‘LaMDA’ directory
- See Also
- Links
- “The Death and Life of Prediction Markets at Google: Over the past Two Decades, Google Has Hosted Two Different Internal Platforms for Predictions. Why Did the First One Fail—And Will the Other Endure?”, Schwarz 2024
- “LLMs Achieve Adult Human Performance on Higher-Order Theory of Mind Tasks”, Street et al 2024
- “Google Is Asking Employees to Test Potential ChatGPT Competitors, including a Chatbot Called ‘Apprentice Bard’”, Elias 2023
- “Creative Writing With Wordcraft, an AI-Powered Writing Assistant: Perspectives from Professional Writers”, Ippolito et al 2022
- “Language Model Cascades”, Dohan et al 2022
- “Exploring Length Generalization in Large Language Models”, Anil et al 2022
- “Least-To-Most Prompting Enables Complex Reasoning in Large Language Models”, Zhou et al 2022
- “Google Is Beta Testing Its AI Future: After Mistakes and Challenges, the Company Is Moving a Little Slower With AI Language Models”, Vincent 2022
- “PaLM: Scaling Language Modeling With Pathways”, Chowdhery et al 2022
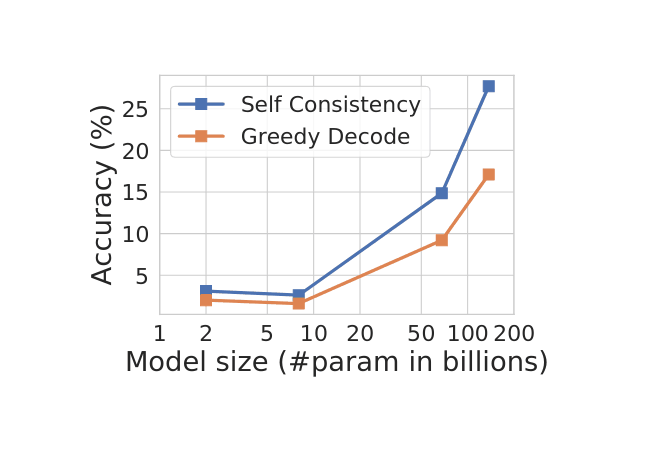
- “Self-Consistency Improves Chain-Of-Thought Reasoning in Language Models”, Wang et al 2022
- “PromptChainer: Chaining Large Language Model Prompts through Visual Programming”, Wu et al 2022
- “Using Natural Language Prompts for Machine Translation”, Garcia & Firat 2022
- “Chain-Of-Thought Prompting Elicits Reasoning in Large Language Models”, Wei et al 2022
- “LaMDA: Language Models for Dialog Applications”, Thoppilan et al 2022
- “Google LaMDA LLM”, Gwern 2022
- “SynthBio: A Case Study in Faster Curation of Text Datasets”, Yuan et al 2022
- “Discovering the Syntax and Strategies of Natural Language Programming With Generative Language Models”, Jiang et al 2022
- “GLaM: Efficient Scaling of Language Models With Mixture-Of-Experts”, Du et al 2021
- “Show Your Work: Scratchpads for Intermediate Computation With Language Models”, Nye et al 2021
- “AI Chains: Transparent and Controllable Human-AI Interaction by Chaining Large Language Model Prompts”, Wu et al 2021
- “A Recipe For Arbitrary Text Style Transfer With Large Language Models”, Reif et al 2021
- “GenLine and GenForm: Two Tools for Interacting With Generative Language Models in a Code Editor”, Jiang et al 2021b
- “FLAN: Finetuned Language Models Are Zero-Shot Learners”, Wei et al 2021
- “Program Synthesis With Large Language Models”, Austin et al 2021
- “Towards a Human-Like Open-Domain Chatbot”, Adiwardana et al 2020
- “LaMDA: Our Breakthrough Conversation Technology”
- “308 Permanent Redirect”
- “Do Large Language Models Understand Us?”
- “The Race to Understand the Thrilling, Dangerous World of Language AI”
- “Watch Google’s AI LaMDA Program Talk to Itself at Length (Full Conversation)”
- Sort By Magic
- Miscellaneous
- Bibliography
See Also
Links
“The Death and Life of Prediction Markets at Google: Over the past Two Decades, Google Has Hosted Two Different Internal Platforms for Predictions. Why Did the First One Fail—And Will the Other Endure?”, Schwarz 2024
“LLMs Achieve Adult Human Performance on Higher-Order Theory of Mind Tasks”, Street et al 2024
LLMs achieve adult human performance on higher-order theory of mind tasks
“Google Is Asking Employees to Test Potential ChatGPT Competitors, including a Chatbot Called ‘Apprentice Bard’”, Elias 2023
“Creative Writing With Wordcraft, an AI-Powered Writing Assistant: Perspectives from Professional Writers”, Ippolito et al 2022
“Language Model Cascades”, Dohan et al 2022
“Exploring Length Generalization in Large Language Models”, Anil et al 2022
“Least-To-Most Prompting Enables Complex Reasoning in Large Language Models”, Zhou et al 2022
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
“Google Is Beta Testing Its AI Future: After Mistakes and Challenges, the Company Is Moving a Little Slower With AI Language Models”, Vincent 2022
“PaLM: Scaling Language Modeling With Pathways”, Chowdhery et al 2022
“Self-Consistency Improves Chain-Of-Thought Reasoning in Language Models”, Wang et al 2022
Self-Consistency Improves Chain-of-Thought Reasoning in Language Models
“PromptChainer: Chaining Large Language Model Prompts through Visual Programming”, Wu et al 2022
PromptChainer: Chaining Large Language Model Prompts through Visual Programming
“Using Natural Language Prompts for Machine Translation”, Garcia & Firat 2022
“Chain-Of-Thought Prompting Elicits Reasoning in Large Language Models”, Wei et al 2022
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
“LaMDA: Language Models for Dialog Applications”, Thoppilan et al 2022
“Google LaMDA LLM”, Gwern 2022
“SynthBio: A Case Study in Faster Curation of Text Datasets”, Yuan et al 2022
“Discovering the Syntax and Strategies of Natural Language Programming With Generative Language Models”, Jiang et al 2022
“GLaM: Efficient Scaling of Language Models With Mixture-Of-Experts”, Du et al 2021
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
“Show Your Work: Scratchpads for Intermediate Computation With Language Models”, Nye et al 2021
Show Your Work: Scratchpads for Intermediate Computation with Language Models
“AI Chains: Transparent and Controllable Human-AI Interaction by Chaining Large Language Model Prompts”, Wu et al 2021
“A Recipe For Arbitrary Text Style Transfer With Large Language Models”, Reif et al 2021
A Recipe For Arbitrary Text Style Transfer with Large Language Models
“GenLine and GenForm: Two Tools for Interacting With Generative Language Models in a Code Editor”, Jiang et al 2021b
GenLine and GenForm: Two Tools for Interacting with Generative Language Models in a Code Editor
“FLAN: Finetuned Language Models Are Zero-Shot Learners”, Wei et al 2021
“Program Synthesis With Large Language Models”, Austin et al 2021
“Towards a Human-Like Open-Domain Chatbot”, Adiwardana et al 2020
“LaMDA: Our Breakthrough Conversation Technology”
“308 Permanent Redirect”
“Do Large Language Models Understand Us?”
“The Race to Understand the Thrilling, Dangerous World of Language AI”
The race to understand the thrilling, dangerous world of language AI
“Watch Google’s AI LaMDA Program Talk to Itself at Length (Full Conversation)”
Watch Google’s AI LaMDA program talk to itself at length (full conversation)
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
theory-of-mind
scaling-models
reasoning
dialogue-ai
Miscellaneous
https://blog.google/technology/ai/bard/-google-ai-search-updates/View External Link:
https://blog.google/technology/ai/bard/-google-ai-search-updates/https://wordcraft-writers-workshop.appspot.com/stories/allison-parrishhttps://wordcraft-writers-workshop.appspot.com/stories/diana-hamiltonhttps://wordcraft-writers-workshop.appspot.com/stories/eugenia-triantafyllou
{kind=link}
Bibliography
https://arxiv.org/abs/2405.18870#google: “LLMs Achieve Adult Human Performance on Higher-Order Theory of Mind Tasks”,https://www.cnbc.com/2023/01/31/google-testing-chatgpt-like-chatbot-apprentice-bard-with-employees.html: “Google Is Asking Employees to Test Potential ChatGPT Competitors, including a Chatbot Called ‘Apprentice Bard’”,https://arxiv.org/abs/2211.05030#google: “Creative Writing With Wordcraft, an AI-Powered Writing Assistant: Perspectives from Professional Writers”,https://arxiv.org/abs/2205.10625#google: “Least-To-Most Prompting Enables Complex Reasoning in Large Language Models”,https://www.theverge.com/2022/5/11/23065072/google-ai-app-test-kitchen-future-io-2022: “Google Is Beta Testing Its AI Future: After Mistakes and Challenges, the Company Is Moving a Little Slower With AI Language Models”,https://arxiv.org/abs/2204.02311#google: “PaLM: Scaling Language Modeling With Pathways”,https://arxiv.org/abs/2203.11171#google: “Self-Consistency Improves Chain-Of-Thought Reasoning in Language Models”,https://arxiv.org/abs/2202.11822#google: “Using Natural Language Prompts for Machine Translation”,https://arxiv.org/abs/2201.11903#google: “Chain-Of-Thought Prompting Elicits Reasoning in Large Language Models”,2021-jiang-2.pdf: “GenLine and GenForm: Two Tools for Interacting With Generative Language Models in a Code Editor”,