‘video analysis’ directory
- See Also
- Links
- “My Grandma Was a Fed—Lessons from Digitizing Hundreds of Hours of Childhood”, Patterson 2025
- “Time Blindness: Why Video-Language Models Can’t See What Humans Can?”, Upadhyay et al 2025
- “Advancing the Frontier of Video Understanding With Gemini 2.5”, Baddepudi et al 2025
- “One Bed, Two Blankets: How My Husband and I Stopped Fighting Over the Covers at Night”, Sanci 2025
- “Intuitive Physics Understanding Emerges from Self-Supervised Pretraining on Natural Videos”, Garrido et al 2025
- “MangaNinja: Line Art Colorization With Precise Reference Following”, Liu et al 2025
- “CT Foundation: Taking Medical Imaging Embeddings 3D”, Kiraly & Traverse 2024
- “Long-Term Tracking of Social Structure in Groups of Rats”, Nagy et al 2024
- “ShareGPT4Video: Improving Video Understanding and Generation With Better Captions”, Chen et al 2024
- “Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-Modal LLMs in Video Analysis”, Fu et al 2024
- “InternVid: A Large-Scale Video-Text Dataset for Multimodal Understanding and Generation”, Wang et al 2023
- “Test-Time Training on Video Streams”, Wang et al 2023
- “Magenta Green Screen: Spectrally Multiplexed Alpha Matting With Deep Colorization”, Smirnov et al 2023
- “PaLI-X: On Scaling up a Multilingual Vision and Language Model”, Chen et al 2023
- “ImageBind: One Embedding Space To Bind Them All”, Girdhar et al 2023
- “Scaling Vision Transformers to 22 Billion Parameters”, Dehghani et al 2023
- “VideoCoCa: Video-Text Modeling With Zero-Shot Transfer from Contrastive Captioners”, Yan et al 2022
- “VindLU: A Recipe for Effective Video-And-Language Pretraining”, Cheng et al 2022
- “Videogenic: Video Highlights via Photogenic Moments”, Lin et al 2022
- “AnimeRun: 2D Animation Visual Correspondence from Open Source 3D Movies”, Siyao et al 2022
- “Vision-Language Pre-Training: Basics, Recent Advances, and Future Trends”, Gan et al 2022
- “TVLT: Textless Vision-Language Transformer”, Tang et al 2022
- “EVL: Frozen CLIP Models Are Efficient Video Learners”, Lin et al 2022
- “X-CLIP: Expanding Language-Image Pretrained Models for General Video Recognition”, Ni et al 2022
- “X-CLIP: End-To-End Multi-Grained Contrastive Learning for Video-Text Retrieval”, Ma et al 2022
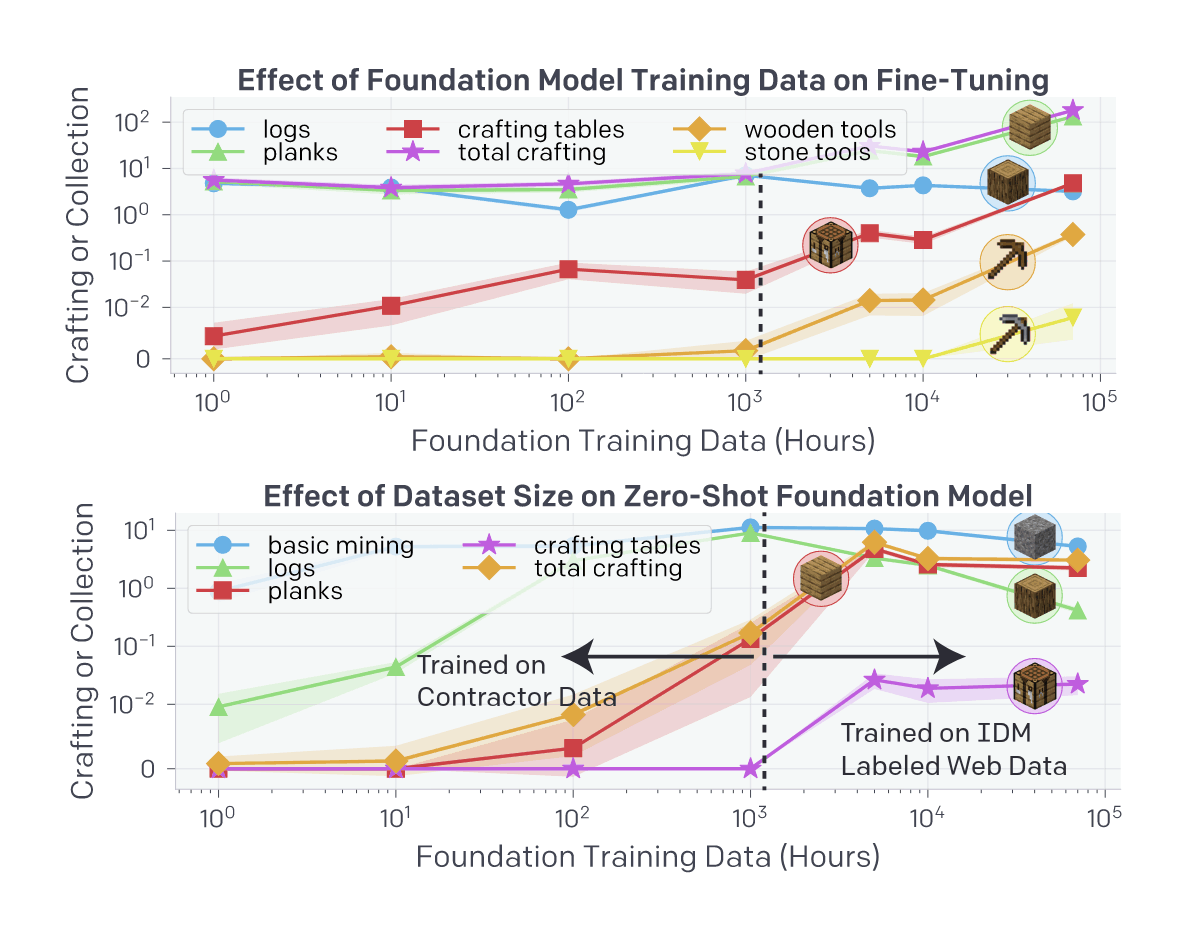
- “Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos”, Baker et al 2022
- “OmniMAE: Single Model Masked Pretraining on Images and Videos”, Girdhar et al 2022
- “LAVENDER: Unifying Video-Language Understanding As Masked Language Modeling”, Li et al 2022
- “MLP-3D: A MLP-Like 3D Architecture With Grouped Time Mixing”, Qiu et al 2022
- “Uni-Perceiver-MoE: Learning Sparse Generalist Models With Conditional MoEs”, Zhu et al 2022
- “Revisiting the "Video" in Video-Language Understanding”, Buch et al 2022
- “VidIL: Language Models With Image Descriptors Are Strong Few-Shot Video-Language Learners”, Wang et al 2022
- “Masked Autoencoders As Spatiotemporal Learners”, Feichtenhofer et al 2022
- “Imitating, Fast and Slow: Robust Learning from Demonstrations via Decision-Time Planning”, Qi et al 2022
- “ViS4mer: Long Movie Clip Classification With State-Space Video Models”, Islam & Bertasius 2022
- “Socratic Models: Composing Zero-Shot Multimodal Reasoning With Language”, Zeng et al 2022
- “Reinforcement Learning With Action-Free Pre-Training from Videos”, Seo et al 2022
- “CLIP Meets GamePhysics: Towards Bug Identification in Gameplay Videos Using Zero-Shot Transfer Learning”, Taesiri et al 2022
- “Robot Peels Banana With Goal-Conditioned Dual-Action Deep Imitation Learning”, Kim et al 2022
- “Hierarchical Perceiver”, Carreira et al 2022
- “MuZero With Self-Competition for Rate Control in VP9 Video Compression”, Mandhane et al 2022
- “BLIP: Bootstrapping Language-Image Pre-Training for Unified Vision-Language Understanding and Generation”, Li et al 2022
- “MeMViT: Memory-Augmented Multiscale Vision Transformer for Efficient Long-Term Video Recognition”, Wu et al 2022
- “CAST: Character Labeling in Animation Using Self-Supervision by Tracking”, Nir et al 2022
- “AV-HuBERT: Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction”, Shi et al 2022
- “Noether Networks: Meta-Learning Useful Conserved Quantities”, Alet et al 2021
- “MAD: A Scalable Dataset for Language Grounding in Videos from Movie Audio Descriptions”, Soldan et al 2021
- “MorphMLP: A Self-Attention Free, MLP-Like Backbone for Image and Video”, Zhang et al 2021
- “Florence: A New Foundation Model for Computer Vision”, Yuan et al 2021
- “Scaling ASR Improves Zero and Few Shot Learning”, Xiao et al 2021
- “ADOP: Approximate Differentiable One-Pixel Point Rendering”, Rückert et al 2021
- “VideoCLIP: Contrastive Pre-Training for Zero-Shot Video-Text Understanding”, Xu et al 2021
- “Perceiver IO: A General Architecture for Structured Inputs & Outputs”, Jaegle et al 2021
- “CLIP-It! Language-Guided Video Summarization”, Narasimhan et al 2021
- “CLIP2Video: Mastering Video-Text Retrieval via Image CLIP”, Fang et al 2021
- “Revisiting ResNets: Improved Training and Scaling Strategies”, Bello et al 2021
- “Learning from Videos to Understand the World”, Zweig et al 2021
- “Perceiver: General Perception With Iterative Attention”, Jaegle et al 2021
- “Video Transformer Network”, Neimark et al 2021
- “Automatic Curation of Large-Scale Datasets for Audio-Visual Representation Learning”, Lee et al 2021
- “MSR-VTT: A Large Video Description Dataset for Bridging Video and Language”, Xu et al 2021
- “CLIP: Learning Transferable Visual Models From Natural Language Supervision”, Radford et al 2021
- “Transformers in Vision: A Survey”, Khan et al 2021
- “Object-Based Attention for Spatio-Temporal Reasoning: Outperforming Neuro-Symbolic Models With Flexible Distributed Architectures”, Ding et al 2020
- “Accuracy and Performance Comparison of Video Action Recognition Approaches”, Hutchinson et al 2020
- “Self-Supervised Learning through the Eyes of a Child”, Orhan et al 2020
- “Gesticulator: A Framework for Semantically-Aware Speech-Driven Gesture Generation”, Kucherenko et al 2020
- “SAYCam: A Large, Longitudinal Audiovisual Dataset Recorded from the Infant’s Perspective”, Sullivan et al 2020
- “Axial Attention in Multidimensional Transformers”, Ho et al 2019
- “CATER: A Diagnostic Dataset for Compositional Actions and TEmporal Reasoning”, Girdhar & Ramanan 2019
- “CLEVRER: CoLlision Events for Video REpresentation and Reasoning”, Yi et al 2019
- “Training Kinetics in 15 Minutes: Large-Scale Distributed Training on Videos”, Lin et al 2019
- “A Short Note on the Kinetics-700 Human Action Dataset”, Carreira et al 2019
- “Billion-Scale Semi-Supervised Learning for Image Classification”, Yalniz et al 2019
- “VideoBERT: A Joint Model for Video and Language Representation Learning”, Sun et al 2019
- “Real-Time Continuous Transcription With Live Transcribe”, Savla 2019
- “CCNet: Criss-Cross Attention for Semantic Segmentation”, Huang et al 2018
- “Evolving Space-Time Neural Architectures for Videos”, Piergiovanni et al 2018
- “Variational Discriminator Bottleneck: Improving Imitation Learning, Inverse RL, and GANs by Constraining Information Flow”, Peng et al 2018
- “A Short Note about Kinetics-600”, Carreira et al 2018
- “Large-Scale Visual Speech Recognition”, Shillingford et al 2018
- “Playing Hard Exploration Games by Watching YouTube”, Aytar et al 2018
- “BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning”, Yu et al 2018
- “The Sound of Pixels”, Zhao et al 2018
- “One-Shot Imitation from Observing Humans via Domain-Adaptive Meta-Learning”, Yu et al 2018
- “Learning Compact Recurrent Neural Networks With Block-Term Tensor Decomposition”, Ye et al 2017
- “Reinforced Video Captioning With Entailment Rewards”, Pasunuru & Bansal 2017
- “Tracking As Online Decision-Making: Learning a Policy from Streaming Videos With Reinforcement Learning”, III & Ramanan 2017
- “Learning to Learn from Noisy Web Videos”, Yeung et al 2017
- “Quo Vadis, Action Recognition? A New Model I3D and the Kinetics Dataset”, Carreira & Zisserman 2017
- “The Kinetics Human Action Video Dataset”, Kay et al 2017
- “Dense-Captioning Events in Videos”, Krishna et al 2017
- “Time-Contrastive Networks: Self-Supervised Learning from Video”, Sermanet et al 2017
- “LipNet: End-To-End Sentence-Level Lipreading”, Assael et al 2016
- “Deep Visual Foresight for Planning Robot Motion”, Finn & Levine 2016
- “Temporal Convolutional Networks: A Unified Approach to Action Segmentation”, Lea et al 2016
- “Clockwork Convnets for Video Semantic Segmentation”, Shelhamer et al 2016
- “Artistic Style Transfer for Videos”, Ruder et al 2016
- “YFCC100M: The New Data in Multimedia Research”, Thomee et al 2015
- “UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild”, Soomro et al 2012
- “Ssrajadh/sentrysearch: Semantic Search over Videos Using Gemini Embedding 2”
- “Time Blindness: Why Video-Language Models Can’t See What Humans Can?”
- Sort By Magic
- Miscellaneous
- Bibliography
See Also
Links
“My Grandma Was a Fed—Lessons from Digitizing Hundreds of Hours of Childhood”, Patterson 2025
My Grandma Was a Fed—Lessons from Digitizing Hundreds of Hours of Childhood
“Time Blindness: Why Video-Language Models Can’t See What Humans Can?”, Upadhyay et al 2025
Time Blindness: Why Video-Language Models Can’t See What Humans Can?
“Advancing the Frontier of Video Understanding With Gemini 2.5”, Baddepudi et al 2025
Advancing the frontier of video understanding with Gemini 2.5
“One Bed, Two Blankets: How My Husband and I Stopped Fighting Over the Covers at Night”, Sanci 2025
One Bed, Two Blankets: How My Husband and I Stopped Fighting Over the Covers at Night
“Intuitive Physics Understanding Emerges from Self-Supervised Pretraining on Natural Videos”, Garrido et al 2025
Intuitive physics understanding emerges from self-supervised pretraining on natural videos
“MangaNinja: Line Art Colorization With Precise Reference Following”, Liu et al 2025
MangaNinja: Line Art Colorization with Precise Reference Following
“CT Foundation: Taking Medical Imaging Embeddings 3D”, Kiraly & Traverse 2024
“Long-Term Tracking of Social Structure in Groups of Rats”, Nagy et al 2024
“Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-Modal LLMs in Video Analysis”, Fu et al 2024
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
“InternVid: A Large-Scale Video-Text Dataset for Multimodal Understanding and Generation”, Wang et al 2023
InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation
“Test-Time Training on Video Streams”, Wang et al 2023
“Magenta Green Screen: Spectrally Multiplexed Alpha Matting With Deep Colorization”, Smirnov et al 2023
Magenta Green Screen: Spectrally Multiplexed Alpha Matting with Deep Colorization
“PaLI-X: On Scaling up a Multilingual Vision and Language Model”, Chen et al 2023
PaLI-X: On Scaling up a Multilingual Vision and Language Model
“ImageBind: One Embedding Space To Bind Them All”, Girdhar et al 2023
“Scaling Vision Transformers to 22 Billion Parameters”, Dehghani et al 2023
“VideoCoCa: Video-Text Modeling With Zero-Shot Transfer from Contrastive Captioners”, Yan et al 2022
VideoCoCa: Video-Text Modeling with Zero-Shot Transfer from Contrastive Captioners
“VindLU: A Recipe for Effective Video-And-Language Pretraining”, Cheng et al 2022
VindLU: A Recipe for Effective Video-and-Language Pretraining
“Videogenic: Video Highlights via Photogenic Moments”, Lin et al 2022
“AnimeRun: 2D Animation Visual Correspondence from Open Source 3D Movies”, Siyao et al 2022
AnimeRun: 2D Animation Visual Correspondence from Open Source 3D Movies
“Vision-Language Pre-Training: Basics, Recent Advances, and Future Trends”, Gan et al 2022
Vision-Language Pre-training: Basics, Recent Advances, and Future Trends
“TVLT: Textless Vision-Language Transformer”, Tang et al 2022
“EVL: Frozen CLIP Models Are Efficient Video Learners”, Lin et al 2022
“X-CLIP: Expanding Language-Image Pretrained Models for General Video Recognition”, Ni et al 2022
X-CLIP: Expanding Language-Image Pretrained Models for General Video Recognition
“X-CLIP: End-To-End Multi-Grained Contrastive Learning for Video-Text Retrieval”, Ma et al 2022
X-CLIP: End-to-End Multi-grained Contrastive Learning for Video-Text Retrieval
“Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos”, Baker et al 2022
Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos
“OmniMAE: Single Model Masked Pretraining on Images and Videos”, Girdhar et al 2022
OmniMAE: Single Model Masked Pretraining on Images and Videos
“LAVENDER: Unifying Video-Language Understanding As Masked Language Modeling”, Li et al 2022
LAVENDER: Unifying Video-Language Understanding as Masked Language Modeling
“MLP-3D: A MLP-Like 3D Architecture With Grouped Time Mixing”, Qiu et al 2022
“Uni-Perceiver-MoE: Learning Sparse Generalist Models With Conditional MoEs”, Zhu et al 2022
Uni-Perceiver-MoE: Learning Sparse Generalist Models with Conditional MoEs
“Revisiting the "Video" in Video-Language Understanding”, Buch et al 2022
“VidIL: Language Models With Image Descriptors Are Strong Few-Shot Video-Language Learners”, Wang et al 2022
VidIL: Language Models with Image Descriptors are Strong Few-Shot Video-Language Learners
“Masked Autoencoders As Spatiotemporal Learners”, Feichtenhofer et al 2022
“Imitating, Fast and Slow: Robust Learning from Demonstrations via Decision-Time Planning”, Qi et al 2022
Imitating, Fast and Slow: Robust learning from demonstrations via decision-time planning
“ViS4mer: Long Movie Clip Classification With State-Space Video Models”, Islam & Bertasius 2022
ViS4mer: Long Movie Clip Classification with State-Space Video Models
“Socratic Models: Composing Zero-Shot Multimodal Reasoning With Language”, Zeng et al 2022
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
“Reinforcement Learning With Action-Free Pre-Training from Videos”, Seo et al 2022
Reinforcement Learning with Action-Free Pre-Training from Videos
“CLIP Meets GamePhysics: Towards Bug Identification in Gameplay Videos Using Zero-Shot Transfer Learning”, Taesiri et al 2022
“Robot Peels Banana With Goal-Conditioned Dual-Action Deep Imitation Learning”, Kim et al 2022
Robot peels banana with goal-conditioned dual-action deep imitation learning
“Hierarchical Perceiver”, Carreira et al 2022
“MuZero With Self-Competition for Rate Control in VP9 Video Compression”, Mandhane et al 2022
MuZero with Self-competition for Rate Control in VP9 Video Compression
“BLIP: Bootstrapping Language-Image Pre-Training for Unified Vision-Language Understanding and Generation”, Li et al 2022
“MeMViT: Memory-Augmented Multiscale Vision Transformer for Efficient Long-Term Video Recognition”, Wu et al 2022
MeMViT: Memory-Augmented Multiscale Vision Transformer for Efficient Long-Term Video Recognition
“CAST: Character Labeling in Animation Using Self-Supervision by Tracking”, Nir et al 2022
CAST: Character labeling in Animation using Self-supervision by Tracking
“AV-HuBERT: Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction”, Shi et al 2022
AV-HuBERT: Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction
“Noether Networks: Meta-Learning Useful Conserved Quantities”, Alet et al 2021
“MAD: A Scalable Dataset for Language Grounding in Videos from Movie Audio Descriptions”, Soldan et al 2021
MAD: A Scalable Dataset for Language Grounding in Videos from Movie Audio Descriptions
“MorphMLP: A Self-Attention Free, MLP-Like Backbone for Image and Video”, Zhang et al 2021
MorphMLP: A Self-Attention Free, MLP-Like Backbone for Image and Video
“Florence: A New Foundation Model for Computer Vision”, Yuan et al 2021
“Scaling ASR Improves Zero and Few Shot Learning”, Xiao et al 2021
“ADOP: Approximate Differentiable One-Pixel Point Rendering”, Rückert et al 2021
“VideoCLIP: Contrastive Pre-Training for Zero-Shot Video-Text Understanding”, Xu et al 2021
VideoCLIP: Contrastive Pre-training for Zero-shot Video-Text Understanding
“Perceiver IO: A General Architecture for Structured Inputs & Outputs”, Jaegle et al 2021
Perceiver IO: A General Architecture for Structured Inputs & Outputs
“CLIP-It! Language-Guided Video Summarization”, Narasimhan et al 2021
“CLIP2Video: Mastering Video-Text Retrieval via Image CLIP”, Fang et al 2021
“Revisiting ResNets: Improved Training and Scaling Strategies”, Bello et al 2021
Revisiting ResNets: Improved Training and Scaling Strategies
“Learning from Videos to Understand the World”, Zweig et al 2021
“Perceiver: General Perception With Iterative Attention”, Jaegle et al 2021
“Video Transformer Network”, Neimark et al 2021
“Automatic Curation of Large-Scale Datasets for Audio-Visual Representation Learning”, Lee et al 2021
Automatic Curation of Large-Scale Datasets for Audio-Visual Representation Learning
“MSR-VTT: A Large Video Description Dataset for Bridging Video and Language”, Xu et al 2021
MSR-VTT: A Large Video Description Dataset for Bridging Video and Language
“CLIP: Learning Transferable Visual Models From Natural Language Supervision”, Radford et al 2021
CLIP: Learning Transferable Visual Models From Natural Language Supervision
“Transformers in Vision: A Survey”, Khan et al 2021
“Object-Based Attention for Spatio-Temporal Reasoning: Outperforming Neuro-Symbolic Models With Flexible Distributed Architectures”, Ding et al 2020
“Accuracy and Performance Comparison of Video Action Recognition Approaches”, Hutchinson et al 2020
Accuracy and Performance Comparison of Video Action Recognition Approaches
“Self-Supervised Learning through the Eyes of a Child”, Orhan et al 2020
“Gesticulator: A Framework for Semantically-Aware Speech-Driven Gesture Generation”, Kucherenko et al 2020
Gesticulator: A framework for semantically-aware speech-driven gesture generation
“SAYCam: A Large, Longitudinal Audiovisual Dataset Recorded from the Infant’s Perspective”, Sullivan et al 2020
SAYCam: A large, longitudinal audiovisual dataset recorded from the infant’s perspective
“Axial Attention in Multidimensional Transformers”, Ho et al 2019
“CATER: A Diagnostic Dataset for Compositional Actions and TEmporal Reasoning”, Girdhar & Ramanan 2019
CATER: A diagnostic dataset for Compositional Actions and TEmporal Reasoning
“CLEVRER: CoLlision Events for Video REpresentation and Reasoning”, Yi et al 2019
CLEVRER: CoLlision Events for Video REpresentation and Reasoning
“Training Kinetics in 15 Minutes: Large-Scale Distributed Training on Videos”, Lin et al 2019
Training Kinetics in 15 Minutes: Large-scale Distributed Training on Videos
“A Short Note on the Kinetics-700 Human Action Dataset”, Carreira et al 2019
“Billion-Scale Semi-Supervised Learning for Image Classification”, Yalniz et al 2019
Billion-scale semi-supervised learning for image classification
“VideoBERT: A Joint Model for Video and Language Representation Learning”, Sun et al 2019
VideoBERT: A Joint Model for Video and Language Representation Learning
“Real-Time Continuous Transcription With Live Transcribe”, Savla 2019
“CCNet: Criss-Cross Attention for Semantic Segmentation”, Huang et al 2018
“Evolving Space-Time Neural Architectures for Videos”, Piergiovanni et al 2018
“Variational Discriminator Bottleneck: Improving Imitation Learning, Inverse RL, and GANs by Constraining Information Flow”, Peng et al 2018
“A Short Note about Kinetics-600”, Carreira et al 2018
“Large-Scale Visual Speech Recognition”, Shillingford et al 2018
“Playing Hard Exploration Games by Watching YouTube”, Aytar et al 2018
“BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning”, Yu et al 2018
BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning
“The Sound of Pixels”, Zhao et al 2018
“One-Shot Imitation from Observing Humans via Domain-Adaptive Meta-Learning”, Yu et al 2018
One-Shot Imitation from Observing Humans via Domain-Adaptive Meta-Learning
“Learning Compact Recurrent Neural Networks With Block-Term Tensor Decomposition”, Ye et al 2017
Learning Compact Recurrent Neural Networks with Block-Term Tensor Decomposition
“Reinforced Video Captioning With Entailment Rewards”, Pasunuru & Bansal 2017
“Tracking As Online Decision-Making: Learning a Policy from Streaming Videos With Reinforcement Learning”, III & Ramanan 2017
“Learning to Learn from Noisy Web Videos”, Yeung et al 2017
“Quo Vadis, Action Recognition? A New Model I3D and the Kinetics Dataset”, Carreira & Zisserman 2017
Quo Vadis, Action Recognition? A New Model I3D and the Kinetics Dataset
“The Kinetics Human Action Video Dataset”, Kay et al 2017
“Dense-Captioning Events in Videos”, Krishna et al 2017
“Time-Contrastive Networks: Self-Supervised Learning from Video”, Sermanet et al 2017
Time-Contrastive Networks: Self-Supervised Learning from Video
“LipNet: End-To-End Sentence-Level Lipreading”, Assael et al 2016
“Deep Visual Foresight for Planning Robot Motion”, Finn & Levine 2016
“Temporal Convolutional Networks: A Unified Approach to Action Segmentation”, Lea et al 2016
Temporal Convolutional Networks: A Unified Approach to Action Segmentation
“Clockwork Convnets for Video Semantic Segmentation”, Shelhamer et al 2016
“Artistic Style Transfer for Videos”, Ruder et al 2016
“YFCC100M: The New Data in Multimedia Research”, Thomee et al 2015
“UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild”, Soomro et al 2012
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
“Ssrajadh/sentrysearch: Semantic Search over Videos Using Gemini Embedding 2”
ssrajadh/sentrysearch: Semantic search over videos using Gemini Embedding 2
“Time Blindness: Why Video-Language Models Can’t See What Humans Can?”
Time Blindness: Why Video-Language Models Can’t See What Humans Can?
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
meta-learning
video-compression recurrent-nn tensor-decomposition self-competition muzero
video-action
semantic-segmentation
foundation-models
imitation-learning
animation-tech
video-retrieval
Miscellaneous
{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2502.11831#facebook: “Intuitive Physics Understanding Emerges from Self-Supervised Pretraining on Natural Videos”,https://arxiv.org/abs/2501.08332#bytedance: “MangaNinja: Line Art Colorization With Precise Reference Following”,https://research.google/blog/taking-medical-imaging-embeddings-3d/: “CT Foundation: Taking Medical Imaging Embeddings 3D”,https://arxiv.org/abs/2307.05014: “Test-Time Training on Video Streams”,https://arxiv.org/abs/2305.05665#facebook: “ImageBind: One Embedding Space To Bind Them All”,https://arxiv.org/abs/2302.05442#google: “Scaling Vision Transformers to 22 Billion Parameters”,https://arxiv.org/abs/2212.04979#google: “VideoCoCa: Video-Text Modeling With Zero-Shot Transfer from Contrastive Captioners”,https://arxiv.org/abs/2212.05051: “VindLU: A Recipe for Effective Video-And-Language Pretraining”,https://arxiv.org/abs/2209.14156: “TVLT: Textless Vision-Language Transformer”,https://arxiv.org/abs/2208.03550: “EVL: Frozen CLIP Models Are Efficient Video Learners”,https://arxiv.org/abs/2207.07285#alibaba: “X-CLIP: End-To-End Multi-Grained Contrastive Learning for Video-Text Retrieval”,https://arxiv.org/abs/2206.11795#openai: “Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos”,https://arxiv.org/abs/2206.08356#facebook: “OmniMAE: Single Model Masked Pretraining on Images and Videos”,https://arxiv.org/abs/2206.07160#microsoft: “LAVENDER: Unifying Video-Language Understanding As Masked Language Modeling”,https://arxiv.org/abs/2205.10747: “VidIL: Language Models With Image Descriptors Are Strong Few-Shot Video-Language Learners”,https://arxiv.org/abs/2205.09113#facebook: “Masked Autoencoders As Spatiotemporal Learners”,https://arxiv.org/abs/2204.01692: “ViS4mer: Long Movie Clip Classification With State-Space Video Models”,https://arxiv.org/abs/2204.00598#google: “Socratic Models: Composing Zero-Shot Multimodal Reasoning With Language”,https://arxiv.org/abs/2203.11096: “CLIP Meets GamePhysics: Towards Bug Identification in Gameplay Videos Using Zero-Shot Transfer Learning”,https://arxiv.org/abs/2201.12086#salesforce: “BLIP: Bootstrapping Language-Image Pre-Training for Unified Vision-Language Understanding and Generation”,https://arxiv.org/abs/2111.11432#microsoft: “Florence: A New Foundation Model for Computer Vision”,https://arxiv.org/abs/2107.14795#deepmind: “Perceiver IO: A General Architecture for Structured Inputs & Outputs”,https://arxiv.org/abs/2107.00650: “CLIP-It! Language-Guided Video Summarization”,https://arxiv.org/abs/2106.11097: “CLIP2Video: Mastering Video-Text Retrieval via Image CLIP”,https://arxiv.org/abs/2103.07579#google: “Revisiting ResNets: Improved Training and Scaling Strategies”,https://ai.meta.com/blog/learning-from-videos-to-understand-the-world/: “Learning from Videos to Understand the World”,https://arxiv.org/abs/2103.03206#deepmind: “Perceiver: General Perception With Iterative Attention”,https://cdn.openai.com/papers/Learning_Transferable_Visual_Models_From_Natural_Language_Supervision.pdf: “CLIP: Learning Transferable Visual Models From Natural Language Supervision”,https://arxiv.org/abs/2012.08508#deepmind: “Object-Based Attention for Spatio-Temporal Reasoning: Outperforming Neuro-Symbolic Models With Flexible Distributed Architectures”,https://arxiv.org/abs/2008.09037: “Accuracy and Performance Comparison of Video Action Recognition Approaches”,https://arxiv.org/abs/1905.00546#facebook: “Billion-Scale Semi-Supervised Learning for Image Classification”,https://arxiv.org/abs/1811.11721: “CCNet: Criss-Cross Attention for Semantic Segmentation”,https://arxiv.org/abs/1808.01340#deepmind: “A Short Note about Kinetics-600”,https://arxiv.org/abs/1705.07750#deepmind: “Quo Vadis, Action Recognition? A New Model I3D and the Kinetics Dataset”,https://arxiv.org/abs/1608.03609: “Clockwork Convnets for Video Semantic Segmentation”,