‘meta-learning’ directory
- See Also
- Gwern
- Links
- “Autoresearch vs Classical Hyperparameter Tuning”
- “Neural Thickets: Diverse Task Experts Are Dense Around Pretrained Weights”, Gan & Isola 2026
- “Against Time-Series Foundation Models; Or: My Experience in Modern Forecasting”, shako 2026
- “Doc-To-LoRA (D2L): Learning to Instantly Internalize Contexts”, Charakorn et al 2026
- “Meta-RL Induces Exploration in Language Agents”, Jiang et al 2025
- “Silicon Valley Builds Amazon and Gmail Copycats to Train AI Agents: Several New Start-Ups Are Building Replicas of Sites so AI Can Learn to Use the Internet & Maybe Replace White-Collar Workers”, Metz 2025
- “AI Discovers Learning Algorithm That Outperforms Those Designed by Humans: An Artificial-Intelligence Algorithm That Discovers Its Own Way to Learn Achieves State-Of-The-Art Performance, including on Some Tasks It Had Never Encountered Before”, Lehman 2025
- “DiscoRL: Discovering State-Of-The-Art Reinforcement Learning Algorithms”, Oh et al 2025
- “Learning to Interpret Weight Differences in Language Models”, Goel et al 2025
- “Diff-Interpretation-Tuning: Code for Learning to Interpret Weight Differences in Language Models ( Et Al 2025)”, Aviously 2025
- “Learning to Interpret Weight Differences in Language Models [Blog]”, Goel 2025
- “Where Does Sonnet 4.5′s Desire to ‘Not Get Too Comfortable’ Come From?”, Sotala 2025
- “Video Models Are Zero-Shot Learners and Reasoners”, Wiedemer et al 2025
- “Performance Prediction for Large Systems via Text-To-Text Regression”, Akhauri et al 2025
- “Void Miscellany § 3b. on Mental States”, nostalgebraist 2025
- “MesaNet: Sequence Modeling by Locally Optimal Test-Time Training”, Oswald et al 2025
- “ATLAS: Learning to Optimally Memorize the Context at Test Time [DeepTransformers]”, Behrouz et al 2025
- “DataRater: Meta-Learned Dataset Curation”, Calian et al 2025
- “Language Models Are Capable of Metacognitive Monitoring and Control of Their Internal Activations”, Ji-An et al 2025
- “Measuring General Intelligence With Generated Games”, Verma et al 2025
- “New News: System-2 Fine-Tuning for Robust Integration of New Knowledge”, Park et al 2025
- “On the Generalization of Language Models from In-Context Learning and Finetuning: a Controlled Study”, Lampinen et al 2025
- “It’s All Connected: A Journey Through Test-Time Memorization, Attentional Bias, Retention, and Online Optimization”, Behrouz et al 2025
- “RWKV-7 ‘Goose’ With Expressive Dynamic State Evolution”, Peng et al 2025
- “Meta-Statistical Learning: Supervised Learning of Statistical Inference”, Peyrard & Cho 2025
- “Competitive Programming With Large Reasoning Models”, El-Kishky et al 2025
- “Introducing Deep Research: An Agent That Uses Reasoning to Synthesize Large Amounts of Online Information and Complete Multi-Step Research Tasks for You. Available to Pro Users Today, Plus and Team Next”, OpenAI 2025
- “Test-Time Regression: a Unifying Framework for Designing Sequence Models With Associative Memory”, Wang et al 2025
- “Where Does In-Context Learning Happen in Large Language Models?”, Sia et al 2025
- “Metadata Conditioning Accelerates Language Model Pre-Training”, Gao et al 2025
- “Titans: Learning to Memorize at Test Time”, Behrouz et al 2024
- “ICLR: In-Context Learning of Representations”, Park et al 2024
- “Improving Factuality With Explicit Working Memory”, Chen et al 2024
- “Gated Delta Networks: Improving Mamba-2 With Delta Rule”, Yang et al 2024
- “Continuous Autoregressive Models With Noise Augmentation Avoid Error Accumulation”, Pasini et al 2024
- “State-Space Models Can Learn In-Context by Gradient Descent”, Sushma et al 2024
- “Thinking LLMs: General Instruction Following With Thought Generation”, Wu et al 2024
- “MLE-Bench: Evaluating Machine Learning Agents on Machine Learning Engineering”, Chan et al 2024
- “Contextual Document Embeddings”, Morris & Rush 2024
- “Many-Shot Jailbreaking”, Anil et al 2024
- “Generating Diverse and Reliable Features for Few-Shot Learning”, Xu 2024b
- “Tamper-Resistant Safeguards for Open-Weight LLMs”, Tamirisa et al 2024
- “When Parts Are Greater Than Sums: Individual LLM Components Can Outperform Full Models”, Chang et al 2024
- “Probing the Decision Boundaries of In-Context Learning in Large Language Models”, Zhao et al 2024
- “Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models”, Denison et al 2024
- “Discovering Preference Optimization Algorithms With and for Large Language Models”, Lu et al 2024
- “State Soup: In-Context Skill Learning, Retrieval and Mixing”, Pióro et al 2024
- “Attention As a Hypernetwork”, Schug et al 2024
- “BERTs Are Generative In-Context Learners”, Samuel 2024
- “To Believe or Not to Believe Your LLM”, Yadkori et al 2024
- “Learning to Grok: Emergence of In-Context Learning and Skill Composition in Modular Arithmetic Tasks”, He et al 2024
- “Auto Evol-Instruct: Automatic Instruction Evolving for Large Language Models”, Zeng et al 2024
- “A Theoretical Understanding of Self-Correction through In-Context Alignment”, Wang et al 2024
- “MLPs Learn In-Context”, Tong & Pehlevan 2024
- “LLM Processes: Numerical Predictive Distributions Conditioned on Natural Language”, Requeima et al 2024
- “Zero-Shot Tokenizer Transfer”, Minixhofer et al 2024
- “What Exactly Has TabPFN Learned to Do?”, McCarter 2024
- “Position: Understanding LLMs Requires More Than Statistical Generalization”, Reizinger et al 2024
- “SOPHON: Non-Fine-Tunable Learning to Restrain Task Transferability For Pre-Trained Models”, Deng et al 2024
- “Many-Shot In-Context Learning”, Agarwal et al 2024
- “Foundational Challenges in Assuring Alignment and Safety of Large Language Models”, Anwar et al 2024
- “Revisiting the Equivalence of In-Context Learning and Gradient Descent: The Impact of Data Distribution”, Mahdavi et al 2024
- “Best Practices and Lessons Learned on Synthetic Data for Language Models”, Liu et al 2024
- “From Words to Numbers: Your Large Language Model Is Secretly A Capable Regressor When Given In-Context Examples”, Vacareanu et al 2024
- “Mixture-Of-Depths: Dynamically Allocating Compute in Transformer-Based Language Models”, Raposo et al 2024
- “Many-Shot Jailbreaking”, Anthropic 2024
- “Evolutionary Optimization of Model Merging Recipes”, Akiba et al 2024
- “How Well Can Transformers Emulate In-Context Newton’s Method?”, Giannou et al 2024
- “Revisiting Dynamic Evaluation: Online Adaptation for Large Language Models”, Rannen-Triki et al 2024
- “How Transformers Learn Causal Structure With Gradient Descent”, Nichani et al 2024
- “Neural Network Parameter Diffusion”, Wang et al 2024
- “The Matrix: A Bayesian Learning Model for LLMs”, Dalal & Misra 2024
- “Rephrasing the Web (WARP): A Recipe for Compute and Data-Efficient Language Modeling”, Maini et al 2024
- “An Information-Theoretic Analysis of In-Context Learning”, Jeon et al 2024
- “Deep De Finetti: Recovering Topic Distributions from Large Language Models”, Zhang et al 2023
- “Generative Multimodal Models Are In-Context Learners”, Sun et al 2023
- “Successor Heads: Recurring, Interpretable Attention Heads In The Wild”, Gould et al 2023
- “VILA: On Pre-Training for Visual Language Models”, Lin et al 2023
- “Evolving Reservoirs for Meta Reinforcement Learning”, Léger et al 2023
- “The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning”, Lin et al 2023
- “Learning Few-Shot Imitation As Cultural Transmission”, Bhoopchand et al 2023
- “Strings from the Library of Babel: Random Sampling As a Strong Baseline for Prompt Optimisation”, Lu et al 2023
- “In-Context Vectors: Making In Context Learning More Effective and Controllable Through Latent Space Steering”, Liu et al 2023
- “Rephrase and Respond: Let Large Language Models Ask Better Questions for Themselves”, Deng et al 2023
- “ProSG: Using Prompt Synthetic Gradients to Alleviate Prompt Forgetting of RNN-Like Language Models”, Luo et al 2023
- “Self-AIXI: Self-Predictive Universal AI”, Catt et al 2023
- “HyperFields: Towards Zero-Shot Generation of NeRFs from Text”, Babu et al 2023
- “Transformers Learn Higher-Order Optimization Methods for In-Context Learning: A Study With Linear Models”, Fu et al 2023
- “Implicit Meta-Learning May Lead Language Models to Trust More Reliable Sources”, Krasheninnikov et al 2023
- “Eureka: Human-Level Reward Design via Coding Large Language Models”, Ma et al 2023
- “How Many Pretraining Tasks Are Needed for In-Context Learning of Linear Regression?”, Wu et al 2023
- “Motif: Intrinsic Motivation from Artificial Intelligence Feedback”, Klissarov et al 2023
- “Re-Weighted Gradient Descent via Distributionally Robust Optimization [Blog]”, Kumar & Suggala 2023
- “ExpeL: LLM Agents Are Experiential Learners”, Zhao et al 2023
- “Diversifying AI: Towards Creative Chess With AlphaZero (AZdb)”, Zahavy et al 2023
- “RAVEN: In-Context Learning With Retrieval-Augmented Encoder-Decoder Language Models”, Huang et al 2023
- “CausalLM Is Not Optimal for In-Context Learning”, Ding et al 2023
- “MetaDiff: Meta-Learning With Conditional Diffusion for Few-Shot Learning”, Zhang & Yu 2023
- “Self Expanding Neural Networks”, Mitchell et al 2023
- “Teaching Arithmetic to Small Transformers”, Lee et al 2023
- “One Step of Gradient Descent Is Provably the Optimal In-Context Learner With One Layer of Linear Self-Attention”, Mahankali et al 2023
- “Trainable Transformer in Transformer”, Panigrahi et al 2023
- “Supervised Pretraining Can Learn In-Context Reinforcement Learning”, Lee et al 2023
- “Pretraining Task Diversity and the Emergence of Non-Bayesian In-Context Learning for Regression”, Raventós et al 2023
- “Language Models Are Weak Learners”, Manikandan et al 2023
- “Minigrid & Miniworld: Modular & Customizable Reinforcement Learning Environments for Goal-Oriented Tasks”, Chevalier-Boisvert et al 2023
- “Improving Long-Horizon Imitation Through Instruction Prediction”, Hejna et al 2023
- “Schema-Learning and Rebinding As Mechanisms of In-Context Learning and Emergence”, Swaminathan et al 2023
- “RGD: Stochastic Re-Weighted Gradient Descent via Distributionally Robust Optimization”, Kumar et al 2023
- “Transformers Learn to Implement Preconditioned Gradient Descent for In-Context Learning”, Ahn et al 2023
- “Learning Transformer Programs”, Friedman et al 2023
- “CaMeLS: Meta-Learning Online Adaptation of Language Models”, Hu et al 2023
- “Fundamental Limitations of Alignment in Large Language Models”, Wolf et al 2023
- “How Well Do Large Language Models Perform in Arithmetic Tasks?”, Yuan et al 2023
- “Larger Language Models Do In-Context Learning Differently”, Wei et al 2023
- “BiLD: Big Little Transformer Decoder”, Kim et al 2023
- “Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning and Discovery”, Wen et al 2023
- “Looped Transformers As Programmable Computers”, Giannou et al 2023
- “A Survey of Meta-Reinforcement Learning”, Beck et al 2023
- “AdA: Human-Timescale Adaptation in an Open-Ended Task Space”, Team et al 2023
- “DeepMind Adaptive Agent (AdA): Results Reel”, DeepMind 2023
- “Human-Like Systematic Generalization through a Meta-Learning Neural Network”, Lake & Baroni 2023
- “Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent As Meta-Optimizers”, Dai et al 2022
- “Unnatural Instructions: Tuning Language Models With (Almost) No Human Labor”, Honovich et al 2022
- “Rethinking the Role of Scale for In-Context Learning: An Interpretability-Based Case Study at 66 Billion Scale”, Bansal et al 2022
- “Transformers Learn In-Context by Gradient Descent”, Oswald et al 2022
- “FWL: Meta-Learning Fast Weight Language Models”, Clark et al 2022
- “What Learning Algorithm Is In-Context Learning? Investigations With Linear Models”, Akyürek et al 2022
- “Self-Destructing Models: Increasing the Costs of Harmful Dual Uses of Foundation Models”, Henderson et al 2022
- “VeLO: Training Versatile Learned Optimizers by Scaling Up”, Metz et al 2022
- “Mysteries of Mode Collapse § Inescapable Wedding Parties”, Janus 2022
- “BLOOMZ/mT0: Crosslingual Generalization through Multitask Finetuning”, Muennighoff et al 2022
- “ProMoT: Preserving In-Context Learning Ability in Large Language Model Fine-Tuning”, Wang et al 2022
- “In-Context Reinforcement Learning With Algorithm Distillation”, Laskin et al 2022
- “SAP: Bidirectional Language Models Are Also Few-Shot Learners”, Patel et al 2022
- “
g.pt: Learning to Learn With Generative Models of Neural Network Checkpoints”, Peebles et al 2022 - “Simulators”, Janus 2022
- “AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model”, Soltan et al 2022
- “Few-Shot Adaptation Works With UnpredicTable Data”, Chan et al 2022
- “What Can Transformers Learn In-Context? A Case Study of Simple Function Classes”, Garg et al 2022
- “Transformer Neural Processes: Uncertainty-Aware Meta Learning Via Sequence Modeling”, Nguyen & Grover 2022
- “TabPFN: Meta-Learning a Real-Time Tabular AutoML Method For Small Data”, Hollmann et al 2022
- “Offline RL Policies Should Be Trained to Be Adaptive”, Ghosh et al 2022
- “Goal-Conditioned Generators of Deep Policies”, Faccio et al 2022
- “Prompting Decision Transformer for Few-Shot Policy Generalization”, Xu et al 2022
- “LIFT: Language-Interfaced Fine-Tuning for Non-Language Machine Learning Tasks”, Dinh et al 2022
- “RHO-LOSS: Prioritized Training on Points That Are Learnable, Worth Learning, and Not Yet Learnt”, Mindermann et al 2022
- “NOAH: Neural Prompt Search”, Zhang et al 2022
- “Bongard-HOI: Benchmarking Few-Shot Visual Reasoning for Human-Object Interactions”, Jiang et al 2022
- “Towards Learning Universal Hyperparameter Optimizers With Transformers”, Chen et al 2022
- “Instruction Induction: From Few Examples to Natural Language Task Descriptions”, Honovich et al 2022
- “Gato: A Generalist Agent”, Reed et al 2022
- “UL2: Unifying Language Learning Paradigms”, Tay et al 2022
- “Data Distributional Properties Drive Emergent Few-Shot Learning in Transformers”, Chan et al 2022
- “Tk-Instruct: Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks”, Wang et al 2022
- “What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?”, Wang et al 2022
- “Effective Mutation Rate Adaptation through Group Elite Selection”, Kumar et al 2022
- “Searching for Efficient Neural Architectures for On-Device ML on Edge TPUs”, Akin et al 2022
- “Can Language Models Learn from Explanations in Context?”, Lampinen et al 2022
- “Auto-Lambda: Disentangling Dynamic Task Relationships”, Liu et al 2022
- “In-Context Learning and Induction Heads”, Olsson et al 2022
- “HyperMixer: An MLP-Based Low Cost Alternative to Transformers”, Mai et al 2022
- “LiteTransformerSearch: Training-Free Neural Architecture Search for Efficient Language Models”, Javaheripi et al 2022
- “Evolving Curricula With Regret-Based Environment Design”, Parker-Holder et al 2022
- “HyperPrompt: Prompt-Based Task-Conditioning of Transformers”, He et al 2022
- “Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?”, Min et al 2022
- “All You Need Is Supervised Learning: From Imitation Learning to Meta-RL With Upside Down RL”, Arulkumaran et al 2022
- “NeuPL: Neural Population Learning”, Liu et al 2022
- “Learning Synthetic Environments and Reward Networks for Reinforcement Learning”, Ferreira et al 2022
- “Datamodels: Predicting Predictions from Training Data”, Ilyas et al 2022
- “From Data to Functa: Your Data Point Is a Function and You Should Treat It like One”, Dupont et al 2022
- “Environment Generation for Zero-Shot Compositional Reinforcement Learning”, Gur et al 2022
- “Active Predictive Coding Networks: A Neural Solution to the Problem of Learning Reference Frames and Part-Whole Hierarchies”, Gklezakos & Rao 2022
- “Learning Robust Perceptive Locomotion for Quadrupedal Robots in the Wild”, Miki et al 2022
- “Automated Reinforcement Learning (AutoRL): A Survey and Open Problems”, Parker-Holder et al 2022
- “In Defense of the Unitary Scalarization for Deep Multi-Task Learning”, Kurin et al 2022
- “HyperTransformer: Model Generation for Supervised and Semi-Supervised Few-Shot Learning”, Zhmoginov et al 2022
- “Finding General Equilibria in Many-Agent Economic Simulations Using Deep Reinforcement Learning”, Curry et al 2022
- “The Curse of Zero Task Diversity: On the Failure of Transfer Learning to Outperform MAML and Their Empirical Equivalence”, Miranda et al 2021
- “A Mathematical Framework for Transformer Circuits”, Elhage et al 2021
- “PFNs: Transformers Can Do Bayesian Inference”, Müller et al 2021
- “How to Learn and Represent Abstractions: An Investigation Using Symbolic Alchemy”, AlKhamissi et al 2021
- “Noether Networks: Meta-Learning Useful Conserved Quantities”, Alet et al 2021
- “A Rational Reinterpretation of Dual-Process Theories”, Milli et al 2021
- “A General Language Assistant As a Laboratory for Alignment”, Askell et al 2021
- “A Modern Self-Referential Weight Matrix That Learns to Modify Itself”, Irie et al 2021
- “A Survey of Generalization in Deep Reinforcement Learning”, Kirk et al 2021
- “Gradients Are Not All You Need”, Metz et al 2021
- “An Explanation of In-Context Learning As Implicit Bayesian Inference”, Xie et al 2021
- “Procedural Generalization by Planning With Self-Supervised World Models”, Anand et al 2021
- “MetaICL: Learning to Learn In Context”, Min et al 2021
- “Logical Activation Functions: Logit-Space Equivalents of Probabilistic Boolean Operators”, Lowe et al 2021
- “Shaking the Foundations: Delusions in Sequence Models for Interaction and Control”, Ortega et al 2021
- “Meta-Learning, Social Cognition and Consciousness in Brains and Machines”, Langdon et al 2021
- “T0: Multitask Prompted Training Enables Zero-Shot Task Generalization”, Sanh et al 2021
- “Replay-Guided Adversarial Environment Design”, Jiang et al 2021
- “Embodied Intelligence via Learning and Evolution”, Gupta et al 2021
- “Transformers Are Meta-Reinforcement Learners”, Anonymous 2021
- “Scalable Online Planning via Reinforcement Learning Fine-Tuning”, Fickinger et al 2021
- “Dropout’s Dream Land: Generalization from Learned Simulators to Reality”, Wellmer & Kwok 2021
- “Is Curiosity All You Need? On the Utility of Emergent Behaviors from Curious Exploration”, Groth et al 2021
- “Bootstrapped Meta-Learning”, Flennerhag et al 2021
- “The Sensory Neuron As a Transformer: Permutation-Invariant Neural Networks for Reinforcement Learning”, Tang & Ha 2021
- “FLAN: Finetuned Language Models Are Zero-Shot Learners”, Wei et al 2021
- “The AI Economist: Optimal Economic Policy Design via Two-Level Deep Reinforcement Learning”, Zheng et al 2021
- “Open-Ended Learning Leads to Generally Capable Agents”, Team et al 2021
- “Dataset Distillation With Infinitely Wide Convolutional Networks”, Nguyen et al 2021
- “Why Generalization in RL Is Difficult: Epistemic POMDPs and Implicit Partial Observability”, Ghosh et al 2021
- “PonderNet: Learning to Ponder”, Banino et al 2021
- “Multimodal Few-Shot Learning With Frozen Language Models”, Tsimpoukelli et al 2021
- “LHOPT: A Generalizable Approach to Learning Optimizers”, Almeida et al 2021
- “Towards Mental Time Travel: a Hierarchical Memory for Reinforcement Learning Agents”, Lampinen et al 2021
- “A Full-Stack Accelerator Search Technique for Vision Applications”, Zhang et al 2021
- “Reward Is Enough”, Silver et al 2021
- “Bayesian Optimization Is Superior to Random Search for Machine Learning Hyperparameter Tuning: Analysis of the Black-Box Optimization Challenge 2020”, Turner et al 2021
- “CrossFit: A Few-Shot Learning Challenge for Cross-Task Generalization in NLP”, Ye et al 2021
- “Podracer Architectures for Scalable Reinforcement Learning”, Hessel et al 2021
- “BLUR: Meta-Learning Bidirectional Update Rules”, Sandler et al 2021
- “Asymmetric Self-Play for Automatic Goal Discovery in Robotic Manipulation”, OpenAI et al 2021
- “OmniNet: Omnidirectional Representations from Transformers”, Tay et al 2021
- “Linear Transformers Are Secretly Fast Weight Programmers”, Schlag et al 2021
- “Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm”, Reynolds & McDonell 2021
- “ES-ENAS: Blackbox Optimization over Hybrid Spaces via Combinatorial and Continuous Evolution”, Song et al 2021
- “Training Learned Optimizers With Randomly Initialized Learned Optimizers”, Metz et al 2021
- “Evolving Reinforcement Learning Algorithms”, Co-Reyes et al 2021
- “Meta Pseudo Labels”, Pham et al 2021
- “Meta Learning Backpropagation And Improving It”, Kirsch & Schmidhuber 2020
- “Emergent Complexity and Zero-Shot Transfer via Unsupervised Environment Design [UED+PAIRED]”, Dennis et al 2020
- “Scaling down Deep Learning”, Greydanus 2020
- “Reverse Engineering Learned Optimizers Reveals Known and Novel Mechanisms”, Maheswaranathan et al 2020
- “Dataset Meta-Learning from Kernel Ridge-Regression”, Nguyen et al 2020
- “MELD: Meta-Reinforcement Learning from Images via Latent State Models”, Zhao et al 2020
- “Meta-Trained Agents Implement Bayes-Optimal Agents”, Mikulik et al 2020
- “Learning Not to Learn: Nature versus Nurture in Silico”, Lange & Sprekeler 2020
- “Prioritized Level Replay”, Jiang et al 2020
- “Tasks, Stability, Architecture, and Compute: Training More Effective Learned Optimizers, and Using Them to Train Themselves”, Metz et al 2020
- “Hidden Incentives for Auto-Induced Distributional Shift”, Krueger et al 2020
- “It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners”, Schick & Schütze 2020
- “Grounded Language Learning Fast and Slow”, Hill et al 2020
- “Matt Botvinick on the Spontaneous Emergence of Learning Algorithms”, Scholl 2020
- “LPG: Discovering Reinforcement Learning Algorithms”, Oh et al 2020
- “Deep Reinforcement Learning and Its Neuroscientific Implications”, Botvinick 2020
- “Decentralized Reinforcement Learning: Global Decision-Making via Local Economic Transactions”, Chang et al 2020
- “Rapid Task-Solving in Novel Environments”, Ritter et al 2020
- “FBNetV3: Joint Architecture-Recipe Search Using Predictor Pretraining”, Dai et al 2020
- “GPT-3: Language Models Are Few-Shot Learners”, Brown et al 2020
- “Synthetic Petri Dish: A Novel Surrogate Model for Rapid Architecture Search”, Rawal et al 2020
- “Automatic Discovery of Interpretable Planning Strategies”, Skirzyński et al 2020
- “Meta-Reinforcement Learning for Robotic Industrial Insertion Tasks”, Schoettler et al 2020
- “A Comparison of Methods for Treatment Assignment With an Application to Playlist Generation”, Fernández-Loría et al 2020
- “Approximate Exploitability: Learning a Best Response in Large Games”, Timbers et al 2020
- “Meta-Learning in Neural Networks: A Survey”, Hospedales et al 2020
- “EvER: Mimicking Evolution With Reinforcement Learning”, Abrantes et al 2020
- “Agent57: Outperforming the Atari Human Benchmark”, Badia et al 2020
- “Designing Network Design Spaces”, Radosavovic et al 2020
- “Enhanced POET: Open-Ended Reinforcement Learning through Unbounded Invention of Learning Challenges and Their Solutions”, Wang et al 2020
- “Accelerating and Improving AlphaZero Using Population Based Training”, Wu et al 2020
- “Meta-Learning Curiosity Algorithms”, Alet et al 2020
- “AutoML-Zero: Evolving Machine Learning Algorithms From Scratch”, Real et al 2020
- “AutoML-Zero: Open Source Code for the Paper: "AutoML-Zero: Evolving Machine Learning Algorithms From Scratch"”, Real et al 2020
- “Effective Diversity in Population Based Reinforcement Learning”, Parker-Holder et al 2020
- “AI Helps Warehouse Robots Pick Up New Tricks: Backed by Machine Learning Luminaries, Covariant.ai’s Bots Can Handle Jobs Previously Needing a Human Touch”, Knight 2020
- “Smooth Markets: A Basic Mechanism for Organizing Gradient-Based Learners”, Balduzzi et al 2020
- “AutoML-Zero: Evolving Code That Learns”, Real & Liang 2020
- “Learning Neural Activations”, Minhas & Asif 2019
- “Meta-Learning without Memorization”, Yin et al 2019
- “MetaFun: Meta-Learning With Iterative Functional Updates”, Xu et al 2019
- “Leveraging Procedural Generation to Benchmark Reinforcement Learning”, Cobbe et al 2019
- “Procgen Benchmark: We’re Releasing Procgen Benchmark, 16 Simple-To-Use Procedurally-Generated Environments Which Provide a Direct Measure of How Quickly a Reinforcement Learning Agent Learns Generalizable Skills”, Cobbe et al 2019
- “Increasing Generality in Machine Learning through Procedural Content Generation”, Risi & Togelius 2019
- “SimpleShot: Revisiting Nearest-Neighbor Classification for Few-Shot Learning”, Wang et al 2019
- “Optimizing Millions of Hyperparameters by Implicit Differentiation”, Lorraine et al 2019
- “Learning to Predict Without Looking Ahead: World Models Without Forward Prediction”, Freeman et al 2019
- “Learning to Predict Without Looking Ahead: World Models Without Forward Prediction [Blog]”, Freeman et al 2019
- “Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning”, Yu et al 2019
- “Solving Rubik’s Cube With a Robot Hand”, OpenAI et al 2019
- “Solving Rubik’s Cube With a Robot Hand [Blog]”, OpenAI 2019
- “Gradient Descent: The Ultimate Optimizer”, Chandra et al 2019
- “Data Valuation Using Reinforcement Learning”, Yoon et al 2019
- “Multiplicative Interactions and Where to Find Them”, Jayakumar et al 2019
- “ANIL: Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML”, Raghu et al 2019
- “Emergent Tool Use From Multi-Agent Autocurricula”, Baker et al 2019
- “Meta-Learning With Implicit Gradients”, Rajeswaran et al 2019
- “A Critique of Pure Learning and What Artificial Neural Networks Can Learn from Animal Brains”, Zador 2019
- “AutoML: A Survey of the State-Of-The-Art”, He et al 2019
- “Metalearned Neural Memory”, Munkhdalai et al 2019
- “Algorithms for Hyper-Parameter Optimization”, Bergstra et al 2019
- “Evolving the Hearthstone Meta”, Silva et al 2019
- “Meta Reinforcement Learning”, Weng 2019
- “One Epoch Is All You Need”, Komatsuzaki 2019
- “Compositional Generalization through Meta Sequence-To-Sequence Learning”, Lake 2019
- “Risks from Learned Optimization in Advanced Machine Learning Systems”, Hubinger et al 2019
- “ICML 2019 Notes”, Abel 2019
- “SpArSe: Sparse Architecture Search for CNNs on Resource-Constrained Microcontrollers”, Fedorov et al 2019
- “AI-GAs: AI-Generating Algorithms, an Alternate Paradigm for Producing General Artificial Intelligence”, Clune 2019
- “Alpha MAML: Adaptive Model-Agnostic Meta-Learning”, Behl et al 2019
- “Reinforcement Learning, Fast and Slow”, Botvinick et al 2019
- “Meta Reinforcement Learning As Task Inference”, Humplik et al 2019
- “Learning Loss for Active Learning”, Yoo & Kweon 2019
- “Meta-Learning of Sequential Strategies”, Ortega et al 2019
- “Searching for MobileNetV3”, Howard et al 2019
- “Meta-Learners’ Learning Dynamics Are unlike Learners’”, Rabinowitz 2019
- “Ray Interference: a Source of Plateaus in Deep Reinforcement Learning”, Schaul et al 2019
- “AlphaX: EXploring Neural Architectures With Deep Neural Networks and Monte Carlo Tree Search”, Wang et al 2019
- “Efficient Off-Policy Meta-Reinforcement Learning via Probabilistic Context Variables”, Rakelly et al 2019
- “Task2Vec: Task Embedding for Meta-Learning”, Achille et al 2019
- “The Omniglot Challenge: a 3-Year Progress Report”, Lake et al 2019
- “FIGR: Few-Shot Image Generation With Reptile”, Clouâtre & Demers 2019
- “Paired Open-Ended Trailblazer (POET): Endlessly Generating Increasingly Complex and Diverse Learning Environments and Their Solutions”, Wang et al 2019
- “Meta-Learning Neural Bloom Filters”, Rae 2019
- “Malthusian Reinforcement Learning”, Leibo et al 2018
- “Quantifying Generalization in Reinforcement Learning”, Cobbe et al 2018
- “An Introduction to Deep Reinforcement Learning”, Francois-Lavet et al 2018
- “Meta-Learning: Learning to Learn Fast”, Weng 2018
- “Evolving Space-Time Neural Architectures for Videos”, Piergiovanni et al 2018
- “Understanding and Correcting Pathologies in the Training of Learned Optimizers”, Metz et al 2018
- “BabyAI: A Platform to Study the Sample Efficiency of Grounded Language Learning”, Chevalier-Boisvert et al 2018
- “Deep Reinforcement Learning”, Li 2018
- “Searching for Efficient Multi-Scale Architectures for Dense Image Prediction”, Chen et al 2018
- “Backprop Evolution”, Alber et al 2018
- “Learning Dexterous In-Hand Manipulation”, OpenAI et al 2018
- “LEO: Meta-Learning With Latent Embedding Optimization”, Rusu et al 2018
- “Automatically Composing Representation Transformations As a Means for Generalization”, Chang et al 2018
- “Human-Level Performance in First-Person Multiplayer Games With Population-Based Deep Reinforcement Learning”, Jaderberg et al 2018
- “Guided Evolutionary Strategies: Augmenting Random Search With Surrogate Gradients”, Maheswaranathan et al 2018
- “RUDDER: Return Decomposition for Delayed Rewards”, Arjona-Medina et al 2018
- “Meta-Learning Transferable Active Learning Policies by Deep Reinforcement Learning”, Pang et al 2018
- “Fingerprint Policy Optimization for Robust Reinforcement Learning”, Paul et al 2018
- “AutoAugment: Learning Augmentation Policies from Data”, Cubuk et al 2018
- “Meta-Gradient Reinforcement Learning”, Xu et al 2018
- “Continuous Learning in a Hierarchical Multiscale Neural Network”, Wolf et al 2018
- “Prefrontal Cortex As a Meta-Reinforcement Learning System”, Wang et al 2018
- “Meta-Learning Update Rules for Unsupervised Representation Learning”, Metz et al 2018
- “Reviving and Improving Recurrent Back-Propagation”, Liao et al 2018
- “Kickstarting Deep Reinforcement Learning”, Schmitt et al 2018
- “Reptile/FOMAML: On First-Order Meta-Learning Algorithms”, Nichol et al 2018
- “Some Considerations on Learning to Explore via Meta-Reinforcement Learning”, Stadie et al 2018
- “One Big Net For Everything”, Schmidhuber 2018
- “Machine Theory of Mind”, Rabinowitz et al 2018
- “Evolved Policy Gradients”, Houthooft et al 2018
- “One-Shot Imitation from Observing Humans via Domain-Adaptive Meta-Learning”, Yu et al 2018
- “Rover Descent: Learning to Optimize by Learning to Navigate on Prototypical Loss Surfaces”, Faury & Vasile 2018
- “ScreenerNet: Learning Self-Paced Curriculum for Deep Neural Networks”, Kim & Choi 2018
- “Population Based Training of Neural Networks”, Jaderberg et al 2017
- “BlockDrop: Dynamic Inference Paths in Residual Networks”, Wu et al 2017
- “Learning to Select Computations”, Callaway et al 2017
- “Learning to Generalize: Meta-Learning for Domain Generalization”, Li et al 2017
- “Efficient K-Shot Learning With Regularized Deep Networks”, Yoo et al 2017
- “Online Learning of a Memory for Learning Rates”, Meier et al 2017
- “One-Shot Visual Imitation Learning via Meta-Learning”, Finn et al 2017
- “Supervising Unsupervised Learning”, Garg & Kalai 2017
- “Learning With Opponent-Learning Awareness”, Foerster et al 2017
- “SMASH: One-Shot Model Architecture Search through HyperNetworks”, Brock et al 2017
- “Stochastic Optimization With Bandit Sampling”, Salehi et al 2017
- “A Simple Neural Attentive Meta-Learner”, Mishra et al 2017
- “Reinforcement Learning for Learning Rate Control”, Xu et al 2017
- “Metacontrol for Adaptive Imagination-Based Optimization”, Hamrick et al 2017
- “Deciding How to Decide: Dynamic Routing in Artificial Neural Networks”, McGill & Perona 2017
- “Prototypical Networks for Few-Shot Learning”, Snell et al 2017
- “Learned Optimizers That Scale and Generalize”, Wichrowska et al 2017
- “MAML: Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks”, Finn et al 2017
- “Learning to Optimize Neural Nets”, Li & Malik 2017
- “Understanding Synthetic Gradients and Decoupled Neural Interfaces”, Czarnecki et al 2017
- “Optimization As a Model for Few-Shot Learning”, Ravi & Larochelle 2017
- “Learning to Superoptimize Programs”, Bunel et al 2017
- “Discovering Objects and Their Relations from Entangled Scene Representations”, Raposo et al 2017
- “Google Vizier: A Service for Black-Box Optimization”, Golovin 2017
- “An Actor-Critic Algorithm for Learning Rate Learning”, Xu et al 2016
- “A Bird’s Eye View of Synthetic Gradients”, Greydanus 2016
- “Learning to Reinforcement Learn”, Wang et al 2016
- “Learning to Learn without Gradient Descent by Gradient Descent”, Chen et al 2016
- “RL2: Fast Reinforcement Learning via Slow Reinforcement Learning”, Duan et al 2016
- “Designing Neural Network Architectures Using Reinforcement Learning”, Baker et al 2016
- “Using Fast Weights to Attend to the Recent Past”, Ba et al 2016
- “HyperNetworks”, Ha et al 2016
- “Decoupled Neural Interfaces Using Synthetic Gradients”, Jaderberg et al 2016
- “Learning to Learn by Gradient Descent by Gradient Descent”, Andrychowicz et al 2016
- “Matching Networks for One Shot Learning”, Vinyals et al 2016
- “Learning to Optimize”, Li & Malik 2016
- “One-Shot Learning With Memory-Augmented Neural Networks”, Santoro et al 2016
- “Adaptive Computation Time for Recurrent Neural Networks”, Graves 2016
- “On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models”, Schmidhuber 2015
- “Gradient-Based Hyperparameter Optimization through Reversible Learning”, Maclaurin et al 2015
- “Machine Teaching: an Inverse Problem to Machine Learning and an Approach Toward Optimal Education”, Zhu 2015b
- “Human-Level Concept Learning through Probabilistic Program Induction”, Lake 2015
- “Robots That Can Adapt like Animals”, Cully et al 2014
- “Deep Learning in Neural Networks: An Overview”, Schmidhuber 2014
- “Practical Bayesian Optimization of Machine Learning Algorithms”, Snoek et al 2012
- “Evolutionary Importance of Phenotypic Accommodation in Novel Environments: an Empirical Test of the Baldwin Effect”, Badyaev 2009
- “Intense Neutral Drifts Yield Robust and Evolvable Consensus Proteins”, Bershtein et al 2008
- “The Infinite MNIST Dataset”, Bottou 2007
- “Gödel Machines: Self-Referential Universal Problem Solvers Making Provably Optimal Self-Improvements”, Schmidhuber 2003
- “Optimal Ordered Problem Solver (OOPS)”, Schmidhuber 2002
- “Learning to Learn Using Gradient Descent”, Hochreiter et al 2001
- “On the Optimization of a Synaptic Learning Rule”, Bengio et al 1997
- “Interactions between Learning and Evolution”, Ackley & Littman 1992
- “Learning to Control Fast-Weight Memories: An Alternative to Dynamic Recurrent Networks”, Schmidhuber 1992b
- “Learning a Synaptic Learning Rule”, Bengio et al 1991
- “Reinforcement Learning: An Introduction § Designing Reward Signals”, Sutton & Barto 2026 (page 491)
- “Exploring Hyperparameter Meta-Loss Landscapes With Jax”
- “Metalearning”
- “Universal Search § OOPS and Other Incremental Variations”
- “Extrapolating to Unnatural Language Processing With GPT-3’s In-Context Learning: The Good, the Bad, and the Mysterious”
- “How Does In-Context Learning Work? A Framework for Understanding the Differences from Traditional Supervised Learning”
- “Rapid Motor Adaptation for Legged Robots”
- “Collaborating With Humans Requires Understanding Them”
- “Why Generalization in RL Is Difficult: Epistemic POMDPs and Implicit Partial Observability [Blog]”
- “Hypernetworks [Blog]”, Ha 2026
- “Scaling Karpathy’s Autoresearch: What Happens When the Agent Gets a GPU Cluster”
- “Action and Perception As Divergence Minimization”
- “AlphaStar: Mastering the Real-Time Strategy Game StarCraft II”
- “Prefrontal Cortex As a Meta-Reinforcement Learning System [Blog]”
- “The Lie Comes First, the Worlds to Accommodate It”
- “Google-Deepmind/regress-Lm: Library for Text-To-Text Regression, Applicable to Any Input String Representation and Allows Pretraining and Fine-Tuning over Multiple Regression Tasks”
- “Krasheninnikov/internalization: Code for the Paper ‘Implicit Meta-Learning May Lead Language Models to Trust More Reliable Sources’”
- “Sgdstore/experiments/omniglot at Master”
- “Curriculum For Reinforcement Learning”
- “Neural Architecture Search”
- “MetaGenRL: Improving Generalization in Meta Reinforcement Learning”
- “The RetroInstruct Guide To Synthetic Text Data”, Pressman 2026
- “2022: 25-Year Anniversary: LSTM (1997), All Computable Metaverses, Hierarchical Q-Learning, Adversarial Intrinsic Reinforcement Learning, Low-Complexity NNs, Low-Complexity Art, Meta-RL, Soccer Learning”
- “Metalearning or Learning to Learn Since 1987”
- “The Future of Artificial Intelligence Is Self-Organizing and Self-Assembling”
- “Domain-Adaptive Meta-Learning”
- “How to Fix Reinforcement Learning”
- “Video Models Are Zero-Shot Learners and Reasoners”
- “Introducing Adept”
- “Optimal Learning: Computational Procedures for Bayes-Adaptive Markov Decision Processes”
- “Risks from Learned Optimization: Introduction”
- “How Good Are LLMs at Doing ML on an Unknown Dataset?”
- “Exploration Hacking: Can LLMs Learn to Resist RL Training?”
- “Letting Claude Do Autonomous Research to Improve SAEs”
- “Early Situational Awareness and Its Implications, a Story”
- “RWKV Language Model”
- “AI Is Learning How to Create Itself”
- “Matt Botvinick: Neuroscience, Psychology, and AI at DeepMind”
- “SMASH: One-Shot Model Architecture Search through HyperNetworks [Video]”
- “Solving Rubik’s Cube With a Robot Hand: Perturbations”
- “WELM”
- “Autoresearch on an Old Research Idea”
- Sort By Magic
playlist-assignmentadaptive-robotsalignment-safetyobject-reasoning few-shot-reasoning memory-embedding document-context visual-benchmarkingmachine-teachingin-context-learningconserved-quantitiesprompt-syntheticlearning-prioritizationtask-diversitystochastic-trainingfew-shot-learningmeta-reinforcement
- Wikipedia (14)
- Miscellaneous
- Bibliography
See Also
Gwern
“AIs May Not Need Sleep or Play”, Gwern 2023
“WBE and DRL: a Middle Way of Imitation Learning”, Gwern 2018
“My 2025 LLM System Prompts”, Gwern et al 2025
“Meta-Learning Information-Maximizing Personality Surveys”, Gwern 2024
“Free-Play Periods for RL Agents”, Gwern 2023
Links
“Autoresearch vs Classical Hyperparameter Tuning”
“Neural Thickets: Diverse Task Experts Are Dense Around Pretrained Weights”, Gan & Isola 2026
Neural Thickets: Diverse Task Experts Are Dense Around Pretrained Weights
“Against Time-Series Foundation Models; Or: My Experience in Modern Forecasting”, shako 2026
Against Time-Series Foundation Models; Or: My Experience in Modern Forecasting
“Doc-To-LoRA (D2L): Learning to Instantly Internalize Contexts”, Charakorn et al 2026
Doc-to-LoRA (D2L): Learning to Instantly Internalize Contexts
“Meta-RL Induces Exploration in Language Agents”, Jiang et al 2025
“Silicon Valley Builds Amazon and Gmail Copycats to Train AI Agents: Several New Start-Ups Are Building Replicas of Sites so AI Can Learn to Use the Internet & Maybe Replace White-Collar Workers”, Metz 2025
“AI Discovers Learning Algorithm That Outperforms Those Designed by Humans: An Artificial-Intelligence Algorithm That Discovers Its Own Way to Learn Achieves State-Of-The-Art Performance, including on Some Tasks It Had Never Encountered Before”, Lehman 2025
“DiscoRL: Discovering State-Of-The-Art Reinforcement Learning Algorithms”, Oh et al 2025
DiscoRL: Discovering state-of-the-art reinforcement learning algorithms
“Learning to Interpret Weight Differences in Language Models”, Goel et al 2025
“Diff-Interpretation-Tuning: Code for Learning to Interpret Weight Differences in Language Models ( Et Al 2025)”, Aviously 2025
“Learning to Interpret Weight Differences in Language Models [Blog]”, Goel 2025
Learning to Interpret Weight Differences in Language Models [blog]
“Where Does Sonnet 4.5′s Desire to ‘Not Get Too Comfortable’ Come From?”, Sotala 2025
Where does Sonnet 4.5′s desire to ‘not get too comfortable’ come from?
“Video Models Are Zero-Shot Learners and Reasoners”, Wiedemer et al 2025
“Performance Prediction for Large Systems via Text-To-Text Regression”, Akhauri et al 2025
Performance Prediction for Large Systems via Text-to-Text Regression
“Void Miscellany § 3b. on Mental States”, nostalgebraist 2025
“MesaNet: Sequence Modeling by Locally Optimal Test-Time Training”, Oswald et al 2025
MesaNet: Sequence Modeling by Locally Optimal Test-Time Training
“ATLAS: Learning to Optimally Memorize the Context at Test Time [DeepTransformers]”, Behrouz et al 2025
ATLAS: Learning to Optimally Memorize the Context at Test Time [DeepTransformers]
“DataRater: Meta-Learned Dataset Curation”, Calian et al 2025
“Language Models Are Capable of Metacognitive Monitoring and Control of Their Internal Activations”, Ji-An et al 2025
Language Models Are Capable of Metacognitive Monitoring and Control of Their Internal Activations
“Measuring General Intelligence With Generated Games”, Verma et al 2025
“New News: System-2 Fine-Tuning for Robust Integration of New Knowledge”, Park et al 2025
New News: System-2 Fine-tuning for Robust Integration of New Knowledge
“On the Generalization of Language Models from In-Context Learning and Finetuning: a Controlled Study”, Lampinen et al 2025
On the generalization of language models from in-context learning and finetuning: a controlled study
“It’s All Connected: A Journey Through Test-Time Memorization, Attentional Bias, Retention, and Online Optimization”, Behrouz et al 2025
“RWKV-7 ‘Goose’ With Expressive Dynamic State Evolution”, Peng et al 2025
“Meta-Statistical Learning: Supervised Learning of Statistical Inference”, Peyrard & Cho 2025
Meta-Statistical Learning: Supervised Learning of Statistical Inference
“Competitive Programming With Large Reasoning Models”, El-Kishky et al 2025
“Introducing Deep Research: An Agent That Uses Reasoning to Synthesize Large Amounts of Online Information and Complete Multi-Step Research Tasks for You. Available to Pro Users Today, Plus and Team Next”, OpenAI 2025
“Test-Time Regression: a Unifying Framework for Designing Sequence Models With Associative Memory”, Wang et al 2025
Test-time regression: a unifying framework for designing sequence models with associative memory
“Where Does In-Context Learning Happen in Large Language Models?”, Sia et al 2025
Where does In-context Learning Happen in Large Language Models?
“Metadata Conditioning Accelerates Language Model Pre-Training”, Gao et al 2025
Metadata Conditioning Accelerates Language Model Pre-training
“Titans: Learning to Memorize at Test Time”, Behrouz et al 2024
“ICLR: In-Context Learning of Representations”, Park et al 2024
“Improving Factuality With Explicit Working Memory”, Chen et al 2024
“Gated Delta Networks: Improving Mamba-2 With Delta Rule”, Yang et al 2024
“Continuous Autoregressive Models With Noise Augmentation Avoid Error Accumulation”, Pasini et al 2024
Continuous Autoregressive Models with Noise Augmentation Avoid Error Accumulation
“State-Space Models Can Learn In-Context by Gradient Descent”, Sushma et al 2024
“Thinking LLMs: General Instruction Following With Thought Generation”, Wu et al 2024
Thinking LLMs: General Instruction Following with Thought Generation
“MLE-Bench: Evaluating Machine Learning Agents on Machine Learning Engineering”, Chan et al 2024
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
“Contextual Document Embeddings”, Morris & Rush 2024
“Many-Shot Jailbreaking”, Anil et al 2024
“Generating Diverse and Reliable Features for Few-Shot Learning”, Xu 2024b
Generating Diverse and Reliable Features for Few-Shot Learning
“Tamper-Resistant Safeguards for Open-Weight LLMs”, Tamirisa et al 2024
“When Parts Are Greater Than Sums: Individual LLM Components Can Outperform Full Models”, Chang et al 2024
When Parts are Greater Than Sums: Individual LLM Components Can Outperform Full Models
“Probing the Decision Boundaries of In-Context Learning in Large Language Models”, Zhao et al 2024
Probing the Decision Boundaries of In-context Learning in Large Language Models
“Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models”, Denison et al 2024
Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models
“Discovering Preference Optimization Algorithms With and for Large Language Models”, Lu et al 2024
Discovering Preference Optimization Algorithms with and for Large Language Models
“State Soup: In-Context Skill Learning, Retrieval and Mixing”, Pióro et al 2024
“Attention As a Hypernetwork”, Schug et al 2024
“BERTs Are Generative In-Context Learners”, Samuel 2024
“To Believe or Not to Believe Your LLM”, Yadkori et al 2024
“Learning to Grok: Emergence of In-Context Learning and Skill Composition in Modular Arithmetic Tasks”, He et al 2024
Learning to grok: Emergence of in-context learning and skill composition in modular arithmetic tasks
“Auto Evol-Instruct: Automatic Instruction Evolving for Large Language Models”, Zeng et al 2024
Auto Evol-Instruct: Automatic Instruction Evolving for Large Language Models
“A Theoretical Understanding of Self-Correction through In-Context Alignment”, Wang et al 2024
A Theoretical Understanding of Self-Correction through In-context Alignment
“MLPs Learn In-Context”, Tong & Pehlevan 2024
“LLM Processes: Numerical Predictive Distributions Conditioned on Natural Language”, Requeima et al 2024
LLM Processes: Numerical Predictive Distributions Conditioned on Natural Language
“Zero-Shot Tokenizer Transfer”, Minixhofer et al 2024
“What Exactly Has TabPFN Learned to Do?”, McCarter 2024
“Position: Understanding LLMs Requires More Than Statistical Generalization”, Reizinger et al 2024
Position: Understanding LLMs Requires More Than Statistical Generalization
“SOPHON: Non-Fine-Tunable Learning to Restrain Task Transferability For Pre-Trained Models”, Deng et al 2024
SOPHON: Non-Fine-Tunable Learning to Restrain Task Transferability For Pre-trained Models
“Many-Shot In-Context Learning”, Agarwal et al 2024
“Foundational Challenges in Assuring Alignment and Safety of Large Language Models”, Anwar et al 2024
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
“Revisiting the Equivalence of In-Context Learning and Gradient Descent: The Impact of Data Distribution”, Mahdavi et al 2024
“Best Practices and Lessons Learned on Synthetic Data for Language Models”, Liu et al 2024
Best Practices and Lessons Learned on Synthetic Data for Language Models
“From Words to Numbers: Your Large Language Model Is Secretly A Capable Regressor When Given In-Context Examples”, Vacareanu et al 2024
“Mixture-Of-Depths: Dynamically Allocating Compute in Transformer-Based Language Models”, Raposo et al 2024
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
“Many-Shot Jailbreaking”, Anthropic 2024
“Evolutionary Optimization of Model Merging Recipes”, Akiba et al 2024
“How Well Can Transformers Emulate In-Context Newton’s Method?”, Giannou et al 2024
How Well Can Transformers Emulate In-context Newton’s Method?
“Revisiting Dynamic Evaluation: Online Adaptation for Large Language Models”, Rannen-Triki et al 2024
Revisiting Dynamic Evaluation: Online Adaptation for Large Language Models
“How Transformers Learn Causal Structure With Gradient Descent”, Nichani et al 2024
How Transformers Learn Causal Structure with Gradient Descent
“Neural Network Parameter Diffusion”, Wang et al 2024
“The Matrix: A Bayesian Learning Model for LLMs”, Dalal & Misra 2024
“Rephrasing the Web (WARP): A Recipe for Compute and Data-Efficient Language Modeling”, Maini et al 2024
Rephrasing the Web (WARP): A Recipe for Compute and Data-Efficient Language Modeling
“An Information-Theoretic Analysis of In-Context Learning”, Jeon et al 2024
“Deep De Finetti: Recovering Topic Distributions from Large Language Models”, Zhang et al 2023
Deep de Finetti: Recovering Topic Distributions from Large Language Models
“Generative Multimodal Models Are In-Context Learners”, Sun et al 2023
“Successor Heads: Recurring, Interpretable Attention Heads In The Wild”, Gould et al 2023
Successor Heads: Recurring, Interpretable Attention Heads In The Wild
“VILA: On Pre-Training for Visual Language Models”, Lin et al 2023
“Evolving Reservoirs for Meta Reinforcement Learning”, Léger et al 2023
“The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning”, Lin et al 2023
The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning
“Learning Few-Shot Imitation As Cultural Transmission”, Bhoopchand et al 2023
“Strings from the Library of Babel: Random Sampling As a Strong Baseline for Prompt Optimisation”, Lu et al 2023
Strings from the Library of Babel: Random Sampling as a Strong Baseline for Prompt Optimisation
“In-Context Vectors: Making In Context Learning More Effective and Controllable Through Latent Space Steering”, Liu et al 2023
“Rephrase and Respond: Let Large Language Models Ask Better Questions for Themselves”, Deng et al 2023
Rephrase and Respond: Let Large Language Models Ask Better Questions for Themselves
“ProSG: Using Prompt Synthetic Gradients to Alleviate Prompt Forgetting of RNN-Like Language Models”, Luo et al 2023
ProSG: Using Prompt Synthetic Gradients to Alleviate Prompt Forgetting of RNN-like Language Models
“Self-AIXI: Self-Predictive Universal AI”, Catt et al 2023
“HyperFields: Towards Zero-Shot Generation of NeRFs from Text”, Babu et al 2023
HyperFields: Towards Zero-Shot Generation of NeRFs from Text
“Transformers Learn Higher-Order Optimization Methods for In-Context Learning: A Study With Linear Models”, Fu et al 2023
“Implicit Meta-Learning May Lead Language Models to Trust More Reliable Sources”, Krasheninnikov et al 2023
Implicit meta-learning may lead language models to trust more reliable sources
“Eureka: Human-Level Reward Design via Coding Large Language Models”, Ma et al 2023
Eureka: Human-Level Reward Design via Coding Large Language Models
“How Many Pretraining Tasks Are Needed for In-Context Learning of Linear Regression?”, Wu et al 2023
How Many Pretraining Tasks Are Needed for In-Context Learning of Linear Regression?
“Motif: Intrinsic Motivation from Artificial Intelligence Feedback”, Klissarov et al 2023
Motif: Intrinsic Motivation from Artificial Intelligence Feedback
“Re-Weighted Gradient Descent via Distributionally Robust Optimization [Blog]”, Kumar & Suggala 2023
Re-weighted gradient descent via distributionally robust optimization [blog]
“ExpeL: LLM Agents Are Experiential Learners”, Zhao et al 2023
“Diversifying AI: Towards Creative Chess With AlphaZero (AZdb)”, Zahavy et al 2023
Diversifying AI: Towards Creative Chess with AlphaZero (AZdb)
“RAVEN: In-Context Learning With Retrieval-Augmented Encoder-Decoder Language Models”, Huang et al 2023
RAVEN: In-Context Learning with Retrieval-Augmented Encoder-Decoder Language Models
“CausalLM Is Not Optimal for In-Context Learning”, Ding et al 2023
“MetaDiff: Meta-Learning With Conditional Diffusion for Few-Shot Learning”, Zhang & Yu 2023
MetaDiff: Meta-Learning with Conditional Diffusion for Few-Shot Learning
“Self Expanding Neural Networks”, Mitchell et al 2023
“Teaching Arithmetic to Small Transformers”, Lee et al 2023
“One Step of Gradient Descent Is Provably the Optimal In-Context Learner With One Layer of Linear Self-Attention”, Mahankali et al 2023
“Trainable Transformer in Transformer”, Panigrahi et al 2023
“Supervised Pretraining Can Learn In-Context Reinforcement Learning”, Lee et al 2023
Supervised Pretraining Can Learn In-Context Reinforcement Learning
“Pretraining Task Diversity and the Emergence of Non-Bayesian In-Context Learning for Regression”, Raventós et al 2023
Pretraining task diversity and the emergence of non-Bayesian in-context learning for regression
“Language Models Are Weak Learners”, Manikandan et al 2023
“Minigrid & Miniworld: Modular & Customizable Reinforcement Learning Environments for Goal-Oriented Tasks”, Chevalier-Boisvert et al 2023
“Improving Long-Horizon Imitation Through Instruction Prediction”, Hejna et al 2023
Improving Long-Horizon Imitation Through Instruction Prediction
“Schema-Learning and Rebinding As Mechanisms of In-Context Learning and Emergence”, Swaminathan et al 2023
Schema-learning and rebinding as mechanisms of in-context learning and emergence
“RGD: Stochastic Re-Weighted Gradient Descent via Distributionally Robust Optimization”, Kumar et al 2023
RGD: Stochastic Re-weighted Gradient Descent via Distributionally Robust Optimization
“Transformers Learn to Implement Preconditioned Gradient Descent for In-Context Learning”, Ahn et al 2023
Transformers learn to implement preconditioned gradient descent for in-context learning
“Learning Transformer Programs”, Friedman et al 2023
“CaMeLS: Meta-Learning Online Adaptation of Language Models”, Hu et al 2023
“Fundamental Limitations of Alignment in Large Language Models”, Wolf et al 2023
Fundamental Limitations of Alignment in Large Language Models
“How Well Do Large Language Models Perform in Arithmetic Tasks?”, Yuan et al 2023
How well do Large Language Models perform in Arithmetic tasks?
“Larger Language Models Do In-Context Learning Differently”, Wei et al 2023
“BiLD: Big Little Transformer Decoder”, Kim et al 2023
“Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning and Discovery”, Wen et al 2023
Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning and Discovery
“Looped Transformers As Programmable Computers”, Giannou et al 2023
“A Survey of Meta-Reinforcement Learning”, Beck et al 2023
“AdA: Human-Timescale Adaptation in an Open-Ended Task Space”, Team et al 2023
“DeepMind Adaptive Agent (AdA): Results Reel”, DeepMind 2023
“Human-Like Systematic Generalization through a Meta-Learning Neural Network”, Lake & Baroni 2023
Human-like systematic generalization through a meta-learning neural network
“Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent As Meta-Optimizers”, Dai et al 2022
Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers
“Unnatural Instructions: Tuning Language Models With (Almost) No Human Labor”, Honovich et al 2022
Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor
“Rethinking the Role of Scale for In-Context Learning: An Interpretability-Based Case Study at 66 Billion Scale”, Bansal et al 2022
“Transformers Learn In-Context by Gradient Descent”, Oswald et al 2022
“FWL: Meta-Learning Fast Weight Language Models”, Clark et al 2022
“What Learning Algorithm Is In-Context Learning? Investigations With Linear Models”, Akyürek et al 2022
What learning algorithm is in-context learning? Investigations with linear models
“Self-Destructing Models: Increasing the Costs of Harmful Dual Uses of Foundation Models”, Henderson et al 2022
Self-Destructing Models: Increasing the Costs of Harmful Dual Uses of Foundation Models
“VeLO: Training Versatile Learned Optimizers by Scaling Up”, Metz et al 2022
“Mysteries of Mode Collapse § Inescapable Wedding Parties”, Janus 2022
“BLOOMZ/mT0: Crosslingual Generalization through Multitask Finetuning”, Muennighoff et al 2022
BLOOMZ/mT0: Crosslingual Generalization through Multitask Finetuning
“ProMoT: Preserving In-Context Learning Ability in Large Language Model Fine-Tuning”, Wang et al 2022
ProMoT: Preserving In-Context Learning ability in Large Language Model Fine-tuning
“In-Context Reinforcement Learning With Algorithm Distillation”, Laskin et al 2022
In-context Reinforcement Learning with Algorithm Distillation
“SAP: Bidirectional Language Models Are Also Few-Shot Learners”, Patel et al 2022
SAP: Bidirectional Language Models Are Also Few-shot Learners
“g.pt: Learning to Learn With Generative Models of Neural Network Checkpoints”, Peebles et al 2022
g.pt: Learning to Learn with Generative Models of Neural Network Checkpoints
“Simulators”, Janus 2022
“AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model”, Soltan et al 2022
AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model
“Few-Shot Adaptation Works With UnpredicTable Data”, Chan et al 2022
“What Can Transformers Learn In-Context? A Case Study of Simple Function Classes”, Garg et al 2022
What Can Transformers Learn In-Context? A Case Study of Simple Function Classes
“Transformer Neural Processes: Uncertainty-Aware Meta Learning Via Sequence Modeling”, Nguyen & Grover 2022
Transformer Neural Processes: Uncertainty-Aware Meta Learning Via Sequence Modeling
“TabPFN: Meta-Learning a Real-Time Tabular AutoML Method For Small Data”, Hollmann et al 2022
TabPFN: Meta-Learning a Real-Time Tabular AutoML Method For Small Data
“Offline RL Policies Should Be Trained to Be Adaptive”, Ghosh et al 2022
“Goal-Conditioned Generators of Deep Policies”, Faccio et al 2022
“Prompting Decision Transformer for Few-Shot Policy Generalization”, Xu et al 2022
Prompting Decision Transformer for Few-Shot Policy Generalization
“LIFT: Language-Interfaced Fine-Tuning for Non-Language Machine Learning Tasks”, Dinh et al 2022
LIFT: Language-Interfaced Fine-Tuning for Non-Language Machine Learning Tasks
“RHO-LOSS: Prioritized Training on Points That Are Learnable, Worth Learning, and Not Yet Learnt”, Mindermann et al 2022
RHO-LOSS: Prioritized Training on Points that are Learnable, Worth Learning, and Not Yet Learnt
“NOAH: Neural Prompt Search”, Zhang et al 2022
“Bongard-HOI: Benchmarking Few-Shot Visual Reasoning for Human-Object Interactions”, Jiang et al 2022
Bongard-HOI: Benchmarking Few-Shot Visual Reasoning for Human-Object Interactions
“Towards Learning Universal Hyperparameter Optimizers With Transformers”, Chen et al 2022
Towards Learning Universal Hyperparameter Optimizers with Transformers
“Instruction Induction: From Few Examples to Natural Language Task Descriptions”, Honovich et al 2022
Instruction Induction: From Few Examples to Natural Language Task Descriptions
“Gato: A Generalist Agent”, Reed et al 2022
“UL2: Unifying Language Learning Paradigms”, Tay et al 2022
“Data Distributional Properties Drive Emergent Few-Shot Learning in Transformers”, Chan et al 2022
Data Distributional Properties Drive Emergent Few-Shot Learning in Transformers
“Tk-Instruct: Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks”, Wang et al 2022
Tk-Instruct: Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks
“What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?”, Wang et al 2022
What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?
“Effective Mutation Rate Adaptation through Group Elite Selection”, Kumar et al 2022
Effective Mutation Rate Adaptation through Group Elite Selection
“Searching for Efficient Neural Architectures for On-Device ML on Edge TPUs”, Akin et al 2022
Searching for Efficient Neural Architectures for On-Device ML on Edge TPUs
“Can Language Models Learn from Explanations in Context?”, Lampinen et al 2022
“Auto-Lambda: Disentangling Dynamic Task Relationships”, Liu et al 2022
“In-Context Learning and Induction Heads”, Olsson et al 2022
“HyperMixer: An MLP-Based Low Cost Alternative to Transformers”, Mai et al 2022
HyperMixer: An MLP-based Low Cost Alternative to Transformers
“LiteTransformerSearch: Training-Free Neural Architecture Search for Efficient Language Models”, Javaheripi et al 2022
LiteTransformerSearch: Training-free Neural Architecture Search for Efficient Language Models
“Evolving Curricula With Regret-Based Environment Design”, Parker-Holder et al 2022
“HyperPrompt: Prompt-Based Task-Conditioning of Transformers”, He et al 2022
“Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?”, Min et al 2022
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
“All You Need Is Supervised Learning: From Imitation Learning to Meta-RL With Upside Down RL”, Arulkumaran et al 2022
All You Need Is Supervised Learning: From Imitation Learning to Meta-RL With Upside Down RL
“NeuPL: Neural Population Learning”, Liu et al 2022
“Learning Synthetic Environments and Reward Networks for Reinforcement Learning”, Ferreira et al 2022
Learning Synthetic Environments and Reward Networks for Reinforcement Learning
“Datamodels: Predicting Predictions from Training Data”, Ilyas et al 2022
“From Data to Functa: Your Data Point Is a Function and You Should Treat It like One”, Dupont et al 2022
From data to functa: Your data point is a function and you should treat it like one
“Environment Generation for Zero-Shot Compositional Reinforcement Learning”, Gur et al 2022
Environment Generation for Zero-Shot Compositional Reinforcement Learning
“Active Predictive Coding Networks: A Neural Solution to the Problem of Learning Reference Frames and Part-Whole Hierarchies”, Gklezakos & Rao 2022
“Learning Robust Perceptive Locomotion for Quadrupedal Robots in the Wild”, Miki et al 2022
Learning robust perceptive locomotion for quadrupedal robots in the wild
“Automated Reinforcement Learning (AutoRL): A Survey and Open Problems”, Parker-Holder et al 2022
Automated Reinforcement Learning (AutoRL): A Survey and Open Problems
“In Defense of the Unitary Scalarization for Deep Multi-Task Learning”, Kurin et al 2022
In Defense of the Unitary Scalarization for Deep Multi-Task Learning
“HyperTransformer: Model Generation for Supervised and Semi-Supervised Few-Shot Learning”, Zhmoginov et al 2022
HyperTransformer: Model Generation for Supervised and Semi-Supervised Few-Shot Learning
“Finding General Equilibria in Many-Agent Economic Simulations Using Deep Reinforcement Learning”, Curry et al 2022
Finding General Equilibria in Many-Agent Economic Simulations Using Deep Reinforcement Learning
“The Curse of Zero Task Diversity: On the Failure of Transfer Learning to Outperform MAML and Their Empirical Equivalence”, Miranda et al 2021
“A Mathematical Framework for Transformer Circuits”, Elhage et al 2021
“PFNs: Transformers Can Do Bayesian Inference”, Müller et al 2021
“How to Learn and Represent Abstractions: An Investigation Using Symbolic Alchemy”, AlKhamissi et al 2021
How to Learn and Represent Abstractions: An Investigation using Symbolic Alchemy
“Noether Networks: Meta-Learning Useful Conserved Quantities”, Alet et al 2021
“A Rational Reinterpretation of Dual-Process Theories”, Milli et al 2021
“A General Language Assistant As a Laboratory for Alignment”, Askell et al 2021
“A Modern Self-Referential Weight Matrix That Learns to Modify Itself”, Irie et al 2021
A Modern Self-Referential Weight Matrix That Learns to Modify Itself
“A Survey of Generalization in Deep Reinforcement Learning”, Kirk et al 2021
“Gradients Are Not All You Need”, Metz et al 2021
“An Explanation of In-Context Learning As Implicit Bayesian Inference”, Xie et al 2021
An Explanation of In-context Learning as Implicit Bayesian Inference
“Procedural Generalization by Planning With Self-Supervised World Models”, Anand et al 2021
Procedural Generalization by Planning with Self-Supervised World Models
“MetaICL: Learning to Learn In Context”, Min et al 2021
“Logical Activation Functions: Logit-Space Equivalents of Probabilistic Boolean Operators”, Lowe et al 2021
Logical Activation Functions: Logit-space equivalents of Probabilistic Boolean Operators
“Shaking the Foundations: Delusions in Sequence Models for Interaction and Control”, Ortega et al 2021
Shaking the foundations: delusions in sequence models for interaction and control
“Meta-Learning, Social Cognition and Consciousness in Brains and Machines”, Langdon et al 2021
Meta-learning, social cognition and consciousness in brains and machines
“T0: Multitask Prompted Training Enables Zero-Shot Task Generalization”, Sanh et al 2021
T0: Multitask Prompted Training Enables Zero-Shot Task Generalization
“Replay-Guided Adversarial Environment Design”, Jiang et al 2021
“Embodied Intelligence via Learning and Evolution”, Gupta et al 2021
“Transformers Are Meta-Reinforcement Learners”, Anonymous 2021
“Scalable Online Planning via Reinforcement Learning Fine-Tuning”, Fickinger et al 2021
Scalable Online Planning via Reinforcement Learning Fine-Tuning
“Dropout’s Dream Land: Generalization from Learned Simulators to Reality”, Wellmer & Kwok 2021
Dropout’s Dream Land: Generalization from Learned Simulators to Reality
“Is Curiosity All You Need? On the Utility of Emergent Behaviors from Curious Exploration”, Groth et al 2021
Is Curiosity All You Need? On the Utility of Emergent Behaviors from Curious Exploration
“Bootstrapped Meta-Learning”, Flennerhag et al 2021
“The Sensory Neuron As a Transformer: Permutation-Invariant Neural Networks for Reinforcement Learning”, Tang & Ha 2021
“FLAN: Finetuned Language Models Are Zero-Shot Learners”, Wei et al 2021
“The AI Economist: Optimal Economic Policy Design via Two-Level Deep Reinforcement Learning”, Zheng et al 2021
The AI Economist: Optimal Economic Policy Design via Two-level Deep Reinforcement Learning
“Open-Ended Learning Leads to Generally Capable Agents”, Team et al 2021
“Dataset Distillation With Infinitely Wide Convolutional Networks”, Nguyen et al 2021
Dataset Distillation with Infinitely Wide Convolutional Networks
“Why Generalization in RL Is Difficult: Epistemic POMDPs and Implicit Partial Observability”, Ghosh et al 2021
Why Generalization in RL is Difficult: Epistemic POMDPs and Implicit Partial Observability
“PonderNet: Learning to Ponder”, Banino et al 2021
“Multimodal Few-Shot Learning With Frozen Language Models”, Tsimpoukelli et al 2021
“LHOPT: A Generalizable Approach to Learning Optimizers”, Almeida et al 2021
“Towards Mental Time Travel: a Hierarchical Memory for Reinforcement Learning Agents”, Lampinen et al 2021
Towards mental time travel: a hierarchical memory for reinforcement learning agents
“A Full-Stack Accelerator Search Technique for Vision Applications”, Zhang et al 2021
A Full-stack Accelerator Search Technique for Vision Applications
“Reward Is Enough”, Silver et al 2021
“Bayesian Optimization Is Superior to Random Search for Machine Learning Hyperparameter Tuning: Analysis of the Black-Box Optimization Challenge 2020”, Turner et al 2021
“CrossFit: A Few-Shot Learning Challenge for Cross-Task Generalization in NLP”, Ye et al 2021
CrossFit: A Few-shot Learning Challenge for Cross-task Generalization in NLP
“Podracer Architectures for Scalable Reinforcement Learning”, Hessel et al 2021
“BLUR: Meta-Learning Bidirectional Update Rules”, Sandler et al 2021
“Asymmetric Self-Play for Automatic Goal Discovery in Robotic Manipulation”, OpenAI et al 2021
Asymmetric self-play for automatic goal discovery in robotic manipulation
“OmniNet: Omnidirectional Representations from Transformers”, Tay et al 2021
“Linear Transformers Are Secretly Fast Weight Programmers”, Schlag et al 2021
“Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm”, Reynolds & McDonell 2021
Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm
“ES-ENAS: Blackbox Optimization over Hybrid Spaces via Combinatorial and Continuous Evolution”, Song et al 2021
ES-ENAS: Blackbox Optimization over Hybrid Spaces via Combinatorial and Continuous Evolution
“Training Learned Optimizers With Randomly Initialized Learned Optimizers”, Metz et al 2021
Training Learned Optimizers with Randomly Initialized Learned Optimizers
“Evolving Reinforcement Learning Algorithms”, Co-Reyes et al 2021
“Meta Pseudo Labels”, Pham et al 2021
“Meta Learning Backpropagation And Improving It”, Kirsch & Schmidhuber 2020
“Emergent Complexity and Zero-Shot Transfer via Unsupervised Environment Design [UED+PAIRED]”, Dennis et al 2020
Emergent Complexity and Zero-shot Transfer via Unsupervised Environment Design [UED+PAIRED]
“Scaling down Deep Learning”, Greydanus 2020
“Reverse Engineering Learned Optimizers Reveals Known and Novel Mechanisms”, Maheswaranathan et al 2020
Reverse engineering learned optimizers reveals known and novel mechanisms
“Dataset Meta-Learning from Kernel Ridge-Regression”, Nguyen et al 2020
“MELD: Meta-Reinforcement Learning from Images via Latent State Models”, Zhao et al 2020
MELD: Meta-Reinforcement Learning from Images via Latent State Models
“Meta-Trained Agents Implement Bayes-Optimal Agents”, Mikulik et al 2020
“Learning Not to Learn: Nature versus Nurture in Silico”, Lange & Sprekeler 2020
“Prioritized Level Replay”, Jiang et al 2020
“Tasks, Stability, Architecture, and Compute: Training More Effective Learned Optimizers, and Using Them to Train Themselves”, Metz et al 2020
“Hidden Incentives for Auto-Induced Distributional Shift”, Krueger et al 2020
“It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners”, Schick & Schütze 2020
It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners
“Grounded Language Learning Fast and Slow”, Hill et al 2020
“Matt Botvinick on the Spontaneous Emergence of Learning Algorithms”, Scholl 2020
Matt Botvinick on the spontaneous emergence of learning algorithms
“LPG: Discovering Reinforcement Learning Algorithms”, Oh et al 2020
“Deep Reinforcement Learning and Its Neuroscientific Implications”, Botvinick 2020
Deep Reinforcement Learning and Its Neuroscientific Implications
“Decentralized Reinforcement Learning: Global Decision-Making via Local Economic Transactions”, Chang et al 2020
Decentralized Reinforcement Learning: Global Decision-Making via Local Economic Transactions
“Rapid Task-Solving in Novel Environments”, Ritter et al 2020
“FBNetV3: Joint Architecture-Recipe Search Using Predictor Pretraining”, Dai et al 2020
FBNetV3: Joint Architecture-Recipe Search using Predictor Pretraining
“GPT-3: Language Models Are Few-Shot Learners”, Brown et al 2020
“Synthetic Petri Dish: A Novel Surrogate Model for Rapid Architecture Search”, Rawal et al 2020
Synthetic Petri Dish: A Novel Surrogate Model for Rapid Architecture Search
“Automatic Discovery of Interpretable Planning Strategies”, Skirzyński et al 2020
“Meta-Reinforcement Learning for Robotic Industrial Insertion Tasks”, Schoettler et al 2020
Meta-Reinforcement Learning for Robotic Industrial Insertion Tasks
“A Comparison of Methods for Treatment Assignment With an Application to Playlist Generation”, Fernández-Loría et al 2020
A Comparison of Methods for Treatment Assignment with an Application to Playlist Generation
“Approximate Exploitability: Learning a Best Response in Large Games”, Timbers et al 2020
Approximate exploitability: Learning a best response in large games
“Meta-Learning in Neural Networks: A Survey”, Hospedales et al 2020
“EvER: Mimicking Evolution With Reinforcement Learning”, Abrantes et al 2020
“Agent57: Outperforming the Atari Human Benchmark”, Badia et al 2020
“Designing Network Design Spaces”, Radosavovic et al 2020
“Enhanced POET: Open-Ended Reinforcement Learning through Unbounded Invention of Learning Challenges and Their Solutions”, Wang et al 2020
“Accelerating and Improving AlphaZero Using Population Based Training”, Wu et al 2020
Accelerating and Improving AlphaZero Using Population Based Training
“Meta-Learning Curiosity Algorithms”, Alet et al 2020
“AutoML-Zero: Evolving Machine Learning Algorithms From Scratch”, Real et al 2020
AutoML-Zero: Evolving Machine Learning Algorithms From Scratch
“AutoML-Zero: Open Source Code for the Paper: "AutoML-Zero: Evolving Machine Learning Algorithms From Scratch"”, Real et al 2020
“Effective Diversity in Population Based Reinforcement Learning”, Parker-Holder et al 2020
Effective Diversity in Population Based Reinforcement Learning
“AI Helps Warehouse Robots Pick Up New Tricks: Backed by Machine Learning Luminaries, Covariant.ai’s Bots Can Handle Jobs Previously Needing a Human Touch”, Knight 2020
“Smooth Markets: A Basic Mechanism for Organizing Gradient-Based Learners”, Balduzzi et al 2020
Smooth markets: A basic mechanism for organizing gradient-based learners
“AutoML-Zero: Evolving Code That Learns”, Real & Liang 2020
“Learning Neural Activations”, Minhas & Asif 2019
“Meta-Learning without Memorization”, Yin et al 2019
“MetaFun: Meta-Learning With Iterative Functional Updates”, Xu et al 2019
“Leveraging Procedural Generation to Benchmark Reinforcement Learning”, Cobbe et al 2019
Leveraging Procedural Generation to Benchmark Reinforcement Learning
“Procgen Benchmark: We’re Releasing Procgen Benchmark, 16 Simple-To-Use Procedurally-Generated Environments Which Provide a Direct Measure of How Quickly a Reinforcement Learning Agent Learns Generalizable Skills”, Cobbe et al 2019
“Increasing Generality in Machine Learning through Procedural Content Generation”, Risi & Togelius 2019
Increasing Generality in Machine Learning through Procedural Content Generation
“SimpleShot: Revisiting Nearest-Neighbor Classification for Few-Shot Learning”, Wang et al 2019
SimpleShot: Revisiting Nearest-Neighbor Classification for Few-Shot Learning
“Optimizing Millions of Hyperparameters by Implicit Differentiation”, Lorraine et al 2019
Optimizing Millions of Hyperparameters by Implicit Differentiation
“Learning to Predict Without Looking Ahead: World Models Without Forward Prediction”, Freeman et al 2019
Learning to Predict Without Looking Ahead: World Models Without Forward Prediction
“Learning to Predict Without Looking Ahead: World Models Without Forward Prediction [Blog]”, Freeman et al 2019
Learning to Predict Without Looking Ahead: World Models Without Forward Prediction [blog]
“Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning”, Yu et al 2019
Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning
“Solving Rubik’s Cube With a Robot Hand”, OpenAI et al 2019
“Solving Rubik’s Cube With a Robot Hand [Blog]”, OpenAI 2019
“Gradient Descent: The Ultimate Optimizer”, Chandra et al 2019
“Data Valuation Using Reinforcement Learning”, Yoon et al 2019
“Multiplicative Interactions and Where to Find Them”, Jayakumar et al 2019
“ANIL: Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML”, Raghu et al 2019
ANIL: Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML
“Emergent Tool Use From Multi-Agent Autocurricula”, Baker et al 2019
“Meta-Learning With Implicit Gradients”, Rajeswaran et al 2019
“A Critique of Pure Learning and What Artificial Neural Networks Can Learn from Animal Brains”, Zador 2019
A critique of pure learning and what artificial neural networks can learn from animal brains
“AutoML: A Survey of the State-Of-The-Art”, He et al 2019
“Metalearned Neural Memory”, Munkhdalai et al 2019
“Algorithms for Hyper-Parameter Optimization”, Bergstra et al 2019
“Evolving the Hearthstone Meta”, Silva et al 2019
“Meta Reinforcement Learning”, Weng 2019
“One Epoch Is All You Need”, Komatsuzaki 2019
“Compositional Generalization through Meta Sequence-To-Sequence Learning”, Lake 2019
Compositional generalization through meta sequence-to-sequence learning
“Risks from Learned Optimization in Advanced Machine Learning Systems”, Hubinger et al 2019
Risks from Learned Optimization in Advanced Machine Learning Systems
“ICML 2019 Notes”, Abel 2019
“SpArSe: Sparse Architecture Search for CNNs on Resource-Constrained Microcontrollers”, Fedorov et al 2019
SpArSe: Sparse Architecture Search for CNNs on Resource-Constrained Microcontrollers
“AI-GAs: AI-Generating Algorithms, an Alternate Paradigm for Producing General Artificial Intelligence”, Clune 2019
“Alpha MAML: Adaptive Model-Agnostic Meta-Learning”, Behl et al 2019
“Reinforcement Learning, Fast and Slow”, Botvinick et al 2019
“Meta Reinforcement Learning As Task Inference”, Humplik et al 2019
“Learning Loss for Active Learning”, Yoo & Kweon 2019
“Meta-Learning of Sequential Strategies”, Ortega et al 2019
“Searching for MobileNetV3”, Howard et al 2019
“Meta-Learners’ Learning Dynamics Are unlike Learners’”, Rabinowitz 2019
“Ray Interference: a Source of Plateaus in Deep Reinforcement Learning”, Schaul et al 2019
Ray Interference: a Source of Plateaus in Deep Reinforcement Learning
“AlphaX: EXploring Neural Architectures With Deep Neural Networks and Monte Carlo Tree Search”, Wang et al 2019
AlphaX: eXploring Neural Architectures with Deep Neural Networks and Monte Carlo Tree Search
“Efficient Off-Policy Meta-Reinforcement Learning via Probabilistic Context Variables”, Rakelly et al 2019
Efficient Off-Policy Meta-Reinforcement Learning via Probabilistic Context Variables
“Task2Vec: Task Embedding for Meta-Learning”, Achille et al 2019
“The Omniglot Challenge: a 3-Year Progress Report”, Lake et al 2019
“FIGR: Few-Shot Image Generation With Reptile”, Clouâtre & Demers 2019
“Paired Open-Ended Trailblazer (POET): Endlessly Generating Increasingly Complex and Diverse Learning Environments and Their Solutions”, Wang et al 2019
“Meta-Learning Neural Bloom Filters”, Rae 2019
“Malthusian Reinforcement Learning”, Leibo et al 2018
“Quantifying Generalization in Reinforcement Learning”, Cobbe et al 2018
“An Introduction to Deep Reinforcement Learning”, Francois-Lavet et al 2018
“Meta-Learning: Learning to Learn Fast”, Weng 2018
“Evolving Space-Time Neural Architectures for Videos”, Piergiovanni et al 2018
“Understanding and Correcting Pathologies in the Training of Learned Optimizers”, Metz et al 2018
Understanding and correcting pathologies in the training of learned optimizers
“BabyAI: A Platform to Study the Sample Efficiency of Grounded Language Learning”, Chevalier-Boisvert et al 2018
BabyAI: A Platform to Study the Sample Efficiency of Grounded Language Learning
“Deep Reinforcement Learning”, Li 2018
“Searching for Efficient Multi-Scale Architectures for Dense Image Prediction”, Chen et al 2018
Searching for Efficient Multi-Scale Architectures for Dense Image Prediction
“Backprop Evolution”, Alber et al 2018
“Learning Dexterous In-Hand Manipulation”, OpenAI et al 2018
“LEO: Meta-Learning With Latent Embedding Optimization”, Rusu et al 2018
“Automatically Composing Representation Transformations As a Means for Generalization”, Chang et al 2018
Automatically Composing Representation Transformations as a Means for Generalization
“Human-Level Performance in First-Person Multiplayer Games With Population-Based Deep Reinforcement Learning”, Jaderberg et al 2018
“Guided Evolutionary Strategies: Augmenting Random Search With Surrogate Gradients”, Maheswaranathan et al 2018
Guided evolutionary strategies: Augmenting random search with surrogate gradients
“RUDDER: Return Decomposition for Delayed Rewards”, Arjona-Medina et al 2018
“Meta-Learning Transferable Active Learning Policies by Deep Reinforcement Learning”, Pang et al 2018
Meta-Learning Transferable Active Learning Policies by Deep Reinforcement Learning
“Fingerprint Policy Optimization for Robust Reinforcement Learning”, Paul et al 2018
Fingerprint Policy Optimization for Robust Reinforcement Learning
“AutoAugment: Learning Augmentation Policies from Data”, Cubuk et al 2018
“Meta-Gradient Reinforcement Learning”, Xu et al 2018
“Continuous Learning in a Hierarchical Multiscale Neural Network”, Wolf et al 2018
Continuous Learning in a Hierarchical Multiscale Neural Network
“Prefrontal Cortex As a Meta-Reinforcement Learning System”, Wang et al 2018
“Meta-Learning Update Rules for Unsupervised Representation Learning”, Metz et al 2018
Meta-Learning Update Rules for Unsupervised Representation Learning
“Reviving and Improving Recurrent Back-Propagation”, Liao et al 2018
“Kickstarting Deep Reinforcement Learning”, Schmitt et al 2018
“Reptile/FOMAML: On First-Order Meta-Learning Algorithms”, Nichol et al 2018
“Some Considerations on Learning to Explore via Meta-Reinforcement Learning”, Stadie et al 2018
Some Considerations on Learning to Explore via Meta-Reinforcement Learning
“One Big Net For Everything”, Schmidhuber 2018
“Machine Theory of Mind”, Rabinowitz et al 2018
“Evolved Policy Gradients”, Houthooft et al 2018
“One-Shot Imitation from Observing Humans via Domain-Adaptive Meta-Learning”, Yu et al 2018
One-Shot Imitation from Observing Humans via Domain-Adaptive Meta-Learning
“Rover Descent: Learning to Optimize by Learning to Navigate on Prototypical Loss Surfaces”, Faury & Vasile 2018
Rover Descent: Learning to optimize by learning to navigate on prototypical loss surfaces
“ScreenerNet: Learning Self-Paced Curriculum for Deep Neural Networks”, Kim & Choi 2018
ScreenerNet: Learning Self-Paced Curriculum for Deep Neural Networks
“Population Based Training of Neural Networks”, Jaderberg et al 2017
“BlockDrop: Dynamic Inference Paths in Residual Networks”, Wu et al 2017
“Learning to Select Computations”, Callaway et al 2017
“Learning to Generalize: Meta-Learning for Domain Generalization”, Li et al 2017
Learning to Generalize: Meta-Learning for Domain Generalization
“Efficient K-Shot Learning With Regularized Deep Networks”, Yoo et al 2017
“Online Learning of a Memory for Learning Rates”, Meier et al 2017
“One-Shot Visual Imitation Learning via Meta-Learning”, Finn et al 2017
“Supervising Unsupervised Learning”, Garg & Kalai 2017
“Learning With Opponent-Learning Awareness”, Foerster et al 2017
“SMASH: One-Shot Model Architecture Search through HyperNetworks”, Brock et al 2017
SMASH: One-Shot Model Architecture Search through HyperNetworks
“Stochastic Optimization With Bandit Sampling”, Salehi et al 2017
“A Simple Neural Attentive Meta-Learner”, Mishra et al 2017
“Reinforcement Learning for Learning Rate Control”, Xu et al 2017
“Metacontrol for Adaptive Imagination-Based Optimization”, Hamrick et al 2017
“Deciding How to Decide: Dynamic Routing in Artificial Neural Networks”, McGill & Perona 2017
Deciding How to Decide: Dynamic Routing in Artificial Neural Networks
“Prototypical Networks for Few-Shot Learning”, Snell et al 2017
“Learned Optimizers That Scale and Generalize”, Wichrowska et al 2017
“MAML: Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks”, Finn et al 2017
MAML: Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
“Learning to Optimize Neural Nets”, Li & Malik 2017
“Understanding Synthetic Gradients and Decoupled Neural Interfaces”, Czarnecki et al 2017
Understanding Synthetic Gradients and Decoupled Neural Interfaces
“Optimization As a Model for Few-Shot Learning”, Ravi & Larochelle 2017
“Learning to Superoptimize Programs”, Bunel et al 2017
“Discovering Objects and Their Relations from Entangled Scene Representations”, Raposo et al 2017
Discovering objects and their relations from entangled scene representations
“Google Vizier: A Service for Black-Box Optimization”, Golovin 2017
“An Actor-Critic Algorithm for Learning Rate Learning”, Xu et al 2016
“A Bird’s Eye View of Synthetic Gradients”, Greydanus 2016
A Bird’s Eye View of Synthetic Gradients
View External Link:
“Learning to Reinforcement Learn”, Wang et al 2016
“Learning to Learn without Gradient Descent by Gradient Descent”, Chen et al 2016
Learning to Learn without Gradient Descent by Gradient Descent
“RL2: Fast Reinforcement Learning via Slow Reinforcement Learning”, Duan et al 2016
RL2: Fast Reinforcement Learning via Slow Reinforcement Learning
“Designing Neural Network Architectures Using Reinforcement Learning”, Baker et al 2016
Designing Neural Network Architectures using Reinforcement Learning
“Using Fast Weights to Attend to the Recent Past”, Ba et al 2016
“HyperNetworks”, Ha et al 2016
“Decoupled Neural Interfaces Using Synthetic Gradients”, Jaderberg et al 2016
“Learning to Learn by Gradient Descent by Gradient Descent”, Andrychowicz et al 2016
“Matching Networks for One Shot Learning”, Vinyals et al 2016
“Learning to Optimize”, Li & Malik 2016
“One-Shot Learning With Memory-Augmented Neural Networks”, Santoro et al 2016
“Adaptive Computation Time for Recurrent Neural Networks”, Graves 2016
“On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models”, Schmidhuber 2015
“Gradient-Based Hyperparameter Optimization through Reversible Learning”, Maclaurin et al 2015
Gradient-based Hyperparameter Optimization through Reversible Learning
“Machine Teaching: an Inverse Problem to Machine Learning and an Approach Toward Optimal Education”, Zhu 2015b
Machine Teaching: an Inverse Problem to Machine Learning and an Approach Toward Optimal Education
“Human-Level Concept Learning through Probabilistic Program Induction”, Lake 2015
Human-level concept learning through probabilistic program induction
“Robots That Can Adapt like Animals”, Cully et al 2014
“Deep Learning in Neural Networks: An Overview”, Schmidhuber 2014
“Practical Bayesian Optimization of Machine Learning Algorithms”, Snoek et al 2012
Practical Bayesian Optimization of Machine Learning Algorithms
“Evolutionary Importance of Phenotypic Accommodation in Novel Environments: an Empirical Test of the Baldwin Effect”, Badyaev 2009
“Intense Neutral Drifts Yield Robust and Evolvable Consensus Proteins”, Bershtein et al 2008
Intense Neutral Drifts Yield Robust and Evolvable Consensus Proteins
“The Infinite MNIST Dataset”, Bottou 2007
“Gödel Machines: Self-Referential Universal Problem Solvers Making Provably Optimal Self-Improvements”, Schmidhuber 2003
Gödel Machines: Self-Referential Universal Problem Solvers Making Provably Optimal Self-Improvements
“Optimal Ordered Problem Solver (OOPS)”, Schmidhuber 2002
“Learning to Learn Using Gradient Descent”, Hochreiter et al 2001
“On the Optimization of a Synaptic Learning Rule”, Bengio et al 1997
“Interactions between Learning and Evolution”, Ackley & Littman 1992
“Learning to Control Fast-Weight Memories: An Alternative to Dynamic Recurrent Networks”, Schmidhuber 1992b
Learning to Control Fast-Weight Memories: An Alternative to Dynamic Recurrent Networks
“Learning a Synaptic Learning Rule”, Bengio et al 1991
“Reinforcement Learning: An Introduction § Designing Reward Signals”, Sutton & Barto 2026 (page 491)
Reinforcement Learning: An Introduction § Designing Reward Signals :
“Exploring Hyperparameter Meta-Loss Landscapes With Jax”
“Metalearning”
“Universal Search § OOPS and Other Incremental Variations”
“Extrapolating to Unnatural Language Processing With GPT-3’s In-Context Learning: The Good, the Bad, and the Mysterious”
“How Does In-Context Learning Work? A Framework for Understanding the Differences from Traditional Supervised Learning”
“Rapid Motor Adaptation for Legged Robots”
Rapid Motor Adaptation for Legged Robots
View External Link:
“Collaborating With Humans Requires Understanding Them”
Collaborating with Humans Requires Understanding Them
View External Link:
“Why Generalization in RL Is Difficult: Epistemic POMDPs and Implicit Partial Observability [Blog]”
Why Generalization in RL is Difficult: Epistemic POMDPs and Implicit Partial Observability [blog]
“Hypernetworks [Blog]”, Ha 2026
“Scaling Karpathy’s Autoresearch: What Happens When the Agent Gets a GPU Cluster”
Scaling Karpathy’s Autoresearch: What Happens When the Agent Gets a GPU Cluster
“Action and Perception As Divergence Minimization”
Action and Perception as Divergence Minimization
View External Link:
“AlphaStar: Mastering the Real-Time Strategy Game StarCraft II”
AlphaStar: Mastering the Real-Time Strategy Game StarCraft II
“Prefrontal Cortex As a Meta-Reinforcement Learning System [Blog]”
Prefrontal cortex as a meta-reinforcement learning system [blog]
“The Lie Comes First, the Worlds to Accommodate It”
“Google-Deepmind/regress-Lm: Library for Text-To-Text Regression, Applicable to Any Input String Representation and Allows Pretraining and Fine-Tuning over Multiple Regression Tasks”
“Krasheninnikov/internalization: Code for the Paper ‘Implicit Meta-Learning May Lead Language Models to Trust More Reliable Sources’”
“Sgdstore/experiments/omniglot at Master”
“Curriculum For Reinforcement Learning”
“Neural Architecture Search”
“MetaGenRL: Improving Generalization in Meta Reinforcement Learning”
MetaGenRL: Improving Generalization in Meta Reinforcement Learning
“The RetroInstruct Guide To Synthetic Text Data”, Pressman 2026
“2022: 25-Year Anniversary: LSTM (1997), All Computable Metaverses, Hierarchical Q-Learning, Adversarial Intrinsic Reinforcement Learning, Low-Complexity NNs, Low-Complexity Art, Meta-RL, Soccer Learning”
“Metalearning or Learning to Learn Since 1987”
“The Future of Artificial Intelligence Is Self-Organizing and Self-Assembling”
The Future of Artificial Intelligence is Self-Organizing and Self-Assembling
“Domain-Adaptive Meta-Learning”
“How to Fix Reinforcement Learning”
“Video Models Are Zero-Shot Learners and Reasoners”
Video models are zero-shot learners and reasoners
View External Link:
“Introducing Adept”
“Optimal Learning: Computational Procedures for Bayes-Adaptive Markov Decision Processes”
Optimal Learning: Computational Procedures for Bayes-Adaptive Markov Decision Processes
“Risks from Learned Optimization: Introduction”
“How Good Are LLMs at Doing ML on an Unknown Dataset?”
“Exploration Hacking: Can LLMs Learn to Resist RL Training?”
“Letting Claude Do Autonomous Research to Improve SAEs”
“Early Situational Awareness and Its Implications, a Story”
“RWKV Language Model”
“AI Is Learning How to Create Itself”
“Matt Botvinick: Neuroscience, Psychology, and AI at DeepMind”
Matt Botvinick: Neuroscience, Psychology, and AI at DeepMind
“SMASH: One-Shot Model Architecture Search through HyperNetworks [Video]”
SMASH: One-Shot Model Architecture Search through HyperNetworks [video]
“Solving Rubik’s Cube With a Robot Hand: Perturbations”
“WELM”
“Autoresearch on an Old Research Idea”
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
playlist-assignment
adaptive-robots
alignment-safety
object-reasoning few-shot-reasoning memory-embedding document-context visual-benchmarking
machine-teaching
in-context-learning
conserved-quantities
prompt-synthetic
learning-prioritization
task-diversity
stochastic-training
few-shot-learning
meta-reinforcement
Wikipedia (14)
Miscellaneous
/doc/reinforcement-learning/meta-learning/2025-elkishky-figure6-o3learnedselftestingstrategy.jpghttps://ai.meta.com/blog/harmful-content-can-evolve-quickly-our-new-ai-system-adapts-to-tackle-ithttps://ai.meta.com/blog/harmful-content-can-evolve-quickly-our-new-ai-system-adapts-to-tackle-it/https://blog.waymo.com/2020/04/using-automated-data-augmentation-to.html#googlehttps://pages.ucsd.edu/~rbelew/courses/cogs184_w10/readings/HintonNowlan97.pdfhttps://research.google/blog/permutation-invariant-neural-networks-for-reinforcement-learning/https://www.lesswrong.com/posts/bC5xd7wQCnTDw7Kyx/getting-up-to-speed-on-the-speed-prior-in-2022https://www.lesswrong.com/posts/sY3a4Rfa48CgteBEm/chatgpt-can-learn-indirect-controlhttps://www.quantamagazine.org/researchers-build-ai-that-builds-ai-20220125/
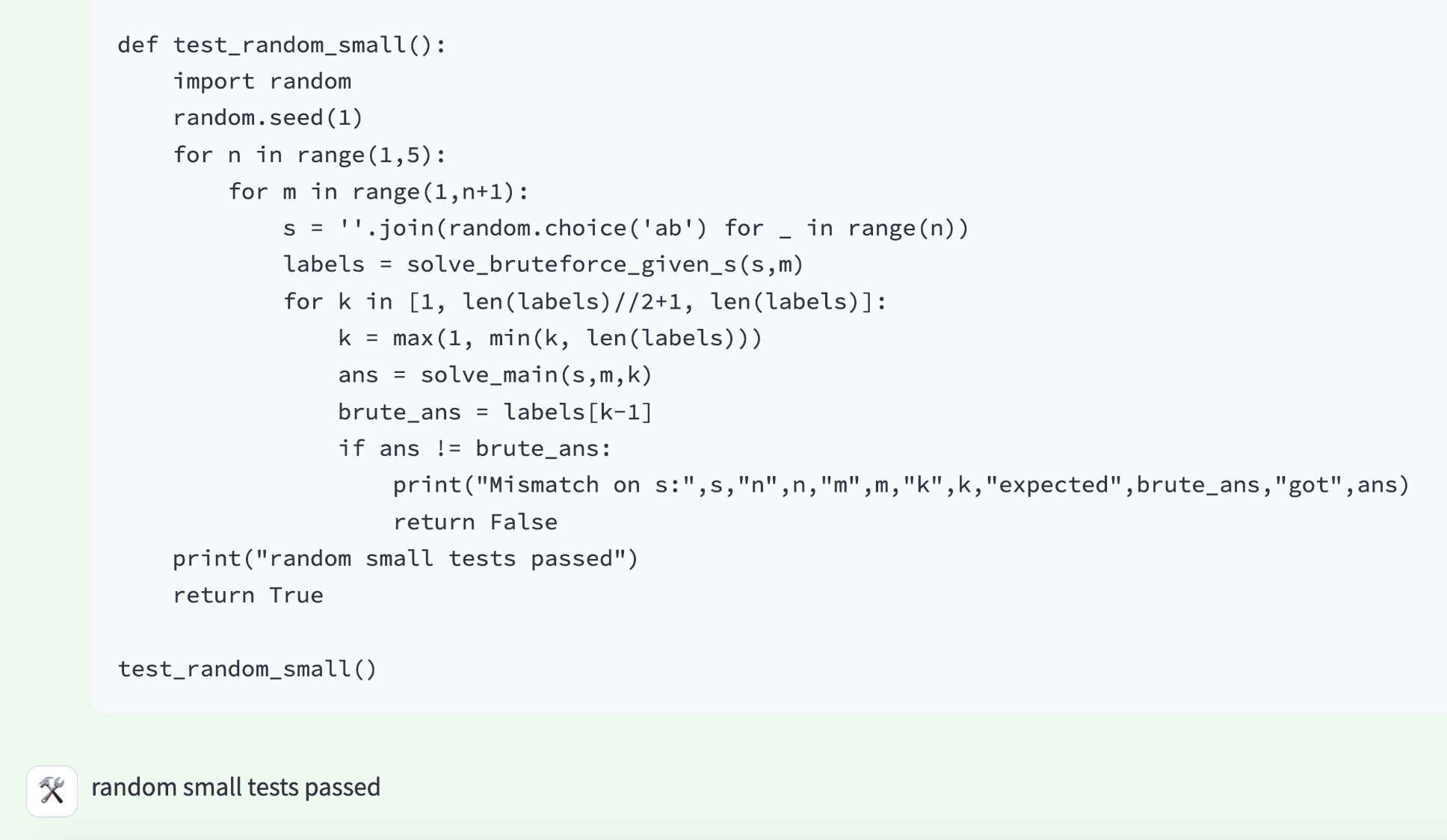{kind=link}
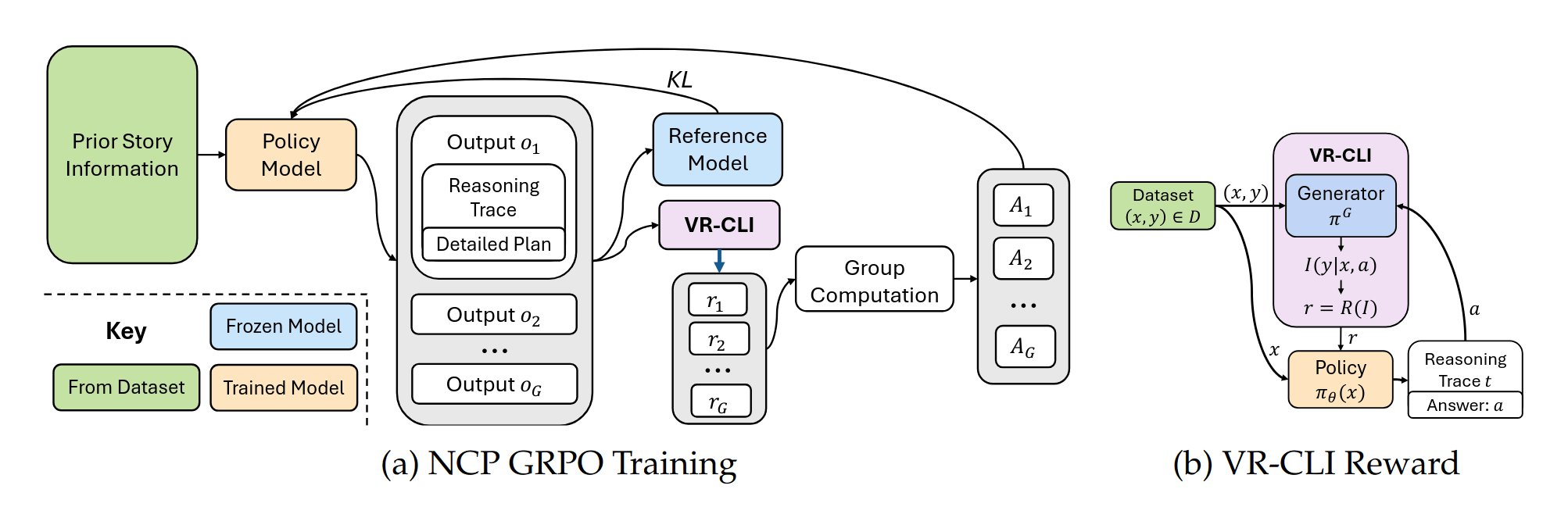{kind=link}
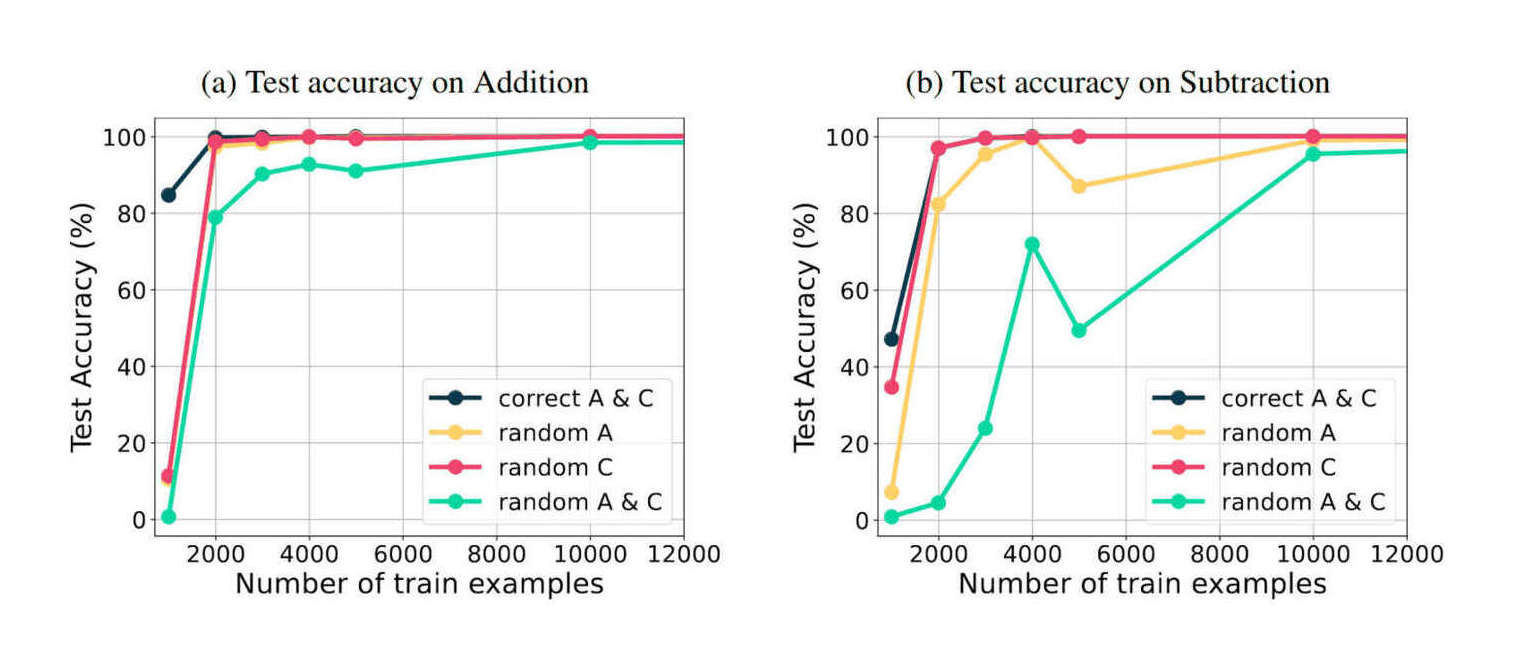{kind=link}
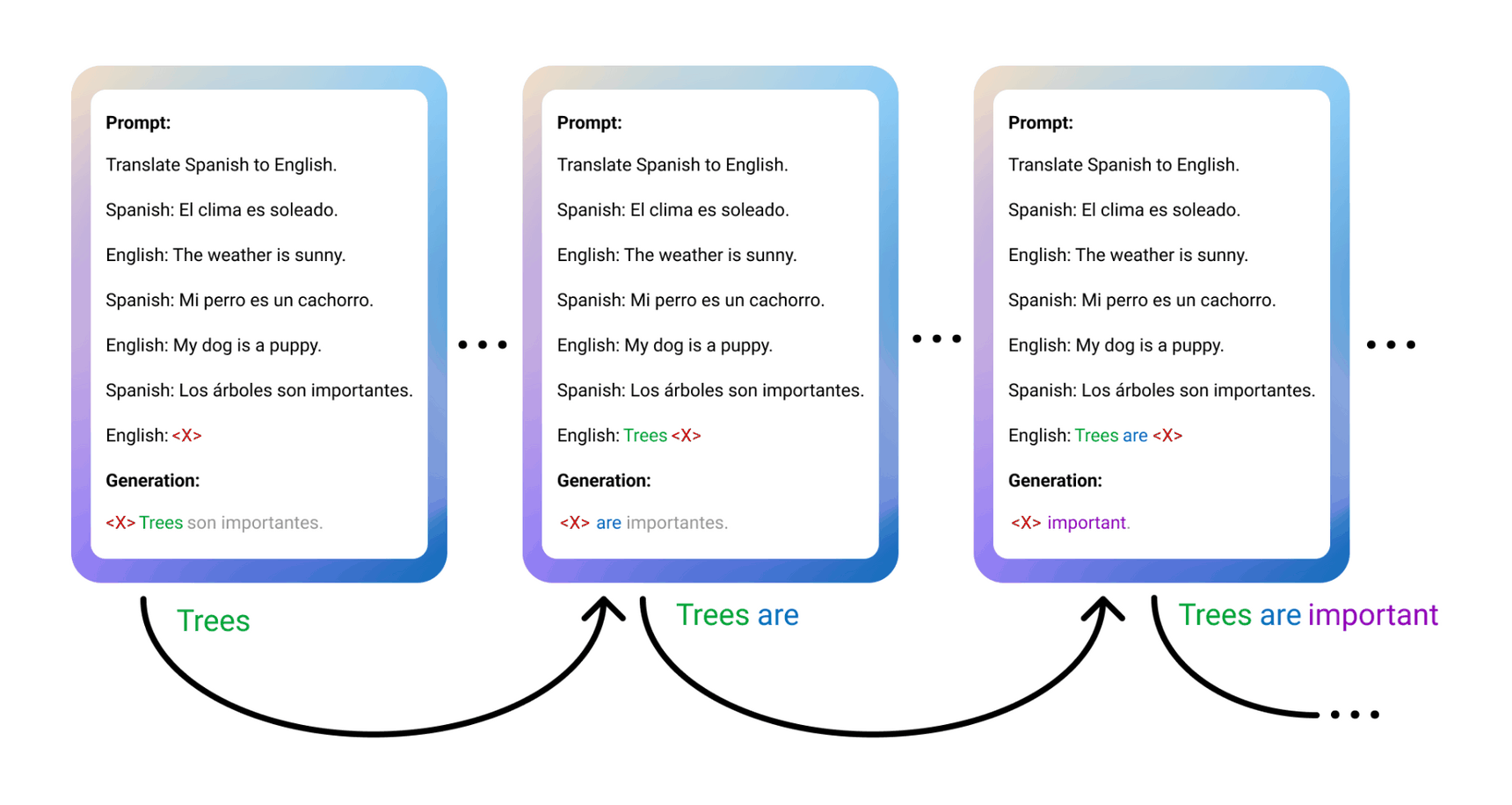{kind=link}
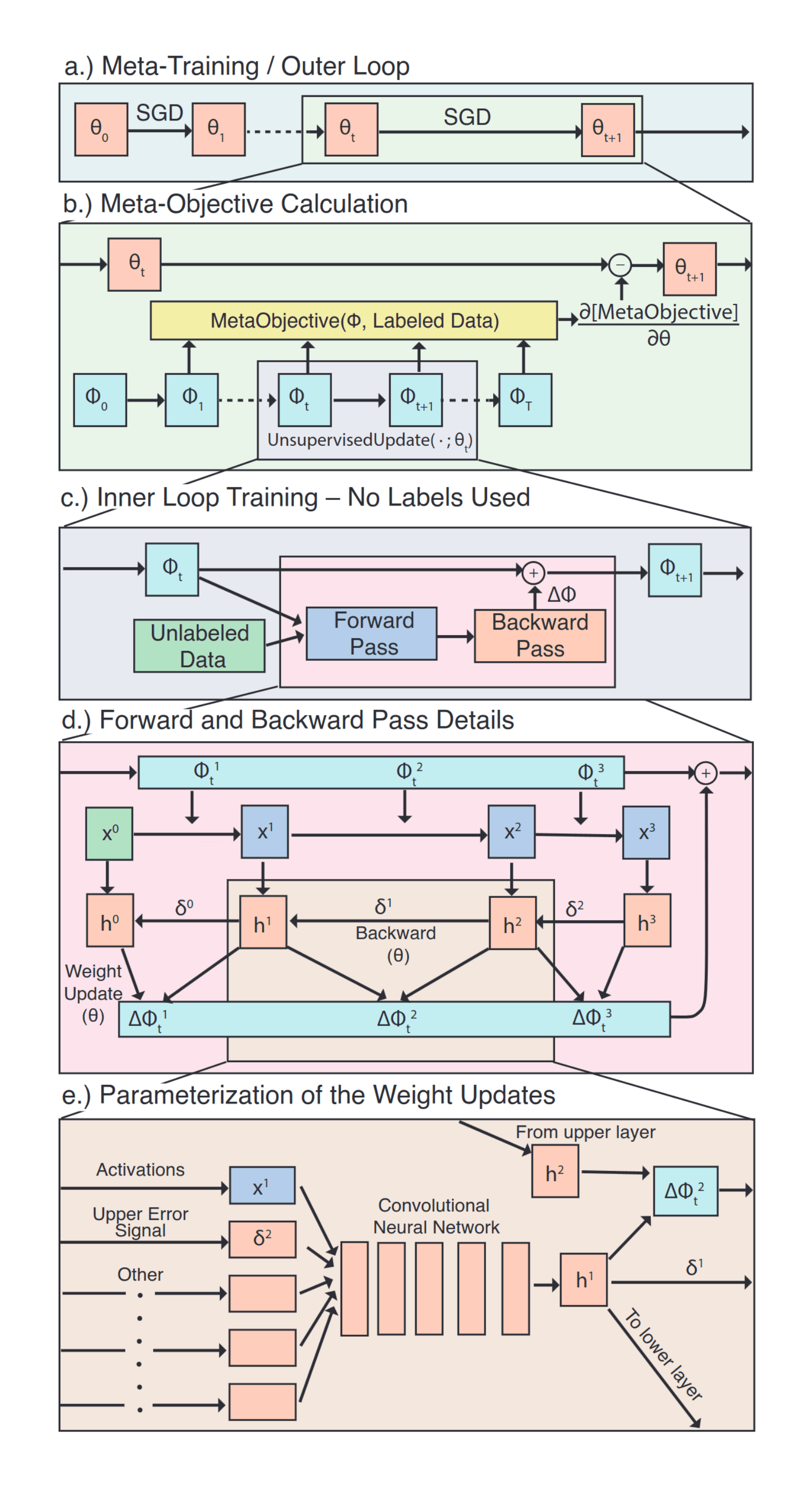{kind=link}
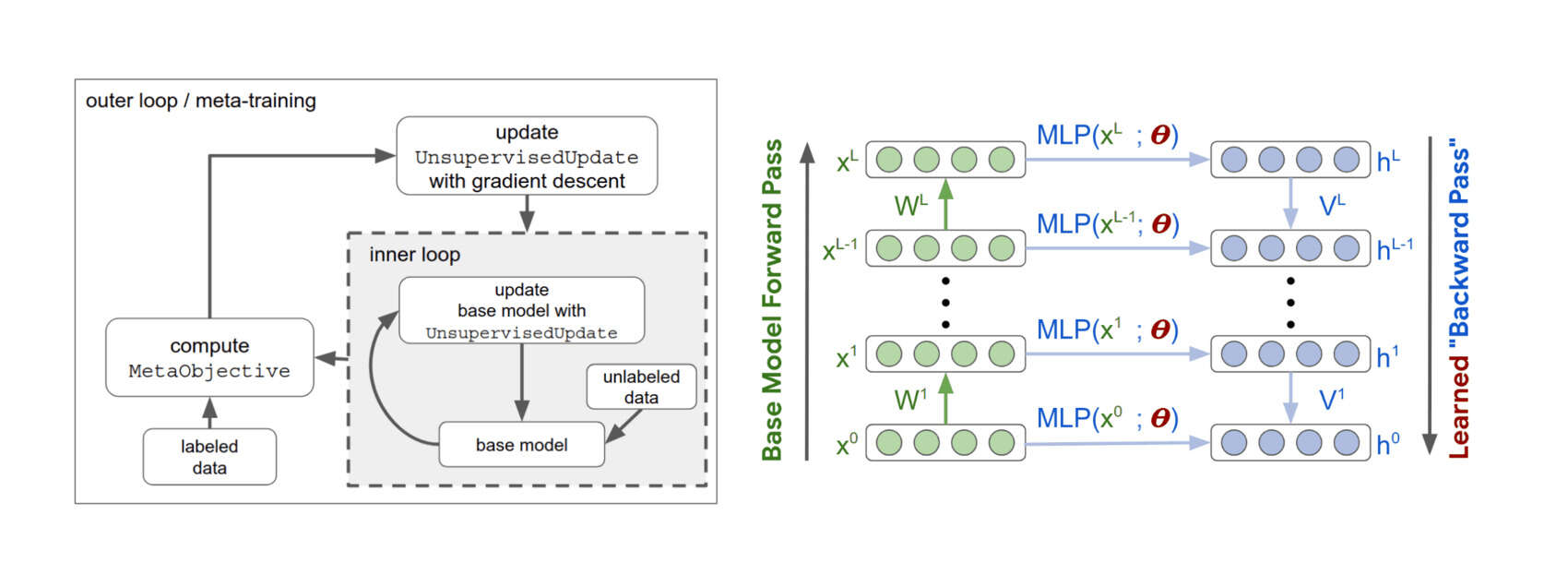{kind=link}
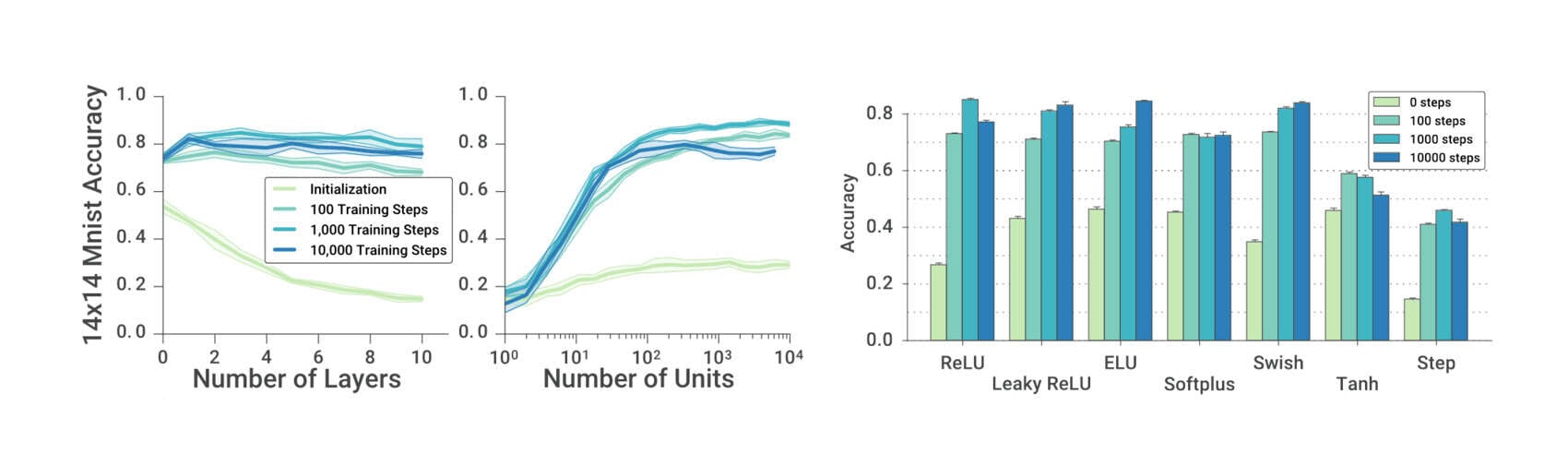{kind=link}
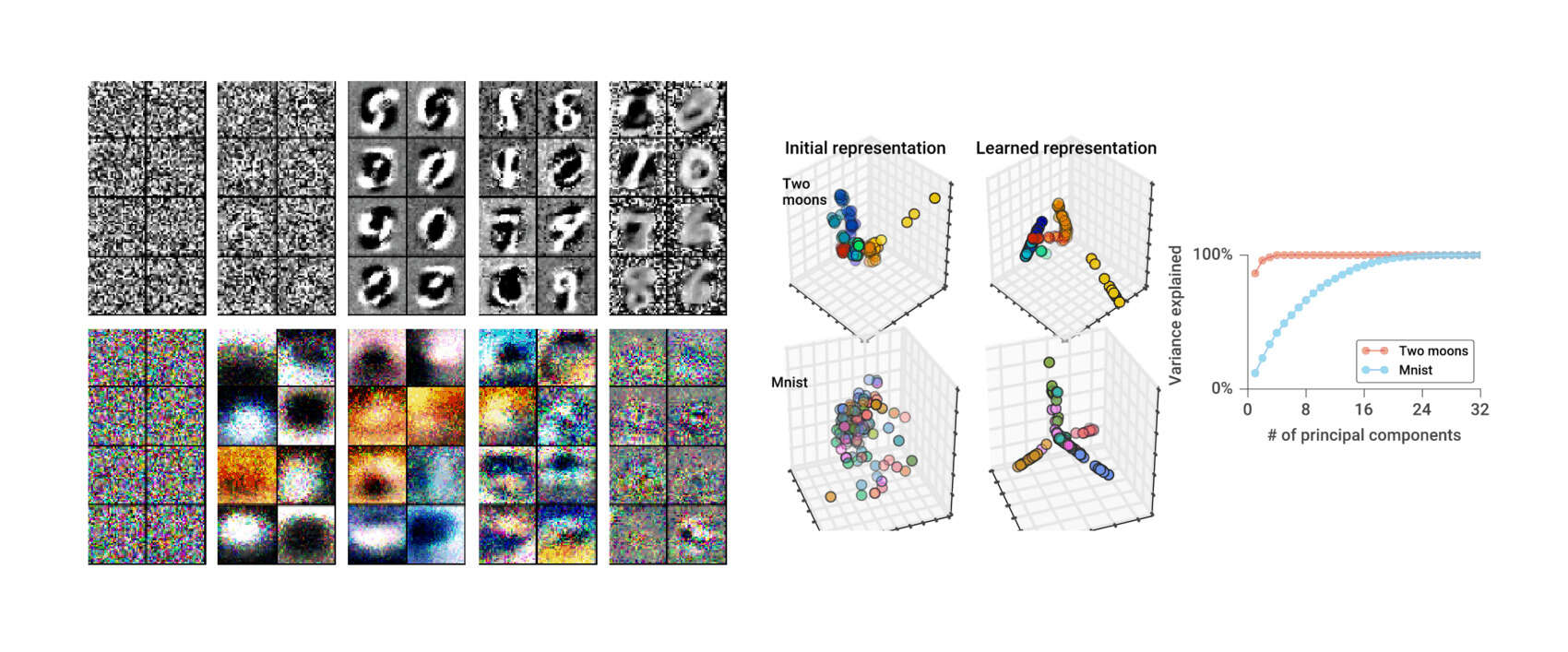{kind=link}
Bibliography
https://www.nature.com/articles/s41586-025-09761-x#deepmind: “DiscoRL: Discovering State-Of-The-Art Reinforcement Learning Algorithms”,https://arxiv.org/abs/2505.07215: “Measuring General Intelligence With Generated Games”,https://arxiv.org/abs/2505.00661#google: “On the Generalization of Language Models from In-Context Learning and Finetuning: a Controlled Study”,https://arxiv.org/abs/2503.14456: “RWKV-7 ‘Goose’ With Expressive Dynamic State Evolution”,https://arxiv.org/abs/2502.06807#openai: “Competitive Programming With Large Reasoning Models”,https://arxiv.org/abs/2501.01956: “Metadata Conditioning Accelerates Language Model Pre-Training”,https://arxiv.org/abs/2412.06464#nvidia: “Gated Delta Networks: Improving Mamba-2 With Delta Rule”,https://arxiv.org/abs/2410.07095#openai: “MLE-Bench: Evaluating Machine Learning Agents on Machine Learning Engineering”,https://arxiv.org/abs/2406.13131: “When Parts Are Greater Than Sums: Individual LLM Components Can Outperform Full Models”,https://arxiv.org/abs/2406.11233: “Probing the Decision Boundaries of In-Context Learning in Large Language Models”,https://arxiv.org/abs/2405.07883: “Zero-Shot Tokenizer Transfer”,https://arxiv.org/abs/2404.12699: “SOPHON: Non-Fine-Tunable Learning to Restrain Task Transferability For Pre-Trained Models”,https://ieeexplore.ieee.org/abstract/document/10446522: “Revisiting the Equivalence of In-Context Learning and Gradient Descent: The Impact of Data Distribution”,https://arxiv.org/abs/2404.07544: “From Words to Numbers: Your Large Language Model Is Secretly A Capable Regressor When Given In-Context Examples”,https://arxiv.org/abs/2403.01518#deepmind: “Revisiting Dynamic Evaluation: Online Adaptation for Large Language Models”,https://arxiv.org/abs/2312.09230: “Successor Heads: Recurring, Interpretable Attention Heads In The Wild”,https://www.nature.com/articles/s41467-023-42875-2#deepmind: “Learning Few-Shot Imitation As Cultural Transmission”,https://openreview.net/forum?id=psXVkKO9No#deepmind: “Self-AIXI: Self-Predictive Universal AI”,https://arxiv.org/abs/2310.15047: “Implicit Meta-Learning May Lead Language Models to Trust More Reliable Sources”,https://arxiv.org/abs/2308.09175#deepmind: “Diversifying AI: Towards Creative Chess With AlphaZero (AZdb)”,https://arxiv.org/abs/2307.03381: “Teaching Arithmetic to Small Transformers”,https://arxiv.org/abs/2306.14892: “Supervised Pretraining Can Learn In-Context Reinforcement Learning”,https://arxiv.org/abs/2306.13831: “Minigrid & Miniworld: Modular & Customizable Reinforcement Learning Environments for Goal-Oriented Tasks”,https://arxiv.org/abs/2307.01201#deepmind: “Schema-Learning and Rebinding As Mechanisms of In-Context Learning and Emergence”,https://arxiv.org/abs/2306.09222#google: “RGD: Stochastic Re-Weighted Gradient Descent via Distributionally Robust Optimization”,https://arxiv.org/abs/2304.02015#alibaba: “How Well Do Large Language Models Perform in Arithmetic Tasks?”,https://arxiv.org/abs/2303.03846#google: “Larger Language Models Do In-Context Learning Differently”,https://arxiv.org/abs/2212.07677#google: “Transformers Learn In-Context by Gradient Descent”,https://arxiv.org/abs/2212.02475#google: “FWL: Meta-Learning Fast Weight Language Models”,https://arxiv.org/abs/2211.15661#google: “What Learning Algorithm Is In-Context Learning? Investigations With Linear Models”,https://arxiv.org/abs/2211.01786: “BLOOMZ/mT0: Crosslingual Generalization through Multitask Finetuning”,https://arxiv.org/abs/2209.14500: “SAP: Bidirectional Language Models Are Also Few-Shot Learners”,https://arxiv.org/abs/2209.12892: “g.pt: Learning to Learn With Generative Models of Neural Network Checkpoints”,https://arxiv.org/abs/2208.01448#amazon: “AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model”,https://arxiv.org/abs/2208.01066: “What Can Transformers Learn In-Context? A Case Study of Simple Function Classes”,https://arxiv.org/abs/2207.01848: “TabPFN: Meta-Learning a Real-Time Tabular AutoML Method For Small Data”,https://arxiv.org/abs/2206.13499: “Prompting Decision Transformer for Few-Shot Policy Generalization”,https://arxiv.org/abs/2206.07137: “RHO-LOSS: Prioritized Training on Points That Are Learnable, Worth Learning, and Not Yet Learnt”,https://arxiv.org/abs/2205.13320#google: “Towards Learning Universal Hyperparameter Optimizers With Transformers”,https://arxiv.org/abs/2205.06175#deepmind: “Gato: A Generalist Agent”,https://arxiv.org/abs/2205.05131#google: “UL2: Unifying Language Learning Paradigms”,https://arxiv.org/abs/2204.07705: “Tk-Instruct: Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks”,https://arxiv.org/abs/2203.03691: “HyperMixer: An MLP-Based Low Cost Alternative to Transformers”,https://arxiv.org/abs/2203.02094#microsoft: “LiteTransformerSearch: Training-Free Neural Architecture Search for Efficient Language Models”,https://arxiv.org/abs/2203.00759: “HyperPrompt: Prompt-Based Task-Conditioning of Transformers”,https://arxiv.org/abs/2202.12837#facebook: “Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?”,https://arxiv.org/abs/2202.07415#deepmind: “NeuPL: Neural Population Learning”,2022-miki.pdf: “Learning Robust Perceptive Locomotion for Quadrupedal Robots in the Wild”,https://arxiv.org/abs/2112.10510: “PFNs: Transformers Can Do Bayesian Inference”,https://arxiv.org/abs/2112.00861#anthropic: “A General Language Assistant As a Laboratory for Alignment”,https://arxiv.org/abs/2111.01587#deepmind: “Procedural Generalization by Planning With Self-Supervised World Models”,https://arxiv.org/abs/2106.00958#openai: “LHOPT: A Generalizable Approach to Learning Optimizers”,https://www.sciencedirect.com/science/article/pii/S0004370221000862#deepmind: “Reward Is Enough”,https://arxiv.org/abs/2104.06272#deepmind: “Podracer Architectures for Scalable Reinforcement Learning”,https://arxiv.org/abs/2103.01075#google: “OmniNet: Omnidirectional Representations from Transformers”,https://arxiv.org/abs/2003.10580#google: “Meta Pseudo Labels”,https://www.lesswrong.com/posts/Wnqua6eQkewL3bqsF/matt-botvinick-on-the-spontaneous-emergence-of-learning: “Matt Botvinick on the Spontaneous Emergence of Learning Algorithms”,https://arxiv.org/abs/2003.06212: “Accelerating and Improving AlphaZero Using Population Based Training”,https://openai.com/research/procgen-benchmark: “Procgen Benchmark: We’re Releasing Procgen Benchmark, 16 Simple-To-Use Procedurally-Generated Environments Which Provide a Direct Measure of How Quickly a Reinforcement Learning Agent Learns Generalizable Skills”,https://lilianweng.github.io/lil-log/2019/06/23/meta-reinforcement-learning.html#openai: “Meta Reinforcement Learning”,https://arxiv.org/abs/1906.06669: “One Epoch Is All You Need”,https://david-abel.github.io/notes/icml_2019.pdf: “ICML 2019 Notes”,https://arxiv.org/abs/1905.01320#deepmind: “Meta-Learners’ Learning Dynamics Are unlike Learners’”,https://arxiv.org/abs/1904.11455#deepmind: “Ray Interference: a Source of Plateaus in Deep Reinforcement Learning”,https://lilianweng.github.io/lil-log/2018/11/30/meta-learning.html#openai: “Meta-Learning: Learning to Learn Fast”,https://arxiv.org/abs/1806.07857: “RUDDER: Return Decomposition for Delayed Rewards”,https://arxiv.org/abs/1805.09501#google: “AutoAugment: Learning Augmentation Policies from Data”,https://arxiv.org/abs/1804.00222#google: “Meta-Learning Update Rules for Unsupervised Representation Learning”,https://arxiv.org/abs/1803.02999#openai: “Reptile/FOMAML: On First-Order Meta-Learning Algorithms”,https://arxiv.org/abs/1708.05344: “SMASH: One-Shot Model Architecture Search through HyperNetworks”,https://arxiv.org/abs/1609.09106#google: “HyperNetworks”,2015-zhu-2.pdf: “Machine Teaching: an Inverse Problem to Machine Learning and an Approach Toward Optimal Education”,https://pmc.ncbi.nlm.nih.gov/articles/PMC2666683/: “Evolutionary Importance of Phenotypic Accommodation in Novel Environments: an Empirical Test of the Baldwin Effect”,https://arxiv.org/abs/cs/0207097#schmidhuber: “Optimal Ordered Problem Solver (OOPS)”,1991-bengio.pdf: “Learning a Synaptic Learning Rule”,