‘masked autoencoder’ directory
- See Also
- Links
- “Gen2seg: Generative Models Enable Generalizable Instance Segmentation”, Khangaonkar & Pirsiavash 2025
- “Intuitive Physics Understanding Emerges from Self-Supervised Pretraining on Natural Videos”, Garrido et al 2025
- “Scaling up Masked Diffusion Models on Text”, Nie et al 2024
- “Meissonic: Revitalizing Masked Generative Transformers for Efficient High-Resolution Text-To-Image Synthesis”, Bai et al 2024
- “Denoising With a Joint-Embedding Predictive Architecture”, Chen et al 2024
- “MaskBit: Embedding-Free Image Generation via Bit Tokens”, Weber et al 2024
- “Stretching Each Dollar: Diffusion Training from Scratch on a Micro-Budget”, Sehwag et al 2024
- “Diffusion Forcing: Next-Token Prediction Meets Full-Sequence Diffusion”, Chen et al 2024
- “MAR: Autoregressive Image Generation without Vector Quantization”, Li et al 2024
- “Simplified and Generalized Masked Diffusion for Discrete Data”, Shi et al 2024
- “SemantiCodec: An Ultra Low Bitrate Semantic Audio Codec for General Sound”, Liu et al 2024
- “Σ-GPTs: A New Approach to Autoregressive Models”, Pannatier et al 2024
- “Rethinking Patch Dependence for Masked Autoencoders”, Fu et al 2024
- “Rich Human Feedback for Text-To-Image Generation”, Liang et al 2023
- “Self-Conditioned Image Generation via Generating Representations”, Li et al 2023
- “Rethinking FID: Towards a Better Evaluation Metric for Image Generation”, Jayasumana et al 2023
- “Learning Unsupervised World Models for Autonomous Driving via Discrete Diffusion”, Zhang et al 2023
- “Limited Data, Unlimited Potential: A Study on ViTs Augmented by Masked Autoencoders (SSAT)”, Das et al 2023
- “Vision Transformers Need Registers”, Darcet et al 2023
- “Diffusion Models Beat GANs on Image Classification”, Mukhopadhyay et al 2023
- “Test-Time Training on Video Streams”, Wang et al 2023
- “Rosetta Neurons: Mining the Common Units in a Model Zoo”, Dravid et al 2023
- “Exposing Flaws of Generative Model Evaluation Metrics and Their Unfair Treatment of Diffusion Models”, Stein et al 2023
- “Generalizable Synthetic Image Detection via Language-Guided Contrastive Learning”, Wu et al 2023
- “SoundStorm: Efficient Parallel Audio Generation”, Borsos et al 2023
- “A Cookbook of Self-Supervised Learning”, Balestriero et al 2023
- “CLaMP: Contrastive Language-Music Pre-Training for Cross-Modal Symbolic Music Information Retrieval”, Wu et al 2023
- “Masked Diffusion Transformer Is a Strong Image Synthesizer”, Gao et al 2023
- “PixMIM: Rethinking Pixel Reconstruction in Masked Image Modeling”, Liu et al 2023
- “John Carmack’s ‘Different Path’ to Artificial General Intelligence”, Carmack 2023
- “JEPA: Self-Supervised Learning from Images With a Joint-Embedding Predictive Architecture”, Assran et al 2023
- “MUG: Vision Learners Meet Web Image-Text Pairs”, Zhao et al 2023
- “TinyMIM: An Empirical Study of Distilling MIM Pre-Trained Models”, Ren et al 2023
- “Muse: Text-To-Image Generation via Masked Generative Transformers”, Chang et al 2023
- “MAGVIT: Masked Generative Video Transformer”, Yu et al 2022
- “Scaling Language-Image Pre-Training via Masking”, Li et al 2022
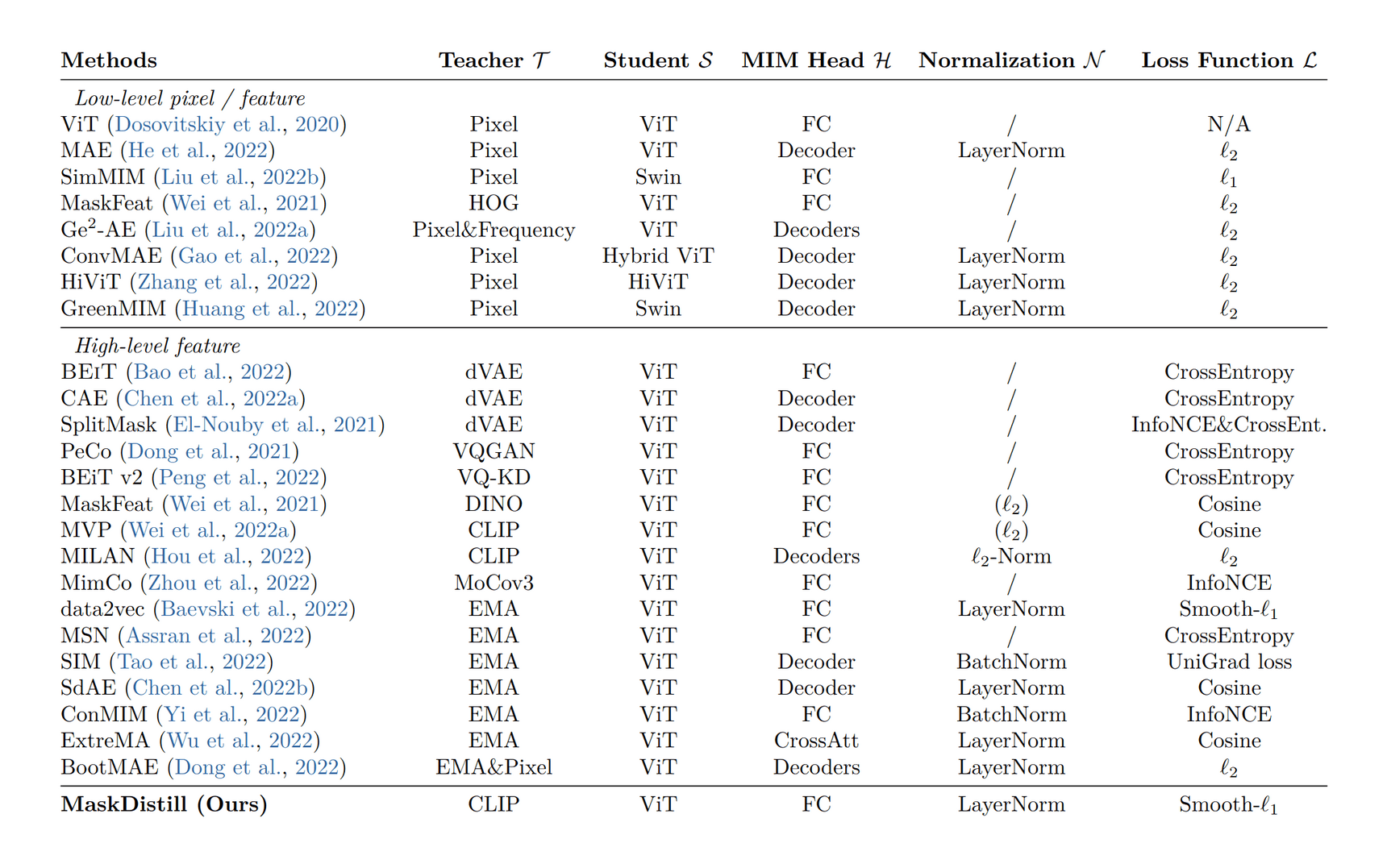
- “MaskDistill: A Unified View of Masked Image Modeling”, Anonymous 2022
- “MAGE: MAsked Generative Encoder to Unify Representation Learning and Image Synthesis”, Li et al 2022
- “Paella: Fast Text-Conditional Discrete Denoising on Vector-Quantized Latent Spaces”, Rampas et al 2022
- “EVA: Exploring the Limits of Masked Visual Representation Learning at Scale”, Fang et al 2022
- “How Mask Matters: Towards Theoretical Understandings of Masked Autoencoders”, Zhang et al 2022
- “Exploring Long-Sequence Masked Autoencoders”, Hu et al 2022
- “TVLT: Textless Vision-Language Transformer”, Tang et al 2022
- “Test-Time Training With Masked Autoencoders”, Gandelsman et al 2022
- “PatchDropout: Economizing Vision Transformers Using Patch Dropout”, Liu et al 2022
- “CMAE: Contrastive Masked Autoencoders Are Stronger Vision Learners”, Huang et al 2022
- “PIXEL: Language Modeling With Pixels”, Rust et al 2022
- “Masked Autoencoders That Listen”, Po-Yao et al 2022
- “MET: Masked Encoding for Tabular Data”, Majmundar et al 2022
- “OmniMAE: Single Model Masked Pretraining on Images and Videos”, Girdhar et al 2022
- “M3AE: Multimodal Masked Autoencoders Learn Transferable Representations”, Geng et al 2022
- “Masked Autoencoders As Spatiotemporal Learners”, Feichtenhofer et al 2022
- “CogView2: Faster and Better Text-To-Image Generation via Hierarchical Transformers”, Ding et al 2022
- “Should You Mask 15% in Masked Language Modeling?”, Wettig et al 2022
- “MaskGIT: Masked Generative Image Transformer”, Chang et al 2022
- “SimMIM: A Simple Framework for Masked Image Modeling”, Xie et al 2021
- “MAE: Masked Autoencoders Are Scalable Vision Learners”, He et al 2021
- “Learning to Ground Multi-Agent Communication With Autoencoders”, Lin et al 2021
- “Hide-And-Seek: A Data Augmentation Technique for Weakly-Supervised Localization and Beyond”, Singh et al 2018
- “Learning to Ground Multi-Agent Communication With Autoencoders [Code]”
- “Learning to Ground Multi-Agent Communication With Autoencoders [Homepage]”
- “Learning to Ground Multi-Agent Communication With Autoencoders [Video]”
- Sort By Magic
- Miscellaneous
- Bibliography
See Also
Links
“Gen2seg: Generative Models Enable Generalizable Instance Segmentation”, Khangaonkar & Pirsiavash 2025
gen2seg: Generative Models Enable Generalizable Instance Segmentation
“Intuitive Physics Understanding Emerges from Self-Supervised Pretraining on Natural Videos”, Garrido et al 2025
Intuitive physics understanding emerges from self-supervised pretraining on natural videos
“Scaling up Masked Diffusion Models on Text”, Nie et al 2024
“Meissonic: Revitalizing Masked Generative Transformers for Efficient High-Resolution Text-To-Image Synthesis”, Bai et al 2024
“Denoising With a Joint-Embedding Predictive Architecture”, Chen et al 2024
“MaskBit: Embedding-Free Image Generation via Bit Tokens”, Weber et al 2024
“Stretching Each Dollar: Diffusion Training from Scratch on a Micro-Budget”, Sehwag et al 2024
Stretching Each Dollar: Diffusion Training from Scratch on a Micro-Budget
“Diffusion Forcing: Next-Token Prediction Meets Full-Sequence Diffusion”, Chen et al 2024
Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion
“MAR: Autoregressive Image Generation without Vector Quantization”, Li et al 2024
MAR: Autoregressive Image Generation without Vector Quantization
“Simplified and Generalized Masked Diffusion for Discrete Data”, Shi et al 2024
Simplified and Generalized Masked Diffusion for Discrete Data
“SemantiCodec: An Ultra Low Bitrate Semantic Audio Codec for General Sound”, Liu et al 2024
SemantiCodec: An Ultra Low Bitrate Semantic Audio Codec for General Sound
“Σ-GPTs: A New Approach to Autoregressive Models”, Pannatier et al 2024
“Rethinking Patch Dependence for Masked Autoencoders”, Fu et al 2024
“Rich Human Feedback for Text-To-Image Generation”, Liang et al 2023
“Self-Conditioned Image Generation via Generating Representations”, Li et al 2023
Self-conditioned Image Generation via Generating Representations
“Rethinking FID: Towards a Better Evaluation Metric for Image Generation”, Jayasumana et al 2023
Rethinking FID: Towards a Better Evaluation Metric for Image Generation
“Learning Unsupervised World Models for Autonomous Driving via Discrete Diffusion”, Zhang et al 2023
Learning Unsupervised World Models for Autonomous Driving via Discrete Diffusion
“Limited Data, Unlimited Potential: A Study on ViTs Augmented by Masked Autoencoders (SSAT)”, Das et al 2023
Limited Data, Unlimited Potential: A Study on ViTs Augmented by Masked Autoencoders (SSAT)
“Vision Transformers Need Registers”, Darcet et al 2023
“Diffusion Models Beat GANs on Image Classification”, Mukhopadhyay et al 2023
“Test-Time Training on Video Streams”, Wang et al 2023
“Rosetta Neurons: Mining the Common Units in a Model Zoo”, Dravid et al 2023
“Exposing Flaws of Generative Model Evaluation Metrics and Their Unfair Treatment of Diffusion Models”, Stein et al 2023
Exposing flaws of generative model evaluation metrics and their unfair treatment of diffusion models
“Generalizable Synthetic Image Detection via Language-Guided Contrastive Learning”, Wu et al 2023
Generalizable Synthetic Image Detection via Language-guided Contrastive Learning
“SoundStorm: Efficient Parallel Audio Generation”, Borsos et al 2023
“A Cookbook of Self-Supervised Learning”, Balestriero et al 2023
“CLaMP: Contrastive Language-Music Pre-Training for Cross-Modal Symbolic Music Information Retrieval”, Wu et al 2023
CLaMP: Contrastive Language-Music Pre-training for Cross-Modal Symbolic Music Information Retrieval
“Masked Diffusion Transformer Is a Strong Image Synthesizer”, Gao et al 2023
“PixMIM: Rethinking Pixel Reconstruction in Masked Image Modeling”, Liu et al 2023
PixMIM: Rethinking Pixel Reconstruction in Masked Image Modeling
“John Carmack’s ‘Different Path’ to Artificial General Intelligence”, Carmack 2023
John Carmack’s ‘Different Path’ to Artificial General Intelligence
“JEPA: Self-Supervised Learning from Images With a Joint-Embedding Predictive Architecture”, Assran et al 2023
JEPA: Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
“MUG: Vision Learners Meet Web Image-Text Pairs”, Zhao et al 2023
“TinyMIM: An Empirical Study of Distilling MIM Pre-Trained Models”, Ren et al 2023
TinyMIM: An Empirical Study of Distilling MIM Pre-trained Models
“Muse: Text-To-Image Generation via Masked Generative Transformers”, Chang et al 2023
Muse: Text-To-Image Generation via Masked Generative Transformers
“MAGVIT: Masked Generative Video Transformer”, Yu et al 2022
“Scaling Language-Image Pre-Training via Masking”, Li et al 2022
“MaskDistill: A Unified View of Masked Image Modeling”, Anonymous 2022
“MAGE: MAsked Generative Encoder to Unify Representation Learning and Image Synthesis”, Li et al 2022
MAGE: MAsked Generative Encoder to Unify Representation Learning and Image Synthesis
“Paella: Fast Text-Conditional Discrete Denoising on Vector-Quantized Latent Spaces”, Rampas et al 2022
Paella: Fast Text-Conditional Discrete Denoising on Vector-Quantized Latent Spaces
“EVA: Exploring the Limits of Masked Visual Representation Learning at Scale”, Fang et al 2022
EVA: Exploring the Limits of Masked Visual Representation Learning at Scale
“How Mask Matters: Towards Theoretical Understandings of Masked Autoencoders”, Zhang et al 2022
How Mask Matters: Towards Theoretical Understandings of Masked Autoencoders
“Exploring Long-Sequence Masked Autoencoders”, Hu et al 2022
“TVLT: Textless Vision-Language Transformer”, Tang et al 2022
“Test-Time Training With Masked Autoencoders”, Gandelsman et al 2022
“PatchDropout: Economizing Vision Transformers Using Patch Dropout”, Liu et al 2022
PatchDropout: Economizing Vision Transformers Using Patch Dropout
“CMAE: Contrastive Masked Autoencoders Are Stronger Vision Learners”, Huang et al 2022
CMAE: Contrastive Masked Autoencoders are Stronger Vision Learners
“PIXEL: Language Modeling With Pixels”, Rust et al 2022
“Masked Autoencoders That Listen”, Po-Yao et al 2022
“MET: Masked Encoding for Tabular Data”, Majmundar et al 2022
“OmniMAE: Single Model Masked Pretraining on Images and Videos”, Girdhar et al 2022
OmniMAE: Single Model Masked Pretraining on Images and Videos
“M3AE: Multimodal Masked Autoencoders Learn Transferable Representations”, Geng et al 2022
M3AE: Multimodal Masked Autoencoders Learn Transferable Representations
“Masked Autoencoders As Spatiotemporal Learners”, Feichtenhofer et al 2022
“CogView2: Faster and Better Text-To-Image Generation via Hierarchical Transformers”, Ding et al 2022
CogView2: Faster and Better Text-to-Image Generation via Hierarchical Transformers
“Should You Mask 15% in Masked Language Modeling?”, Wettig et al 2022
“MaskGIT: Masked Generative Image Transformer”, Chang et al 2022
“SimMIM: A Simple Framework for Masked Image Modeling”, Xie et al 2021
“MAE: Masked Autoencoders Are Scalable Vision Learners”, He et al 2021
“Learning to Ground Multi-Agent Communication With Autoencoders”, Lin et al 2021
Learning to Ground Multi-Agent Communication with Autoencoders
“Hide-And-Seek: A Data Augmentation Technique for Weakly-Supervised Localization and Beyond”, Singh et al 2018
Hide-and-Seek: A Data Augmentation Technique for Weakly-Supervised Localization and Beyond
“Learning to Ground Multi-Agent Communication With Autoencoders [Code]”
Learning to Ground Multi-Agent Communication with Autoencoders [code]
“Learning to Ground Multi-Agent Communication With Autoencoders [Homepage]”
Learning to Ground Multi-Agent Communication with Autoencoders [homepage]
“Learning to Ground Multi-Agent Communication With Autoencoders [Video]”
Learning to Ground Multi-Agent Communication with Autoencoders [video]
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
agi-path
audio-generation
multi-agent-communication
self-supervised
masked-learning
Miscellaneous
{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2502.11831#facebook: “Intuitive Physics Understanding Emerges from Self-Supervised Pretraining on Natural Videos”,https://arxiv.org/abs/2410.18514: “Scaling up Masked Diffusion Models on Text”,https://arxiv.org/abs/2410.03755#meituan: “Denoising With a Joint-Embedding Predictive Architecture”,https://arxiv.org/abs/2409.16211#bytedance: “MaskBit: Embedding-Free Image Generation via Bit Tokens”,https://arxiv.org/abs/2406.04329#deepmind: “Simplified and Generalized Masked Diffusion for Discrete Data”,https://arxiv.org/abs/2401.14391: “Rethinking Patch Dependence for Masked Autoencoders”,https://arxiv.org/abs/2311.01017: “Learning Unsupervised World Models for Autonomous Driving via Discrete Diffusion”,https://arxiv.org/abs/2307.05014: “Test-Time Training on Video Streams”,https://arxiv.org/abs/2306.09346: “Rosetta Neurons: Mining the Common Units in a Model Zoo”,https://arxiv.org/abs/2306.04675#layer6ai: “Exposing Flaws of Generative Model Evaluation Metrics and Their Unfair Treatment of Diffusion Models”,https://arxiv.org/abs/2305.09636#google: “SoundStorm: Efficient Parallel Audio Generation”,https://arxiv.org/abs/2303.14389: “Masked Diffusion Transformer Is a Strong Image Synthesizer”,https://arxiv.org/abs/2301.07088#bytedance: “MUG: Vision Learners Meet Web Image-Text Pairs”,https://arxiv.org/abs/2301.01296#microsoft: “TinyMIM: An Empirical Study of Distilling MIM Pre-Trained Models”,https://arxiv.org/abs/2301.00704#google: “Muse: Text-To-Image Generation via Masked Generative Transformers”,https://arxiv.org/abs/2212.05199#google: “MAGVIT: Masked Generative Video Transformer”,https://openreview.net/forum?id=wmGlMhaBe0: “MaskDistill: A Unified View of Masked Image Modeling”,https://arxiv.org/abs/2211.09117#google: “MAGE: MAsked Generative Encoder to Unify Representation Learning and Image Synthesis”,https://arxiv.org/abs/2211.07292: “Paella: Fast Text-Conditional Discrete Denoising on Vector-Quantized Latent Spaces”,https://arxiv.org/abs/2211.07636#baai: “EVA: Exploring the Limits of Masked Visual Representation Learning at Scale”,https://arxiv.org/abs/2210.08344: “How Mask Matters: Towards Theoretical Understandings of Masked Autoencoders”,https://arxiv.org/abs/2209.14156: “TVLT: Textless Vision-Language Transformer”,https://arxiv.org/abs/2207.13532#bytedance: “CMAE: Contrastive Masked Autoencoders Are Stronger Vision Learners”,https://arxiv.org/abs/2207.06991: “PIXEL: Language Modeling With Pixels”,https://arxiv.org/abs/2207.06405#facebook: “Masked Autoencoders That Listen”,https://arxiv.org/abs/2206.08356#facebook: “OmniMAE: Single Model Masked Pretraining on Images and Videos”,https://arxiv.org/abs/2205.14204#google: “M3AE: Multimodal Masked Autoencoders Learn Transferable Representations”,https://arxiv.org/abs/2205.09113#facebook: “Masked Autoencoders As Spatiotemporal Learners”,https://arxiv.org/abs/2204.14217#baai: “CogView2: Faster and Better Text-To-Image Generation via Hierarchical Transformers”,https://arxiv.org/abs/2111.09886#microsoft: “SimMIM: A Simple Framework for Masked Image Modeling”,https://arxiv.org/abs/2111.06377#facebook: “MAE: Masked Autoencoders Are Scalable Vision Learners”,https://arxiv.org/abs/2110.15349: “Learning to Ground Multi-Agent Communication With Autoencoders”,