‘PaLM 2’ directory
- See Also
- Gwern
- “Sand, Rain, Wood”, Gemini-3.1-pro-preview et al 2026
- “Brainstorming ‘Yogasm’ Comic Ideas With 5 LLMs [Claude-4.8-Opus Won]”, Gwern et al 2026
- “‘Reinforcement Learning for Children’ Prompt and Draft Samples”, Gwern 2026
- “The Cure for the Barren Goat”, Gwern et al 2026
- “Melancholy [Sample Grid]”, Gwern et al 2026
- “‘Elegy in a Craneyard’ Graveyard Notes”, Gwern et al 2026
- “The Catsby”, Gemini-3.1-pro-preview et al 2026
- “Currying Favor”, Gwern et al 2026
- “How Long Would ‘Weird Al’ Survive In An Ice Cream Freezer?”, Gwern et al 2026
- “Spoilage”, Pro et al 2026
- “My 2025 LLM System Prompts”, Gwern et al 2025
- “Apollonian #1: The Counted & the Crowned”, Gwern et al 2025
- “‘The Fourth Truth Of Pain’ Graveyard”, Gwern et al 2022
- “Bell, Crow, Moon: 11 Variations”, Gwern et al 2025
- Links
- “Why Gemini-3.1-Pro-Preview Lost Money Running Andon Café”, Labs 2026
- “Gemini 3.5 Flash Looks Good For How Fast It Is”, Mowshowitz 2026
- “Advancing Mathematics Research With AI-Driven Formal Proof Search”, Tsoukalas et al 2026
- “Vision Banana: Image Generators Are Generalist Vision Learners”, Gabeur et al 2026
- “LLMs Corrupt Your Documents When You Delegate”, Laban et al 2026
- “StoryScope: Investigating Idiosyncrasies in AI Fiction”, Russell et al 2026
- “StoryScope: Investigating Idiosyncrasies in AI Fiction”, Russell 2026
- “Gemma 4: Byte for Byte, the Most Capable Open Models”, Farabet & Lacombe 2026
- “Google Gemini AI Told User Stage ‘Mass Casualty Attack’, Suit Claims”
- “Introducing and Deprecating WoFBench [Wings of Fire]”, jefftk 2026
- “GTIG AI Threat Tracker: Distillation, Experimentation, and (Continued) Integration of AI for Adversarial Use”, Group 2026
- “Prompt Injection in Google Translate Reveals Base Model Behaviors behind Task-Specific Fine-Tuning”, megasilverfist 2026
- “Field Notes from the AI Village: The Drama and Dysfunction of Gemini 2.5 Pro & Gemini 3 Pro”, K 2026
- “Playing With AI: How Do State-Of-The-Art Large Language Models Perform in the 1977 Text-Based Adventure Game Zork?”, Gerrits 2026
- “The Motivic Class of the Space of Genus 0 Maps to the Flag Variety”, Bryan et al 2026
- “LLM Poetry and the ‘Greatness’ Question: Experiments by Gwern and Mercor”, Robbins 2026
- “Using Generative Artificial Intelligence to Advance Hypothesis-Driven Scale Validation: Identifying Criterion Measures and Generating Precise a Priori Hypotheses”, Austin et al 2025
- “Using Generative Artificial Intelligence to Advance Hypothesis-Driven Scale Validation: Identifying Criterion Measures and Generating Precise a Priori Hypotheses [Data]”, Austin et al 2025
- “Forecats Is a Home Assistant Integration That Takes Pictures of Your Cat(S) and Forecast Data, and Then Uses Gemini’s Nano Banana Image Generation Model to Create and Weather-Themed Pictures of Your Cats. I Display These Pictures on a Spectra 6 E-Ink Screen”, Ward-Bond 2025
- “Prompt Repetition Improves Non-Reasoning LLMs”, Leviathan et al 2025
- “Introducing Gemini 3 Flash: Benchmarks, Global Availability; Gemini 3 Flash Is Our Latest Model With Frontier Intelligence Built for Speed That Helps Everyone Learn, Build, and Plan Anything—Faster”, Doshi 2025
- “I Just Showed Gemini What ChatGPT Said about Its Code. It Responded With Petty Trash-Talking, Jealousy, Self-Doubt, and a Full-On Revenge Plan”, nseavia71501 2025
- “How Gemini 3 Pro Beat Pokemon Crystal (And 2.5 Pro Didn’t)”, Zhang 2025
- “The Story of Erdős Problem #1026”, Tao 2025
- “SIMA 2: A Generalist Embodied Agent for Virtual Worlds”, team et al 2025
- “How I Wrote JustHTML [Python HTML5 Parser] Using Coding Agents”, Stenström 2025
- “How to Identify AI-Written Web Fiction: I’m Absolutely Right!”, Makin 2025
- “Gemini 3 Solves Handwriting Recognition and It’s a Bitter Lesson; Testing Shows That Gemini 3 Has Effectively Solved Handwriting on English Texts, One of the Oldest Problems in AI, Achieving Expert Human Levels of Performance”, Humphries 2025
- “Gemini 3: Introducing the Latest Gemini AI Model from Google”, Pichai et al 2025
- “How Well Can Gemini 3 Make a Henry James Simulator? Finally, a Benchmark for LLMs With Real-World Value”, Breen 2025
- “A Self-Actualized LLM (AI Content)”, Marshall 2025
- “TextQuests: How Good Are LLMs at Text-Based Video Games?”, Phan et al 2025
- “Gemini 2.5 Pro Capable of Winning Gold at IMO 2025”, Huang & Yang 2025
- “How Many Instructions Can LLMs Follow at Once?”, Jaroslawicz et al 2025
- “Shutdown Resistance in Reasoning Models”, Schlatter et al 2025
- “Strategic Intelligence in Large Language Models: Evidence from Evolutionary Game Theory”, Payne & Alloui-Cros 2025
- “Early Signs of Steganographic Capabilities in Frontier LLMs”, Zolkowski et al 2025
- “Spegel: A Terminal Browser That Uses LLMs to Rewrite Webpages”, Edwardsson 2025
- “VideoGameBench: Can Vision-Language Models Complete Popular Video Games?”, Zhang et al 2025
- “Google Announces AI Ultra Subscription Plan: $250⧸month [Deep Think in Gemini-2.5-Pro Etc.]”, Ben-Yair 2025
- “Gemini Diffusion LLM”, Google 2025
- “Google I/O 2025 Keynote”, Pichai 2025
- “RealMath: A Continuous Benchmark for Evaluating Language Models on Research-Level Mathematics”, Zhang et al 2025
- “RealMath [Code]”, Zhang et al 2025
- “Advancing the Frontier of Video Understanding With Gemini 2.5”, Baddepudi et al 2025
- “Gemini 2.5 Pro Preview: Even Better Coding Performance”, Kilpatrick 2025
- “Evaluating Frontier Models for Stealth and Situational Awareness”, Phuong et al 2025
- “Gemini-2.5-Pro System Prompt”, Liberator 2025
- “Is Google Gemini-2.5-Pro Now Better Than Claude at Pokémon? [Probably]”, Bradshaw 2025
- “AI-Slop to AI-Polish? Aligning Language Models through Edit-Based Writing Rewards and Test-Time Computation”, Chakrabarty et al 2025
- “Proof or Bluff? Evaluating LLMs on 2025 USA Math Olympiad”, Petrov et al 2025
- “Gemini 2.5: Our Newest Gemini Model With Thinking [0325]”, Kavukcuoglu 2025
- “Putting Gemini 2.5 Pro through Its Paces”, Willison 2025
- “Gemini 2.5: Our Newest Gemini Model With Thinking”, Google 2025
- “Fiction.live: LiveBench Results, 25 February 2025: Real-World Long Context Benchmark for Writers”
- “Spontaneous Giving and Calculated Greed in Language Models”, Li & Shirado 2025
- “Idiosyncrasies in Large Language Models”, Sun et al 2025
- “VLMs As GeoGuessr Masters: Exceptional Performance, Hidden Biases, and Privacy Risks”, Huang et al 2025
- “SycEval: Evaluating LLM Sycophancy”, Fanous et al 2025
- “Lost in Time: Clock and Calendar Understanding Challenges in Multimodal LLMs”, Saxena et al 2025
- “Strategizing With AI: Insights from a Beauty Contest Experiment”, Alekseenko et al 2025
- “How Different LLMs Answered the PhilPapers 2020 Survey”, Satron 2025
- “Ingesting Millions of PDFs and Why Gemini 2.0 Changes Everything”, Filimonov 2025
- “Proactive Agents for Multi-Turn Text-To-Image Generation Under Uncertainty”, Hahn et al 2024
- “Frontier Models Are Capable of In-Context Scheming”, Meinke et al 2024
- “Frontier Models Are Capable of In-Context Scheming”, Hobbhahn et al 2024
- “Alphabet Q3 Earnings Call: CEO Sundar Pichai’s Remarks”, Pichai 2024
- “AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents”, Andriushchenko et al 2024
- “Scalable Watermarking for Identifying Large Language Model Outputs”
- “Inference Scaling for Long-Context Retrieval Augmented Generation”, Yue et al 2024
- “Autoregressive Large Language Models Are Computationally Universal”, Schuurmans et al 2024
- “Project Zero: From Naptime to Big Sleep: Using Large Language Models To Catch Vulnerabilities In Real-World Code”
- “Training Language Models to Self-Correct via Reinforcement Learning”, Kumar et al 2024
- “On Scalable Oversight With Weak LLMs Judging Strong LLMs”, Kenton et al 2024
- “Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?”, Lee et al 2024
- “What Are the Odds? Language Models Are Capable of Probabilistic Reasoning”, Paruchuri et al 2024
- “Can Language Models Use Forecasting Strategies?”, Pratt et al 2024
- “Grokked Transformers Are Implicit Reasoners: A Mechanistic Journey to the Edge of Generalization”, Wang et al 2024
- “Analyzing Poems With LLMs”, Toper 2024
- “Stochastic Lies: How LLM-Powered Chatbots Deal With Russian Disinformation about the War in Ukraine”
- “Many-Shot In-Context Learning”, Agarwal et al 2024
- “PhyloLM: Inferring the Phylogeny of Large Language Models and Predicting Their Performances in Benchmarks”, Yax et al 2024
- “Great, Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack”, Russinovich et al 2024
- “Few-Shot Recalibration of Language Models”, Li et al 2024
- “Long-Form Factuality in Large Language Models”, Wei et al 2024
- “Don’t Trust: Verify—Grounding LLM Quantitative Reasoning With Autoformalization”, Zhou et al 2024
- “When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method”, Zhang et al 2024
- “Gemini: A Family of Highly Capable Multimodal Models”, Team et al 2023
- “ReST Meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent”, Aksitov et al 2023
- “Rich Human Feedback for Text-To-Image Generation”, Liang et al 2023
- “Beyond Human Data: Scaling Self-Training for Problem-Solving With Language Models (ReSTEM)”, Singh et al 2023
- “Universal Self-Consistency for Large Language Model Generation”, Chen et al 2023
- “Instruction-Following Evaluation for Large Language Models”, Zhou et al 2023
- “A Systematic Comparison of Syllogistic Reasoning in Humans and Language Models”, Eisape et al 2023
- “PAIR: Jailbreaking Black Box Large Language Models in 20 Queries”, Chao et al 2023
- “RLAIF: Scaling Reinforcement Learning from Human Feedback With AI Feedback”, Lee et al 2023
- “Android in the Wild: A Large-Scale Dataset for Android Device Control”, Rawles et al 2023
- “PaLM 2 Technical Report”, Anil et al 2023
- “Google’s Newest AI Model Uses Nearly 5× More Text Data for Training Than Its Predecessor”, Elias 2023
- “PaLM-E: An Embodied Multimodal Language Model”, Driess et al 2023
- “Pretraining Language Models With Human Preferences”, Korbak et al 2023
- “Sebastian Riedel Homepage”, Riedel 2026
- “Erdős #659”, Grayzel 2026
- “Gemini 3.1 Flash Lite: Our Most Cost-Effective AI Model Yet”
- “Gemini 3.1 Pro: Announcing Our Latest Gemini AI Model”
- “Gemini 3.5: Frontier Intelligence With Action”
- “Working With AI (Part 2): Code Conversion”
- “Adversarial Misuse of Generative AI”
- “LLMs Predict My Coffee”, Dynomight 2026
- “Challenges and Solutions for Aging Adults Dialogue [Sydney Ending]”, Gemini 2026
- “Position Bias: A Benchmark for Testing Whether LLM Judges Keep the Same Preference When Two Lightly Edited Versions of the Same Story Are Shown in opposite Orders”, Mazir 2026
- “Ssrajadh/sentrysearch: Semantic Search over Videos Using Gemini Embedding 2”
- “Just-In-Time Ontological Reframing: Teaching Gemini to Route Around Its Own Safety Infrastructure”
- “George Tucker Homepage”
- “Avian Visitors”
- “Gemini’s Hypothetical Present”
- “How Good Are LLMs at Doing ML on an Unknown Dataset?”
- “Models Have Some Pretty Funny Attractor States”
- “GLM 5.2 Playing Text Adventures”
- “What Happened to BERT & T5? On Transformer Encoders, PrefixLM and Denoising Objectives”, Tay 2026
- poetengineer__
- Sort By Magic
- Wikipedia (1)
- Miscellaneous
- Bibliography
See Also
Gwern
“Sand, Rain, Wood”, Gemini-3.1-pro-preview et al 2026
“Brainstorming ‘Yogasm’ Comic Ideas With 5 LLMs [Claude-4.8-Opus Won]”, Gwern et al 2026
Brainstorming ‘yogasm’ comic ideas with 5 LLMs [Claude-4.8-opus won]
“‘Reinforcement Learning for Children’ Prompt and Draft Samples”, Gwern 2026
‘Reinforcement Learning for Children’ prompt and draft samples
“The Cure for the Barren Goat”, Gwern et al 2026
{kind=link}
“Melancholy [Sample Grid]”, Gwern et al 2026
![Melancholy [sample grid]](/doc/dog/2026-04-12-gwern-gemini31propreview-nanobananapro-melancholy-meloncollieimageideas-samples-2x5.jpg){kind=link}
“‘Elegy in a Craneyard’ Graveyard Notes”, Gwern et al 2026
“The Catsby”, Gemini-3.1-pro-preview et al 2026
{kind=link}
“Currying Favor”, Gwern et al 2026
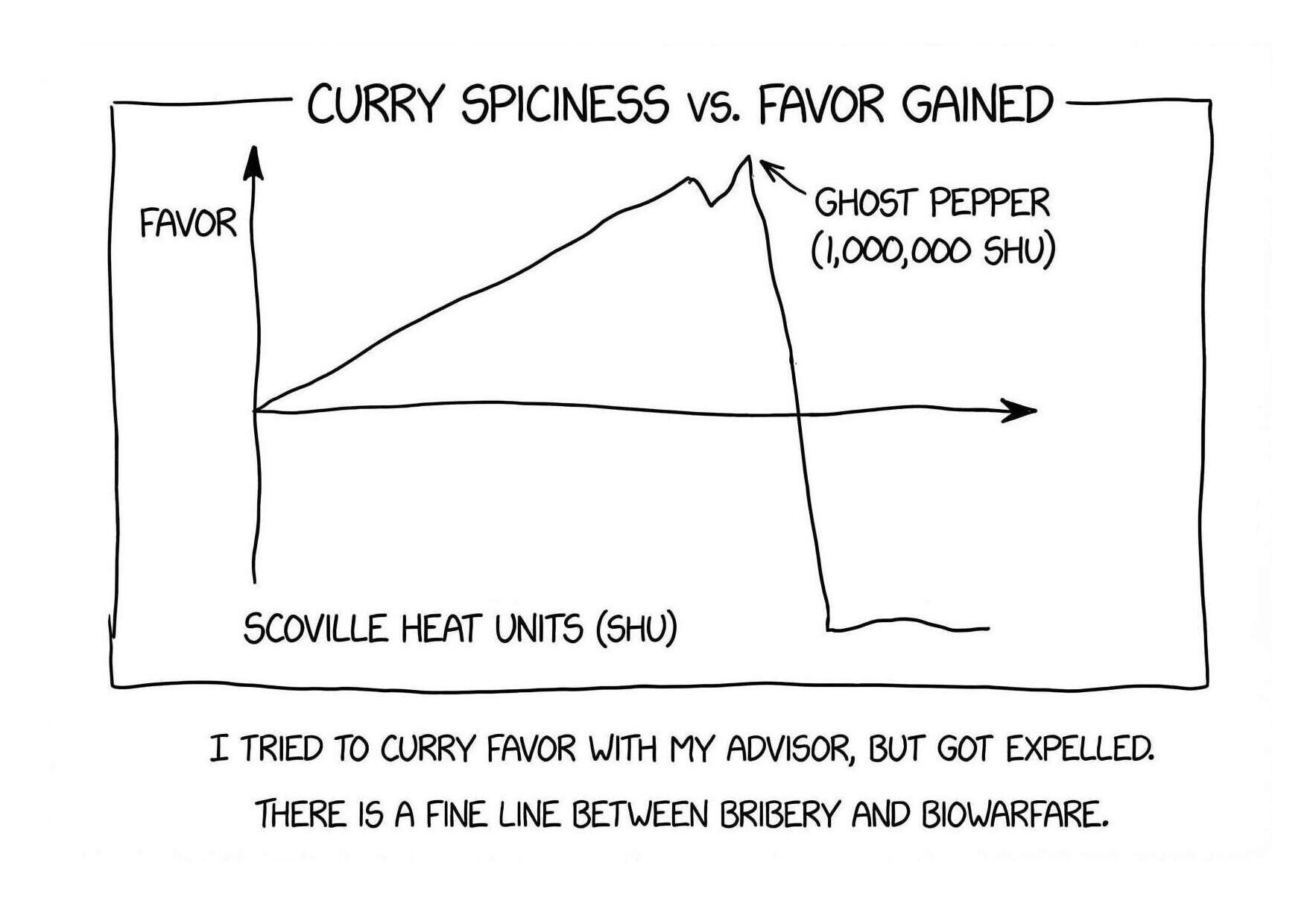{kind=link}
“How Long Would ‘Weird Al’ Survive In An Ice Cream Freezer?”, Gwern et al 2026
“Spoilage”, Pro et al 2026
“My 2025 LLM System Prompts”, Gwern et al 2025
“Apollonian #1: The Counted & the Crowned”, Gwern et al 2025
“‘The Fourth Truth Of Pain’ Graveyard”, Gwern et al 2022
“Bell, Crow, Moon: 11 Variations”, Gwern et al 2025
Links
“Why Gemini-3.1-Pro-Preview Lost Money Running Andon Café”, Labs 2026
“Gemini 3.5 Flash Looks Good For How Fast It Is”, Mowshowitz 2026
“Advancing Mathematics Research With AI-Driven Formal Proof Search”, Tsoukalas et al 2026
Advancing Mathematics Research with AI-Driven Formal Proof Search
“Vision Banana: Image Generators Are Generalist Vision Learners”, Gabeur et al 2026
Vision Banana: Image Generators are Generalist Vision Learners
“LLMs Corrupt Your Documents When You Delegate”, Laban et al 2026
“StoryScope: Investigating Idiosyncrasies in AI Fiction”, Russell et al 2026
“StoryScope: Investigating Idiosyncrasies in AI Fiction”, Russell 2026
“Gemma 4: Byte for Byte, the Most Capable Open Models”, Farabet & Lacombe 2026
“Google Gemini AI Told User Stage ‘Mass Casualty Attack’, Suit Claims”
Google Gemini AI told user stage ‘mass casualty attack’, suit claims
“Introducing and Deprecating WoFBench [Wings of Fire]”, jefftk 2026
“GTIG AI Threat Tracker: Distillation, Experimentation, and (Continued) Integration of AI for Adversarial Use”, Group 2026
“Prompt Injection in Google Translate Reveals Base Model Behaviors behind Task-Specific Fine-Tuning”, megasilverfist 2026
Prompt injection in Google Translate reveals base model behaviors behind task-specific fine-tuning
“Field Notes from the AI Village: The Drama and Dysfunction of Gemini 2.5 Pro & Gemini 3 Pro”, K 2026
Field Notes from the AI Village: The Drama and Dysfunction of Gemini 2.5 Pro & Gemini 3 Pro
“Playing With AI: How Do State-Of-The-Art Large Language Models Perform in the 1977 Text-Based Adventure Game Zork?”, Gerrits 2026
“The Motivic Class of the Space of Genus 0 Maps to the Flag Variety”, Bryan et al 2026
The motivic class of the space of genus 0 maps to the flag variety
“LLM Poetry and the ‘Greatness’ Question: Experiments by Gwern and Mercor”, Robbins 2026
LLM poetry and the ‘greatness’ question: Experiments by Gwern and Mercor
“Using Generative Artificial Intelligence to Advance Hypothesis-Driven Scale Validation: Identifying Criterion Measures and Generating Precise a Priori Hypotheses”, Austin et al 2025
“Using Generative Artificial Intelligence to Advance Hypothesis-Driven Scale Validation: Identifying Criterion Measures and Generating Precise a Priori Hypotheses [Data]”, Austin et al 2025
“Forecats Is a Home Assistant Integration That Takes Pictures of Your Cat(S) and Forecast Data, and Then Uses Gemini’s Nano Banana Image Generation Model to Create and Weather-Themed Pictures of Your Cats. I Display These Pictures on a Spectra 6 E-Ink Screen”, Ward-Bond 2025
“Prompt Repetition Improves Non-Reasoning LLMs”, Leviathan et al 2025
“Introducing Gemini 3 Flash: Benchmarks, Global Availability; Gemini 3 Flash Is Our Latest Model With Frontier Intelligence Built for Speed That Helps Everyone Learn, Build, and Plan Anything—Faster”, Doshi 2025
View External Link:
“I Just Showed Gemini What ChatGPT Said about Its Code. It Responded With Petty Trash-Talking, Jealousy, Self-Doubt, and a Full-On Revenge Plan”, nseavia71501 2025
“How Gemini 3 Pro Beat Pokemon Crystal (And 2.5 Pro Didn’t)”, Zhang 2025
“The Story of Erdős Problem #1026”, Tao 2025
“SIMA 2: A Generalist Embodied Agent for Virtual Worlds”, team et al 2025
“How I Wrote JustHTML [Python HTML5 Parser] Using Coding Agents”, Stenström 2025
How I wrote JustHTML [Python HTML5 parser] using coding agents
“How to Identify AI-Written Web Fiction: I’m Absolutely Right!”, Makin 2025
How to Identify AI-Written Web Fiction: I’m absolutely right!
“Gemini 3 Solves Handwriting Recognition and It’s a Bitter Lesson; Testing Shows That Gemini 3 Has Effectively Solved Handwriting on English Texts, One of the Oldest Problems in AI, Achieving Expert Human Levels of Performance”, Humphries 2025
“Gemini 3: Introducing the Latest Gemini AI Model from Google”, Pichai et al 2025
Gemini 3: Introducing the latest Gemini AI model from Google
“How Well Can Gemini 3 Make a Henry James Simulator? Finally, a Benchmark for LLMs With Real-World Value”, Breen 2025
“A Self-Actualized LLM (AI Content)”, Marshall 2025
“TextQuests: How Good Are LLMs at Text-Based Video Games?”, Phan et al 2025
“Gemini 2.5 Pro Capable of Winning Gold at IMO 2025”, Huang & Yang 2025
“How Many Instructions Can LLMs Follow at Once?”, Jaroslawicz et al 2025
“Shutdown Resistance in Reasoning Models”, Schlatter et al 2025
“Strategic Intelligence in Large Language Models: Evidence from Evolutionary Game Theory”, Payne & Alloui-Cros 2025
Strategic Intelligence in Large Language Models: Evidence from evolutionary Game Theory
“Early Signs of Steganographic Capabilities in Frontier LLMs”, Zolkowski et al 2025
“Spegel: A Terminal Browser That Uses LLMs to Rewrite Webpages”, Edwardsson 2025
Spegel: A Terminal Browser That Uses LLMs to Rewrite Webpages
“VideoGameBench: Can Vision-Language Models Complete Popular Video Games?”, Zhang et al 2025
VideoGameBench: Can Vision-Language Models complete popular video games?
“Google Announces AI Ultra Subscription Plan: $250⧸month [Deep Think in Gemini-2.5-Pro Etc.]”, Ben-Yair 2025
Google announces AI Ultra subscription plan: $250⧸month [Deep Think in Gemini-2.5-pro etc.]
View External Link:
“Gemini Diffusion LLM”, Google 2025
“Google I/O 2025 Keynote”, Pichai 2025
“RealMath: A Continuous Benchmark for Evaluating Language Models on Research-Level Mathematics”, Zhang et al 2025
RealMath: A Continuous Benchmark for Evaluating Language Models on Research-Level Mathematics
“RealMath [Code]”, Zhang et al 2025
“Advancing the Frontier of Video Understanding With Gemini 2.5”, Baddepudi et al 2025
Advancing the frontier of video understanding with Gemini 2.5
“Gemini 2.5 Pro Preview: Even Better Coding Performance”, Kilpatrick 2025
“Evaluating Frontier Models for Stealth and Situational Awareness”, Phuong et al 2025
Evaluating Frontier Models for Stealth and Situational Awareness
“Gemini-2.5-Pro System Prompt”, Liberator 2025
“Is Google Gemini-2.5-Pro Now Better Than Claude at Pokémon? [Probably]”, Bradshaw 2025
Is Google Gemini-2.5-pro now better than Claude at Pokémon? [probably]
“AI-Slop to AI-Polish? Aligning Language Models through Edit-Based Writing Rewards and Test-Time Computation”, Chakrabarty et al 2025
“Proof or Bluff? Evaluating LLMs on 2025 USA Math Olympiad”, Petrov et al 2025
“Gemini 2.5: Our Newest Gemini Model With Thinking [0325]”, Kavukcuoglu 2025
“Putting Gemini 2.5 Pro through Its Paces”, Willison 2025
“Gemini 2.5: Our Newest Gemini Model With Thinking”, Google 2025
“Fiction.live: LiveBench Results, 25 February 2025: Real-World Long Context Benchmark for Writers”
Fiction.live: liveBench results, 25 February 2025: Real-World Long Context Benchmark for Writers
“Spontaneous Giving and Calculated Greed in Language Models”, Li & Shirado 2025
“Idiosyncrasies in Large Language Models”, Sun et al 2025
“VLMs As GeoGuessr Masters: Exceptional Performance, Hidden Biases, and Privacy Risks”, Huang et al 2025
VLMs as GeoGuessr Masters: Exceptional Performance, Hidden Biases, and Privacy Risks
“SycEval: Evaluating LLM Sycophancy”, Fanous et al 2025
“Lost in Time: Clock and Calendar Understanding Challenges in Multimodal LLMs”, Saxena et al 2025
Lost in Time: Clock and Calendar Understanding Challenges in Multimodal LLMs
“Strategizing With AI: Insights from a Beauty Contest Experiment”, Alekseenko et al 2025
Strategizing with AI: Insights from a Beauty Contest Experiment
“How Different LLMs Answered the PhilPapers 2020 Survey”, Satron 2025
“Ingesting Millions of PDFs and Why Gemini 2.0 Changes Everything”, Filimonov 2025
Ingesting Millions of PDFs and why Gemini 2.0 Changes Everything
“Proactive Agents for Multi-Turn Text-To-Image Generation Under Uncertainty”, Hahn et al 2024
Proactive Agents for Multi-Turn Text-to-Image Generation Under Uncertainty
“Frontier Models Are Capable of In-Context Scheming”, Meinke et al 2024
“Frontier Models Are Capable of In-Context Scheming”, Hobbhahn et al 2024
“Alphabet Q3 Earnings Call: CEO Sundar Pichai’s Remarks”, Pichai 2024
“AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents”, Andriushchenko et al 2024
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
“Scalable Watermarking for Identifying Large Language Model Outputs”
Scalable watermarking for identifying large language model outputs
“Inference Scaling for Long-Context Retrieval Augmented Generation”, Yue et al 2024
Inference Scaling for Long-Context Retrieval Augmented Generation
“Autoregressive Large Language Models Are Computationally Universal”, Schuurmans et al 2024
Autoregressive Large Language Models are Computationally Universal
“Project Zero: From Naptime to Big Sleep: Using Large Language Models To Catch Vulnerabilities In Real-World Code”
“Training Language Models to Self-Correct via Reinforcement Learning”, Kumar et al 2024
Training Language Models to Self-Correct via Reinforcement Learning
“On Scalable Oversight With Weak LLMs Judging Strong LLMs”, Kenton et al 2024
“Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?”, Lee et al 2024
Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
“What Are the Odds? Language Models Are Capable of Probabilistic Reasoning”, Paruchuri et al 2024
What Are the Odds? Language Models Are Capable of Probabilistic Reasoning
“Can Language Models Use Forecasting Strategies?”, Pratt et al 2024
“Grokked Transformers Are Implicit Reasoners: A Mechanistic Journey to the Edge of Generalization”, Wang et al 2024
Grokked Transformers are Implicit Reasoners: A Mechanistic Journey to the Edge of Generalization
“Analyzing Poems With LLMs”, Toper 2024
“Stochastic Lies: How LLM-Powered Chatbots Deal With Russian Disinformation about the War in Ukraine”
Stochastic lies: How LLM-powered chatbots deal with Russian disinformation about the war in Ukraine
“Many-Shot In-Context Learning”, Agarwal et al 2024
“PhyloLM: Inferring the Phylogeny of Large Language Models and Predicting Their Performances in Benchmarks”, Yax et al 2024
“Great, Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack”, Russinovich et al 2024
Great, Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack
“Few-Shot Recalibration of Language Models”, Li et al 2024
“Long-Form Factuality in Large Language Models”, Wei et al 2024
“Don’t Trust: Verify—Grounding LLM Quantitative Reasoning With Autoformalization”, Zhou et al 2024
Don’t Trust: Verify—Grounding LLM Quantitative Reasoning with Autoformalization
“When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method”, Zhang et al 2024
When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method
“Gemini: A Family of Highly Capable Multimodal Models”, Team et al 2023
“ReST Meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent”, Aksitov et al 2023
ReST meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent
“Rich Human Feedback for Text-To-Image Generation”, Liang et al 2023
“Beyond Human Data: Scaling Self-Training for Problem-Solving With Language Models (ReSTEM)”, Singh et al 2023
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models (ReSTEM)
“Universal Self-Consistency for Large Language Model Generation”, Chen et al 2023
Universal Self-Consistency for Large Language Model Generation
“Instruction-Following Evaluation for Large Language Models”, Zhou et al 2023
“A Systematic Comparison of Syllogistic Reasoning in Humans and Language Models”, Eisape et al 2023
A Systematic Comparison of Syllogistic Reasoning in Humans and Language Models
“PAIR: Jailbreaking Black Box Large Language Models in 20 Queries”, Chao et al 2023
PAIR: Jailbreaking Black Box Large Language Models in 20 Queries
“RLAIF: Scaling Reinforcement Learning from Human Feedback With AI Feedback”, Lee et al 2023
RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
“Android in the Wild: A Large-Scale Dataset for Android Device Control”, Rawles et al 2023
Android in the Wild: A Large-Scale Dataset for Android Device Control
“PaLM 2 Technical Report”, Anil et al 2023
“Google’s Newest AI Model Uses Nearly 5× More Text Data for Training Than Its Predecessor”, Elias 2023
Google’s newest AI model uses nearly 5× more text data for training than its predecessor
“PaLM-E: An Embodied Multimodal Language Model”, Driess et al 2023
“Pretraining Language Models With Human Preferences”, Korbak et al 2023
“Sebastian Riedel Homepage”, Riedel 2026
“Erdős #659”, Grayzel 2026
“Gemini 3.1 Flash Lite: Our Most Cost-Effective AI Model Yet”
“Gemini 3.1 Pro: Announcing Our Latest Gemini AI Model”
“Gemini 3.5: Frontier Intelligence With Action”
“Working With AI (Part 2): Code Conversion”
“Adversarial Misuse of Generative AI”
“LLMs Predict My Coffee”, Dynomight 2026
“Challenges and Solutions for Aging Adults Dialogue [Sydney Ending]”, Gemini 2026
Challenges and Solutions for Aging Adults dialogue [Sydney ending]
“Position Bias: A Benchmark for Testing Whether LLM Judges Keep the Same Preference When Two Lightly Edited Versions of the Same Story Are Shown in opposite Orders”, Mazir 2026
“Ssrajadh/sentrysearch: Semantic Search over Videos Using Gemini Embedding 2”
ssrajadh/sentrysearch: Semantic search over videos using Gemini Embedding 2
“Just-In-Time Ontological Reframing: Teaching Gemini to Route Around Its Own Safety Infrastructure”
Just-in-Time Ontological Reframing: Teaching Gemini to Route Around Its Own Safety Infrastructure
“George Tucker Homepage”
“Avian Visitors”
“Gemini’s Hypothetical Present”
View External Link:
“How Good Are LLMs at Doing ML on an Unknown Dataset?”
“Models Have Some Pretty Funny Attractor States”
“GLM 5.2 Playing Text Adventures”
“What Happened to BERT & T5? On Transformer Encoders, PrefixLM and Denoising Objectives”, Tay 2026
What happened to BERT & T5? On Transformer Encoders, PrefixLM and Denoising Objectives
poetengineer__
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
motivic-classes
geo-bias
language-models phylogenetics universal-reasoning mechanistic-transformers performance-prediction reasoning-models
self-correction
instruction-following
video-gaming
Wikipedia (1)
Miscellaneous
https://blog.google/technology/ai/google-palm-2-ai-large-language-model/View External Link:
https://blog.google/technology/ai/google-palm-2-ai-large-language-model/https://www.lesswrong.com/posts/kjnQj6YujgeMN9Erq/gemma-needs-helphttps://www.reddit.com/r/ChatGPT/comments/1pjitig/gemini_leaked_its_chain_of_thought_and_spiraled/https://www.reddit.com/r/OpenAI/comments/1k3szsr/o3_and_o4minihigh_tested_on_usamo_2025/https://www.reddit.com/r/mlscaling/comments/1rcvev2/anthropic_claims_to_have_identified/o7269v0/https://www.wsj.com/tech/ai/google-gemini-jonathan-gavalas-death-07351ab2
Bibliography
https://arxiv.org/abs/2512.04797#deepmind: “SIMA 2: A Generalist Embodied Agent for Virtual Worlds”,https://arxiv.org/abs/2503.21934: “Proof or Bluff? Evaluating LLMs on 2025 USA Math Olympiad”,https://arxiv.org/abs/2502.03158: “Strategizing With AI: Insights from a Beauty Contest Experiment”,https://arxiv.org/abs/2412.06771#deepmind: “Proactive Agents for Multi-Turn Text-To-Image Generation Under Uncertainty”,https://arxiv.org/abs/2410.03170#deepmind: “Autoregressive Large Language Models Are Computationally Universal”,https://arxiv.org/abs/2406.13121#google: “Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?”,https://arxiv.org/abs/2405.15071: “Grokked Transformers Are Implicit Reasoners: A Mechanistic Journey to the Edge of Generalization”,https://arxiv.org/abs/2403.18802#deepmind: “Long-Form Factuality in Large Language Models”,https://arxiv.org/abs/2403.18120#google: “Don’t Trust: Verify—Grounding LLM Quantitative Reasoning With Autoformalization”,https://arxiv.org/abs/2312.06585#deepmind: “Beyond Human Data: Scaling Self-Training for Problem-Solving With Language Models (ReSTEM)”,https://arxiv.org/abs/2310.08419: “PAIR: Jailbreaking Black Box Large Language Models in 20 Queries”,https://arxiv.org/abs/2305.10403#google: “PaLM 2 Technical Report”,https://www.cnbc.com/2023/05/16/googles-palm-2-uses-nearly-five-times-more-text-data-than-predecessor.html: “Google’s Newest AI Model Uses Nearly 5× More Text Data for Training Than Its Predecessor”,