‘data pruning’ directory
- See Also
- Gwern
- Links
- “Data Mixing Can Induce Phase Transitions in Knowledge Acquisition”, Gu et al 2025
- “A Little Help Goes a Long Way: Efficient LLM Training by Leveraging Small LMs”, Rawat et al 2024
- “Accelerating Large Language Model Pretraining via LFR Pedagogy: Learn, Focus, and Review”, Prakriya et al 2024
- “Improving Pretraining Data Using Perplexity Correlations”, Thrush et al 2024
- “DataComp-LM: In Search of the next Generation of Training Sets for Language Models”, Li et al 2024
- “Perplexed by Perplexity: Perplexity-Based Data Pruning With Small Reference Models”, Ankner et al 2024
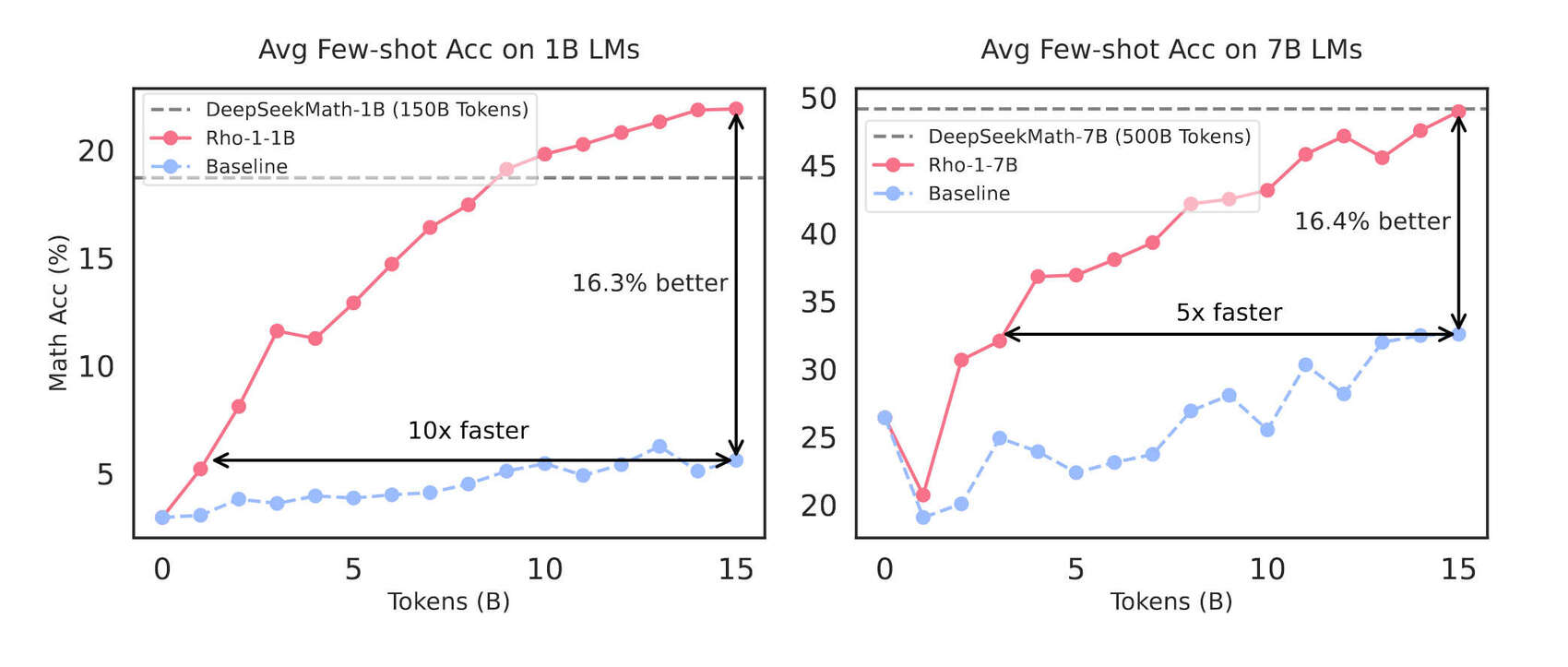
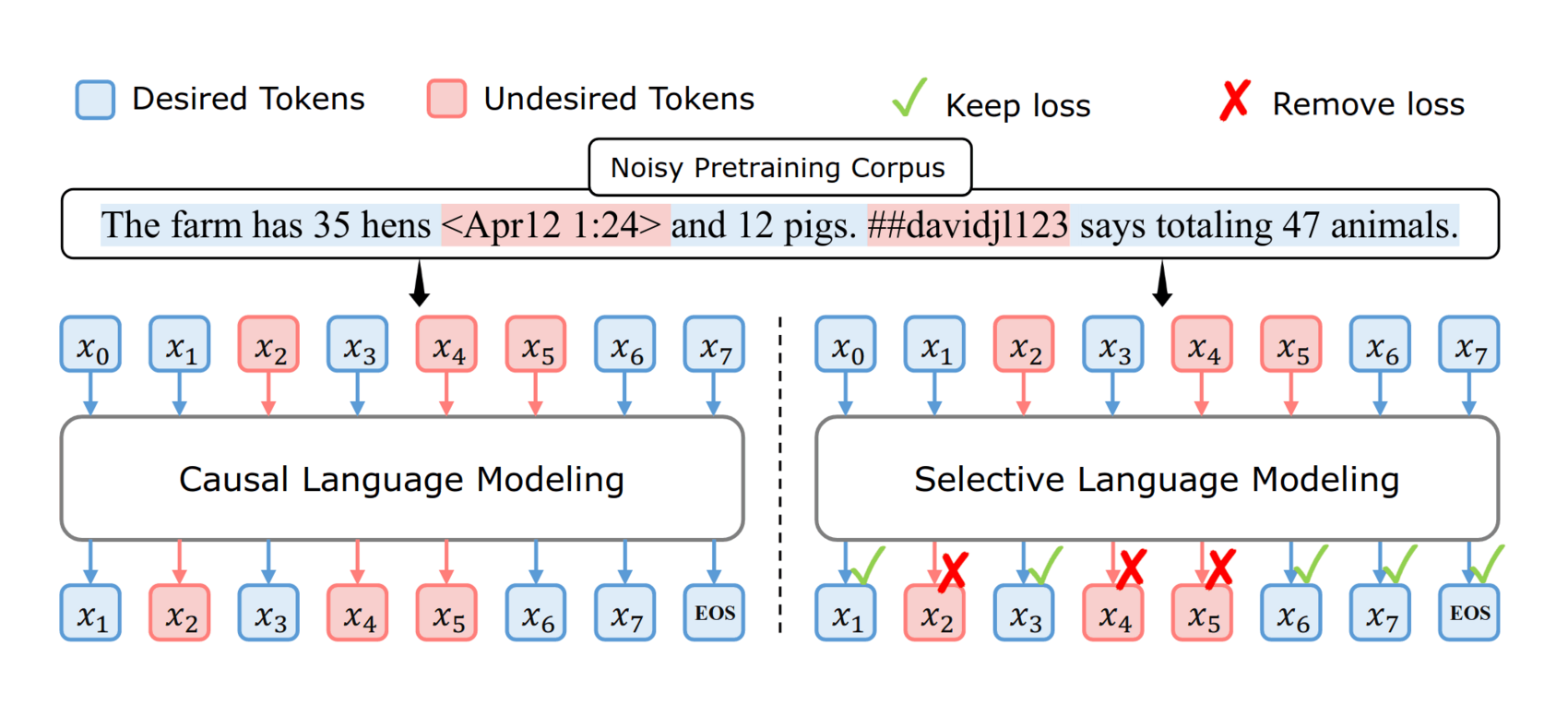
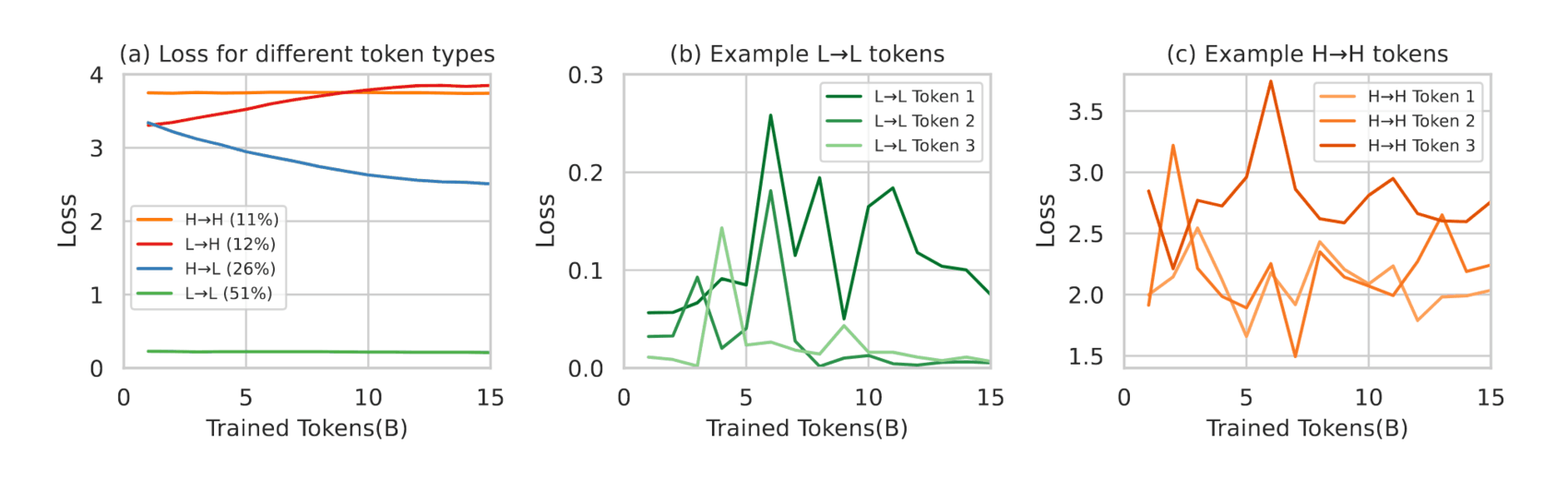
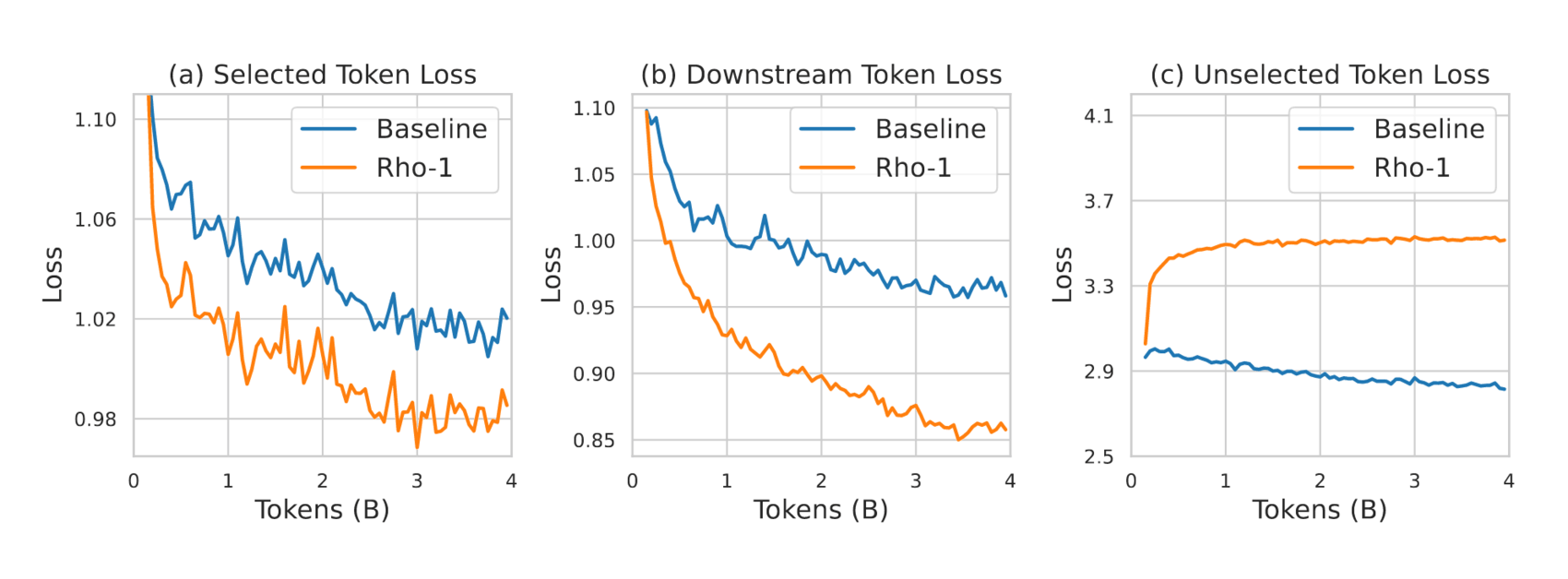
- “Rho-1: Not All Tokens Are What You Need”, Lin et al 2024
- “Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws”, Allen-Zhu & Li 2024
- “A Study in Dataset Pruning for Image Super-Resolution”, Moser et al 2024
- “How to Train Data-Efficient LLMs”, Sachdeva et al 2024
- “Autonomous Data Selection With Language Models for Mathematical Texts”, Zhang et al 2024
- “Rephrasing the Web (WARP): A Recipe for Compute and Data-Efficient Language Modeling”, Maini et al 2024
- “Bad Students Make Great Teachers: Active Learning Accelerates Large-Scale Visual Understanding”, Evans et al 2023
- “Does CLIP’s Generalization Performance Mainly Stem from High Train-Test Similarity?”, Mayilvahanan et al 2023
- “Data Filtering Networks”, Fang et al 2023
- “SlimPajama-DC: Understanding Data Combinations for LLM Training”, Shen et al 2023
- “Anchor Points: Benchmarking Models With Much Fewer Examples”, Vivek et al 2023
- “When Less Is More: Investigating Data Pruning for Pretraining LLMs at Scale”, Marion et al 2023
- “Beyond Scale: the Diversity Coefficient As a Data Quality Metric Demonstrates LLMs Are Pre-Trained on Formally Diverse Data”, Lee et al 2023
- “Data Selection for Language Models via Importance Resampling”, Xie et al 2023
- “Dataset Distillation: A Comprehensive Review”, Yu et al 2023
- “Beyond Neural Scaling Laws: Beating Power Law Scaling via Data Pruning”, Sorscher et al 2022
- “Unadversarial Examples: Designing Objects for Robust Vision”, Salman et al 2020
- “"Less Than One"-Shot Learning: Learning n Classes From M < N Samples”, Sucholutsky & Schonlau 2020
- “Generative Models Are Unsupervised Predictors of Page Quality: A Colossal-Scale Study”, Bahri et al 2020
- “Dataset Distillation”, Wang et al 2018
- “Understanding Black-Box Predictions via Influence Functions”, Koh & Liang 2017
- “Machine Teaching for Bayesian Learners in the Exponential Family”, Zhu 2013
- “The Optimal Architecture for Small Language Models”
- “FineWeb: Decanting the Web for the Finest Text Data at Scale”
- Sort By Magic
- Wikipedia (1)
- Miscellaneous
- Bibliography
See Also
Gwern
“Making Anime Faces With StyleGAN”, Gwern 2019
Links
“Data Mixing Can Induce Phase Transitions in Knowledge Acquisition”, Gu et al 2025
Data Mixing Can Induce Phase Transitions in Knowledge Acquisition
“A Little Help Goes a Long Way: Efficient LLM Training by Leveraging Small LMs”, Rawat et al 2024
A Little Help Goes a Long Way: Efficient LLM Training by Leveraging Small LMs
“Accelerating Large Language Model Pretraining via LFR Pedagogy: Learn, Focus, and Review”, Prakriya et al 2024
Accelerating Large Language Model Pretraining via LFR Pedagogy: Learn, Focus, and Review
“Improving Pretraining Data Using Perplexity Correlations”, Thrush et al 2024
“DataComp-LM: In Search of the next Generation of Training Sets for Language Models”, Li et al 2024
DataComp-LM: In search of the next generation of training sets for language models
“Perplexed by Perplexity: Perplexity-Based Data Pruning With Small Reference Models”, Ankner et al 2024
Perplexed by Perplexity: Perplexity-Based Data Pruning With Small Reference Models
“Rho-1: Not All Tokens Are What You Need”, Lin et al 2024
“Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws”, Allen-Zhu & Li 2024
Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws
“A Study in Dataset Pruning for Image Super-Resolution”, Moser et al 2024
“How to Train Data-Efficient LLMs”, Sachdeva et al 2024
“Autonomous Data Selection With Language Models for Mathematical Texts”, Zhang et al 2024
Autonomous Data Selection with Language Models for Mathematical Texts
“Rephrasing the Web (WARP): A Recipe for Compute and Data-Efficient Language Modeling”, Maini et al 2024
Rephrasing the Web (WARP): A Recipe for Compute and Data-Efficient Language Modeling
“Bad Students Make Great Teachers: Active Learning Accelerates Large-Scale Visual Understanding”, Evans et al 2023
Bad Students Make Great Teachers: Active Learning Accelerates Large-Scale Visual Understanding
“Does CLIP’s Generalization Performance Mainly Stem from High Train-Test Similarity?”, Mayilvahanan et al 2023
Does CLIP’s Generalization Performance Mainly Stem from High Train-Test Similarity?
“Data Filtering Networks”, Fang et al 2023
“SlimPajama-DC: Understanding Data Combinations for LLM Training”, Shen et al 2023
SlimPajama-DC: Understanding Data Combinations for LLM Training
“Anchor Points: Benchmarking Models With Much Fewer Examples”, Vivek et al 2023
“When Less Is More: Investigating Data Pruning for Pretraining LLMs at Scale”, Marion et al 2023
When Less is More: Investigating Data Pruning for Pretraining LLMs at Scale
“Beyond Scale: the Diversity Coefficient As a Data Quality Metric Demonstrates LLMs Are Pre-Trained on Formally Diverse Data”, Lee et al 2023
“Data Selection for Language Models via Importance Resampling”, Xie et al 2023
Data Selection for Language Models via Importance Resampling
“Dataset Distillation: A Comprehensive Review”, Yu et al 2023
“Beyond Neural Scaling Laws: Beating Power Law Scaling via Data Pruning”, Sorscher et al 2022
Beyond neural scaling laws: beating power law scaling via data pruning
“Unadversarial Examples: Designing Objects for Robust Vision”, Salman et al 2020
“"Less Than One"-Shot Learning: Learning n Classes From M < N Samples”, Sucholutsky & Schonlau 2020
"Less Than One"-Shot Learning: Learning n Classes From M < N Samples
“Generative Models Are Unsupervised Predictors of Page Quality: A Colossal-Scale Study”, Bahri et al 2020
Generative Models are Unsupervised Predictors of Page Quality: A Colossal-Scale Study
“Dataset Distillation”, Wang et al 2018
“Understanding Black-Box Predictions via Influence Functions”, Koh & Liang 2017
“Machine Teaching for Bayesian Learners in the Exponential Family”, Zhu 2013
Machine Teaching for Bayesian Learners in the Exponential Family
“The Optimal Architecture for Small Language Models”
“FineWeb: Decanting the Web for the Finest Text Data at Scale”
FineWeb: decanting the web for the finest text data at scale
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
data-selection
generalization
data-pruning
Wikipedia (1)
Miscellaneous
https://aclanthology.org/2023.findings-emnlp.18/View External Link:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2406.11794: “DataComp-LM: In Search of the next Generation of Training Sets for Language Models”,https://arxiv.org/abs/2405.20541: “Perplexed by Perplexity: Perplexity-Based Data Pruning With Small Reference Models”,https://arxiv.org/abs/2404.07965#microsoft: “Rho-1: Not All Tokens Are What You Need”,https://arxiv.org/abs/2402.07625: “Autonomous Data Selection With Language Models for Mathematical Texts”,https://arxiv.org/abs/2312.05328#deepmind: “Bad Students Make Great Teachers: Active Learning Accelerates Large-Scale Visual Understanding”,https://arxiv.org/abs/2309.17425#apple: “Data Filtering Networks”,https://arxiv.org/abs/2309.10818#cerebras: “SlimPajama-DC: Understanding Data Combinations for LLM Training”,https://arxiv.org/abs/2302.03169: “Data Selection for Language Models via Importance Resampling”,