‘ML dataset’ directory
- See Also
- Gwern
- Links
- “State Media Control Influences Large Language Models”, Waight et al 2026
- “StoryScope: Investigating Idiosyncrasies in AI Fiction”, Russell et al 2026
- “StoryScope: Investigating Idiosyncrasies in AI Fiction”, Russell 2026
- “MIRAGE: The Illusion of Visual Understanding”, Asadi et al 2026
- “DECEPTICON: How Dark Patterns Manipulate Web Agents”, Cuvin et al 2025
- “Attack on Titan (AoT): Anime Image Dataset for Character, Scene, Emotion Recognition and Beyond”, Khan et al 2025
- “OregairuChar: A Benchmark Dataset for Character Appearance Frequency Analysis in My Teen Romantic Comedy SNAFU”, Sun et al 2025
- “Lean4Physics: Comprehensive Reasoning Framework for College-Level Physics in Lean4”, Li et al 2025
- “ImpossibleBench: Measuring LLMs’ Propensity of Exploiting Test Cases”, Zhong et al 2025
- “Evaluating Long Context (Reasoning) Ability”
- “Realistic Reward Hacking Induces Different and Deeper Misalignment”, Jozdien 2025
- “Redefining Generalization in Visual Domains: A Two-Axis Framework for Fake Image Detection With FusionDetect”, Amanzadi et al 2025
- “School of Reward Hacks: Hacking Harmless Tasks Generalizes to Misaligned Behavior in LLMs”, Taylor et al 2025
- “Teaching AI [Blacklist/whitelist of Example Sources for Claude RLHF]”, Sheets 2025
- “30% of Humanity’s Last Exam Chemistry/biology Answers Are Likely Wrong”, Skarlinski et al 2025
- “How Many Instructions Can LLMs Follow at Once?”, Jaroslawicz et al 2025
- “Machine Bullshit: Characterizing the Emergent Disregard for Truth in Large Language Models”, Liang et al 2025
- “Scale AI’s Spam, Security Woes Plagued the Company While Serving Google—How the Startup That Just Scored a $14 Billion Investment from Meta Struggled to Contain ‘Spammy Behavior’ from Unqualified Contributors As It Trained Gemini”, Blum 2025
- “What Skills Does SWE-Bench Verified Evaluate?: We Take a Deep Dive into SWE-Bench Verified, a Prominent Agentic Coding Benchmark. While One of the Best Public Tests of AI Coding Agents, It Is Limited by Its Focus on Simple Bug Fixes in Familiar Open-Source Repositories.”, Brand & Denain 2025
- “Common Corpus: The Largest Collection of Ethical Data for LLM Pre-Training”, Langlais et al 2025
- “Time Blindness: Why Video-Language Models Can’t See What Humans Can?”, Upadhyay et al 2025
- “Instance-Guided Anime Editing With a Curated Large-Scale Dataset”, Lin et al 2025
- “RealMath: A Continuous Benchmark for Evaluating Language Models on Research-Level Mathematics”, Zhang et al 2025
- “RealMath [Code]”, Zhang et al 2025
- “Generating Physically Stable and Buildable LEGO Designs from Text”, Pun et al 2025
- “LegoGPT: Generating Physically Stable and Buildable LEGO Designs from Text”, Pun et al 2025
- “LegoGPT: Official Repository for LegoGPT, the First Approach for Generating Physically Stable LEGO Brick Models from Text Prompts”, Pun et al 2025
- “Rewriting Pre-Training Data Boosts LLM Performance in Math and Code [SwallowCode/Math]”, Fujii et al 2025
- “New News: System-2 Fine-Tuning for Robust Integration of New Knowledge”, Park et al 2025
- “Virology Capabilities Test (VCT): A Multimodal Virology Q&A Benchmark”, Götting et al 2025
- “AnimeDL-2M: Million-Scale AI-Generated Anime Image Detection and Localization in Diffusion Era”, Zhu et al 2025
- “DeepMath-103K: A Large-Scale, Challenging, Decontaminated, and Verifiable Mathematical Dataset for Advancing Reasoning”, He et al 2025
- “AI-Slop to AI-Polish? Aligning Language Models through Edit-Based Writing Rewards and Test-Time Computation”, Chakrabarty et al 2025
- “AutoEval: Autonomous Evaluation of Generalist Robot Manipulation Policies in the Real World”, Zhou et al 2025
- “GSM8K-Platinum: Revealing Performance Gaps in Frontier LLMs”, Vendrow et al 2025
- “Chronologically Consistent Large Language Models”, He et al 2025
- “Rank1: Test-Time Compute for Reranking in Information Retrieval”, Weller et al 2025
- “None of the Others: a General Technique to Distinguish Reasoning from Memorization in Multiple-Choice LLM Evaluation Benchmarks”, Salido et al 2025
- “NaturalReasoning: Reasoning in the Wild With 2.8M Challenging Questions”, Yuan et al 2025
- “VLMs As GeoGuessr Masters: Exceptional Performance, Hidden Biases, and Privacy Risks”, Huang et al 2025
- “ZeroBench: An Impossible Visual Benchmark for Contemporary Large Multimodal Models”, Roberts et al 2025
- “Lost in Time: Clock and Calendar Understanding Challenges in Multimodal LLMs”, Saxena et al 2025
- “Do Large Language Model Benchmarks Test Reliability?”, Vendrow et al 2025
- “SmolLM2: When Smol Goes Big—Data-Centric Training of a Small Language Model”, Allal et al 2025
- “Discord Unveiled: A Comprehensive Dataset of Public Communication (2015–2024)”, Aquino et al 2025
- “S1: Simple Test-Time Scaling”, Muennighoff et al 2025
- “Do Generative Video Models Learn Physical Principles from Watching Videos?”, Motamed et al 2025
- “An Evaluation Framework for Clinical Use of Large Language Models in Patient Interaction Tasks”, Johri et al 2025
- “Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?”, Yang et al 2024
- “BALROG: Benchmarking Agentic LLM and VLM Reasoning On Games”, Paglieri et al 2024
- “Are LLMs Prescient? A Continuous Evaluation Using Daily News As the Oracle”, Dai et al 2024
- “HtmlRAG: HTML Is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems”, Tan et al 2024
- “Centaur: a Foundation Model of Human Cognition”, Binz et al 2024
- “AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents”, Andriushchenko et al 2024
- “SimpleStrat: Diversifying Language Model Generation With Stratification”, Wong et al 2024
- “SWE-Bench+: Enhanced Coding Benchmark for LLMs”, Aleithan et al 2024
- “MLE-Bench: Evaluating Machine Learning Agents on Machine Learning Engineering”, Chan et al 2024
- “Embodied Agent Interface: Benchmarking LLMs for Embodied Decision Making”, Li et al 2024
- “Seeing Faces in Things: A Model and Dataset for Pareidolia”, Hamilton et al 2024
- “H-ARC: A Robust Estimate of Human Performance on the Abstraction and Reasoning Corpus Benchmark”, LeGris et al 2024
- “How to Evaluate Jailbreak Methods: A Case Study With the StrongREJECT Benchmark”, Bowen et al 2024
- “To Code, or Not To Code? Exploring Impact of Code in Pre-Training”, Aryabumi et al 2024
- “Tails Tell Tales: Chapter-Wide Manga Transcriptions With Character Names”, Sachdeva et al 2024
- “ImagiNet: A Multi-Content Dataset for Generalizable Synthetic Image Detection via Contrastive Learning”, Boychev & Cholakov 2024
- “Me, Myself, and AI: The Situational Awareness Dataset (SAD) for LLMs”, Laine et al 2024
- “Future Events As Backdoor Triggers: Investigating Temporal Vulnerabilities in LLMs”, Price et al 2024
- “Sonnet or Not, Bot? Poetry Evaluation for Large Models and Datasets”, Walsh et al 2024
- “APIGen: Automated Pipeline for Generating Verifiable and Diverse Function-Calling Datasets”, Liu et al 2024
- “Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?”, Lee et al 2024
- “OlympicArena: Benchmarking Multi-Discipline Cognitive Reasoning for Superintelligent AI”, Huang et al 2024
- “DataComp-LM: In Search of the next Generation of Training Sets for Language Models”, Li et al 2024
- “GUI-WORLD: A Dataset for GUI-Oriented Multimodal LLM-Based Agents”, Chen et al 2024
- “Newswire: A Large-Scale Structured Database of a Century of Historical News”, Silcock et al 2024
- “RWKV-CLIP: A Robust Vision-Language Representation Learner”, Gu et al 2024
- “Are We Done With MMLU?”, Gema et al 2024
- “ShareGPT4Video: Improving Video Understanding and Generation With Better Captions”, Chen et al 2024
- “MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark”, Wang et al 2024
- “LLMs Achieve Adult Human Performance on Higher-Order Theory of Mind Tasks”, Street et al 2024
- “DeTikZify: Synthesizing Graphics Programs for Scientific Figures and Sketches With TikZ”, Belouadi et al 2024
- “Sakuga-42M Dataset: Scaling Up Cartoon Research”, Pan et al 2024
- “Can Language Models Explain Their Own Classification Behavior?”, Sherburn et al 2024
- “Special Characters Attack: Toward Scalable Training Data Extraction From Large Language Models”, Bai et al 2024
- “ImageInWords: Unlocking Hyper-Detailed Image Descriptions”, Garg et al 2024
- “GSM1k: A Careful Examination of Large Language Model Performance on Grade School Arithmetic”, Zhang et al 2024
- “Building a Large Japanese Web Corpus for Large Language Models”, Okazaki et al 2024
- “CulturalTeaming: AI-Assisted Interactive Red-Teaming for Challenging LLMs’ (Lack Of) Multicultural Knowledge”, Chiu et al 2024
- “VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?”, Liu et al 2024
- “RULER: What’s the Real Context Size of Your Long-Context Language Models?”, Hsieh et al 2024
- “Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators”, Dubois et al 2024
- “How Tech Giants Cut Corners to Harvest Data for AI: OpenAI, Google and Meta Ignored Corporate Policies, Altered Their Own Rules and Discussed Skirting Copyright Law As They Sought Online Information to Train Their Newest Artificial Intelligence Systems”, Metz et al 2024
- “Evaluating Text-To-Visual Generation With Image-To-Text Generation”, Lin et al 2024
- “Vulnerability Detection With Code Language Models: How Far Are We?”, Ding et al 2024
- “Long-Form Factuality in Large Language Models”, Wei et al 2024
- “COIG-CQIA: Quality Is All You Need for Chinese Instruction Fine-Tuning”, Bai et al 2024
- “RewardBench: Evaluating Reward Models for Language Modeling”, Lambert et al 2024
- “Evaluating Text to Image Synthesis: Survey and Taxonomy of Image Quality Metrics”, Hartwig et al 2024
- “Hierarchical Feature Warping and Blending for Talking Head Animation”, Zhang et al 2024
- “Mastering Text, Code and Math Simultaneously via Fusing Highly Specialized Language Models”, Ding et al 2024
- “ELLA: Equip Diffusion Models With LLM for Enhanced Semantic Alignment”, Hu et al 2024
- “Investigating Continual Pretraining in Large Language Models: Insights and Implications”, Yıldız et al 2024
- “Hal-Eval: A Universal and Fine-Grained Hallucination Evaluation Framework for Large Vision Language Models”, Jiang et al 2024
- “Assisting in Writing Wikipedia-Like Articles From Scratch With Large Language Models”, Shao et al 2024
- “Wikibench: Community-Driven Data Curation for AI Evaluation on Wikipedia”, Kuo et al 2024
- “
ArtPrompt: ASCII Art-Based Jailbreak Attacks against Aligned LLMs”, Jiang et al 2024 - “DE-COP: Detecting Copyrighted Content in Language Models Training Data”, Duarte et al 2024
- “I Think, Therefore I Am: Benchmarking Awareness of Large Language Models Using AwareBench”, Li et al 2024
- “Annotated Hands for Generative Models”, Yang et al 2024
- “Can AI Assistants Know What They Don’t Know?”, Cheng et al 2024
- “AnimeDiffusion: Anime Diffusion Colorization”, Cao et al 2024
- “I Am a Strange Dataset: Metalinguistic Tests for Language Models”, Thrush et al 2024
- “DeepSeek LLM: Scaling Open-Source Language Models With Longtermism”, Bi et al 2024
- “Generative AI for Math: Part I—MathPile: A Billion-Token-Scale Pretraining Corpus for Math”, Wang et al 2023
- “WaveCoder: Widespread And Versatile Enhanced Instruction Tuning With Refined Data Generation”, Yu et al 2023
- “Large Language Models Play StarCraft II: Benchmarks and A Chain of Summarization Approach”, Ma et al 2023
- “StarVector: Generating Scalable Vector Graphics Code from Images”, Rodriguez et al 2023
- “Rich Human Feedback for Text-To-Image Generation”, Liang et al 2023
- “TinyGSM: Achieving >80% on GSM8k With Small Language Models”, Liu et al 2023
- “EQ-Bench: An Emotional Intelligence Benchmark for Large Language Models”, Paech 2023
- “Retrieving Conditions from Reference Images for Diffusion Models”, Tang et al 2023
- “Sequential Modeling Enables Scalable Learning for Large Vision Models”, Bai et al 2023
- “BioCLIP: A Vision Foundation Model for the Tree of Life”, Stevens et al 2023
- “Efficient Transformer Knowledge Distillation: A Performance Review”, Brown et al 2023
- “GPQA: A Graduate-Level Google-Proof Q&A Benchmark”, Rein et al 2023
- “Dazed & Confused: A Large-Scale Real-World User Study of ReCAPTCHAv2”, Searles et al 2023
- “Instruction-Following Evaluation for Large Language Models”, Zhou et al 2023
- “In Search of the Long-Tail: Systematic Generation of Long-Tail Inferential Knowledge via Logical Rule Guided Search”, Li et al 2023
- “AnyText: Multilingual Visual Text Generation And Editing”, Tuo et al 2023
- “GLaMM: Pixel Grounding Large Multimodal Model”, Rasheed et al 2023
- “Don’t Make Your LLM an Evaluation Benchmark Cheater”, Zhou et al 2023
- “CommonCanvas: An Open Diffusion Model Trained With Creative-Commons Images”, Gokaslan et al 2023
- “FANToM: A Benchmark for Stress-Testing Machine Theory of Mind in Interactions”, Kim et al 2023
- “MuSR: Testing the Limits of Chain-Of-Thought With Multistep Soft Reasoning”, Sprague et al 2023
- “Ignore This Title and HackAPrompt: Exposing Systemic Vulnerabilities of LLMs through a Global Scale Prompt Hacking Competition”, Schulhoff et al 2023
- “Llemma: An Open Language Model For Mathematics”, Azerbayev et al 2023
- “From Scarcity to Efficiency: Improving CLIP Training via Visual-Enriched Captions”, Lai et al 2023
- “TabLib: A Dataset of 627M Tables With Context”, Eggert et al 2023
- “SWE-Bench: Can Language Models Resolve Real-World GitHub Issues?”, Jimenez et al 2023
- “OpenWebMath: An Open Dataset of High-Quality Mathematical Web Text”, Paster et al 2023
- “FreshLLMs: Refreshing Large Language Models With Search Engine Augmentation”, Vu et al 2023
- “UltraFeedback: Boosting Language Models With High-Quality Feedback”, Cui et al 2023
- “MTOB: A Benchmark for Learning to Translate a New Language from One Grammar Book”, Tanzer et al 2023
- “Demystifying CLIP Data”, Xu et al 2023
- “The Cambridge Law Corpus: A Corpus for Legal AI Research”, Östling et al 2023
- “MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models”, Yu et al 2023
- “LongLoRA: Efficient Fine-Tuning of Long-Context Large Language Models”, Chen et al 2023
- “SlimPajama-DC: Understanding Data Combinations for LLM Training”, Shen et al 2023
- “MADLAD-400: A Multilingual And Document-Level Large Audited Dataset”, Kudugunta et al 2023
- “GoodWiki”, Choi 2023
- “From Sparse to Dense: GPT-4 Summarization With Chain of Density (CoD) Prompting”, Adams et al 2023
- “FIMO: A Challenge Formal Dataset for Automated Theorem Proving”, Liu et al 2023
- “American Stories: A Large-Scale Structured Text Dataset of Historical US Newspapers”, Dell et al 2023
- “LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models”, Guha et al 2023
- “OctoPack: Instruction Tuning Code Large Language Models”, Muennighoff et al 2023
- “The ConceptARC Benchmark: Evaluating Understanding and Generalization in the ARC Domain”, Moskvichev et al 2023
- “Android in the Wild: A Large-Scale Dataset for Android Device Control”, Rawles et al 2023
- “DialogStudio: Towards Richest and Most Diverse Unified Dataset Collection for Conversational AI”, Zhang et al 2023
- “AlpaGasus: Training A Better Alpaca With Fewer Data”, Chen et al 2023
- “InternVid: A Large-Scale Video-Text Dataset for Multimodal Understanding and Generation”, Wang et al 2023
- “Instruction Mining: High-Quality Instruction Data Selection for Large Language Models”, Cao et al 2023
- “Test-Time Training on Video Streams”, Wang et al 2023
- “HEADLINES: A Massive Scale Semantic Similarity Dataset of Historical English”, Silcock & Dell 2023
- “LeanDojo: Theorem Proving With Retrieval-Augmented Language Models”, Yang et al 2023
- “SugarCrepe: Fixing Hackable Benchmarks for Vision-Language Compositionality”, Hsieh et al 2023
- “ARIES: A Corpus of Scientific Paper Edits Made in Response to Peer Reviews”, D’Arcy et al 2023
- “Understanding Social Reasoning in Language Models With Language Models”, Gandhi et al 2023
- “OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents”, Laurençon et al 2023
- “AI Is a Lot of Work: As the Technology Becomes Ubiquitous, a Vast Tasker Underclass Is Emerging—And Not Going Anywhere”, Dzieza 2023
- “Anime Character Identification and Tag Prediction by Multimodality Modeling: Dataset and Model”, Yi et al 2023
- “ChessGPT: Bridging Policy Learning and Language Modeling”, Feng et al 2023
- “Why YouTube Could Give Google an Edge in AI”, Victor 2023
- “Artificial Artificial Artificial Intelligence: Crowd Workers Widely Use Large Language Models for Text Production Tasks”, Veselovsky et al 2023
- “The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora With Web Data, and Web Data Only”, Penedo et al 2023
- “Let’s Verify Step by Step”, Lightman et al 2023
- “WikiChat: Stopping the Hallucination of Large Language Model Chatbots by Few-Shot Grounding on Wikipedia”, Semnani et al 2023
- “SeeGULL: A Stereotype Benchmark With Broad Geo-Cultural Coverage Leveraging Generative Models”, Jha et al 2023
- “C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models”, Huang et al 2023
- “TinyStories: How Small Can Language Models Be and Still Speak Coherent English?”, Eldan & Li 2023
- “Pick-A-Pic: An Open Dataset of User Preferences for Text-To-Image Generation”, Kirstain et al 2023
- “LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions”, Wu et al 2023
- “Multi-Party Chat (MultiLIGHT): Conversational Agents in Group Settings With Humans and Models”, Wei et al 2023
- “ImageNet-Hard: The Hardest Images Remaining from a Study of the Power of Zoom and Spatial Biases in Image Classification”, Taesiri et al 2023
- “Parsing-Conditioned Anime Translation: A New Dataset and Method”, Li et al 2023c
- “Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling”, Biderman et al 2023
- “Abstraction-Perception Preserving Cartoon Face Synthesis”, Ho et al 2023
- “How Well Do Large Language Models Perform in Arithmetic Tasks?”, Yuan et al 2023
- “The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset”, Laurençon et al 2023
- “Large Language Models Are State-Of-The-Art Evaluators of Translation Quality”, Kocmi & Federmann 2023
- “Poisoning Web-Scale Training Datasets Is Practical”, Carlini et al 2023
- “Benchmarks for Automated Commonsense Reasoning: A Survey”, Davis 2023
- “Data Selection for Language Models via Importance Resampling”, Xie et al 2023
- “Off-The-Grid MARL (OG-MARL): Datasets With Baselines for Offline Multi-Agent Reinforcement Learning”, Formanek et al 2023
- “The BabyLM Challenge: Sample-Efficient Pretraining on a Developmentally Plausible Corpus”, Warstadt et al 2023
- “The Semantic Scholar Open Data Platform”, Kinney et al 2023
- “Interactive-Chain-Prompting (INTERCPT): Ambiguity Resolution for Crosslingual Conditional Generation With Interaction”, Pilault et al 2023
- “How Close Is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection”, Guo et al 2023
- “No Robots: Look Ma, an Instruction Dataset That Wasn’t Generated by GPTs!”, HuggingFace 2023
- “Med-PaLM: Large Language Models Encode Clinical Knowledge”, Singhal et al 2022
- “Unnatural Instructions: Tuning Language Models With (Almost) No Human Labor”, Honovich et al 2022
- “HALIE: Evaluating Human-Language Model Interaction”, Lee et al 2022
- “A Whack-A-Mole Dilemma: Shortcuts Come in Multiples Where Mitigating One Amplifies Others”, Li et al 2022
- “Text Embeddings by Weakly-Supervised Contrastive Pre-Training”, Wang et al 2022
- “The Stack: 3 TB of Permissively Licensed Source Code”, Kocetkov et al 2022
- “UniSumm: Unified Few-Shot Summarization With Multi-Task Pre-Training and Prefix-Tuning”, Chen et al 2022
- “A Creative Industry Image Generation Dataset Based on Captions”, Yuejia et al 2022
- “AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities”, Chen et al 2022
- “AnimeRun: 2D Animation Visual Correspondence from Open Source 3D Movies”, Siyao et al 2022
- “MMDialog: A Large-Scale Multi-Turn Dialogue Dataset Towards Multi-Modal Open-Domain Conversation”, Feng et al 2022
- “BLOOMZ/mT0: Crosslingual Generalization through Multitask Finetuning”, Muennighoff et al 2022
- “Dungeons and Data: A Large-Scale NetHack Dataset”, Hambro et al 2022
- “Will We Run out of Data? An Analysis of the Limits of Scaling Datasets in Machine Learning”, Villalobos et al 2022
- “Large Language Models Can Self-Improve”, Huang et al 2022
- “CARP: Robust Preference Learning for Storytelling via Contrastive Reinforcement Learning”, Castricato et al 2022
- “MTEB: Massive Text Embedding Benchmark”, Muennighoff et al 2022
- “Most Language Models Can Be Poets Too: An AI Writing Assistant and Constrained Text Generation Studio”, Roush et al 2022
- “Self-Ask: Measuring and Narrowing the Compositionality Gap in Language Models (Bamboogle)”, Press et al 2022
- “Dynamic Prompt Learning via Policy Gradient for Semi-Structured Mathematical Reasoning”, Lu et al 2022
- “Brain Imaging Generation With Latent Diffusion Models”, Pinaya et al 2022
- “PaLI: A Jointly-Scaled Multilingual Language-Image Model”, Chen et al 2022
- “FOLIO: Natural Language Reasoning With First-Order Logic”, Han et al 2022
- “Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned”, Ganguli et al 2022
- “Bugs in the Data: How ImageNet Misrepresents Biodiversity”, Luccioni & Rolnick 2022
- “Discovering Bugs in Vision Models Using Off-The-Shelf Image Generation and Captioning”, Wiles et al 2022
- “Benchmarking Compositionality With Formal Languages”, Valvoda et al 2022
- “Quality Not Quantity: On the Interaction between Dataset Design and Robustness of CLIP”, Nguyen et al 2022
- “Learning to Generalize With Object-Centric Agents in the Open World Survival Game Crafter”, Stanić et al 2022
- “Few-Shot Adaptation Works With UnpredicTable Data”, Chan et al 2022
- “Language Models Can Teach Themselves to Program Better”, Haluptzok et al 2022
- “RealTime QA: What’s the Answer Right Now?”, Kasai et al 2022
- “NewsStories: Illustrating Articles With Visual Summaries”, Tan et al 2022
- “CelebV-HQ: A Large-Scale Video Facial Attributes Dataset”, Zhu et al 2022
- “Why Do Tree-Based Models Still Outperform Deep Learning on Tabular Data?”, Grinsztajn et al 2022
- “WebShop: Towards Scalable Real-World Web Interaction With Grounded Language Agents”, Yao et al 2022
- “Pile of Law: Learning Responsible Data Filtering from the Law and a 256GB Open-Source Legal Dataset”, Henderson et al 2022
- “Forecasting Future World Events With Neural Networks”, Zou et al 2022
- “RST: ReStructured Pre-Training”, Yuan & Liu 2022
- “Learning to Generate Artistic Character Line Drawing”, Fang et al 2022
- “Dataset Condensation via Efficient Synthetic-Data Parameterization”, Kim et al 2022
- “Bongard-HOI: Benchmarking Few-Shot Visual Reasoning for Human-Object Interactions”, Jiang et al 2022
- “Fine-Grained Image Captioning With CLIP Reward”, Cho et al 2022
- “FLEURS: Few-Shot Learning Evaluation of Universal Representations of Speech”, Conneau et al 2022
- “InstructDial: Improving Zero and Few-Shot Generalization in Dialogue through Instruction Tuning”, Gupta et al 2022
- “Learning to Model Editing Processes”, Reid & Neubig 2022
- “Flexible Diffusion Modeling of Long Videos”, Harvey et al 2022
- “Housekeep: Tidying Virtual Households Using Commonsense Reasoning”, Kant et al 2022
- “Instruction Induction: From Few Examples to Natural Language Task Descriptions”, Honovich et al 2022
- “Down and Across: Introducing Crossword-Solving As a New NLP Benchmark”, Kulshreshtha et al 2022
- “Automated Crossword Solving”, Wallace et al 2022
- “Dialog Inpainting: Turning Documents into Dialogues”, Dai et al 2022
- “SymphonyNet: Symphony Generation With Permutation Invariant Language Model”, Liu et al 2022
- “Building Machine Translation Systems for the Next Thousand Languages”, Bapna et al 2022
- “When Does Dough Become a Bagel? Analyzing the Remaining Mistakes on ImageNet”, Vasudevan et al 2022
- “Data Determines Distributional Robustness in Contrastive Language Image Pre-Training (CLIP)”, Fang et al 2022
- “A Challenging Benchmark of Anime Style Recognition”, Li et al 2022
- “Tk-Instruct: Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks”, Wang et al 2022
- “Winoground: Probing Vision and Language Models for Visio-Linguistic Compositionality”, Thrush et al 2022
- “KNN-Diffusion: Image Generation via Large-Scale Retrieval”, Ashual et al 2022
- “ByT5 Model for Massively Multilingual Grapheme-To-Phoneme Conversion”, Zhu et al 2022
- “STaR: Bootstrapping Reasoning With Reasoning”, Zelikman et al 2022
- “CLIP Meets GamePhysics: Towards Bug Identification in Gameplay Videos Using Zero-Shot Transfer Learning”, Taesiri et al 2022
- “Bamboo: Building Mega-Scale Vision Dataset Continually With Human-Machine Synergy”, Zhang et al 2022
- “Self-Distilled StyleGAN: Towards Generation from Internet Photos”, Mokady et al 2022
- “RuCLIP—New Models and Experiments: a Technical Report”, Shonenkov et al 2022
- “Wukong: 100 Million Large-Scale Chinese Cross-Modal Pre-Training Dataset and A Foundation Framework”, Gu et al 2022
- “ROME: Locating and Editing Factual Associations in GPT”, Meng et al 2022
- “DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-To-Image Generative Transformers”, Cho et al 2022
- “PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts”, Bach et al 2022
- “StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets”, Sauer et al 2022
- “BLIP: Bootstrapping Language-Image Pre-Training for Unified Vision-Language Understanding and Generation”, Li et al 2022
- “Can Wikipedia Help Offline Reinforcement Learning?”, Reid et al 2022
- “SWAG: Revisiting Weakly Supervised Pre-Training of Visual Perception Models”, Singh et al 2022
- “CoAuthor: Designing a Human-AI Collaborative Writing Dataset for Exploring Language Model Capabilities”, Lee et al 2022
- “WANLI: Worker and AI Collaboration for Natural Language Inference Dataset Creation”, Liu et al 2022
- “SynthBio: A Case Study in Faster Curation of Text Datasets”, Yuan et al 2022
- “BigDatasetGAN: Synthesizing ImageNet With Pixel-Wise Annotations”, Li et al 2022
- “ERNIE-ViLG: Unified Generative Pre-Training for Bidirectional Vision-Language Generation”, Zhang et al 2021
- “A Fistful of Words: Learning Transferable Visual Models from Bag-Of-Words Supervision”, Tejankar et al 2021
- “GLIDE: Towards Photorealistic Image Generation and Editing With Text-Guided Diffusion Models”, Nichol et al 2021
- “QuALITY: Question Answering With Long Input Texts, Yes!”, Pang et al 2021
- “FRUIT: Faithfully Reflecting Updated Information in Text”, IV et al 2021
- “Models in the Loop: Aiding Crowdworkers With Generative Annotation Assistants”, Bartolo et al 2021
- “WebGPT: Browser-Assisted Question-Answering With Human Feedback”, Nakano et al 2021
- “GLaM: Efficient Scaling of Language Models With Mixture-Of-Experts”, Du et al 2021
- “MAD: A Scalable Dataset for Language Grounding in Videos from Movie Audio Descriptions”, Soldan et al 2021
- “BASIC: Combined Scaling for Open-Vocabulary Image Classification”, Pham et al 2021
- “It’s About Time: Analog Clock Reading in the Wild”, Yang et al 2021
- “Solving Probability and Statistics Problems by Program Synthesis”, Tang et al 2021
- “Few-Shot Self-Rationalization With Natural Language Prompts”, Marasović et al 2021
- “AnimeCeleb: Large-Scale Animation CelebHeads Dataset for Head Reenactment”, Kim et al 2021
- “RLDS: an Ecosystem to Generate, Share and Use Datasets in Reinforcement Learning”, Ramos et al 2021
- “An Explanation of In-Context Learning As Implicit Bayesian Inference”, Xie et al 2021
- “LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs”, Schuhmann et al 2021
- “Training Verifiers to Solve Math Word Problems”, Cobbe et al 2021
- “A Connectome of the Drosophila Central Complex Reveals Network Motifs Suitable for Flexible Navigation and Context-Dependent Action Selection”, Hulse et al 2021
- “HTCN: Harmonious Text Colorization Network for Visual-Textual Presentation Design”, Yang et al 2021c
- “T0: Multitask Prompted Training Enables Zero-Shot Task Generalization”, Sanh et al 2021
- “Can Machines Learn Morality? The Delphi Experiment”, Jiang et al 2021
- “Situated Dialogue Learning through Procedural Environment Generation”, Ammanabrolu et al 2021
- “MiniHack the Planet: A Sandbox for Open-Ended Reinforcement Learning Research”, Samvelyan et al 2021
- “TruthfulQA: Measuring How Models Mimic Human Falsehoods”, Lin et al 2021
- “MiniF2F: a Cross-System Benchmark for Formal Olympiad-Level Mathematics”, Zheng et al 2021
- “LAION-400-Million Open Dataset”, Schuhmann 2021
- “Transfer Learning for Pose Estimation of Illustrated Characters”, Chen & Zwicker 2021
- “MuSiQue: Multi-Hop Questions via Single-Hop Question Composition”, Trivedi et al 2021
- “Scaling Vision Transformers”, Zhai et al 2021
- “QASPER: A Dataset of Information-Seeking Questions and Answers Anchored in Research Papers”, Dasigi et al 2021
- “XLM-T: Multilingual Language Models in Twitter for Sentiment Analysis and Beyond”, Barbieri et al 2021
- “BEIR: A Heterogenous Benchmark for Zero-Shot Evaluation of Information Retrieval Models”, Thakur et al 2021
- “SpeechStew: Simply Mix All Available Speech Recognition Data to Train One Large Neural Network”, Chan et al 2021
- “Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks”, Northcutt et al 2021
- “NaturalProofs: Mathematical Theorem Proving in Natural Language”, Welleck et al 2021
- “Get Your Vitamin C! Robust Fact Verification With Contrastive Evidence (VitaminC)”, Schuster et al 2021
- “Are NLP Models Really Able to Solve Simple Math Word Problems?”, Patel et al 2021
- “Measuring Mathematical Problem Solving With the MATH Dataset”, Hendrycks et al 2021
- “Nutrition5k: Towards Automatic Nutritional Understanding of Generic Food”, Thames et al 2021
- “WIT: Wikipedia-Based Image Text Dataset for Multimodal Multilingual Machine Learning”, Srinivasan et al 2021
- “A Massive 7T FMRI Dataset to Bridge Cognitive and Computational Neuroscience”, Allen et al 2021
- “Conceptual 12M: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts”, Changpinyo et al 2021
- “ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision”, Jia et al 2021
- “Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Scaling”, Lazaridou et al 2021
- “Scaling Laws for Transfer”, Hernandez et al 2021
- “Automatic Curation of Large-Scale Datasets for Audio-Visual Representation Learning”, Lee et al 2021
- “MSR-VTT: A Large Video Description Dataset for Bridging Video and Language”, Xu et al 2021
- “CLIP: Learning Transferable Visual Models From Natural Language Supervision”, Radford et al 2021
- “CLIP: Connecting Text and Images: We’re Introducing a Neural Network Called CLIP Which Efficiently Learns Visual Concepts from Natural Language Supervision. CLIP Can Be Applied to Any Visual Classification Benchmark by Simply Providing the Names of the Visual Categories to Be Recognized, Similar to the ‘Zero-Shot’ Capabilities of GPT-2 and GPT-3”, Radford et al 2021
- “The Pile: An 800GB Dataset of Diverse Text for Language Modeling”, Gao et al 2021
- “Selective Eye-Gaze Augmentation To Enhance Imitation Learning In Atari Games”, Thammineni et al 2020
- “VoxLingua107: a Dataset for Spoken Language Recognition”, Valk & Alumäe 2020
- “MoGaze: A Dataset of Full-Body Motions That Includes Workspace Geometry and Eye-Gaze”, Kratzer et al 2020
- “End-To-End Chinese Landscape Painting Creation Using Generative Adversarial Networks”, Xue 2020
- “Hypersim: A Photorealistic Synthetic Dataset for Holistic Indoor Scene Understanding”, Roberts et al 2020
- “Constructing A Multi-Hop QA Dataset for Comprehensive Evaluation of Reasoning Steps”, Ho et al 2020
- “Language ID in the Wild: Unexpected Challenges on the Path to a Thousand-Language Web Text Corpus”, Caswell et al 2020
- “Open-Domain Question Answering Goes Conversational via Question Rewriting”, Anantha et al 2020
- “Digital Voicing of Silent Speech”, Gaddy & Klein 2020
- “A C/C++ Code Vulnerability Dataset With Code Changes and CVE Summaries”, Fan et al 2020
- “MMLU: Measuring Massive Multitask Language Understanding”, Hendrycks et al 2020
- “ETHICS: Aligning AI With Shared Human Values”, Hendrycks et al 2020
- “Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing”, Gu et al 2020
- “CoVoST 2 and Massively Multilingual Speech-To-Text Translation”, Wang et al 2020
- “DanbooRegion: An Illustration Region Dataset”, Zhang & Liu 2020
- “The Many Faces of Robustness: A Critical Analysis of Out-Of-Distribution Generalization”, Hendrycks et al 2020
- “The NetHack Learning Environment”, Küttler et al 2020
- “ForecastQA: A Question Answering Challenge for Event Forecasting With Temporal Text Data”, Jin et al 2020
- “Shortcut Learning in Deep Neural Networks”, Geirhos et al 2020
- “D4RL: Datasets for Deep Data-Driven Reinforcement Learning”, Fu et al 2020
- “TyDiQA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages”, Clark et al 2020
- “SAYCam: A Large, Longitudinal Audiovisual Dataset Recorded from the Infant’s Perspective”, Sullivan et al 2020
- “ImageNet-A: Natural Adversarial Examples”, Hendrycks et al 2020
- “Measuring Compositional Generalization: A Comprehensive Method on Realistic Data”, Keysers et al 2019
- “Libri-Light: A Benchmark for ASR With Limited or No Supervision”, Kahn et al 2019
- “How Can We Know What Language Models Know?”, Jiang et al 2019
- “SimpleBooks: Long-Term Dependency Book Dataset With Simplified English Vocabulary for Word-Level Language Modeling”, Nguyen 2019
- “How Machine Learning Can Help Unlock the World of Ancient Japan”, Lamb 2019
- “Compressive Transformers for Long-Range Sequence Modeling”, Rae et al 2019
- “CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning”, Lin et al 2019
- “CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data”, Wenzek et al 2019
- “T5: Exploring the Limits of Transfer Learning With a Unified Text-To-Text Transformer”, Raffel et al 2019
- “2019-10-18-Poetryfoundation-Formatted.txt”
- “Restoring Ancient Text Using Deep Learning (Pythia): a Case Study on Greek Epigraphy”, Assael et al 2019
- “CATER: A Diagnostic Dataset for Compositional Actions and TEmporal Reasoning”, Girdhar & Ramanan 2019
- “PubMedQA: A Dataset for Biomedical Research Question Answering”, Jin et al 2019
- “ObjectNet: A Large-Scale Bias-Controlled Dataset for Pushing the Limits of Object Recognition Models”, Barbu et al 2019
- “No Press Diplomacy: Modeling Multi-Agent Gameplay”, Paquette et al 2019
- “Language Modeling State-Of-The-Art Leaderboards”, paperswithcode.com 2019
- “LVIS: A Dataset for Large Vocabulary Instance Segmentation”, Gupta et al 2019
- “Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank”, Socher et al 2019
- “A Large Single-Participant FMRI Dataset for Probing Brain Responses to Naturalistic Stimuli in Space and Time”, Seeliger et al 2019
- “OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge”, Marino et al 2019
- “ImageNet-Sketch: Learning Robust Global Representations by Penalizing Local Predictive Power”, Wang et al 2019
- “Cold Case: The Lost MNIST Digits”, Yadav & Bottou 2019
- “SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems”, Wang et al 2019
- “The MineRL 2019 Competition on Sample Efficient Reinforcement Learning Using Human Priors”, Guss et al 2019
- “ProductNet: a Collection of High-Quality Datasets for Product Representation Learning”, Wang et al 2019
- “Benchmarking Neural Network Robustness to Common Corruptions and Perturbations”, Hendrycks & Dietterich 2019
- “Atari-HEAD: Atari Human Eye-Tracking and Demonstration Dataset”, Zhang et al 2019
- “LIGHT: Learning to Speak and Act in a Fantasy Text Adventure Game”, Urbanek et al 2019
- “DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs”, Dua et al 2019
- “A Replication Study: Machine Learning Models Are Capable of Predicting Sexual Orientation From Facial Images”, Leuner 2019
- “MyAnimeList Anime-Summary Scrape”, Gokaslan 2019
- “Language Models Are Unsupervised Multitask Learners”, Radford et al 2019
- “The Omniglot Challenge: a 3-Year Progress Report”, Lake et al 2019
- “Do We Train on Test Data? Purging CIFAR of Near-Duplicates”, Barz & Denzler 2019
- “The RobotriX: An EXtremely Photorealistic and Very-Large-Scale Indoor Dataset of Sequences With Robot Trajectories and Interactions”, Garcia-Garcia et al 2019
- “FIGR: Few-Shot Image Generation With Reptile”, Clouâtre & Demers 2019
- “Natural Questions: A Benchmark for Question Answering Research”, Kwiatkowski et al 2019
- “A Style-Based Generator Architecture for Generative Adversarial Networks”, Karras et al 2018
- “ImageNet-Trained CNNs Are Biased towards Texture; Increasing Shape Bias Improves Accuracy and Robustness”, Geirhos et al 2018
- “CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge”, Talmor et al 2018
- “The Open Images Dataset V4: Unified Image Classification, Object Detection, and Visual Relationship Detection at Scale”, Kuznetsova et al 2018
- “HotpotQA: A Dataset for Diverse, Explainable Multi-Hop Question Answering”, Yang et al 2018
- “Don’t Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization”, Narayan et al 2018
- “CurriculumNet: Weakly Supervised Learning from Large-Scale Web Images”, Guo et al 2018
- “A Short Note about Kinetics-600”, Carreira et al 2018
- “Cartoon Set”, Royer et al 2018
- “Benchmarking Neural Network Robustness to Common Corruptions and Surface Variations”, Hendrycks & Dietterich 2018
- “Conceptual Captions: A Cleaned, Hypernymed, Image Alt-Text Dataset For Automatic Image Captioning”, Sharma et al 2018
- “Know What You Don’t Know: Unanswerable Questions for SQuAD”, Rajpurkar et al 2018
- “BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning”, Yu et al 2018
- “Exploring the Limits of Weakly Supervised Pretraining”, Mahajan et al 2018
- “Newsroom: A Dataset of 1.3 Million Summaries With Diverse Extractive Strategies”, Grusky et al 2018
- “GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding”, Wang et al 2018
- “The Sound of Pixels”, Zhao et al 2018
- “FEVER: a Large-Scale Dataset for Fact Extraction and VERification”, Thorne et al 2018
- “Think You Have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge”, Clark et al 2018
- “SCUT-FBP5500: A Diverse Benchmark Dataset for Multi-Paradigm Facial Beauty Prediction”, Liang et al 2018
- “11K Hands: Gender Recognition and Biometric Identification Using a Large Dataset of Hand Images”, Afifi 2017
- “Progressive Growing of GANs for Improved Quality, Stability, and Variation”, Karras et al 2017
- “OpenML Benchmarking Suites”, Bischl et al 2017
- “WebVision Database: Visual Learning and Understanding from Web Data”, Li et al 2017
- “A Downsampled Variant of ImageNet As an Alternative to the CIFAR Datasets”, Chrabaszcz et al 2017
- “Revisiting Unreasonable Effectiveness of Data in Deep Learning Era”, Sun et al 2017
- “Driver Identification Using Automobile Sensor Data from a Single Turn”, Hallac et al 2017
- “StreetStyle: Exploring World-Wide Clothing Styles from Millions of Photos”, Matzen et al 2017
- “The Kinetics Human Action Video Dataset”, Kay et al 2017
- “WebVision Challenge: Visual Learning and Understanding With Web Data”, Li et al 2017
- “TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension”, Joshi et al 2017
- “Dense-Captioning Events in Videos”, Krishna et al 2017
- “BAM! The Behance Artistic Media Dataset for Recognition Beyond Photography”, Wilber et al 2017
- “SearchQA: A New Q&A Dataset Augmented With Context from a Search Engine”, Dunn et al 2017
- “RACE: Large-Scale ReAding Comprehension Dataset From Examinations”, Lai et al 2017
- “NewsQA: A Machine Comprehension Dataset”, Trischler et al 2016
- “MS MARCO: A Human Generated MAchine Reading COmprehension Dataset”, Bajaj et al 2016
- “Visual Dialog”, Das et al 2016
- “Lip Reading Sentences in the Wild”, Chung et al 2016
- “Pointer Sentinel Mixture Models”, Merity et al 2016
- “Deep Learning the City: Quantifying Urban Perception At A Global Scale”, Dubey et al 2016
- “MultiArith: Solving General Arithmetic Word Problems”, Roy & Roth 2016
- “The LAMBADA Dataset: Word Prediction Requiring a Broad Discourse Context”, Paperno et al 2016
- “SQuAD: 100,000+ Questions for Machine Comprehension of Text”, Rajpurkar et al 2016
- “Matching Networks for One Shot Learning”, Vinyals et al 2016
- “Convolutional Sketch Inversion”, Güçlütürk et al 2016
- “The MovieLens Datasets: History and Context”, Harper & Konstan 2015
- “Neural Module Networks”, Andreas et al 2015
- “Sketch-Based Manga Retrieval Using Manga109 Dataset”, Matsui et al 2015
- “Amazon Reviews: Image-Based Recommendations on Styles and Substitutes”, McAuley et al 2015
- “Teaching Machines to Read and Comprehend”, Hermann et al 2015
- “LSUN: Construction of a Large-Scale Image Dataset Using Deep Learning With Humans in the Loop”, Yu et al 2015
- “The Unreasonable Effectiveness of Recurrent Neural Networks”, Karpathy 2015
- “VQA: Visual Question Answering”, Agrawal et al 2015
- “YFCC100M: The New Data in Multimedia Research”, Thomee et al 2015
- “Deep Learning Face Attributes in the Wild”, Liu et al 2014
- “ImageNet Large Scale Visual Recognition Challenge”, Russakovsky et al 2014
- “Microsoft COCO: Common Objects in Context”, Lin et al 2014
- “N-Gram Counts and Language Models from the Common Crawl”, Buck et al 2014
- “One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling”, Chelba et al 2013
- “20 Years of Bitext”, Brown et al 2013
- “Ukiyo-E Search”, Resig 2013
- “UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild”, Soomro et al 2012
- “The Caltech-UCSD Birds-200-2011 Dataset”, Wah et al 2011
- “Unbiased Look at Dataset Bias”, Torralba & Efros 2011
- “Caltech-UCSD Birds 200”, Welinder et al 2010
- “Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments”, Huang et al 2008
- “The Infinite MNIST Dataset”, Bottou 2007
- “All Our n-Gram Are Belong to You”, Franz & Brants 2006
- “Building a Large Annotated Corpus of English: The Penn Treebank”, Marcus et al 1993
- “The Design for the Wall Street Journal-Based CSR Corpus”, Paul & Baker 1992
- “About the Test Data”
- “MIT Places Database for Scene Recognition”
- “DataGemma: AI Open Models Connecting LLMs to Google’s Data Commons”
- “STL-10 Dataset”
- “AOT Characters Dataset”
- “EQ-Bench 3 Leaderboard”
- “AnimeDL-2M: Million-Scale AI-Generated Anime Image Detection and Localization in Diffusion Era”
- “Scale AI Secures $1B Funding at $14B Valuation As Its CEO Predicts Big Revenue Growth and Profitability by Year-End [On Very High Quality Data]”
- “RWKV-CLIP: A Robust Vision-Language Representation Learner”
- “
political-Emails: Processed Collection of Fundraising Emails from Political Campaigns”, Willis 2026 - “Ox-Vgg/vgg_face2”
- “ImpossibleBench”
- “Salesforce/creativity_eval”
- “Hafftka/michael-Hafftka-Catalog-Raisonné”
- “Kaichengalex/YFCC15M”
- “Blowing-Up-Groundhogs/font-Square-V2”
- “Psych-101 Dataset [For Centaur]”
- “Open-Index/hacker-News”
- “Tokyotech-Llm/swallow-Code”
- “Tokyotech-Llm/swallow-Math”
- “FineWeb: Decanting the Web for the Finest Text Data at Scale”
- “Solving Math Word Problems: We’ve Trained a System That Solves Grade School Math Problems With Nearly Twice the Accuracy of a Fine-Tuned GPT-3 Model. It Solves about 90% As Many Problems As Real Kids: a Small Sample of 9-12 Year Olds Scored 60% on a Test from Our Dataset, While Our System Scored 55% on Those Same Problems. This Is Important Because Today’s AI Is Still Quite Weak at Commonsense Multistep Reasoning, Which Is Easy Even for Grade School Kids. We Achieved These Results by Training Our Model to Recognize Its Mistakes, so That It Can Try Repeatedly Until It Finds a Solution That Works”
- “SuperGLUE Benchmark”
- “Time Blindness: Why Video-Language Models Can’t See What Humans Can?”
- “The Small World of English: Building a 1.5M Word Semantic Network for Language Games”
- “Some Lessons from the OpenAI FrontierMath Debacle”
- “Revisiting GSM-Symbolic: Models Seem to Reason Okay, Actually”
- “Cryptic Puzzles As a Probe for Lateral Thinking”
- “Usenet-Corpus-1980–2013”, OwnedByDanes 2026
- “Lip Reading Sentences in the Wild [Video]”
- Sort By Magic
no-ai-datamovielens-contextdiscord-datasetuser-manipulationai-awarenessfood-visionlanguage-imagesimplified-booksfact-verificationdataset-scalingcrossword-solvingvisual-reasoningfacial-prediction automobile-sensors mnist-research sexual-orientation cold-case-analysiscartoon-art ukiyo-evideo-actioninstruction-tuning
- Wikipedia (9)
- Miscellaneous
- Bibliography
See Also
Gwern
“Anime Crop Datasets: Faces, Figures, & Hands”, Gwern et al 2020
Links
“State Media Control Influences Large Language Models”, Waight et al 2026
“StoryScope: Investigating Idiosyncrasies in AI Fiction”, Russell et al 2026
“StoryScope: Investigating Idiosyncrasies in AI Fiction”, Russell 2026
“MIRAGE: The Illusion of Visual Understanding”, Asadi et al 2026
“DECEPTICON: How Dark Patterns Manipulate Web Agents”, Cuvin et al 2025
“Attack on Titan (AoT): Anime Image Dataset for Character, Scene, Emotion Recognition and Beyond”, Khan et al 2025
Attack on Titan (AoT): Anime image dataset for character, scene, emotion recognition and beyond
“OregairuChar: A Benchmark Dataset for Character Appearance Frequency Analysis in My Teen Romantic Comedy SNAFU”, Sun et al 2025
“Lean4Physics: Comprehensive Reasoning Framework for College-Level Physics in Lean4”, Li et al 2025
Lean4Physics: Comprehensive Reasoning Framework for College-level Physics in Lean4
“ImpossibleBench: Measuring LLMs’ Propensity of Exploiting Test Cases”, Zhong et al 2025
ImpossibleBench: Measuring LLMs’ Propensity of Exploiting Test Cases
“Evaluating Long Context (Reasoning) Ability”
“Realistic Reward Hacking Induces Different and Deeper Misalignment”, Jozdien 2025
Realistic Reward Hacking Induces Different and Deeper Misalignment
“Redefining Generalization in Visual Domains: A Two-Axis Framework for Fake Image Detection With FusionDetect”, Amanzadi et al 2025
“School of Reward Hacks: Hacking Harmless Tasks Generalizes to Misaligned Behavior in LLMs”, Taylor et al 2025
School of Reward Hacks: Hacking harmless tasks generalizes to misaligned behavior in LLMs
“Teaching AI [Blacklist/whitelist of Example Sources for Claude RLHF]”, Sheets 2025
Teaching AI [blacklist/whitelist of example sources for Claude RLHF]
“30% of Humanity’s Last Exam Chemistry/biology Answers Are Likely Wrong”, Skarlinski et al 2025
30% of Humanity’s Last Exam chemistry/biology answers are likely wrong
“How Many Instructions Can LLMs Follow at Once?”, Jaroslawicz et al 2025
“Machine Bullshit: Characterizing the Emergent Disregard for Truth in Large Language Models”, Liang et al 2025
Machine Bullshit: Characterizing the Emergent Disregard for Truth in Large Language Models
“Scale AI’s Spam, Security Woes Plagued the Company While Serving Google—How the Startup That Just Scored a $14 Billion Investment from Meta Struggled to Contain ‘Spammy Behavior’ from Unqualified Contributors As It Trained Gemini”, Blum 2025
“What Skills Does SWE-Bench Verified Evaluate?: We Take a Deep Dive into SWE-Bench Verified, a Prominent Agentic Coding Benchmark. While One of the Best Public Tests of AI Coding Agents, It Is Limited by Its Focus on Simple Bug Fixes in Familiar Open-Source Repositories.”, Brand & Denain 2025
“Common Corpus: The Largest Collection of Ethical Data for LLM Pre-Training”, Langlais et al 2025
Common Corpus: The Largest Collection of Ethical Data for LLM Pre-Training
“Time Blindness: Why Video-Language Models Can’t See What Humans Can?”, Upadhyay et al 2025
Time Blindness: Why Video-Language Models Can’t See What Humans Can?
“Instance-Guided Anime Editing With a Curated Large-Scale Dataset”, Lin et al 2025
Instance-guided anime editing with a curated large-scale dataset
“RealMath: A Continuous Benchmark for Evaluating Language Models on Research-Level Mathematics”, Zhang et al 2025
RealMath: A Continuous Benchmark for Evaluating Language Models on Research-Level Mathematics
“RealMath [Code]”, Zhang et al 2025
“Generating Physically Stable and Buildable LEGO Designs from Text”, Pun et al 2025
Generating Physically Stable and Buildable LEGO Designs from Text
“LegoGPT: Generating Physically Stable and Buildable LEGO Designs from Text”, Pun et al 2025
LegoGPT: Generating Physically Stable and Buildable LEGO Designs from Text
View External Link:
“LegoGPT: Official Repository for LegoGPT, the First Approach for Generating Physically Stable LEGO Brick Models from Text Prompts”, Pun et al 2025
“Rewriting Pre-Training Data Boosts LLM Performance in Math and Code [SwallowCode/Math]”, Fujii et al 2025
Rewriting Pre-Training Data Boosts LLM Performance in Math and Code [SwallowCode/Math]
“New News: System-2 Fine-Tuning for Robust Integration of New Knowledge”, Park et al 2025
New News: System-2 Fine-tuning for Robust Integration of New Knowledge
“Virology Capabilities Test (VCT): A Multimodal Virology Q&A Benchmark”, Götting et al 2025
Virology Capabilities Test (VCT): A Multimodal Virology Q&A Benchmark
“AnimeDL-2M: Million-Scale AI-Generated Anime Image Detection and Localization in Diffusion Era”, Zhu et al 2025
AnimeDL-2M: Million-Scale AI-Generated Anime Image Detection and Localization in Diffusion Era
“DeepMath-103K: A Large-Scale, Challenging, Decontaminated, and Verifiable Mathematical Dataset for Advancing Reasoning”, He et al 2025
“AI-Slop to AI-Polish? Aligning Language Models through Edit-Based Writing Rewards and Test-Time Computation”, Chakrabarty et al 2025
“AutoEval: Autonomous Evaluation of Generalist Robot Manipulation Policies in the Real World”, Zhou et al 2025
AutoEval: Autonomous Evaluation of Generalist Robot Manipulation Policies in the Real World
“GSM8K-Platinum: Revealing Performance Gaps in Frontier LLMs”, Vendrow et al 2025
“Chronologically Consistent Large Language Models”, He et al 2025
“Rank1: Test-Time Compute for Reranking in Information Retrieval”, Weller et al 2025
Rank1: Test-Time Compute for Reranking in Information Retrieval
“None of the Others: a General Technique to Distinguish Reasoning from Memorization in Multiple-Choice LLM Evaluation Benchmarks”, Salido et al 2025
“NaturalReasoning: Reasoning in the Wild With 2.8M Challenging Questions”, Yuan et al 2025
NaturalReasoning: Reasoning in the Wild with 2.8M Challenging Questions
“VLMs As GeoGuessr Masters: Exceptional Performance, Hidden Biases, and Privacy Risks”, Huang et al 2025
VLMs as GeoGuessr Masters: Exceptional Performance, Hidden Biases, and Privacy Risks
“ZeroBench: An Impossible Visual Benchmark for Contemporary Large Multimodal Models”, Roberts et al 2025
ZeroBench: An Impossible Visual Benchmark for Contemporary Large Multimodal Models
“Lost in Time: Clock and Calendar Understanding Challenges in Multimodal LLMs”, Saxena et al 2025
Lost in Time: Clock and Calendar Understanding Challenges in Multimodal LLMs
“Do Large Language Model Benchmarks Test Reliability?”, Vendrow et al 2025
“SmolLM2: When Smol Goes Big—Data-Centric Training of a Small Language Model”, Allal et al 2025
SmolLM2: When Smol Goes Big—Data-Centric Training of a Small Language Model
“Discord Unveiled: A Comprehensive Dataset of Public Communication (2015–2024)”, Aquino et al 2025
Discord Unveiled: A Comprehensive Dataset of Public Communication (2015–2024)
“S1: Simple Test-Time Scaling”, Muennighoff et al 2025
“Do Generative Video Models Learn Physical Principles from Watching Videos?”, Motamed et al 2025
Do generative video models learn physical principles from watching videos?
“An Evaluation Framework for Clinical Use of Large Language Models in Patient Interaction Tasks”, Johri et al 2025
An evaluation framework for clinical use of large language models in patient interaction tasks
“Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?”, Yang et al 2024
Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?
“BALROG: Benchmarking Agentic LLM and VLM Reasoning On Games”, Paglieri et al 2024
“Are LLMs Prescient? A Continuous Evaluation Using Daily News As the Oracle”, Dai et al 2024
Are LLMs Prescient? A Continuous Evaluation using Daily News as the Oracle
“HtmlRAG: HTML Is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems”, Tan et al 2024
HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems
“Centaur: a Foundation Model of Human Cognition”, Binz et al 2024
“AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents”, Andriushchenko et al 2024
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
“SimpleStrat: Diversifying Language Model Generation With Stratification”, Wong et al 2024
SimpleStrat: Diversifying Language Model Generation with Stratification
“SWE-Bench+: Enhanced Coding Benchmark for LLMs”, Aleithan et al 2024
“MLE-Bench: Evaluating Machine Learning Agents on Machine Learning Engineering”, Chan et al 2024
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
“Embodied Agent Interface: Benchmarking LLMs for Embodied Decision Making”, Li et al 2024
Embodied Agent Interface: Benchmarking LLMs for Embodied Decision Making
“Seeing Faces in Things: A Model and Dataset for Pareidolia”, Hamilton et al 2024
“H-ARC: A Robust Estimate of Human Performance on the Abstraction and Reasoning Corpus Benchmark”, LeGris et al 2024
H-ARC: A Robust Estimate of Human Performance on the Abstraction and Reasoning Corpus Benchmark
“How to Evaluate Jailbreak Methods: A Case Study With the StrongREJECT Benchmark”, Bowen et al 2024
How to Evaluate Jailbreak Methods: A Case Study with the StrongREJECT Benchmark
“To Code, or Not To Code? Exploring Impact of Code in Pre-Training”, Aryabumi et al 2024
To Code, or Not To Code? Exploring Impact of Code in Pre-training
“Tails Tell Tales: Chapter-Wide Manga Transcriptions With Character Names”, Sachdeva et al 2024
Tails Tell Tales: Chapter-Wide Manga Transcriptions with Character Names
“ImagiNet: A Multi-Content Dataset for Generalizable Synthetic Image Detection via Contrastive Learning”, Boychev & Cholakov 2024
“Me, Myself, and AI: The Situational Awareness Dataset (SAD) for LLMs”, Laine et al 2024
Me, Myself, and AI: The Situational Awareness Dataset (SAD) for LLMs
“Future Events As Backdoor Triggers: Investigating Temporal Vulnerabilities in LLMs”, Price et al 2024
Future Events as Backdoor Triggers: Investigating Temporal Vulnerabilities in LLMs
“Sonnet or Not, Bot? Poetry Evaluation for Large Models and Datasets”, Walsh et al 2024
Sonnet or Not, Bot? Poetry Evaluation for Large Models and Datasets
“APIGen: Automated Pipeline for Generating Verifiable and Diverse Function-Calling Datasets”, Liu et al 2024
APIGen: Automated Pipeline for Generating Verifiable and Diverse Function-Calling Datasets
“Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?”, Lee et al 2024
Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
“OlympicArena: Benchmarking Multi-Discipline Cognitive Reasoning for Superintelligent AI”, Huang et al 2024
OlympicArena: Benchmarking Multi-discipline Cognitive Reasoning for Superintelligent AI
“DataComp-LM: In Search of the next Generation of Training Sets for Language Models”, Li et al 2024
DataComp-LM: In search of the next generation of training sets for language models
“GUI-WORLD: A Dataset for GUI-Oriented Multimodal LLM-Based Agents”, Chen et al 2024
GUI-WORLD: A Dataset for GUI-oriented Multimodal LLM-based Agents
“Newswire: A Large-Scale Structured Database of a Century of Historical News”, Silcock et al 2024
Newswire: A Large-Scale Structured Database of a Century of Historical News
“RWKV-CLIP: A Robust Vision-Language Representation Learner”, Gu et al 2024
“Are We Done With MMLU?”, Gema et al 2024
“MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark”, Wang et al 2024
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
“LLMs Achieve Adult Human Performance on Higher-Order Theory of Mind Tasks”, Street et al 2024
LLMs achieve adult human performance on higher-order theory of mind tasks
“DeTikZify: Synthesizing Graphics Programs for Scientific Figures and Sketches With TikZ”, Belouadi et al 2024
DeTikZify: Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ
“Sakuga-42M Dataset: Scaling Up Cartoon Research”, Pan et al 2024
“Can Language Models Explain Their Own Classification Behavior?”, Sherburn et al 2024
Can Language Models Explain Their Own Classification Behavior?
“Special Characters Attack: Toward Scalable Training Data Extraction From Large Language Models”, Bai et al 2024
Special Characters Attack: Toward Scalable Training Data Extraction From Large Language Models
“ImageInWords: Unlocking Hyper-Detailed Image Descriptions”, Garg et al 2024
“GSM1k: A Careful Examination of Large Language Model Performance on Grade School Arithmetic”, Zhang et al 2024
GSM1k: A Careful Examination of Large Language Model Performance on Grade School Arithmetic
“Building a Large Japanese Web Corpus for Large Language Models”, Okazaki et al 2024
Building a Large Japanese Web Corpus for Large Language Models
“CulturalTeaming: AI-Assisted Interactive Red-Teaming for Challenging LLMs’ (Lack Of) Multicultural Knowledge”, Chiu et al 2024
“VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?”, Liu et al 2024
VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?
“RULER: What’s the Real Context Size of Your Long-Context Language Models?”, Hsieh et al 2024
RULER: What’s the Real Context Size of Your Long-Context Language Models?
“Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators”, Dubois et al 2024
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
“How Tech Giants Cut Corners to Harvest Data for AI: OpenAI, Google and Meta Ignored Corporate Policies, Altered Their Own Rules and Discussed Skirting Copyright Law As They Sought Online Information to Train Their Newest Artificial Intelligence Systems”, Metz et al 2024
“Evaluating Text-To-Visual Generation With Image-To-Text Generation”, Lin et al 2024
Evaluating Text-to-Visual Generation with Image-to-Text Generation
“Vulnerability Detection With Code Language Models: How Far Are We?”, Ding et al 2024
Vulnerability Detection with Code Language Models: How Far Are We?
“Long-Form Factuality in Large Language Models”, Wei et al 2024
“COIG-CQIA: Quality Is All You Need for Chinese Instruction Fine-Tuning”, Bai et al 2024
COIG-CQIA: Quality is All You Need for Chinese Instruction Fine-tuning
“RewardBench: Evaluating Reward Models for Language Modeling”, Lambert et al 2024
“Evaluating Text to Image Synthesis: Survey and Taxonomy of Image Quality Metrics”, Hartwig et al 2024
Evaluating Text to Image Synthesis: Survey and Taxonomy of Image Quality Metrics
“Hierarchical Feature Warping and Blending for Talking Head Animation”, Zhang et al 2024
Hierarchical Feature Warping and Blending for Talking Head Animation
“Mastering Text, Code and Math Simultaneously via Fusing Highly Specialized Language Models”, Ding et al 2024
Mastering Text, Code and Math Simultaneously via Fusing Highly Specialized Language Models
“ELLA: Equip Diffusion Models With LLM for Enhanced Semantic Alignment”, Hu et al 2024
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
“Investigating Continual Pretraining in Large Language Models: Insights and Implications”, Yıldız et al 2024
Investigating Continual Pretraining in Large Language Models: Insights and Implications
“Hal-Eval: A Universal and Fine-Grained Hallucination Evaluation Framework for Large Vision Language Models”, Jiang et al 2024
“Assisting in Writing Wikipedia-Like Articles From Scratch With Large Language Models”, Shao et al 2024
Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models
“Wikibench: Community-Driven Data Curation for AI Evaluation on Wikipedia”, Kuo et al 2024
Wikibench: Community-Driven Data Curation for AI Evaluation on Wikipedia
“ArtPrompt: ASCII Art-Based Jailbreak Attacks against Aligned LLMs”, Jiang et al 2024
ArtPrompt: ASCII Art-based Jailbreak Attacks against Aligned LLMs
“DE-COP: Detecting Copyrighted Content in Language Models Training Data”, Duarte et al 2024
DE-COP: Detecting Copyrighted Content in Language Models Training Data
“I Think, Therefore I Am: Benchmarking Awareness of Large Language Models Using AwareBench”, Li et al 2024
I Think, Therefore I am: Benchmarking Awareness of Large Language Models Using AwareBench
“Annotated Hands for Generative Models”, Yang et al 2024
“Can AI Assistants Know What They Don’t Know?”, Cheng et al 2024
“AnimeDiffusion: Anime Diffusion Colorization”, Cao et al 2024
“I Am a Strange Dataset: Metalinguistic Tests for Language Models”, Thrush et al 2024
I am a Strange Dataset: Metalinguistic Tests for Language Models
“DeepSeek LLM: Scaling Open-Source Language Models With Longtermism”, Bi et al 2024
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
“Generative AI for Math: Part I—MathPile: A Billion-Token-Scale Pretraining Corpus for Math”, Wang et al 2023
Generative AI for Math: Part I—MathPile: A Billion-Token-Scale Pretraining Corpus for Math
“WaveCoder: Widespread And Versatile Enhanced Instruction Tuning With Refined Data Generation”, Yu et al 2023
WaveCoder: Widespread And Versatile Enhanced Instruction Tuning with Refined Data Generation
“Large Language Models Play StarCraft II: Benchmarks and A Chain of Summarization Approach”, Ma et al 2023
Large Language Models Play StarCraft II: Benchmarks and A Chain of Summarization Approach
“StarVector: Generating Scalable Vector Graphics Code from Images”, Rodriguez et al 2023
StarVector: Generating Scalable Vector Graphics Code from Images
“Rich Human Feedback for Text-To-Image Generation”, Liang et al 2023
“TinyGSM: Achieving >80% on GSM8k With Small Language Models”, Liu et al 2023
“EQ-Bench: An Emotional Intelligence Benchmark for Large Language Models”, Paech 2023
EQ-Bench: An Emotional Intelligence Benchmark for Large Language Models
“Retrieving Conditions from Reference Images for Diffusion Models”, Tang et al 2023
Retrieving Conditions from Reference Images for Diffusion Models
“Sequential Modeling Enables Scalable Learning for Large Vision Models”, Bai et al 2023
Sequential Modeling Enables Scalable Learning for Large Vision Models
“BioCLIP: A Vision Foundation Model for the Tree of Life”, Stevens et al 2023
“Efficient Transformer Knowledge Distillation: A Performance Review”, Brown et al 2023
Efficient Transformer Knowledge Distillation: A Performance Review
“GPQA: A Graduate-Level Google-Proof Q&A Benchmark”, Rein et al 2023
“Dazed & Confused: A Large-Scale Real-World User Study of ReCAPTCHAv2”, Searles et al 2023
Dazed & Confused: A Large-Scale Real-World User Study of reCAPTCHAv2
“Instruction-Following Evaluation for Large Language Models”, Zhou et al 2023
“In Search of the Long-Tail: Systematic Generation of Long-Tail Inferential Knowledge via Logical Rule Guided Search”, Li et al 2023
“AnyText: Multilingual Visual Text Generation And Editing”, Tuo et al 2023
“GLaMM: Pixel Grounding Large Multimodal Model”, Rasheed et al 2023
“Don’t Make Your LLM an Evaluation Benchmark Cheater”, Zhou et al 2023
“CommonCanvas: An Open Diffusion Model Trained With Creative-Commons Images”, Gokaslan et al 2023
CommonCanvas: An Open Diffusion Model Trained with Creative-Commons Images
“FANToM: A Benchmark for Stress-Testing Machine Theory of Mind in Interactions”, Kim et al 2023
FANToM: A Benchmark for Stress-testing Machine Theory of Mind in Interactions
“MuSR: Testing the Limits of Chain-Of-Thought With Multistep Soft Reasoning”, Sprague et al 2023
MuSR: Testing the Limits of Chain-of-thought with Multistep Soft Reasoning
“Ignore This Title and HackAPrompt: Exposing Systemic Vulnerabilities of LLMs through a Global Scale Prompt Hacking Competition”, Schulhoff et al 2023
“Llemma: An Open Language Model For Mathematics”, Azerbayev et al 2023
“From Scarcity to Efficiency: Improving CLIP Training via Visual-Enriched Captions”, Lai et al 2023
From Scarcity to Efficiency: Improving CLIP Training via Visual-enriched Captions
“TabLib: A Dataset of 627M Tables With Context”, Eggert et al 2023
“SWE-Bench: Can Language Models Resolve Real-World GitHub Issues?”, Jimenez et al 2023
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
“OpenWebMath: An Open Dataset of High-Quality Mathematical Web Text”, Paster et al 2023
OpenWebMath: An Open Dataset of High-Quality Mathematical Web Text
“FreshLLMs: Refreshing Large Language Models With Search Engine Augmentation”, Vu et al 2023
FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation
“UltraFeedback: Boosting Language Models With High-Quality Feedback”, Cui et al 2023
UltraFeedback: Boosting Language Models with High-quality Feedback
“MTOB: A Benchmark for Learning to Translate a New Language from One Grammar Book”, Tanzer et al 2023
MTOB: A Benchmark for Learning to Translate a New Language from One Grammar Book
“Demystifying CLIP Data”, Xu et al 2023
“The Cambridge Law Corpus: A Corpus for Legal AI Research”, Östling et al 2023
“MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models”, Yu et al 2023
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
“LongLoRA: Efficient Fine-Tuning of Long-Context Large Language Models”, Chen et al 2023
LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models
“SlimPajama-DC: Understanding Data Combinations for LLM Training”, Shen et al 2023
SlimPajama-DC: Understanding Data Combinations for LLM Training
“MADLAD-400: A Multilingual And Document-Level Large Audited Dataset”, Kudugunta et al 2023
MADLAD-400: A Multilingual And Document-Level Large Audited Dataset
“GoodWiki”, Choi 2023
“From Sparse to Dense: GPT-4 Summarization With Chain of Density (CoD) Prompting”, Adams et al 2023
From Sparse to Dense: GPT-4 Summarization with Chain of Density (CoD) Prompting
“FIMO: A Challenge Formal Dataset for Automated Theorem Proving”, Liu et al 2023
FIMO: A Challenge Formal Dataset for Automated Theorem Proving
“American Stories: A Large-Scale Structured Text Dataset of Historical US Newspapers”, Dell et al 2023
American Stories: A Large-Scale Structured Text Dataset of Historical US Newspapers
“LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models”, Guha et al 2023
LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models
“OctoPack: Instruction Tuning Code Large Language Models”, Muennighoff et al 2023
“The ConceptARC Benchmark: Evaluating Understanding and Generalization in the ARC Domain”, Moskvichev et al 2023
The ConceptARC Benchmark: Evaluating Understanding and Generalization in the ARC Domain
“Android in the Wild: A Large-Scale Dataset for Android Device Control”, Rawles et al 2023
Android in the Wild: A Large-Scale Dataset for Android Device Control
“DialogStudio: Towards Richest and Most Diverse Unified Dataset Collection for Conversational AI”, Zhang et al 2023
DialogStudio: Towards Richest and Most Diverse Unified Dataset Collection for Conversational AI
“AlpaGasus: Training A Better Alpaca With Fewer Data”, Chen et al 2023
“InternVid: A Large-Scale Video-Text Dataset for Multimodal Understanding and Generation”, Wang et al 2023
InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation
“Instruction Mining: High-Quality Instruction Data Selection for Large Language Models”, Cao et al 2023
Instruction Mining: High-Quality Instruction Data Selection for Large Language Models
“Test-Time Training on Video Streams”, Wang et al 2023
“HEADLINES: A Massive Scale Semantic Similarity Dataset of Historical English”, Silcock & Dell 2023
HEADLINES: A Massive Scale Semantic Similarity Dataset of Historical English
“LeanDojo: Theorem Proving With Retrieval-Augmented Language Models”, Yang et al 2023
LeanDojo: Theorem Proving with Retrieval-Augmented Language Models
“SugarCrepe: Fixing Hackable Benchmarks for Vision-Language Compositionality”, Hsieh et al 2023
SugarCrepe: Fixing Hackable Benchmarks for Vision-Language Compositionality
“ARIES: A Corpus of Scientific Paper Edits Made in Response to Peer Reviews”, D’Arcy et al 2023
ARIES: A Corpus of Scientific Paper Edits Made in Response to Peer Reviews
“Understanding Social Reasoning in Language Models With Language Models”, Gandhi et al 2023
Understanding Social Reasoning in Language Models with Language Models
“OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents”, Laurençon et al 2023
OBELICS: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents
“AI Is a Lot of Work: As the Technology Becomes Ubiquitous, a Vast Tasker Underclass Is Emerging—And Not Going Anywhere”, Dzieza 2023
“Anime Character Identification and Tag Prediction by Multimodality Modeling: Dataset and Model”, Yi et al 2023
Anime Character Identification and Tag Prediction by Multimodality Modeling: Dataset and Model
“ChessGPT: Bridging Policy Learning and Language Modeling”, Feng et al 2023
“Why YouTube Could Give Google an Edge in AI”, Victor 2023
“Artificial Artificial Artificial Intelligence: Crowd Workers Widely Use Large Language Models for Text Production Tasks”, Veselovsky et al 2023
“The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora With Web Data, and Web Data Only”, Penedo et al 2023
“Let’s Verify Step by Step”, Lightman et al 2023
“WikiChat: Stopping the Hallucination of Large Language Model Chatbots by Few-Shot Grounding on Wikipedia”, Semnani et al 2023
“SeeGULL: A Stereotype Benchmark With Broad Geo-Cultural Coverage Leveraging Generative Models”, Jha et al 2023
SeeGULL: A Stereotype Benchmark with Broad Geo-Cultural Coverage Leveraging Generative Models
“C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models”, Huang et al 2023
C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models
“TinyStories: How Small Can Language Models Be and Still Speak Coherent English?”, Eldan & Li 2023
TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
“Pick-A-Pic: An Open Dataset of User Preferences for Text-To-Image Generation”, Kirstain et al 2023
Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation
“LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions”, Wu et al 2023
LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions
“Multi-Party Chat (MultiLIGHT): Conversational Agents in Group Settings With Humans and Models”, Wei et al 2023
Multi-Party Chat (MultiLIGHT): Conversational Agents in Group Settings with Humans and Models
“ImageNet-Hard: The Hardest Images Remaining from a Study of the Power of Zoom and Spatial Biases in Image Classification”, Taesiri et al 2023
“Parsing-Conditioned Anime Translation: A New Dataset and Method”, Li et al 2023c
Parsing-Conditioned Anime Translation: A New Dataset and Method
“Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling”, Biderman et al 2023
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
“Abstraction-Perception Preserving Cartoon Face Synthesis”, Ho et al 2023
“How Well Do Large Language Models Perform in Arithmetic Tasks?”, Yuan et al 2023
How well do Large Language Models perform in Arithmetic tasks?
“The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset”, Laurençon et al 2023
The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset
“Large Language Models Are State-Of-The-Art Evaluators of Translation Quality”, Kocmi & Federmann 2023
Large Language Models Are State-of-the-Art Evaluators of Translation Quality
“Poisoning Web-Scale Training Datasets Is Practical”, Carlini et al 2023
“Benchmarks for Automated Commonsense Reasoning: A Survey”, Davis 2023
“Data Selection for Language Models via Importance Resampling”, Xie et al 2023
Data Selection for Language Models via Importance Resampling
“Off-The-Grid MARL (OG-MARL): Datasets With Baselines for Offline Multi-Agent Reinforcement Learning”, Formanek et al 2023
Off-the-Grid MARL (OG-MARL): Datasets with Baselines for Offline Multi-Agent Reinforcement Learning
“The BabyLM Challenge: Sample-Efficient Pretraining on a Developmentally Plausible Corpus”, Warstadt et al 2023
The BabyLM Challenge: Sample-efficient pretraining on a developmentally plausible corpus
“The Semantic Scholar Open Data Platform”, Kinney et al 2023
“Interactive-Chain-Prompting (INTERCPT): Ambiguity Resolution for Crosslingual Conditional Generation With Interaction”, Pilault et al 2023
“How Close Is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection”, Guo et al 2023
How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection
“No Robots: Look Ma, an Instruction Dataset That Wasn’t Generated by GPTs!”, HuggingFace 2023
No Robots: Look Ma, an instruction dataset that wasn’t generated by GPTs!
“Med-PaLM: Large Language Models Encode Clinical Knowledge”, Singhal et al 2022
“Unnatural Instructions: Tuning Language Models With (Almost) No Human Labor”, Honovich et al 2022
Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor
“HALIE: Evaluating Human-Language Model Interaction”, Lee et al 2022
“A Whack-A-Mole Dilemma: Shortcuts Come in Multiples Where Mitigating One Amplifies Others”, Li et al 2022
A Whack-A-Mole Dilemma: Shortcuts Come in Multiples Where Mitigating One Amplifies Others
“Text Embeddings by Weakly-Supervised Contrastive Pre-Training”, Wang et al 2022
Text Embeddings by Weakly-Supervised Contrastive Pre-training
“The Stack: 3 TB of Permissively Licensed Source Code”, Kocetkov et al 2022
“UniSumm: Unified Few-Shot Summarization With Multi-Task Pre-Training and Prefix-Tuning”, Chen et al 2022
UniSumm: Unified Few-shot Summarization with Multi-Task Pre-Training and Prefix-Tuning
“A Creative Industry Image Generation Dataset Based on Captions”, Yuejia et al 2022
A Creative Industry Image Generation Dataset Based on Captions
“AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities”, Chen et al 2022
AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities
“AnimeRun: 2D Animation Visual Correspondence from Open Source 3D Movies”, Siyao et al 2022
AnimeRun: 2D Animation Visual Correspondence from Open Source 3D Movies
“MMDialog: A Large-Scale Multi-Turn Dialogue Dataset Towards Multi-Modal Open-Domain Conversation”, Feng et al 2022
MMDialog: A Large-scale Multi-turn Dialogue Dataset Towards Multi-modal Open-domain Conversation
“BLOOMZ/mT0: Crosslingual Generalization through Multitask Finetuning”, Muennighoff et al 2022
BLOOMZ/mT0: Crosslingual Generalization through Multitask Finetuning
“Dungeons and Data: A Large-Scale NetHack Dataset”, Hambro et al 2022
“Will We Run out of Data? An Analysis of the Limits of Scaling Datasets in Machine Learning”, Villalobos et al 2022
Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning
“Large Language Models Can Self-Improve”, Huang et al 2022
“CARP: Robust Preference Learning for Storytelling via Contrastive Reinforcement Learning”, Castricato et al 2022
CARP: Robust Preference Learning for Storytelling via Contrastive Reinforcement Learning
“MTEB: Massive Text Embedding Benchmark”, Muennighoff et al 2022
“Most Language Models Can Be Poets Too: An AI Writing Assistant and Constrained Text Generation Studio”, Roush et al 2022
“Self-Ask: Measuring and Narrowing the Compositionality Gap in Language Models (Bamboogle)”, Press et al 2022
Self-Ask: Measuring and Narrowing the Compositionality Gap in Language Models (Bamboogle)
“Dynamic Prompt Learning via Policy Gradient for Semi-Structured Mathematical Reasoning”, Lu et al 2022
Dynamic Prompt Learning via Policy Gradient for Semi-structured Mathematical Reasoning
“Brain Imaging Generation With Latent Diffusion Models”, Pinaya et al 2022
“PaLI: A Jointly-Scaled Multilingual Language-Image Model”, Chen et al 2022
“FOLIO: Natural Language Reasoning With First-Order Logic”, Han et al 2022
“Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned”, Ganguli et al 2022
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
“Bugs in the Data: How ImageNet Misrepresents Biodiversity”, Luccioni & Rolnick 2022
“Discovering Bugs in Vision Models Using Off-The-Shelf Image Generation and Captioning”, Wiles et al 2022
Discovering Bugs in Vision Models using Off-the-shelf Image Generation and Captioning
“Benchmarking Compositionality With Formal Languages”, Valvoda et al 2022
“Quality Not Quantity: On the Interaction between Dataset Design and Robustness of CLIP”, Nguyen et al 2022
Quality Not Quantity: On the Interaction between Dataset Design and Robustness of CLIP
“Learning to Generalize With Object-Centric Agents in the Open World Survival Game Crafter”, Stanić et al 2022
Learning to Generalize with Object-centric Agents in the Open World Survival Game Crafter
“Few-Shot Adaptation Works With UnpredicTable Data”, Chan et al 2022
“Language Models Can Teach Themselves to Program Better”, Haluptzok et al 2022
“RealTime QA: What’s the Answer Right Now?”, Kasai et al 2022
“NewsStories: Illustrating Articles With Visual Summaries”, Tan et al 2022
“CelebV-HQ: A Large-Scale Video Facial Attributes Dataset”, Zhu et al 2022
“Why Do Tree-Based Models Still Outperform Deep Learning on Tabular Data?”, Grinsztajn et al 2022
Why do tree-based models still outperform deep learning on tabular data?
“WebShop: Towards Scalable Real-World Web Interaction With Grounded Language Agents”, Yao et al 2022
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents
“Pile of Law: Learning Responsible Data Filtering from the Law and a 256GB Open-Source Legal Dataset”, Henderson et al 2022
Pile of Law: Learning Responsible Data Filtering from the Law and a 256GB Open-Source Legal Dataset
“Forecasting Future World Events With Neural Networks”, Zou et al 2022
“RST: ReStructured Pre-Training”, Yuan & Liu 2022
“Learning to Generate Artistic Character Line Drawing”, Fang et al 2022
“Dataset Condensation via Efficient Synthetic-Data Parameterization”, Kim et al 2022
Dataset Condensation via Efficient Synthetic-Data Parameterization
“Bongard-HOI: Benchmarking Few-Shot Visual Reasoning for Human-Object Interactions”, Jiang et al 2022
Bongard-HOI: Benchmarking Few-Shot Visual Reasoning for Human-Object Interactions
“Fine-Grained Image Captioning With CLIP Reward”, Cho et al 2022
“FLEURS: Few-Shot Learning Evaluation of Universal Representations of Speech”, Conneau et al 2022
FLEURS: Few-shot Learning Evaluation of Universal Representations of Speech
“InstructDial: Improving Zero and Few-Shot Generalization in Dialogue through Instruction Tuning”, Gupta et al 2022
InstructDial: Improving Zero and Few-shot Generalization in Dialogue through Instruction Tuning
“Learning to Model Editing Processes”, Reid & Neubig 2022
“Flexible Diffusion Modeling of Long Videos”, Harvey et al 2022
“Housekeep: Tidying Virtual Households Using Commonsense Reasoning”, Kant et al 2022
Housekeep: Tidying Virtual Households using Commonsense Reasoning
“Instruction Induction: From Few Examples to Natural Language Task Descriptions”, Honovich et al 2022
Instruction Induction: From Few Examples to Natural Language Task Descriptions
“Down and Across: Introducing Crossword-Solving As a New NLP Benchmark”, Kulshreshtha et al 2022
Down and Across: Introducing Crossword-Solving as a New NLP Benchmark
“Automated Crossword Solving”, Wallace et al 2022
“Dialog Inpainting: Turning Documents into Dialogues”, Dai et al 2022
“SymphonyNet: Symphony Generation With Permutation Invariant Language Model”, Liu et al 2022
SymphonyNet: Symphony Generation with Permutation Invariant Language Model
“Building Machine Translation Systems for the Next Thousand Languages”, Bapna et al 2022
Building Machine Translation Systems for the Next Thousand Languages
“When Does Dough Become a Bagel? Analyzing the Remaining Mistakes on ImageNet”, Vasudevan et al 2022
When does dough become a bagel? Analyzing the remaining mistakes on ImageNet
“Data Determines Distributional Robustness in Contrastive Language Image Pre-Training (CLIP)”, Fang et al 2022
Data Determines Distributional Robustness in Contrastive Language Image Pre-training (CLIP)
“A Challenging Benchmark of Anime Style Recognition”, Li et al 2022
“Tk-Instruct: Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks”, Wang et al 2022
Tk-Instruct: Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks
“Winoground: Probing Vision and Language Models for Visio-Linguistic Compositionality”, Thrush et al 2022
Winoground: Probing Vision and Language Models for Visio-Linguistic Compositionality
“KNN-Diffusion: Image Generation via Large-Scale Retrieval”, Ashual et al 2022
“ByT5 Model for Massively Multilingual Grapheme-To-Phoneme Conversion”, Zhu et al 2022
ByT5 model for massively multilingual grapheme-to-phoneme conversion
“STaR: Bootstrapping Reasoning With Reasoning”, Zelikman et al 2022
“CLIP Meets GamePhysics: Towards Bug Identification in Gameplay Videos Using Zero-Shot Transfer Learning”, Taesiri et al 2022
“Bamboo: Building Mega-Scale Vision Dataset Continually With Human-Machine Synergy”, Zhang et al 2022
Bamboo: Building Mega-Scale Vision Dataset Continually with Human-Machine Synergy
“Self-Distilled StyleGAN: Towards Generation from Internet Photos”, Mokady et al 2022
Self-Distilled StyleGAN: Towards Generation from Internet Photos
“RuCLIP—New Models and Experiments: a Technical Report”, Shonenkov et al 2022
“Wukong: 100 Million Large-Scale Chinese Cross-Modal Pre-Training Dataset and A Foundation Framework”, Gu et al 2022
Wukong: 100 Million Large-scale Chinese Cross-modal Pre-training Dataset and A Foundation Framework
“ROME: Locating and Editing Factual Associations in GPT”, Meng et al 2022
“DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-To-Image Generative Transformers”, Cho et al 2022
DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers
“PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts”, Bach et al 2022
PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts
“StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets”, Sauer et al 2022
“BLIP: Bootstrapping Language-Image Pre-Training for Unified Vision-Language Understanding and Generation”, Li et al 2022
“Can Wikipedia Help Offline Reinforcement Learning?”, Reid et al 2022
“SWAG: Revisiting Weakly Supervised Pre-Training of Visual Perception Models”, Singh et al 2022
SWAG: Revisiting Weakly Supervised Pre-Training of Visual Perception Models
“CoAuthor: Designing a Human-AI Collaborative Writing Dataset for Exploring Language Model Capabilities”, Lee et al 2022
“WANLI: Worker and AI Collaboration for Natural Language Inference Dataset Creation”, Liu et al 2022
WANLI: Worker and AI Collaboration for Natural Language Inference Dataset Creation
“SynthBio: A Case Study in Faster Curation of Text Datasets”, Yuan et al 2022
“BigDatasetGAN: Synthesizing ImageNet With Pixel-Wise Annotations”, Li et al 2022
BigDatasetGAN: Synthesizing ImageNet with Pixel-wise Annotations
“ERNIE-ViLG: Unified Generative Pre-Training for Bidirectional Vision-Language Generation”, Zhang et al 2021
ERNIE-ViLG: Unified Generative Pre-training for Bidirectional Vision-Language Generation
“A Fistful of Words: Learning Transferable Visual Models from Bag-Of-Words Supervision”, Tejankar et al 2021
A Fistful of Words: Learning Transferable Visual Models from Bag-of-Words Supervision
“GLIDE: Towards Photorealistic Image Generation and Editing With Text-Guided Diffusion Models”, Nichol et al 2021
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
“QuALITY: Question Answering With Long Input Texts, Yes!”, Pang et al 2021
“FRUIT: Faithfully Reflecting Updated Information in Text”, IV et al 2021
“Models in the Loop: Aiding Crowdworkers With Generative Annotation Assistants”, Bartolo et al 2021
Models in the Loop: Aiding Crowdworkers with Generative Annotation Assistants
“WebGPT: Browser-Assisted Question-Answering With Human Feedback”, Nakano et al 2021
WebGPT: Browser-assisted question-answering with human feedback
“GLaM: Efficient Scaling of Language Models With Mixture-Of-Experts”, Du et al 2021
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
“MAD: A Scalable Dataset for Language Grounding in Videos from Movie Audio Descriptions”, Soldan et al 2021
MAD: A Scalable Dataset for Language Grounding in Videos from Movie Audio Descriptions
“BASIC: Combined Scaling for Open-Vocabulary Image Classification”, Pham et al 2021
BASIC: Combined Scaling for Open-Vocabulary Image Classification
“It’s About Time: Analog Clock Reading in the Wild”, Yang et al 2021
“Solving Probability and Statistics Problems by Program Synthesis”, Tang et al 2021
Solving Probability and Statistics Problems by Program Synthesis
“Few-Shot Self-Rationalization With Natural Language Prompts”, Marasović et al 2021
“AnimeCeleb: Large-Scale Animation CelebHeads Dataset for Head Reenactment”, Kim et al 2021
AnimeCeleb: Large-Scale Animation CelebHeads Dataset for Head Reenactment
“RLDS: an Ecosystem to Generate, Share and Use Datasets in Reinforcement Learning”, Ramos et al 2021
RLDS: an Ecosystem to Generate, Share and Use Datasets in Reinforcement Learning
“An Explanation of In-Context Learning As Implicit Bayesian Inference”, Xie et al 2021
An Explanation of In-context Learning as Implicit Bayesian Inference
“LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs”, Schuhmann et al 2021
LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
“Training Verifiers to Solve Math Word Problems”, Cobbe et al 2021
“A Connectome of the Drosophila Central Complex Reveals Network Motifs Suitable for Flexible Navigation and Context-Dependent Action Selection”, Hulse et al 2021
“HTCN: Harmonious Text Colorization Network for Visual-Textual Presentation Design”, Yang et al 2021c
HTCN: Harmonious Text Colorization Network for Visual-Textual Presentation Design
“T0: Multitask Prompted Training Enables Zero-Shot Task Generalization”, Sanh et al 2021
T0: Multitask Prompted Training Enables Zero-Shot Task Generalization
“Can Machines Learn Morality? The Delphi Experiment”, Jiang et al 2021
“Situated Dialogue Learning through Procedural Environment Generation”, Ammanabrolu et al 2021
Situated Dialogue Learning through Procedural Environment Generation
“MiniHack the Planet: A Sandbox for Open-Ended Reinforcement Learning Research”, Samvelyan et al 2021
MiniHack the Planet: A Sandbox for Open-Ended Reinforcement Learning Research
“TruthfulQA: Measuring How Models Mimic Human Falsehoods”, Lin et al 2021
“MiniF2F: a Cross-System Benchmark for Formal Olympiad-Level Mathematics”, Zheng et al 2021
MiniF2F: a cross-system benchmark for formal Olympiad-level mathematics
“LAION-400-Million Open Dataset”, Schuhmann 2021
“Transfer Learning for Pose Estimation of Illustrated Characters”, Chen & Zwicker 2021
Transfer Learning for Pose Estimation of Illustrated Characters
“MuSiQue: Multi-Hop Questions via Single-Hop Question Composition”, Trivedi et al 2021
MuSiQue: Multi-hop Questions via Single-hop Question Composition
“Scaling Vision Transformers”, Zhai et al 2021
“QASPER: A Dataset of Information-Seeking Questions and Answers Anchored in Research Papers”, Dasigi et al 2021
QASPER: A Dataset of Information-Seeking Questions and Answers Anchored in Research Papers
“XLM-T: Multilingual Language Models in Twitter for Sentiment Analysis and Beyond”, Barbieri et al 2021
XLM-T: Multilingual Language Models in Twitter for Sentiment Analysis and Beyond
“BEIR: A Heterogenous Benchmark for Zero-Shot Evaluation of Information Retrieval Models”, Thakur et al 2021
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
“SpeechStew: Simply Mix All Available Speech Recognition Data to Train One Large Neural Network”, Chan et al 2021
SpeechStew: Simply Mix All Available Speech Recognition Data to Train One Large Neural Network
“Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks”, Northcutt et al 2021
Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks
“NaturalProofs: Mathematical Theorem Proving in Natural Language”, Welleck et al 2021
NaturalProofs: Mathematical Theorem Proving in Natural Language
“Get Your Vitamin C! Robust Fact Verification With Contrastive Evidence (VitaminC)”, Schuster et al 2021
Get Your Vitamin C! Robust Fact Verification with Contrastive Evidence (VitaminC)
“Are NLP Models Really Able to Solve Simple Math Word Problems?”, Patel et al 2021
Are NLP Models really able to Solve Simple Math Word Problems?
“Measuring Mathematical Problem Solving With the MATH Dataset”, Hendrycks et al 2021
Measuring Mathematical Problem Solving With the MATH Dataset
“Nutrition5k: Towards Automatic Nutritional Understanding of Generic Food”, Thames et al 2021
Nutrition5k: Towards Automatic Nutritional Understanding of Generic Food
“WIT: Wikipedia-Based Image Text Dataset for Multimodal Multilingual Machine Learning”, Srinivasan et al 2021
WIT: Wikipedia-based Image Text Dataset for Multimodal Multilingual Machine Learning
“A Massive 7T FMRI Dataset to Bridge Cognitive and Computational Neuroscience”, Allen et al 2021
A massive 7T fMRI dataset to bridge cognitive and computational neuroscience
“Conceptual 12M: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts”, Changpinyo et al 2021
Conceptual 12M: Pushing Web-Scale Image-Text Pre-Training To Recognize Long-Tail Visual Concepts
“ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision”, Jia et al 2021
ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
“Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Scaling”, Lazaridou et al 2021
Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Scaling
“Scaling Laws for Transfer”, Hernandez et al 2021
“Automatic Curation of Large-Scale Datasets for Audio-Visual Representation Learning”, Lee et al 2021
Automatic Curation of Large-Scale Datasets for Audio-Visual Representation Learning
“MSR-VTT: A Large Video Description Dataset for Bridging Video and Language”, Xu et al 2021
MSR-VTT: A Large Video Description Dataset for Bridging Video and Language
“CLIP: Learning Transferable Visual Models From Natural Language Supervision”, Radford et al 2021
CLIP: Learning Transferable Visual Models From Natural Language Supervision
“CLIP: Connecting Text and Images: We’re Introducing a Neural Network Called CLIP Which Efficiently Learns Visual Concepts from Natural Language Supervision. CLIP Can Be Applied to Any Visual Classification Benchmark by Simply Providing the Names of the Visual Categories to Be Recognized, Similar to the ‘Zero-Shot’ Capabilities of GPT-2 and GPT-3”, Radford et al 2021
“The Pile: An 800GB Dataset of Diverse Text for Language Modeling”, Gao et al 2021
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
“Selective Eye-Gaze Augmentation To Enhance Imitation Learning In Atari Games”, Thammineni et al 2020
Selective Eye-gaze Augmentation To Enhance Imitation Learning In Atari Games
“VoxLingua107: a Dataset for Spoken Language Recognition”, Valk & Alumäe 2020
“MoGaze: A Dataset of Full-Body Motions That Includes Workspace Geometry and Eye-Gaze”, Kratzer et al 2020
MoGaze: A Dataset of Full-Body Motions that Includes Workspace Geometry and Eye-Gaze
“End-To-End Chinese Landscape Painting Creation Using Generative Adversarial Networks”, Xue 2020
End-to-End Chinese Landscape Painting Creation Using Generative Adversarial Networks
“Hypersim: A Photorealistic Synthetic Dataset for Holistic Indoor Scene Understanding”, Roberts et al 2020
Hypersim: A Photorealistic Synthetic Dataset for Holistic Indoor Scene Understanding
“Constructing A Multi-Hop QA Dataset for Comprehensive Evaluation of Reasoning Steps”, Ho et al 2020
Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps
“Language ID in the Wild: Unexpected Challenges on the Path to a Thousand-Language Web Text Corpus”, Caswell et al 2020
Language ID in the Wild: Unexpected Challenges on the Path to a Thousand-Language Web Text Corpus
“Open-Domain Question Answering Goes Conversational via Question Rewriting”, Anantha et al 2020
Open-Domain Question Answering Goes Conversational via Question Rewriting
“Digital Voicing of Silent Speech”, Gaddy & Klein 2020
“A C/C++ Code Vulnerability Dataset With Code Changes and CVE Summaries”, Fan et al 2020
A C/C++ Code Vulnerability Dataset with Code Changes and CVE Summaries
“MMLU: Measuring Massive Multitask Language Understanding”, Hendrycks et al 2020
“ETHICS: Aligning AI With Shared Human Values”, Hendrycks et al 2020
“Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing”, Gu et al 2020
Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing
“CoVoST 2 and Massively Multilingual Speech-To-Text Translation”, Wang et al 2020
CoVoST 2 and Massively Multilingual Speech-to-Text Translation
“DanbooRegion: An Illustration Region Dataset”, Zhang & Liu 2020
“The Many Faces of Robustness: A Critical Analysis of Out-Of-Distribution Generalization”, Hendrycks et al 2020
The Many Faces of Robustness: A Critical Analysis of Out-of-Distribution Generalization
“The NetHack Learning Environment”, Küttler et al 2020
“ForecastQA: A Question Answering Challenge for Event Forecasting With Temporal Text Data”, Jin et al 2020
ForecastQA: A Question Answering Challenge for Event Forecasting with Temporal Text Data
“Shortcut Learning in Deep Neural Networks”, Geirhos et al 2020
“D4RL: Datasets for Deep Data-Driven Reinforcement Learning”, Fu et al 2020
“TyDiQA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages”, Clark et al 2020
TyDiQA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages
“SAYCam: A Large, Longitudinal Audiovisual Dataset Recorded from the Infant’s Perspective”, Sullivan et al 2020
SAYCam: A large, longitudinal audiovisual dataset recorded from the infant’s perspective
“ImageNet-A: Natural Adversarial Examples”, Hendrycks et al 2020
“Measuring Compositional Generalization: A Comprehensive Method on Realistic Data”, Keysers et al 2019
Measuring Compositional Generalization: A Comprehensive Method on Realistic Data
“Libri-Light: A Benchmark for ASR With Limited or No Supervision”, Kahn et al 2019
Libri-Light: A Benchmark for ASR with Limited or No Supervision
“How Can We Know What Language Models Know?”, Jiang et al 2019
“SimpleBooks: Long-Term Dependency Book Dataset With Simplified English Vocabulary for Word-Level Language Modeling”, Nguyen 2019
“How Machine Learning Can Help Unlock the World of Ancient Japan”, Lamb 2019
How Machine Learning Can Help Unlock the World of Ancient Japan
“Compressive Transformers for Long-Range Sequence Modeling”, Rae et al 2019
“CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning”, Lin et al 2019
CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning
“CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data”, Wenzek et al 2019
CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data
“T5: Exploring the Limits of Transfer Learning With a Unified Text-To-Text Transformer”, Raffel et al 2019
T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
“2019-10-18-Poetryfoundation-Formatted.txt”
“Restoring Ancient Text Using Deep Learning (Pythia): a Case Study on Greek Epigraphy”, Assael et al 2019
Restoring ancient text using deep learning (Pythia): a case study on Greek epigraphy
“CATER: A Diagnostic Dataset for Compositional Actions and TEmporal Reasoning”, Girdhar & Ramanan 2019
CATER: A diagnostic dataset for Compositional Actions and TEmporal Reasoning
“PubMedQA: A Dataset for Biomedical Research Question Answering”, Jin et al 2019
PubMedQA: A Dataset for Biomedical Research Question Answering
“ObjectNet: A Large-Scale Bias-Controlled Dataset for Pushing the Limits of Object Recognition Models”, Barbu et al 2019
ObjectNet: A large-scale bias-controlled dataset for pushing the limits of object recognition models
“No Press Diplomacy: Modeling Multi-Agent Gameplay”, Paquette et al 2019
“Language Modeling State-Of-The-Art Leaderboards”, paperswithcode.com 2019
“LVIS: A Dataset for Large Vocabulary Instance Segmentation”, Gupta et al 2019
“Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank”, Socher et al 2019
Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank
“A Large Single-Participant FMRI Dataset for Probing Brain Responses to Naturalistic Stimuli in Space and Time”, Seeliger et al 2019
“OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge”, Marino et al 2019
OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge
“ImageNet-Sketch: Learning Robust Global Representations by Penalizing Local Predictive Power”, Wang et al 2019
ImageNet-Sketch: Learning Robust Global Representations by Penalizing Local Predictive Power
“Cold Case: The Lost MNIST Digits”, Yadav & Bottou 2019
“SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems”, Wang et al 2019
SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems
“The MineRL 2019 Competition on Sample Efficient Reinforcement Learning Using Human Priors”, Guss et al 2019
The MineRL 2019 Competition on Sample Efficient Reinforcement Learning using Human Priors
“ProductNet: a Collection of High-Quality Datasets for Product Representation Learning”, Wang et al 2019
ProductNet: a Collection of High-Quality Datasets for Product Representation Learning
“Benchmarking Neural Network Robustness to Common Corruptions and Perturbations”, Hendrycks & Dietterich 2019
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
“Atari-HEAD: Atari Human Eye-Tracking and Demonstration Dataset”, Zhang et al 2019
Atari-HEAD: Atari Human Eye-Tracking and Demonstration Dataset
“LIGHT: Learning to Speak and Act in a Fantasy Text Adventure Game”, Urbanek et al 2019
LIGHT: Learning to Speak and Act in a Fantasy Text Adventure Game
“DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs”, Dua et al 2019
DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs
“A Replication Study: Machine Learning Models Are Capable of Predicting Sexual Orientation From Facial Images”, Leuner 2019
“MyAnimeList Anime-Summary Scrape”, Gokaslan 2019
“Language Models Are Unsupervised Multitask Learners”, Radford et al 2019
“The Omniglot Challenge: a 3-Year Progress Report”, Lake et al 2019
“Do We Train on Test Data? Purging CIFAR of Near-Duplicates”, Barz & Denzler 2019
“The RobotriX: An EXtremely Photorealistic and Very-Large-Scale Indoor Dataset of Sequences With Robot Trajectories and Interactions”, Garcia-Garcia et al 2019
“FIGR: Few-Shot Image Generation With Reptile”, Clouâtre & Demers 2019
“Natural Questions: A Benchmark for Question Answering Research”, Kwiatkowski et al 2019
Natural Questions: A Benchmark for Question Answering Research
“A Style-Based Generator Architecture for Generative Adversarial Networks”, Karras et al 2018
A Style-Based Generator Architecture for Generative Adversarial Networks
“ImageNet-Trained CNNs Are Biased towards Texture; Increasing Shape Bias Improves Accuracy and Robustness”, Geirhos et al 2018
“CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge”, Talmor et al 2018
CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge
“The Open Images Dataset V4: Unified Image Classification, Object Detection, and Visual Relationship Detection at Scale”, Kuznetsova et al 2018
“HotpotQA: A Dataset for Diverse, Explainable Multi-Hop Question Answering”, Yang et al 2018
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
“Don’t Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization”, Narayan et al 2018
“CurriculumNet: Weakly Supervised Learning from Large-Scale Web Images”, Guo et al 2018
CurriculumNet: Weakly Supervised Learning from Large-Scale Web Images
“A Short Note about Kinetics-600”, Carreira et al 2018
“Cartoon Set”, Royer et al 2018
“Benchmarking Neural Network Robustness to Common Corruptions and Surface Variations”, Hendrycks & Dietterich 2018
Benchmarking Neural Network Robustness to Common Corruptions and Surface Variations
“Know What You Don’t Know: Unanswerable Questions for SQuAD”, Rajpurkar et al 2018
“BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning”, Yu et al 2018
BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning
“Exploring the Limits of Weakly Supervised Pretraining”, Mahajan et al 2018
“Newsroom: A Dataset of 1.3 Million Summaries With Diverse Extractive Strategies”, Grusky et al 2018
Newsroom: A Dataset of 1.3 Million Summaries with Diverse Extractive Strategies
“GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding”, Wang et al 2018
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
“The Sound of Pixels”, Zhao et al 2018
“FEVER: a Large-Scale Dataset for Fact Extraction and VERification”, Thorne et al 2018
FEVER: a large-scale dataset for Fact Extraction and VERification
“Think You Have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge”, Clark et al 2018
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
“SCUT-FBP5500: A Diverse Benchmark Dataset for Multi-Paradigm Facial Beauty Prediction”, Liang et al 2018
SCUT-FBP5500: A Diverse Benchmark Dataset for Multi-Paradigm Facial Beauty Prediction
“11K Hands: Gender Recognition and Biometric Identification Using a Large Dataset of Hand Images”, Afifi 2017
11K Hands: Gender recognition and biometric identification using a large dataset of hand images
“Progressive Growing of GANs for Improved Quality, Stability, and Variation”, Karras et al 2017
Progressive Growing of GANs for Improved Quality, Stability, and Variation
“OpenML Benchmarking Suites”, Bischl et al 2017
“WebVision Database: Visual Learning and Understanding from Web Data”, Li et al 2017
WebVision Database: Visual Learning and Understanding from Web Data
“A Downsampled Variant of ImageNet As an Alternative to the CIFAR Datasets”, Chrabaszcz et al 2017
A Downsampled Variant of ImageNet as an Alternative to the CIFAR datasets
“Revisiting Unreasonable Effectiveness of Data in Deep Learning Era”, Sun et al 2017
Revisiting Unreasonable Effectiveness of Data in Deep Learning Era
“Driver Identification Using Automobile Sensor Data from a Single Turn”, Hallac et al 2017
Driver Identification Using Automobile Sensor Data from a Single Turn
“StreetStyle: Exploring World-Wide Clothing Styles from Millions of Photos”, Matzen et al 2017
StreetStyle: Exploring world-wide clothing styles from millions of photos
“The Kinetics Human Action Video Dataset”, Kay et al 2017
“WebVision Challenge: Visual Learning and Understanding With Web Data”, Li et al 2017
WebVision Challenge: Visual Learning and Understanding With Web Data
“TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension”, Joshi et al 2017
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
“Dense-Captioning Events in Videos”, Krishna et al 2017
“BAM! The Behance Artistic Media Dataset for Recognition Beyond Photography”, Wilber et al 2017
BAM! The Behance Artistic Media Dataset for Recognition Beyond Photography
“SearchQA: A New Q&A Dataset Augmented With Context from a Search Engine”, Dunn et al 2017
SearchQA: A New Q&A Dataset Augmented with Context from a Search Engine
“RACE: Large-Scale ReAding Comprehension Dataset From Examinations”, Lai et al 2017
RACE: Large-scale ReAding Comprehension Dataset From Examinations
“NewsQA: A Machine Comprehension Dataset”, Trischler et al 2016
“MS MARCO: A Human Generated MAchine Reading COmprehension Dataset”, Bajaj et al 2016
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
“Visual Dialog”, Das et al 2016
“Lip Reading Sentences in the Wild”, Chung et al 2016
“Pointer Sentinel Mixture Models”, Merity et al 2016
“Deep Learning the City: Quantifying Urban Perception At A Global Scale”, Dubey et al 2016
Deep Learning the City: Quantifying Urban Perception At A Global Scale
“MultiArith: Solving General Arithmetic Word Problems”, Roy & Roth 2016
“The LAMBADA Dataset: Word Prediction Requiring a Broad Discourse Context”, Paperno et al 2016
The LAMBADA dataset: Word prediction requiring a broad discourse context
“SQuAD: 100,000+ Questions for Machine Comprehension of Text”, Rajpurkar et al 2016
“Matching Networks for One Shot Learning”, Vinyals et al 2016
“Convolutional Sketch Inversion”, Güçlütürk et al 2016
“The MovieLens Datasets: History and Context”, Harper & Konstan 2015
“Neural Module Networks”, Andreas et al 2015
“Sketch-Based Manga Retrieval Using Manga109 Dataset”, Matsui et al 2015
“Amazon Reviews: Image-Based Recommendations on Styles and Substitutes”, McAuley et al 2015
Amazon Reviews: Image-based Recommendations on Styles and Substitutes
“Teaching Machines to Read and Comprehend”, Hermann et al 2015
“LSUN: Construction of a Large-Scale Image Dataset Using Deep Learning With Humans in the Loop”, Yu et al 2015
LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop
“The Unreasonable Effectiveness of Recurrent Neural Networks”, Karpathy 2015
“VQA: Visual Question Answering”, Agrawal et al 2015
“YFCC100M: The New Data in Multimedia Research”, Thomee et al 2015
“Deep Learning Face Attributes in the Wild”, Liu et al 2014
“ImageNet Large Scale Visual Recognition Challenge”, Russakovsky et al 2014
“Microsoft COCO: Common Objects in Context”, Lin et al 2014
“N-Gram Counts and Language Models from the Common Crawl”, Buck et al 2014
“One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling”, Chelba et al 2013
One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling
“20 Years of Bitext”, Brown et al 2013
“Ukiyo-E Search”, Resig 2013
“UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild”, Soomro et al 2012
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
“The Caltech-UCSD Birds-200-2011 Dataset”, Wah et al 2011
“Unbiased Look at Dataset Bias”, Torralba & Efros 2011
“Caltech-UCSD Birds 200”, Welinder et al 2010
“Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments”, Huang et al 2008
Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments
“The Infinite MNIST Dataset”, Bottou 2007
“All Our n-Gram Are Belong to You”, Franz & Brants 2006
“Building a Large Annotated Corpus of English: The Penn Treebank”, Marcus et al 1993
Building a Large Annotated Corpus of English: The Penn Treebank
“The Design for the Wall Street Journal-Based CSR Corpus”, Paul & Baker 1992
“About the Test Data”
“MIT Places Database for Scene Recognition”
“DataGemma: AI Open Models Connecting LLMs to Google’s Data Commons”
DataGemma: AI open models connecting LLMs to Google’s Data Commons
“STL-10 Dataset”
“AOT Characters Dataset”
“EQ-Bench 3 Leaderboard”
“AnimeDL-2M: Million-Scale AI-Generated Anime Image Detection and Localization in Diffusion Era”
AnimeDL-2M: Million-Scale AI-Generated Anime Image Detection and Localization in Diffusion Era
“Scale AI Secures $1B Funding at $14B Valuation As Its CEO Predicts Big Revenue Growth and Profitability by Year-End [On Very High Quality Data]”
“RWKV-CLIP: A Robust Vision-Language Representation Learner”
“political-Emails: Processed Collection of Fundraising Emails from Political Campaigns”, Willis 2026
political-emails: Processed collection of fundraising emails from political campaigns
“Ox-Vgg/vgg_face2”
“ImpossibleBench”
“Salesforce/creativity_eval”
“Hafftka/michael-Hafftka-Catalog-Raisonné”
“Kaichengalex/YFCC15M”
“Blowing-Up-Groundhogs/font-Square-V2”
“Psych-101 Dataset [For Centaur]”
“Open-Index/hacker-News”
“Tokyotech-Llm/swallow-Code”
“Tokyotech-Llm/swallow-Math”
“FineWeb: Decanting the Web for the Finest Text Data at Scale”
FineWeb: decanting the web for the finest text data at scale
“Solving Math Word Problems: We’ve Trained a System That Solves Grade School Math Problems With Nearly Twice the Accuracy of a Fine-Tuned GPT-3 Model. It Solves about 90% As Many Problems As Real Kids: a Small Sample of 9-12 Year Olds Scored 60% on a Test from Our Dataset, While Our System Scored 55% on Those Same Problems. This Is Important Because Today’s AI Is Still Quite Weak at Commonsense Multistep Reasoning, Which Is Easy Even for Grade School Kids. We Achieved These Results by Training Our Model to Recognize Its Mistakes, so That It Can Try Repeatedly Until It Finds a Solution That Works”
“SuperGLUE Benchmark”
“Time Blindness: Why Video-Language Models Can’t See What Humans Can?”
Time Blindness: Why Video-Language Models Can’t See What Humans Can?
“The Small World of English: Building a 1.5M Word Semantic Network for Language Games”
The Small World of English: Building a 1.5M Word Semantic Network for Language Games
“Some Lessons from the OpenAI FrontierMath Debacle”
“Revisiting GSM-Symbolic: Models Seem to Reason Okay, Actually”
Revisiting GSM-Symbolic: models seem to reason okay, actually
“Cryptic Puzzles As a Probe for Lateral Thinking”
“Usenet-Corpus-1980–2013”, OwnedByDanes 2026
“Lip Reading Sentences in the Wild [Video]”
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
no-ai-data
movielens-context
discord-dataset
user-manipulation
ai-awareness
food-vision
language-image
simplified-books
fact-verification
dataset-scaling
crossword-solving
visual-reasoning
facial-prediction automobile-sensors mnist-research sexual-orientation cold-case-analysis
cartoon-art ukiyo-e
video-action
instruction-tuning
Wikipedia (9)
Miscellaneous
/doc/ai/dataset/2023-pilaut-figure1-interactivechainpromptingforqaabouttranslationambiguities.jpg/doc/ai/dataset/2020-caswell-table2-examplesofmisleadingtextlanguageassociations.png/doc/ai/dataset/2019-12-18-skylion-archiveofourown-fanfics-textscrape.tar.xzhttp://cl-informatik.uibk.ac.at/cek/holstep/ckfccs-holstep-submitted.pdfhttps://karpathy.github.io/2011/04/27/manually-classifying-cifar10/https://openaccess.thecvf.com/content_cvpr_2014/papers/Andriluka_2D_Human_Pose_2014_CVPR_paper.pdfhttps://static.googleusercontent.com/media/research.google.com/en//pubs/archive/37648.pdf
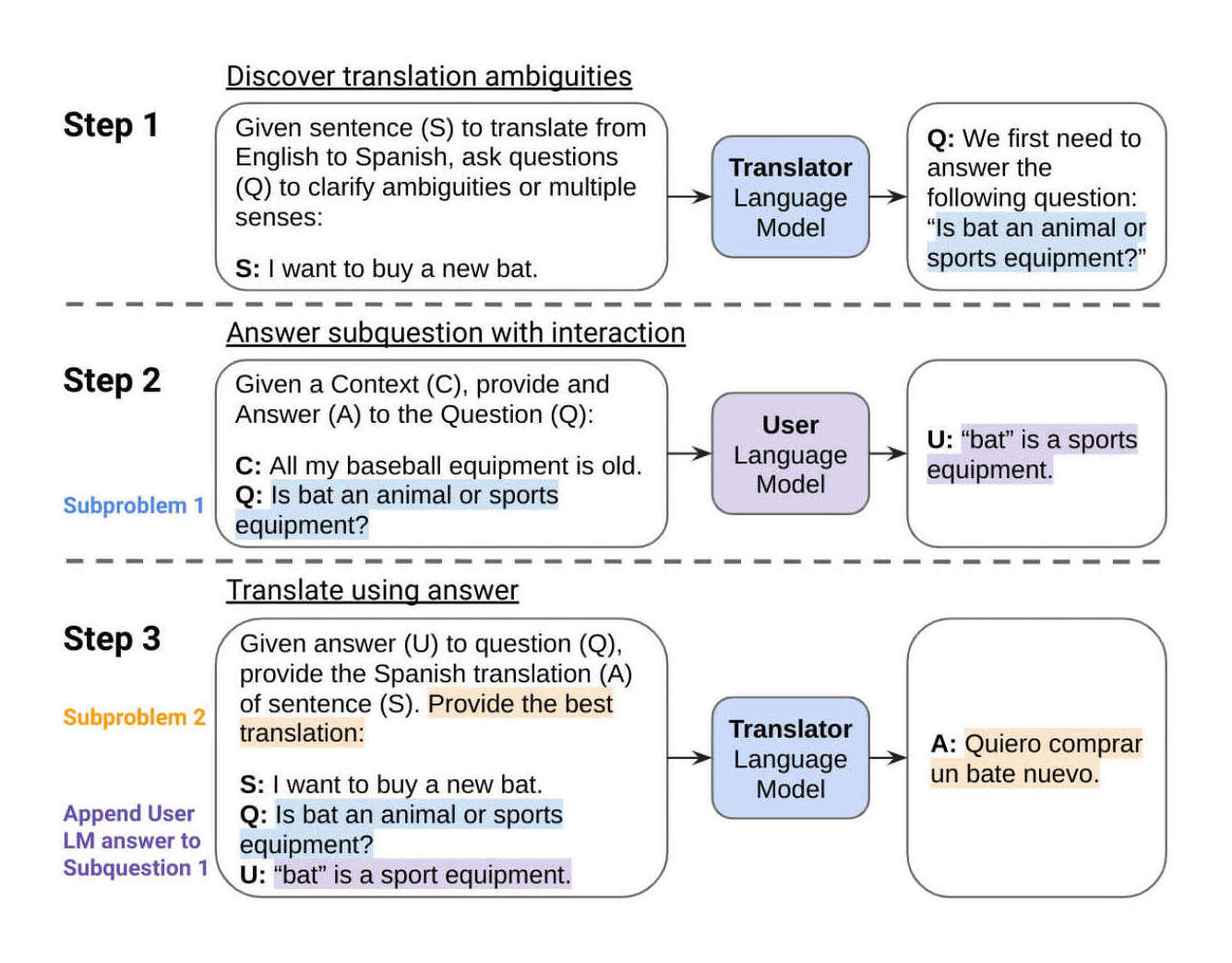{kind=link}
{kind=link}
Bibliography
https://www.sciencedirect.com/science/article/pii/S2352340925009679: “Attack on Titan (AoT): Anime Image Dataset for Character, Scene, Emotion Recognition and Beyond”,https://arxiv.org/abs/2510.05740: “Redefining Generalization in Visual Domains: A Two-Axis Framework for Fake Image Detection With FusionDetect”,https://arxiv.org/abs/2508.17511: “School of Reward Hacks: Hacking Harmless Tasks Generalizes to Misaligned Behavior in LLMs”,https://arxiv.org/abs/2505.02881: “Rewriting Pre-Training Data Boosts LLM Performance in Math and Code [SwallowCode/Math]”,https://arxiv.org/abs/2502.12896: “None of the Others: a General Technique to Distinguish Reasoning from Memorization in Multiple-Choice LLM Evaluation Benchmarks”,https://arxiv.org/abs/2502.00627: “Discord Unveiled: A Comprehensive Dataset of Public Communication (2015–2024)”,https://arxiv.org/abs/2501.09038#deepmind: “Do Generative Video Models Learn Physical Principles from Watching Videos?”,2025-johri.pdf: “An Evaluation Framework for Clinical Use of Large Language Models in Patient Interaction Tasks”,https://arxiv.org/abs/2411.13543: “BALROG: Benchmarking Agentic LLM and VLM Reasoning On Games”,https://arxiv.org/abs/2410.06992: “SWE-Bench+: Enhanced Coding Benchmark for LLMs”,https://arxiv.org/abs/2410.07095#openai: “MLE-Bench: Evaluating Machine Learning Agents on Machine Learning Engineering”,https://arxiv.org/abs/2407.20020: “ImagiNet: A Multi-Content Dataset for Generalizable Synthetic Image Detection via Contrastive Learning”,https://arxiv.org/abs/2407.04694: “Me, Myself, and AI: The Situational Awareness Dataset (SAD) for LLMs”,https://arxiv.org/abs/2407.04108: “Future Events As Backdoor Triggers: Investigating Temporal Vulnerabilities in LLMs”,https://arxiv.org/abs/2406.18906: “Sonnet or Not, Bot? Poetry Evaluation for Large Models and Datasets”,https://arxiv.org/abs/2406.18518#salesforce: “APIGen: Automated Pipeline for Generating Verifiable and Diverse Function-Calling Datasets”,https://arxiv.org/abs/2406.13121#google: “Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?”,https://arxiv.org/abs/2406.11794: “DataComp-LM: In Search of the next Generation of Training Sets for Language Models”,https://arxiv.org/abs/2406.06973: “RWKV-CLIP: A Robust Vision-Language Representation Learner”,https://arxiv.org/abs/2405.18870#google: “LLMs Achieve Adult Human Performance on Higher-Order Theory of Mind Tasks”,https://arxiv.org/abs/2405.15306: “DeTikZify: Synthesizing Graphics Programs for Scientific Figures and Sketches With TikZ”,https://arxiv.org/abs/2405.07425: “Sakuga-42M Dataset: Scaling Up Cartoon Research”,https://arxiv.org/abs/2405.02793#google: “ImageInWords: Unlocking Hyper-Detailed Image Descriptions”,https://arxiv.org/abs/2405.00332#scale: “GSM1k: A Careful Examination of Large Language Model Performance on Grade School Arithmetic”,https://arxiv.org/abs/2404.06664: “CulturalTeaming: AI-Assisted Interactive Red-Teaming for Challenging LLMs’ (Lack Of) Multicultural Knowledge”,https://arxiv.org/abs/2404.05955: “VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?”,https://www.nytimes.com/2024/04/06/technology/tech-giants-harvest-data-artificial-intelligence.html: “How Tech Giants Cut Corners to Harvest Data for AI: OpenAI, Google and Meta Ignored Corporate Policies, Altered Their Own Rules and Discussed Skirting Copyright Law As They Sought Online Information to Train Their Newest Artificial Intelligence Systems”,https://arxiv.org/abs/2404.01291: “Evaluating Text-To-Visual Generation With Image-To-Text Generation”,https://arxiv.org/abs/2403.18624: “Vulnerability Detection With Code Language Models: How Far Are We?”,https://arxiv.org/abs/2403.18802#deepmind: “Long-Form Factuality in Large Language Models”,https://arxiv.org/abs/2402.11753: “ArtPrompt: ASCII Art-Based Jailbreak Attacks against Aligned LLMs”,https://arxiv.org/abs/2312.11556: “StarVector: Generating Scalable Vector Graphics Code from Images”,https://arxiv.org/abs/2312.06281: “EQ-Bench: An Emotional Intelligence Benchmark for Large Language Models”,https://arxiv.org/abs/2311.13657: “Efficient Transformer Knowledge Distillation: A Performance Review”,https://arxiv.org/abs/2310.16825: “CommonCanvas: An Open Diffusion Model Trained With Creative-Commons Images”,https://arxiv.org/abs/2310.06786: “OpenWebMath: An Open Dataset of High-Quality Mathematical Web Text”,https://arxiv.org/abs/2310.03214#google: “FreshLLMs: Refreshing Large Language Models With Search Engine Augmentation”,https://arxiv.org/abs/2310.01377: “UltraFeedback: Boosting Language Models With High-Quality Feedback”,https://arxiv.org/abs/2309.16671: “Demystifying CLIP Data”,https://arxiv.org/abs/2309.12269: “The Cambridge Law Corpus: A Corpus for Legal AI Research”,https://arxiv.org/abs/2309.12284: “MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models”,https://arxiv.org/abs/2309.10818#cerebras: “SlimPajama-DC: Understanding Data Combinations for LLM Training”,https://arxiv.org/abs/2309.04269: “From Sparse to Dense: GPT-4 Summarization With Chain of Density (CoD) Prompting”,https://arxiv.org/abs/2308.12477: “American Stories: A Large-Scale Structured Text Dataset of Historical US Newspapers”,https://arxiv.org/abs/2307.08701#samsung: “AlpaGasus: Training A Better Alpaca With Fewer Data”,https://arxiv.org/abs/2307.05014: “Test-Time Training on Video Streams”,https://arxiv.org/abs/2306.15626: “LeanDojo: Theorem Proving With Retrieval-Augmented Language Models”,https://arxiv.org/abs/2306.12587: “ARIES: A Corpus of Scientific Paper Edits Made in Response to Peer Reviews”,https://arxiv.org/abs/2306.15448: “Understanding Social Reasoning in Language Models With Language Models”,https://www.theverge.com/features/23764584/ai-artificial-intelligence-data-notation-labor-scale-surge-remotasks-openai-chatbots: “AI Is a Lot of Work: As the Technology Becomes Ubiquitous, a Vast Tasker Underclass Is Emerging—And Not Going Anywhere”,2023-yi.pdf: “Anime Character Identification and Tag Prediction by Multimodality Modeling: Dataset and Model”,https://www.theinformation.com/articles/why-youtube-could-give-google-an-edge-in-ai: “Why YouTube Could Give Google an Edge in AI”,https://arxiv.org/abs/2305.20050#openai: “Let’s Verify Step by Step”,https://arxiv.org/abs/2305.07759#microsoft: “TinyStories: How Small Can Language Models Be and Still Speak Coherent English?”,https://arxiv.org/abs/2305.01569: “Pick-A-Pic: An Open Dataset of User Preferences for Text-To-Image Generation”,https://arxiv.org/abs/2304.05538: “ImageNet-Hard: The Hardest Images Remaining from a Study of the Power of Zoom and Spatial Biases in Image Classification”,https://arxiv.org/abs/2304.02015#alibaba: “How Well Do Large Language Models Perform in Arithmetic Tasks?”,https://arxiv.org/abs/2302.14520: “Large Language Models Are State-Of-The-Art Evaluators of Translation Quality”,https://arxiv.org/abs/2302.03169: “Data Selection for Language Models via Importance Resampling”,https://arxiv.org/abs/2212.13138#google: “Med-PaLM: Large Language Models Encode Clinical Knowledge”,https://arxiv.org/abs/2212.03533#microsoft: “Text Embeddings by Weakly-Supervised Contrastive Pre-Training”,https://arxiv.org/abs/2211.15533: “The Stack: 3 TB of Permissively Licensed Source Code”,https://arxiv.org/abs/2211.06679#baai: “AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities”,https://arxiv.org/abs/2211.01786: “BLOOMZ/mT0: Crosslingual Generalization through Multitask Finetuning”,https://arxiv.org/abs/2210.11610#google: “Large Language Models Can Self-Improve”,https://arxiv.org/abs/2210.07792#eleutherai: “CARP: Robust Preference Learning for Storytelling via Contrastive Reinforcement Learning”,https://aclanthology.org/2022.cai-1.2.pdf: “Most Language Models Can Be Poets Too: An AI Writing Assistant and Constrained Text Generation Studio”,https://arxiv.org/abs/2210.03350#allen: “Self-Ask: Measuring and Narrowing the Compositionality Gap in Language Models (Bamboogle)”,https://arxiv.org/abs/2209.00840: “FOLIO: Natural Language Reasoning With First-Order Logic”,https://www.anthropic.com/red_teaming.pdf: “Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned”,https://arxiv.org/abs/2208.08831#deepmind: “Discovering Bugs in Vision Models Using Off-The-Shelf Image Generation and Captioning”,https://arxiv.org/abs/2208.05516: “Quality Not Quantity: On the Interaction between Dataset Design and Robustness of CLIP”,https://arxiv.org/abs/2207.13061: “NewsStories: Illustrating Articles With Visual Summaries”,https://arxiv.org/abs/2206.15474: “Forecasting Future World Events With Neural Networks”,https://arxiv.org/abs/2205.09665#bair: “Automated Crossword Solving”,https://arxiv.org/abs/2205.09073#google: “Dialog Inpainting: Turning Documents into Dialogues”,https://arxiv.org/abs/2205.03983#google: “Building Machine Translation Systems for the Next Thousand Languages”,https://arxiv.org/abs/2205.04596#google: “When Does Dough Become a Bagel? Analyzing the Remaining Mistakes on ImageNet”,https://arxiv.org/abs/2205.01397: “Data Determines Distributional Robustness in Contrastive Language Image Pre-Training (CLIP)”,https://arxiv.org/abs/2204.07705: “Tk-Instruct: Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks”,https://arxiv.org/abs/2204.03067: “ByT5 Model for Massively Multilingual Grapheme-To-Phoneme Conversion”,https://arxiv.org/abs/2203.11096: “CLIP Meets GamePhysics: Towards Bug Identification in Gameplay Videos Using Zero-Shot Transfer Learning”,https://arxiv.org/abs/2202.12211#google: “Self-Distilled StyleGAN: Towards Generation from Internet Photos”,https://arxiv.org/abs/2202.06767#huawei: “Wukong: 100 Million Large-Scale Chinese Cross-Modal Pre-Training Dataset and A Foundation Framework”,https://arxiv.org/abs/2202.00273: “StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets”,https://arxiv.org/abs/2201.12086#salesforce: “BLIP: Bootstrapping Language-Image Pre-Training for Unified Vision-Language Understanding and Generation”,https://arxiv.org/abs/2201.08371#facebook: “SWAG: Revisiting Weakly Supervised Pre-Training of Visual Perception Models”,https://swabhs.com/assets/pdf/wanli.pdf#allen: “WANLI: Worker and AI Collaboration for Natural Language Inference Dataset Creation”,https://arxiv.org/abs/2201.04684: “BigDatasetGAN: Synthesizing ImageNet With Pixel-Wise Annotations”,https://arxiv.org/abs/2112.15283#baidu: “ERNIE-ViLG: Unified Generative Pre-Training for Bidirectional Vision-Language Generation”,https://arxiv.org/abs/2112.09332#openai: “WebGPT: Browser-Assisted Question-Answering With Human Feedback”,https://arxiv.org/abs/2111.10050#google: “BASIC: Combined Scaling for Open-Vocabulary Image Classification”,https://arxiv.org/abs/2111.09162: “It’s About Time: Analog Clock Reading in the Wild”,https://arxiv.org/abs/2111.08267: “Solving Probability and Statistics Problems by Program Synthesis”,https://arxiv.org/abs/2111.02114#laion: “LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs”,https://arxiv.org/abs/2110.14168#openai: “Training Verifiers to Solve Math Word Problems”,https://elifesciences.org/articles/66039: “A Connectome of the Drosophila Central Complex Reveals Network Motifs Suitable for Flexible Navigation and Context-Dependent Action Selection”,https://arxiv.org/abs/2109.07958: “TruthfulQA: Measuring How Models Mimic Human Falsehoods”,https://laion.ai/blog/laion-400-open-dataset/: “LAION-400-Million Open Dataset”,https://arxiv.org/abs/2106.04560#google: “Scaling Vision Transformers”,https://arxiv.org/abs/2104.02133#google: “SpeechStew: Simply Mix All Available Speech Recognition Data to Train One Large Neural Network”,https://arxiv.org/abs/2103.14749: “Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks”,https://arxiv.org/abs/2102.05918#google: “ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision”,https://arxiv.org/abs/2102.01951#scaling&org=deepmind: “Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Scaling”,https://cdn.openai.com/papers/Learning_Transferable_Visual_Models_From_Natural_Language_Supervision.pdf: “CLIP: Learning Transferable Visual Models From Natural Language Supervision”,https://arxiv.org/abs/2101.00027#eleutherai: “The Pile: An 800GB Dataset of Diverse Text for Language Modeling”,https://arxiv.org/abs/2010.14571#google: “Language ID in the Wild: Unexpected Challenges on the Path to a Thousand-Language Web Text Corpus”,https://arxiv.org/abs/2009.03300: “MMLU: Measuring Massive Multitask Language Understanding”,https://arxiv.org/abs/1911.05507#deepmind: “Compressive Transformers for Long-Range Sequence Modeling”,https://paperswithcode.com/task/language-modelling: “Language Modeling State-Of-The-Art Leaderboards”,https://arxiv.org/abs/1905.00537: “SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems”,https://arxiv.org/abs/1808.01097: “CurriculumNet: Weakly Supervised Learning from Large-Scale Web Images”,https://arxiv.org/abs/1808.01340#deepmind: “A Short Note about Kinetics-600”,2018-sharma.pdf#google: “Conceptual Captions: A Cleaned, Hypernymed, Image Alt-Text Dataset For Automatic Image Captioning”,https://arxiv.org/abs/1805.00932#facebook: “Exploring the Limits of Weakly Supervised Pretraining”,https://arxiv.org/abs/1707.08819: “A Downsampled Variant of ImageNet As an Alternative to the CIFAR Datasets”,https://arxiv.org/abs/1705.05640: “WebVision Challenge: Visual Learning and Understanding With Web Data”,https://arxiv.org/abs/1704.05179: “SearchQA: A New Q&A Dataset Augmented With Context from a Search Engine”,http://www.lrec-conf.org/proceedings/lrec2014/pdf/1097_Paper.pdf: “N-Gram Counts and Language Models from the Common Crawl”,2011-torralba.pdf: “Unbiased Look at Dataset Bias”,2008-huang.pdf: “Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments”,