‘recurrent Transformer’ directory
- See Also
- Links
- “EGGROLL: Evolution Strategies at the Hyperscale”, Sarkar et al 2025
- “ATLAS: Learning to Optimally Memorize the Context at Test Time [DeepTransformers]”, Behrouz et al 2025
- “Scaling up Test-Time Compute With Latent Reasoning: A Recurrent Depth Approach”, Geiping et al 2025
- “Titans: Learning to Memorize at Test Time”, Behrouz et al 2024
- “Byte Latent Transformer (BLT): Patches Scale Better Than Tokens”, Pagnoni et al 2024
- “Transformers Can Do Arithmetic With the Right Embeddings”, McLeish et al 2024
- “RecurrentGemma: Moving Past Transformers for Efficient Open Language Models”, Botev et al 2024
- “Revisiting Dynamic Evaluation: Online Adaptation for Large Language Models”, Rannen-Triki et al 2024
- “Transformers Are Multi-State RNNs”, Oren et al 2024
- “Think Before You Speak: Training Language Models With Pause Tokens”, Goyal et al 2023
- “Retentive Network: A Successor to Transformer for Large Language Models”, Sun et al 2023
- “Block-State Transformers”, Fathi et al 2023
- “Looped Transformers As Programmable Computers”, Giannou et al 2023
- “FWL: Meta-Learning Fast Weight Language Models”, Clark et al 2022
- “Fine-Tuning Pre-Trained Transformers into Decaying Fast Weights”, Mao 2022
- “Simple Recurrence Improves Masked Language Models”, Lei et al 2022
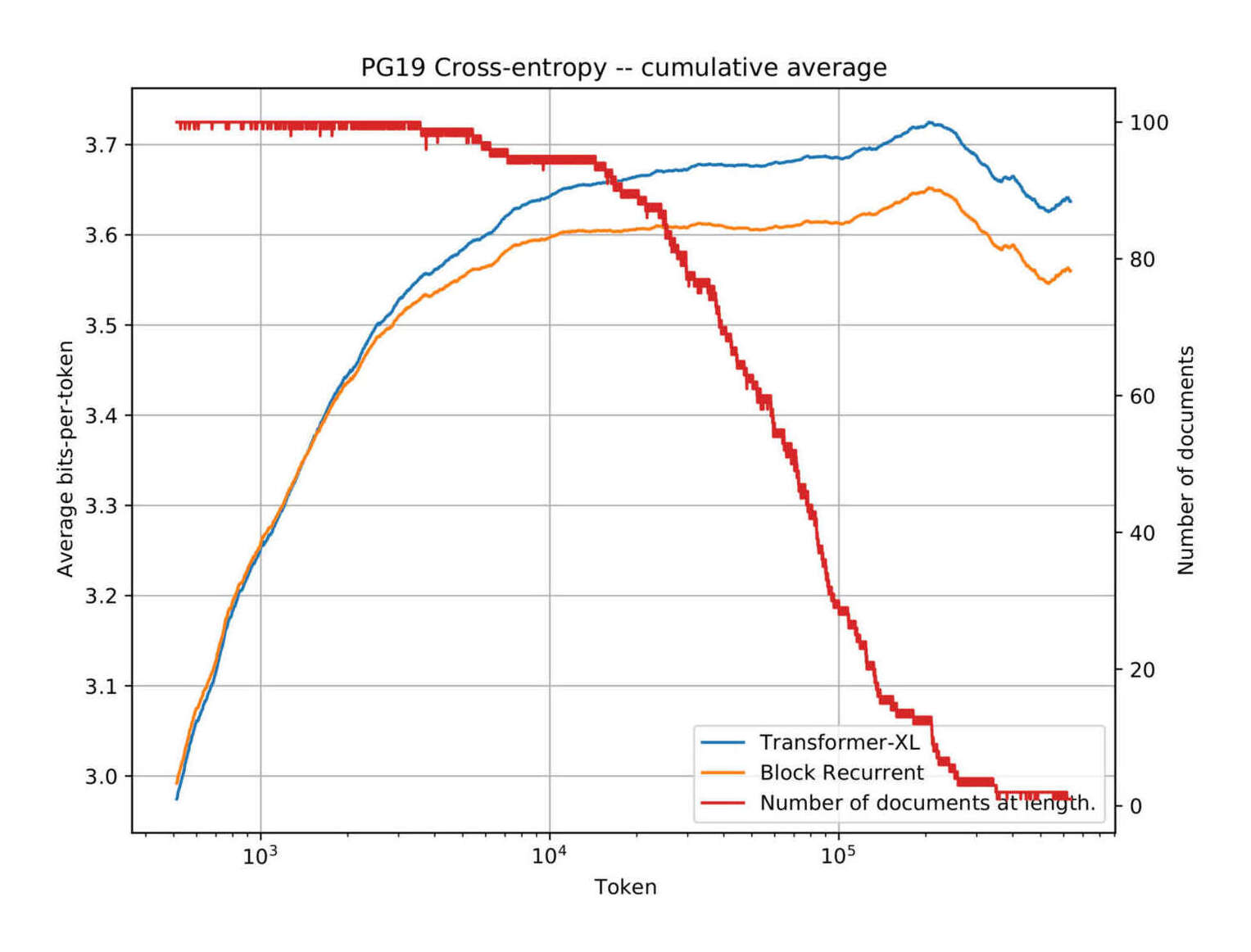
- “Block-Recurrent Transformers”, Hutchins et al 2022
- “Scaling Transformers: Sparse Is Enough in Scaling Transformers”, Jaszczur et al 2021
- “S4: Efficiently Modeling Long Sequences With Structured State Spaces”, Gu et al 2021
- “LSSL: Combining Recurrent, Convolutional, and Continuous-Time Models With Linear State-Space Layers”, Gu et al 2021
- “Do Long-Range Language Models Actually Use Long-Range Context?”, Sun et al 2021
- “Finetuning Pretrained Transformers into RNNs”, Kasai et al 2021
- “When Attention Meets Fast Recurrence: Training SRU++ Language Models With Reduced Compute”, Lei 2021
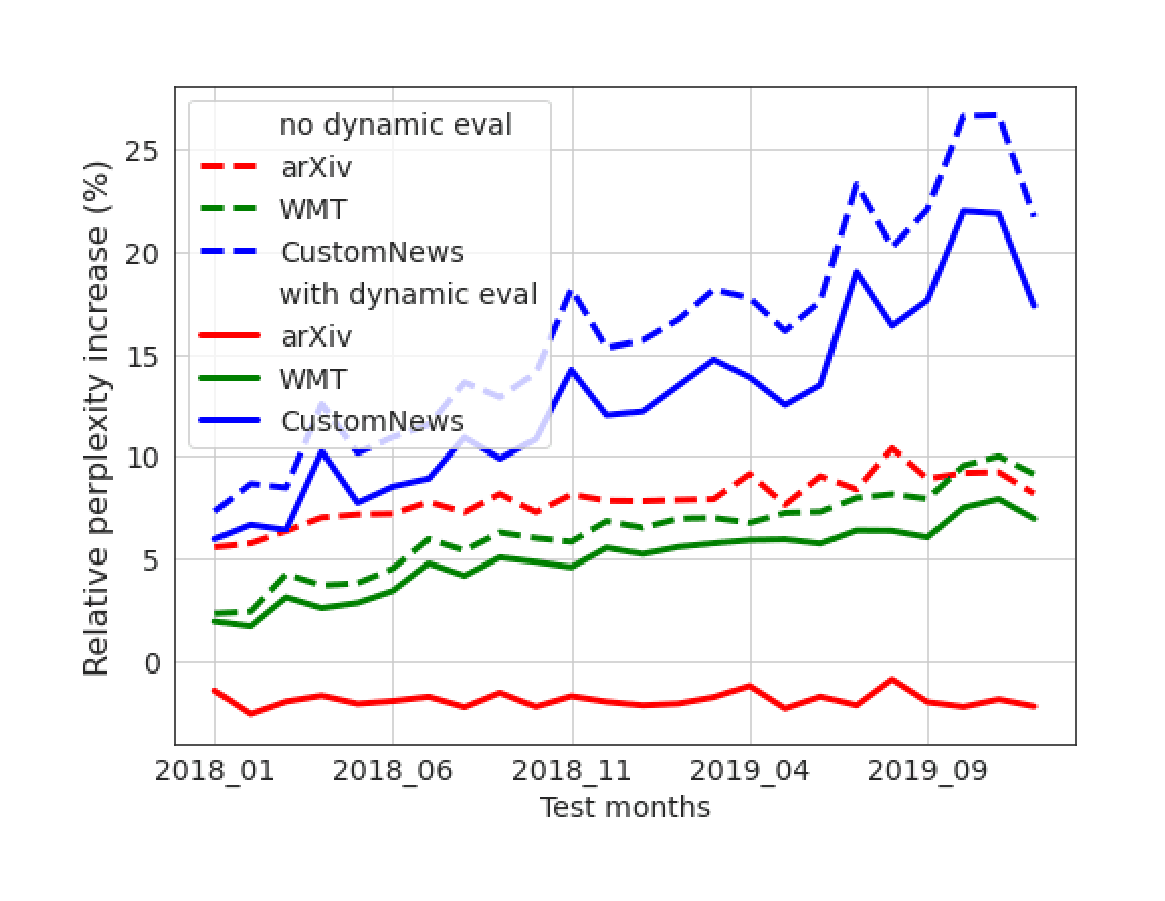
- “Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Dynamic Evaluation”, Lazaridou et al 2021 (page 7 org deepmind)
- “Shortformer: Better Language Modeling Using Shorter Inputs”, Press et al 2020
- “Untangling Tradeoffs between Recurrence and Self-Attention in Neural Networks”, Kerg et al 2020
- “Addressing Some Limitations of Transformers With Feedback Memory”, Fan et al 2020
- “DEQ: Deep Equilibrium Models”, Bai et al 2019
- “XLNet: Generalized Autoregressive Pretraining for Language Understanding”, Yang et al 2019
- “Dynamic Evaluation of Transformer Language Models”, Krause et al 2019
- “Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context”, Dai et al 2019
- “Transformer-XL—Combining Transformers and RNNs Into a State-Of-The-Art Language Model”, Horev 2019
- “Universal Transformers”, Dehghani et al 2018
- “Hyperbolic Attention Networks”, Gulcehre et al 2018
- “Improving Neural Language Models With a Continuous Cache”, Grave et al 2016
- “Context Caching”
- “LLM Neuroanatomy II: Modern LLM Hacking and Hints of a Universal Language?”
- joeddav
- Sort By Magic
- Miscellaneous
- Bibliography
See Also
Links
“EGGROLL: Evolution Strategies at the Hyperscale”, Sarkar et al 2025
“ATLAS: Learning to Optimally Memorize the Context at Test Time [DeepTransformers]”, Behrouz et al 2025
ATLAS: Learning to Optimally Memorize the Context at Test Time [DeepTransformers]
“Scaling up Test-Time Compute With Latent Reasoning: A Recurrent Depth Approach”, Geiping et al 2025
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
“Titans: Learning to Memorize at Test Time”, Behrouz et al 2024
“Byte Latent Transformer (BLT): Patches Scale Better Than Tokens”, Pagnoni et al 2024
Byte Latent Transformer (BLT): Patches Scale Better Than Tokens
“Transformers Can Do Arithmetic With the Right Embeddings”, McLeish et al 2024
“RecurrentGemma: Moving Past Transformers for Efficient Open Language Models”, Botev et al 2024
RecurrentGemma: Moving Past Transformers for Efficient Open Language Models
“Revisiting Dynamic Evaluation: Online Adaptation for Large Language Models”, Rannen-Triki et al 2024
Revisiting Dynamic Evaluation: Online Adaptation for Large Language Models
“Transformers Are Multi-State RNNs”, Oren et al 2024
“Think Before You Speak: Training Language Models With Pause Tokens”, Goyal et al 2023
Think before you speak: Training Language Models With Pause Tokens
“Retentive Network: A Successor to Transformer for Large Language Models”, Sun et al 2023
Retentive Network: A Successor to Transformer for Large Language Models
“Block-State Transformers”, Fathi et al 2023
“Looped Transformers As Programmable Computers”, Giannou et al 2023
“FWL: Meta-Learning Fast Weight Language Models”, Clark et al 2022
“Fine-Tuning Pre-Trained Transformers into Decaying Fast Weights”, Mao 2022
Fine-Tuning Pre-trained Transformers into Decaying Fast Weights
“Simple Recurrence Improves Masked Language Models”, Lei et al 2022
“Block-Recurrent Transformers”, Hutchins et al 2022
“Scaling Transformers: Sparse Is Enough in Scaling Transformers”, Jaszczur et al 2021
Scaling Transformers: Sparse is Enough in Scaling Transformers
“S4: Efficiently Modeling Long Sequences With Structured State Spaces”, Gu et al 2021
S4: Efficiently Modeling Long Sequences with Structured State Spaces
“LSSL: Combining Recurrent, Convolutional, and Continuous-Time Models With Linear State-Space Layers”, Gu et al 2021
LSSL: Combining Recurrent, Convolutional, and Continuous-time Models with Linear State-Space Layers
“Do Long-Range Language Models Actually Use Long-Range Context?”, Sun et al 2021
Do Long-Range Language Models Actually Use Long-Range Context?
“Finetuning Pretrained Transformers into RNNs”, Kasai et al 2021
“When Attention Meets Fast Recurrence: Training SRU++ Language Models With Reduced Compute”, Lei 2021
When Attention Meets Fast Recurrence: Training SRU++ Language Models with Reduced Compute
“Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Dynamic Evaluation”, Lazaridou et al 2021 (page 7 org deepmind)
Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Dynamic Evaluation
“Shortformer: Better Language Modeling Using Shorter Inputs”, Press et al 2020
“Untangling Tradeoffs between Recurrence and Self-Attention in Neural Networks”, Kerg et al 2020
Untangling tradeoffs between recurrence and self-attention in neural networks
“Addressing Some Limitations of Transformers With Feedback Memory”, Fan et al 2020
Addressing Some Limitations of Transformers with Feedback Memory
“DEQ: Deep Equilibrium Models”, Bai et al 2019
“XLNet: Generalized Autoregressive Pretraining for Language Understanding”, Yang et al 2019
XLNet: Generalized Autoregressive Pretraining for Language Understanding
“Dynamic Evaluation of Transformer Language Models”, Krause et al 2019
“Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context”, Dai et al 2019
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
“Transformer-XL—Combining Transformers and RNNs Into a State-Of-The-Art Language Model”, Horev 2019
Transformer-XL—Combining Transformers and RNNs Into a State-of-the-art Language Model
“Universal Transformers”, Dehghani et al 2018
“Hyperbolic Attention Networks”, Gulcehre et al 2018
“Improving Neural Language Models With a Continuous Cache”, Grave et al 2016
“Context Caching”
“LLM Neuroanatomy II: Modern LLM Hacking and Hints of a Universal Language?”
LLM Neuroanatomy II: Modern LLM Hacking and hints of a Universal Language?
joeddav
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
pause-token
recurrent-models
scaling-transformers
short-context
Miscellaneous
{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2511.16652: “EGGROLL: Evolution Strategies at the Hyperscale”,https://arxiv.org/abs/2403.01518#deepmind: “Revisiting Dynamic Evaluation: Online Adaptation for Large Language Models”,https://arxiv.org/abs/2310.02226: “Think Before You Speak: Training Language Models With Pause Tokens”,https://arxiv.org/abs/2212.02475#google: “FWL: Meta-Learning Fast Weight Language Models”,https://arxiv.org/abs/2210.04243: “Fine-Tuning Pre-Trained Transformers into Decaying Fast Weights”,https://arxiv.org/abs/2203.07852: “Block-Recurrent Transformers”,https://arxiv.org/abs/2111.12763#google: “Scaling Transformers: Sparse Is Enough in Scaling Transformers”,https://arxiv.org/abs/2111.00396: “S4: Efficiently Modeling Long Sequences With Structured State Spaces”,https://arxiv.org/abs/2109.09115: “Do Long-Range Language Models Actually Use Long-Range Context?”,https://arxiv.org/pdf/2102.01951#page=7&org=deepmind: “Mind the Gap: Assessing Temporal Generalization in Neural Language Models § Dynamic Evaluation”,https://arxiv.org/abs/1906.08237: “XLNet: Generalized Autoregressive Pretraining for Language Understanding”,https://arxiv.org/abs/1904.08378: “Dynamic Evaluation of Transformer Language Models”,https://arxiv.org/abs/1901.02860: “Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context”,https://arxiv.org/abs/1807.03819#googledeepmind: “Universal Transformers”,