‘self-attention’ directory
- See Also
- Gwern
- Links
- “Pretraining Recurrent Networks without Recurrence”, Kumar & Isola 2026
- “Do Transformers Need 3 Projections? Systematic Study of QKV Variants”, Kayyam et al 2026
- “A Large-Scale Study on the Accuracy vs Cost Trade-Offs of Training and Evaluation Settings in Fine-Grained Image Recognition”, Rios et al 2026
- “RoPE Distinguishes Neither Positions Nor Tokens in Long Contexts, Provably”, Du et al 2026
- “Negation Neglect: When Models Fail to Learn Negations in Training”, Mayne et al 2026
- “Convergent Evolution: How Different Language Models Learn Similar Number Representations”, Fu et al 2026
- “Slot Machines: How LLMs Keep Track of Multiple Entities”, Bogdan & Lindsey 2026
- “Current Activation Oracles Are Hard to Use”
- “Doc-To-LoRA (D2L): Learning to Instantly Internalize Contexts”, Charakorn et al 2026
- “Debunking Claims about Sub-Quadratic Attention”, Ivanov 2026
- “DeepSeek-V3.2 Is Okay & Cheap But Slow”, Mowshowitz 2025
- “Kimi Linear: An Expressive, Efficient Attention Architecture”, Team et al 2025
- “Transformers Are Inherently Succinct”, Bergsträßer et al 2025
- “When Models Manipulate Manifolds: The Geometry of a Counting Task”, Gurnee et al 2025
- “Evaluating Long Context (Reasoning) Ability”
- “Language Models [Activations] Are Injective and Hence Invertible”, Nikolaou et al 2025
- “Tensor Logic: The Language of AI”, Domingos 2025
- “Tensor Logic Homepage”, Domingos 2025
- “Why Can’t Transformers Learn Multiplication? Reverse-Engineering Reveals Long-Range Dependency Pitfalls”, Bai et al 2025
- “Reasoning-Finetuning Repurposes Latent Representations in Base Models”, Ward et al 2025
- “Fast and Simplex: 2-Simplicial Attention in Triton”, Roy et al 2025
- “Transformers Pretrained on Procedural Data Contain Modular Structures for Algorithmic Reasoning”, Shinnick et al 2025
- “Language Models Are Capable of Metacognitive Monitoring and Control of Their Internal Activations”, Ji-An et al 2025
- “LLMs Get Lost In Multi-Turn Conversation”, Laban et al 2025
- “The Geometry of Self-Verification in a Task-Specific Reasoning Model”, Lee et al 2025
- “It’s All Connected: A Journey Through Test-Time Memorization, Attentional Bias, Retention, and Online Optimization”, Behrouz et al 2025
- “Content-Addressable Memory With a Content-Free Energy Function”, Benoist et al 2025
- “Dynamic Tanh: Transformers without Normalization”, Zhu et al 2025
- “(How) Do Language Models Track State?”, Li et al 2025
- “Thinking Slow, Fast: Scaling Inference Compute With Distilled Reasoners”, Paliotta et al 2025
- “μnit Scaling: Simple and Scalable FP8 LLM Training”, Narayan et al 2025
- “Leveraging the True Depth of LLMs”, González et al 2025
- “Language Models Use Trigonometry to Do Addition”, Kantamneni 2025
- “Test-Time Regression: a Unifying Framework for Designing Sequence Models With Associative Memory”, Wang et al 2025
- “How Has DeepSeek Improved the Transformer Architecture?”, Erdil 2025
- “MiniMax-01: Scaling Foundation Models With Lightning Attention”, MiniMax et al 2025
- “Emergent Effects of Scaling on the Functional Hierarchies within Large Language Models”, Foop 2025
- “ICLR: In-Context Learning of Representations”, Park et al 2024
- “Hymba: A Hybrid-Head Architecture for Small Language Models”, Dong et al 2024
- “Procedural Knowledge in Pretraining Drives Reasoning in Large Language Models”, Ruis et al 2024
- “You Could Have Designed State-Of-The-Art Positional Encoding”, Fleetwood 2024
- “Long Context RAG Performance of Large Language Models”, Leng et al 2024
- “Ask, and It Shall Be Given: Turing Completeness of Prompting”, Qiu et al 2024
- “The Belief State Transformer”, Hu et al 2024
- “Arithmetic Without Algorithms: Language Models Solve Math With a Bag of Heuristics”, Nikankin et al 2024
- “ALTA: Compiler-Based Analysis of Transformers”, Shaw et al 2024
- “Tackling the Abstraction and Reasoning Corpus With Vision Transformers: the Importance of 2D Representation, Positions, and Objects”, Li et al 2024
- “Differential Transformer”, Ye et al 2024
- “Were RNNs All We Needed?”, Feng et al 2024
- “NGPT: Normalized Transformer With Representation Learning on the Hypersphere”, Loshchilov et al 2024
- “Many-Shot Jailbreaking”, Anil et al 2024
- “Masked Mixers for Language Generation and Retrieval”, Badger 2024
- “The Mamba in the Llama: Distilling and Accelerating Hybrid Models”, Wang et al 2024
- “When Can Transformers Count to n?”, Yehudai et al 2024
- “Just Read Twice: Closing the Recall Gap for Recurrent Language Models”, Arora et al 2024
- “What Matters in Transformers? Not All Attention Is Needed”, He et al 2024
- “Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?”, Lee et al 2024
- “An Empirical Study of Mamba-Based Language Models”, Waleffe et al 2024
- “Attention As a Hypernetwork”, Schug et al 2024
- “Automata Extraction from Transformers”, Zhang et al 2024
- “Scalable Matmul-Free Language Modeling”, Zhu et al 2024
- “A Theoretical Understanding of Self-Correction through In-Context Alignment”, Wang et al 2024
- “Attention As an RNN”, Feng et al 2024
- “Your Transformer Is Secretly Linear”, Razzhigaev et al 2024
- “Retrieval Head Mechanistically Explains Long-Context Factuality”, Wu et al 2024
- “Let’s Think Dot by Dot: Hidden Computation in Transformer Language Models”, Pfau et al 2024
- “Towards Smaller, Faster Decoder-Only Transformers: Architectural Variants and Their Implications”, Suresh & P 2024
- “RULER: What’s the Real Context Size of Your Long-Context Language Models?”, Hsieh et al 2024
- “ReFT: Representation Finetuning for Language Models”, Wu et al 2024
- “Many-Shot Jailbreaking”, Anthropic 2024
- “Do Language Models Plan Ahead for Future Tokens?”, Wu et al 2024
- “Streamlining Redundant Layers to Compress Large Language Models”, Chen et al 2024
- “Long-Form Factuality in Large Language Models”, Wei et al 2024
- “Mechanistic Design and Scaling of Hybrid Architectures”, Poli et al 2024
- “8 Google Employees Invented Modern AI. Here’s the Inside Story: They Met by Chance, Got Hooked on an Idea, and Wrote the Transformers Paper—The Most Consequential Tech Breakthrough in Recent History”, Levy 2024
- “RNNs Are Not Transformers (Yet): The Key Bottleneck on In-Context Retrieval”, Wen et al 2024
- “How Transformers Learn Causal Structure With Gradient Descent”, Nichani et al 2024
- “A Phase Transition between Positional and Semantic Learning in a Solvable Model of Dot-Product Attention”, Cui et al 2024
- “Rethinking Patch Dependence for Masked Autoencoders”, Fu et al 2024
- “Attention versus Contrastive Learning of Tabular Data—A Data-Centric Benchmarking”, Rabbani et al 2024
- “Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet”
- “Successor Heads: Recurring, Interpretable Attention Heads In The Wild”, Gould et al 2023
- “SwitchHead: Accelerating Transformers With Mixture-Of-Experts Attention”, Csordás et al 2023
- “Look Before You Leap: A Universal Emergent Decomposition of Retrieval Tasks in Language Models”, Variengien & Winsor 2023
- “Can a Transformer Represent a Kalman Filter?”, Goel & Bartlett 2023
- “Long Context Prompting for Claude 2.1: Claude 2.1 Excels at Retrieving Information across Its 200K Context Window, With a Simple Prompt Adjustment Improving Accuracy from 27% to 98%”, Anthropic 2023
- “Efficient Transformer Knowledge Distillation: A Performance Review”, Brown et al 2023
- “Rethinking Attention: Exploring Shallow Feed-Forward Neural Networks As an Alternative to Attention Layers in Transformers”, Bozic et al 2023
- “In-Context Vectors: Making In Context Learning More Effective and Controllable Through Latent Space Steering”, Liu et al 2023
- “On Prefrontal Working Memory and Hippocampal Episodic Memory: Unifying Memories Stored in Weights and Activation Slots”, Whittington et al 2023
- “LSS Transformer: Ultra-Long Sequence Distributed Transformer”, Wang et al 2023
- “Simplifying Transformer Blocks”, He & Hofmann 2023
- “GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling”, Katsch 2023
- “Not All Layers Are Equally As Important: Every Layer Counts BERT”, Charpentier & Samuel 2023
- “Implicit Chain-Of-Thought Reasoning via Knowledge Distillation”, Deng et al 2023
- “Training Dynamics of Contextual N-Grams in Language Models”, Quirke et al 2023
- “The Impact of Depth and Width on Transformer Language Model Generalization”, Petty et al 2023
- “Characterizing Mechanisms for Factual Recall in Language Models”, Yu et al 2023
- “Linear Representations of Sentiment in Large Language Models”, Tigges et al 2023
- “Masked Hard-Attention Transformers and Boolean RASP Recognize Exactly the Star-Free Languages”, Angluin et al 2023
- “How Many Pretraining Tasks Are Needed for In-Context Learning of Linear Regression?”, Wu et al 2023
- “Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors”, Amos et al 2023
- “Vision Transformers Need Registers”, Darcet et al 2023
- “Interpret Vision Transformers As ConvNets With Dynamic Convolutions”, Zhou et al 2023
- “Replacing Softmax With ReLU in Vision Transformers”, Wortsman et al 2023
- “Gated Recurrent Neural Networks Discover Attention”, Zucchet et al 2023
- “One Wide Feedforward Is All You Need”, Pires et al 2023
- “Activation Addition: Steering Language Models Without Optimization”, Turner et al 2023
- “Linearity of Relation Decoding in Transformer Language Models”, Hernandez et al 2023
- “The Hydra Effect: Emergent Self-Repair in Language Model Computations”, McGrath et al 2023
- “Does Circuit Analysis Interpretability Scale? Evidence from Multiple Choice Capabilities in Chinchilla”, Lieberum et al 2023
- “FlashAttention-2: Faster Attention With Better Parallelism and Work Partitioning”, Dao 2023
- “Lost in the Middle: How Language Models Use Long Contexts”, Liu et al 2023
- “Trainable Transformer in Transformer”, Panigrahi et al 2023
- “Transformers Learn to Implement Preconditioned Gradient Descent for In-Context Learning”, Ahn et al 2023
- “White-Box Transformers via Sparse Rate Reduction”, Yu et al 2023
- “Blockwise Parallel Transformer for Long Context Large Models”, Liu & Abbeel 2023
- “TTT-NN: Test-Time Training on Nearest Neighbors for Large Language Models”, Hardt & Sun 2023
- “Brainformers: Trading Simplicity for Efficiency”, Zhou et al 2023
- “GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints”, Ainslie et al 2023
- “Mimetic Initialization of Self-Attention Layers”, Trockman & Kolter 2023
- “Simplicial Hopfield Networks”, Burns & Fukai 2023
- “Toeplitz Neural Network for Sequence Modeling”, Qin et al 2023
- “Finding Neurons in a Haystack: Case Studies With Sparse Probing”, Gurnee et al 2023
- “How Does GPT-2 Compute Greater-Than?: Interpreting Mathematical Abilities in a Pre-Trained Language Model”, Hanna et al 2023
- “Theory of Coupled Neuronal-Synaptic Dynamics”, Clark & Abbott 2023
- “Coinductive Guide to Inductive Transformer Heads”, Nemecek 2023
- “Tighter Bounds on the Expressivity of Transformer Encoders”, Chiang et al 2023
- “Tracr: Compiled Transformers As a Laboratory for Interpretability”, Lindner et al 2023
- “Skip-Attention: Improving Vision Transformers by Paying Less Attention”, Venkataramanan et al 2023
- “Hungry Hungry Hippos: Towards Language Modeling With State Space Models”, Fu et al 2022
- “Scalable Adaptive Computation for Iterative Generation”, Jabri et al 2022
- “Pretraining Without Attention”, Wang et al 2022
- “Transformers Learn In-Context by Gradient Descent”, Oswald et al 2022
- “Efficiently Scaling Transformer Inference”, Pope et al 2022
- “Transformers Learn Shortcuts to Automata”, Liu et al 2022
- “Multi-CLS BERT: An Efficient Alternative to Traditional Ensembling”, Chang et al 2022
- “Transformers Implement First-Order Logic With Majority Quantifiers”, Merrill & Sabharwal 2022
- “The Lie Derivative for Measuring Learned Equivariance”, Gruver et al 2022
- “Relaxed Attention for Transformer Models”, Lohrenz et al 2022
- “Multitrack Music Transformer: Learning Long-Term Dependencies in Music With Diverse Instruments”, Dong et al 2022
- “N-Grammer: Augmenting Transformers With Latent n-Grams”, Roy et al 2022
- “Log-Precision Transformers Are Constant-Depth Uniform Threshold Circuits”, Merrill & Sabharwal 2022
- “Neural Differential Equations for Learning to Program Neural Nets Through Continuous Learning Rules”, Irie et al 2022
- “FlashAttention: Fast and Memory-Efficient Exact Attention With IO-Awareness”, Dao et al 2022
- “Simplicial Attention Networks”, Goh et al 2022
- “TATS: Long Video Generation With Time-Agnostic VQGAN and Time-Sensitive Transformer”, Ge et al 2022
- “Transformer Language Models without Positional Encodings Still Learn Positional Information”, Haviv et al 2022
- “Overcoming a Theoretical Limitation of Self-Attention”, Chiang & Cholak 2022
- “It’s Raw! Audio Generation With State-Space Models”, Goel et al 2022
- “General-Purpose, Long-Context Autoregressive Modeling With Perceiver AR”, Hawthorne et al 2022
- “Transformer Memory As a Differentiable Search Index”, Tay et al 2022
- “The Dual Form of Neural Networks Revisited: Connecting Test Time Predictions to Training Patterns via Spotlights of Attention”, Irie et al 2022
- “Attention Approximates Sparse Distributed Memory”, Bricken & Pehlevan 2021
- “Long-Range Transformers for Dynamic Spatiotemporal Forecasting”, Grigsby et al 2021
- “Train Short, Test Long: Attention With Linear Biases (ALiBi) Enables Input Length Extrapolation”, Press et al 2021
- “Counterfactual Attention Learning for Fine-Grained Visual Categorization and Re-Identification”, Rao et al 2021
- “Do Vision Transformers See Like Convolutional Neural Networks?”, Raghu et al 2021
- “Stable, Fast and Accurate: Kernelized Attention With Relative Positional Encoding”, Luo et al 2021
- “RASP: Thinking Like Transformers”, Weiss et al 2021
- “On the Distribution, Sparsity, and Inference-Time Quantization of Attention Values in Transformers”, Ji et al 2021
- “SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training”, Somepalli et al 2021
- “Not All Images Are Worth 16×16 Words: Dynamic Transformers for Efficient Image Recognition”, Wang et al 2021
- “Less Is More: Pay Less Attention in Vision Transformers”, Pan et al 2021
- “FNet: Mixing Tokens With Fourier Transforms”, Lee-Thorp et al 2021
- “Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet”, Melas-Kyriazi 2021
- “RoFormer: Enhanced Transformer With Rotary Position Embedding”, Su et al 2021
- “ALD: Efficient Transformers in Reinforcement Learning Using Actor-Learner Distillation”, Parisotto & Salakhutdinov 2021
- “Attention Is Not All You Need: Pure Attention Loses Rank Doubly Exponentially With Depth”, Dong et al 2021
- “Do Transformer Modifications Transfer Across Implementations and Applications?”, Narang et al 2021
- “Linear Transformers Are Secretly Fast Weight Programmers”, Schlag et al 2021
- “Unlocking Pixels for Reinforcement Learning via Implicit Attention”, Choromanski et al 2021
- “Transformer Feed-Forward Layers Are Key-Value Memories”, Pipek et al 2020
- “AdnFM: An Attentive DenseNet Based Factorization Machine for CTR Prediction”, Wang et al 2020
- “Inductive Biases for Deep Learning of Higher-Level Cognition”, Goyal & Bengio 2020
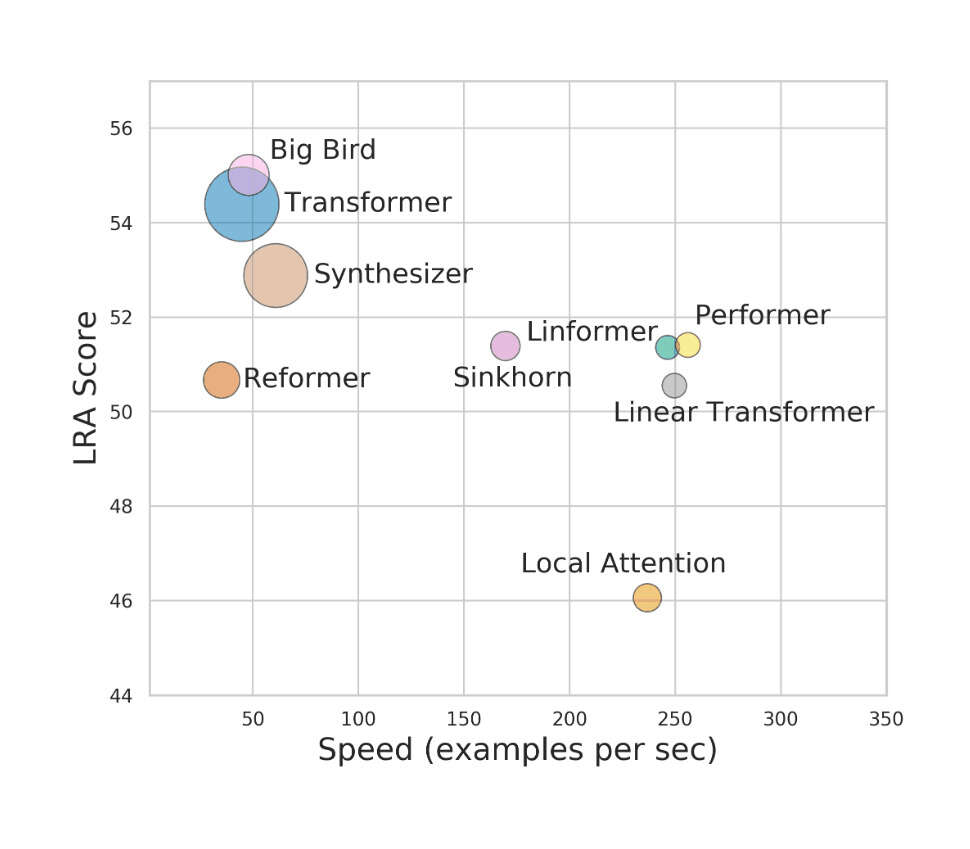
- “Long Range Arena (LRA): A Benchmark for Efficient Transformers”, Tay et al 2020
- “Current Limitations of Language Models: What You Need Is Retrieval”, Komatsuzaki 2020
- “Efficient Transformers: A Survey”, Tay et al 2020
- “HiPPO: Recurrent Memory With Optimal Polynomial Projections”, Gu et al 2020
- “Efficient Attention: Breaking The Quadratic Transformer Bottleneck”, Gwern 2020
- “Pre-Training via Paraphrasing”, Lewis et al 2020
- “Masked Language Modeling for Proteins via Linearly Scalable Long-Context Transformers”, Choromanski et al 2020
- “GPT-3: Language Models Are Few-Shot Learners”, Brown et al 2020
- “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”, Lewis et al 2020
- “Synthesizer: Rethinking Self-Attention in Transformer Models”, Tay et al 2020
- “PowerNorm: Rethinking Batch Normalization in Transformers”, Shen et al 2020
- “On Layer Normalization in the Transformer Architecture”, Xiong et al 2020
- “REALM: Retrieval-Augmented Language Model Pre-Training”, Guu et al 2020
- “BERT’s Output Layer Recognizes All Hidden Layers? Some Intriguing Phenomena and a Simple Way to Boost BERT”, Kao et al 2020
- “Rethinking Attention With Performers”, Choromanski & Colwell 2020
- “Are Transformers Universal Approximators of Sequence-To-Sequence Functions?”, Yun et al 2019
- “Dynamic Convolution: Attention over Convolution Kernels”, Chen et al 2019
- “Generalization through Memorization: Nearest Neighbor Language Models”, Khandelwal et al 2019
- “Multiplicative Interactions and Where to Find Them”, Jayakumar et al 2019
- “The Bottom-Up Evolution of Representations in the Transformer: A Study With Machine Translation and Language Modeling Objectives”, Voita et al 2019
- “Logic and the 2-Simplicial Transformer”, Clift et al 2019
- “PKM: Large Memory Layers With Product Keys”, Lample et al 2019
- “What Does BERT Look At? An Analysis of BERT’s Attention”, Clark et al 2019
- “Are 16 Heads Really Better Than One?”, Michel et al 2019
- “Paper Review: Set Transformers. A Framework for Attention-Based…”
- “Pay Less Attention With Lightweight and Dynamic Convolutions”, Wu et al 2019
- “On the Turing Completeness of Modern Neural Network Architectures”, Pérez et al 2019
- “Music Transformer”, Huang et al 2018
- “Character-Level Language Modeling With Deeper Self-Attention”, Al-Rfou et al 2018
- “Attention Is All You Need”, Vaswani et al 2017
- “A Deep Reinforced Model for Abstractive Summarization”, Paulus et al 2017
- “Get To The Point: Summarization With Pointer-Generator Networks”, See et al 2017
- “RAM: Dynamic Computational Time for Visual Attention”, Li et al 2017
- “Hybrid Computing Using a Neural Network With Dynamic External Memory”, Graves et al 2016
- “Scaling Memory-Augmented Neural Networks With Sparse Reads and Writes”, Rae et al 2016
- “Modeling Human Reading With Neural Attention”, Hahn & Keller 2016
- “Iterative Alternating Neural Attention for Machine Reading”, Sordoni et al 2016
- “Adaptive Computation Time for Recurrent Neural Networks”, Graves 2016
- “Foveation-Based Mechanisms Alleviate Adversarial Examples”, Luo et al 2015
- “Generating Images from Captions With Attention”, Mansimov et al 2015
- “DRAW: A Recurrent Neural Network For Image Generation”, Gregor et al 2015
- “Neural Turing Machines”, Graves et al 2014
- “Neural Machine Translation by Jointly Learning to Align and Translate”, Bahdanau et al 2014
- “On Learning Where To Look”, Ranzato 2014
- “Generating Sequences With Recurrent Neural Networks”, Graves 2013
- “Building a Minimal Transformer for 10-Digit Addition”, Litzenberger 2026
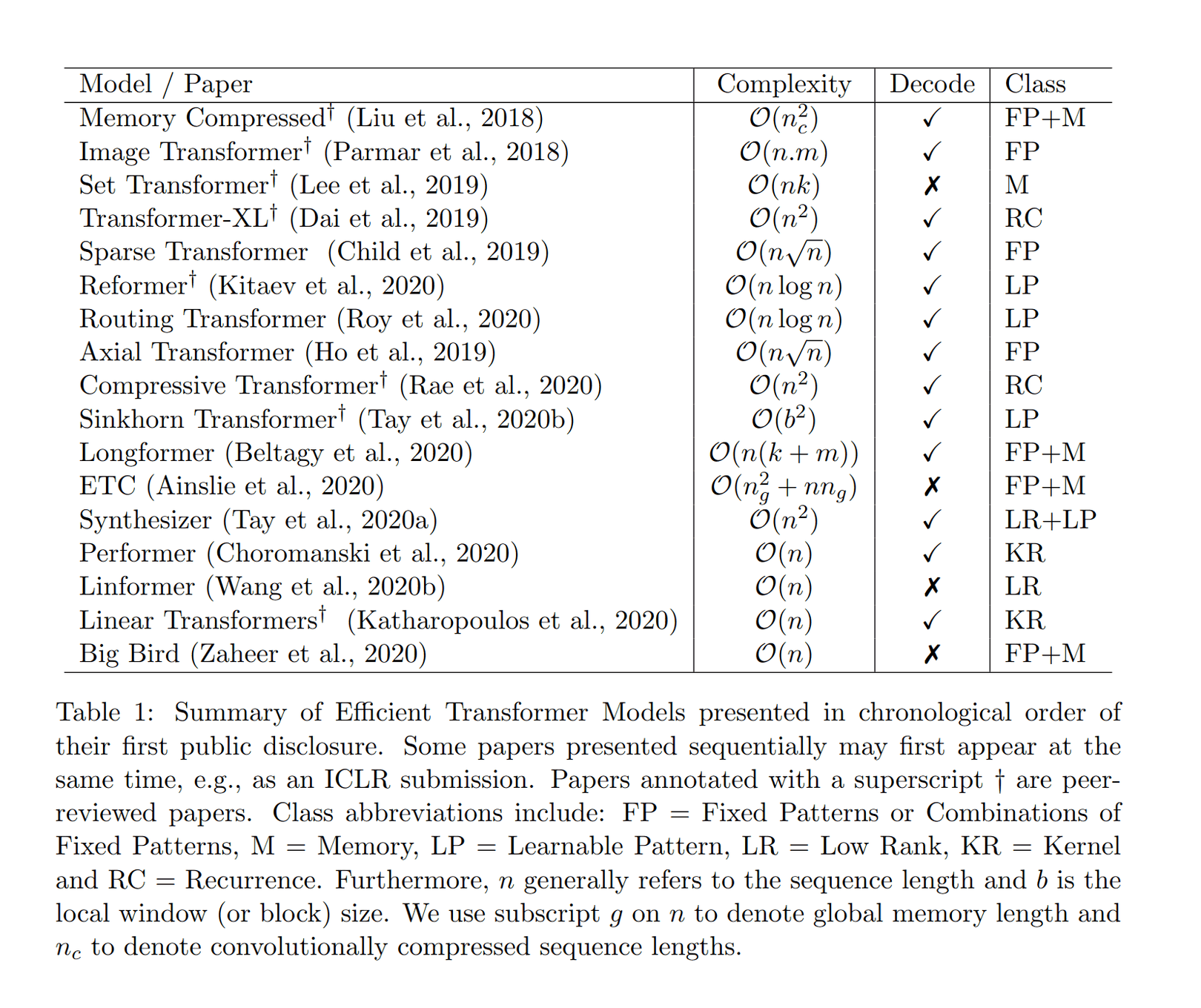
- “Efficient Transformers: A Survey § Table 1”
- “1M Context Is Now Generally Available for Opus 4.6 and Sonnet 4.6”
- “Attention and Augmented Recurrent Neural Networks”
- “AdderBoard: Contest for Smallest Transformer That Can Add Two 10-Digit Numbers”
- “Digit-Addition-311p: a Grokked 311-Parameter Transformer for 10-Digit Addition”
- “Technion-Cs-Nlp/llm-Arithmetic-Heuristics”
- “Hierarchical Object Detection With Deep Reinforcement Learning”
- “The Transformer Family: Attention and Self-Attention • Multi-Head Self-Attention • Transformer • Adaptive Computation Time (ACT) • Improved Attention Span: (Longer Attention Span (Transformer-XL) / Adaptive Attention Span / Localized Attention Span (Image Transformer)) • Less Time and Memory Cost: (Sparse Attention Matrix Factorization (Sparse Transformers) / Locality-Sensitive Hashing (Reformer)) • Make It Recurrent (Universal Transformer) • Stabilization for RL (GTrXL)”
- “100M Token Context Windows”
- “Learning to Combine Foveal Glimpses With a Third-Order Boltzmann Machine”
- “Show, Attend and Tell: Neural Image Caption Generation With Visual Attention”
- “Recurrent Models of Visual Attention”
- “Can Active Memory Replace Attention?”
- “Dzmitry Bahdanau”
- “Scaling Automatic Neuron Description”
- “Monitor: An AI-Driven Observability Interface”
- “Interpreting GPT: the Logit Lens”
- “A Sober Look at Steering Vectors for LLMs”
- “Antonym Heads Predict Semantic Opposites in Language Models”
- “One-Shot Steering Vectors Cause Emergent Misalignment, Too”
- “A Survey of Long-Term Context in Transformers: Sparse Transformers • Adaptive Span Transformers • Transformer-XL • Compressive Transformers • Reformer • Routing Transformer • Sinkhorn Transformer • Linformer • Efficient Attention: Attention With Linear Complexities • Transformers Are RNNs • ETC • Longformer”
- “FlashAttention-3: Fast and Accurate Attention With Asynchrony and Low-Precision”
- Sort By Magic
adversarial-robustnessalignment-translationoptimal-projectionspretraining-taskstabular-attention contrastive-learning data-benchmarking neural-interpretability model-comparisonmany-shot cognition-context tensor-logic steered-prompting cognition-architecturescaling-llm long-context heuristics generalization few-shot-negationmodel-interpretationlong-context
- Miscellaneous
- Bibliography
See Also
Gwern
“Absolute Unit NNs: Regression-Based MLPs for Everything”, Gwern 2023
“Research Ideas”, Gwern 2017
“GPT-3 Creative Fiction”, Gwern 2020
Links
“Pretraining Recurrent Networks without Recurrence”, Kumar & Isola 2026
“Do Transformers Need 3 Projections? Systematic Study of QKV Variants”, Kayyam et al 2026
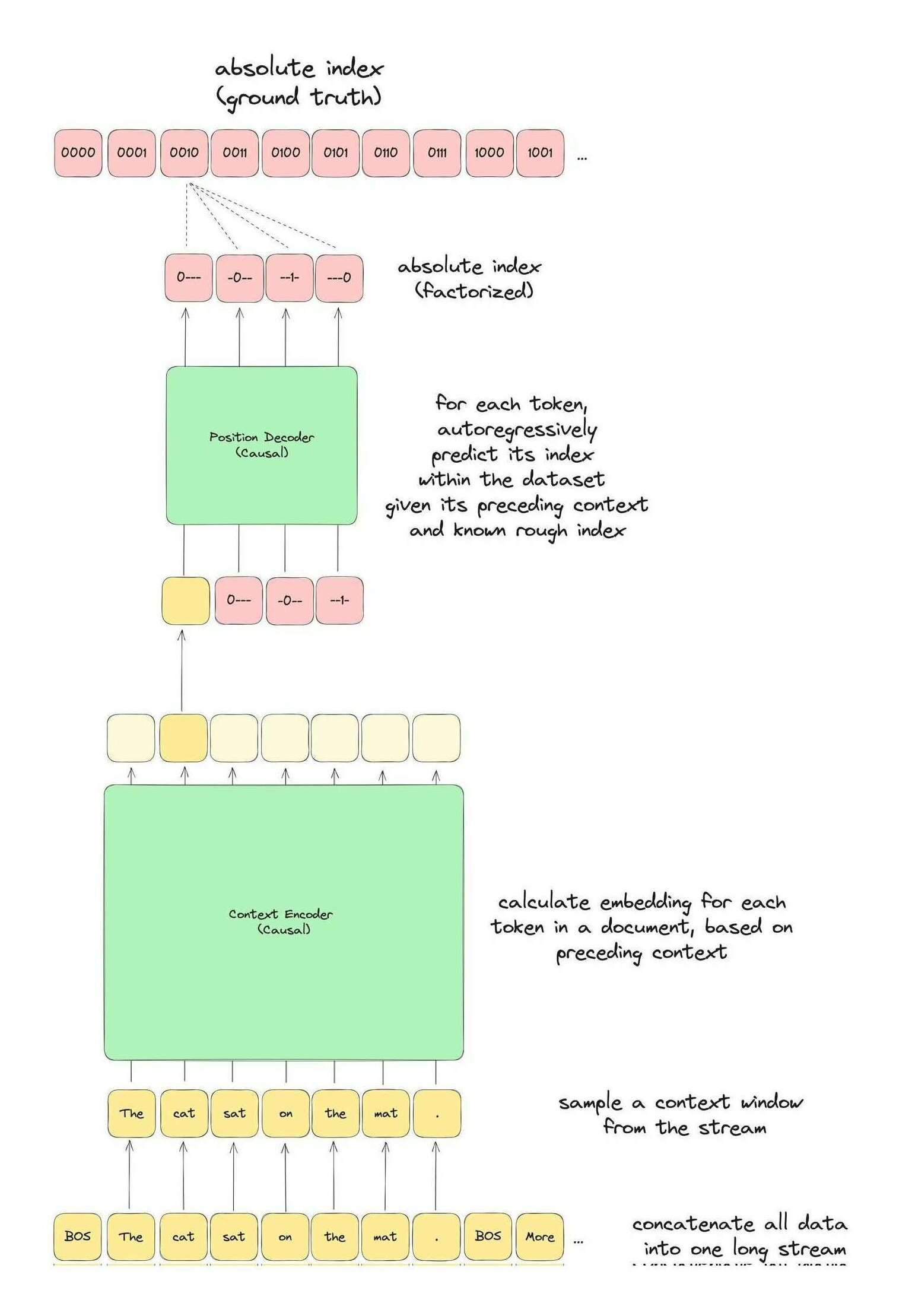
Do Transformers Need 3 Projections? Systematic Study of QKV Variants
“A Large-Scale Study on the Accuracy vs Cost Trade-Offs of Training and Evaluation Settings in Fine-Grained Image Recognition”, Rios et al 2026
“RoPE Distinguishes Neither Positions Nor Tokens in Long Contexts, Provably”, Du et al 2026
RoPE Distinguishes Neither Positions Nor Tokens in Long Contexts, Provably
“Negation Neglect: When Models Fail to Learn Negations in Training”, Mayne et al 2026
Negation Neglect: When models fail to learn negations in training
“Convergent Evolution: How Different Language Models Learn Similar Number Representations”, Fu et al 2026
Convergent Evolution: How Different Language Models Learn Similar Number Representations
“Slot Machines: How LLMs Keep Track of Multiple Entities”, Bogdan & Lindsey 2026
“Current Activation Oracles Are Hard to Use”
“Doc-To-LoRA (D2L): Learning to Instantly Internalize Contexts”, Charakorn et al 2026
Doc-to-LoRA (D2L): Learning to Instantly Internalize Contexts
“Debunking Claims about Sub-Quadratic Attention”, Ivanov 2026
“DeepSeek-V3.2 Is Okay & Cheap But Slow”, Mowshowitz 2025
“Kimi Linear: An Expressive, Efficient Attention Architecture”, Team et al 2025
Kimi Linear: An Expressive, Efficient Attention Architecture
“Transformers Are Inherently Succinct”, Bergsträßer et al 2025
“When Models Manipulate Manifolds: The Geometry of a Counting Task”, Gurnee et al 2025
When Models Manipulate Manifolds: The Geometry of a Counting Task
“Evaluating Long Context (Reasoning) Ability”
“Language Models [Activations] Are Injective and Hence Invertible”, Nikolaou et al 2025
Language Models [Activations] are Injective and Hence Invertible
“Tensor Logic: The Language of AI”, Domingos 2025
“Tensor Logic Homepage”, Domingos 2025
“Why Can’t Transformers Learn Multiplication? Reverse-Engineering Reveals Long-Range Dependency Pitfalls”, Bai et al 2025
“Reasoning-Finetuning Repurposes Latent Representations in Base Models”, Ward et al 2025
Reasoning-Finetuning Repurposes Latent Representations in Base Models
“Fast and Simplex: 2-Simplicial Attention in Triton”, Roy et al 2025
“Transformers Pretrained on Procedural Data Contain Modular Structures for Algorithmic Reasoning”, Shinnick et al 2025
Transformers Pretrained on Procedural Data Contain Modular Structures for Algorithmic Reasoning
“Language Models Are Capable of Metacognitive Monitoring and Control of Their Internal Activations”, Ji-An et al 2025
Language Models Are Capable of Metacognitive Monitoring and Control of Their Internal Activations
“LLMs Get Lost In Multi-Turn Conversation”, Laban et al 2025
“The Geometry of Self-Verification in a Task-Specific Reasoning Model”, Lee et al 2025
The Geometry of Self-Verification in a Task-Specific Reasoning Model
“It’s All Connected: A Journey Through Test-Time Memorization, Attentional Bias, Retention, and Online Optimization”, Behrouz et al 2025
“Content-Addressable Memory With a Content-Free Energy Function”, Benoist et al 2025
Content-Addressable Memory with a Content-Free Energy Function
“Dynamic Tanh: Transformers without Normalization”, Zhu et al 2025
“(How) Do Language Models Track State?”, Li et al 2025
“Thinking Slow, Fast: Scaling Inference Compute With Distilled Reasoners”, Paliotta et al 2025
Thinking Slow, Fast: Scaling Inference Compute with Distilled Reasoners
“μnit Scaling: Simple and Scalable FP8 LLM Training”, Narayan et al 2025
“Leveraging the True Depth of LLMs”, González et al 2025
“Language Models Use Trigonometry to Do Addition”, Kantamneni 2025
“Test-Time Regression: a Unifying Framework for Designing Sequence Models With Associative Memory”, Wang et al 2025
Test-time regression: a unifying framework for designing sequence models with associative memory
“How Has DeepSeek Improved the Transformer Architecture?”, Erdil 2025
“MiniMax-01: Scaling Foundation Models With Lightning Attention”, MiniMax et al 2025
MiniMax-01: Scaling Foundation Models with Lightning Attention
“Emergent Effects of Scaling on the Functional Hierarchies within Large Language Models”, Foop 2025
Emergent effects of scaling on the functional hierarchies within large language models
“ICLR: In-Context Learning of Representations”, Park et al 2024
“Hymba: A Hybrid-Head Architecture for Small Language Models”, Dong et al 2024
“Procedural Knowledge in Pretraining Drives Reasoning in Large Language Models”, Ruis et al 2024
Procedural Knowledge in Pretraining Drives Reasoning in Large Language Models
“You Could Have Designed State-Of-The-Art Positional Encoding”, Fleetwood 2024
You could have designed state-of-the-art Positional Encoding
“Long Context RAG Performance of Large Language Models”, Leng et al 2024
“Ask, and It Shall Be Given: Turing Completeness of Prompting”, Qiu et al 2024
Ask, and it shall be given: Turing completeness of prompting
“The Belief State Transformer”, Hu et al 2024
“Arithmetic Without Algorithms: Language Models Solve Math With a Bag of Heuristics”, Nikankin et al 2024
Arithmetic Without Algorithms: Language Models Solve Math With a Bag of Heuristics
“ALTA: Compiler-Based Analysis of Transformers”, Shaw et al 2024
“Tackling the Abstraction and Reasoning Corpus With Vision Transformers: the Importance of 2D Representation, Positions, and Objects”, Li et al 2024
“Differential Transformer”, Ye et al 2024
“Were RNNs All We Needed?”, Feng et al 2024
“NGPT: Normalized Transformer With Representation Learning on the Hypersphere”, Loshchilov et al 2024
nGPT: Normalized Transformer with Representation Learning on the Hypersphere
“Many-Shot Jailbreaking”, Anil et al 2024
“Masked Mixers for Language Generation and Retrieval”, Badger 2024
“The Mamba in the Llama: Distilling and Accelerating Hybrid Models”, Wang et al 2024
The Mamba in the Llama: Distilling and Accelerating Hybrid Models
“When Can Transformers Count to n?”, Yehudai et al 2024
“Just Read Twice: Closing the Recall Gap for Recurrent Language Models”, Arora et al 2024
Just read twice: closing the recall gap for recurrent language models
“What Matters in Transformers? Not All Attention Is Needed”, He et al 2024
“Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?”, Lee et al 2024
Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
“An Empirical Study of Mamba-Based Language Models”, Waleffe et al 2024
“Attention As a Hypernetwork”, Schug et al 2024
“Automata Extraction from Transformers”, Zhang et al 2024
“Scalable Matmul-Free Language Modeling”, Zhu et al 2024
“A Theoretical Understanding of Self-Correction through In-Context Alignment”, Wang et al 2024
A Theoretical Understanding of Self-Correction through In-context Alignment
“Attention As an RNN”, Feng et al 2024
“Your Transformer Is Secretly Linear”, Razzhigaev et al 2024
“Retrieval Head Mechanistically Explains Long-Context Factuality”, Wu et al 2024
Retrieval Head Mechanistically Explains Long-Context Factuality
“Let’s Think Dot by Dot: Hidden Computation in Transformer Language Models”, Pfau et al 2024
Let’s Think Dot by Dot: Hidden Computation in Transformer Language Models
“Towards Smaller, Faster Decoder-Only Transformers: Architectural Variants and Their Implications”, Suresh & P 2024
Towards smaller, faster decoder-only transformers: Architectural variants and their implications
“RULER: What’s the Real Context Size of Your Long-Context Language Models?”, Hsieh et al 2024
RULER: What’s the Real Context Size of Your Long-Context Language Models?
“ReFT: Representation Finetuning for Language Models”, Wu et al 2024
“Many-Shot Jailbreaking”, Anthropic 2024
“Do Language Models Plan Ahead for Future Tokens?”, Wu et al 2024
“Streamlining Redundant Layers to Compress Large Language Models”, Chen et al 2024
Streamlining Redundant Layers to Compress Large Language Models
“Long-Form Factuality in Large Language Models”, Wei et al 2024
“Mechanistic Design and Scaling of Hybrid Architectures”, Poli et al 2024
“8 Google Employees Invented Modern AI. Here’s the Inside Story: They Met by Chance, Got Hooked on an Idea, and Wrote the Transformers Paper—The Most Consequential Tech Breakthrough in Recent History”, Levy 2024
“RNNs Are Not Transformers (Yet): The Key Bottleneck on In-Context Retrieval”, Wen et al 2024
RNNs are not Transformers (Yet): The Key Bottleneck on In-context Retrieval
“How Transformers Learn Causal Structure With Gradient Descent”, Nichani et al 2024
How Transformers Learn Causal Structure with Gradient Descent
“A Phase Transition between Positional and Semantic Learning in a Solvable Model of Dot-Product Attention”, Cui et al 2024
“Rethinking Patch Dependence for Masked Autoencoders”, Fu et al 2024
“Attention versus Contrastive Learning of Tabular Data—A Data-Centric Benchmarking”, Rabbani et al 2024
Attention versus Contrastive Learning of Tabular Data—A Data-centric Benchmarking
“Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet”
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet
“Successor Heads: Recurring, Interpretable Attention Heads In The Wild”, Gould et al 2023
Successor Heads: Recurring, Interpretable Attention Heads In The Wild
“SwitchHead: Accelerating Transformers With Mixture-Of-Experts Attention”, Csordás et al 2023
SwitchHead: Accelerating Transformers with Mixture-of-Experts Attention
“Look Before You Leap: A Universal Emergent Decomposition of Retrieval Tasks in Language Models”, Variengien & Winsor 2023
Look Before You Leap: A Universal Emergent Decomposition of Retrieval Tasks in Language Models
“Can a Transformer Represent a Kalman Filter?”, Goel & Bartlett 2023
“Long Context Prompting for Claude 2.1: Claude 2.1 Excels at Retrieving Information across Its 200K Context Window, With a Simple Prompt Adjustment Improving Accuracy from 27% to 98%”, Anthropic 2023
“Efficient Transformer Knowledge Distillation: A Performance Review”, Brown et al 2023
Efficient Transformer Knowledge Distillation: A Performance Review
“Rethinking Attention: Exploring Shallow Feed-Forward Neural Networks As an Alternative to Attention Layers in Transformers”, Bozic et al 2023
“In-Context Vectors: Making In Context Learning More Effective and Controllable Through Latent Space Steering”, Liu et al 2023
“On Prefrontal Working Memory and Hippocampal Episodic Memory: Unifying Memories Stored in Weights and Activation Slots”, Whittington et al 2023
“LSS Transformer: Ultra-Long Sequence Distributed Transformer”, Wang et al 2023
LSS Transformer: Ultra-Long Sequence Distributed Transformer
“Simplifying Transformer Blocks”, He & Hofmann 2023
“GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling”, Katsch 2023
GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling
“Not All Layers Are Equally As Important: Every Layer Counts BERT”, Charpentier & Samuel 2023
Not all layers are equally as important: Every Layer Counts BERT
“Implicit Chain-Of-Thought Reasoning via Knowledge Distillation”, Deng et al 2023
Implicit Chain-of-Thought Reasoning via Knowledge Distillation
“Training Dynamics of Contextual N-Grams in Language Models”, Quirke et al 2023
“The Impact of Depth and Width on Transformer Language Model Generalization”, Petty et al 2023
The Impact of Depth and Width on Transformer Language Model Generalization
“Characterizing Mechanisms for Factual Recall in Language Models”, Yu et al 2023
Characterizing Mechanisms for Factual Recall in Language Models
“Linear Representations of Sentiment in Large Language Models”, Tigges et al 2023
Linear Representations of Sentiment in Large Language Models
“Masked Hard-Attention Transformers and Boolean RASP Recognize Exactly the Star-Free Languages”, Angluin et al 2023
Masked Hard-Attention Transformers and Boolean RASP Recognize Exactly the Star-Free Languages
“How Many Pretraining Tasks Are Needed for In-Context Learning of Linear Regression?”, Wu et al 2023
How Many Pretraining Tasks Are Needed for In-Context Learning of Linear Regression?
“Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors”, Amos et al 2023
Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors
“Vision Transformers Need Registers”, Darcet et al 2023
“Interpret Vision Transformers As ConvNets With Dynamic Convolutions”, Zhou et al 2023
Interpret Vision Transformers as ConvNets with Dynamic Convolutions
“Replacing Softmax With ReLU in Vision Transformers”, Wortsman et al 2023
“Gated Recurrent Neural Networks Discover Attention”, Zucchet et al 2023
“One Wide Feedforward Is All You Need”, Pires et al 2023
“Activation Addition: Steering Language Models Without Optimization”, Turner et al 2023
Activation Addition: Steering Language Models Without Optimization
“Linearity of Relation Decoding in Transformer Language Models”, Hernandez et al 2023
Linearity of Relation Decoding in Transformer Language Models
“The Hydra Effect: Emergent Self-Repair in Language Model Computations”, McGrath et al 2023
The Hydra Effect: Emergent Self-repair in Language Model Computations
“Does Circuit Analysis Interpretability Scale? Evidence from Multiple Choice Capabilities in Chinchilla”, Lieberum et al 2023
“FlashAttention-2: Faster Attention With Better Parallelism and Work Partitioning”, Dao 2023
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
“Lost in the Middle: How Language Models Use Long Contexts”, Liu et al 2023
“Trainable Transformer in Transformer”, Panigrahi et al 2023
“Transformers Learn to Implement Preconditioned Gradient Descent for In-Context Learning”, Ahn et al 2023
Transformers learn to implement preconditioned gradient descent for in-context learning
“White-Box Transformers via Sparse Rate Reduction”, Yu et al 2023
“Blockwise Parallel Transformer for Long Context Large Models”, Liu & Abbeel 2023
Blockwise Parallel Transformer for Long Context Large Models
“TTT-NN: Test-Time Training on Nearest Neighbors for Large Language Models”, Hardt & Sun 2023
TTT-NN: Test-Time Training on Nearest Neighbors for Large Language Models
“Brainformers: Trading Simplicity for Efficiency”, Zhou et al 2023
“GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints”, Ainslie et al 2023
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
“Mimetic Initialization of Self-Attention Layers”, Trockman & Kolter 2023
“Simplicial Hopfield Networks”, Burns & Fukai 2023
“Toeplitz Neural Network for Sequence Modeling”, Qin et al 2023
“Finding Neurons in a Haystack: Case Studies With Sparse Probing”, Gurnee et al 2023
Finding Neurons in a Haystack: Case Studies with Sparse Probing
“How Does GPT-2 Compute Greater-Than?: Interpreting Mathematical Abilities in a Pre-Trained Language Model”, Hanna et al 2023
“Theory of Coupled Neuronal-Synaptic Dynamics”, Clark & Abbott 2023
“Coinductive Guide to Inductive Transformer Heads”, Nemecek 2023
“Tighter Bounds on the Expressivity of Transformer Encoders”, Chiang et al 2023
“Tracr: Compiled Transformers As a Laboratory for Interpretability”, Lindner et al 2023
Tracr: Compiled Transformers as a Laboratory for Interpretability
“Skip-Attention: Improving Vision Transformers by Paying Less Attention”, Venkataramanan et al 2023
Skip-Attention: Improving Vision Transformers by Paying Less Attention
“Hungry Hungry Hippos: Towards Language Modeling With State Space Models”, Fu et al 2022
Hungry Hungry Hippos: Towards Language Modeling with State Space Models
“Scalable Adaptive Computation for Iterative Generation”, Jabri et al 2022
“Pretraining Without Attention”, Wang et al 2022
“Transformers Learn In-Context by Gradient Descent”, Oswald et al 2022
“Efficiently Scaling Transformer Inference”, Pope et al 2022
“Transformers Learn Shortcuts to Automata”, Liu et al 2022
“Multi-CLS BERT: An Efficient Alternative to Traditional Ensembling”, Chang et al 2022
Multi-CLS BERT: An Efficient Alternative to Traditional Ensembling
“Transformers Implement First-Order Logic With Majority Quantifiers”, Merrill & Sabharwal 2022
Transformers Implement First-Order Logic with Majority Quantifiers
“The Lie Derivative for Measuring Learned Equivariance”, Gruver et al 2022
“Relaxed Attention for Transformer Models”, Lohrenz et al 2022
“Multitrack Music Transformer: Learning Long-Term Dependencies in Music With Diverse Instruments”, Dong et al 2022
Multitrack Music Transformer: Learning Long-Term Dependencies in Music with Diverse Instruments
“N-Grammer: Augmenting Transformers With Latent n-Grams”, Roy et al 2022
“Log-Precision Transformers Are Constant-Depth Uniform Threshold Circuits”, Merrill & Sabharwal 2022
Log-Precision Transformers are Constant-Depth Uniform Threshold Circuits
“Neural Differential Equations for Learning to Program Neural Nets Through Continuous Learning Rules”, Irie et al 2022
Neural Differential Equations for Learning to Program Neural Nets Through Continuous Learning Rules
“FlashAttention: Fast and Memory-Efficient Exact Attention With IO-Awareness”, Dao et al 2022
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
“Simplicial Attention Networks”, Goh et al 2022
“TATS: Long Video Generation With Time-Agnostic VQGAN and Time-Sensitive Transformer”, Ge et al 2022
TATS: Long Video Generation with Time-Agnostic VQGAN and Time-Sensitive Transformer
“Transformer Language Models without Positional Encodings Still Learn Positional Information”, Haviv et al 2022
Transformer Language Models without Positional Encodings Still Learn Positional Information
“Overcoming a Theoretical Limitation of Self-Attention”, Chiang & Cholak 2022
“It’s Raw! Audio Generation With State-Space Models”, Goel et al 2022
“General-Purpose, Long-Context Autoregressive Modeling With Perceiver AR”, Hawthorne et al 2022
General-purpose, long-context autoregressive modeling with Perceiver AR
“Transformer Memory As a Differentiable Search Index”, Tay et al 2022
“The Dual Form of Neural Networks Revisited: Connecting Test Time Predictions to Training Patterns via Spotlights of Attention”, Irie et al 2022
“Attention Approximates Sparse Distributed Memory”, Bricken & Pehlevan 2021
“Long-Range Transformers for Dynamic Spatiotemporal Forecasting”, Grigsby et al 2021
Long-Range Transformers for Dynamic Spatiotemporal Forecasting
“Train Short, Test Long: Attention With Linear Biases (ALiBi) Enables Input Length Extrapolation”, Press et al 2021
Train Short, Test Long: Attention with Linear Biases (ALiBi) Enables Input Length Extrapolation
“Counterfactual Attention Learning for Fine-Grained Visual Categorization and Re-Identification”, Rao et al 2021
Counterfactual Attention Learning for Fine-Grained Visual Categorization and Re-identification
“Do Vision Transformers See Like Convolutional Neural Networks?”, Raghu et al 2021
Do Vision Transformers See Like Convolutional Neural Networks?
“Stable, Fast and Accurate: Kernelized Attention With Relative Positional Encoding”, Luo et al 2021
Stable, Fast and Accurate: Kernelized Attention with Relative Positional Encoding
“RASP: Thinking Like Transformers”, Weiss et al 2021
“On the Distribution, Sparsity, and Inference-Time Quantization of Attention Values in Transformers”, Ji et al 2021
On the Distribution, Sparsity, and Inference-time Quantization of Attention Values in Transformers
“SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training”, Somepalli et al 2021
SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training
“Not All Images Are Worth 16×16 Words: Dynamic Transformers for Efficient Image Recognition”, Wang et al 2021
Not All Images are Worth 16×16 Words: Dynamic Transformers for Efficient Image Recognition
“Less Is More: Pay Less Attention in Vision Transformers”, Pan et al 2021
“FNet: Mixing Tokens With Fourier Transforms”, Lee-Thorp et al 2021
“Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet”, Melas-Kyriazi 2021
Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet
“RoFormer: Enhanced Transformer With Rotary Position Embedding”, Su et al 2021
RoFormer: Enhanced Transformer with Rotary Position Embedding
“ALD: Efficient Transformers in Reinforcement Learning Using Actor-Learner Distillation”, Parisotto & Salakhutdinov 2021
ALD: Efficient Transformers in Reinforcement Learning using Actor-Learner Distillation
“Attention Is Not All You Need: Pure Attention Loses Rank Doubly Exponentially With Depth”, Dong et al 2021
Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth
“Do Transformer Modifications Transfer Across Implementations and Applications?”, Narang et al 2021
Do Transformer Modifications Transfer Across Implementations and Applications?
“Linear Transformers Are Secretly Fast Weight Programmers”, Schlag et al 2021
“Unlocking Pixels for Reinforcement Learning via Implicit Attention”, Choromanski et al 2021
Unlocking Pixels for Reinforcement Learning via Implicit Attention
“Transformer Feed-Forward Layers Are Key-Value Memories”, Pipek et al 2020
“AdnFM: An Attentive DenseNet Based Factorization Machine for CTR Prediction”, Wang et al 2020
AdnFM: An Attentive DenseNet based Factorization Machine for CTR Prediction
“Inductive Biases for Deep Learning of Higher-Level Cognition”, Goyal & Bengio 2020
Inductive Biases for Deep Learning of Higher-Level Cognition
“Long Range Arena (LRA): A Benchmark for Efficient Transformers”, Tay et al 2020
Long Range Arena (LRA): A Benchmark for Efficient Transformers
“Current Limitations of Language Models: What You Need Is Retrieval”, Komatsuzaki 2020
Current Limitations of Language Models: What You Need is Retrieval
“Efficient Transformers: A Survey”, Tay et al 2020
“HiPPO: Recurrent Memory With Optimal Polynomial Projections”, Gu et al 2020
“Efficient Attention: Breaking The Quadratic Transformer Bottleneck”, Gwern 2020
Efficient Attention: Breaking The Quadratic Transformer Bottleneck
“Pre-Training via Paraphrasing”, Lewis et al 2020
“Masked Language Modeling for Proteins via Linearly Scalable Long-Context Transformers”, Choromanski et al 2020
Masked Language Modeling for Proteins via Linearly Scalable Long-Context Transformers
“GPT-3: Language Models Are Few-Shot Learners”, Brown et al 2020
“Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”, Lewis et al 2020
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
“Synthesizer: Rethinking Self-Attention in Transformer Models”, Tay et al 2020
Synthesizer: Rethinking Self-Attention in Transformer Models
“PowerNorm: Rethinking Batch Normalization in Transformers”, Shen et al 2020
“On Layer Normalization in the Transformer Architecture”, Xiong et al 2020
“REALM: Retrieval-Augmented Language Model Pre-Training”, Guu et al 2020
“BERT’s Output Layer Recognizes All Hidden Layers? Some Intriguing Phenomena and a Simple Way to Boost BERT”, Kao et al 2020
“Rethinking Attention With Performers”, Choromanski & Colwell 2020
“Are Transformers Universal Approximators of Sequence-To-Sequence Functions?”, Yun et al 2019
Are Transformers universal approximators of sequence-to-sequence functions?
“Dynamic Convolution: Attention over Convolution Kernels”, Chen et al 2019
“Generalization through Memorization: Nearest Neighbor Language Models”, Khandelwal et al 2019
Generalization through Memorization: Nearest Neighbor Language Models
“Multiplicative Interactions and Where to Find Them”, Jayakumar et al 2019
“The Bottom-Up Evolution of Representations in the Transformer: A Study With Machine Translation and Language Modeling Objectives”, Voita et al 2019
“Logic and the 2-Simplicial Transformer”, Clift et al 2019
“PKM: Large Memory Layers With Product Keys”, Lample et al 2019
“What Does BERT Look At? An Analysis of BERT’s Attention”, Clark et al 2019
“Are 16 Heads Really Better Than One?”, Michel et al 2019
“Paper Review: Set Transformers. A Framework for Attention-Based…”
Paper Review: Set Transformers. A Framework for Attention-based…
“Pay Less Attention With Lightweight and Dynamic Convolutions”, Wu et al 2019
Pay Less Attention with Lightweight and Dynamic Convolutions
“On the Turing Completeness of Modern Neural Network Architectures”, Pérez et al 2019
On the Turing Completeness of Modern Neural Network Architectures
“Music Transformer”, Huang et al 2018
“Character-Level Language Modeling With Deeper Self-Attention”, Al-Rfou et al 2018
Character-Level Language Modeling with Deeper Self-Attention
“Attention Is All You Need”, Vaswani et al 2017
“A Deep Reinforced Model for Abstractive Summarization”, Paulus et al 2017
“Get To The Point: Summarization With Pointer-Generator Networks”, See et al 2017
Get To The Point: Summarization with Pointer-Generator Networks
“RAM: Dynamic Computational Time for Visual Attention”, Li et al 2017
“Hybrid Computing Using a Neural Network With Dynamic External Memory”, Graves et al 2016
Hybrid computing using a neural network with dynamic external memory
“Scaling Memory-Augmented Neural Networks With Sparse Reads and Writes”, Rae et al 2016
Scaling Memory-Augmented Neural Networks with Sparse Reads and Writes
“Modeling Human Reading With Neural Attention”, Hahn & Keller 2016
“Iterative Alternating Neural Attention for Machine Reading”, Sordoni et al 2016
“Adaptive Computation Time for Recurrent Neural Networks”, Graves 2016
“Foveation-Based Mechanisms Alleviate Adversarial Examples”, Luo et al 2015
“Generating Images from Captions With Attention”, Mansimov et al 2015
“DRAW: A Recurrent Neural Network For Image Generation”, Gregor et al 2015
“Neural Turing Machines”, Graves et al 2014
“Neural Machine Translation by Jointly Learning to Align and Translate”, Bahdanau et al 2014
Neural Machine Translation by Jointly Learning to Align and Translate
“On Learning Where To Look”, Ranzato 2014
“Generating Sequences With Recurrent Neural Networks”, Graves 2013
“Building a Minimal Transformer for 10-Digit Addition”, Litzenberger 2026
“Efficient Transformers: A Survey § Table 1”
“1M Context Is Now Generally Available for Opus 4.6 and Sonnet 4.6”
1M context is now generally available for Opus 4.6 and Sonnet 4.6
“Attention and Augmented Recurrent Neural Networks”
“AdderBoard: Contest for Smallest Transformer That Can Add Two 10-Digit Numbers”
AdderBoard: contest for smallest Transformer that can add two 10-digit numbers
“Digit-Addition-311p: a Grokked 311-Parameter Transformer for 10-Digit Addition”
digit-addition-311p: a grokked 311-parameter Transformer for 10-digit addition
“Technion-Cs-Nlp/llm-Arithmetic-Heuristics”
“Hierarchical Object Detection With Deep Reinforcement Learning”
Hierarchical Object Detection with Deep Reinforcement Learning
“The Transformer Family: Attention and Self-Attention • Multi-Head Self-Attention • Transformer • Adaptive Computation Time (ACT) • Improved Attention Span: (Longer Attention Span (Transformer-XL) / Adaptive Attention Span / Localized Attention Span (Image Transformer)) • Less Time and Memory Cost: (Sparse Attention Matrix Factorization (Sparse Transformers) / Locality-Sensitive Hashing (Reformer)) • Make It Recurrent (Universal Transformer) • Stabilization for RL (GTrXL)”
“100M Token Context Windows”
“Learning to Combine Foveal Glimpses With a Third-Order Boltzmann Machine”
Learning to combine foveal glimpses with a third-order Boltzmann machine
“Show, Attend and Tell: Neural Image Caption Generation With Visual Attention”
Show, attend and tell: Neural image caption generation with visual attention
“Recurrent Models of Visual Attention”
“Can Active Memory Replace Attention?”
“Dzmitry Bahdanau”
“Scaling Automatic Neuron Description”
“Monitor: An AI-Driven Observability Interface”
“Interpreting GPT: the Logit Lens”
“A Sober Look at Steering Vectors for LLMs”
“Antonym Heads Predict Semantic Opposites in Language Models”
“One-Shot Steering Vectors Cause Emergent Misalignment, Too”
“A Survey of Long-Term Context in Transformers: Sparse Transformers • Adaptive Span Transformers • Transformer-XL • Compressive Transformers • Reformer • Routing Transformer • Sinkhorn Transformer • Linformer • Efficient Attention: Attention With Linear Complexities • Transformers Are RNNs • ETC • Longformer”
“FlashAttention-3: Fast and Accurate Attention With Asynchrony and Low-Precision”
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
adversarial-robustness
alignment-translation
optimal-projections
pretraining-tasks
tabular-attention contrastive-learning data-benchmarking neural-interpretability model-comparison
many-shot cognition-context tensor-logic steered-prompting cognition-architecture
scaling-llm long-context heuristics generalization few-shot-negation
model-interpretation
long-context
Miscellaneous
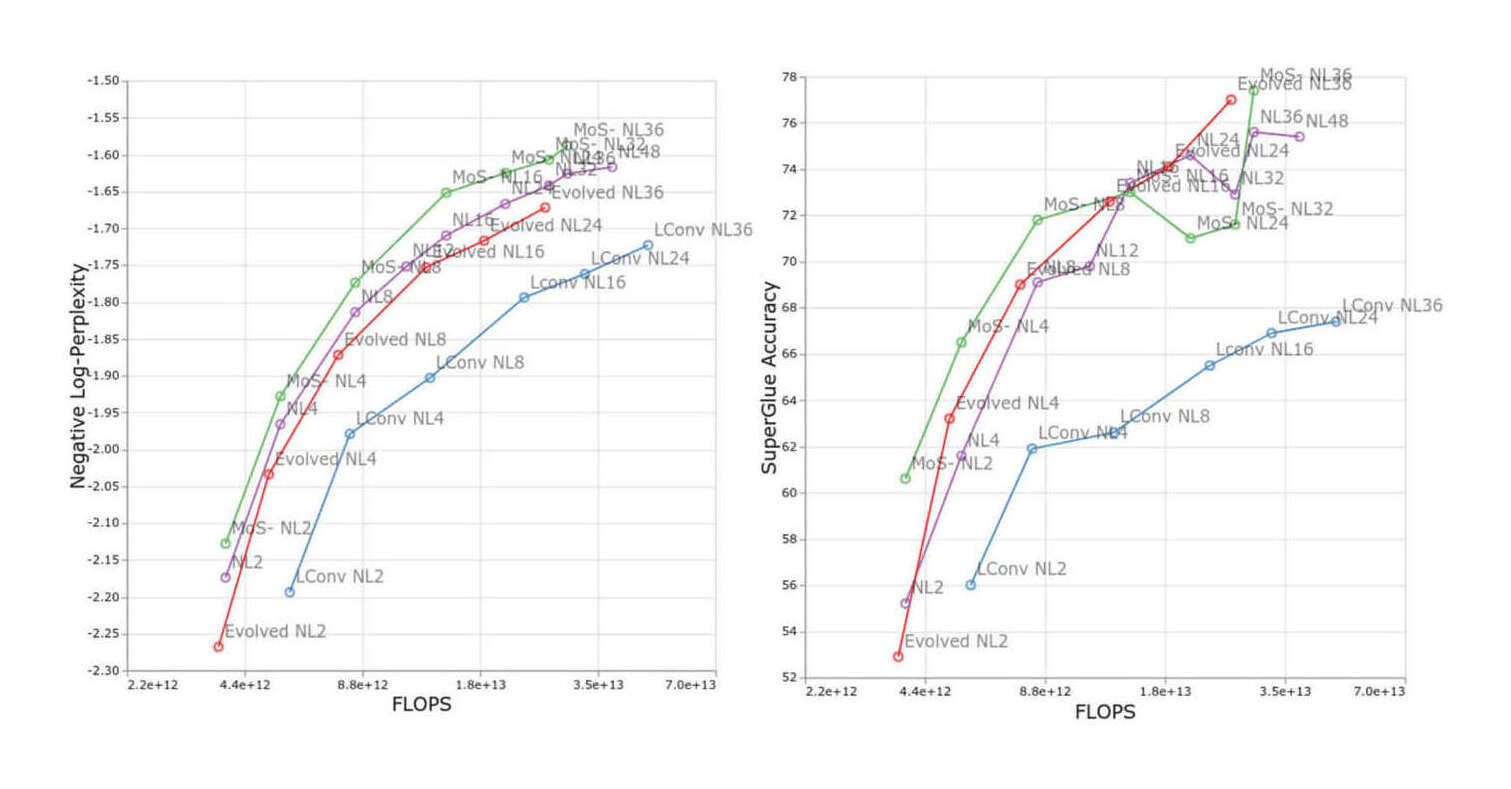
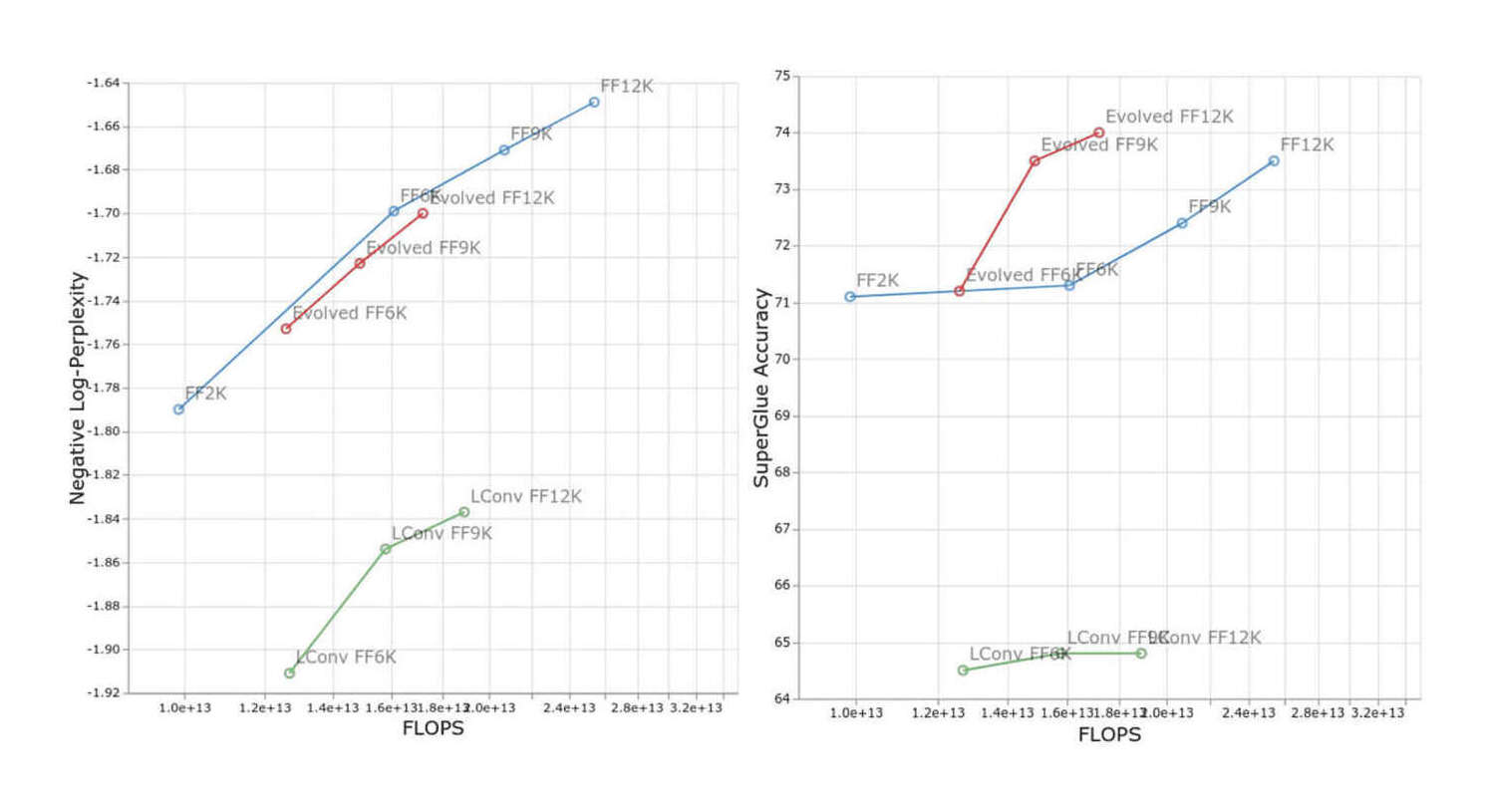
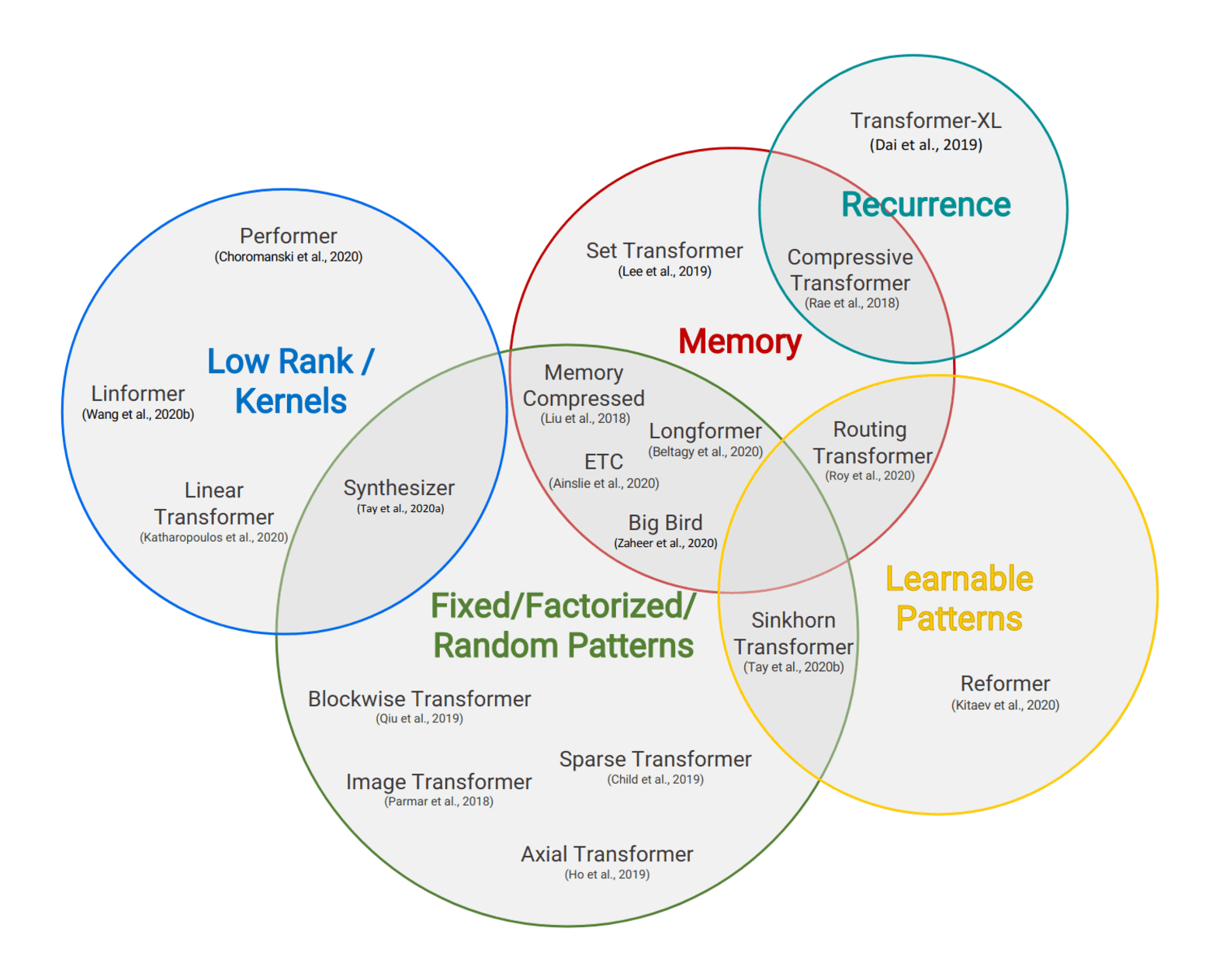
/doc/ai/nn/transformer/attention/2023-09-08-charlesfoster-aunn-variantwithcausaldecoderattention.jpg/doc/ai/nn/transformer/attention/2023-trockman-figure7-gpt2attentionmatrixpatterns.png/doc/ai/nn/transformer/attention/2022-tay-figure4-scalingofmodelbydepth.jpg/doc/ai/nn/transformer/attention/2022-tay-figure5-scalingofmodelbymlpfeedforwardparameters.jpg/doc/ai/nn/transformer/attention/2020-longrangearena-figure3-performancefrontier.jpg/doc/ai/nn/transformer/attention/2020-tay-figure2-efficientattentiontaxonomy.png/doc/ai/nn/transformer/attention/2020-tay-table1-efficienttransformermodels.pnghttps://bclarkson-code.github.io/posts/llm-from-scratch-scalar-autograd/post.htmlhttps://magazine.sebastianraschka.com/p/understanding-and-coding-self-attentionhttps://nostalgebraist.tumblr.com/post/740164510909890560/information-flow-in-transformershttps://www.beren.io/2024-03-03-Linear-Attention-as-Iterated-Hopfield-Networks/https://www.dipkumar.dev/becoming-the-unbeatable/posts/gpt-kvcache/https://www.lesswrong.com/posts/euam65XjigaCJQkcN/an-analogy-for-understanding-transformershttps://www.lesswrong.com/posts/jGuXSZgv6qfdhMCuJ/refusal-in-llms-is-mediated-by-a-single-directionhttps://www.lesswrong.com/posts/thePw6qdyabD8XR4y/interpreting-openai-s-whisperhttps://www.perfectlynormal.co.uk/blog-induction-heads-illustrated
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2507.02754#facebook: “Fast and Simplex: 2-Simplicial Attention in Triton”,https://arxiv.org/abs/2504.14379: “The Geometry of Self-Verification in a Task-Specific Reasoning Model”,https://arxiv.org/abs/2503.10622#facebook: “Dynamic Tanh: Transformers without Normalization”,https://arxiv.org/abs/2502.20339: “Thinking Slow, Fast: Scaling Inference Compute With Distilled Reasoners”,https://arxiv.org/abs/2501.08313#minimax: “MiniMax-01: Scaling Foundation Models With Lightning Attention”,https://arxiv.org/abs/2410.18077#deepmind: “ALTA: Compiler-Based Analysis of Transformers”,https://arxiv.org/abs/2410.06405: “Tackling the Abstraction and Reasoning Corpus With Vision Transformers: the Importance of 2D Representation, Positions, and Objects”,https://arxiv.org/abs/2410.01201: “Were RNNs All We Needed?”,https://arxiv.org/abs/2408.15237: “The Mamba in the Llama: Distilling and Accelerating Hybrid Models”,https://arxiv.org/abs/2406.15786: “What Matters in Transformers? Not All Attention Is Needed”,https://arxiv.org/abs/2406.13121#google: “Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?”,https://arxiv.org/abs/2406.07887: “An Empirical Study of Mamba-Based Language Models”,https://arxiv.org/abs/2406.05564: “Automata Extraction from Transformers”,https://arxiv.org/abs/2404.15574: “Retrieval Head Mechanistically Explains Long-Context Factuality”,https://arxiv.org/abs/2404.15758: “Let’s Think Dot by Dot: Hidden Computation in Transformer Language Models”,https://arxiv.org/abs/2403.18802#deepmind: “Long-Form Factuality in Large Language Models”,https://arxiv.org/abs/2403.17844: “Mechanistic Design and Scaling of Hybrid Architectures”,https://www.wired.com/story/eight-google-employees-invented-modern-ai-transformers-paper/: “8 Google Employees Invented Modern AI. Here’s the Inside Story: They Met by Chance, Got Hooked on an Idea, and Wrote the Transformers Paper—The Most Consequential Tech Breakthrough in Recent History”,https://arxiv.org/abs/2401.14391: “Rethinking Patch Dependence for Masked Autoencoders”,https://arxiv.org/abs/2312.09230: “Successor Heads: Recurring, Interpretable Attention Heads In The Wild”,https://arxiv.org/abs/2311.13657: “Efficient Transformer Knowledge Distillation: A Performance Review”,https://arxiv.org/abs/2311.02265: “Not All Layers Are Equally As Important: Every Layer Counts BERT”,https://arxiv.org/abs/2310.15154: “Linear Representations of Sentiment in Large Language Models”,https://arxiv.org/abs/2310.02980: “Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors”,https://arxiv.org/abs/2309.10713: “Interpret Vision Transformers As ConvNets With Dynamic Convolutions”,https://arxiv.org/abs/2309.08586: “Replacing Softmax With ReLU in Vision Transformers”,https://arxiv.org/abs/2308.10248: “Activation Addition: Steering Language Models Without Optimization”,https://arxiv.org/abs/2305.18466: “TTT-NN: Test-Time Training on Nearest Neighbors for Large Language Models”,https://arxiv.org/abs/2306.00008#google: “Brainformers: Trading Simplicity for Efficiency”,https://arxiv.org/abs/2305.09828: “Mimetic Initialization of Self-Attention Layers”,https://arxiv.org/abs/2301.02240: “Skip-Attention: Improving Vision Transformers by Paying Less Attention”,https://arxiv.org/abs/2212.14052: “Hungry Hungry Hippos: Towards Language Modeling With State Space Models”,https://arxiv.org/abs/2212.10544: “Pretraining Without Attention”,https://arxiv.org/abs/2212.07677#google: “Transformers Learn In-Context by Gradient Descent”,https://arxiv.org/abs/2211.05102#google: “Efficiently Scaling Transformer Inference”,https://arxiv.org/abs/2210.05043: “Multi-CLS BERT: An Efficient Alternative to Traditional Ensembling”,https://arxiv.org/abs/2206.01649#schmidhuber: “Neural Differential Equations for Learning to Program Neural Nets Through Continuous Learning Rules”,https://arxiv.org/abs/2205.14135: “FlashAttention: Fast and Memory-Efficient Exact Attention With IO-Awareness”,https://arxiv.org/abs/2204.03638#facebook: “TATS: Long Video Generation With Time-Agnostic VQGAN and Time-Sensitive Transformer”,https://arxiv.org/abs/2202.09729: “It’s Raw! Audio Generation With State-Space Models”,https://arxiv.org/abs/2202.07765#deepmind: “General-Purpose, Long-Context Autoregressive Modeling With Perceiver AR”,https://arxiv.org/abs/2108.12409#facebook: “Train Short, Test Long: Attention With Linear Biases (ALiBi) Enables Input Length Extrapolation”,https://arxiv.org/abs/2108.08810#google: “Do Vision Transformers See Like Convolutional Neural Networks?”,https://arxiv.org/abs/2106.06981: “RASP: Thinking Like Transformers”,https://arxiv.org/abs/2105.15075: “Not All Images Are Worth 16×16 Words: Dynamic Transformers for Efficient Image Recognition”,https://arxiv.org/abs/2105.14217: “Less Is More: Pay Less Attention in Vision Transformers”,https://arxiv.org/abs/2105.03824#google: “FNet: Mixing Tokens With Fourier Transforms”,https://arxiv.org/abs/2105.02723: “Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet”,https://openreview.net/forum?id=qVyeW-grC2k#google: “Long Range Arena (LRA): A Benchmark for Efficient Transformers”,https://arxiv.org/abs/2009.06732#google: “Efficient Transformers: A Survey”,https://arxiv.org/abs/2008.07669: “HiPPO: Recurrent Memory With Optimal Polynomial Projections”,abstract: “Efficient Attention: Breaking The Quadratic Transformer Bottleneck”,https://arxiv.org/abs/2005.00743#google: “Synthesizer: Rethinking Self-Attention in Transformer Models”,https://arxiv.org/abs/2003.07845: “PowerNorm: Rethinking Batch Normalization in Transformers”,https://arxiv.org/abs/2001.09309: “BERT’s Output Layer Recognizes All Hidden Layers? Some Intriguing Phenomena and a Simple Way to Boost BERT”,https://arxiv.org/abs/1912.03458#microsoft: “Dynamic Convolution: Attention over Convolution Kernels”,