‘CLIP’ directory
- See Also
- Gwern
- Links
- “Anime-2026: A Large-Scale Anime Character Dataset for Anime-Related AI Tasks”, Xuyang et al 2026
- “Vec2vec: Harnessing the Universal Geometry of Embeddings”, Jha et al 2025
- “Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment”, Thasarathan et al 2025
- “LLMs Can See and Hear without Any Training”, Ashutosh et al 2025
- “Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps”, Ma et al 2025
- “PaliGemma 2: A Family of Versatile VLMs for Transfer”, Steiner et al 2024
- “CT Foundation: Taking Medical Imaging Embeddings 3D”, Kiraly & Traverse 2024
- “Ensemble Everything Everywhere: Multi-Scale Aggregation for Adversarial Robustness”, Fort & Lakshminarayanan 2024
- “Scaling Law in Neural Data: Non-Invasive Speech Decoding With 175 Hours of EEG Data”, Sato et al 2024
- “Explore the Limits of Omni-Modal Pretraining at Scale”, Zhang et al 2024
- “RWKV-CLIP: A Robust Vision-Language Representation Learner”, Gu et al 2024
- “Sakuga-42M Dataset: Scaling Up Cartoon Research”, Pan et al 2024
- “ImageInWords: Unlocking Hyper-Detailed Image Descriptions”, Garg et al 2024
- “CatLIP: CLIP-Level Visual Recognition Accuracy With 2.7× Faster Pre-Training on Web-Scale Image-Text Data”, Mehta et al 2024
- “Towards Generated Image Provenance Analysis Via Conceptual-Similar-Guided-SLIP Retrieval”, Xia et al 2024
- “Scaling (Down) CLIP: A Comprehensive Analysis of Data, Architecture, and Training Strategies”, Li et al 2024
- “Evaluating Text-To-Visual Generation With Image-To-Text Generation”, Lin et al 2024
- “TextCraftor: Your Text Encoder Can Be Image Quality Controller”, Li et al 2024
- “MM1: Methods, Analysis & Insights from Multimodal LLM Pre-Training”, McKinzie et al 2024
- “Discovering Universal Semantic Triggers for Text-To-Image Synthesis”, Zhai et al 2024
- “Grounded Language Acquisition through the Eyes and Ears of a Single Child”, Vong et al 2024
- “TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones”, Yuan et al 2023
- “Parrot Captions Teach CLIP to Spot Text”, Lin et al 2023
- “StarVector: Generating Scalable Vector Graphics Code from Images”, Rodriguez et al 2023
- “Vision-Language Models As a Source of Rewards”, Baumli et al 2023
- “Bad Students Make Great Teachers: Active Learning Accelerates Large-Scale Visual Understanding”, Evans et al 2023
- “ECLIPSE: A Resource-Efficient Text-To-Image Prior for Image Generations”, Patel et al 2023
- “Alpha-CLIP: A CLIP Model Focusing on Wherever You Want”, Sun et al 2023
- “Are Vision Transformers More Data Hungry Than Newborn Visual Systems?”, Pandey et al 2023
- “BioCLIP: A Vision Foundation Model for the Tree of Life”, Stevens et al 2023
- “Rethinking FID: Towards a Better Evaluation Metric for Image Generation”, Jayasumana et al 2023
- “SatCLIP: Global, General-Purpose Location Embeddings With Satellite Imagery”, Klemmer et al 2023
- “Test-Time Adaptation of Discriminative Models via Diffusion Generative Feedback”, Prabhudesai et al 2023
- “One-For-All: Towards Universal Domain Translation With a Single StyleGAN”, Du et al 2023
- “Does CLIP’s Generalization Performance Mainly Stem from High Train-Test Similarity?”, Mayilvahanan et al 2023
- “From Scarcity to Efficiency: Improving CLIP Training via Visual-Enriched Captions”, Lai et al 2023
- “LLaVA-1.5: Improved Baselines With Visual Instruction Tuning”, Liu et al 2023
- “Data Filtering Networks”, Fang et al 2023
- “Vision Transformers Need Registers”, Darcet et al 2023
- “Demystifying CLIP Data”, Xu et al 2023
- “Multimodal Neurons in Pretrained Text-Only Transformers”, Schwettmann et al 2023
- “Investigating the Existence of ‘Secret Language’ in Language Models”, Wang et al 2023
- “InternVid: A Large-Scale Video-Text Dataset for Multimodal Understanding and Generation”, Wang et al 2023
- “PIGEON: Predicting Image Geolocations”, Haas et al 2023
- “CLIPMasterPrints: Fooling Contrastive Language-Image Pre-Training Using Latent Variable Evolution”, Freiberger et al 2023
- “SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis”, Podell et al 2023
- “CLIPA-V2: Scaling CLIP Training With 81.1% Zero-Shot ImageNet Accuracy within a $10,000 Budget; An Extra $4,000 Unlocks 81.8% Accuracy”, Li et al 2023
- “SugarCrepe: Fixing Hackable Benchmarks for Vision-Language Compositionality”, Hsieh et al 2023
- “Anime Character Identification and Tag Prediction by Multimodality Modeling: Dataset and Model”, Yi et al 2023
- “ChessGPT: Bridging Policy Learning and Language Modeling”, Feng et al 2023
- “Rosetta Neurons: Mining the Common Units in a Model Zoo”, Dravid et al 2023
- “Image Captioners Are Scalable Vision Learners Too”, Tschannen et al 2023
- “Improving Neural Network Representations Using Human Similarity Judgments”, Muttenthaler et al 2023
- “Artificial Intelligence and Art: Identifying the Esthetic Judgment Factors That Distinguish Human & Machine-Generated Artwork”, Samo & Highhouse 2023
- “On Evaluating Adversarial Robustness of Large Vision-Language Models”, Zhao et al 2023
- “Generalizable Synthetic Image Detection via Language-Guided Contrastive Learning”, Wu et al 2023
- “TorToise: Better Speech Synthesis through Scaling”, Betker 2023
- “An Inverse Scaling Law for CLIP Training”, Li et al 2023
- “ImageBind: One Embedding Space To Bind Them All”, Girdhar et al 2023
- “Pick-A-Pic: An Open Dataset of User Preferences for Text-To-Image Generation”, Kirstain et al 2023
- “A Cookbook of Self-Supervised Learning”, Balestriero et al 2023
- “DINOv2: Learning Robust Visual Features without Supervision”, Oquab et al 2023
- “What Does CLIP Know about a Red Circle? Visual Prompt Engineering for VLMs”, Shtedritski et al 2023
- “ImageNet-Hard: The Hardest Images Remaining from a Study of the Power of Zoom and Spatial Biases in Image Classification”, Taesiri et al 2023
- “KD-DLGAN: Data Limited Image Generation via Knowledge Distillation”, Cui et al 2023
- “MaMMUT: A Simple Architecture for Joint Learning for MultiModal Tasks”, Kuo et al 2023
- “Sigmoid Loss for Language Image Pre-Training”, Zhai et al 2023
- “HiCLIP: Contrastive Language-Image Pretraining With Hierarchy-Aware Attention”, Geng et al 2023
- “When and Why Vision-Language Models Behave like Bags-Of-Words, and What to Do About It?”, Yuksekgonul et al 2023
- “Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning and Discovery”, Wen et al 2023
- “BLIP-2: Bootstrapping Language-Image Pre-Training With Frozen Image Encoders and Large Language Models”, Li et al 2023
- “MUG: Vision Learners Meet Web Image-Text Pairs”, Zhao et al 2023
- “Reaching 80% Zero-Shot Accuracy With OpenCLIP: VIT-G/14 Trained On LAION-2B”, Wortsman 2023
- “Reproducible Scaling Laws for Contrastive Language-Image Learning”, Cherti et al 2022
- “CLIP Itself Is a Strong Fine-Tuner: Achieving 85.7% and 88.0% Top-1 Accuracy With ViT-B and ViT-L on ImageNet”, Dong et al 2022
- “A Whack-A-Mole Dilemma: Shortcuts Come in Multiples Where Mitigating One Amplifies Others”, Li et al 2022
- “Scaling Language-Image Pre-Training via Masking”, Li et al 2022
- “Videogenic: Video Highlights via Photogenic Moments”, Lin et al 2022
- “Retrieval-Augmented Multimodal Language Modeling”, Yasunaga et al 2022
- “ClipCrop: Conditioned Cropping Driven by Vision-Language Model”, Zhong et al 2022
- “I Can’t Believe There’s No Images! Learning Visual Tasks Using Only Language Data”, Gu et al 2022
- “MaskDistill: A Unified View of Masked Image Modeling”, Anonymous 2022
- “Paella: Fast Text-Conditional Discrete Denoising on Vector-Quantized Latent Spaces”, Rampas et al 2022
- “AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities”, Chen et al 2022
- “EDiff-I: Text-To-Image Diffusion Models With an Ensemble of Expert Denoisers”, Balaji et al 2022
- “Text-Only Training for Image Captioning Using Noise-Injected CLIP”, Nukrai et al 2022
- “3DALL·E: Integrating Text-To-Image AI in 3D Design Workflows”, Liu et al 2022
- “Vision-Language Pre-Training: Basics, Recent Advances, and Future Trends”, Gan et al 2022
- “ASIF: Coupled Data Turns Unimodal Models to Multimodal Without Training”, Norelli et al 2022
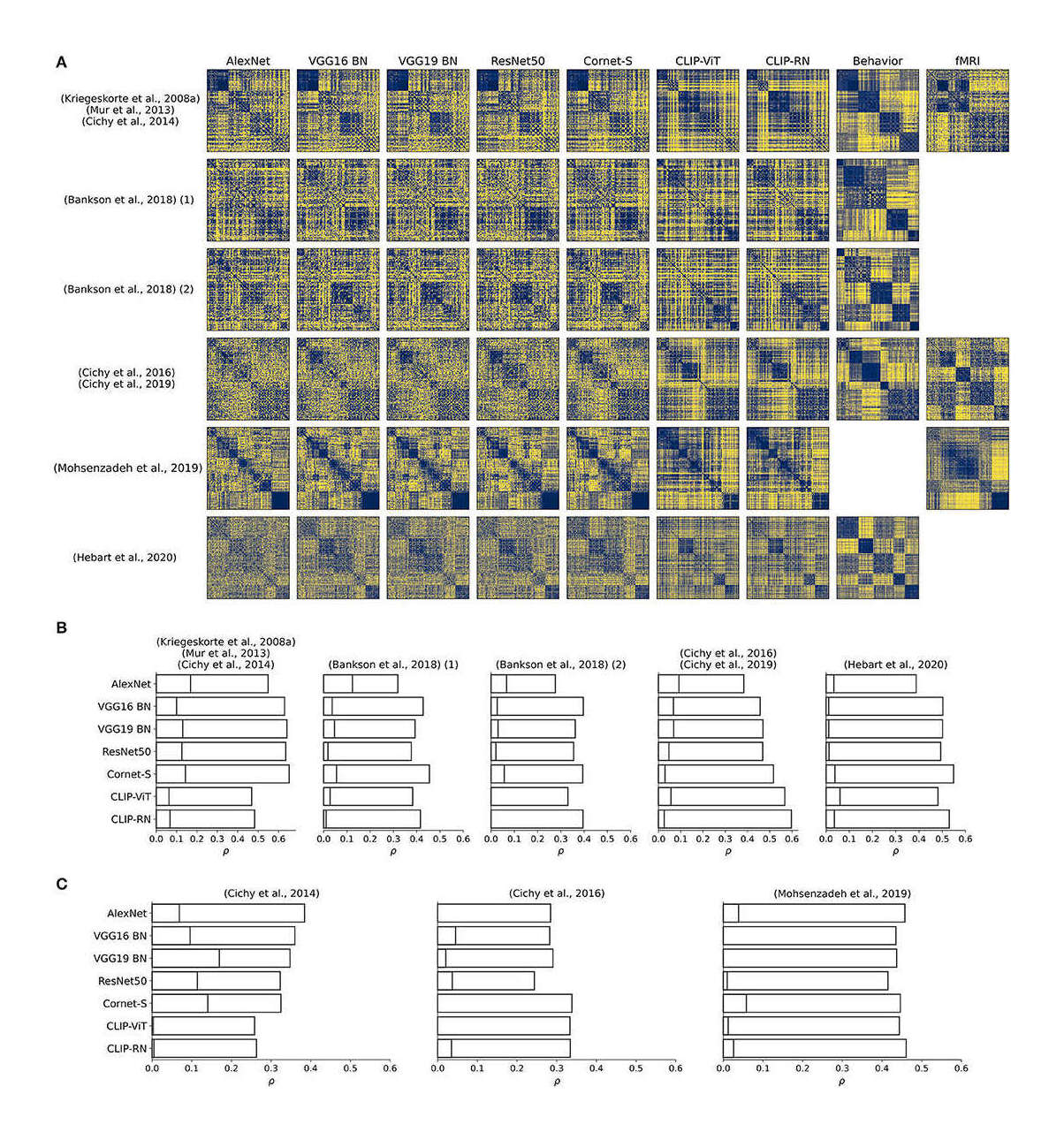
- “Incorporating Natural Language into Vision Models Improves Prediction and Understanding of Higher Visual Cortex”, Wang et al 2022
- “Do Androids Laugh at Electric Sheep? Humor "Understanding" Benchmarks from The New Yorker Caption Contest”, Hessel et al 2022
- “Fast Text2StyleGAN: Text-Free Learning of a Natural Language Interface for Pretrained Face Generators”, Du et al 2022
- “What Does a Platypus Look Like? Generating Customized Prompts for Zero-Shot Image Classification (CuPL)”, Pratt et al 2022
- “Efficient Vision-Language Pretraining With Visual Concepts and Hierarchical Alignment”, Shukor et al 2022
- “Decoding Speech from Non-Invasive Brain Recordings”, Défossez et al 2022
- “Quality Not Quantity: On the Interaction between Dataset Design and Robustness of CLIP”, Nguyen et al 2022
- “CLIP-Based Neural Neighbor Style Transfer for 3D Assets”, Mishra & Granskog 2022
- “EVL: Frozen CLIP Models Are Efficient Video Learners”, Lin et al 2022
- “X-CLIP: Expanding Language-Image Pretrained Models for General Video Recognition”, Ni et al 2022
- “LaTTe: Language Trajectory TransformEr”, Bucker et al 2022
- “Adversarial Attacks on Image Generation With Made-Up Words”, Millière 2022
- “TOnICS: Curriculum Learning for Data-Efficient Vision-Language Alignment”, Srinivasan et al 2022
- “MS-CLIP: Learning Visual Representation from Modality-Shared Contrastive Language-Image Pre-Training”, You et al 2022
- “Text-Guided Synthesis of Artistic Images With Retrieval-Augmented Diffusion Models”, Rombach et al 2022
- “NewsStories: Illustrating Articles With Visual Summaries”, Tan et al 2022
- “Semantic Abstraction (SemAbs): Open-World 3D Scene Understanding from 2D Vision-Language Models”, Ha & Song 2022
- “Don’t Stop Learning: Towards Continual Learning for the CLIP Model (VR-LwF)”, Ding et al 2022
- “X-CLIP: End-To-End Multi-Grained Contrastive Learning for Video-Text Retrieval”, Ma et al 2022
- “Is a Caption Worth a Thousand Images? A Controlled Study for Representation Learning”, Santurkar et al 2022
- “LM-Nav: Robotic Navigation With Large Pre-Trained Models of Language, Vision, and Action”, Shah et al 2022
- “CLAP: Learning Audio Concepts From Natural Language Supervision”, Elizalde et al 2022
- “ADAPT: Vision-Language Navigation With Modality-Aligned Action Prompts”, Lin et al 2022
- “Improved Vector Quantized Diffusion Models”, Tang et al 2022
- “CyCLIP: Cyclic Contrastive Language-Image Pretraining”, Goel et al 2022
- “Fine-Grained Image Captioning With CLIP Reward”, Cho et al 2022
- “VidIL: Language Models With Image Descriptors Are Strong Few-Shot Video-Language Learners”, Wang et al 2022
- “AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars”, Hong et al 2022
- “CoCa: Contrastive Captioners Are Image-Text Foundation Models”, Yu et al 2022
- “Data Determines Distributional Robustness in Contrastive Language Image Pre-Training (CLIP)”, Fang et al 2022
- “Retrieval-Augmented Diffusion Models: Semi-Parametric Neural Image Synthesis”, Blattmann et al 2022
- “Can Foundation Models Perform Zero-Shot Task Specification For Robot Manipulation?”, Cui et al 2022
- “Opal: Multimodal Image Generation for News Illustration”, Liu et al 2022
- “VQGAN-CLIP: Open Domain Image Generation and Editing With Natural Language Guidance”, Crowson et al 2022
- “DALL·E 2: Hierarchical Text-Conditional Image Generation With CLIP Latents § 7. Limitations and Risks”, Ramesh et al 2022 (page 16 org openai)
- “No Token Left Behind: Explainability-Aided Image Classification and Generation”, Paiss et al 2022
- “Semantic Exploration from Language Abstractions and Pretrained Representations”, Tam et al 2022
- “Winoground: Probing Vision and Language Models for Visio-Linguistic Compositionality”, Thrush et al 2022
- “Unified Contrastive Learning in Image-Text-Label Space”, Yang et al 2022
- “Socratic Models: Composing Zero-Shot Multimodal Reasoning With Language”, Zeng et al 2022
- “Learning to Generate Line Drawings That Convey Geometry and Semantics”, Chan et al 2022
- “CLIP Meets GamePhysics: Towards Bug Identification in Gameplay Videos Using Zero-Shot Transfer Learning”, Taesiri et al 2022
- “CLIP on Wheels (CoW): Zero-Shot Object Navigation As Object Localization and Exploration”, Gadre et al 2022
- “Bamboo: Building Mega-Scale Vision Dataset Continually With Human-Machine Synergy”, Zhang et al 2022
- “CLIP Models Are Few-Shot Learners: Empirical Studies on VQA and Visual Entailment”, Song et al 2022
- “Democratizing Contrastive Language-Image Pre-Training: A CLIP Benchmark of Data, Model, and Supervision”, Cui et al 2022
- “Model Soups: Averaging Weights of Multiple Fine-Tuned Models Improves Accuracy without Increasing Inference Time”, Wortsman et al 2022
- “The Unsurprising Effectiveness of Pre-Trained Vision Models for Control”, Parisi et al 2022
- “Unsupervised Vision-And-Language Pre-Training via Retrieval-Based Multi-Granular Alignment”, Zhou et al 2022
- “RuCLIP—New Models and Experiments: a Technical Report”, Shonenkov et al 2022
- “Wukong: 100 Million Large-Scale Chinese Cross-Modal Pre-Training Dataset and A Foundation Framework”, Gu et al 2022
- “CLIPasso: Semantically-Aware Object Sketching”, Vinker et al 2022
- “BLIP: Bootstrapping Language-Image Pre-Training for Unified Vision-Language Understanding and Generation”, Li et al 2022
- “Can Wikipedia Help Offline Reinforcement Learning?”, Reid et al 2022
- “SWAG: Revisiting Weakly Supervised Pre-Training of Visual Perception Models”, Singh et al 2022
- “CM3: A Causal Masked Multimodal Model of the Internet”, Aghajanyan et al 2022
- “LSeg: Language-Driven Semantic Segmentation”, Li et al 2022
- “Design Guidelines for Prompt Engineering Text-To-Image Generative Models”, Liu & Chilton 2022b
- “Detecting Twenty-Thousand Classes Using Image-Level Supervision”, Zhou et al 2022
- “A Fistful of Words: Learning Transferable Visual Models from Bag-Of-Words Supervision”, Tejankar et al 2021
- “High-Resolution Image Synthesis With Latent Diffusion Models”, Rombach et al 2021
- “RegionCLIP: Region-Based Language-Image Pretraining”, Zhong et al 2021
- “More Control for Free! Image Synthesis With Semantic Diffusion Guidance”, Liu et al 2021
- “CLIP2StyleGAN: Unsupervised Extraction of StyleGAN Edit Directions”, Abdal et al 2021
- “MAGMA—Multimodal Augmentation of Generative Models through Adapter-Based Finetuning”, Eichenberg et al 2021
- “DenseCLIP: Extract Free Dense Labels from CLIP”, Zhou et al 2021
- “Zero-Shot Text-Guided Object Generation With Dream Fields”, Jain et al 2021
- “FuseDream: Training-Free Text-To-Image Generation With Improved CLIP+GAN Space Optimization”, Liu et al 2021
- “MAD: A Scalable Dataset for Language Grounding in Videos from Movie Audio Descriptions”, Soldan et al 2021
- “CRIS: CLIP-Driven Referring Image Segmentation”, Wang et al 2021
- “Zero-Shot Image-To-Text Generation for Visual-Semantic Arithmetic”, Tewel et al 2021
- “Blended Diffusion for Text-Driven Editing of Natural Images”, Avrahami et al 2021
- “LAFITE: Towards Language-Free Training for Text-To-Image Generation”, Zhou et al 2021
- “Florence: A New Foundation Model for Computer Vision”, Yuan et al 2021
- “BASIC: Combined Scaling for Open-Vocabulary Image Classification”, Pham et al 2021
- “ClipCap: CLIP Prefix for Image Captioning”, Mokady et al 2021
- “Simple but Effective: CLIP Embeddings for Embodied AI”, Khandelwal et al 2021
- “INTERN: A New Learning Paradigm Towards General Vision”, Shao et al 2021
- “LiT: Zero-Shot Transfer With Locked-Image Text Tuning”, Zhai et al 2021
- “Tip-Adapter: Training-Free CLIP-Adapter for Better Vision-Language Modeling”, Zhang et al 2021
- “StyleCLIPDraw: Coupling Content and Style in Text-To-Drawing Synthesis”, Schaldenbrand et al 2021
- “LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs”, Schuhmann et al 2021
- “Projected GANs Converge Faster”, Sauer et al 2021
- “Telling Creative Stories Using Generative Visual Aids”, Ali & Parikh 2021
- “Image-Based CLIP-Guided Essence Transfer”, Chefer et al 2021
- “Wav2CLIP: Learning Robust Audio Representations From CLIP”, Wu et al 2021
- “No One Representation to Rule Them All: Overlapping Features of Training Methods”, Gontijo-Lopes et al 2021
- “Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-Training Paradigm (DeCLIP)”, Li et al 2021
- “CLIP-Forge: Towards Zero-Shot Text-To-Shape Generation”, Sanghi et al 2021
- “MA-CLIP: Towards Modality-Agnostic Contrastive Language-Image Pre-Training”, You et al 2021
- “OTTER: Data Efficient Language-Supervised Zero-Shot Recognition With Optimal Transport Distillation”, Wu et al 2021
- “DiffusionCLIP: Text-Guided Image Manipulation Using Diffusion Models”, Kim & Ye 2021
- “CLOOB: Modern Hopfield Networks With InfoLOOB Outperform CLIP”, Fürst et al 2021
- “VideoCLIP: Contrastive Pre-Training for Zero-Shot Video-Text Understanding”, Xu et al 2021
- “ZSD-YOLO: Zero-Shot YOLO Detection Using Vision-Language Knowledge Distillation”, Xie & Zheng 2021
- “CLIPort: What and Where Pathways for Robotic Manipulation”, Shridhar et al 2021
- “
THINGSvision: A Python Toolbox for Streamlining the Extraction of Activations From Deep Neural Networks”, Muttenthaler & Hebart 2021 - “Modern Evolution Strategies for Creativity: Fitting Concrete Images and Abstract Concepts”, Tian & Ha 2021
- “What Vision-Language Models ‘See’ When They See Scenes”, Cafagna et al 2021
- “EfficientCLIP: Efficient Cross-Modal Pre-Training by Ensemble Confident Learning and Language Modeling”, Wang et al 2021
- “Zero-Shot Open Set Detection by Extending CLIP”, Esmaeilpour et al 2021
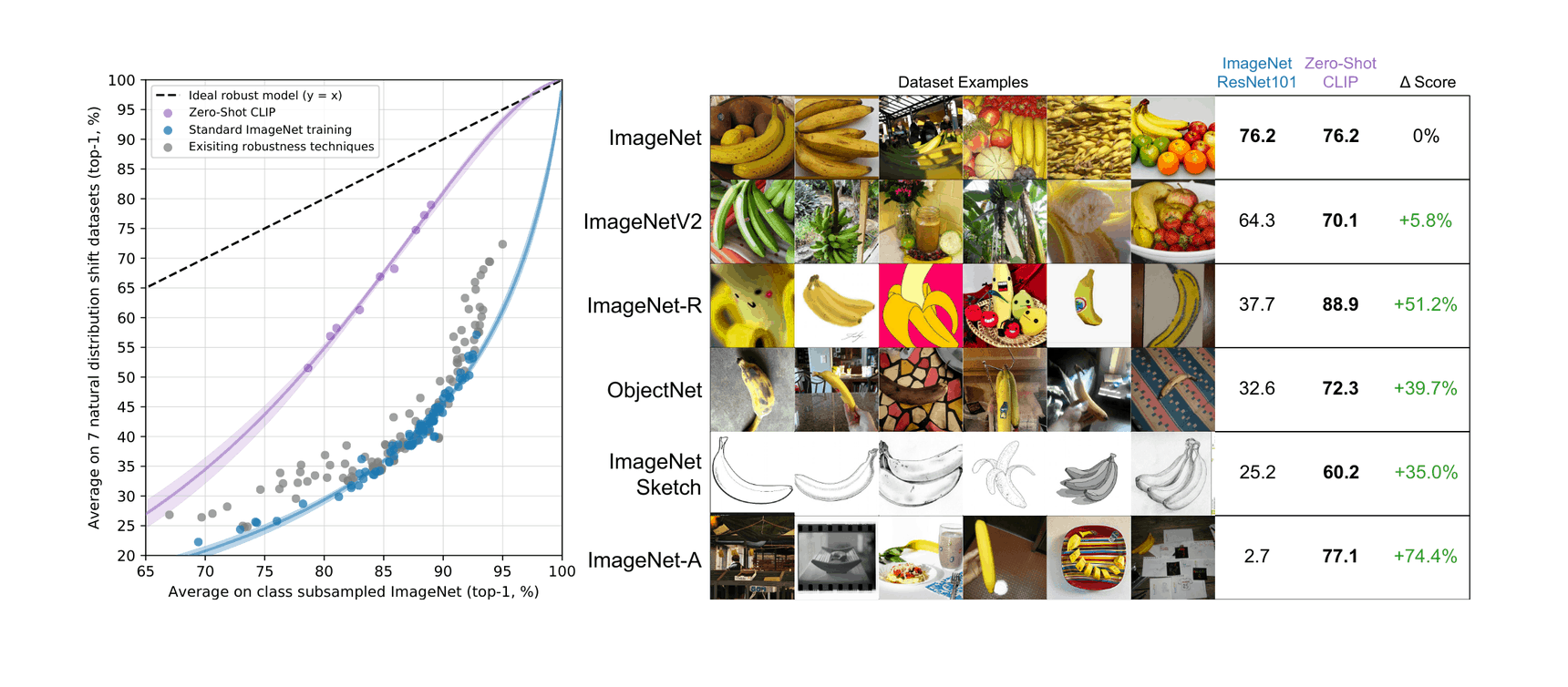
- “Robust Fine-Tuning of Zero-Shot Models”, Wortsman et al 2021
- “What Users Want? WARHOL: A Generative Model for Recommendation”, Samaran et al 2021
- “LAION-400-Million Open Dataset”, Schuhmann 2021
- “Contrastive Language-Image Pre-Training for the Italian Language”, Bianchi et al 2021
- “Evaluating CLIP: Towards Characterization of Broader Capabilities and Downstream Implications”, Agarwal et al 2021
- “StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators”, Gal et al 2021
- “Language Grounding With 3D Objects”, Thomason et al 2021
- “Segmentation in Style: Unsupervised Semantic Image Segmentation With StyleGAN and CLIP”, Pakhomov et al 2021
- “How Much Can CLIP Benefit Vision-And-Language Tasks?”, Shen et al 2021
- “FairyTailor: A Multimodal Generative Framework for Storytelling”, Bensaid et al 2021
- “CLIP-It! Language-Guided Video Summarization”, Narasimhan et al 2021
- “Small In-Distribution Changes in 3D Perspective and Lighting Fool Both CNNs and Transformers”, Madan et al 2021
- “CLIPDraw: Exploring Text-To-Drawing Synthesis through Language-Image Encoders”, Frans et al 2021
- “AudioCLIP: Extending CLIP to Image, Text and Audio”, Guzhov et al 2021
- “CLIP2Video: Mastering Video-Text Retrieval via Image CLIP”, Fang et al 2021
- “A Fair and Comprehensive Comparison of Multimodal Tweet Sentiment Analysis Methods”, Cheema et al 2021
- “Partial Success in Closing the Gap between Human and Machine Vision”, Geirhos et al 2021
- “ImaginE: An Imagination-Based Automatic Evaluation Metric for Natural Language Generation”, Zhu et al 2021
- “Exploring the Limits of Out-Of-Distribution Detection”, Fort et al 2021
- “Chinese AI Lab Challenges Google, OpenAI With a Model of 1.75 Trillion Parameters”, Du 2021
- “Generative Art Using Neural Visual Grammars and Dual Encoders”, Fernando et al 2021
- “Zero-Shot Detection via Vision and Language Knowledge Distillation”, Gu et al 2021
- “CLIPScore: A Reference-Free Evaluation Metric for Image Captioning”, Hessel et al 2021
- “Data-Efficient Language-Supervised Zero-Shot Learning With Self-Distillation”, Cheng et al 2021
- “Paint by Word”, Bau et al 2021
- “WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training”, Huo et al 2021
- “Multimodal Neurons in Artificial Neural Networks [CLIP]”, Goh et al 2021
- “Zero-Shot Text-To-Image Generation”, Ramesh et al 2021
- “ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision”, Jia et al 2021
- “Generating Images from Caption and vice Versa via CLIP-Guided Generative Latent Space Search”, Galatolo et al 2021
- “Decoupling the Role of Data, Attention, and Losses in Multimodal Transformers”, Hendricks et al 2021
- “Scoring Images from TADNE With CLIP”, nagolinc 2021
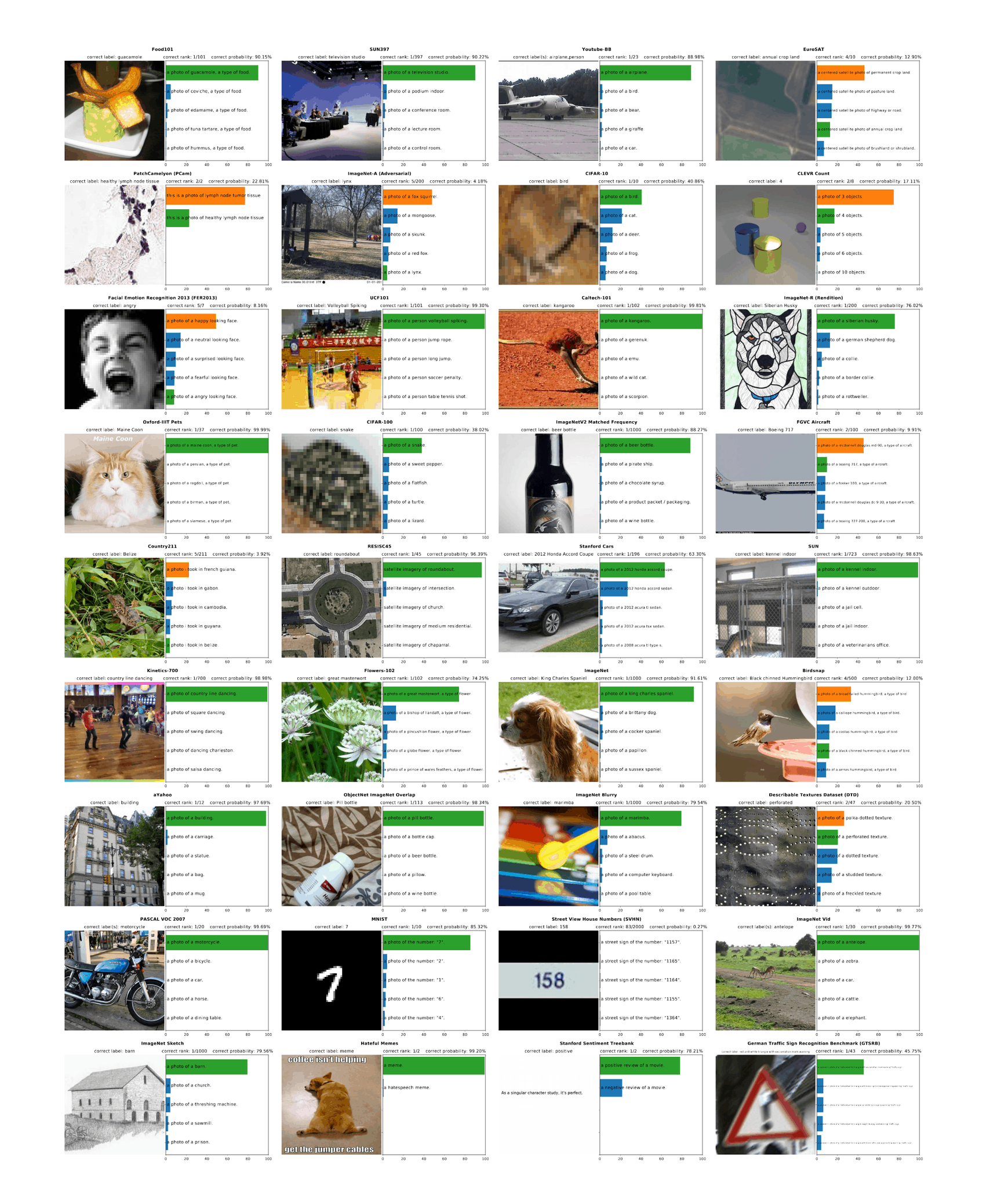
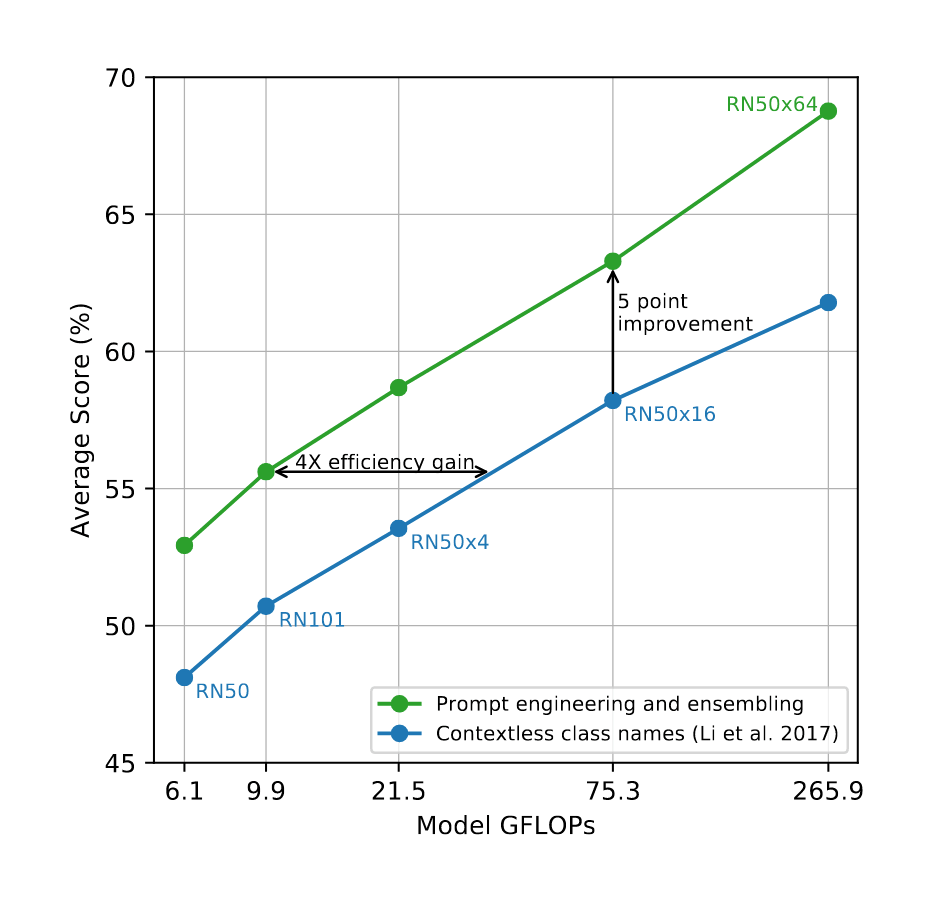
- “CLIP: Learning Transferable Visual Models From Natural Language Supervision”, Radford et al 2021
- “CLIP: Connecting Text and Images: We’re Introducing a Neural Network Called CLIP Which Efficiently Learns Visual Concepts from Natural Language Supervision. CLIP Can Be Applied to Any Visual Classification Benchmark by Simply Providing the Names of the Visual Categories to Be Recognized, Similar to the ‘Zero-Shot’ Capabilities of GPT-2 and GPT-3”, Radford et al 2021
- “DALL·E 1: Creating Images from Text: We’ve Trained a Neural Network Called DALL·E That Creates Images from Text Captions for a Wide Range of Concepts Expressible in Natural Language”, Ramesh et al 2021
- “Transformers in Vision: A Survey”, Khan et al 2021
- “Vision Transformer: An Image Is Worth 16×16 Words: Transformers for Image Recognition at Scale”, Dosovitskiy et al 2020
- “M3P: Learning Universal Representations via Multitask Multilingual Multimodal Pre-Training”, Ni et al 2020
- “Learning to Scale Multilingual Representations for Vision-Language Tasks”, Burns et al 2020
- “The Messy, Secretive Reality behind OpenAI’s Bid to save the World: The AI Moonshot Was Founded in the Spirit of Transparency. This Is the inside Story of How Competitive Pressure Eroded That Idealism”, Hao 2020
- “MULE: Multimodal Universal Language Embedding”, Kim et al 2019
- “What A Long, Strange Trip It’s Been: EleutherAI One Year Retrospective”
- “CLIP: Zero-Shot Jack of All Trades”
- “This Anime Does Not Exist, Search: This Notebook Uses the Precomputed CLIP Feature Vectors for 100k Images from TADNE”
- “CLIPIT PixelDraw Demo”
- “Vqgan-Clip/notebooks”
- “Combination of OpenAI GLIDE and Latent Diffusion”
- “LAION-AI/laion-Datasets”
- “Anima-Style-Explorer: Anima 2B Style Explorer—A Fast, Visual Reference Library for 20,000+ Artist Styles Optimized for the Anima 2B Model and Danbooru Tagging System”, ThetaCursed 2026
- “CLIP Implementation for Russian Language”
- “Christophschuhmann/4MC-4M-Image-Text-Pairs-With-CLIP-Embeddings: I Have Created a Dataset of Image-Text-Pairs by Using the Cosine Similarity of the CLIP Embeddings of the Image & Its Caption Derrived from YFCC100M. I Have Also Added Probabilities from a NSFW Detector & More”
- “CLIP (Contrastive Language–Image Pre-Training) for Italian”
- “Crowsonkb/simulacra-Aesthetic-Models”
- “RWKV-CLIP: A Robust Vision-Language Representation Learner”
- “Neural Image Generation”
- “An Open Source Implementation of CLIP”
- “CLIP/data/yfcc100m.md”
- “StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery”
- “Clustering-Laion400m: Script and Models for Clustering LAION-400m CLIP Embeddings. Models Were Fit on the First Million or so Image Embeddings.”
- “Rinongal/StyleGAN-Nada”
- “Simple Image Captioning Model”
- “Robgon-Art/CLIPandPASTE: CLIP and PASTE: Using AI to Create Photo Collages from Text Prompts”
- “
sam2_hierarch: Unsupervised Human-Friendly Online Object Categorization”, UtilityHotbar 2026 - “AI-Powered Command-Line Photo Search Tool”
- “Kaichengalex/YFCC15M”
- “Alien Dreams: An Emerging Art Scene”
- “The Bouba/Kiki Effect And Sound Symbolism In CLIP”
- “Image Captioning”
- “Same Energy”
- “Guidance: a Cheat Code for Diffusion Models”
- “Pixels Still Beat Text: Attacking the OpenAI CLIP Model With Text Patches and Adversarial Pixel Perturbations”
- “Case Study: Interpreting, Manipulating, and Controlling CLIP With Sparse Autoencoders”
- “[P] List of Sites/programs/projects That Use OpenAI’s CLIP Neural Network for Steering Image/video Creation to Match a Text Description”
- “Writing Good VQGAN+CLIP Prompts Part One – Basic Prompts and Style Modifiers”
- “Writing Good VQGAN+CLIP Prompts Part Two – Artist and Genre Modifiers”
- “Writing Good VQGAN+CLIP Prompts Part Three – Environmental Modifiers”
- “New AI Tools CLIP+VQ-GAN Can Create Impressive Works of Art Based on Just a Few Words of Input”
- “Apple or IPod? Easy Fix for Adversarial Textual Attacks on OpenAI’s CLIP Model!”
- “Autoresearch on an Old Research Idea”
- Sort By Magic
- Miscellaneous
- Bibliography
See Also
Gwern
“Utext: Rich Unicode Documents”, Gwern 2023
Links
“Anime-2026: A Large-Scale Anime Character Dataset for Anime-Related AI Tasks”, Xuyang et al 2026
Anime-2026: A Large-scale Anime Character Dataset for Anime-related AI Tasks
“Vec2vec: Harnessing the Universal Geometry of Embeddings”, Jha et al 2025
“Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment”, Thasarathan et al 2025
Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment
“LLMs Can See and Hear without Any Training”, Ashutosh et al 2025
“Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps”, Ma et al 2025
Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps
“PaliGemma 2: A Family of Versatile VLMs for Transfer”, Steiner et al 2024
“CT Foundation: Taking Medical Imaging Embeddings 3D”, Kiraly & Traverse 2024
“Ensemble Everything Everywhere: Multi-Scale Aggregation for Adversarial Robustness”, Fort & Lakshminarayanan 2024
Ensemble everything everywhere: Multi-scale aggregation for adversarial robustness
“Scaling Law in Neural Data: Non-Invasive Speech Decoding With 175 Hours of EEG Data”, Sato et al 2024
Scaling Law in Neural Data: Non-Invasive Speech Decoding with 175 Hours of EEG Data
“Explore the Limits of Omni-Modal Pretraining at Scale”, Zhang et al 2024
“RWKV-CLIP: A Robust Vision-Language Representation Learner”, Gu et al 2024
“Sakuga-42M Dataset: Scaling Up Cartoon Research”, Pan et al 2024
“ImageInWords: Unlocking Hyper-Detailed Image Descriptions”, Garg et al 2024
“CatLIP: CLIP-Level Visual Recognition Accuracy With 2.7× Faster Pre-Training on Web-Scale Image-Text Data”, Mehta et al 2024
“Towards Generated Image Provenance Analysis Via Conceptual-Similar-Guided-SLIP Retrieval”, Xia et al 2024
Towards Generated Image Provenance Analysis Via Conceptual-Similar-Guided-SLIP Retrieval
“Scaling (Down) CLIP: A Comprehensive Analysis of Data, Architecture, and Training Strategies”, Li et al 2024
Scaling (Down) CLIP: A Comprehensive Analysis of Data, Architecture, and Training Strategies
“Evaluating Text-To-Visual Generation With Image-To-Text Generation”, Lin et al 2024
Evaluating Text-to-Visual Generation with Image-to-Text Generation
“TextCraftor: Your Text Encoder Can Be Image Quality Controller”, Li et al 2024
TextCraftor: Your Text Encoder Can be Image Quality Controller
“MM1: Methods, Analysis & Insights from Multimodal LLM Pre-Training”, McKinzie et al 2024
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
“Discovering Universal Semantic Triggers for Text-To-Image Synthesis”, Zhai et al 2024
Discovering Universal Semantic Triggers for Text-to-Image Synthesis
“Grounded Language Acquisition through the Eyes and Ears of a Single Child”, Vong et al 2024
Grounded language acquisition through the eyes and ears of a single child
“TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones”, Yuan et al 2023
TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones
“Parrot Captions Teach CLIP to Spot Text”, Lin et al 2023
“StarVector: Generating Scalable Vector Graphics Code from Images”, Rodriguez et al 2023
StarVector: Generating Scalable Vector Graphics Code from Images
“Vision-Language Models As a Source of Rewards”, Baumli et al 2023
“Bad Students Make Great Teachers: Active Learning Accelerates Large-Scale Visual Understanding”, Evans et al 2023
Bad Students Make Great Teachers: Active Learning Accelerates Large-Scale Visual Understanding
“ECLIPSE: A Resource-Efficient Text-To-Image Prior for Image Generations”, Patel et al 2023
ECLIPSE: A Resource-Efficient Text-to-Image Prior for Image Generations
“Alpha-CLIP: A CLIP Model Focusing on Wherever You Want”, Sun et al 2023
“Are Vision Transformers More Data Hungry Than Newborn Visual Systems?”, Pandey et al 2023
Are Vision Transformers More Data Hungry Than Newborn Visual Systems?
“BioCLIP: A Vision Foundation Model for the Tree of Life”, Stevens et al 2023
“Rethinking FID: Towards a Better Evaluation Metric for Image Generation”, Jayasumana et al 2023
Rethinking FID: Towards a Better Evaluation Metric for Image Generation
“SatCLIP: Global, General-Purpose Location Embeddings With Satellite Imagery”, Klemmer et al 2023
SatCLIP: Global, General-Purpose Location Embeddings with Satellite Imagery
“Test-Time Adaptation of Discriminative Models via Diffusion Generative Feedback”, Prabhudesai et al 2023
Test-time Adaptation of Discriminative Models via Diffusion Generative Feedback
“One-For-All: Towards Universal Domain Translation With a Single StyleGAN”, Du et al 2023
One-for-All: Towards Universal Domain Translation with a Single StyleGAN
“Does CLIP’s Generalization Performance Mainly Stem from High Train-Test Similarity?”, Mayilvahanan et al 2023
Does CLIP’s Generalization Performance Mainly Stem from High Train-Test Similarity?
“From Scarcity to Efficiency: Improving CLIP Training via Visual-Enriched Captions”, Lai et al 2023
From Scarcity to Efficiency: Improving CLIP Training via Visual-enriched Captions
“LLaVA-1.5: Improved Baselines With Visual Instruction Tuning”, Liu et al 2023
LLaVA-1.5: Improved Baselines with Visual Instruction Tuning
“Data Filtering Networks”, Fang et al 2023
“Vision Transformers Need Registers”, Darcet et al 2023
“Demystifying CLIP Data”, Xu et al 2023
“Multimodal Neurons in Pretrained Text-Only Transformers”, Schwettmann et al 2023
“Investigating the Existence of ‘Secret Language’ in Language Models”, Wang et al 2023
Investigating the Existence of ‘Secret Language’ in Language Models
“InternVid: A Large-Scale Video-Text Dataset for Multimodal Understanding and Generation”, Wang et al 2023
InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation
“PIGEON: Predicting Image Geolocations”, Haas et al 2023
“CLIPMasterPrints: Fooling Contrastive Language-Image Pre-Training Using Latent Variable Evolution”, Freiberger et al 2023
CLIPMasterPrints: Fooling Contrastive Language-Image Pre-training Using Latent Variable Evolution
“SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis”, Podell et al 2023
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
“CLIPA-V2: Scaling CLIP Training With 81.1% Zero-Shot ImageNet Accuracy within a $10,000 Budget; An Extra $4,000 Unlocks 81.8% Accuracy”, Li et al 2023
“SugarCrepe: Fixing Hackable Benchmarks for Vision-Language Compositionality”, Hsieh et al 2023
SugarCrepe: Fixing Hackable Benchmarks for Vision-Language Compositionality
“Anime Character Identification and Tag Prediction by Multimodality Modeling: Dataset and Model”, Yi et al 2023
Anime Character Identification and Tag Prediction by Multimodality Modeling: Dataset and Model
“ChessGPT: Bridging Policy Learning and Language Modeling”, Feng et al 2023
“Rosetta Neurons: Mining the Common Units in a Model Zoo”, Dravid et al 2023
“Image Captioners Are Scalable Vision Learners Too”, Tschannen et al 2023
“Improving Neural Network Representations Using Human Similarity Judgments”, Muttenthaler et al 2023
Improving neural network representations using human similarity judgments
“Artificial Intelligence and Art: Identifying the Esthetic Judgment Factors That Distinguish Human & Machine-Generated Artwork”, Samo & Highhouse 2023
“On Evaluating Adversarial Robustness of Large Vision-Language Models”, Zhao et al 2023
On Evaluating Adversarial Robustness of Large Vision-Language Models
“Generalizable Synthetic Image Detection via Language-Guided Contrastive Learning”, Wu et al 2023
Generalizable Synthetic Image Detection via Language-guided Contrastive Learning
“TorToise: Better Speech Synthesis through Scaling”, Betker 2023
“An Inverse Scaling Law for CLIP Training”, Li et al 2023
“ImageBind: One Embedding Space To Bind Them All”, Girdhar et al 2023
“Pick-A-Pic: An Open Dataset of User Preferences for Text-To-Image Generation”, Kirstain et al 2023
Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation
“A Cookbook of Self-Supervised Learning”, Balestriero et al 2023
“DINOv2: Learning Robust Visual Features without Supervision”, Oquab et al 2023
“What Does CLIP Know about a Red Circle? Visual Prompt Engineering for VLMs”, Shtedritski et al 2023
What does CLIP know about a red circle? Visual prompt engineering for VLMs
“ImageNet-Hard: The Hardest Images Remaining from a Study of the Power of Zoom and Spatial Biases in Image Classification”, Taesiri et al 2023
“KD-DLGAN: Data Limited Image Generation via Knowledge Distillation”, Cui et al 2023
KD-DLGAN: Data Limited Image Generation via Knowledge Distillation
“MaMMUT: A Simple Architecture for Joint Learning for MultiModal Tasks”, Kuo et al 2023
MaMMUT: A Simple Architecture for Joint Learning for MultiModal Tasks
“Sigmoid Loss for Language Image Pre-Training”, Zhai et al 2023
“HiCLIP: Contrastive Language-Image Pretraining With Hierarchy-Aware Attention”, Geng et al 2023
HiCLIP: Contrastive Language-Image Pretraining with Hierarchy-aware Attention
“When and Why Vision-Language Models Behave like Bags-Of-Words, and What to Do About It?”, Yuksekgonul et al 2023
When and Why Vision-Language Models Behave like Bags-Of-Words, and What to Do About It?
“Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning and Discovery”, Wen et al 2023
Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning and Discovery
“BLIP-2: Bootstrapping Language-Image Pre-Training With Frozen Image Encoders and Large Language Models”, Li et al 2023
“MUG: Vision Learners Meet Web Image-Text Pairs”, Zhao et al 2023
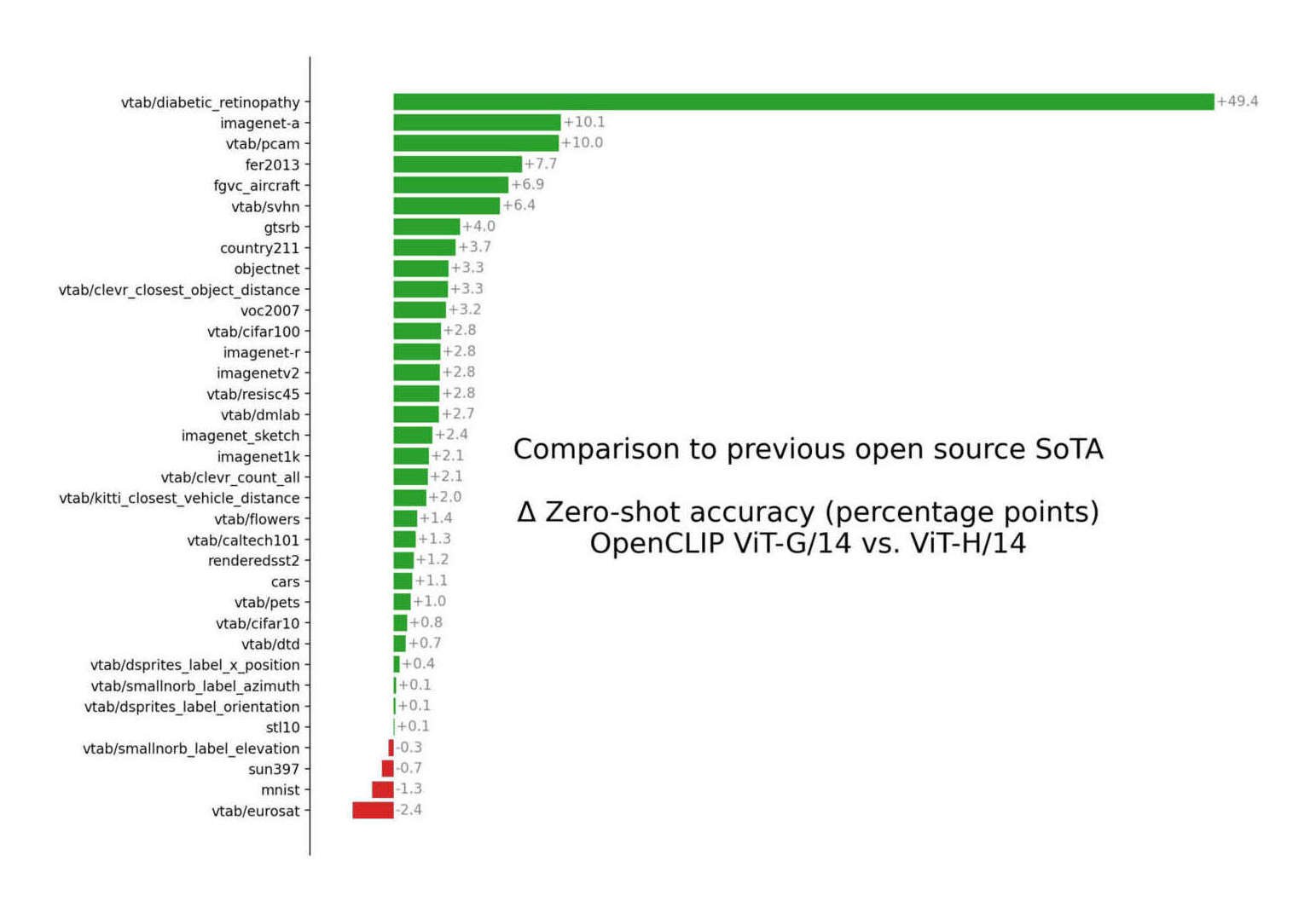
“Reaching 80% Zero-Shot Accuracy With OpenCLIP: VIT-G/14 Trained On LAION-2B”, Wortsman 2023
Reaching 80% Zero-Shot Accuracy With OpenCLIP: VIT-G/14 Trained On LAION-2B
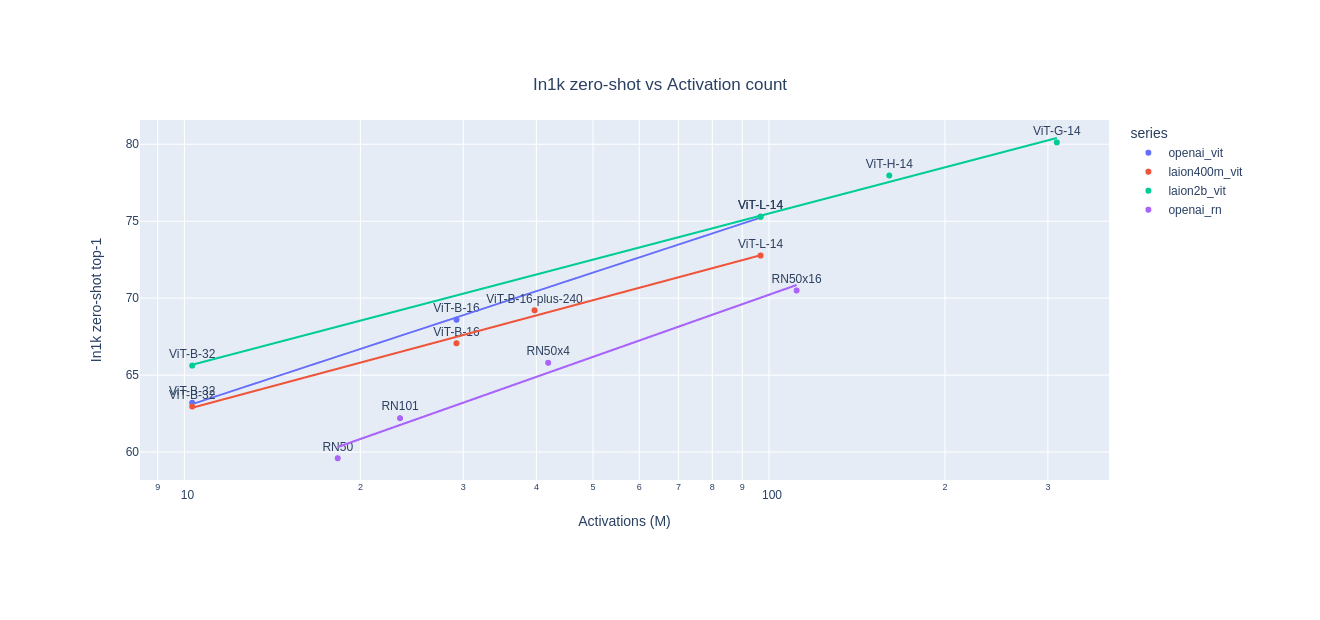
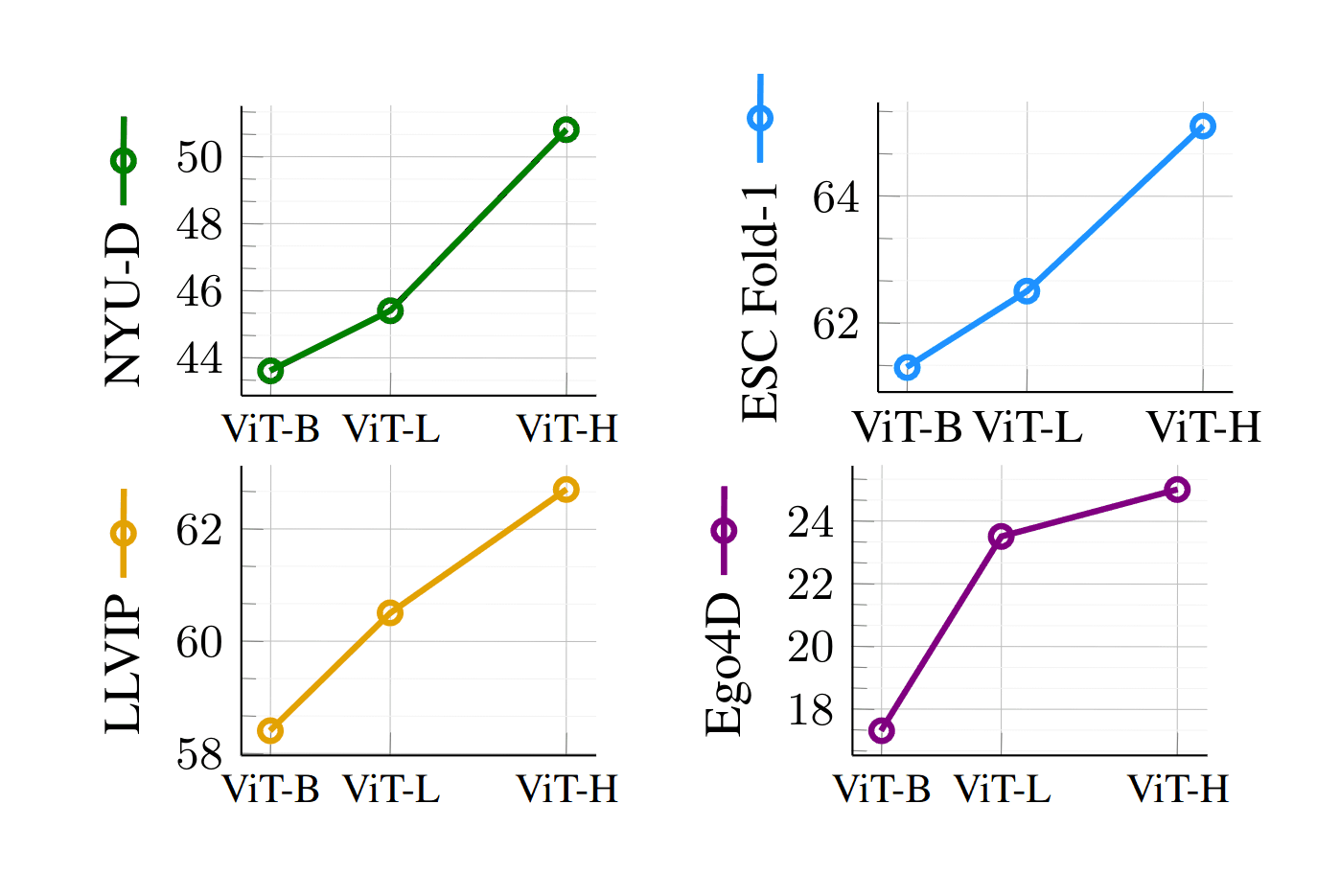
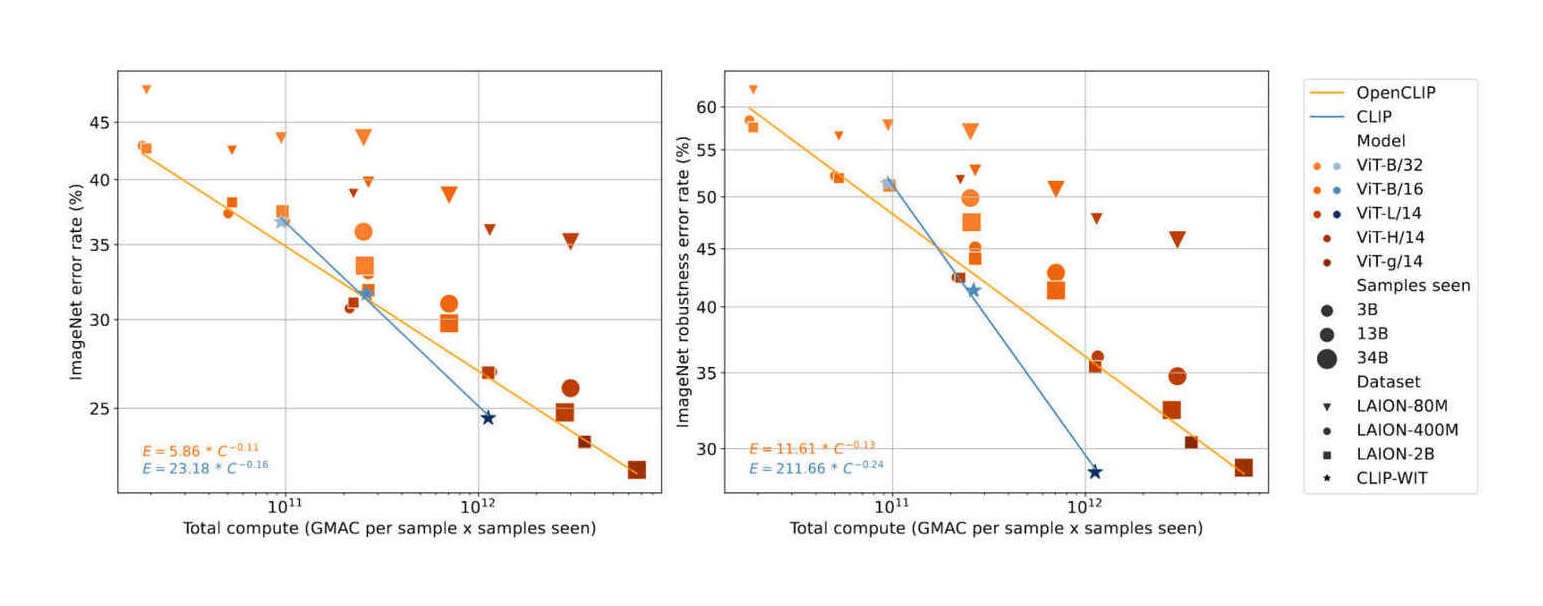
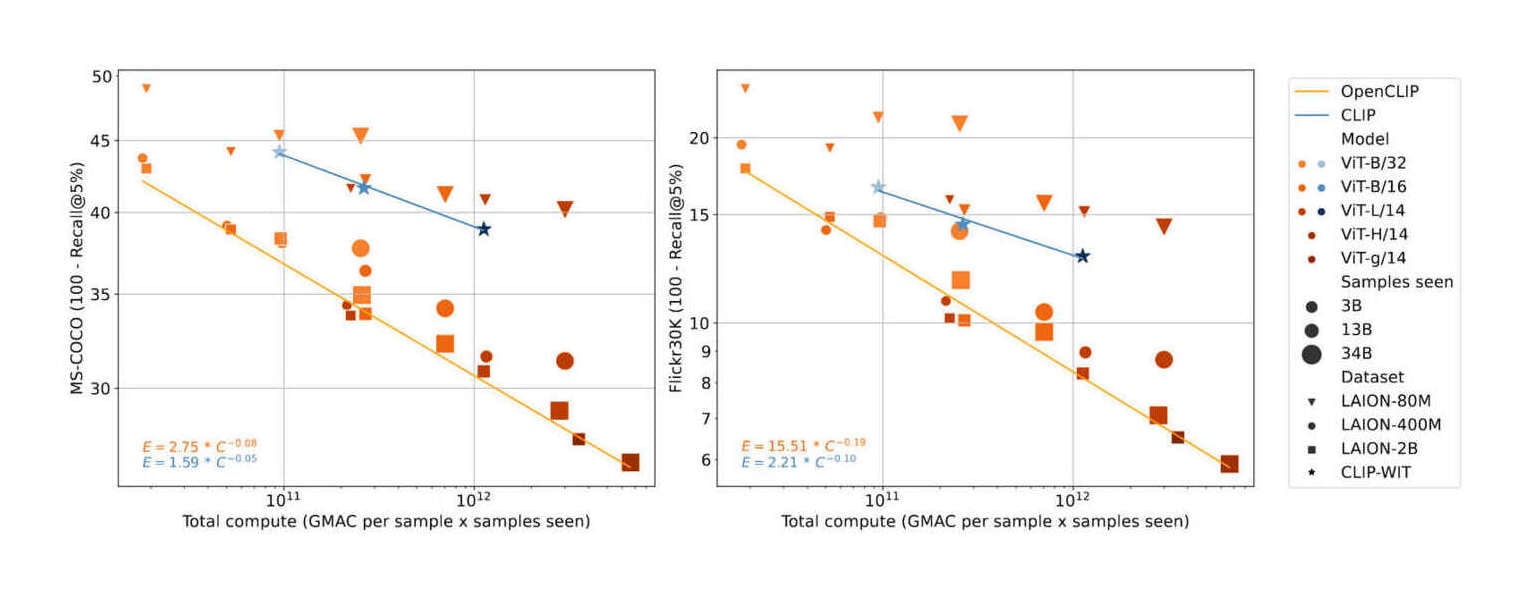
“Reproducible Scaling Laws for Contrastive Language-Image Learning”, Cherti et al 2022
Reproducible scaling laws for contrastive language-image learning
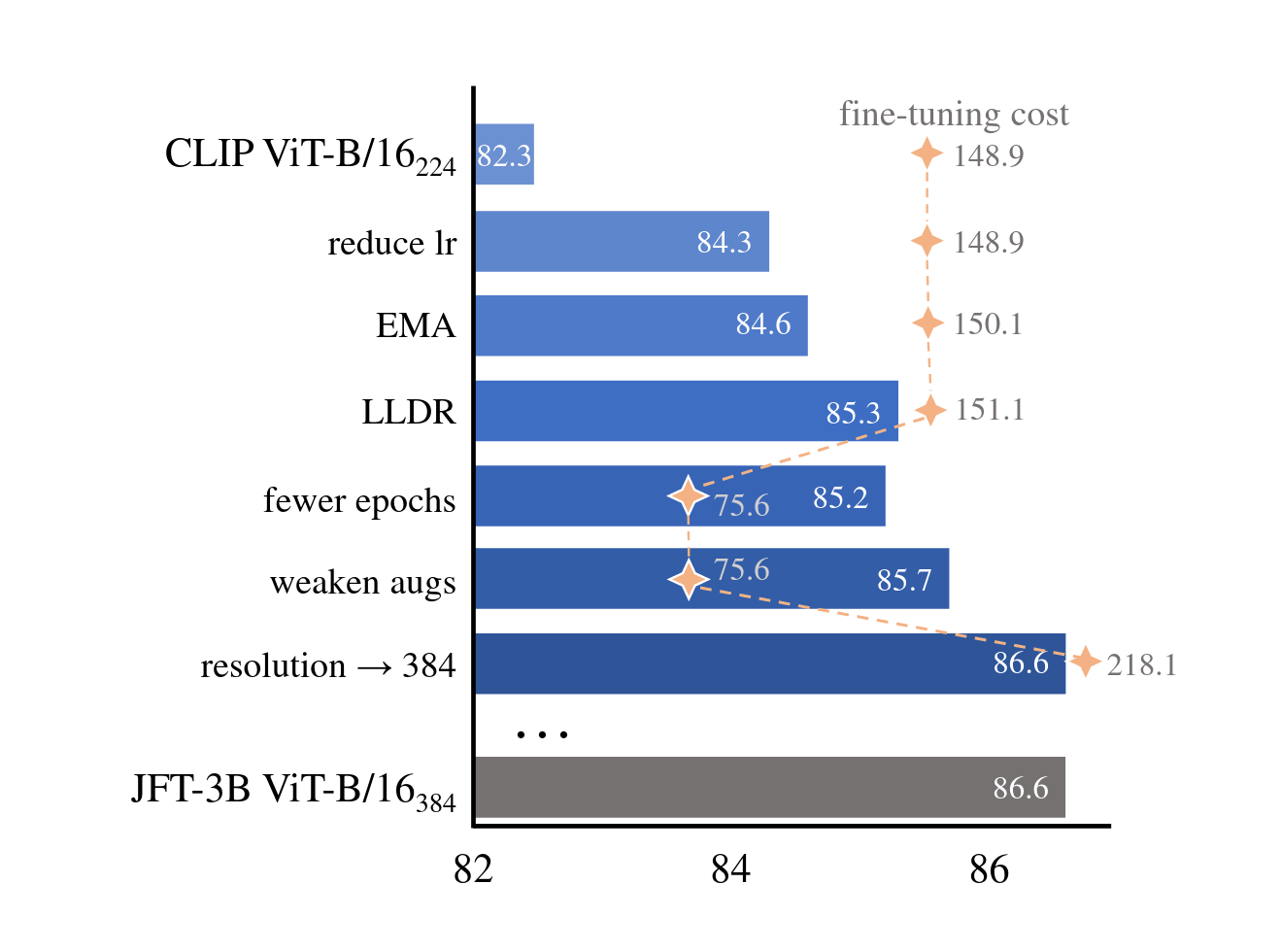
“CLIP Itself Is a Strong Fine-Tuner: Achieving 85.7% and 88.0% Top-1 Accuracy With ViT-B and ViT-L on ImageNet”, Dong et al 2022
“A Whack-A-Mole Dilemma: Shortcuts Come in Multiples Where Mitigating One Amplifies Others”, Li et al 2022
A Whack-A-Mole Dilemma: Shortcuts Come in Multiples Where Mitigating One Amplifies Others
“Scaling Language-Image Pre-Training via Masking”, Li et al 2022
“Videogenic: Video Highlights via Photogenic Moments”, Lin et al 2022
“Retrieval-Augmented Multimodal Language Modeling”, Yasunaga et al 2022
“ClipCrop: Conditioned Cropping Driven by Vision-Language Model”, Zhong et al 2022
ClipCrop: Conditioned Cropping Driven by Vision-Language Model
“I Can’t Believe There’s No Images! Learning Visual Tasks Using Only Language Data”, Gu et al 2022
I Can’t Believe There’s No Images! Learning Visual Tasks Using only Language Data
“MaskDistill: A Unified View of Masked Image Modeling”, Anonymous 2022
“Paella: Fast Text-Conditional Discrete Denoising on Vector-Quantized Latent Spaces”, Rampas et al 2022
Paella: Fast Text-Conditional Discrete Denoising on Vector-Quantized Latent Spaces
“AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities”, Chen et al 2022
AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities
“EDiff-I: Text-To-Image Diffusion Models With an Ensemble of Expert Denoisers”, Balaji et al 2022
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
“Text-Only Training for Image Captioning Using Noise-Injected CLIP”, Nukrai et al 2022
Text-Only Training for Image Captioning using Noise-Injected CLIP
“3DALL·E: Integrating Text-To-Image AI in 3D Design Workflows”, Liu et al 2022
3DALL·E: Integrating Text-to-Image AI in 3D Design Workflows
“Vision-Language Pre-Training: Basics, Recent Advances, and Future Trends”, Gan et al 2022
Vision-Language Pre-training: Basics, Recent Advances, and Future Trends
“ASIF: Coupled Data Turns Unimodal Models to Multimodal Without Training”, Norelli et al 2022
ASIF: Coupled Data Turns Unimodal Models to Multimodal Without Training
“Incorporating Natural Language into Vision Models Improves Prediction and Understanding of Higher Visual Cortex”, Wang et al 2022
“Do Androids Laugh at Electric Sheep? Humor "Understanding" Benchmarks from The New Yorker Caption Contest”, Hessel et al 2022
“Fast Text2StyleGAN: Text-Free Learning of a Natural Language Interface for Pretrained Face Generators”, Du et al 2022
“What Does a Platypus Look Like? Generating Customized Prompts for Zero-Shot Image Classification (CuPL)”, Pratt et al 2022
“Efficient Vision-Language Pretraining With Visual Concepts and Hierarchical Alignment”, Shukor et al 2022
Efficient Vision-Language Pretraining with Visual Concepts and Hierarchical Alignment
“Decoding Speech from Non-Invasive Brain Recordings”, Défossez et al 2022
“Quality Not Quantity: On the Interaction between Dataset Design and Robustness of CLIP”, Nguyen et al 2022
Quality Not Quantity: On the Interaction between Dataset Design and Robustness of CLIP
“CLIP-Based Neural Neighbor Style Transfer for 3D Assets”, Mishra & Granskog 2022
“EVL: Frozen CLIP Models Are Efficient Video Learners”, Lin et al 2022
“X-CLIP: Expanding Language-Image Pretrained Models for General Video Recognition”, Ni et al 2022
X-CLIP: Expanding Language-Image Pretrained Models for General Video Recognition
“LaTTe: Language Trajectory TransformEr”, Bucker et al 2022
“Adversarial Attacks on Image Generation With Made-Up Words”, Millière 2022
“TOnICS: Curriculum Learning for Data-Efficient Vision-Language Alignment”, Srinivasan et al 2022
TOnICS: Curriculum Learning for Data-Efficient Vision-Language Alignment
“MS-CLIP: Learning Visual Representation from Modality-Shared Contrastive Language-Image Pre-Training”, You et al 2022
MS-CLIP: Learning Visual Representation from Modality-Shared Contrastive Language-Image Pre-training
“Text-Guided Synthesis of Artistic Images With Retrieval-Augmented Diffusion Models”, Rombach et al 2022
Text-Guided Synthesis of Artistic Images with Retrieval-Augmented Diffusion Models
“NewsStories: Illustrating Articles With Visual Summaries”, Tan et al 2022
“Semantic Abstraction (SemAbs): Open-World 3D Scene Understanding from 2D Vision-Language Models”, Ha & Song 2022
Semantic Abstraction (SemAbs): Open-World 3D Scene Understanding from 2D Vision-Language Models
“Don’t Stop Learning: Towards Continual Learning for the CLIP Model (VR-LwF)”, Ding et al 2022
Don’t Stop Learning: Towards Continual Learning for the CLIP Model (VR-LwF)
“X-CLIP: End-To-End Multi-Grained Contrastive Learning for Video-Text Retrieval”, Ma et al 2022
X-CLIP: End-to-End Multi-grained Contrastive Learning for Video-Text Retrieval
“Is a Caption Worth a Thousand Images? A Controlled Study for Representation Learning”, Santurkar et al 2022
Is a Caption Worth a Thousand Images? A Controlled Study for Representation Learning
“LM-Nav: Robotic Navigation With Large Pre-Trained Models of Language, Vision, and Action”, Shah et al 2022
LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action
“CLAP: Learning Audio Concepts From Natural Language Supervision”, Elizalde et al 2022
CLAP: Learning Audio Concepts From Natural Language Supervision
“ADAPT: Vision-Language Navigation With Modality-Aligned Action Prompts”, Lin et al 2022
ADAPT: Vision-Language Navigation with Modality-Aligned Action Prompts
“Improved Vector Quantized Diffusion Models”, Tang et al 2022
“CyCLIP: Cyclic Contrastive Language-Image Pretraining”, Goel et al 2022
“Fine-Grained Image Captioning With CLIP Reward”, Cho et al 2022
“VidIL: Language Models With Image Descriptors Are Strong Few-Shot Video-Language Learners”, Wang et al 2022
VidIL: Language Models with Image Descriptors are Strong Few-Shot Video-Language Learners
“AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars”, Hong et al 2022
AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars
“CoCa: Contrastive Captioners Are Image-Text Foundation Models”, Yu et al 2022
CoCa: Contrastive Captioners are Image-Text Foundation Models
“Data Determines Distributional Robustness in Contrastive Language Image Pre-Training (CLIP)”, Fang et al 2022
Data Determines Distributional Robustness in Contrastive Language Image Pre-training (CLIP)
“Retrieval-Augmented Diffusion Models: Semi-Parametric Neural Image Synthesis”, Blattmann et al 2022
Retrieval-Augmented Diffusion Models: Semi-Parametric Neural Image Synthesis
“Can Foundation Models Perform Zero-Shot Task Specification For Robot Manipulation?”, Cui et al 2022
Can Foundation Models Perform Zero-Shot Task Specification For Robot Manipulation?
“Opal: Multimodal Image Generation for News Illustration”, Liu et al 2022
“VQGAN-CLIP: Open Domain Image Generation and Editing With Natural Language Guidance”, Crowson et al 2022
VQGAN-CLIP: Open Domain Image Generation and Editing with Natural Language Guidance
“DALL·E 2: Hierarchical Text-Conditional Image Generation With CLIP Latents § 7. Limitations and Risks”, Ramesh et al 2022 (page 16 org openai)
“No Token Left Behind: Explainability-Aided Image Classification and Generation”, Paiss et al 2022
No Token Left Behind: Explainability-Aided Image Classification and Generation
“Semantic Exploration from Language Abstractions and Pretrained Representations”, Tam et al 2022
Semantic Exploration from Language Abstractions and Pretrained Representations
“Winoground: Probing Vision and Language Models for Visio-Linguistic Compositionality”, Thrush et al 2022
Winoground: Probing Vision and Language Models for Visio-Linguistic Compositionality
“Unified Contrastive Learning in Image-Text-Label Space”, Yang et al 2022
“Socratic Models: Composing Zero-Shot Multimodal Reasoning With Language”, Zeng et al 2022
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
“Learning to Generate Line Drawings That Convey Geometry and Semantics”, Chan et al 2022
Learning to generate line drawings that convey geometry and semantics
“CLIP Meets GamePhysics: Towards Bug Identification in Gameplay Videos Using Zero-Shot Transfer Learning”, Taesiri et al 2022
“CLIP on Wheels (CoW): Zero-Shot Object Navigation As Object Localization and Exploration”, Gadre et al 2022
CLIP on Wheels (CoW): Zero-Shot Object Navigation as Object Localization and Exploration
“Bamboo: Building Mega-Scale Vision Dataset Continually With Human-Machine Synergy”, Zhang et al 2022
Bamboo: Building Mega-Scale Vision Dataset Continually with Human-Machine Synergy
“CLIP Models Are Few-Shot Learners: Empirical Studies on VQA and Visual Entailment”, Song et al 2022
CLIP Models are Few-shot Learners: Empirical Studies on VQA and Visual Entailment
“Democratizing Contrastive Language-Image Pre-Training: A CLIP Benchmark of Data, Model, and Supervision”, Cui et al 2022
“Model Soups: Averaging Weights of Multiple Fine-Tuned Models Improves Accuracy without Increasing Inference Time”, Wortsman et al 2022
“The Unsurprising Effectiveness of Pre-Trained Vision Models for Control”, Parisi et al 2022
The Unsurprising Effectiveness of Pre-Trained Vision Models for Control
“Unsupervised Vision-And-Language Pre-Training via Retrieval-Based Multi-Granular Alignment”, Zhou et al 2022
Unsupervised Vision-and-Language Pre-training via Retrieval-based Multi-Granular Alignment
“RuCLIP—New Models and Experiments: a Technical Report”, Shonenkov et al 2022
“Wukong: 100 Million Large-Scale Chinese Cross-Modal Pre-Training Dataset and A Foundation Framework”, Gu et al 2022
Wukong: 100 Million Large-scale Chinese Cross-modal Pre-training Dataset and A Foundation Framework
“CLIPasso: Semantically-Aware Object Sketching”, Vinker et al 2022
“BLIP: Bootstrapping Language-Image Pre-Training for Unified Vision-Language Understanding and Generation”, Li et al 2022
“Can Wikipedia Help Offline Reinforcement Learning?”, Reid et al 2022
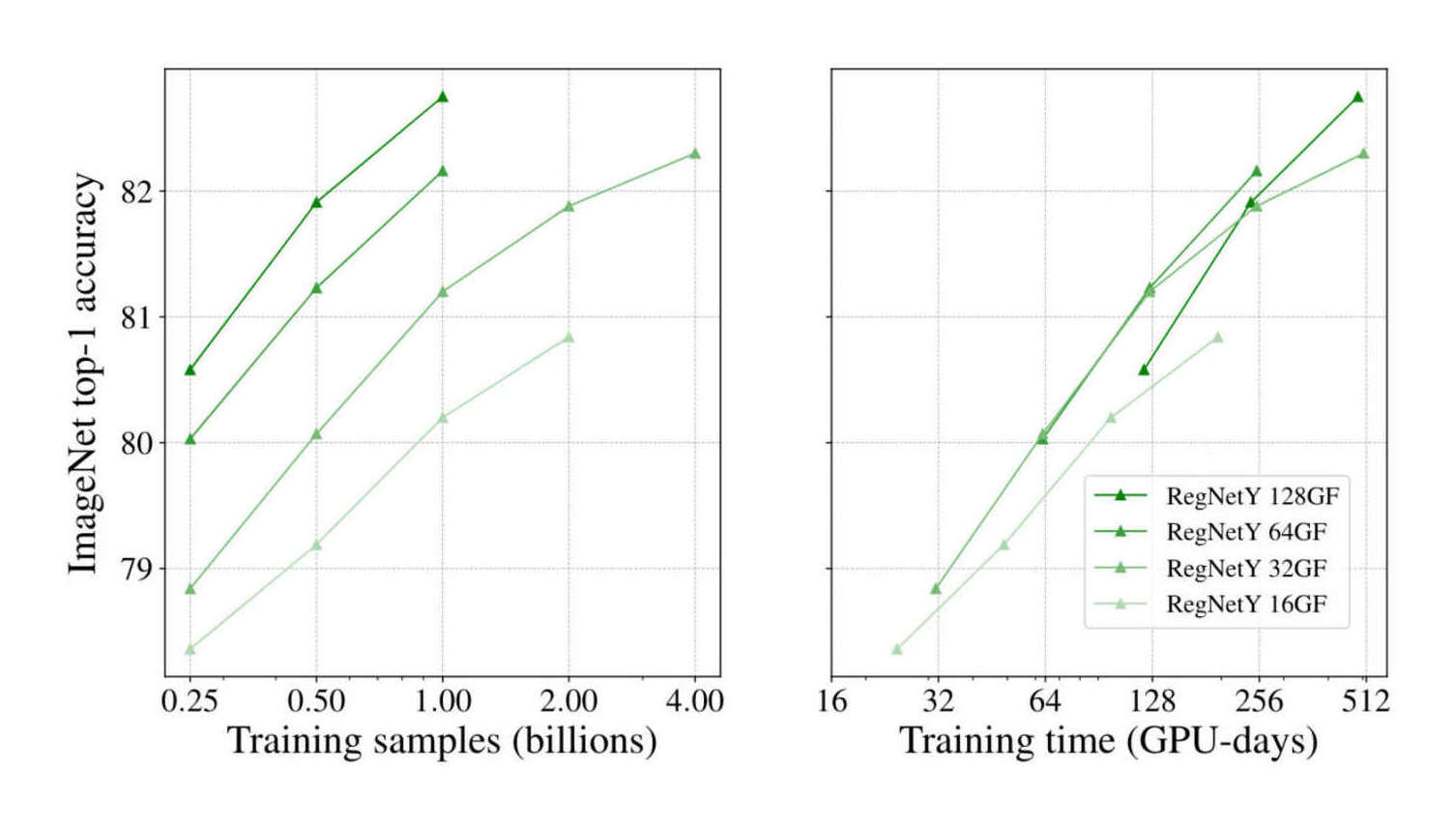
“SWAG: Revisiting Weakly Supervised Pre-Training of Visual Perception Models”, Singh et al 2022
SWAG: Revisiting Weakly Supervised Pre-Training of Visual Perception Models
“CM3: A Causal Masked Multimodal Model of the Internet”, Aghajanyan et al 2022
“LSeg: Language-Driven Semantic Segmentation”, Li et al 2022
“Design Guidelines for Prompt Engineering Text-To-Image Generative Models”, Liu & Chilton 2022b
Design Guidelines for Prompt Engineering Text-to-Image Generative Models
“Detecting Twenty-Thousand Classes Using Image-Level Supervision”, Zhou et al 2022
Detecting Twenty-thousand Classes using Image-level Supervision
“A Fistful of Words: Learning Transferable Visual Models from Bag-Of-Words Supervision”, Tejankar et al 2021
A Fistful of Words: Learning Transferable Visual Models from Bag-of-Words Supervision
“High-Resolution Image Synthesis With Latent Diffusion Models”, Rombach et al 2021
High-Resolution Image Synthesis with Latent Diffusion Models
“RegionCLIP: Region-Based Language-Image Pretraining”, Zhong et al 2021
“More Control for Free! Image Synthesis With Semantic Diffusion Guidance”, Liu et al 2021
More Control for Free! Image Synthesis with Semantic Diffusion Guidance
“CLIP2StyleGAN: Unsupervised Extraction of StyleGAN Edit Directions”, Abdal et al 2021
CLIP2StyleGAN: Unsupervised Extraction of StyleGAN Edit Directions
“MAGMA—Multimodal Augmentation of Generative Models through Adapter-Based Finetuning”, Eichenberg et al 2021
MAGMA—Multimodal Augmentation of Generative Models through Adapter-based Finetuning
“DenseCLIP: Extract Free Dense Labels from CLIP”, Zhou et al 2021
“Zero-Shot Text-Guided Object Generation With Dream Fields”, Jain et al 2021
“FuseDream: Training-Free Text-To-Image Generation With Improved CLIP+GAN Space Optimization”, Liu et al 2021
FuseDream: Training-Free Text-to-Image Generation with Improved CLIP+GAN Space Optimization
“MAD: A Scalable Dataset for Language Grounding in Videos from Movie Audio Descriptions”, Soldan et al 2021
MAD: A Scalable Dataset for Language Grounding in Videos from Movie Audio Descriptions
“CRIS: CLIP-Driven Referring Image Segmentation”, Wang et al 2021
“Zero-Shot Image-To-Text Generation for Visual-Semantic Arithmetic”, Tewel et al 2021
Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic
“Blended Diffusion for Text-Driven Editing of Natural Images”, Avrahami et al 2021
“LAFITE: Towards Language-Free Training for Text-To-Image Generation”, Zhou et al 2021
LAFITE: Towards Language-Free Training for Text-to-Image Generation
“Florence: A New Foundation Model for Computer Vision”, Yuan et al 2021
“BASIC: Combined Scaling for Open-Vocabulary Image Classification”, Pham et al 2021
BASIC: Combined Scaling for Open-Vocabulary Image Classification
“ClipCap: CLIP Prefix for Image Captioning”, Mokady et al 2021
“Simple but Effective: CLIP Embeddings for Embodied AI”, Khandelwal et al 2021
“INTERN: A New Learning Paradigm Towards General Vision”, Shao et al 2021
“LiT: Zero-Shot Transfer With Locked-Image Text Tuning”, Zhai et al 2021
“Tip-Adapter: Training-Free CLIP-Adapter for Better Vision-Language Modeling”, Zhang et al 2021
Tip-Adapter: Training-free CLIP-Adapter for Better Vision-Language Modeling
“StyleCLIPDraw: Coupling Content and Style in Text-To-Drawing Synthesis”, Schaldenbrand et al 2021
StyleCLIPDraw: Coupling Content and Style in Text-to-Drawing Synthesis
“LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs”, Schuhmann et al 2021
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
“Projected GANs Converge Faster”, Sauer et al 2021
“Telling Creative Stories Using Generative Visual Aids”, Ali & Parikh 2021
“Image-Based CLIP-Guided Essence Transfer”, Chefer et al 2021
“Wav2CLIP: Learning Robust Audio Representations From CLIP”, Wu et al 2021
“No One Representation to Rule Them All: Overlapping Features of Training Methods”, Gontijo-Lopes et al 2021
No One Representation to Rule Them All: Overlapping Features of Training Methods
“Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-Training Paradigm (DeCLIP)”, Li et al 2021
“CLIP-Forge: Towards Zero-Shot Text-To-Shape Generation”, Sanghi et al 2021
“MA-CLIP: Towards Modality-Agnostic Contrastive Language-Image Pre-Training”, You et al 2021
MA-CLIP: Towards Modality-Agnostic Contrastive Language-Image Pre-training
“OTTER: Data Efficient Language-Supervised Zero-Shot Recognition With Optimal Transport Distillation”, Wu et al 2021
OTTER: Data Efficient Language-Supervised Zero-Shot Recognition with Optimal Transport Distillation
“DiffusionCLIP: Text-Guided Image Manipulation Using Diffusion Models”, Kim & Ye 2021
DiffusionCLIP: Text-guided Image Manipulation Using Diffusion Models
“CLOOB: Modern Hopfield Networks With InfoLOOB Outperform CLIP”, Fürst et al 2021
CLOOB: Modern Hopfield Networks with InfoLOOB Outperform CLIP
“VideoCLIP: Contrastive Pre-Training for Zero-Shot Video-Text Understanding”, Xu et al 2021
VideoCLIP: Contrastive Pre-training for Zero-shot Video-Text Understanding
“ZSD-YOLO: Zero-Shot YOLO Detection Using Vision-Language Knowledge Distillation”, Xie & Zheng 2021
ZSD-YOLO: Zero-Shot YOLO Detection using Vision-Language Knowledge Distillation
“CLIPort: What and Where Pathways for Robotic Manipulation”, Shridhar et al 2021
“THINGSvision: A Python Toolbox for Streamlining the Extraction of Activations From Deep Neural Networks”, Muttenthaler & Hebart 2021
“Modern Evolution Strategies for Creativity: Fitting Concrete Images and Abstract Concepts”, Tian & Ha 2021
Modern Evolution Strategies for Creativity: Fitting Concrete Images and Abstract Concepts
“What Vision-Language Models ‘See’ When They See Scenes”, Cafagna et al 2021
“EfficientCLIP: Efficient Cross-Modal Pre-Training by Ensemble Confident Learning and Language Modeling”, Wang et al 2021
“Zero-Shot Open Set Detection by Extending CLIP”, Esmaeilpour et al 2021
“Robust Fine-Tuning of Zero-Shot Models”, Wortsman et al 2021
“What Users Want? WARHOL: A Generative Model for Recommendation”, Samaran et al 2021
What Users Want? WARHOL: A Generative Model for Recommendation
“LAION-400-Million Open Dataset”, Schuhmann 2021
“Contrastive Language-Image Pre-Training for the Italian Language”, Bianchi et al 2021
Contrastive Language-Image Pre-training for the Italian Language
“Evaluating CLIP: Towards Characterization of Broader Capabilities and Downstream Implications”, Agarwal et al 2021
Evaluating CLIP: Towards Characterization of Broader Capabilities and Downstream Implications
“StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators”, Gal et al 2021
StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators
“Language Grounding With 3D Objects”, Thomason et al 2021
“Segmentation in Style: Unsupervised Semantic Image Segmentation With StyleGAN and CLIP”, Pakhomov et al 2021
Segmentation in Style: Unsupervised Semantic Image Segmentation with StyleGAN and CLIP
“How Much Can CLIP Benefit Vision-And-Language Tasks?”, Shen et al 2021
“FairyTailor: A Multimodal Generative Framework for Storytelling”, Bensaid et al 2021
FairyTailor: A Multimodal Generative Framework for Storytelling
“CLIP-It! Language-Guided Video Summarization”, Narasimhan et al 2021
“Small In-Distribution Changes in 3D Perspective and Lighting Fool Both CNNs and Transformers”, Madan et al 2021
Small in-distribution changes in 3D perspective and lighting fool both CNNs and Transformers
“CLIPDraw: Exploring Text-To-Drawing Synthesis through Language-Image Encoders”, Frans et al 2021
CLIPDraw: Exploring Text-to-Drawing Synthesis through Language-Image Encoders
“AudioCLIP: Extending CLIP to Image, Text and Audio”, Guzhov et al 2021
“CLIP2Video: Mastering Video-Text Retrieval via Image CLIP”, Fang et al 2021
“A Fair and Comprehensive Comparison of Multimodal Tweet Sentiment Analysis Methods”, Cheema et al 2021
A Fair and Comprehensive Comparison of Multimodal Tweet Sentiment Analysis Methods
“Partial Success in Closing the Gap between Human and Machine Vision”, Geirhos et al 2021
Partial success in closing the gap between human and machine vision
“ImaginE: An Imagination-Based Automatic Evaluation Metric for Natural Language Generation”, Zhu et al 2021
ImaginE: An Imagination-Based Automatic Evaluation Metric for Natural Language Generation
“Exploring the Limits of Out-Of-Distribution Detection”, Fort et al 2021
“Chinese AI Lab Challenges Google, OpenAI With a Model of 1.75 Trillion Parameters”, Du 2021
Chinese AI lab challenges Google, OpenAI with a model of 1.75 trillion parameters
“Generative Art Using Neural Visual Grammars and Dual Encoders”, Fernando et al 2021
Generative Art Using Neural Visual Grammars and Dual Encoders
“Zero-Shot Detection via Vision and Language Knowledge Distillation”, Gu et al 2021
Zero-Shot Detection via Vision and Language Knowledge Distillation
“CLIPScore: A Reference-Free Evaluation Metric for Image Captioning”, Hessel et al 2021
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
“Data-Efficient Language-Supervised Zero-Shot Learning With Self-Distillation”, Cheng et al 2021
Data-Efficient Language-Supervised Zero-Shot Learning with Self-Distillation
“Paint by Word”, Bau et al 2021
“WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training”, Huo et al 2021
WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training
“Multimodal Neurons in Artificial Neural Networks [CLIP]”, Goh et al 2021
“Zero-Shot Text-To-Image Generation”, Ramesh et al 2021
“ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision”, Jia et al 2021
ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
“Generating Images from Caption and vice Versa via CLIP-Guided Generative Latent Space Search”, Galatolo et al 2021
Generating images from caption and vice versa via CLIP-Guided Generative Latent Space Search
“Decoupling the Role of Data, Attention, and Losses in Multimodal Transformers”, Hendricks et al 2021
Decoupling the Role of Data, Attention, and Losses in Multimodal Transformers
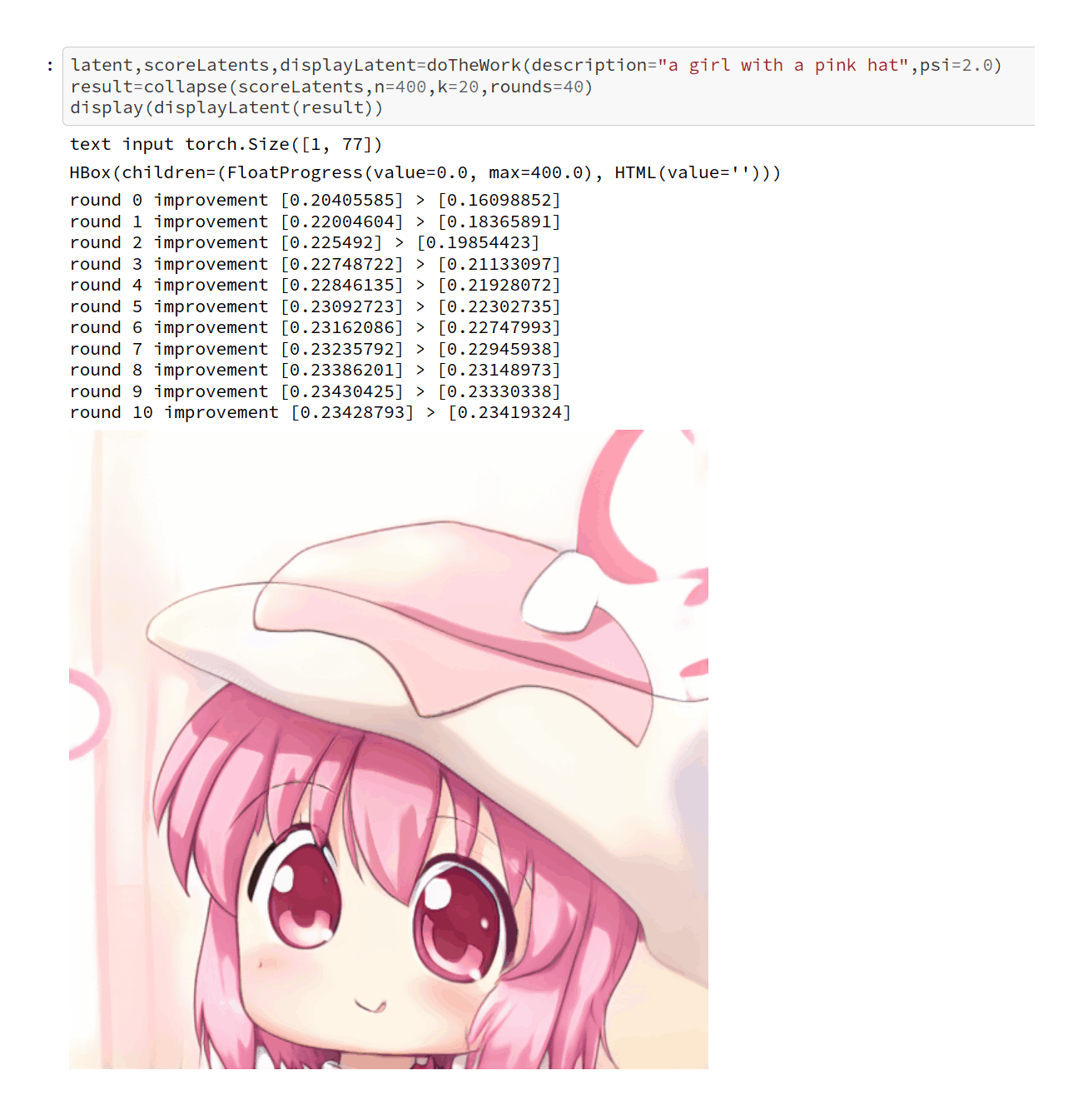
“Scoring Images from TADNE With CLIP”, nagolinc 2021
“CLIP: Learning Transferable Visual Models From Natural Language Supervision”, Radford et al 2021
CLIP: Learning Transferable Visual Models From Natural Language Supervision
“CLIP: Connecting Text and Images: We’re Introducing a Neural Network Called CLIP Which Efficiently Learns Visual Concepts from Natural Language Supervision. CLIP Can Be Applied to Any Visual Classification Benchmark by Simply Providing the Names of the Visual Categories to Be Recognized, Similar to the ‘Zero-Shot’ Capabilities of GPT-2 and GPT-3”, Radford et al 2021
“DALL·E 1: Creating Images from Text: We’ve Trained a Neural Network Called DALL·E That Creates Images from Text Captions for a Wide Range of Concepts Expressible in Natural Language”, Ramesh et al 2021
“Transformers in Vision: A Survey”, Khan et al 2021
“Vision Transformer: An Image Is Worth 16×16 Words: Transformers for Image Recognition at Scale”, Dosovitskiy et al 2020
Vision Transformer: An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale
“M3P: Learning Universal Representations via Multitask Multilingual Multimodal Pre-Training”, Ni et al 2020
M3P: Learning Universal Representations via Multitask Multilingual Multimodal Pre-training
“Learning to Scale Multilingual Representations for Vision-Language Tasks”, Burns et al 2020
Learning to Scale Multilingual Representations for Vision-Language Tasks
“The Messy, Secretive Reality behind OpenAI’s Bid to save the World: The AI Moonshot Was Founded in the Spirit of Transparency. This Is the inside Story of How Competitive Pressure Eroded That Idealism”, Hao 2020
“MULE: Multimodal Universal Language Embedding”, Kim et al 2019
“What A Long, Strange Trip It’s Been: EleutherAI One Year Retrospective”
What A Long, Strange Trip It’s Been: EleutherAI One Year Retrospective
View External Link:
“CLIP: Zero-Shot Jack of All Trades”
“This Anime Does Not Exist, Search: This Notebook Uses the Precomputed CLIP Feature Vectors for 100k Images from TADNE”
“CLIPIT PixelDraw Demo”
“Vqgan-Clip/notebooks”
“Combination of OpenAI GLIDE and Latent Diffusion”
“LAION-AI/laion-Datasets”
“Anima-Style-Explorer: Anima 2B Style Explorer—A Fast, Visual Reference Library for 20,000+ Artist Styles Optimized for the Anima 2B Model and Danbooru Tagging System”, ThetaCursed 2026
“CLIP Implementation for Russian Language”
“Christophschuhmann/4MC-4M-Image-Text-Pairs-With-CLIP-Embeddings: I Have Created a Dataset of Image-Text-Pairs by Using the Cosine Similarity of the CLIP Embeddings of the Image & Its Caption Derrived from YFCC100M. I Have Also Added Probabilities from a NSFW Detector & More”
“CLIP (Contrastive Language–Image Pre-Training) for Italian”
“Crowsonkb/simulacra-Aesthetic-Models”
“RWKV-CLIP: A Robust Vision-Language Representation Learner”
“Neural Image Generation”
“An Open Source Implementation of CLIP”
“CLIP/data/yfcc100m.md”
“StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery”
“Clustering-Laion400m: Script and Models for Clustering LAION-400m CLIP Embeddings. Models Were Fit on the First Million or so Image Embeddings.”
“Rinongal/StyleGAN-Nada”
“Simple Image Captioning Model”
“Robgon-Art/CLIPandPASTE: CLIP and PASTE: Using AI to Create Photo Collages from Text Prompts”
robgon-art/CLIPandPASTE: CLIP and PASTE: Using AI to Create Photo Collages from Text Prompts
“sam2_hierarch: Unsupervised Human-Friendly Online Object Categorization”, UtilityHotbar 2026
sam2_hierarch: Unsupervised Human-Friendly Online Object Categorization
“AI-Powered Command-Line Photo Search Tool”
“Kaichengalex/YFCC15M”
“Alien Dreams: An Emerging Art Scene”
“The Bouba/Kiki Effect And Sound Symbolism In CLIP”
“Image Captioning”
“Same Energy”
“Guidance: a Cheat Code for Diffusion Models”
“Pixels Still Beat Text: Attacking the OpenAI CLIP Model With Text Patches and Adversarial Pixel Perturbations”
“Case Study: Interpreting, Manipulating, and Controlling CLIP With Sparse Autoencoders”
Case Study: Interpreting, Manipulating, and Controlling CLIP With Sparse Autoencoders
“[P] List of Sites/programs/projects That Use OpenAI’s CLIP Neural Network for Steering Image/video Creation to Match a Text Description”
“Writing Good VQGAN+CLIP Prompts Part One – Basic Prompts and Style Modifiers”
Writing good VQGAN+CLIP prompts part one – basic prompts and style modifiers
“Writing Good VQGAN+CLIP Prompts Part Two – Artist and Genre Modifiers”
Writing good VQGAN+CLIP prompts part two – artist and genre modifiers
“Writing Good VQGAN+CLIP Prompts Part Three – Environmental Modifiers”
Writing good VQGAN+CLIP prompts part three – environmental modifiers
“New AI Tools CLIP+VQ-GAN Can Create Impressive Works of Art Based on Just a Few Words of Input”
New AI tools CLIP+VQ-GAN can create impressive works of art based on just a few words of input
“Apple or IPod? Easy Fix for Adversarial Textual Attacks on OpenAI’s CLIP Model!”
Apple or iPod? Easy Fix for Adversarial Textual Attacks on OpenAI’s CLIP Model!
“Autoresearch on an Old Research Idea”
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
generative-recommendation
self-supervised
language-grounding
humorous-evaluation
ai-fundamentals ai-competition transparency-issues secretive-practices moonshot-vision
text-to-image
geospatial-prediction
prompt-tuning
multimodal-learning
language-trajectory
vision-language
Miscellaneous
/doc/ai/nn/transformer/clip/2023-01-01-ross-openclipscalingforclipvitbigg14laion2b39bb160k.png/doc/ai/nn/transformer/clip/2022-04-04-rombach-compvistxt2imgpreview.png/doc/ai/nn/transformer/clip/2022-cherti-figure1b-openclipcomputezeroshotretrievalscalingcurve.jpg/doc/ai/nn/transformer/clip/2022-singh-figure3-scalingmodelanddatasetsizes.jpg/doc/ai/nn/transformer/clip/2021-04-22-rivershavewings-clipvqgan-theshadowyhackergroupeleuther.png/doc/ai/nn/gan/stylegan/anime/2021-01-20-nagolinc-tadne-clipbasedgeneration-agirlwithapinkhat.png/doc/ai/nn/transformer/clip/2021-radford-clip-figure13-cliprobustness.png/doc/ai/nn/transformer/clip/2021-radford-clip-figure21-zeroshot36differenttasks.png/doc/ai/nn/transformer/clip/2021-radford-clip-figure4-promptengineering.png/doc/ai/nn/transformer/clip/2021-radford-clip-figure5-clipzeroshotvsfullresnet.png/doc/ai/nn/transformer/clip/2021-radford-clip-figure9-clipcomputescaling.jpghttps://colab.research.google.com/drive/189LHTpYaefMhKNIGOzTLHHavlgmoIWg9https://colab.research.google.com/drive/1N8Cc9yYzNR4M9J2NtE3n3jL2Jy25KAl_https://colab.research.google.com/drive/1c6VccMPsOMAUQCKU4BVDRd5Y32qkozmKhttps://colab.research.google.com/github/kvfrans/clipdraw/blob/main/clipdraw.ipynbhttps://creator.nightcafe.studio/vqgan-clip-keyword-modifier-comparisonhttps://huggingface.co/laion/CLIP-convnext_xxlarge-laion2B-s34B-b82K-augreg-souphttps://jxmo.notion.site/The-Weird-and-Wonderful-World-of-AI-Art-b9615a2e7278435b98380ff81ae1cf09https://stanislavfort.com/2021/01/12/OpenAI_CLIP_adversarial_examples.htmlhttps://stanislavfort.github.io/blog/OpenAI_CLIP_adversarial_examples/https://stanislavfort.github.io/blog/OpenAI_CLIP_stickers_and_adversarial_examples/https://tech.pic-collage.com/distillation-of-clip-model-and-other-experiments-f8394b7321cehttps://wandb.ai/dalle-mini/dalle-mini/reports/DALL-E-mini--Vmlldzo4NjIxODAhttps://web.media.mit.edu/~echu/assets/projects/evolving-views/paper.pdfhttps://www.lesswrong.com/posts/cqGEQeLNbcptYsifz/this-week-in-fashionView External Link:
https://www.lesswrong.com/posts/cqGEQeLNbcptYsifz/this-week-in-fashionhttps://www.reddit.com/r/MachineLearning/comments/nq4es7/d_unreal_engine_trick_with_vqgan_clip/https://www.unum.cloud/blog/2023-02-20-efficient-multimodality
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
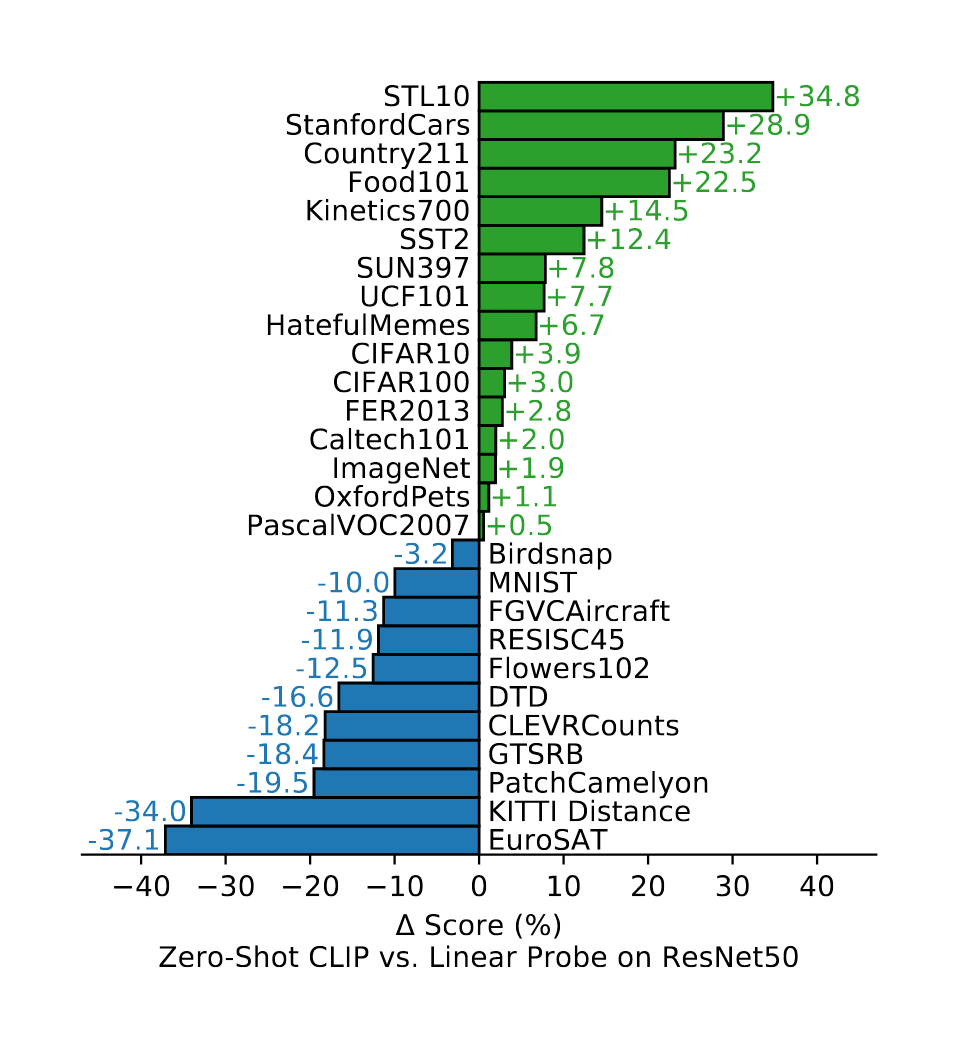{kind=link}
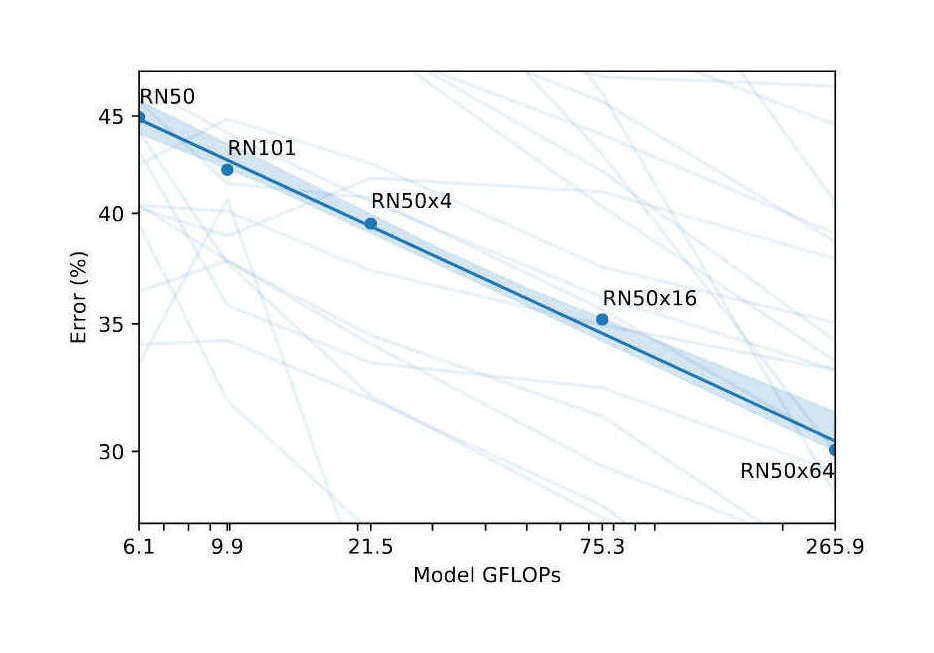{kind=link}
Bibliography
https://research.google/blog/taking-medical-imaging-embeddings-3d/: “CT Foundation: Taking Medical Imaging Embeddings 3D”,https://arxiv.org/abs/2408.05446: “Ensemble Everything Everywhere: Multi-Scale Aggregation for Adversarial Robustness”,https://arxiv.org/abs/2406.06973: “RWKV-CLIP: A Robust Vision-Language Representation Learner”,https://arxiv.org/abs/2405.07425: “Sakuga-42M Dataset: Scaling Up Cartoon Research”,https://arxiv.org/abs/2405.02793#google: “ImageInWords: Unlocking Hyper-Detailed Image Descriptions”,https://arxiv.org/abs/2404.01291: “Evaluating Text-To-Visual Generation With Image-To-Text Generation”,2024-vong.pdf: “Grounded Language Acquisition through the Eyes and Ears of a Single Child”,https://arxiv.org/abs/2312.16862: “TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones”,https://arxiv.org/abs/2312.11556: “StarVector: Generating Scalable Vector Graphics Code from Images”,https://arxiv.org/abs/2312.05328#deepmind: “Bad Students Make Great Teachers: Active Learning Accelerates Large-Scale Visual Understanding”,https://arxiv.org/abs/2309.17425#apple: “Data Filtering Networks”,https://arxiv.org/abs/2309.16671: “Demystifying CLIP Data”,https://arxiv.org/abs/2307.01952#stability: “SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis”,https://arxiv.org/abs/2306.15658: “CLIPA-V2: Scaling CLIP Training With 81.1% Zero-Shot ImageNet Accuracy within a $10,000 Budget; An Extra $4,000 Unlocks 81.8% Accuracy”,2023-yi.pdf: “Anime Character Identification and Tag Prediction by Multimodality Modeling: Dataset and Model”,https://arxiv.org/abs/2306.09346: “Rosetta Neurons: Mining the Common Units in a Model Zoo”,2023-samo.pdf: “Artificial Intelligence and Art: Identifying the Esthetic Judgment Factors That Distinguish Human & Machine-Generated Artwork”,https://arxiv.org/abs/2305.16934: “On Evaluating Adversarial Robustness of Large Vision-Language Models”,https://arxiv.org/abs/2305.07017: “An Inverse Scaling Law for CLIP Training”,https://arxiv.org/abs/2305.05665#facebook: “ImageBind: One Embedding Space To Bind Them All”,https://arxiv.org/abs/2305.01569: “Pick-A-Pic: An Open Dataset of User Preferences for Text-To-Image Generation”,https://arxiv.org/abs/2304.07193#facebook: “DINOv2: Learning Robust Visual Features without Supervision”,https://arxiv.org/abs/2304.06712: “What Does CLIP Know about a Red Circle? Visual Prompt Engineering for VLMs”,https://arxiv.org/abs/2304.05538: “ImageNet-Hard: The Hardest Images Remaining from a Study of the Power of Zoom and Spatial Biases in Image Classification”,https://arxiv.org/abs/2303.15343#google: “Sigmoid Loss for Language Image Pre-Training”,https://openreview.net/forum?id=KRLUvxh8uaX: “When and Why Vision-Language Models Behave like Bags-Of-Words, and What to Do About It?”,https://arxiv.org/abs/2301.12597#salesforce: “BLIP-2: Bootstrapping Language-Image Pre-Training With Frozen Image Encoders and Large Language Models”,https://arxiv.org/abs/2301.07088#bytedance: “MUG: Vision Learners Meet Web Image-Text Pairs”,https://laion.ai/blog/giant-openclip/: “Reaching 80% Zero-Shot Accuracy With OpenCLIP: VIT-G/14 Trained On LAION-2B”,https://arxiv.org/abs/2212.07143: “Reproducible Scaling Laws for Contrastive Language-Image Learning”,https://arxiv.org/abs/2212.06138#microsoft: “CLIP Itself Is a Strong Fine-Tuner: Achieving 85.7% and 88.0% Top-1 Accuracy With ViT-B and ViT-L on ImageNet”,https://arxiv.org/abs/2211.12561#facebook: “Retrieval-Augmented Multimodal Language Modeling”,https://openreview.net/forum?id=wmGlMhaBe0: “MaskDistill: A Unified View of Masked Image Modeling”,https://arxiv.org/abs/2211.07292: “Paella: Fast Text-Conditional Discrete Denoising on Vector-Quantized Latent Spaces”,https://arxiv.org/abs/2211.06679#baai: “AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities”,https://arxiv.org/abs/2211.01324#nvidia: “EDiff-I: Text-To-Image Diffusion Models With an Ensemble of Expert Denoisers”,https://www.biorxiv.org/content/10.1101/2022.09.27.508760.full: “Incorporating Natural Language into Vision Models Improves Prediction and Understanding of Higher Visual Cortex”,https://arxiv.org/abs/2209.03953: “Fast Text2StyleGAN: Text-Free Learning of a Natural Language Interface for Pretrained Face Generators”,https://arxiv.org/abs/2209.03320: “What Does a Platypus Look Like? Generating Customized Prompts for Zero-Shot Image Classification (CuPL)”,https://arxiv.org/abs/2208.12266#facebook: “Decoding Speech from Non-Invasive Brain Recordings”,https://arxiv.org/abs/2208.05516: “Quality Not Quantity: On the Interaction between Dataset Design and Robustness of CLIP”,https://arxiv.org/abs/2208.03550: “EVL: Frozen CLIP Models Are Efficient Video Learners”,https://arxiv.org/abs/2207.14525: “TOnICS: Curriculum Learning for Data-Efficient Vision-Language Alignment”,https://arxiv.org/abs/2207.12661#microsoft: “MS-CLIP: Learning Visual Representation from Modality-Shared Contrastive Language-Image Pre-Training”,https://arxiv.org/abs/2207.13061: “NewsStories: Illustrating Articles With Visual Summaries”,https://arxiv.org/abs/2207.07285#alibaba: “X-CLIP: End-To-End Multi-Grained Contrastive Learning for Video-Text Retrieval”,https://arxiv.org/abs/2207.07635: “Is a Caption Worth a Thousand Images? A Controlled Study for Representation Learning”,https://arxiv.org/abs/2207.04429: “LM-Nav: Robotic Navigation With Large Pre-Trained Models of Language, Vision, and Action”,https://arxiv.org/abs/2205.16007#microsoft: “Improved Vector Quantized Diffusion Models”,https://arxiv.org/abs/2205.14459: “CyCLIP: Cyclic Contrastive Language-Image Pretraining”,https://arxiv.org/abs/2205.10747: “VidIL: Language Models With Image Descriptors Are Strong Few-Shot Video-Language Learners”,https://arxiv.org/abs/2205.08535: “AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars”,https://arxiv.org/abs/2205.01917#google: “CoCa: Contrastive Captioners Are Image-Text Foundation Models”,https://arxiv.org/abs/2205.01397: “Data Determines Distributional Robustness in Contrastive Language Image Pre-Training (CLIP)”,https://arxiv.org/pdf/2204.06125#page=16&org=openai: “DALL·E 2: Hierarchical Text-Conditional Image Generation With CLIP Latents § 7. Limitations and Risks”,https://arxiv.org/abs/2204.05080#deepmind: “Semantic Exploration from Language Abstractions and Pretrained Representations”,https://arxiv.org/abs/2204.03610#microsoft: “Unified Contrastive Learning in Image-Text-Label Space”,https://arxiv.org/abs/2204.00598#google: “Socratic Models: Composing Zero-Shot Multimodal Reasoning With Language”,https://arxiv.org/abs/2203.11096: “CLIP Meets GamePhysics: Towards Bug Identification in Gameplay Videos Using Zero-Shot Transfer Learning”,https://arxiv.org/abs/2203.05482: “Model Soups: Averaging Weights of Multiple Fine-Tuned Models Improves Accuracy without Increasing Inference Time”,https://arxiv.org/abs/2202.06767#huawei: “Wukong: 100 Million Large-Scale Chinese Cross-Modal Pre-Training Dataset and A Foundation Framework”,https://arxiv.org/abs/2201.12086#salesforce: “BLIP: Bootstrapping Language-Image Pre-Training for Unified Vision-Language Understanding and Generation”,https://arxiv.org/abs/2201.08371#facebook: “SWAG: Revisiting Weakly Supervised Pre-Training of Visual Perception Models”,https://arxiv.org/abs/2201.07520#facebook: “CM3: A Causal Masked Multimodal Model of the Internet”,2022-liu-2.pdf: “Design Guidelines for Prompt Engineering Text-To-Image Generative Models”,https://arxiv.org/abs/2201.02605#facebook: “Detecting Twenty-Thousand Classes Using Image-Level Supervision”,https://arxiv.org/abs/2112.10752: “High-Resolution Image Synthesis With Latent Diffusion Models”,https://arxiv.org/abs/2112.09106#microsoft: “RegionCLIP: Region-Based Language-Image Pretraining”,https://arxiv.org/abs/2112.05744: “More Control for Free! Image Synthesis With Semantic Diffusion Guidance”,https://arxiv.org/abs/2112.05253: “MAGMA—Multimodal Augmentation of Generative Models through Adapter-Based Finetuning”,https://arxiv.org/abs/2112.01071: “DenseCLIP: Extract Free Dense Labels from CLIP”,https://arxiv.org/abs/2112.01573: “FuseDream: Training-Free Text-To-Image Generation With Improved CLIP+GAN Space Optimization”,https://arxiv.org/abs/2111.11432#microsoft: “Florence: A New Foundation Model for Computer Vision”,https://arxiv.org/abs/2111.10050#google: “BASIC: Combined Scaling for Open-Vocabulary Image Classification”,https://arxiv.org/abs/2111.09734: “ClipCap: CLIP Prefix for Image Captioning”,https://arxiv.org/abs/2111.07991#google: “LiT: Zero-Shot Transfer With Locked-Image Text Tuning”,https://arxiv.org/abs/2111.03930: “Tip-Adapter: Training-Free CLIP-Adapter for Better Vision-Language Modeling”,https://arxiv.org/abs/2111.03133: “StyleCLIPDraw: Coupling Content and Style in Text-To-Drawing Synthesis”,https://arxiv.org/abs/2111.02114#laion: “LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs”,https://arxiv.org/abs/2111.01007: “Projected GANs Converge Faster”,https://arxiv.org/abs/2110.05208: “Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-Training Paradigm (DeCLIP)”,https://openreview.net/forum?id=ROteIE-4A6W: “MA-CLIP: Towards Modality-Agnostic Contrastive Language-Image Pre-Training”,https://openreview.net/forum?id=G89-1yZLFHk: “OTTER: Data Efficient Language-Supervised Zero-Shot Recognition With Optimal Transport Distillation”,https://openreview.net/forum?id=qw674L9PfQE: “CLOOB: Modern Hopfield Networks With InfoLOOB Outperform CLIP”,https://arxiv.org/abs/2109.12066: “ZSD-YOLO: Zero-Shot YOLO Detection Using Vision-Language Knowledge Distillation”,https://www.frontiersin.org/articles/10.3389/fninf.2021.679838/full: “THINGSvision: A Python Toolbox for Streamlining the Extraction of Activations From Deep Neural Networks”,https://arxiv.org/abs/2109.08857#google: “Modern Evolution Strategies for Creativity: Fitting Concrete Images and Abstract Concepts”,https://arxiv.org/abs/2109.07301: “What Vision-Language Models ‘See’ When They See Scenes”,https://laion.ai/blog/laion-400-open-dataset/: “LAION-400-Million Open Dataset”,https://arxiv.org/abs/2107.12518: “Segmentation in Style: Unsupervised Semantic Image Segmentation With StyleGAN and CLIP”,https://arxiv.org/abs/2107.06383: “How Much Can CLIP Benefit Vision-And-Language Tasks?”,https://arxiv.org/abs/2107.00650: “CLIP-It! Language-Guided Video Summarization”,https://arxiv.org/abs/2106.16198: “Small In-Distribution Changes in 3D Perspective and Lighting Fool Both CNNs and Transformers”,https://arxiv.org/abs/2106.13043: “AudioCLIP: Extending CLIP to Image, Text and Audio”,https://arxiv.org/abs/2106.11097: “CLIP2Video: Mastering Video-Text Retrieval via Image CLIP”,https://arxiv.org/abs/2106.07411: “Partial Success in Closing the Gap between Human and Machine Vision”,https://arxiv.org/abs/2106.03004#google: “Exploring the Limits of Out-Of-Distribution Detection”,https://en.pingwest.com/a/8693#baai: “Chinese AI Lab Challenges Google, OpenAI With a Model of 1.75 Trillion Parameters”,https://arxiv.org/abs/2104.13921#google: “Zero-Shot Detection via Vision and Language Knowledge Distillation”,https://arxiv.org/abs/2104.08945#facebook: “Data-Efficient Language-Supervised Zero-Shot Learning With Self-Distillation”,https://arxiv.org/abs/2103.06561: “WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training”,https://distill.pub/2021/multimodal-neurons/#openai: “Multimodal Neurons in Artificial Neural Networks [CLIP]”,https://arxiv.org/abs/2102.05918#google: “ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision”,https://arxiv.org/abs/2102.01645: “Generating Images from Caption and vice Versa via CLIP-Guided Generative Latent Space Search”,https://github.com/nagolinc/notebooks/blob/main/TADNE_and_CLIP.ipynb: “Scoring Images from TADNE With CLIP”,https://cdn.openai.com/papers/Learning_Transferable_Visual_Models_From_Natural_Language_Supervision.pdf: “CLIP: Learning Transferable Visual Models From Natural Language Supervision”,https://openai.com/index/dall-e/: “DALL·E 1: Creating Images from Text: We’ve Trained a Neural Network Called DALL·E That Creates Images from Text Captions for a Wide Range of Concepts Expressible in Natural Language”,https://arxiv.org/abs/2010.11929#google: “Vision Transformer: An Image Is Worth 16×16 Words: Transformers for Image Recognition at Scale”,https://www.technologyreview.com/2020/02/17/844721/ai-openai-moonshot-elon-musk-sam-altman-greg-brockman-messy-secretive-reality/: “The Messy, Secretive Reality behind OpenAI’s Bid to save the World: The AI Moonshot Was Founded in the Spirit of Transparency. This Is the inside Story of How Competitive Pressure Eroded That Idealism”,https://github.com/utilityhotbar/sam2_hierarch: “sam2_hierarch: Unsupervised Human-Friendly Online Object Categorization”,