‘continual learning’ directory
- See Also
- Links
- “Why Does Off-Model SFT Degrade Capabilities?”, SebastianP et al 2026
- “Zork-Bench: An LLM Reasoning Eval Based on Text Adventure Games; a Tale As Old As Time, or at Least As Old As Computers”, Aiken 2026
- “SlopCodeBench: Benchmarking How Coding Agents Degrade Over Long-Horizon Iterative Tasks”, Orlanski et al 2026
- “Playing With AI: How Do State-Of-The-Art Large Language Models Perform in the 1977 Text-Based Adventure Game Zork?”, Gerrits 2026
- “Shared Sensitivity to Data Distribution during Learning in Humans and Transformer Networks”, Lerousseau & Summerfield 2025
- “Insights into Claude-4.5-Opus from Pokémon Red”, Bradshaw 2025
- “Thoughts on AI Progress (Dec 2025)”, Patel 2025
- “Continual Learning via Sparse Memory Finetuning”, Lin et al 2025
- “Text-To-LoRA (T2L): Instant Transformer Adaption”, Charakorn et al 2025
- “Why I Don’t Think AGI Is Right around the Corner: Continual Learning Is a Huge Bottleneck”, Patel 2025
- “Why I Don’t Think AGI Is Right around the Corner”, Patel 2025
- “Chronologically Consistent Large Language Models”, He et al 2025
- “Memory Layers at Scale”, Berges et al 2024
- “Flexible Task Abstractions Emerge in Linear Networks With Fast and Bounded Units”, Sandbrink et al 2024
- “LoRA vs Full Fine-Tuning: An Illusion of Equivalence”, Shuttleworth et al 2024
- “Investigating Learning-Independent Abstract Reasoning in Artificial Neural Networks”, Barak & Loewenstein 2024
- “PEER: Mixture of A Million Experts”, He 2024
- “How Do Large Language Models Acquire Factual Knowledge During Pretraining?”, Chang et al 2024
- “Learning to Continually Learn With the Bayesian Principle”, Lee et al 2024
- “LoRA Learns Less and Forgets Less”, Biderman et al 2024
- “Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data”, Gerstgrasser et al 2024
- “Simple and Scalable Strategies to Continually Pre-Train Large Language Models”, Ibrahim et al 2024
- “Online Adaptation of Language Models With a Memory of Amortized Contexts (MAC)”, Tack et al 2024
- “When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method”, Zhang et al 2024
- “Investigating Continual Pretraining in Large Language Models: Insights and Implications”, Yıldız et al 2024
- “RAG vs Fine-Tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture”, Balaguer et al 2024
- “LLaMA Pro: Progressive LLaMA With Block Expansion”, Wu et al 2024
- “Large Language Models Relearn Removed Concepts”, Lo et al 2024
- “Language Model Alignment With Elastic Reset”, Noukhovitch et al 2023
- “In-Context Pretraining (ICP): Language Modeling Beyond Document Boundaries”, Shi et al 2023
- “Loss of Plasticity in Deep Continual Learning (Continual Backpropagation)”, Dohare et al 2023
- “Continual Diffusion: Continual Customization of Text-To-Image Diffusion With C-LoRA”, Smith et al 2023
- “PaLM-E: An Embodied Multimodal Language Model”, Driess et al 2023
- “Understanding Plasticity in Neural Networks”, Lyle et al 2023
- “The Forward-Forward Algorithm: Some Preliminary Investigations”, Hinton 2022
- “Broken Neural Scaling Laws”, Caballero et al 2022
- “Exclusive Supermask Subnetwork Training for Continual Learning”, Yadav & Bansal 2022
- “Learn the Time to Learn: Replay Scheduling in Continual Learning”, Klasson et al 2022
- “On the Effectiveness of Compact Biomedical Transformers (✱BioBERT)”, Rohanian et al 2022
- “Don’t Stop Learning: Towards Continual Learning for the CLIP Model (VR-LwF)”, Ding et al 2022
- “Fleet-DAgger: Interactive Robot Fleet Learning With Scalable Human Supervision”, Hoque et al 2022
- “Task-Agnostic Continual Reinforcement Learning: In Praise of a Simple Baseline (3RL)”, Caccia et al 2022
- “CT0: Fine-Tuned Language Models Are Continual Learners”, Scialom et al 2022
- “Memorization Without Overfitting: Analyzing the Training Dynamics of Large Language Models”, Tirumala et al 2022
- “Continual Pre-Training Mitigates Forgetting in Language and Vision”, Cossu et al 2022
- “Continual Learning With Foundation Models: An Empirical Study of Latent Replay”, Ostapenko et al 2022
- “DualPrompt: Complementary Prompting for Rehearsal-Free Continual Learning”, Wang et al 2022
- “Effect of Scale on Catastrophic Forgetting in Neural Networks”, Ramasesh et al 2022
- “The Dual Form of Neural Networks Revisited: Connecting Test Time Predictions to Training Patterns via Spotlights of Attention”, Irie et al 2022
- “Learning to Prompt for Continual Learning”, Wang et al 2021
- “An Empirical Investigation of the Role of Pre-Training in Lifelong Learning”, Mehta et al 2021
- “The Geometry of Representational Drift in Natural and Artificial Neural Networks”, Aitken et al 2021
- “Wide Neural Networks Forget Less Catastrophically”, Mirzadeh et al 2021
- “Lifelong Pretraining: Continually Adapting Language Models to Emerging Corpora”, Jin et al 2021
- “Continuous Coordination As a Realistic Scenario for Lifelong Learning”, Nekoei et al 2021
- “Inductive Biases for Deep Learning of Higher-Level Cognition”, Goyal & Bengio 2020
- “Learning from the Past: Meta-Continual Learning With Knowledge Embedding for Jointly Sketch, Cartoon, and Caricature Face Recognition”, Zheng et al 2020b
- “Meta-Learning through Hebbian Plasticity in Random Networks”, Najarro & Risi 2020
- “Learning to Learn With Feedback and Local Plasticity”, Lindsey & Litwin-Kumar 2020
- “Understanding the Role of Training Regimes in Continual Learning”, Mirzadeh et al 2020
- “Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks”, Gururangan et al 2020
- “Never Stop Learning: The Effectiveness of Fine-Tuning in Robotic Reinforcement Learning”, Julian et al 2020
- “On Warm-Starting Neural Network Training”, Ash & Adams 2019
- “Gated Linear Networks”, Veness et al 2019
- “Learning and Evaluating General Linguistic Intelligence”, Yogatama et al 2019
- “Self-Net: Lifelong Learning via Continual Self-Modeling”, Camp et al 2018
- “Unicorn: Continual Learning With a Universal, Off-Policy Agent”, Mankowitz et al 2018
- “Meta Networks”, Munkhdalai & Yu 2017
- “PathNet: Evolution Channels Gradient Descent in Super Neural Networks”, Fernando et al 2017
- “Overcoming Catastrophic Forgetting in Neural Networks”, Kirkpatrick et al 2016
- “Optimal Direct Policy Search”, Glasmachers & Schmidhuber 2011
- “On Learning How to Learn Learning Strategies: Technical Report FKI-198-94 (Revised)”, Schmidhuber 1995
- “Repeat Before Forgetting: Spaced Repetition for Efficient and Effective Training of Neural Networks”
- “Claudeception: A Claude Code Skill for Autonomous Skill Extraction and Continuous Learning. Have Claude Code Get Smarter As It Works”
- “Can LLMs Learn from a Single Example?”
- Sort By Magic
- Wikipedia (1)
- Miscellaneous
- Bibliography
See Also
Links
“Why Does Off-Model SFT Degrade Capabilities?”, SebastianP et al 2026
“Zork-Bench: An LLM Reasoning Eval Based on Text Adventure Games; a Tale As Old As Time, or at Least As Old As Computers”, Aiken 2026
“SlopCodeBench: Benchmarking How Coding Agents Degrade Over Long-Horizon Iterative Tasks”, Orlanski et al 2026
SlopCodeBench: Benchmarking How Coding Agents Degrade Over Long-Horizon Iterative Tasks
“Playing With AI: How Do State-Of-The-Art Large Language Models Perform in the 1977 Text-Based Adventure Game Zork?”, Gerrits 2026
“Shared Sensitivity to Data Distribution during Learning in Humans and Transformer Networks”, Lerousseau & Summerfield 2025
Shared sensitivity to data distribution during learning in humans and Transformer networks
“Insights into Claude-4.5-Opus from Pokémon Red”, Bradshaw 2025
“Thoughts on AI Progress (Dec 2025)”, Patel 2025
“Continual Learning via Sparse Memory Finetuning”, Lin et al 2025
“Text-To-LoRA (T2L): Instant Transformer Adaption”, Charakorn et al 2025
“Why I Don’t Think AGI Is Right around the Corner: Continual Learning Is a Huge Bottleneck”, Patel 2025
Why I don’t think AGI is right around the corner: Continual learning is a huge bottleneck
“Why I Don’t Think AGI Is Right around the Corner”, Patel 2025
“Chronologically Consistent Large Language Models”, He et al 2025
“Memory Layers at Scale”, Berges et al 2024
“Flexible Task Abstractions Emerge in Linear Networks With Fast and Bounded Units”, Sandbrink et al 2024
Flexible task abstractions emerge in linear networks with fast and bounded units
“LoRA vs Full Fine-Tuning: An Illusion of Equivalence”, Shuttleworth et al 2024
“Investigating Learning-Independent Abstract Reasoning in Artificial Neural Networks”, Barak & Loewenstein 2024
Investigating learning-independent abstract reasoning in artificial neural networks
“PEER: Mixture of A Million Experts”, He 2024
“How Do Large Language Models Acquire Factual Knowledge During Pretraining?”, Chang et al 2024
How Do Large Language Models Acquire Factual Knowledge During Pretraining?
“Learning to Continually Learn With the Bayesian Principle”, Lee et al 2024
“LoRA Learns Less and Forgets Less”, Biderman et al 2024
“Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data”, Gerstgrasser et al 2024
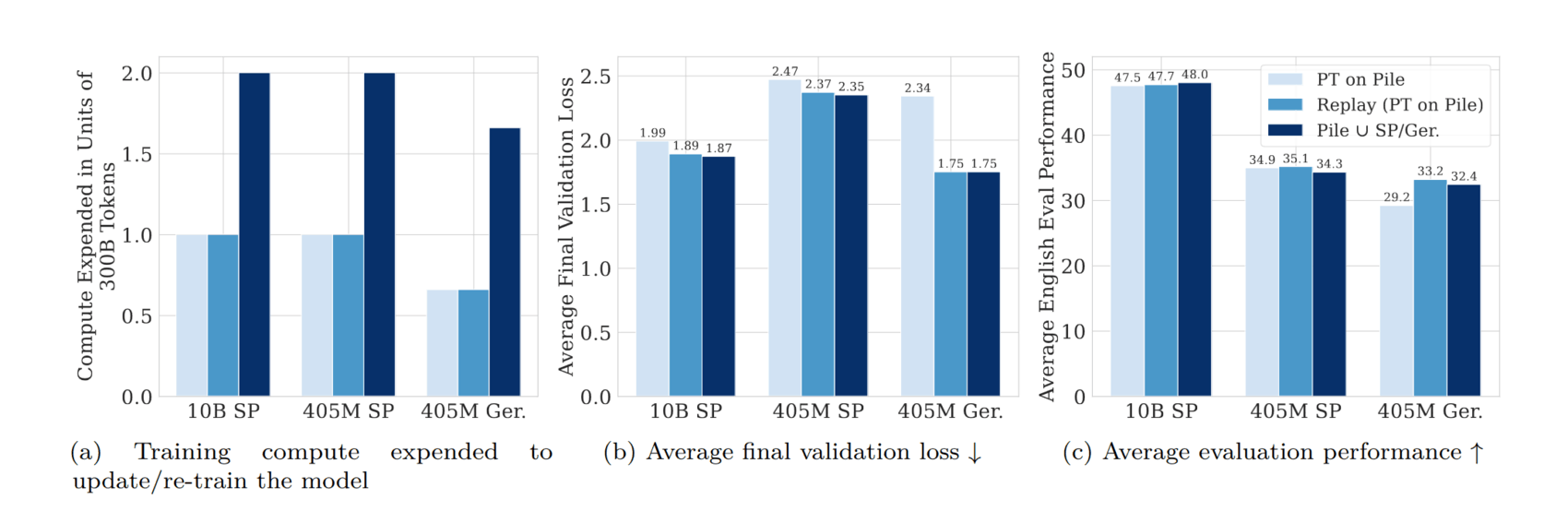
“Simple and Scalable Strategies to Continually Pre-Train Large Language Models”, Ibrahim et al 2024
Simple and Scalable Strategies to Continually Pre-train Large Language Models
“Online Adaptation of Language Models With a Memory of Amortized Contexts (MAC)”, Tack et al 2024
Online Adaptation of Language Models with a Memory of Amortized Contexts (MAC)
“When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method”, Zhang et al 2024
When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method
“Investigating Continual Pretraining in Large Language Models: Insights and Implications”, Yıldız et al 2024
Investigating Continual Pretraining in Large Language Models: Insights and Implications
“RAG vs Fine-Tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture”, Balaguer et al 2024
RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture
“LLaMA Pro: Progressive LLaMA With Block Expansion”, Wu et al 2024
“Large Language Models Relearn Removed Concepts”, Lo et al 2024
“Language Model Alignment With Elastic Reset”, Noukhovitch et al 2023
“In-Context Pretraining (ICP): Language Modeling Beyond Document Boundaries”, Shi et al 2023
In-Context Pretraining (ICP): Language Modeling Beyond Document Boundaries
“Loss of Plasticity in Deep Continual Learning (Continual Backpropagation)”, Dohare et al 2023
Loss of Plasticity in Deep Continual Learning (Continual Backpropagation)
“Continual Diffusion: Continual Customization of Text-To-Image Diffusion With C-LoRA”, Smith et al 2023
Continual Diffusion: Continual Customization of Text-to-Image Diffusion with C-LoRA
“PaLM-E: An Embodied Multimodal Language Model”, Driess et al 2023
“Understanding Plasticity in Neural Networks”, Lyle et al 2023
“The Forward-Forward Algorithm: Some Preliminary Investigations”, Hinton 2022
The Forward-Forward Algorithm: Some Preliminary Investigations
“Broken Neural Scaling Laws”, Caballero et al 2022
“Exclusive Supermask Subnetwork Training for Continual Learning”, Yadav & Bansal 2022
Exclusive Supermask Subnetwork Training for Continual Learning
“Learn the Time to Learn: Replay Scheduling in Continual Learning”, Klasson et al 2022
Learn the Time to Learn: Replay Scheduling in Continual Learning
“On the Effectiveness of Compact Biomedical Transformers (✱BioBERT)”, Rohanian et al 2022
On the Effectiveness of Compact Biomedical Transformers (✱BioBERT)
“Don’t Stop Learning: Towards Continual Learning for the CLIP Model (VR-LwF)”, Ding et al 2022
Don’t Stop Learning: Towards Continual Learning for the CLIP Model (VR-LwF)
“Fleet-DAgger: Interactive Robot Fleet Learning With Scalable Human Supervision”, Hoque et al 2022
Fleet-DAgger: Interactive Robot Fleet Learning with Scalable Human Supervision
“Task-Agnostic Continual Reinforcement Learning: In Praise of a Simple Baseline (3RL)”, Caccia et al 2022
Task-Agnostic Continual Reinforcement Learning: In Praise of a Simple Baseline (3RL)
“CT0: Fine-Tuned Language Models Are Continual Learners”, Scialom et al 2022
“Memorization Without Overfitting: Analyzing the Training Dynamics of Large Language Models”, Tirumala et al 2022
Memorization Without Overfitting: Analyzing the Training Dynamics of Large Language Models
“Continual Pre-Training Mitigates Forgetting in Language and Vision”, Cossu et al 2022
Continual Pre-Training Mitigates Forgetting in Language and Vision
“Continual Learning With Foundation Models: An Empirical Study of Latent Replay”, Ostapenko et al 2022
Continual Learning with Foundation Models: An Empirical Study of Latent Replay
“DualPrompt: Complementary Prompting for Rehearsal-Free Continual Learning”, Wang et al 2022
DualPrompt: Complementary Prompting for Rehearsal-free Continual Learning
“Effect of Scale on Catastrophic Forgetting in Neural Networks”, Ramasesh et al 2022
Effect of scale on catastrophic forgetting in neural networks
“The Dual Form of Neural Networks Revisited: Connecting Test Time Predictions to Training Patterns via Spotlights of Attention”, Irie et al 2022
“Learning to Prompt for Continual Learning”, Wang et al 2021
“An Empirical Investigation of the Role of Pre-Training in Lifelong Learning”, Mehta et al 2021
An Empirical Investigation of the Role of Pre-training in Lifelong Learning
“The Geometry of Representational Drift in Natural and Artificial Neural Networks”, Aitken et al 2021
The Geometry of Representational Drift in Natural and Artificial Neural Networks
“Wide Neural Networks Forget Less Catastrophically”, Mirzadeh et al 2021
“Lifelong Pretraining: Continually Adapting Language Models to Emerging Corpora”, Jin et al 2021
Lifelong Pretraining: Continually Adapting Language Models to Emerging Corpora
“Continuous Coordination As a Realistic Scenario for Lifelong Learning”, Nekoei et al 2021
Continuous Coordination As a Realistic Scenario for Lifelong Learning
“Inductive Biases for Deep Learning of Higher-Level Cognition”, Goyal & Bengio 2020
Inductive Biases for Deep Learning of Higher-Level Cognition
“Learning from the Past: Meta-Continual Learning With Knowledge Embedding for Jointly Sketch, Cartoon, and Caricature Face Recognition”, Zheng et al 2020b
“Meta-Learning through Hebbian Plasticity in Random Networks”, Najarro & Risi 2020
“Learning to Learn With Feedback and Local Plasticity”, Lindsey & Litwin-Kumar 2020
“Understanding the Role of Training Regimes in Continual Learning”, Mirzadeh et al 2020
Understanding the Role of Training Regimes in Continual Learning
“Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks”, Gururangan et al 2020
Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks
“Never Stop Learning: The Effectiveness of Fine-Tuning in Robotic Reinforcement Learning”, Julian et al 2020
Never Stop Learning: The Effectiveness of Fine-Tuning in Robotic Reinforcement Learning
“On Warm-Starting Neural Network Training”, Ash & Adams 2019
“Gated Linear Networks”, Veness et al 2019
“Learning and Evaluating General Linguistic Intelligence”, Yogatama et al 2019
“Self-Net: Lifelong Learning via Continual Self-Modeling”, Camp et al 2018
“Unicorn: Continual Learning With a Universal, Off-Policy Agent”, Mankowitz et al 2018
Unicorn: Continual Learning with a Universal, Off-policy Agent
“Meta Networks”, Munkhdalai & Yu 2017
“PathNet: Evolution Channels Gradient Descent in Super Neural Networks”, Fernando et al 2017
PathNet: Evolution Channels Gradient Descent in Super Neural Networks
“Overcoming Catastrophic Forgetting in Neural Networks”, Kirkpatrick et al 2016
“Optimal Direct Policy Search”, Glasmachers & Schmidhuber 2011
“On Learning How to Learn Learning Strategies: Technical Report FKI-198-94 (Revised)”, Schmidhuber 1995
On Learning How to Learn Learning Strategies: Technical Report FKI-198-94 (revised)
“Repeat Before Forgetting: Spaced Repetition for Efficient and Effective Training of Neural Networks”
Repeat before Forgetting: Spaced Repetition for Efficient and Effective Training of Neural Networks
View External Link:
“Claudeception: A Claude Code Skill for Autonomous Skill Extraction and Continuous Learning. Have Claude Code Get Smarter As It Works”
“Can LLMs Learn from a Single Example?”
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
policy-search
continuous-learning
abstract-reasoning
long-horizon-training
model-evaluation
lifelong-training
Wikipedia (1)
Miscellaneous
{kind=link}
Bibliography
https://www.lowimpactfruit.com/p/zork-bench-an-llm-reasoning-eval: “Zork-Bench: An LLM Reasoning Eval Based on Text Adventure Games; a Tale As Old As Time, or at Least As Old As Computers”,https://arxiv.org/abs/2510.15103#facebook: “Continual Learning via Sparse Memory Finetuning”,https://arxiv.org/abs/2506.06105: “Text-To-LoRA (T2L): Instant Transformer Adaption”,https://arxiv.org/abs/2401.08406#microsoft: “RAG vs Fine-Tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture”,https://arxiv.org/abs/2312.07551: “Language Model Alignment With Elastic Reset”,https://arxiv.org/abs/2206.14349: “Fleet-DAgger: Interactive Robot Fleet Learning With Scalable Human Supervision”,https://arxiv.org/abs/2205.12393: “CT0: Fine-Tuned Language Models Are Continual Learners”,https://arxiv.org/abs/2110.11526#deepmind: “Wide Neural Networks Forget Less Catastrophically”,