‘sparse Transformer’ directory
- See Also
- Links
- “TurboDiffusion: Accelerating Video Diffusion Models by 100–200 Times”, Zhang et al 2025
- “DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models”, DeepSeek et al 2025
- “Native Sparse Attention (NSA): Hardware-Aligned and Natively Trainable Sparse Attention”, Yuan et al 2025
- “What Makes a Good Feedforward Computational Graph?”, Vitvitskyi et al 2025
- “Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference”, Warner et al 2024
- “When Parts Are Greater Than Sums: Individual LLM Components Can Outperform Full Models”, Chang et al 2024
- “AI Is a Black Box. Anthropic Figured Out a Way to Look Inside: What Goes on in Artificial Neural Networks Work Is Largely a Mystery, Even to Their Creators. But Researchers from Anthropic Have Caught a Glimpse”, Levy 2024
- “DeepSeek-V2: A Strong, Economical, and Efficient Mixture-Of-Experts Language Model”, DeepSeek et al 2024
- “Revisiting the Equivalence of In-Context Learning and Gradient Descent: The Impact of Data Distribution”, Mahdavi et al 2024
- “Zoology: Measuring and Improving Recall in Efficient Language Models”, Arora et al 2023
- “HyperAttention: Long-Context Attention in Near-Linear Time”, Han et al 2023
- “LongLoRA: Efficient Fine-Tuning of Long-Context Large Language Models”, Chen et al 2023
- “H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models”, Zhang et al 2023
- “Unlimiformer: Long-Range Transformers With Unlimited Length Input”, Bertsch et al 2023
- “How Much Does Attention Actually Attend? Questioning the Importance of Attention in Pretrained Transformers”, Hassid et al 2022
- “Scaling Laws vs Model Architectures: How Does Inductive Bias Influence Scaling?”, Tay et al 2022
- “Random Feature Attention”, Peng et al 2022
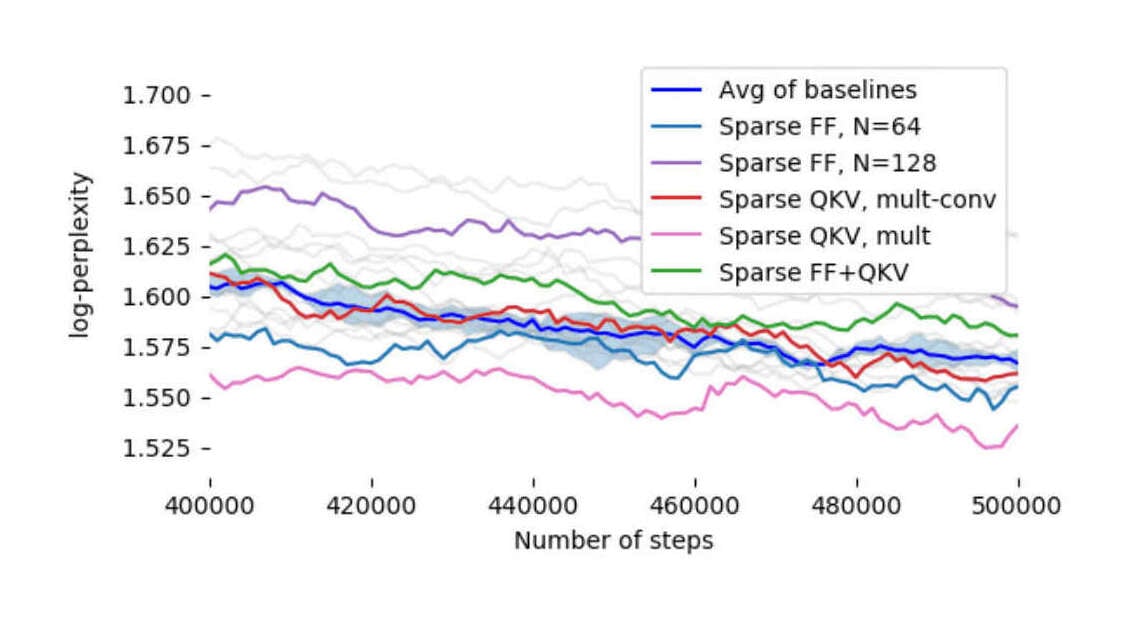
- “Scaling Transformers: Sparse Is Enough in Scaling Transformers”, Jaszczur et al 2021
- “You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling”, Zeng et al 2021
- “Scatterbrain: Unifying Sparse and Low-Rank Attention Approximation”, Chen et al 2021
- “Combiner: Full Attention Transformer With Sparse Computation Cost”, Ren et al 2021
- “OmniNet: Omnidirectional Representations from Transformers”, Tay et al 2021
- “Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention”, Xiong et al 2021
- “Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting”, Zhou et al 2020
- “SMYRF: Efficient Attention Using Asymmetric Clustering”, Daras et al 2020
- “FAVOR+: Rethinking Attention With Performers”, Choromanski et al 2020
- “Cluster-Former: Clustering-Based Sparse Transformer for Long-Range Dependency Encoding”, Wang et al 2020
- “DeepSpeed Sparse Attention”, Team 2020
- “BigBird: Transformers for Longer Sequences”, Zaheer et al 2020
- “Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation”, Wang et al 2020
- “Efficient Content-Based Sparse Attention With Routing Transformers”, Roy et al 2020
- “Sparse Sinkhorn Attention”, Tay et al 2020
- “Reformer: The Efficient Transformer”, Kitaev et al 2020
- “The Reformer—Pushing the Limits of Language Modeling”, Platen 2020
- “Axial Attention in Multidimensional Transformers”, Ho et al 2019
- “Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting”, Li et al 2019
- “Scaling Autoregressive Video Models”, Weissenborn et al 2019
- “Adaptive Attention Span in Transformers”, Sukhbaatar et al 2019
- “Generating Long Sequences With Sparse Transformers”, Child et al 2019
- “Generative Modeling With Sparse Transformers: We’ve Developed the Sparse Transformer, a Deep Neural Network Which Sets New Records at Predicting What Comes next in a Sequence—Whether Text, Images, or Sound. It Uses an Algorithmic Improvement of the attention Mechanism to Extract Patterns from Sequences 30× Longer Than Possible Previously”, Child & Gray 2019
- “Star-Transformer”, Guo et al 2019
- “CCNet: Criss-Cross Attention for Semantic Segmentation”, Huang et al 2018
- “Image Transformer”, Parmar et al 2018
- “Finally, a Replacement for BERT: Introducing ModernBERT”
- “On MLA”
- “Constructing Transformers For Longer Sequences With Sparse Attention Methods”
- “A Deep Dive into the Reformer”
- “Optimal Transport and the Sinkhorn Transformer”
- Sort By Magic
- Miscellaneous
- Bibliography
See Also
Links
“TurboDiffusion: Accelerating Video Diffusion Models by 100–200 Times”, Zhang et al 2025
TurboDiffusion: Accelerating Video Diffusion Models by 100–200 Times
“DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models”, DeepSeek et al 2025
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
“Native Sparse Attention (NSA): Hardware-Aligned and Natively Trainable Sparse Attention”, Yuan et al 2025
Native Sparse Attention (NSA): Hardware-Aligned and Natively Trainable Sparse Attention
“What Makes a Good Feedforward Computational Graph?”, Vitvitskyi et al 2025
“Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference”, Warner et al 2024
“When Parts Are Greater Than Sums: Individual LLM Components Can Outperform Full Models”, Chang et al 2024
When Parts are Greater Than Sums: Individual LLM Components Can Outperform Full Models
“AI Is a Black Box. Anthropic Figured Out a Way to Look Inside: What Goes on in Artificial Neural Networks Work Is Largely a Mystery, Even to Their Creators. But Researchers from Anthropic Have Caught a Glimpse”, Levy 2024
“DeepSeek-V2: A Strong, Economical, and Efficient Mixture-Of-Experts Language Model”, DeepSeek et al 2024
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
“Revisiting the Equivalence of In-Context Learning and Gradient Descent: The Impact of Data Distribution”, Mahdavi et al 2024
“Zoology: Measuring and Improving Recall in Efficient Language Models”, Arora et al 2023
Zoology: Measuring and Improving Recall in Efficient Language Models
“HyperAttention: Long-Context Attention in Near-Linear Time”, Han et al 2023
“LongLoRA: Efficient Fine-Tuning of Long-Context Large Language Models”, Chen et al 2023
LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models
“H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models”, Zhang et al 2023
H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
“Unlimiformer: Long-Range Transformers With Unlimited Length Input”, Bertsch et al 2023
Unlimiformer: Long-Range Transformers with Unlimited Length Input
“How Much Does Attention Actually Attend? Questioning the Importance of Attention in Pretrained Transformers”, Hassid et al 2022
“Scaling Laws vs Model Architectures: How Does Inductive Bias Influence Scaling?”, Tay et al 2022
Scaling Laws vs Model Architectures: How does Inductive Bias Influence Scaling?
“Random Feature Attention”, Peng et al 2022
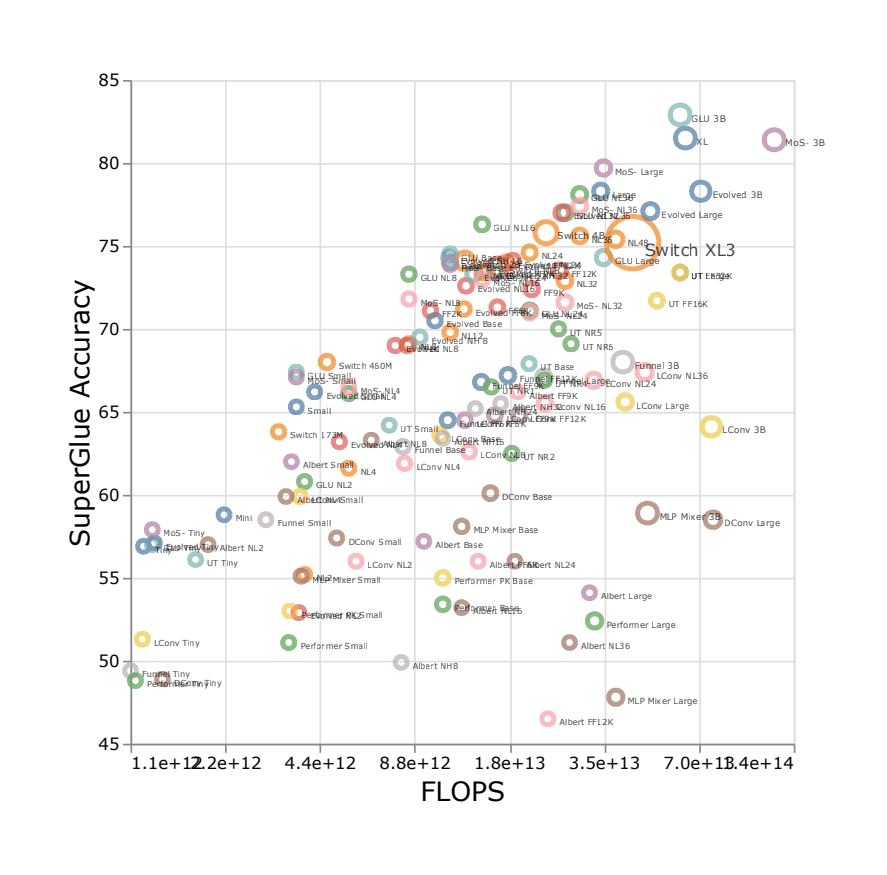
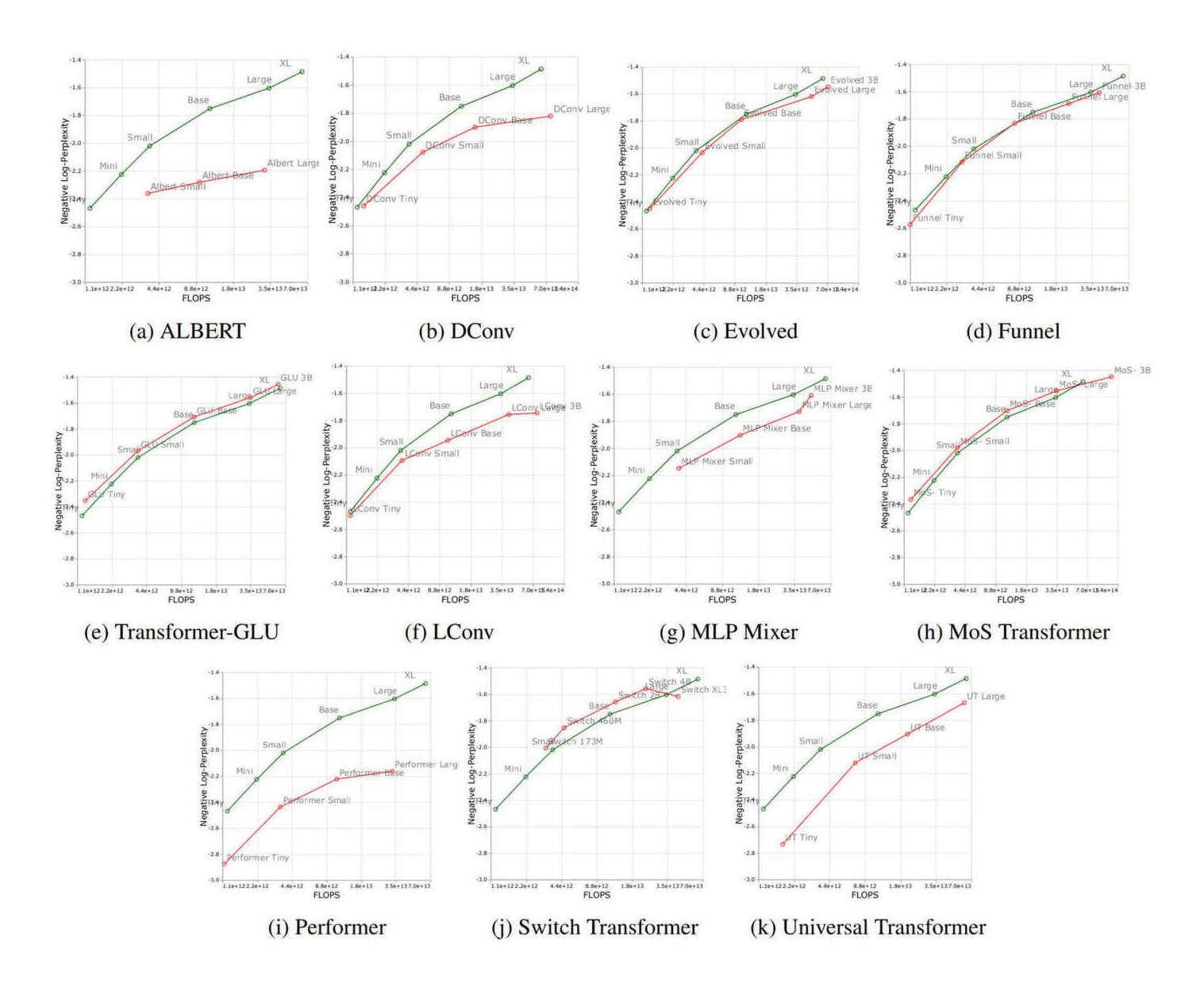
“Scaling Transformers: Sparse Is Enough in Scaling Transformers”, Jaszczur et al 2021
Scaling Transformers: Sparse is Enough in Scaling Transformers
“You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling”, Zeng et al 2021
You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling
“Scatterbrain: Unifying Sparse and Low-Rank Attention Approximation”, Chen et al 2021
Scatterbrain: Unifying Sparse and Low-rank Attention Approximation
“Combiner: Full Attention Transformer With Sparse Computation Cost”, Ren et al 2021
Combiner: Full Attention Transformer with Sparse Computation Cost
“OmniNet: Omnidirectional Representations from Transformers”, Tay et al 2021
“Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention”, Xiong et al 2021
Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention
“Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting”, Zhou et al 2020
Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
“SMYRF: Efficient Attention Using Asymmetric Clustering”, Daras et al 2020
“FAVOR+: Rethinking Attention With Performers”, Choromanski et al 2020
“Cluster-Former: Clustering-Based Sparse Transformer for Long-Range Dependency Encoding”, Wang et al 2020
Cluster-Former: Clustering-based Sparse Transformer for Long-Range Dependency Encoding
“DeepSpeed Sparse Attention”, Team 2020
“BigBird: Transformers for Longer Sequences”, Zaheer et al 2020
“Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation”, Wang et al 2020
Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation
“Efficient Content-Based Sparse Attention With Routing Transformers”, Roy et al 2020
Efficient Content-Based Sparse Attention with Routing Transformers
“Sparse Sinkhorn Attention”, Tay et al 2020
“Reformer: The Efficient Transformer”, Kitaev et al 2020
“The Reformer—Pushing the Limits of Language Modeling”, Platen 2020
“Axial Attention in Multidimensional Transformers”, Ho et al 2019
“Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting”, Li et al 2019
Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting
“Scaling Autoregressive Video Models”, Weissenborn et al 2019
“Adaptive Attention Span in Transformers”, Sukhbaatar et al 2019
“Generating Long Sequences With Sparse Transformers”, Child et al 2019
“Generative Modeling With Sparse Transformers: We’ve Developed the Sparse Transformer, a Deep Neural Network Which Sets New Records at Predicting What Comes next in a Sequence—Whether Text, Images, or Sound. It Uses an Algorithmic Improvement of the attention Mechanism to Extract Patterns from Sequences 30× Longer Than Possible Previously”, Child & Gray 2019
“Star-Transformer”, Guo et al 2019
“CCNet: Criss-Cross Attention for Semantic Segmentation”, Huang et al 2018
“Image Transformer”, Parmar et al 2018
“Finally, a Replacement for BERT: Introducing ModernBERT”
“On MLA”
“Constructing Transformers For Longer Sequences With Sparse Attention Methods”
Constructing Transformers For Longer Sequences with Sparse Attention Methods
“A Deep Dive into the Reformer”
“Optimal Transport and the Sinkhorn Transformer”
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
model-insight graph-analysis interpretability algorithm-trace neural-exploration model-clarity
turbo-models
long-context-optimization
component-performance
sparse-attention
Miscellaneous
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2512.02556#deepseek: “DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models”,https://arxiv.org/abs/2406.13131: “When Parts Are Greater Than Sums: Individual LLM Components Can Outperform Full Models”,https://www.wired.com/story/anthropic-black-box-ai-research-neurons-features/: “AI Is a Black Box. Anthropic Figured Out a Way to Look Inside: What Goes on in Artificial Neural Networks Work Is Largely a Mystery, Even to Their Creators. But Researchers from Anthropic Have Caught a Glimpse”,https://ieeexplore.ieee.org/abstract/document/10446522: “Revisiting the Equivalence of In-Context Learning and Gradient Descent: The Impact of Data Distribution”,https://arxiv.org/abs/2312.04927: “Zoology: Measuring and Improving Recall in Efficient Language Models”,https://arxiv.org/abs/2306.14048: “H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models”,https://arxiv.org/abs/2305.01625: “Unlimiformer: Long-Range Transformers With Unlimited Length Input”,https://arxiv.org/abs/2211.03495: “How Much Does Attention Actually Attend? Questioning the Importance of Attention in Pretrained Transformers”,https://arxiv.org/abs/2207.10551#google: “Scaling Laws vs Model Architectures: How Does Inductive Bias Influence Scaling?”,https://arxiv.org/abs/2111.12763#google: “Scaling Transformers: Sparse Is Enough in Scaling Transformers”,https://arxiv.org/abs/2111.09714: “You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling”,https://arxiv.org/abs/2110.15343#facebook: “Scatterbrain: Unifying Sparse and Low-Rank Attention Approximation”,https://arxiv.org/abs/2103.01075#google: “OmniNet: Omnidirectional Representations from Transformers”,https://arxiv.org/abs/2102.03902: “Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention”,https://arxiv.org/abs/2010.05315: “SMYRF: Efficient Attention Using Asymmetric Clustering”,https://arxiv.org/abs/2009.14794#google: “FAVOR+: Rethinking Attention With Performers”,https://arxiv.org/abs/2003.07853#google: “Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation”,https://arxiv.org/abs/2003.05997#google: “Efficient Content-Based Sparse Attention With Routing Transformers”,https://arxiv.org/abs/2001.04451#google: “Reformer: The Efficient Transformer”,https://arxiv.org/abs/1811.11721: “CCNet: Criss-Cross Attention for Semantic Segmentation”,