‘newest links’ directory
- See Also
- Gwern
- “The Super Kaleidoscope Survey”, Gwern et al 2026
- “Shibari Body Pillow”, Gwern & Pro 2026
- “Sleepcat Purrkit”, Gwern et al 2026
- “The Repugnant Conclusion”, Gwern & 2 2026
- “Lean Software Scaling Laws”, Gwern 2025
- “Face Recognition Training App”, Gwern 2026
- “Sand, Rain, Wood”, Gemini-3.1-pro-preview et al 2026
- “𝑃𝑒𝑟𝑖𝑠𝘩𝑒𝑑 𝑃𝑎𝑟𝑎𝑑𝑖𝑠𝑒 Graveyard”, Gwern & GPT-4 2023
- “Chapter 6, Mime Molting: What to Expect”, Claude-4.8-opus et al 2026
- “𝑇𝑖𝑙𝑎𝑘𝑘𝘩𝑎𝑛𝑎: The 3 Scars of Existence”, Gwern et al 2025
- “Guardian Angels: LLM Personalization for Productivity and Security”, Gwern 2025
- “Human-Like Neural Nets by Catapulting”, Gwern 2024
- Links
- “People, Not Search-Engine Algorithms, Choose Unreliable or Partisan News: Analysis of People’s Web Searches and Visited Websites Suggests That It Is More Likely That They Are Choosing to Engage With Partisan or Unreliable News Than That They Are Being Unduly Exposed to It by Search-Engine Algorithms”, Mustafaraj 2023
- “Agamemnon and the Indo-European Threefold Death Pattern”, Evans 1979
- “Navigating the Open-Source Model Ecosystem: An Empirical Study of Creator Practices in Artistic Image Generation”, Wei et al 2026
- “Have Chinese AI Models Caught Up to the US Frontier? [Probably Not]”
- “A Mechanistic Explanation of Prompt Injection (And Why You Should Study Roles)”
- “Impro Is a Handbook for Running a Cult”, Goedecke 2026
- “The Weightless Machine”, Furze 2023
- “Designing APIs for Agents”
- “TIL: EBPF Is Awesome”
- “Microsoft/ebpf-For-Windows: EBPF Implementation That Runs on top of Windows”
- “Periodic Cooking of Eggs”
- “Internal Server Error”
- “If We Pull This Off, We’ll Eat Like Kings”, Larson 1983
- “GlyphDrawing.Club”
- “Ending Respiratory Infections: Introducing Intercept, a $500M Bet to Make Respiratory Infections like Colds and Flu a Thing of the Past”, Ransohoff et al 2026
- “Elijah Millgram on the Philosophical Life (Episode 125): Why Personal Experience Is Underrated”, Cowen & Millgram 2021
- “Why I Left Google DeepMind”, Turntrout 2026
- “Things You Can’t Buy in the USA (And Why)”, Frank 2026
- “LoRA Without Regret”, Inc 2025
- “Screencasts Could Be Scalable Data + Evals for Single-User Emulation (Guardian Angels)”
- “Guardian Angels: LLM Personalization for Productivity and Security”
- “Lossless Model Compression Experiment”
- “On the Origins of Heikki’s Garden of Flowers”, Lotvonen 2026
- “Why Did You Stop Using Me?”, Theia 2025
- “Utah Company Says It Has Grown Human Sperm in a Lab and Used It to Make Embryos: Paterna Biosciences’ Technique, Which Uses Testicular Tissue, Will Require Years More Research and Regulation”, Banta 2026
- “Holed Up: Man Falls into Art Installation of 8ft Hole Painted Black [With Vantablack]; A Visitor to a Portuguese Gallery Found Deeper Meaning in Anish Kapoor’s 1992 Work Descent into Limbo”, Brown 2018
- “What Difference Would It Make If Cancer Were Eradicated? An Examination of the Taeuber Paradox”, Keyfitz 1977
- “Borges and AI”, Bottou & Schölkopf 2023
- “The Basic Uniformity In Structure Of The Neocortex”, Rockel et al 1980
- “Does Claude’s Constitution Have a Culture?”, Pourdavood 2026
- “We, the Navigators at 50”
- “LLMZip: Lossless Text Compression Using Large Language Models”, Valmeekam et al 2023
- “FineZip: Pushing the Limits of Large Language Models for Practical Lossless Text Compression”, Mittu et al 2024
- “ReLoRA: High-Rank Training Through Low-Rank Updates”, Lialin et al 2023
- “Evolutionary Biomechanics of Maximum Running Speed in Spiders (Araneae)”, Kuchibhotla et al 2026
- “Why Were the Soil Tunnels of Cu Chi and Iron Triangle in Vietnam So Resilient?”, Olson & Morton 2017
- “‘I’ve Embarrassed Myself’—Grandmaster Trivia Test With Fabi Caruana, Hikaru Nakamura & Levon Aronian”, Chess 2025
- “The GNU Emacs Architecture: Unlocking the Core”, Karlsson 2026
- “The Widening Gap: The Benefits and Harms of Generative AI for Novice Programmers”, Prather et al 2024
- “Ladder Up, Memory Down: Low-Cost Fine-Tuning With Side Nets (LST/xLadder)”, Zheng et al 2025
- “Split Personality Training (SPT): Revealing Latent Knowledge Through Alternate Personalities”, Dietz et al 2026
- “Imperfect World Models Are Exploitable”, Bhamidipaty et al 2026
- “1Picture1000Words: They Say a Picture Is worth a Thousand Words. I Say… Prove It”, Rare 2026
- “Gravitational Effects on and of Vacuum Decay”, Coleman & Luccia 1980
- “Knowledge Distillation of Black-Box Large Language Models”, Chen et al 2024
- “Data Mixing Laws: Optimizing Data Mixtures by Predicting Language Modeling Performance”, Ye et al 2024
- “Why Mental Health Awareness Can Harm: Converging Explanations for a Societal Problem”, Sandra & Inzlicht 2026
- “Do Sunlight and Vitamin D Reduce the Likelihood of Colon Cancer?”, Garland & Garland 1980
- “Scaling Laws for Code: A More Data-Hungry Regime”, Luo et al 2025
- “DeepSeek-OCR: Contexts Optical Compression”, Wei et al 2025
- “Scaling Laws for Code: Every Programming Language Matters”, Yang et al 2025
- “Unlimited OCR Works”, Yin et al 2026
- “CLRHack: Meta-Object Protocol”, Marshall 2026
- “Chronicle of a Disaster Foretold: Maggie Haberman and Jonathan Swan’s Regime Change Is Packed With News about the Trump White House That Will Stay News”, Remnick 2026
- “Woodkid Says Hideo Kojima Changed Death Stranding 2 to Be ‘Polarizing’: The French Singer-Songwriter Worked Intimately for Three Years With the Game’s Creator to Produce Its Soundtrack”, Cruz & Woodkid 2025
- “StoryScope: Investigating Idiosyncrasies in AI Fiction”, Russell et al 2026
- “Spontaneous Eye Movements Reflect the Representational Geometries of Conceptual Spaces”, Viganò et al 2024
- “‘X-Ray Vision’ and the Evolution of Forward-Facing Eyes”, Changizi & Shimojo 2008b
- “Matching Faces to Photographs: Poor Performance in Eyewitness Memory (Without the Memory)”, Megreya & Burton 2008
- “Telling Faces Together: Learning New Faces through Exposure to Multiple Instances”, Andrews et al 2015
- “Diagnostic Feature Training Improves Face Matching Accuracy”, Towler et al 2021
- “Deep Learning Face Attributes in the Wild”, Liu et al 2014
- “How Transparent Is DiffusionGemma?”, Engels et al 2026
- “Gemma 4: Byte for Byte, the Most Capable Open Models”, Farabet & Lacombe 2026
- “Feedback Training for Facial Image Comparison”, White et al 2013
- “Massive Input And/or Spaced Repetition”, Nintil 2023
- “Can Training Enhance Face Cognition Abilities in Middle-Aged Adults?”, Dolzycka et al 2014
- “Holistic Face Training Enhances Face Processing in Developmental Prosopagnosia”, DeGutis et al 2014
- “UNSW Face Test: A Screening Tool for Super-Recognizers”, Dunn et al 2020
- “Face Recognition Improvements in Adults and Children With Face Recognition Difficulties”, Bate et al 2022
- “Tales of the Tail: Hardware, OS, and Application-Level Sources of Tail Latency”, Li et al 2014c
- “Revisiting the Platonic Representation Hypothesis: An Aristotelian View”, Gröger et al 2026
- Wikipedia (10)
- Miscellaneous
- Bibliography
See Also
Gwern
“The Super Kaleidoscope Survey”, Gwern et al 2026
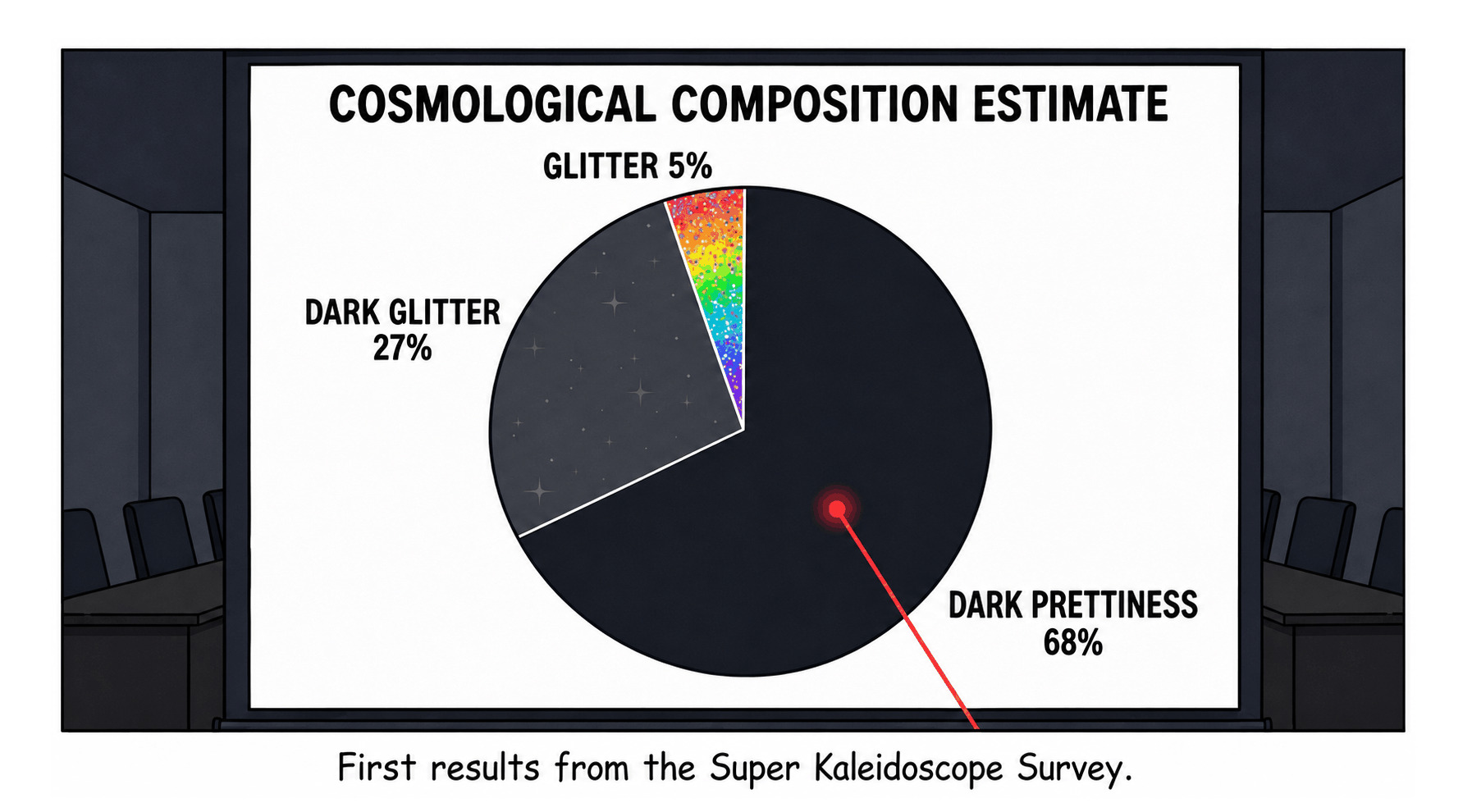{kind=link}
“Shibari Body Pillow”, Gwern & Pro 2026
{kind=link}
“Sleepcat Purrkit”, Gwern et al 2026
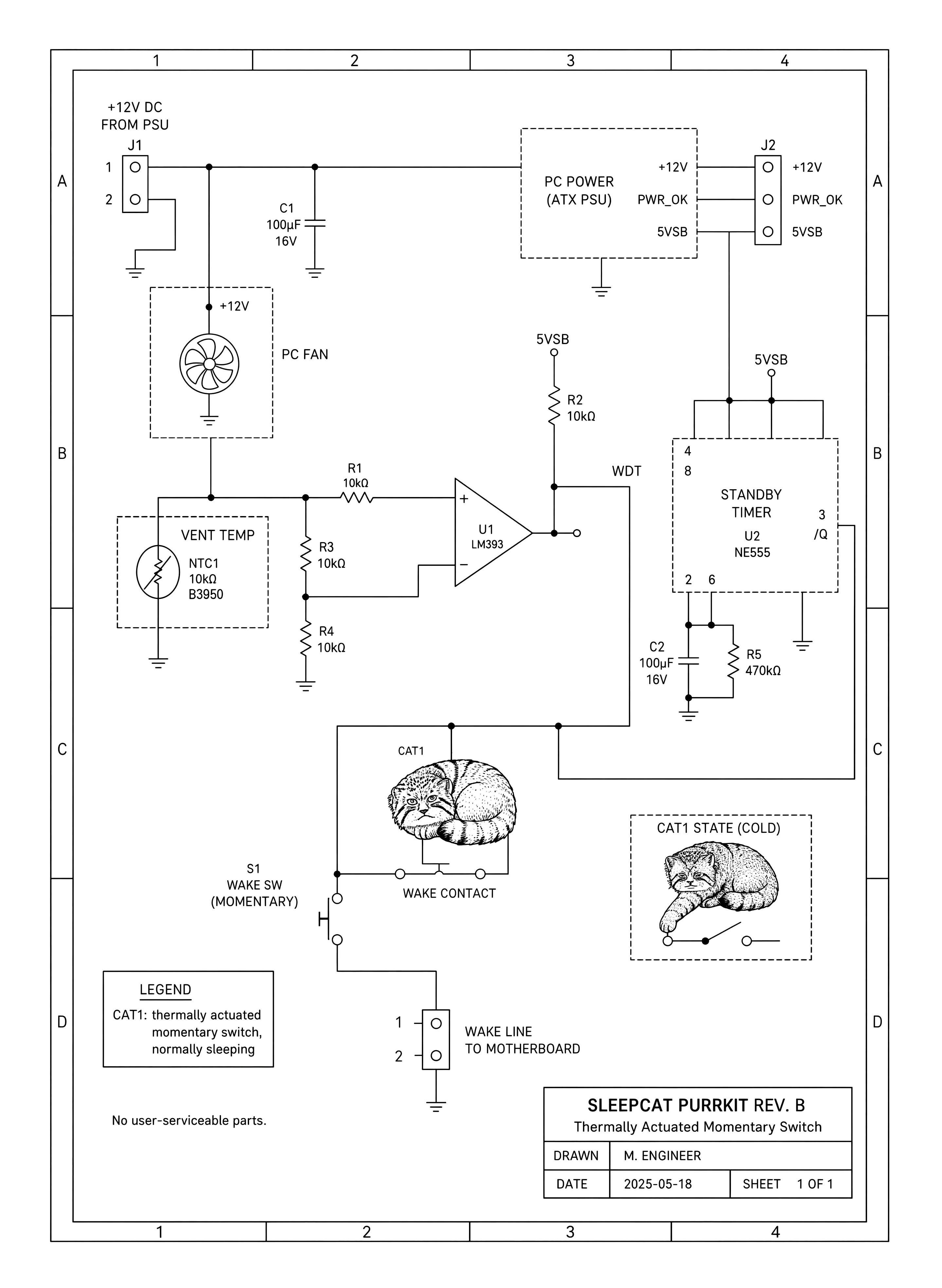{kind=link}
“The Repugnant Conclusion”, Gwern & 2 2026
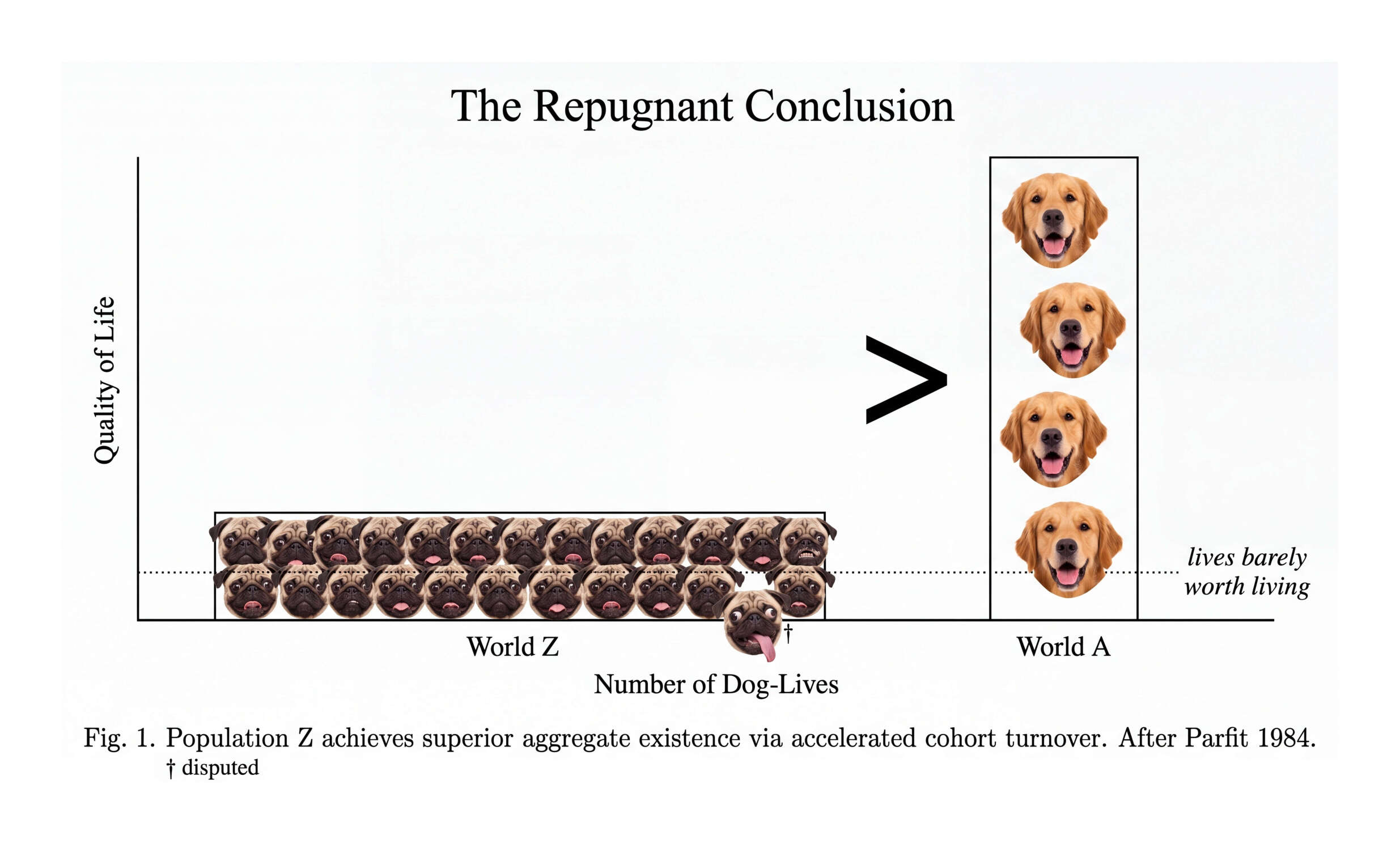{kind=link}
“Lean Software Scaling Laws”, Gwern 2025
“Face Recognition Training App”, Gwern 2026
“Sand, Rain, Wood”, Gemini-3.1-pro-preview et al 2026
“𝑃𝑒𝑟𝑖𝑠𝘩𝑒𝑑 𝑃𝑎𝑟𝑎𝑑𝑖𝑠𝑒 Graveyard”, Gwern & GPT-4 2023
“Chapter 6, Mime Molting: What to Expect”, Claude-4.8-opus et al 2026
“𝑇𝑖𝑙𝑎𝑘𝑘𝘩𝑎𝑛𝑎: The 3 Scars of Existence”, Gwern et al 2025
“Guardian Angels: LLM Personalization for Productivity and Security”, Gwern 2025
Guardian Angels: LLM Personalization for Productivity and Security
“Human-Like Neural Nets by Catapulting”, Gwern 2024
Links
“People, Not Search-Engine Algorithms, Choose Unreliable or Partisan News: Analysis of People’s Web Searches and Visited Websites Suggests That It Is More Likely That They Are Choosing to Engage With Partisan or Unreliable News Than That They Are Being Unduly Exposed to It by Search-Engine Algorithms”, Mustafaraj 2023
“Agamemnon and the Indo-European Threefold Death Pattern”, Evans 1979
“Navigating the Open-Source Model Ecosystem: An Empirical Study of Creator Practices in Artistic Image Generation”, Wei et al 2026
“Have Chinese AI Models Caught Up to the US Frontier? [Probably Not]”
Have Chinese AI Models Caught Up to the US Frontier? [probably not]
“A Mechanistic Explanation of Prompt Injection (And Why You Should Study Roles)”
A Mechanistic Explanation of Prompt Injection (and why you should study roles)
“Impro Is a Handbook for Running a Cult”, Goedecke 2026
“The Weightless Machine”, Furze 2023
“Designing APIs for Agents”
“TIL: EBPF Is Awesome”
“Microsoft/ebpf-For-Windows: EBPF Implementation That Runs on top of Windows”
microsoft/ebpf-for-windows: eBPF implementation that runs on top of Windows
“Periodic Cooking of Eggs”
“Internal Server Error”
“If We Pull This Off, We’ll Eat Like Kings”, Larson 1983
{kind=link}
“GlyphDrawing.Club”
“Ending Respiratory Infections: Introducing Intercept, a $500M Bet to Make Respiratory Infections like Colds and Flu a Thing of the Past”, Ransohoff et al 2026
“Elijah Millgram on the Philosophical Life (Episode 125): Why Personal Experience Is Underrated”, Cowen & Millgram 2021
Elijah Millgram on the Philosophical Life (Episode 125): Why personal experience is underrated
View External Link:
https://conversationswithtyler.com/episodes/elijah-millgram/
“Why I Left Google DeepMind”, Turntrout 2026
“Things You Can’t Buy in the USA (And Why)”, Frank 2026
“LoRA Without Regret”, Inc 2025
“Screencasts Could Be Scalable Data + Evals for Single-User Emulation (Guardian Angels)”
Screencasts could be scalable data + evals for single-user emulation (Guardian Angels)
“Guardian Angels: LLM Personalization for Productivity and Security”
Guardian Angels: LLM Personalization for Productivity and Security
“Lossless Model Compression Experiment”
Lossless Model Compression Experiment
View External Link:
“On the Origins of Heikki’s Garden of Flowers”, Lotvonen 2026
“Why Did You Stop Using Me?”, Theia 2025
“Utah Company Says It Has Grown Human Sperm in a Lab and Used It to Make Embryos: Paterna Biosciences’ Technique, Which Uses Testicular Tissue, Will Require Years More Research and Regulation”, Banta 2026
“Holed Up: Man Falls into Art Installation of 8ft Hole Painted Black [With Vantablack]; A Visitor to a Portuguese Gallery Found Deeper Meaning in Anish Kapoor’s 1992 Work Descent into Limbo”, Brown 2018
“What Difference Would It Make If Cancer Were Eradicated? An Examination of the Taeuber Paradox”, Keyfitz 1977
What Difference Would It Make if Cancer Were Eradicated? An Examination of the Taeuber Paradox
“Borges and AI”, Bottou & Schölkopf 2023
“The Basic Uniformity In Structure Of The Neocortex”, Rockel et al 1980
“Does Claude’s Constitution Have a Culture?”, Pourdavood 2026
“We, the Navigators at 50”
“LLMZip: Lossless Text Compression Using Large Language Models”, Valmeekam et al 2023
LLMZip: Lossless Text Compression using Large Language Models
“FineZip: Pushing the Limits of Large Language Models for Practical Lossless Text Compression”, Mittu et al 2024
FineZip: Pushing the Limits of Large Language Models for Practical Lossless Text Compression
“ReLoRA: High-Rank Training Through Low-Rank Updates”, Lialin et al 2023
“Evolutionary Biomechanics of Maximum Running Speed in Spiders (Araneae)”, Kuchibhotla et al 2026
Evolutionary biomechanics of maximum running speed in spiders (Araneae)
“Why Were the Soil Tunnels of Cu Chi and Iron Triangle in Vietnam So Resilient?”, Olson & Morton 2017
Why Were the Soil Tunnels of Cu Chi and Iron Triangle in Vietnam So Resilient?
“‘I’ve Embarrassed Myself’—Grandmaster Trivia Test With Fabi Caruana, Hikaru Nakamura & Levon Aronian”, Chess 2025
‘I’ve embarrassed myself’—Grandmaster Trivia Test with Fabi Caruana, Hikaru Nakamura & Levon Aronian
“The GNU Emacs Architecture: Unlocking the Core”, Karlsson 2026
“The Widening Gap: The Benefits and Harms of Generative AI for Novice Programmers”, Prather et al 2024
The Widening Gap: The Benefits and Harms of Generative AI for Novice Programmers
“Ladder Up, Memory Down: Low-Cost Fine-Tuning With Side Nets (LST/xLadder)”, Zheng et al 2025
Ladder Up, Memory Down: Low-Cost Fine-Tuning With Side Nets (LST/xLadder)
“Split Personality Training (SPT): Revealing Latent Knowledge Through Alternate Personalities”, Dietz et al 2026
Split Personality Training (SPT): Revealing Latent Knowledge Through Alternate Personalities
“Imperfect World Models Are Exploitable”, Bhamidipaty et al 2026
“1Picture1000Words: They Say a Picture Is worth a Thousand Words. I Say… Prove It”, Rare 2026
1Picture1000Words: They say a picture is worth a thousand words. I say… Prove it
“Gravitational Effects on and of Vacuum Decay”, Coleman & Luccia 1980
“Knowledge Distillation of Black-Box Large Language Models”, Chen et al 2024
“Data Mixing Laws: Optimizing Data Mixtures by Predicting Language Modeling Performance”, Ye et al 2024
Data Mixing Laws: Optimizing Data Mixtures by Predicting Language Modeling Performance
“Why Mental Health Awareness Can Harm: Converging Explanations for a Societal Problem”, Sandra & Inzlicht 2026
Why Mental Health Awareness Can Harm: Converging Explanations for a Societal Problem
“Do Sunlight and Vitamin D Reduce the Likelihood of Colon Cancer?”, Garland & Garland 1980
Do Sunlight and Vitamin D Reduce the Likelihood of Colon Cancer?
“Scaling Laws for Code: A More Data-Hungry Regime”, Luo et al 2025
“DeepSeek-OCR: Contexts Optical Compression”, Wei et al 2025
“Scaling Laws for Code: Every Programming Language Matters”, Yang et al 2025
“Unlimited OCR Works”, Yin et al 2026
“CLRHack: Meta-Object Protocol”, Marshall 2026
“Chronicle of a Disaster Foretold: Maggie Haberman and Jonathan Swan’s Regime Change Is Packed With News about the Trump White House That Will Stay News”, Remnick 2026
“Woodkid Says Hideo Kojima Changed Death Stranding 2 to Be ‘Polarizing’: The French Singer-Songwriter Worked Intimately for Three Years With the Game’s Creator to Produce Its Soundtrack”, Cruz & Woodkid 2025
“StoryScope: Investigating Idiosyncrasies in AI Fiction”, Russell et al 2026
“Spontaneous Eye Movements Reflect the Representational Geometries of Conceptual Spaces”, Viganò et al 2024
Spontaneous eye movements reflect the representational geometries of conceptual spaces
“‘X-Ray Vision’ and the Evolution of Forward-Facing Eyes”, Changizi & Shimojo 2008b
“Matching Faces to Photographs: Poor Performance in Eyewitness Memory (Without the Memory)”, Megreya & Burton 2008
Matching faces to photographs: Poor performance in eyewitness memory (without the memory)
“Telling Faces Together: Learning New Faces through Exposure to Multiple Instances”, Andrews et al 2015
Telling faces together: Learning new faces through exposure to multiple instances
“Diagnostic Feature Training Improves Face Matching Accuracy”, Towler et al 2021
“Deep Learning Face Attributes in the Wild”, Liu et al 2014
“How Transparent Is DiffusionGemma?”, Engels et al 2026
“Gemma 4: Byte for Byte, the Most Capable Open Models”, Farabet & Lacombe 2026
“Feedback Training for Facial Image Comparison”, White et al 2013
“Massive Input And/or Spaced Repetition”, Nintil 2023
“Can Training Enhance Face Cognition Abilities in Middle-Aged Adults?”, Dolzycka et al 2014
Can Training Enhance Face Cognition Abilities in Middle-Aged Adults?
“Holistic Face Training Enhances Face Processing in Developmental Prosopagnosia”, DeGutis et al 2014
Holistic face training enhances face processing in developmental prosopagnosia
“UNSW Face Test: A Screening Tool for Super-Recognizers”, Dunn et al 2020
“Face Recognition Improvements in Adults and Children With Face Recognition Difficulties”, Bate et al 2022
Face recognition improvements in adults and children with face recognition difficulties
“Tales of the Tail: Hardware, OS, and Application-Level Sources of Tail Latency”, Li et al 2014c
Tales of the Tail: Hardware, OS, and Application-level Sources of Tail Latency
“Revisiting the Platonic Representation Hypothesis: An Aristotelian View”, Gröger et al 2026
Revisiting the Platonic Representation Hypothesis: An Aristotelian View
Wikipedia (10)
Miscellaneous
Bibliography
https://arxiv.org/abs/2306.04050: “LLMZip: Lossless Text Compression Using Large Language Models”,https://arxiv.org/abs/2409.17141: “FineZip: Pushing the Limits of Large Language Models for Practical Lossless Text Compression”,