
Beating OpenAI CLIP with 100x less data and compute
Efficient pre-training of Vision-Language transformers for Semantic Search
Hello from the Unum AI team! We have been silently pre-training numerous Multi-Modal Models for Semantic Search for the last year. Now we are bundling it with our DataBase and releasing several extremely performant checkpoints on the HuggingFace portal!
So how have we done that? Isn’t training models like OpenAI CLIP only reserved for Google-scale companies? We don’t think so, and today we will dissect how to train a more precise Vision-Language transformer than the multi-lingual mCLIP, which also works much faster!
Semantic Search Vertical
Semantic search is built from 3 pieces.
| Embeddings service | used to vectorize the content and the queries |
| Nearest-Neighbors index | used to search for closest vectors |
| Persistent database | used to store and retrieve the data |
Countless companies are rushing into the space. Similar to how “Postgres on RocksDB” was the hottest topic of 2021, “Future of Search” is the theme of 2023.
| Product | Providers |
|---|---|
| Embeddings service | OpenAI, Co:here, HuggingFace, Unum UForm |
| Nearest-Neighbors index | Elastic, Algolia, Pinecone, Unum USearch |
| Persistent database | MongoDB, CockroachDB, Neo4J, Unum UStore |
In this post, we will not bore you with advances in Computational Geometry applied to indexing or the advanced Linux kernel bypass techniques we have spent years designing.
This post focuses just on the Embeddings, the Representation Learning part. And as the multi-modal representations started with CLIP, we will do the same!
CLIP Fundamentals
“Contrastive Language-Image Pre-training” aims to align vector representations (embeddings) of text and image encoder models by training them with contrastive loss function.
- BERT model is often used for the text encoder.
- ViT is used for images, with older versions referencing ResNets.
The original plan was:
- Take the CommonCrawl dataset,
- Extract 400 Million
imgtags from HTML pages, - Pair each image with 128 tokens of text around it.
Contrastive Loss is also trivial. To more experienced ML/CS practitioners, it reminds Force-Based Graph drawing algorithms.
- Sample a random batch of text and image pairs.
- Build a similarity matrix between vectors produced by BERT and ViT.
- Compare it against the identity matrix, i.e. ground truth.
- Use the difference as the loss.

The ablation studies from the original CLIP paper suggest that bigger global batch sizes with significantly more negative samples lead to better models. Still, growing the global batch size means allocating more GPUs.
- The original
CLIPwas trained on 500x A100 Nvidia GPUs. - The latest
Open_CLIPtrained on 1024x GPUs.
Where is the catch? How to compete in Language-Vision Pre-training (VLP) on 100x fewer GPUs?
Data-efficient Approaches
TLDR: If you want to be efficient, you need more, often cross-modal pre-training tasks and higher quality data.
ALBEF by Salesforce
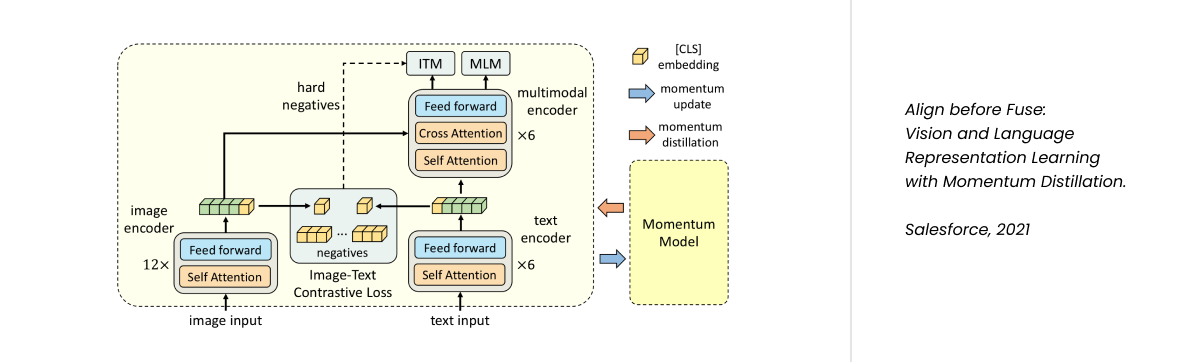
ALBEF was trained on two datasets, with 4 and 14 Million text-image pairs. The smaller version takes a day to train on 8 GPUs. Unlike CLIP, the quality of data was a priority, rather than quantity. Here is a list of their innovations:
- Multimodal encoder utilizes the embeddings from the text-encoder applying cross-attention on the output features of the image encoder output.
- Image-Text Matching (ITM) loss function based on the probability of the image complementing the text.
- Masked Language Modeling (MLM) task is stacked on top of the multimodal encoder.
We can use a multimodal encoder as a re-ranker during inference!
ViCHA

For ViCHA pre-training authors used 1.1 M and 800 K dataset sizes. On 4 GPUs this takes less than a day.
Innovations:
- Hierarchical Image-Text Contrastive (H-ITC) alignment compares representations across layers.
- Visual Concepts Extraction (VCE) used Stanford Scene Graph Parser to implement something similar to object detection on the attached textual captions.
- Masked Image Modeling (SSL) on top of the image encoder.
UForm by Unum
We trained on the setup of 3x workstations, with 4x RTX 3090 consumer-grade GPUs in each, connected over 200 GBit InfiniBand HDR. A single experiment would take around a day. Let’s evaluate the results.
Zero-Shot Image Retrieval, English-only
To produce UForm checkpoints, we further extended the ALBEF setup, and filtered the datasets. Garbage-in, garbage-out, after all. Let’s start with the Flickr dataset.
| Model | Dataset | Recall@1 | Recall@5 | Recall@10 |
|---|---|---|---|---|
| CLIP | 400 M | 0.687 | 0.906 | 0.952 |
| ALBEF | 14 M | 0.759 | 0.963 | 0.981 |
| ViCHA | 1.1 M | 0.726 | 0.911 | 0.950 |
| UForm | 4 M | 0.727 | 0.915 | 0.949 |
With 100x smaller dataset ALBEF, ViCHA, and our UForm all essentially match or surpass original OpenAI CLIP. Good start! AI evaluation, however, is much trickier, than even database benchmarks. ALBEF experiments, for one, were fine-tuned on MS-COCO before evaluating on Flickr, so the reported results are not indeed zero-shot. Let’s compare the MS-COCO results.
| Model | Dataset | Recall@1 | Recall@5 | Recall@10 |
|---|---|---|---|---|
| CLIP | 400 M | 0.378 | 0.624 | 0.722 |
| ViCHA | 1.1 M | 0.471 | 0.738 | 0.828 |
| UForm | 4 M | 0.510 | 0.761 | 0.838 |
ALBEF wasn’t evaluated on the MS-COCO dataset.
Zero-shot Image Retrieval, Multilingual
Classic approach to add multilingual capabilities to CLIP, is to distill that knowledge from much larger Language Models. We took a different path, and added a few more cross-lingual pre-training tasks. Of course.
| Model | English | German | Spanish | French | Italian | Russian | Japanese | Korean | Turkish | Chinese |
|---|---|---|---|---|---|---|---|---|---|---|
| mCLIP | 95.0 | 93.0 | 93.6 | 93.1 | 93.1 | 90.0 | 84.2 | 89.0 | 93.0 | 94.0 |
| UForm | 96.6 | 93.3 | 94.7 | 94.0 | 93.9 | 90.6 | 88.0 | 92.5 | 94.8 | 93.4 |
UForm outperforms mCLIP on every language, except for Chinese.
Inference Speed
Accuracy improvement is fine for a PhD paper, but for production, it has to be efficient. We would previously go to extreme lengths to manually quantize third-party models. Now we are shipping ours!
Let’s compare our uform to bert-base-uncased used in CLIP, and the distilbert-base-uncased, the smallest commonly used transformer.
| Model | Multilingual | Backend | Samples per Second | Speedup |
|---|---|---|---|---|
bert-base-uncased | No | PyTorch | 1’612 | |
distilbert-base-uncased | No | PyTorch | 3’174 | x 1.96 |
MiniLM-L12 | Yes | PyTorch | 3’604 | x 2.24 |
MiniLM-L6 | No | PyTorch | 6’107 | x 3.79 |
uform | Yes | PyTorch | 6’809 | x 4.22 |
| UForm | Yes | - | 20’787 | x 12.89 |
All of those measurements were conducted on a consumer-grade Nvidia RTX 3090 GPU. Best of all, you don’t need to wait for our UForm SaaS product, you can already start using our Neural Networks!
Try It!
There must be a paywall, right? No! Go get it on the Hugging Face portal!
Python
import uform
from PIL import Image
text = 'a small red panda in a zoo'
image = Image.open('red_panda.jpg')
model = uform.get_model('unum-cloud/uform-vl-multilingual') # or 'english'
image_info = model.preprocess_image(image).unsqueeze(0)
text_info = model.preprocess_text(text)
image_embedding = model.encode_image(image_info)
text_embedding = model.encode_text(text_info)
joint_embedding = model.encode_multimodal(image=image_info, text=text_info)UForm models come with a homonymous package, already available on our GitHub.
They not only extend the Hugging Face transformers library to support Mid-Fusion used in our models, but also bring nifty helpers for all things Multi-Modal!
We are actively adding new modalities, like documents, audio, and video, and you can request early access on our Discord. Who knows, maybe once we reach 1’000 stars on GitHub, we will release our pre-training libraries as well 😉