‘instruct-tuning LLMs’ directory
- See Also
- Links
- “Vision Banana: Image Generators Are Generalist Vision Learners”, Gabeur et al 2026
- “Neural Thickets: Diverse Task Experts Are Dense Around Pretrained Weights”, Gan & Isola 2026
- “Trained on Tokens, Calibrated on Concepts: The Emergence of Semantic Calibration in LLMs”, Nakkiran et al 2025
- “How Many Instructions Can LLMs Follow at Once?”, Jaroslawicz et al 2025
- “Native Sparse Attention (NSA): Hardware-Aligned and Natively Trainable Sparse Attention”, Yuan et al 2025
- “LLaDA: Large Language Diffusion Models”, Nie et al 2025
- “What’s the Deal With Mid-Training?”, Doria 2025
- “SANA: Efficient High-Resolution Image Synthesis With Linear Diffusion Transformers”, Xie et al 2024
- “Instruction Following without Instruction Tuning”, Hewitt et al 2024
- “Hermes 3 Technical Report”, Teknium et al 2024
- “Freedom at the Frontier: Hermes 3 § Amnesia Mode”, ARIA 2024
- “State Soup: In-Context Skill Learning, Retrieval and Mixing”, Pióro et al 2024
- “Auto Evol-Instruct: Automatic Instruction Evolving for Large Language Models”, Zeng et al 2024
- “Instruction Modeling: Instruction Tuning With Loss Over Instructions”, Shi et al 2024
- “LoRA Learns Less and Forgets Less”, Biderman et al 2024
- “The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions”, Wallace et al 2024
- “Best Practices and Lessons Learned on Synthetic Data for Language Models”, Liu et al 2024
- “RecurrentGemma: Moving Past Transformers for Efficient Open Language Models”, Botev et al 2024
- “Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators”, Dubois et al 2024
- “COIG-CQIA: Quality Is All You Need for Chinese Instruction Fine-Tuning”, Bai et al 2024
- “MetaAligner: Conditional Weak-To-Strong Correction for Generalizable Multi-Objective Alignment of Language Models”, Yang et al 2024
- “Mastering Text, Code and Math Simultaneously via Fusing Highly Specialized Language Models”, Ding et al 2024
- “StructLM: Towards Building Generalist Models for Structured Knowledge Grounding”, Zhuang et al 2024
- “How to Train Data-Efficient LLMs”, Sachdeva et al 2024
- “Rephrasing the Web (WARP): A Recipe for Compute and Data-Efficient Language Modeling”, Maini et al 2024
- “WaveCoder: Widespread And Versatile Enhanced Instruction Tuning With Refined Data Generation”, Yu et al 2023
- “VILA: On Pre-Training for Visual Language Models”, Lin et al 2023
- “Instruction-Tuning Aligns LLMs to the Human Brain”, Aw et al 2023
- “R-Tuning: Teaching Large Language Models to Refuse Unknown Questions”, Zhang et al 2023
- “When ‘A Helpful Assistant’ Is Not Really Helpful: Personas in System Prompts Do Not Improve Performances of Large Language Models”, Zheng et al 2023
- “Language Models Are Super Mario (DARE): Absorbing Abilities from Homologous Models As a Free Lunch”, Yu et al 2023
- “ChipNeMo: Domain-Adapted LLMs for Chip Design”, Liu et al 2023
- “Mistral-7B”, Jiang et al 2023
- “LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models”, Jiang et al 2023
- “LLaVA-1.5: Improved Baselines With Visual Instruction Tuning”, Liu et al 2023
- “UltraFeedback: Boosting Language Models With High-Quality Feedback”, Cui et al 2023
- “AceGPT, Localizing Large Language Models in Arabic”, Huang et al 2023
- “Can Programming Languages Boost Each Other via Instruction Tuning?”, Zan et al 2023
- “DialogStudio: Towards Richest and Most Diverse Unified Dataset Collection for Conversational AI”, Zhang et al 2023
- “LLaMA-2: Open Foundation and Fine-Tuned Chat Models”, Touvron et al 2023
- “AlpaGasus: Training A Better Alpaca With Fewer Data”, Chen et al 2023
- “Instruction Mining: High-Quality Instruction Data Selection for Large Language Models”, Cao et al 2023
- “Lost in the Middle: How Language Models Use Long Contexts”, Liu et al 2023
- “On the Exploitability of Instruction Tuning”, Shu et al 2023
- “ChessGPT: Bridging Policy Learning and Language Modeling”, Feng et al 2023
- “Dr. LLaMa: Improving Small Language Models in Domain-Specific QA via Generative Data Augmentation”, Guo et al 2023
- “SELF-ALIGN: Principle-Driven Self-Alignment of Language Models from Scratch With Minimal Human Supervision”, Sun et al 2023
- “Distilling Step-By-Step! Outperforming Larger Language Models With Less Training Data and Smaller Model Sizes”, Hsieh et al 2023
- “LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions”, Wu et al 2023
- “WizardLM: Empowering Large Language Models to Follow Complex Instructions”, Xu et al 2023
- “TANGO: Text-To-Audio Generation Using Instruction-Tuned LLM and Latent Diffusion Model”, Ghosal et al 2023
- “Phoenix: Democratizing ChatGPT across Languages”, Chen et al 2023
- “How Well Do Large Language Models Perform in Arithmetic Tasks?”, Yuan et al 2023
- “Larger Language Models Do In-Context Learning Differently”, Wei et al 2023
- “LLaMa-1: Open and Efficient Foundation Language Models”, Touvron et al 2023
- “How Does In-Context Learning Help Prompt Tuning?”, Sun et al 2023
- “No Robots: Look Ma, an Instruction Dataset That Wasn’t Generated by GPTs!”, HuggingFace 2023
- “Med-PaLM: Large Language Models Encode Clinical Knowledge”, Singhal et al 2022
- “Self-Instruct: Aligning Language Models With Self-Generated Instructions”, Wang et al 2022
- “Unnatural Instructions: Tuning Language Models With (Almost) No Human Labor”, Honovich et al 2022
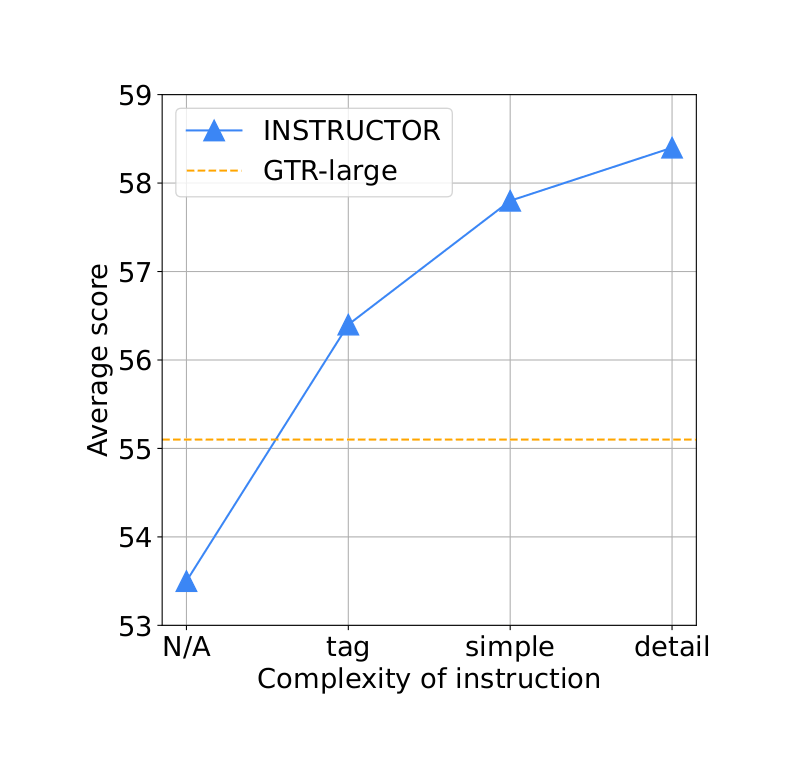
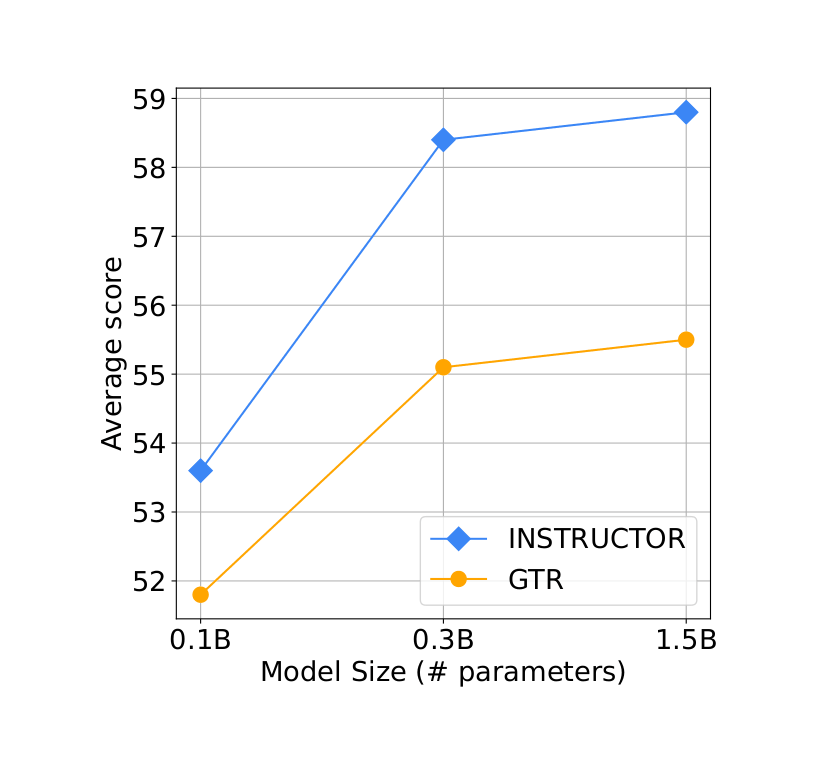
- “One Embedder, Any Task: Instruction-Finetuned Text Embeddings (INSTRUCTOR)”, Su et al 2022
- “HALIE: Evaluating Human-Language Model Interaction”, Lee et al 2022
- “BLOOMZ/mT0: Crosslingual Generalization through Multitask Finetuning”, Muennighoff et al 2022
- “Help Me Write a Poem: Instruction Tuning As a Vehicle for Collaborative Poetry Writing (CoPoet)”, Chakrabarty et al 2022
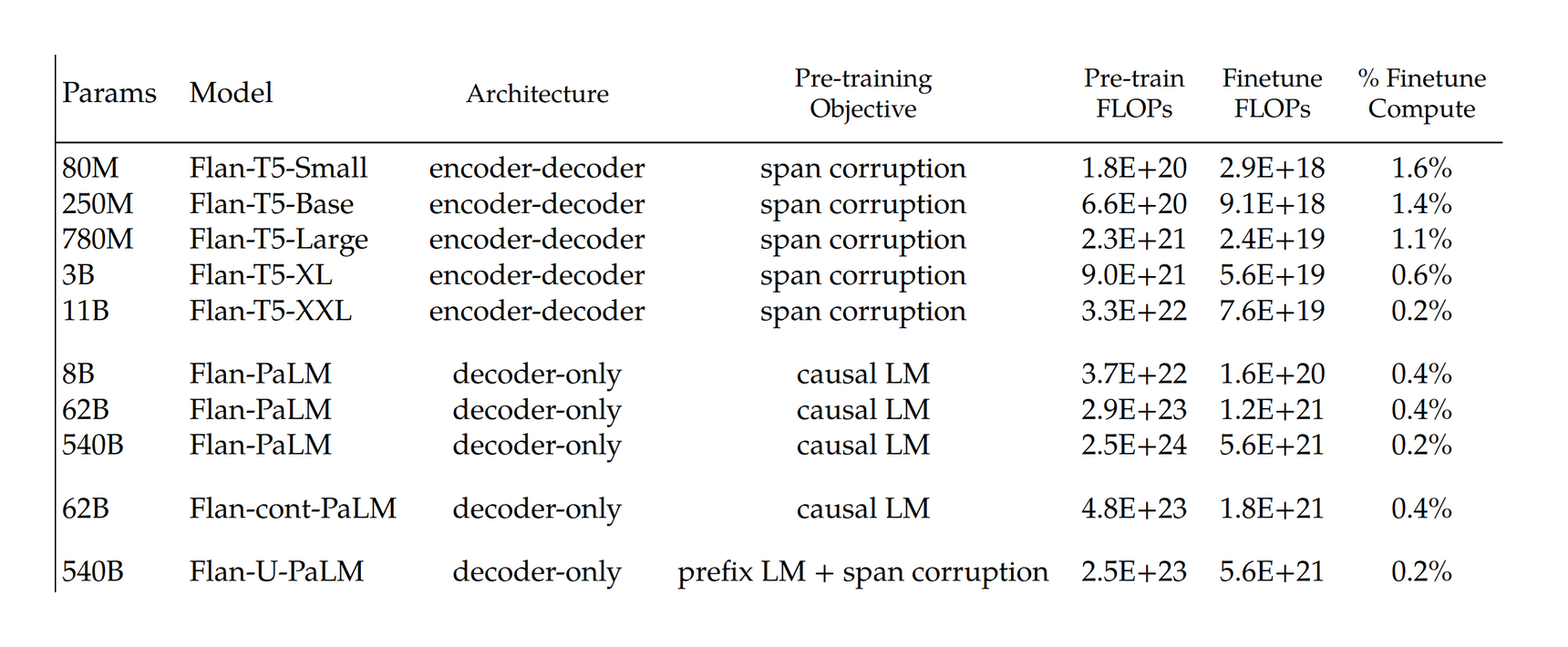
- “FLAN: Scaling Instruction-Finetuned Language Models”, Chung et al 2022
- “Language Models Are Multilingual Chain-Of-Thought Reasoners”, Shi et al 2022
- “LINGUIST: Language Model Instruction Tuning to Generate Annotated Utterances for Intent Classification and Slot Tagging”, Rosenbaum et al 2022
- “Z-Code++: A Pre-Trained Language Model Optimized for Abstractive Summarization”, He et al 2022
- “Few-Shot Adaptation Works With UnpredicTable Data”, Chan et al 2022
- “RST: ReStructured Pre-Training”, Yuan & Liu 2022
- “InstructDial: Improving Zero and Few-Shot Generalization in Dialogue through Instruction Tuning”, Gupta et al 2022
- “CT0: Fine-Tuned Language Models Are Continual Learners”, Scialom et al 2022
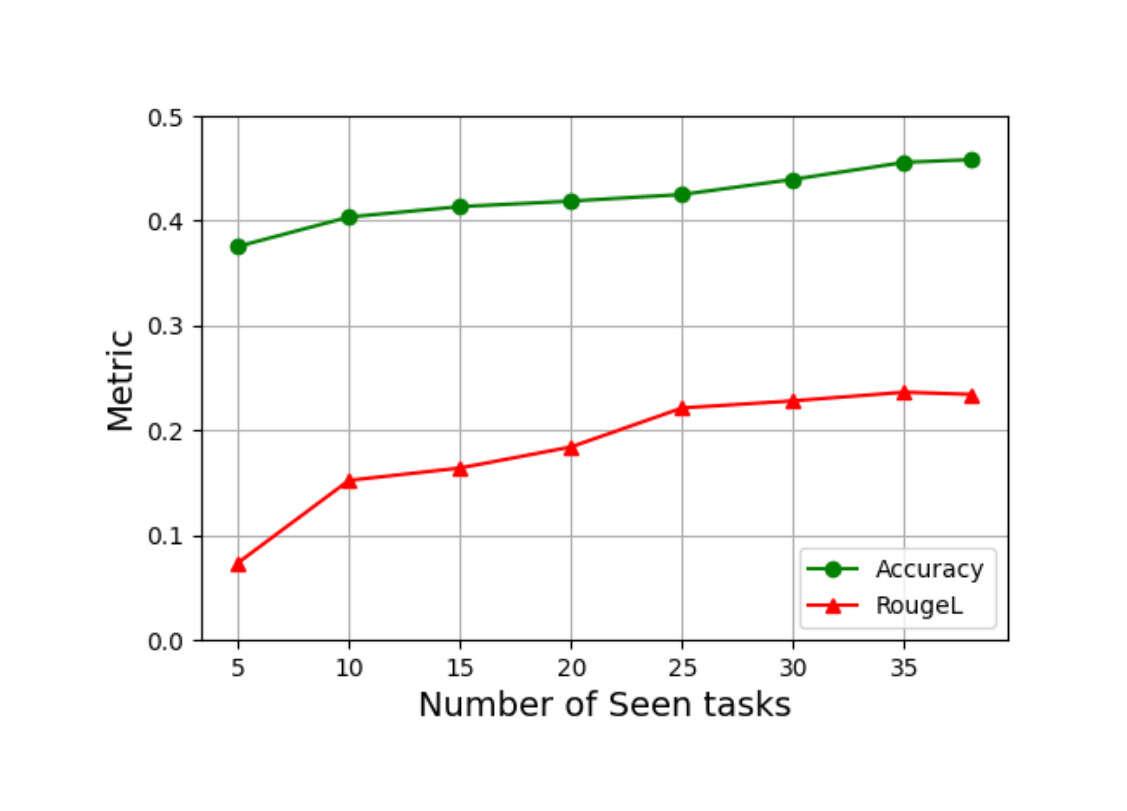
- “Tk-Instruct: Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks”, Wang et al 2022
- “What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?”, Wang et al 2022
- “UnifiedQA-V2: Stronger Generalization via Broader Cross-Format Training”, Khashabi et al 2022
- “Reasoning Like Program Executors”, Pi et al 2022
- “ZeroPrompt: Scaling Prompt-Based Pretraining to 1,000 Tasks Improves Zero-Shot Generalization”, Xu et al 2022
- “ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning”, Aribandi et al 2021
- “MetaICL: Learning to Learn In Context”, Min et al 2021
- “T0: Multitask Prompted Training Enables Zero-Shot Task Generalization”, Sanh et al 2021
- “FLAN: Finetuned Language Models Are Zero-Shot Learners”, Wei et al 2021
- “Cross-Task Generalization via Natural Language Crowdsourcing Instructions”, Mishra et al 2021
- “CrossFit: A Few-Shot Learning Challenge for Cross-Task Generalization in NLP”, Ye et al 2021
- “Adapting Language Models for Zero-Shot Learning by Meta-Tuning on Dataset and Prompt Collections”, Zhong et al 2021
- “Muppet: Massive Multi-Task Representations With Pre-Finetuning”, Aghajanyan et al 2021
- “UnifiedQA: Crossing Format Boundaries With a Single QA System”, Khashabi et al 2020
- “The Natural Language Decathlon: Multitask Learning As Question Answering”, McCann et al 2018
- “The RetroInstruct Guide To Synthetic Text Data”, Pressman 2026
- Sort By Magic
- Miscellaneous
- Bibliography
See Also
Links
“Vision Banana: Image Generators Are Generalist Vision Learners”, Gabeur et al 2026
Vision Banana: Image Generators are Generalist Vision Learners
“Neural Thickets: Diverse Task Experts Are Dense Around Pretrained Weights”, Gan & Isola 2026
Neural Thickets: Diverse Task Experts Are Dense Around Pretrained Weights
“Trained on Tokens, Calibrated on Concepts: The Emergence of Semantic Calibration in LLMs”, Nakkiran et al 2025
Trained on Tokens, Calibrated on Concepts: The Emergence of Semantic Calibration in LLMs
“How Many Instructions Can LLMs Follow at Once?”, Jaroslawicz et al 2025
“Native Sparse Attention (NSA): Hardware-Aligned and Natively Trainable Sparse Attention”, Yuan et al 2025
Native Sparse Attention (NSA): Hardware-Aligned and Natively Trainable Sparse Attention
“LLaDA: Large Language Diffusion Models”, Nie et al 2025
“What’s the Deal With Mid-Training?”, Doria 2025
“SANA: Efficient High-Resolution Image Synthesis With Linear Diffusion Transformers”, Xie et al 2024
SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
“Instruction Following without Instruction Tuning”, Hewitt et al 2024
“Hermes 3 Technical Report”, Teknium et al 2024
“Freedom at the Frontier: Hermes 3 § Amnesia Mode”, ARIA 2024
“State Soup: In-Context Skill Learning, Retrieval and Mixing”, Pióro et al 2024
“Auto Evol-Instruct: Automatic Instruction Evolving for Large Language Models”, Zeng et al 2024
Auto Evol-Instruct: Automatic Instruction Evolving for Large Language Models
“Instruction Modeling: Instruction Tuning With Loss Over Instructions”, Shi et al 2024
Instruction Modeling: Instruction Tuning With Loss Over Instructions
“LoRA Learns Less and Forgets Less”, Biderman et al 2024
“The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions”, Wallace et al 2024
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
“Best Practices and Lessons Learned on Synthetic Data for Language Models”, Liu et al 2024
Best Practices and Lessons Learned on Synthetic Data for Language Models
“RecurrentGemma: Moving Past Transformers for Efficient Open Language Models”, Botev et al 2024
RecurrentGemma: Moving Past Transformers for Efficient Open Language Models
“Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators”, Dubois et al 2024
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
“COIG-CQIA: Quality Is All You Need for Chinese Instruction Fine-Tuning”, Bai et al 2024
COIG-CQIA: Quality is All You Need for Chinese Instruction Fine-tuning
“MetaAligner: Conditional Weak-To-Strong Correction for Generalizable Multi-Objective Alignment of Language Models”, Yang et al 2024
“Mastering Text, Code and Math Simultaneously via Fusing Highly Specialized Language Models”, Ding et al 2024
Mastering Text, Code and Math Simultaneously via Fusing Highly Specialized Language Models
“StructLM: Towards Building Generalist Models for Structured Knowledge Grounding”, Zhuang et al 2024
StructLM: Towards Building Generalist Models for Structured Knowledge Grounding
“How to Train Data-Efficient LLMs”, Sachdeva et al 2024
“Rephrasing the Web (WARP): A Recipe for Compute and Data-Efficient Language Modeling”, Maini et al 2024
Rephrasing the Web (WARP): A Recipe for Compute and Data-Efficient Language Modeling
“WaveCoder: Widespread And Versatile Enhanced Instruction Tuning With Refined Data Generation”, Yu et al 2023
WaveCoder: Widespread And Versatile Enhanced Instruction Tuning with Refined Data Generation
“VILA: On Pre-Training for Visual Language Models”, Lin et al 2023
“Instruction-Tuning Aligns LLMs to the Human Brain”, Aw et al 2023
“R-Tuning: Teaching Large Language Models to Refuse Unknown Questions”, Zhang et al 2023
R-Tuning: Teaching Large Language Models to Refuse Unknown Questions
“When ‘A Helpful Assistant’ Is Not Really Helpful: Personas in System Prompts Do Not Improve Performances of Large Language Models”, Zheng et al 2023
“Language Models Are Super Mario (DARE): Absorbing Abilities from Homologous Models As a Free Lunch”, Yu et al 2023
Language Models are Super Mario (DARE): Absorbing Abilities from Homologous Models as a Free Lunch
“ChipNeMo: Domain-Adapted LLMs for Chip Design”, Liu et al 2023
“Mistral-7B”, Jiang et al 2023
“LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models”, Jiang et al 2023
LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models
“LLaVA-1.5: Improved Baselines With Visual Instruction Tuning”, Liu et al 2023
LLaVA-1.5: Improved Baselines with Visual Instruction Tuning
“UltraFeedback: Boosting Language Models With High-Quality Feedback”, Cui et al 2023
UltraFeedback: Boosting Language Models with High-quality Feedback
“AceGPT, Localizing Large Language Models in Arabic”, Huang et al 2023
“Can Programming Languages Boost Each Other via Instruction Tuning?”, Zan et al 2023
Can Programming Languages Boost Each Other via Instruction Tuning?
“DialogStudio: Towards Richest and Most Diverse Unified Dataset Collection for Conversational AI”, Zhang et al 2023
DialogStudio: Towards Richest and Most Diverse Unified Dataset Collection for Conversational AI
“LLaMA-2: Open Foundation and Fine-Tuned Chat Models”, Touvron et al 2023
“AlpaGasus: Training A Better Alpaca With Fewer Data”, Chen et al 2023
“Instruction Mining: High-Quality Instruction Data Selection for Large Language Models”, Cao et al 2023
Instruction Mining: High-Quality Instruction Data Selection for Large Language Models
“Lost in the Middle: How Language Models Use Long Contexts”, Liu et al 2023
“On the Exploitability of Instruction Tuning”, Shu et al 2023
“ChessGPT: Bridging Policy Learning and Language Modeling”, Feng et al 2023
“Dr. LLaMa: Improving Small Language Models in Domain-Specific QA via Generative Data Augmentation”, Guo et al 2023
Dr. LLaMa: Improving Small Language Models in Domain-Specific QA via Generative Data Augmentation
“SELF-ALIGN: Principle-Driven Self-Alignment of Language Models from Scratch With Minimal Human Supervision”, Sun et al 2023
“Distilling Step-By-Step! Outperforming Larger Language Models With Less Training Data and Smaller Model Sizes”, Hsieh et al 2023
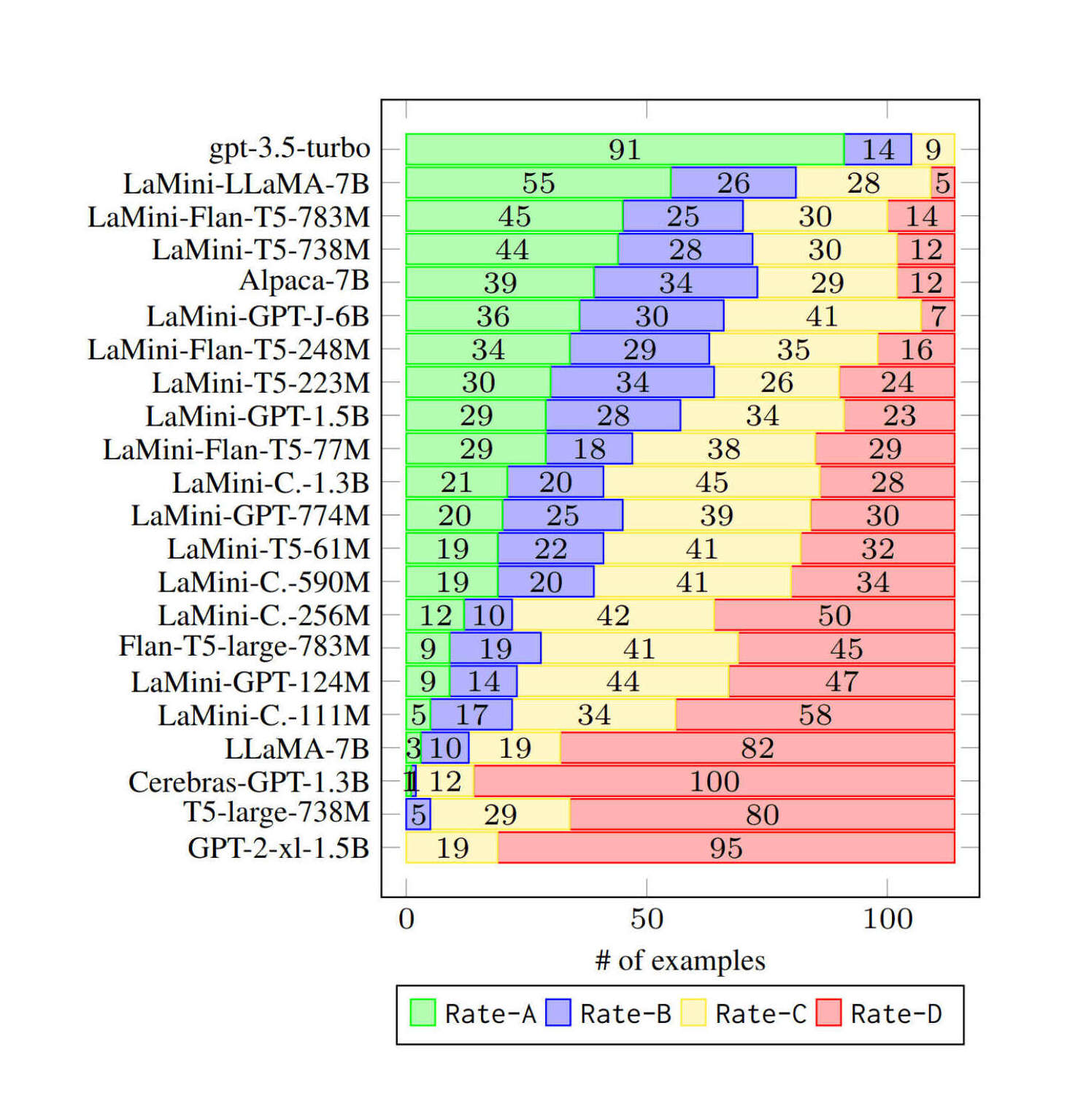
“LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions”, Wu et al 2023
LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions
“WizardLM: Empowering Large Language Models to Follow Complex Instructions”, Xu et al 2023
WizardLM: Empowering Large Language Models to Follow Complex Instructions
“TANGO: Text-To-Audio Generation Using Instruction-Tuned LLM and Latent Diffusion Model”, Ghosal et al 2023
TANGO: Text-to-Audio Generation using Instruction-Tuned LLM and Latent Diffusion Model
“Phoenix: Democratizing ChatGPT across Languages”, Chen et al 2023
“How Well Do Large Language Models Perform in Arithmetic Tasks?”, Yuan et al 2023
How well do Large Language Models perform in Arithmetic tasks?
“Larger Language Models Do In-Context Learning Differently”, Wei et al 2023
“LLaMa-1: Open and Efficient Foundation Language Models”, Touvron et al 2023
“How Does In-Context Learning Help Prompt Tuning?”, Sun et al 2023
“No Robots: Look Ma, an Instruction Dataset That Wasn’t Generated by GPTs!”, HuggingFace 2023
No Robots: Look Ma, an instruction dataset that wasn’t generated by GPTs!
“Med-PaLM: Large Language Models Encode Clinical Knowledge”, Singhal et al 2022
“Self-Instruct: Aligning Language Models With Self-Generated Instructions”, Wang et al 2022
Self-Instruct: Aligning Language Models with Self-Generated Instructions
“Unnatural Instructions: Tuning Language Models With (Almost) No Human Labor”, Honovich et al 2022
Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor
“One Embedder, Any Task: Instruction-Finetuned Text Embeddings (INSTRUCTOR)”, Su et al 2022
One Embedder, Any Task: Instruction-Finetuned Text Embeddings (INSTRUCTOR)
“HALIE: Evaluating Human-Language Model Interaction”, Lee et al 2022
“BLOOMZ/mT0: Crosslingual Generalization through Multitask Finetuning”, Muennighoff et al 2022
BLOOMZ/mT0: Crosslingual Generalization through Multitask Finetuning
“Help Me Write a Poem: Instruction Tuning As a Vehicle for Collaborative Poetry Writing (CoPoet)”, Chakrabarty et al 2022
Help me write a poem: Instruction Tuning as a Vehicle for Collaborative Poetry Writing (CoPoet)
“FLAN: Scaling Instruction-Finetuned Language Models”, Chung et al 2022
“Language Models Are Multilingual Chain-Of-Thought Reasoners”, Shi et al 2022
“LINGUIST: Language Model Instruction Tuning to Generate Annotated Utterances for Intent Classification and Slot Tagging”, Rosenbaum et al 2022
“Z-Code++: A Pre-Trained Language Model Optimized for Abstractive Summarization”, He et al 2022
Z-Code++: A Pre-trained Language Model Optimized for Abstractive Summarization
“Few-Shot Adaptation Works With UnpredicTable Data”, Chan et al 2022
“RST: ReStructured Pre-Training”, Yuan & Liu 2022
“InstructDial: Improving Zero and Few-Shot Generalization in Dialogue through Instruction Tuning”, Gupta et al 2022
InstructDial: Improving Zero and Few-shot Generalization in Dialogue through Instruction Tuning
“CT0: Fine-Tuned Language Models Are Continual Learners”, Scialom et al 2022
“Tk-Instruct: Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks”, Wang et al 2022
Tk-Instruct: Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks
“What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?”, Wang et al 2022
What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?
“UnifiedQA-V2: Stronger Generalization via Broader Cross-Format Training”, Khashabi et al 2022
UnifiedQA-v2: Stronger Generalization via Broader Cross-Format Training
“Reasoning Like Program Executors”, Pi et al 2022
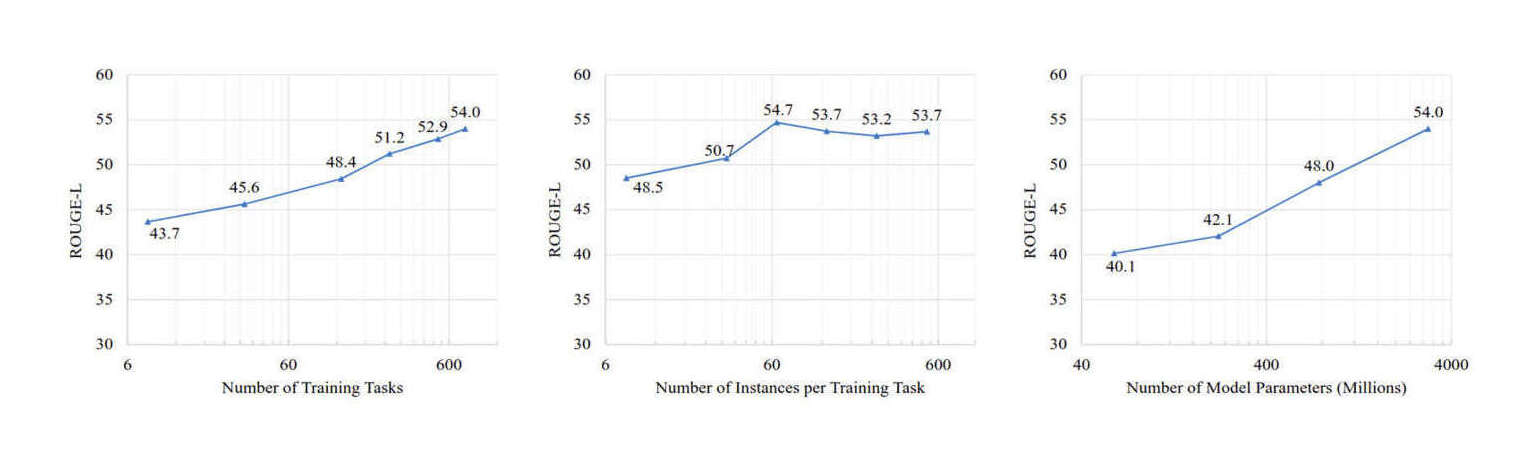
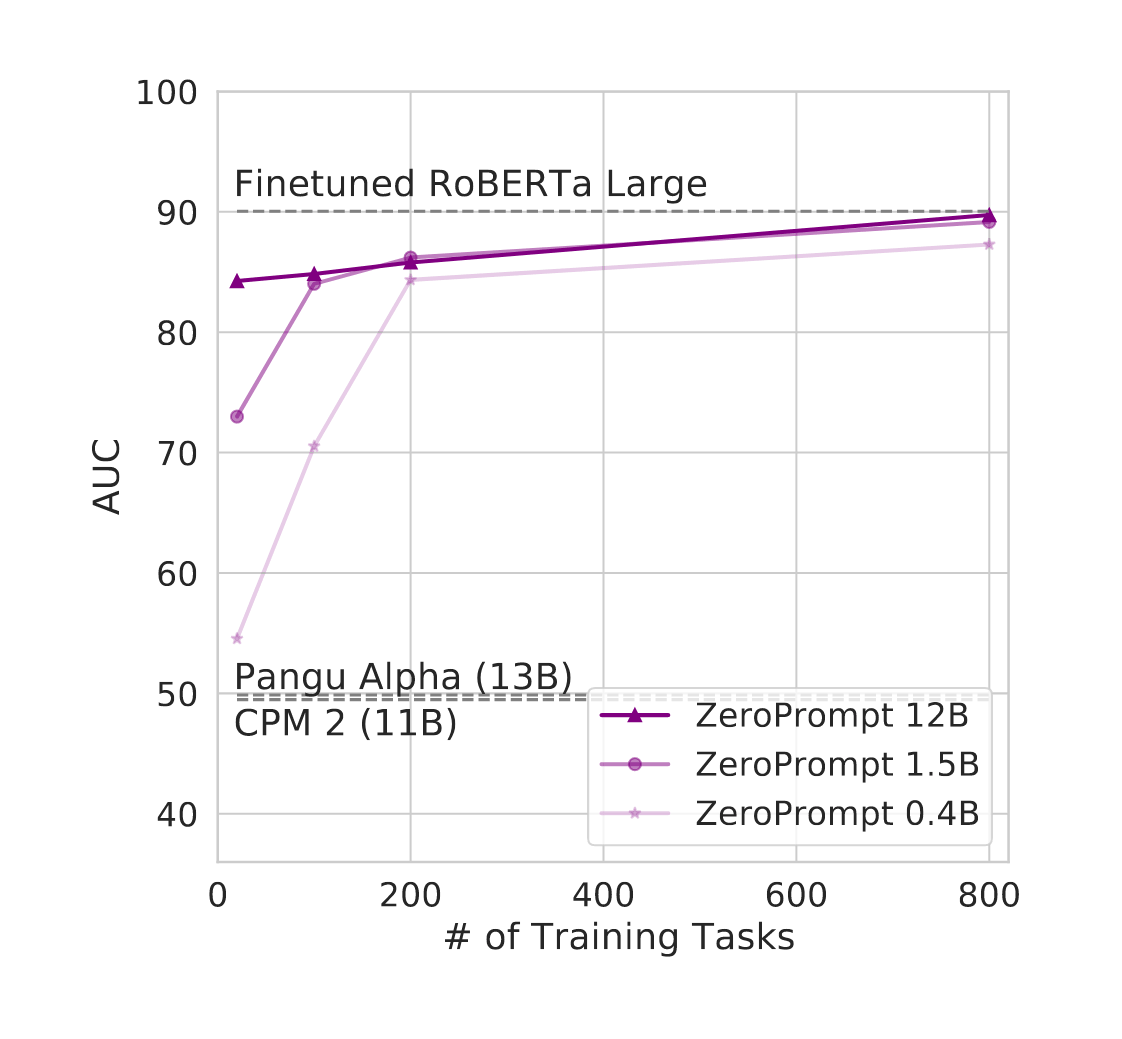
“ZeroPrompt: Scaling Prompt-Based Pretraining to 1,000 Tasks Improves Zero-Shot Generalization”, Xu et al 2022
ZeroPrompt: Scaling Prompt-Based Pretraining to 1,000 Tasks Improves Zero-Shot Generalization
“ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning”, Aribandi et al 2021
ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning
“MetaICL: Learning to Learn In Context”, Min et al 2021
“T0: Multitask Prompted Training Enables Zero-Shot Task Generalization”, Sanh et al 2021
T0: Multitask Prompted Training Enables Zero-Shot Task Generalization
“FLAN: Finetuned Language Models Are Zero-Shot Learners”, Wei et al 2021
“Cross-Task Generalization via Natural Language Crowdsourcing Instructions”, Mishra et al 2021
Cross-Task Generalization via Natural Language Crowdsourcing Instructions
“CrossFit: A Few-Shot Learning Challenge for Cross-Task Generalization in NLP”, Ye et al 2021
CrossFit: A Few-shot Learning Challenge for Cross-task Generalization in NLP
“Adapting Language Models for Zero-Shot Learning by Meta-Tuning on Dataset and Prompt Collections”, Zhong et al 2021
Adapting Language Models for Zero-shot Learning by Meta-tuning on Dataset and Prompt Collections
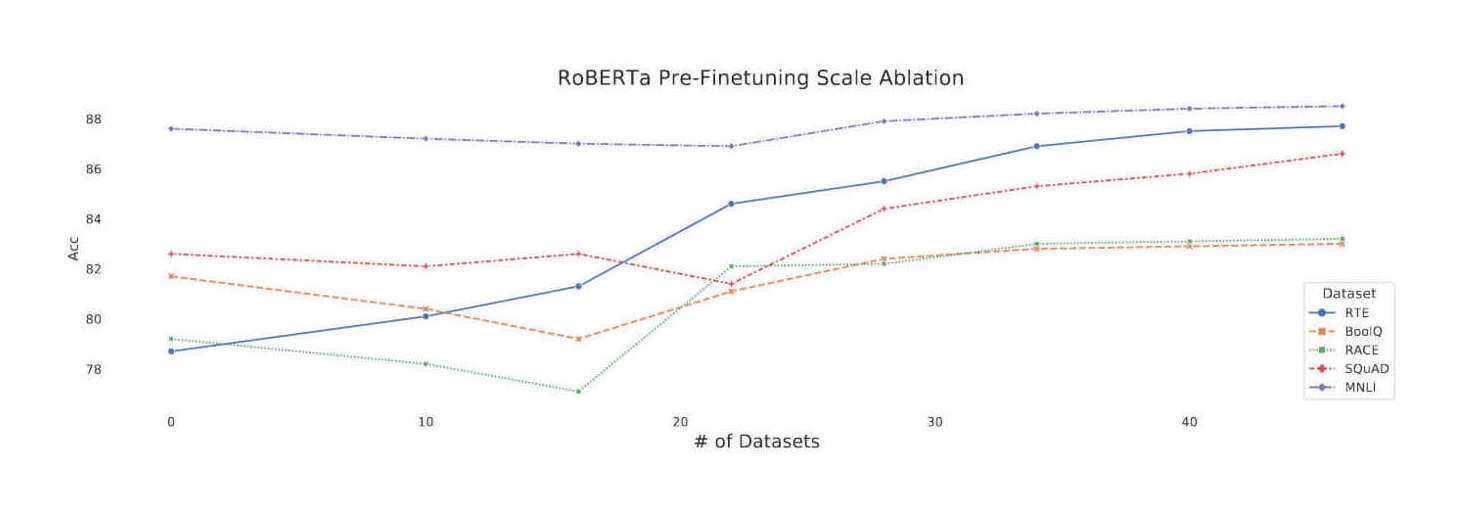
“Muppet: Massive Multi-Task Representations With Pre-Finetuning”, Aghajanyan et al 2021
Muppet: Massive Multi-task Representations with Pre-Finetuning
“UnifiedQA: Crossing Format Boundaries With a Single QA System”, Khashabi et al 2020
UnifiedQA: Crossing Format Boundaries With a Single QA System
“The Natural Language Decathlon: Multitask Learning As Question Answering”, McCann et al 2018
The Natural Language Decathlon: Multitask Learning as Question Answering
“The RetroInstruct Guide To Synthetic Text Data”, Pressman 2026
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
dialog-datasets instruction-collection instruction-rare conversational-dataset unified-dialog understanding-datasets conversational-ai
learning-forgetting
sparse-attention
hermes-mistral
instruction-finetuning
Miscellaneous
https://github.com/bigscience-workshop/architecture-objectivehttps://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpointshttps://www.databricks.com/blog/2023/03/24/hello-dolly-democratizing-magic-chatgpt-open-models.htmlhttps://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2502.09992: “LLaDA: Large Language Diffusion Models”,https://arxiv.org/abs/2410.10629#nvidia: “SANA: Efficient High-Resolution Image Synthesis With Linear Diffusion Transformers”,https://arxiv.org/abs/2402.16671: “StructLM: Towards Building Generalist Models for Structured Knowledge Grounding”,https://arxiv.org/abs/2310.06825#mistral: “Mistral-7B”,https://arxiv.org/abs/2310.05736: “LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models”,https://arxiv.org/abs/2310.01377: “UltraFeedback: Boosting Language Models With High-Quality Feedback”,https://arxiv.org/abs/2309.12053: “AceGPT, Localizing Large Language Models in Arabic”,https://arxiv.org/abs/2307.08701#samsung: “AlpaGasus: Training A Better Alpaca With Fewer Data”,https://arxiv.org/abs/2305.07804: “Dr. LLaMa: Improving Small Language Models in Domain-Specific QA via Generative Data Augmentation”,https://arxiv.org/abs/2305.03047#ibm: “SELF-ALIGN: Principle-Driven Self-Alignment of Language Models from Scratch With Minimal Human Supervision”,https://arxiv.org/abs/2305.02301#google: “Distilling Step-By-Step! Outperforming Larger Language Models With Less Training Data and Smaller Model Sizes”,https://arxiv.org/abs/2304.12244: “WizardLM: Empowering Large Language Models to Follow Complex Instructions”,https://arxiv.org/abs/2304.13731: “TANGO: Text-To-Audio Generation Using Instruction-Tuned LLM and Latent Diffusion Model”,https://arxiv.org/abs/2304.02015#alibaba: “How Well Do Large Language Models Perform in Arithmetic Tasks?”,https://arxiv.org/abs/2303.03846#google: “Larger Language Models Do In-Context Learning Differently”,https://arxiv.org/abs/2212.13138#google: “Med-PaLM: Large Language Models Encode Clinical Knowledge”,https://arxiv.org/abs/2212.10560: “Self-Instruct: Aligning Language Models With Self-Generated Instructions”,https://arxiv.org/abs/2212.09741: “One Embedder, Any Task: Instruction-Finetuned Text Embeddings (INSTRUCTOR)”,https://arxiv.org/abs/2211.01786: “BLOOMZ/mT0: Crosslingual Generalization through Multitask Finetuning”,https://arxiv.org/abs/2210.13669: “Help Me Write a Poem: Instruction Tuning As a Vehicle for Collaborative Poetry Writing (CoPoet)”,https://arxiv.org/abs/2210.11416#google: “FLAN: Scaling Instruction-Finetuned Language Models”,https://arxiv.org/abs/2210.03057#google: “Language Models Are Multilingual Chain-Of-Thought Reasoners”,https://arxiv.org/abs/2208.09770#microsoft: “Z-Code++: A Pre-Trained Language Model Optimized for Abstractive Summarization”,https://arxiv.org/abs/2205.12393: “CT0: Fine-Tuned Language Models Are Continual Learners”,https://arxiv.org/abs/2204.07705: “Tk-Instruct: Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks”,https://arxiv.org/abs/2201.11473#microsoft: “Reasoning Like Program Executors”,https://arxiv.org/abs/2201.06910: “ZeroPrompt: Scaling Prompt-Based Pretraining to 1,000 Tasks Improves Zero-Shot Generalization”,https://arxiv.org/abs/1806.08730#salesforce: “The Natural Language Decathlon: Multitask Learning As Question Answering”,