‘knowledge distillation’ directory
- See Also
- Gwern
- Links
- “Claude-5-Sonnet Is Not Frontier But Has Its Uses”, Mowshowitz 2026
- “Pretraining Recurrent Networks without Recurrence”, Kumar & Isola 2026
- “Subliminal Learning Is a LoRA Artifact”, Nief et al 2026
- “Gemma 4: Byte for Byte, the Most Capable Open Models”, Farabet & Lacombe 2026
- “Introducing GPT-5.4-Mini and GPT-5.4-Nano: Fast and Efficient Models Optimized for Coding and Sub-Agents”, OpenAI 2026
- “Detecting and Preventing Distillation Attacks [DeepSeek, Moonshot AI, & MiniMax: >16m Conversations from >24k Sockpuppets]”, Anthropic 2026
- “GTIG AI Threat Tracker: Distillation, Experimentation, and (Continued) Integration of AI for Adversarial Use”, Group 2026
- “I Solved Cartpole-V1 Using Only Bitwise Ops With Differentiable Logic Synthesis”, kiockete 2026
- “Reverse Engineering a Phase Change in GPT’s Training Data… With the Seahorse Emoji 🌊🐴: Why Non-Thinking Models Have Started ‘Thinking Out Loud’, and What It Reveals about How Frontier Labs Train Their Latest Models [(Benchmarking the Rise of Inner-Monologue Reasoning Data in OA, 2023-06–2025-08)]”, Maini 2025
- “Introducing Gemini 3 Flash: Benchmarks, Global Availability; Gemini 3 Flash Is Our Latest Model With Frontier Intelligence Built for Speed That Helps Everyone Learn, Build, and Plan Anything—Faster”, Doshi 2025
- “Subliminal Learning: Transmitting Misalignment via Paraphrased Datasets”, Bozoukov et al 2025
- “LLaDA2.0: Scaling Up Diffusion Language Models to 100B”, Bie et al 2025
- “On-Policy Distillation [DAgger for LLMs]”, Lu 2025
- “Pre-Training under Infinite Compute”, Kim et al 2025
- “Introducing Gpt-Oss:
gpt-Oss-120bandgpt-Oss-20bPush the Frontier of Open-Weight Reasoning Models”, OpenAI 2025 - “Wan 2.2 Human Image Generation Is Very Good. This Open Model Has a Great Future.Workflow Included [Video Generation → Image Generation]”, yomasexbomb 2025
- “On the Creation of Narrow AI: Hierarchy and Nonlocality of Neural Network Skills”, Michaud et al 2025
- “Reinforcement Learning for Reasoning in Large Language Models With One Training Example”, Wang et al 2025
- “Alignment Is Not Free: How Model Upgrades Can Silence Your Confidence Signals”, Lin 2025
- “Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?”, Yue et al 2025
- “M1: Towards Scalable Test-Time Compute With Mamba Reasoning Models”, Wang et al 2025
- “
llama2.c64: Inference Llama-2 on a Commodore 64”, Witkowiak 2025 - “Thinking Slow, Fast: Scaling Inference Compute With Distilled Reasoners”, Paliotta et al 2025
- “NaturalReasoning: Reasoning in the Wild With 2.8M Challenging Questions”, Yuan et al 2025
- “On Teacher Hacking in Language Model Distillation”, Tiapkin et al 2025
- “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning”, Guo et al 2025
- “Jasper and Stella: Distillation of SOTA Embedding Models”, Zhang & Wang 2024
- “Densing Law of LLMs”, Xiao et al 2024
- “A Little Help Goes a Long Way: Efficient LLM Training by Leveraging Small LMs”, Rawat et al 2024
- “LoLCATs: On Low-Rank Linearizing of Large Language Models”, Zhang et al 2024
- “The Mamba in the Llama: Distilling and Accelerating Hybrid Models”, Wang et al 2024
- “Gemma 2: Improving Open Language Models at a Practical Size”, Riviere et al 2024
- “Scaling the Codebook Size of VQGAN to 100,000 With a Utilization Rate of 99%”, Zhu et al 2024
- “From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step”, Deng et al 2024
- “How Bad Is Training on Synthetic Data? A Statistical Analysis of Language Model Collapse”, Seddik et al 2024
- “Streamlining Redundant Layers to Compress Large Language Models”, Chen et al 2024
- “SDXS: Real-Time One-Step Latent Diffusion Models With Image Conditions”, Song et al 2024
- “Do Not Worry If You Do Not Have Data: Building Pretrained Language Models Using Translationese”, Doshi et al 2024
- “CLLMs: Consistency Large Language Models”, Kou et al 2024
- “Bridging the Gap: Sketch to Color Diffusion Model With Semantic Prompt Learning”, Wang et al 2024
- “Knowledge Distillation of Black-Box Large Language Models”, Chen et al 2024
- “Improving Text Embeddings With Large Language Models”, Wang et al 2023
- “ReST Meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent”, Aksitov et al 2023
- “ByteDance Is Secretly Using OpenAI’s Tech to Build a Competitor”, Heath 2023
- “SMERF: Streamable Memory Efficient Radiance Fields for Real-Time Large-Scene Exploration”, Duckworth et al 2023
- “Beyond Human Data: Scaling Self-Training for Problem-Solving With Language Models (ReSTEM)”, Singh et al 2023
- “Generative Models: What Do They Know? Do They Know Things? Let’s Find Out!”, Du et al 2023
- “Efficient Transformer Knowledge Distillation: A Performance Review”, Brown et al 2023
- “Implicit Chain-Of-Thought Reasoning via Knowledge Distillation”, Deng et al 2023
- “Distil-Whisper: Robust Knowledge Distillation via Large-Scale Pseudo Labelling”, Gandhi et al 2023
- “HyperFields: Towards Zero-Shot Generation of NeRFs from Text”, Babu et al 2023
- “Polynomial Time Cryptanalytic Extraction of Neural Network Models”, Shamir et al 2023
- “OSD: Online Speculative Decoding”, Liu et al 2023
- “ReST: Reinforced Self-Training (ReST) for Language Modeling”, Gulcehre et al 2023
- “Composable Function-Preserving Expansions for Transformer Architectures”, Gesmundo & Maile 2023
- “Distilling Large Language Models for Biomedical Knowledge Extraction: A Case Study on Adverse Drug Events”, Gu et al 2023
- “Explaining Competitive-Level Programming Solutions Using LLMs”, Li et al 2023
- “GKD: Generalized Knowledge Distillation for Auto-Regressive Sequence Models”, Agarwal et al 2023
- “WikiChat: Stopping the Hallucination of Large Language Model Chatbots by Few-Shot Grounding on Wikipedia”, Semnani et al 2023
- “VanillaNet: the Power of Minimalism in Deep Learning”, Chen et al 2023
- “Mimetic Initialization of Self-Attention Layers”, Trockman & Kolter 2023
- “TinyStories: How Small Can Language Models Be and Still Speak Coherent English?”, Eldan & Li 2023
- “Dr. LLaMa: Improving Small Language Models in Domain-Specific QA via Generative Data Augmentation”, Guo et al 2023
- “Distilling Step-By-Step! Outperforming Larger Language Models With Less Training Data and Smaller Model Sizes”, Hsieh et al 2023
- “LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions”, Wu et al 2023
- “Learning Agile Soccer Skills for a Bipedal Robot With Deep Reinforcement Learning”, Haarnoja et al 2023
- “A Cookbook of Self-Supervised Learning”, Balestriero et al 2023
- “KD-DLGAN: Data Limited Image Generation via Knowledge Distillation”, Cui et al 2023
- “TRACT: Denoising Diffusion Models With Transitive Closure Time-Distillation”, Berthelot et al 2023
- “Learning Humanoid Locomotion With Transformers”, Radosavovic et al 2023
- “Consistency Models”, Song et al 2023
- “ProofNet: Autoformalizing and Formally Proving Undergraduate-Level Mathematics”, Azerbayev et al 2023
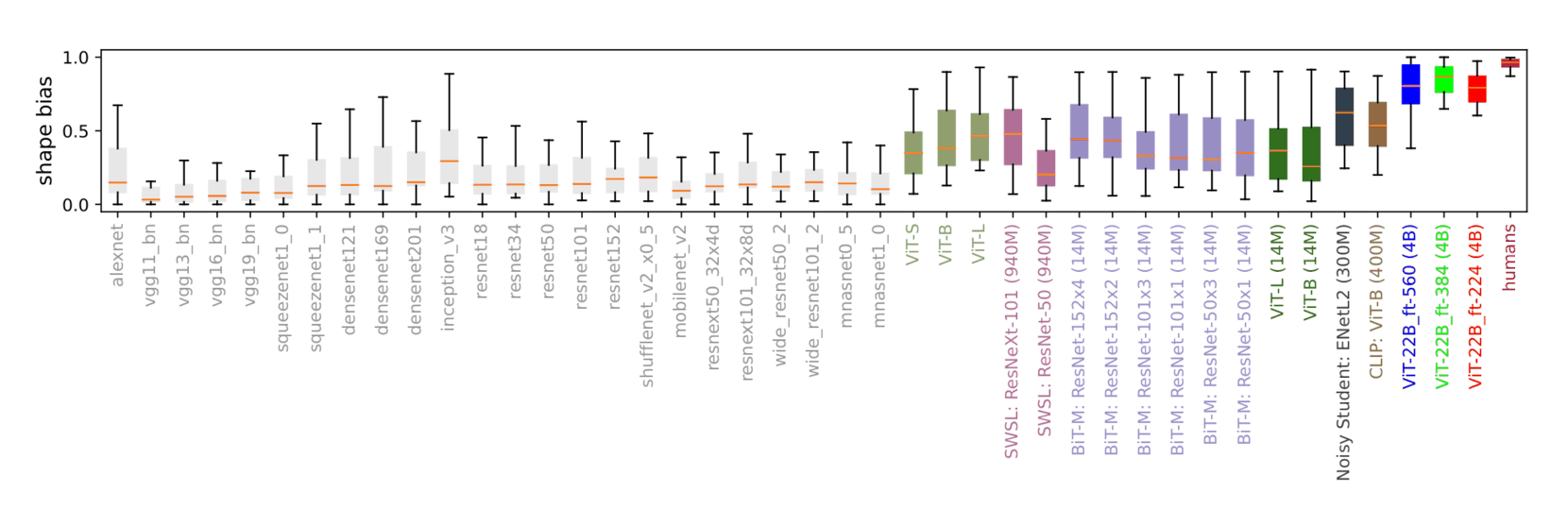
- “Scaling Vision Transformers to 22 Billion Parameters”, Dehghani et al 2023
- “BMT: Binarized Neural Machine Translation”, Zhang et al 2023
- “Use GPT-3 Incorrectly: Reduce Costs 40× and Increase Speed by 5×”, Pullen 2023
- “TinyMIM: An Empirical Study of Distilling MIM Pre-Trained Models”, Ren et al 2023
- “Sparse Upcycling: Training Mixture-Of-Experts from Dense Checkpoints”, Komatsuzaki et al 2022
- “Solving Math Word Problems With Process & Outcome-Based Feedback”, Uesato et al 2022
- “Distilled DeepConsensus: Knowledge Distillation for Fast and Accurate DNA Sequence Correction”, Belyaeva et al 2022
- “MaskDistill: A Unified View of Masked Image Modeling”, Anonymous 2022
- “EVA: Exploring the Limits of Masked Visual Representation Learning at Scale”, Fang et al 2022
- “Legged Locomotion in Challenging Terrains Using Egocentric Vision”, Agarwal et al 2022
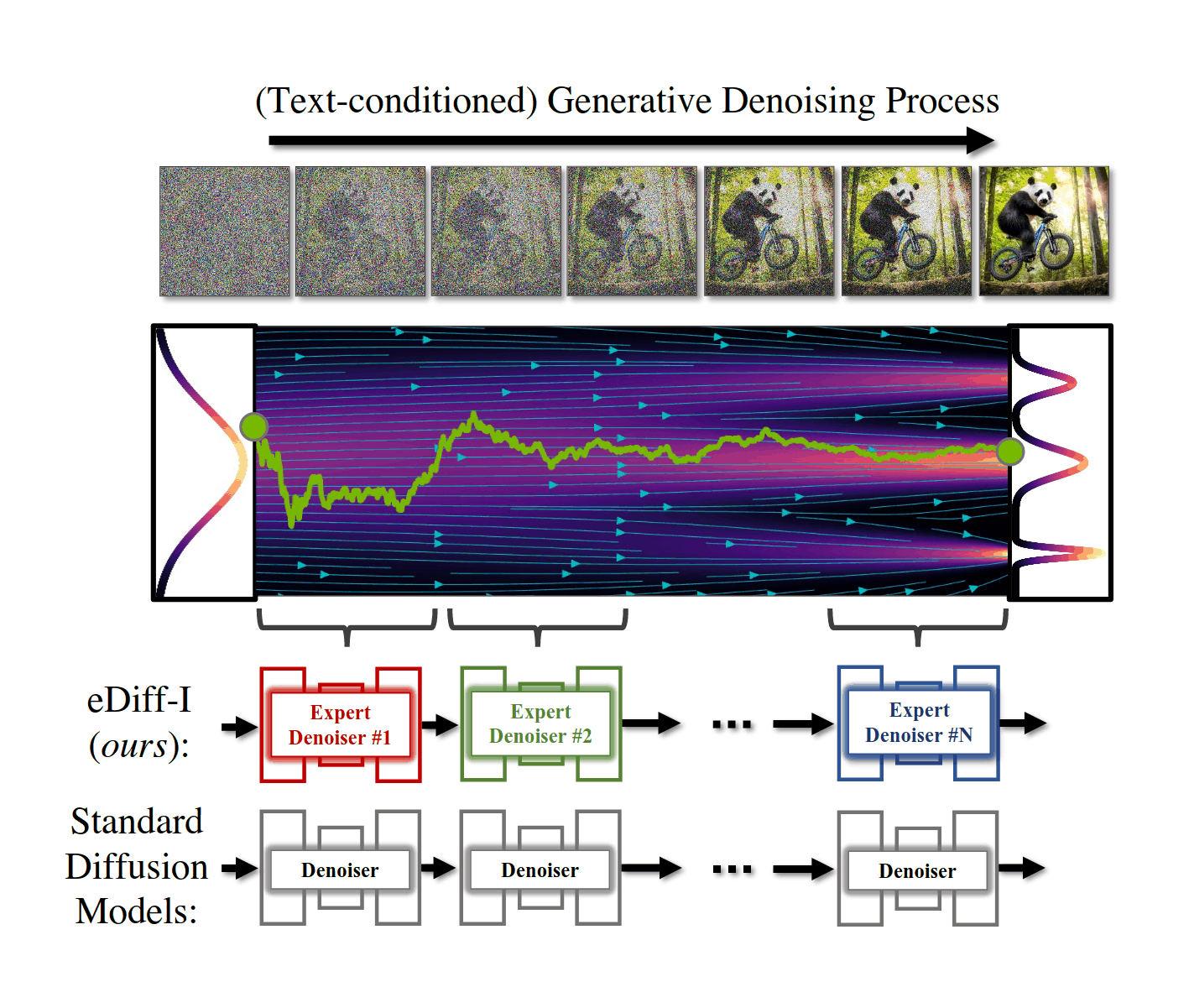
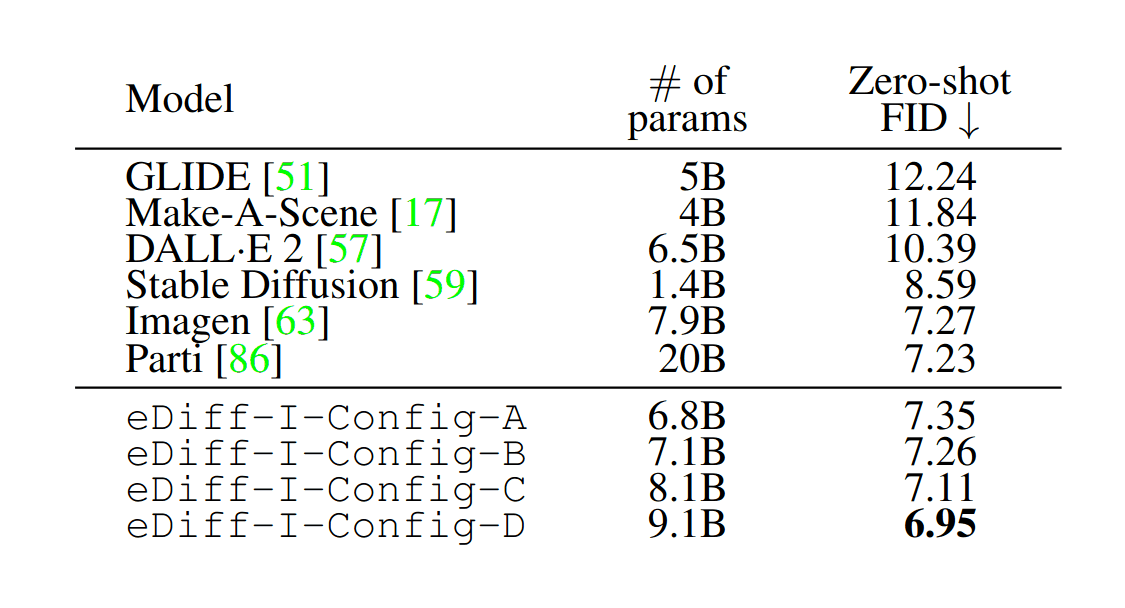
- “EDiff-I: Text-To-Image Diffusion Models With an Ensemble of Expert Denoisers”, Balaji et al 2022
- “Fast DistilBERT on CPUs”, Shen et al 2022
- “Large Language Models Can Self-Improve”, Huang et al 2022
- “Exclusive Supermask Subnetwork Training for Continual Learning”, Yadav & Bansal 2022
- “The Unreasonable Effectiveness of Fully-Connected Layers for Low-Data Regimes”, Kocsis et al 2022
- “On Distillation of Guided Diffusion Models”, Meng et al 2022
- “Small Character Models Match Large Word Models for Autocomplete Under Memory Constraints”, Jawahar et al 2022
- “Omnigrok: Grokking Beyond Algorithmic Data”, Liu et al 2022
- “Context Distillation: Learning by Distilling Context”, Snell et al 2022
- “Human-Level Atari 200× Faster”, Kapturowski et al 2022
- “On the Effectiveness of Compact Biomedical Transformers (✱BioBERT)”, Rohanian et al 2022
- “Neural Payoff Machines: Predicting Fair and Stable Payoff Allocations Among Team Members”, Cornelisse et al 2022
- “Re2G: Retrieve, Rerank, Generate”, Glass et al 2022
- “Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems”, FitzGerald et al 2022
- “SBERT Studies Meaning Representations: Decomposing Sentence Embeddings into Explainable Semantic Features”, Opitz & Frank 2022
- “ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers”, Yao et al 2022
- “Dataset Condensation via Efficient Synthetic-Data Parameterization”, Kim et al 2022
- “UViM: A Unified Modeling Approach for Vision With Learned Guiding Codes”, Kolesnikov et al 2022
- “Dialog Inpainting: Turning Documents into Dialogues”, Dai et al 2022
- “Solving ImageNet: a Unified Scheme for Training Any Backbone to Top Results”, Ridnik et al 2022
- “STaR: Bootstrapping Reasoning With Reasoning”, Zelikman et al 2022
- “Knowledge Distillation: Bad Models Can Be Good Role Models”, Kaplun et al 2022
- “PPCD-GAN: Progressive Pruning and Class-Aware Distillation for Large-Scale Conditional GANs Compression”, Vo et al 2022
- “Self-Distilled StyleGAN: Towards Generation from Internet Photos”, Mokady et al 2022
- “AutoDistil: Few-Shot Task-Agnostic Neural Architecture Search for Distilling Large Language Models”, Xu et al 2022
- “DeepSpeed-MoE: Advancing Mixture-Of-Experts Inference and Training to Power Next-Generation AI Scale”, Rajbhandari et al 2022
- “Microdosing: Knowledge Distillation for GAN Based Compression”, Helminger et al 2022
- “ERNIE 3.0 Titan: Exploring Larger-Scale Knowledge Enhanced Pre-Training for Language Understanding and Generation”, Wang et al 2021
- “Amortized Noisy Channel Neural Machine Translation”, Pang et al 2021
- “Causal Distillation for Language Models”, Wu et al 2021
- “Extrapolating from a Single Image to a Thousand Classes Using Distillation”, Asano & Saeed 2021
- “Prune Once for All: Sparse Pre-Trained Language Models”, Zafrir et al 2021
- “Training Verifiers to Solve Math Word Problems”, Cobbe et al 2021
- “Wav2CLIP: Learning Robust Audio Representations From CLIP”, Wu et al 2021
- “When in Doubt, Summon the Titans: Efficient Inference With Large Models”, Rawat et al 2021
- “Lifelong Pretraining: Continually Adapting Language Models to Emerging Corpora”, Jin et al 2021
- “Symbolic Knowledge Distillation: from General Language Models to Commonsense Models”, West et al 2021
- “Language Modeling via Learning to Rank”, Frydenlund et al 2021
- “Beyond Pick-And-Place: Tackling Robotic Stacking of Diverse Shapes”, Lee et al 2021
- “Unsupervised Neural Machine Translation With Generative Language Models Only”, Han et al 2021
- “OTTER: Data Efficient Language-Supervised Zero-Shot Recognition With Optimal Transport Distillation”, Wu et al 2021
- “Progressive Distillation for Fast Sampling of Diffusion Models”, Salimans & Ho 2021
- “On the Interplay Between Sparsity, Naturalness, Intelligibility, and Prosody in Speech Synthesis”, Lai et al 2021
- “ZSD-YOLO: Zero-Shot YOLO Detection Using Vision-Language Knowledge Distillation”, Xie & Zheng 2021
- “Beyond Distillation: Task-Level Mixture-Of-Experts (TaskMoE) for Efficient Inference”, Kudugunta et al 2021
- “SPLADE V2: Sparse Lexical and Expansion Model for Information Retrieval”, Formal et al 2021
- “KroneckerBERT: Learning Kronecker Decomposition for Pre-Trained Language Models via Knowledge Distillation”, Tahaei et al 2021
- “Multi-Task Self-Training for Learning General Representations”, Ghiasi et al 2021
- “Dataset Distillation With Infinitely Wide Convolutional Networks”, Nguyen et al 2021
- “Knowledge-Adaptation Priors”, Khan & Swaroop 2021
- “Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better”, Menghani 2021
- “Knowledge Distillation: A Good Teacher Is Patient and Consistent”, Beyer et al 2021
- “ResMLP: Feedforward Networks for Image Classification With Data-Efficient Training”, Touvron et al 2021
- “DINO: Emerging Properties in Self-Supervised Vision Transformers”, Caron et al 2021
- “Zero-Shot Detection via Vision and Language Knowledge Distillation”, Gu et al 2021
- “Data-Efficient Language-Supervised Zero-Shot Learning With Self-Distillation”, Cheng et al 2021
- “ALD: Efficient Transformers in Reinforcement Learning Using Actor-Learner Distillation”, Parisotto & Salakhutdinov 2021
- “KiloNeRF: Speeding up Neural Radiance Fields With Thousands of Tiny MLPs”, Reiser et al 2021
- “China’s GPT-3? BAAI Introduces Superscale Intelligence Model ‘Wu Dao 1.0’: The Beijing Academy of Artificial Intelligence (BAAI) Releases Wu Dao 1.0, China’s First Large-Scale Pretraining Model.”, Synced 2021
- “Understanding Invariance via Feedforward Inversion of Discriminatively Trained Classifiers”, Teterwak et al 2021
- “Distilling Large Language Models into Tiny and Effective Students Using PQRNN”, Kaliamoorthi et al 2021
- “Training Data-Efficient Image Transformers & Distillation through Attention”, Touvron et al 2020
- “Towards Understanding Ensemble, Knowledge Distillation and Self-Distillation in Deep Learning”, Allen-Zhu & Li 2020
- “Towards Playing Full MOBA Games With Deep Reinforcement Learning”, Ye et al 2020
- “A Primer in BERTology: What We Know about How BERT Works”, Rogers et al 2020
- “Dataset Meta-Learning from Kernel Ridge-Regression”, Nguyen et al 2020
- “TernaryBERT: Distillation-Aware Ultra-Low Bit BERT”, Zhang et al 2020
- “"Less Than One"-Shot Learning: Learning n Classes From M < N Samples”, Sucholutsky & Schonlau 2020
- “SimCLRv2: Big Self-Supervised Models Are Strong Semi-Supervised Learners”, Chen et al 2020
- “Movement Pruning: Adaptive Sparsity by Fine-Tuning”, Sanh et al 2020
- “General Purpose Text Embeddings from Pre-Trained Language Models for Scalable Inference”, Du et al 2020
- “Cryptanalytic Extraction of Neural Network Models”, Carlini et al 2020
- “MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers”, Wang et al 2020
- “Towards a Conversational Agent That Can Chat About…Anything”, Adiwardana & Luong 2020
- “Understanding the Generalization of ‘Lottery Tickets’ in Neural Networks”, Morcos & Tian 2019
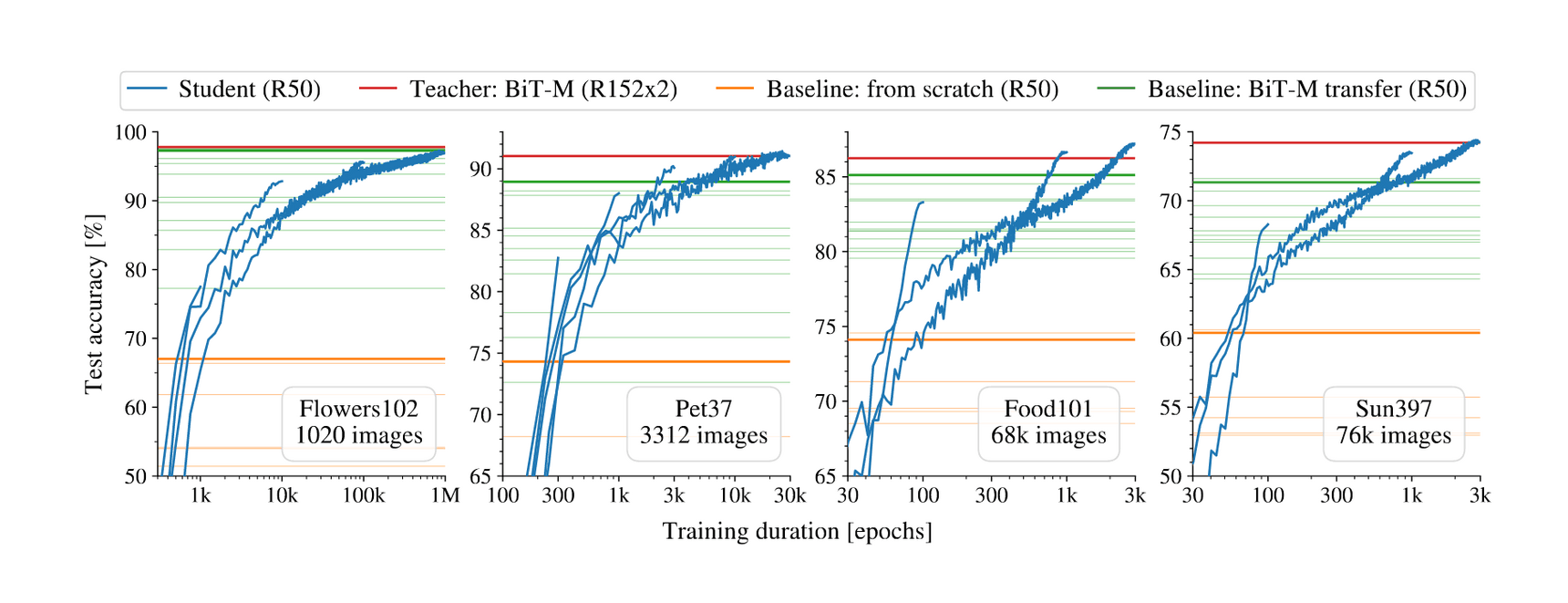
- “Self-Training With Noisy Student Improves ImageNet Classification”, Xie et al 2019
- “On Warm-Starting Neural Network Training”, Ash & Adams 2019
- “DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter”, Sanh et al 2019
- “TinyBERT: Distilling BERT for Natural Language Understanding”, Jiao et al 2019
- “Smaller, Faster, Cheaper, Lighter: Introducing DistilGPT, a Distilled Version of GPT”, Sanh 2019
- “Well-Read Students Learn Better: On the Importance of Pre-Training Compact Models”, Turc et al 2019
- “ICML 2019 Notes”, Abel 2019
- “NoGAN: Decrappification, DeOldification, and Super Resolution”, Antic et al 2019
- “Mask-Predict: Parallel Decoding of Conditional Masked Language Models”, Ghazvininejad et al 2019
- “Distilling Policy Distillation”, Czarnecki et al 2019
- “Compressing GANs Using Knowledge Distillation”, Aguinaldo et al 2019
- “Neural Probabilistic Motor Primitives for Humanoid Control”, Merel et al 2018
- “Dataset Distillation”, Wang et al 2018
- “Exploration by Random Network Distillation”, Burda et al 2018
- “OCD: Optimal Completion Distillation for Sequence Learning”, Sabour et al 2018
- “Network Recasting: A Universal Method for Network Architecture Transformation”, Yu et al 2018
- “ClariNet: Parallel Wave Generation in End-To-End Text-To-Speech”, Ping et al 2018
- “Self-Net: Lifelong Learning via Continual Self-Modeling”, Camp et al 2018
- “Self-Distillation: Born Again Neural Networks”, Furlanello et al 2018
- “Large Scale Distributed Neural Network Training through Online Distillation”, Anil et al 2018
- “Kickstarting Deep Reinforcement Learning”, Schmitt et al 2018
- “Faster Gaze Prediction With Dense Networks and Fisher Pruning”, Theis et al 2018
- “Parallel WaveNet: Fast High-Fidelity Speech Synthesis”, Oord et al 2017
- “Knowledge Concentration: Learning 100K Object Classifiers in a Single CNN”, Gao et al 2017
- “Policy Optimization by Genetic Distillation”, Gangwani & Peng 2017
- “N2N Learning: Network to Network Compression via Policy Gradient Reinforcement Learning”, Ashok et al 2017
- “Training Shallow and Thin Networks for Acceleration via Knowledge Distillation With Conditional Adversarial Networks”, Xu et al 2017
- “Distral: Robust Multitask Reinforcement Learning”, Teh et al 2017
- “Biased Importance Sampling for Deep Neural Network Training”, Katharopoulos & Fleuret 2017
- “Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer”, Zagoruyko & Komodakis 2016
- “Sequence-Level Knowledge Distillation”, Kim & Rush 2016
- “FractalNet: Ultra-Deep Neural Networks without Residuals”, Larsson et al 2016
- “Do Deep Convolutional Nets Really Need to Be Deep and Convolutional?”, Urban et al 2016
- “Face Model Compression by Distilling Knowledge from Neurons”, Luo et al 2016
- “Policy Distillation”, Rusu et al 2015
- “Actor-Mimic: Deep Multitask and Transfer Reinforcement Learning”, Parisotto et al 2015
- “Net2Net: Accelerating Learning via Knowledge Transfer”, Chen et al 2015
- “Bayesian Dark Knowledge”, Korattikara et al 2015
- “Distilling the Knowledge in a Neural Network”, Hinton et al 2015
- “FitNets: Hints for Thin Deep Nets”, Romero et al 2014
- “Do Deep Nets Really Need to Be Deep?”, Ba & Caruana 2013
- “Model Compression”, Bucila 2006
- “Learning Complex, Extended Sequences Using the Principle of History Compression”, Schmidhuber 1992
- “Dota 2 With Large Scale Deep Reinforcement Learning § Pg11”, Rerun 2026 (page 11 org openai)
- “Gemini 3.1 Flash Lite: Our Most Cost-Effective AI Model Yet”
- “Gemini 3.5: Frontier Intelligence With Action”
- “Google DeepMind’s Grandmaster-Level Chess Without Search”
- “Sky-T1: Train Your Own
o1-PreviewModel With $450” - “
o3-Mini”, OpenAI 2026 - “From Vision to Language: Semi-Supervised Learning in Action…at Scale”
- “A High Level Closed-Door Session Discussing DeepSeek: Vision Trumps Technology”
- “Research Log: Monet/PEER Sparse Experts”
- Sort By Magic
llama-inference commodore64 retro-ai small-models tiny-architecture llama2sparse-retrievalembedding-exploration biomedical-transformers sentence-representations compact-embeddings explainable-features embedding-distillationautocomplete-optimizationself-supervisedlifelong-learning continual-adaptation incremental-training supermask-method self-modelingopen-models scaling-optimization ai-threat-tracking reasoning-advanced gemma-innovationproblem-solvingpolicy-synthesisfast-learningcompact-models
- Wikipedia (1)
- Miscellaneous
- Bibliography
See Also
Gwern
“AI Cannibalism Can Be Good”, Gwern 2025
“Research Ideas”, Gwern 2017
Links
“Claude-5-Sonnet Is Not Frontier But Has Its Uses”, Mowshowitz 2026
“Pretraining Recurrent Networks without Recurrence”, Kumar & Isola 2026
“Subliminal Learning Is a LoRA Artifact”, Nief et al 2026
“Gemma 4: Byte for Byte, the Most Capable Open Models”, Farabet & Lacombe 2026
“Introducing GPT-5.4-Mini and GPT-5.4-Nano: Fast and Efficient Models Optimized for Coding and Sub-Agents”, OpenAI 2026
“Detecting and Preventing Distillation Attacks [DeepSeek, Moonshot AI, & MiniMax: >16m Conversations from >24k Sockpuppets]”, Anthropic 2026
“GTIG AI Threat Tracker: Distillation, Experimentation, and (Continued) Integration of AI for Adversarial Use”, Group 2026
“I Solved Cartpole-V1 Using Only Bitwise Ops With Differentiable Logic Synthesis”, kiockete 2026
I solved Cartpole-v1 using only bitwise ops with Differentiable Logic Synthesis
“Reverse Engineering a Phase Change in GPT’s Training Data… With the Seahorse Emoji 🌊🐴: Why Non-Thinking Models Have Started ‘Thinking Out Loud’, and What It Reveals about How Frontier Labs Train Their Latest Models [(Benchmarking the Rise of Inner-Monologue Reasoning Data in OA, 2023-06–2025-08)]”, Maini 2025
“Introducing Gemini 3 Flash: Benchmarks, Global Availability; Gemini 3 Flash Is Our Latest Model With Frontier Intelligence Built for Speed That Helps Everyone Learn, Build, and Plan Anything—Faster”, Doshi 2025
View External Link:
“Subliminal Learning: Transmitting Misalignment via Paraphrased Datasets”, Bozoukov et al 2025
Subliminal Learning: Transmitting Misalignment via Paraphrased Datasets
“LLaDA2.0: Scaling Up Diffusion Language Models to 100B”, Bie et al 2025
“On-Policy Distillation [DAgger for LLMs]”, Lu 2025
“Pre-Training under Infinite Compute”, Kim et al 2025
“Introducing Gpt-Oss: gpt-Oss-120b and gpt-Oss-20b Push the Frontier of Open-Weight Reasoning Models”, OpenAI 2025
Introducing gpt-oss: gpt-oss-120b and gpt-oss-20b push the frontier of open-weight reasoning models
“Wan 2.2 Human Image Generation Is Very Good. This Open Model Has a Great Future.Workflow Included [Video Generation → Image Generation]”, yomasexbomb 2025
“On the Creation of Narrow AI: Hierarchy and Nonlocality of Neural Network Skills”, Michaud et al 2025
On the creation of narrow AI: hierarchy and nonlocality of neural network skills
“Reinforcement Learning for Reasoning in Large Language Models With One Training Example”, Wang et al 2025
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
“Alignment Is Not Free: How Model Upgrades Can Silence Your Confidence Signals”, Lin 2025
Alignment is not free: How model upgrades can silence your confidence signals
“Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?”, Yue et al 2025
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
“M1: Towards Scalable Test-Time Compute With Mamba Reasoning Models”, Wang et al 2025
M1: Towards Scalable Test-Time Compute with Mamba Reasoning Models
“llama2.c64: Inference Llama-2 on a Commodore 64”, Witkowiak 2025
“Thinking Slow, Fast: Scaling Inference Compute With Distilled Reasoners”, Paliotta et al 2025
Thinking Slow, Fast: Scaling Inference Compute with Distilled Reasoners
“NaturalReasoning: Reasoning in the Wild With 2.8M Challenging Questions”, Yuan et al 2025
NaturalReasoning: Reasoning in the Wild with 2.8M Challenging Questions
“On Teacher Hacking in Language Model Distillation”, Tiapkin et al 2025
“DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning”, Guo et al 2025
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
“Jasper and Stella: Distillation of SOTA Embedding Models”, Zhang & Wang 2024
“Densing Law of LLMs”, Xiao et al 2024
“A Little Help Goes a Long Way: Efficient LLM Training by Leveraging Small LMs”, Rawat et al 2024
A Little Help Goes a Long Way: Efficient LLM Training by Leveraging Small LMs
“LoLCATs: On Low-Rank Linearizing of Large Language Models”, Zhang et al 2024
“The Mamba in the Llama: Distilling and Accelerating Hybrid Models”, Wang et al 2024
The Mamba in the Llama: Distilling and Accelerating Hybrid Models
“Gemma 2: Improving Open Language Models at a Practical Size”, Riviere et al 2024
“Scaling the Codebook Size of VQGAN to 100,000 With a Utilization Rate of 99%”, Zhu et al 2024
Scaling the Codebook Size of VQGAN to 100,000 with a Utilization Rate of 99%
“From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step”, Deng et al 2024
From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step
“How Bad Is Training on Synthetic Data? A Statistical Analysis of Language Model Collapse”, Seddik et al 2024
How Bad is Training on Synthetic Data? A Statistical Analysis of Language Model Collapse
“Streamlining Redundant Layers to Compress Large Language Models”, Chen et al 2024
Streamlining Redundant Layers to Compress Large Language Models
“SDXS: Real-Time One-Step Latent Diffusion Models With Image Conditions”, Song et al 2024
SDXS: Real-Time One-Step Latent Diffusion Models with Image Conditions
“Do Not Worry If You Do Not Have Data: Building Pretrained Language Models Using Translationese”, Doshi et al 2024
Do Not Worry if You Do Not Have Data: Building Pretrained Language Models Using Translationese
“CLLMs: Consistency Large Language Models”, Kou et al 2024
“Bridging the Gap: Sketch to Color Diffusion Model With Semantic Prompt Learning”, Wang et al 2024
Bridging the Gap: Sketch to Color Diffusion Model with Semantic Prompt Learning
“Knowledge Distillation of Black-Box Large Language Models”, Chen et al 2024
“Improving Text Embeddings With Large Language Models”, Wang et al 2023
“ReST Meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent”, Aksitov et al 2023
ReST meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent
“ByteDance Is Secretly Using OpenAI’s Tech to Build a Competitor”, Heath 2023
ByteDance is secretly using OpenAI’s tech to build a competitor
“SMERF: Streamable Memory Efficient Radiance Fields for Real-Time Large-Scene Exploration”, Duckworth et al 2023
SMERF: Streamable Memory Efficient Radiance Fields for Real-Time Large-Scene Exploration
“Beyond Human Data: Scaling Self-Training for Problem-Solving With Language Models (ReSTEM)”, Singh et al 2023
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models (ReSTEM)
“Generative Models: What Do They Know? Do They Know Things? Let’s Find Out!”, Du et al 2023
Generative Models: What do they know? Do they know things? Let’s find out!
“Efficient Transformer Knowledge Distillation: A Performance Review”, Brown et al 2023
Efficient Transformer Knowledge Distillation: A Performance Review
“Implicit Chain-Of-Thought Reasoning via Knowledge Distillation”, Deng et al 2023
Implicit Chain-of-Thought Reasoning via Knowledge Distillation
“Distil-Whisper: Robust Knowledge Distillation via Large-Scale Pseudo Labelling”, Gandhi et al 2023
Distil-Whisper: Robust Knowledge Distillation via Large-Scale Pseudo Labelling
“HyperFields: Towards Zero-Shot Generation of NeRFs from Text”, Babu et al 2023
HyperFields: Towards Zero-Shot Generation of NeRFs from Text
“Polynomial Time Cryptanalytic Extraction of Neural Network Models”, Shamir et al 2023
Polynomial Time Cryptanalytic Extraction of Neural Network Models
“OSD: Online Speculative Decoding”, Liu et al 2023
“ReST: Reinforced Self-Training (ReST) for Language Modeling”, Gulcehre et al 2023
“Composable Function-Preserving Expansions for Transformer Architectures”, Gesmundo & Maile 2023
Composable Function-preserving Expansions for Transformer Architectures
“Distilling Large Language Models for Biomedical Knowledge Extraction: A Case Study on Adverse Drug Events”, Gu et al 2023
“Explaining Competitive-Level Programming Solutions Using LLMs”, Li et al 2023
Explaining Competitive-Level Programming Solutions using LLMs
“GKD: Generalized Knowledge Distillation for Auto-Regressive Sequence Models”, Agarwal et al 2023
GKD: Generalized Knowledge Distillation for Auto-regressive Sequence Models
“WikiChat: Stopping the Hallucination of Large Language Model Chatbots by Few-Shot Grounding on Wikipedia”, Semnani et al 2023
“VanillaNet: the Power of Minimalism in Deep Learning”, Chen et al 2023
“Mimetic Initialization of Self-Attention Layers”, Trockman & Kolter 2023
“TinyStories: How Small Can Language Models Be and Still Speak Coherent English?”, Eldan & Li 2023
TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
“Dr. LLaMa: Improving Small Language Models in Domain-Specific QA via Generative Data Augmentation”, Guo et al 2023
Dr. LLaMa: Improving Small Language Models in Domain-Specific QA via Generative Data Augmentation
“Distilling Step-By-Step! Outperforming Larger Language Models With Less Training Data and Smaller Model Sizes”, Hsieh et al 2023
“LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions”, Wu et al 2023
LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions
“Learning Agile Soccer Skills for a Bipedal Robot With Deep Reinforcement Learning”, Haarnoja et al 2023
Learning Agile Soccer Skills for a Bipedal Robot with Deep Reinforcement Learning
“A Cookbook of Self-Supervised Learning”, Balestriero et al 2023
“KD-DLGAN: Data Limited Image Generation via Knowledge Distillation”, Cui et al 2023
KD-DLGAN: Data Limited Image Generation via Knowledge Distillation
“TRACT: Denoising Diffusion Models With Transitive Closure Time-Distillation”, Berthelot et al 2023
TRACT: Denoising Diffusion Models with Transitive Closure Time-Distillation
“Learning Humanoid Locomotion With Transformers”, Radosavovic et al 2023
“Consistency Models”, Song et al 2023
“ProofNet: Autoformalizing and Formally Proving Undergraduate-Level Mathematics”, Azerbayev et al 2023
ProofNet: Autoformalizing and Formally Proving Undergraduate-Level Mathematics
“Scaling Vision Transformers to 22 Billion Parameters”, Dehghani et al 2023
“BMT: Binarized Neural Machine Translation”, Zhang et al 2023
“Use GPT-3 Incorrectly: Reduce Costs 40× and Increase Speed by 5×”, Pullen 2023
Use GPT-3 incorrectly: reduce costs 40× and increase speed by 5×
“TinyMIM: An Empirical Study of Distilling MIM Pre-Trained Models”, Ren et al 2023
TinyMIM: An Empirical Study of Distilling MIM Pre-trained Models
“Sparse Upcycling: Training Mixture-Of-Experts from Dense Checkpoints”, Komatsuzaki et al 2022
Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints
“Solving Math Word Problems With Process & Outcome-Based Feedback”, Uesato et al 2022
Solving math word problems with process & outcome-based feedback
“Distilled DeepConsensus: Knowledge Distillation for Fast and Accurate DNA Sequence Correction”, Belyaeva et al 2022
Distilled DeepConsensus: Knowledge distillation for fast and accurate DNA sequence correction
“MaskDistill: A Unified View of Masked Image Modeling”, Anonymous 2022
“EVA: Exploring the Limits of Masked Visual Representation Learning at Scale”, Fang et al 2022
EVA: Exploring the Limits of Masked Visual Representation Learning at Scale
“Legged Locomotion in Challenging Terrains Using Egocentric Vision”, Agarwal et al 2022
Legged Locomotion in Challenging Terrains using Egocentric Vision
“EDiff-I: Text-To-Image Diffusion Models With an Ensemble of Expert Denoisers”, Balaji et al 2022
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
“Fast DistilBERT on CPUs”, Shen et al 2022
“Large Language Models Can Self-Improve”, Huang et al 2022
“Exclusive Supermask Subnetwork Training for Continual Learning”, Yadav & Bansal 2022
Exclusive Supermask Subnetwork Training for Continual Learning
“The Unreasonable Effectiveness of Fully-Connected Layers for Low-Data Regimes”, Kocsis et al 2022
The Unreasonable Effectiveness of Fully-Connected Layers for Low-Data Regimes
“On Distillation of Guided Diffusion Models”, Meng et al 2022
“Small Character Models Match Large Word Models for Autocomplete Under Memory Constraints”, Jawahar et al 2022
Small Character Models Match Large Word Models for Autocomplete Under Memory Constraints
“Omnigrok: Grokking Beyond Algorithmic Data”, Liu et al 2022
“Context Distillation: Learning by Distilling Context”, Snell et al 2022
“Human-Level Atari 200× Faster”, Kapturowski et al 2022
“On the Effectiveness of Compact Biomedical Transformers (✱BioBERT)”, Rohanian et al 2022
On the Effectiveness of Compact Biomedical Transformers (✱BioBERT)
“Neural Payoff Machines: Predicting Fair and Stable Payoff Allocations Among Team Members”, Cornelisse et al 2022
Neural Payoff Machines: Predicting Fair and Stable Payoff Allocations Among Team Members
“Re2G: Retrieve, Rerank, Generate”, Glass et al 2022
“Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems”, FitzGerald et al 2022
“SBERT Studies Meaning Representations: Decomposing Sentence Embeddings into Explainable Semantic Features”, Opitz & Frank 2022
“ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers”, Yao et al 2022
ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers
“Dataset Condensation via Efficient Synthetic-Data Parameterization”, Kim et al 2022
Dataset Condensation via Efficient Synthetic-Data Parameterization
“UViM: A Unified Modeling Approach for Vision With Learned Guiding Codes”, Kolesnikov et al 2022
UViM: A Unified Modeling Approach for Vision with Learned Guiding Codes
“Dialog Inpainting: Turning Documents into Dialogues”, Dai et al 2022
“Solving ImageNet: a Unified Scheme for Training Any Backbone to Top Results”, Ridnik et al 2022
Solving ImageNet: a Unified Scheme for Training any Backbone to Top Results
“STaR: Bootstrapping Reasoning With Reasoning”, Zelikman et al 2022
“Knowledge Distillation: Bad Models Can Be Good Role Models”, Kaplun et al 2022
“PPCD-GAN: Progressive Pruning and Class-Aware Distillation for Large-Scale Conditional GANs Compression”, Vo et al 2022
“Self-Distilled StyleGAN: Towards Generation from Internet Photos”, Mokady et al 2022
Self-Distilled StyleGAN: Towards Generation from Internet Photos
“AutoDistil: Few-Shot Task-Agnostic Neural Architecture Search for Distilling Large Language Models”, Xu et al 2022
AutoDistil: Few-shot Task-agnostic Neural Architecture Search for Distilling Large Language Models
“DeepSpeed-MoE: Advancing Mixture-Of-Experts Inference and Training to Power Next-Generation AI Scale”, Rajbhandari et al 2022
DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale
“Microdosing: Knowledge Distillation for GAN Based Compression”, Helminger et al 2022
Microdosing: Knowledge Distillation for GAN based Compression
“ERNIE 3.0 Titan: Exploring Larger-Scale Knowledge Enhanced Pre-Training for Language Understanding and Generation”, Wang et al 2021
“Amortized Noisy Channel Neural Machine Translation”, Pang et al 2021
“Causal Distillation for Language Models”, Wu et al 2021
“Extrapolating from a Single Image to a Thousand Classes Using Distillation”, Asano & Saeed 2021
Extrapolating from a Single Image to a Thousand Classes using Distillation
“Prune Once for All: Sparse Pre-Trained Language Models”, Zafrir et al 2021
“Training Verifiers to Solve Math Word Problems”, Cobbe et al 2021
“Wav2CLIP: Learning Robust Audio Representations From CLIP”, Wu et al 2021
“When in Doubt, Summon the Titans: Efficient Inference With Large Models”, Rawat et al 2021
When in Doubt, Summon the Titans: Efficient Inference with Large Models
“Lifelong Pretraining: Continually Adapting Language Models to Emerging Corpora”, Jin et al 2021
Lifelong Pretraining: Continually Adapting Language Models to Emerging Corpora
“Symbolic Knowledge Distillation: from General Language Models to Commonsense Models”, West et al 2021
Symbolic Knowledge Distillation: from General Language Models to Commonsense Models
“Language Modeling via Learning to Rank”, Frydenlund et al 2021
“Beyond Pick-And-Place: Tackling Robotic Stacking of Diverse Shapes”, Lee et al 2021
Beyond Pick-and-Place: Tackling Robotic Stacking of Diverse Shapes
“Unsupervised Neural Machine Translation With Generative Language Models Only”, Han et al 2021
Unsupervised Neural Machine Translation with Generative Language Models Only
“OTTER: Data Efficient Language-Supervised Zero-Shot Recognition With Optimal Transport Distillation”, Wu et al 2021
OTTER: Data Efficient Language-Supervised Zero-Shot Recognition with Optimal Transport Distillation
“Progressive Distillation for Fast Sampling of Diffusion Models”, Salimans & Ho 2021
Progressive Distillation for Fast Sampling of Diffusion Models
“On the Interplay Between Sparsity, Naturalness, Intelligibility, and Prosody in Speech Synthesis”, Lai et al 2021
On the Interplay Between Sparsity, Naturalness, Intelligibility, and Prosody in Speech Synthesis
“ZSD-YOLO: Zero-Shot YOLO Detection Using Vision-Language Knowledge Distillation”, Xie & Zheng 2021
ZSD-YOLO: Zero-Shot YOLO Detection using Vision-Language Knowledge Distillation
“Beyond Distillation: Task-Level Mixture-Of-Experts (TaskMoE) for Efficient Inference”, Kudugunta et al 2021
Beyond Distillation: Task-level Mixture-of-Experts (TaskMoE) for Efficient Inference
“SPLADE V2: Sparse Lexical and Expansion Model for Information Retrieval”, Formal et al 2021
SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval
“KroneckerBERT: Learning Kronecker Decomposition for Pre-Trained Language Models via Knowledge Distillation”, Tahaei et al 2021
“Multi-Task Self-Training for Learning General Representations”, Ghiasi et al 2021
Multi-Task Self-Training for Learning General Representations
“Dataset Distillation With Infinitely Wide Convolutional Networks”, Nguyen et al 2021
Dataset Distillation with Infinitely Wide Convolutional Networks
“Knowledge-Adaptation Priors”, Khan & Swaroop 2021
“Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better”, Menghani 2021
Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better
“Knowledge Distillation: A Good Teacher Is Patient and Consistent”, Beyer et al 2021
Knowledge distillation: A good teacher is patient and consistent
“ResMLP: Feedforward Networks for Image Classification With Data-Efficient Training”, Touvron et al 2021
ResMLP: Feedforward networks for image classification with data-efficient training
“DINO: Emerging Properties in Self-Supervised Vision Transformers”, Caron et al 2021
DINO: Emerging Properties in Self-Supervised Vision Transformers
“Zero-Shot Detection via Vision and Language Knowledge Distillation”, Gu et al 2021
Zero-Shot Detection via Vision and Language Knowledge Distillation
“Data-Efficient Language-Supervised Zero-Shot Learning With Self-Distillation”, Cheng et al 2021
Data-Efficient Language-Supervised Zero-Shot Learning with Self-Distillation
“ALD: Efficient Transformers in Reinforcement Learning Using Actor-Learner Distillation”, Parisotto & Salakhutdinov 2021
ALD: Efficient Transformers in Reinforcement Learning using Actor-Learner Distillation
“KiloNeRF: Speeding up Neural Radiance Fields With Thousands of Tiny MLPs”, Reiser et al 2021
KiloNeRF: Speeding up Neural Radiance Fields with Thousands of Tiny MLPs
“China’s GPT-3? BAAI Introduces Superscale Intelligence Model ‘Wu Dao 1.0’: The Beijing Academy of Artificial Intelligence (BAAI) Releases Wu Dao 1.0, China’s First Large-Scale Pretraining Model.”, Synced 2021
“Understanding Invariance via Feedforward Inversion of Discriminatively Trained Classifiers”, Teterwak et al 2021
Understanding Invariance via Feedforward Inversion of Discriminatively Trained Classifiers
“Distilling Large Language Models into Tiny and Effective Students Using PQRNN”, Kaliamoorthi et al 2021
Distilling Large Language Models into Tiny and Effective Students using pQRNN
“Training Data-Efficient Image Transformers & Distillation through Attention”, Touvron et al 2020
Training data-efficient image transformers & distillation through attention
“Towards Understanding Ensemble, Knowledge Distillation and Self-Distillation in Deep Learning”, Allen-Zhu & Li 2020
Towards Understanding Ensemble, Knowledge Distillation and Self-Distillation in Deep Learning
“Towards Playing Full MOBA Games With Deep Reinforcement Learning”, Ye et al 2020
Towards Playing Full MOBA Games with Deep Reinforcement Learning
“A Primer in BERTology: What We Know about How BERT Works”, Rogers et al 2020
“Dataset Meta-Learning from Kernel Ridge-Regression”, Nguyen et al 2020
“TernaryBERT: Distillation-Aware Ultra-Low Bit BERT”, Zhang et al 2020
“"Less Than One"-Shot Learning: Learning n Classes From M < N Samples”, Sucholutsky & Schonlau 2020
"Less Than One"-Shot Learning: Learning n Classes From M < N Samples
“SimCLRv2: Big Self-Supervised Models Are Strong Semi-Supervised Learners”, Chen et al 2020
SimCLRv2: Big Self-Supervised Models are Strong Semi-Supervised Learners
“Movement Pruning: Adaptive Sparsity by Fine-Tuning”, Sanh et al 2020
“General Purpose Text Embeddings from Pre-Trained Language Models for Scalable Inference”, Du et al 2020
General Purpose Text Embeddings from Pre-trained Language Models for Scalable Inference
“Cryptanalytic Extraction of Neural Network Models”, Carlini et al 2020
“MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers”, Wang et al 2020
MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers
“Towards a Conversational Agent That Can Chat About…Anything”, Adiwardana & Luong 2020
“Understanding the Generalization of ‘Lottery Tickets’ in Neural Networks”, Morcos & Tian 2019
Understanding the generalization of ‘lottery tickets’ in neural networks
“Self-Training With Noisy Student Improves ImageNet Classification”, Xie et al 2019
Self-training with Noisy Student improves ImageNet classification
“On Warm-Starting Neural Network Training”, Ash & Adams 2019
“DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter”, Sanh et al 2019
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
“TinyBERT: Distilling BERT for Natural Language Understanding”, Jiao et al 2019
TinyBERT: Distilling BERT for Natural Language Understanding
“Smaller, Faster, Cheaper, Lighter: Introducing DistilGPT, a Distilled Version of GPT”, Sanh 2019
Smaller, faster, cheaper, lighter: Introducing DistilGPT, a distilled version of GPT
“Well-Read Students Learn Better: On the Importance of Pre-Training Compact Models”, Turc et al 2019
Well-Read Students Learn Better: On the Importance of Pre-training Compact Models
“ICML 2019 Notes”, Abel 2019
“NoGAN: Decrappification, DeOldification, and Super Resolution”, Antic et al 2019
NoGAN: Decrappification, DeOldification, and Super Resolution
“Mask-Predict: Parallel Decoding of Conditional Masked Language Models”, Ghazvininejad et al 2019
Mask-Predict: Parallel Decoding of Conditional Masked Language Models
“Distilling Policy Distillation”, Czarnecki et al 2019
“Compressing GANs Using Knowledge Distillation”, Aguinaldo et al 2019
“Neural Probabilistic Motor Primitives for Humanoid Control”, Merel et al 2018
“Dataset Distillation”, Wang et al 2018
“Exploration by Random Network Distillation”, Burda et al 2018
“OCD: Optimal Completion Distillation for Sequence Learning”, Sabour et al 2018
“Network Recasting: A Universal Method for Network Architecture Transformation”, Yu et al 2018
Network Recasting: A Universal Method for Network Architecture Transformation
“ClariNet: Parallel Wave Generation in End-To-End Text-To-Speech”, Ping et al 2018
ClariNet: Parallel Wave Generation in End-to-End Text-to-Speech
“Self-Net: Lifelong Learning via Continual Self-Modeling”, Camp et al 2018
“Self-Distillation: Born Again Neural Networks”, Furlanello et al 2018
“Large Scale Distributed Neural Network Training through Online Distillation”, Anil et al 2018
Large scale distributed neural network training through online distillation
“Kickstarting Deep Reinforcement Learning”, Schmitt et al 2018
“Faster Gaze Prediction With Dense Networks and Fisher Pruning”, Theis et al 2018
Faster gaze prediction with dense networks and Fisher pruning
“Parallel WaveNet: Fast High-Fidelity Speech Synthesis”, Oord et al 2017
“Knowledge Concentration: Learning 100K Object Classifiers in a Single CNN”, Gao et al 2017
Knowledge Concentration: Learning 100K Object Classifiers in a Single CNN
“Policy Optimization by Genetic Distillation”, Gangwani & Peng 2017
“N2N Learning: Network to Network Compression via Policy Gradient Reinforcement Learning”, Ashok et al 2017
N2N Learning: Network to Network Compression via Policy Gradient Reinforcement Learning
“Training Shallow and Thin Networks for Acceleration via Knowledge Distillation With Conditional Adversarial Networks”, Xu et al 2017
“Distral: Robust Multitask Reinforcement Learning”, Teh et al 2017
“Biased Importance Sampling for Deep Neural Network Training”, Katharopoulos & Fleuret 2017
“Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer”, Zagoruyko & Komodakis 2016
“Sequence-Level Knowledge Distillation”, Kim & Rush 2016
“FractalNet: Ultra-Deep Neural Networks without Residuals”, Larsson et al 2016
“Do Deep Convolutional Nets Really Need to Be Deep and Convolutional?”, Urban et al 2016
Do Deep Convolutional Nets Really Need to be Deep and Convolutional?
“Face Model Compression by Distilling Knowledge from Neurons”, Luo et al 2016
“Policy Distillation”, Rusu et al 2015
“Actor-Mimic: Deep Multitask and Transfer Reinforcement Learning”, Parisotto et al 2015
Actor-Mimic: Deep Multitask and Transfer Reinforcement Learning
“Net2Net: Accelerating Learning via Knowledge Transfer”, Chen et al 2015
“Bayesian Dark Knowledge”, Korattikara et al 2015
“Distilling the Knowledge in a Neural Network”, Hinton et al 2015
“FitNets: Hints for Thin Deep Nets”, Romero et al 2014
“Do Deep Nets Really Need to Be Deep?”, Ba & Caruana 2013
“Model Compression”, Bucila 2006
“Learning Complex, Extended Sequences Using the Principle of History Compression”, Schmidhuber 1992
Learning Complex, Extended Sequences Using the Principle of History Compression
“Dota 2 With Large Scale Deep Reinforcement Learning § Pg11”, Rerun 2026 (page 11 org openai)
Dota 2 with Large Scale Deep Reinforcement Learning § pg11 :
“Gemini 3.1 Flash Lite: Our Most Cost-Effective AI Model Yet”
“Gemini 3.5: Frontier Intelligence With Action”
“Google DeepMind’s Grandmaster-Level Chess Without Search”
“Sky-T1: Train Your Own o1-Preview Model With $450”
“o3-Mini”, OpenAI 2026
“From Vision to Language: Semi-Supervised Learning in Action…at Scale”
From Vision to Language: Semi-Supervised Learning in Action…at Scale
“A High Level Closed-Door Session Discussing DeepSeek: Vision Trumps Technology”
A High Level Closed-Door Session Discussing DeepSeek: Vision Trumps Technology
“Research Log: Monet/PEER Sparse Experts”
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
llama-inference commodore64 retro-ai small-models tiny-architecture llama2
sparse-retrieval
embedding-exploration biomedical-transformers sentence-representations compact-embeddings explainable-features embedding-distillation
autocomplete-optimization
self-supervised
lifelong-learning continual-adaptation incremental-training supermask-method self-modeling
open-models scaling-optimization ai-threat-tracking reasoning-advanced gemma-innovation
problem-solving
policy-synthesis
fast-learning
compact-models
Wikipedia (1)
Miscellaneous
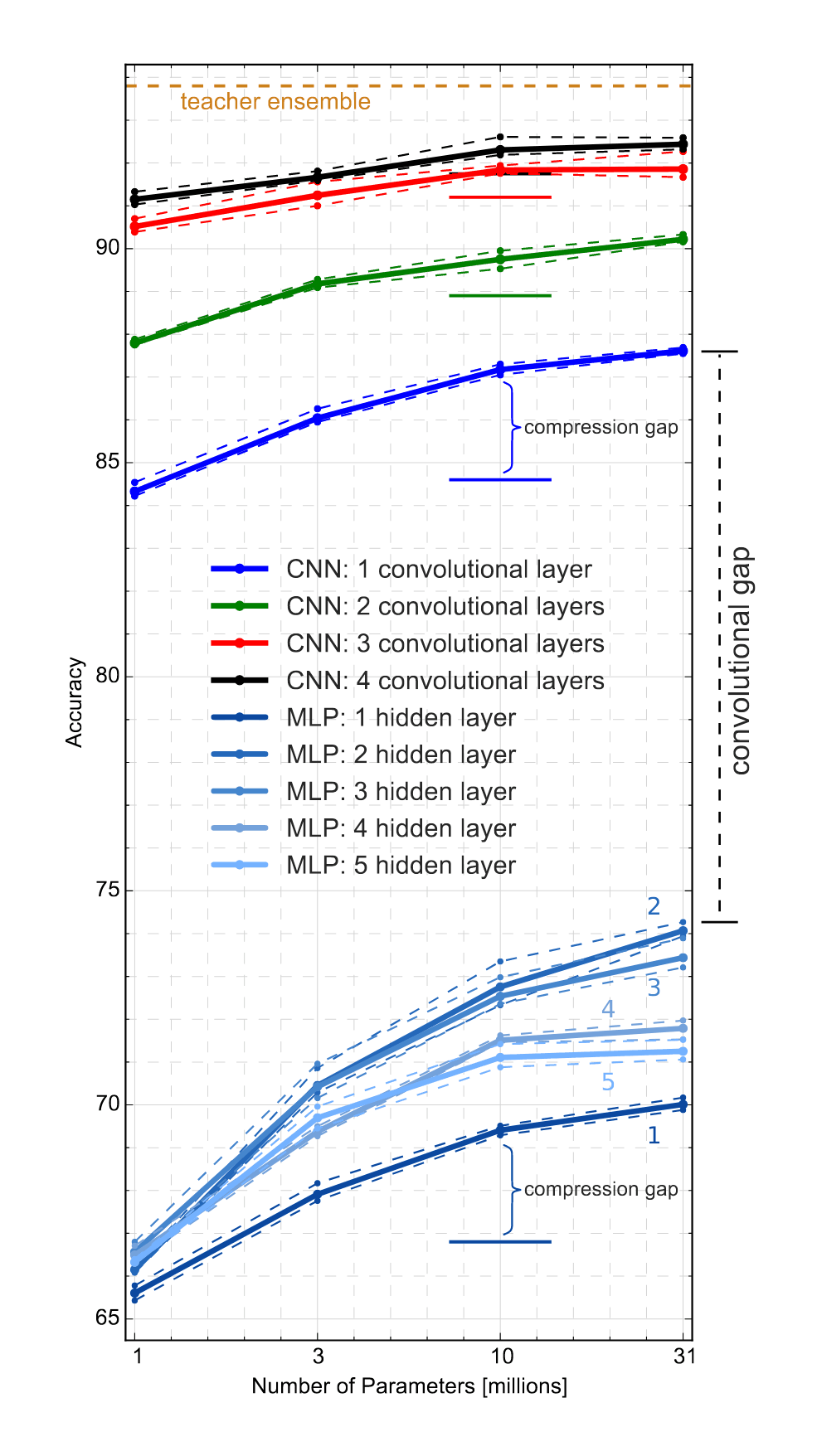
/doc/ai/nn/sparsity/knowledge-distillation/2016-urban-figure1-mlpvscnnscaling.pnghttps://discuss.luxonis.com/blog/3272-datadreamer-creating-custom-datasets-made-easyhttps://medium.com/neuralmachine/knowledge-distillation-dc241d7c2322https://sander.ai/2024/02/28/paradox.htmlView HTML:
https://www.reddit.com/r/mlscaling/comments/1rcvev2/anthropic_claims_to_have_identified/o7269v0/https://www.theverge.com/2023/3/29/23662621/google-bard-chatgpt-sharegpt-training-denies
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2504.20571: “Reinforcement Learning for Reasoning in Large Language Models With One Training Example”,https://github.com/ytmytm/llama2.c64/tree/main#llama2c64: “llama2.c64: Inference Llama-2 on a Commodore 64”,https://arxiv.org/abs/2502.20339: “Thinking Slow, Fast: Scaling Inference Compute With Distilled Reasoners”,https://arxiv.org/abs/2408.15237: “The Mamba in the Llama: Distilling and Accelerating Hybrid Models”,https://arxiv.org/abs/2408.00118#google: “Gemma 2: Improving Open Language Models at a Practical Size”,https://arxiv.org/abs/2406.11837: “Scaling the Codebook Size of VQGAN to 100,000 With a Utilization Rate of 99%”,https://arxiv.org/abs/2405.14838: “From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step”,https://arxiv.org/abs/2312.06585#deepmind: “Beyond Human Data: Scaling Self-Training for Problem-Solving With Language Models (ReSTEM)”,https://arxiv.org/abs/2311.13657: “Efficient Transformer Knowledge Distillation: A Performance Review”,https://arxiv.org/abs/2311.00430: “Distil-Whisper: Robust Knowledge Distillation via Large-Scale Pseudo Labelling”,https://arxiv.org/abs/2310.08708: “Polynomial Time Cryptanalytic Extraction of Neural Network Models”,https://arxiv.org/abs/2307.06439#microsoft: “Distilling Large Language Models for Biomedical Knowledge Extraction: A Case Study on Adverse Drug Events”,https://arxiv.org/abs/2305.12972: “VanillaNet: the Power of Minimalism in Deep Learning”,https://arxiv.org/abs/2305.09828: “Mimetic Initialization of Self-Attention Layers”,https://arxiv.org/abs/2305.07759#microsoft: “TinyStories: How Small Can Language Models Be and Still Speak Coherent English?”,https://arxiv.org/abs/2305.07804: “Dr. LLaMa: Improving Small Language Models in Domain-Specific QA via Generative Data Augmentation”,https://arxiv.org/abs/2305.02301#google: “Distilling Step-By-Step! Outperforming Larger Language Models With Less Training Data and Smaller Model Sizes”,https://arxiv.org/abs/2304.13653#deepmind: “Learning Agile Soccer Skills for a Bipedal Robot With Deep Reinforcement Learning”,https://arxiv.org/abs/2303.01469#openai: “Consistency Models”,https://arxiv.org/abs/2302.12433: “ProofNet: Autoformalizing and Formally Proving Undergraduate-Level Mathematics”,https://arxiv.org/abs/2302.05442#google: “Scaling Vision Transformers to 22 Billion Parameters”,https://arxiv.org/abs/2301.01296#microsoft: “TinyMIM: An Empirical Study of Distilling MIM Pre-Trained Models”,https://arxiv.org/abs/2212.05055#google: “Sparse Upcycling: Training Mixture-Of-Experts from Dense Checkpoints”,https://openreview.net/forum?id=wmGlMhaBe0: “MaskDistill: A Unified View of Masked Image Modeling”,https://arxiv.org/abs/2211.07636#baai: “EVA: Exploring the Limits of Masked Visual Representation Learning at Scale”,https://arxiv.org/abs/2211.07638: “Legged Locomotion in Challenging Terrains Using Egocentric Vision”,https://arxiv.org/abs/2211.01324#nvidia: “EDiff-I: Text-To-Image Diffusion Models With an Ensemble of Expert Denoisers”,https://arxiv.org/abs/2210.11610#google: “Large Language Models Can Self-Improve”,https://arxiv.org/abs/2210.03142#google: “On Distillation of Guided Diffusion Models”,https://arxiv.org/abs/2210.01117: “Omnigrok: Grokking Beyond Algorithmic Data”,https://arxiv.org/abs/2209.07550#deepmind: “Human-Level Atari 200× Faster”,https://arxiv.org/abs/2207.06300#ibm: “Re2G: Retrieve, Rerank, Generate”,https://arxiv.org/abs/2206.07808#amazon: “Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems”,https://arxiv.org/abs/2206.01861#microsoft: “ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers”,https://arxiv.org/abs/2205.09073#google: “Dialog Inpainting: Turning Documents into Dialogues”,https://arxiv.org/abs/2204.03475#alibaba: “Solving ImageNet: a Unified Scheme for Training Any Backbone to Top Results”,https://arxiv.org/abs/2202.12211#google: “Self-Distilled StyleGAN: Towards Generation from Internet Photos”,https://arxiv.org/abs/2201.05596#microsoft: “DeepSpeed-MoE: Advancing Mixture-Of-Experts Inference and Training to Power Next-Generation AI Scale”,https://arxiv.org/abs/2111.05754: “Prune Once for All: Sparse Pre-Trained Language Models”,https://arxiv.org/abs/2110.14168#openai: “Training Verifiers to Solve Math Word Problems”,https://arxiv.org/abs/2110.06961: “Language Modeling via Learning to Rank”,https://openreview.net/forum?id=G89-1yZLFHk: “OTTER: Data Efficient Language-Supervised Zero-Shot Recognition With Optimal Transport Distillation”,https://arxiv.org/abs/2109.12066: “ZSD-YOLO: Zero-Shot YOLO Detection Using Vision-Language Knowledge Distillation”,https://arxiv.org/abs/2109.06243#huawei: “KroneckerBERT: Learning Kronecker Decomposition for Pre-Trained Language Models via Knowledge Distillation”,https://arxiv.org/abs/2106.05237#google: “Knowledge Distillation: A Good Teacher Is Patient and Consistent”,https://arxiv.org/abs/2104.14294#facebook: “DINO: Emerging Properties in Self-Supervised Vision Transformers”,https://arxiv.org/abs/2104.13921#google: “Zero-Shot Detection via Vision and Language Knowledge Distillation”,https://arxiv.org/abs/2104.08945#facebook: “Data-Efficient Language-Supervised Zero-Shot Learning With Self-Distillation”,https://syncedreview.com/2021/03/23/chinas-gpt-3-baai-introduces-superscale-intelligence-model-wu-dao-1-0/#baai: “China’s GPT-3? BAAI Introduces Superscale Intelligence Model ‘Wu Dao 1.0’: The Beijing Academy of Artificial Intelligence (BAAI) Releases Wu Dao 1.0, China’s First Large-Scale Pretraining Model.”,https://arxiv.org/abs/2103.07470: “Understanding Invariance via Feedforward Inversion of Discriminatively Trained Classifiers”,https://arxiv.org/abs/2012.12877#facebook: “Training Data-Efficient Image Transformers & Distillation through Attention”,https://arxiv.org/abs/2011.12692#tencent: “Towards Playing Full MOBA Games With Deep Reinforcement Learning”,https://arxiv.org/abs/2002.10957#microsoft: “MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers”,https://research.google/blog/towards-a-conversational-agent-that-can-chat-aboutanything/: “Towards a Conversational Agent That Can Chat About…Anything”,https://arxiv.org/abs/1911.04252#google: “Self-Training With Noisy Student Improves ImageNet Classification”,https://arxiv.org/abs/1909.10351: “TinyBERT: Distilling BERT for Natural Language Understanding”,https://david-abel.github.io/notes/icml_2019.pdf: “ICML 2019 Notes”,https://arxiv.org/abs/1902.02186#deepmind: “Distilling Policy Distillation”,https://arxiv.org/abs/1810.01398: “OCD: Optimal Completion Distillation for Sequence Learning”,2016-luo.pdf: “Face Model Compression by Distilling Knowledge from Neurons”,