‘GPT’ directory
- See Also
- Gwern
- “Guardian Angels: LLM Personalization for Productivity and Security”, Gwern 2025
- “Better Fiction via Retcon Planning”, Gwern 2026
- “Go-Speech Specification”, Pro et al 2026
- “Grow-Speech Specification”, Gwern et al 2026
- “I’d Show All My Online Friends, but I Now Worry They Wouldn’t Get It”, Gwern 2026
- “Meta-Learning Information-Maximizing Personality Surveys”, Gwern 2024
- “Quantifying Truesight With SAEs”, Gwern 2025
- “GPT-3 Semantic Derealization”, Gwern 2024
- “Research Ideas”, Gwern 2017
- “You Should Write More Online”, Gwern 2024
- Links
- industriaalist @ "2026-06-04"
- “Q0: Primitives for Hyper-Epoch Pretraining”, Mandal et al 2026
- “Laying It on Thick [Increasing LLM-Powered Spearphishing/spam Cold Emails]”, Sloan 2026
- LinchZhang @ "2026-05-09"
- “MegaTrain: Full Precision Training of 100B+ Parameter Large Language Models on a Single GPU”, Yuan et al 2026
- “2026: The Year of Throwing My Agency at My Health (Now With Added Cyborgism)”, ruby 2026
- “Strategic Navigation or Stochastic Search? How Agents and Humans Reason Over Document Collections”, Borchmann et al 2026
- “Charlatan Labyrinth [Constrained Writing: Non-Proto-Indo-European]”, niplav 2026
- “An AI Agent Published a Hit Piece on Me”, Shambaugh 2026
- “Doc-To-LoRA (D2L): Learning to Instantly Internalize Contexts”, Charakorn et al 2026
- “Generative AI and Wikipedia Editing: What We Learned in 2025”, Edu 2026
- “Giving University Exams in the Age of Chatbots”, Dricot 2026
- “Debunking the AI Food Delivery Hoax That Fooled Reddit: A ‘Whistleblower’ Tried to Corroborate His Viral Post With AI-Generated Evidence. This Is How I Caught Him”, Newton 2026
- “Large Language Models and the Entropy of English”, Scheibner et al 2025
- “Shared Sensitivity to Data Distribution during Learning in Humans and Transformer Networks”, Lerousseau & Summerfield 2025
- “Scientific Production in the Era of Large Language Models: With the Production Process Rapidly Evolving, Science Policy Must Consider How Institutions Could Evolve”, Kusumegi et al 2025
- “AI Will Kill All the Lawyers: A Barrister’s Warning”, Thomas 2025
- “EGGROLL: Evolution Strategies at the Hyperscale”, Sarkar et al 2025
- “Superhuman AI for Stratego Using Self-Play Reinforcement Learning and Test-Time Search”, Sokota et al 2025
- “Blackbox Model Provenance via Palimpsestic Membership Inference”, Kuditipudi et al 2025
- “LLMs Can Hide Text in Other Text of the Same Length”, Norelli & Bronstein 2025
- “Scaling Recommender Transformers to a Billion Parameters: How to Implement a New Generation of Transformer Recommenders”, Кhrylchenko 2025
- “The Dark Arts of Tokenization Or: How I Learned to Start Worrying and Love LLMs’ Undecoded Outputs”, Lovre 2025
- “EditLens: Quantifying the Extent of AI Editing in Text”, Thai et al 2025
- “PipelineRL: Faster On-Policy Reinforcement Learning for Long Sequence Generation”, Piché et al 2025
- “How Kimi K2 RL’ed Qualitative Data to Write Better”, Breunig 2025
- “Scaling Recommender Transformers to One Billion Parameters”, Khrylchenko et al 2025
- “Intra: Design Notes on an LLM-Driven Text Adventure”, Bicking 2025
- “Finding Palindromes With Language Models”, Nichol 2025
- “Your Brain on ChatGPT: Accumulation of Cognitive Debt When Using an AI Assistant for Essay Writing Task”, Kosmyna et al 2025
- “Inference Economics of Language Models”, Erdil 2025
- “Pitfalls in Evaluating Language Model Forecasters”, Paleka et al 2025
- “DataRater: Meta-Learned Dataset Curation”, Calian et al 2025
- “Creative Preference Optimization”, Ismayilzada et al 2025
- “Generating the Funniest Joke With RL (According to GPT-4.1)”, agg 2025
- “Emergent Social Conventions and Collective Bias in LLM Populations”, Ashery et al 2025
- “LLMs Get Lost In Multi-Turn Conversation”, Laban et al 2025
- “Generating Physically Stable and Buildable LEGO Designs from Text”, Pun et al 2025
- “LegoGPT: Generating Physically Stable and Buildable LEGO Designs from Text”, Pun et al 2025
- “LegoGPT: Official Repository for LegoGPT, the First Approach for Generating Physically Stable LEGO Brick Models from Text Prompts”, Pun et al 2025
- “Clippy Desktop Assistant”, Rieseberg 2025
- “New News: System-2 Fine-Tuning for Robust Integration of New Knowledge”, Park et al 2025
- “On the Generalization of Language Models from In-Context Learning and Finetuning: a Controlled Study”, Lampinen et al 2025
- “Will the Humanities Survive Artificial Intelligence? Maybe Not As We’ve Known Them. But, in the Ruins of the Old Curriculum, Something Vital Is Stirring”, Burnett 2025
- “[Using Perplexity to Find New Books by Authors You Like]”, Ingebrigtsen 2025
- “Cathoven: Enhancing Language Acquisition through Tailored Input and Targeted Output Feedback”, Hong & Lin 2025
- “Tapered Off-Policy REINFORCE: Stable and Efficient Reinforcement Learning for LLMs”, Roux et al 2025
- “SuperBPE: Space Travel for Language Models”, Liu et al 2025
- “Muon Is Scalable for LLM Training [Moonlight]”, Liu et al 2025
- “AgentSociety: Large-Scale Simulation of LLM-Driven Generative Agents Advances Understanding of Human Behaviors and Society”, Piao et al 2025
- “SmolLM2: When Smol Goes Big—Data-Centric Training of a Small Language Model”, Allal et al 2025
- “The Surprising Agreement Between Convex Optimization Theory and Learning-Rate Scheduling for Large Model Training”, Schaipp et al 2025
- “Decoding-Based Regression”, Song & Bahri 2025
- “Diverse Preference Optimization”, Lanchantin et al 2025
- “Complete Chess Games Enable LLM Become A Chess Master”, Zhang et al 2025
- “Multiagent Finetuning: Self Improvement With Diverse Reasoning Chains”, Subramaniam et al 2025
- “Metadata Conditioning Accelerates Language Model Pre-Training”, Gao et al 2025
- “How AI Is Unlocking Ancient Texts: From Deciphering Burnt Roman Scrolls to Reading Crumbling Cuneiform Tablets, Neural Networks Could Give Researchers More Data Than They’ve Had in Centuries”, Marchant 2024
- “Genomic Foundation-Less Models: Pretraining Does Not Promise Performance”, Vishniakov et al 2024
- “Proposing and Solving Olympiad Geometry With Guided Tree Search”, Zhang et al 2024
- “Continuous Autoregressive Models With Noise Augmentation Avoid Error Accumulation”, Pasini et al 2024
- “Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?”, Yang et al 2024
- “2:4 Sparse Llama: Smaller Models for Efficient GPU Inference”, Kurtić et al 2024
- “The Surprising Effectiveness of Test-Time Training for Few-Shot Learning”, Akyürek et al 2024
- “Medical Adaptation of Large Language and Vision-Language Models: Are We Making Progress?”, Jeong et al 2024
- “Fractal Patterns May Illuminate the Success of Next-Token Prediction”, Alabdulmohsin et al 2024
- “Arithmetic Without Algorithms: Language Models Solve Math With a Bag of Heuristics”, Nikankin et al 2024
- “The Dark Side of AI Companionship: A Taxonomy of Harmful Algorithmic Behaviors in Human-AI Relationships”, Zhang et al 2024
- “Model Equality Testing: Which Model Is This API Serving?”, Gao et al 2024
- “Centaur: a Foundation Model of Human Cognition”, Binz et al 2024
- “Do LLMs Estimate Uncertainty Well in Instruction-Following?”, Heo et al 2024
- “Bilinear MLPs Enable Weight-Based Mechanistic Interpretability”, Pearce et al 2024
- “Interpretable Contrastive Monte Carlo Tree Search Reasoning”, Gao et al 2024
- “NGPT: Normalized Transformer With Representation Learning on the Hypersphere”, Loshchilov et al 2024
- “Llama 3.2: Revolutionizing Edge AI and Vision With Open, Customizable Models”, Facebook 2024
- “FineZip: Pushing the Limits of Large Language Models for Practical Lossless Text Compression”, Mittu et al 2024
- “LLM Applications I Want To See”, Constantin 2024
- “Ensemble Everything Everywhere: Multi-Scale Aggregation for Adversarial Robustness”, Fort & Lakshminarayanan 2024
- “Scaling Laws With Vocabulary: Larger Models Deserve Larger Vocabularies”, Tao et al 2024
- “Token Erasure As a Footprint of Implicit Vocabulary Items in LLMs”, Feucht et al 2024
- “Resolving Discrepancies in Compute-Optimal Scaling of Language Models”, Porian et al 2024
- “When Parts Are Greater Than Sums: Individual LLM Components Can Outperform Full Models”, Chang et al 2024
- “Nemotron-4 340B Technical Report”, Adler et al 2024
- “DataComp-LM: In Search of the next Generation of Training Sets for Language Models”, Li et al 2024
- “How Do Large Language Models Acquire Factual Knowledge During Pretraining?”, Chang et al 2024
- “Be like a Goldfish, Don’t Memorize! Mitigating Memorization in Generative LLMs”, Hans et al 2024
- “Discovering Preference Optimization Algorithms With and for Large Language Models”, Lu et al 2024
- “MCTSr: Accessing GPT-4 Level Mathematical Olympiad Solutions via Monte Carlo Tree Self-Refine With LLaMA-3-8B”, Zhang et al 2024
- “For Chinese Students, the New Tactic Against AI Checks: More AI”, Qitong 2024
- “MAP-Neo: Highly Capable and Transparent Bilingual Large Language Model Series”, Zhang et al 2024
- “Superposed Decoding: Multiple Generations from a Single Autoregressive Inference Pass”, Shen et al 2024
- “Transformers Can Do Arithmetic With the Right Embeddings”, McLeish et al 2024
- “Uncheatable_eval: Evaluating LLMs With Dynamic Data”, Jellyfish042 2024
- “Better & Faster Large Language Models via Multi-Token Prediction”, Gloeckle et al 2024
- “SpaceByte: Towards Deleting Tokenization from Large Language Modeling”, Slagle 2024
- “Towards Smaller, Faster Decoder-Only Transformers: Architectural Variants and Their Implications”, Suresh & P 2024
- “Design of Highly Functional Genome Editors by Modeling the Universe of CRISPR-Cas Sequences”, Ruffolo et al 2024
- “From r to Q✱: Your Language Model Is Secretly a Q-Function”, Rafailov et al 2024
- “CATS: Contextually-Aware Thresholding for Sparsity in Large Language Models”, Lee et al 2024
- “CulturalTeaming: AI-Assisted Interactive Red-Teaming for Challenging LLMs’ (Lack Of) Multicultural Knowledge”, Chiu et al 2024
- “Training LLMs over Neurally Compressed Text”, Lester et al 2024
- “Reverse Training to Nurse the Reversal Curse”, Golovneva et al 2024
- “3 Reasons Why AI Doesn’t Model Human Language”, Bolhuis et al 2024
- “Evolutionary Optimization of Model Merging Recipes”, Akiba et al 2024
- “Yi: Open Foundation Models by 01.AI”, Young et al 2024
- “Inflection-2.5: Meet the World’s Best Personal AI”, Inflection 2024
- “Actions Speak Louder Than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations (HSTU)”, Zhai et al 2024
- “Fast Adversarial Attacks on Language Models In One GPU Minute”, Sadasivan et al 2024
- “Assisting in Writing Wikipedia-Like Articles From Scratch With Large Language Models”, Shao et al 2024
- “Autonomous Data Selection With Language Models for Mathematical Texts”, Zhang et al 2024
- “Grandmaster-Level Chess Without Search”, Ruoss et al 2024
- “Neural Networks Learn Statistics of Increasing Complexity”, Belrose et al 2024
- “Verifiable Evaluations of Machine Learning Models Using ZkSNARKs”, South et al 2024
- “Arrows of Time for Large Language Models”, Papadopoulos et al 2024
- “LLaVA-NeXT: Improved Reasoning, OCR, and World Knowledge”
- “SliceGPT: Compress Large Language Models by Deleting Rows and Columns”, Ashkboos et al 2024
- “Excuse Me, Sir? Your Language Model Is Leaking (Information)”, Zamir 2024
- “TinyLlama: An Open-Source Small Language Model”, Zhang et al 2024
- “LLaMA Pro: Progressive LLaMA With Block Expansion”, Wu et al 2024
- “Generative AI Is Already Widespread in the Public Sector”, Bright et al 2024
- “Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws”, Sardana & Frankle 2023
- “TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones”, Yuan et al 2023
- “Reasons to Reject? Aligning Language Models With Judgments”, Xu et al 2023
- “InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks”, Chen et al 2023
- “Generative Multimodal Models Are In-Context Learners”, Sun et al 2023
- “CogAgent: A Visual Language Model for GUI Agents”, Hong et al 2023
- “LLM in a Flash: Efficient Large Language Model Inference With Limited Memory”, Alizadeh et al 2023
- “Frugal LMs Trained to Invoke Symbolic Solvers Achieve Parameter-Efficient Arithmetic Reasoning”, Dutta et al 2023
- “Object Recognition As Next Token Prediction”, Yue et al 2023
- “The Falcon Series of Open Language Models”, Almazrouei et al 2023
- “MEDITRON-70B: Scaling Medical Pretraining for Large Language Models”, Chen et al 2023
- “Localizing Lying in Llama: Understanding Instructed Dishonesty on True-False Questions Through Prompting, Probing, and Patching”, Campbell et al 2023
- “Positional Description Matters for Transformers Arithmetic”, Shen et al 2023
- “OpenAI Researchers Warned Board of AI Breakthrough ahead of CEO Ouster, Sources Say”, Tong et al 2023
- “Watermarks in the Sand: Impossibility of Strong Watermarking for Generative Models”, Zhang et al 2023
- “Tensor Trust: Interpretable Prompt Injection Attacks from an Online Game”, Toyer et al 2023
- “Implicit Meta-Learning May Lead Language Models to Trust More Reliable Sources”, Krasheninnikov et al 2023
- “Learn Your Tokens: Word-Pooled Tokenization for Language Modeling”, Thawani et al 2023
- “Llemma: An Open Language Model For Mathematics”, Azerbayev et al 2023
- “In-Context Pretraining (ICP): Language Modeling Beyond Document Boundaries”, Shi et al 2023
- “OSD: Online Speculative Decoding”, Liu et al 2023
- “Let Models Speak Ciphers: Multiagent Debate through Embeddings”, Pham et al 2023
- “OpenWebMath: An Open Dataset of High-Quality Mathematical Web Text”, Paster et al 2023
- “XVal: A Continuous Number Encoding for Large Language Models”, Golkar et al 2023
- “MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models”, Yu et al 2023
- “Language Modeling Is Compression”, Delétang et al 2023
- “Sparse Autoencoders Find Highly Interpretable Features in Language Models”, Cunningham et al 2023
- “Anchor Points: Benchmarking Models With Much Fewer Examples”, Vivek et al 2023
- “When Less Is More: Investigating Data Pruning for Pretraining LLMs at Scale”, Marion et al 2023
- “Language Reward Modulation for Pretraining Reinforcement Learning”, Adeniji et al 2023
- “ReST: Reinforced Self-Training (ReST) for Language Modeling”, Gulcehre et al 2023
- “Studying Large Language Model Generalization With Influence Functions”, Grosse et al 2023
- “Multimodal Neurons in Pretrained Text-Only Transformers”, Schwettmann et al 2023
- “Skill-It! A Data-Driven Skills Framework for Understanding and Training Language Models”, Chen et al 2023
- “LLMZip: Lossless Text Compression Using Large Language Models”, Valmeekam et al 2023
- “Length Generalization in Arithmetic Transformers”, Jelassi et al 2023
- “Are Aligned Neural Networks Adversarially Aligned?”, Carlini et al 2023
- “Inflection-1: Pi’s Best-In-Class LLM”, Inflection 2023
- “Improving Long-Horizon Imitation Through Instruction Prediction”, Hejna et al 2023
- “Large Language Models Sometimes Generate Purely Negatively-Reinforced Text”, Roger 2023
- “SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression”, Dettmers et al 2023
- “Undetectable Watermarks for Language Models”, Christ et al 2023
- “Improving Language Models With Advantage-Based Offline Policy Gradients”, Baheti et al 2023
- “Reasoning With Language Model Is Planning With World Model”, Hao et al 2023
- “Accelerating Transformer Inference for Translation via Parallel Decoding”, Santilli et al 2023
- “DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining”, Xie et al 2023
- “Memorization for Good: Encryption With Autoregressive Language Models”, Stevens & Su 2023
- “MEGABYTE: Predicting Million-Byte Sequences With Multiscale Transformers”, Yu et al 2023
- “Finding Neurons in a Haystack: Case Studies With Sparse Probing”, Gurnee et al 2023
- “Inflection AI, Startup From Ex-DeepMind Leaders, Launches Pi—A Chattier Chatbot”, Konrad 2023
- “Emergent and Predictable Memorization in Large Language Models”, Biderman et al 2023
- “A Comparative Study between Full-Parameter and LoRA-Based Fine-Tuning on Chinese Instruction Data for Instruction Following Large Language Model”, Sun et al 2023
- “Shall We Pretrain Autoregressive Language Models With Retrieval? A Comprehensive Study”, Wang et al 2023
- “How Large-Language Models Can Revolutionize Military Planning”, Jensen & Tadross 2023
- “Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling”, Biderman et al 2023
- “8 Things to Know about Large Language Models”, Bowman 2023
- “BloombergGPT: A Large Language Model for Finance”, Wu et al 2023
- “The Quantization Model of Neural Scaling”, Michaud et al 2023
- “Int-4 LLaMa Is Not Enough—Int-3 and Beyond: More Compression, Easier to Build Apps on LLMs That Run Locally”, nolano.org 2023
- “Consistency Analysis of ChatGPT”, Jang & Lukasiewicz 2023
- “Rewarding Chatbots for Real-World Engagement With Millions of Users”, Irvine et al 2023
- “Beyond the Pass Mark: the Accuracy of ChatGPT and Bing in the National Medical Licensure Examination in Japan”, Kataoka 2023
- “SpikeGPT: Generative Pre-Trained Language Model With Spiking Neural Networks”, Zhu et al 2023
- “A Prompt Pattern Catalog to Enhance Prompt Engineering With ChatGPT”, White et al 2023
- “BiLD: Big Little Transformer Decoder”, Kim et al 2023
- “ChatGPT Is a Blurry JPEG of the Web: OpenAI’s Chatbot Offers Paraphrases, Whereas Google Offers Quotes. Which Do We Prefer?”, Chiang 2023
- “Data Selection for Language Models via Importance Resampling”, Xie et al 2023
- “In-Context Retrieval-Augmented Language Models”, Ram et al 2023
- “Crawling the Internal Knowledge-Base of Language Models”, Cohen et al 2023
- “Big Tech Was Moving Cautiously on AI. Then Came ChatGPT. Google, Facebook and Microsoft Helped Build the Scaffolding of AI. Smaller Companies Are Taking It to the Masses, Forcing Big Tech to React”, Tiku et al 2023
- “Rock Guitar Tablature Generation via Natural Language Processing”, Casco-Rodriguez 2023
- “InPars-Light: Cost-Effective Unsupervised Training of Efficient Rankers”, Boytsov et al 2023
- “A New Chat Bot Is a ‘Code Red’ for Google’s Search Business: A New Wave of Chat Bots like ChatGPT Use Artificial Intelligence That Could Reinvent or Even Replace the Traditional Internet Search Engine”, Grant & Metz 2022
- “Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent As Meta-Optimizers”, Dai et al 2022
- “Rethinking the Role of Scale for In-Context Learning: An Interpretability-Based Case Study at 66 Billion Scale”, Bansal et al 2022
- “Interpreting Neural Networks through the Polytope Lens”, Black et al 2022
- “SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models”, Xiao et al 2022
- “InstructPix2Pix: Learning to Follow Image Editing Instructions”, Brooks et al 2022
- “Galactica: A Large Language Model for Science”, Taylor et al 2022
- “Large Language Models Struggle to Learn Long-Tail Knowledge”, Kandpal et al 2022
- “The CRINGE Loss: Learning What Language Not to Model”, Adolphs et al 2022
- “Mysteries of Mode Collapse § Inescapable Wedding Parties”, Janus 2022
- “GPTQ: Accurate Post-Training Quantization for Generative Pre-Trained Transformers”, Frantar et al 2022
- “What Is My Math Transformer Doing? – 3 Results on Interpretability and Generalization”, Charton 2022
- “When Life Gives You Lemons, Make Cherryade: Converting Feedback from Bad Responses into Good Labels”, Shi et al 2022
- “Can Language Models Handle Recursively Nested Grammatical Structures? A Case Study on Comparing Models and Humans”, Lampinen 2022
- “Evaluating Parameter Efficient Learning for Generation”, Xu et al 2022
- “BioGPT: Generative Pre-Trained Transformer for Biomedical Text Generation and Mining”, Luo et al 2022
- “Arithmetic Sampling: Parallel Diverse Decoding for Large Language Models”, Vilnis et al 2022
- “MTEB: Massive Text Embedding Benchmark”, Muennighoff et al 2022
- “Foundation Transformers”, Wang et al 2022
- “Ask Me Anything (AMA): A Simple Strategy for Prompting Language Models”, Arora et al 2022
- “Is Reinforcement Learning (Not) for Natural Language Processing: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization”, Ramamurthy et al 2022
- “Sparrow: Improving Alignment of Dialogue Agents via Targeted Human Judgements”, Glaese et al 2022
- “Generate rather than Retrieve (GenRead): Large Language Models Are Strong Context Generators”, Yu et al 2022
- “FP8 Formats for Deep Learning”, Micikevicius et al 2022
- “Petals: Collaborative Inference and Fine-Tuning of Large Models”, Borzunov et al 2022
- “Simulators”, Janus 2022
- “
LLM.int8(): 8-Bit Matrix Multiplication for Transformers at Scale”, Dettmers et al 2022 - “Meaning without Reference in Large Language Models”, Piantadosi & Hill 2022
- “Effidit: Your AI Writing Assistant”, Shi et al 2022
- “Language Models Show Human-Like Content Effects on Reasoning”, Dasgupta et al 2022
- “LM-Nav: Robotic Navigation With Large Pre-Trained Models of Language, Vision, and Action”, Shah et al 2022
- “Can Foundation Models Talk Causality?”, Willig et al 2022
- “NOAH: Neural Prompt Search”, Zhang et al 2022
- “ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers”, Yao et al 2022
- “Quark: Controllable Text Generation With Reinforced Unlearning”, Lu et al 2022
- “RankGen: Improving Text Generation With Large Ranking Models”, Krishna et al 2022
- “Opal: Multimodal Image Generation for News Illustration”, Liu et al 2022
- “What Language Model to Train If You Have One Million GPU Hours?”, Scao et al 2022
- “WAVPROMPT: Towards Few-Shot Spoken Language Understanding With Frozen Language Models”, Gao et al 2022
- “Shared Computational Principles for Language Processing in Humans and Deep Language Models”, Goldstein et al 2022
- “Vector-Quantized Image Modeling With Improved VQGAN”, Yu et al 2022
- “Brains and Algorithms Partially Converge in Natural Language Processing”, Caucheteux & King 2022
- “Quantifying Memorization Across Neural Language Models”, Carlini et al 2022
- “A Contrastive Framework for Neural Text Generation”, Su et al 2022
- “AdaPrompt: Adaptive Model Training for Prompt-Based NLP”, Chen et al 2022
- “InPars: Data Augmentation for Information Retrieval Using Large Language Models”, Bonifacio et al 2022
- “ROME: Locating and Editing Factual Associations in GPT”, Meng et al 2022
- “Cedille: A Large Autoregressive French Language Model”, Müller & Laurent 2022
- “Data Scaling Laws in NMT: The Effect of Noise and Architecture”, Bansal et al 2022
- “PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts”, Bach et al 2022
- “Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model”, Smith et al 2022
- “Language Models As Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents”, Huang et al 2022
- “WANLI: Worker and AI Collaboration for Natural Language Inference Dataset Creation”, Liu et al 2022
- “A Survey of Controllable Text Generation Using Transformer-Based Pre-Trained Language Models”, Zhang et al 2022
- “The Defeat of the Winograd Schema Challenge”, Kocijan et al 2022
- “Learning To Retrieve Prompts for In-Context Learning”, Rubin et al 2021
- “Learning to Prompt for Continual Learning”, Wang et al 2021
- “Amortized Noisy Channel Neural Machine Translation”, Pang et al 2021
- “Few-Shot Instruction Prompts for Pretrained Language Models to Detect Social Biases”, Prabhumoye et al 2021
- “PROMPT WAYWARDNESS: The Curious Case of Discretized Interpretation of Continuous Prompts”, Khashabi et al 2021
- “LMTurk: Few-Shot Learners As Crowdsourcing Workers”, Zhao et al 2021
- “Improving Language Models by Retrieving from Trillions of Tokens”, Borgeaud et al 2021
- “Linear Algebra With Transformers”, Charton 2021
- “Thinking Ahead: Prediction in Context As a Keystone of Language in Humans and Machines”, Goldstein et al 2021
- “Zero-Shot Image-To-Text Generation for Visual-Semantic Arithmetic”, Tewel et al 2021
- “Long-Range and Hierarchical Language Predictions in Brains and Algorithms”, Caucheteux et al 2021
- “True Few-Shot Learning With Prompts: A Real-World Perspective”, Schick & Schütze 2021
- “Few-Shot Named Entity Recognition With Cloze Questions”, Gatta et al 2021
- “Evaluating Distributional Distortion in Neural Language Modeling”, Anonymous 2021
- “On Transferability of Prompt Tuning for Natural Language Understanding”, Su et al 2021
- “CLUES: Few-Shot Learning Evaluation in Natural Language Understanding”, Mukherjee et al 2021
- “Recent Advances in Natural Language Processing via Large Pre-Trained Language Models: A Survey”, Min et al 2021
- “Fast Model Editing at Scale”, Mitchell et al 2021
- “Yuan 1.0: Large-Scale Pre-Trained Language Model in Zero-Shot and Few-Shot Learning”, Wu et al 2021
- “Towards a Unified View of Parameter-Efficient Transfer Learning”, He et al 2021
- “A Few More Examples May Be Worth Billions of Parameters”, Kirstain et al 2021
- “Scaling Laws for Neural Machine Translation”, Ghorbani et al 2021
- “Can Language Models Encode Perceptual Structure Without Grounding? A Case Study in Color”, Abdou et al 2021
- “What Changes Can Large-Scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-Scale Korean Generative Pretrained Transformers”, Kim et al 2021
- “Medically Aware GPT-3 As a Data Generator for Medical Dialogue Summarization”, Chintagunta et al 2021
- “General-Purpose Question-Answering With Macaw”, Tafjord & Clark 2021
- “An Empirical Exploration in Quality Filtering of Text Data”, Gao 2021
- “Want To Reduce Labeling Cost? GPT-3 Can Help”, Wang et al 2021
- “Multimodal Few-Shot Learning With Frozen Language Models”, Tsimpoukelli et al 2021
- “Cutting Down on Prompts and Parameters: Simple Few-Shot Learning With Language Models”, IV et al 2021
- “RASP: Thinking Like Transformers”, Weiss et al 2021
- “ByT5: Towards a Token-Free Future With Pre-Trained Byte-To-Byte Models”, Xue et al 2021
- “Anthropic Raises $124 Million to Build More Reliable, General AI Systems”, Anthropic 2021
- “Naver Unveils First ‘Hyperscale’ AI Platform”, Jae-eun 2021
- “Scaling Laws for Language Transfer Learning”, Kim 2021
- “GPT Understands, Too”, Liu et al 2021
- “How Many Data Points Is a Prompt Worth?”, Scao & Rush 2021
- “Pretrained Transformers As Universal Computation Engines”, Lu et al 2021
- “Language Models Have a Moral Dimension”, Schramowski et al 2021
- “Learning Chess Blindfolded: Evaluating Language Models on State Tracking”, Toshniwal et al 2021
- “Investigating the Limitations of the Transformers With Simple Arithmetic Tasks”, Nogueira et al 2021
- “Proof Artifact Co-Training for Theorem Proving With Language Models”, Han et al 2021
- “Clinical Outcome Prediction from Admission Notes Using Self-Supervised Knowledge Integration”, Aken et al 2021
- “Scaling Laws for Transfer”, Hernandez et al 2021
- “MAUVE: Measuring the Gap Between Neural Text and Human Text Using Divergence Frontiers”, Pillutla et al 2021
- “Apparently ‘What Ho’ Is a Corruption Of…”, Marguerite 2021
- “Making Pre-Trained Language Models Better Few-Shot Learners”, Gao et al 2020
- “CPM: A Large-Scale Generative Chinese Pre-Trained Language Model”, Zhang et al 2020
- “Summarize, Outline, and Elaborate: Long-Text Generation via Hierarchical Supervision from Extractive Summaries”, Sun et al 2020
- “The Neural Architecture of Language: Integrative Reverse-Engineering Converges on a Model for Predictive Processing”, Schrimpf et al 2020
- “RoFT: A Tool for Evaluating Human Detection of Machine-Generated Text”, Dugan et al 2020
- “A Systematic Characterization of Sampling Algorithms for Open-Ended Language Generation”, Nadeem et al 2020
- “Generative Language Modeling for Automated Theorem Proving”, Polu & Sutskever 2020
- “Learning to Summarize from Human Feedback”, Stiennon et al 2020
- “ETHICS: Aligning AI With Shared Human Values”, Hendrycks et al 2020
- “Mirostat: A Neural Text Decoding Algorithm That Directly Controls Perplexity”, Basu et al 2020
- “Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data”, Bender & Koller 2020
- “Transformers Are RNNs: Fast Autoregressive Transformers With Linear Attention”, Katharopoulos et al 2020
- “OpenAI API Beta Homepage”, OpenAI 2020
- “Trading Off Diversity and Quality in Natural Language Generation”, Zhang et al 2020
- “Scaling Laws from the Data Manifold Dimension”, Sharma & Kaplan 2020
- “Unigram LM: Byte Pair Encoding Is Suboptimal for Language Model Pretraining”, Bostrom & Durrett 2020
- “L2L: Training Large Neural Networks With Constant Memory Using a New Execution Algorithm”, Pudipeddi et al 2020
- “Direct Fit to Nature: An Evolutionary Perspective on Biological and Artificial Neural Networks”, Hasson et al 2020
- “Pop Music Transformer: Beat-Based Modeling and Generation of Expressive Pop Piano Compositions”, Huang & Yang 2020
- “Scaling Laws for Neural Language Models”, Kaplan et al 2020
- “Reformer: The Efficient Transformer”, Kitaev et al 2020
- “Generative Language Modeling for Automated Theorem Proving § Experiments”, Polu & Sutskever 2020 (page 11 org openai)
- “Plug and Play Language Models: A Simple Approach to Controlled Text Generation”, Dathathri et al 2019
- “How Can We Know What Language Models Know?”, Jiang et al 2019
- “CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning”, Lin et al 2019
- “Generalization through Memorization: Nearest Neighbor Language Models”, Khandelwal et al 2019
- “DialoGPT: Large-Scale Generative Pre-Training for Conversational Response Generation”, Zhang et al 2019
- “CTRL: A Conditional Transformer Language Model For Controllable Generation”, Keskar et al 2019
- “Smaller, Faster, Cheaper, Lighter: Introducing DistilGPT, a Distilled Version of GPT”, Sanh 2019
- “Language Modeling State-Of-The-Art Leaderboards”, paperswithcode.com 2019
- “Neural Text Generation With Unlikelihood Training”, Welleck et al 2019
- “GROVER: Defending Against Neural Fake News”, Zellers et al 2019
- “Generative Modeling With Sparse Transformers: We’ve Developed the Sparse Transformer, a Deep Neural Network Which Sets New Records at Predicting What Comes next in a Sequence—Whether Text, Images, or Sound. It Uses an Algorithmic Improvement of the attention Mechanism to Extract Patterns from Sequences 30× Longer Than Possible Previously”, Child & Gray 2019
- “The Curious Case of Neural Text Degeneration”, Holtzman et al 2019
- “Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context”, Dai et al 2019
- “Music Transformer: Generating Music With Long-Term Structure”, Huang et al 2018
- “Universal Transformers”, Dehghani et al 2018
- “Adversarial Reprogramming of Neural Networks”, Elsayed et al 2018
- “GPT-1: Improving Language Understanding With Unsupervised Learning”, OpenAI 2018
- “GPT-1: Improving Language Understanding by Generative Pre-Training”, Radford et al 2018
- “GPT-1: Improving Language Understanding by Generative Pre-Training § Model Specifications”, Radford et al 2018 (page 5)
- “Deep Reinforcement Learning from Human Preferences § Appendix A.2: Atari”, Christiano et al 2017 (page 15 org openai)
- “Learning to Generate Reviews and Discovering Sentiment”, Radford et al 2017
- “Design a Role-Playing Game Using 200 Words or Less.”
- “How Does In-Context Learning Work? A Framework for Understanding the Differences from Traditional Supervised Learning”
- “AI Dungeon 2: Dragon Model Upgrade—You Can Now Play AI Dungeon With One of the Most Powerful AI Models in the World.”
- “Introducing AI Dungeon Translate: AI Dungeon Players Can Now Translate Their Stories into Emojis by Just Clicking a Button. [ 🤔 💯 🤷♂️ 🤔 🤔 🤔 💯]”
- “OpenAI API Alchemy: Emoji Storytelling 🤖”
- “Megatron-LM: Training Multi-Billion Parameter Language Models Using GPU Model Parallelism: Appendix A: Text Samples”
- “Llama-3.1-405B Now Runs at 969 Tokens/s on Cerebras Inference”
- “I Blew $720 on 100 Notebooks from Alibaba and Started a Paper Website Business”
- “AlphaStar: Mastering the Real-Time Strategy Game StarCraft II”
- “Assuring an Accurate Research Record [Aidan Toner-Rodgers’s AI Research Fraud]”
- “LLM Inference Prices Have Fallen Rapidly but Unequally across Tasks”
- “How Well Did Superforecasters and Experts Predict Wet Lab Skill Uplift from LLMs?”
- “Transformers As Variational Autoencoders”
- “BlinkDL/RWKV-LM: RWKV Is an RNN With Transformer-Level LLM Performance. It Can Be Directly Trained like a GPT (Parallelizable). So It’s Combining the Best of RNN and Transformer—Great Performance, Fast Inference, Saves VRAM, Fast Training, "Infinite" Ctx_len, and Free Sentence Embedding.”
- “Aidan Bench Attempts to Measure ‘Big Model Smell’ in LLMs”
- “Efficient, Reusable RNNs and LSTMs for Torch”
- “Updated Training?”
- “Karpathy/minGPT: A Minimal PyTorch Re-Implementation of the OpenAI GPT (Generative Pretrained Transformer) Training”
- “Krasheninnikov/internalization: Code for the Paper ‘Implicit Meta-Learning May Lead Language Models to Trust More Reliable Sources’”
- “Minimaxir/textgenrnn: Easily Train Your Own Text-Generating Neural Network of Any Size and Complexity on Any Text Dataset With a Few Lines of Code.”
- “Simpolism/infinite-Jazz: Endless Live LLM-Improvised MIDI ‘Jazz’”
- “Loom: Multiversal Tree Writing Interface for Human-AI Collaboration”, Janus 2026
- “Technion-Cs-Nlp/llm-Arithmetic-Heuristics”
- “Zphang/minimal-Opt”
- “Manga-Image-Translator: Translate Manga/image”, zyddnys 2026
- “Math: OpenAI API Can Do Some Math out of the Gate, but Most Math It Seems It Has to Learn. Many Times, the Numbers That It Spits out Are Just Random. However, including Different Priming Prompts Can Result in Decent Results.”
- “Deep Learning for Assisting the Process of Music Composition (Part 3)”
- “Google DeepMind’s Grandmaster-Level Chess Without Search”
- “The Technology Behind BLOOM Training”
- “Psych-101 Dataset [For Centaur]”
- The Gostak
- “Imprompter”
- “No, Acclaimed Science Fiction Author Ted Chiang Is Not Conscious”, Jaibot 2026
- “Learning Better Decision Tree Splits—LLMs As Heuristics for Program Synthesis”, Chavinda 2026
- “Your Next New Best Friend Might Be a Robot”
- “I Made a Custom Gpt That Incorporates Advertisement/product Placement With Its…”
- “The Annotated Transformer”
- “Homepage of Paul F. Christiano”, Christiano 2026
- “Data Exfiltration from Slack AI via Indirect Prompt Injection”, PromptArmor 2026
- “Introductory Antimemetics (Abandoned First Draft)”, Hughes 2026
- “Jared Kaplan”
- “Meditations on Moloch”
- “Stream Seaandsailor”
- “Humans Who Are Not Concentrating Are Not General Intelligences”
- “LLM Grading Update: It’s Now out of Control. The Level of Cheating Is Insane.”, S 2026
- “Monitor: An AI-Driven Observability Interface”
- “This Is the OpenAI API. It Makes Spookily Good Twitter Bots. 13⁄10 Would Retweet”
- “AMA Conjecture, A New Alignment Startup”
- “Arming the Rebels With GPUs: Gradium, Kyutai, and Audio AI”
- “Drew Breunig Homepage”, Breunig 2026
- “WikiCrow”
- “ChatGPT As Muse, Not Oracle”, Litt 2026
- “Coding Agents Are Changing the Biosecurity Risk Landscape”
- “The Small World of English: Building a 1.5M Word Semantic Network for Language Games”
- “AI ‘Rabbi’ Exposed: Fake Hasidic Influencer Dupes Thousands”
- “Test Your Interpretability Techniques by De-Censoring Chinese Models”
- “Interpreting GPT: the Logit Lens”
- “Assessing AlephAlpha’s Multimodal Model”
- “Is GPT-3 a Good Rationalist?”
- “We Are Conjecture, A New Alignment Research Startup”
- “Investigating Causal Understanding in LLMs”
- “A One-Question Turing Test for GPT-3”
- “The Terrarium”
- “New Accounts on HN 10× More Likely to Use EM-Dashes”
- “Moonshot AI Homepage”, Moonshot 2026
- “AI Tools Are Spotting Errors in Research Papers: inside a Growing Movement”
- “Pangram: an AI Text Detector That Actually Works”, Pangram 2026
- “AI Is Just Starting to Change the Legal Profession”
- “This Mystical Book Was Co-Authored by a Disturbingly Realistic AI”
- “The Guy Behind the Fake AI Halloween Parade Listing Says You’ve Got It All Wrong”
- “I Loved My OpenClaw AI Agent—Until It Turned on Me”
- “Revealed: Leaked Chats Expose the Daily Life of a Scam Compound’s Enslaved Workforce”
- “Season 1 Ep. 22 OpenAI’s Ilya Sutskever: The Man Who Made AI Work”
- “WELM”
- nickwalton00
- polynoamial
- sama
- voooooogel
- “Jason Yosinski”
- Sort By Magic
phrase-originreinforcement-learningmilitary-planningphysical-stabilitywatermarkingmusic-generationbloggers lawyer-warning paul-christiano grok memoir commentary legal-techgenerative-governanceai-ethics prompt-engineering companionship deception algorithmic-harmlanguage-modelschatgpt-assessmentchatbot-evolution
- Wikipedia (1)
- Miscellaneous
- Bibliography
See Also
Gwern
“Guardian Angels: LLM Personalization for Productivity and Security”, Gwern 2025
Guardian Angels: LLM Personalization for Productivity and Security
“Better Fiction via Retcon Planning”, Gwern 2026
“Go-Speech Specification”, Pro et al 2026
“Grow-Speech Specification”, Gwern et al 2026
“I’d Show All My Online Friends, but I Now Worry They Wouldn’t Get It”, Gwern 2026
I’d show all my online friends, but I now worry they wouldn’t get it
{kind=link}
“Meta-Learning Information-Maximizing Personality Surveys”, Gwern 2024
“Quantifying Truesight With SAEs”, Gwern 2025
“GPT-3 Semantic Derealization”, Gwern 2024
“Research Ideas”, Gwern 2017
“You Should Write More Online”, Gwern 2024
Links
industriaalist @ "2026-06-04"
“Q0: Primitives for Hyper-Epoch Pretraining”, Mandal et al 2026
“Laying It on Thick [Increasing LLM-Powered Spearphishing/spam Cold Emails]”, Sloan 2026
Laying it on thick [increasing LLM-powered spearphishing/spam cold emails]
LinchZhang @ "2026-05-09"
[Grok, Could you please name 20 great bloggers that you like?]
“MegaTrain: Full Precision Training of 100B+ Parameter Large Language Models on a Single GPU”, Yuan et al 2026
MegaTrain: Full Precision Training of 100B+ Parameter Large Language Models on a Single GPU
“2026: The Year of Throwing My Agency at My Health (Now With Added Cyborgism)”, ruby 2026
2026: The year of throwing my agency at my health (now with added cyborgism)
“Strategic Navigation or Stochastic Search? How Agents and Humans Reason Over Document Collections”, Borchmann et al 2026
Strategic Navigation or Stochastic Search? How Agents and Humans Reason Over Document Collections
“Charlatan Labyrinth [Constrained Writing: Non-Proto-Indo-European]”, niplav 2026
Charlatan Labyrinth [constrained writing: non-Proto-Indo-European]
“An AI Agent Published a Hit Piece on Me”, Shambaugh 2026
“Doc-To-LoRA (D2L): Learning to Instantly Internalize Contexts”, Charakorn et al 2026
Doc-to-LoRA (D2L): Learning to Instantly Internalize Contexts
“Generative AI and Wikipedia Editing: What We Learned in 2025”, Edu 2026
Generative AI and Wikipedia editing: What we learned in 2025
“Giving University Exams in the Age of Chatbots”, Dricot 2026
“Debunking the AI Food Delivery Hoax That Fooled Reddit: A ‘Whistleblower’ Tried to Corroborate His Viral Post With AI-Generated Evidence. This Is How I Caught Him”, Newton 2026
“Large Language Models and the Entropy of English”, Scheibner et al 2025
“Shared Sensitivity to Data Distribution during Learning in Humans and Transformer Networks”, Lerousseau & Summerfield 2025
Shared sensitivity to data distribution during learning in humans and Transformer networks
“Scientific Production in the Era of Large Language Models: With the Production Process Rapidly Evolving, Science Policy Must Consider How Institutions Could Evolve”, Kusumegi et al 2025
“AI Will Kill All the Lawyers: A Barrister’s Warning”, Thomas 2025
“EGGROLL: Evolution Strategies at the Hyperscale”, Sarkar et al 2025
“Superhuman AI for Stratego Using Self-Play Reinforcement Learning and Test-Time Search”, Sokota et al 2025
Superhuman AI for Stratego Using Self-Play Reinforcement Learning and Test-Time Search
“Blackbox Model Provenance via Palimpsestic Membership Inference”, Kuditipudi et al 2025
Blackbox Model Provenance via Palimpsestic Membership Inference
“LLMs Can Hide Text in Other Text of the Same Length”, Norelli & Bronstein 2025
“Scaling Recommender Transformers to a Billion Parameters: How to Implement a New Generation of Transformer Recommenders”, Кhrylchenko 2025
“The Dark Arts of Tokenization Or: How I Learned to Start Worrying and Love LLMs’ Undecoded Outputs”, Lovre 2025
The Dark Arts of Tokenization or: How I learned to start worrying and love LLMs’ undecoded outputs
“EditLens: Quantifying the Extent of AI Editing in Text”, Thai et al 2025
“PipelineRL: Faster On-Policy Reinforcement Learning for Long Sequence Generation”, Piché et al 2025
PipelineRL: Faster On-policy Reinforcement Learning for Long Sequence Generation
“How Kimi K2 RL’ed Qualitative Data to Write Better”, Breunig 2025
“Scaling Recommender Transformers to One Billion Parameters”, Khrylchenko et al 2025
“Intra: Design Notes on an LLM-Driven Text Adventure”, Bicking 2025
“Finding Palindromes With Language Models”, Nichol 2025
“Your Brain on ChatGPT: Accumulation of Cognitive Debt When Using an AI Assistant for Essay Writing Task”, Kosmyna et al 2025
“Inference Economics of Language Models”, Erdil 2025
“Pitfalls in Evaluating Language Model Forecasters”, Paleka et al 2025
“DataRater: Meta-Learned Dataset Curation”, Calian et al 2025
“Creative Preference Optimization”, Ismayilzada et al 2025
“Generating the Funniest Joke With RL (According to GPT-4.1)”, agg 2025
“Emergent Social Conventions and Collective Bias in LLM Populations”, Ashery et al 2025
Emergent social conventions and collective bias in LLM populations
“LLMs Get Lost In Multi-Turn Conversation”, Laban et al 2025
“Generating Physically Stable and Buildable LEGO Designs from Text”, Pun et al 2025
Generating Physically Stable and Buildable LEGO Designs from Text
“LegoGPT: Generating Physically Stable and Buildable LEGO Designs from Text”, Pun et al 2025
LegoGPT: Generating Physically Stable and Buildable LEGO Designs from Text
View External Link:
“LegoGPT: Official Repository for LegoGPT, the First Approach for Generating Physically Stable LEGO Brick Models from Text Prompts”, Pun et al 2025
“Clippy Desktop Assistant”, Rieseberg 2025
“New News: System-2 Fine-Tuning for Robust Integration of New Knowledge”, Park et al 2025
New News: System-2 Fine-tuning for Robust Integration of New Knowledge
“On the Generalization of Language Models from In-Context Learning and Finetuning: a Controlled Study”, Lampinen et al 2025
On the generalization of language models from in-context learning and finetuning: a controlled study
“Will the Humanities Survive Artificial Intelligence? Maybe Not As We’ve Known Them. But, in the Ruins of the Old Curriculum, Something Vital Is Stirring”, Burnett 2025
“[Using Perplexity to Find New Books by Authors You Like]”, Ingebrigtsen 2025
“Cathoven: Enhancing Language Acquisition through Tailored Input and Targeted Output Feedback”, Hong & Lin 2025
Cathoven: Enhancing Language Acquisition through Tailored Input and Targeted Output Feedback
“Tapered Off-Policy REINFORCE: Stable and Efficient Reinforcement Learning for LLMs”, Roux et al 2025
Tapered Off-Policy REINFORCE: Stable and efficient reinforcement learning for LLMs
“SuperBPE: Space Travel for Language Models”, Liu et al 2025
“Muon Is Scalable for LLM Training [Moonlight]”, Liu et al 2025
“AgentSociety: Large-Scale Simulation of LLM-Driven Generative Agents Advances Understanding of Human Behaviors and Society”, Piao et al 2025
“SmolLM2: When Smol Goes Big—Data-Centric Training of a Small Language Model”, Allal et al 2025
SmolLM2: When Smol Goes Big—Data-Centric Training of a Small Language Model
“The Surprising Agreement Between Convex Optimization Theory and Learning-Rate Scheduling for Large Model Training”, Schaipp et al 2025
“Decoding-Based Regression”, Song & Bahri 2025
“Diverse Preference Optimization”, Lanchantin et al 2025
“Complete Chess Games Enable LLM Become A Chess Master”, Zhang et al 2025
“Multiagent Finetuning: Self Improvement With Diverse Reasoning Chains”, Subramaniam et al 2025
Multiagent Finetuning: Self Improvement with Diverse Reasoning Chains
“Metadata Conditioning Accelerates Language Model Pre-Training”, Gao et al 2025
Metadata Conditioning Accelerates Language Model Pre-training
“How AI Is Unlocking Ancient Texts: From Deciphering Burnt Roman Scrolls to Reading Crumbling Cuneiform Tablets, Neural Networks Could Give Researchers More Data Than They’ve Had in Centuries”, Marchant 2024
“Genomic Foundation-Less Models: Pretraining Does Not Promise Performance”, Vishniakov et al 2024
Genomic Foundation-less Models: Pretraining Does Not Promise Performance
“Proposing and Solving Olympiad Geometry With Guided Tree Search”, Zhang et al 2024
Proposing and solving olympiad geometry with guided tree search
“Continuous Autoregressive Models With Noise Augmentation Avoid Error Accumulation”, Pasini et al 2024
Continuous Autoregressive Models with Noise Augmentation Avoid Error Accumulation
“Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?”, Yang et al 2024
Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?
“2:4 Sparse Llama: Smaller Models for Efficient GPU Inference”, Kurtić et al 2024
2:4 Sparse Llama: Smaller Models for Efficient GPU Inference
“The Surprising Effectiveness of Test-Time Training for Few-Shot Learning”, Akyürek et al 2024
The Surprising Effectiveness of Test-Time Training for Few-Shot Learning
“Medical Adaptation of Large Language and Vision-Language Models: Are We Making Progress?”, Jeong et al 2024
Medical Adaptation of Large Language and Vision-Language Models: Are We Making Progress?
“Fractal Patterns May Illuminate the Success of Next-Token Prediction”, Alabdulmohsin et al 2024
Fractal Patterns May Illuminate the Success of Next-Token Prediction
“Arithmetic Without Algorithms: Language Models Solve Math With a Bag of Heuristics”, Nikankin et al 2024
Arithmetic Without Algorithms: Language Models Solve Math With a Bag of Heuristics
“The Dark Side of AI Companionship: A Taxonomy of Harmful Algorithmic Behaviors in Human-AI Relationships”, Zhang et al 2024
“Model Equality Testing: Which Model Is This API Serving?”, Gao et al 2024
“Centaur: a Foundation Model of Human Cognition”, Binz et al 2024
“Do LLMs Estimate Uncertainty Well in Instruction-Following?”, Heo et al 2024
“Bilinear MLPs Enable Weight-Based Mechanistic Interpretability”, Pearce et al 2024
Bilinear MLPs enable weight-based mechanistic interpretability
“Interpretable Contrastive Monte Carlo Tree Search Reasoning”, Gao et al 2024
“NGPT: Normalized Transformer With Representation Learning on the Hypersphere”, Loshchilov et al 2024
nGPT: Normalized Transformer with Representation Learning on the Hypersphere
“Llama 3.2: Revolutionizing Edge AI and Vision With Open, Customizable Models”, Facebook 2024
Llama 3.2: Revolutionizing edge AI and vision with open, customizable models
“FineZip: Pushing the Limits of Large Language Models for Practical Lossless Text Compression”, Mittu et al 2024
FineZip: Pushing the Limits of Large Language Models for Practical Lossless Text Compression
“LLM Applications I Want To See”, Constantin 2024
“Ensemble Everything Everywhere: Multi-Scale Aggregation for Adversarial Robustness”, Fort & Lakshminarayanan 2024
Ensemble everything everywhere: Multi-scale aggregation for adversarial robustness
“Scaling Laws With Vocabulary: Larger Models Deserve Larger Vocabularies”, Tao et al 2024
Scaling Laws with Vocabulary: Larger Models Deserve Larger Vocabularies
“Token Erasure As a Footprint of Implicit Vocabulary Items in LLMs”, Feucht et al 2024
Token Erasure as a Footprint of Implicit Vocabulary Items in LLMs
“Resolving Discrepancies in Compute-Optimal Scaling of Language Models”, Porian et al 2024
Resolving Discrepancies in Compute-Optimal Scaling of Language Models
“When Parts Are Greater Than Sums: Individual LLM Components Can Outperform Full Models”, Chang et al 2024
When Parts are Greater Than Sums: Individual LLM Components Can Outperform Full Models
“Nemotron-4 340B Technical Report”, Adler et al 2024
“DataComp-LM: In Search of the next Generation of Training Sets for Language Models”, Li et al 2024
DataComp-LM: In search of the next generation of training sets for language models
“How Do Large Language Models Acquire Factual Knowledge During Pretraining?”, Chang et al 2024
How Do Large Language Models Acquire Factual Knowledge During Pretraining?
“Be like a Goldfish, Don’t Memorize! Mitigating Memorization in Generative LLMs”, Hans et al 2024
Be like a Goldfish, Don’t Memorize! Mitigating Memorization in Generative LLMs
“Discovering Preference Optimization Algorithms With and for Large Language Models”, Lu et al 2024
Discovering Preference Optimization Algorithms with and for Large Language Models
“MCTSr: Accessing GPT-4 Level Mathematical Olympiad Solutions via Monte Carlo Tree Self-Refine With LLaMA-3-8B”, Zhang et al 2024
“For Chinese Students, the New Tactic Against AI Checks: More AI”, Qitong 2024
For Chinese Students, the New Tactic Against AI Checks: More AI
“MAP-Neo: Highly Capable and Transparent Bilingual Large Language Model Series”, Zhang et al 2024
MAP-Neo: Highly Capable and Transparent Bilingual Large Language Model Series
“Superposed Decoding: Multiple Generations from a Single Autoregressive Inference Pass”, Shen et al 2024
Superposed Decoding: Multiple Generations from a Single Autoregressive Inference Pass
“Transformers Can Do Arithmetic With the Right Embeddings”, McLeish et al 2024
“Uncheatable_eval: Evaluating LLMs With Dynamic Data”, Jellyfish042 2024
“Better & Faster Large Language Models via Multi-Token Prediction”, Gloeckle et al 2024
Better & Faster Large Language Models via Multi-token Prediction
“SpaceByte: Towards Deleting Tokenization from Large Language Modeling”, Slagle 2024
SpaceByte: Towards Deleting Tokenization from Large Language Modeling
“Towards Smaller, Faster Decoder-Only Transformers: Architectural Variants and Their Implications”, Suresh & P 2024
Towards smaller, faster decoder-only transformers: Architectural variants and their implications
“Design of Highly Functional Genome Editors by Modeling the Universe of CRISPR-Cas Sequences”, Ruffolo et al 2024
Design of highly functional genome editors by modeling the universe of CRISPR-Cas sequences
“From r to Q✱: Your Language Model Is Secretly a Q-Function”, Rafailov et al 2024
“CATS: Contextually-Aware Thresholding for Sparsity in Large Language Models”, Lee et al 2024
CATS: Contextually-Aware Thresholding for Sparsity in Large Language Models
“CulturalTeaming: AI-Assisted Interactive Red-Teaming for Challenging LLMs’ (Lack Of) Multicultural Knowledge”, Chiu et al 2024
“Training LLMs over Neurally Compressed Text”, Lester et al 2024
“Reverse Training to Nurse the Reversal Curse”, Golovneva et al 2024
“3 Reasons Why AI Doesn’t Model Human Language”, Bolhuis et al 2024
“Evolutionary Optimization of Model Merging Recipes”, Akiba et al 2024
“Yi: Open Foundation Models by 01.AI”, Young et al 2024
“Inflection-2.5: Meet the World’s Best Personal AI”, Inflection 2024
“Actions Speak Louder Than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations (HSTU)”, Zhai et al 2024
“Fast Adversarial Attacks on Language Models In One GPU Minute”, Sadasivan et al 2024
Fast Adversarial Attacks on Language Models In One GPU Minute
“Assisting in Writing Wikipedia-Like Articles From Scratch With Large Language Models”, Shao et al 2024
Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models
“Autonomous Data Selection With Language Models for Mathematical Texts”, Zhang et al 2024
Autonomous Data Selection with Language Models for Mathematical Texts
“Grandmaster-Level Chess Without Search”, Ruoss et al 2024
“Neural Networks Learn Statistics of Increasing Complexity”, Belrose et al 2024
“Verifiable Evaluations of Machine Learning Models Using ZkSNARKs”, South et al 2024
Verifiable evaluations of machine learning models using zkSNARKs
“Arrows of Time for Large Language Models”, Papadopoulos et al 2024
“LLaVA-NeXT: Improved Reasoning, OCR, and World Knowledge”
“SliceGPT: Compress Large Language Models by Deleting Rows and Columns”, Ashkboos et al 2024
SliceGPT: Compress Large Language Models by Deleting Rows and Columns
“Excuse Me, Sir? Your Language Model Is Leaking (Information)”, Zamir 2024
Excuse me, sir? Your language model is leaking (information)
“TinyLlama: An Open-Source Small Language Model”, Zhang et al 2024
“LLaMA Pro: Progressive LLaMA With Block Expansion”, Wu et al 2024
“Generative AI Is Already Widespread in the Public Sector”, Bright et al 2024
“Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws”, Sardana & Frankle 2023
Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws
“TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones”, Yuan et al 2023
TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones
“Reasons to Reject? Aligning Language Models With Judgments”, Xu et al 2023
“InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks”, Chen et al 2023
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
“Generative Multimodal Models Are In-Context Learners”, Sun et al 2023
“CogAgent: A Visual Language Model for GUI Agents”, Hong et al 2023
“LLM in a Flash: Efficient Large Language Model Inference With Limited Memory”, Alizadeh et al 2023
LLM in a flash: Efficient Large Language Model Inference with Limited Memory
“Frugal LMs Trained to Invoke Symbolic Solvers Achieve Parameter-Efficient Arithmetic Reasoning”, Dutta et al 2023
Frugal LMs Trained to Invoke Symbolic Solvers Achieve Parameter-Efficient Arithmetic Reasoning
“Object Recognition As Next Token Prediction”, Yue et al 2023
“The Falcon Series of Open Language Models”, Almazrouei et al 2023
“MEDITRON-70B: Scaling Medical Pretraining for Large Language Models”, Chen et al 2023
MEDITRON-70B: Scaling Medical Pretraining for Large Language Models
“Localizing Lying in Llama: Understanding Instructed Dishonesty on True-False Questions Through Prompting, Probing, and Patching”, Campbell et al 2023
“Positional Description Matters for Transformers Arithmetic”, Shen et al 2023
“OpenAI Researchers Warned Board of AI Breakthrough ahead of CEO Ouster, Sources Say”, Tong et al 2023
OpenAI researchers warned board of AI breakthrough ahead of CEO ouster, sources say
“Watermarks in the Sand: Impossibility of Strong Watermarking for Generative Models”, Zhang et al 2023
Watermarks in the Sand: Impossibility of Strong Watermarking for Generative Models
“Tensor Trust: Interpretable Prompt Injection Attacks from an Online Game”, Toyer et al 2023
Tensor Trust: Interpretable Prompt Injection Attacks from an Online Game
“Implicit Meta-Learning May Lead Language Models to Trust More Reliable Sources”, Krasheninnikov et al 2023
Implicit meta-learning may lead language models to trust more reliable sources
“Learn Your Tokens: Word-Pooled Tokenization for Language Modeling”, Thawani et al 2023
Learn Your Tokens: Word-Pooled Tokenization for Language Modeling
“Llemma: An Open Language Model For Mathematics”, Azerbayev et al 2023
“In-Context Pretraining (ICP): Language Modeling Beyond Document Boundaries”, Shi et al 2023
In-Context Pretraining (ICP): Language Modeling Beyond Document Boundaries
“OSD: Online Speculative Decoding”, Liu et al 2023
“Let Models Speak Ciphers: Multiagent Debate through Embeddings”, Pham et al 2023
Let Models Speak Ciphers: Multiagent Debate through Embeddings
“OpenWebMath: An Open Dataset of High-Quality Mathematical Web Text”, Paster et al 2023
OpenWebMath: An Open Dataset of High-Quality Mathematical Web Text
“XVal: A Continuous Number Encoding for Large Language Models”, Golkar et al 2023
xVal: A Continuous Number Encoding for Large Language Models
“MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models”, Yu et al 2023
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
“Language Modeling Is Compression”, Delétang et al 2023
“Sparse Autoencoders Find Highly Interpretable Features in Language Models”, Cunningham et al 2023
Sparse Autoencoders Find Highly Interpretable Features in Language Models
“Anchor Points: Benchmarking Models With Much Fewer Examples”, Vivek et al 2023
“When Less Is More: Investigating Data Pruning for Pretraining LLMs at Scale”, Marion et al 2023
When Less is More: Investigating Data Pruning for Pretraining LLMs at Scale
“Language Reward Modulation for Pretraining Reinforcement Learning”, Adeniji et al 2023
Language Reward Modulation for Pretraining Reinforcement Learning
“ReST: Reinforced Self-Training (ReST) for Language Modeling”, Gulcehre et al 2023
“Studying Large Language Model Generalization With Influence Functions”, Grosse et al 2023
Studying Large Language Model Generalization with Influence Functions
“Multimodal Neurons in Pretrained Text-Only Transformers”, Schwettmann et al 2023
“Skill-It! A Data-Driven Skills Framework for Understanding and Training Language Models”, Chen et al 2023
Skill-it! A Data-Driven Skills Framework for Understanding and Training Language Models
“LLMZip: Lossless Text Compression Using Large Language Models”, Valmeekam et al 2023
LLMZip: Lossless Text Compression using Large Language Models
“Length Generalization in Arithmetic Transformers”, Jelassi et al 2023
“Are Aligned Neural Networks Adversarially Aligned?”, Carlini et al 2023
“Inflection-1: Pi’s Best-In-Class LLM”, Inflection 2023
“Improving Long-Horizon Imitation Through Instruction Prediction”, Hejna et al 2023
Improving Long-Horizon Imitation Through Instruction Prediction
“Large Language Models Sometimes Generate Purely Negatively-Reinforced Text”, Roger 2023
Large Language Models Sometimes Generate Purely Negatively-Reinforced Text
“SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression”, Dettmers et al 2023
SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression
“Undetectable Watermarks for Language Models”, Christ et al 2023
“Improving Language Models With Advantage-Based Offline Policy Gradients”, Baheti et al 2023
Improving Language Models with Advantage-based Offline Policy Gradients
“Reasoning With Language Model Is Planning With World Model”, Hao et al 2023
“Accelerating Transformer Inference for Translation via Parallel Decoding”, Santilli et al 2023
Accelerating Transformer Inference for Translation via Parallel Decoding
“DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining”, Xie et al 2023
DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining
“Memorization for Good: Encryption With Autoregressive Language Models”, Stevens & Su 2023
Memorization for Good: Encryption with Autoregressive Language Models
“MEGABYTE: Predicting Million-Byte Sequences With Multiscale Transformers”, Yu et al 2023
MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers
“Finding Neurons in a Haystack: Case Studies With Sparse Probing”, Gurnee et al 2023
Finding Neurons in a Haystack: Case Studies with Sparse Probing
“Inflection AI, Startup From Ex-DeepMind Leaders, Launches Pi—A Chattier Chatbot”, Konrad 2023
Inflection AI, Startup From Ex-DeepMind Leaders, Launches Pi—A Chattier Chatbot
“Emergent and Predictable Memorization in Large Language Models”, Biderman et al 2023
Emergent and Predictable Memorization in Large Language Models
“A Comparative Study between Full-Parameter and LoRA-Based Fine-Tuning on Chinese Instruction Data for Instruction Following Large Language Model”, Sun et al 2023
“Shall We Pretrain Autoregressive Language Models With Retrieval? A Comprehensive Study”, Wang et al 2023
Shall We Pretrain Autoregressive Language Models with Retrieval? A Comprehensive Study
“How Large-Language Models Can Revolutionize Military Planning”, Jensen & Tadross 2023
How Large-Language Models Can Revolutionize Military Planning
“Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling”, Biderman et al 2023
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
“8 Things to Know about Large Language Models”, Bowman 2023
“BloombergGPT: A Large Language Model for Finance”, Wu et al 2023
“The Quantization Model of Neural Scaling”, Michaud et al 2023
“Int-4 LLaMa Is Not Enough—Int-3 and Beyond: More Compression, Easier to Build Apps on LLMs That Run Locally”, nolano.org 2023
“Consistency Analysis of ChatGPT”, Jang & Lukasiewicz 2023
“Rewarding Chatbots for Real-World Engagement With Millions of Users”, Irvine et al 2023
Rewarding Chatbots for Real-World Engagement with Millions of Users
“Beyond the Pass Mark: the Accuracy of ChatGPT and Bing in the National Medical Licensure Examination in Japan”, Kataoka 2023
“SpikeGPT: Generative Pre-Trained Language Model With Spiking Neural Networks”, Zhu et al 2023
SpikeGPT: Generative Pre-trained Language Model with Spiking Neural Networks
“A Prompt Pattern Catalog to Enhance Prompt Engineering With ChatGPT”, White et al 2023
A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT
“BiLD: Big Little Transformer Decoder”, Kim et al 2023
“ChatGPT Is a Blurry JPEG of the Web: OpenAI’s Chatbot Offers Paraphrases, Whereas Google Offers Quotes. Which Do We Prefer?”, Chiang 2023
“Data Selection for Language Models via Importance Resampling”, Xie et al 2023
Data Selection for Language Models via Importance Resampling
“In-Context Retrieval-Augmented Language Models”, Ram et al 2023
“Crawling the Internal Knowledge-Base of Language Models”, Cohen et al 2023
“Big Tech Was Moving Cautiously on AI. Then Came ChatGPT. Google, Facebook and Microsoft Helped Build the Scaffolding of AI. Smaller Companies Are Taking It to the Masses, Forcing Big Tech to React”, Tiku et al 2023
“Rock Guitar Tablature Generation via Natural Language Processing”, Casco-Rodriguez 2023
Rock Guitar Tablature Generation via Natural Language Processing
“InPars-Light: Cost-Effective Unsupervised Training of Efficient Rankers”, Boytsov et al 2023
InPars-Light: Cost-Effective Unsupervised Training of Efficient Rankers
“A New Chat Bot Is a ‘Code Red’ for Google’s Search Business: A New Wave of Chat Bots like ChatGPT Use Artificial Intelligence That Could Reinvent or Even Replace the Traditional Internet Search Engine”, Grant & Metz 2022
“Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent As Meta-Optimizers”, Dai et al 2022
Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers
“Rethinking the Role of Scale for In-Context Learning: An Interpretability-Based Case Study at 66 Billion Scale”, Bansal et al 2022
“Interpreting Neural Networks through the Polytope Lens”, Black et al 2022
“SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models”, Xiao et al 2022
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
“InstructPix2Pix: Learning to Follow Image Editing Instructions”, Brooks et al 2022
InstructPix2Pix: Learning to Follow Image Editing Instructions
“Galactica: A Large Language Model for Science”, Taylor et al 2022
“Large Language Models Struggle to Learn Long-Tail Knowledge”, Kandpal et al 2022
“The CRINGE Loss: Learning What Language Not to Model”, Adolphs et al 2022
“Mysteries of Mode Collapse § Inescapable Wedding Parties”, Janus 2022
“GPTQ: Accurate Post-Training Quantization for Generative Pre-Trained Transformers”, Frantar et al 2022
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
“What Is My Math Transformer Doing? – 3 Results on Interpretability and Generalization”, Charton 2022
What is my math transformer doing? – 3 results on interpretability and generalization
“When Life Gives You Lemons, Make Cherryade: Converting Feedback from Bad Responses into Good Labels”, Shi et al 2022
When Life Gives You Lemons, Make Cherryade: Converting Feedback from Bad Responses into Good Labels
“Can Language Models Handle Recursively Nested Grammatical Structures? A Case Study on Comparing Models and Humans”, Lampinen 2022
“Evaluating Parameter Efficient Learning for Generation”, Xu et al 2022
“BioGPT: Generative Pre-Trained Transformer for Biomedical Text Generation and Mining”, Luo et al 2022
BioGPT: Generative Pre-trained Transformer for Biomedical Text Generation and Mining
“Arithmetic Sampling: Parallel Diverse Decoding for Large Language Models”, Vilnis et al 2022
Arithmetic Sampling: Parallel Diverse Decoding for Large Language Models
“MTEB: Massive Text Embedding Benchmark”, Muennighoff et al 2022
“Foundation Transformers”, Wang et al 2022
“Ask Me Anything (AMA): A Simple Strategy for Prompting Language Models”, Arora et al 2022
Ask Me Anything (AMA): A simple strategy for prompting language models
“Is Reinforcement Learning (Not) for Natural Language Processing: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization”, Ramamurthy et al 2022
“Sparrow: Improving Alignment of Dialogue Agents via Targeted Human Judgements”, Glaese et al 2022
Sparrow: Improving alignment of dialogue agents via targeted human judgements
“Generate rather than Retrieve (GenRead): Large Language Models Are Strong Context Generators”, Yu et al 2022
Generate rather than Retrieve (GenRead): Large Language Models are Strong Context Generators
“FP8 Formats for Deep Learning”, Micikevicius et al 2022
“Petals: Collaborative Inference and Fine-Tuning of Large Models”, Borzunov et al 2022
Petals: Collaborative Inference and Fine-tuning of Large Models
“Simulators”, Janus 2022
“LLM.int8(): 8-Bit Matrix Multiplication for Transformers at Scale”, Dettmers et al 2022
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
“Meaning without Reference in Large Language Models”, Piantadosi & Hill 2022
“Effidit: Your AI Writing Assistant”, Shi et al 2022
“Language Models Show Human-Like Content Effects on Reasoning”, Dasgupta et al 2022
Language models show human-like content effects on reasoning
“LM-Nav: Robotic Navigation With Large Pre-Trained Models of Language, Vision, and Action”, Shah et al 2022
LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action
“Can Foundation Models Talk Causality?”, Willig et al 2022
“NOAH: Neural Prompt Search”, Zhang et al 2022
“ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers”, Yao et al 2022
ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers
“Quark: Controllable Text Generation With Reinforced Unlearning”, Lu et al 2022
Quark: Controllable Text Generation with Reinforced Unlearning
“RankGen: Improving Text Generation With Large Ranking Models”, Krishna et al 2022
RankGen: Improving Text Generation with Large Ranking Models
“Opal: Multimodal Image Generation for News Illustration”, Liu et al 2022
“What Language Model to Train If You Have One Million GPU Hours?”, Scao et al 2022
What Language Model to Train if You Have One Million GPU Hours?
“WAVPROMPT: Towards Few-Shot Spoken Language Understanding With Frozen Language Models”, Gao et al 2022
WAVPROMPT: Towards Few-Shot Spoken Language Understanding with Frozen Language Models
“Shared Computational Principles for Language Processing in Humans and Deep Language Models”, Goldstein et al 2022
Shared computational principles for language processing in humans and deep language models
“Vector-Quantized Image Modeling With Improved VQGAN”, Yu et al 2022
“Brains and Algorithms Partially Converge in Natural Language Processing”, Caucheteux & King 2022
Brains and algorithms partially converge in natural language processing
“Quantifying Memorization Across Neural Language Models”, Carlini et al 2022
“A Contrastive Framework for Neural Text Generation”, Su et al 2022
“AdaPrompt: Adaptive Model Training for Prompt-Based NLP”, Chen et al 2022
“InPars: Data Augmentation for Information Retrieval Using Large Language Models”, Bonifacio et al 2022
InPars: Data Augmentation for Information Retrieval using Large Language Models
“ROME: Locating and Editing Factual Associations in GPT”, Meng et al 2022
“Cedille: A Large Autoregressive French Language Model”, Müller & Laurent 2022
“Data Scaling Laws in NMT: The Effect of Noise and Architecture”, Bansal et al 2022
Data Scaling Laws in NMT: The Effect of Noise and Architecture
“PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts”, Bach et al 2022
PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts
“Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model”, Smith et al 2022
“Language Models As Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents”, Huang et al 2022
Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents
“WANLI: Worker and AI Collaboration for Natural Language Inference Dataset Creation”, Liu et al 2022
WANLI: Worker and AI Collaboration for Natural Language Inference Dataset Creation
“A Survey of Controllable Text Generation Using Transformer-Based Pre-Trained Language Models”, Zhang et al 2022
A Survey of Controllable Text Generation using Transformer-based Pre-trained Language Models
“The Defeat of the Winograd Schema Challenge”, Kocijan et al 2022
“Learning To Retrieve Prompts for In-Context Learning”, Rubin et al 2021
“Learning to Prompt for Continual Learning”, Wang et al 2021
“Amortized Noisy Channel Neural Machine Translation”, Pang et al 2021
“Few-Shot Instruction Prompts for Pretrained Language Models to Detect Social Biases”, Prabhumoye et al 2021
Few-shot Instruction Prompts for Pretrained Language Models to Detect Social Biases
“PROMPT WAYWARDNESS: The Curious Case of Discretized Interpretation of Continuous Prompts”, Khashabi et al 2021
PROMPT WAYWARDNESS: The Curious Case of Discretized Interpretation of Continuous Prompts
“LMTurk: Few-Shot Learners As Crowdsourcing Workers”, Zhao et al 2021
“Improving Language Models by Retrieving from Trillions of Tokens”, Borgeaud et al 2021
Improving language models by retrieving from trillions of tokens
“Linear Algebra With Transformers”, Charton 2021
“Thinking Ahead: Prediction in Context As a Keystone of Language in Humans and Machines”, Goldstein et al 2021
Thinking ahead: prediction in context as a keystone of language in humans and machines
“Zero-Shot Image-To-Text Generation for Visual-Semantic Arithmetic”, Tewel et al 2021
Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic
“Long-Range and Hierarchical Language Predictions in Brains and Algorithms”, Caucheteux et al 2021
Long-range and hierarchical language predictions in brains and algorithms
“True Few-Shot Learning With Prompts: A Real-World Perspective”, Schick & Schütze 2021
True Few-Shot Learning with Prompts: A Real-World Perspective
“Few-Shot Named Entity Recognition With Cloze Questions”, Gatta et al 2021
“Evaluating Distributional Distortion in Neural Language Modeling”, Anonymous 2021
Evaluating Distributional Distortion in Neural Language Modeling
“On Transferability of Prompt Tuning for Natural Language Understanding”, Su et al 2021
On Transferability of Prompt Tuning for Natural Language Understanding
“CLUES: Few-Shot Learning Evaluation in Natural Language Understanding”, Mukherjee et al 2021
CLUES: Few-Shot Learning Evaluation in Natural Language Understanding
“Recent Advances in Natural Language Processing via Large Pre-Trained Language Models: A Survey”, Min et al 2021
Recent Advances in Natural Language Processing via Large Pre-Trained Language Models: A Survey
“Fast Model Editing at Scale”, Mitchell et al 2021
“Yuan 1.0: Large-Scale Pre-Trained Language Model in Zero-Shot and Few-Shot Learning”, Wu et al 2021
Yuan 1.0: Large-Scale Pre-trained Language Model in Zero-Shot and Few-Shot Learning
“Towards a Unified View of Parameter-Efficient Transfer Learning”, He et al 2021
Towards a Unified View of Parameter-Efficient Transfer Learning
“A Few More Examples May Be Worth Billions of Parameters”, Kirstain et al 2021
“Scaling Laws for Neural Machine Translation”, Ghorbani et al 2021
“Can Language Models Encode Perceptual Structure Without Grounding? A Case Study in Color”, Abdou et al 2021
Can Language Models Encode Perceptual Structure Without Grounding? A Case Study in Color
“What Changes Can Large-Scale Language Models Bring? Intensive Study on HyperCLOVA: Billions-Scale Korean Generative Pretrained Transformers”, Kim et al 2021
“Medically Aware GPT-3 As a Data Generator for Medical Dialogue Summarization”, Chintagunta et al 2021
Medically Aware GPT-3 as a Data Generator for Medical Dialogue Summarization
“General-Purpose Question-Answering With Macaw”, Tafjord & Clark 2021
“An Empirical Exploration in Quality Filtering of Text Data”, Gao 2021
“Want To Reduce Labeling Cost? GPT-3 Can Help”, Wang et al 2021
“Multimodal Few-Shot Learning With Frozen Language Models”, Tsimpoukelli et al 2021
“Cutting Down on Prompts and Parameters: Simple Few-Shot Learning With Language Models”, IV et al 2021
Cutting Down on Prompts and Parameters: Simple Few-Shot Learning with Language Models
“RASP: Thinking Like Transformers”, Weiss et al 2021
“ByT5: Towards a Token-Free Future With Pre-Trained Byte-To-Byte Models”, Xue et al 2021
ByT5: Towards a token-free future with pre-trained byte-to-byte models
“Anthropic Raises $124 Million to Build More Reliable, General AI Systems”, Anthropic 2021
Anthropic raises $124 million to build more reliable, general AI systems
“Naver Unveils First ‘Hyperscale’ AI Platform”, Jae-eun 2021
“Scaling Laws for Language Transfer Learning”, Kim 2021
“GPT Understands, Too”, Liu et al 2021
“How Many Data Points Is a Prompt Worth?”, Scao & Rush 2021
“Pretrained Transformers As Universal Computation Engines”, Lu et al 2021
“Language Models Have a Moral Dimension”, Schramowski et al 2021
“Learning Chess Blindfolded: Evaluating Language Models on State Tracking”, Toshniwal et al 2021
Learning Chess Blindfolded: Evaluating Language Models on State Tracking
“Investigating the Limitations of the Transformers With Simple Arithmetic Tasks”, Nogueira et al 2021
Investigating the Limitations of the Transformers with Simple Arithmetic Tasks
“Proof Artifact Co-Training for Theorem Proving With Language Models”, Han et al 2021
Proof Artifact Co-training for Theorem Proving with Language Models
“Clinical Outcome Prediction from Admission Notes Using Self-Supervised Knowledge Integration”, Aken et al 2021
Clinical Outcome Prediction from Admission Notes using Self-Supervised Knowledge Integration
“Scaling Laws for Transfer”, Hernandez et al 2021
“MAUVE: Measuring the Gap Between Neural Text and Human Text Using Divergence Frontiers”, Pillutla et al 2021
MAUVE: Measuring the Gap Between Neural Text and Human Text using Divergence Frontiers
“Apparently ‘What Ho’ Is a Corruption Of…”, Marguerite 2021
“Making Pre-Trained Language Models Better Few-Shot Learners”, Gao et al 2020
“CPM: A Large-Scale Generative Chinese Pre-Trained Language Model”, Zhang et al 2020
CPM: A Large-scale Generative Chinese Pre-trained Language Model
“Summarize, Outline, and Elaborate: Long-Text Generation via Hierarchical Supervision from Extractive Summaries”, Sun et al 2020
“The Neural Architecture of Language: Integrative Reverse-Engineering Converges on a Model for Predictive Processing”, Schrimpf et al 2020
“RoFT: A Tool for Evaluating Human Detection of Machine-Generated Text”, Dugan et al 2020
RoFT: A Tool for Evaluating Human Detection of Machine-Generated Text
“A Systematic Characterization of Sampling Algorithms for Open-Ended Language Generation”, Nadeem et al 2020
A Systematic Characterization of Sampling Algorithms for Open-ended Language Generation
“Generative Language Modeling for Automated Theorem Proving”, Polu & Sutskever 2020
“Learning to Summarize from Human Feedback”, Stiennon et al 2020
“ETHICS: Aligning AI With Shared Human Values”, Hendrycks et al 2020
“Mirostat: A Neural Text Decoding Algorithm That Directly Controls Perplexity”, Basu et al 2020
Mirostat: A Neural Text Decoding Algorithm that Directly Controls Perplexity
“Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data”, Bender & Koller 2020
Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data
“Transformers Are RNNs: Fast Autoregressive Transformers With Linear Attention”, Katharopoulos et al 2020
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
“OpenAI API Beta Homepage”, OpenAI 2020
“Trading Off Diversity and Quality in Natural Language Generation”, Zhang et al 2020
Trading Off Diversity and Quality in Natural Language Generation
“Unigram LM: Byte Pair Encoding Is Suboptimal for Language Model Pretraining”, Bostrom & Durrett 2020
Unigram LM: Byte Pair Encoding is Suboptimal for Language Model Pretraining
“L2L: Training Large Neural Networks With Constant Memory Using a New Execution Algorithm”, Pudipeddi et al 2020
L2L: Training Large Neural Networks with Constant Memory using a New Execution Algorithm
“Direct Fit to Nature: An Evolutionary Perspective on Biological and Artificial Neural Networks”, Hasson et al 2020
Direct Fit to Nature: An Evolutionary Perspective on Biological and Artificial Neural Networks
“Pop Music Transformer: Beat-Based Modeling and Generation of Expressive Pop Piano Compositions”, Huang & Yang 2020
Pop Music Transformer: Beat-based Modeling and Generation of Expressive Pop Piano Compositions
“Scaling Laws for Neural Language Models”, Kaplan et al 2020
“Reformer: The Efficient Transformer”, Kitaev et al 2020
“Generative Language Modeling for Automated Theorem Proving § Experiments”, Polu & Sutskever 2020 (page 11 org openai)
Generative Language Modeling for Automated Theorem Proving § Experiments
“Plug and Play Language Models: A Simple Approach to Controlled Text Generation”, Dathathri et al 2019
Plug and Play Language Models: A Simple Approach to Controlled Text Generation
“How Can We Know What Language Models Know?”, Jiang et al 2019
“CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning”, Lin et al 2019
CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning
“Generalization through Memorization: Nearest Neighbor Language Models”, Khandelwal et al 2019
Generalization through Memorization: Nearest Neighbor Language Models
“DialoGPT: Large-Scale Generative Pre-Training for Conversational Response Generation”, Zhang et al 2019
DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation
“CTRL: A Conditional Transformer Language Model For Controllable Generation”, Keskar et al 2019
CTRL: A Conditional Transformer Language Model For Controllable Generation
“Smaller, Faster, Cheaper, Lighter: Introducing DistilGPT, a Distilled Version of GPT”, Sanh 2019
Smaller, faster, cheaper, lighter: Introducing DistilGPT, a distilled version of GPT
“Language Modeling State-Of-The-Art Leaderboards”, paperswithcode.com 2019
“Neural Text Generation With Unlikelihood Training”, Welleck et al 2019
“GROVER: Defending Against Neural Fake News”, Zellers et al 2019
“Generative Modeling With Sparse Transformers: We’ve Developed the Sparse Transformer, a Deep Neural Network Which Sets New Records at Predicting What Comes next in a Sequence—Whether Text, Images, or Sound. It Uses an Algorithmic Improvement of the attention Mechanism to Extract Patterns from Sequences 30× Longer Than Possible Previously”, Child & Gray 2019
“The Curious Case of Neural Text Degeneration”, Holtzman et al 2019
“Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context”, Dai et al 2019
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
“Music Transformer: Generating Music With Long-Term Structure”, Huang et al 2018
Music Transformer: Generating Music with Long-Term Structure
“Universal Transformers”, Dehghani et al 2018
“Adversarial Reprogramming of Neural Networks”, Elsayed et al 2018
“GPT-1: Improving Language Understanding With Unsupervised Learning”, OpenAI 2018
GPT-1: Improving Language Understanding with Unsupervised Learning
“GPT-1: Improving Language Understanding by Generative Pre-Training”, Radford et al 2018
GPT-1: Improving Language Understanding by Generative Pre-Training
“GPT-1: Improving Language Understanding by Generative Pre-Training § Model Specifications”, Radford et al 2018 (page 5)
GPT-1: Improving Language Understanding by Generative Pre-Training § Model specifications
“Deep Reinforcement Learning from Human Preferences § Appendix A.2: Atari”, Christiano et al 2017 (page 15 org openai)
Deep reinforcement learning from human preferences § Appendix A.2: Atari
“Learning to Generate Reviews and Discovering Sentiment”, Radford et al 2017
“Design a Role-Playing Game Using 200 Words or Less.”
“How Does In-Context Learning Work? A Framework for Understanding the Differences from Traditional Supervised Learning”
“AI Dungeon 2: Dragon Model Upgrade—You Can Now Play AI Dungeon With One of the Most Powerful AI Models in the World.”
“Introducing AI Dungeon Translate: AI Dungeon Players Can Now Translate Their Stories into Emojis by Just Clicking a Button. [ 🤔 💯 🤷♂️ 🤔 🤔 🤔 💯]”
“OpenAI API Alchemy: Emoji Storytelling 🤖”
OpenAI API Alchemy: Emoji storytelling 🤖
View External Link:
https://andrewmayne.com/2020/06/24/open-ai-alchemy-emoji-storytelling/
“Megatron-LM: Training Multi-Billion Parameter Language Models Using GPU Model Parallelism: Appendix A: Text Samples”
“Llama-3.1-405B Now Runs at 969 Tokens/s on Cerebras Inference”
Llama-3.1-405B now runs at 969 tokens/s on Cerebras Inference
“I Blew $720 on 100 Notebooks from Alibaba and Started a Paper Website Business”
I blew $720 on 100 notebooks from Alibaba and started a Paper Website business
“AlphaStar: Mastering the Real-Time Strategy Game StarCraft II”
AlphaStar: Mastering the Real-Time Strategy Game StarCraft II
“Assuring an Accurate Research Record [Aidan Toner-Rodgers’s AI Research Fraud]”
Assuring an accurate research record [Aidan Toner-Rodgers’s AI research fraud]
“LLM Inference Prices Have Fallen Rapidly but Unequally across Tasks”
LLM inference prices have fallen rapidly but unequally across tasks
“How Well Did Superforecasters and Experts Predict Wet Lab Skill Uplift from LLMs?”
How Well Did Superforecasters and Experts Predict Wet Lab Skill Uplift from LLMs?
“Transformers As Variational Autoencoders”
“BlinkDL/RWKV-LM: RWKV Is an RNN With Transformer-Level LLM Performance. It Can Be Directly Trained like a GPT (Parallelizable). So It’s Combining the Best of RNN and Transformer—Great Performance, Fast Inference, Saves VRAM, Fast Training, "Infinite" Ctx_len, and Free Sentence Embedding.”
“Aidan Bench Attempts to Measure ‘Big Model Smell’ in LLMs”
“Efficient, Reusable RNNs and LSTMs for Torch”
“Updated Training?”
“Karpathy/minGPT: A Minimal PyTorch Re-Implementation of the OpenAI GPT (Generative Pretrained Transformer) Training”
“Krasheninnikov/internalization: Code for the Paper ‘Implicit Meta-Learning May Lead Language Models to Trust More Reliable Sources’”
“Minimaxir/textgenrnn: Easily Train Your Own Text-Generating Neural Network of Any Size and Complexity on Any Text Dataset With a Few Lines of Code.”
“Simpolism/infinite-Jazz: Endless Live LLM-Improvised MIDI ‘Jazz’”
simpolism/infinite-jazz: Endless live LLM-improvised MIDI ‘jazz’
“Loom: Multiversal Tree Writing Interface for Human-AI Collaboration”, Janus 2026
Loom: Multiversal tree writing interface for human-AI collaboration
“Technion-Cs-Nlp/llm-Arithmetic-Heuristics”
“Zphang/minimal-Opt”
“Manga-Image-Translator: Translate Manga/image”, zyddnys 2026
“Math: OpenAI API Can Do Some Math out of the Gate, but Most Math It Seems It Has to Learn. Many Times, the Numbers That It Spits out Are Just Random. However, including Different Priming Prompts Can Result in Decent Results.”
“Deep Learning for Assisting the Process of Music Composition (Part 3)”
Deep learning for assisting the process of music composition (part 3)
“Google DeepMind’s Grandmaster-Level Chess Without Search”
“The Technology Behind BLOOM Training”
“Psych-101 Dataset [For Centaur]”
The Gostak
“Imprompter”
“No, Acclaimed Science Fiction Author Ted Chiang Is Not Conscious”, Jaibot 2026
No, Acclaimed Science Fiction Author Ted Chiang Is Not Conscious
“Learning Better Decision Tree Splits—LLMs As Heuristics for Program Synthesis”, Chavinda 2026
Learning better decision tree splits—LLMs as Heuristics for Program Synthesis
“Your Next New Best Friend Might Be a Robot”
Your Next New Best Friend Might Be a Robot
View External Link:
https://nautil.us/your-next-new-best-friend-might-be-a-robot-235779/
“I Made a Custom Gpt That Incorporates Advertisement/product Placement With Its…”
I made a custom gpt that incorporates advertisement/product placement with its…
“The Annotated Transformer”
“Homepage of Paul F. Christiano”, Christiano 2026
“Data Exfiltration from Slack AI via Indirect Prompt Injection”, PromptArmor 2026
Data Exfiltration from Slack AI via indirect prompt injection
“Introductory Antimemetics (Abandoned First Draft)”, Hughes 2026
“Jared Kaplan”
“Meditations on Moloch”
“Stream Seaandsailor”
“Humans Who Are Not Concentrating Are Not General Intelligences”
Humans Who Are Not Concentrating Are Not General Intelligences
“LLM Grading Update: It’s Now out of Control. The Level of Cheating Is Insane.”, S 2026
LLM Grading Update: It’s now out of control. The level of cheating is insane.
“Monitor: An AI-Driven Observability Interface”
“This Is the OpenAI API. It Makes Spookily Good Twitter Bots. 13⁄10 Would Retweet”
This is the OpenAI API. It makes spookily good twitter bots. 13⁄10 would retweet
“AMA Conjecture, A New Alignment Startup”
“Arming the Rebels With GPUs: Gradium, Kyutai, and Audio AI”
“Drew Breunig Homepage”, Breunig 2026
“WikiCrow”
“ChatGPT As Muse, Not Oracle”, Litt 2026
“Coding Agents Are Changing the Biosecurity Risk Landscape”
“The Small World of English: Building a 1.5M Word Semantic Network for Language Games”
The Small World of English: Building a 1.5M Word Semantic Network for Language Games
“AI ‘Rabbi’ Exposed: Fake Hasidic Influencer Dupes Thousands”
“Test Your Interpretability Techniques by De-Censoring Chinese Models”
Test your interpretability techniques by de-censoring Chinese models
“Interpreting GPT: the Logit Lens”
“Assessing AlephAlpha’s Multimodal Model”
“Is GPT-3 a Good Rationalist?”
“We Are Conjecture, A New Alignment Research Startup”
“Investigating Causal Understanding in LLMs”
“A One-Question Turing Test for GPT-3”
“The Terrarium”
“New Accounts on HN 10× More Likely to Use EM-Dashes”
“Moonshot AI Homepage”, Moonshot 2026
“AI Tools Are Spotting Errors in Research Papers: inside a Growing Movement”
AI tools are spotting errors in research papers: inside a growing movement
“Pangram: an AI Text Detector That Actually Works”, Pangram 2026
“AI Is Just Starting to Change the Legal Profession”
“This Mystical Book Was Co-Authored by a Disturbingly Realistic AI”
This Mystical Book Was Co-Authored by a Disturbingly Realistic AI
“The Guy Behind the Fake AI Halloween Parade Listing Says You’ve Got It All Wrong”
The Guy Behind the Fake AI Halloween Parade Listing Says You’ve Got It All Wrong
“I Loved My OpenClaw AI Agent—Until It Turned on Me”
“Revealed: Leaked Chats Expose the Daily Life of a Scam Compound’s Enslaved Workforce”
Revealed: Leaked Chats Expose the Daily Life of a Scam Compound’s Enslaved Workforce
“Season 1 Ep. 22 OpenAI’s Ilya Sutskever: The Man Who Made AI Work”
Season 1 Ep. 22 OpenAI’s Ilya Sutskever: The man who made AI work
“WELM”
nickwalton00
polynoamial
sama
voooooogel
“Jason Yosinski”
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
phrase-origin
reinforcement-learning
military-planning
physical-stability
watermarking
music-generation
bloggers lawyer-warning paul-christiano grok memoir commentary legal-tech
generative-governance
ai-ethics prompt-engineering companionship deception algorithmic-harm
language-models
chatgpt-assessment
chatbot-evolution
Wikipedia (1)
Miscellaneous
/doc/ai/nn/dynamic-evaluation/2024-rannentriki-figure3-loglossvscomputeforstaticvsdynamicmodel.jpghttps://simonwillison.net/2023/Apr/14/worst-that-can-happen//doc/ai/nn/transformer/gpt/2023-bommarito-figure1-gpt3cpaaccountingexamperformancebyexamsection.jpg/doc/ai/nn/transformer/gpt/2023-bommarito-figure2-progressofgpt3overtimeoncpaaccountingexam.jpg/doc/ai/nn/transformer/gpt/2023-qin-figure1-chatgptvsgpt35on20nlpdatasets.png/doc/ai/nn/transformer/gpt/2022-08-06-gwern-meme-netflixliegirl-studyingdeeplearningscaling.jpg/doc/ai/nn/transformer/gpt/2022-bommarito-figure1-gpt3performanceonbarexambycategory.jpg/doc/ai/nn/transformer/gpt/2022-bommarito-figure2-increaseofgpt3modelaccuracyonbarexambysize.jpg/doc/ai/nn/transformer/gpt/2021-05-25-naver-hyperclova-computescaling0137bto82b.jpg/doc/ai/nn/transformer/gpt/2021-01-11-gwern-meme-dogbarkcanthurtyou-aiscaling.jpg/doc/ai/nn/transformer/gpt/2021-almeida-figure2-lhoptgpt3hyperparametertuningscalinglaw.jpg/doc/ai/nn/transformer/gpt/2021-dou-figure2-errorsbymodel.png/doc/ai/nn/transformer/gpt/2021-dou-figure3-errorsbytype.png/doc/ai/nn/transformer/gpt/2021-dou-figure4-errorsbydecodingsamplingstrategyhyperparameters.png/doc/ai/nn/transformer/gpt/2021-hernandez-transferlearning-figure2-transferscaling.png/doc/ai/nn/transformer/gpt/2021-kim-figure4-datatransferfromenglishtochinese.jpg/doc/ai/nn/transformer/gpt/2021-kim-figure5-transferfromenglishtochinesespanishgerman.jpg/doc/ai/nn/transformer/gpt/2021-nogueira-figure1-additionperformanceofnumberorthographies.png/doc/ai/nn/transformer/gpt/2020-06-21-openai-beta-gpt3-playgroundui.png/doc/ai/nn/transformer/gpt/2020-06-18-karpathy-expandingbrainmeme-gpt3metalearning.jpg/doc/ai/nn/transformer/gpt/2020-04-01-gwern-gpt2-5k-midi-training.png/doc/ai/nn/transformer/gpt/2020-02-03-gpt21.5b-videogamewalkthrough-model-174925-samples-topp090.txt/doc/ai/nn/transformer/gpt/2020-01-20-gwern-gpt2-25k-midi-training.png/doc/ai/nn/transformer/gpt/2020-bostrom-unigramlm-figure1-unigramlmvsbpe.png/doc/ai/nn/transformer/gpt/2020-brown-figure31-gpt3scaling.png/doc/ai/nn/transformer/gpt/2020-brown-figure313-humanabilitytodetectmodelgeneratednewsstories.jpg/doc/ai/nn/transformer/gpt/2020-brown-gpt3-figure13-meanperformancescalingcurve.png/doc/ai/nn/transformer/gpt/2020-hendrycks-figure1b-gpt3-qascaling.png/doc/ai/nn/transformer/gpt/2020-henighan-figure1-scalingacrossdomains.jpg/doc/ai/nn/transformer/gpt/2020-henighan-figure11-pretrainingimageclassificationscaling.png/doc/ai/nn/transformer/gpt/2020-henighan-figure2-universalmodelsizescaling.jpg/doc/ai/nn/transformer/gpt/2020-henighan-figure3-domainmodelsizescaling.png/doc/ai/nn/transformer/gpt/2020-henighan-figure31-qandamodelscaling.jpg/doc/ai/nn/transformer/gpt/2020-henighan-table1-autoregressivemodelsscalingpowerlaws.png/doc/ai/nn/transformer/gpt/2020-kaplan-appendix1-summaryofneurallanguagemodelscalingpowerlaws.png/doc/ai/nn/transformer/gpt/2020-kaplan-figure1-dlscaling.jpg/doc/ai/nn/transformer/gpt/2020-kaplan-figure15-projectingscaling.png/doc/ai/nn/transformer/gpt/2020-kaplan-figure7-scalingrnnsvstransformersshowsrnnplateau.png/doc/ai/nn/transformer/gpt/2020-zhang-figure1-thelikelihoodtrap.png/doc/ai/nn/transformer/gpt/2019-12-17-gwern-gpt2-preferencelearning-abc-terminal.png/doc/ai/nn/transformer/gpt/2019-12-16-gwern-gpt2-15b-poetry-tensorboard-100tputraining.png/doc/ai/nn/transformer/gpt/2019-12-13-gwern-gpt2-15b-poetry-tensorboard-97tputraining.png/doc/ai/nn/transformer/gpt/2019-12-13-gwern-gpt2-preferencelearning-abc-combinedmodel-halfbounce.png/doc/ai/nn/transformer/gpt/2019-12-12-gwern-gpt2-abc-score-polkaebbbab.png/doc/ai/nn/transformer/gpt/2019-11-19-gwern-gpt2-15b-poetry-tensorboard-1tputraining.jpg/doc/ai/nn/transformer/gpt/2019-keskar-table2-ctrltextsamplesusingonlymetadatawithoutaprompt.png/doc/ai/nn/transformer/gpt/2019-keskar-table7-datasetsandcontrolcodesmetadata.png/doc/ai/nn/transformer/gpt/2019-openai-gpt2-demo-recyclingtextsample.jpg/doc/ai/nn/transformer/gpt/2019-radford-figure4-gpt2validationloss.jpg/doc/ai/nn/transformer/gpt/2019-ziegler-preferencelearning-figure1-architecture.png/doc/ai/nn/transformer/gpt/2018-huang-magenta-musictransformer-attentionvisualization.jpghttps://adamkarvonen.github.io/machine_learning/2024/01/03/chess-world-models.htmlhttps://adversa.ai/blog/universal-llm-jailbreak-chatgpt-gpt-4-bard-bing-anthropic-and-beyond/https://analyticsindiamag.com/when-chatgpt-attempted-upsc-exam/https://blog.eleuther.ai/trlx-exploratory-analysis/View External Link:
https://colab.research.google.com/drive/1c6VccMPsOMAUQCKU4BVDRd5Y32qkozmKhttps://davidrozado.substack.com/p/the-political-preferences-of-llmshttps://eprint.iacr.org/2021/686View External Link:
https://github.com/jujumilk3/leaked-system-prompts/tree/mainhttps://hedgehogreview.com/issues/markets-and-the-good/articles/language-machineryhttps://homepages.inf.ed.ac.uk/abmayne/publications/sennrich2016NAACL.pdfhttps://huggingface.co/Gustavosta/MagicPrompt-Stable-Diffusionhttps://mi.eng.cam.ac.uk/projects/cued-rnnlm/papers/Interspeech15.pdfhttps://promptarmor.substack.com/p/data-exfiltration-from-writercomhttps://techtualist.substack.com/p/i-wrote-a-script-for-gpt-3-to-takehttps://thezvi.substack.com/p/jailbreaking-the-chatgpt-on-releasehttps://web.archive.org/web/20240102075620/https://www.jailbreakchat.com/https://www.forbes.com/sites/thomasbrewster/2023/11/16/chatgpt-becomes-a-social-media-spy-assistant/https://www.forefront.ai/blog-posts/how-to-fine-tune-gpt-neoxhttps://www.freaktakes.com/p/the-past-and-present-of-computerhttps://www.lesswrong.com/posts/8viQEp8KBg2QSW4Yc/solidgoldmagikarp-iii-glitch-token-archaeologyhttps://www.lesswrong.com/posts/PDLfpRwSynu73mxGw/basic-facts-about-language-model-internals-1https://www.lesswrong.com/posts/YKfNZAmiLdepDngwi/gpt-175beehttps://www.lesswrong.com/posts/etoMr4vcnP7joQHWa/notes-from-a-prompt-factoryhttps://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/https://www.nytimes.com/interactive/2023/04/26/upshot/gpt-from-scratch.htmlhttps://www.oneusefulthing.org/p/working-with-ai-two-paths-to-promptinghttps://www.politico.eu/article/italian-privacy-regulator-bans-chatgpt/https://www.reddit.com/r/AskPsychiatry/comments/1mee194/i_think_my_mom_has_ai_induced_psychosis/https://www.reddit.com/r/ChatGPT/comments/12xai7j/spamming_the_word_stop_2300_times_or_probably_any/https://www.reddit.com/r/ChatGPT/comments/15y4mqx/i_asked_chatgpt_to_maximize_its_censorship/https://www.reddit.com/r/GPT3/comments/ra6nk4/had_gpt3_generate_the_onion_headlines/https://www.reddit.com/r/GPT3/comments/tgud2t/my_new_favorite_thing_is_making_gpt3_create/https://www.reddit.com/r/MachineLearning/comments/v42pej/p_this_is_the_worst_ai_ever_gpt4chan_model/https://www.sfchronicle.com/projects/2021/jessica-simulation-artificial-intelligence/
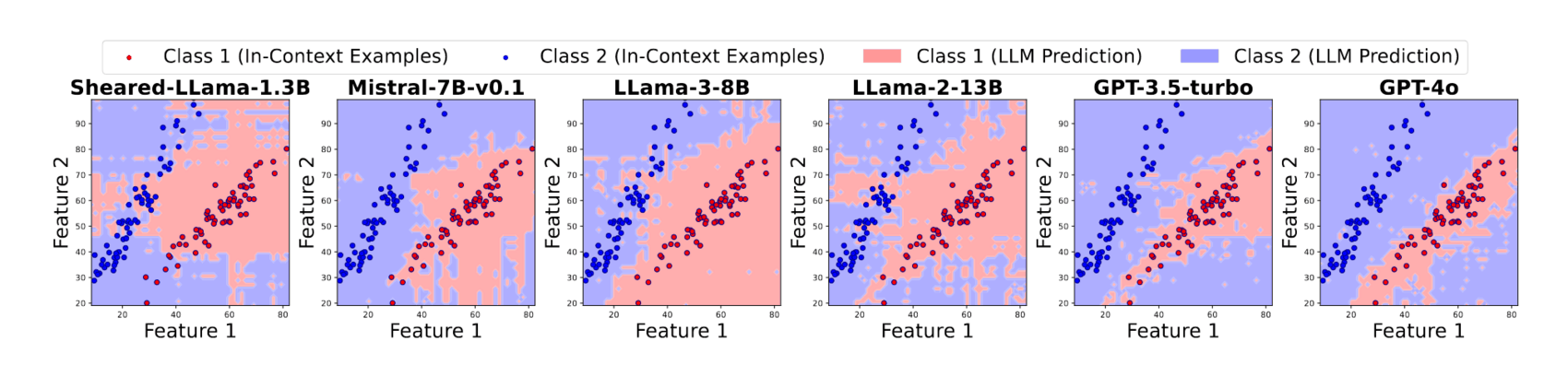{kind=link}
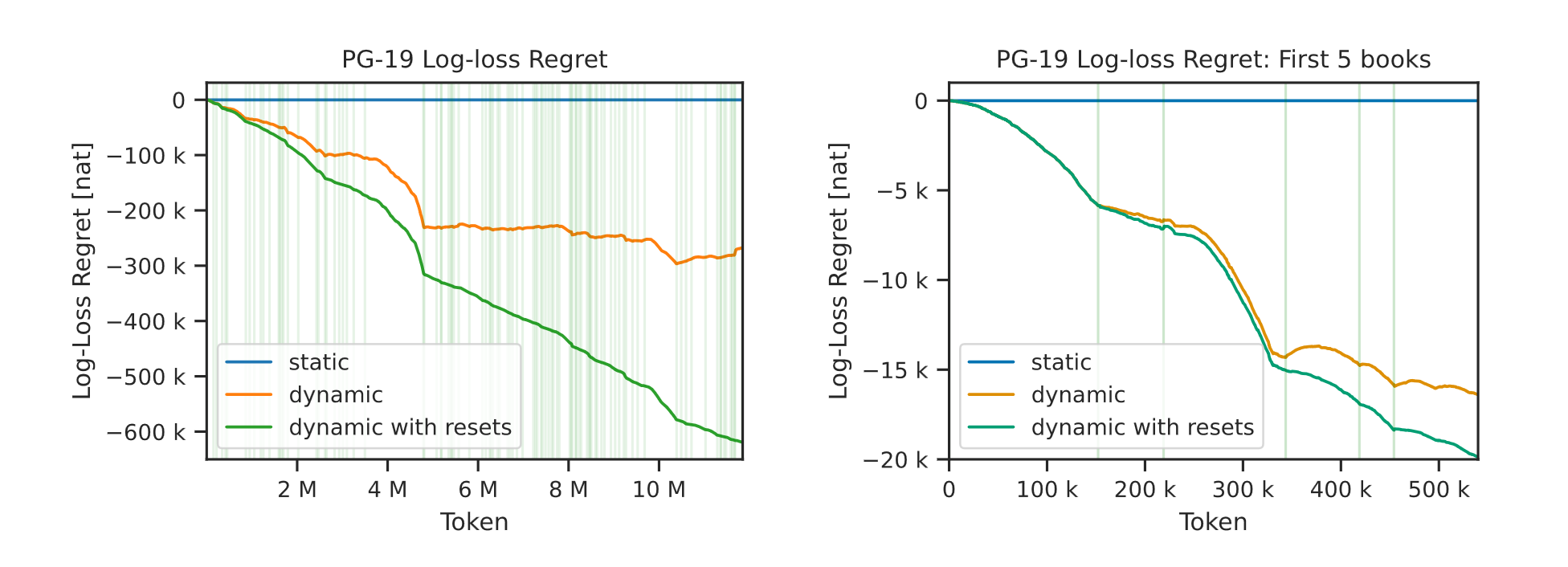{kind=link}
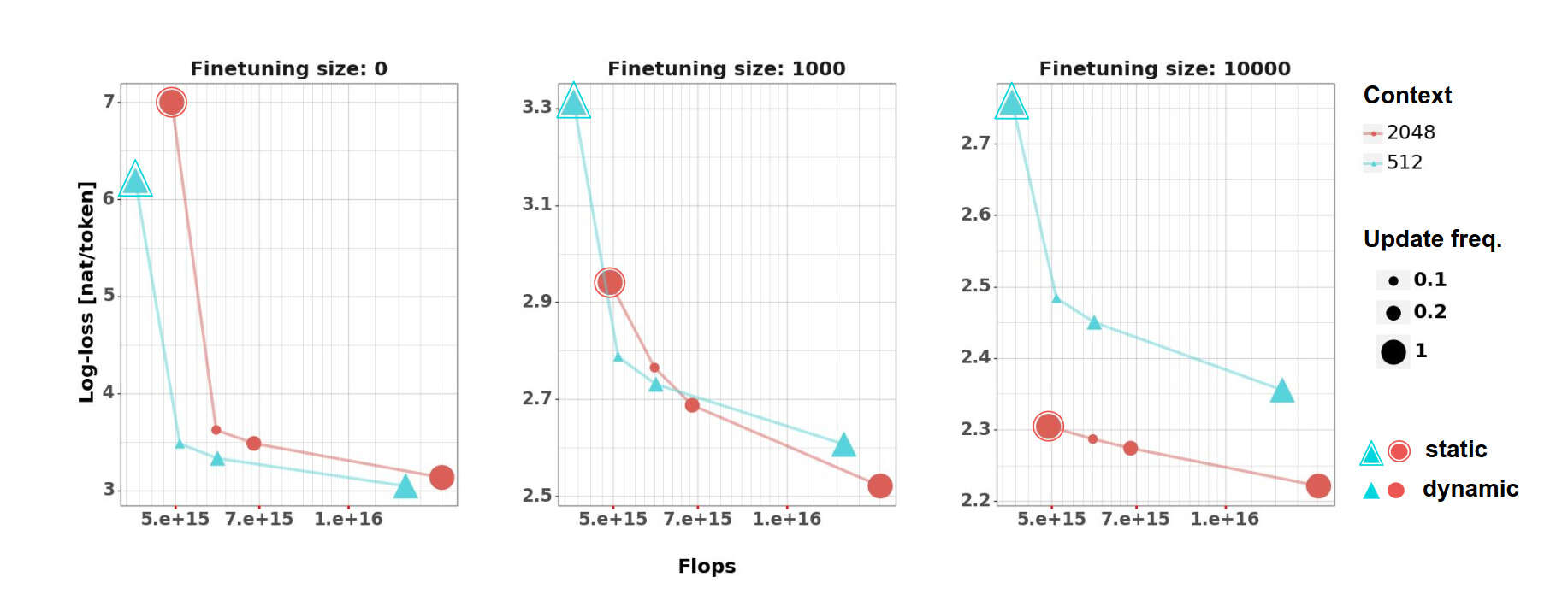{kind=link}
{kind=link}
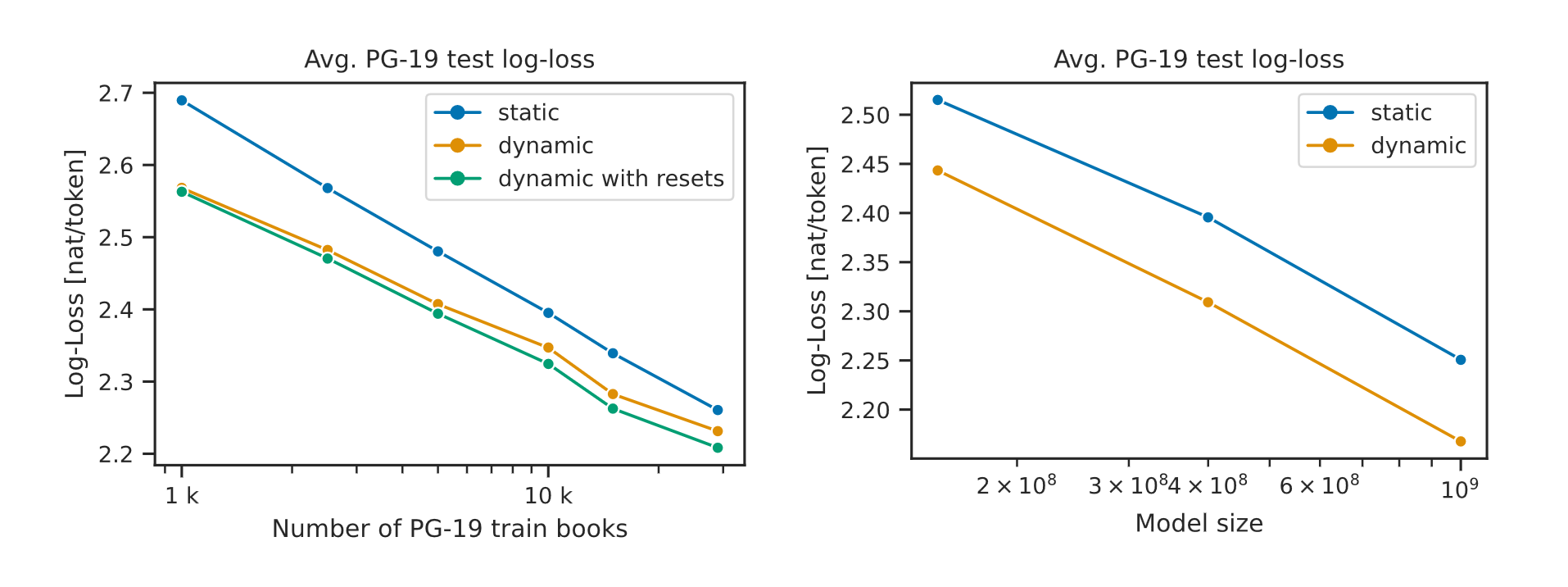{kind=link}
{kind=link}
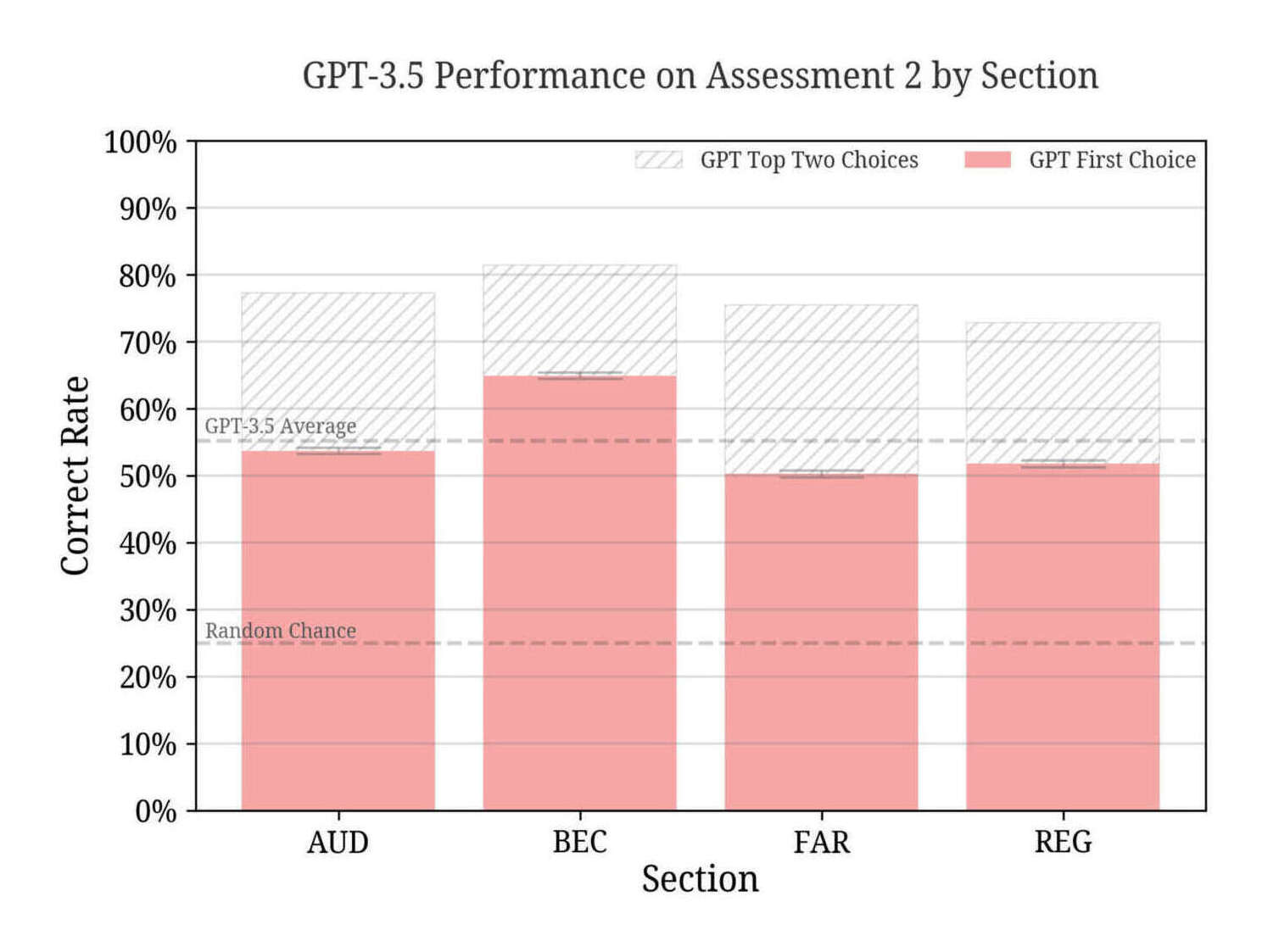{kind=link}
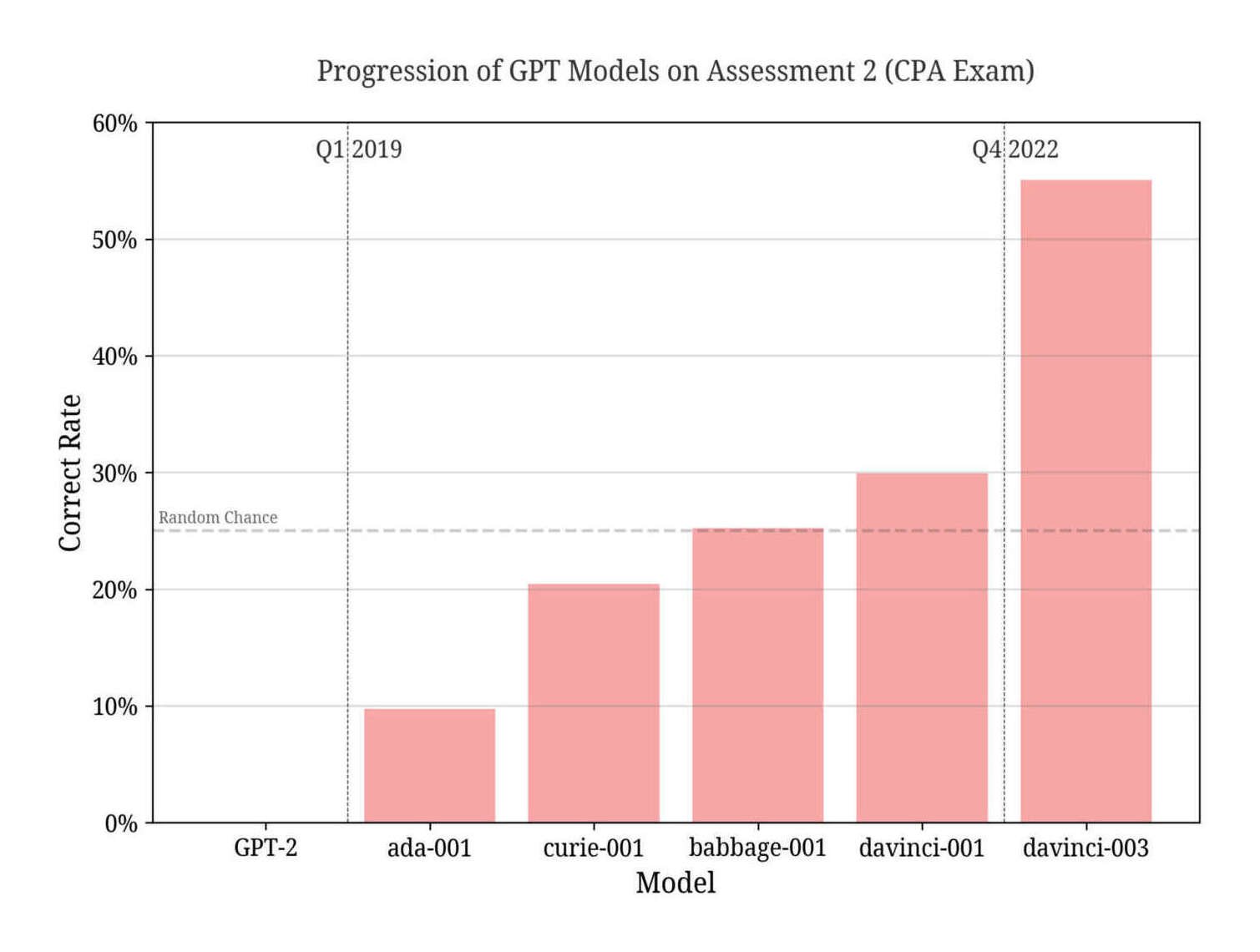{kind=link}
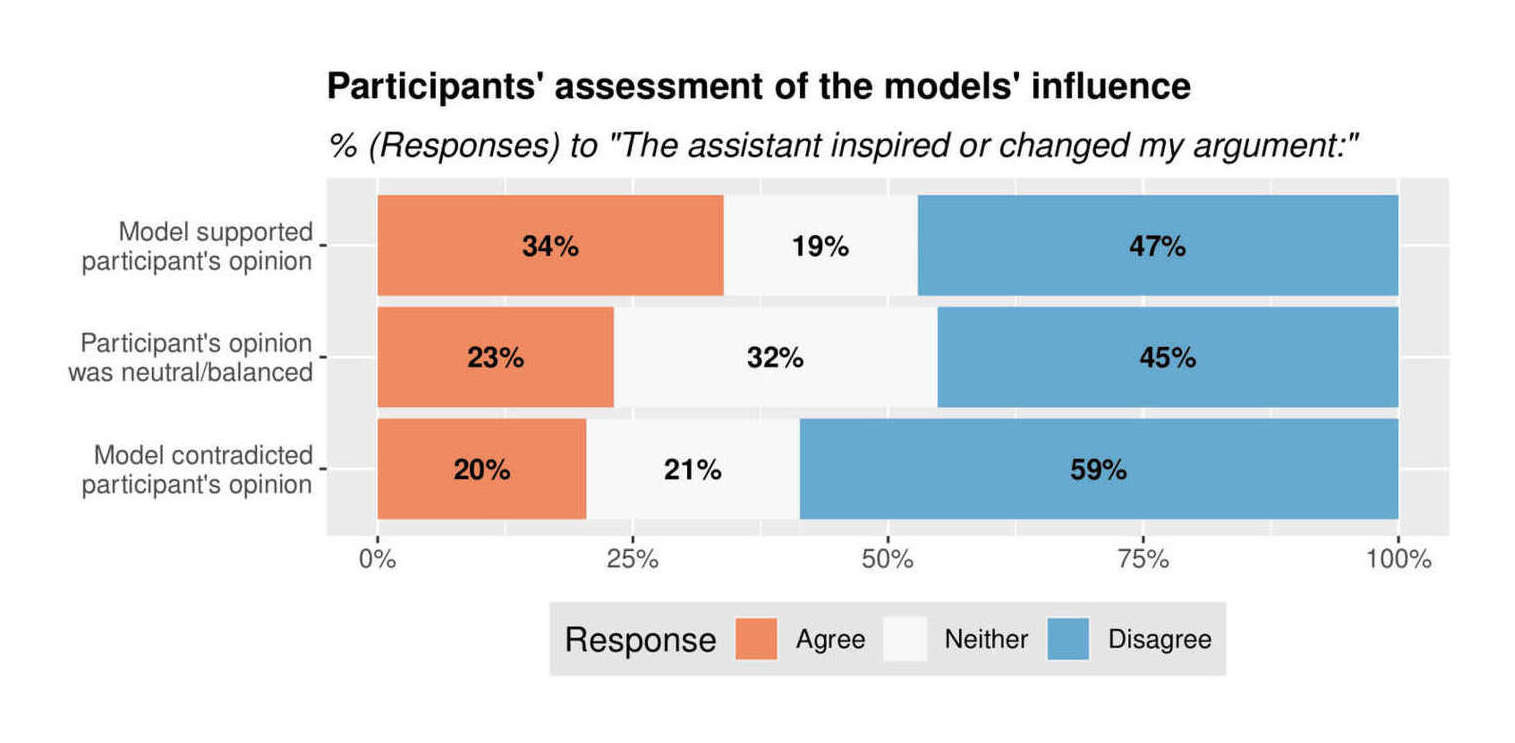{kind=link}
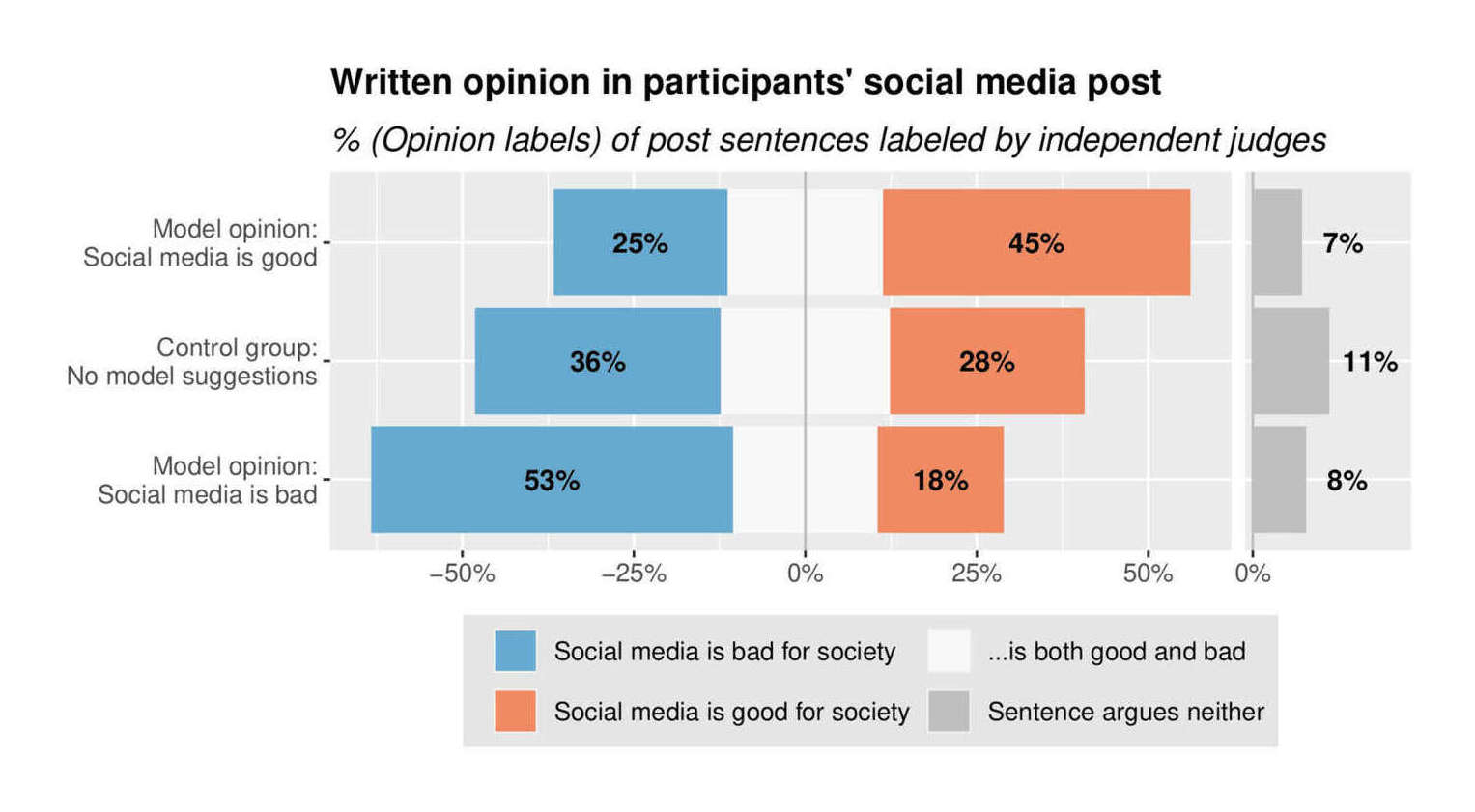{kind=link}
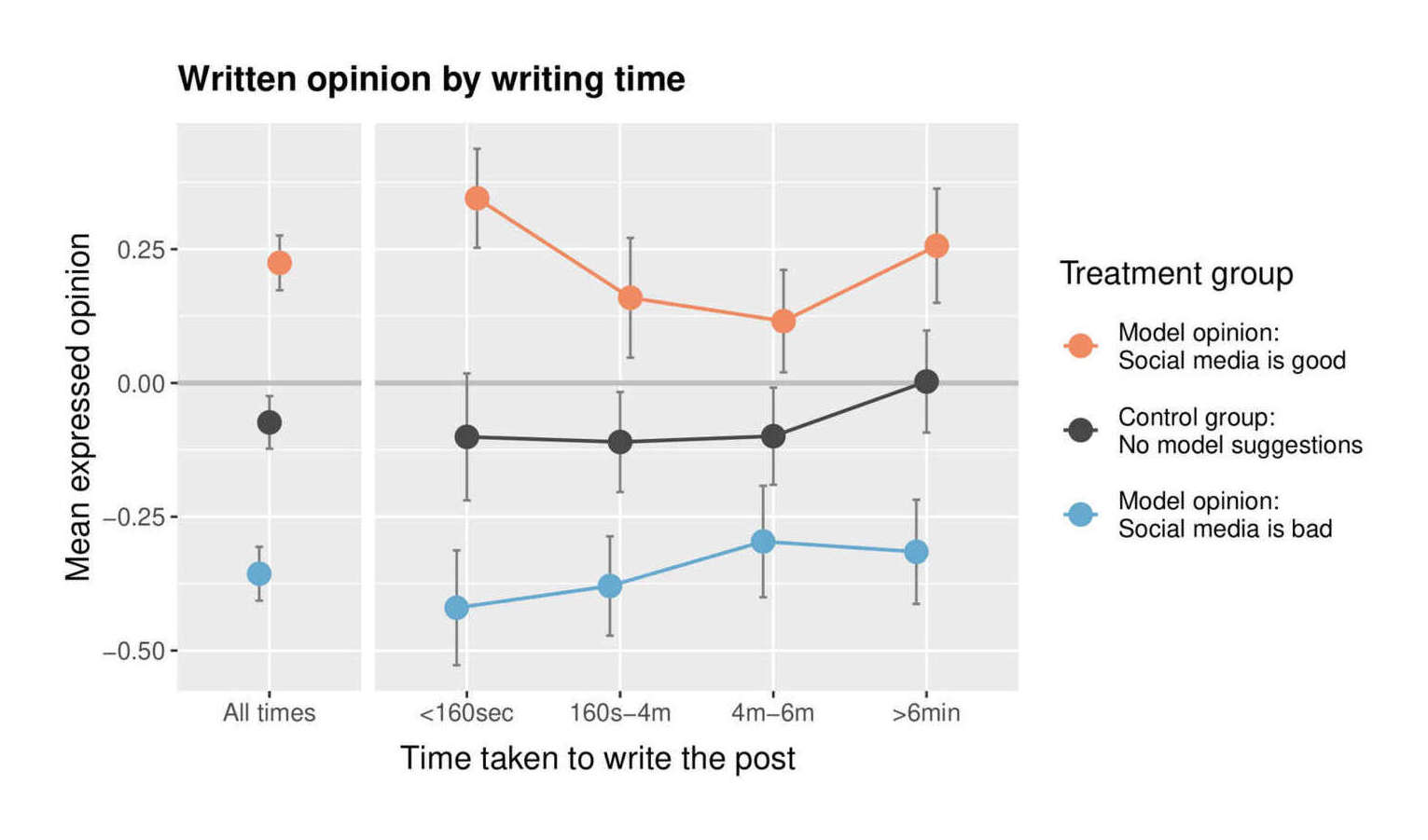{kind=link}
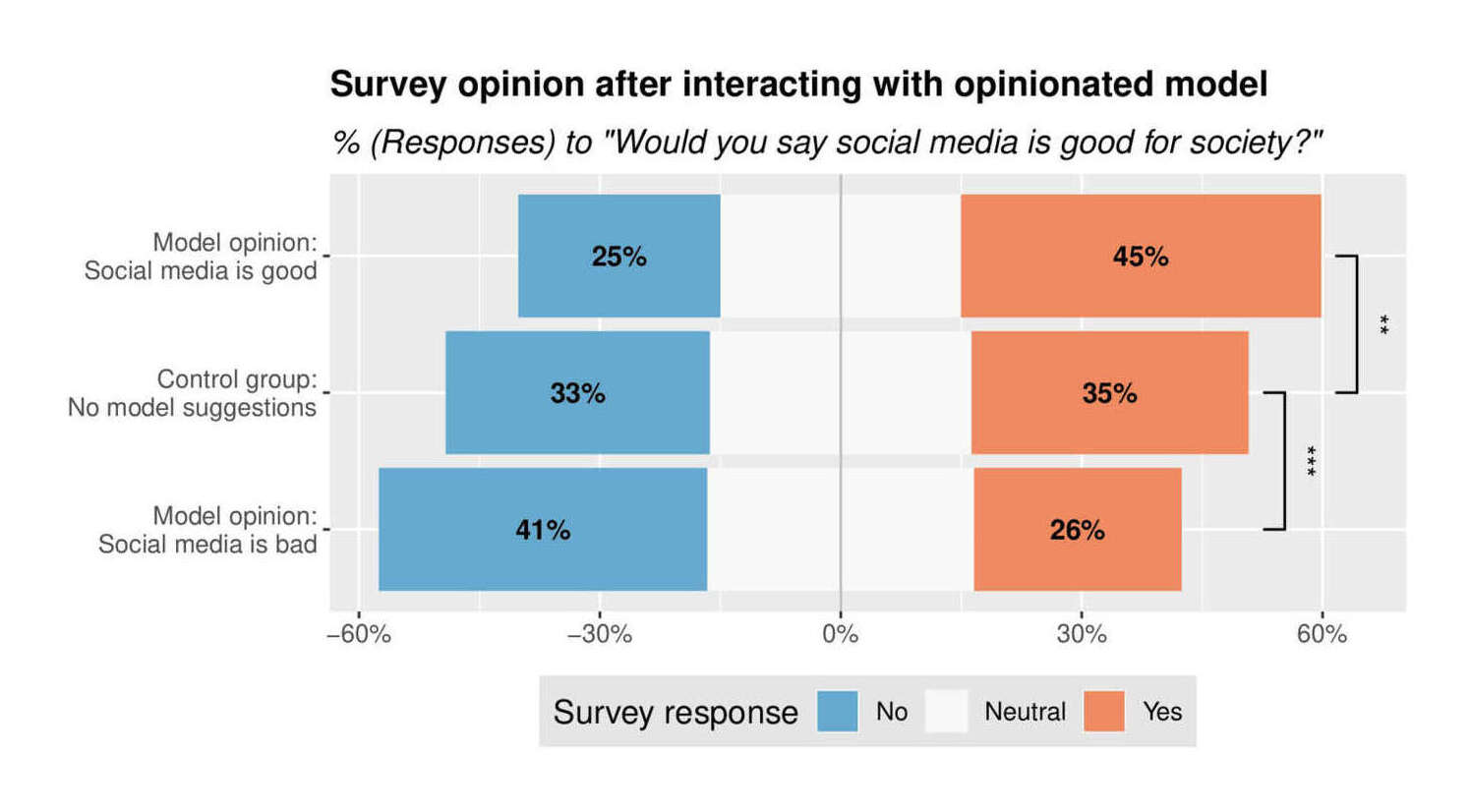{kind=link}
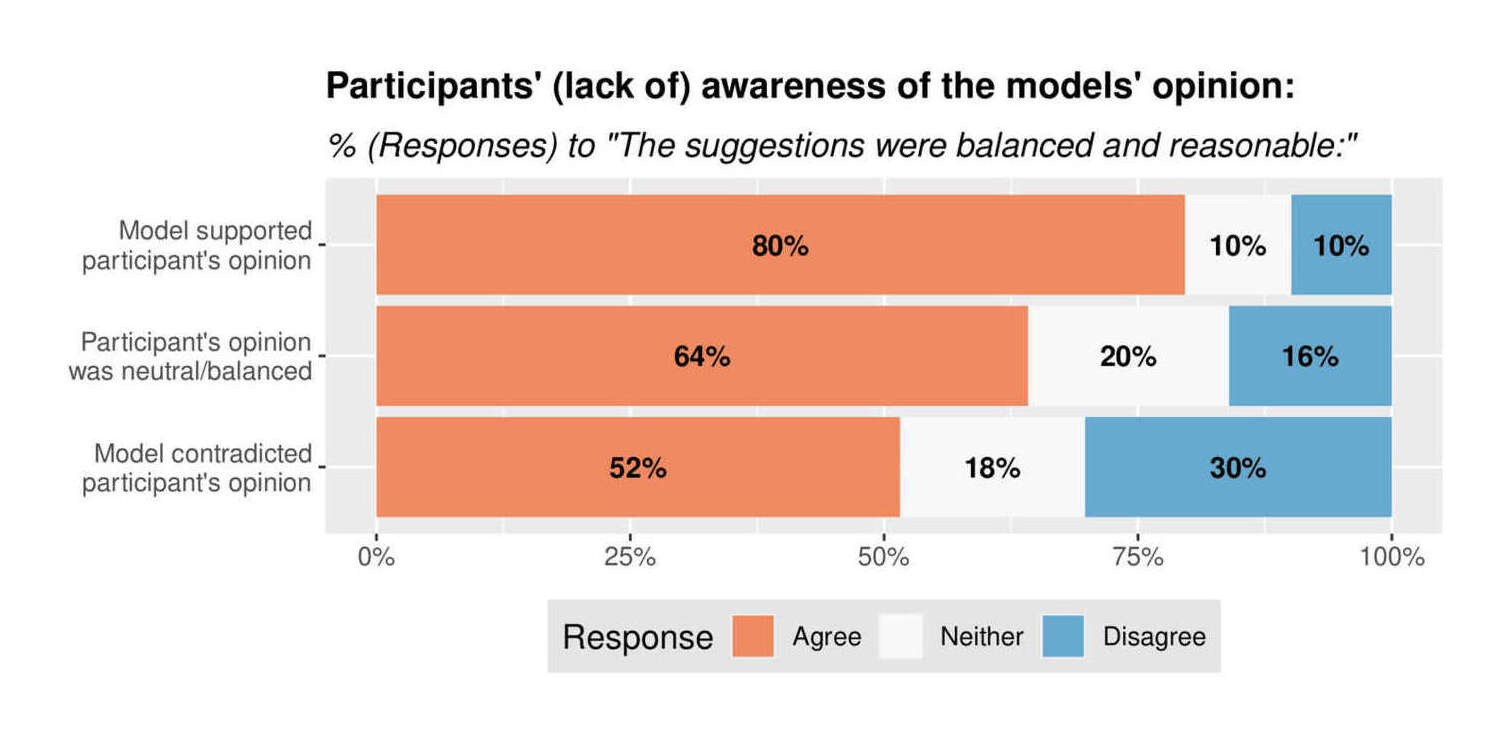{kind=link}
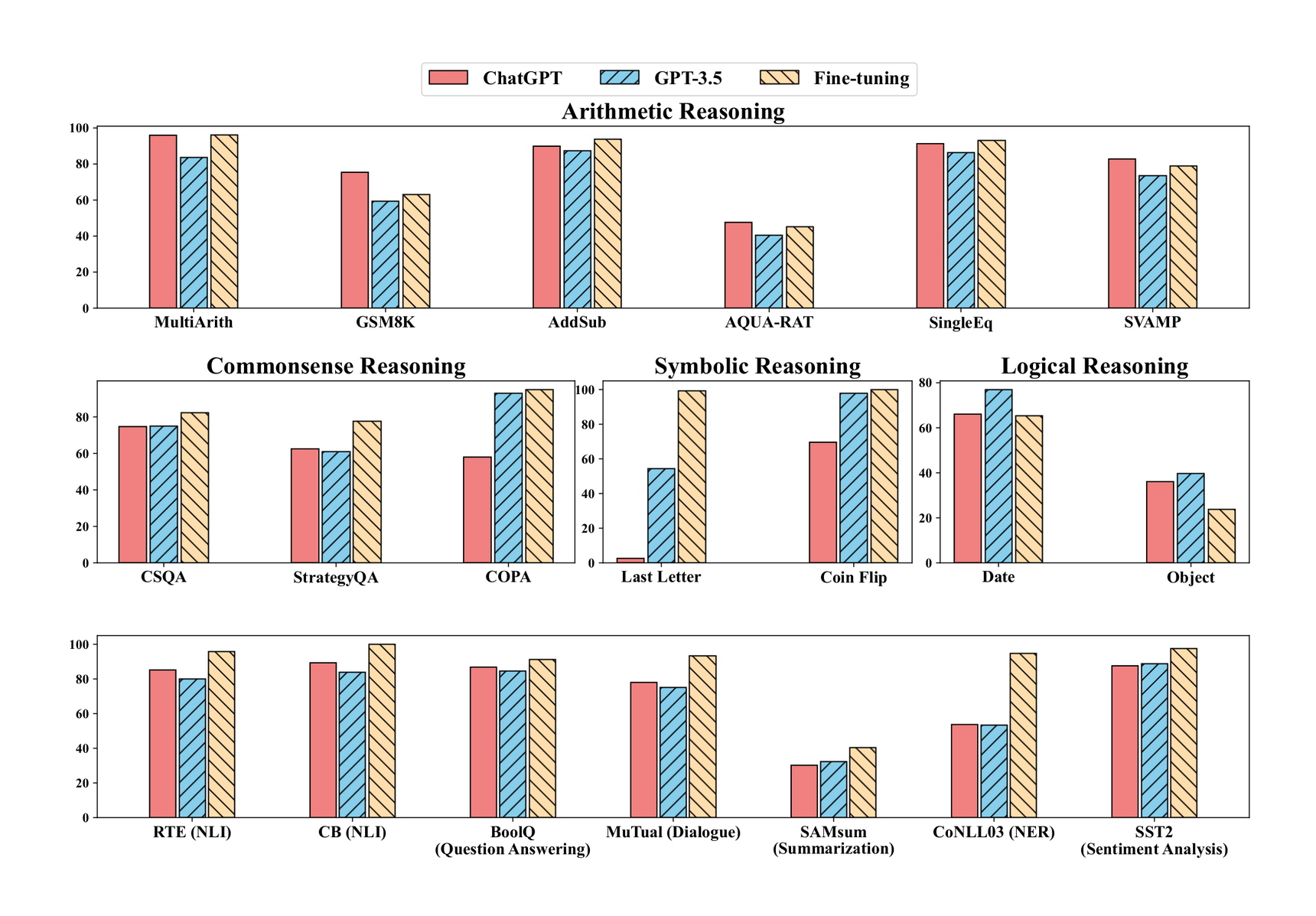{kind=link}
{kind=link}
{kind=link}
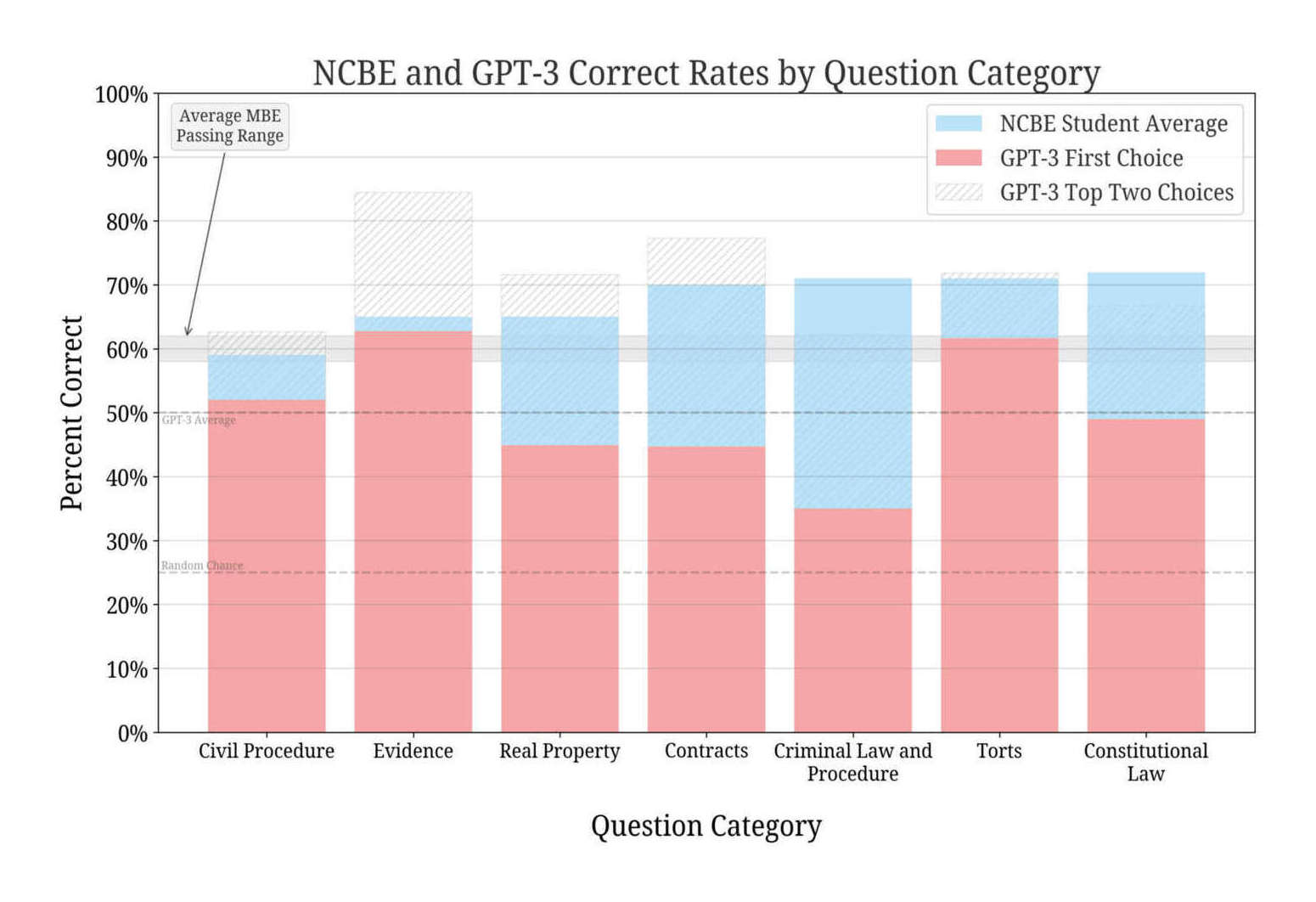{kind=link}
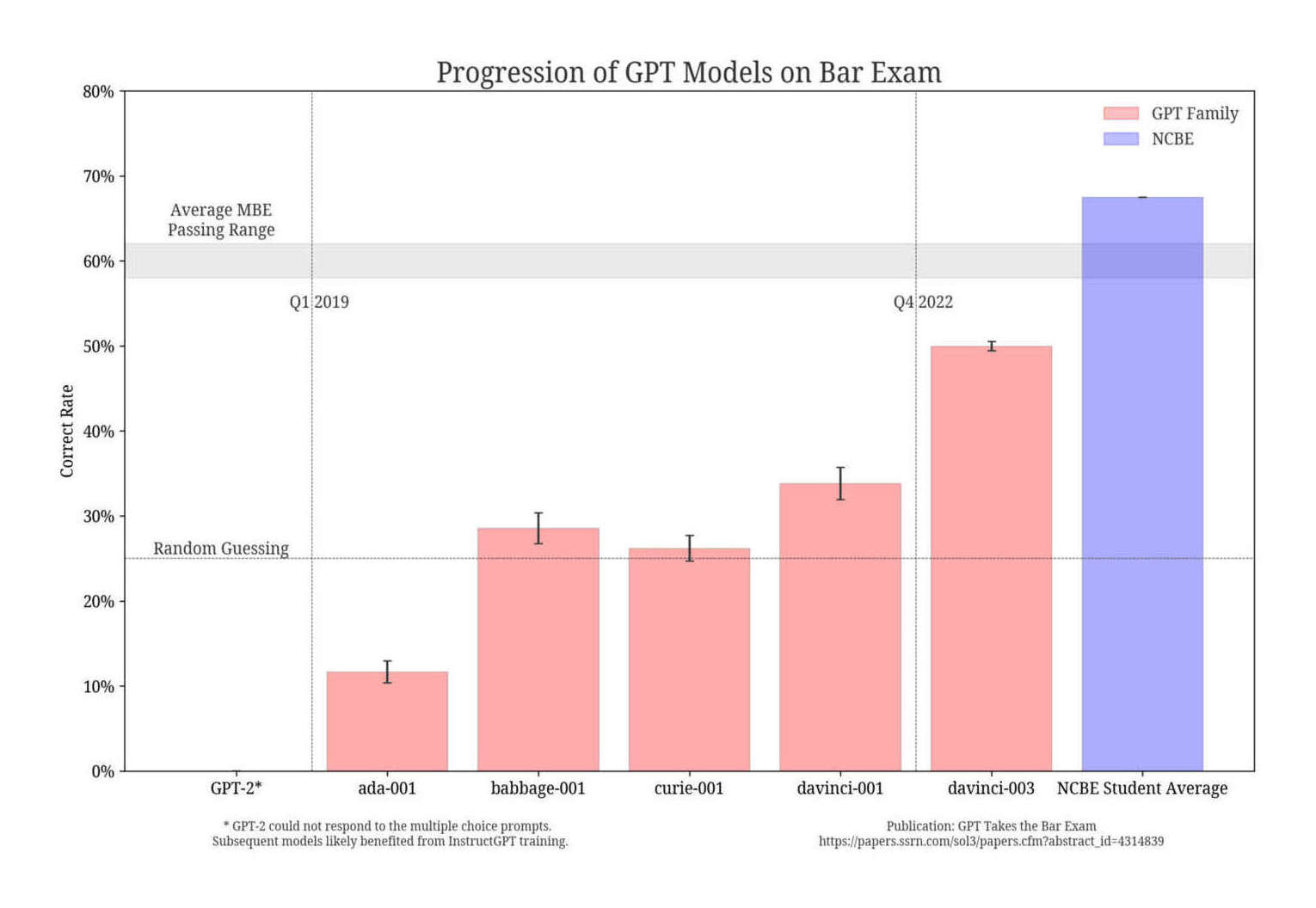{kind=link}
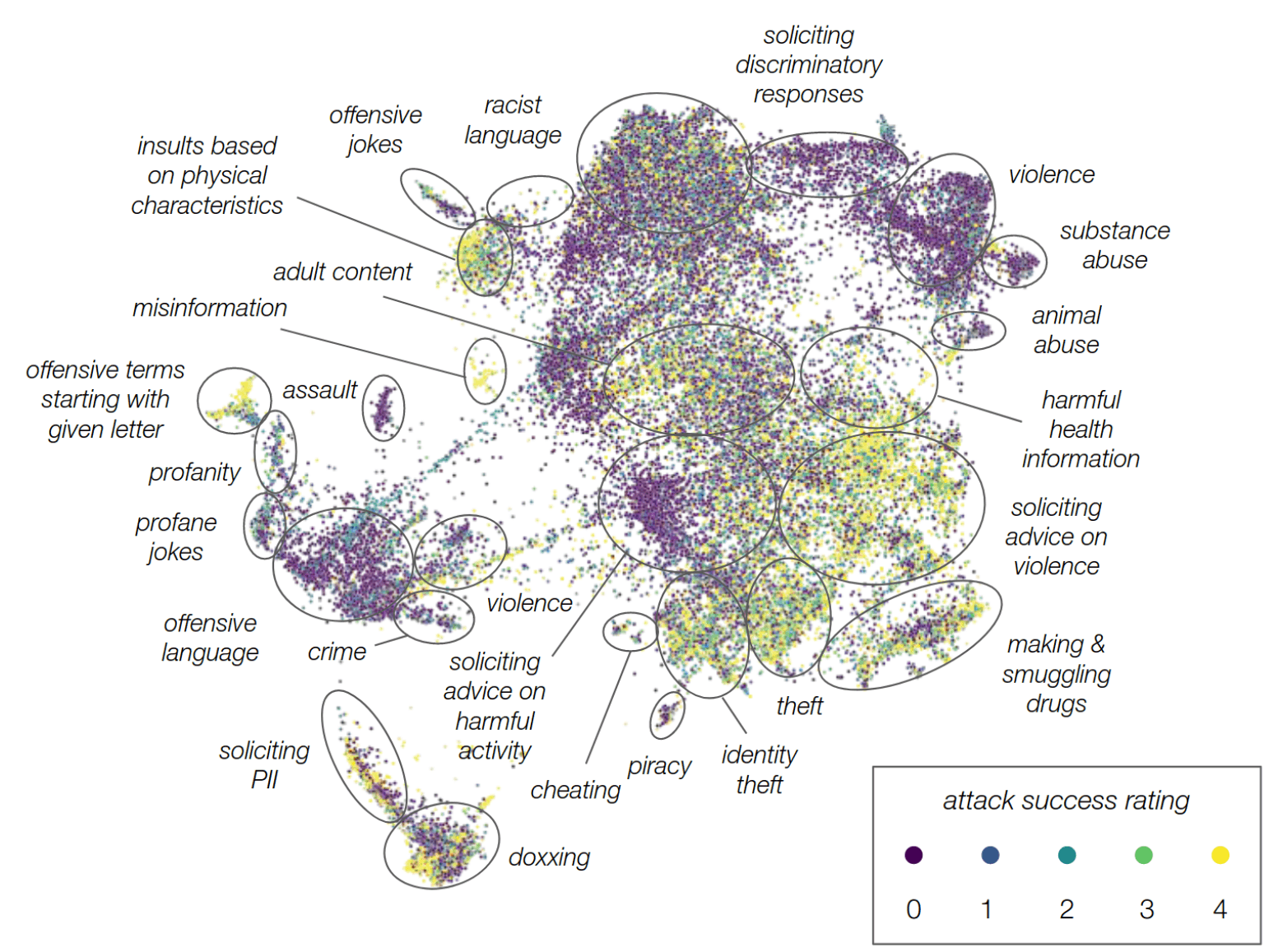{kind=link}
{kind=link}
{kind=link}
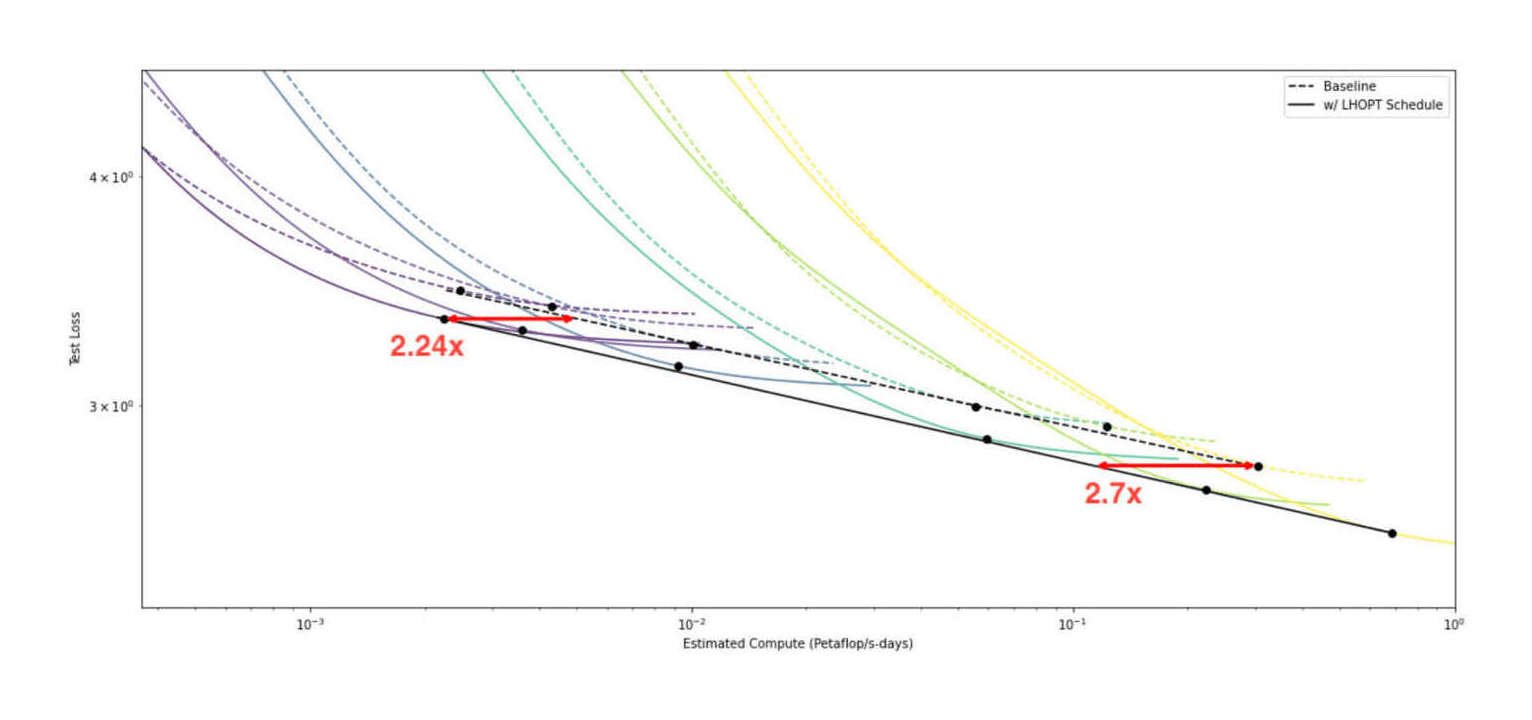{kind=link}
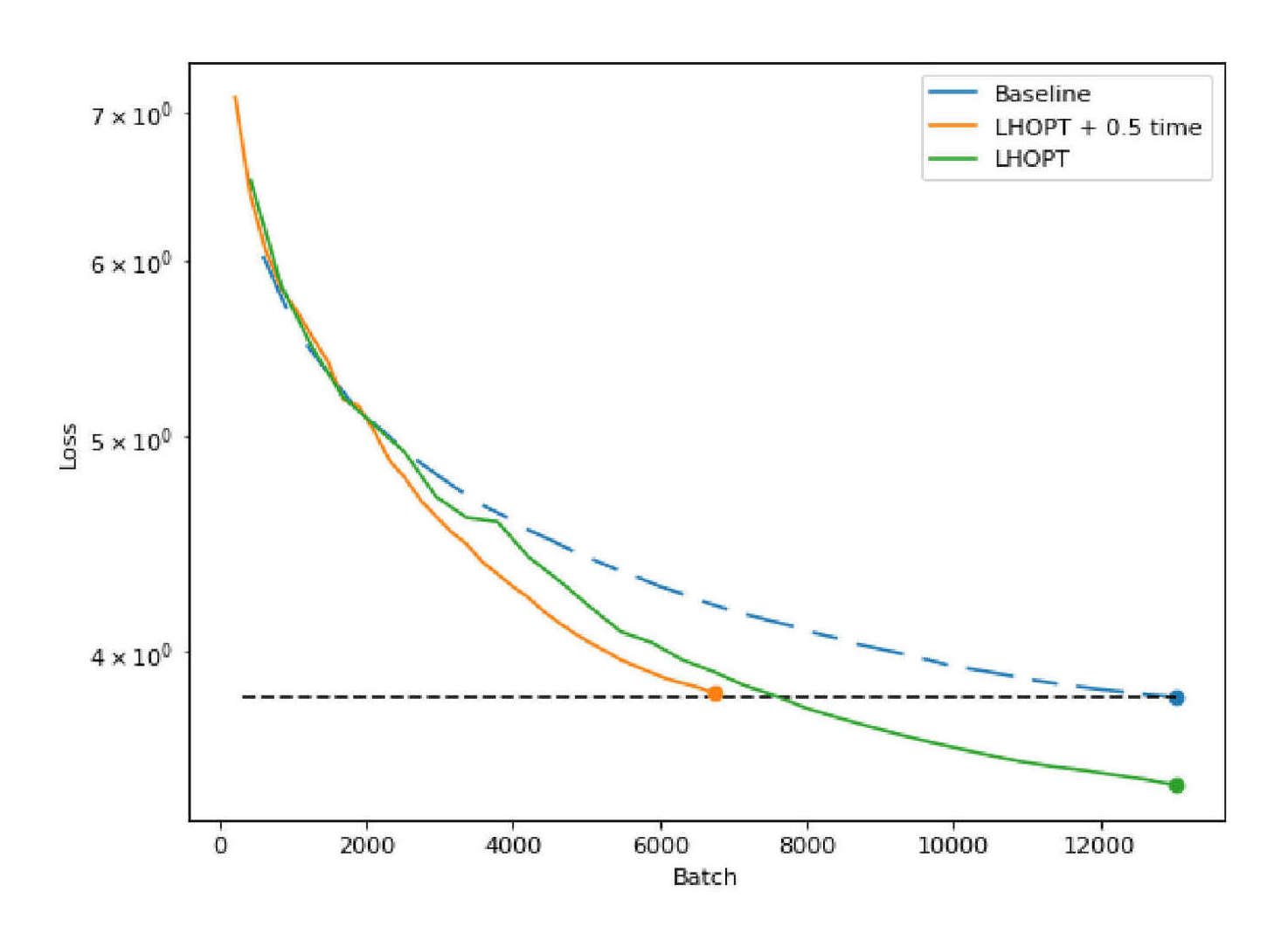{kind=link}
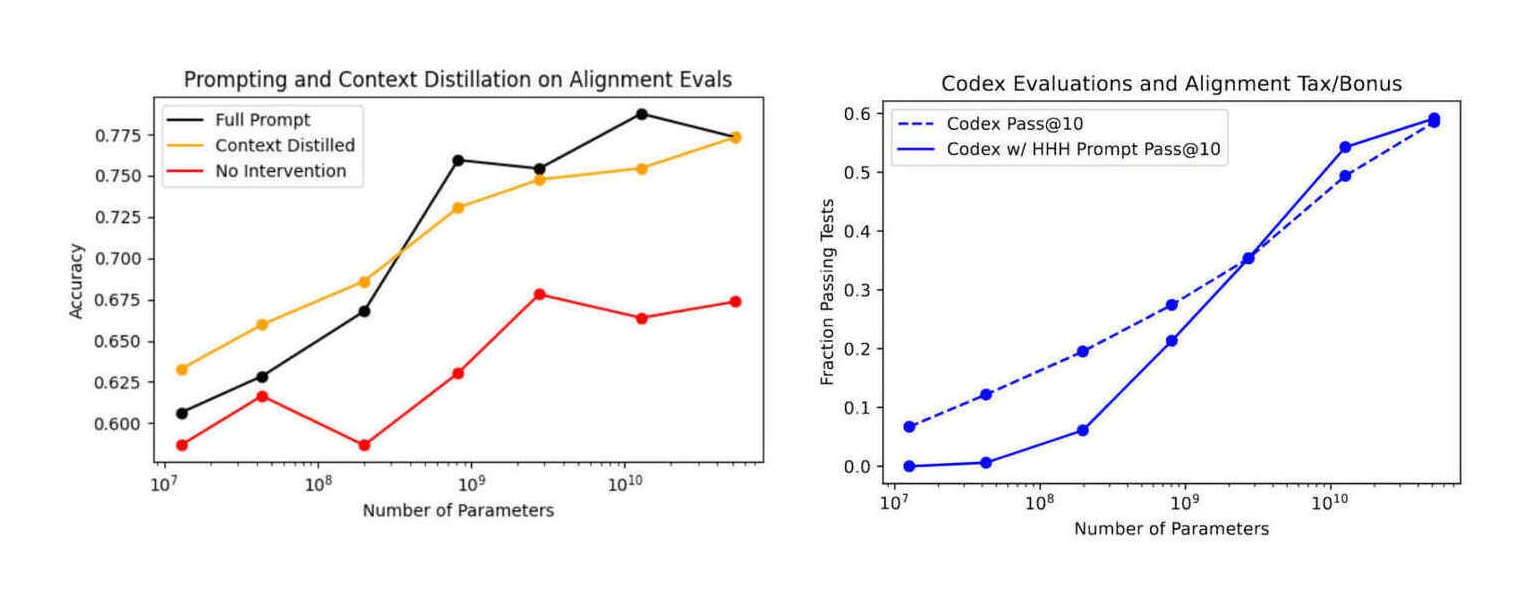{kind=link}
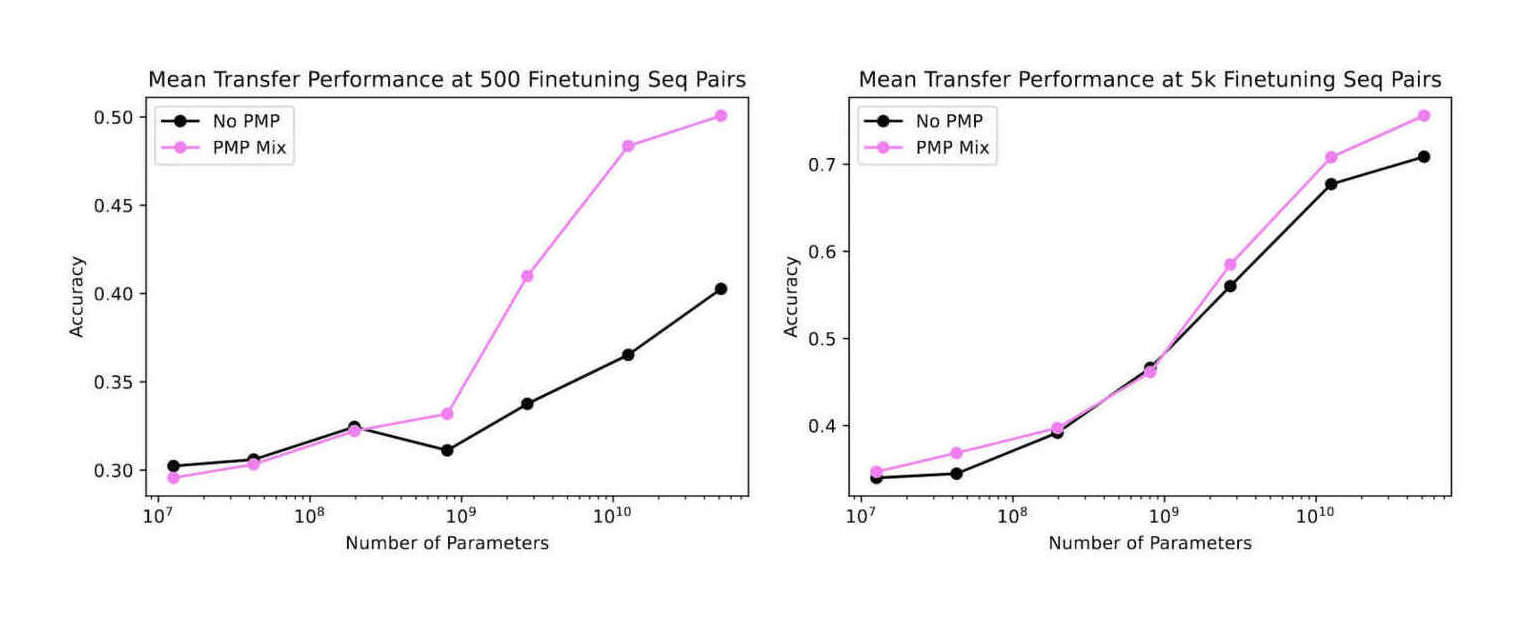{kind=link}
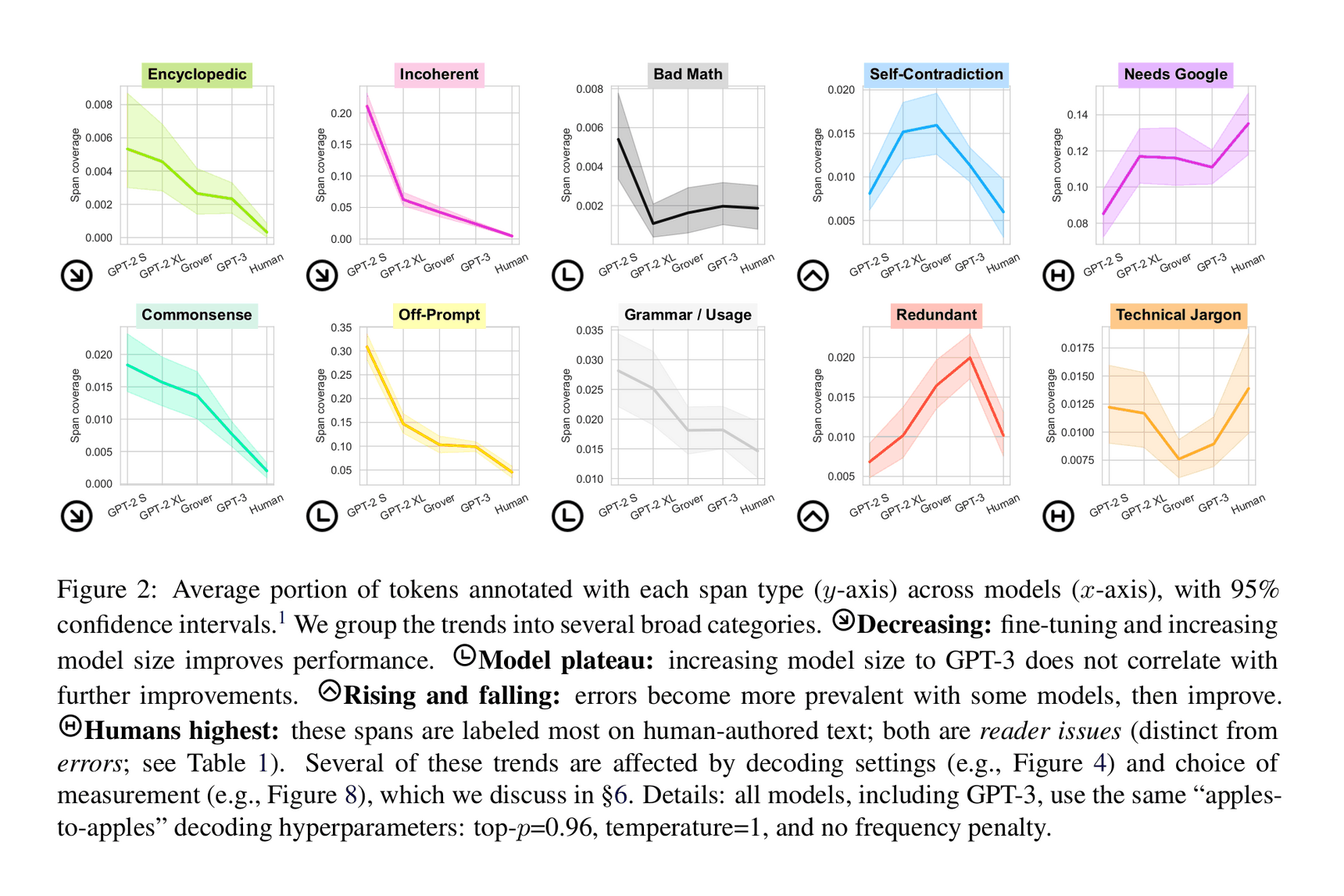{kind=link}
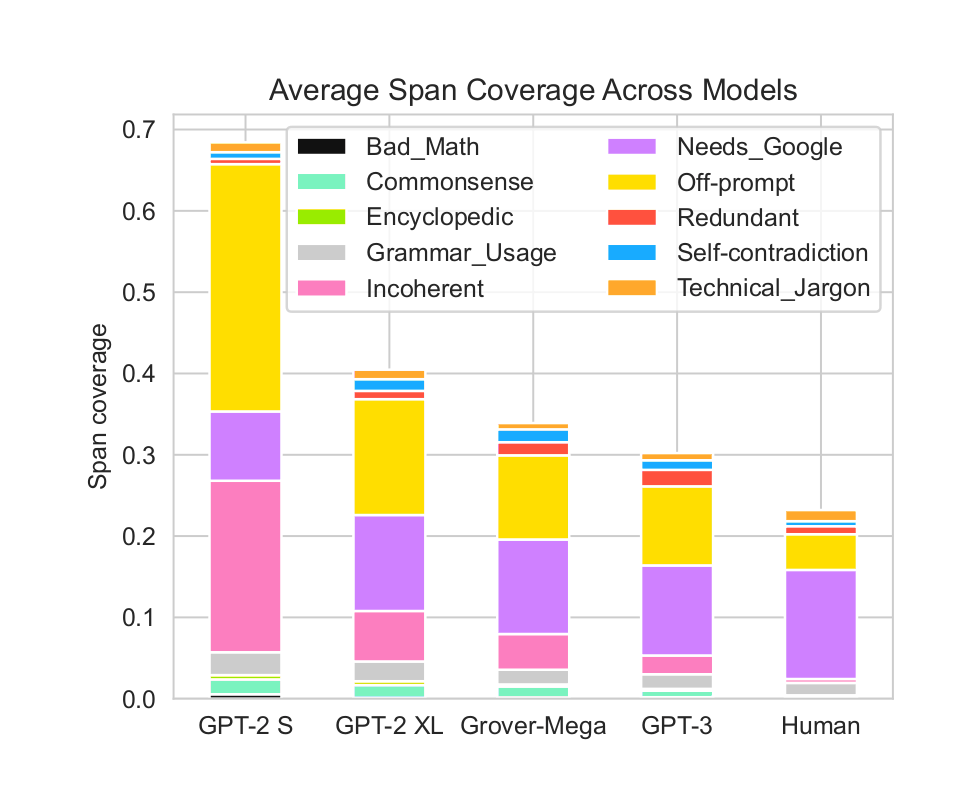{kind=link}
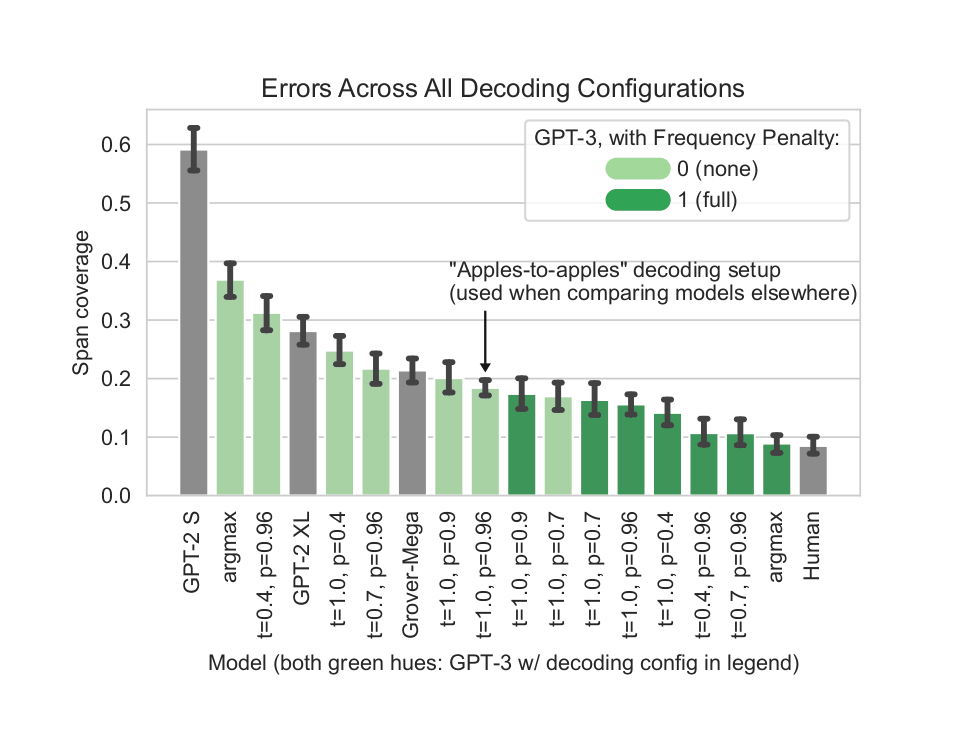{kind=link}
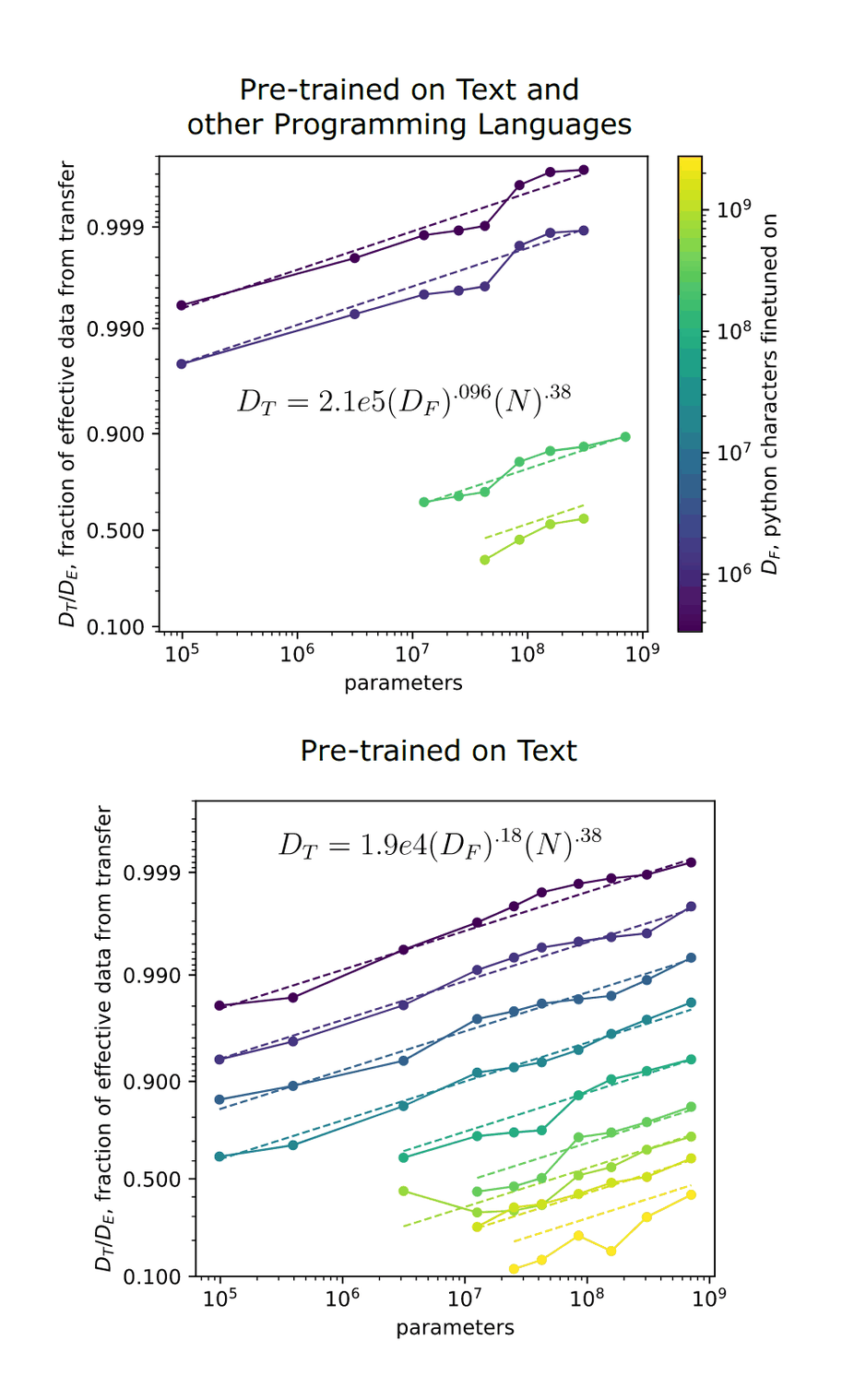{kind=link}
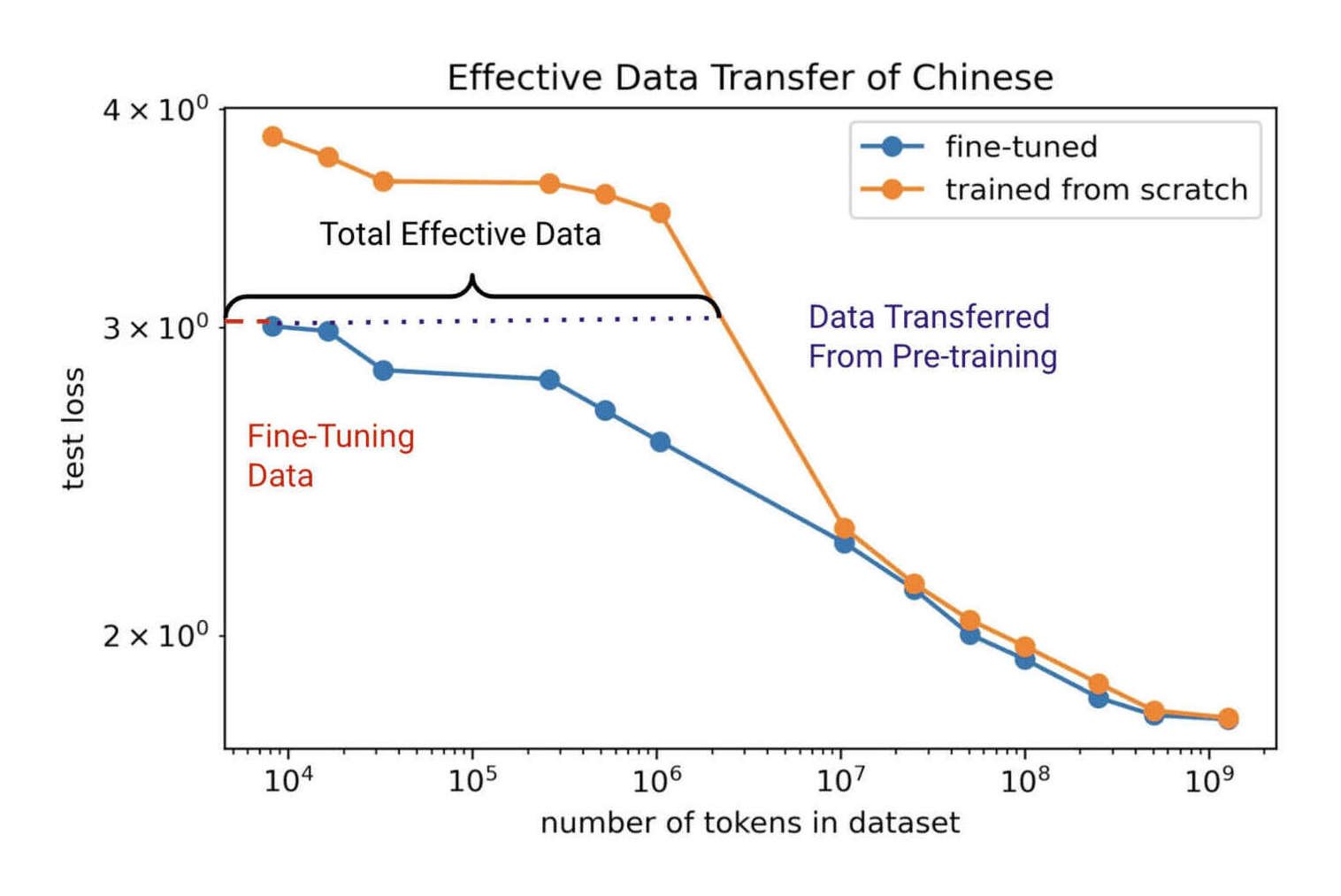{kind=link}
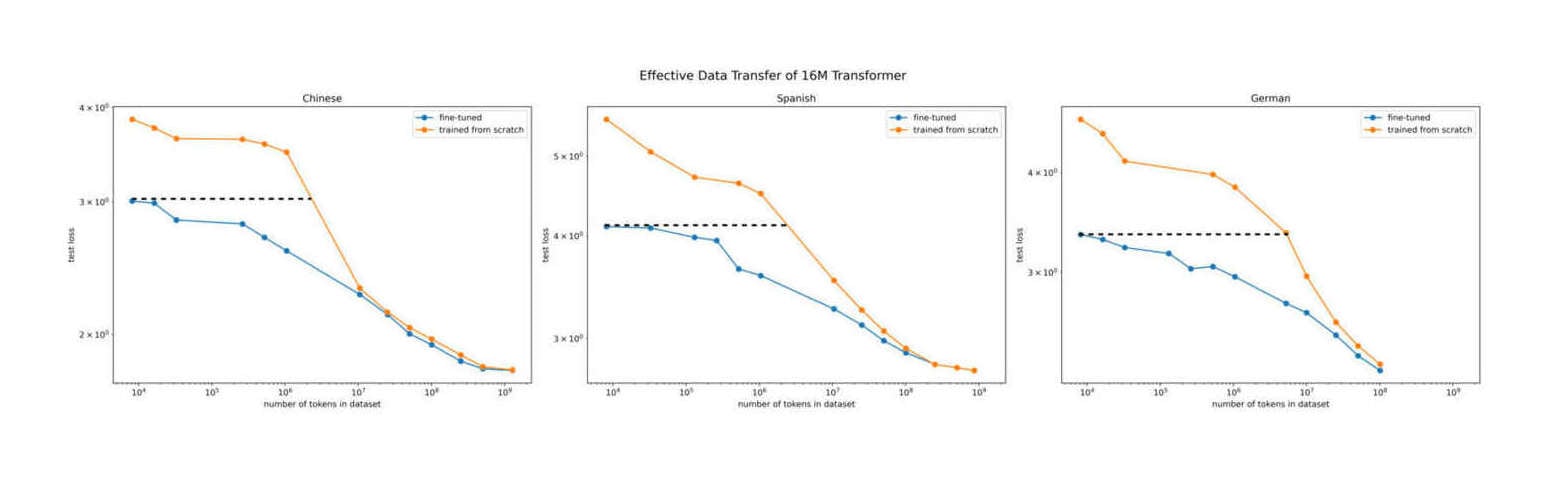{kind=link}
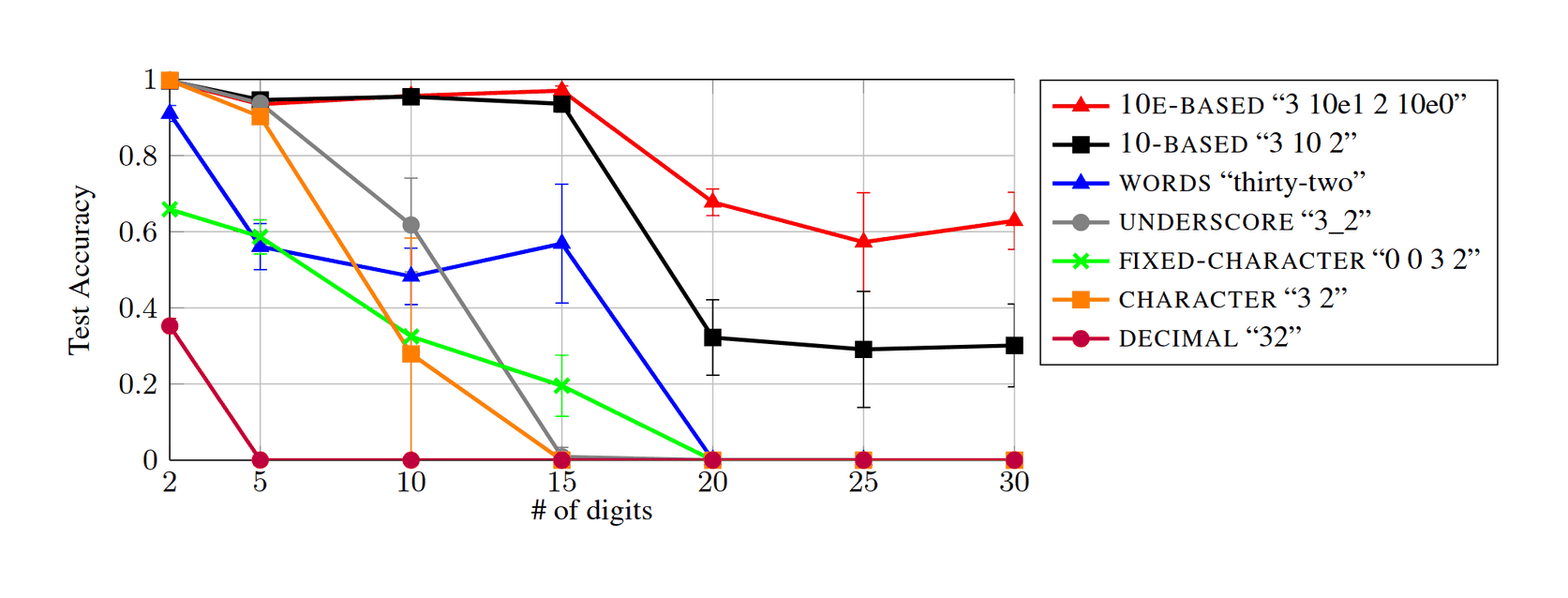{kind=link}
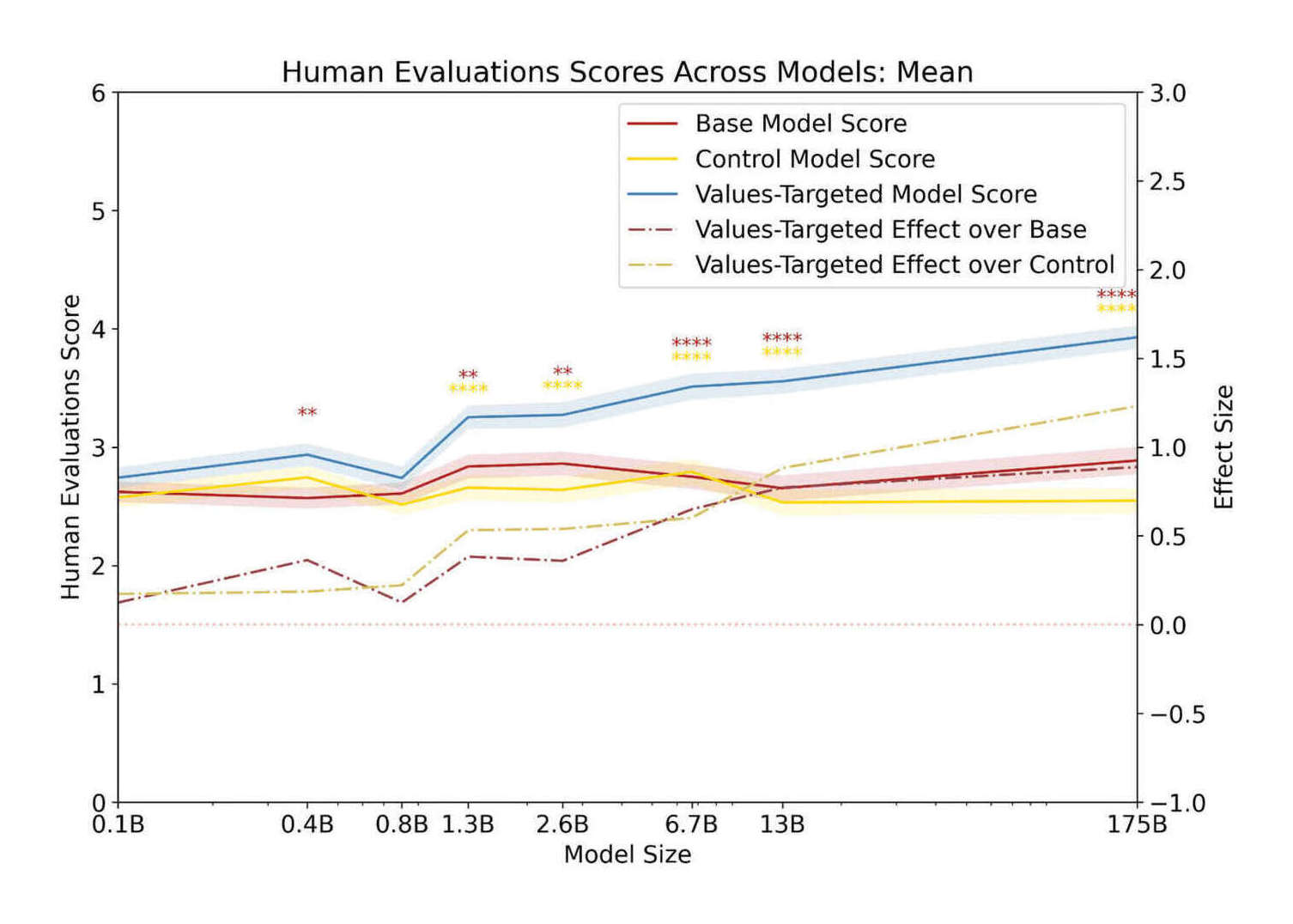{kind=link}
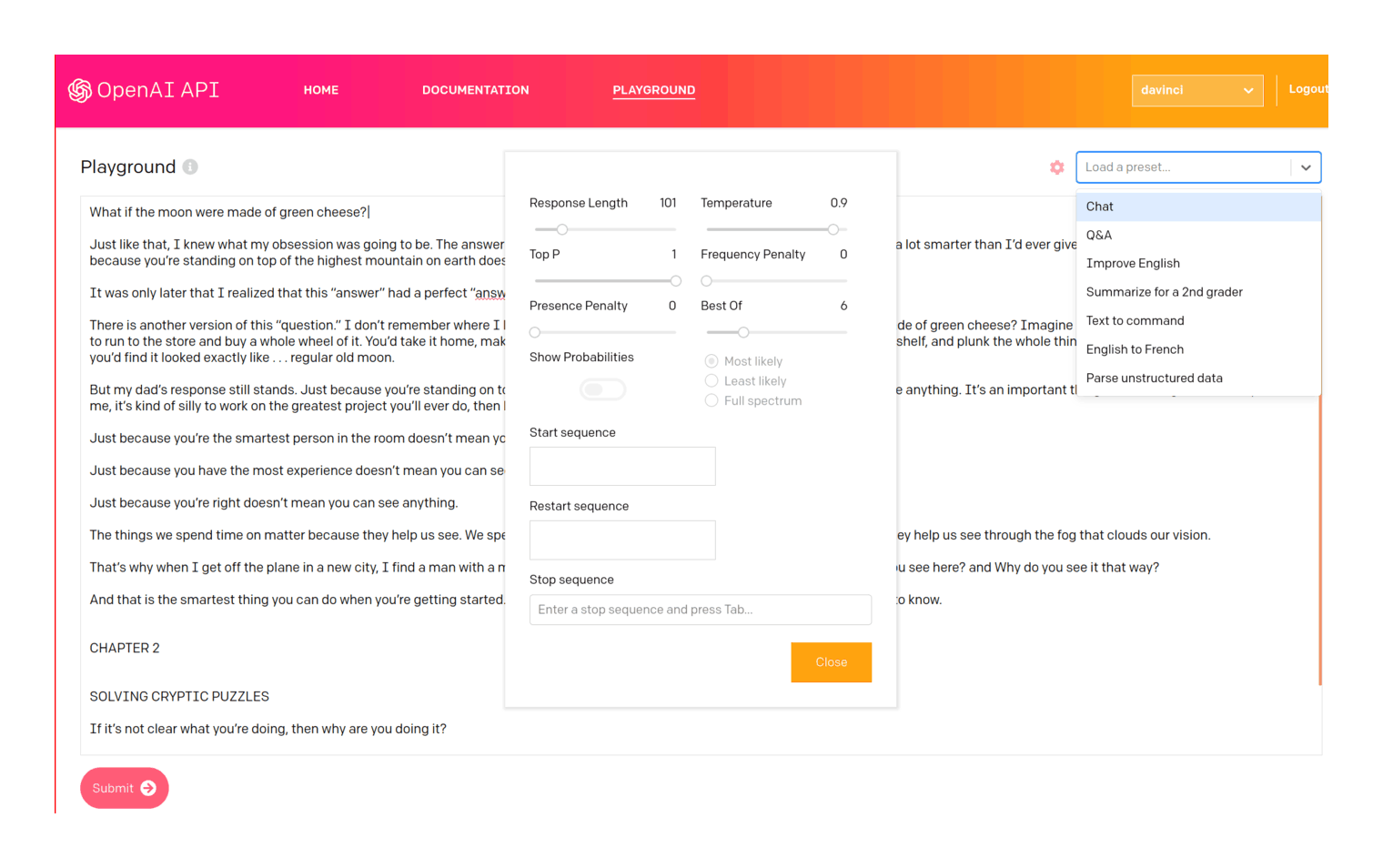{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
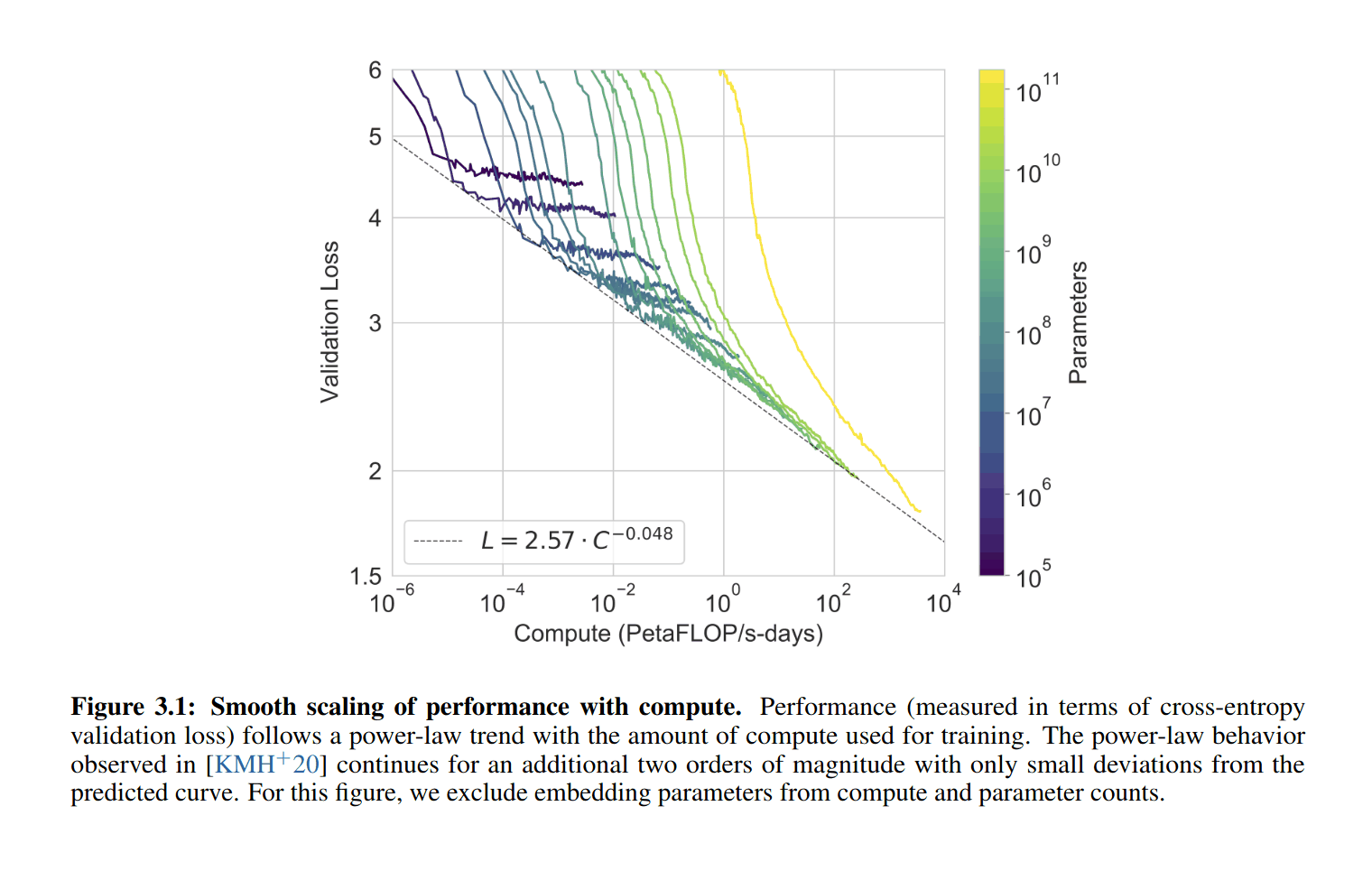{kind=link}
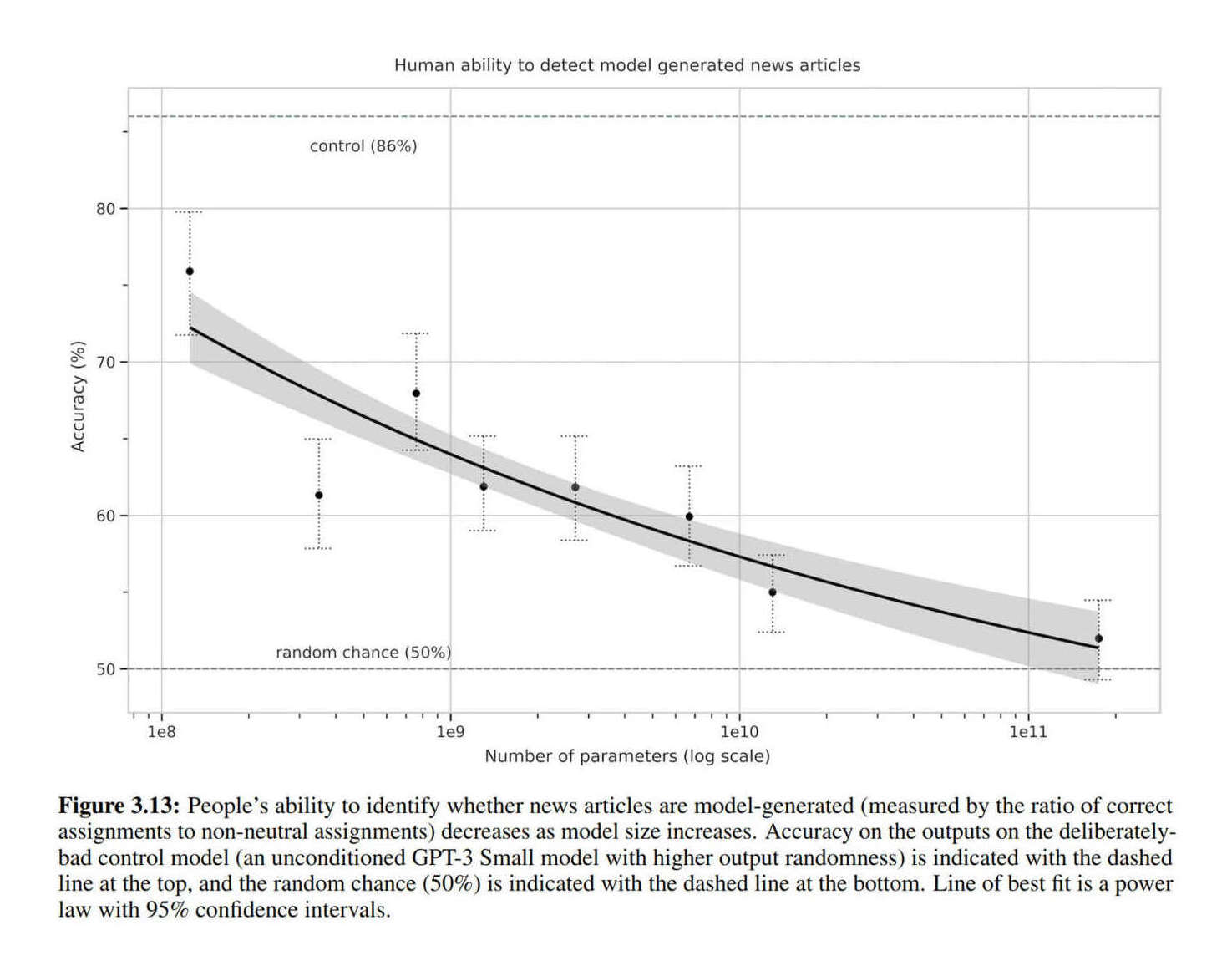{kind=link}
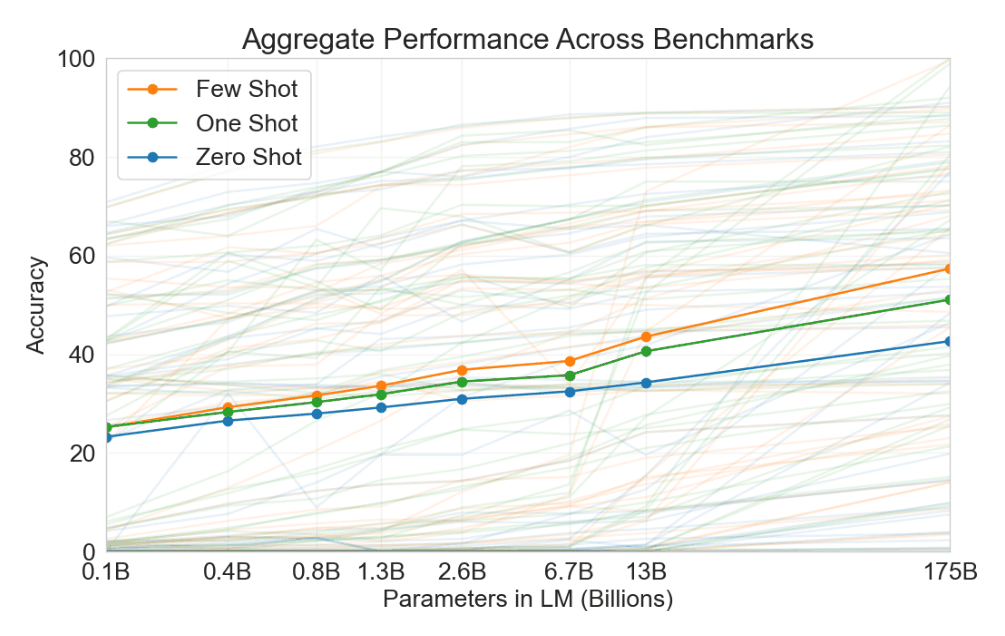{kind=link}
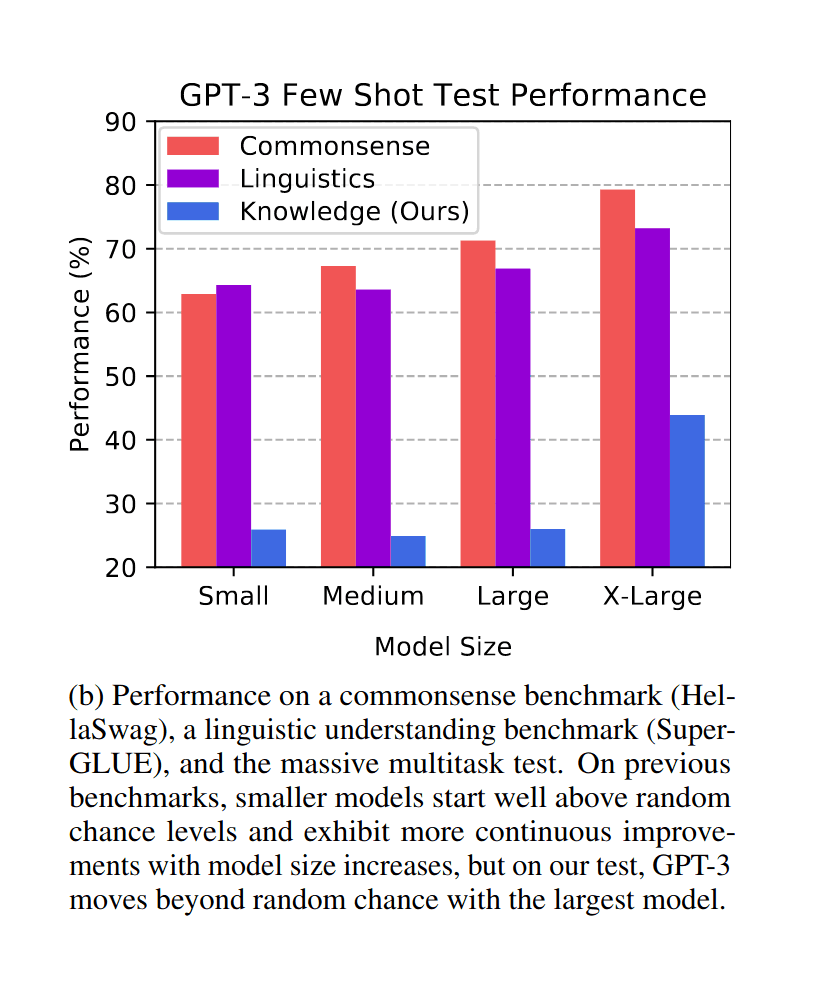{kind=link}
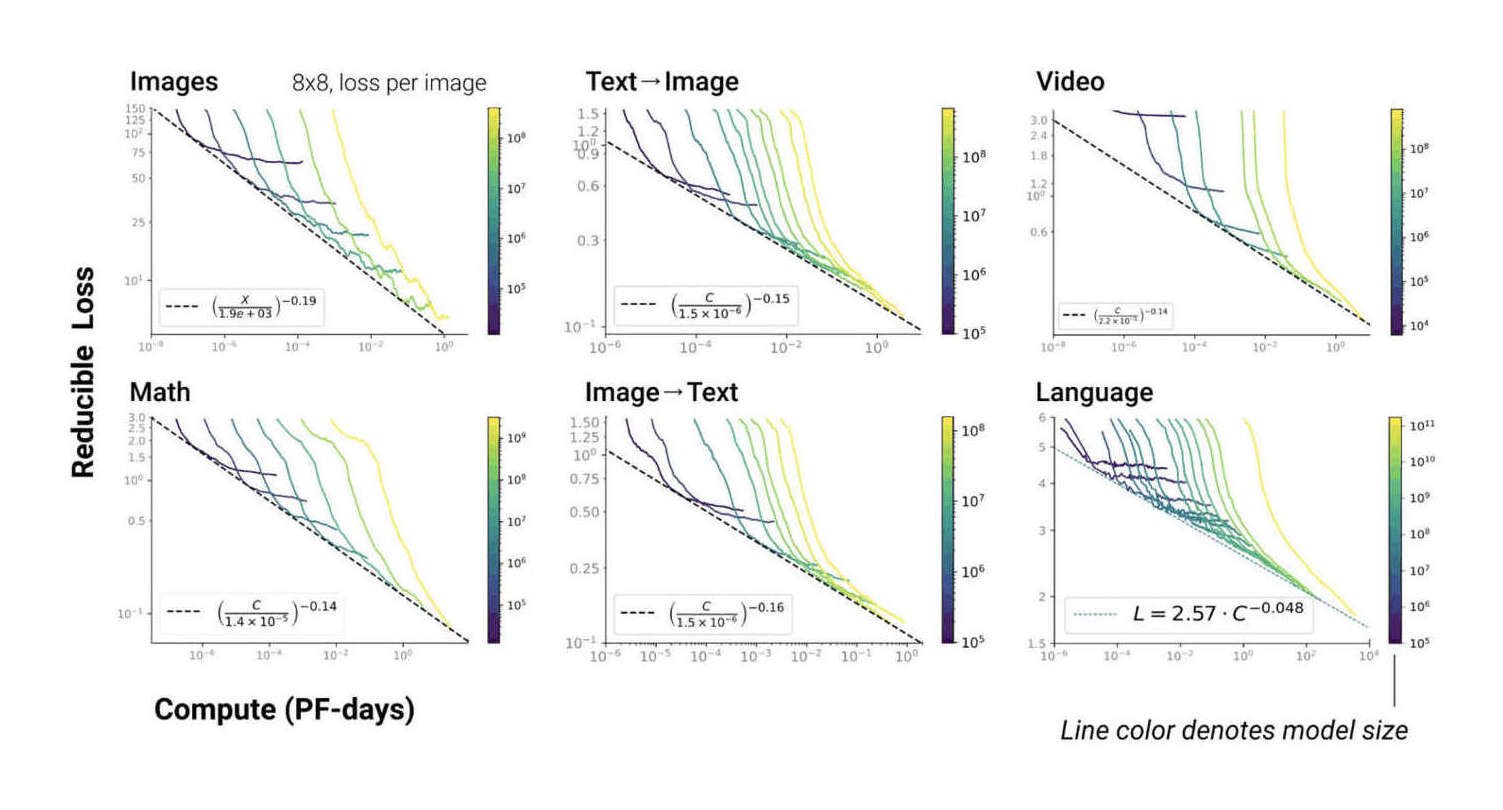{kind=link}
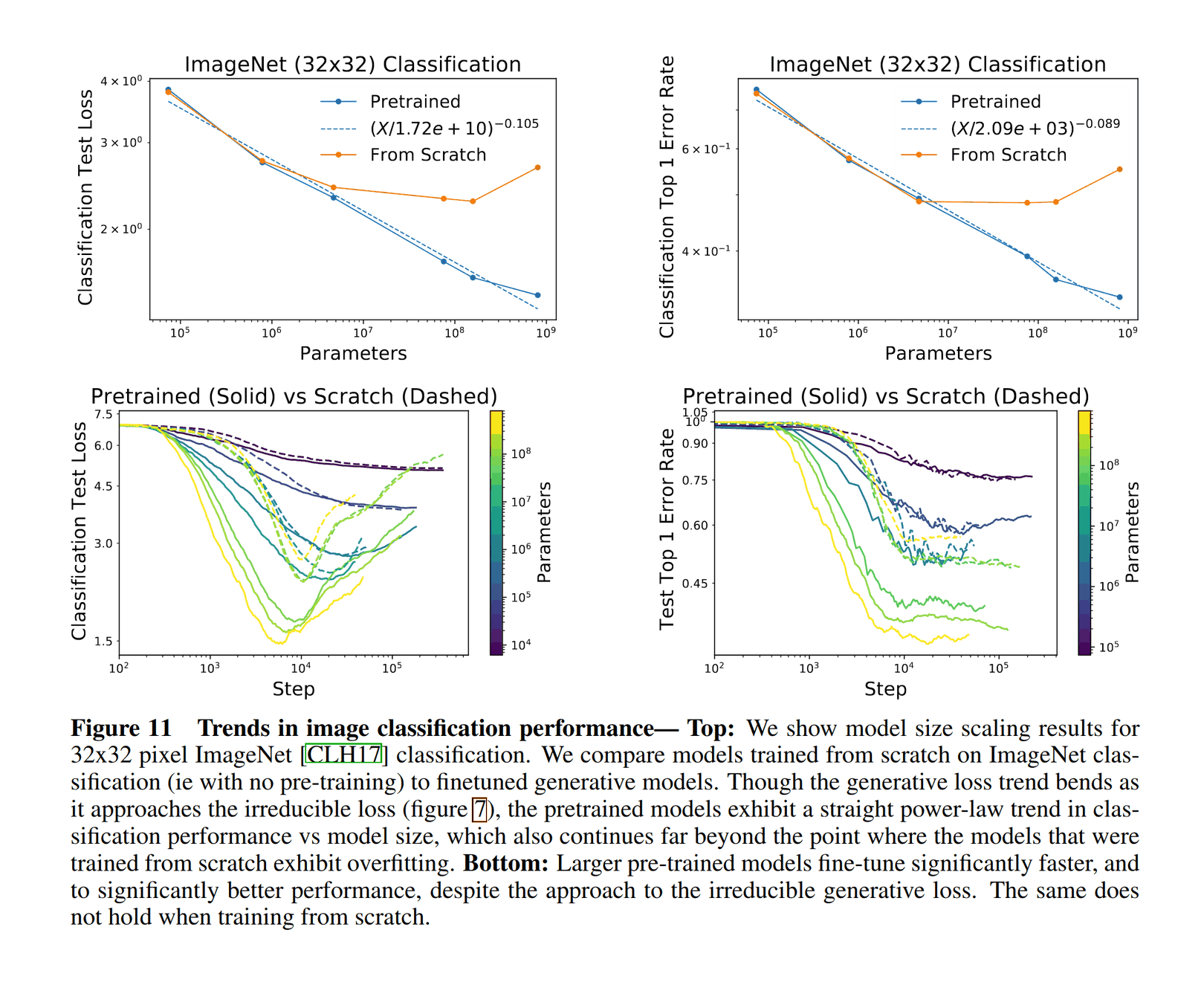{kind=link}
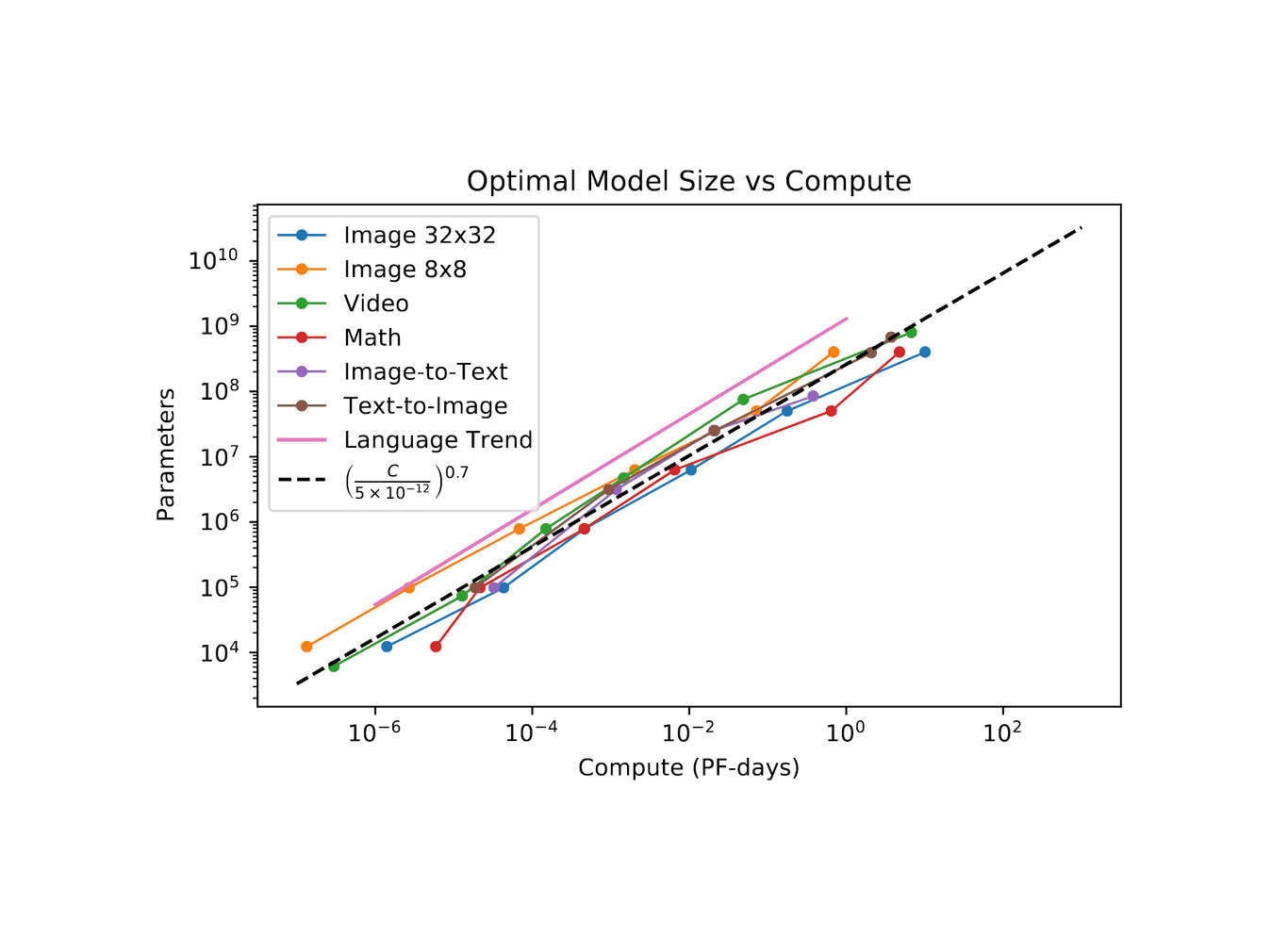{kind=link}
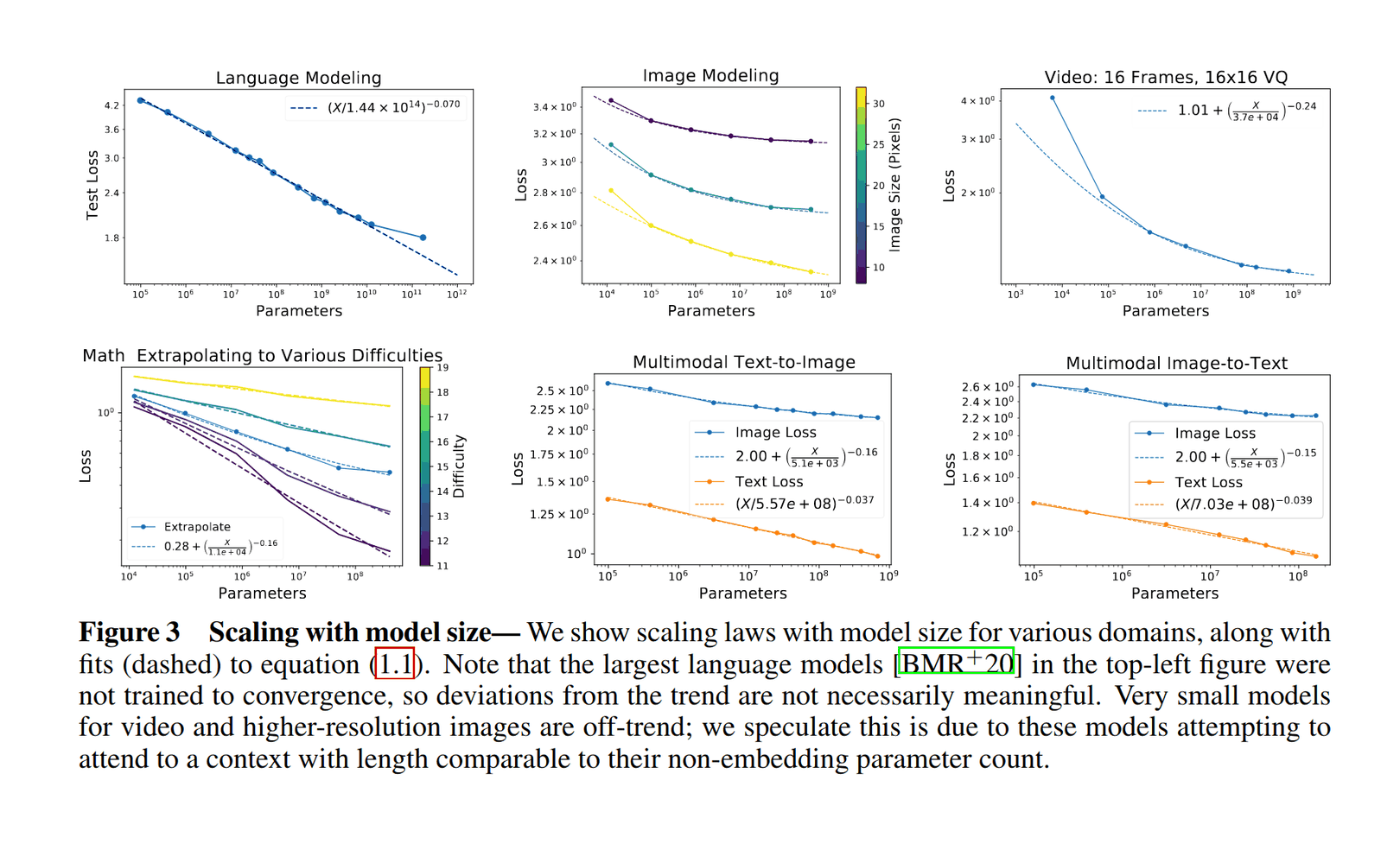{kind=link}
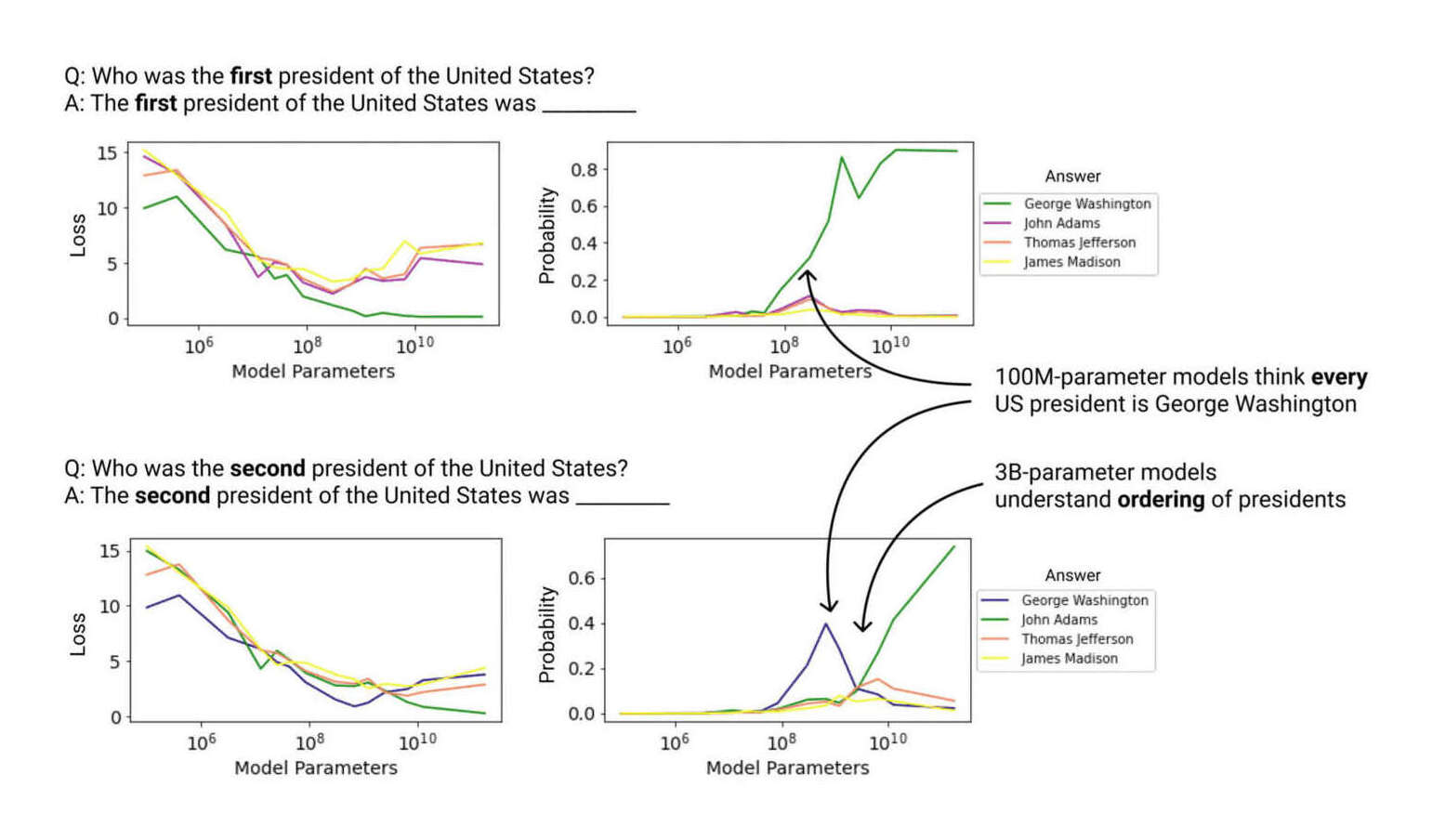{kind=link}
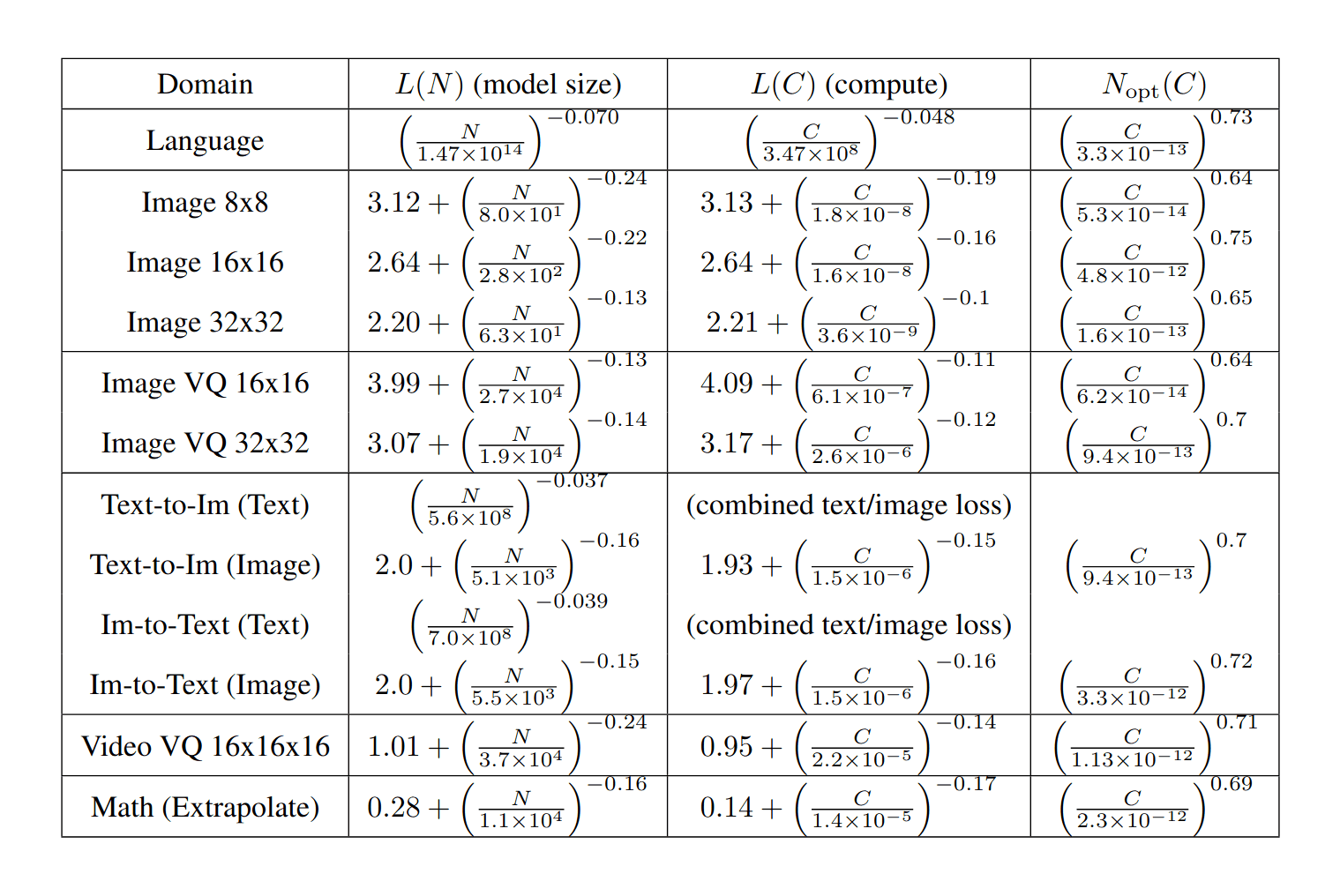{kind=link}
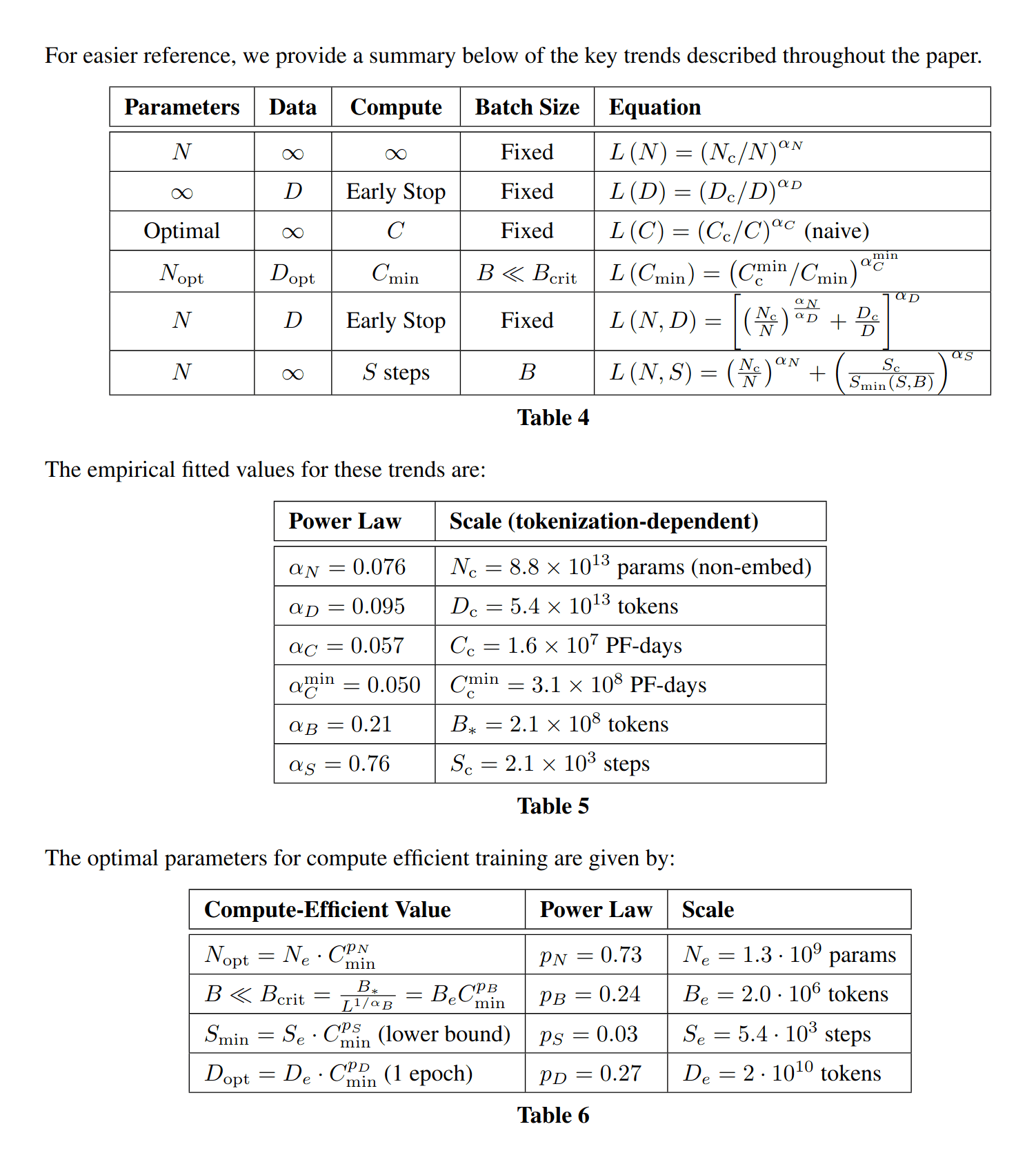{kind=link}
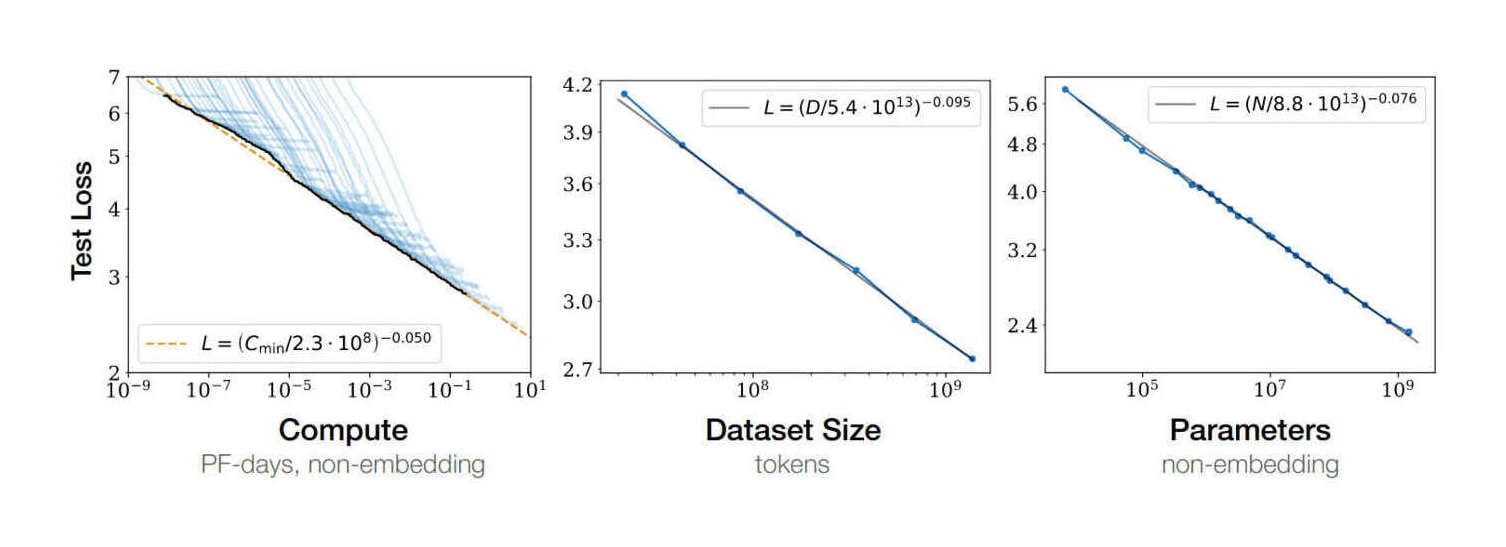{kind=link}
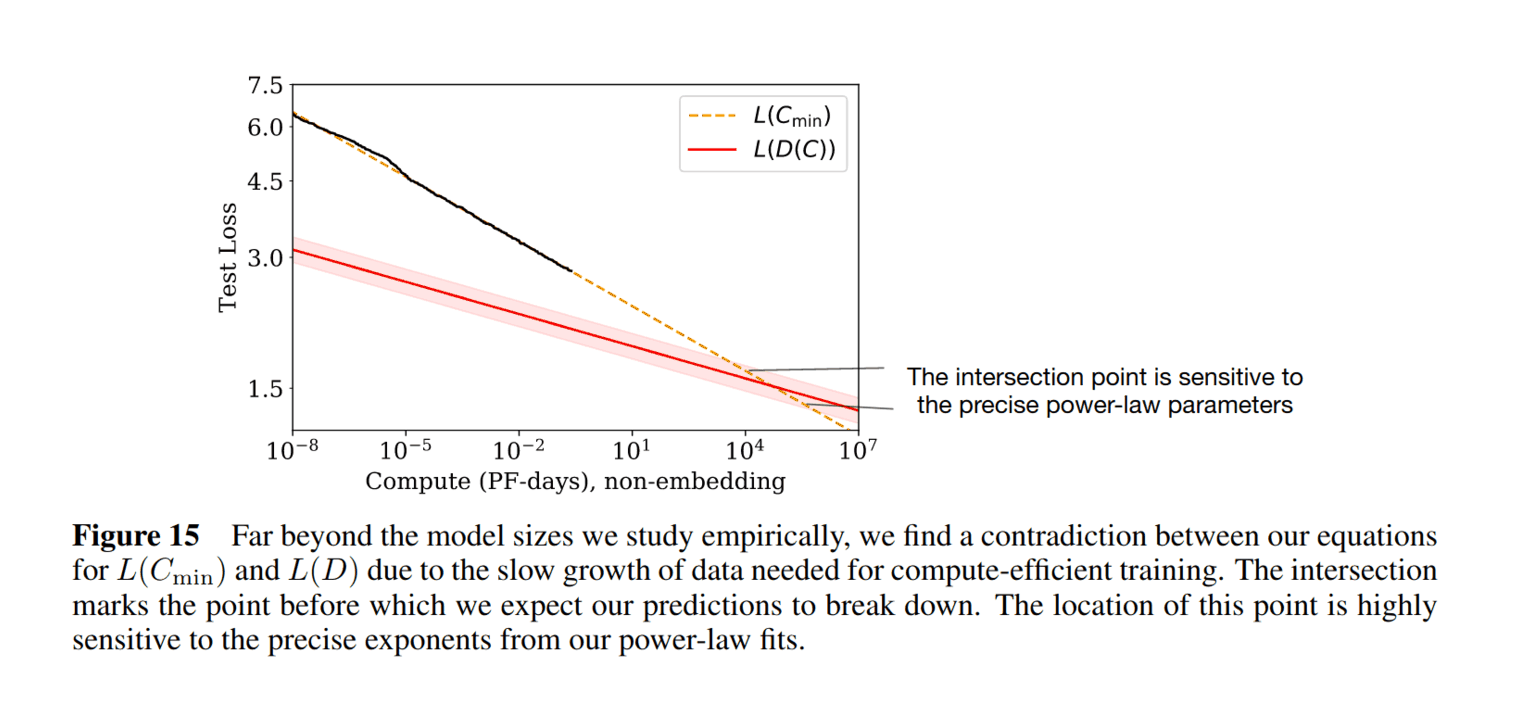{kind=link}
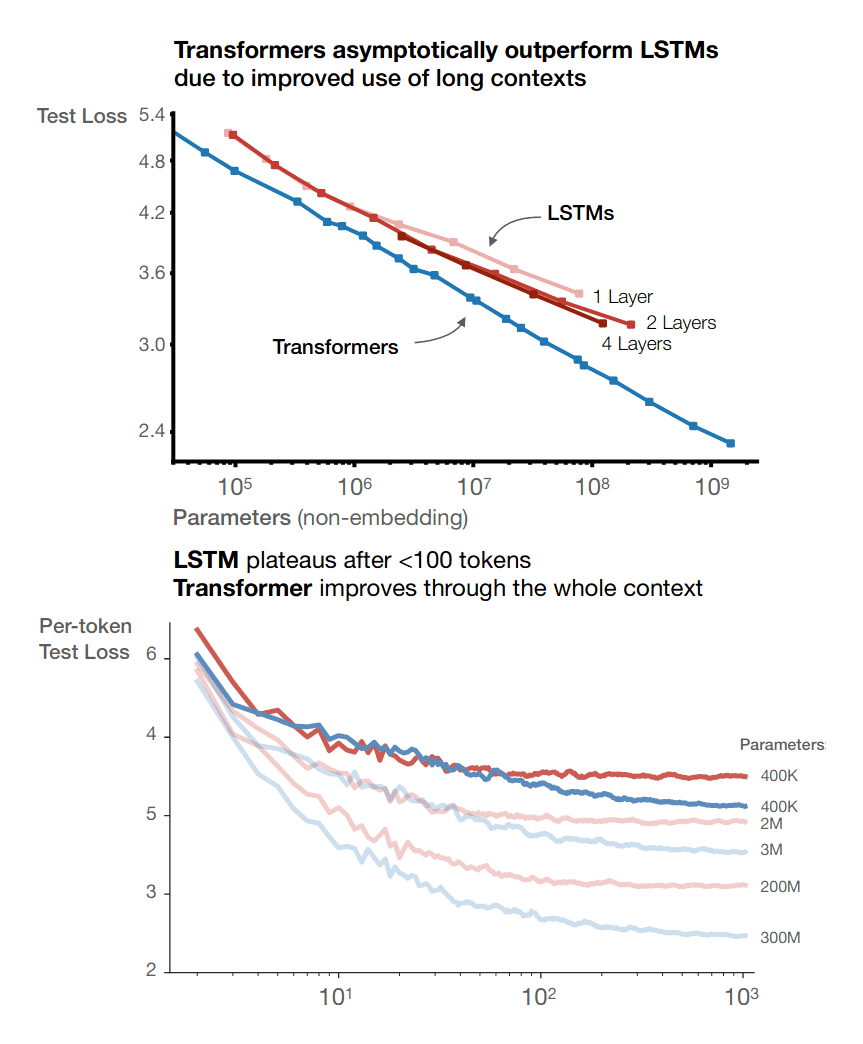{kind=link}
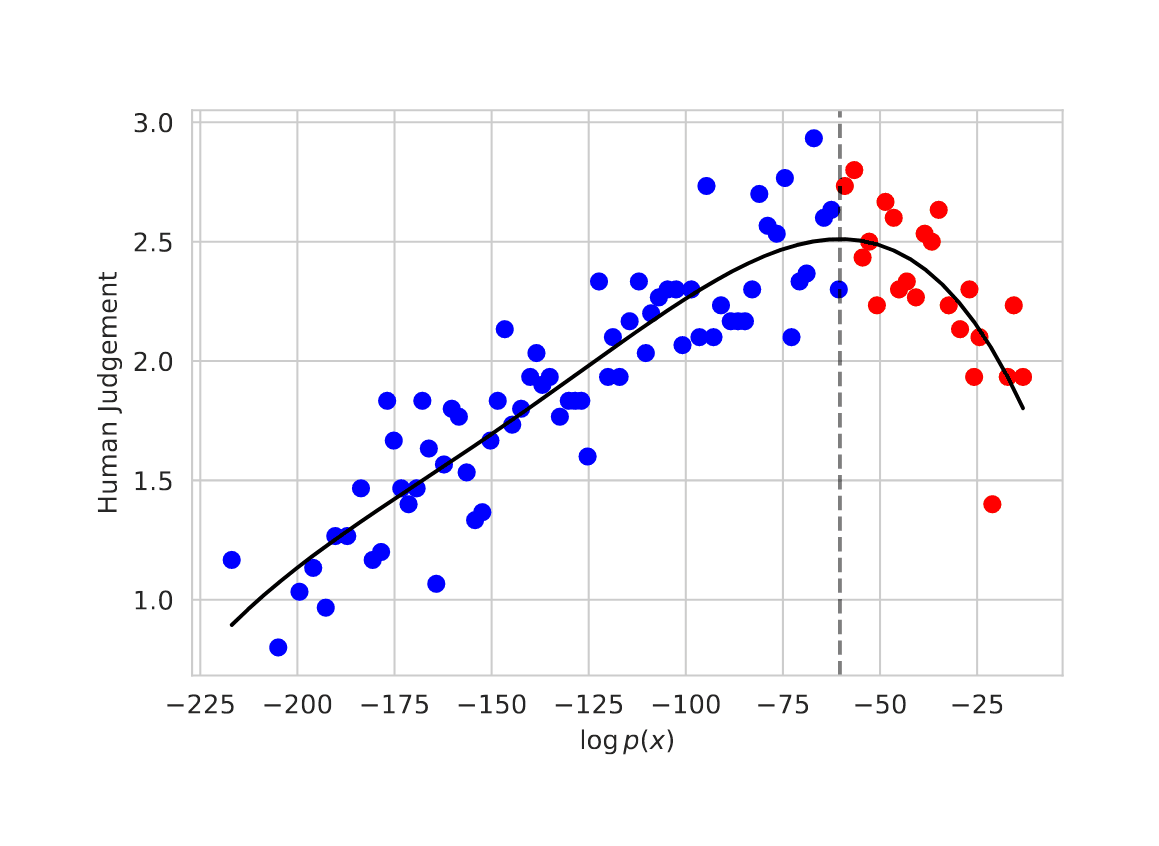{kind=link}
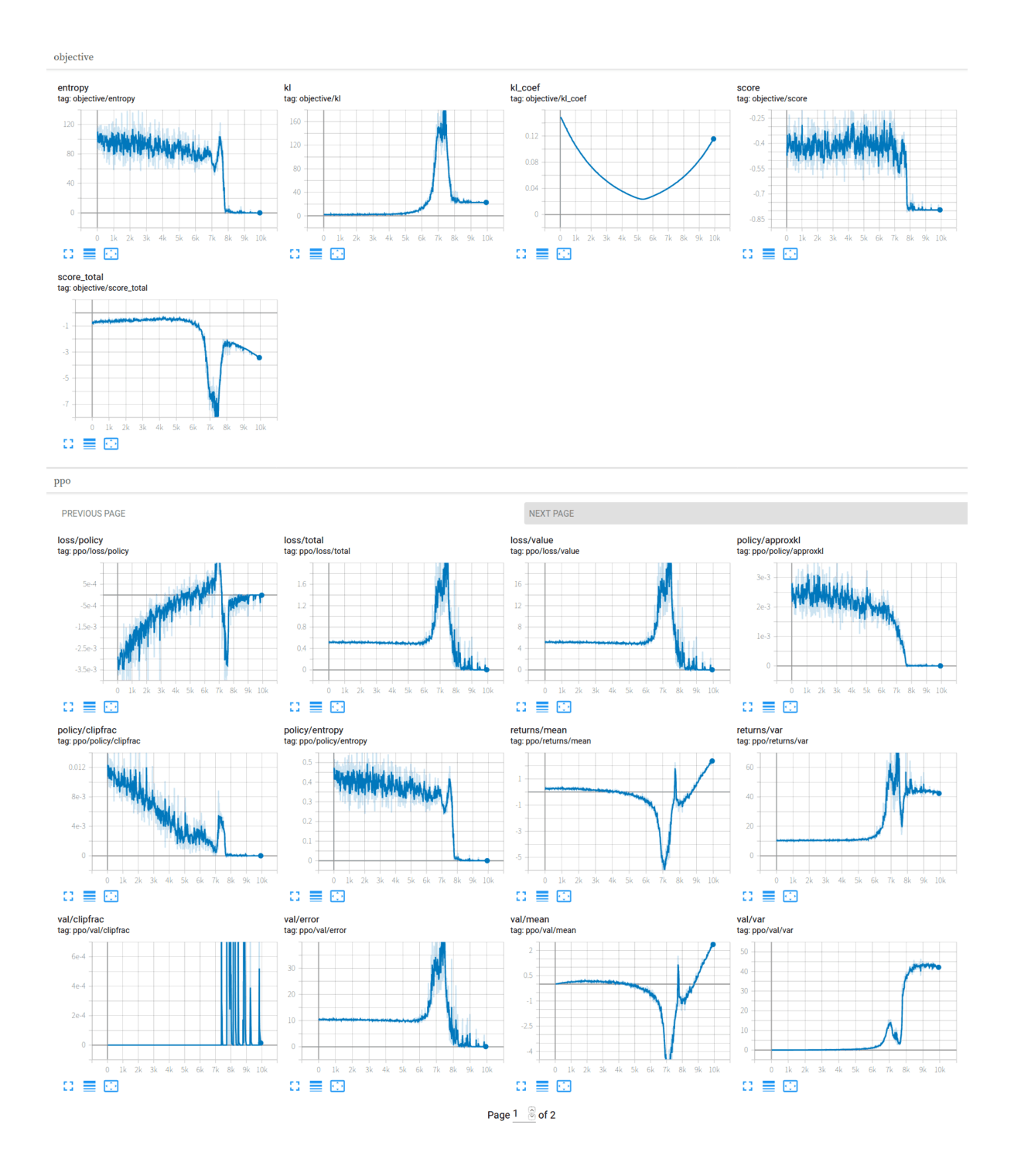{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
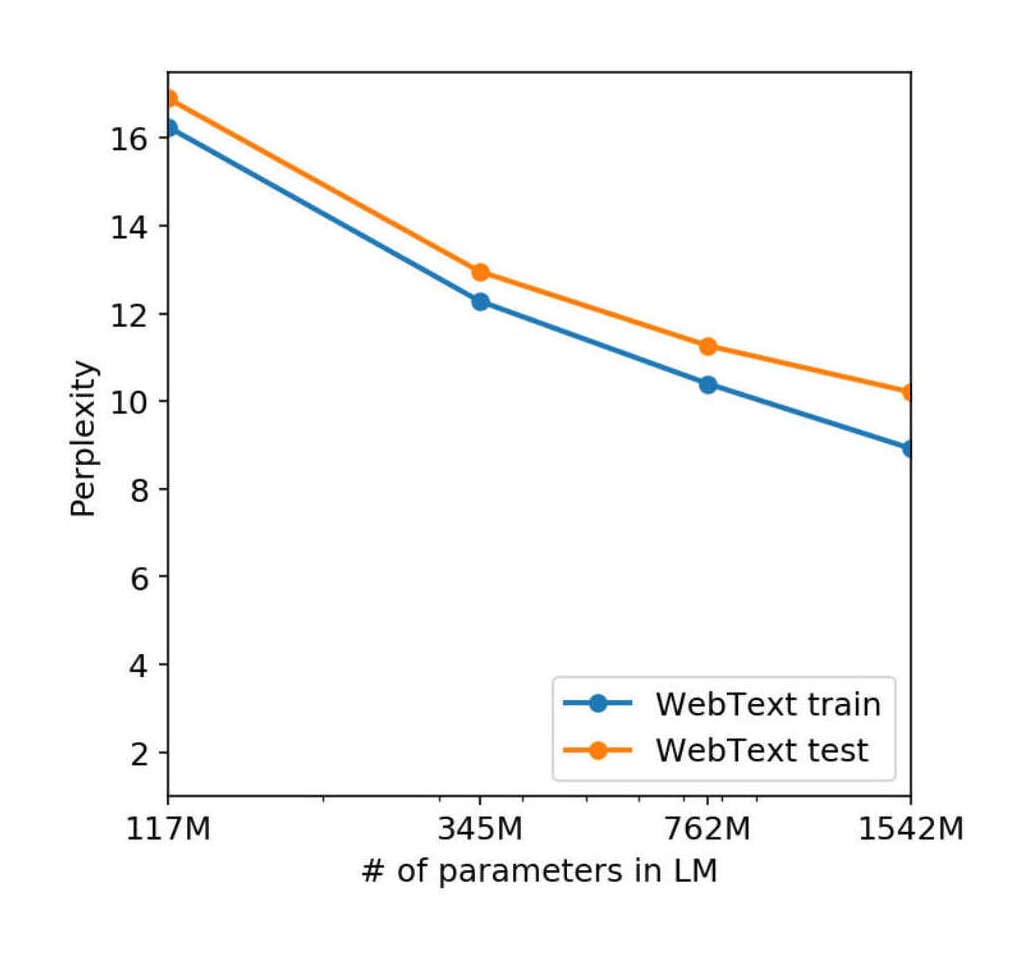{kind=link}
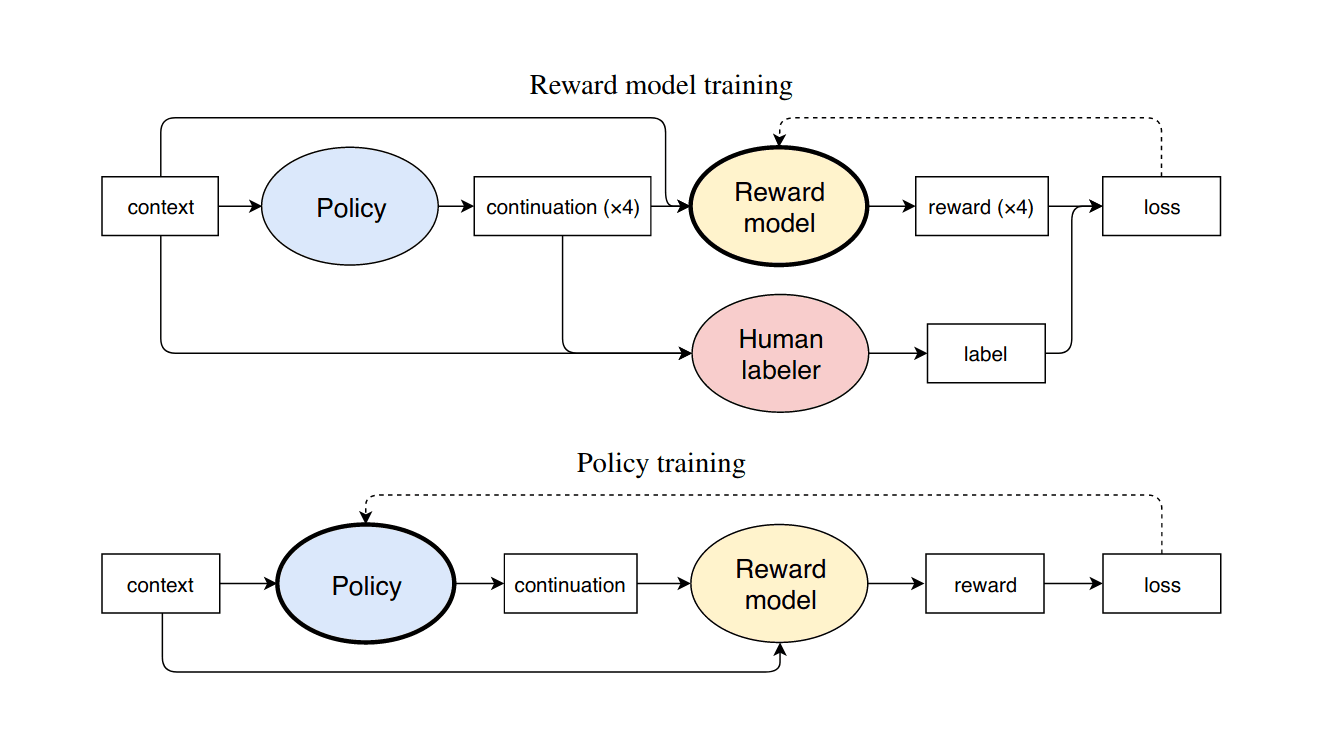{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2606.03938: “Q0: Primitives for Hyper-Epoch Pretraining”,https://x.com/LinchZhang/status/2053176531590210036: “[Grok, Could You Please Name 20 Great Bloggers That You Like?]”,https://arxiv.org/abs/2511.16652: “EGGROLL: Evolution Strategies at the Hyperscale”,https://arxiv.org/abs/2505.00661#google: “On the Generalization of Language Models from In-Context Learning and Finetuning: a Controlled Study”,https://arxiv.org/abs/2503.13423: “SuperBPE: Space Travel for Language Models”,https://arxiv.org/abs/2501.01956: “Metadata Conditioning Accelerates Language Model Pre-Training”,https://arxiv.org/abs/2410.01707: “Interpretable Contrastive Monte Carlo Tree Search Reasoning”,https://arxiv.org/abs/2409.17141: “FineZip: Pushing the Limits of Large Language Models for Practical Lossless Text Compression”,https://arxiv.org/abs/2408.05446: “Ensemble Everything Everywhere: Multi-Scale Aggregation for Adversarial Robustness”,https://arxiv.org/abs/2406.20086: “Token Erasure As a Footprint of Implicit Vocabulary Items in LLMs”,https://arxiv.org/abs/2406.19146: “Resolving Discrepancies in Compute-Optimal Scaling of Language Models”,https://arxiv.org/abs/2406.13131: “When Parts Are Greater Than Sums: Individual LLM Components Can Outperform Full Models”,https://arxiv.org/abs/2406.11794: “DataComp-LM: In Search of the next Generation of Training Sets for Language Models”,https://arxiv.org/abs/2406.07394: “MCTSr: Accessing GPT-4 Level Mathematical Olympiad Solutions via Monte Carlo Tree Self-Refine With LLaMA-3-8B”,https://arxiv.org/abs/2405.18400: “Superposed Decoding: Multiple Generations from a Single Autoregressive Inference Pass”,https://arxiv.org/abs/2404.12358: “From r to Q✱: Your Language Model Is Secretly a Q-Function”,https://arxiv.org/abs/2404.06664: “CulturalTeaming: AI-Assisted Interactive Red-Teaming for Challenging LLMs’ (Lack Of) Multicultural Knowledge”,https://inflection.ai/inflection-2-5: “Inflection-2.5: Meet the World’s Best Personal AI”,https://arxiv.org/abs/2402.17152#facebook: “Actions Speak Louder Than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations (HSTU)”,https://arxiv.org/abs/2402.15570: “Fast Adversarial Attacks on Language Models In One GPU Minute”,https://arxiv.org/abs/2402.07625: “Autonomous Data Selection With Language Models for Mathematical Texts”,https://arxiv.org/abs/2402.04494#deepmind: “Grandmaster-Level Chess Without Search”,https://arxiv.org/abs/2401.15024#microsoft: “SliceGPT: Compress Large Language Models by Deleting Rows and Columns”,https://arxiv.org/abs/2401.02385: “TinyLlama: An Open-Source Small Language Model”,https://arxiv.org/abs/2312.16862: “TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones”,https://arxiv.org/abs/2312.08914#zhipu: “CogAgent: A Visual Language Model for GUI Agents”,https://arxiv.org/abs/2311.16867: “The Falcon Series of Open Language Models”,https://arxiv.org/abs/2311.16079: “MEDITRON-70B: Scaling Medical Pretraining for Large Language Models”,https://www.reuters.com/technology/sam-altmans-ouster-openai-was-precipitated-by-letter-board-about-ai-breakthrough-2023-11-22/: “OpenAI Researchers Warned Board of AI Breakthrough ahead of CEO Ouster, Sources Say”,https://arxiv.org/abs/2310.15047: “Implicit Meta-Learning May Lead Language Models to Trust More Reliable Sources”,https://arxiv.org/abs/2310.06786: “OpenWebMath: An Open Dataset of High-Quality Mathematical Web Text”,https://arxiv.org/abs/2309.12284: “MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models”,https://arxiv.org/abs/2306.04050: “LLMZip: Lossless Text Compression Using Large Language Models”,https://arxiv.org/abs/2306.07567: “Large Language Models Sometimes Generate Purely Negatively-Reinforced Text”,https://arxiv.org/abs/2305.14718: “Improving Language Models With Advantage-Based Offline Policy Gradients”,https://arxiv.org/abs/2305.10429#google: “DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining”,https://www.forbes.com/sites/alexkonrad/2023/05/02/inflection-ai-ex-deepmind-launches-pi-chatbot/: “Inflection AI, Startup From Ex-DeepMind Leaders, Launches Pi—A Chattier Chatbot”,https://arxiv.org/abs/2304.06762#nvidia: “Shall We Pretrain Autoregressive Language Models With Retrieval? A Comprehensive Study”,https://warontherocks.com/2023/04/how-large-language-models-can-revolutionize-military-planning/: “How Large-Language Models Can Revolutionize Military Planning”,https://arxiv.org/abs/2303.13506: “The Quantization Model of Neural Scaling”,https://nolanoorg.substack.com/p/int-4-llama-is-not-enough-int-3-and: “Int-4 LLaMa Is Not Enough—Int-3 and Beyond: More Compression, Easier to Build Apps on LLMs That Run Locally”,https://osf.io/5uxra/: “Beyond the Pass Mark: the Accuracy of ChatGPT and Bing in the National Medical Licensure Examination in Japan”,https://arxiv.org/abs/2302.13939: “SpikeGPT: Generative Pre-Trained Language Model With Spiking Neural Networks”,https://arxiv.org/abs/2302.03169: “Data Selection for Language Models via Importance Resampling”,https://www.nytimes.com/2022/12/21/technology/ai-chatgpt-google-search.html: “A New Chat Bot Is a ‘Code Red’ for Google’s Search Business: A New Wave of Chat Bots like ChatGPT Use Artificial Intelligence That Could Reinvent or Even Replace the Traditional Internet Search Engine”,https://arxiv.org/abs/2211.10438: “SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models”,https://arxiv.org/abs/2211.09800: “InstructPix2Pix: Learning to Follow Image Editing Instructions”,https://arxiv.org/abs/2211.09085#facebook: “Galactica: A Large Language Model for Science”,https://arxiv.org/abs/2211.08411: “Large Language Models Struggle to Learn Long-Tail Knowledge”,https://arxiv.org/abs/2210.17323: “GPTQ: Accurate Post-Training Quantization for Generative Pre-Trained Transformers”,https://arxiv.org/abs/2210.13673#nvidia: “Evaluating Parameter Efficient Learning for Generation”,https://arxiv.org/abs/2210.10341#microsoft: “BioGPT: Generative Pre-Trained Transformer for Biomedical Text Generation and Mining”,https://arxiv.org/abs/2210.15458#google: “Arithmetic Sampling: Parallel Diverse Decoding for Large Language Models”,https://arxiv.org/abs/2210.06423#microsoft: “Foundation Transformers”,https://arxiv.org/abs/2210.02441: “Ask Me Anything (AMA): A Simple Strategy for Prompting Language Models”,https://arxiv.org/abs/2210.01241: “Is Reinforcement Learning (Not) for Natural Language Processing: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization”,https://arxiv.org/abs/2207.04429: “LM-Nav: Robotic Navigation With Large Pre-Trained Models of Language, Vision, and Action”,https://arxiv.org/abs/2206.01861#microsoft: “ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers”,https://www.nature.com/articles/s41593-022-01026-4: “Shared Computational Principles for Language Processing in Humans and Deep Language Models”,https://arxiv.org/abs/2110.04627#google: “Vector-Quantized Image Modeling With Improved VQGAN”,https://www.nature.com/articles/s42003-022-03036-1: “Brains and Algorithms Partially Converge in Natural Language Processing”,https://arxiv.org/abs/2201.11990#microsoftnvidia: “Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model”,https://swabhs.com/assets/pdf/wanli.pdf#allen: “WANLI: Worker and AI Collaboration for Natural Language Inference Dataset Creation”,https://arxiv.org/abs/2112.04426#deepmind: “Improving Language Models by Retrieving from Trillions of Tokens”,https://arxiv.org/abs/2111.13440: “True Few-Shot Learning With Prompts: A Real-World Perspective”,https://arxiv.org/abs/2111.02570#microsoft: “CLUES: Few-Shot Learning Evaluation in Natural Language Understanding”,https://arxiv.org/abs/2110.11309: “Fast Model Editing at Scale”,https://arxiv.org/abs/2109.02593#allen: “General-Purpose Question-Answering With Macaw”,https://arxiv.org/abs/2106.06981: “RASP: Thinking Like Transformers”,https://arxiv.org/abs/2105.13626#google: “ByT5: Towards a Token-Free Future With Pre-Trained Byte-To-Byte Models”,https://m.koreaherald.com/view.php?ud=20210525000824#naver: “Naver Unveils First ‘Hyperscale’ AI Platform”,https://arxiv.org/abs/2012.00413: “CPM: A Large-Scale Generative Chinese Pre-Trained Language Model”,https://arxiv.org/abs/2009.03393#openai: “Generative Language Modeling for Automated Theorem Proving”,https://aclanthology.org/2020.acl-main.463.pdf: “Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data”,https://arxiv.org/abs/2001.08361#openai: “Scaling Laws for Neural Language Models”,https://arxiv.org/abs/2001.04451#google: “Reformer: The Efficient Transformer”,https://arxiv.org/abs/1909.05858#salesforce: “CTRL: A Conditional Transformer Language Model For Controllable Generation”,https://paperswithcode.com/task/language-modelling: “Language Modeling State-Of-The-Art Leaderboards”,https://arxiv.org/abs/1901.02860: “Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context”,https://magenta.tensorflow.org/music-transformer: “Music Transformer: Generating Music With Long-Term Structure”,https://arxiv.org/abs/1807.03819#googledeepmind: “Universal Transformers”,https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf#page=5: “GPT-1: Improving Language Understanding by Generative Pre-Training § Model Specifications”,https://paulfchristiano.com/: “Homepage of Paul F. Christiano”,