https://github.com/OSU-NLP-Group/GrokkedTransformer
https://x.com/BoshiWang2/status/1795294846212567089
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets [paper]
https://openai.com/index/gpt-4-research/
Unified View of Grokking, Double Descent and Emergent Abilities: A Perspective from Circuits Competition
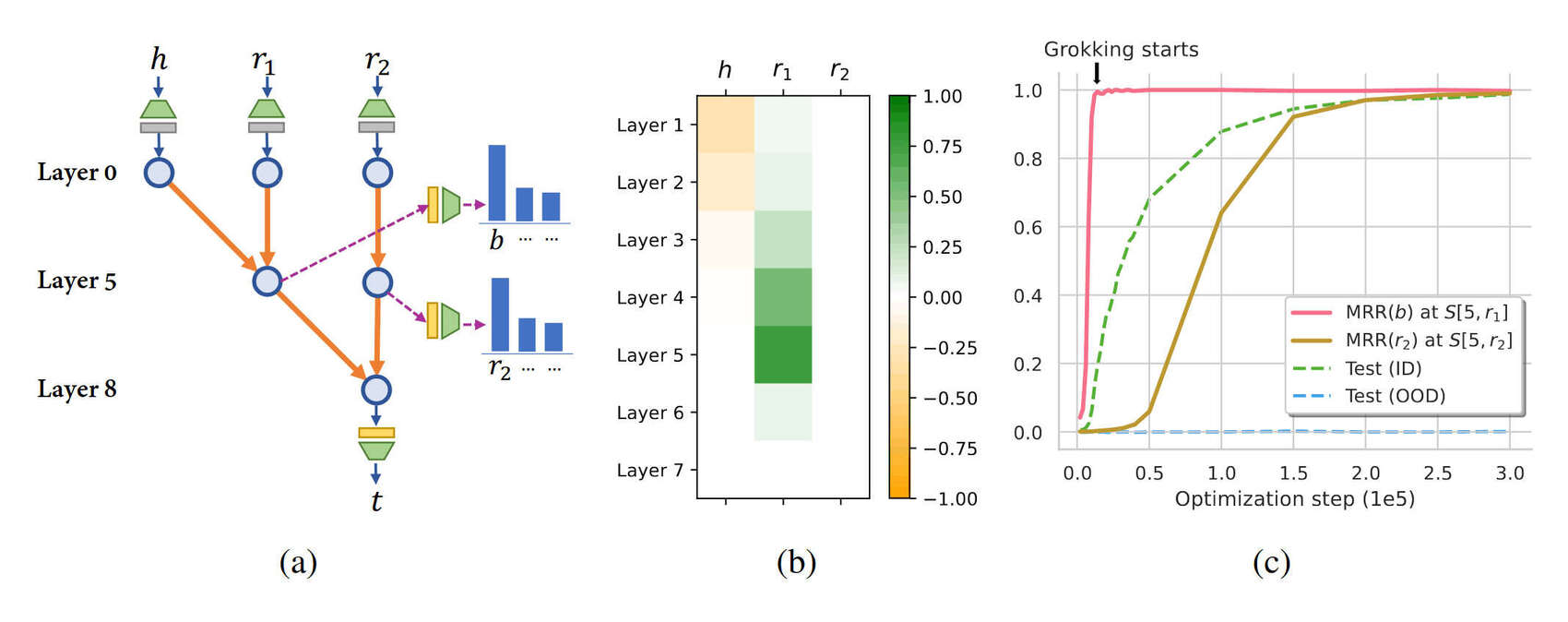
2024-wang-figure4-grokkingphasetransitionofcompositionalcircuitintransformer.jpg
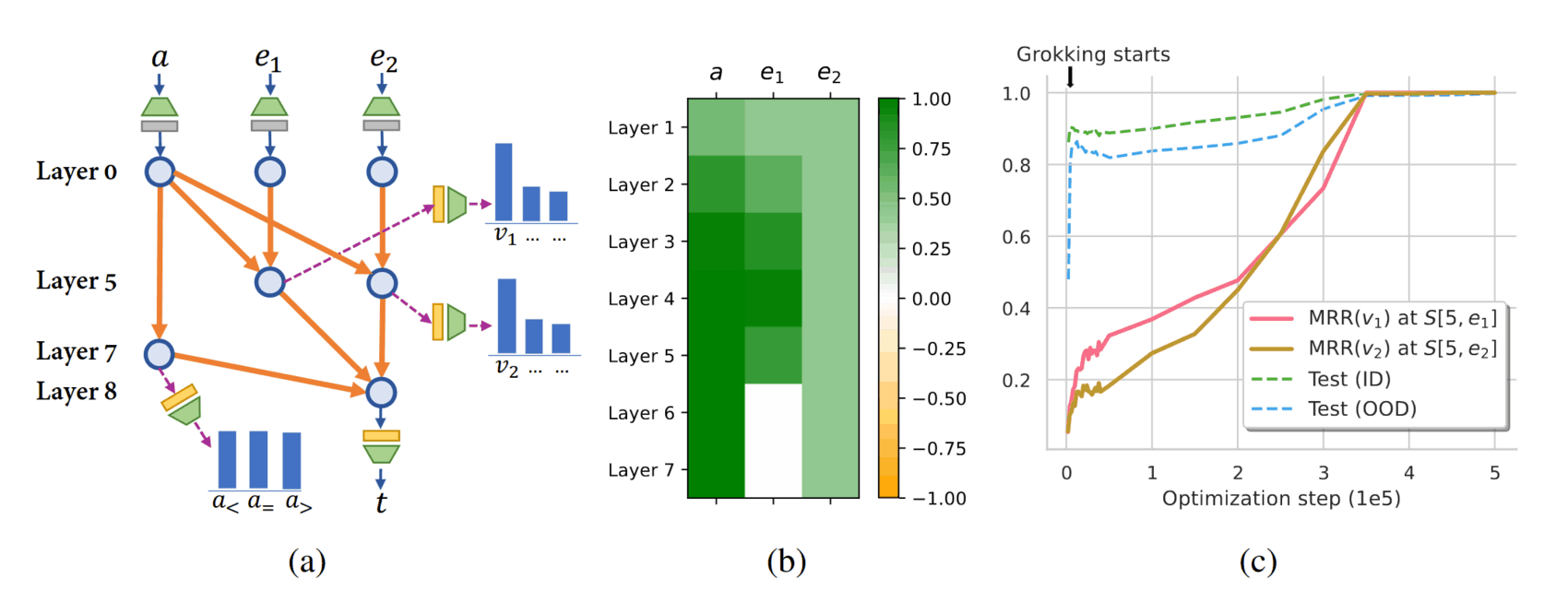
2024-wang-figure5-grokkingphasetransitionofcomparisoncircuitintransformer.png
Omnigrok: Grokking Beyond Algorithmic Data
Critical Data Size of Language Models from a Grokking Perspective
Memorization Without Overfitting: Analyzing the Training Dynamics of Large Language Models
Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers
Explaining grokking through circuit efficiency
Decoupled Weight Decay Regularization
https://arxiv.org/pdf/2405.15071#page=19
https://arxiv.org/pdf/2405.15071#page=17
https://x.com/OwainEvans_UK/status/1804931838529638896
Taken out of context: On measuring situational awareness in LLMs
Connecting the Dots: LLMs can Infer and Verbalize Latent Structure from Disparate Training Data
{kind=link}
{kind=link}