I modestly propose a simple general-purpose Absolute Unit NN architecture for scaling up meta-learning prediction of arbitrary data inputs & outputs.
The training data is encoded into a list, and the NN is trained to predict, from the absolute index (a 1D input) the corresponding data point. Predictions of new data are made by regressing the first unseen index; these predictions can be conditioned on by taking an additional gradient descent step on each new index+datapoint pair.
By memorizing & compressing the data, the NN generalizes, and at scale, like other self-supervised architectures, will learn to meta-learn datapoints, becoming a compact encoding of the distribution which rapidly learns each new datapoint in a single gradient descent step (like Hopfield nets or Reptile). Because of the uniformity and small dimensionality of input/output, the NN can be a deep MLP rather than a CNN, Transformer, or MoE.
Training can be done by ordinary SGD, but also by any local learning rule, or any mix thereof (eg. SGD at training time in compute-optimal large batches for offline training datasets, and then a local learning rule at ‘runtime’ when conditioning online with new inputs).
The advantages of this Absolute Unit include:
simplicity (can be just an MLP)
minimal inductive bias (using MLPs)
generality of input/output (arbitrary modalities, mixtures, and tasks)
generality of architectures, which interpolates between:
prediction losses (arbitrary ‘masking’ can be done based on the order in which indices are trained)
‘Transformer’ & ‘RNN’-like training modes (large-batch vs small-batch)
hardware-friendliness (uniform feedforward computation patterns in small MLPs, large minibatches, local learning rules, and capable of Transformer-like full history training while still allowing RNN-like 𝒪(1) updates)
extensibility in many ways (eg. more complicated architectures can be plugged in, recurrent state can be enabled by adding unused parameters); two highly speculative such proposals:
Language-Conditioned AUNNs: an example proposed application is given for the Herculaneum papyri, using Greco-Roman LLMs to instill linguistic & world knowledge into an AUNN reconstructing papyrus text
Modular Brain AUNNs: handle brain complexity by creating a DAG of AUNNs, which optimize data prediction but also global constraints; the AUNN surrogates can be replaced one by one by superior neurological models, and can help pick what to model
an even more simplified Input-Free NN proposal, which removes all inputs by requiring serial training so the index is implicit
The primary disadvantage is that lacking so many inductive biases & high-dimensional input/output, AUNNs may require a truly chonky level of scale (in data & compute, likely not parameters) before they learn to generalize & meta-learn or become competitive with existing architectures. However, AUNN appears to work at small scale on at least one toy problem, so who knows?
New LLM approaches have been successful by pursuing a simple objective of raw “prediction”: ‘predict the next datapoint in the list’ and variations thereof (like ‘predict the middle datapoint’ or ‘predict a random datapoint in a small context window’). ‘Next’ prediction is a simple & general approach, because everything can be turned into a list—but is it the most general possible prediction? Why privilege the ‘next’ datapoint, or indeed, any datapoint which happens to be within some arbitrary constraint like ‘a window’? Why can’t we “predict” every datapoint everywhere, on equal terms? Why can’t we predict any past datapoint as easily as any future datapoint?
“Well wait, how would you do that? We can talk about ‘past’ datapoints because they are just part of the list, with a known address or index; and the ‘next’ datapoint because it’s the last index in the list, and we just pretend we don’t know it yet; but how do you even talk about ‘future datapoints’?” It’s simple, if we have the courage of our convictions: every datapoint has an index, including the ones we haven’t seen yet. We discard all concepts of ‘next’ or ‘past’ or ‘future’, or shortcuts like ‘windows’: we simply predict the datapoint of every logically-possible index—period. Our new NN simply takes an arbitrary natural number, and predicts the datapoint that was, is, or will be associated with it. That’s it.
This new prediction architecture can still express everything we want it to, but is even simpler than next-datapoint prediction architectures.
Hopfield networks: a classic associative memory paradigm using fully-connected networks; Transformer self-attention has been interpreted as a Hopfield net, but do we really need the self-attention part?
My original question was: “how could I apply MLPs to arbitrary input/output modalities, which can match RNNs with long memories or Transformers with context windows in the thousands—without the infeasible explosion of all-to-all parameters for fully-connected dense layers taking complex input and computing complex output?”
Heaps of data. For example, suppose I had various kinds of X-ray scans of carbonizedHerculaneum papyri (see the Vesuvius Challenge); these scrolls are all different 3D sizes with tightly-wrapped ‘sheets’ in 3D space, the scans different resolutions, and often inherently different kinds of scans; each scan will be different in almost every way, despite clearly heavily overlapping and being highly mutually informative. Similar questions arise in brain scanning & emulation: this is a problem so hard we cannot afford to throw out any data, so how can we use brain connectome slices, fMRI data, transcriptomes, DNA barcoding, all from different brains, labs, methods, and eras, in the same model to create a unified view of brains? How do we handle this sort of data? We obviously cannot use standard solutions from text or image processing of tokenizing into a list or taking a fixed Transformer context window of a few thousand pixels.
(X,Y) → Pixel. A solution to this was demonstrated by NeRFs & single-pixel GANs: as impossible as it may seem, NNs can take a single specific pixel coordinate of an image, and predict the pixel value, and they can do each prediction independently in a separate forward pass, and the result is good rather than a blurry incoherent mishmash of individually-sensible-but-globally-incoherent pixel predictions. (Something similar is demonstrated by Perceiver’s ability to flexibly iteratively attend over large variable-dimensional sparse datasets like LIDAR point clouds.)
ID+(X,Y) → Pixel. NeRFs are usually applied to a single specific image or ‘scene’, and are more like a file-compression method which yields a ‘compressed scene’ than a traditional generative model. However, there is no reason a NeRF must be trained only on a single scene, and single-pixel GANs demonstrate that with an appropriate input which distinguishes the possible outputs (such as a random “ID” or latent z), this works fine. We can just take our pile of data, assign each a unique ID, and force the NN to ‘predict’ each pixel of each ID3, and it will memorize but also generalize; it’s cheating and should not work! But it does. That’s DL for you.4
Predict all the things. So, an ID+coordinate ‘generative model’ is a promising start for the Herculaneum scrolls. We can take our piles of weird irregular scan data, and just feed them into a big NN: turn them into a bunch of giant 3D volumes with an ID containing many individual little voxels which have whatever measurements, regress on each ID+voxel, and now we have a generative model of the scrolls which will concentrate deep inside the NN all sorts of knowledge about the geometry of scrolls, how they warp and carbonize, what subtle traces of ink there may be, what synchrotrons are temperamental and have noisy data… We simply need the courage to throw away explicit hand-engineering of inductive biases like dimensionality, and let the model learn on its own that text is 1D, images are 2D with spatial invariances, point-clouds are 3D, etc.
Just ask for generalization. We can ask the NN to predict, for a trained-on scroll, the value of voxels we don’t have data on. This is useful to reconstruct that scroll better. OK, but we just got a new Herculaneum scroll scanned, and we want to use our model; now what? Well, you just train the model on the new one! Yes, even if it’s just n = 1. You can just train the model a little more, and it’ll learn everything it can from the available data about the new scroll, and then you generate the ‘full’ version just as if it had been in the original large training dataset. And we can do this for the next one as well, with the model getting better and better.
Generalize at higher levels. If we do so, this provides transfer learning: each time the model gets a little better at peering into the heart of the little scroll-briquettes, and eventually, meta-learning. The more data trained on, the better the modeling becomes, and the more sample-efficient finetuning on new data becomes. And we know that at scale, given appropriate data diversity & model capacity with everything scaled up in tandem, such models begin to manifest meta-learning (without any need for tailored mechanisms or training intended to elicit meta-learning): given a history (or ‘hidden state’, ‘context’, ‘prompt’, ‘conditioning’…), a model learns the Bayes-optimal output over a large family of similar tasks, as opposed to simply solving a fixed set of tasks, where the question of which task is as important as the actual task-solving (see also “prompt programming”).
Weights ≈ State. While the single-input NN may look like there is nothing in it which could support meta-learning, such as the recurrent hidden state of an RNN or the context/history of a Transformer, the information can be encoded into the model-weights by gradient descent; this is, in fact, how many meta-learning systems used to work.6
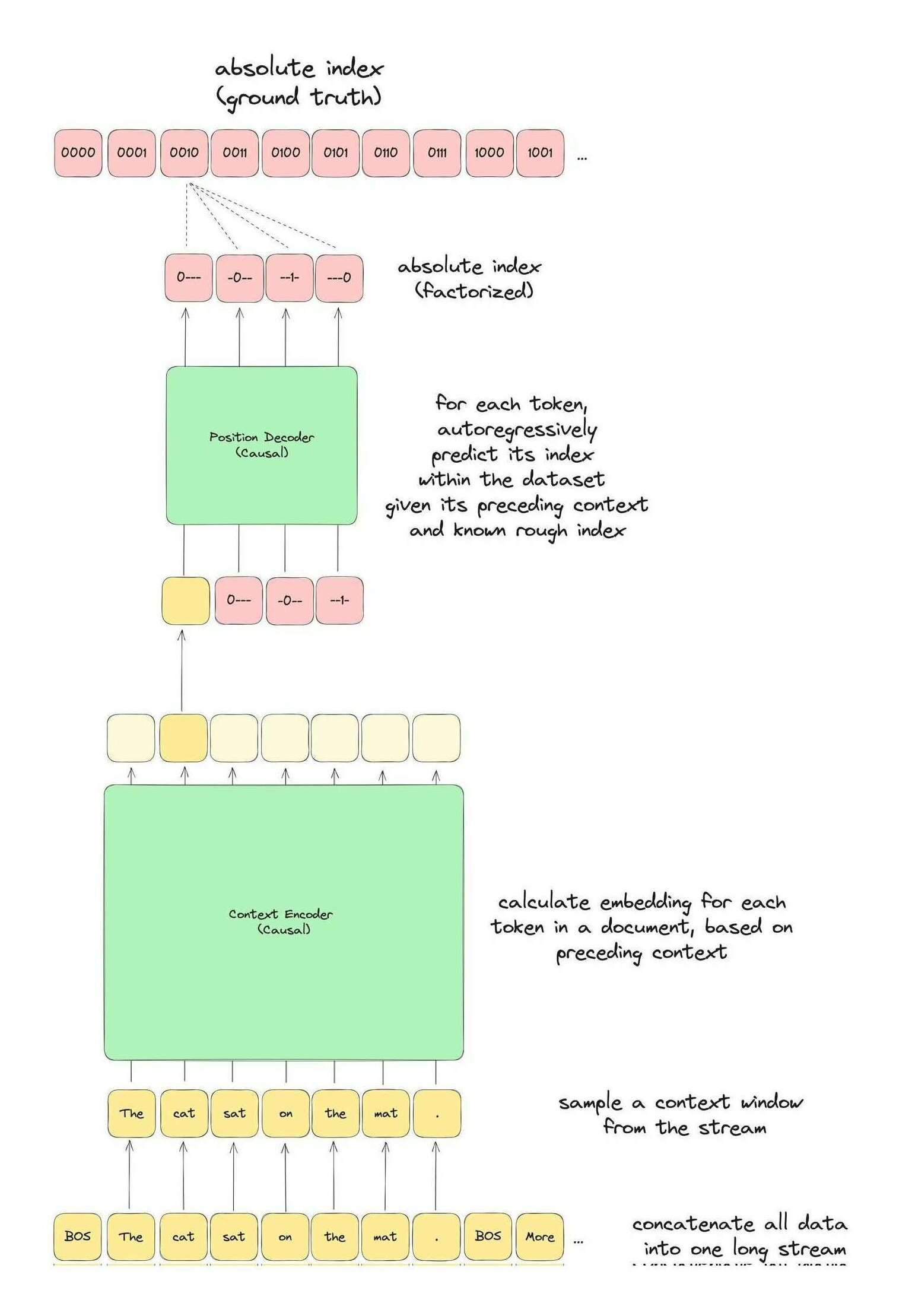
Let’s keep generalizing. Do we actually need IDs? They don’t always make sense, and are inconvenient to work with. The point of an ID is to disambiguate pixel coordinates which would otherwise collide and be aliased: pixel (32,10) might be different in each image, so we augment it with an ID so it’s (1,32,10) vs (2,32,10) vs (3,32,10) etc. We can remove the need for an ID by simply concatenating all the data, and dealing with much larger coordinates. And the easiest way to concatenate it all is to turn them into a single giant list; future datapoints simply get added to the end.7
We talk about it as if it’s a single type of data like an RGB image or LIDAR point-cloud or X-ray scan.
Each of the datapoints, however, can be an arbitrary data type, as long as they are all in a common lingua franca of bits (or bytes, to be, ahem, a bit more efficient). This extends to continuous nonlinear data, like AUNN’s inspirations, SIREN/NeRF; samples can be at any resolution or timestamp, with any degree of sparsity.
The model will now learn implicitly what ranges in the list are what data types, because that will change predictions dramatically—one learns quite fast that ASCII text is rather different from RGB images or X-ray scans, so we don’t need to support any kind of explicit data type switching, the NN will learn to do so internally. (We can, and should, include any metadata we have about each data type as well; the format of this metadata is unimportant, as that’s just more stuff to learn.)
The source of the data is also unimportant. It can be images, Internet text scrapes, chess games, reinforcement learning episodes, etc. Some of these will share more information with others, but all will be useful at scale.
So we now have the basic Absolute Unit NN (AUNN) architecture outlined: we have some multi-terabyte bitstring which our MLP learns by predicting the byte value of it for each possible address in it.
This compresses the bitstring into the AUNN as a generative model, sharing arbitrary information between all datapoints. Without relying on retrieval or in-context short-term memory, it must learn as much as possible, and this greater memorization may foster generalization that models relying on the crutch of lookups may struggle with—knowledge is the father of understanding, rather than glibly rewriting inputs handed to you. To use the AUNN to predict an entire datapoint, we simply predict each address in it for an unconditional prediction; for the much more useful conditional prediction, such as to generate a text string, one simply feeds the next-predicted-character back in to the training process ‘as if’ it was always in the dataset (like feeding sampled tokens back into an RNN/Transformer), and trains the AUNN a little more.8
This generation lets us do all the usual things: for example, if we have information from agents like human beings inside the dataset, then it will have reinforcement learning capabilities like planning & decision-making.
Sounds reasonable and appears feasible, in some form.
The next question is: how well? Particularly the use of an MLP: is that enough? With no explicit recurrence or attention, how could an MLP work well enough? And if we do need them, how exactly do we add them? The architecture would seem to explicitly bar any kind of recurrence (where is it stored, and how is it trained to be useful via an algorithm like BPTT?), or attention over its inputs (you could stick Transformer heads anywhere later in the MLP, but how can it attend over a large context window of inputs if there are not inputs beyond an essentially meaningless ID?).
Curves cross. While we cannot yet prove that at scale the performance of MLPs ≈ Transformers ≈ RNN, there’s a long history of “the learning curves crossing” due to the blessings of scale, like decision-tree methods eventually outperforming logistic regression, or how Transformers were initially soundly beaten by CNNs but shown to learn convolution-like attention patterns and have since exceeded them, or methods like AlphaZero being surpassed by MuZero, or the extent to which generative models of radically different families like diffusion vs GAN all converge at scale (even when a model family has been given up for dead by the entire field). We can further point out that for Transformers, most of their heads can be pruned away, and as they scale up they intrinsically devote more & more of their FLOPS to their MLP layers rather than their self-attention operations; MLP-heavy Transformers can remove almost all their self-attention withminimal impact, while the few scaling laws run for MLPs vs Transformers don’t show the MLP-only architectures failing too badly (Tay et al 2022), and when using contemporary design principles like normalization and regularization, MLPs scale much better than anyone believed. MLPs are appealingly simple, and they look GPU-friendly in having relatively small parameter-count models intensively using dense matrix-multiplication operations rather than sparse operations like self-attention which have proven tricky to get high usage on and lead to models with large parameter counts (especially MoEs); as GPU hardware gets ever more memory-bound, the performance tradeoff favors MLPs (and perhaps even more exotic architectures like logic gate blobs).
When might the curves cross? Historically, it has required several OOMs for a new architecture to convincingly replace an old one. Tabular datasets had to reach n > 50,000 in many cases, in an era where n ~ 1,000 was considered substantial, before decision-trees could shine, while Vision Transformers had to be applied to datasets of 100m+ images like JFT-300M before they were neck-and-neck with the best CNNs or CNN-Transformer hybrids, and reach 1b+ to beat them with models like ViT-22B. Multimodality makes it harder to compare, but it seems safe to say based on Transformer data requirements that MLP-centric approaches like AUNN may require billions of datapoints. (We may also observe grokking as the MLPs overfit heavily initially, and require a lot of training to finally generalize.)
“This [art of writing]”, said Theuth, “will make the Egyptians wiser and give them better memories; it is a specific both for the memory and for the wit.”
Thamus replied: “O most ingenious Theuth…you who are the father of letters, from a paternal love of your own children have been led to attribute to them a quality which they cannot have; for this discovery of yours will create forgetfulness in the learners’ souls, because they will not use their memories; they will trust to the external written characters and not remember of themselves. The specific which you have discovered is an aid not to memory, but to reminiscence, and you give your disciples not truth, but only the semblance of truth; they will be hearers of many things and will have learned nothing; they will appear to be omniscient and will generally know nothing; they will be tiresome company, having the show of wisdom without the reality.”
More formally, Transformers and RNNs are so closely related as to be duals.
Training vs running. A Transformer (particularly one with tied weights like ALBERT) looks like an RNN which has been unrolled and a Transformer can be made more RNN-like (eg. Transformer-XL), while an RNN can look much more like a Transformer by using more ‘history stacking’ inputs or by being a multi-headed or ‘single-headed RNN’; and we can train our SOTA Transformer and then effectively finetune itinto an RNN, while approaches like RWKV/RetNetqueer the Transformer/RNN binary. A Transformer’s advantage is that it bypasses the recurrent state bottleneck: instead of being hamstrung by the need to encode & preserve just the right information it will need later, while fighting all the other possible datapoints or summary statistics or partial-computations it could be encoding into the same blob of recurrent state, it can just look at the entire history, consider every possible pair of keys/queries, extract the part of the full history it needs and use the right data immediately; this provides a clean gradient on how to better use the history. It processes the full history from scratch each time, and so an error one step doesn’t screw up all the later steps, which also makes it all parallelizable during training and enables large batch sizes so ‘GPUs go brr’ (especially for RL). The disadvantage, however, is that it is processing the full history from scratch each time, and so later steps don’t enjoy any savings from earlier steps, and the burden of recomputation gets worse each time step as nothing is forgotten nor remembered, and it must recompute everything every time during runtime. An RNN is the reverse: it is terrible to train and does not benefit from large batches easily and forgetful, and RNNs in practice often struggle to remember anything from before a few paragraphs ago (while Transformers with tricks can retrieve things from up to a million tokens before); but then they are lightning-fast to sample.
So it’s almost like RNNs and Transformers just swap their 𝒪s around: you can be good at training, or you can be good at runtime, or you can be mediocre in some ratio9, but you can’t be as good as both.
Further, the better attention works over large corpuses, the more it simply looks like ‘training a model’. If we make attention scale to extremely large contexts like millions of tokens, we face a paradox of attention: “to know what to focus on, you must at some point think hard about what not to focus on.”
To process 𝒪(n) tokens with the highest accuracy, we must pay 𝒪(n) costs to in some way think very hard about each token before ‘focusing’ on it in the ‘main computation’; while if we use cheaper (ie. stupider) approaches which omit relevant tokens, then our larger context window is increasingly useless as it fails to pull out the subtlest necessary tokens. (Early on, it’s easy to use simple heuristics like mere embedding similarity or n-gram-like overlap in order to pick out many of the most relevant tokens, but as the corpus size increases with more false positives & negatives and the problems become harder and precision becomes more important and more intelligence is expected, the more work is required to know how a token is relevant before you can know that it is relevant.) And the more computation you do to analyze each token before focusing on it, the more it looks like you are running the full model on that token and doing dynamic evaluation—but throwing away the training each time.
A secret third thing. The MLP would probably hit the points in between, and look more biologically plausible, more like Hebbian learning—after all, while brains do ‘recur’ and ‘pay attention’ to things, they definitely do not have clean discrete chunks set aside for a recurrent hidden state, nor any global ‘QKV’ computation. From the perspective of the MLP, recurrence is just a poor man’s lossy summary of the entire dataset, the incremental computation and attention is just an overly-hardwired mechanism for routing information whose inductive biases will eventually limit it. It would be better to truly memorize the entire dataset, then focus on relevant parts; better to compute using the entire MLP as the ‘hidden state’; and it would be better to learn to focus using powerful fully-connected layers which can learn any arbitrary patterns. It can do all these by training as an AUNN: it memorizes the data, while amortizing compute into itself by each gradient step, and gradually develops implicit attention as the optimal solution to both.10
What point in-between? Well, that may depend on the training. There are two extremes we could do the training in, which correspond to RNNs vs Transformers.
RNN-style. We could do it serially, starting at index #1 with a minibatch of 1, and proceeding to the end of the dataset in a continual-learning/online-learning style. This would be terrible on hardware efficiency or parallelization, but it would leverage the MLP ‘recurrence’ to the maximum extent possible: each index would be predicted by an MLP fresh off the previous index, almost like an RNN, and learn sample-efficiently, particularly on RL data.11
Transformer-style. We could also do standard SGD minibatch training, where we fill up a large minibatch with a list of indices (sampling the starting point at random); this would be more Transformer-like in providing ‘direct’ access to the entire list (history) and resembling ‘packed’ training12, but then the MLP would not be encouraged to optimize for serial updating, but independent updating. This would learn the distribution well, but it would not encourage the model to reach a parameterization that would naturally meta-learn how to online/continually-learn. (We could also sample indices at random, without attempting to learn anything about updating serially. This might be useful to boot up the model, but risks destabilizing the learning.) And we can interpolate between them: start with the maximum throughput training of filling up big minibatches, and then over the course of training, anneal to 100% serial training so as finetune the implicit recurrence. Indeed, depending on hardware characteristics, we might do both: within each node, do serial training on different independent batches, and merge full batches. This might give us the best of both worlds in terms of efficient training & runtime.
We hand-waved the issue of the tokenization as just a bit or byte-level tokenization for simplicity & generality, and ignored the compute cost. This is unfortunate because the compute-cost of low-level tokenization is a serious overhead, and low-level tokenization may also impede learning in general.13 So while byte-level tokenization has advantages, it also has disadvantages.
However, if we take the AUNN idea seriously, we may be able to have our tokenization cake and eat it too, by thinking of text as being multiple modalities, composed of all possible tokenizations. As noted before, we can sample data at different ‘resolutions’, and so we can encode text at different ‘resolutions’ (ie. tokenizations) as we wish.
Because we do not need to train on all indices in the dataset, we can define the native AUNN ‘tokenization’ as all tokenizations simultaneously: a datapoint is every possible tokenization of that datapoint, concatenated. (The alternate tokenizations can be lazily computed.)
Then we simply train, and sample, as computationally convenient. We can train on the whole thing, or we can try to be smarter about it. For example, we might train in a progressive way: starting with only the indices corresponding to the byte tokenization of the raw data, to teach low-level spelling and phonetics, and then annealing through BPEs (possibly multiple BPEs with increasingly large vocabularies) to the highest (densest) tokenization (WordPiece?). We can also train on exotic alternatives like different modalities (eg. VAE tokens encoding the text as the screenshot of a PDF of it). At the end, we may train using just the final densest tokenization, simplifying index calculation, and use that for all serious work.
This gets us all the benefits of the lowest rawest tokenization ensuring no information is lost and everything can be learned, with the learning & compute efficiency of working on dense tokenizations, in a way which requires no modifications to the AUNN at all, only modification to the data formatting.
The most straightforward way of representing indexes is as bitstrings or integers. But that might be limiting.
We could also allow for fractional indexes, like instead of ‘1’, ‘1.5’. The AUNN then predicts an intermediate ‘in between’ value.
We could know the intermediate values if we are teaching the AUNN to imitate some function f, and we can simply evaluate f(1.5), but we could also be doing interpolation between the two integer indexes, like in a time-series. This has many benefits, like letting a user search through an interval or at only the level of coarseness that they need.
More exotically, we could ask for indexes which may not seem to make sense; if we assign “dog” an index of 1, and “cat” an index of 2, what does querying ‘1.5’ return…? Some sort of semantic interpolation, presumably (perhaps it will return “fox”, or the cartoon character CatDog).
Runtime may be adequately efficient already using backprop; as a rule of thumb, gradient descent is 2× the cost of a forward pass, so any AUNN which is ~3× faster than a competing model in its forward pass is then equal as a total forward+backward pass. But the AUNN could easily be far better than a comparable RNN or Transformer, because it may train to be much better than the RNN and equal to a Transformer, yet still has the RNN’s 𝒪(1)-per-token runtime while the Transformer continues to suffer from 𝒪(n). But if we needed to improve the runtime efficiency, we could try to change the gradient descent step. (If nothing else, the gradient descent step is annoying from a software-engineering/product perspective—your hardware might be designed to be inference-only, for example.) Instead of backprop, we could use a local learning rule. (Examples include target propagation, direct feedback alignment, Z-IL, PES, & forward gradients.) This would simply run in place on the GPU, perhaps as part of the forward pass itself and invisible to the caller, merely adding a modest slowdown.
Local learning is enough. Local learning rules are not yet as good as true backprop, but they may not have to be for AUNN. One of the most common themes of scaling research is that larger better models learn linear & low-dimensional representations which enable the sample-efficiency, few-shot meta-learning14, and generalization; this is part of why self-attention can so usefully update the model even within a fraction of a forward pass. So, since the pretraining with backprop does all the hard work, the runtime learning rule doesn’t need to be as perfect as backprop, and one can anneal from true backprop to a more expensive but local learning rule to finetuning the model with a final unrealistic cheap local learning rule.
One can pick the final local learning rule to be maximally GPU-friendly; if it is a forward pass only rule, then it can be fused with the model itself, so there is no ‘update’ phase separate from the forward phase (eg. Kirsch & Schmidhuber 2020’s RNNs).
Just forward passes. Then the model simply updates itself on-GPU based on inputs, at lower cost & hassle, simultaneously increasing performance by optimizing using recent inputs (like dynamic evaluation, which typically boosts predictive power considerably15) and getting ‘finetuning’ for free—just snapshot the weights. From an engineering perspective, removing the distinction between phases, and no longer having to worry about context windows or recurrent states, is an attractive simplification. Just a big blackbox.
It is probably not necessary to train on old data to avoid catastrophic forgetting, if we are training at scale and receiving highly diverse user inputs, because continual learning appears to be another ‘blessing of scale’ where large overparameterized NNs implicitly do continual learning automatically. But if that is a concern, we can replay old data as convenient to soak up excess compute (and maybe we would want to do that anyway).
Or we could improve runtime efficiency by multiplexing queries: predict a datapoint which is multiple tuples of user IDs and outputs.
Another useful trick would be to use the MAE-like generating capability to generate only sparse outputs until more is required—one could generate just the 64px version of an image instead of the full 1024px, say. The broader version of this trick would be decoding in parallel: we do not necessarily need to sample from just one range of indices (corresponding to a single datapoint), we can sample from arbitrarily many in parallel as a minibatch to improve throughput.
Progressive Growing: We could improve training efficiency by progressive growing.
This is not hard because the AUNN MLP’s structure is so uniform.
Knowledge Distillation: While doing model surgery, it would also be easy to do knowledge distillation of any other NN into the AUNN: simply swap the real datapoint for an embedding of that datapoint.
This would enable distilling CNNs or Transformers into the AUNN, kickstarting it with the good parts of inductive bias while avoiding the bad parts.
Implicit Memory Units: Another architectural modification would be to encourage the creation of a recurrent memory stored in the model parameters by providing parameters especially easy to cannibalize into a memory, rather than being part of computation circuits.
eg. some parameters could be given especially high learning rates so they adapt fastest to inputs and specialize that way; or they could be simply disconnected from the index input, so cannot compute anything other than serving as ‘constant’ inputs into the rest of the AUNN (and so they will be heavily updated by the gradient descent to do something useful and become ‘fast weights’).
Hard Sampling/Active Learning: One strange idea enabled by the index approach would be running the AUNN ‘backwards’: instead of predicting the output from the index, predict the index from the output. This could enable prioritizing datapoints during training, and since training ≈ runtime, active learning on new data too.
Per the BLUR paper, the generative model is also a classifier, and so we can feed in ‘uncertain outputs’16 to run it backwards (or do gradient ascent instead) to extract ‘uncertain indices’ to resample & retrain on to prioritize hard datapoints.17
For active learning, the AUNN just trains on a small fraction of the datapoint (such as a few dozen random pixels), and if the new image’s indices do not turn up while searching for uncertain indices, then the image is too easy.
AUNNs do learning & memory through synaptic plasticity. This is a ‘soft’ or ‘internal’ memory, and has been highly successful for LLMs; however, many dislike the approach of storing all knowledge in model parameters and want some sort of explicit memory.
Model expansion & updating.“Retrieval” has been a highly popular add-on mechanism for LLMs, to save on model parameters, update their world-knowledge, and create de facto large context windows. Unlike many memory mechanism proposals, they can be learned or used without too much architectural changes: in the simplest retrieval approach, one simply uses a pretrained embedding model to look up in a text database a set of text snippets which are most ‘similar to’ the prompt, and appends them to the prompt just in case they might be useful. The model then figures out how, if at all, to use the retrieved snippets to change its behavior in-context.
Depending on the learning rules & memory mechanism used, it may be possible to bolt on various memory mechanisms to an AUNN; some require differentiability, others are fine with blackbox losses, others require loops etc. So it’s unclear which one would be best.
But a more natural AUNN version of retrieval/memory might be to incorporate the retrieval directly into the model, by making the model predict document IDs (ie. ‘external’ indices), which are then retrieved. This can be trained into an AUNN without direct architectural modification, only appropriate data inputs, to enable imitation-learning of retrieval: train the AUNN in the ordinary self-supervised way on the set of documents turned into (document ID, document) pairs, and then on transcripts of (prompt, (ID, snippet), result). The AUNN memorizes IDs & high-level summaries of documents (and perhaps even entire documents) in the document pretraining phase; then it learns from demonstrations how to select & use documents in the imitation-learning phase.
When training is finished, the AUNN can then be:
prompted for relevant IDs,
those IDs used out-of-band by some software wrapper to retrieve the actual documents from the database#. the snippets (the raw text, or the embedding, or embedding concatenated with the raw text) fed into it & trained on to teach the AUNN about the broad semantics of the text as summarized in the embedding, and teach it the raw text details18
finally, the desired completion generated.
Experience replay. The snippets do not just help the generation, but train the AUNN. With normal retrieval-augmented generation (RAG) approaches for Transformers, the benefit of retrieval is limited strictly to a single generation: once the completion is over, the results of the self-attention are thrown away. With AUNNs mixing learning & generation, retrieval becomes an opportunity to prioritize important training data: one retrieves entire ranges before & after the focal point.
This replay serves to refresh its memory of the context of nearby indices (which will often be relevant, due to temporal or other locality, and, based on later training or prompting, have become relevant). So every time an AUNN does some RAG, it learns better whether the retrieved documents were relevant, what their contents were, and to extract more information from them to generalize further. And in an RL context, this looks like a form of experience replay, helping the agent ponder the past for lessons.
Good retrieval also potentially enables retrieval using partial documents or hypothetical fragments (rendering it closer to ‘content-based addressing’); feed in a desired output, or a sketch or fragment of it, and see what document IDs or embeddings the AUNN predicts for retrieval.
How could an AUNN do planning or search? As an agent, it can use external tools, but can the AUNN do its own internal ‘pondering’ beyond that supported by synaptic plasticity/meta-learning?
Predicting futures. It seems possible, if we recall the original goal: to an AUNN, the future is just a large range of indices, the same as the past or present. It can “remember” the future as well as the past; so, it can ‘remember’ things like “successfully executing a plan”. The memory of planning and then executing the plan is simply a particular range; if it has just been prompted with a task, then that range will be near the most recent indices, indeed, it might immediately follow the index of the prompt! So prompting it with a task will imply that the following (untrained) indices will generate the most plausible episode, including its (predicted) actions and (predicted) outcomes and the (predicted) reward. This is simply the AUNN functioning as a good generative model.
What if the AUNN has been trained on data where attributes like ‘final reward’ are included at the beginning? Now it’s equivalent to an upside-down/reward-conditioned agent like a Decision Transformer! We can ask the AUNN to act as a skillful agent by simply prompting with the task & stating a high reward ‘was’ the result. The AUNN now predicts a skillful agent as best as it can, confabulating the entire episode. The AUNN now act online in the usual fashion, predicting the next action, training on the result, iteratively.
Daydreaming. The confabulated episode could even be used to iterate before acting by training and feeding back in confabulated predictions in timestep order; one could try to use it in a discrete diffusion model relaxation fashion by noising the predictions and retraining until the episode confabulation has converged. (This would be analogous to fantasizing about how something might happen, again and again, until all the inconsistencies and improbabilities have been smoothed away.)
A confabulated episode is a limited form of planning because it represents only a single, possibly just modal, episode. It does not encode a full decision tree or search process, like a game tree, which would allow it to explore many possible plans in parallel, even low-probability ones, and find surprises.
How can an AUNN do full tree search, like for theorem proving or game-playing? The synaptic plasticity can presumably encode some degree of search, but one would not expect this to work well (even in an AUNN otherwise highly intelligent). We can of course use it in hybrid architectures like an AlphaZero, where the tree search will work well, but only because the MCTS provides the scaffolding for the search. We want something more like MuZero, which exploits the RNN’s hidden state; MuZero outperforms AlphaZero, and can be generalized to multiplayer games, imperfect andhidden-information games like poker, continuous states/moves, offline learning etc.
Well, an AUNN has something better than a hidden state: it has all its parameters! If an AUNN can confabulate an episode and act like a Decision Transformer for a single episode, it can confabulate multiple episodes, and it can stitch them together into an implicit serialized tree, no different than the other kinds of tree-like data it has been trained on (eg. documents like source code).
Tree → list. It is Data Structures 101 that any tree, like a binary tree, can be flattened into a list. For real lists, density is important, which requires limits on the tree pattern or adding in additional pointers. However, the ‘list’ for an AUNN is purely virtual and not a dense but sparse array; there is no reason we cannot simply assign every node its own unique non-contiguous index (cf. Gödel numbering, 64-bit single-address spacevirtual memory/capabilities, Hashlife). So, we have a way to encode an entire tree into an AUNN, and train on arbitrary nodes, and thus to generate and to plan on.
To take a concrete example: chess. Chess has a finite number of possible board positions—Shannon number of 10120—which to encode into a number would require only log2(10120) ⧸ 8 = 50 bytes. Each number expressible in 50 bytes would map to a unique chess board position.19 (As usual, the IDs can be located at a large random offset to ensure they never overlap with other kinds of data, such as the decision-tree objects for all other tasks.)
Thus, if one wanted to teach an AUNN to play chess, one approach would be to use an expert like Stockfish to create a large collection of chess game trees which have been evaluated to high precision; serialize each game-state to its corresponding unique ID and its value (ie. the board-state with all possible moves’ value-estimate/win-probability); and train the AUNN on the millions of pairs. These pairs will not cover more than a vanishingly small faction of all possible chess IDs, of course, but they will teach it how to play chess.
This implicit tree can be used by an external tree algorithm like MCTS to search, as it is simply an odd form of encoding state where the AUNN evaluates an “ID” input instead of a normal board state. It starts at the opening move, gets the list of possible moves ranked by value, samples the best-looking move, and so on.
Can the implicit tree be leveraged internally, and the results of search fed back in to improve the model, also like MuZero? If we add in another layer of abstraction, why not? Like everything else, a tree search can itself be serialized into a list of actions/results/updates…
A MCTS could be linearized into a series of actions querying the AUNN, including at the end, the appropriate back-up operations which improve the value estimates: “the win-probability of board position #123 was actually 0.57; the win-probability of board position #12 was actually 0.99; the win-probability of board position #1 was actually 0.49; search finished. Action chosen: B.” This can be confabulated as an inner monologue-style list: after all, if the AUNN samples a list of tokens like “#123, 0.57”, then that probably is what #123’s index would be when predicted ‘directly’—what else would it be?20 And when it finishes the search by computing corrected estimates and it trains as usual on its self-sampled list, then those new corrected estimates, having been ‘observed’, will override the weaker original predictions, which are typically just extrapolated from other training data.
Thus, we can encode decision trees into the AUNN, plan & search explicitly over them externally, and imitate that same explicit plan/search process internally, and automatically update the internal predictions based on the results of the imitated process to self-improve.
What if…? The fact that the ‘tree’ is implicit to the model means we can do something with it that is harder to do with an explicit tree like a MCTS data structure or even an implicit hidden-state-defined state like a MuZero: instead of merely predicting a particular index, we can forcibly overwrite it, making an ‘edit’ to the tree which change the entire tree (rather than simply recalculate the child nodes), and explore the new tree. That is, the internal simulation enabled by the “Inner Monologue” lends itself to exploring counterfactuals—asking “what if?”.
This forced update acts as a dynamic injection of the counterfactual premise directly into the AUNN’s internal state (its weights) at that specific point in the tree space. It’s like temporarily editing the model’s own “memory” or “understanding” of that point in its virtual history.
Simulating Beliefs. Consequently, when the AUNN subsequently predicts later indices (idx_counterfactual+1, idx_counterfactual+2, …), these predictions are conditioned not just on the index itself, but on the model state that has just been explicitly rewritten to reflect the counterfactual assumption. This seems particularly potent for imperfect or hidden information games like poker. An AUNN could represent “belief states” over opponent hands or hidden world states via specific indices. By dynamically injecting a specific hypothesis (eg. “opponent holds Ace of Spades”) via a gradient step, it can then predict the likely consequences (opponent actions, game outcomes) from that specific adapted state, allowing deeper exploration than just averaging over the entire belief distribution. It allows asking, “How does the game likely unfold if this specific hidden information were true?”
Opponent Modeling. This extends naturally to sophisticated opponent modeling and simulating a rudimentary theory of mind. (For example, instead of assuming the opponent is as skilled a player as oneself, and trying to play a safe Nash equilibrium move, one could observe their moves, conclude that they are incompetent, and then start ruthlessly exploiting them with riskier moves.)
The AUNN could represent opponent types or beliefs via indices, like a range which corresponds to an embedding of “opponent’s beliefs about me”. To reason about “what if my opponent thinks I’m bluffing?”, it could identify idx_opp_believes_im_bluffing, dynamically inject that belief via a gradient step (adapting its state as if it were the opponent holding that belief), and then predict the opponent’s likely action from this altered perspective (AUNN(idx_opp_action_given_belief)). When the opponent does act, the observed action trains the AUNN as usual, implicitly refining its model of that opponent. This allows the AUNN to move beyond static policy evaluation towards simulating the opponent’s reasoning process, conditioned on hypothesized beliefs—beliefs which can be updated based on actual observed behavior.
Latency has become a major focus of LLM engineering optimization. While most latency reduction methods like ‘drafting’ or ‘speculative decoding’ would not transfer as is (except perhaps to the extent that a particular implementation moves towards Transformers by using them internally or by predicting multiple tokens at each index), there are doubtless many ways to lower AUNN latency.
One can switch back and forth between online gradient descent (lowest latency, and can train on inputs in realtime and begin sampling a response the moment the full input finishes) and batch gradient descent, to get the benefits of both low latency and also squeeze out as much as possible from the data for the best response.21
An AUNN could be sampled in the usual way but skipping most indices, to sample an “outline” or “draft”, and then much lower-latency smaller AUNNs conditioned on that to fill out predictable details cheaply. (This would lower latency from the AUNNs being much shallower, but also from being able to sample them all in parallel, if the outline is enough to lock down all of the details.) One could also try to sample from the low-latency AUNNs and spot-check some indices in parallel with the big one to decide if the divergence is too great and to throw away the cheap fast samples.
Simple experiments should be enough to establish most of the key properties: ability to memorize data, extrapolate out to distant indices, and condition-by-updating.
This can be done with simple n-gram models, or the char-RNN classic, Tiny Shakespeare. In other modalities, I like binarized MNIST as a test bed for generative modeling of MNIST digits and classification: one can test various capabilities (classification of previous pixel points, generation conditioned on a label, unconditional generation, digit completion), including Permuted MNIST.
Permuted MNIST is good because it then can be used to test continual-learning/meta-learning: train on an indefinitely large number of permutations sequentially, and an AUNN should eventually have a phase transition to learning how to classify each new permutation after only a few datapoints, rather than learning from scratch each time.
After Permuted MNIST, CIFAR-10 is a natural next step.
One might wonder: is an AUNN truly the very simplest possible NN architecture?
Maybe not. We still have the index input making it more complex.
Do we truly need indexes? It is noteworthy that strictly speaking, Transformers do not need ‘indexes’, in the form of positional embeddings, at all. Causal language models still work well without them. (Not as well, of course, but a lot better than you’d expect.) The causal language model analysis shows that the causal language model implicitly learns to encode the position of tokens based on distance from the missing token.
This is initially surprising, but on closer examination makes sense. Often, positions can be reconstructed and a sensible prediction made even if the input is randomly shuffled or is in a set-like representation.
It is clearly possible in principle, if you know what you are doing, to receive corrections for the previous token, and then make a prediction for the next token: humans can do that easily. If I show you the sorted input ["The", "brown", "fox", "jumps", "lazy", "over", "quick", "the"], with a little thought, you can easily predict that the next token is “dog”. And if you predict wrong, you will be able to make a better guess about the next token too. You can change your next guess based on the feedback for your previous guess. (“What is the next token?” “I think the next token is ‘over’.” “Wrong: it was actually ‘the’. Now what is the next token?” “Oh. Uh… ‘lazy’.” “Right. Now what is the next token?” “‘Dog’.” etc)
Nor does this seem implausible for an artificial neural network to be capable of doing. All this requires is that gradient descent be able to copy a datapoint into a model in a single update (which we know is possible from NNs being able to memorize data they have seen only once), and for the model to be able to think about a datapoint it has memorized (which they must be able to do in order to do anything which is not explicitly mentioned in an input).
So, do AUNNs need an index input? How could an AUNN work if we just drop the index inputs entirely?
Well, we’ve already seen how this can work by invoking neuroplasticity & dynamic evaluation! We can move further away from memorization and double down pure, continuous online learning for everything, even without any explicit memory mechanisms. We simply need the index to be implicit and inferred during training. (Arguably, this is what a dynamically-evaluated ICL-heavy model like TTT RNNs or RWKV-7 is doing already, when the ‘outer’ network calls the ‘inner’ network, and perhaps is like an extreme Belief State Transformer.)
We remove the index (let’s call this AUNN variant an Input-Free NN or IFNN), and we change the training scheme to simply proceeding through the data, which is in a coherent (usually temporal) order, and we take a single gradient descent step for each token to train the IFNN to predict that token. Hence, an IFFN is an arbitrary feedforward blackbox, with no input, which outputs a single binary variable, and our AUNN reduces to just this:
The full IFNN architecture (schematic diagram).
Of course, the token changes each time. So how does this work?
Well, repeated over enough data, with enough model capacity, what we are teaching the IFNN to do is to engage in online learning, and to find a meta-learned model which rapidly updates first-order REPTILE-style “where in the data it is” and based on that, the gradient descent updates it to predict based on the training target, the next token after that. As before, we expect some of the weights to automatically specialize over the course of training to become ‘fragile’ and the equivalent of self-attention or hidden states, encoding the sufficient statistics for a task, and those weights are what is mostly changed in the gradient descent step. (Language models already are non-myopic: they must implicitly plan and reason about future unseen tokens in order to more accurately predict the current token, and this has beenconfirmed by mechanistic analysis; we just incentivize that more.)
This won’t be easy, because our standard first-order SGD is aimed directly at the wrong thing: predicting the (now stale) current token. It can be quite hard to train even normal neural networks, and it’s taken many decades to discover current deep learning recipes and that even the safest-seeming choices like sigmoid activations are dead-ends. So I do not claim that IFNNs are easy to train, just theoretically possible. Our NN may have to be trained for a long time in order to be able to update in just the right way. This is something that might be better off done using a second-order gradient descent algorithm (like the original MAML, rather than REPTILE), or perhaps using an evolutionary algorithm (which can ignore deceptive gradients entirely and travel directly towards optimizing the ‘next-next token loss’, as it were). One could experiment by training IFNNs which predict multiple tokens in parallel, rather than just one, which should be more Transformer-like and stabilize training; and gradually anneal to a single output.
OK, so that, weirdly enough, trains a generative causal language model.
And once you have that, you can then engage in the usual prompt programming, encoding of tasks and delimiters, multi-modality tokens to interleave images and text, reinforcement learning by imitation learning, and so on and so forth—as long as you always ‘sample’ from the IFNN by generating and then updating the model, to increment the implicit index. We are not constrained to simply sampling forward either; like an RNN, we can run forwards or backwards or in arbitrary ‘directions’ across our ‘data’. The ‘temporal index’ is about the gradient descent, and we do have to update the model serially in time, but there is no restriction on the data, and we could go backwards through an list and then forwards as we please, as long as the IFNN can predict the changes in direction and avoid a catastrophically destructive update.
So an IFNN can do whatever you want.
What are the advantages of an IFNN?
it is pathologically simple
It is unclear to me how a NN architecture could be simpler even in theory. (How could one use a NN which has neither inputs nor outputs?)
may have better inductive biases towards time-varying dynamic systems, including ones where the system itself changes, because of its own path-dependence and not forcing any a priori distinction between ‘state’ and ‘weights’
free anomaly detection via gradient spikes?
much more flexible updating patterns: things like bidirectional RNNs or recursive NNs have fallen out of favor due to not being GPU-friendly and being trickier to implement; however, for an IFNN, every update pattern is the same.
This might be the best part of an IFNN. An AUNN requires careful thought about the layout of indices, to avoid clobbering already-used indices, and wants you to go in specific access patterns. But an IFNN may be happy to pivot instantaneously in any direction and forget about stale data as quickly as possible. One may be able to casually dump in data and change tasks on the fly in ways hard to foresee.
more parameter-efficient as no longer incentivized to memorize as heavily as an AUNN
? ? ?
we could wonder if the online-learning-by-neuroplasticity paradigm could have some sort of biological interpretation or have unique scaling behavior, which contrasts with the AUNN “memorize the world” strategy which is highly biologically implausible.
The idea of learning point by point purely by neuroplasticity is certainly reminiscent of how organisms must learn; they cannot stop and train their brains for a few months by repeatedly doing a big minibatch over data randomly sampled throughout history.
Perhaps an IFNN would become extremely sample-efficient and adept at meta-learning in general because it is trained solely online; or perhaps an IFNN could generalize unusually well and be adversarially robust, as the training implicitly heavily regularizes it?
What are the disadvantages of an IFNN?
training is inherently serial as an IFNN is fundamentally path-dependent.
I cannot immediately think of any plausible parallelization training scheme which can deliver meaningful updates. Not just every activation, but every parameter is dependent on the training history and updates, like RNNs.
It is possible that training for many serial tokens on non-overlapping datasets could allow for the equivalent of large minibatches, by averaging the final gradients (because we expect parameter updates to be relatively sparse and non-overlapping, while the ‘hidden state’ weights average out). But this is an empirical question.
Using other tricks, like initializing an IFNN from a successful Transformer or AUNN checkpoint, would seem to somewhat defeat the point, and might compromise any of the speculative advantages—if IFNN training produces adversarial robustness, an initialization from a non-robust model might destroy that by providing too strong an initialization to modify substantially and reach a different region in the model landscape.
it may be possible to minimize the damage by using hardware optimized for low-latency updates. One should be able to fit an extremely powerful NN into the memory of a Cerebras chip, and then run at full speed with n = 1 minibatches (background).
sampling is inherently serial
Unlike an AUNN, which lets you sample arbitrarily, which helps a lot for the weirder use cases like reifying game trees as a giant sparse ‘array’, an IFNN cannot easily jump around. So you need to either much more carefully engineer the encoding to be ‘dense’ in some way or accept an unbounded amount of overhead to increment the implicit pointer through the ‘array’ or come up with some other method still (directly modifying the implicit hidden state, akin to methods like activation steering or lightweight finetuning? Try to encode explicit index jumps as tokenized text commands to let you input ‘increment +152’ and hope that it Just Works™?).
While we can imagine an AUNN being practical someday, the serial limitation on an IFNN is so severe that it’s hard to imagine any improvement could fix it, unless some form of parallel training can be made to work.
Overall, the IFNN is probably most valuable as a thought-experiment or a pedagogical example, to expand our imaginations about what a neural net could be.
The AUNN framework offers a lot of directions to investigate, and could help with generalized models which can be applied to any problem and updated incrementally while not having the serious runtime performance drawbacks of Transformers. It’d be interesting if it worked!
Because of the centrality of raster data to image/video tasks or coordinates to physics, there are many more examples one could mention, eg. Fourier neural operators, neural ODEs↩︎
And to a lesser extent, the existence of single-forward-pass generative models at all like GANs or MAEs, which cannot iterate or attend like autoregressive or energy or diffusion models, and generally do not have all that many layers, limiting the ability of any ‘within-forward-pass’ coordination. This is demonstrated to a lesser extent by the many architectures which can iteratively generate but in more flexible order than strict raster or causal order: eg. PixelCNN++, Parallel WaveNet/FloWaveNet/WaveRNN, Iterative Refinement Transformer/Mask-Predict/Insertion Transformer↩︎
Specifically: One-hot or zero-hot embeddings won’t work, and relative embeddings are problematic, so let’s say that it’s a 38-bit binary index, which should be a reasonably dense input while still covering >100tb of training data with plenty of room to spare for sampling or empty regions.↩︎
The ability to do this is perhaps less shocking if we recall the absurdly vast amounts of declarative material, often recallable verbatim, that a model like GPT-3 has learned and encoded into its weights, with no need for further retrieval.↩︎
Charles Foster proposes a variant adding back in some attention:
AUNN variant with causal decoder embedding & self-attention bottleneck.
Indeed, one of the most common reactions c. 2020 to claims that Transformers like GPT-3 implement meta-learning was that they couldn’t because their parameters were not being changed by a gradient descent step! How could they meta-learn without second-order gradients like MAML/REPTILE? Of course, the meta-learning was just being done by the self-attention/feed-forward layers, which were in the classic ‘slow weights vs fast weights’ paradigm, and the self-attention activations which were eventually shown to (at least in somelimited cases) be equivalent to gradient descent/fast weights. (See also HyperNetworks which rely on indices for generating tailored weights, external memory like Neural Turing Machines, and MetaFun.)↩︎
This leads to ‘sharp’ transitions between the indices at the beginning & end, which might play havoc with most (relative) embeddings like sinusoidal or RoPE or ALiBi which are trying to be ‘smooth’ as an inductive bias—but that’s not really a problem if we’re passing it into deep fully-connected networks, because MLPs are notorious for their non-smooth behavior (visualization) & piece-wise linearity, so it may be feasible for MLPs.↩︎
That is, to sample conditional on a prompt, you append the prompt to the dataset to get its indices, and train on them to initialize the prompt. (This ‘finetuned’ snapshot can be saved & reused indefinitely, similar to saving an RNN’s hidden state after initializing using an episode.) Then it can predict the first unseen index given that prompt; so far so good, but how do we sample beyond that? How do we condition?
We then pretend the prediction was exact by rounding (or applying another sampling strategy like Boltzmann temperature sampling): if for index #12345, AUNN predicts a bit-value of 0.9 (probably actually the logit equivalent), we simply round to 1, and train using the (#12345 → 1) tuple; then we predict the next index, #12346, and so on.
Bit modeling is the simplest & most general possible approach, but we will probably want to use more complex data types for efficiency. Byte-level modeling would be a good compromise between the simple but inefficient raw bit modeling and much higher domain-specific complex but efficient approaches like WordPiece or VAE tokens. For byte-level modeling, DL researchers usually find it best to parameterize bytes as 256 separate values and treat it as a softmax categorical classification problem.
However, we may be able to avoid making a hard choice here by using lazy evaluation of possible encodings.↩︎
The huge number of attempts to improve on standard quadratic Transformers since 2020, which have essentially all failed, and simply sweep out a Pareto frontier from slow-but-smart to fast-but-dumb, is another testament to this apparent duality.↩︎
From this perspective, we are reinventing Hopfield networks—which is no accident, as everything is a Hopfield network, particularly RNNs and Transformers. (See also Irie et al 2022.) Where in a Hopfield network is ‘the’ recurrence, or ‘the’ attention? It’s just a large blob of densely connected neurons which computes to a fixed point which optimally minimizes energy/loss.↩︎
One wonders if there is a connection here with arguments that Transformers are much worse in some way than human brains: human brains may be much more efficient by some measures like pretraining sample-efficiency (even if the final NNs increasingly rival human sample-efficiency on new tasks), and perhaps this is not ‘despite’ the 18 years of wallclock serial learning, but because it is serial. (From this perspective, human gains from active learning & exploration, or raw computational power, are much less important than they now appear.)↩︎
The AUNN instance being trained on a later index does not have direct access to earlier indices like a packed Transformer batch, true, but the AUNN can do minibatch persistency to do multiple gradient descent steps on a minibatch of data, which enables access to the newly-encoded data. (This has parallels in GANs & reinforcement learning, where taking multiple steps was common to increase stability & sample-efficiency & hardware usage, and avoid throttling by dataset/environment latency.)↩︎
While an AUNN doesn’t have the exact issue that Transformers do of entangling context window length with tokenization, inasmuch as there is no context window per se, there is still a fundamental statistical challenge of learning long-range correlations. The less ‘dense’ the input representation, the harder it is to learn the connections.↩︎
The classic debate: is meta-learning ‘just’ feature/representation learning? From the Bayesian perspective, they are the same thing because the goal is to infer the latent variables governing the current POMDP instance, and you cannot infer efficiently without appropriate features.↩︎
A way to test this possibility in the context of dynamic evaluation would be to test whether a model trained with dynamic evaluation at scale gets better at dynamic evaluation—whether it learns to learn online.
For example, one could take a large pretrained LLM (to bracket out any issues of pretraining stability) and a large temporally-ordered text corpus, hold out the last year of data (perhaps dropping the year before that entirely to minimize dynamic-evaluation advantage), and compare training strategies on the rest of the data (with sample-size & compute held equal): the usual i.i.d. finetuning approach, versus training sequentially dynamic-evaluation-style. Then evaluate perplexity of both models when evaluated & dynamically-evaluated on the heldout final year. (If newspaper datasets are unavailable, then one could attempt to instead sort the dataset to maximize similarity of adjacent datapoints; for example, estimate mutual information cheaply by the classic trick of comparing compression efficiency of A-then-B vs B-then-A lists, or using embeddings to ‘sort by similarity’, or hooking into long-range compression utilities like rzip or utilities like binsort.)
If online learning can be learned, then the two models should be roughly equal when evaluated normally (with a small advantage for the dynamic model, perhaps), and the dynamic-evaluation-trained model should outperform the i.i.d.-trained model when evaluated dynamically. Finally, one could run other benchmarks like meta-learning-oriented benchmarks to verify that any dynamic-evaluation gains did not come with a penalty elsewhere.↩︎
If the AUNN is predicting bit-level, then this would be ~0.5. If it’s predicting bytes, then ~128, If it’s predicting pixels, then the average RGB value, etc.↩︎
There are other active learning approaches, like retraining multiple instances from different random initializations because DL models approximate posterior samples from the true underlying Bayesian posterior, but these are so expensive that they would be impractical for most AUNN uses. And cheap active learning methods, like training with dropout to get MC-dropout, are known to poorly estimate the uncertainty because they in effect only slightly vary a single posterior sample, and are much worse than a posterior ensemble. Active learning remains a major unsolved problem in DL.↩︎
There would be two natural ways to do this, depending on whether the documents in question were in the training dataset or are ‘external’, such as a set of live Internet search engine results. If the documents are in the training dataset and the predicted indices are the AUNN indices, then one can simply ‘jump back’ and repeat the original training on those indices. But if they have never been seen before & so have no AUNN indices, or it’s undesirable for some other reason to repeat the original training, then one can simply treat them as fresh new datapoints to train on, appropriately formatted with their metadata, and then ‘train’ on (prompt, (ID, snippet), completion). If one wants, one could go further meta: if there is some way to judge outputs, then one can create a dataset which contains the optimal prompt + data (text vs embedding vs text+embedding), and eventually an AUNN should meta-learn for new tasks which of the 3 is most suited. (I would generally expect text+embedding to win, so this may not be worthwhile, but if the AUNN gets good enough at implicit embedding of text, then the embeddings might start to damage performance.)↩︎
We can expect a generalist AUNN to have this limited ‘introspection’ because this would be a desirable capability for other tasks like retrieval-augmented Q&A: retrieve documents from their indices to put into a ‘context’ range before generating the final answer.↩︎
Online stochastic gradient descent, such as the self-attention of a causal/decoder Transformer, is less efficient than a batch form like a bidirectional Transformer.↩︎


{kind=link}