‘RNN’ directory
- See Also
- Gwern
- Links
- “Pretraining Recurrent Networks without Recurrence”, Kumar & Isola 2026
- “Convergent Evolution: How Different Language Models Learn Similar Number Representations”, Fu et al 2026
- “Shared Sensitivity to Data Distribution during Learning in Humans and Transformer Networks”, Lerousseau & Summerfield 2025
- “Kimi Linear: An Expressive, Efficient Attention Architecture”, Team et al 2025
- “DiscoRL: Discovering State-Of-The-Art Reinforcement Learning Algorithms”, Oh et al 2025
- “LSTM or Transformer As ‘Malware Packer’”, Bednarskiwsieci 2025
- “MesaNet: Sequence Modeling by Locally Optimal Test-Time Training”, Oswald et al 2025
- “It’s All Connected: A Journey Through Test-Time Memorization, Attentional Bias, Retention, and Online Optimization”, Behrouz et al 2025
- “M1: Towards Scalable Test-Time Compute With Mamba Reasoning Models”, Wang et al 2025
- “One-Minute Video Generation With Test-Time Training”, Dalal et al 2025
- “RWKV-7 ‘Goose’ With Expressive Dynamic State Evolution”, Peng et al 2025
- “Training Language Models for Social Deduction With Multi-Agent Reinforcement Learning”, Sarkar et al 2025
- “Test-Time Regression: a Unifying Framework for Designing Sequence Models With Associative Memory”, Wang et al 2025
- “Titans: Learning to Memorize at Test Time”, Behrouz et al 2024
- “Human-Like Bots for Tactical Shooters Using Compute-Efficient Sensors”, Justesen et al 2024
- “How AI Is Unlocking Ancient Texts: From Deciphering Burnt Roman Scrolls to Reading Crumbling Cuneiform Tablets, Neural Networks Could Give Researchers More Data Than They’ve Had in Centuries”, Marchant 2024
- “FlashRNN: Optimizing Traditional RNNs on Modern Hardware”, Pöppel et al 2024
- “Gated Delta Networks: Improving Mamba-2 With Delta Rule”, Yang et al 2024
- “Hymba: A Hybrid-Head Architecture for Small Language Models”, Dong et al 2024
- “State-Space Models Can Learn In-Context by Gradient Descent”, Sushma et al 2024
- “Were RNNs All We Needed?”, Feng et al 2024
- “The Mamba in the Llama: Distilling and Accelerating Hybrid Models”, Wang et al 2024
- “
handwriter.ttf: Handwriting Synthesis With Harfbuzz WASM”, Jingyi 2024 - “Just Read Twice: Closing the Recall Gap for Recurrent Language Models”, Arora et al 2024
- “Learning to (Learn at Test Time): RNNs With Expressive Hidden States”, Sun et al 2024
- “An Empirical Study of Mamba-Based Language Models”, Waleffe et al 2024
- “State Soup: In-Context Skill Learning, Retrieval and Mixing”, Pióro et al 2024
- “RWKV-CLIP: A Robust Vision-Language Representation Learner”, Gu et al 2024
- “Transformers Are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality”, Dao & Gu 2024
- “Grokfast: Accelerated Grokking by Amplifying Slow Gradients”, Lee et al 2024
- “DiM: Scaling Diffusion Mamba With Bidirectional SSMs for Efficient Image and Video Generation”, Mo & Tian 2024
- “Attention As an RNN”, Feng et al 2024
- “XLSTM: Extended Long Short-Term Memory”, Beck et al 2024
- “Megalodon: Efficient LLM Pretraining and Inference With Unlimited Context Length”, Ma et al 2024
- “The Illusion of State in State-Space Models”, Merrill et al 2024
- “An Accurate and Rapidly Calibrating Speech Neuroprosthesis”, Card et al 2024
- “Does Transformer Interpretability Transfer to RNNs?”, Paulo et al 2024
- “Mechanistic Design and Scaling of Hybrid Architectures”, Poli et al 2024
- “GLE: Backpropagation through Space, Time, and the Brain”, Ellenberger et al 2024
- “ZigMa: Zigzag Mamba Diffusion Model”, Hu et al 2024
- “RNNs Are Not Transformers (Yet): The Key Bottleneck on In-Context Retrieval”, Wen et al 2024
- “Verifiable Evaluations of Machine Learning Models Using ZkSNARKs”, South et al 2024
- “MambaByte: Token-Free Selective State Space Model”, Wang et al 2024
- “MoE-Mamba: Efficient Selective State Space Models With Mixture of Experts”, Pióro et al 2024
- “Evolving Reservoirs for Meta Reinforcement Learning”, Léger et al 2023
- “Zoology: Measuring and Improving Recall in Efficient Language Models”, Arora et al 2023
- “Mamba: Linear-Time Sequence Modeling With Selective State Spaces”, Gu & Dao 2023
- “Diffusion Models Without Attention”, Yan et al 2023
- “Learning Few-Shot Imitation As Cultural Transmission”, Bhoopchand et al 2023
- “Compositional Capabilities of Autoregressive Transformers: A Study on Synthetic, Interpretable Tasks”, Ramesh et al 2023
- “HGRN: Hierarchically Gated Recurrent Neural Network for Sequence Modeling”, Qin et al 2023
- “On Prefrontal Working Memory and Hippocampal Episodic Memory: Unifying Memories Stored in Weights and Activation Slots”, Whittington et al 2023
- “GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling”, Katsch 2023
- “ProSG: Using Prompt Synthetic Gradients to Alleviate Prompt Forgetting of RNN-Like Language Models”, Luo et al 2023
- “Transformers Learn Higher-Order Optimization Methods for In-Context Learning: A Study With Linear Models”, Fu et al 2023
- “Generalization in Sensorimotor Networks Configured With Natural Language Instructions”, Riveland & Pouget 2023
- “Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors”, Amos et al 2023
- “Parallelizing Non-Linear Sequential Models over the Sequence Length”, Lim et al 2023
- “Gated Recurrent Neural Networks Discover Attention”, Zucchet et al 2023
- “A High-Performance Neuroprosthesis for Speech Decoding and Avatar Control”, Metzger et al 2023
- “
ts_zip: Text Compression Using Large Language Models [RWKV 169M V4]”, Bellard 2023 - “Learning to Model the World With Language”, Lin et al 2023
- “Retentive Network: A Successor to Transformer for Large Language Models”, Sun et al 2023
- “Using Sequences of Life-Events to Predict Human Lives”, Savcisens et al 2023
- “Thought Cloning: Learning to Think While Acting by Imitating Human Thinking”, Hu & Clune 2023
- “RWKV: Reinventing RNNs for the Transformer Era”, Peng et al 2023
- “Emergence of Belief-Like Representations through Reinforcement Learning”, Hennig et al 2023
- “Model Scale versus Domain Knowledge in Statistical Forecasting of Chaotic Systems”, Gilpin 2023
- “Resurrecting Recurrent Neural Networks for Long Sequences”, Orvieto et al 2023
- “SpikeGPT: Generative Pre-Trained Language Model With Spiking Neural Networks”, Zhu et al 2023
- “Theory of Coupled Neuronal-Synaptic Dynamics”, Clark & Abbott 2023
- “Organic Reaction Mechanism Classification Using Machine Learning”, Burés & Larrosa 2023
- “A High-Performance Speech Neuroprosthesis”, Willett et al 2023
- “Hungry Hungry Hippos: Towards Language Modeling With State Space Models”, Fu et al 2022
- “Pretraining Without Attention”, Wang et al 2022
- “A 64-Core Mixed-Signal In-Memory Compute Chip Based on Phase-Change Memory for Deep Neural Network Inference”, Gallo et al 2022
- “Melting Pot 2.0”, Agapiou et al 2022
- “VeLO: Training Versatile Learned Optimizers by Scaling Up”, Metz et al 2022
- “Legged Locomotion in Challenging Terrains Using Egocentric Vision”, Agarwal et al 2022
- “Massively Multilingual ASR on 70 Languages: Tokenization, Architecture, and Generalization Capabilities”, Tjandra et al 2022
- “Perfectly Secure Steganography Using Minimum Entropy Coupling”, Witt et al 2022
- “Omnigrok: Grokking Beyond Algorithmic Data”, Liu et al 2022
- “Semantic Scene Descriptions As an Objective of Human Vision”, Doerig et al 2022
- “Benchmarking Compositionality With Formal Languages”, Valvoda et al 2022
- “Learning to Generalize With Object-Centric Agents in the Open World Survival Game Crafter”, Stanić et al 2022
- “PI-ARS: Accelerating Evolution-Learned Visual-Locomotion With Predictive Information Representations”, Lee et al 2022
- “Spatial Representation by Ramping Activity of Neurons in the Retrohippocampal Cortex”, Tennant et al 2022
- “Neural Networks and the Chomsky Hierarchy”, Delétang et al 2022
- “BYOL-Explore: Exploration by Bootstrapped Prediction”, Guo et al 2022
- “AnimeSR: Learning Real-World Super-Resolution Models for Animation Videos”, Wu et al 2022
- “Task-Agnostic Continual Reinforcement Learning: In Praise of a Simple Baseline (3RL)”, Caccia et al 2022
- “Simple Recurrence Improves Masked Language Models”, Lei et al 2022
- “Sequencer: Deep LSTM for Image Classification”, Tatsunami & Taki 2022
- “Data Distributional Properties Drive Emergent Few-Shot Learning in Transformers”, Chan et al 2022
- “Semantic Projection Recovers Rich Human Knowledge of Multiple Object Features from Word Embeddings”, Grand et al 2022
- “Block-Recurrent Transformers”, Hutchins et al 2022
- “All You Need Is Supervised Learning: From Imitation Learning to Meta-RL With Upside Down RL”, Arulkumaran et al 2022
- “Retrieval-Augmented Reinforcement Learning”, Goyal et al 2022
- “Learning by Directional Gradient Descent”, Silver et al 2022
- “General-Purpose, Long-Context Autoregressive Modeling With Perceiver AR”, Hawthorne et al 2022
- “End-To-End Algorithm Synthesis With Recurrent Networks: Logical Extrapolation Without Overthinking”, Bansal et al 2022
- “Data Scaling Laws in NMT: The Effect of Noise and Architecture”, Bansal et al 2022
- “Active Predictive Coding Networks: A Neural Solution to the Problem of Learning Reference Frames and Part-Whole Hierarchies”, Gklezakos & Rao 2022
- “Learning Robust Perceptive Locomotion for Quadrupedal Robots in the Wild”, Miki et al 2022
- “Inducing Causal Structure for Interpretable Neural Networks (IIT)”, Geiger et al 2021
- “Evaluating Distributional Distortion in Neural Language Modeling”, Anonymous 2021
- “Gradients Are Not All You Need”, Metz et al 2021
- “An Explanation of In-Context Learning As Implicit Bayesian Inference”, Xie et al 2021
- “S4: Efficiently Modeling Long Sequences With Structured State Spaces”, Gu et al 2021
- “Minimum Description Length Recurrent Neural Networks”, Lan et al 2021
- “LSSL: Combining Recurrent, Convolutional, and Continuous-Time Models With Linear State-Space Layers”, Gu et al 2021
- “A Connectome of the Drosophila Central Complex Reveals Network Motifs Suitable for Flexible Navigation and Context-Dependent Action Selection”, Hulse et al 2021
- “Recurrent Model-Free RL Is a Strong Baseline for Many POMDPs”, Ni et al 2021
- “AFT: An Attention Free Transformer”, Zhai et al 2021
- “Photos Are All You Need for Reciprocal Recommendation in Online Dating”, Neve & McConville 2021
- “Perceiver IO: A General Architecture for Structured Inputs & Outputs”, Jaegle et al 2021
- “PES: Unbiased Gradient Estimation in Unrolled Computation Graphs With Persistent Evolution Strategies”, Vicol et al 2021
- “Shelley: A Crowd-Sourced Collaborative Horror Writer”, Delul et al 2021
- “Ten Lessons From Three Generations Shaped Google’s TPUv4i”, Jouppi et al 2021
- “RASP: Thinking Like Transformers”, Weiss et al 2021
- “Scaling Laws for Acoustic Models”, Droppo & Elibol 2021
- “Scaling End-To-End Models for Large-Scale Multilingual ASR”, Li et al 2021
- “Sensitivity As a Complexity Measure for Sequence Classification Tasks”, Hahn et al 2021
- “ALD: Efficient Transformers in Reinforcement Learning Using Actor-Learner Distillation”, Parisotto & Salakhutdinov 2021
- “Finetuning Pretrained Transformers into RNNs”, Kasai et al 2021
- “Pretrained Transformers As Universal Computation Engines”, Lu et al 2021
- “Perceiver: General Perception With Iterative Attention”, Jaegle et al 2021
- “When Attention Meets Fast Recurrence: Training SRU++ Language Models With Reduced Compute”, Lei 2021
- “Generative Speech Coding With Predictive Variance Regularization”, Kleijn et al 2021
- “Predictive Coding Is a Consequence of Energy Efficiency in Recurrent Neural Networks”, Ali et al 2021
- “Deep Residual Learning in Spiking Neural Networks”, Fang et al 2021
- “Distilling Large Language Models into Tiny and Effective Students Using PQRNN”, Kaliamoorthi et al 2021
- “Meta Learning Backpropagation And Improving It”, Kirsch & Schmidhuber 2020
- “On the Binding Problem in Artificial Neural Networks”, Greff et al 2020
- “A Recurrent Vision-And-Language BERT for Navigation”, Hong et al 2020
- “Towards Playing Full MOBA Games With Deep Reinforcement Learning”, Ye et al 2020
- “Multimodal Dynamics Modeling for Off-Road Autonomous Vehicles”, Tremblay et al 2020
- “Adversarial Vulnerabilities of Human Decision-Making”, Dezfouli et al 2020
- “Learning to Summarize Long Texts With Memory Compression and Transfer”, Park et al 2020
- “Human-Centric Dialog Training via Offline Reinforcement Learning”, Jaques et al 2020
- “Deep Reinforcement Learning for Closed-Loop Blood Glucose Control”, Fox et al 2020
- “HiPPO: Recurrent Memory With Optimal Polynomial Projections”, Gu et al 2020
- “Adding Recurrence to Pretrained Transformers for Improved Efficiency and Context Size”, Yoshida et al 2020
- “Matt Botvinick on the Spontaneous Emergence of Learning Algorithms”, Scholl 2020
- “Cultural Influences on Word Meanings Revealed through Large-Scale Semantic Alignment”, Thompson et al 2020
- “DeepSinger: Singing Voice Synthesis With Data Mined From the Web”, Ren et al 2020
- “High-Performance Brain-To-Text Communication via Imagined Handwriting”, Willett et al 2020
- “Transformers Are RNNs: Fast Autoregressive Transformers With Linear Attention”, Katharopoulos et al 2020
- “The Recurrent Neural Tangent Kernel”, Alemohammad et al 2020
- “Untangling Tradeoffs between Recurrence and Self-Attention in Neural Networks”, Kerg et al 2020
- “Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing”, Dai et al 2020
- “Learning Music Helps You Read: Using Transfer to Study Linguistic Structure in Language Models”, Papadimitriou & Jurafsky 2020
- “Syntactic Structure from Deep Learning”, Linzen & Baroni 2020
- “Agent57: Outperforming the Human Atari Benchmark”, Puigdomènech et al 2020
- “Machine Translation of Cortical Activity to Text With an Encoder-Decoder Framework”, Makin et al 2020
- “Learning-Based Memory Allocation for C++ Server Workloads”, Maas et al 2020
- “Accelerating Feedforward Computation via Parallel Nonlinear Equation Solving”, Song et al 2020
- “Direct Fit to Nature: An Evolutionary Perspective on Biological and Artificial Neural Networks”, Hasson et al 2020
- “Scaling Laws for Neural Language Models”, Kaplan et al 2020
- “Estimating the Deep Replicability of Scientific Findings Using Human and Artificial Intelligence”, Yang et al 2020
- “Placing Language in an Integrated Understanding System: Next Steps toward Human-Level Performance in Neural Language Models”, McClelland et al 2020
- “Measuring Compositional Generalization: A Comprehensive Method on Realistic Data”, Keysers et al 2019
- “SimpleBooks: Long-Term Dependency Book Dataset With Simplified English Vocabulary for Word-Level Language Modeling”, Nguyen 2019
- “Single Headed Attention RNN: Stop Thinking With Your Head”, Merity 2019
- “Excavate”, Lynch 2019
- “MuZero: Mastering Atari, Go, Chess and Shogi by Planning With a Learned Model”, Schrittwieser et al 2019
- “CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning”, Lin et al 2019
- “High Fidelity Video Prediction With Large Stochastic Recurrent Neural Networks”, Villegas et al 2019
- “Legendre Memory Units: Continuous-Time Representation in Recurrent Neural Networks”, Voelker et al 2019
- “SEED RL: Scalable and Efficient Deep-RL With Accelerated Central Inference”, Espeholt et al 2019
- “Mixed-Signal Neuromorphic Processors: Quo Vadis?”, Bavandpour et al 2019
- “Restoring Ancient Text Using Deep Learning (Pythia): a Case Study on Greek Epigraphy”, Assael et al 2019
- “Mogrifier LSTM”, Melis et al 2019
- “R2D3: Making Efficient Use of Demonstrations to Solve Hard Exploration Problems”, Paine et al 2019
- “Language Modeling State-Of-The-Art Leaderboards”, paperswithcode.com 2019
- “Metalearned Neural Memory”, Munkhdalai et al 2019
- “Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank”, Socher et al 2019
- “Generating Text With Recurrent Neural Networks”, Sutskever et al 2019
- “XLNet: Generalized Autoregressive Pretraining for Language Understanding”, Yang et al 2019
- “Playing the Lottery With Rewards and Multiple Languages: Lottery Tickets in RL and NLP”, Yu et al 2019
- “MoGlow: Probabilistic and Controllable Motion Synthesis Using Normalizing Flows”, Henter et al 2019
- “Reinforcement Learning, Fast and Slow”, Botvinick et al 2019
- “Meta-Learners’ Learning Dynamics Are unlike Learners’”, Rabinowitz 2019
- “Speech Synthesis from Neural Decoding of Spoken Sentences”, Anumanchipalli et al 2019
- “Good News, Everyone! Context Driven Entity-Aware Captioning for News Images”, Biten et al 2019
- “Surrogate Gradient Learning in Spiking Neural Networks”, Neftci et al 2019
- “On the Turing Completeness of Modern Neural Network Architectures”, Pérez et al 2019
- “Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context”, Dai et al 2019
- “Natural Questions: A Benchmark for Question Answering Research”, Kwiatkowski et al 2019
- “High Fidelity Video Prediction With Large Stochastic Recurrent Neural Networks: Videos”, Villegas et al 2019
- “Bayesian Layers: A Module for Neural Network Uncertainty”, Tran et al 2018
- “Meta-Learning: Learning to Learn Fast”, Weng 2018
- “Piano Genie”, Donahue et al 2018
- “Learning Recurrent Binary/Ternary Weights”, Ardakani et al 2018
- “R2D2: Recurrent Experience Replay in Distributed Reinforcement Learning”, Kapturowski et al 2018
- “HotpotQA: A Dataset for Diverse, Explainable Multi-Hop Question Answering”, Yang et al 2018
- “Adversarial Reprogramming of Text Classification Neural Networks”, Neekhara et al 2018
- “Object Hallucination in Image Captioning”, Rohrbach et al 2018
- “This Time With Feeling: Learning Expressive Musical Performance”, Oore et al 2018
- “Character-Level Language Modeling With Deeper Self-Attention”, Al-Rfou et al 2018
- “General Value Function Networks”, Schlegel et al 2018
- “Deep-Speare: A Joint Neural Model of Poetic Language, Meter and Rhyme”, Lau et al 2018
- “Universal Transformers”, Dehghani et al 2018
- “Accurate Uncertainties for Deep Learning Using Calibrated Regression”, Kuleshov et al 2018
- “The Natural Language Decathlon: Multitask Learning As Question Answering”, McCann et al 2018
- “Neural Ordinary Differential Equations”, Chen et al 2018
- “Know What You Don’t Know: Unanswerable Questions for SQuAD”, Rajpurkar et al 2018
- “DVRL: Deep Variational Reinforcement Learning for POMDPs”, Igl et al 2018
- “Greedy Attack and Gumbel Attack: Generating Adversarial Examples for Discrete Data”, Yang et al 2018
- “Hierarchical Neural Story Generation”, Fan et al 2018
- “Sharp Nearby, Fuzzy Far Away: How Neural Language Models Use Context”, Khandelwal et al 2018
- “Newsroom: A Dataset of 1.3 Million Summaries With Diverse Extractive Strategies”, Grusky et al 2018
- “A Tree Search Algorithm for Sequence Labeling”, Lao et al 2018
- “Large Scale Distributed Neural Network Training through Online Distillation”, Anil et al 2018
- “An Analysis of Neural Language Modeling at Multiple Scales”, Merity et al 2018
- “Reviving and Improving Recurrent Back-Propagation”, Liao et al 2018
- “Learning Memory Access Patterns”, Hashemi et al 2018
- “Learning Longer-Term Dependencies in RNNs With Auxiliary Losses”, Trinh et al 2018
- “One Big Net For Everything”, Schmidhuber 2018
- “Efficient Neural Audio Synthesis”, Kalchbrenner et al 2018
- “Deep Contextualized Word Representations”, Peters et al 2018
- “M-Walk: Learning to Walk over Graphs Using Monte Carlo Tree Search”, Shen et al 2018
- “Overcoming the Vanishing Gradient Problem in Plain Recurrent Networks”, Hu et al 2018
- “ULMFiT: Universal Language Model Fine-Tuning for Text Classification”, Howard & Ruder 2018
- “The Compute and Data Moats Are Dead”, Merity 2018
- “Large-Scale Comparison of Machine Learning Methods for Drug Target Prediction on ChEMBL”, Mayr et al 2018
- “A Flexible Approach to Automated RNN Architecture Generation”, Schrimpf et al 2017
- “The NarrativeQA Reading Comprehension Challenge”, Kočiský et al 2017
- “Learning Compact Recurrent Neural Networks With Block-Term Tensor Decomposition”, Ye et al 2017
- “LBA: Learning by Asking Questions”, Misra et al 2017
- “Mastering the Dungeon: Grounded Language Learning by Mechanical Turker Descent”, Yang et al 2017
- “Evaluating Prose Style Transfer With the Bible”, Carlson et al 2017
- “Breaking the Softmax Bottleneck: A High-Rank RNN Language Model”, Yang et al 2017
- “Neural Speed Reading via Skim-RNN”, Seo et al 2017
- “Unsupervised Machine Translation Using Monolingual Corpora Only”, Lample et al 2017
- “Generalization without Systematicity: On the Compositional Skills of Sequence-To-Sequence Recurrent Networks”, Lake & Baroni 2017
- “Mixed Precision Training”, Micikevicius et al 2017
- “To Prune, or Not to Prune: Exploring the Efficacy of Pruning for Model Compression”, Zhu & Gupta 2017
- “Dynamic Evaluation of Neural Sequence Models”, Krause et al 2017
- “Online Learning of a Memory for Learning Rates”, Meier et al 2017
- “Why Pay More When You Can Pay Less: A Joint Learning Framework for Active Feature Acquisition and Classification”, Shim et al 2017
- “N2N Learning: Network to Network Compression via Policy Gradient Reinforcement Learning”, Ashok et al 2017
- “SRU: Simple Recurrent Units for Highly Parallelizable Recurrence”, Lei et al 2017
- “Learning to Look Around: Intelligently Exploring Unseen Environments for Unknown Tasks”, Jayaraman & Grauman 2017
- “Twin Networks: Matching the Future for Sequence Generation”, Serdyuk et al 2017
- “Skip RNN: Learning to Skip State Updates in Recurrent Neural Networks”, Campos et al 2017
- “Regularizing and Optimizing LSTM Language Models”, Merity et al 2017
- “Revisiting Activation Regularization for Language RNNs”, Merity et al 2017
- “Bayesian Sparsification of Recurrent Neural Networks”, Lobacheva et al 2017
- “On the State-Of-The-Art of Evaluation in Neural Language Models”, Melis et al 2017
- “Controlling Linguistic Style Aspects in Neural Language Generation”, Ficler & Goldberg 2017
- “Device Placement Optimization With Reinforcement Learning”, Mirhoseini et al 2017
- “Six Challenges for Neural Machine Translation”, Koehn & Knowles 2017
- “Towards Synthesizing Complex Programs from Input-Output Examples”, Chen et al 2017
- “Language Generation With Recurrent Generative Adversarial Networks without Pre-Training”, Press et al 2017
- “Biased Importance Sampling for Deep Neural Network Training”, Katharopoulos & Fleuret 2017
- “Deriving Neural Architectures from Sequence and Graph Kernels”, Lei et al 2017
- “A Deep Reinforced Model for Abstractive Summarization”, Paulus et al 2017
- “TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension”, Joshi et al 2017
- “DeepTingle”, Khalifa et al 2017
- “A Neural Network System for Transformation of Regional Cuisine Style”, Kazama et al 2017
- “Sharp Models on Dull Hardware: Fast and Accurate Neural Machine Translation Decoding on the CPU”, Devlin 2017
- “Adversarial Neural Machine Translation”, Wu et al 2017
- “SearchQA: A New Q&A Dataset Augmented With Context from a Search Engine”, Dunn et al 2017
- “Learning to Reason: End-To-End Module Networks for Visual Question Answering”, Hu et al 2017
- “Exploring Sparsity in Recurrent Neural Networks”, Narang et al 2017
- “Get To The Point: Summarization With Pointer-Generator Networks”, See et al 2017
- “DeepAR: Probabilistic Forecasting With Autoregressive Recurrent Networks”, Salinas et al 2017
- “Bayesian Recurrent Neural Networks”, Fortunato et al 2017
- “Recurrent Environment Simulators”, Chiappa et al 2017
- “Learning to Generate Reviews and Discovering Sentiment”, Radford et al 2017
- “Learning Simpler Language Models With the Differential State Framework”, II et al 2017
- “I2T2I: Learning Text to Image Synthesis With Textual Data Augmentation”, Dong et al 2017
- “Improving Neural Machine Translation With Conditional Sequence Generative Adversarial Nets”, Yang et al 2017
- “Learned Optimizers That Scale and Generalize”, Wichrowska et al 2017
- “Parallel Multiscale Autoregressive Density Estimation”, Reed et al 2017
- “Tracking the World State With Recurrent Entity Networks”, Henaff et al 2017
- “Optimization As a Model for Few-Shot Learning”, Ravi & Larochelle 2017
- “Neural Combinatorial Optimization With Reinforcement Learning”, Bello et al 2017
- “Frustratingly Short Attention Spans in Neural Language Modeling”, Daniluk et al 2017
- “Tuning Recurrent Neural Networks With Reinforcement Learning”, Jaques et al 2017
- “Outrageously Large Neural Networks: The Sparsely-Gated Mixture-Of-Experts Layer”, Shazeer et al 2017
- “Neural Data Filter for Bootstrapping Stochastic Gradient Descent”, Fan et al 2017
- “Learning the Enigma With Recurrent Neural Networks”, Greydanus 2017
- “Your TL;DR by an AI: A Deep Reinforced Model for Abstractive Summarization”, Paulus 2017
- “SampleRNN: An Unconditional End-To-End Neural Audio Generation Model”, Mehri et al 2016
- “Improving Neural Language Models With a Continuous Cache”, Grave et al 2016
- “NewsQA: A Machine Comprehension Dataset”, Trischler et al 2016
- “Neural Combinatorial Optimization With Reinforcement Learning”, Bello et al 2016
- “Visual Dialog”, Das et al 2016
- “Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation”, Johnson et al 2016
- “Learning to Learn without Gradient Descent by Gradient Descent”, Chen et al 2016
- “RL2: Fast Reinforcement Learning via Slow Reinforcement Learning”, Duan et al 2016
- “DeepCoder: Learning to Write Programs”, Balog et al 2016
- “QRNNs: Quasi-Recurrent Neural Networks”, Bradbury et al 2016
- “Neural Architecture Search With Reinforcement Learning”, Zoph & Le 2016
- “Bidirectional Attention Flow for Machine Comprehension”, Seo et al 2016
- “Hybrid Computing Using a Neural Network With Dynamic External Memory”, Graves et al 2016
- “Scaling Memory-Augmented Neural Networks With Sparse Reads and Writes”, Rae et al 2016
- “Using Fast Weights to Attend to the Recent Past”, Ba et al 2016
- “Achieving Human Parity in Conversational Speech Recognition”, Xiong et al 2016
- “VPN: Video Pixel Networks”, Kalchbrenner et al 2016
- “HyperNetworks”, Ha et al 2016
- “Pointer Sentinel Mixture Models”, Merity et al 2016
- “Multiplicative LSTM for Sequence Modeling”, Krause et al 2016
- “Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation”, Wu et al 2016
- “One Sentence One Model for Neural Machine Translation”, Li et al 2016
- “Image-To-Markup Generation With Coarse-To-Fine Attention”, Deng et al 2016
- “Hierarchical Multiscale Recurrent Neural Networks”, Chung et al 2016
- “Deep Learning Human Mind for Automated Visual Classification”, Spampinato et al 2016
- “Using the Output Embedding to Improve Language Models”, Press & Wolf 2016
- “Full Resolution Image Compression With Recurrent Neural Networks”, Toderici et al 2016
- “Decoupled Neural Interfaces Using Synthetic Gradients”, Jaderberg et al 2016
- “Clockwork Convnets for Video Semantic Segmentation”, Shelhamer et al 2016
- “Layer Normalization”, Ba et al 2016
- “Sequence-Level Knowledge Distillation”, Kim & Rush 2016
- “LSTMVis: A Tool for Visual Analysis of Hidden State Dynamics in Recurrent Neural Networks”, Strobelt et al 2016
- “Learning to Learn by Gradient Descent by Gradient Descent”, Andrychowicz et al 2016
- “Iterative Alternating Neural Attention for Machine Reading”, Sordoni et al 2016
- “Deep Reinforcement Learning for Dialogue Generation”, Li et al 2016
- “Programming With a Differentiable Forth Interpreter”, Bošnjak et al 2016
- “Training Deep Nets With Sublinear Memory Cost”, Chen et al 2016
- “Bridging the Gaps Between Residual Learning, Recurrent Neural Networks and Visual Cortex”, Liao & Poggio 2016
- “Improving Sentence Compression by Learning to Predict Gaze”, Klerke et al 2016
- “Adaptive Computation Time for Recurrent Neural Networks”, Graves 2016
- “Dynamic Memory Networks for Visual and Textual Question Answering”, Xiong et al 2016
- “PlaNet—Photo Geolocation With Convolutional Neural Networks”, Weyand et al 2016
- “Learning Distributed Representations of Sentences from Unlabeled Data”, Hill et al 2016
- “Exploring the Limits of Language Modeling”, Jozefowicz et al 2016
- “PixelRNN: Pixel Recurrent Neural Networks”, Oord et al 2016
- “Persistent RNNs: Stashing Recurrent Weights On-Chip”, Diamos et al 2016
- “Exploring the Limits of Language Modeling § 5.9: Samples from the Model”
- “Deep-Spying: Spying Using Smartwatch and Deep Learning”, Beltramelli & Risi 2015
- “Deep Speech 2: End-To-End Speech Recognition in English and Mandarin”, Amodei et al 2015
- “On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models”, Schmidhuber 2015
- “Neural GPUs Learn Algorithms”, Kaiser & Sutskever 2015
- “Sequence Level Training With Recurrent Neural Networks”, Ranzato et al 2015
- “Neural Programmer-Interpreters”, Reed & Freitas 2015
- “Generating Sentences from a Continuous Space”, Bowman et al 2015
- “Generative Concatenative Nets Jointly Learn to Write and Classify Reviews”, Lipton et al 2015
- “Generating Images from Captions With Attention”, Mansimov et al 2015
- “Semi-Supervised Sequence Learning”, Dai & Le 2015
- “BPEs: Neural Machine Translation of Rare Words With Subword Units”, Sennrich et al 2015
- “Training Recurrent Networks Online without Backtracking”, Ollivier et al 2015
- “Deep Recurrent Q-Learning for Partially Observable MDPs”, Hausknecht & Stone 2015
- “A Neural Conversational Model”, Vinyals & Le 2015
- “Teaching Machines to Read and Comprehend”, Hermann et al 2015
- “Scheduled Sampling for Sequence Prediction With Recurrent Neural Networks”, Bengio et al 2015
- “Visualizing and Understanding Recurrent Networks”, Karpathy et al 2015
- “The Unreasonable Effectiveness of Recurrent Neural Networks”, Karpathy 2015
- “Deep Neural Networks for Large Vocabulary Handwritten Text Recognition”, Bluche 2015
- “Reinforcement Learning Neural Turing Machines—Revised”, Zaremba & Sutskever 2015
- “End-To-End Memory Networks”, Sukhbaatar et al 2015
- “LSTM: A Search Space Odyssey”, Greff et al 2015
- “Inferring Algorithmic Patterns With Stack-Augmented Recurrent Nets”, Joulin & Mikolov 2015
- “DRAW: A Recurrent Neural Network For Image Generation”, Gregor et al 2015
- “Ensemble of Generative and Discriminative Techniques for Sentiment Analysis of Movie Reviews”, Mesnil et al 2014
- “Deep Speech 1: Scaling up End-To-End Speech Recognition”, Hannun et al 2014
- “Neural Turing Machines”, Graves et al 2014
- “Learning to Execute”, Zaremba & Sutskever 2014
- “Neural Machine Translation by Jointly Learning to Align and Translate”, Bahdanau et al 2014
- “Identifying and Attacking the Saddle Point Problem in High-Dimensional Non-Convex Optimization”, Dauphin et al 2014
- “GRU: Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation”, Cho et al 2014
- “
doc2vec: Distributed Representations of Sentences and Documents”, Le & Mikolov 2014 - “A Clockwork RNN”, Koutník et al 2014
- “One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling”, Chelba et al 2013
- “Generating Sequences With Recurrent Neural Networks”, Graves 2013
- “Context Dependent Recurrent Neural Network Language Model”, Mikolov & Zweig 2012
- “On the Difficulty of Training Recurrent Neural Networks”, Pascanu et al 2012
- “[Fitness Landscape of a Small RNN]”, evolvingstuff 2011
- “Recurrent Neural Network Based Language Model”, Mikolov et al 2010
- “Learning Fast Approximations of Sparse Coding”, Gregor & LeCun 2010
- “Large Language Models in Machine Translation”, Brants et al 2007
- “Learning to Learn Using Gradient Descent”, Hochreiter et al 2001
- “Paul J. Werbos Interview”, Werbos 1998
- “Long Short-Term Memory”, Hochreiter & Schmidhuber 1997
- “Flat Minima”, Hochreiter & Schmidhuber 1997
- “RTRL: Gradient-Based Learning Algorithms for Recurrent Networks and Their Computational Complexity”, Williams & Zipser 1995
- “A Focused Backpropagation Algorithm for Temporal Pattern Recognition”, Mozer 1995
- “Learning Complex, Extended Sequences Using the Principle of History Compression”, Schmidhuber 1992
- “Learning to Control Fast-Weight Memories: An Alternative to Dynamic Recurrent Networks”, Schmidhuber 1992b
- “Untersuchungen Zu Dynamischen Neuronalen Netzen [Studies of Dynamic Neural Networks]”, Hochreiter 1991
- “Finding Structure In Time”, Elman 1990
- “Connectionist Music Composition Based on Melodic, Stylistic, and Psychophysical Constraints [Technical Report CU-CS-495-90]”, Mozer 1990
- “A Learning Algorithm for Continually Running Fully Recurrent Neural Networks”, Williams & Zipser 1989b
- “Recurrent Backpropagation and Hopfield Networks”, Almeida & Neto 1989b
- “Backpropagation in Perceptrons With Feedback”, Almeida 1989
- “A Local Learning Algorithm for Dynamic Feedforward and Recurrent Networks”, Schmidhuber 1989
- “Experimental Analysis of the Real-Time Recurrent Learning Algorithm”, Williams & Zipser 1989
- “A Sticky-Bit Approach for Learning to Represent State”, Bachrach 1988
- “Generalization of Backpropagation With Application to a Recurrent Gas Market Model”, Werbos 1988
- “Generalization of Back-Propagation to Recurrent Neural Networks”, Pineda 1987
- “The Utility Driven Dynamic Error Propagation Network (RTRL)”, Robinson & Fallside 1987
- “A Self-Optimizing, Non-Symmetrical Neural Net for Content Addressable Memory and Pattern Recognition”, Lapedes & Farber 1986
- “Programming a Massively Parallel, Computation Universal System: Static Behavior”, Lapedes & Farber 1986b
- “Serial Order: A Parallel Distributed Processing Approach”, Jordan 1986
- “Found in Translation: More Accurate, Fluent Sentences in Google Translate”
- “Hypernetworks [Blog]”, Ha 2026
- “Safety-First AI for Autonomous Data Center Cooling and Industrial Control”
- “Attention and Augmented Recurrent Neural Networks”
- “BlinkDL/RWKV-LM: RWKV Is an RNN With Transformer-Level LLM Performance. It Can Be Directly Trained like a GPT (Parallelizable). So It’s Combining the Best of RNN and Transformer—Great Performance, Fast Inference, Saves VRAM, Fast Training, "Infinite" Ctx_len, and Free Sentence Embedding.”
- “RWKV-CLIP: A Robust Vision-Language Representation Learner”
- “Efficient, Reusable RNNs and LSTMs for Torch”
- “Updated Training?”
- “Minimaxir/textgenrnn: Easily Train Your Own Text-Generating Neural Network of Any Size and Complexity on Any Text Dataset With a Few Lines of Code.”
- “Deep Learning for Assisting the Process of Music Composition (Part 3)”
- “Kaichengalex/YFCC15M”
- “Metalearning or Learning to Learn Since 1987”
- “Stream Seaandsailor”
- “Caglar Gulcehre Homepage”, Gulcehre 2026
- “Composing Music With Recurrent Neural Networks”
- “RWKV Language Model”
- Sort By Magic
connectome-navigationmemory-optimizationdependency-modeling summarization-simplified extractive-representation language-corpus simplified-englishprose-transfersecure-evaluation steganography smart-device deep-learning machine-securitydrug-predictionblood-glucosesuper-resolution-modelsvideo-segmentationspeech-interface neuroprosthesis text-generation brain-computer-image captioning speech-translationimitation-simulationadversarial-learningrecurrent-architecture
- Wikipedia (5)
- Miscellaneous
- Bibliography
See Also
Gwern
“Absolute Unit NNs: Regression-Based MLPs for Everything”, Gwern 2023
“RNN Metadata for Mimicking Author Style”, Gwern 2015
Links
“Pretraining Recurrent Networks without Recurrence”, Kumar & Isola 2026
“Convergent Evolution: How Different Language Models Learn Similar Number Representations”, Fu et al 2026
Convergent Evolution: How Different Language Models Learn Similar Number Representations
“Shared Sensitivity to Data Distribution during Learning in Humans and Transformer Networks”, Lerousseau & Summerfield 2025
Shared sensitivity to data distribution during learning in humans and Transformer networks
“Kimi Linear: An Expressive, Efficient Attention Architecture”, Team et al 2025
Kimi Linear: An Expressive, Efficient Attention Architecture
“DiscoRL: Discovering State-Of-The-Art Reinforcement Learning Algorithms”, Oh et al 2025
DiscoRL: Discovering state-of-the-art reinforcement learning algorithms
“LSTM or Transformer As ‘Malware Packer’”, Bednarskiwsieci 2025
“MesaNet: Sequence Modeling by Locally Optimal Test-Time Training”, Oswald et al 2025
MesaNet: Sequence Modeling by Locally Optimal Test-Time Training
“It’s All Connected: A Journey Through Test-Time Memorization, Attentional Bias, Retention, and Online Optimization”, Behrouz et al 2025
“M1: Towards Scalable Test-Time Compute With Mamba Reasoning Models”, Wang et al 2025
M1: Towards Scalable Test-Time Compute with Mamba Reasoning Models
“One-Minute Video Generation With Test-Time Training”, Dalal et al 2025
“RWKV-7 ‘Goose’ With Expressive Dynamic State Evolution”, Peng et al 2025
“Training Language Models for Social Deduction With Multi-Agent Reinforcement Learning”, Sarkar et al 2025
Training Language Models for Social Deduction with Multi-Agent Reinforcement Learning
“Test-Time Regression: a Unifying Framework for Designing Sequence Models With Associative Memory”, Wang et al 2025
Test-time regression: a unifying framework for designing sequence models with associative memory
“Titans: Learning to Memorize at Test Time”, Behrouz et al 2024
“Human-Like Bots for Tactical Shooters Using Compute-Efficient Sensors”, Justesen et al 2024
Human-like Bots for Tactical Shooters Using Compute-Efficient Sensors
“How AI Is Unlocking Ancient Texts: From Deciphering Burnt Roman Scrolls to Reading Crumbling Cuneiform Tablets, Neural Networks Could Give Researchers More Data Than They’ve Had in Centuries”, Marchant 2024
“FlashRNN: Optimizing Traditional RNNs on Modern Hardware”, Pöppel et al 2024
“Gated Delta Networks: Improving Mamba-2 With Delta Rule”, Yang et al 2024
“Hymba: A Hybrid-Head Architecture for Small Language Models”, Dong et al 2024
“State-Space Models Can Learn In-Context by Gradient Descent”, Sushma et al 2024
“Were RNNs All We Needed?”, Feng et al 2024
“The Mamba in the Llama: Distilling and Accelerating Hybrid Models”, Wang et al 2024
The Mamba in the Llama: Distilling and Accelerating Hybrid Models
“handwriter.ttf: Handwriting Synthesis With Harfbuzz WASM”, Jingyi 2024
“Just Read Twice: Closing the Recall Gap for Recurrent Language Models”, Arora et al 2024
Just read twice: closing the recall gap for recurrent language models
“Learning to (Learn at Test Time): RNNs With Expressive Hidden States”, Sun et al 2024
Learning to (Learn at Test Time): RNNs with Expressive Hidden States
“An Empirical Study of Mamba-Based Language Models”, Waleffe et al 2024
“State Soup: In-Context Skill Learning, Retrieval and Mixing”, Pióro et al 2024
“RWKV-CLIP: A Robust Vision-Language Representation Learner”, Gu et al 2024
“Transformers Are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality”, Dao & Gu 2024
“Grokfast: Accelerated Grokking by Amplifying Slow Gradients”, Lee et al 2024
“DiM: Scaling Diffusion Mamba With Bidirectional SSMs for Efficient Image and Video Generation”, Mo & Tian 2024
DiM: Scaling Diffusion Mamba with Bidirectional SSMs for Efficient Image and Video Generation
“Attention As an RNN”, Feng et al 2024
“XLSTM: Extended Long Short-Term Memory”, Beck et al 2024
“Megalodon: Efficient LLM Pretraining and Inference With Unlimited Context Length”, Ma et al 2024
Megalodon: Efficient LLM Pretraining and Inference with Unlimited Context Length
“The Illusion of State in State-Space Models”, Merrill et al 2024
“An Accurate and Rapidly Calibrating Speech Neuroprosthesis”, Card et al 2024
“Does Transformer Interpretability Transfer to RNNs?”, Paulo et al 2024
“Mechanistic Design and Scaling of Hybrid Architectures”, Poli et al 2024
“GLE: Backpropagation through Space, Time, and the Brain”, Ellenberger et al 2024
“ZigMa: Zigzag Mamba Diffusion Model”, Hu et al 2024
“RNNs Are Not Transformers (Yet): The Key Bottleneck on In-Context Retrieval”, Wen et al 2024
RNNs are not Transformers (Yet): The Key Bottleneck on In-context Retrieval
“Verifiable Evaluations of Machine Learning Models Using ZkSNARKs”, South et al 2024
Verifiable evaluations of machine learning models using zkSNARKs
“MambaByte: Token-Free Selective State Space Model”, Wang et al 2024
“MoE-Mamba: Efficient Selective State Space Models With Mixture of Experts”, Pióro et al 2024
MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts
“Evolving Reservoirs for Meta Reinforcement Learning”, Léger et al 2023
“Zoology: Measuring and Improving Recall in Efficient Language Models”, Arora et al 2023
Zoology: Measuring and Improving Recall in Efficient Language Models
“Mamba: Linear-Time Sequence Modeling With Selective State Spaces”, Gu & Dao 2023
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
“Diffusion Models Without Attention”, Yan et al 2023
“Learning Few-Shot Imitation As Cultural Transmission”, Bhoopchand et al 2023
“Compositional Capabilities of Autoregressive Transformers: A Study on Synthetic, Interpretable Tasks”, Ramesh et al 2023
Compositional Capabilities of Autoregressive Transformers: A Study on Synthetic, Interpretable Tasks
“HGRN: Hierarchically Gated Recurrent Neural Network for Sequence Modeling”, Qin et al 2023
HGRN: Hierarchically Gated Recurrent Neural Network for Sequence Modeling
“On Prefrontal Working Memory and Hippocampal Episodic Memory: Unifying Memories Stored in Weights and Activation Slots”, Whittington et al 2023
“GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling”, Katsch 2023
GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling
“ProSG: Using Prompt Synthetic Gradients to Alleviate Prompt Forgetting of RNN-Like Language Models”, Luo et al 2023
ProSG: Using Prompt Synthetic Gradients to Alleviate Prompt Forgetting of RNN-like Language Models
“Transformers Learn Higher-Order Optimization Methods for In-Context Learning: A Study With Linear Models”, Fu et al 2023
“Generalization in Sensorimotor Networks Configured With Natural Language Instructions”, Riveland & Pouget 2023
Generalization in Sensorimotor Networks Configured with Natural Language Instructions
“Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors”, Amos et al 2023
Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors
“Parallelizing Non-Linear Sequential Models over the Sequence Length”, Lim et al 2023
Parallelizing non-linear sequential models over the sequence length
“Gated Recurrent Neural Networks Discover Attention”, Zucchet et al 2023
“A High-Performance Neuroprosthesis for Speech Decoding and Avatar Control”, Metzger et al 2023
A high-performance neuroprosthesis for speech decoding and avatar control
“ts_zip: Text Compression Using Large Language Models [RWKV 169M V4]”, Bellard 2023
ts_zip: Text Compression using Large Language Models [RWKV 169M v4]
“Learning to Model the World With Language”, Lin et al 2023
“Retentive Network: A Successor to Transformer for Large Language Models”, Sun et al 2023
Retentive Network: A Successor to Transformer for Large Language Models
“Using Sequences of Life-Events to Predict Human Lives”, Savcisens et al 2023
“Thought Cloning: Learning to Think While Acting by Imitating Human Thinking”, Hu & Clune 2023
Thought Cloning: Learning to Think while Acting by Imitating Human Thinking
“RWKV: Reinventing RNNs for the Transformer Era”, Peng et al 2023
“Emergence of Belief-Like Representations through Reinforcement Learning”, Hennig et al 2023
Emergence of belief-like representations through reinforcement learning
“Model Scale versus Domain Knowledge in Statistical Forecasting of Chaotic Systems”, Gilpin 2023
Model scale versus domain knowledge in statistical forecasting of chaotic systems
“Resurrecting Recurrent Neural Networks for Long Sequences”, Orvieto et al 2023
“SpikeGPT: Generative Pre-Trained Language Model With Spiking Neural Networks”, Zhu et al 2023
SpikeGPT: Generative Pre-trained Language Model with Spiking Neural Networks
“Theory of Coupled Neuronal-Synaptic Dynamics”, Clark & Abbott 2023
“Organic Reaction Mechanism Classification Using Machine Learning”, Burés & Larrosa 2023
Organic reaction mechanism classification using machine learning
“A High-Performance Speech Neuroprosthesis”, Willett et al 2023
“Hungry Hungry Hippos: Towards Language Modeling With State Space Models”, Fu et al 2022
Hungry Hungry Hippos: Towards Language Modeling with State Space Models
“Pretraining Without Attention”, Wang et al 2022
“A 64-Core Mixed-Signal In-Memory Compute Chip Based on Phase-Change Memory for Deep Neural Network Inference”, Gallo et al 2022
“Melting Pot 2.0”, Agapiou et al 2022
“VeLO: Training Versatile Learned Optimizers by Scaling Up”, Metz et al 2022
“Legged Locomotion in Challenging Terrains Using Egocentric Vision”, Agarwal et al 2022
Legged Locomotion in Challenging Terrains using Egocentric Vision
“Massively Multilingual ASR on 70 Languages: Tokenization, Architecture, and Generalization Capabilities”, Tjandra et al 2022
“Perfectly Secure Steganography Using Minimum Entropy Coupling”, Witt et al 2022
Perfectly Secure Steganography Using Minimum Entropy Coupling
“Omnigrok: Grokking Beyond Algorithmic Data”, Liu et al 2022
“Semantic Scene Descriptions As an Objective of Human Vision”, Doerig et al 2022
“Benchmarking Compositionality With Formal Languages”, Valvoda et al 2022
“Learning to Generalize With Object-Centric Agents in the Open World Survival Game Crafter”, Stanić et al 2022
Learning to Generalize with Object-centric Agents in the Open World Survival Game Crafter
“PI-ARS: Accelerating Evolution-Learned Visual-Locomotion With Predictive Information Representations”, Lee et al 2022
PI-ARS: Accelerating Evolution-Learned Visual-Locomotion with Predictive Information Representations
“Spatial Representation by Ramping Activity of Neurons in the Retrohippocampal Cortex”, Tennant et al 2022
Spatial representation by ramping activity of neurons in the retrohippocampal cortex
“Neural Networks and the Chomsky Hierarchy”, Delétang et al 2022
“BYOL-Explore: Exploration by Bootstrapped Prediction”, Guo et al 2022
“AnimeSR: Learning Real-World Super-Resolution Models for Animation Videos”, Wu et al 2022
AnimeSR: Learning Real-World Super-Resolution Models for Animation Videos
“Task-Agnostic Continual Reinforcement Learning: In Praise of a Simple Baseline (3RL)”, Caccia et al 2022
Task-Agnostic Continual Reinforcement Learning: In Praise of a Simple Baseline (3RL)
“Simple Recurrence Improves Masked Language Models”, Lei et al 2022
“Sequencer: Deep LSTM for Image Classification”, Tatsunami & Taki 2022
“Data Distributional Properties Drive Emergent Few-Shot Learning in Transformers”, Chan et al 2022
Data Distributional Properties Drive Emergent Few-Shot Learning in Transformers
“Semantic Projection Recovers Rich Human Knowledge of Multiple Object Features from Word Embeddings”, Grand et al 2022
Semantic projection recovers rich human knowledge of multiple object features from word embeddings
“Block-Recurrent Transformers”, Hutchins et al 2022
“All You Need Is Supervised Learning: From Imitation Learning to Meta-RL With Upside Down RL”, Arulkumaran et al 2022
All You Need Is Supervised Learning: From Imitation Learning to Meta-RL With Upside Down RL
“Retrieval-Augmented Reinforcement Learning”, Goyal et al 2022
“Learning by Directional Gradient Descent”, Silver et al 2022
“General-Purpose, Long-Context Autoregressive Modeling With Perceiver AR”, Hawthorne et al 2022
General-purpose, long-context autoregressive modeling with Perceiver AR
“End-To-End Algorithm Synthesis With Recurrent Networks: Logical Extrapolation Without Overthinking”, Bansal et al 2022
End-to-end Algorithm Synthesis with Recurrent Networks: Logical Extrapolation Without Overthinking
“Data Scaling Laws in NMT: The Effect of Noise and Architecture”, Bansal et al 2022
Data Scaling Laws in NMT: The Effect of Noise and Architecture
“Active Predictive Coding Networks: A Neural Solution to the Problem of Learning Reference Frames and Part-Whole Hierarchies”, Gklezakos & Rao 2022
“Learning Robust Perceptive Locomotion for Quadrupedal Robots in the Wild”, Miki et al 2022
Learning robust perceptive locomotion for quadrupedal robots in the wild
“Inducing Causal Structure for Interpretable Neural Networks (IIT)”, Geiger et al 2021
Inducing Causal Structure for Interpretable Neural Networks (IIT)
“Evaluating Distributional Distortion in Neural Language Modeling”, Anonymous 2021
Evaluating Distributional Distortion in Neural Language Modeling
“Gradients Are Not All You Need”, Metz et al 2021
“An Explanation of In-Context Learning As Implicit Bayesian Inference”, Xie et al 2021
An Explanation of In-context Learning as Implicit Bayesian Inference
“S4: Efficiently Modeling Long Sequences With Structured State Spaces”, Gu et al 2021
S4: Efficiently Modeling Long Sequences with Structured State Spaces
“Minimum Description Length Recurrent Neural Networks”, Lan et al 2021
“LSSL: Combining Recurrent, Convolutional, and Continuous-Time Models With Linear State-Space Layers”, Gu et al 2021
LSSL: Combining Recurrent, Convolutional, and Continuous-time Models with Linear State-Space Layers
“A Connectome of the Drosophila Central Complex Reveals Network Motifs Suitable for Flexible Navigation and Context-Dependent Action Selection”, Hulse et al 2021
“Recurrent Model-Free RL Is a Strong Baseline for Many POMDPs”, Ni et al 2021
Recurrent Model-Free RL is a Strong Baseline for Many POMDPs
“AFT: An Attention Free Transformer”, Zhai et al 2021
“Photos Are All You Need for Reciprocal Recommendation in Online Dating”, Neve & McConville 2021
Photos Are All You Need for Reciprocal Recommendation in Online Dating
“Perceiver IO: A General Architecture for Structured Inputs & Outputs”, Jaegle et al 2021
Perceiver IO: A General Architecture for Structured Inputs & Outputs
“PES: Unbiased Gradient Estimation in Unrolled Computation Graphs With Persistent Evolution Strategies”, Vicol et al 2021
“Shelley: A Crowd-Sourced Collaborative Horror Writer”, Delul et al 2021
“Ten Lessons From Three Generations Shaped Google’s TPUv4i”, Jouppi et al 2021
“RASP: Thinking Like Transformers”, Weiss et al 2021
“Scaling Laws for Acoustic Models”, Droppo & Elibol 2021
“Scaling End-To-End Models for Large-Scale Multilingual ASR”, Li et al 2021
“Sensitivity As a Complexity Measure for Sequence Classification Tasks”, Hahn et al 2021
Sensitivity as a Complexity Measure for Sequence Classification Tasks
“ALD: Efficient Transformers in Reinforcement Learning Using Actor-Learner Distillation”, Parisotto & Salakhutdinov 2021
ALD: Efficient Transformers in Reinforcement Learning using Actor-Learner Distillation
“Finetuning Pretrained Transformers into RNNs”, Kasai et al 2021
“Pretrained Transformers As Universal Computation Engines”, Lu et al 2021
“Perceiver: General Perception With Iterative Attention”, Jaegle et al 2021
“When Attention Meets Fast Recurrence: Training SRU++ Language Models With Reduced Compute”, Lei 2021
When Attention Meets Fast Recurrence: Training SRU++ Language Models with Reduced Compute
“Generative Speech Coding With Predictive Variance Regularization”, Kleijn et al 2021
Generative Speech Coding with Predictive Variance Regularization
“Predictive Coding Is a Consequence of Energy Efficiency in Recurrent Neural Networks”, Ali et al 2021
Predictive coding is a consequence of energy efficiency in recurrent neural networks
“Deep Residual Learning in Spiking Neural Networks”, Fang et al 2021
“Distilling Large Language Models into Tiny and Effective Students Using PQRNN”, Kaliamoorthi et al 2021
Distilling Large Language Models into Tiny and Effective Students using pQRNN
“Meta Learning Backpropagation And Improving It”, Kirsch & Schmidhuber 2020
“On the Binding Problem in Artificial Neural Networks”, Greff et al 2020
“A Recurrent Vision-And-Language BERT for Navigation”, Hong et al 2020
“Towards Playing Full MOBA Games With Deep Reinforcement Learning”, Ye et al 2020
Towards Playing Full MOBA Games with Deep Reinforcement Learning
“Multimodal Dynamics Modeling for Off-Road Autonomous Vehicles”, Tremblay et al 2020
Multimodal dynamics modeling for off-road autonomous vehicles
“Adversarial Vulnerabilities of Human Decision-Making”, Dezfouli et al 2020
“Learning to Summarize Long Texts With Memory Compression and Transfer”, Park et al 2020
Learning to Summarize Long Texts with Memory Compression and Transfer
“Human-Centric Dialog Training via Offline Reinforcement Learning”, Jaques et al 2020
Human-centric Dialog Training via Offline Reinforcement Learning
“Deep Reinforcement Learning for Closed-Loop Blood Glucose Control”, Fox et al 2020
Deep Reinforcement Learning for Closed-Loop Blood Glucose Control
“HiPPO: Recurrent Memory With Optimal Polynomial Projections”, Gu et al 2020
“Adding Recurrence to Pretrained Transformers for Improved Efficiency and Context Size”, Yoshida et al 2020
Adding Recurrence to Pretrained Transformers for Improved Efficiency and Context Size
“Matt Botvinick on the Spontaneous Emergence of Learning Algorithms”, Scholl 2020
Matt Botvinick on the spontaneous emergence of learning algorithms
“Cultural Influences on Word Meanings Revealed through Large-Scale Semantic Alignment”, Thompson et al 2020
Cultural influences on word meanings revealed through large-scale semantic alignment
“DeepSinger: Singing Voice Synthesis With Data Mined From the Web”, Ren et al 2020
DeepSinger: Singing Voice Synthesis with Data Mined From the Web
“High-Performance Brain-To-Text Communication via Imagined Handwriting”, Willett et al 2020
High-performance brain-to-text communication via imagined handwriting
“Transformers Are RNNs: Fast Autoregressive Transformers With Linear Attention”, Katharopoulos et al 2020
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
“The Recurrent Neural Tangent Kernel”, Alemohammad et al 2020
“Untangling Tradeoffs between Recurrence and Self-Attention in Neural Networks”, Kerg et al 2020
Untangling tradeoffs between recurrence and self-attention in neural networks
“Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing”, Dai et al 2020
Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing
“Learning Music Helps You Read: Using Transfer to Study Linguistic Structure in Language Models”, Papadimitriou & Jurafsky 2020
Learning Music Helps You Read: Using Transfer to Study Linguistic Structure in Language Models
“Syntactic Structure from Deep Learning”, Linzen & Baroni 2020
“Agent57: Outperforming the Human Atari Benchmark”, Puigdomènech et al 2020
“Machine Translation of Cortical Activity to Text With an Encoder-Decoder Framework”, Makin et al 2020
Machine translation of cortical activity to text with an encoder-decoder framework
“Learning-Based Memory Allocation for C++ Server Workloads”, Maas et al 2020
“Accelerating Feedforward Computation via Parallel Nonlinear Equation Solving”, Song et al 2020
Accelerating Feedforward Computation via Parallel Nonlinear Equation Solving
“Direct Fit to Nature: An Evolutionary Perspective on Biological and Artificial Neural Networks”, Hasson et al 2020
Direct Fit to Nature: An Evolutionary Perspective on Biological and Artificial Neural Networks
“Scaling Laws for Neural Language Models”, Kaplan et al 2020
“Estimating the Deep Replicability of Scientific Findings Using Human and Artificial Intelligence”, Yang et al 2020
Estimating the deep replicability of scientific findings using human and artificial intelligence
“Placing Language in an Integrated Understanding System: Next Steps toward Human-Level Performance in Neural Language Models”, McClelland et al 2020
“Measuring Compositional Generalization: A Comprehensive Method on Realistic Data”, Keysers et al 2019
Measuring Compositional Generalization: A Comprehensive Method on Realistic Data
“SimpleBooks: Long-Term Dependency Book Dataset With Simplified English Vocabulary for Word-Level Language Modeling”, Nguyen 2019
“Single Headed Attention RNN: Stop Thinking With Your Head”, Merity 2019
“Excavate”, Lynch 2019
“MuZero: Mastering Atari, Go, Chess and Shogi by Planning With a Learned Model”, Schrittwieser et al 2019
MuZero: Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
“CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning”, Lin et al 2019
CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning
“High Fidelity Video Prediction With Large Stochastic Recurrent Neural Networks”, Villegas et al 2019
High Fidelity Video Prediction with Large Stochastic Recurrent Neural Networks
“Legendre Memory Units: Continuous-Time Representation in Recurrent Neural Networks”, Voelker et al 2019
Legendre Memory Units: Continuous-Time Representation in Recurrent Neural Networks
“SEED RL: Scalable and Efficient Deep-RL With Accelerated Central Inference”, Espeholt et al 2019
SEED RL: Scalable and Efficient Deep-RL with Accelerated Central Inference
“Mixed-Signal Neuromorphic Processors: Quo Vadis?”, Bavandpour et al 2019
“Restoring Ancient Text Using Deep Learning (Pythia): a Case Study on Greek Epigraphy”, Assael et al 2019
Restoring ancient text using deep learning (Pythia): a case study on Greek epigraphy
“Mogrifier LSTM”, Melis et al 2019
“R2D3: Making Efficient Use of Demonstrations to Solve Hard Exploration Problems”, Paine et al 2019
R2D3: Making Efficient Use of Demonstrations to Solve Hard Exploration Problems
“Language Modeling State-Of-The-Art Leaderboards”, paperswithcode.com 2019
“Metalearned Neural Memory”, Munkhdalai et al 2019
“Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank”, Socher et al 2019
Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank
“Generating Text With Recurrent Neural Networks”, Sutskever et al 2019
“XLNet: Generalized Autoregressive Pretraining for Language Understanding”, Yang et al 2019
XLNet: Generalized Autoregressive Pretraining for Language Understanding
“Playing the Lottery With Rewards and Multiple Languages: Lottery Tickets in RL and NLP”, Yu et al 2019
Playing the lottery with rewards and multiple languages: lottery tickets in RL and NLP
“MoGlow: Probabilistic and Controllable Motion Synthesis Using Normalizing Flows”, Henter et al 2019
MoGlow: Probabilistic and controllable motion synthesis using normalizing flows
“Reinforcement Learning, Fast and Slow”, Botvinick et al 2019
“Meta-Learners’ Learning Dynamics Are unlike Learners’”, Rabinowitz 2019
“Speech Synthesis from Neural Decoding of Spoken Sentences”, Anumanchipalli et al 2019
“Good News, Everyone! Context Driven Entity-Aware Captioning for News Images”, Biten et al 2019
Good News, Everyone! Context driven entity-aware captioning for news images
“Surrogate Gradient Learning in Spiking Neural Networks”, Neftci et al 2019
“On the Turing Completeness of Modern Neural Network Architectures”, Pérez et al 2019
On the Turing Completeness of Modern Neural Network Architectures
“Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context”, Dai et al 2019
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
“Natural Questions: A Benchmark for Question Answering Research”, Kwiatkowski et al 2019
Natural Questions: A Benchmark for Question Answering Research
“High Fidelity Video Prediction With Large Stochastic Recurrent Neural Networks: Videos”, Villegas et al 2019
High Fidelity Video Prediction with Large Stochastic Recurrent Neural Networks: Videos
“Bayesian Layers: A Module for Neural Network Uncertainty”, Tran et al 2018
“Meta-Learning: Learning to Learn Fast”, Weng 2018
“Piano Genie”, Donahue et al 2018
“Learning Recurrent Binary/Ternary Weights”, Ardakani et al 2018
“R2D2: Recurrent Experience Replay in Distributed Reinforcement Learning”, Kapturowski et al 2018
R2D2: Recurrent Experience Replay in Distributed Reinforcement Learning
“HotpotQA: A Dataset for Diverse, Explainable Multi-Hop Question Answering”, Yang et al 2018
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
“Adversarial Reprogramming of Text Classification Neural Networks”, Neekhara et al 2018
Adversarial Reprogramming of Text Classification Neural Networks
“Object Hallucination in Image Captioning”, Rohrbach et al 2018
“This Time With Feeling: Learning Expressive Musical Performance”, Oore et al 2018
This Time with Feeling: Learning Expressive Musical Performance
“Character-Level Language Modeling With Deeper Self-Attention”, Al-Rfou et al 2018
Character-Level Language Modeling with Deeper Self-Attention
“General Value Function Networks”, Schlegel et al 2018
“Deep-Speare: A Joint Neural Model of Poetic Language, Meter and Rhyme”, Lau et al 2018
Deep-speare: A Joint Neural Model of Poetic Language, Meter and Rhyme
“Universal Transformers”, Dehghani et al 2018
“Accurate Uncertainties for Deep Learning Using Calibrated Regression”, Kuleshov et al 2018
Accurate Uncertainties for Deep Learning Using Calibrated Regression
“The Natural Language Decathlon: Multitask Learning As Question Answering”, McCann et al 2018
The Natural Language Decathlon: Multitask Learning as Question Answering
“Neural Ordinary Differential Equations”, Chen et al 2018
“Know What You Don’t Know: Unanswerable Questions for SQuAD”, Rajpurkar et al 2018
“DVRL: Deep Variational Reinforcement Learning for POMDPs”, Igl et al 2018
“Greedy Attack and Gumbel Attack: Generating Adversarial Examples for Discrete Data”, Yang et al 2018
Greedy Attack and Gumbel Attack: Generating Adversarial Examples for Discrete Data
“Hierarchical Neural Story Generation”, Fan et al 2018
“Sharp Nearby, Fuzzy Far Away: How Neural Language Models Use Context”, Khandelwal et al 2018
Sharp Nearby, Fuzzy Far Away: How Neural Language Models Use Context
“Newsroom: A Dataset of 1.3 Million Summaries With Diverse Extractive Strategies”, Grusky et al 2018
Newsroom: A Dataset of 1.3 Million Summaries with Diverse Extractive Strategies
“A Tree Search Algorithm for Sequence Labeling”, Lao et al 2018
“Large Scale Distributed Neural Network Training through Online Distillation”, Anil et al 2018
Large scale distributed neural network training through online distillation
“An Analysis of Neural Language Modeling at Multiple Scales”, Merity et al 2018
“Reviving and Improving Recurrent Back-Propagation”, Liao et al 2018
“Learning Memory Access Patterns”, Hashemi et al 2018
“Learning Longer-Term Dependencies in RNNs With Auxiliary Losses”, Trinh et al 2018
Learning Longer-term Dependencies in RNNs with Auxiliary Losses
“One Big Net For Everything”, Schmidhuber 2018
“Efficient Neural Audio Synthesis”, Kalchbrenner et al 2018
“Deep Contextualized Word Representations”, Peters et al 2018
“M-Walk: Learning to Walk over Graphs Using Monte Carlo Tree Search”, Shen et al 2018
M-Walk: Learning to Walk over Graphs using Monte Carlo Tree Search
“Overcoming the Vanishing Gradient Problem in Plain Recurrent Networks”, Hu et al 2018
Overcoming the vanishing gradient problem in plain recurrent networks
“ULMFiT: Universal Language Model Fine-Tuning for Text Classification”, Howard & Ruder 2018
ULMFiT: Universal Language Model Fine-tuning for Text Classification
“The Compute and Data Moats Are Dead”, Merity 2018
“Large-Scale Comparison of Machine Learning Methods for Drug Target Prediction on ChEMBL”, Mayr et al 2018
Large-scale comparison of machine learning methods for drug target prediction on ChEMBL
“A Flexible Approach to Automated RNN Architecture Generation”, Schrimpf et al 2017
A Flexible Approach to Automated RNN Architecture Generation
“The NarrativeQA Reading Comprehension Challenge”, Kočiský et al 2017
“Learning Compact Recurrent Neural Networks With Block-Term Tensor Decomposition”, Ye et al 2017
Learning Compact Recurrent Neural Networks with Block-Term Tensor Decomposition
“LBA: Learning by Asking Questions”, Misra et al 2017
“Mastering the Dungeon: Grounded Language Learning by Mechanical Turker Descent”, Yang et al 2017
Mastering the Dungeon: Grounded Language Learning by Mechanical Turker Descent
“Evaluating Prose Style Transfer With the Bible”, Carlson et al 2017
“Breaking the Softmax Bottleneck: A High-Rank RNN Language Model”, Yang et al 2017
Breaking the Softmax Bottleneck: A High-Rank RNN Language Model
“Neural Speed Reading via Skim-RNN”, Seo et al 2017
“Unsupervised Machine Translation Using Monolingual Corpora Only”, Lample et al 2017
Unsupervised Machine Translation Using Monolingual Corpora Only
“Generalization without Systematicity: On the Compositional Skills of Sequence-To-Sequence Recurrent Networks”, Lake & Baroni 2017
“Mixed Precision Training”, Micikevicius et al 2017
“To Prune, or Not to Prune: Exploring the Efficacy of Pruning for Model Compression”, Zhu & Gupta 2017
To prune, or not to prune: exploring the efficacy of pruning for model compression
“Dynamic Evaluation of Neural Sequence Models”, Krause et al 2017
“Online Learning of a Memory for Learning Rates”, Meier et al 2017
“Why Pay More When You Can Pay Less: A Joint Learning Framework for Active Feature Acquisition and Classification”, Shim et al 2017
“N2N Learning: Network to Network Compression via Policy Gradient Reinforcement Learning”, Ashok et al 2017
N2N Learning: Network to Network Compression via Policy Gradient Reinforcement Learning
“SRU: Simple Recurrent Units for Highly Parallelizable Recurrence”, Lei et al 2017
SRU: Simple Recurrent Units for Highly Parallelizable Recurrence
“Learning to Look Around: Intelligently Exploring Unseen Environments for Unknown Tasks”, Jayaraman & Grauman 2017
Learning to Look Around: Intelligently Exploring Unseen Environments for Unknown Tasks
“Twin Networks: Matching the Future for Sequence Generation”, Serdyuk et al 2017
“Skip RNN: Learning to Skip State Updates in Recurrent Neural Networks”, Campos et al 2017
Skip RNN: Learning to Skip State Updates in Recurrent Neural Networks
“Regularizing and Optimizing LSTM Language Models”, Merity et al 2017
“Revisiting Activation Regularization for Language RNNs”, Merity et al 2017
“Bayesian Sparsification of Recurrent Neural Networks”, Lobacheva et al 2017
“On the State-Of-The-Art of Evaluation in Neural Language Models”, Melis et al 2017
On the State-of-the-Art of Evaluation in Neural Language Models
“Controlling Linguistic Style Aspects in Neural Language Generation”, Ficler & Goldberg 2017
Controlling Linguistic Style Aspects in Neural Language Generation
“Device Placement Optimization With Reinforcement Learning”, Mirhoseini et al 2017
“Six Challenges for Neural Machine Translation”, Koehn & Knowles 2017
“Towards Synthesizing Complex Programs from Input-Output Examples”, Chen et al 2017
Towards Synthesizing Complex Programs from Input-Output Examples
“Language Generation With Recurrent Generative Adversarial Networks without Pre-Training”, Press et al 2017
Language Generation with Recurrent Generative Adversarial Networks without Pre-training
“Biased Importance Sampling for Deep Neural Network Training”, Katharopoulos & Fleuret 2017
“Deriving Neural Architectures from Sequence and Graph Kernels”, Lei et al 2017
Deriving Neural Architectures from Sequence and Graph Kernels
“A Deep Reinforced Model for Abstractive Summarization”, Paulus et al 2017
“TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension”, Joshi et al 2017
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
“DeepTingle”, Khalifa et al 2017
“A Neural Network System for Transformation of Regional Cuisine Style”, Kazama et al 2017
A neural network system for transformation of regional cuisine style
“Sharp Models on Dull Hardware: Fast and Accurate Neural Machine Translation Decoding on the CPU”, Devlin 2017
Sharp Models on Dull Hardware: Fast and Accurate Neural Machine Translation Decoding on the CPU
“Adversarial Neural Machine Translation”, Wu et al 2017
“SearchQA: A New Q&A Dataset Augmented With Context from a Search Engine”, Dunn et al 2017
SearchQA: A New Q&A Dataset Augmented with Context from a Search Engine
“Learning to Reason: End-To-End Module Networks for Visual Question Answering”, Hu et al 2017
Learning to Reason: End-to-End Module Networks for Visual Question Answering
“Exploring Sparsity in Recurrent Neural Networks”, Narang et al 2017
“Get To The Point: Summarization With Pointer-Generator Networks”, See et al 2017
Get To The Point: Summarization with Pointer-Generator Networks
“DeepAR: Probabilistic Forecasting With Autoregressive Recurrent Networks”, Salinas et al 2017
DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks
“Bayesian Recurrent Neural Networks”, Fortunato et al 2017
“Recurrent Environment Simulators”, Chiappa et al 2017
“Learning to Generate Reviews and Discovering Sentiment”, Radford et al 2017
“Learning Simpler Language Models With the Differential State Framework”, II et al 2017
Learning Simpler Language Models with the Differential State Framework
“I2T2I: Learning Text to Image Synthesis With Textual Data Augmentation”, Dong et al 2017
I2T2I: Learning Text to Image Synthesis with Textual Data Augmentation
“Improving Neural Machine Translation With Conditional Sequence Generative Adversarial Nets”, Yang et al 2017
Improving Neural Machine Translation with Conditional Sequence Generative Adversarial Nets
“Learned Optimizers That Scale and Generalize”, Wichrowska et al 2017
“Parallel Multiscale Autoregressive Density Estimation”, Reed et al 2017
“Tracking the World State With Recurrent Entity Networks”, Henaff et al 2017
“Optimization As a Model for Few-Shot Learning”, Ravi & Larochelle 2017
“Neural Combinatorial Optimization With Reinforcement Learning”, Bello et al 2017
Neural Combinatorial Optimization with Reinforcement Learning
“Frustratingly Short Attention Spans in Neural Language Modeling”, Daniluk et al 2017
Frustratingly Short Attention Spans in Neural Language Modeling
“Tuning Recurrent Neural Networks With Reinforcement Learning”, Jaques et al 2017
Tuning Recurrent Neural Networks with Reinforcement Learning
“Outrageously Large Neural Networks: The Sparsely-Gated Mixture-Of-Experts Layer”, Shazeer et al 2017
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
“Neural Data Filter for Bootstrapping Stochastic Gradient Descent”, Fan et al 2017
Neural Data Filter for Bootstrapping Stochastic Gradient Descent
“Learning the Enigma With Recurrent Neural Networks”, Greydanus 2017
Learning the Enigma with Recurrent Neural Networks
View External Link:
“Your TL;DR by an AI: A Deep Reinforced Model for Abstractive Summarization”, Paulus 2017
Your TL;DR by an AI: A Deep Reinforced Model for Abstractive Summarization
“SampleRNN: An Unconditional End-To-End Neural Audio Generation Model”, Mehri et al 2016
SampleRNN: An Unconditional End-to-End Neural Audio Generation Model
“Improving Neural Language Models With a Continuous Cache”, Grave et al 2016
“NewsQA: A Machine Comprehension Dataset”, Trischler et al 2016
“Neural Combinatorial Optimization With Reinforcement Learning”, Bello et al 2016
Neural Combinatorial Optimization with Reinforcement Learning
“Visual Dialog”, Das et al 2016
“Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation”, Johnson et al 2016
Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation
“Learning to Learn without Gradient Descent by Gradient Descent”, Chen et al 2016
Learning to Learn without Gradient Descent by Gradient Descent
“RL2: Fast Reinforcement Learning via Slow Reinforcement Learning”, Duan et al 2016
RL2: Fast Reinforcement Learning via Slow Reinforcement Learning
“DeepCoder: Learning to Write Programs”, Balog et al 2016
“QRNNs: Quasi-Recurrent Neural Networks”, Bradbury et al 2016
“Neural Architecture Search With Reinforcement Learning”, Zoph & Le 2016
“Bidirectional Attention Flow for Machine Comprehension”, Seo et al 2016
“Hybrid Computing Using a Neural Network With Dynamic External Memory”, Graves et al 2016
Hybrid computing using a neural network with dynamic external memory
“Scaling Memory-Augmented Neural Networks With Sparse Reads and Writes”, Rae et al 2016
Scaling Memory-Augmented Neural Networks with Sparse Reads and Writes
“Using Fast Weights to Attend to the Recent Past”, Ba et al 2016
“Achieving Human Parity in Conversational Speech Recognition”, Xiong et al 2016
“VPN: Video Pixel Networks”, Kalchbrenner et al 2016
“HyperNetworks”, Ha et al 2016
“Pointer Sentinel Mixture Models”, Merity et al 2016
“Multiplicative LSTM for Sequence Modeling”, Krause et al 2016
“Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation”, Wu et al 2016
Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
“One Sentence One Model for Neural Machine Translation”, Li et al 2016
“Image-To-Markup Generation With Coarse-To-Fine Attention”, Deng et al 2016
“Hierarchical Multiscale Recurrent Neural Networks”, Chung et al 2016
“Deep Learning Human Mind for Automated Visual Classification”, Spampinato et al 2016
Deep Learning Human Mind for Automated Visual Classification
“Using the Output Embedding to Improve Language Models”, Press & Wolf 2016
“Full Resolution Image Compression With Recurrent Neural Networks”, Toderici et al 2016
Full Resolution Image Compression with Recurrent Neural Networks
“Decoupled Neural Interfaces Using Synthetic Gradients”, Jaderberg et al 2016
“Clockwork Convnets for Video Semantic Segmentation”, Shelhamer et al 2016
“Layer Normalization”, Ba et al 2016
“Sequence-Level Knowledge Distillation”, Kim & Rush 2016
“LSTMVis: A Tool for Visual Analysis of Hidden State Dynamics in Recurrent Neural Networks”, Strobelt et al 2016
LSTMVis: A Tool for Visual Analysis of Hidden State Dynamics in Recurrent Neural Networks
“Learning to Learn by Gradient Descent by Gradient Descent”, Andrychowicz et al 2016
“Iterative Alternating Neural Attention for Machine Reading”, Sordoni et al 2016
“Deep Reinforcement Learning for Dialogue Generation”, Li et al 2016
“Programming With a Differentiable Forth Interpreter”, Bošnjak et al 2016
“Training Deep Nets With Sublinear Memory Cost”, Chen et al 2016
“Bridging the Gaps Between Residual Learning, Recurrent Neural Networks and Visual Cortex”, Liao & Poggio 2016
Bridging the Gaps Between Residual Learning, Recurrent Neural Networks and Visual Cortex
“Improving Sentence Compression by Learning to Predict Gaze”, Klerke et al 2016
“Adaptive Computation Time for Recurrent Neural Networks”, Graves 2016
“Dynamic Memory Networks for Visual and Textual Question Answering”, Xiong et al 2016
Dynamic Memory Networks for Visual and Textual Question Answering
“PlaNet—Photo Geolocation With Convolutional Neural Networks”, Weyand et al 2016
“Learning Distributed Representations of Sentences from Unlabeled Data”, Hill et al 2016
Learning Distributed Representations of Sentences from Unlabeled Data
“Exploring the Limits of Language Modeling”, Jozefowicz et al 2016
“PixelRNN: Pixel Recurrent Neural Networks”, Oord et al 2016
“Persistent RNNs: Stashing Recurrent Weights On-Chip”, Diamos et al 2016
“Exploring the Limits of Language Modeling § 5.9: Samples from the Model”
Exploring the Limits of Language Modeling § 5.9: Samples from the model :
“Deep-Spying: Spying Using Smartwatch and Deep Learning”, Beltramelli & Risi 2015
“Deep Speech 2: End-To-End Speech Recognition in English and Mandarin”, Amodei et al 2015
Deep Speech 2: End-to-End Speech Recognition in English and Mandarin
“On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models”, Schmidhuber 2015
“Neural GPUs Learn Algorithms”, Kaiser & Sutskever 2015
“Sequence Level Training With Recurrent Neural Networks”, Ranzato et al 2015
“Neural Programmer-Interpreters”, Reed & Freitas 2015
“Generating Sentences from a Continuous Space”, Bowman et al 2015
“Generative Concatenative Nets Jointly Learn to Write and Classify Reviews”, Lipton et al 2015
Generative Concatenative Nets Jointly Learn to Write and Classify Reviews
“Generating Images from Captions With Attention”, Mansimov et al 2015
“Semi-Supervised Sequence Learning”, Dai & Le 2015
“BPEs: Neural Machine Translation of Rare Words With Subword Units”, Sennrich et al 2015
BPEs: Neural Machine Translation of Rare Words with Subword Units
“Training Recurrent Networks Online without Backtracking”, Ollivier et al 2015
“Deep Recurrent Q-Learning for Partially Observable MDPs”, Hausknecht & Stone 2015
“A Neural Conversational Model”, Vinyals & Le 2015
“Teaching Machines to Read and Comprehend”, Hermann et al 2015
“Scheduled Sampling for Sequence Prediction With Recurrent Neural Networks”, Bengio et al 2015
Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks
“Visualizing and Understanding Recurrent Networks”, Karpathy et al 2015
“The Unreasonable Effectiveness of Recurrent Neural Networks”, Karpathy 2015
“Deep Neural Networks for Large Vocabulary Handwritten Text Recognition”, Bluche 2015
Deep Neural Networks for Large Vocabulary Handwritten Text Recognition
“Reinforcement Learning Neural Turing Machines—Revised”, Zaremba & Sutskever 2015
“End-To-End Memory Networks”, Sukhbaatar et al 2015
“LSTM: A Search Space Odyssey”, Greff et al 2015
“Inferring Algorithmic Patterns With Stack-Augmented Recurrent Nets”, Joulin & Mikolov 2015
Inferring Algorithmic Patterns with Stack-Augmented Recurrent Nets
“DRAW: A Recurrent Neural Network For Image Generation”, Gregor et al 2015
“Ensemble of Generative and Discriminative Techniques for Sentiment Analysis of Movie Reviews”, Mesnil et al 2014
Ensemble of Generative and Discriminative Techniques for Sentiment Analysis of Movie Reviews
“Deep Speech 1: Scaling up End-To-End Speech Recognition”, Hannun et al 2014
“Neural Turing Machines”, Graves et al 2014
“Learning to Execute”, Zaremba & Sutskever 2014
“Neural Machine Translation by Jointly Learning to Align and Translate”, Bahdanau et al 2014
Neural Machine Translation by Jointly Learning to Align and Translate
“Identifying and Attacking the Saddle Point Problem in High-Dimensional Non-Convex Optimization”, Dauphin et al 2014
Identifying and attacking the saddle point problem in high-dimensional non-convex optimization
“GRU: Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation”, Cho et al 2014
GRU: Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
“doc2vec: Distributed Representations of Sentences and Documents”, Le & Mikolov 2014
doc2vec: Distributed Representations of Sentences and Documents
“A Clockwork RNN”, Koutník et al 2014
“One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling”, Chelba et al 2013
One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling
“Generating Sequences With Recurrent Neural Networks”, Graves 2013
“Context Dependent Recurrent Neural Network Language Model”, Mikolov & Zweig 2012
“On the Difficulty of Training Recurrent Neural Networks”, Pascanu et al 2012
“[Fitness Landscape of a Small RNN]”, evolvingstuff 2011
“Recurrent Neural Network Based Language Model”, Mikolov et al 2010
“Learning Fast Approximations of Sparse Coding”, Gregor & LeCun 2010
“Large Language Models in Machine Translation”, Brants et al 2007
“Learning to Learn Using Gradient Descent”, Hochreiter et al 2001
“Paul J. Werbos Interview”, Werbos 1998
“Long Short-Term Memory”, Hochreiter & Schmidhuber 1997
“Flat Minima”, Hochreiter & Schmidhuber 1997
“RTRL: Gradient-Based Learning Algorithms for Recurrent Networks and Their Computational Complexity”, Williams & Zipser 1995
RTRL: Gradient-Based Learning Algorithms for Recurrent Networks and Their Computational Complexity
“A Focused Backpropagation Algorithm for Temporal Pattern Recognition”, Mozer 1995
A Focused Backpropagation Algorithm for Temporal Pattern Recognition
“Learning Complex, Extended Sequences Using the Principle of History Compression”, Schmidhuber 1992
Learning Complex, Extended Sequences Using the Principle of History Compression
“Learning to Control Fast-Weight Memories: An Alternative to Dynamic Recurrent Networks”, Schmidhuber 1992b
Learning to Control Fast-Weight Memories: An Alternative to Dynamic Recurrent Networks
“Untersuchungen Zu Dynamischen Neuronalen Netzen [Studies of Dynamic Neural Networks]”, Hochreiter 1991
Untersuchungen zu dynamischen neuronalen Netzen [Studies of dynamic neural networks]
“Finding Structure In Time”, Elman 1990
“Connectionist Music Composition Based on Melodic, Stylistic, and Psychophysical Constraints [Technical Report CU-CS-495-90]”, Mozer 1990
“A Learning Algorithm for Continually Running Fully Recurrent Neural Networks”, Williams & Zipser 1989b
A Learning Algorithm for Continually Running Fully Recurrent Neural Networks
“Recurrent Backpropagation and Hopfield Networks”, Almeida & Neto 1989b
“Backpropagation in Perceptrons With Feedback”, Almeida 1989
“A Local Learning Algorithm for Dynamic Feedforward and Recurrent Networks”, Schmidhuber 1989
A Local Learning Algorithm for Dynamic Feedforward and Recurrent Networks
“Experimental Analysis of the Real-Time Recurrent Learning Algorithm”, Williams & Zipser 1989
Experimental Analysis of the Real-time Recurrent Learning Algorithm
“A Sticky-Bit Approach for Learning to Represent State”, Bachrach 1988
“Generalization of Backpropagation With Application to a Recurrent Gas Market Model”, Werbos 1988
Generalization of backpropagation with application to a recurrent gas market model
“Generalization of Back-Propagation to Recurrent Neural Networks”, Pineda 1987
Generalization of back-propagation to recurrent neural networks
“The Utility Driven Dynamic Error Propagation Network (RTRL)”, Robinson & Fallside 1987
“A Self-Optimizing, Non-Symmetrical Neural Net for Content Addressable Memory and Pattern Recognition”, Lapedes & Farber 1986
A self-optimizing, non-symmetrical neural net for content addressable memory and pattern recognition
“Programming a Massively Parallel, Computation Universal System: Static Behavior”, Lapedes & Farber 1986b
Programming a massively parallel, computation universal system: Static behavior
“Serial Order: A Parallel Distributed Processing Approach”, Jordan 1986
“Found in Translation: More Accurate, Fluent Sentences in Google Translate”
Found in translation: More accurate, fluent sentences in Google Translate
“Hypernetworks [Blog]”, Ha 2026
“Safety-First AI for Autonomous Data Center Cooling and Industrial Control”
Safety-first AI for autonomous data center cooling and industrial control
“Attention and Augmented Recurrent Neural Networks”
“BlinkDL/RWKV-LM: RWKV Is an RNN With Transformer-Level LLM Performance. It Can Be Directly Trained like a GPT (Parallelizable). So It’s Combining the Best of RNN and Transformer—Great Performance, Fast Inference, Saves VRAM, Fast Training, "Infinite" Ctx_len, and Free Sentence Embedding.”
“RWKV-CLIP: A Robust Vision-Language Representation Learner”
“Efficient, Reusable RNNs and LSTMs for Torch”
“Updated Training?”
“Minimaxir/textgenrnn: Easily Train Your Own Text-Generating Neural Network of Any Size and Complexity on Any Text Dataset With a Few Lines of Code.”
“Deep Learning for Assisting the Process of Music Composition (Part 3)”
Deep learning for assisting the process of music composition (part 3)
“Kaichengalex/YFCC15M”
“Metalearning or Learning to Learn Since 1987”
“Stream Seaandsailor”
“Caglar Gulcehre Homepage”, Gulcehre 2026
“Composing Music With Recurrent Neural Networks”
“RWKV Language Model”
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
memory-optimization
dependency-modeling summarization-simplified extractive-representation language-corpus simplified-english
prose-transfer
secure-evaluation steganography smart-device deep-learning machine-security
drug-prediction
blood-glucose
super-resolution-models
video-segmentation
speech-interface neuroprosthesis text-generation brain-computer-image captioning speech-translation
imitation-simulation
adversarial-learning
recurrent-architecture
Wikipedia (5)
Miscellaneous
/doc/ai/nn/rnn/2021-droppo-figure5-lstmvstransformerscaling.png/doc/ai/nn/rnn/2021-jaegle-figure2-perceiverioarchitecture.png/doc/ai/nn/rnn/2020-deepmind-agent57-figure3-deepreinforcementlearningtimeline.svg/doc/ai/nn/rnn/2017-khalifa-example3-incoherentdeeptinglesamplepromptedwithmobydickcallmeishmael.png/doc/ai/nn/rnn/2016-06-09-rossgoodwin-adventuresinnarratedreality-2.html/doc/ai/nn/rnn/2016-03-19-rossgoodwin-adventuresinnarratedreality-1.html/doc/ai/nn/rnn/2015-08-05-gwern-charrnn-cssgeneration-csscomments-bestsamples.txt/doc/ai/nn/rnn/2015-08-05-gwern-charrnn-cssgeneration-lm_css_epoch24.00_0.7660.t7/doc/ai/nn/rnn/2015-06-03-karpathy-charrnn-visualization.tar.xzhttps://ahrm.github.io/jekyll/update/2022/04/14/using-languge-models-to-read-faster.htmlhttps://cprimozic.net/blog/growing-sparse-computational-graphs-with-rnns/https://homepages.inf.ed.ac.uk/abmayne/publications/sennrich2016NAACL.pdfhttps://mi.eng.cam.ac.uk/projects/cued-rnnlm/papers/Interspeech15.pdfhttps://patentimages.storage.googleapis.com/57/53/22/91b8a6792dbb1e/US20180204116A1.pdf#deepmindhttps://wandb.ai/wandb_fc/articles/reports/Image-to-LaTeX--Vmlldzo1NDQ0MTAxhttps://www.cs.utoronto.ca/~ilya/pubs/ilya_sutskever_phd_thesis.pdf#page=67:https://www.lesswrong.com/posts/bD4B2MF7nsGAfH9fj/basic-mathematics-of-predictive-codinghttps://www.lesswrong.com/posts/mxa7XZ8ajE2oarWcr/lawrencec-s-shortform?commentId=pEqfzPMpqsnhaGrNKhttps://www.reddit.com/r/MachineLearning/comments/umq908/r_rwkvv2rnn_a_parallelizable_rnn_with/
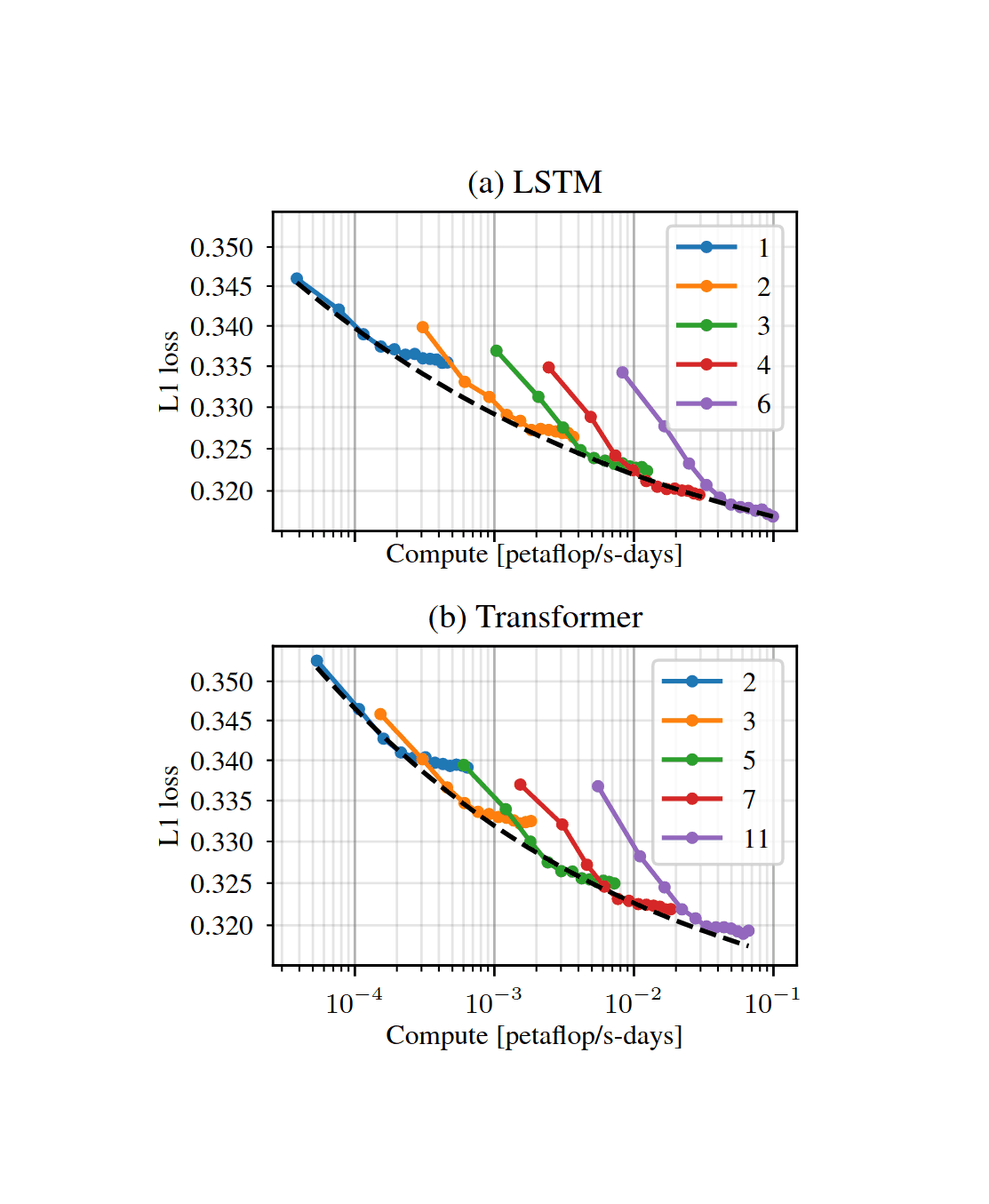{kind=link}
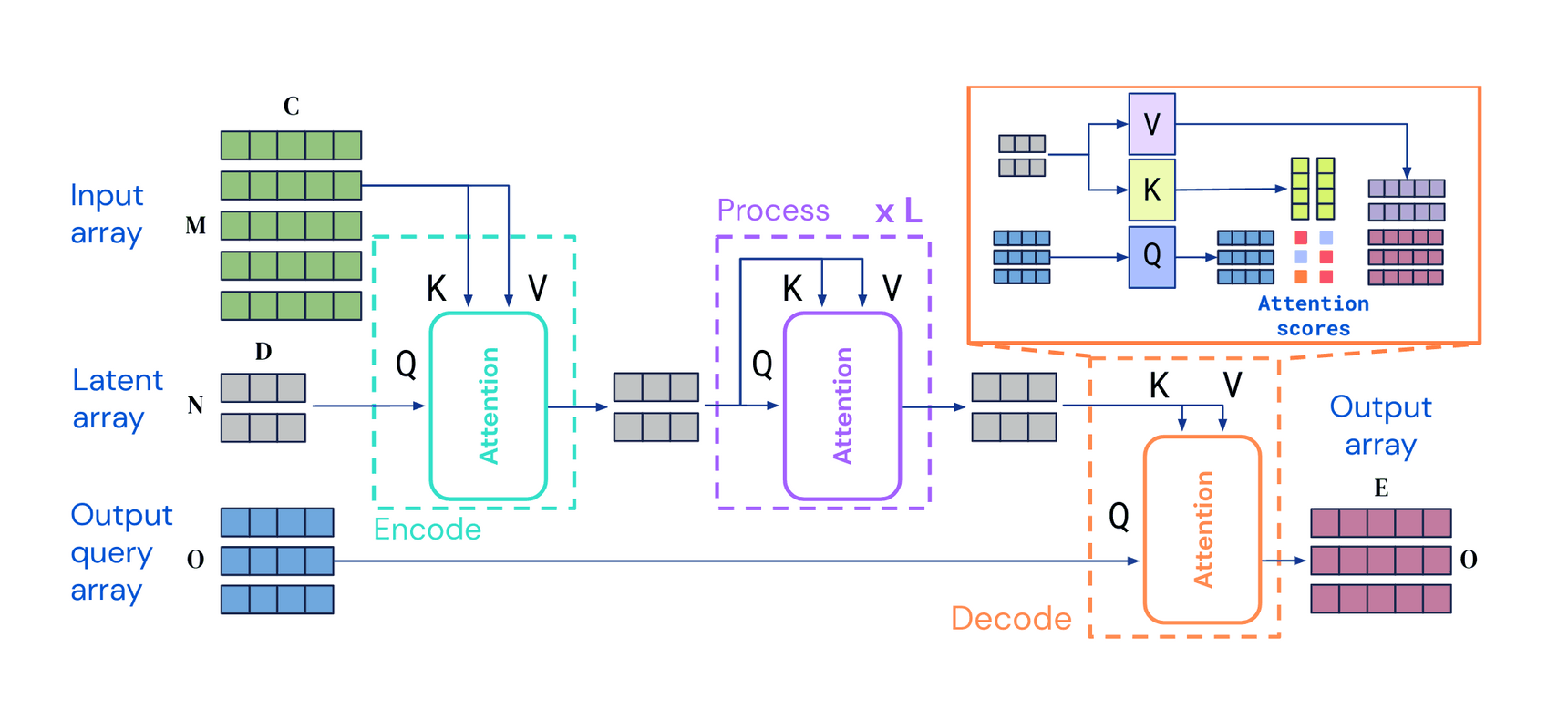{kind=link}
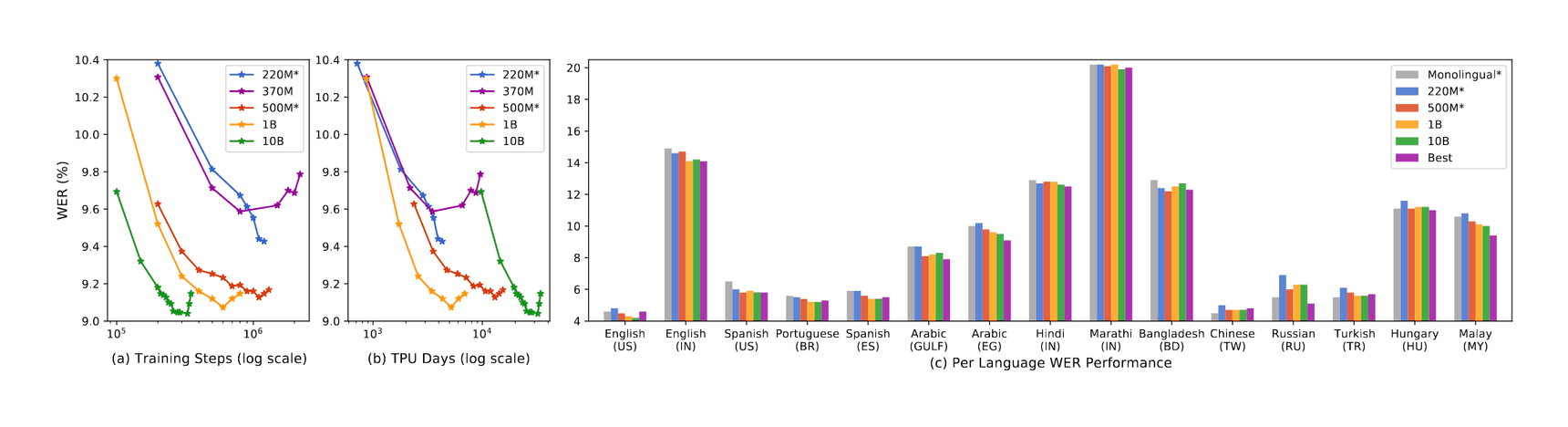{kind=link}
{kind=link}
{kind=link}
{kind=link}
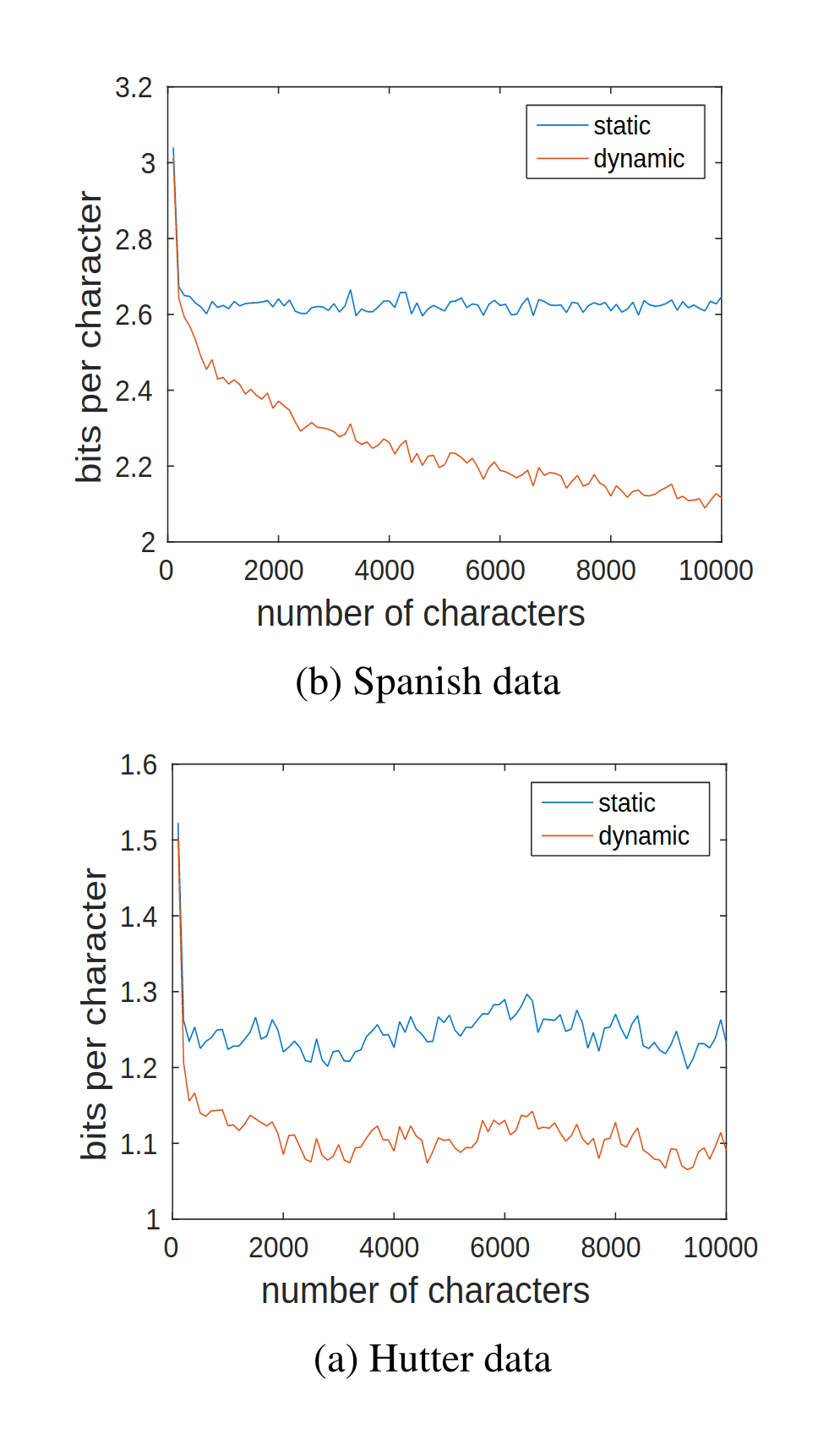{kind=link}
Bibliography
https://www.nature.com/articles/s41586-025-09761-x#deepmind: “DiscoRL: Discovering State-Of-The-Art Reinforcement Learning Algorithms”,https://arxiv.org/abs/2504.05298#nvidia: “One-Minute Video Generation With Test-Time Training”,https://arxiv.org/abs/2503.14456: “RWKV-7 ‘Goose’ With Expressive Dynamic State Evolution”,https://arxiv.org/abs/2412.07752: “FlashRNN: Optimizing Traditional RNNs on Modern Hardware”,https://arxiv.org/abs/2412.06464#nvidia: “Gated Delta Networks: Improving Mamba-2 With Delta Rule”,https://arxiv.org/abs/2410.01201: “Were RNNs All We Needed?”,https://arxiv.org/abs/2408.15237: “The Mamba in the Llama: Distilling and Accelerating Hybrid Models”,https://arxiv.org/abs/2406.07887: “An Empirical Study of Mamba-Based Language Models”,https://arxiv.org/abs/2406.06973: “RWKV-CLIP: A Robust Vision-Language Representation Learner”,https://arxiv.org/abs/2405.20233: “Grokfast: Accelerated Grokking by Amplifying Slow Gradients”,https://arxiv.org/abs/2404.08801#facebook: “Megalodon: Efficient LLM Pretraining and Inference With Unlimited Context Length”,https://arxiv.org/abs/2404.05971#eleutherai: “Does Transformer Interpretability Transfer to RNNs?”,https://arxiv.org/abs/2403.17844: “Mechanistic Design and Scaling of Hybrid Architectures”,https://arxiv.org/abs/2403.13802: “ZigMa: Zigzag Mamba Diffusion Model”,https://arxiv.org/abs/2312.04927: “Zoology: Measuring and Improving Recall in Efficient Language Models”,https://arxiv.org/abs/2312.00752: “Mamba: Linear-Time Sequence Modeling With Selective State Spaces”,https://www.nature.com/articles/s41467-023-42875-2#deepmind: “Learning Few-Shot Imitation As Cultural Transmission”,https://arxiv.org/abs/2310.02980: “Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors”,https://arxiv.org/abs/2306.00323: “Thought Cloning: Learning to Think While Acting by Imitating Human Thinking”,https://arxiv.org/abs/2305.13048: “RWKV: Reinventing RNNs for the Transformer Era”,https://arxiv.org/abs/2303.06349#deepmind: “Resurrecting Recurrent Neural Networks for Long Sequences”,https://arxiv.org/abs/2302.13939: “SpikeGPT: Generative Pre-Trained Language Model With Spiking Neural Networks”,2023-bures.pdf: “Organic Reaction Mechanism Classification Using Machine Learning”,https://arxiv.org/abs/2212.14052: “Hungry Hungry Hippos: Towards Language Modeling With State Space Models”,https://arxiv.org/abs/2212.10544: “Pretraining Without Attention”,https://arxiv.org/abs/2211.07638: “Legged Locomotion in Challenging Terrains Using Egocentric Vision”,https://arxiv.org/abs/2210.01117: “Omnigrok: Grokking Beyond Algorithmic Data”,https://arxiv.org/abs/2209.11737: “Semantic Scene Descriptions As an Objective of Human Vision”,https://arxiv.org/abs/2205.01972: “Sequencer: Deep LSTM for Image Classification”,2022-grand.pdf: “Semantic Projection Recovers Rich Human Knowledge of Multiple Object Features from Word Embeddings”,https://arxiv.org/abs/2203.07852: “Block-Recurrent Transformers”,https://arxiv.org/abs/2202.07765#deepmind: “General-Purpose, Long-Context Autoregressive Modeling With Perceiver AR”,2022-miki.pdf: “Learning Robust Perceptive Locomotion for Quadrupedal Robots in the Wild”,https://arxiv.org/abs/2111.00396: “S4: Efficiently Modeling Long Sequences With Structured State Spaces”,https://elifesciences.org/articles/66039: “A Connectome of the Drosophila Central Complex Reveals Network Motifs Suitable for Flexible Navigation and Context-Dependent Action Selection”,https://arxiv.org/abs/2107.14795#deepmind: “Perceiver IO: A General Architecture for Structured Inputs & Outputs”,https://proceedings.mlr.press/v139/vicol21a.html: “PES: Unbiased Gradient Estimation in Unrolled Computation Graphs With Persistent Evolution Strategies”,2021-delul.pdf: “Shelley: A Crowd-Sourced Collaborative Horror Writer”,2021-jouppi.pdf: “Ten Lessons From Three Generations Shaped Google’s TPUv4i”,https://arxiv.org/abs/2106.06981: “RASP: Thinking Like Transformers”,https://arxiv.org/abs/2103.03206#deepmind: “Perceiver: General Perception With Iterative Attention”,https://arxiv.org/abs/2102.04159: “Deep Residual Learning in Spiking Neural Networks”,https://arxiv.org/abs/2011.12692#tencent: “Towards Playing Full MOBA Games With Deep Reinforcement Learning”,https://arxiv.org/abs/2008.07669: “HiPPO: Recurrent Memory With Optimal Polynomial Projections”,https://www.lesswrong.com/posts/Wnqua6eQkewL3bqsF/matt-botvinick-on-the-spontaneous-emergence-of-learning: “Matt Botvinick on the Spontaneous Emergence of Learning Algorithms”,https://deepmind.google/discover/blog/agent57-outperforming-the-human-atari-benchmark/: “Agent57: Outperforming the Human Atari Benchmark”,https://arxiv.org/abs/2002.03629: “Accelerating Feedforward Computation via Parallel Nonlinear Equation Solving”,https://arxiv.org/abs/2001.08361#openai: “Scaling Laws for Neural Language Models”,https://arxiv.org/abs/1911.11423: “Single Headed Attention RNN: Stop Thinking With Your Head”,https://openreview.net/forum?id=HyxlRHBlUB: “Legendre Memory Units: Continuous-Time Representation in Recurrent Neural Networks”,https://arxiv.org/abs/1910.06591#deepmind: “SEED RL: Scalable and Efficient Deep-RL With Accelerated Central Inference”,https://arxiv.org/abs/1909.01792#deepmind: “Mogrifier LSTM”,https://paperswithcode.com/task/language-modelling: “Language Modeling State-Of-The-Art Leaderboards”,https://arxiv.org/abs/1906.08237: “XLNet: Generalized Autoregressive Pretraining for Language Understanding”,https://arxiv.org/abs/1905.01320#deepmind: “Meta-Learners’ Learning Dynamics Are unlike Learners’”,https://arxiv.org/abs/1901.02860: “Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context”,https://lilianweng.github.io/lil-log/2018/11/30/meta-learning.html#openai: “Meta-Learning: Learning to Learn Fast”,https://openreview.net/forum?id=r1lyTjAqYX#deepmind: “R2D2: Recurrent Experience Replay in Distributed Reinforcement Learning”,https://arxiv.org/abs/1807.03819#googledeepmind: “Universal Transformers”,https://arxiv.org/abs/1806.08730#salesforce: “The Natural Language Decathlon: Multitask Learning As Question Answering”,https://arxiv.org/abs/1801.06146: “ULMFiT: Universal Language Model Fine-Tuning for Text Classification”,https://smerity.com/articles/2018/limited_compute.html: “The Compute and Data Moats Are Dead”,https://arxiv.org/abs/1709.07432: “Dynamic Evaluation of Neural Sequence Models”,https://arxiv.org/abs/1709.02755: “SRU: Simple Recurrent Units for Highly Parallelizable Recurrence”,https://arxiv.org/abs/1704.05179: “SearchQA: A New Q&A Dataset Augmented With Context from a Search Engine”,https://arxiv.org/abs/1704.05526: “Learning to Reason: End-To-End Module Networks for Visual Question Answering”,https://arxiv.org/abs/1609.09106#google: “HyperNetworks”,https://arxiv.org/abs/1608.03609: “Clockwork Convnets for Video Semantic Segmentation”,https://arxiv.org/abs/1512.02595#baidu: “Deep Speech 2: End-To-End Speech Recognition in English and Mandarin”,https://arxiv.org/abs/1503.08895: “End-To-End Memory Networks”,2012-mikolov.pdf: “Context Dependent Recurrent Neural Network Language Model”,2010-mikolov.pdf: “Recurrent Neural Network Based Language Model”,1991-hochreiter.pdf: “Untersuchungen Zu Dynamischen Neuronalen Netzen [Studies of Dynamic Neural Networks]”,1989-williams.pdf: “Experimental Analysis of the Real-Time Recurrent Learning Algorithm”,1988-werbos.pdf: “Generalization of Backpropagation With Application to a Recurrent Gas Market Model”,1987-pineda.pdf: “Generalization of Back-Propagation to Recurrent Neural Networks”,