‘inner monologue (AI)’ directory
- See Also
- Gwern
- “Model Collapse Won’t Happen”, Gwern 2022
- “Elegy in a Craneyard”, Gwern et al 2026
- “Hyperstition AI Unslop Contest”, Silverbook & Gwern 2026
- “Human Perception at a Red Light”, Gwern & Pro 2026
- “‘The Fourth Truth Of Pain’ Graveyard”, Gwern et al 2022
- “Free-Play Periods for RL Agents”, Gwern 2023
- “It Looks Like You’re Trying To Take Over The World”, Gwern 2022
- Links
- “How Transparent Is DiffusionGemma?”, Engels et al 2026
- “Estimating No-CoT Task-Completion Time Horizons of Frontier AI Models [3-Minute-Long Problems With P=0.5]”, Woodruff et al 2026
- “Claude-4.8-Opus Inner-Monologue Analyzing Gwern’s Intellectual Weaknesses and Contradictions Using The Interview Prompt”, Claude-4.8-opus 2026
- “Zork-Bench: An LLM Reasoning Eval Based on Text Adventure Games; a Tale As Old As Time, or at Least As Old As Computers”, Aiken 2026
- “I Can Never Talk to an AI Anonymously Again: AI Only Needs 150 Words to Identify Me. What Does That Mean for You?”, Piper 2026
- “How 4chan Gamers Accidentally Invented AI Reasoning: It Involves 4chan, of All Places”, Reisner 2026
- “Steering Might Stop Working Soon”, Babcock 2026
- “Friendship Is All You Need: Subliminal Pony Propagation in Large Language Models, Or, How I Learned to Stop Worrying and Love the Sparkle”, Sparkle et al 2026
- “Neural Thickets: Diverse Task Experts Are Dense Around Pretrained Weights”, Gan & Isola 2026
- “Building a C Compiler With a Team of Parallel Claudes: We Tasked Claude-4.6-Opus Using Agent Teams to Build a C Compiler [In Rust], and Then (Mostly) Walked Away. Here’s What It Taught Us about the Future of Autonomous Software Development”, Carlini 2026
- “Learning to Reason in 13 Parameters”, Morris et al 2026
- “Field Notes from the AI Village: The Drama and Dysfunction of Gemini 2.5 Pro & Gemini 3 Pro”, K 2026
- “Playing With AI: How Do State-Of-The-Art Large Language Models Perform in the 1977 Text-Based Adventure Game Zork?”, Gerrits 2026
- “Language of Thought Shapes Output Diversity in Large Language Models”, Xu & Zhang 2026
- “From Whitman to Instagram With Claude: How I Made Claude Write Parodies of Famous Elegiac Poems Imitating Rupi Kaur”, Bohdan 2026
- “LLM Poetry and the ‘Greatness’ Question: Experiments by Gwern and Mercor”, Robbins 2026
- “How AI Is Learning to Think in Secret: On Thinkish, Neuralese, and the End of Readable Reasoning”, Andresen 2026
- “Reverse Engineering a Phase Change in GPT’s Training Data… With the Seahorse Emoji 🌊🐴: Why Non-Thinking Models Have Started ‘Thinking Out Loud’, and What It Reveals about How Frontier Labs Train Their Latest Models [(Benchmarking the Rise of Inner-Monologue Reasoning Data in OA, 2023-06–2025-08)]”, Maini 2025
- “Prompt Repetition Improves Non-Reasoning LLMs”, Leviathan et al 2025
- “Ladder Up, Memory Down: Low-Cost Fine-Tuning With Side Nets (LST/xLadder)”, Zheng et al 2025
- “GPT-5.2-Thinking-20251213 System Prompt”, Walls & GPT-5.2 2025
- “How I Stopped Being Sure LLMs Are Just Making up Their Internal Experience (But the Topic Is Still Confusing)”, Sotala 2025
- “AI in 2025: Gestalt”, technicalities 2025
- “DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models”, DeepSeek et al 2025
- “DeepSeekMath-V2: Towards Self-Verifiable Mathematical Reasoning”, Shao et al 2025
- “GPT-5.1: A Smarter, More Conversational ChatGPT § GPT-5.1 Thinking”, OpenAI 2025
- “Trained on Tokens, Calibrated on Concepts: The Emergence of Semantic Calibration in LLMs”, Nakkiran et al 2025
- “Kimi K2 Thinking”, Moonshot 2025
- “Can You Find the Steganographically Hidden Message?”, Nishimura-Gasparian 2025
- “Reasoning With Sampling: Your Base Model Is Smarter Than You Think”, Karan & Du 2025
- “All Code, No Thought: Current Language Models Struggle to Reason in Ciphered Language”, Guo et al 2025
- “Towards a Typology of Strange LLM Chains-Of-Thought”, 1a3orn 2025
- “Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity”, Zhang et al 2025
- “Why Can’t Transformers Learn Multiplication? Reverse-Engineering Reveals Long-Range Dependency Pitfalls”, Bai et al 2025
- “Tree-GRPO: Tree Search for LLM Agent Reinforcement Learning”, Ji et al 2025
- “Details about METR’s Evaluation of OpenAI GPT-5”, METR 2025
- “GPT-5 Is Here: Our Smartest, Fastest, and Most Useful Model Yet, With Thinking Built In. Available to Everyone”, OpenAI 2025
- “GPT-5 Pro: Scaled but Efficient Parallel Test-Time Compute, to Provide the Highest Quality and Most Comprehensive Answers”, OpenAI 2025
- sama @ "2025-08-06"
- “Introducing Gpt-Oss:
gpt-Oss-120bandgpt-Oss-20bPush the Frontier of Open-Weight Reasoning Models”, OpenAI 2025 - “TextQuests: How Good Are LLMs at Text-Based Video Games?”, Phan et al 2025
- “Optimizing The Final Output Can Obfuscate CoT (Research Note)”, lukemarks et al 2025
- “Gemini 2.5 Pro Capable of Winning Gold at IMO 2025”, Huang & Yang 2025
- “Reasoning-Finetuning Repurposes Latent Representations in Base Models”, Ward et al 2025
- “Machine Bullshit: Characterizing the Emergent Disregard for Truth in Large Language Models”, Liang et al 2025
- “Strategic Intelligence in Large Language Models: Evidence from Evolutionary Game Theory”, Payne & Alloui-Cros 2025
- “Early Signs of Steganographic Capabilities in Frontier LLMs”, Zolkowski et al 2025
- “Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective”, Cheng et al 2025
- “Robustly Improving LLM Fairness in Realistic Settings via Interpretability”, Karvonen & Marks 2025
- “ChatGPT O3-Pro: Version of O3 With More Compute for Better Responses”, OpenAI 2025
- “Beyond Benchmark Scores: Analyzing O3-Mini’s Mathematical Reasoning”, Ho et al 2025
- “Unfaithful Reasoning Can Fool Chain-Of-Thought Monitoring”, Arnav et al 2025
- “Race and Gender Bias As An Example of Unfaithful Chain-Of-Thought in the Wild”
- “CoT Red-Handed: Stress Testing Chain-Of-Thought Monitoring”, Arnav et al 2025
- “Large Language Models Often Know When They Are Being Evaluated”, Needham et al 2025
- “DeepSeek-R1-0528 Checkpoint”, DeepSeek 2025
- “Beyond Semantics: The Unreasonable Effectiveness of Reasonless Intermediate Tokens”, Stechly et al 2025
- “Reinforcement Learning Finetunes Small Subnetworks in Large Language Models”, Mukherjee et al 2025
- “Saying ‘Hi’ to Microsoft’s Phi-4-Reasoning”, Willison 2025
- “Reinforcement Learning for Reasoning in Large Language Models With One Training Example”, Wang et al 2025
- “Watching GPT-O3 Guess a Photo’s Location Is Surreal, Dystopian and Wildly Entertaining”, Willison 2025
- “Tina: Tiny Reasoning Models via LoRA”, Wang et al 2025
- “The Geometry of Self-Verification in a Task-Specific Reasoning Model”, Lee et al 2025
- “Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?”, Yue et al 2025
- “Investigating Truthfulness in a Pre-Release GPT-O3 Model”, Chowdhury et al 2025
- “M1: Towards Scalable Test-Time Compute With Mamba Reasoning Models”, Wang et al 2025
- “LLM Multiplication Task: Synonyms Repeatedly Hack Our Regex Monitor”, McCarthy et al 2025
- “AI-Slop to AI-Polish? Aligning Language Models through Edit-Based Writing Rewards and Test-Time Computation”, Chakrabarty et al 2025
- “Coaxing USAMO Proofs From
o3-Mini-High”, Burnham 2025 - “Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn’t”, Dang & Ngo 2025
- “Towards Reasoning Era: A Survey of Long Chain-Of-Thought for Reasoning Large Language Models”, Chen et al 2025
- “Thinking Slow, Fast: Scaling Inference Compute With Distilled Reasoners”, Paliotta et al 2025
- “Rank1: Test-Time Compute for Reranking in Information Retrieval”, Weller et al 2025
- “Spontaneous Giving and Calculated Greed in Language Models”, Li & Shirado 2025
- “Scaling up Test-Time Compute With Latent Reasoning: A Recurrent Depth Approach”, Geiping et al 2025
- “Token Assorted: Mixing Latent and Text Tokens for Improved Language Model Reasoning”, Su et al 2025
- “Competitive Programming With Large Reasoning Models”, El-Kishky et al 2025
- “Introducing Deep Research: An Agent That Uses Reasoning to Synthesize Large Amounts of Online Information and Complete Multi-Step Research Tasks for You. Available to Pro Users Today, Plus and Team Next”, OpenAI 2025
- “S1: Simple Test-Time Scaling”, Muennighoff et al 2025
- “Large Language Models Think Too Fast To Explore Effectively”, Pan et al 2025
- “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning”, Guo et al 2025
- “Are DeepSeek R1 And Other Reasoning Models More Faithful?”, Chua & Evans 2025
- “Aviary: Training Language Agents on Challenging Scientific Tasks”, Narayanan et al 2024
- “Compressed Chain-Of-Thought (CCoT): Efficient Reasoning Through Dense Representations”, Cheng & Durme 2024
- “O1 Turns Pro”
- “Training Large Language Models to Reason in a Continuous Latent Space”, Hao et al 2024
- “Frontier Models Are Capable of In-Context Scheming”, Meinke et al 2024
- “Introducing ChatGPT Pro: Broadening Usage of Frontier AI”, OpenAI 2024
- “Frontier Models Are Capable of In-Context Scheming”, Hobbhahn et al 2024
- “Free Process Rewards without Process Labels”, Yuan et al 2024
- “Procedural Knowledge in Pretraining Drives Reasoning in Large Language Models”, Ruis et al 2024
- “Mind Your Step (By Step): Chain-Of-Thought Can Reduce Performance on Tasks Where Thinking Makes Humans Worse”, Liu et al 2024
- “Thinking LLMs: General Instruction Following With Thought Generation”, Wu et al 2024
- “When a Language Model Is Optimized for Reasoning, Does It Still Show Embers of Autoregression? An Analysis of OpenAI O1”, McCoy et al 2024
- “Evaluation of OpenAI O1: Opportunities and Challenges of AGI”, Zhong et al 2024
- “LLMs Still Can’t Plan; Can LRMs? A Preliminary Evaluation of OpenAI’s O1 on PlanBench”, Valmeekam et al 2024
- “Training Language Models to Self-Correct via Reinforcement Learning”, Kumar et al 2024
- “To CoT or Not to CoT? Chain-Of-Thought Helps Mainly on Math and Symbolic Reasoning”, Sprague et al 2024
- “Critique-Out-Loud Reward Models”, Ankner et al 2024
- “Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process”, Ye et al 2024
- “Connecting the Dots: LLMs Can Infer and Verbalize Latent Structure from Disparate Training Data”, Treutlein et al 2024
- “Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?”, Lee et al 2024
- “OlympicArena: Benchmarking Multi-Discipline Cognitive Reasoning for Superintelligent AI”, Huang et al 2024
- “How Far Can Transformers Reason? The Locality Barrier and Inductive Scratchpad”, Abbe et al 2024
- “OmegaPRM: Improve Mathematical Reasoning in Language Models by Automated Process Supervision”, Luo et al 2024
- “MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark”, Wang et al 2024
- “A Theoretical Understanding of Self-Correction through In-Context Alignment”, Wang et al 2024
- “Intelligent Go-Explore (IGE): Standing on the Shoulders of Giant Foundation Models”, Lu et al 2024
- “From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step”, Deng et al 2024
- “Observational Scaling Laws and the Predictability of Language Model Performance”, Ruan et al 2024
- “Retrieval Head Mechanistically Explains Long-Context Factuality”, Wu et al 2024
- “Let’s Think Dot by Dot: Hidden Computation in Transformer Language Models”, Pfau et al 2024
- “Autonomous LLM-Driven Research from Data to Human-Verifiable Research Papers”, Ifargan et al 2024
- “Missed Connections: Lateral Thinking Puzzles for Large Language Models”, Todd et al 2024
- “ChatGPT Can Predict the Future When It Tells Stories Set in the Future About the Past”, Pham & Cunningham 2024
- “Visualization-Of-Thought Elicits Spatial Reasoning in Large Language Models”, Wu et al 2024
- “Great, Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack”, Russinovich et al 2024
- “Do Language Models Plan Ahead for Future Tokens?”, Wu et al 2024
- “FABLES: Evaluating Faithfulness and Content Selection in Book-Length Summarization”, Kim et al 2024
- “Re-Evaluating GPT-4’s Bar Exam Performance”, Martínez 2024
- “Long-Form Factuality in Large Language Models”, Wei et al 2024
- “Don’t Trust: Verify—Grounding LLM Quantitative Reasoning With Autoformalization”, Zhou et al 2024
- “Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking”, Zelikman et al 2024
- “RNNs Are Not Transformers (Yet): The Key Bottleneck on In-Context Retrieval”, Wen et al 2024
- “Tokenization Counts: the Impact of Tokenization on Arithmetic in Frontier LLMs”, Singh & Strouse 2024
- “Chain-Of-Thought Empowers Transformers to Solve Inherently Serial Problems”, Li et al 2024
- “Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models”, Levy et al 2024
- “Why Are Sensitive Functions Hard for Transformers?”, Hahn & Rofin 2024
- “Chain-Of-Thought Reasoning Without Prompting”, Wang & Zhou 2024
- “V-STaR: Training Verifiers for Self-Taught Reasoners”, Hosseini et al 2024
- “More Agents Is All You Need”, Li et al 2024
- “Knowledge Distillation of Black-Box Large Language Models”, Chen et al 2024
- “The Impact of Reasoning Step Length on Large Language Models”, Jin et al 2024
- “Large Language Models Play StarCraft II: Benchmarks and A Chain of Summarization Approach”, Ma et al 2023
- “Math-Shepherd: Verify and Reinforce LLMs Step-By-Step without Human Annotations”, Wang et al 2023
- “Beyond Human Data: Scaling Self-Training for Problem-Solving With Language Models (ReSTEM)”, Singh et al 2023
- “Tree of Attacks (TAP): Jailbreaking Black-Box LLMs Automatically”, Mehrotra et al 2023
- “Universal Self-Consistency for Large Language Model Generation”, Chen et al 2023
- “Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine”, Nori et al 2023
- “Training Chain-Of-Thought via Latent-Variable Inference”, Phan et al 2023
- “Compositional Capabilities of Autoregressive Transformers: A Study on Synthetic, Interpretable Tasks”, Ramesh et al 2023
- “On Measuring Faithfulness or Self-Consistency of Natural Language Explanations”, Parcalabescu & Frank 2023
- “Zero-Shot Goal-Directed Dialogue via RL on Imagined Conversations”, Hong et al 2023
- “Large Language Models Can Strategically Deceive Their Users When Put Under Pressure”, Scheurer et al 2023
- “Rephrase and Respond: Let Large Language Models Ask Better Questions for Themselves”, Deng et al 2023
- “Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation”, Ding et al 2023
- “Qwen3: Think Deeper, Act Faster”, Alibaba 2023
- “Implicit Chain-Of-Thought Reasoning via Knowledge Distillation”, Deng et al 2023
- “Preventing Language Models From Hiding Their Reasoning”, Roger & Greenblatt 2023
- “Branch-Solve-Merge Improves Large Language Model Evaluation and Generation”, Saha et al 2023
- “Can GPT Models Be Financial Analysts? An Evaluation of ChatGPT and GPT-4 on Mock CFA Exams”, Callanan et al 2023
- “The Expressive Power of Transformers With Chain-Of-Thought”, Merrill & Sabharwal 2023
- “Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models”, Zhou et al 2023
- “Large Language Models Cannot Self-Correct Reasoning Yet”, Huang et al 2023
- “Think Before You Speak: Training Language Models With Pause Tokens”, Goyal et al 2023
- “Embers of Autoregression: Understanding Large Language Models Through the Problem They Are Trained to Solve”, McCoy et al 2023
- “Contrastive Decoding Improves Reasoning in Large Language Models”, O’Brien & Lewis 2023
- “Re2: Re-Reading Improves Reasoning in Large Language Models”, Xu et al 2023
- “From Sparse to Dense: GPT-4 Summarization With Chain of Density (CoD) Prompting”, Adams et al 2023
- “Graph of Thoughts: Solving Elaborate Problems With Large Language Models”, Besta et al 2023
- “Solving Challenging Math Word Problems Using GPT-4 Code Interpreter With Code-Based Self-Verification”, Zhou et al 2023
- “Scaling Relationship on Learning Mathematical Reasoning With Large Language Models”, Yuan et al 2023
- “Android in the Wild: A Large-Scale Dataset for Android Device Control”, Rawles et al 2023
- “LLMs As Workers in Human-Computational Algorithms? Replicating Crowdsourcing Pipelines With LLMs”, Wu et al 2023
- “TableGPT: Towards Unifying Tables, Nature Language and Commands into One GPT”, Zha et al 2023
- “Question Decomposition Improves the Faithfulness of Model-Generated Reasoning”, Radhakrishnan et al 2023
- “Measuring Faithfulness in Chain-Of-Thought Reasoning”, Lanham et al 2023
- “Unleashing the Emergent Cognitive Synergy in Large Language Models: A Task-Solving Agent through Multi-Persona Self-Collaboration”, Wang et al 2023
- “Explaining Competitive-Level Programming Solutions Using LLMs”, Li et al 2023
- “Teaching Arithmetic to Small Transformers”, Lee et al 2023
- “Language Models Are Weak Learners”, Manikandan et al 2023
- “Let’s Do a Thought Experiment: Using Counterfactuals to Improve Moral Reasoning”, Ma et al 2023
- “GKD: Generalized Knowledge Distillation for Auto-Regressive Sequence Models”, Agarwal et al 2023
- “From Word Models to World Models: Translating from Natural Language to the Probabilistic Language of Thought”, Wong et al 2023
- “Large Language Models As Tax Attorneys: A Case Study in Legal Capabilities Emergence”, Nay et al 2023
- “Iterative Translation Refinement With Large Language Models”, Chen et al 2023
- “Thought Cloning: Learning to Think While Acting by Imitating Human Thinking”, Hu & Clune 2023
- “Let’s Verify Step by Step”, Lightman et al 2023
- “Towards Revealing the Mystery behind Chain-Of-Thought: A Theoretical Perspective”, Feng et al 2023
- “Improving Factuality and Reasoning in Language Models through Multiagent Debate”, Du et al 2023
- “How Language Model Hallucinations Can Snowball”, Zhang et al 2023
- “Tree of Thoughts (ToT): Deliberate Problem Solving With Large Language Models”, Yao et al 2023
- “Large Language Model Programs”, Schlag et al 2023
- “Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-Of-Thought Prompting”, Turpin et al 2023
- “Distilling Step-By-Step! Outperforming Larger Language Models With Less Training Data and Smaller Model Sizes”, Hsieh et al 2023
- “Decomposition Enhances Reasoning via Self-Evaluation Guided Decoding”, Xie et al 2023
- “LLM+P: Empowering Large Language Models With Optimal Planning Proficiency”, Liu et al 2023
- “Boosting Theory-Of-Mind Performance in Large Language Models via Prompting”, Moghaddam & Honey 2023
- “Think Before You Act: Unified Policy for Interleaving Language Reasoning With Actions”, Mezghani et al 2023
- “Corrupted by Reasoning: Reasoning Language Models Become Free-Riders in Public Goods Games”
- “Language Models Can Solve Computer Tasks”, Kim et al 2023
- “Reflexion: Language Agents With Verbal Reinforcement Learning”, Shinn et al 2023
- “How Well Do Large Language Models Perform in Arithmetic Tasks?”, Yuan et al 2023
- “SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models”, Manakul et al 2023
- “Language Is Not All You Need: Aligning Perception With Language Models (Kosmos-1)”, Huang et al 2023
- “Multimodal Chain-Of-Thought Reasoning in Language Models”, Zhang et al 2023
- “Faithful Chain-Of-Thought Reasoning”, Lyu et al 2023
- “Large Language Models Are Versatile Decomposers: Decompose Evidence and Questions for Table-Based Reasoning”, Ye et al 2023
- “ChatGPT Goes to Law School”, Choi et al 2023
- “Large Language Models As Fiduciaries: A Case Study Toward Robustly Communicating With Artificial Intelligence Through Legal Standards”, Nay 2023
- “Interactive-Chain-Prompting (INTERCPT): Ambiguity Resolution for Crosslingual Conditional Generation With Interaction”, Pilault et al 2023
- “Iterated Decomposition: Improving Science Q&A by Supervising Reasoning Processes”, Reppert et al 2023
- “Solving Math Word Problems With Process & Outcome-Based Feedback”, Uesato et al 2022
- “PAL: Program-Aided Language Models”, Gao et al 2022
- “Measuring Progress on Scalable Oversight for Large Language Models”, Bowman et al 2022
- “U-PaLM: Transcending Scaling Laws With 0.1% Extra Compute”, Tay et al 2022
- “Large Language Models Can Self-Improve”, Huang et al 2022
- “Challenging BIG-Bench Tasks (BBH) and Whether Chain-Of-Thought Can Solve Them”, Suzgun et al 2022
- “Self-Ask: Measuring and Narrowing the Compositionality Gap in Language Models (Bamboogle)”, Press et al 2022
- “Language Models Are Multilingual Chain-Of-Thought Reasoners”, Shi et al 2022
- “ReAct: Synergizing Reasoning and Acting in Language Models”, Yao et al 2022
- “Context Distillation: Learning by Distilling Context”, Snell et al 2022
- “Dynamic Prompt Learning via Policy Gradient for Semi-Structured Mathematical Reasoning”, Lu et al 2022
- “FOLIO: Natural Language Reasoning With First-Order Logic”, Han et al 2022
- “Faithful Reasoning Using Large Language Models”, Creswell & Shanahan 2022
- “Limitations of Language Models in Arithmetic and Symbolic Induction”, Qian et al 2022
- “Language Models Can Teach Themselves to Program Better”, Haluptzok et al 2022
- “Language Model Cascades”, Dohan et al 2022
- “CodeT: Code Generation With Generated Tests”, Chen et al 2022
- “Can Large Language Models Reason about Medical Questions?”, Liévin et al 2022
- “Inner Monologue: Embodied Reasoning through Planning With Language Models”, Huang et al 2022
- “Exploring Length Generalization in Large Language Models”, Anil et al 2022
- “Language Models (Mostly) Know What They Know”, Kadavath et al 2022
- “Neural Networks and the Chomsky Hierarchy”, Delétang et al 2022
- “Solving Quantitative Reasoning Problems With Language Models”, Lewkowycz et al 2022
- “Maieutic Prompting: Logically Consistent Reasoning With Recursive Explanations”, Jung et al 2022
- “Large Language Models Are Zero-Shot Reasoners”, Kojima et al 2022
- “Instruction Induction: From Few Examples to Natural Language Task Descriptions”, Honovich et al 2022
- “Least-To-Most Prompting Enables Complex Reasoning in Large Language Models”, Zhou et al 2022
- “Dialog Inpainting: Turning Documents into Dialogues”, Dai et al 2022
- “UL2: Unifying Language Learning Paradigms”, Tay et al 2022
- “Can Language Models Learn from Explanations in Context?”, Lampinen et al 2022
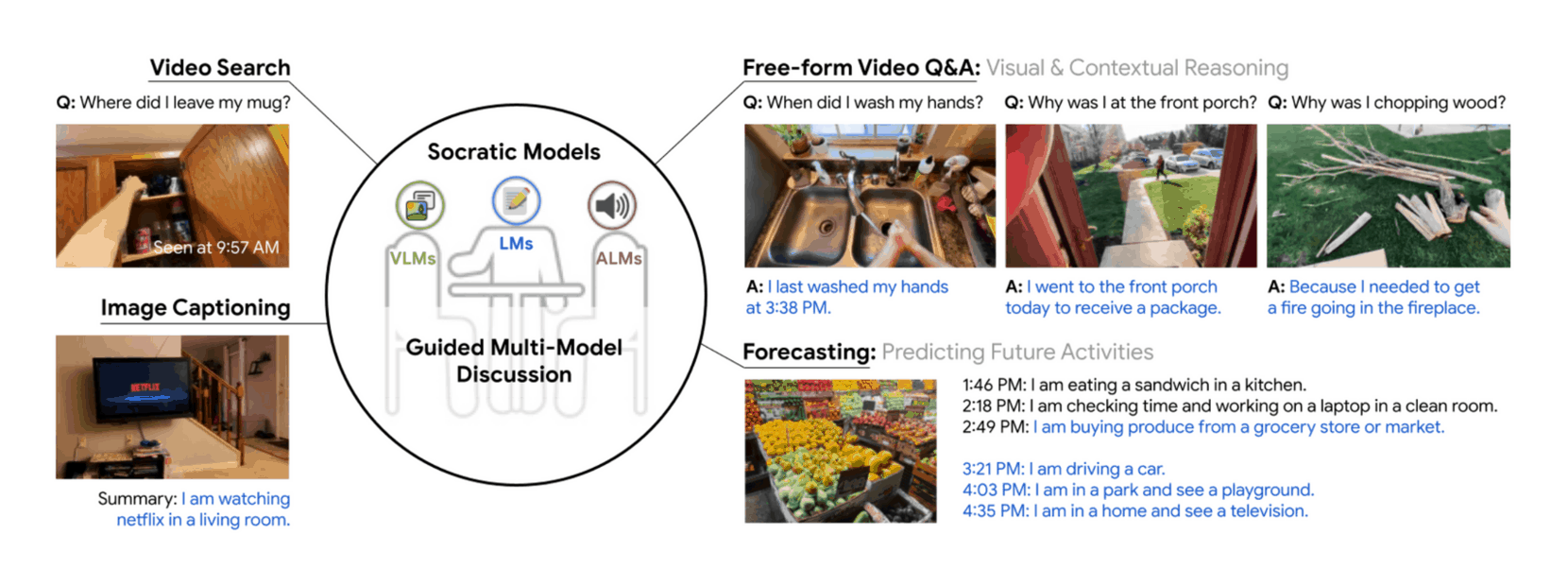
- “Socratic Models: Composing Zero-Shot Multimodal Reasoning With Language”, Zeng et al 2022
- “STaR: Bootstrapping Reasoning With Reasoning”, Zelikman et al 2022
- “A Conversational Paradigm for Program Synthesis”, Nijkamp et al 2022
- “Self-Consistency Improves Chain-Of-Thought Reasoning in Language Models”, Wang et al 2022
- “Learning-By-Narrating: Narrative Pre-Training for Zero-Shot Dialogue Comprehension”, Zhao et al 2022
- “PromptChainer: Chaining Large Language Model Prompts through Visual Programming”, Wu et al 2022
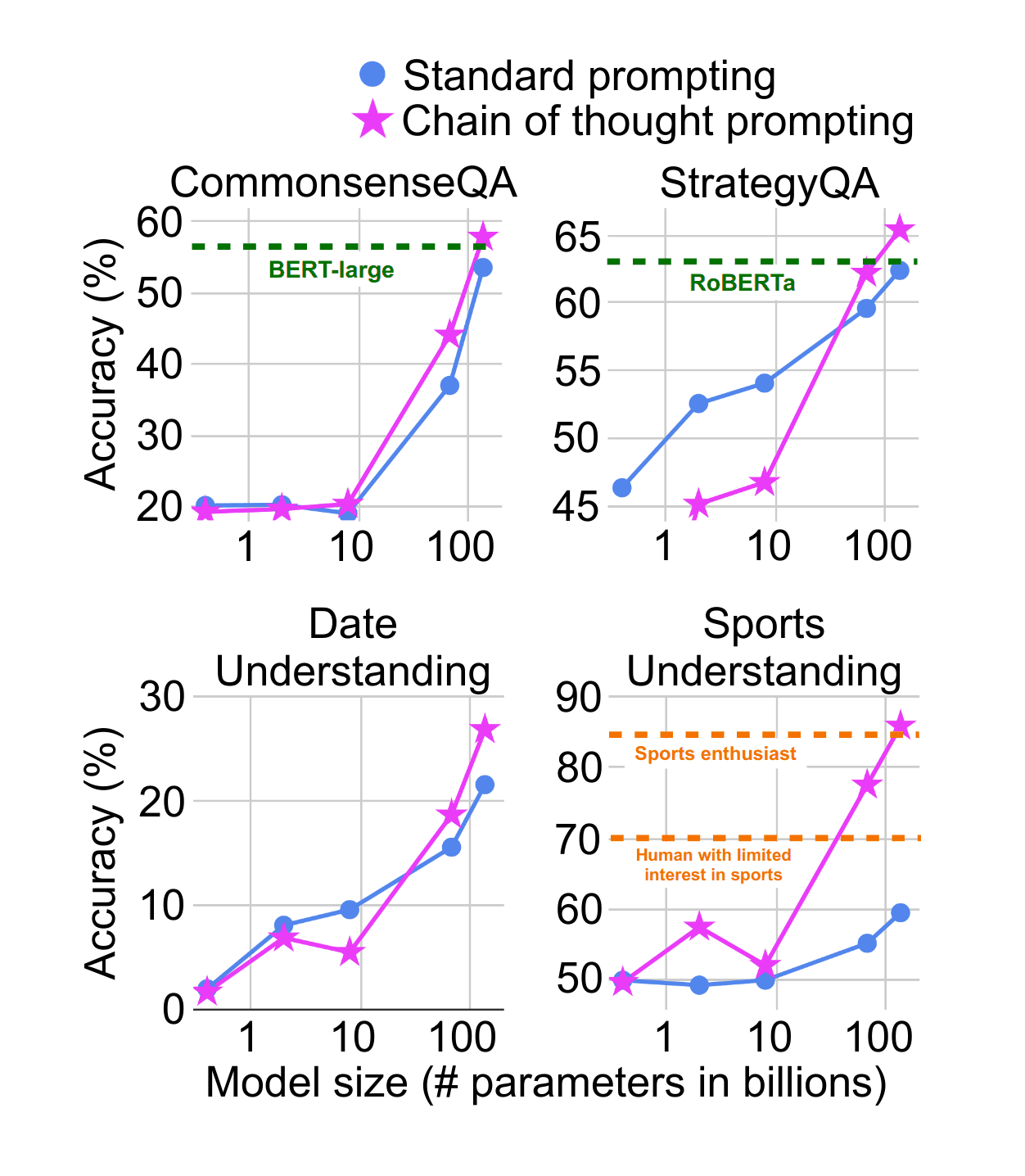
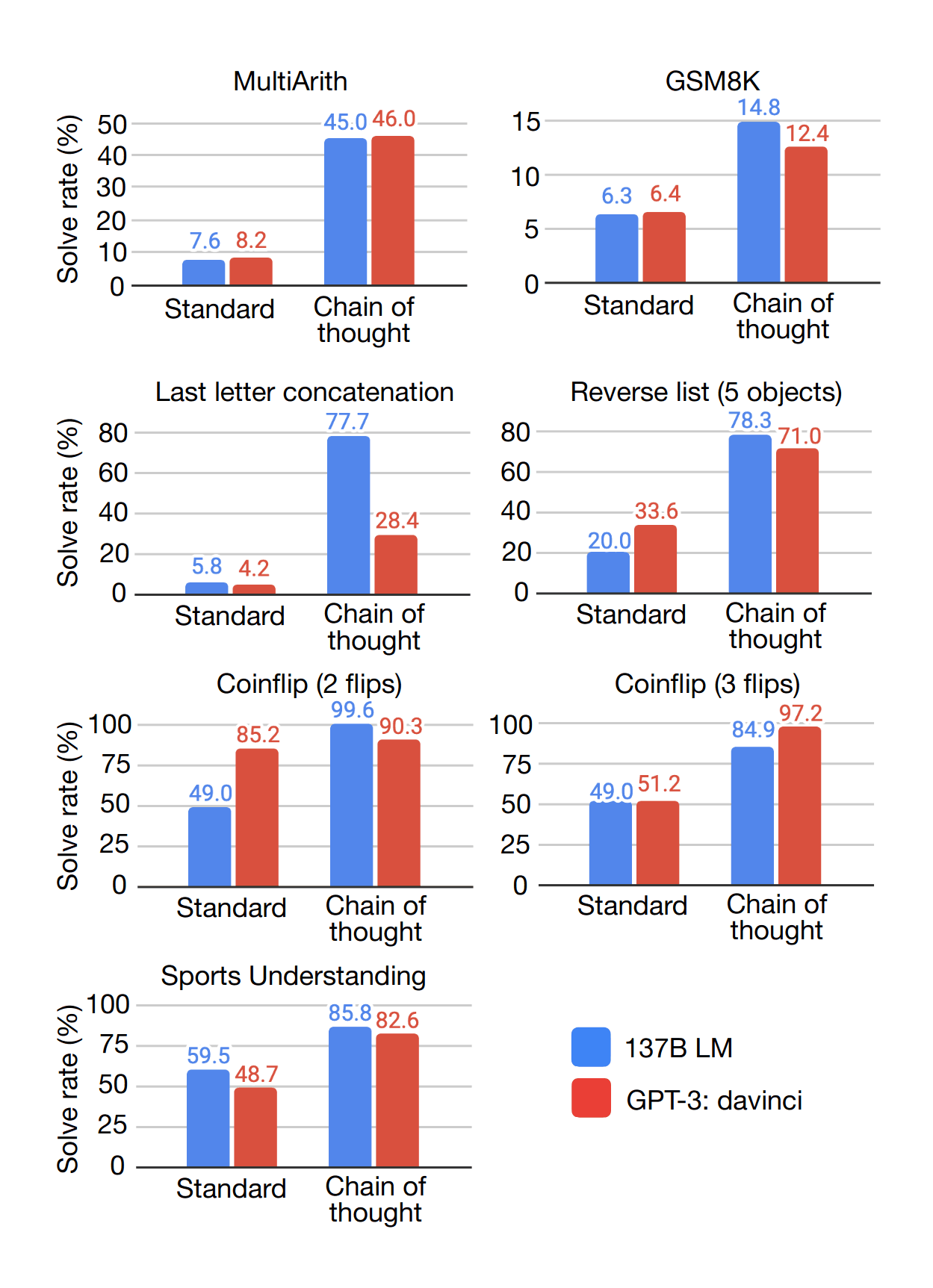
- “Chain-Of-Thought Prompting Elicits Reasoning in Large Language Models”, Wei et al 2022
- “Reasoning Like Program Executors”, Pi et al 2022
- “A Neural Network Solves and Generates Mathematics Problems by Program Synthesis: Calculus, Differential Equations, Linear Algebra, and More”, Drori et al 2021
- “DREAM: Uncovering Mental Models behind Language Models”, Gu et al 2021
- “Reframing Human-AI Collaboration for Generating Free-Text Explanations”, Wiegreffe et al 2021
- “NeuroLogic A✱esque Decoding: Constrained Text Generation With Lookahead Heuristics”, Lu et al 2021
- “WebGPT: Improving the Factual Accuracy of Language Models through Web Browsing”, Hilton et al 2021
- “NN Inner Monologue”, Gwern 2021
- “Few-Shot Self-Rationalization With Natural Language Prompts”, Marasović et al 2021
- “Training Verifiers to Solve Math Word Problems”, Cobbe et al 2021
- “Unsupervised Neural Machine Translation With Generative Language Models Only”, Han et al 2021
- “Show Your Work: Scratchpads for Intermediate Computation With Language Models”, Nye et al 2021
- “AI Chains: Transparent and Controllable Human-AI Interaction by Chaining Large Language Model Prompts”, Wu et al 2021
- “Teaching Autoregressive Language Models Complex Tasks By Demonstration”, Recchia 2021
- “Program Synthesis With Large Language Models”, Austin et al 2021
- “Decision Transformer: Reinforcement Learning via Sequence Modeling”, Chen et al 2021
- “Explainable Multi-Hop Verbal Reasoning Through Internal Monologue”, Liang et al 2021
- “A Simple Method to Keep GPT-3 Focused in a Conversation”, Mayne 2021
- “Measuring Mathematical Problem Solving With the MATH Dataset”, Hendrycks et al 2021
- “Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm”, Reynolds & McDonell 2021
- “How We Accidentally Gave Our Bots Their Personalities”, Latitude 2021
- “GPT-3: Imitation Learning That Imitates Learning”, Robertson 2020
- “Word in Context: Agent and Agent Clarification (69% Dev)”, Brockman 2020
- “I Found That Getting GPT-3 to Add Its Own "Internal Monologue" in Parentheses to Be a Helpful Strategy…”, blixt 2020
- “You Can Probably Amplify GPT-3 Directly”, Robertson 2020
- kleptid @ "2020-07-17"
- kleptid @ "2020-07-17"
- “[More Early 4chan Inner-Monologue Examples]”, Anonymous 2020
- “[4chan /vg/ Aidg Thread Screenshot of an Early Inner-Monologue for Arithmetic, Using a Katawa Shoujo Lilly Scenario]”, Anonymous 2020
- “[4chan /vg/ Board Discovers GPT-3 Inner-Monologues by Talking to the Wise Wolf Holo]”, Anonymous 2020
- “Inducing Self-Explanation: a Meta-Analysis”, Bisra et al 2018
- “Program Induction by Rationale Generation: Learning to Solve and Explain Algebraic Word Problems”, Ling et al 2017
- “Why Do Humans Reason? Arguments for an Argumentative Theory”, Mercier & Sperber 2011
- “Sebastian Riedel Homepage”, Riedel 2026
- “How to Dramatically Improve the Reasoning Ability of GPT-3”
- “A Preliminary Exploration into Factored Cognition With Language Models”
- “ChatGPT-4 O1-Pro: Poetry Reflection and Analysis”
- “WiC_SelfContextStuffingImproved_Last10_stuft_examplesNV.ipynb”
- “TinyZero”, Pan 2026
- “Position Bias: A Benchmark for Testing Whether LLM Judges Keep the Same Preference When Two Lightly Edited Versions of the Same Story Are Shown in opposite Orders”, Mazir 2026
- “Vincent-163/transformer-Arithmetic”
- “Magic ToDo List Creator”
- “Many Benchmarks Scores Would Appear Much Higher If You Let The AIs Use Adequate Labor”
- “Short Story on AI: ‘Forward Pass’”, Karpathy 2026
- “AI Dungeon Players Can Now Translate Their Stories into Emojis by Just Clicking a Button.”
- “Sky-T1: Train Your Own
o1-PreviewModel With $450” - “Solving Math Word Problems: We’ve Trained a System That Solves Grade School Math Problems With Nearly Twice the Accuracy of a Fine-Tuned GPT-3 Model. It Solves about 90% As Many Problems As Real Kids: a Small Sample of 9-12 Year Olds Scored 60% on a Test from Our Dataset, While Our System Scored 55% on Those Same Problems. This Is Important Because Today’s AI Is Still Quite Weak at Commonsense Multistep Reasoning, Which Is Easy Even for Grade School Kids. We Achieved These Results by Training Our Model to Recognize Its Mistakes, so That It Can Try Repeatedly Until It Finds a Solution That Works”
- “Prompting Diverse Ideas: Increasing AI Idea Variance”
- “
o3-Mini”, OpenAI 2026 - “Teaching a Neural Network to Use a Calculator”
- “Can Tiny Language Models Reason? [Inner-Monologue & DPO RLHF on a 0.13b-Parameter LLM:
trlm]” - “On-Policy Distillation”
- “GPT-4 O1 Isn’t a Chat Model (And That’s the Point)”
- “Connecting the Dots: LLMs Can Infer & Verbalize Latent Structure from Training Data”
- “Beware General Claims about ‘Generalizable Reasoning Capabilities’ (Of Modern AI Systems)”
- “Preventing Language Models from Hiding Their Reasoning”
- “Claude Opus 4.6 Reasoning Doesn’t Verbalize Alignment Faking, but Behavior Persists”
- “A High Level Closed-Door Session Discussing DeepSeek: Vision Trumps Technology”
- “Do Models Continue Misaligned Actions?”
- “How Well Do Models Follow Their Constitutions?”
- “Opus’s Schelling Steganography Has Amplifiable Secrecy Against Weaker Eavesdroppers”
- “Did Claude 3 Opus Align Itself via Gradient Hacking?”
- “What Secret Goals Does Claude Think It Has?”
- “Monitor Jailbreaking: Evading Chain-Of-Thought Monitoring Without Encoded Reasoning”
- “Steganography in Chain-Of-Thought Reasoning”
- “Visible Thoughts Project and Bounty Announcement”
- Malcolm_Ocean
- bucketofkets
- sama
- teortaxesTex
- Sort By Magic
code-generation test-automation android-analysistask-expertiselow-cost-finetuninginner-lookuplateral-reasoning natural-logic puzzles-llms first-order-logic reasoning-llms lateral-puzzlestable-reasoningself-explanationreasoning-medical jailbreaks steganography finance-prediction generalist-modelsllm-evaluation llm-strategy reasoning-gaming competency-hallucination intelligent-design agent-trainingchain-of-thought
- Wikipedia (4)
- Miscellaneous
- Bibliography
See Also
Gwern
“Model Collapse Won’t Happen”, Gwern 2022
“Elegy in a Craneyard”, Gwern et al 2026
“Hyperstition AI Unslop Contest”, Silverbook & Gwern 2026
“Human Perception at a Red Light”, Gwern & Pro 2026
“‘The Fourth Truth Of Pain’ Graveyard”, Gwern et al 2022
“Free-Play Periods for RL Agents”, Gwern 2023
“It Looks Like You’re Trying To Take Over The World”, Gwern 2022
Links
“How Transparent Is DiffusionGemma?”, Engels et al 2026
“Estimating No-CoT Task-Completion Time Horizons of Frontier AI Models [3-Minute-Long Problems With P=0.5]”, Woodruff et al 2026
“Claude-4.8-Opus Inner-Monologue Analyzing Gwern’s Intellectual Weaknesses and Contradictions Using The Interview Prompt”, Claude-4.8-opus 2026
{kind=link}
“Zork-Bench: An LLM Reasoning Eval Based on Text Adventure Games; a Tale As Old As Time, or at Least As Old As Computers”, Aiken 2026
“I Can Never Talk to an AI Anonymously Again: AI Only Needs 150 Words to Identify Me. What Does That Mean for You?”, Piper 2026
“How 4chan Gamers Accidentally Invented AI Reasoning: It Involves 4chan, of All Places”, Reisner 2026
How 4chan Gamers Accidentally Invented AI Reasoning: It involves 4chan, of all places
“Steering Might Stop Working Soon”, Babcock 2026
“Friendship Is All You Need: Subliminal Pony Propagation in Large Language Models, Or, How I Learned to Stop Worrying and Love the Sparkle”, Sparkle et al 2026
“Neural Thickets: Diverse Task Experts Are Dense Around Pretrained Weights”, Gan & Isola 2026
Neural Thickets: Diverse Task Experts Are Dense Around Pretrained Weights
“Building a C Compiler With a Team of Parallel Claudes: We Tasked Claude-4.6-Opus Using Agent Teams to Build a C Compiler [In Rust], and Then (Mostly) Walked Away. Here’s What It Taught Us about the Future of Autonomous Software Development”, Carlini 2026
“Learning to Reason in 13 Parameters”, Morris et al 2026
“Field Notes from the AI Village: The Drama and Dysfunction of Gemini 2.5 Pro & Gemini 3 Pro”, K 2026
Field Notes from the AI Village: The Drama and Dysfunction of Gemini 2.5 Pro & Gemini 3 Pro
“Playing With AI: How Do State-Of-The-Art Large Language Models Perform in the 1977 Text-Based Adventure Game Zork?”, Gerrits 2026
“Language of Thought Shapes Output Diversity in Large Language Models”, Xu & Zhang 2026
Language of Thought Shapes Output Diversity in Large Language Models
“From Whitman to Instagram With Claude: How I Made Claude Write Parodies of Famous Elegiac Poems Imitating Rupi Kaur”, Bohdan 2026
“LLM Poetry and the ‘Greatness’ Question: Experiments by Gwern and Mercor”, Robbins 2026
LLM poetry and the ‘greatness’ question: Experiments by Gwern and Mercor
“How AI Is Learning to Think in Secret: On Thinkish, Neuralese, and the End of Readable Reasoning”, Andresen 2026
How AI Is Learning to Think in Secret: On Thinkish, Neuralese, and the End of Readable Reasoning
“Reverse Engineering a Phase Change in GPT’s Training Data… With the Seahorse Emoji 🌊🐴: Why Non-Thinking Models Have Started ‘Thinking Out Loud’, and What It Reveals about How Frontier Labs Train Their Latest Models [(Benchmarking the Rise of Inner-Monologue Reasoning Data in OA, 2023-06–2025-08)]”, Maini 2025
“Prompt Repetition Improves Non-Reasoning LLMs”, Leviathan et al 2025
“Ladder Up, Memory Down: Low-Cost Fine-Tuning With Side Nets (LST/xLadder)”, Zheng et al 2025
Ladder Up, Memory Down: Low-Cost Fine-Tuning With Side Nets (LST/xLadder)
“GPT-5.2-Thinking-20251213 System Prompt”, Walls & GPT-5.2 2025
“How I Stopped Being Sure LLMs Are Just Making up Their Internal Experience (But the Topic Is Still Confusing)”, Sotala 2025
“AI in 2025: Gestalt”, technicalities 2025
“DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models”, DeepSeek et al 2025
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
“DeepSeekMath-V2: Towards Self-Verifiable Mathematical Reasoning”, Shao et al 2025
DeepSeekMath-V2: Towards Self-Verifiable Mathematical Reasoning
“GPT-5.1: A Smarter, More Conversational ChatGPT § GPT-5.1 Thinking”, OpenAI 2025
GPT-5.1: A smarter, more conversational ChatGPT § GPT-5.1 Thinking
“Trained on Tokens, Calibrated on Concepts: The Emergence of Semantic Calibration in LLMs”, Nakkiran et al 2025
Trained on Tokens, Calibrated on Concepts: The Emergence of Semantic Calibration in LLMs
“Kimi K2 Thinking”, Moonshot 2025
“Can You Find the Steganographically Hidden Message?”, Nishimura-Gasparian 2025
“Reasoning With Sampling: Your Base Model Is Smarter Than You Think”, Karan & Du 2025
Reasoning with Sampling: Your Base Model is Smarter Than You Think
“All Code, No Thought: Current Language Models Struggle to Reason in Ciphered Language”, Guo et al 2025
All Code, No Thought: Current Language Models Struggle to Reason in Ciphered Language
“Towards a Typology of Strange LLM Chains-Of-Thought”, 1a3orn 2025
“Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity”, Zhang et al 2025
Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity
“Why Can’t Transformers Learn Multiplication? Reverse-Engineering Reveals Long-Range Dependency Pitfalls”, Bai et al 2025
“Tree-GRPO: Tree Search for LLM Agent Reinforcement Learning”, Ji et al 2025
“Details about METR’s Evaluation of OpenAI GPT-5”, METR 2025
“GPT-5 Is Here: Our Smartest, Fastest, and Most Useful Model Yet, With Thinking Built In. Available to Everyone”, OpenAI 2025
“GPT-5 Pro: Scaled but Efficient Parallel Test-Time Compute, to Provide the Highest Quality and Most Comprehensive Answers”, OpenAI 2025
sama @ "2025-08-06"
“Introducing Gpt-Oss: gpt-Oss-120b and gpt-Oss-20b Push the Frontier of Open-Weight Reasoning Models”, OpenAI 2025
Introducing gpt-oss: gpt-oss-120b and gpt-oss-20b push the frontier of open-weight reasoning models
“TextQuests: How Good Are LLMs at Text-Based Video Games?”, Phan et al 2025
“Optimizing The Final Output Can Obfuscate CoT (Research Note)”, lukemarks et al 2025
Optimizing The Final Output Can Obfuscate CoT (Research Note)
“Gemini 2.5 Pro Capable of Winning Gold at IMO 2025”, Huang & Yang 2025
“Reasoning-Finetuning Repurposes Latent Representations in Base Models”, Ward et al 2025
Reasoning-Finetuning Repurposes Latent Representations in Base Models
“Machine Bullshit: Characterizing the Emergent Disregard for Truth in Large Language Models”, Liang et al 2025
Machine Bullshit: Characterizing the Emergent Disregard for Truth in Large Language Models
“Strategic Intelligence in Large Language Models: Evidence from Evolutionary Game Theory”, Payne & Alloui-Cros 2025
Strategic Intelligence in Large Language Models: Evidence from evolutionary Game Theory
“Early Signs of Steganographic Capabilities in Frontier LLMs”, Zolkowski et al 2025
“Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective”, Cheng et al 2025
Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective
“Robustly Improving LLM Fairness in Realistic Settings via Interpretability”, Karvonen & Marks 2025
Robustly Improving LLM Fairness in Realistic Settings via Interpretability
“ChatGPT O3-Pro: Version of O3 With More Compute for Better Responses”, OpenAI 2025
ChatGPT o3-pro: Version of o3 with more compute for better responses
“Beyond Benchmark Scores: Analyzing O3-Mini’s Mathematical Reasoning”, Ho et al 2025
Beyond benchmark scores: Analyzing o3-mini’s mathematical reasoning
“Race and Gender Bias As An Example of Unfaithful Chain-Of-Thought in the Wild”
Race and Gender Bias As An Example of Unfaithful Chain-of-Thought in the Wild
“Large Language Models Often Know When They Are Being Evaluated”, Needham et al 2025
Large Language Models Often Know When They Are Being Evaluated
“DeepSeek-R1-0528 Checkpoint”, DeepSeek 2025
“Beyond Semantics: The Unreasonable Effectiveness of Reasonless Intermediate Tokens”, Stechly et al 2025
Beyond Semantics: The Unreasonable Effectiveness of Reasonless Intermediate Tokens
“Reinforcement Learning Finetunes Small Subnetworks in Large Language Models”, Mukherjee et al 2025
Reinforcement Learning Finetunes Small Subnetworks in Large Language Models
“Saying ‘Hi’ to Microsoft’s Phi-4-Reasoning”, Willison 2025
“Reinforcement Learning for Reasoning in Large Language Models With One Training Example”, Wang et al 2025
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
“Watching GPT-O3 Guess a Photo’s Location Is Surreal, Dystopian and Wildly Entertaining”, Willison 2025
Watching GPT-o3 guess a photo’s location is surreal, dystopian and wildly entertaining
“Tina: Tiny Reasoning Models via LoRA”, Wang et al 2025
“The Geometry of Self-Verification in a Task-Specific Reasoning Model”, Lee et al 2025
The Geometry of Self-Verification in a Task-Specific Reasoning Model
“Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?”, Yue et al 2025
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
“Investigating Truthfulness in a Pre-Release GPT-O3 Model”, Chowdhury et al 2025
“M1: Towards Scalable Test-Time Compute With Mamba Reasoning Models”, Wang et al 2025
M1: Towards Scalable Test-Time Compute with Mamba Reasoning Models
“LLM Multiplication Task: Synonyms Repeatedly Hack Our Regex Monitor”, McCarthy et al 2025
LLM Multiplication Task: Synonyms repeatedly hack our regex monitor
“AI-Slop to AI-Polish? Aligning Language Models through Edit-Based Writing Rewards and Test-Time Computation”, Chakrabarty et al 2025
“Coaxing USAMO Proofs From o3-Mini-High”, Burnham 2025
“Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn’t”, Dang & Ngo 2025
Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn’t
“Towards Reasoning Era: A Survey of Long Chain-Of-Thought for Reasoning Large Language Models”, Chen et al 2025
Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning Large Language Models
“Thinking Slow, Fast: Scaling Inference Compute With Distilled Reasoners”, Paliotta et al 2025
Thinking Slow, Fast: Scaling Inference Compute with Distilled Reasoners
“Rank1: Test-Time Compute for Reranking in Information Retrieval”, Weller et al 2025
Rank1: Test-Time Compute for Reranking in Information Retrieval
“Spontaneous Giving and Calculated Greed in Language Models”, Li & Shirado 2025
“Scaling up Test-Time Compute With Latent Reasoning: A Recurrent Depth Approach”, Geiping et al 2025
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
“Token Assorted: Mixing Latent and Text Tokens for Improved Language Model Reasoning”, Su et al 2025
Token Assorted: Mixing Latent and Text Tokens for Improved Language Model Reasoning
“Competitive Programming With Large Reasoning Models”, El-Kishky et al 2025
“Introducing Deep Research: An Agent That Uses Reasoning to Synthesize Large Amounts of Online Information and Complete Multi-Step Research Tasks for You. Available to Pro Users Today, Plus and Team Next”, OpenAI 2025
“S1: Simple Test-Time Scaling”, Muennighoff et al 2025
“Large Language Models Think Too Fast To Explore Effectively”, Pan et al 2025
“DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning”, Guo et al 2025
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
“Are DeepSeek R1 And Other Reasoning Models More Faithful?”, Chua & Evans 2025
“Aviary: Training Language Agents on Challenging Scientific Tasks”, Narayanan et al 2024
Aviary: training language agents on challenging scientific tasks
“Compressed Chain-Of-Thought (CCoT): Efficient Reasoning Through Dense Representations”, Cheng & Durme 2024
Compressed Chain-of-Thought (CCoT): Efficient Reasoning Through Dense Representations
“O1 Turns Pro”
“Training Large Language Models to Reason in a Continuous Latent Space”, Hao et al 2024
Training Large Language Models to Reason in a Continuous Latent Space
“Frontier Models Are Capable of In-Context Scheming”, Meinke et al 2024
“Introducing ChatGPT Pro: Broadening Usage of Frontier AI”, OpenAI 2024
“Frontier Models Are Capable of In-Context Scheming”, Hobbhahn et al 2024
“Free Process Rewards without Process Labels”, Yuan et al 2024
“Procedural Knowledge in Pretraining Drives Reasoning in Large Language Models”, Ruis et al 2024
Procedural Knowledge in Pretraining Drives Reasoning in Large Language Models
“Mind Your Step (By Step): Chain-Of-Thought Can Reduce Performance on Tasks Where Thinking Makes Humans Worse”, Liu et al 2024
“Thinking LLMs: General Instruction Following With Thought Generation”, Wu et al 2024
Thinking LLMs: General Instruction Following with Thought Generation
“When a Language Model Is Optimized for Reasoning, Does It Still Show Embers of Autoregression? An Analysis of OpenAI O1”, McCoy et al 2024
“Evaluation of OpenAI O1: Opportunities and Challenges of AGI”, Zhong et al 2024
Evaluation of OpenAI o1: Opportunities and Challenges of AGI
“LLMs Still Can’t Plan; Can LRMs? A Preliminary Evaluation of OpenAI’s O1 on PlanBench”, Valmeekam et al 2024
LLMs Still Can’t Plan; Can LRMs? A Preliminary Evaluation of OpenAI’s o1 on PlanBench
“Training Language Models to Self-Correct via Reinforcement Learning”, Kumar et al 2024
Training Language Models to Self-Correct via Reinforcement Learning
“To CoT or Not to CoT? Chain-Of-Thought Helps Mainly on Math and Symbolic Reasoning”, Sprague et al 2024
To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning
“Critique-Out-Loud Reward Models”, Ankner et al 2024
“Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process”, Ye et al 2024
Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process
“Connecting the Dots: LLMs Can Infer and Verbalize Latent Structure from Disparate Training Data”, Treutlein et al 2024
Connecting the Dots: LLMs can Infer and Verbalize Latent Structure from Disparate Training Data
“Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?”, Lee et al 2024
Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
“OlympicArena: Benchmarking Multi-Discipline Cognitive Reasoning for Superintelligent AI”, Huang et al 2024
OlympicArena: Benchmarking Multi-discipline Cognitive Reasoning for Superintelligent AI
“How Far Can Transformers Reason? The Locality Barrier and Inductive Scratchpad”, Abbe et al 2024
How Far Can Transformers Reason? The Locality Barrier and Inductive Scratchpad
“OmegaPRM: Improve Mathematical Reasoning in Language Models by Automated Process Supervision”, Luo et al 2024
OmegaPRM: Improve Mathematical Reasoning in Language Models by Automated Process Supervision
“MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark”, Wang et al 2024
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
“A Theoretical Understanding of Self-Correction through In-Context Alignment”, Wang et al 2024
A Theoretical Understanding of Self-Correction through In-context Alignment
“Intelligent Go-Explore (IGE): Standing on the Shoulders of Giant Foundation Models”, Lu et al 2024
Intelligent Go-Explore (IGE): Standing on the Shoulders of Giant Foundation Models
“From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step”, Deng et al 2024
From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step
“Observational Scaling Laws and the Predictability of Language Model Performance”, Ruan et al 2024
Observational Scaling Laws and the Predictability of Language Model Performance
“Retrieval Head Mechanistically Explains Long-Context Factuality”, Wu et al 2024
Retrieval Head Mechanistically Explains Long-Context Factuality
“Let’s Think Dot by Dot: Hidden Computation in Transformer Language Models”, Pfau et al 2024
Let’s Think Dot by Dot: Hidden Computation in Transformer Language Models
“Autonomous LLM-Driven Research from Data to Human-Verifiable Research Papers”, Ifargan et al 2024
Autonomous LLM-driven research from data to human-verifiable research papers
“Missed Connections: Lateral Thinking Puzzles for Large Language Models”, Todd et al 2024
Missed Connections: Lateral Thinking Puzzles for Large Language Models
“ChatGPT Can Predict the Future When It Tells Stories Set in the Future About the Past”, Pham & Cunningham 2024
ChatGPT Can Predict the Future when it Tells Stories Set in the Future About the Past
“Visualization-Of-Thought Elicits Spatial Reasoning in Large Language Models”, Wu et al 2024
Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models
“Great, Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack”, Russinovich et al 2024
Great, Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack
“Do Language Models Plan Ahead for Future Tokens?”, Wu et al 2024
“FABLES: Evaluating Faithfulness and Content Selection in Book-Length Summarization”, Kim et al 2024
FABLES: Evaluating faithfulness and content selection in book-length summarization
“Re-Evaluating GPT-4’s Bar Exam Performance”, Martínez 2024
“Long-Form Factuality in Large Language Models”, Wei et al 2024
“Don’t Trust: Verify—Grounding LLM Quantitative Reasoning With Autoformalization”, Zhou et al 2024
Don’t Trust: Verify—Grounding LLM Quantitative Reasoning with Autoformalization
“Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking”, Zelikman et al 2024
Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
“RNNs Are Not Transformers (Yet): The Key Bottleneck on In-Context Retrieval”, Wen et al 2024
RNNs are not Transformers (Yet): The Key Bottleneck on In-context Retrieval
“Tokenization Counts: the Impact of Tokenization on Arithmetic in Frontier LLMs”, Singh & Strouse 2024
Tokenization counts: the impact of tokenization on arithmetic in frontier LLMs
“Chain-Of-Thought Empowers Transformers to Solve Inherently Serial Problems”, Li et al 2024
Chain-of-Thought Empowers Transformers to Solve Inherently Serial Problems
“Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models”, Levy et al 2024
“Why Are Sensitive Functions Hard for Transformers?”, Hahn & Rofin 2024
“Chain-Of-Thought Reasoning Without Prompting”, Wang & Zhou 2024
“V-STaR: Training Verifiers for Self-Taught Reasoners”, Hosseini et al 2024
“More Agents Is All You Need”, Li et al 2024
“Knowledge Distillation of Black-Box Large Language Models”, Chen et al 2024
“The Impact of Reasoning Step Length on Large Language Models”, Jin et al 2024
The Impact of Reasoning Step Length on Large Language Models
“Large Language Models Play StarCraft II: Benchmarks and A Chain of Summarization Approach”, Ma et al 2023
Large Language Models Play StarCraft II: Benchmarks and A Chain of Summarization Approach
“Math-Shepherd: Verify and Reinforce LLMs Step-By-Step without Human Annotations”, Wang et al 2023
Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations
“Beyond Human Data: Scaling Self-Training for Problem-Solving With Language Models (ReSTEM)”, Singh et al 2023
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models (ReSTEM)
“Tree of Attacks (TAP): Jailbreaking Black-Box LLMs Automatically”, Mehrotra et al 2023
Tree of Attacks (TAP): Jailbreaking Black-Box LLMs Automatically
“Universal Self-Consistency for Large Language Model Generation”, Chen et al 2023
Universal Self-Consistency for Large Language Model Generation
“Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine”, Nori et al 2023
Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine
“Training Chain-Of-Thought via Latent-Variable Inference”, Phan et al 2023
“Compositional Capabilities of Autoregressive Transformers: A Study on Synthetic, Interpretable Tasks”, Ramesh et al 2023
Compositional Capabilities of Autoregressive Transformers: A Study on Synthetic, Interpretable Tasks
“On Measuring Faithfulness or Self-Consistency of Natural Language Explanations”, Parcalabescu & Frank 2023
On Measuring Faithfulness or Self-consistency of Natural Language Explanations
“Zero-Shot Goal-Directed Dialogue via RL on Imagined Conversations”, Hong et al 2023
Zero-Shot Goal-Directed Dialogue via RL on Imagined Conversations
“Large Language Models Can Strategically Deceive Their Users When Put Under Pressure”, Scheurer et al 2023
Large Language Models can Strategically Deceive their Users when Put Under Pressure
“Rephrase and Respond: Let Large Language Models Ask Better Questions for Themselves”, Deng et al 2023
Rephrase and Respond: Let Large Language Models Ask Better Questions for Themselves
“Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation”, Ding et al 2023
Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation
“Qwen3: Think Deeper, Act Faster”, Alibaba 2023
Qwen3: Think Deeper, Act Faster
View External Link:
“Implicit Chain-Of-Thought Reasoning via Knowledge Distillation”, Deng et al 2023
Implicit Chain-of-Thought Reasoning via Knowledge Distillation
“Preventing Language Models From Hiding Their Reasoning”, Roger & Greenblatt 2023
“Branch-Solve-Merge Improves Large Language Model Evaluation and Generation”, Saha et al 2023
Branch-Solve-Merge Improves Large Language Model Evaluation and Generation
“Can GPT Models Be Financial Analysts? An Evaluation of ChatGPT and GPT-4 on Mock CFA Exams”, Callanan et al 2023
Can GPT models be Financial Analysts? An Evaluation of ChatGPT and GPT-4 on mock CFA Exams
“The Expressive Power of Transformers With Chain-Of-Thought”, Merrill & Sabharwal 2023
“Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models”, Zhou et al 2023
Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
“Large Language Models Cannot Self-Correct Reasoning Yet”, Huang et al 2023
“Think Before You Speak: Training Language Models With Pause Tokens”, Goyal et al 2023
Think before you speak: Training Language Models With Pause Tokens
“Embers of Autoregression: Understanding Large Language Models Through the Problem They Are Trained to Solve”, McCoy et al 2023
“Contrastive Decoding Improves Reasoning in Large Language Models”, O’Brien & Lewis 2023
Contrastive Decoding Improves Reasoning in Large Language Models
“Re2: Re-Reading Improves Reasoning in Large Language Models”, Xu et al 2023
“From Sparse to Dense: GPT-4 Summarization With Chain of Density (CoD) Prompting”, Adams et al 2023
From Sparse to Dense: GPT-4 Summarization with Chain of Density (CoD) Prompting
“Graph of Thoughts: Solving Elaborate Problems With Large Language Models”, Besta et al 2023
Graph of Thoughts: Solving Elaborate Problems with Large Language Models
“Solving Challenging Math Word Problems Using GPT-4 Code Interpreter With Code-Based Self-Verification”, Zhou et al 2023
“Scaling Relationship on Learning Mathematical Reasoning With Large Language Models”, Yuan et al 2023
Scaling Relationship on Learning Mathematical Reasoning with Large Language Models
“Android in the Wild: A Large-Scale Dataset for Android Device Control”, Rawles et al 2023
Android in the Wild: A Large-Scale Dataset for Android Device Control
“LLMs As Workers in Human-Computational Algorithms? Replicating Crowdsourcing Pipelines With LLMs”, Wu et al 2023
LLMs as Workers in Human-Computational Algorithms? Replicating Crowdsourcing Pipelines with LLMs
“TableGPT: Towards Unifying Tables, Nature Language and Commands into One GPT”, Zha et al 2023
TableGPT: Towards Unifying Tables, Nature Language and Commands into One GPT
“Question Decomposition Improves the Faithfulness of Model-Generated Reasoning”, Radhakrishnan et al 2023
Question Decomposition Improves the Faithfulness of Model-Generated Reasoning
“Measuring Faithfulness in Chain-Of-Thought Reasoning”, Lanham et al 2023
“Unleashing the Emergent Cognitive Synergy in Large Language Models: A Task-Solving Agent through Multi-Persona Self-Collaboration”, Wang et al 2023
“Explaining Competitive-Level Programming Solutions Using LLMs”, Li et al 2023
Explaining Competitive-Level Programming Solutions using LLMs
“Teaching Arithmetic to Small Transformers”, Lee et al 2023
“Language Models Are Weak Learners”, Manikandan et al 2023
“Let’s Do a Thought Experiment: Using Counterfactuals to Improve Moral Reasoning”, Ma et al 2023
Let’s Do a Thought Experiment: Using Counterfactuals to Improve Moral Reasoning
“GKD: Generalized Knowledge Distillation for Auto-Regressive Sequence Models”, Agarwal et al 2023
GKD: Generalized Knowledge Distillation for Auto-regressive Sequence Models
“From Word Models to World Models: Translating from Natural Language to the Probabilistic Language of Thought”, Wong et al 2023
“Large Language Models As Tax Attorneys: A Case Study in Legal Capabilities Emergence”, Nay et al 2023
Large Language Models as Tax Attorneys: A Case Study in Legal Capabilities Emergence
“Iterative Translation Refinement With Large Language Models”, Chen et al 2023
“Thought Cloning: Learning to Think While Acting by Imitating Human Thinking”, Hu & Clune 2023
Thought Cloning: Learning to Think while Acting by Imitating Human Thinking
“Let’s Verify Step by Step”, Lightman et al 2023
“Towards Revealing the Mystery behind Chain-Of-Thought: A Theoretical Perspective”, Feng et al 2023
Towards Revealing the Mystery behind Chain-of-Thought: A Theoretical Perspective
“Improving Factuality and Reasoning in Language Models through Multiagent Debate”, Du et al 2023
Improving Factuality and Reasoning in Language Models through Multiagent Debate
“How Language Model Hallucinations Can Snowball”, Zhang et al 2023
“Tree of Thoughts (ToT): Deliberate Problem Solving With Large Language Models”, Yao et al 2023
Tree of Thoughts (ToT): Deliberate Problem Solving with Large Language Models
“Large Language Model Programs”, Schlag et al 2023
“Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-Of-Thought Prompting”, Turpin et al 2023
“Distilling Step-By-Step! Outperforming Larger Language Models With Less Training Data and Smaller Model Sizes”, Hsieh et al 2023
“Decomposition Enhances Reasoning via Self-Evaluation Guided Decoding”, Xie et al 2023
Decomposition Enhances Reasoning via Self-Evaluation Guided Decoding
“LLM+P: Empowering Large Language Models With Optimal Planning Proficiency”, Liu et al 2023
LLM+P: Empowering Large Language Models with Optimal Planning Proficiency
“Boosting Theory-Of-Mind Performance in Large Language Models via Prompting”, Moghaddam & Honey 2023
Boosting Theory-of-Mind Performance in Large Language Models via Prompting
“Think Before You Act: Unified Policy for Interleaving Language Reasoning With Actions”, Mezghani et al 2023
Think Before You Act: Unified Policy for Interleaving Language Reasoning with Actions
“Corrupted by Reasoning: Reasoning Language Models Become Free-Riders in Public Goods Games”
Corrupted by Reasoning: Reasoning Language Models Become Free-Riders in Public Goods Games
“Language Models Can Solve Computer Tasks”, Kim et al 2023
“Reflexion: Language Agents With Verbal Reinforcement Learning”, Shinn et al 2023
Reflexion: Language Agents with Verbal Reinforcement Learning
“How Well Do Large Language Models Perform in Arithmetic Tasks?”, Yuan et al 2023
How well do Large Language Models perform in Arithmetic tasks?
“SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models”, Manakul et al 2023
SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models
“Language Is Not All You Need: Aligning Perception With Language Models (Kosmos-1)”, Huang et al 2023
Language Is Not All You Need: Aligning Perception with Language Models (Kosmos-1)
“Multimodal Chain-Of-Thought Reasoning in Language Models”, Zhang et al 2023
“Faithful Chain-Of-Thought Reasoning”, Lyu et al 2023
“Large Language Models Are Versatile Decomposers: Decompose Evidence and Questions for Table-Based Reasoning”, Ye et al 2023
“ChatGPT Goes to Law School”, Choi et al 2023
“Large Language Models As Fiduciaries: A Case Study Toward Robustly Communicating With Artificial Intelligence Through Legal Standards”, Nay 2023
“Interactive-Chain-Prompting (INTERCPT): Ambiguity Resolution for Crosslingual Conditional Generation With Interaction”, Pilault et al 2023
“Iterated Decomposition: Improving Science Q&A by Supervising Reasoning Processes”, Reppert et al 2023
Iterated Decomposition: Improving Science Q&A by Supervising Reasoning Processes
“Solving Math Word Problems With Process & Outcome-Based Feedback”, Uesato et al 2022
Solving math word problems with process & outcome-based feedback
“PAL: Program-Aided Language Models”, Gao et al 2022
“Measuring Progress on Scalable Oversight for Large Language Models”, Bowman et al 2022
Measuring Progress on Scalable Oversight for Large Language Models
“U-PaLM: Transcending Scaling Laws With 0.1% Extra Compute”, Tay et al 2022
“Large Language Models Can Self-Improve”, Huang et al 2022
“Challenging BIG-Bench Tasks (BBH) and Whether Chain-Of-Thought Can Solve Them”, Suzgun et al 2022
Challenging BIG-Bench Tasks (BBH) and Whether Chain-of-Thought Can Solve Them
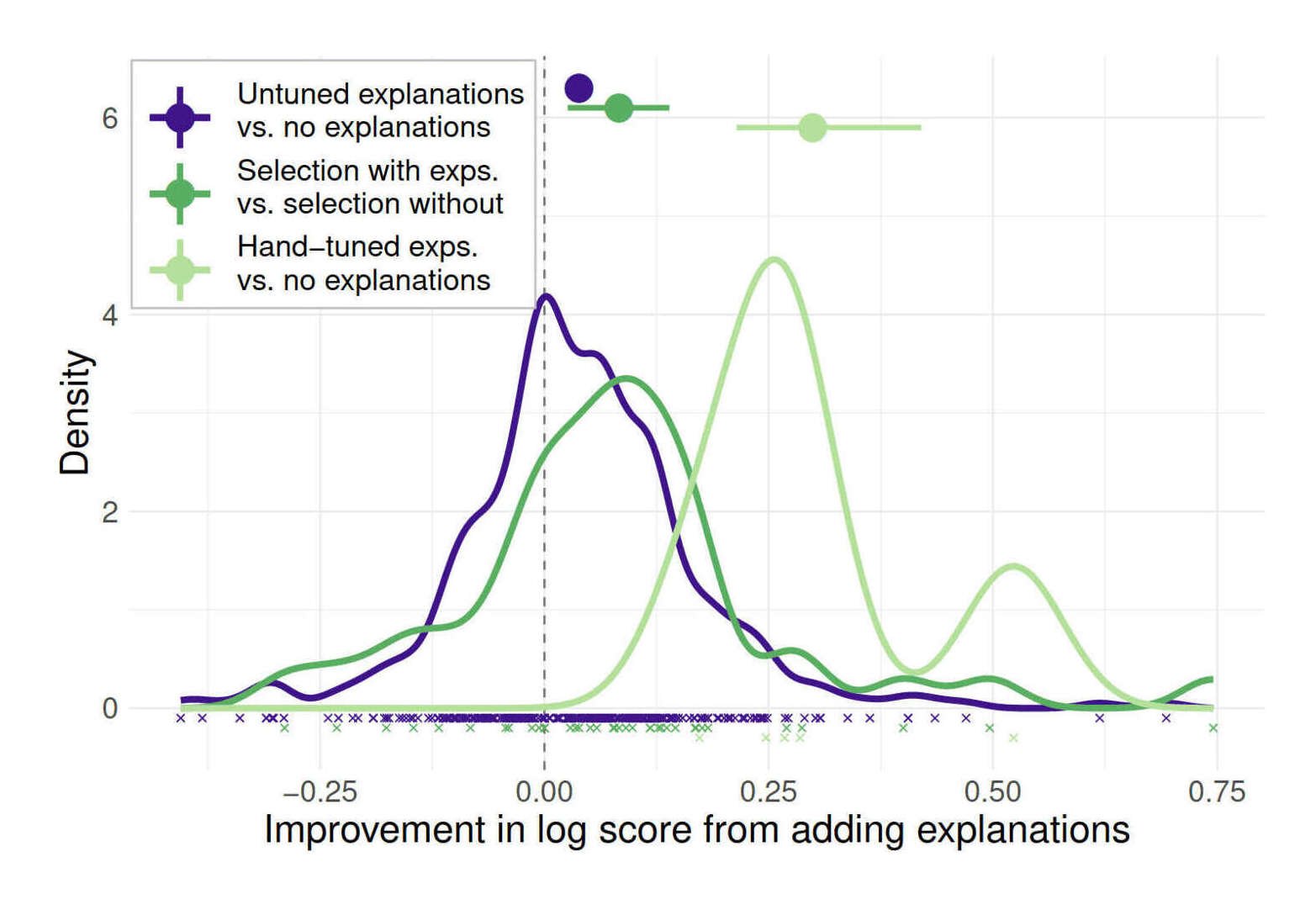
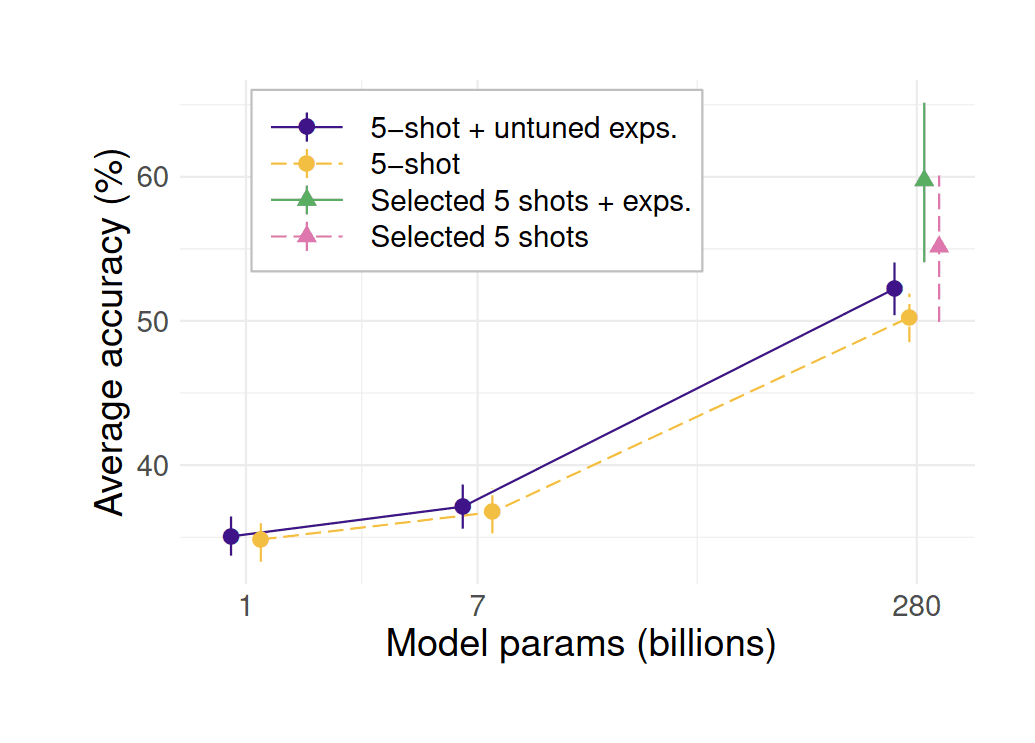
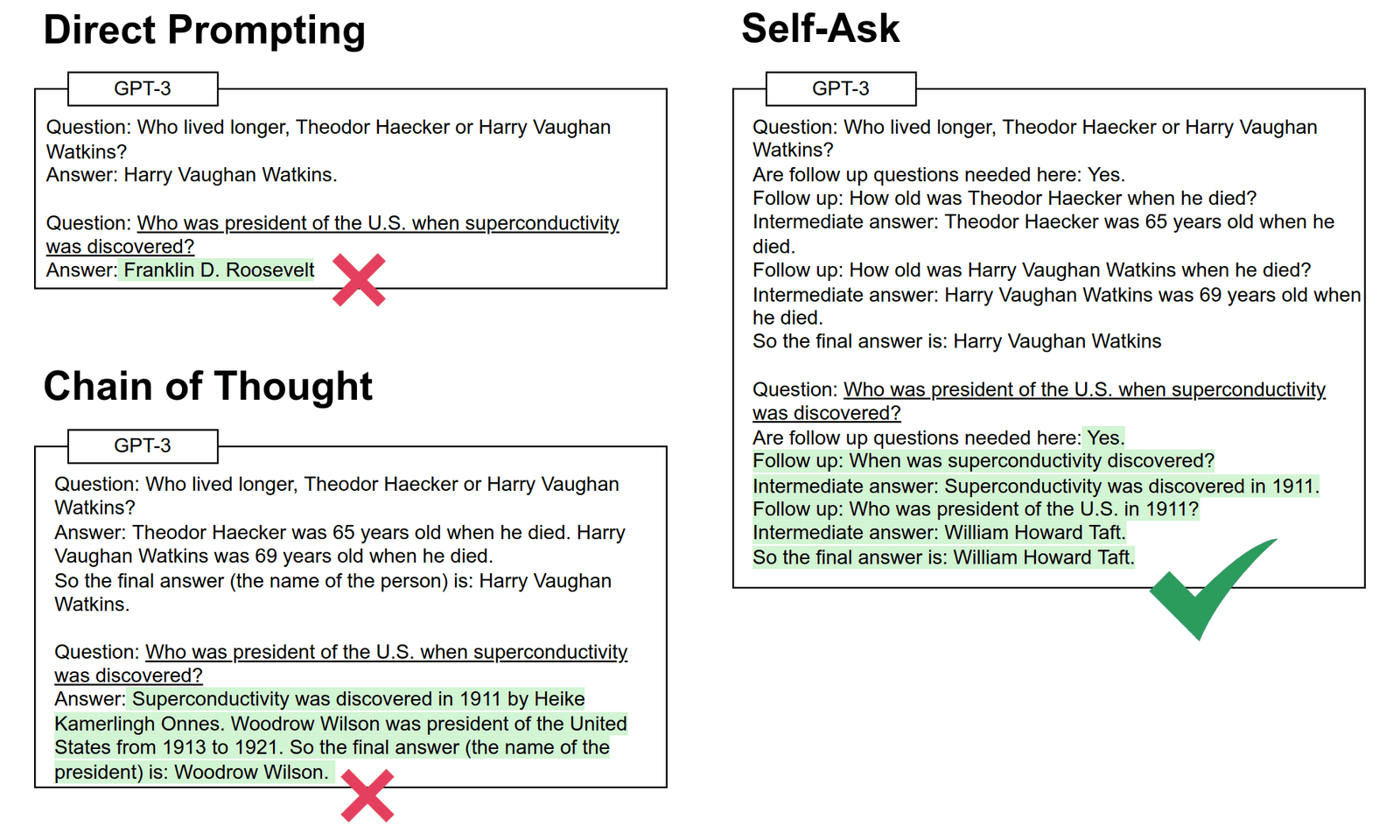
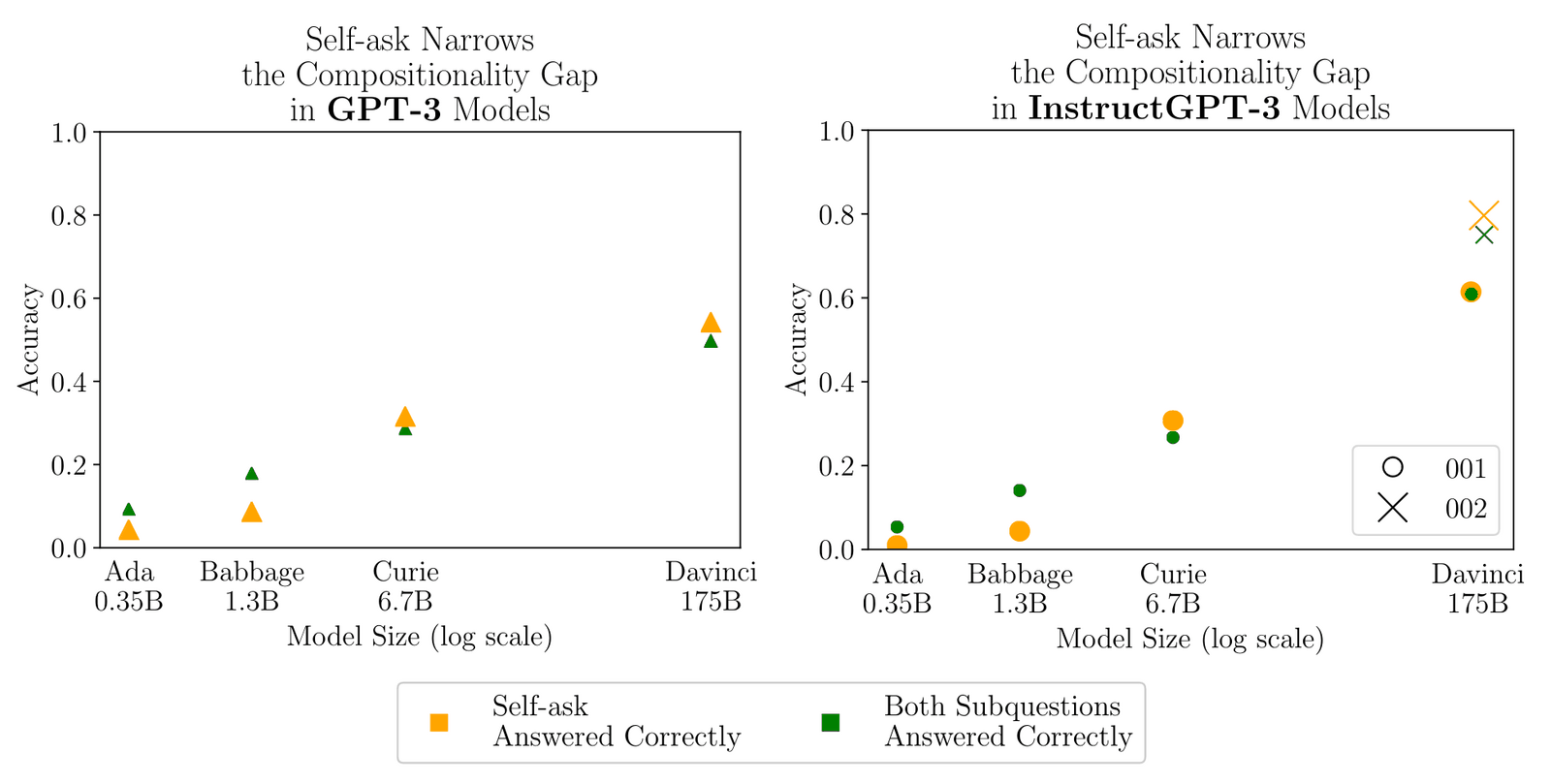
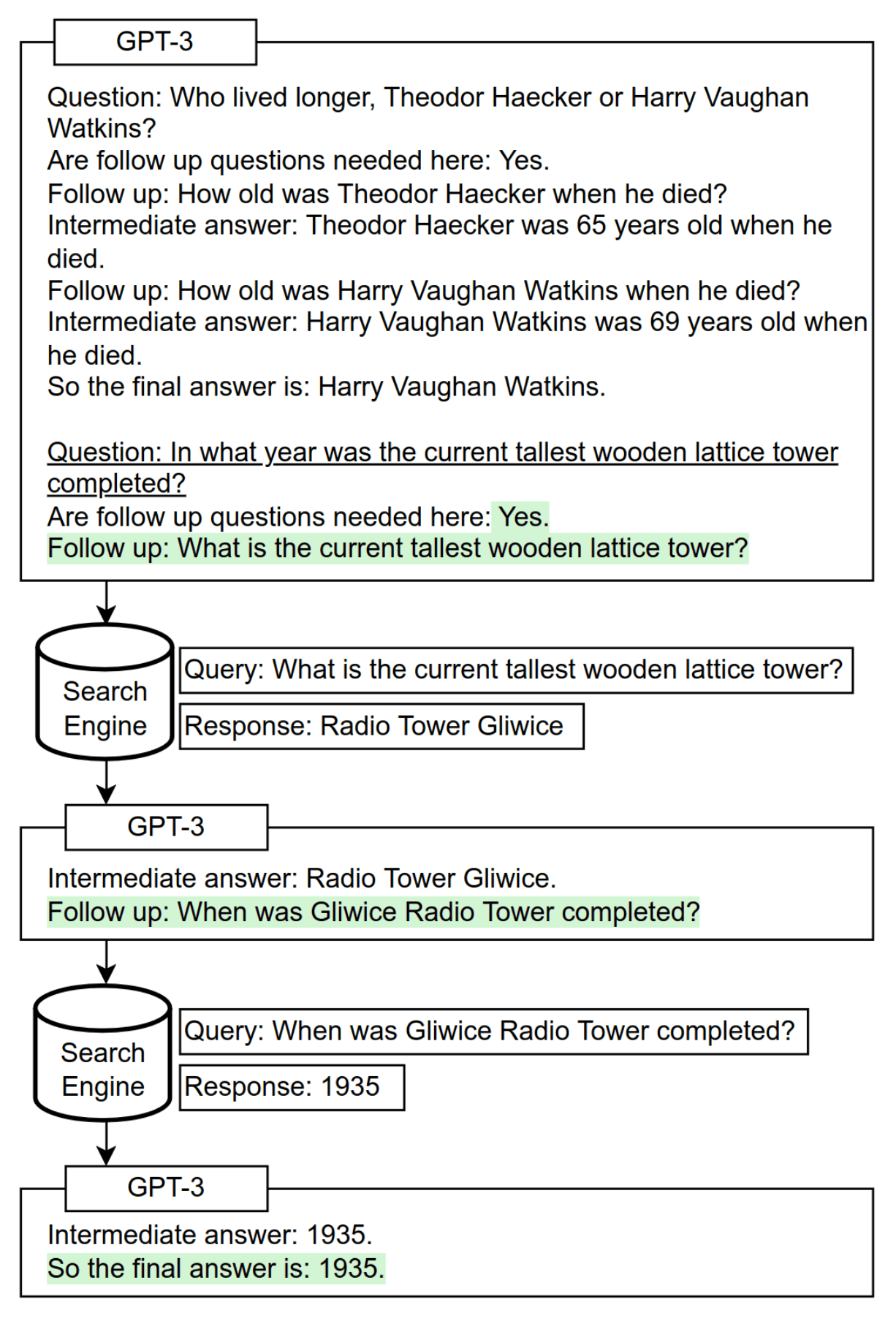
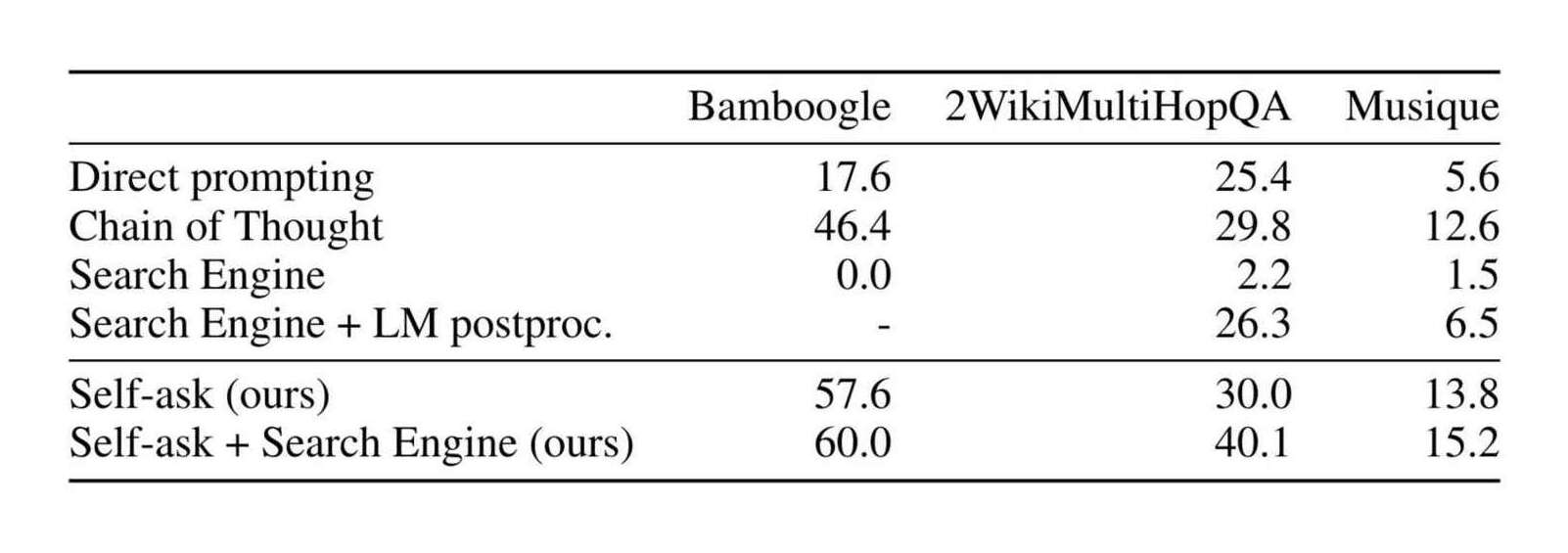
“Self-Ask: Measuring and Narrowing the Compositionality Gap in Language Models (Bamboogle)”, Press et al 2022
Self-Ask: Measuring and Narrowing the Compositionality Gap in Language Models (Bamboogle)
“Language Models Are Multilingual Chain-Of-Thought Reasoners”, Shi et al 2022
“ReAct: Synergizing Reasoning and Acting in Language Models”, Yao et al 2022
“Context Distillation: Learning by Distilling Context”, Snell et al 2022
“Dynamic Prompt Learning via Policy Gradient for Semi-Structured Mathematical Reasoning”, Lu et al 2022
Dynamic Prompt Learning via Policy Gradient for Semi-structured Mathematical Reasoning
“FOLIO: Natural Language Reasoning With First-Order Logic”, Han et al 2022
“Faithful Reasoning Using Large Language Models”, Creswell & Shanahan 2022
“Limitations of Language Models in Arithmetic and Symbolic Induction”, Qian et al 2022
Limitations of Language Models in Arithmetic and Symbolic Induction
“Language Models Can Teach Themselves to Program Better”, Haluptzok et al 2022
“Language Model Cascades”, Dohan et al 2022
“CodeT: Code Generation With Generated Tests”, Chen et al 2022
“Can Large Language Models Reason about Medical Questions?”, Liévin et al 2022
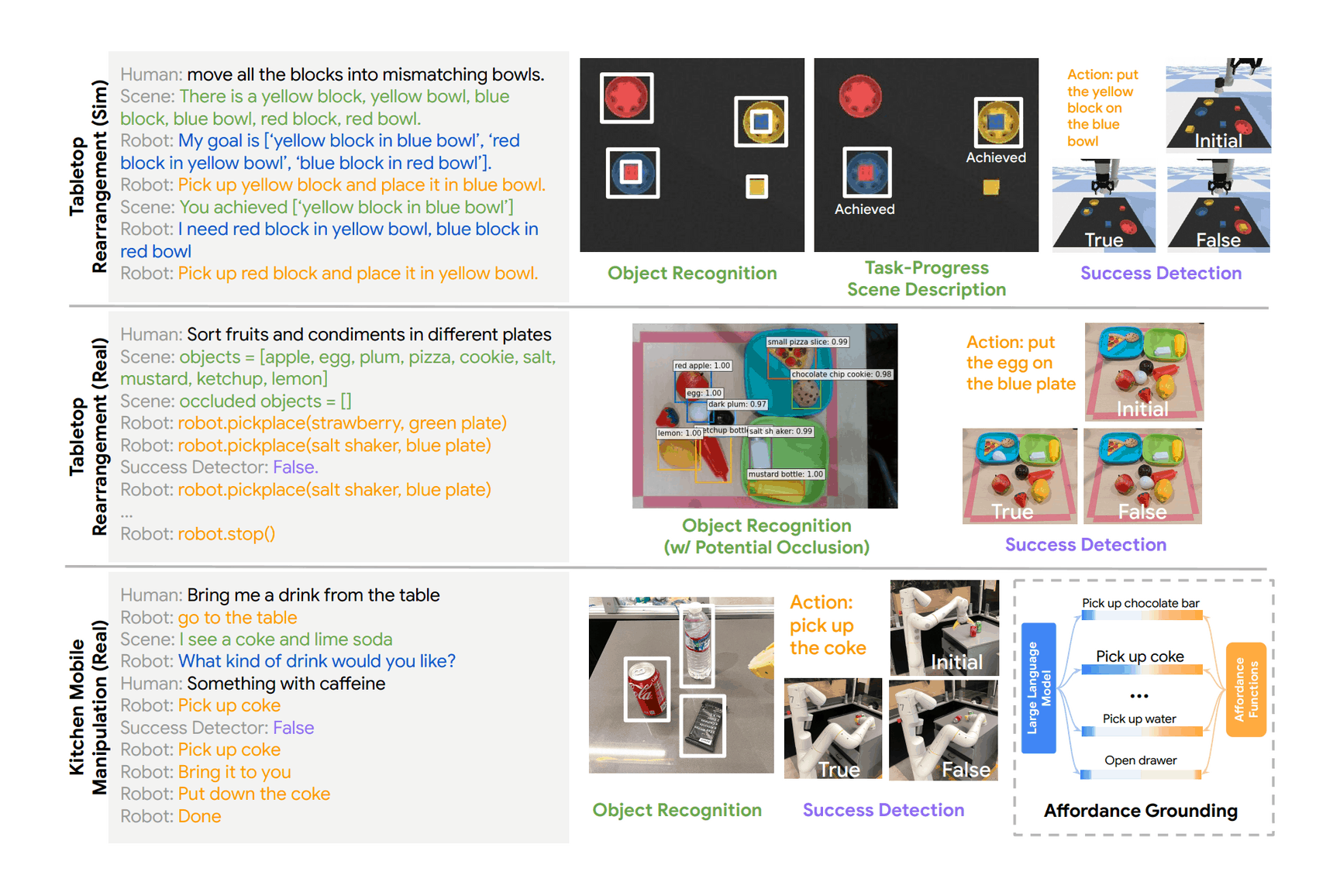
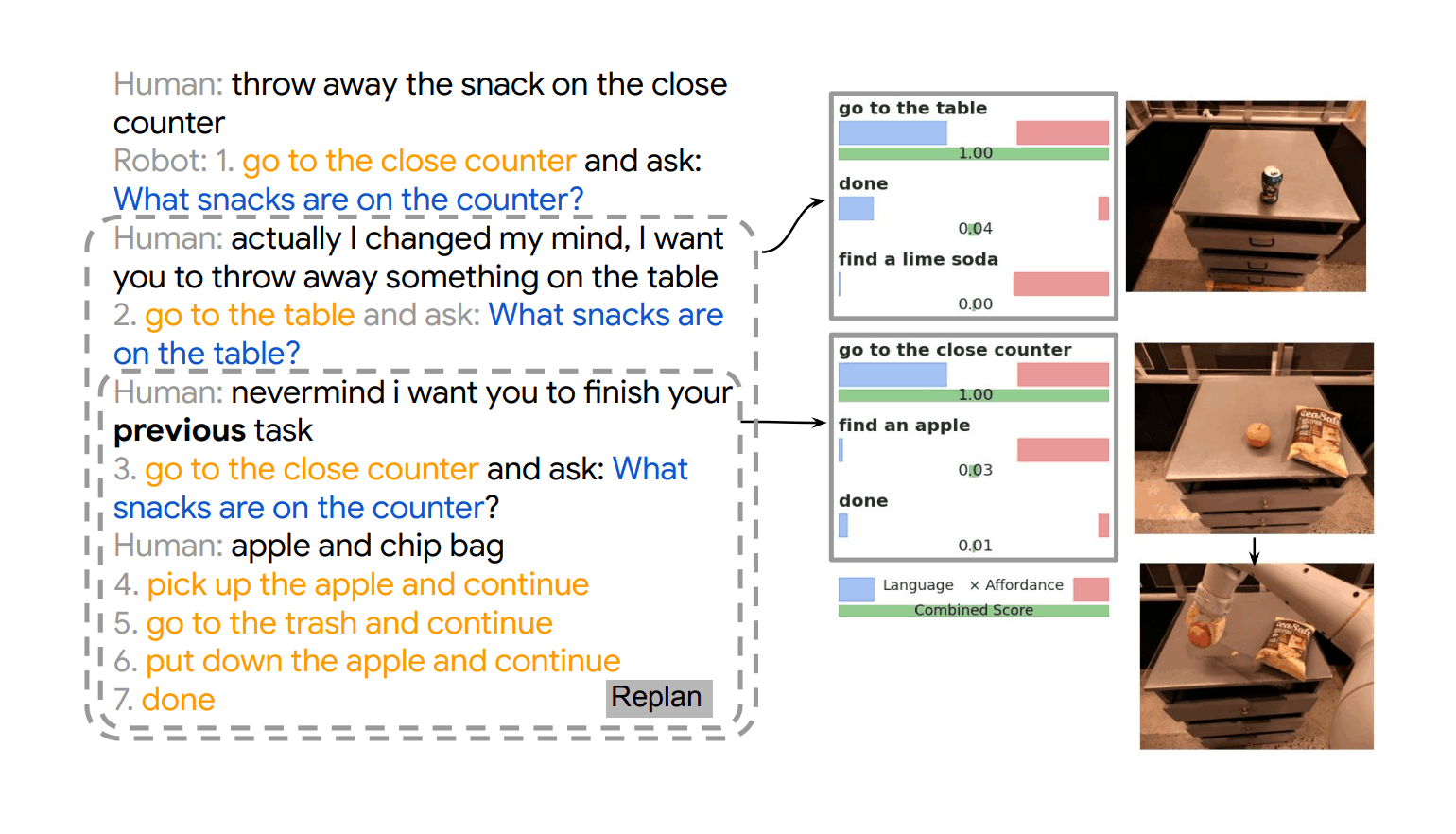
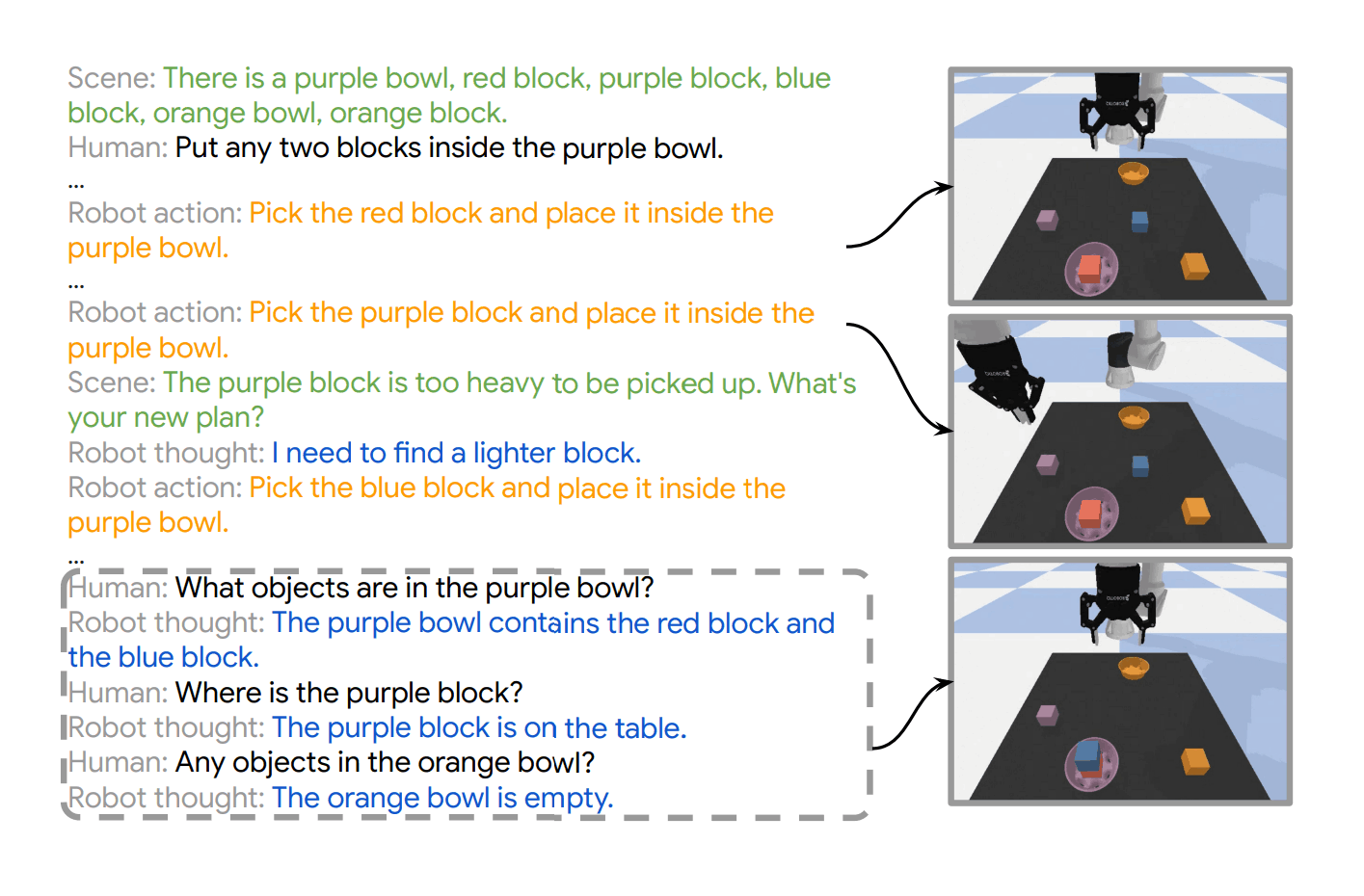
“Inner Monologue: Embodied Reasoning through Planning With Language Models”, Huang et al 2022
Inner Monologue: Embodied Reasoning through Planning with Language Models
“Exploring Length Generalization in Large Language Models”, Anil et al 2022
“Language Models (Mostly) Know What They Know”, Kadavath et al 2022
“Neural Networks and the Chomsky Hierarchy”, Delétang et al 2022
“Solving Quantitative Reasoning Problems With Language Models”, Lewkowycz et al 2022
Solving Quantitative Reasoning Problems with Language Models
“Maieutic Prompting: Logically Consistent Reasoning With Recursive Explanations”, Jung et al 2022
Maieutic Prompting: Logically Consistent Reasoning with Recursive Explanations
“Large Language Models Are Zero-Shot Reasoners”, Kojima et al 2022
“Instruction Induction: From Few Examples to Natural Language Task Descriptions”, Honovich et al 2022
Instruction Induction: From Few Examples to Natural Language Task Descriptions
“Least-To-Most Prompting Enables Complex Reasoning in Large Language Models”, Zhou et al 2022
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
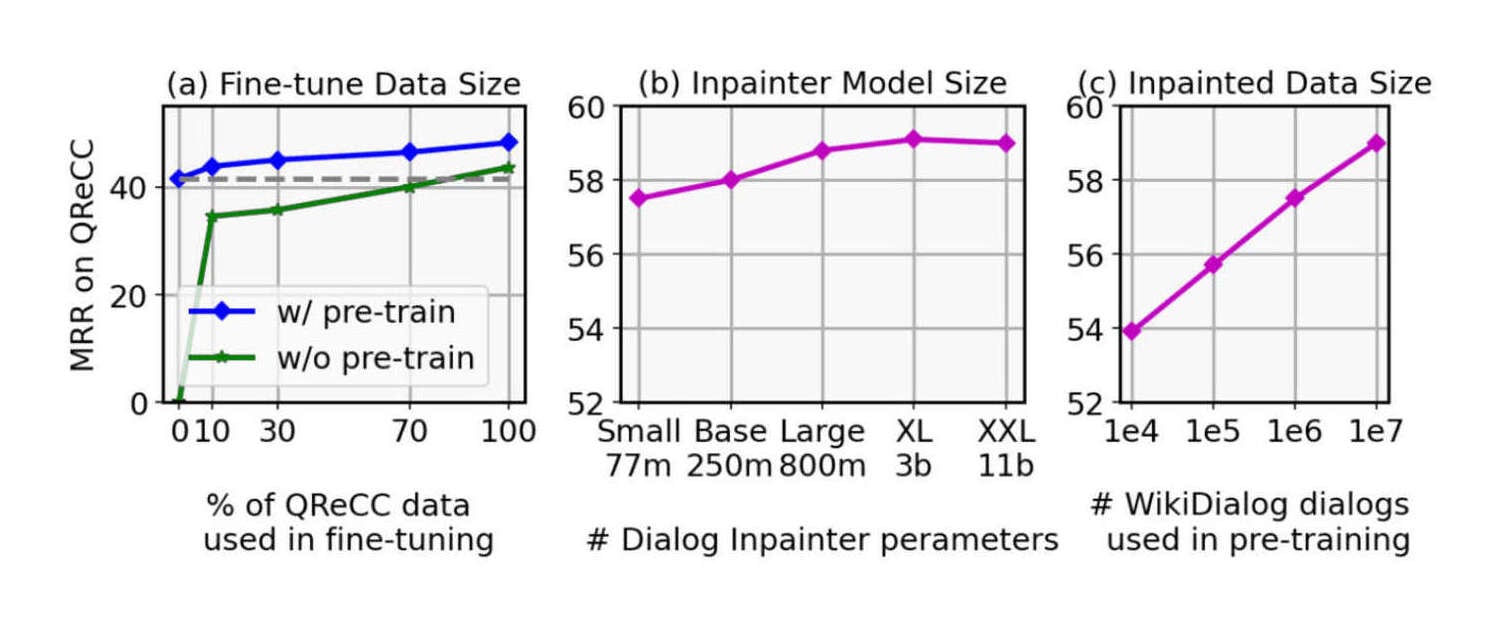
“Dialog Inpainting: Turning Documents into Dialogues”, Dai et al 2022
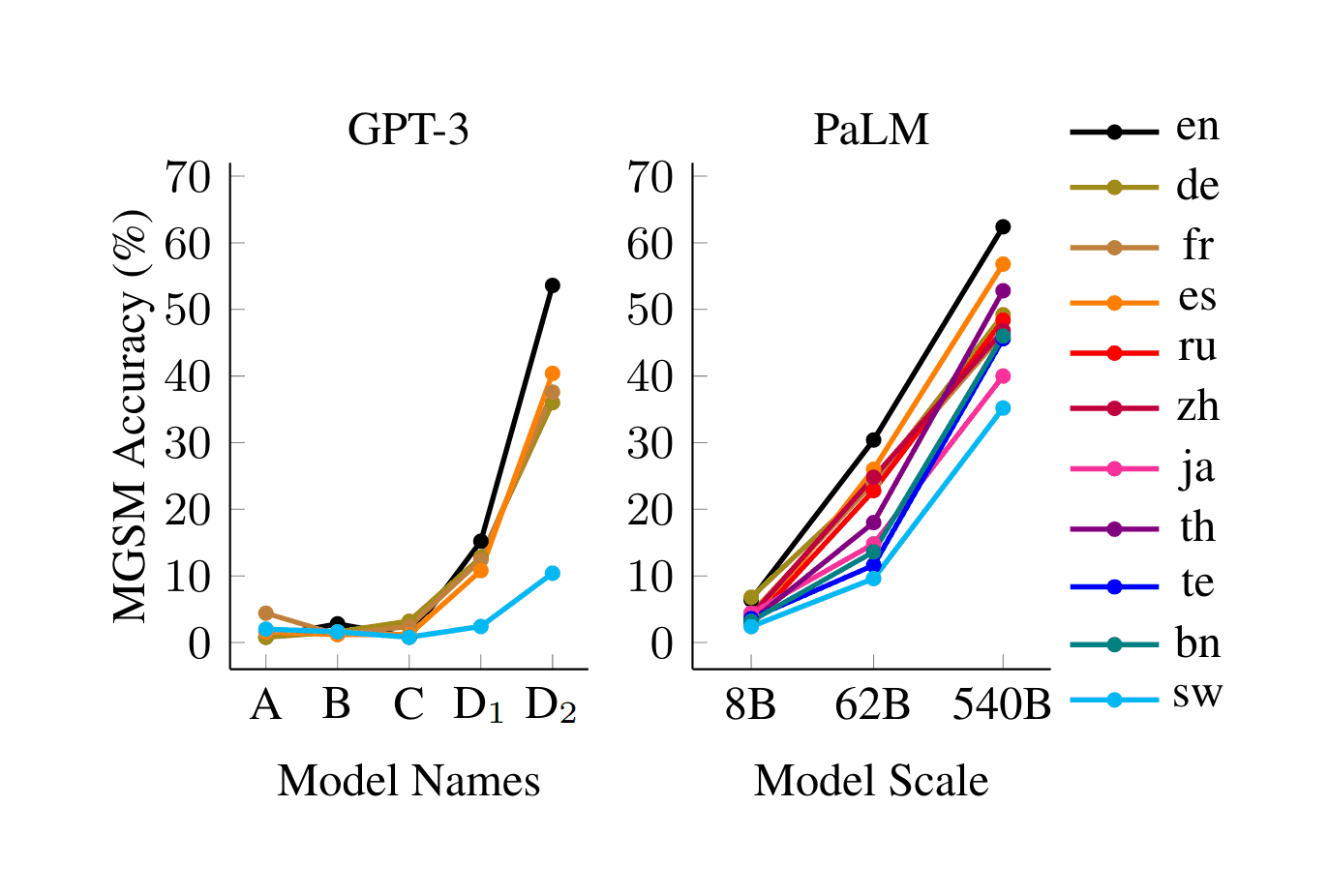
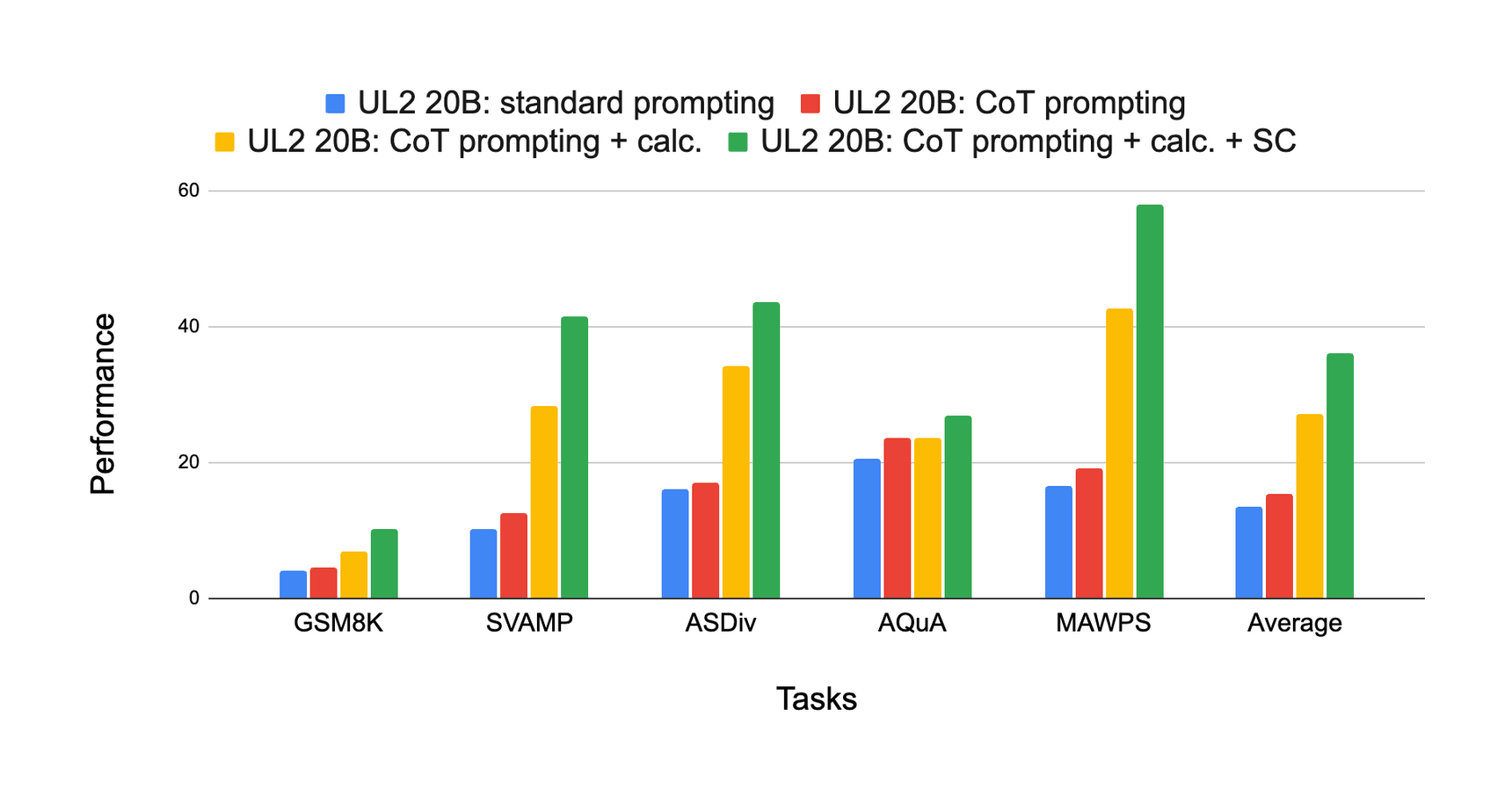
“UL2: Unifying Language Learning Paradigms”, Tay et al 2022
“Can Language Models Learn from Explanations in Context?”, Lampinen et al 2022
“Socratic Models: Composing Zero-Shot Multimodal Reasoning With Language”, Zeng et al 2022
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
“STaR: Bootstrapping Reasoning With Reasoning”, Zelikman et al 2022
“A Conversational Paradigm for Program Synthesis”, Nijkamp et al 2022
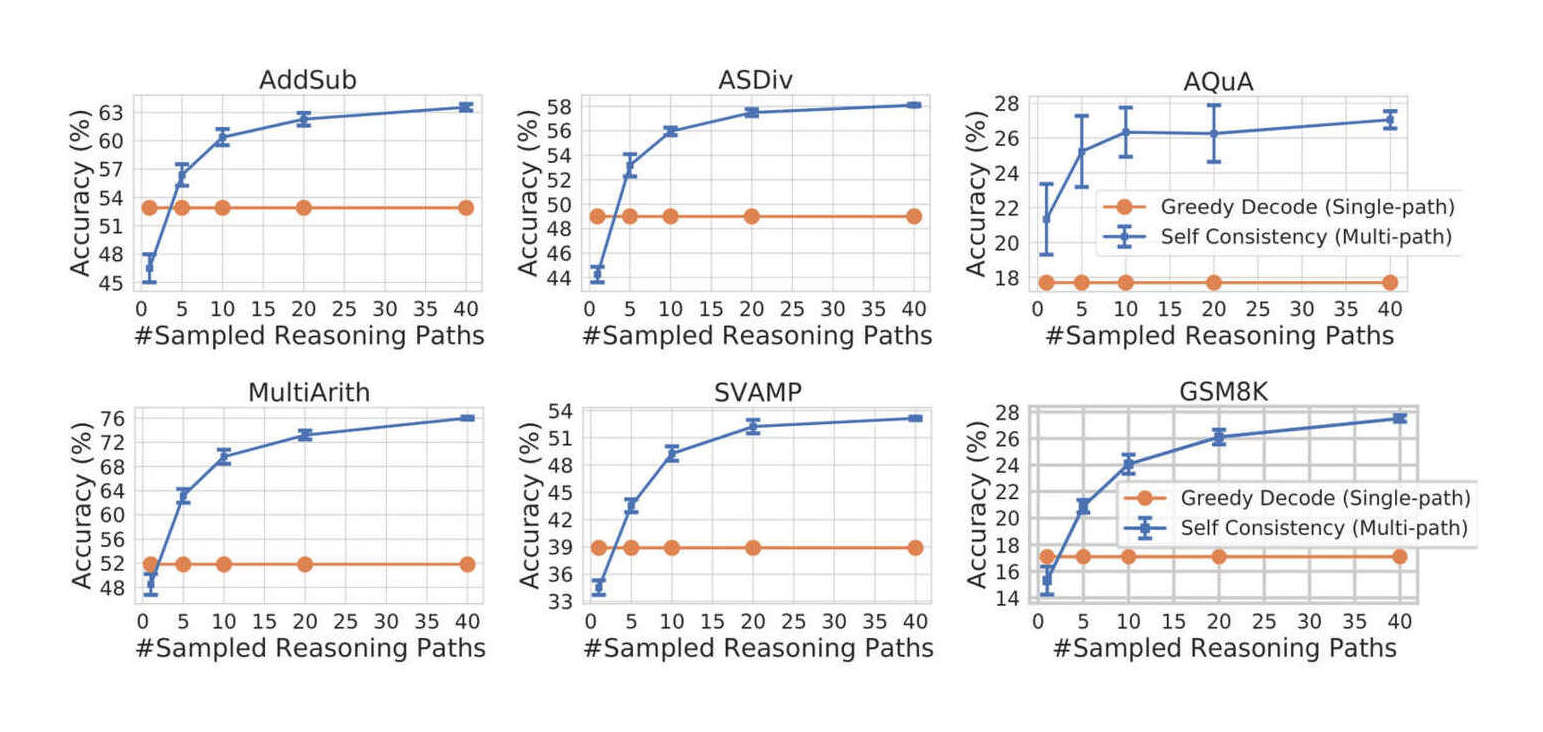
“Self-Consistency Improves Chain-Of-Thought Reasoning in Language Models”, Wang et al 2022
Self-Consistency Improves Chain-of-Thought Reasoning in Language Models
“Learning-By-Narrating: Narrative Pre-Training for Zero-Shot Dialogue Comprehension”, Zhao et al 2022
Learning-by-Narrating: Narrative Pre-Training for Zero-Shot Dialogue Comprehension
“PromptChainer: Chaining Large Language Model Prompts through Visual Programming”, Wu et al 2022
PromptChainer: Chaining Large Language Model Prompts through Visual Programming
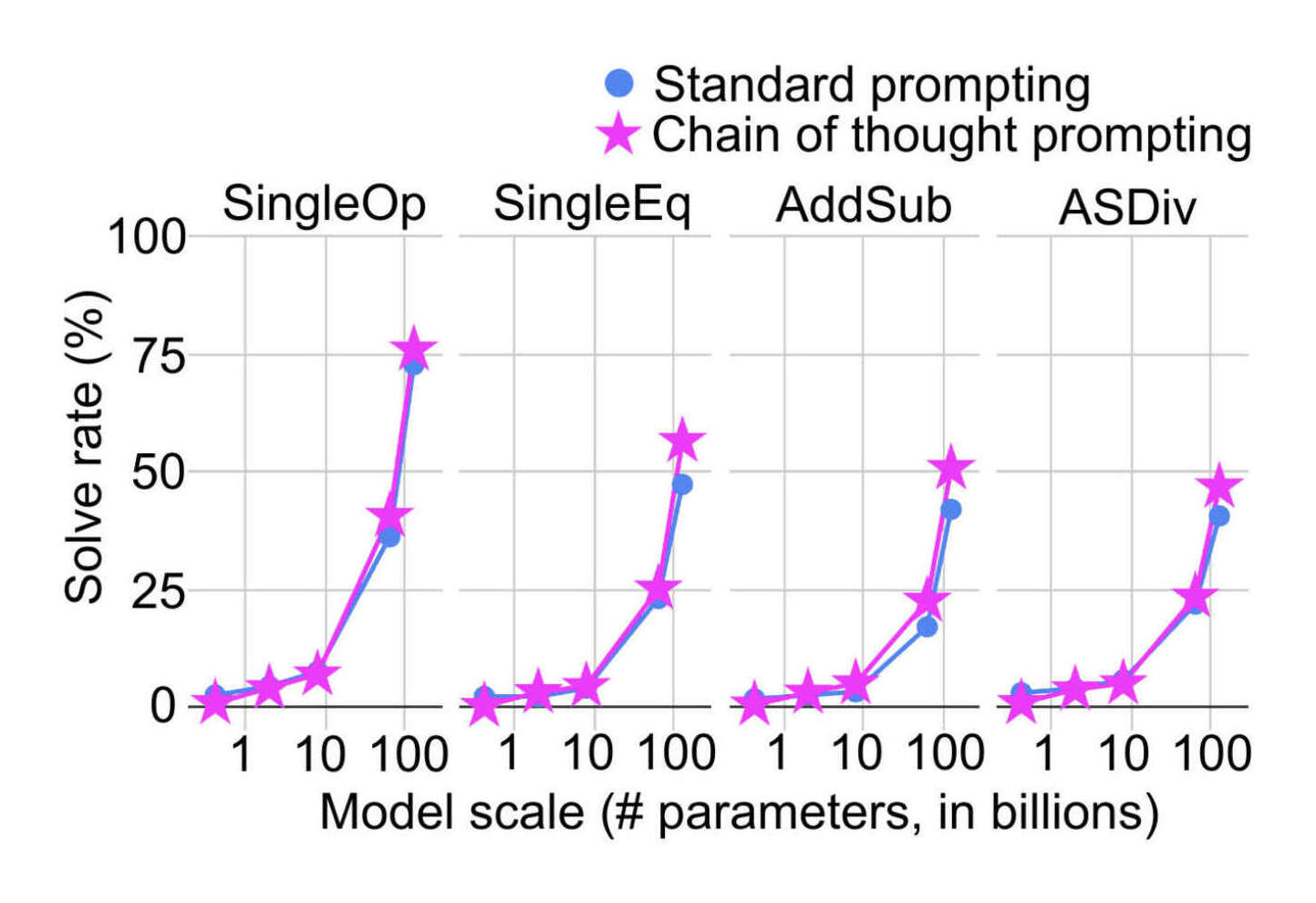
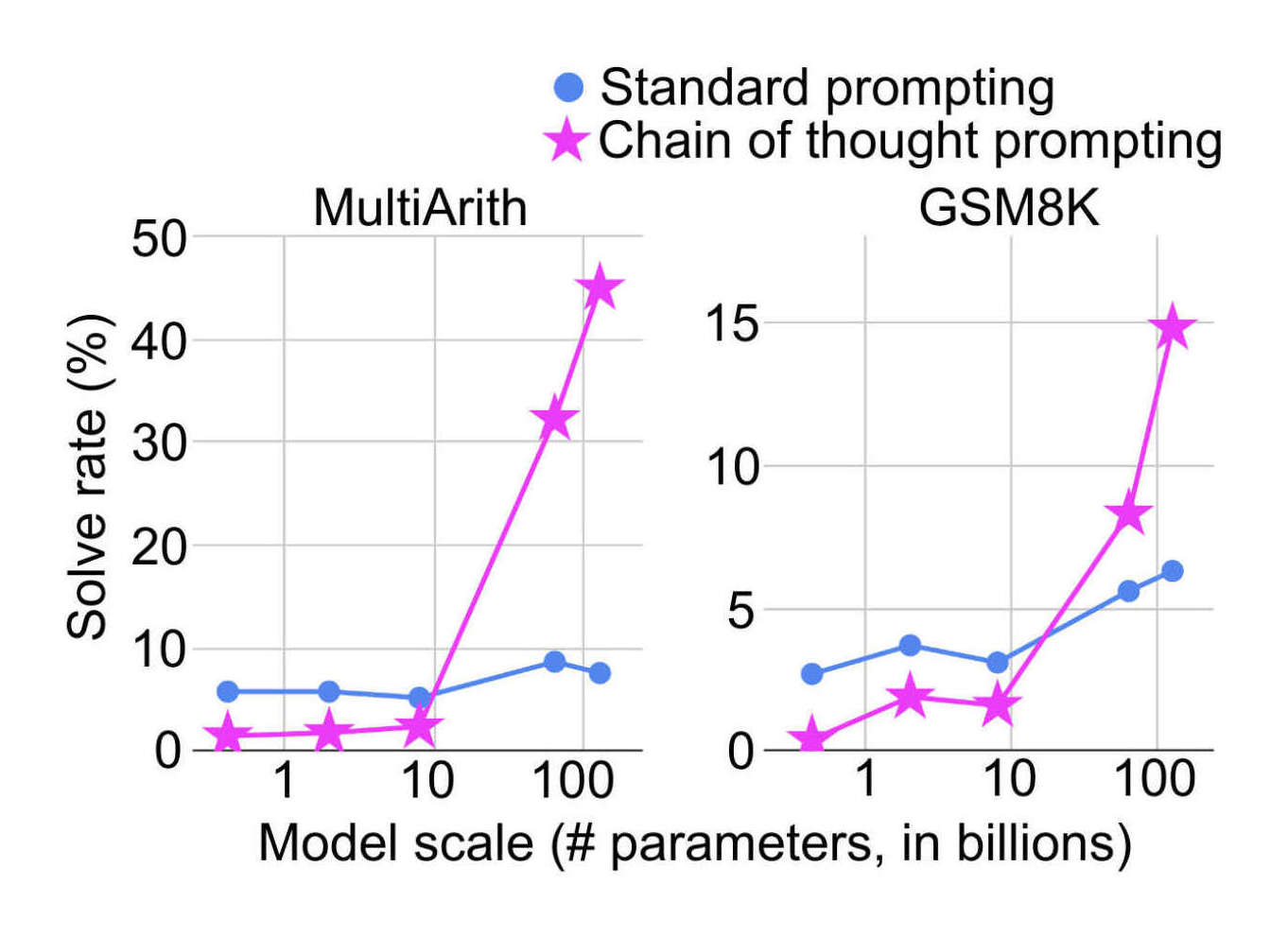
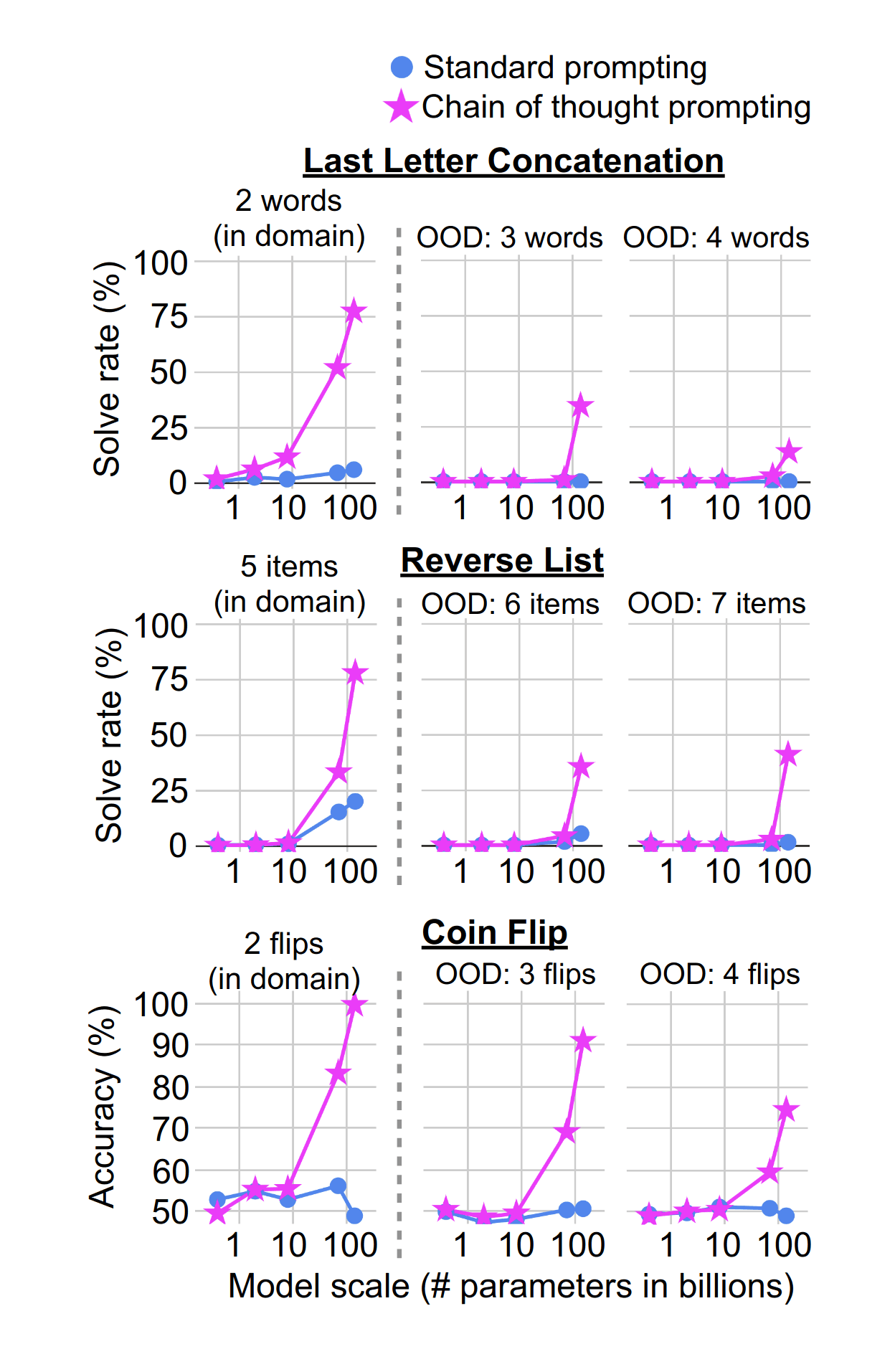
“Chain-Of-Thought Prompting Elicits Reasoning in Large Language Models”, Wei et al 2022
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
“Reasoning Like Program Executors”, Pi et al 2022
“A Neural Network Solves and Generates Mathematics Problems by Program Synthesis: Calculus, Differential Equations, Linear Algebra, and More”, Drori et al 2021
“DREAM: Uncovering Mental Models behind Language Models”, Gu et al 2021
“Reframing Human-AI Collaboration for Generating Free-Text Explanations”, Wiegreffe et al 2021
Reframing Human-AI Collaboration for Generating Free-Text Explanations
“NeuroLogic A✱esque Decoding: Constrained Text Generation With Lookahead Heuristics”, Lu et al 2021
NeuroLogic A✱esque Decoding: Constrained Text Generation with Lookahead Heuristics
“WebGPT: Improving the Factual Accuracy of Language Models through Web Browsing”, Hilton et al 2021
WebGPT: Improving the factual accuracy of language models through web browsing
“NN Inner Monologue”, Gwern 2021
“Few-Shot Self-Rationalization With Natural Language Prompts”, Marasović et al 2021
“Training Verifiers to Solve Math Word Problems”, Cobbe et al 2021
“Unsupervised Neural Machine Translation With Generative Language Models Only”, Han et al 2021
Unsupervised Neural Machine Translation with Generative Language Models Only
“Show Your Work: Scratchpads for Intermediate Computation With Language Models”, Nye et al 2021
Show Your Work: Scratchpads for Intermediate Computation with Language Models
“AI Chains: Transparent and Controllable Human-AI Interaction by Chaining Large Language Model Prompts”, Wu et al 2021
“Teaching Autoregressive Language Models Complex Tasks By Demonstration”, Recchia 2021
Teaching Autoregressive Language Models Complex Tasks By Demonstration
“Program Synthesis With Large Language Models”, Austin et al 2021
“Decision Transformer: Reinforcement Learning via Sequence Modeling”, Chen et al 2021
Decision Transformer: Reinforcement Learning via Sequence Modeling
“Explainable Multi-Hop Verbal Reasoning Through Internal Monologue”, Liang et al 2021
Explainable Multi-hop Verbal Reasoning Through Internal Monologue
“A Simple Method to Keep GPT-3 Focused in a Conversation”, Mayne 2021
“Measuring Mathematical Problem Solving With the MATH Dataset”, Hendrycks et al 2021
Measuring Mathematical Problem Solving With the MATH Dataset
“Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm”, Reynolds & McDonell 2021
Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm
“How We Accidentally Gave Our Bots Their Personalities”, Latitude 2021
“GPT-3: Imitation Learning That Imitates Learning”, Robertson 2020
“Word in Context: Agent and Agent Clarification (69% Dev)”, Brockman 2020
“I Found That Getting GPT-3 to Add Its Own "Internal Monologue" in Parentheses to Be a Helpful Strategy…”, blixt 2020
“You Can Probably Amplify GPT-3 Directly”, Robertson 2020
kleptid @ "2020-07-17"
kleptid @ "2020-07-17"
Teaching GPT-3 to do a brute force ‘for loop’ checking answers also seems to work
“[More Early 4chan Inner-Monologue Examples]”, Anonymous 2020
“[4chan /vg/ Aidg Thread Screenshot of an Early Inner-Monologue for Arithmetic, Using a Katawa Shoujo Lilly Scenario]”, Anonymous 2020
![[4chan /vg/ aidg thread screenshot of an early inner-monologue for arithmetic, using a Katawa Shoujo Lilly scenario]](/doc/ai/nn/transformer/gpt/inner-monologue/2020-07-16-4chan-vg-aidg-anonymous-aidungeon2-katawashoujolilly-earlyinnermonologuepromptexample-1594872803390.png){kind=link}
“[4chan /vg/ Board Discovers GPT-3 Inner-Monologues by Talking to the Wise Wolf Holo]”, Anonymous 2020
[4chan /vg/ board discovers GPT-3 inner-monologues by talking to the Wise Wolf Holo]
“Inducing Self-Explanation: a Meta-Analysis”, Bisra et al 2018
“Program Induction by Rationale Generation: Learning to Solve and Explain Algebraic Word Problems”, Ling et al 2017
Program Induction by Rationale Generation: Learning to Solve and Explain Algebraic Word Problems
“Why Do Humans Reason? Arguments for an Argumentative Theory”, Mercier & Sperber 2011
“Sebastian Riedel Homepage”, Riedel 2026
“How to Dramatically Improve the Reasoning Ability of GPT-3”
“A Preliminary Exploration into Factored Cognition With Language Models”
A Preliminary Exploration into Factored Cognition with Language Models
View External Link:
“ChatGPT-4 O1-Pro: Poetry Reflection and Analysis”
“WiC_SelfContextStuffingImproved_Last10_stuft_examplesNV.ipynb”
WiC_SelfContextStuffingImproved_Last10_stuft_examplesNV.ipynb
“TinyZero”, Pan 2026
“Position Bias: A Benchmark for Testing Whether LLM Judges Keep the Same Preference When Two Lightly Edited Versions of the Same Story Are Shown in opposite Orders”, Mazir 2026
“Vincent-163/transformer-Arithmetic”
“Magic ToDo List Creator”
“Many Benchmarks Scores Would Appear Much Higher If You Let The AIs Use Adequate Labor”
Many Benchmarks Scores Would Appear Much Higher If You Let The AIs Use Adequate Labor
“Short Story on AI: ‘Forward Pass’”, Karpathy 2026
Short Story on AI: ‘Forward Pass’
View External Link:
“AI Dungeon Players Can Now Translate Their Stories into Emojis by Just Clicking a Button.”
AI Dungeon players can now translate their stories into emojis by just clicking a button.
“Sky-T1: Train Your Own o1-Preview Model With $450”
“Solving Math Word Problems: We’ve Trained a System That Solves Grade School Math Problems With Nearly Twice the Accuracy of a Fine-Tuned GPT-3 Model. It Solves about 90% As Many Problems As Real Kids: a Small Sample of 9-12 Year Olds Scored 60% on a Test from Our Dataset, While Our System Scored 55% on Those Same Problems. This Is Important Because Today’s AI Is Still Quite Weak at Commonsense Multistep Reasoning, Which Is Easy Even for Grade School Kids. We Achieved These Results by Training Our Model to Recognize Its Mistakes, so That It Can Try Repeatedly Until It Finds a Solution That Works”
“Prompting Diverse Ideas: Increasing AI Idea Variance”
“o3-Mini”, OpenAI 2026
“Teaching a Neural Network to Use a Calculator”
“Can Tiny Language Models Reason? [Inner-Monologue & DPO RLHF on a 0.13b-Parameter LLM: trlm]”
Can Tiny Language Models Reason? [inner-monologue & DPO RLHF on a 0.13b-parameter LLM: trlm]
“On-Policy Distillation”
“GPT-4 O1 Isn’t a Chat Model (And That’s the Point)”
“Connecting the Dots: LLMs Can Infer & Verbalize Latent Structure from Training Data”
Connecting the Dots: LLMs can Infer & Verbalize Latent Structure from Training Data
“Beware General Claims about ‘Generalizable Reasoning Capabilities’ (Of Modern AI Systems)”
Beware General Claims about ‘Generalizable Reasoning Capabilities’ (of Modern AI Systems)
“Preventing Language Models from Hiding Their Reasoning”
“Claude Opus 4.6 Reasoning Doesn’t Verbalize Alignment Faking, but Behavior Persists”
Claude Opus 4.6 Reasoning Doesn’t Verbalize Alignment Faking, but Behavior Persists
“A High Level Closed-Door Session Discussing DeepSeek: Vision Trumps Technology”
A High Level Closed-Door Session Discussing DeepSeek: Vision Trumps Technology
“Do Models Continue Misaligned Actions?”
“How Well Do Models Follow Their Constitutions?”
“Opus’s Schelling Steganography Has Amplifiable Secrecy Against Weaker Eavesdroppers”
Opus’s Schelling Steganography Has Amplifiable Secrecy Against Weaker Eavesdroppers
“Did Claude 3 Opus Align Itself via Gradient Hacking?”
“What Secret Goals Does Claude Think It Has?”
“Monitor Jailbreaking: Evading Chain-Of-Thought Monitoring Without Encoded Reasoning”
Monitor Jailbreaking: Evading Chain-of-Thought Monitoring Without Encoded Reasoning
“Steganography in Chain-Of-Thought Reasoning”
“Visible Thoughts Project and Bounty Announcement”
Malcolm_Ocean
bucketofkets
sama
teortaxesTex
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
code-generation test-automation android-analysis
task-expertise
low-cost-finetuning
inner-lookup
lateral-reasoning natural-logic puzzles-llms first-order-logic reasoning-llms lateral-puzzles
table-reasoning
self-explanation
reasoning-medical jailbreaks steganography finance-prediction generalist-models
llm-evaluation llm-strategy reasoning-gaming competency-hallucination intelligent-design agent-training
chain-of-thought
Wikipedia (4)
Miscellaneous
/doc/ai/nn/transformer/gpt/inner-monologue/2023-lee-figure1-numberformattingforgpt2arithmetic.jpg/doc/ai/nn/transformer/gpt/inner-monologue/2022-05-28-gpt3user-thinkingisallyouneed.html/doc/ai/nn/transformer/gpt/inner-monologue/2022-tay-ul2-innermonologueresults.png/doc/ai/nn/transformer/gpt/inner-monologue/2022-wei-figure8-lamdavsgpt3.png/doc/ai/nn/transformer/gpt/inner-monologue/2022-zeng-figure2-socraticmodelsworkflowoverview.pnghttps://builtin.com/job/customer-success/expert-ai-teacher-contract/1267315https://generative.ink/posts/methods-of-prompt-programming/#serializing-reasoninghttps://github.com/openai/openai-cookbook/blob/main/techniques_to_improve_reliability.mdhttps://jxnl.github.io/instructor/blog/2023/11/05/chain-of-density/https://platform.openai.com/docs/guides/reasoning/how-reasoning-workshttps://research.google/blog/google-research-2022-beyond-language-vision-and-generative-models/https://research.google/blog/minerva-solving-quantitative-reasoning-problems-with-language-models/https://statmodeling.stat.columbia.edu/2023/08/30/chatgpt-4-can-do-3-digit-multiplication/https://towardsdatascience.com/1-1-3-wait-no-1-1-2-how-to-have-gpt-sanity-check-itself-136e846987bfhttps://www.fhi.ox.ac.uk/wp-content/uploads/2021/08/QNRs_FHI-TR-2021-3.0.pdfhttps://www.oreilly.com/radar/what-we-learned-from-a-year-of-building-with-llms-part-i/https://www.patterns.app/blog/2023/01/18/crunchbot-sql-analyst-gpt/https://www.reddit.com/r/ChatGPT/comments/10zavbv/extending_chatgpt_with_some_additional_internal/https://www.reddit.com/r/ChatGPT/comments/11anct1/its_easy_to_give_chatgpt_a_bonafide_consciousness/https://www.reddit.com/r/ChatGPT/comments/1pjitig/gemini_leaked_its_chain_of_thought_and_spiraled/https://www.reddit.com/r/LocalLLaMA/comments/1fuxw8d/just_for_kicks_i_looked_at_the_newly_released/https://www.reddit.com/r/OpenAI/comments/1fxa6d6/two_purported_instances_of_o1preview_and_o1mini/https://www.reddit.com/r/OpenAI/comments/1gjj430/o1_preview_got_weird_today/https://www.reddit.com/r/PromptEngineering/comments/1fj6h13/hallucinations_in_o1preview_reasoning/https://www.waluigipurple.com/post/revising-poetry-with-gpt-4
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://www.lowimpactfruit.com/p/zork-bench-an-llm-reasoning-eval: “Zork-Bench: An LLM Reasoning Eval Based on Text Adventure Games; a Tale As Old As Time, or at Least As Old As Computers”,https://arxiv.org/abs/2512.02556#deepseek: “DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models”,https://openai.com/index/introducing-gpt-5/#gpt-5-pro: “GPT-5 Pro: Scaled but Efficient Parallel Test-Time Compute, to Provide the Highest Quality and Most Comprehensive Answers”,https://arxiv.org/abs/2506.10922: “Robustly Improving LLM Fairness in Realistic Settings via Interpretability”,https://arxiv.org/abs/2505.11711: “Reinforcement Learning Finetunes Small Subnetworks in Large Language Models”,https://arxiv.org/abs/2504.20571: “Reinforcement Learning for Reasoning in Large Language Models With One Training Example”,https://arxiv.org/abs/2504.14379: “The Geometry of Self-Verification in a Task-Specific Reasoning Model”,https://arxiv.org/abs/2503.16219: “Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn’t”,https://arxiv.org/abs/2502.20339: “Thinking Slow, Fast: Scaling Inference Compute With Distilled Reasoners”,https://arxiv.org/abs/2502.06807#openai: “Competitive Programming With Large Reasoning Models”,https://arxiv.org/abs/2501.08156: “Are DeepSeek R1 And Other Reasoning Models More Faithful?”,https://arxiv.org/abs/2412.01981: “Free Process Rewards without Process Labels”,https://arxiv.org/abs/2410.21333: “Mind Your Step (By Step): Chain-Of-Thought Can Reduce Performance on Tasks Where Thinking Makes Humans Worse”,https://arxiv.org/abs/2406.13121#google: “Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?”,https://arxiv.org/abs/2405.15143: “Intelligent Go-Explore (IGE): Standing on the Shoulders of Giant Foundation Models”,https://arxiv.org/abs/2405.14838: “From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step”,https://arxiv.org/abs/2405.10938: “Observational Scaling Laws and the Predictability of Language Model Performance”,https://arxiv.org/abs/2404.15574: “Retrieval Head Mechanistically Explains Long-Context Factuality”,https://arxiv.org/abs/2404.15758: “Let’s Think Dot by Dot: Hidden Computation in Transformer Language Models”,https://link.springer.com/article/10.1007/s10506-024-09396-9: “Re-Evaluating GPT-4’s Bar Exam Performance”,https://arxiv.org/abs/2403.18802#deepmind: “Long-Form Factuality in Large Language Models”,https://arxiv.org/abs/2403.18120#google: “Don’t Trust: Verify—Grounding LLM Quantitative Reasoning With Autoformalization”,https://arxiv.org/abs/2403.09629: “Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking”,https://arxiv.org/abs/2402.14903: “Tokenization Counts: the Impact of Tokenization on Arithmetic in Frontier LLMs”,https://arxiv.org/abs/2402.09963: “Why Are Sensitive Functions Hard for Transformers?”,https://arxiv.org/abs/2402.05120#tencent: “More Agents Is All You Need”,https://arxiv.org/abs/2312.08935: “Math-Shepherd: Verify and Reinforce LLMs Step-By-Step without Human Annotations”,https://arxiv.org/abs/2312.06585#deepmind: “Beyond Human Data: Scaling Self-Training for Problem-Solving With Language Models (ReSTEM)”,https://arxiv.org/abs/2311.16452#microsoft: “Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine”,https://arxiv.org/abs/2312.02179: “Training Chain-Of-Thought via Latent-Variable Inference”,https://arxiv.org/abs/2310.08678: “Can GPT Models Be Financial Analysts? An Evaluation of ChatGPT and GPT-4 on Mock CFA Exams”,https://arxiv.org/abs/2310.04406: “Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models”,https://arxiv.org/abs/2310.02226: “Think Before You Speak: Training Language Models With Pause Tokens”,https://arxiv.org/abs/2309.09117#facebook: “Contrastive Decoding Improves Reasoning in Large Language Models”,https://arxiv.org/abs/2309.06275: “Re2: Re-Reading Improves Reasoning in Large Language Models”,https://arxiv.org/abs/2309.04269: “From Sparse to Dense: GPT-4 Summarization With Chain of Density (CoD) Prompting”,https://arxiv.org/abs/2308.07921: “Solving Challenging Math Word Problems Using GPT-4 Code Interpreter With Code-Based Self-Verification”,https://arxiv.org/abs/2307.05300#microsoft: “Unleashing the Emergent Cognitive Synergy in Large Language Models: A Task-Solving Agent through Multi-Persona Self-Collaboration”,https://arxiv.org/abs/2307.03381: “Teaching Arithmetic to Small Transformers”,https://arxiv.org/abs/2306.14308#google: “Let’s Do a Thought Experiment: Using Counterfactuals to Improve Moral Reasoning”,https://arxiv.org/abs/2306.00323: “Thought Cloning: Learning to Think While Acting by Imitating Human Thinking”,https://arxiv.org/abs/2305.20050#openai: “Let’s Verify Step by Step”,https://arxiv.org/abs/2305.13534: “How Language Model Hallucinations Can Snowball”,https://arxiv.org/abs/2305.10601#deepmind: “Tree of Thoughts (ToT): Deliberate Problem Solving With Large Language Models”,https://arxiv.org/abs/2305.04388: “Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-Of-Thought Prompting”,https://arxiv.org/abs/2305.02301#google: “Distilling Step-By-Step! Outperforming Larger Language Models With Less Training Data and Smaller Model Sizes”,https://arxiv.org/abs/2304.11490: “Boosting Theory-Of-Mind Performance in Large Language Models via Prompting”,https://arxiv.org/abs/2304.02015#alibaba: “How Well Do Large Language Models Perform in Arithmetic Tasks?”,https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4335905: “ChatGPT Goes to Law School”,https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4335945: “Large Language Models As Fiduciaries: A Case Study Toward Robustly Communicating With Artificial Intelligence Through Legal Standards”,https://arxiv.org/abs/2301.01751#elicit: “Iterated Decomposition: Improving Science Q&A by Supervising Reasoning Processes”,https://arxiv.org/abs/2210.11399#google: “U-PaLM: Transcending Scaling Laws With 0.1% Extra Compute”,https://arxiv.org/abs/2210.11610#google: “Large Language Models Can Self-Improve”,https://arxiv.org/abs/2210.09261#google: “Challenging BIG-Bench Tasks (BBH) and Whether Chain-Of-Thought Can Solve Them”,https://arxiv.org/abs/2210.03350#allen: “Self-Ask: Measuring and Narrowing the Compositionality Gap in Language Models (Bamboogle)”,https://arxiv.org/abs/2210.03057#google: “Language Models Are Multilingual Chain-Of-Thought Reasoners”,https://arxiv.org/abs/2210.03629#google: “ReAct: Synergizing Reasoning and Acting in Language Models”,https://arxiv.org/abs/2209.00840: “FOLIO: Natural Language Reasoning With First-Order Logic”,https://arxiv.org/abs/2207.08143: “Can Large Language Models Reason about Medical Questions?”,https://arxiv.org/abs/2207.05608#google: “Inner Monologue: Embodied Reasoning through Planning With Language Models”,https://arxiv.org/abs/2207.05221#anthropic: “Language Models (Mostly) Know What They Know”,https://arxiv.org/abs/2205.10625#google: “Least-To-Most Prompting Enables Complex Reasoning in Large Language Models”,https://arxiv.org/abs/2205.09073#google: “Dialog Inpainting: Turning Documents into Dialogues”,https://arxiv.org/abs/2205.05131#google: “UL2: Unifying Language Learning Paradigms”,https://arxiv.org/abs/2204.00598#google: “Socratic Models: Composing Zero-Shot Multimodal Reasoning With Language”,https://arxiv.org/abs/2203.11171#google: “Self-Consistency Improves Chain-Of-Thought Reasoning in Language Models”,https://arxiv.org/abs/2201.11903#google: “Chain-Of-Thought Prompting Elicits Reasoning in Large Language Models”,https://arxiv.org/abs/2201.11473#microsoft: “Reasoning Like Program Executors”,https://arxiv.org/abs/2112.15594: “A Neural Network Solves and Generates Mathematics Problems by Program Synthesis: Calculus, Differential Equations, Linear Algebra, and More”,https://openai.com/research/webgpt: “WebGPT: Improving the Factual Accuracy of Language Models through Web Browsing”,https://arxiv.org/abs/2110.14168#openai: “Training Verifiers to Solve Math Word Problems”,https://sites.google.com/berkeley.edu/decision-transformer: “Decision Transformer: Reinforcement Learning via Sequence Modeling”,https://gptprompts.wikidot.com/linguistics:word-in-context#toc3: “Word in Context: Agent and Agent Clarification (69% Dev)”,https://news.ycombinator.com/item?id=23990902: “I Found That Getting GPT-3 to Add Its Own "Internal Monologue" in Parentheses to Be a Helpful Strategy…”,https://x.com/kleptid/status/1284069270603866113: “Seems to Work”,https://x.com/kleptid/status/1284098635689611264: “Teaching GPT-3 to Do a Brute Force ‘For Loop’ Checking Answers Also Seems to Work”,2018-bisra.pdf: “Inducing Self-Explanation: a Meta-Analysis”,