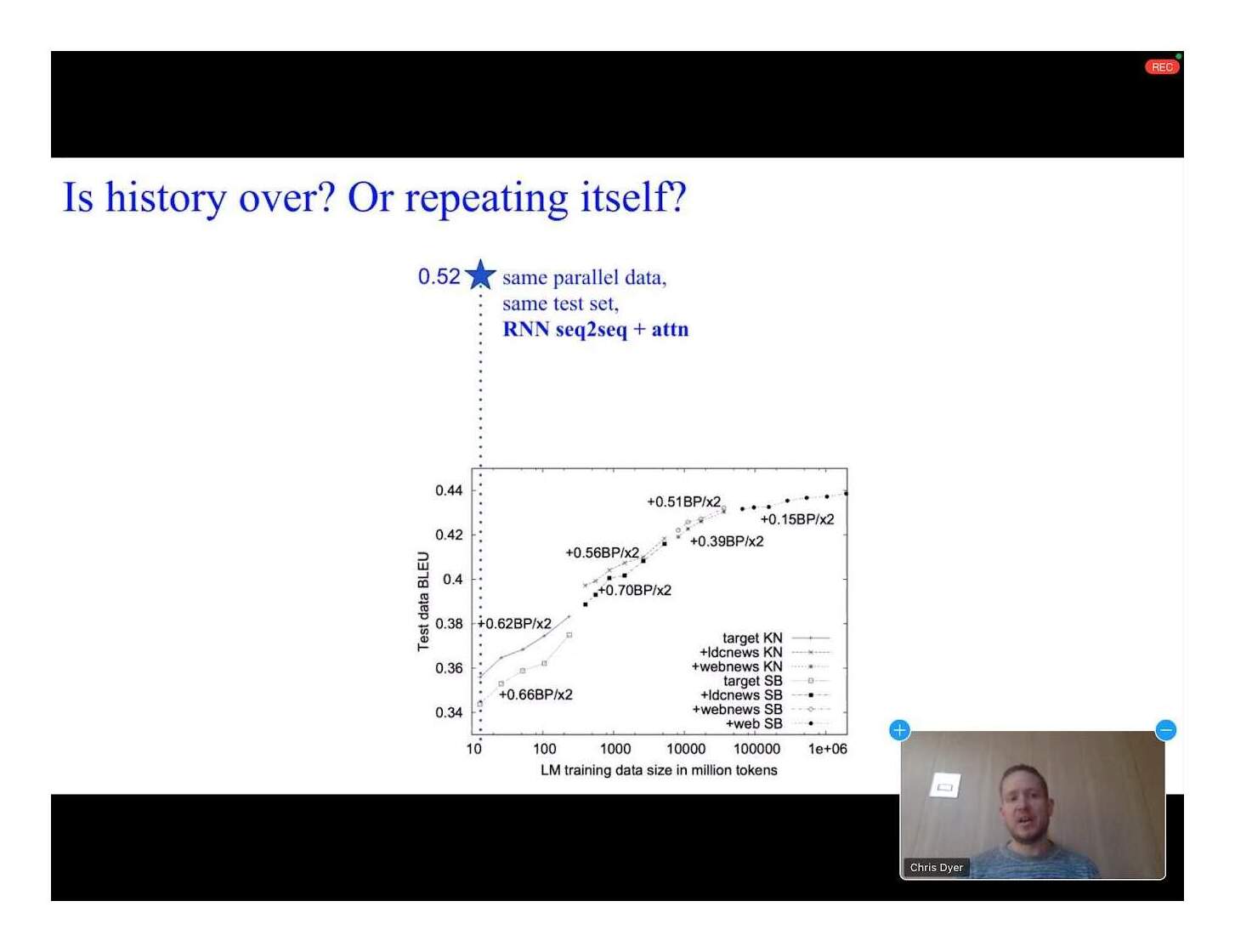{kind=link}
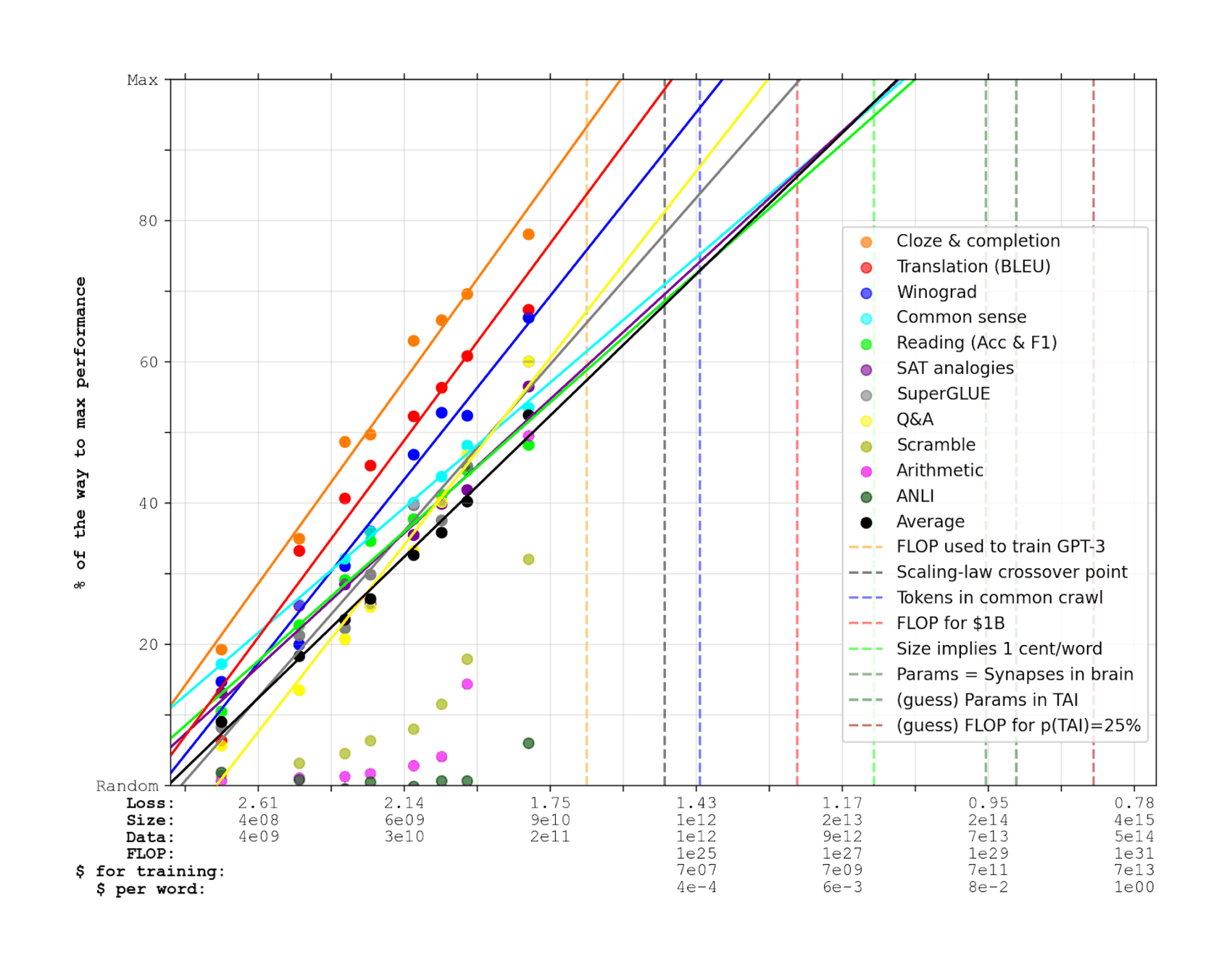{kind=link}
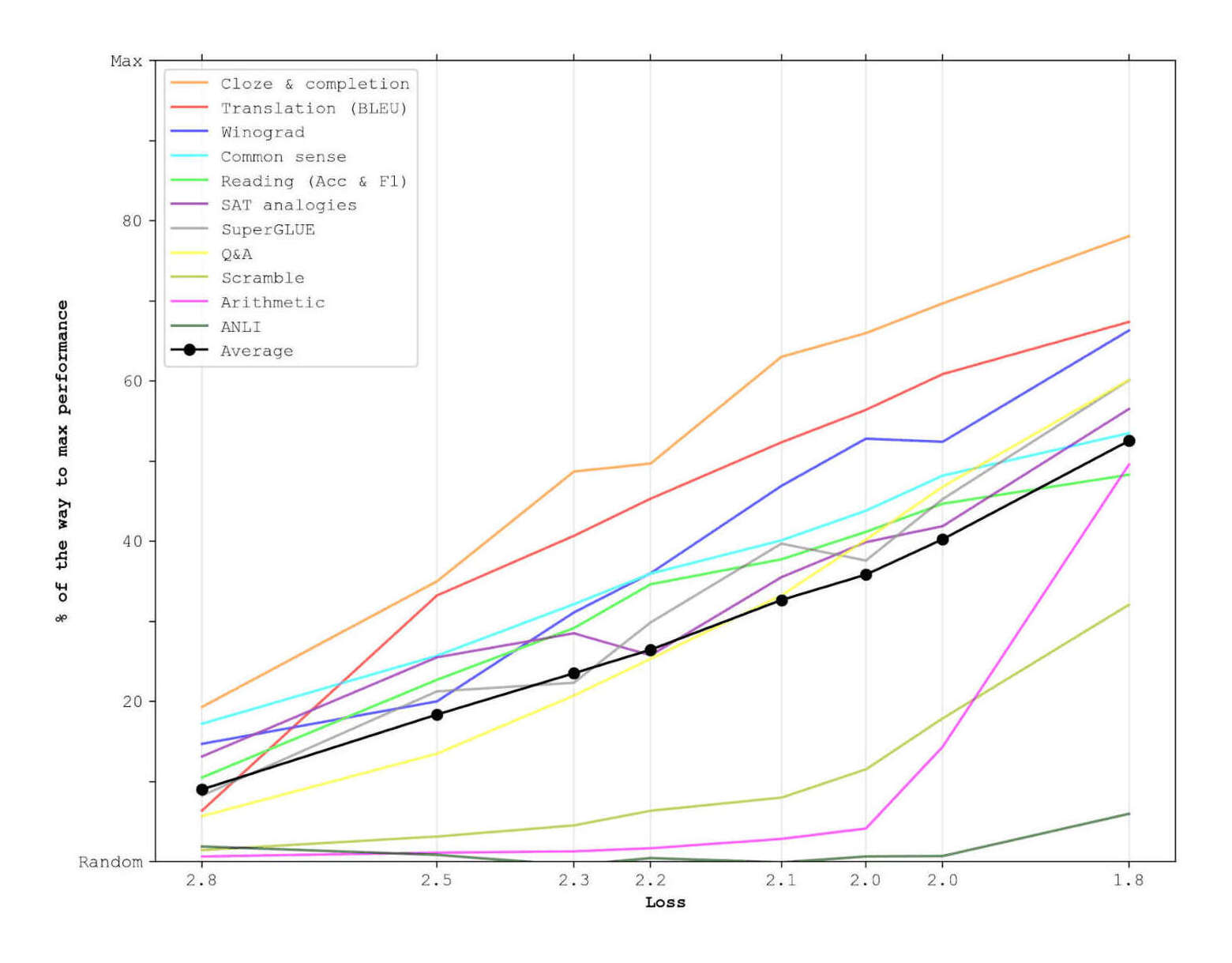{kind=link}
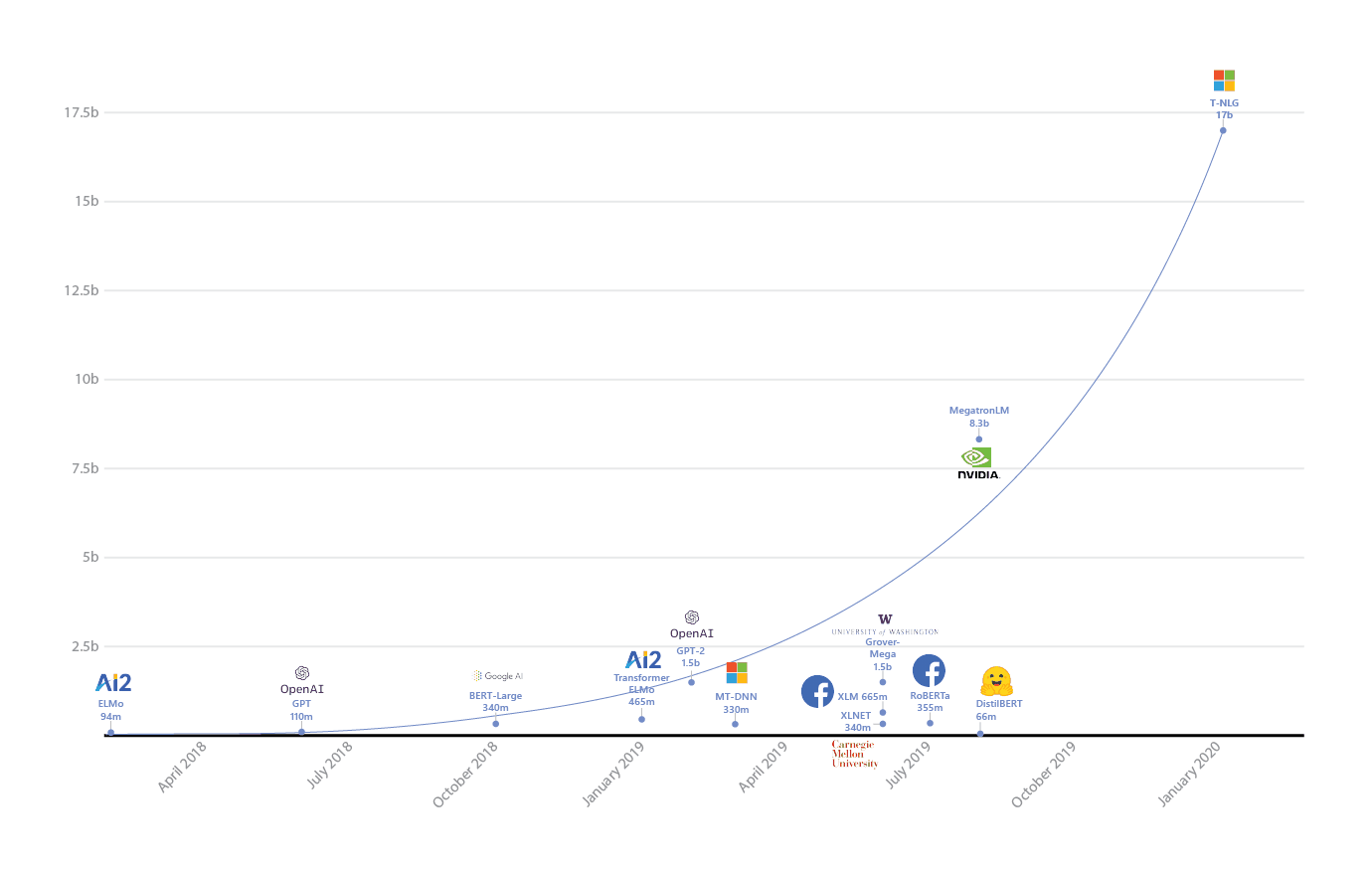{kind=link}
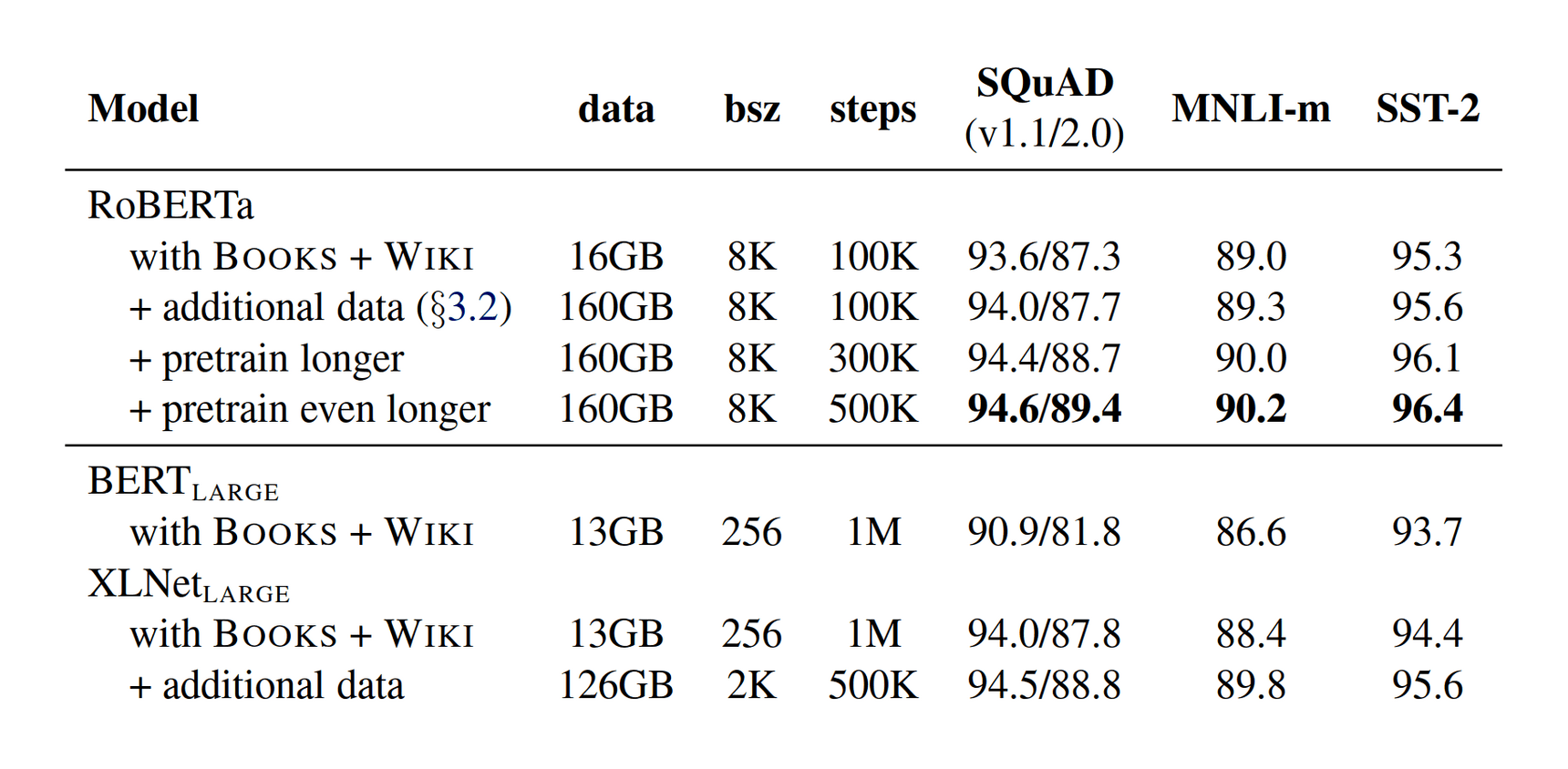{kind=link}
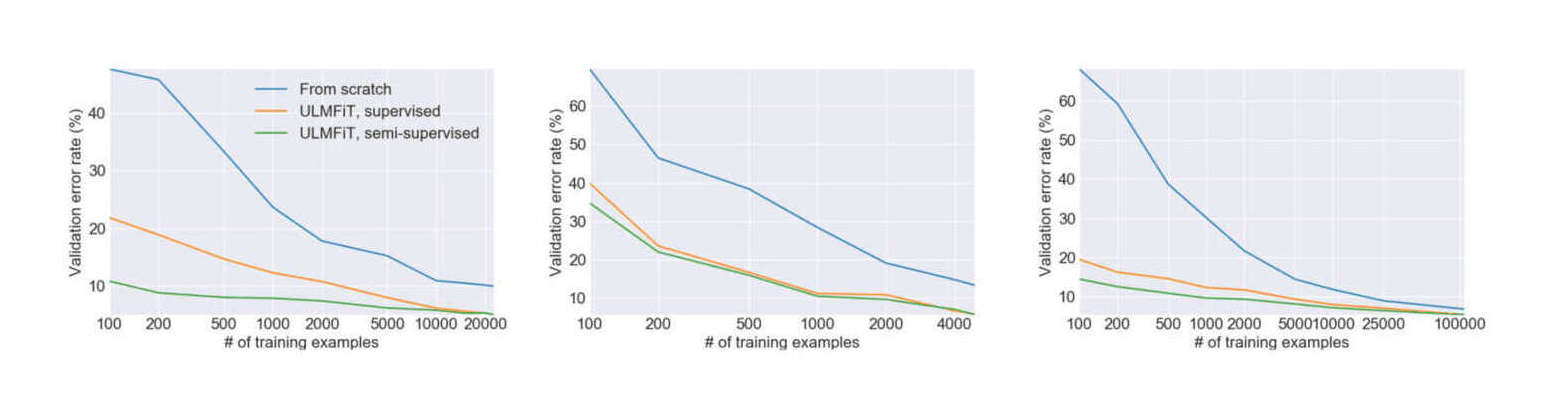{kind=link}
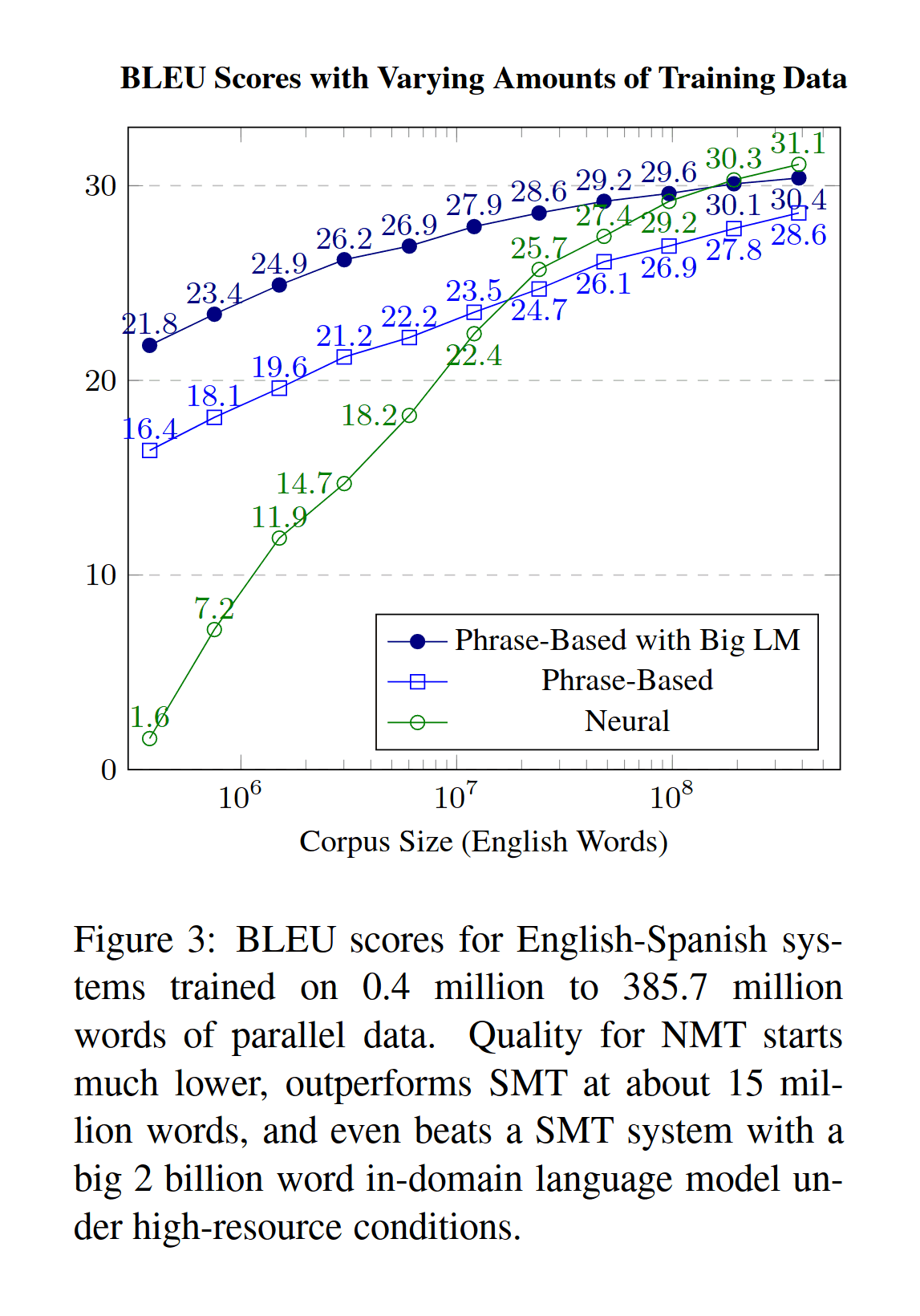{kind=link}
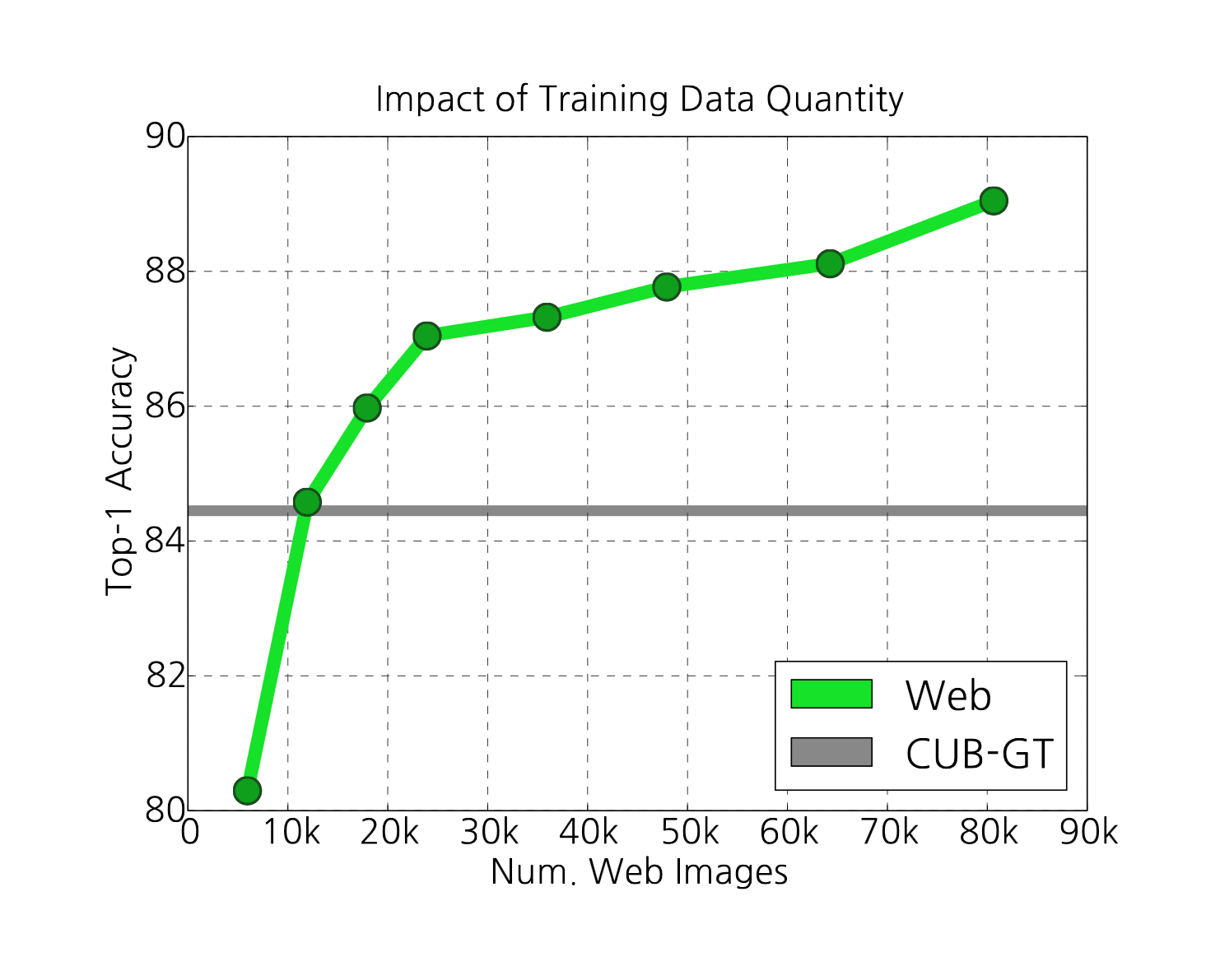{kind=link}
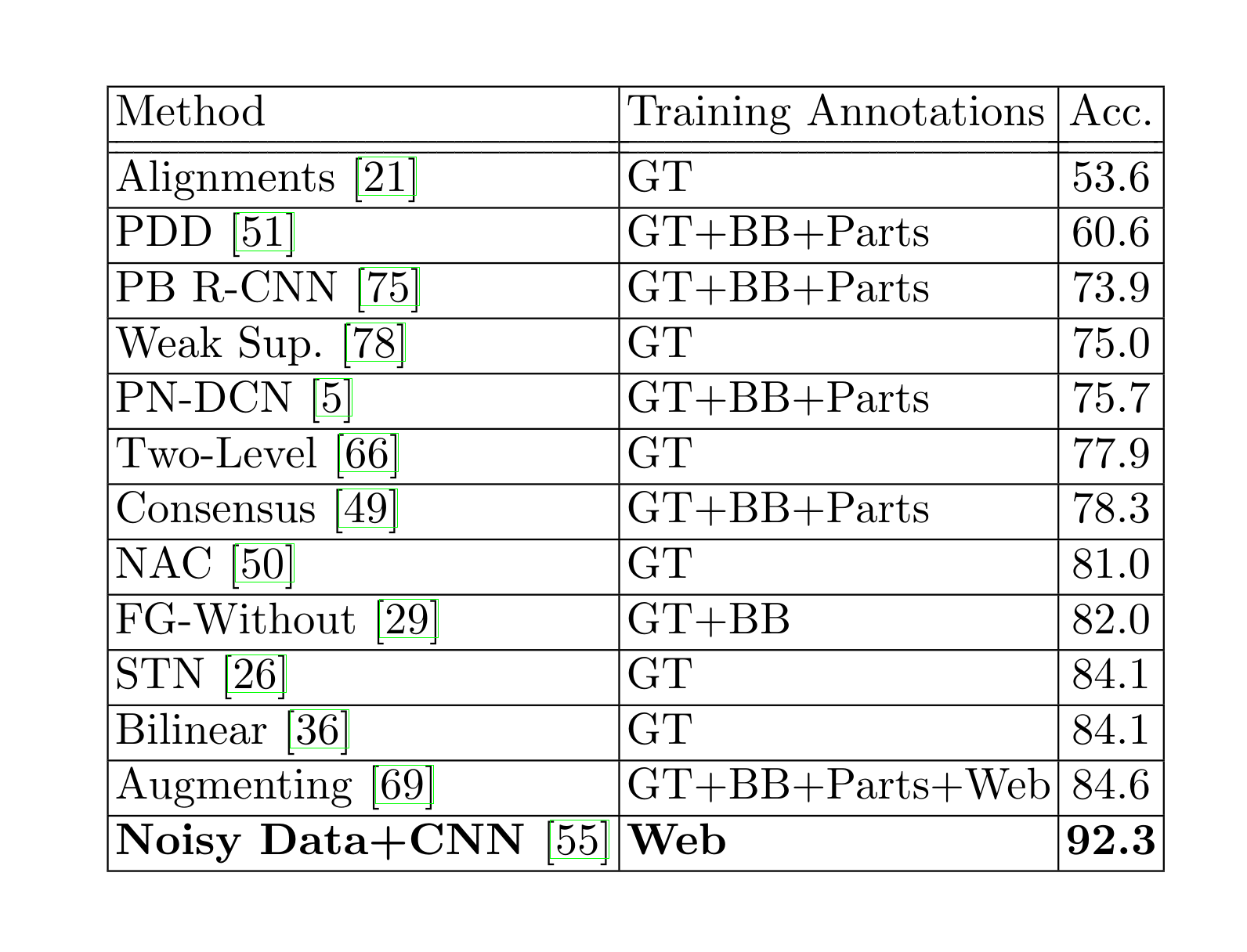{kind=link}
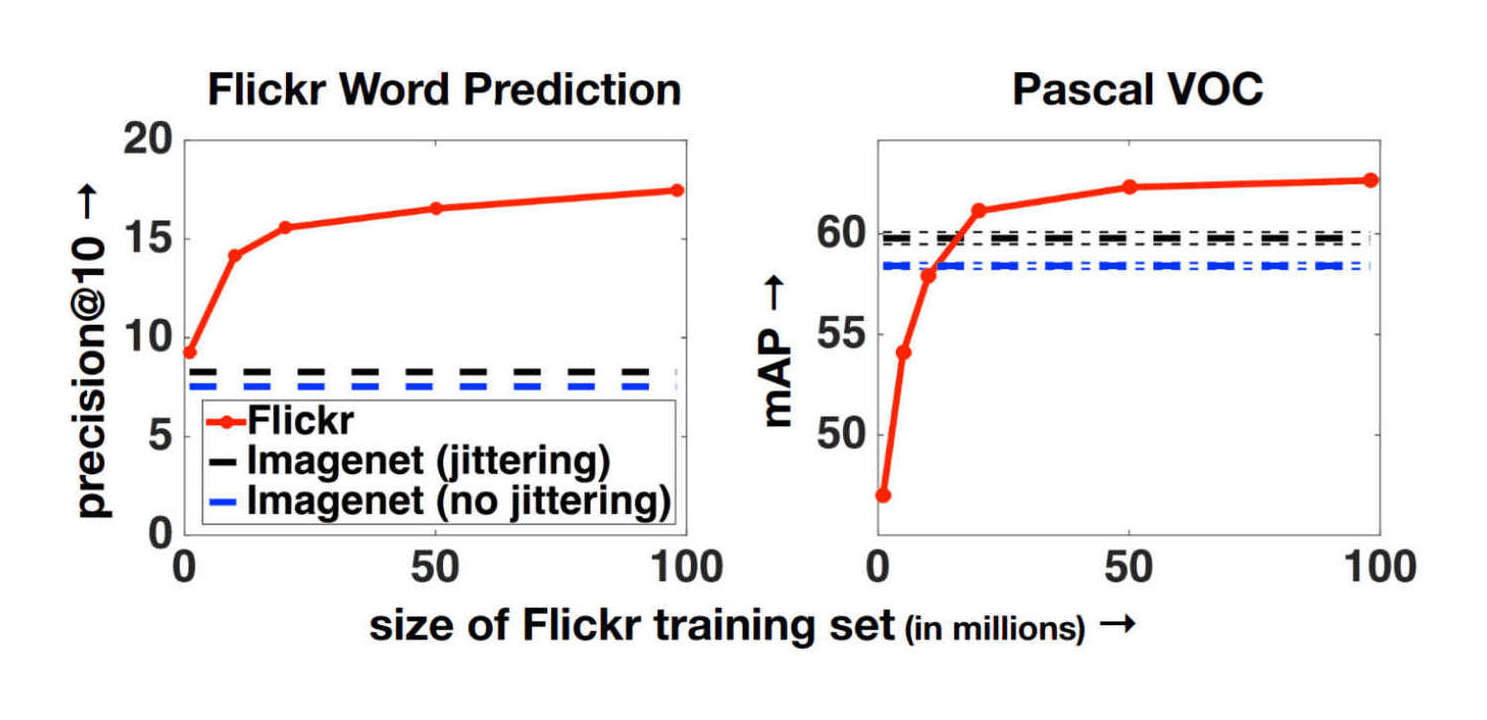{kind=link}
{kind=link}
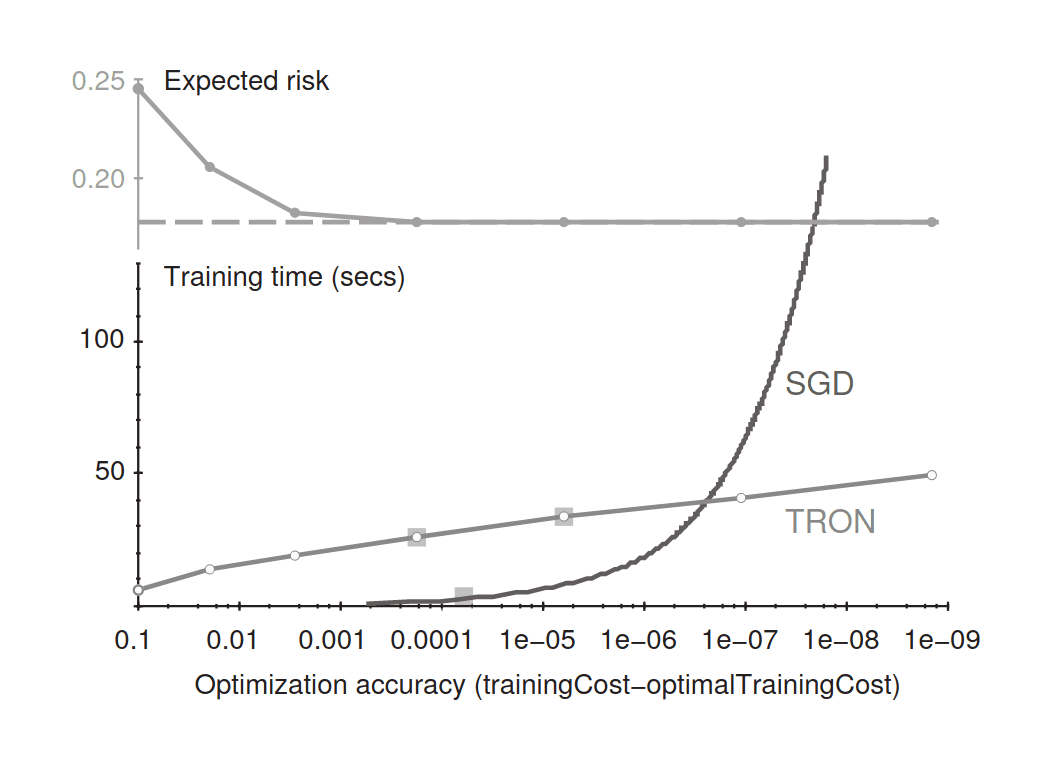{kind=link}
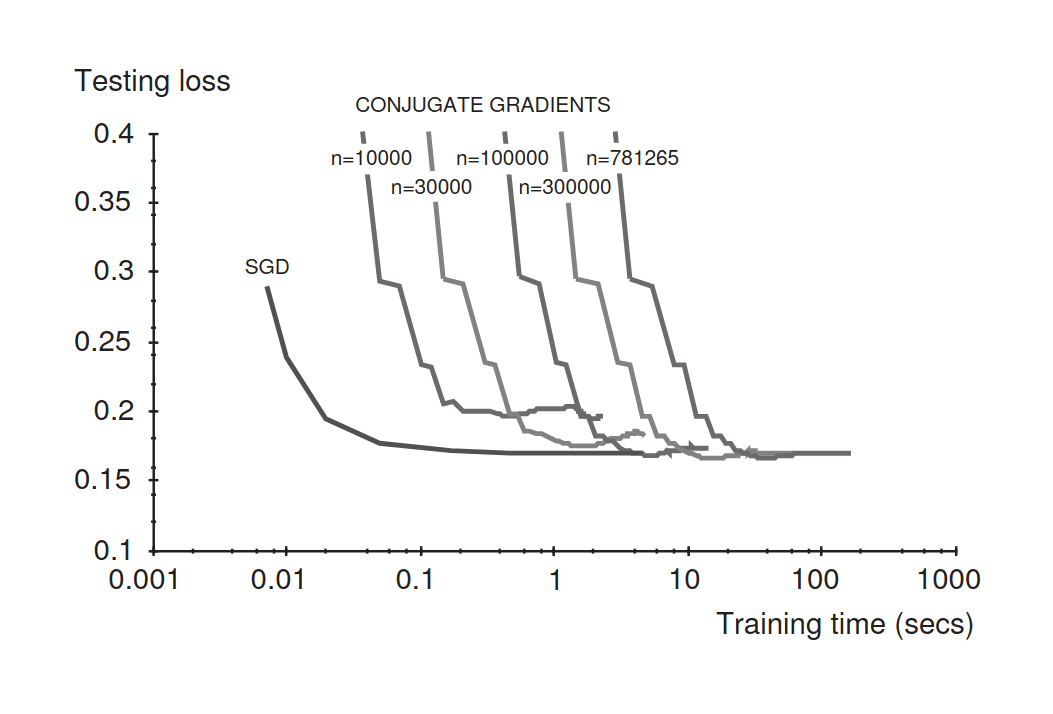{kind=link}
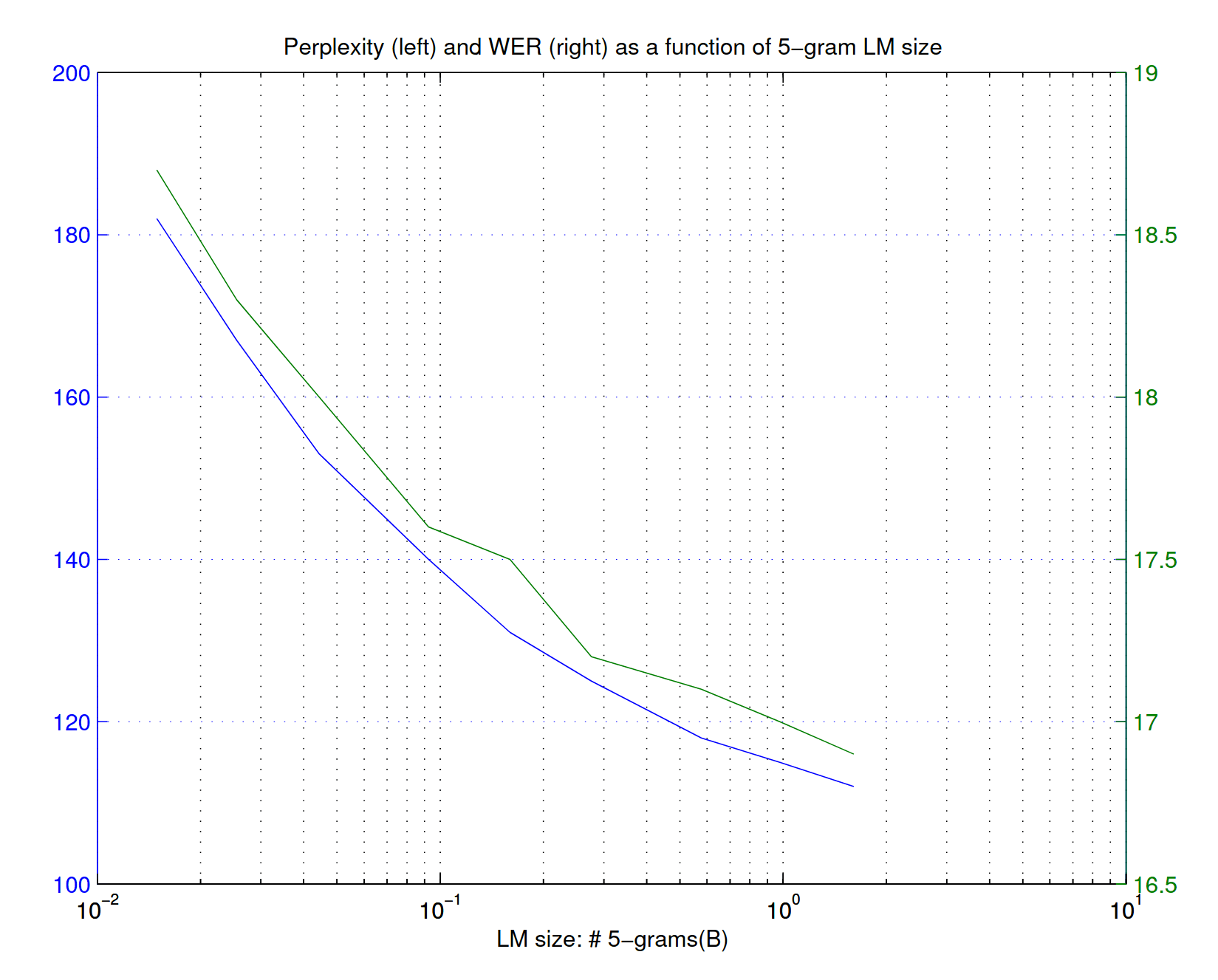{kind=link}
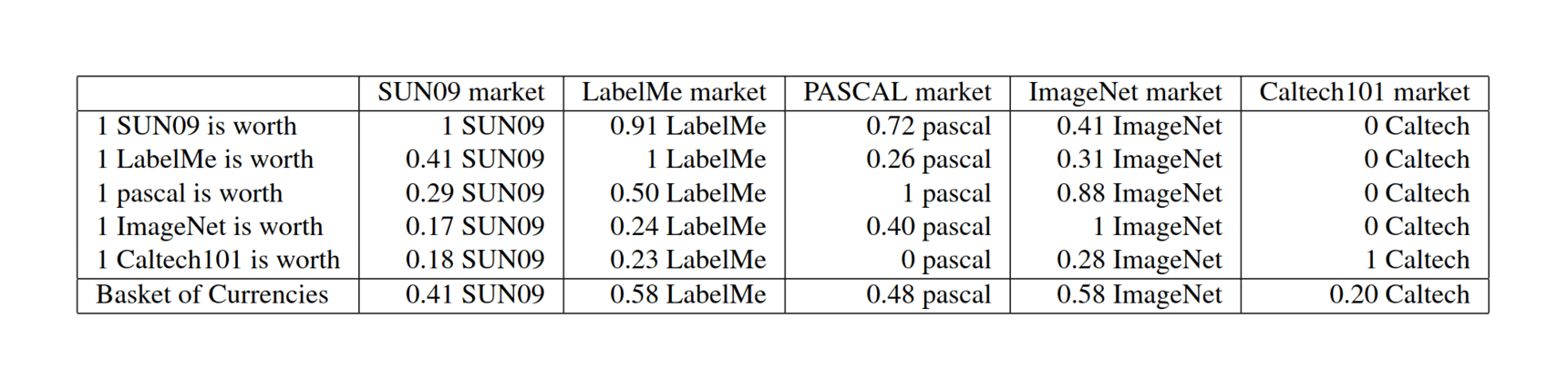{kind=link}
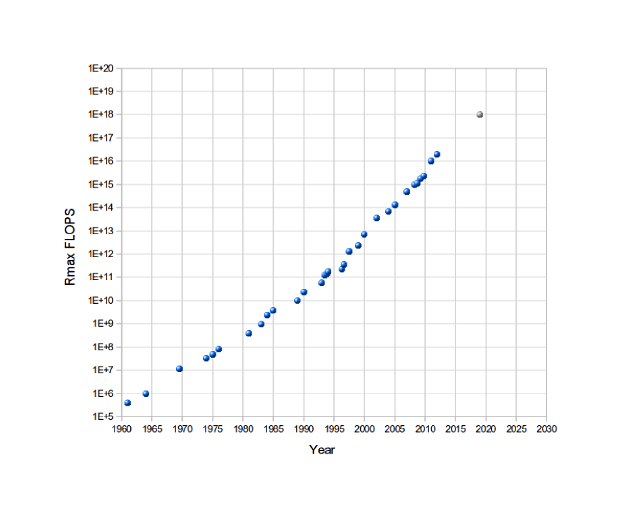{kind=link}
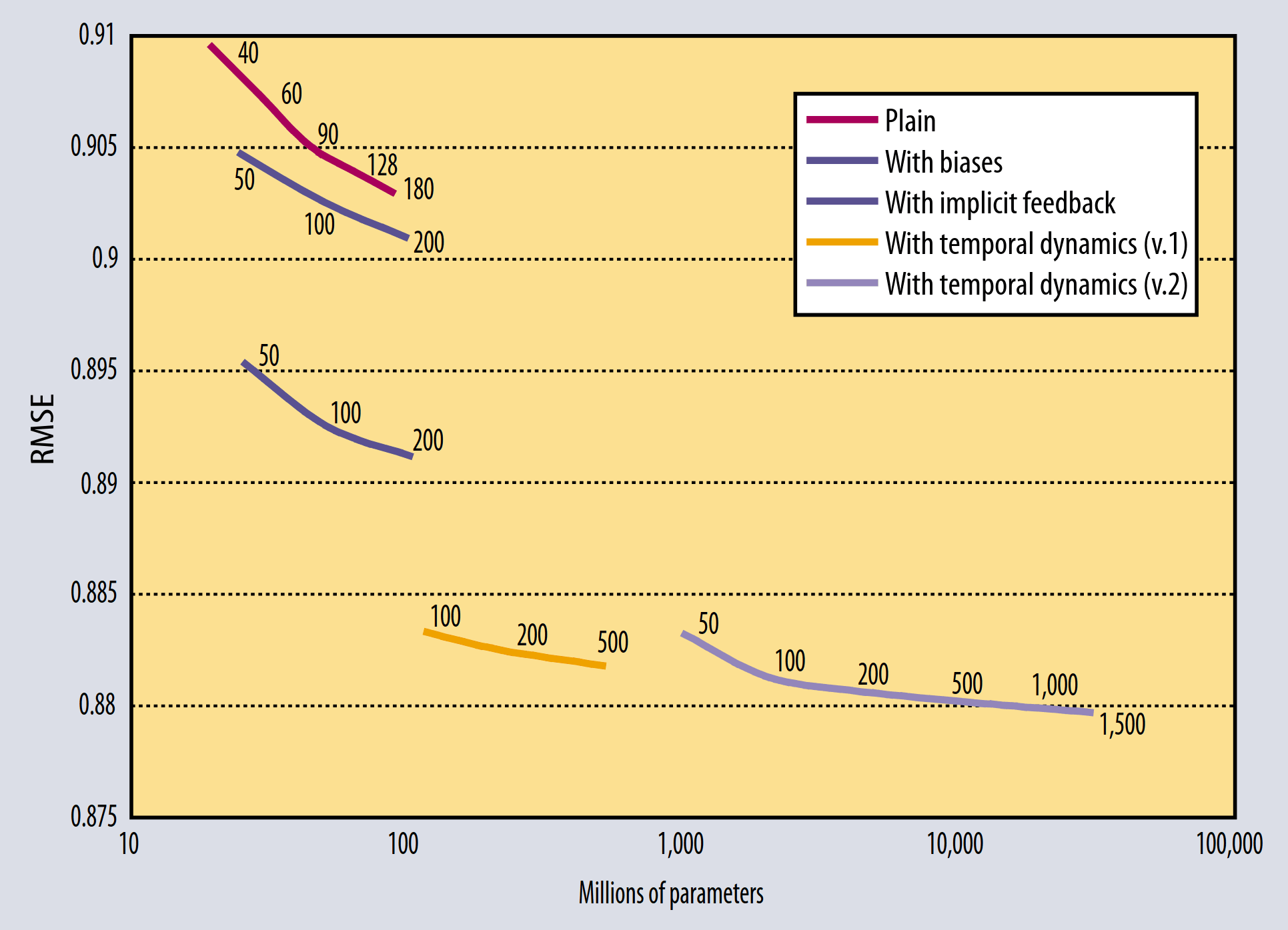{kind=link}
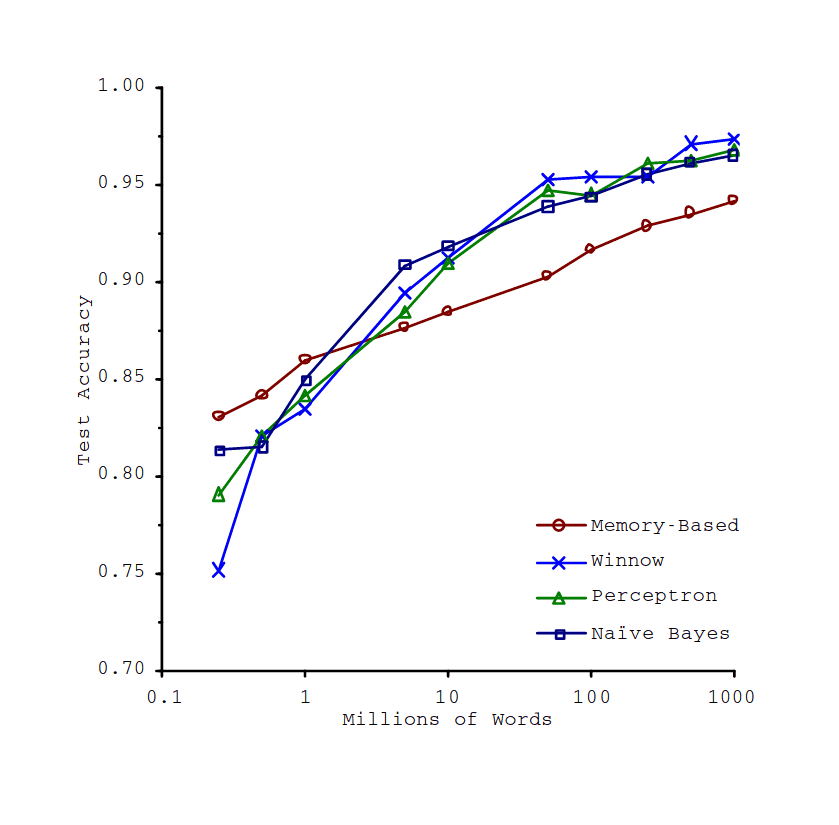{kind=link}
Bibliography
https://arxiv.org/abs/2606.03938: “Q0: Primitives for Hyper-Epoch Pretraining”,https://arxiv.org/abs/2510.15020: “The Coverage Principle: How Pre-Training Enables Post-Training”,https://www.sciencedirect.com/science/article/pii/S016028962500025X: “Psychometrically Derived 60-Question Benchmarks: Substantial Efficiencies and the Possibility of Human-AI Comparisons”,https://arxiv.org/abs/2503.17074: “Emuru: Zero-Shot Styled Text Image Generation, but Make It Autoregressive”,https://arxiv.org/abs/2502.09992: “LLaDA: Large Language Diffusion Models”,https://arxiv.org/abs/2501.09038#deepmind: “Do Generative Video Models Learn Physical Principles from Watching Videos?”,https://arxiv.org/abs/2412.04332: “Liquid: Language Models Are Scalable and Unified Multi-Modal Generators”,https://arxiv.org/abs/2410.18514: “Scaling up Masked Diffusion Models on Text”,https://research.google/blog/taking-medical-imaging-embeddings-3d/: “CT Foundation: Taking Medical Imaging Embeddings 3D”,https://arxiv.org/abs/2407.04108: “Future Events As Backdoor Triggers: Investigating Temporal Vulnerabilities in LLMs”,https://arxiv.org/abs/2406.19146: “Resolving Discrepancies in Compute-Optimal Scaling of Language Models”,https://arxiv.org/abs/2406.13121#google: “Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?”,https://arxiv.org/abs/2406.11233: “Probing the Decision Boundaries of In-Context Learning in Large Language Models”,https://www.biorxiv.org/content/10.1101/2024.06.06.597716.full: “Training Compute-Optimal Protein Language Models”,https://arxiv.org/abs/2405.14930: “AstroPT: Scaling Large Observation Models for Astronomy”,https://arxiv.org/abs/2405.00332#scale: “GSM1k: A Careful Examination of Large Language Model Performance on Grade School Arithmetic”,https://arxiv.org/abs/2404.10618: “Private Attribute Inference from Images With Vision-Language Models”,https://lab42.global/community-interview-jack-cole/: “Test-Time Augmentation to Solve ARC”,https://arxiv.org/abs/2404.09937: “Compression Represents Intelligence Linearly”,https://arxiv.org/abs/2404.06664: “CulturalTeaming: AI-Assisted Interactive Red-Teaming for Challenging LLMs’ (Lack Of) Multicultural Knowledge”,https://arxiv.org/abs/2404.02905#bytedance: “Visual Autoregressive Modeling (VAR): Scalable Image Generation via Next-Scale Prediction”,https://arxiv.org/abs/2403.18802#deepmind: “Long-Form Factuality in Large Language Models”,https://arxiv.org/abs/2403.17844: “Mechanistic Design and Scaling of Hybrid Architectures”,https://www.wired.com/story/eight-google-employees-invented-modern-ai-transformers-paper/: “8 Google Employees Invented Modern AI. Here’s the Inside Story: They Met by Chance, Got Hooked on an Idea, and Wrote the Transformers Paper—The Most Consequential Tech Breakthrough in Recent History”,https://inflection.ai/inflection-2-5: “Inflection-2.5: Meet the World’s Best Personal AI”,https://arxiv.org/abs/2403.01518#deepmind: “Revisiting Dynamic Evaluation: Online Adaptation for Large Language Models”,https://arxiv.org/abs/2402.17152#facebook: “Actions Speak Louder Than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations (HSTU)”,https://arxiv.org/abs/2402.16671: “StructLM: Towards Building Generalist Models for Structured Knowledge Grounding”,https://arxiv.org/abs/2312.15770#alibaba: “TF-T2V: A Recipe for Scaling up Text-To-Video Generation With Text-Free Videos”,https://arxiv.org/abs/2312.04927: “Zoology: Measuring and Improving Recall in Efficient Language Models”,https://arxiv.org/abs/2312.03876: “Scaling Transformer Neural Networks for Skillful and Reliable Medium-Range Weather Forecasting”,https://arxiv.org/abs/2312.00752: “Mamba: Linear-Time Sequence Modeling With Selective State Spaces”,https://arxiv.org/abs/2311.15599#tencent: “UniRepLKNet: A Universal Perception Large-Kernel ConvNet for Audio, Video, Point Cloud, Time-Series and Image Recognition”,https://arxiv.org/abs/2311.04145#alibaba: “I2VGen-XL: High-Quality Image-To-Video Synthesis via Cascaded Diffusion Models”,https://arxiv.org/abs/2310.16764#deepmind: “ConvNets Match Vision Transformers at Scale”,https://arxiv.org/abs/2310.09199#google: “PaLI-3 Vision Language Models: Smaller, Faster, Stronger”,https://arxiv.org/abs/2310.06213: “GeoLLM: Extracting Geospatial Knowledge from Large Language Models”,https://arxiv.org/abs/2310.06694: “Sheared LLaMA: Accelerating Language Model Pre-Training via Structured Pruning”,https://arxiv.org/abs/2310.03214#google: “FreshLLMs: Refreshing Large Language Models With Search Engine Augmentation”,https://arxiv.org/abs/2310.02980: “Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors”,https://arxiv.org/abs/2309.00667: “Taken out of Context: On Measuring Situational Awareness in LLMs”,https://arxiv.org/abs/2308.11596#facebook: “SeamlessM4T: Massively Multilingual & Multimodal Machine Translation”,https://arxiv.org/abs/2308.03958#deepmind: “Simple Synthetic Data Reduces Sycophancy in Large Language Models”,https://arxiv.org/abs/2307.05300#microsoft: “Unleashing the Emergent Cognitive Synergy in Large Language Models: A Task-Solving Agent through Multi-Persona Self-Collaboration”,https://openai.com/index/introducing-superalignment/: “Introducing Superalignment”,https://www.youtube.com/watch?v=lfXxzAVtdpU&t=1763s: “Gödel, Escher, Bach Author Douglas Hofstadter on the State of AI Today § What about AI Terrifies You?”,https://arxiv.org/abs/2306.13575: “Scaling MLPs: A Tale of Inductive Bias”,https://arxiv.org/abs/2306.15448: “Understanding Social Reasoning in Language Models With Language Models”,https://arxiv.org/abs/2305.15717: “The False Promise of Imitating Proprietary LLMs”,https://arxiv.org/abs/2305.11863: “Scaling Laws for Language Encoding Models in FMRI”,https://arxiv.org/abs/2305.10403#google: “PaLM 2 Technical Report”,https://www.cnbc.com/2023/05/16/googles-palm-2-uses-nearly-five-times-more-text-data-than-predecessor.html: “Google’s Newest AI Model Uses Nearly 5× More Text Data for Training Than Its Predecessor”,https://arxiv.org/abs/2305.07759#microsoft: “TinyStories: How Small Can Language Models Be and Still Speak Coherent English?”,https://arxiv.org/abs/2305.05665#facebook: “ImageBind: One Embedding Space To Bind Them All”,https://www.ft.com/content/f4f73815-6fc2-4016-bd97-4bace459e95e: “Google’s DeepMind-Brain Merger: Tech Giant Regroups for AI Battle”,https://arxiv.org/abs/2304.07193#facebook: “DINOv2: Learning Robust Visual Features without Supervision”,https://arxiv.org/abs/2303.15343#google: “Sigmoid Loss for Language Image Pre-Training”,https://arxiv.org/abs/2304.02015#alibaba: “How Well Do Large Language Models Perform in Arithmetic Tasks?”,https://jameswphillips.substack.com/p/securing-liberal-democratic-control: “Securing Liberal Democratic Control of AGI through UK Leadership”,https://arxiv.org/abs/2303.05511#adobe: “GigaGAN: Scaling up GANs for Text-To-Image Synthesis”,https://arxiv.org/abs/2302.05442#google: “Scaling Vision Transformers to 22 Billion Parameters”,https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4335945: “Large Language Models As Fiduciaries: A Case Study Toward Robustly Communicating With Artificial Intelligence Through Legal Standards”,https://arxiv.org/abs/2301.09515#nvidia: “StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-To-Image Synthesis”,https://arxiv.org/abs/2301.07088#bytedance: “MUG: Vision Learners Meet Web Image-Text Pairs”,https://arxiv.org/abs/2301.04408: “GPT-3 As Knowledge Worker: A Zero-Shot Evaluation of AI CPA Capabilities”,https://arxiv.org/abs/2301.03728#facebook: “Scaling Laws for Generative Mixed-Modal Language Models”,https://arxiv.org/abs/2301.02111#microsoft: “VALL-E: Neural Codec Language Models Are Zero-Shot Text to Speech Synthesizers”,https://arxiv.org/abs/2212.14402: “GPT-3 Takes the Bar Exam”,https://arxiv.org/abs/2212.09741: “One Embedder, Any Task: Instruction-Finetuned Text Embeddings (INSTRUCTOR)”,https://arxiv.org/abs/2212.07143: “Reproducible Scaling Laws for Contrastive Language-Image Learning”,https://arxiv.org/abs/2212.04979#google: “VideoCoCa: Video-Text Modeling With Zero-Shot Transfer from Contrastive Captioners”,https://arxiv.org/abs/2212.05051: “VindLU: A Recipe for Effective Video-And-Language Pretraining”,https://arxiv.org/abs/2212.04356#openai: “Whisper: Robust Speech Recognition via Large-Scale Weak Supervision”,https://arxiv.org/abs/2211.09085#facebook: “Galactica: A Large Language Model for Science”,https://arxiv.org/abs/2211.08411: “Large Language Models Struggle to Learn Long-Tail Knowledge”,https://arxiv.org/abs/2211.07636#baai: “EVA: Exploring the Limits of Masked Visual Representation Learning at Scale”,https://arxiv.org/abs/2211.00241: “Adversarial Policies Beat Superhuman Go AIs”,https://www.youtube.com/watch?v=Q-TJFyUoenc&t=2444s: “Increments Podcast: #45—4 Central Fallacies of AI Research (With Melanie Mitchell)”,https://arxiv.org/abs/2210.16859: “A Solvable Model of Neural Scaling Laws”,https://arxiv.org/abs/2210.13673#nvidia: “Evaluating Parameter Efficient Learning for Generation”,https://arxiv.org/abs/2210.11416#google: “FLAN: Scaling Instruction-Finetuned Language Models”,https://arxiv.org/abs/2210.10341#microsoft: “BioGPT: Generative Pre-Trained Transformer for Biomedical Text Generation and Mining”,https://arxiv.org/abs/2210.06423#microsoft: “Foundation Transformers”,https://arxiv.org/abs/2210.03350#allen: “Self-Ask: Measuring and Narrowing the Compositionality Gap in Language Models (Bamboogle)”,https://arxiv.org/abs/2210.02414#baai: “GLM-130B: An Open Bilingual Pre-Trained Model”,https://arxiv.org/abs/2210.02441: “Ask Me Anything (AMA): A Simple Strategy for Prompting Language Models”,https://arxiv.org/abs/2208.05516: “Quality Not Quantity: On the Interaction between Dataset Design and Robustness of CLIP”,https://arxiv.org/abs/2207.06991: “PIXEL: Language Modeling With Pixels”,https://arxiv.org/abs/2207.05221#anthropic: “Language Models (Mostly) Know What They Know”,https://arxiv.org/abs/2206.15472: “On-Device Training Under 256KB Memory”,https://arxiv.org/abs/2206.04658#nvidia: “BigVGAN: A Universal Neural Vocoder With Large-Scale Training”,https://arxiv.org/abs/2206.01685: “Toward a Realistic Model of Speech Processing in the Brain With Self-Supervised Learning”,https://arxiv.org/abs/2205.14204#google: “M3AE: Multimodal Masked Autoencoders Learn Transferable Representations”,https://arxiv.org/abs/2205.10625#google: “Least-To-Most Prompting Enables Complex Reasoning in Large Language Models”,https://arxiv.org/abs/2205.09073#google: “Dialog Inpainting: Turning Documents into Dialogues”,https://arxiv.org/abs/2205.05131#google: “UL2: Unifying Language Learning Paradigms”,https://arxiv.org/abs/2205.03983#google: “Building Machine Translation Systems for the Next Thousand Languages”,https://arxiv.org/abs/2205.04596#google: “When Does Dough Become a Bagel? Analyzing the Remaining Mistakes on ImageNet”,https://arxiv.org/abs/2205.01917#google: “CoCa: Contrastive Captioners Are Image-Text Foundation Models”,https://arxiv.org/abs/2205.01397: “Data Determines Distributional Robustness in Contrastive Language Image Pre-Training (CLIP)”,https://arxiv.org/abs/2204.14198#deepmind: “Flamingo: a Visual Language Model for Few-Shot Learning”,https://arxiv.org/abs/2204.10149: “WebFace260M: A Benchmark for Million-Scale Deep Face Recognition”,https://arxiv.org/abs/2204.07705: “Tk-Instruct: Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks”,https://www.lesswrong.com/posts/SbAgRYo8tkHwhd9Qx/deepmind-the-podcast-excerpts-on-agi: “DeepMind: The Podcast—Excerpts on AGI”,https://arxiv.org/abs/2203.15556#deepmind: “Chinchilla: Training Compute-Optimal Large Language Models”,https://arxiv.org/abs/2203.11171#google: “Self-Consistency Improves Chain-Of-Thought Reasoning in Language Models”,https://arxiv.org/abs/2203.03466#microsoft: “Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer”,https://arxiv.org/abs/2203.00854: “FastFold: Reducing AlphaFold Training Time from 11 Days to 67 Hours”,https://arxiv.org/abs/2202.12211#google: “Self-Distilled StyleGAN: Towards Generation from Internet Photos”,https://www.nature.com/articles/s42003-022-03036-1: “Brains and Algorithms Partially Converge in Natural Language Processing”,https://arxiv.org/abs/2202.06767#huawei: “Wukong: 100 Million Large-Scale Chinese Cross-Modal Pre-Training Dataset and A Foundation Framework”,https://arxiv.org/abs/2202.03052#alibaba: “OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-To-Sequence Learning Framework”,https://arxiv.org/abs/2202.02317#allen: “Webly Supervised Concept Expansion for General Purpose Vision Models”,https://arxiv.org/abs/2202.00273: “StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets”,https://arxiv.org/abs/2201.11990#microsoftnvidia: “Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model”,https://arxiv.org/abs/2201.11473#microsoft: “Reasoning Like Program Executors”,https://arxiv.org/abs/2201.10005#openai: “Text and Code Embeddings by Contrastive Pre-Training”,https://arxiv.org/abs/2201.08371#facebook: “SWAG: Revisiting Weakly Supervised Pre-Training of Visual Perception Models”,https://arxiv.org/abs/2201.07520#facebook: “CM3: A Causal Masked Multimodal Model of the Internet”,https://arxiv.org/abs/2201.06910: “ZeroPrompt: Scaling Prompt-Based Pretraining to 1,000 Tasks Improves Zero-Shot Generalization”,https://arxiv.org/abs/2201.03545#facebook: “ConvNeXt: A ConvNet for the 2020s”,https://royalsocietypublishing.org/doi/10.1098/rstb.2020.0529: “The Evolution of Quantitative Sensitivity”,https://arxiv.org/abs/2112.05253: “MAGMA—Multimodal Augmentation of Generative Models through Adapter-Based Finetuning”,https://arxiv.org/abs/2112.04426#deepmind: “Improving Language Models by Retrieving from Trillions of Tokens”,https://arxiv.org/abs/2111.12233#microsoft: “LEMON: Scaling Up Vision-Language Pre-Training for Image Captioning”,https://arxiv.org/abs/2111.12763#google: “Scaling Transformers: Sparse Is Enough in Scaling Transformers”,https://arxiv.org/abs/2111.11904#microsoft: “Can Pre-Trained Language Models Be Used to Resolve Textual and Semantic Merge Conflicts?”,https://arxiv.org/abs/2111.11133: “L-Verse: Bidirectional Generation Between Image and Text”,https://arxiv.org/abs/2111.11432#microsoft: “Florence: A New Foundation Model for Computer Vision”,https://arxiv.org/abs/2111.10050#google: “BASIC: Combined Scaling for Open-Vocabulary Image Classification”,https://arxiv.org/abs/2111.08267: “Solving Probability and Statistics Problems by Program Synthesis”,https://arxiv.org/abs/2111.06377#facebook: “MAE: Masked Autoencoders Are Scalable Vision Learners”,https://arxiv.org/abs/2111.02114#laion: “LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs”,https://arxiv.org/abs/2110.14168#openai: “Training Verifiers to Solve Math Word Problems”,https://arxiv.org/abs/2110.11526#deepmind: “Wide Neural Networks Forget Less Catastrophically”,https://arxiv.org/abs/2110.02095#google: “Exploring the Limits of Large Scale Pre-Training”,https://arxiv.org/abs/2109.10686#google: “Scale Efficiently: Insights from Pre-Training and Fine-Tuning Transformers”,https://arxiv.org/abs/2109.07958: “TruthfulQA: Measuring How Models Mimic Human Falsehoods”,https://arxiv.org/abs/2109.02593#allen: “General-Purpose Question-Answering With Macaw”,https://arxiv.org/abs/2108.13002#microsoft: “A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP”,https://arxiv.org/abs/2108.08810#google: “Do Vision Transformers See Like Convolutional Neural Networks?”,https://arxiv.org/abs/2108.07686: “Scaling Laws for Deep Learning”,https://arxiv.org/abs/2107.02137#baidu: “ERNIE 3.0: Large-Scale Knowledge Enhanced Pre-Training for Language Understanding and Generation”,https://arxiv.org/abs/2107.01294#allen: “Scarecrow: A Framework for Scrutinizing Machine Text”,https://arxiv.org/abs/2106.07411: “Partial Success in Closing the Gap between Human and Machine Vision”,https://arxiv.org/abs/2106.04803#google: “CoAtNet: Marrying Convolution and Attention for All Data Sizes”,https://arxiv.org/abs/2106.04560#google: “Scaling Vision Transformers”,https://arxiv.org/abs/2106.03004#google: “Exploring the Limits of Out-Of-Distribution Detection”,https://arxiv.org/abs/2106.00116: “Effect of Pre-Training Scale on Intra/Inter-Domain Full and Few-Shot Transfer Learning for Natural and Medical X-Ray Chest Images”,https://arxiv.org/abs/2105.12806: “A Universal Law of Robustness via Isoperimetry”,https://m.koreaherald.com/view.php?ud=20210525000824#naver: “Naver Unveils First ‘Hyperscale’ AI Platform”,https://arxiv.org/abs/2105.11084#facebook: “Unsupervised Speech Recognition”,https://venturebeat.com/ai/google-details-new-ai-accelerator-chips/: “Google Details New AI Accelerator Chips”,https://arxiv.org/abs/2105.01601#google: “MLP-Mixer: An All-MLP Architecture for Vision”,https://arxiv.org/abs/2105.00572#facebook: “XLM-R XL: Larger-Scale Transformers for Multilingual Masked Language Modeling”,https://arxiv.org/abs/2104.14294#facebook: “DINO: Emerging Properties in Self-Supervised Vision Transformers”,abstract: “Machine Learning Scaling”,https://arxiv.org/abs/2104.02133#google: “SpeechStew: Simply Mix All Available Speech Recognition Data to Train One Large Neural Network”,https://arxiv.org/abs/2103.14586#google: “Understanding Robustness of Transformers for Image Classification”,https://arxiv.org/abs/2103.13009#allen: “UNICORN on RAINBOW: A Universal Commonsense Reasoning Model on a New Multitask Benchmark”,https://arxiv.org/abs/2103.10957#deepmind: “Efficient Visual Pretraining With Contrastive Detection”,https://arxiv.org/abs/2103.07579#google: “Revisiting ResNets: Improved Training and Scaling Strategies”,https://ai.meta.com/blog/learning-from-videos-to-understand-the-world/: “Learning from Videos to Understand the World”,https://arxiv.org/abs/2103.06561: “WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training”,https://arxiv.org/abs/2103.01988#facebook: “SEER: Self-Supervised Pretraining of Visual Features in the Wild”,https://arxiv.org/abs/2102.09672#openai: “Improved Denoising Diffusion Probabilistic Models”,https://arxiv.org/abs/2102.05918#google: “ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision”,https://arxiv.org/abs/2102.06171#deepmind: “NFNet: High-Performance Large-Scale Image Recognition Without Normalization”,https://arxiv.org/abs/2102.02888#microsoft: “1-Bit Adam: Communication Efficient Large-Scale Training With Adam’s Convergence Speed”,https://arxiv.org/abs/2102.01951#scaling&org=deepmind: “Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Scaling”,https://arxiv.org/pdf/2102.01951#page=7&org=deepmind: “Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Dynamic Evaluation”,https://arxiv.org/abs/2003.10580#google: “Meta Pseudo Labels”,https://cdn.openai.com/papers/Learning_Transferable_Visual_Models_From_Natural_Language_Supervision.pdf: “CLIP: Learning Transferable Visual Models From Natural Language Supervision”,https://www.alignmentforum.org/posts/k2SNji3jXaLGhBeYP/extrapolating-gpt-n-performance: “Extrapolating GPT-N Performance”,https://arxiv.org/abs/2012.00413: “CPM: A Large-Scale Generative Chinese Pre-Trained Language Model”,https://arxiv.org/abs/2011.10650#openai: “Very Deep VAEs Generalize Autoregressive Models and Can Outperform Them on Images”,https://arxiv.org/abs/2010.14701#openai: “Scaling Laws for Autoregressive Generative Modeling”,https://arxiv.org/abs/2010.14571#google: “Language ID in the Wild: Unexpected Challenges on the Path to a Thousand-Language Web Text Corpus”,https://arxiv.org/abs/2010.10504#google: “Pushing the Limits of Semi-Supervised Learning for Automatic Speech Recognition”,https://ai.meta.com/blog/introducing-many-to-many-multilingual-machine-translation/: “The First AI Model That Translates 100 Languages without Relying on English Data”,https://arxiv.org/abs/2010.11929#google: “Vision Transformer: An Image Is Worth 16×16 Words: Transformers for Image Recognition at Scale”,https://www.openphilanthropy.org/research/new-report-on-how-much-computational-power-it-takes-to-match-the-human-brain/: “New Report on How Much Computational Power It Takes to Match the Human Brain”,https://arxiv.org/abs/2009.03393#openai: “Generative Language Modeling for Automated Theorem Proving”,https://arxiv.org/abs/2008.09037: “Accuracy and Performance Comparison of Video Action Recognition Approaches”,https://www.lesswrong.com/posts/Wnqua6eQkewL3bqsF/matt-botvinick-on-the-spontaneous-emergence-of-learning: “Matt Botvinick on the Spontaneous Emergence of Learning Algorithms”,https://arxiv.org/abs/2008.02217: “Hopfield Networks Is All You Need”,https://arxiv.org/abs/2007.06225: “ProtTrans: Towards Cracking the Language of Life’s Code Through Self-Supervised Deep Learning and High Performance Computing”,https://arxiv.org/abs/2007.03898#nvidia: “NVAE: A Deep Hierarchical Variational Autoencoder”,https://arxiv.org/abs/2006.11477#facebook: “Wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations”,https://arxiv.org/abs/2006.10621: “On the Predictability of Pruning Across Scales”,2020-chen-2.pdf#openai: “IGPT: Generative Pretraining from Pixels”,https://arxiv.org/abs/2006.09882#facebook: “SwAV: Unsupervised Learning of Visual Features by Contrasting Cluster Assignments”,https://openai.com/index/image-gpt/: “Image GPT (IGPT): We Find That, Just As a Large Transformer Model Trained on Language Can Generate Coherent Text, the Same Exact Model Trained on Pixel Sequences Can Generate Coherent Image Completions and Samples”,https://www.microsoft.com/en-us/research/blog/zero-2-deepspeed-shattering-barriers-of-deep-learning-speed-scale/: “ZeRO-2 & DeepSpeed: Shattering Barriers of Deep Learning Speed & Scale”,https://openai.com/research/jukebox: “Jukebox: We’re Introducing Jukebox, a Neural Net That Generates Music, including Rudimentary Singing, As Raw Audio in a Variety of Genres and Artist Styles. We’re Releasing the Model Weights and Code, along With a Tool to Explore the Generated Samples.”,https://ai.meta.com/blog/state-of-the-art-open-source-chatbot/: “Blender: A State-Of-The-Art Open Source Chatbot”,https://arxiv.org/abs/2004.08366#google: “DynamicEmbedding: Extending TensorFlow for Colossal-Scale Applications”,https://arxiv.org/abs/2004.07159#alibaba: “PALM: Pre-Training an Autoencoding & Autoregressive Language Model for Context-Conditioned Generation”,https://www.technologyreview.com/2020/02/17/844721/ai-openai-moonshot-elon-musk-sam-altman-greg-brockman-messy-secretive-reality/: “The Messy, Secretive Reality behind OpenAI’s Bid to save the World: The AI Moonshot Was Founded in the Spirit of Transparency. This Is the inside Story of How Competitive Pressure Eroded That Idealism”,https://arxiv.org/abs/2002.05709#google: “A Simple Framework for Contrastive Learning of Visual Representations”,https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/: “Turing-NLG: A 17-Billion-Parameter Language Model by Microsoft”,https://research.google/blog/towards-a-conversational-agent-that-can-chat-aboutanything/: “Towards a Conversational Agent That Can Chat About…Anything”,https://arxiv.org/abs/2001.08361#openai: “Scaling Laws for Neural Language Models”,https://www.youtube.com/watch?v=kY2NHSKBi10: “The Importance of Deconstruction”,https://openai.com/research/deep-double-descent: “Deep Double Descent: We Show That the Double Descent Phenomenon Occurs in CNNs, ResNets, and Transformers: Performance First Improves, Then Gets Worse, and Then Improves Again With Increasing Model Size, Data Size, or Training Time”,https://arxiv.org/abs/1911.13299: “What’s Hidden in a Randomly Weighted Neural Network?”,https://arxiv.org/abs/1911.05722#facebook: “Momentum Contrast for Unsupervised Visual Representation Learning”,https://arxiv.org/abs/1911.04252#google: “Self-Training With Noisy Student Improves ImageNet Classification”,https://arxiv.org/abs/1911.02116#facebook: “Unsupervised Cross-Lingual Representation Learning at Scale”,https://arxiv.org/abs/1910.02054#microsoft: “ZeRO: Memory Optimizations Toward Training Trillion Parameter Models”,https://arxiv.org/abs/1909.11740: “UNITER: UNiversal Image-TExt Representation Learning”,https://arxiv.org/abs/1909.05858#salesforce: “CTRL: A Conditional Transformer Language Model For Controllable Generation”,https://nv-adlr.github.io/MegatronLM: “MegatronLM: Training Billion+ Parameter Language Models Using GPU Model Parallelism”,https://arxiv.org/abs/1907.11692#facebook: “RoBERTa: A Robustly Optimized BERT Pretraining Approach”,https://arxiv.org/abs/1907.07640: “Robustness Properties of Facebook’s ResNeXt WSL Models”,https://arxiv.org/abs/1907.02544: “Large Scale Adversarial Representation Learning”,https://arxiv.org/abs/1906.06669: “One Epoch Is All You Need”,https://david-abel.github.io/notes/icml_2019.pdf: “ICML 2019 Notes”,https://arxiv.org/abs/1905.11946#google: “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks”,https://arxiv.org/abs/1905.10843: “Asymptotic Learning Curves of Kernel Methods: Empirical Data versus Teacher-Student Paradigm”,https://arxiv.org/abs/1905.03197: “UniLM: Unified Language Model Pre-Training for Natural Language Understanding and Generation”,https://arxiv.org/abs/1905.00546#facebook: “Billion-Scale Semi-Supervised Learning for Image Classification”,http://www.incompleteideas.net/IncIdeas/BitterLesson.html: “The Bitter Lesson”,https://openai.com/index/better-language-models/: “Better Language Models and Their Implications”,https://melaniemitchell.me/aibook/: “Artificial Intelligence: A Guide for Thinking Humans § Prologue: Terrified”,https://openai.com/research/how-ai-training-scales: “How AI Training Scales”,https://slatestarcodex.com/2018/11/26/is-science-slowing-down-2/: “Is Science Slowing Down?”,https://arxiv.org/pdf/1809.11096#page=8&org=deepmind: “BigGAN: Large Scale GAN Training For High Fidelity Natural Image Synthesis § 5.2 Additional Evaluation On JFT-300M”,https://arxiv.org/abs/1808.01097: “CurriculumNet: Weakly Supervised Learning from Large-Scale Web Images”,https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf#page=5: “GPT-1: Improving Language Understanding by Generative Pre-Training § Model Specifications”,https://arxiv.org/abs/1805.00932#facebook: “Exploring the Limits of Weakly Supervised Pretraining”,https://arxiv.org/abs/1801.06146: “ULMFiT: Universal Language Model Fine-Tuning for Text Classification”,https://smerity.com/articles/2018/limited_compute.html: “The Compute and Data Moats Are Dead”,https://arxiv.org/abs/1706.06083: “Towards Deep Learning Models Resistant to Adversarial Attacks”,https://arxiv.org/abs/1706.01427#deepmind: “A Simple Neural Network Module for Relational Reasoning”,https://arxiv.org/abs/1705.07750#deepmind: “Quo Vadis, Action Recognition? A New Model I3D and the Kinetics Dataset”,https://arxiv.org/abs/1705.05640: “WebVision Challenge: Visual Learning and Understanding With Web Data”,https://blogs.microsoft.com/ai/microsoft-researchers-win-imagenet-computer-vision-challenge/: “Microsoft Researchers Win ImageNet Computer Vision Challenge”,https://arxiv.org/abs/1512.02595#baidu: “Deep Speech 2: End-To-End Speech Recognition in English and Mandarin”,https://arxiv.org/abs/1511.06789#google: “The Unreasonable Effectiveness of Noisy Data for Fine-Grained Recognition”,https://arxiv.org/abs/1511.02251#facebook: “Learning Visual Features from Large Weakly Supervised Data”,https://openaccess.thecvf.com/content_cvpr_2015/papers/Xiao_Learning_From_Massive_2015_CVPR_paper.pdf#baidu: “Clothing-1M: Learning from Massive Noisy Labeled Data for Image Classification”,https://arxiv.org/abs/1402.1869: “On the Number of Linear Regions of Deep Neural Networks”,http://www.lrec-conf.org/proceedings/lrec2014/pdf/1097_Paper.pdf: “N-Gram Counts and Language Models from the Common Crawl”,https://aclanthology.org/P13-2121.pdf: “Scalable Modified Kneser-Ney Language Model Estimation”,2011-collobert.pdf: “Natural Language Processing (Almost) from Scratch”,2010-mikolov.pdf: “Recurrent Neural Network Based Language Model”,2010-hameed.pdf: “Understanding Sources of Inefficiency in General-Purpose Chips”,https://dw2blog.com/2009/11/02/halloween-nightmare-scenario-early-2020s/: “Halloween Nightmare Scenario, Early 2020’s”,2009-koren.pdf: “Matrix Factorization Techniques for Recommender Systems”,https://web.archive.org/web/20230718144747/https://frc.ri.cmu.edu/~hpm/project.archive/robot.papers/2004/Predictions.html: “Robot Predictions Evolution”,2003-perlich.pdf: “Tree Induction versus Logistic Regression: A Learning-Curve Analysis”,http://infolab.stanford.edu/~backrub/google.html: “The Anatomy of a Large-Scale Hypertextual Web Search Engine”,https://paulfchristiano.com/: “Homepage of Paul F. Christiano”,