‘GPT-2’ directory
- See Also
- Gwern
- Links
- “How LLMs Set My Fiction Free: Writing No Longer Felt like Experimenting. AI Made It Fun Again”, Sorrentino 2026
- “Autoresearch vs Classical Hyperparameter Tuning”
- “Introducing
talkie: a 13b-Parameter Vintage Language Model from 1930”, Levine et al 2026 - “MicroGPT”, Karpathy 2026
- “Let’s Build the GPT Tokenizer: A Complete Guide to Tokenization in LLMs; A Text and Code Version of Karpathy’s Famous Tokenizer Video”, Karpathy & Turgutlu 2025
- “Introducing Nanochat: The Best ChatGPT That $100 Can Buy”, Karpathy 2025
- “How the NanoGPT Speedrun WR Dropped by 20% in 3 Months”, larry-dial 2025
- “Shorter Tokens Are More Likely [In LLM Sampling]”, Long 2025
- “Data Mixing Can Induce Phase Transitions in Knowledge Acquisition”, Gu et al 2025
- “Bigram Subnetworks: Mapping to Next Tokens in Transformer Language Models”, Chang & Bergen 2025
- “(How) Do Language Models Track State?”, Li et al 2025
- “Chronologically Consistent Large Language Models”, He et al 2025
- “NotaGen: Advancing Musicality in Symbolic Music Generation With Large Language Model Training Paradigms”, Wang et al 2025
- “Inner Thinking Transformer (ITT): Leveraging Dynamic Depth Scaling to Foster Adaptive Internal Thinking”, Chen et al 2025
- tamaybes @ "2025-02-13"
- “Language Models Use Trigonometry to Do Addition”, Kantamneni 2025
- “Position: Scaling LLM Agents Requires Asymptotic Analysis With LLM Primitives”, Meyerson & Qiu 2025
- “[RLHF As Motivation for OpenAI Scaling GPT-2]”, Lang 2025
- “Training Large Language Models to Reason in a Continuous Latent Space”, Hao et al 2024
- “The Hyperfitting Phenomenon: Sharpening and Stabilizing LLMs for Open-Ended Text Generation”, Carlsson et al 2024
- “Evaluating the Fairness of Task-Adaptive Pretraining on Unlabeled Test Data Before Few-Shot Text Classification”, Dubey 2024
- “Accelerating Large Language Model Pretraining via LFR Pedagogy: Learn, Focus, and Review”, Prakriya et al 2024
- “Improving Pretraining Data Using Perplexity Correlations”, Thrush et al 2024
- “Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process”, Ye et al 2024
- “Super(Ficial)-Alignment: Strong Models May Deceive Weak Models in Weak-To-Strong Generalization”, Yang et al 2024
- “The Scaling Law in Stellar Light Curves”, Pan et al 2024
- “From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step”, Deng et al 2024
- “Grokked Transformers Are Implicit Reasoners: A Mechanistic Journey to the Edge of Generalization”, Wang et al 2024
- “Fishing for Magikarp: Automatically Detecting Under-Trained Tokens in Large Language Models”, Land & Bartolo 2024
- “Test-Time Augmentation to Solve ARC”, Cole 2024
- “Σ-GPTs: A New Approach to Autoregressive Models”, Pannatier et al 2024
- “Language Imbalance Can Boost Cross-Lingual Generalization”, Schäfer et al 2024
- “Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws”, Allen-Zhu & Li 2024
- “Do Language Models Plan Ahead for Future Tokens?”, Wu et al 2024
- “Neural Redshift: Random Networks Are Not Random Functions”, Teney et al 2024
- “Beyond Language Models (BGPT): Byte Models Are Digital World Simulators”, Wu et al 2024
- “A Mechanistic Analysis of a Transformer Trained on a Symbolic Multi-Step Reasoning Task”, Brinkmann et al 2024
- “Mission: Impossible Language Models”, Kallini et al 2024
- “A Mechanistic Understanding of Alignment Algorithms: A Case Study on DPO and Toxicity”, Lee et al 2024
- “Successor Heads: Recurring, Interpretable Attention Heads In The Wild”, Gould et al 2023
- “Language Model Alignment With Elastic Reset”, Noukhovitch et al 2023
- “Eliciting Language Model Behaviors Using Reverse Language Models”, Pfau et al 2023
- “Controlled Text Generation via Language Model Arithmetic”, Dekoninck et al 2023
- “Compositional Capabilities of Autoregressive Transformers: A Study on Synthetic, Interpretable Tasks”, Ramesh et al 2023
- “Tokenizer Choice For LLM Training: Negligible or Crucial?”, Ali et al 2023
- “What OpenAI Really Wants”, Levy 2023
- “Linearity of Relation Decoding in Transformer Language Models”, Hernandez et al 2023
- “Accelerating LLM Inference With Staged Speculative Decoding”, Spector & Re 2023
- “GPT-2’s Positional Embedding Matrix Is a Helix”, Yedidia 2023
- “Stay on Topic With Classifier-Free Guidance”, Sanchez et al 2023
- “Likelihood-Based Diffusion Language Models”, Gulrajani & Hashimoto 2023
- “CaMeLS: Meta-Learning Online Adaptation of Language Models”, Hu et al 2023
- “Mimetic Initialization of Self-Attention Layers”, Trockman & Kolter 2023
- “How Does GPT-2 Compute Greater-Than?: Interpreting Mathematical Abilities in a Pre-Trained Language Model”, Hanna et al 2023
- “LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions”, Wu et al 2023
- “Tractable Control for Autoregressive Language Generation”, Zhang et al 2023
- “Why Didn’t We Get GPT-2 in 2005?”, Dynomight 2023
- “How Does In-Context Learning Help Prompt Tuning?”, Sun et al 2023
- “MarioGPT: Open-Ended Text2Level Generation through Large Language Models”, Sudhakaran et al 2023
- “GPT-3 As Knowledge Worker: A Zero-Shot Evaluation of AI CPA Capabilities”, Bommarito et al 2023
- “Geographic and Geopolitical Biases of Language Models”, Faisal & Anastasopoulos 2022
- “Structured Prompting: Scaling In-Context Learning to 1,000 Examples”, Hao et al 2022
- “Contrastive Decoding: Open-Ended Text Generation As Optimization”, Li et al 2022
- “Contrastive Search Is What You Need For Neural Text Generation”, Su & Collier 2022
- “Perfectly Secure Steganography Using Minimum Entropy Coupling”, Witt et al 2022
- “Fine-Tuning Pre-Trained Transformers into Decaying Fast Weights”, Mao 2022
- “Semantic Reconstruction of Continuous Language from Non-Invasive Brain Recordings”, Tang et al 2022
- “Deep Language Algorithms Predict Semantic Comprehension from Brain Activity”, Caucheteux et al 2022
- “Correspondence between the Layered Structure of Deep Language Models and Temporal Structure of Natural Language Processing in the Human Brain”, Goldstein et al 2022
- “DIRECTOR: Generator-Classifiers For Supervised Language Modeling”, Arora et al 2022
- “LIFT: Language-Interfaced Fine-Tuning for Non-Language Machine Learning Tasks”, Dinh et al 2022
- “Offline RL for Natural Language Generation With Implicit Language Q Learning”, Snell et al 2022
- “FlashAttention: Fast and Memory-Efficient Exact Attention With IO-Awareness”, Dao et al 2022
- “Memorization Without Overfitting: Analyzing the Training Dynamics of Large Language Models”, Tirumala et al 2022
- “AdaVAE: Exploring Adaptive GPT-2s in Variational Autoencoders for Language Modeling”, Tu et al 2022
- “FLOTA: An Embarrassingly Simple Method to Mitigate Und-Es-Ira-Ble Properties of Pretrained Language Model Tokenizers”, Hofmann et al 2022
- “Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space”, Pipek et al 2022
- “Time Control: Language Modeling via Stochastic Processes”, Wang et al 2022
- “Quantifying and Alleviating Political Bias in Language Models”, Liu et al 2022c
- “Controllable Natural Language Generation With Contrastive Prefixes”, Qian et al 2022
- “LID: Pre-Trained Language Models for Interactive Decision-Making”, Li et al 2022
- “Typical Decoding for Natural Language Generation”, Meister et al 2022
- “Can Wikipedia Help Offline Reinforcement Learning?”, Reid et al 2022
- “ClipCap: CLIP Prefix for Image Captioning”, Mokady et al 2021
- “Mapping Language Models to Grounded Conceptual Spaces”, Patel & Pavlick 2021
- “Relating Neural Text Degeneration to Exposure Bias”, Chiang & Chen 2021
- “TruthfulQA: Measuring How Models Mimic Human Falsehoods”, Lin et al 2021
- “Scarecrow: A Framework for Scrutinizing Machine Text”, Dou et al 2021
- “LoRA: Low-Rank Adaptation of Large Language Models”, Hu et al 2021
- “Let the Algorithm Speak: How to Use Neural Networks for Automatic Item Generation in Psychological Scale Development”, Götz et al 2021
- “GPT-J-6B: 6B JAX-Based Transformer”, EleutherAI 2021
- “LHOPT: A Generalizable Approach to Learning Optimizers”, Almeida et al 2021
- “A Hierarchy of Linguistic Predictions during Natural Language Comprehension”, Heilbron et al 2021
- “Why Are Tar.xz Files 15× Smaller When Using Python’s Tar Library Compared to MacOS Tar?”, Lindestøkke 2021
- “The Pile: An 800GB Dataset of Diverse Text for Language Modeling”, Gao et al 2021
- “Prefix-Tuning: Optimizing Continuous Prompts for Generation”, Li & Liang 2021
- “Bot-Adversarial Dialogue for Safe Conversational Agents”, Xu et al 2021
- “NNCP V2: Lossless Data Compression With Transformer § Pg4”, Bellard 2021 (page 4)
- “Extracting Training Data from Large Language Models”, Carlini et al 2020
- “NeuroLogic Decoding: (Un)supervised Neural Text Generation With Predicate Logic Constraints”, Lu et al 2020
- “Interacting With GPT-2 to Generate Controlled and Believable Musical Sequences in ABC Notation”, Geerlings & Meroño-Peñuela 2020
- “GeDi: Generative Discriminator Guided Sequence Generation”, Krause et al 2020
- “Generative Models Are Unsupervised Predictors of Page Quality: A Colossal-Scale Study”, Bahri et al 2020
- “Adding Recurrence to Pretrained Transformers for Improved Efficiency and Context Size”, Yoshida et al 2020
- “The Chess Transformer: Mastering Play Using Generative Language Models”, Noever et al 2020
- “True_poetry: Poetry Generator by GPT-2 With Meter and Rhyme Constraints”, Summers-Stay 2020
- “2020-04-12-Gwern-Gpt-2-117m-Midi-30588051.tar.xz”
- “TREC CAsT 2019: The Conversational Assistance Track Overview”, Dalton et al 2020
- “OpenAI Text Generator GPT-2 Creates Video Game Walkthrough for ‘Most Tedious Game in History’”, Whalen 2020
- “Reducing Non-Normative Text Generation from Language Models”, Peng et al 2020
- “How Novelists Use Generative Language Models: An Exploratory User Study”, Calderwood et al 2020
- “Writing the Next American Hit: Using GPT-2 to Explore the Possibility of Creating Successful AI-Generated Song Lyrics Possibility of Creating Successful AI-Generated Song Lyric”, Barrio 2020
- “Controlling Text Generation With Plug and Play Language Models”, Liu et al 2019
- AI Dungeon 2, Walton 2019
- “GPT-2: 1.5B Release”, Solaiman et al 2019
- “Fine-Tuning GPT-2 from Human Preferences § Bugs Can Optimize for Bad Behavior”, Ziegler et al 2019
- “Fine-Tuning GPT-2 from Human Preferences”, Ziegler et al 2019
- “Fine-Tuning Language Models from Human Preferences”, Ziegler et al 2019
- “Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism”, Shoeybi et al 2019
- “Lm-Human-Preferences”, Ziegler et al 2019
- “How To Make Custom AI-Generated Text With GPT-2”, Woolf 2019
- “Release Strategies and the Social Impacts of Language Models”, Solaiman et al 2019
- “OpenGPT-2: We Replicated GPT-2-1.5b Because You Can Too”, Gokaslan & Cohen 2019
- “Universal Adversarial Triggers for Attacking and Analyzing NLP”, Wallace et al 2019
- “GPT-2: 6-Month Follow-Up”, OpenAI 2019
- “MegatronLM: Training Billion+ Parameter Language Models Using GPU Model Parallelism”, ADLR 2019
- “Addendum: Evaluation of My Model”, Leahy 2019
- “Replicating GPT-2-1.5B”, Leahy 2019
- “OpenAI’s New Language AI Is Available to Try Yourself”
- “Unraveling the JPEG: JPEG Images Are Everywhere in Our Digital Lives, but behind the Veil of Familiarity Lie Algorithms That Remove Details That Are Imperceptible to the Human Eye. This Produces the Highest Visual Quality With the Smallest File Size—But What Does That Look Like? Let’s See What Our Eyes Can’t See!”, Shehata 2019
- “Smart Vet: Autocompleting Sentences in Veterinary Medical Records”, Ginn 2019
- “Some Pretty Impressive Machine-Learning Generated Poetry Courtesy of GPT-2”
- “LM Explorer (Alpha)”, Intelligence 2019
- “GPT-2 As Step Toward General Intelligence”, Alexander 2019
- “Language Models Are Unsupervised Multitask Learners”, Radford et al 2019
- “Better Language Models and Their Implications”, Radford et al 2019
- “Talk To Transformer”, King 2019
- “Notes on a New Philosophy of Empirical Science”, Burfoot 2011
- “Google-Wide Profiling: A Continuous Profiling Infrastructure for Data Centers”, Ren et al 2010
- “Timm S. Mueller”
- “Scaling Karpathy’s Autoresearch: What Happens When the Agent Gets a GPU Cluster”
- “The Difficulties of Text Generation Using Autoregressive Language Models: A Brief Overview”, Gao 2026
- “Beyond Language Models: Byte Models Are Digital World Simulators [Homepage]”, Wu et al 2026
- “TimeCapsuleLLM: An LLM Trained Only on Data from Certain Time Periods to Reduce Modern Bias”
- “Let’s Reproduce GPT-2 (1.6B): One 8×H100 Node, 24 Hours, $672”
- “
bgpt: Beyond Language Models: Byte Models Are Digital World Simulators”, Wu et al 2026 - “The Optimal Architecture for Small Language Models”
- “
bgptat Main”, Wu et al 2026 - “Alec Radford”
- “TensorFlow Research Cloud (TRC): Accelerate Your Cutting-Edge Machine Learning Research With Free Cloud TPUs”, TRC 2026
- “Talking to Myself or How I Trained GPT-2-1.5b for Rubber Ducking Using My Facebook Chat Data: Using Only Google Colab”
- “I Built ChatGPT With Minecraft Redstone!”
- Sort By Magic
- Wikipedia (9)
- Miscellaneous
- Bibliography
See Also
Gwern
“GPT-2 Folk Music”, Gwern & Presser 2019
Links
“How LLMs Set My Fiction Free: Writing No Longer Felt like Experimenting. AI Made It Fun Again”, Sorrentino 2026
How LLMs Set My Fiction Free: Writing no longer felt like experimenting. AI made it fun again
“Autoresearch vs Classical Hyperparameter Tuning”
“Introducing talkie: a 13b-Parameter Vintage Language Model from 1930”, Levine et al 2026
Introducing talkie: a 13b-parameter vintage language model from 1930
“MicroGPT”, Karpathy 2026
“Let’s Build the GPT Tokenizer: A Complete Guide to Tokenization in LLMs; A Text and Code Version of Karpathy’s Famous Tokenizer Video”, Karpathy & Turgutlu 2025
“Introducing Nanochat: The Best ChatGPT That $100 Can Buy”, Karpathy 2025
“How the NanoGPT Speedrun WR Dropped by 20% in 3 Months”, larry-dial 2025
“Shorter Tokens Are More Likely [In LLM Sampling]”, Long 2025
“Data Mixing Can Induce Phase Transitions in Knowledge Acquisition”, Gu et al 2025
Data Mixing Can Induce Phase Transitions in Knowledge Acquisition
“Bigram Subnetworks: Mapping to Next Tokens in Transformer Language Models”, Chang & Bergen 2025
Bigram Subnetworks: Mapping to Next Tokens in Transformer Language Models
“(How) Do Language Models Track State?”, Li et al 2025
“Chronologically Consistent Large Language Models”, He et al 2025
“NotaGen: Advancing Musicality in Symbolic Music Generation With Large Language Model Training Paradigms”, Wang et al 2025
“Inner Thinking Transformer (ITT): Leveraging Dynamic Depth Scaling to Foster Adaptive Internal Thinking”, Chen et al 2025
tamaybes @ "2025-02-13"
“Language Models Use Trigonometry to Do Addition”, Kantamneni 2025
“Position: Scaling LLM Agents Requires Asymptotic Analysis With LLM Primitives”, Meyerson & Qiu 2025
Position: Scaling LLM Agents Requires Asymptotic Analysis with LLM Primitives
“[RLHF As Motivation for OpenAI Scaling GPT-2]”, Lang 2025
“Training Large Language Models to Reason in a Continuous Latent Space”, Hao et al 2024
Training Large Language Models to Reason in a Continuous Latent Space
“The Hyperfitting Phenomenon: Sharpening and Stabilizing LLMs for Open-Ended Text Generation”, Carlsson et al 2024
The Hyperfitting Phenomenon: Sharpening and Stabilizing LLMs for Open-Ended Text Generation
“Evaluating the Fairness of Task-Adaptive Pretraining on Unlabeled Test Data Before Few-Shot Text Classification”, Dubey 2024
“Accelerating Large Language Model Pretraining via LFR Pedagogy: Learn, Focus, and Review”, Prakriya et al 2024
Accelerating Large Language Model Pretraining via LFR Pedagogy: Learn, Focus, and Review
“Improving Pretraining Data Using Perplexity Correlations”, Thrush et al 2024
“Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process”, Ye et al 2024
Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process
“Super(Ficial)-Alignment: Strong Models May Deceive Weak Models in Weak-To-Strong Generalization”, Yang et al 2024
Super(ficial)-alignment: Strong Models May Deceive Weak Models in Weak-to-Strong Generalization
“The Scaling Law in Stellar Light Curves”, Pan et al 2024
“From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step”, Deng et al 2024
From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step
“Grokked Transformers Are Implicit Reasoners: A Mechanistic Journey to the Edge of Generalization”, Wang et al 2024
Grokked Transformers are Implicit Reasoners: A Mechanistic Journey to the Edge of Generalization
“Fishing for Magikarp: Automatically Detecting Under-Trained Tokens in Large Language Models”, Land & Bartolo 2024
Fishing for Magikarp: Automatically Detecting Under-trained Tokens in Large Language Models
“Test-Time Augmentation to Solve ARC”, Cole 2024
“Σ-GPTs: A New Approach to Autoregressive Models”, Pannatier et al 2024
“Language Imbalance Can Boost Cross-Lingual Generalization”, Schäfer et al 2024
“Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws”, Allen-Zhu & Li 2024
Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws
“Do Language Models Plan Ahead for Future Tokens?”, Wu et al 2024
“Neural Redshift: Random Networks Are Not Random Functions”, Teney et al 2024
“Beyond Language Models (BGPT): Byte Models Are Digital World Simulators”, Wu et al 2024
Beyond Language Models (bGPT): Byte Models are Digital World Simulators
“A Mechanistic Analysis of a Transformer Trained on a Symbolic Multi-Step Reasoning Task”, Brinkmann et al 2024
A Mechanistic Analysis of a Transformer Trained on a Symbolic Multi-Step Reasoning Task
“Mission: Impossible Language Models”, Kallini et al 2024
“A Mechanistic Understanding of Alignment Algorithms: A Case Study on DPO and Toxicity”, Lee et al 2024
A Mechanistic Understanding of Alignment Algorithms: A Case Study on DPO and Toxicity
“Successor Heads: Recurring, Interpretable Attention Heads In The Wild”, Gould et al 2023
Successor Heads: Recurring, Interpretable Attention Heads In The Wild
“Language Model Alignment With Elastic Reset”, Noukhovitch et al 2023
“Eliciting Language Model Behaviors Using Reverse Language Models”, Pfau et al 2023
Eliciting Language Model Behaviors using Reverse Language Models
“Controlled Text Generation via Language Model Arithmetic”, Dekoninck et al 2023
“Compositional Capabilities of Autoregressive Transformers: A Study on Synthetic, Interpretable Tasks”, Ramesh et al 2023
Compositional Capabilities of Autoregressive Transformers: A Study on Synthetic, Interpretable Tasks
“Tokenizer Choice For LLM Training: Negligible or Crucial?”, Ali et al 2023
“What OpenAI Really Wants”, Levy 2023
“Linearity of Relation Decoding in Transformer Language Models”, Hernandez et al 2023
Linearity of Relation Decoding in Transformer Language Models
“Accelerating LLM Inference With Staged Speculative Decoding”, Spector & Re 2023
“GPT-2’s Positional Embedding Matrix Is a Helix”, Yedidia 2023
“Stay on Topic With Classifier-Free Guidance”, Sanchez et al 2023
“Likelihood-Based Diffusion Language Models”, Gulrajani & Hashimoto 2023
“CaMeLS: Meta-Learning Online Adaptation of Language Models”, Hu et al 2023
“Mimetic Initialization of Self-Attention Layers”, Trockman & Kolter 2023
“How Does GPT-2 Compute Greater-Than?: Interpreting Mathematical Abilities in a Pre-Trained Language Model”, Hanna et al 2023
“LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions”, Wu et al 2023
LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions
“Tractable Control for Autoregressive Language Generation”, Zhang et al 2023
“Why Didn’t We Get GPT-2 in 2005?”, Dynomight 2023
Why didn’t we get GPT-2 in 2005?
View External Link:
“How Does In-Context Learning Help Prompt Tuning?”, Sun et al 2023
“MarioGPT: Open-Ended Text2Level Generation through Large Language Models”, Sudhakaran et al 2023
MarioGPT: Open-Ended Text2Level Generation through Large Language Models
“GPT-3 As Knowledge Worker: A Zero-Shot Evaluation of AI CPA Capabilities”, Bommarito et al 2023
GPT-3 as Knowledge Worker: A Zero-Shot Evaluation of AI CPA Capabilities
“Geographic and Geopolitical Biases of Language Models”, Faisal & Anastasopoulos 2022
“Structured Prompting: Scaling In-Context Learning to 1,000 Examples”, Hao et al 2022
Structured Prompting: Scaling In-Context Learning to 1,000 Examples
“Contrastive Decoding: Open-Ended Text Generation As Optimization”, Li et al 2022
Contrastive Decoding: Open-ended Text Generation as Optimization
“Contrastive Search Is What You Need For Neural Text Generation”, Su & Collier 2022
Contrastive Search Is What You Need For Neural Text Generation
“Perfectly Secure Steganography Using Minimum Entropy Coupling”, Witt et al 2022
Perfectly Secure Steganography Using Minimum Entropy Coupling
“Fine-Tuning Pre-Trained Transformers into Decaying Fast Weights”, Mao 2022
Fine-Tuning Pre-trained Transformers into Decaying Fast Weights
“Semantic Reconstruction of Continuous Language from Non-Invasive Brain Recordings”, Tang et al 2022
Semantic reconstruction of continuous language from non-invasive brain recordings
“Deep Language Algorithms Predict Semantic Comprehension from Brain Activity”, Caucheteux et al 2022
Deep language algorithms predict semantic comprehension from brain activity
“Correspondence between the Layered Structure of Deep Language Models and Temporal Structure of Natural Language Processing in the Human Brain”, Goldstein et al 2022
“DIRECTOR: Generator-Classifiers For Supervised Language Modeling”, Arora et al 2022
DIRECTOR: Generator-Classifiers For Supervised Language Modeling
“LIFT: Language-Interfaced Fine-Tuning for Non-Language Machine Learning Tasks”, Dinh et al 2022
LIFT: Language-Interfaced Fine-Tuning for Non-Language Machine Learning Tasks
“Offline RL for Natural Language Generation With Implicit Language Q Learning”, Snell et al 2022
Offline RL for Natural Language Generation with Implicit Language Q Learning
“FlashAttention: Fast and Memory-Efficient Exact Attention With IO-Awareness”, Dao et al 2022
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
“Memorization Without Overfitting: Analyzing the Training Dynamics of Large Language Models”, Tirumala et al 2022
Memorization Without Overfitting: Analyzing the Training Dynamics of Large Language Models
“AdaVAE: Exploring Adaptive GPT-2s in Variational Autoencoders for Language Modeling”, Tu et al 2022
AdaVAE: Exploring Adaptive GPT-2s in Variational Autoencoders for Language Modeling
“FLOTA: An Embarrassingly Simple Method to Mitigate Und-Es-Ira-Ble Properties of Pretrained Language Model Tokenizers”, Hofmann et al 2022
“Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space”, Pipek et al 2022
Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space
“Time Control: Language Modeling via Stochastic Processes”, Wang et al 2022
“Quantifying and Alleviating Political Bias in Language Models”, Liu et al 2022c
Quantifying and alleviating political bias in language models
“Controllable Natural Language Generation With Contrastive Prefixes”, Qian et al 2022
Controllable Natural Language Generation with Contrastive Prefixes
“LID: Pre-Trained Language Models for Interactive Decision-Making”, Li et al 2022
LID: Pre-Trained Language Models for Interactive Decision-Making
“Typical Decoding for Natural Language Generation”, Meister et al 2022
“Can Wikipedia Help Offline Reinforcement Learning?”, Reid et al 2022
“ClipCap: CLIP Prefix for Image Captioning”, Mokady et al 2021
“Mapping Language Models to Grounded Conceptual Spaces”, Patel & Pavlick 2021
“Relating Neural Text Degeneration to Exposure Bias”, Chiang & Chen 2021
“TruthfulQA: Measuring How Models Mimic Human Falsehoods”, Lin et al 2021
“Scarecrow: A Framework for Scrutinizing Machine Text”, Dou et al 2021
“LoRA: Low-Rank Adaptation of Large Language Models”, Hu et al 2021
“Let the Algorithm Speak: How to Use Neural Networks for Automatic Item Generation in Psychological Scale Development”, Götz et al 2021
“GPT-J-6B: 6B JAX-Based Transformer”, EleutherAI 2021
“LHOPT: A Generalizable Approach to Learning Optimizers”, Almeida et al 2021
“A Hierarchy of Linguistic Predictions during Natural Language Comprehension”, Heilbron et al 2021
A hierarchy of linguistic predictions during natural language comprehension
“Why Are Tar.xz Files 15× Smaller When Using Python’s Tar Library Compared to MacOS Tar?”, Lindestøkke 2021
Why are tar.xz files 15× smaller when using Python’s tar library compared to macOS tar?
“The Pile: An 800GB Dataset of Diverse Text for Language Modeling”, Gao et al 2021
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
“Prefix-Tuning: Optimizing Continuous Prompts for Generation”, Li & Liang 2021
“Bot-Adversarial Dialogue for Safe Conversational Agents”, Xu et al 2021
“NNCP V2: Lossless Data Compression With Transformer § Pg4”, Bellard 2021 (page 4)
“Extracting Training Data from Large Language Models”, Carlini et al 2020
“NeuroLogic Decoding: (Un)supervised Neural Text Generation With Predicate Logic Constraints”, Lu et al 2020
NeuroLogic Decoding: (Un)supervised Neural Text Generation with Predicate Logic Constraints
“Interacting With GPT-2 to Generate Controlled and Believable Musical Sequences in ABC Notation”, Geerlings & Meroño-Peñuela 2020
Interacting with GPT-2 to Generate Controlled and Believable Musical Sequences in ABC Notation
“GeDi: Generative Discriminator Guided Sequence Generation”, Krause et al 2020
“Generative Models Are Unsupervised Predictors of Page Quality: A Colossal-Scale Study”, Bahri et al 2020
Generative Models are Unsupervised Predictors of Page Quality: A Colossal-Scale Study
“Adding Recurrence to Pretrained Transformers for Improved Efficiency and Context Size”, Yoshida et al 2020
Adding Recurrence to Pretrained Transformers for Improved Efficiency and Context Size
“The Chess Transformer: Mastering Play Using Generative Language Models”, Noever et al 2020
The Chess Transformer: Mastering Play using Generative Language Models
“True_poetry: Poetry Generator by GPT-2 With Meter and Rhyme Constraints”, Summers-Stay 2020
true_poetry: Poetry generator by GPT-2 with meter and rhyme constraints
“2020-04-12-Gwern-Gpt-2-117m-Midi-30588051.tar.xz”
“TREC CAsT 2019: The Conversational Assistance Track Overview”, Dalton et al 2020
TREC CAsT 2019: The Conversational Assistance Track Overview
“OpenAI Text Generator GPT-2 Creates Video Game Walkthrough for ‘Most Tedious Game in History’”, Whalen 2020
OpenAI Text Generator GPT-2 Creates Video Game Walkthrough for ‘Most Tedious Game in History’
“Reducing Non-Normative Text Generation from Language Models”, Peng et al 2020
“How Novelists Use Generative Language Models: An Exploratory User Study”, Calderwood et al 2020
How Novelists Use Generative Language Models: An Exploratory User Study
“Writing the Next American Hit: Using GPT-2 to Explore the Possibility of Creating Successful AI-Generated Song Lyrics Possibility of Creating Successful AI-Generated Song Lyric”, Barrio 2020
“Controlling Text Generation With Plug and Play Language Models”, Liu et al 2019
Controlling Text Generation with Plug and Play Language Models
AI Dungeon 2, Walton 2019
“GPT-2: 1.5B Release”, Solaiman et al 2019
“Fine-Tuning GPT-2 from Human Preferences § Bugs Can Optimize for Bad Behavior”, Ziegler et al 2019
Fine-Tuning GPT-2 from Human Preferences § Bugs can optimize for bad behavior
“Fine-Tuning GPT-2 from Human Preferences”, Ziegler et al 2019
“Fine-Tuning Language Models from Human Preferences”, Ziegler et al 2019
“Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism”, Shoeybi et al 2019
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
“Lm-Human-Preferences”, Ziegler et al 2019
“How To Make Custom AI-Generated Text With GPT-2”, Woolf 2019
“Release Strategies and the Social Impacts of Language Models”, Solaiman et al 2019
Release Strategies and the Social Impacts of Language Models
“OpenGPT-2: We Replicated GPT-2-1.5b Because You Can Too”, Gokaslan & Cohen 2019
“Universal Adversarial Triggers for Attacking and Analyzing NLP”, Wallace et al 2019
Universal Adversarial Triggers for Attacking and Analyzing NLP
“GPT-2: 6-Month Follow-Up”, OpenAI 2019
“MegatronLM: Training Billion+ Parameter Language Models Using GPU Model Parallelism”, ADLR 2019
MegatronLM: Training Billion+ Parameter Language Models Using GPU Model Parallelism
“Addendum: Evaluation of My Model”, Leahy 2019
“Replicating GPT-2-1.5B”, Leahy 2019
“OpenAI’s New Language AI Is Available to Try Yourself”
“Unraveling the JPEG: JPEG Images Are Everywhere in Our Digital Lives, but behind the Veil of Familiarity Lie Algorithms That Remove Details That Are Imperceptible to the Human Eye. This Produces the Highest Visual Quality With the Smallest File Size—But What Does That Look Like? Let’s See What Our Eyes Can’t See!”, Shehata 2019
“Smart Vet: Autocompleting Sentences in Veterinary Medical Records”, Ginn 2019
Smart Vet: Autocompleting Sentences in Veterinary Medical Records
“Some Pretty Impressive Machine-Learning Generated Poetry Courtesy of GPT-2”
Some pretty impressive machine-learning generated poetry courtesy of GPT-2
“LM Explorer (Alpha)”, Intelligence 2019
“GPT-2 As Step Toward General Intelligence”, Alexander 2019
“Language Models Are Unsupervised Multitask Learners”, Radford et al 2019
“Better Language Models and Their Implications”, Radford et al 2019
“Talk To Transformer”, King 2019
“Notes on a New Philosophy of Empirical Science”, Burfoot 2011
“Google-Wide Profiling: A Continuous Profiling Infrastructure for Data Centers”, Ren et al 2010
Google-Wide Profiling: A Continuous Profiling Infrastructure for Data Centers
“Timm S. Mueller”
“Scaling Karpathy’s Autoresearch: What Happens When the Agent Gets a GPU Cluster”
Scaling Karpathy’s Autoresearch: What Happens When the Agent Gets a GPU Cluster
“The Difficulties of Text Generation Using Autoregressive Language Models: A Brief Overview”, Gao 2026
The Difficulties of Text Generation using Autoregressive Language Models: A Brief Overview
“Beyond Language Models: Byte Models Are Digital World Simulators [Homepage]”, Wu et al 2026
Beyond Language Models: Byte Models are Digital World Simulators [homepage]
“TimeCapsuleLLM: An LLM Trained Only on Data from Certain Time Periods to Reduce Modern Bias”
TimeCapsuleLLM: An LLM trained only on data from certain time periods to reduce modern bias
“Let’s Reproduce GPT-2 (1.6B): One 8×H100 Node, 24 Hours, $672”
Let’s reproduce GPT-2 (1.6B): one 8×H100 node, 24 hours, $672
“bgpt: Beyond Language Models: Byte Models Are Digital World Simulators”, Wu et al 2026
“The Optimal Architecture for Small Language Models”
“bgpt at Main”, Wu et al 2026
“Alec Radford”
“TensorFlow Research Cloud (TRC): Accelerate Your Cutting-Edge Machine Learning Research With Free Cloud TPUs”, TRC 2026
“Talking to Myself or How I Trained GPT-2-1.5b for Rubber Ducking Using My Facebook Chat Data: Using Only Google Colab”
“I Built ChatGPT With Minecraft Redstone!”
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
poetry-generation
vet-tech
steganography jpeg-optimization visual-compression entropy-minimization image-processing
empirical-science
dataset-collection
music-composition
interpretation
Wikipedia (9)
Miscellaneous
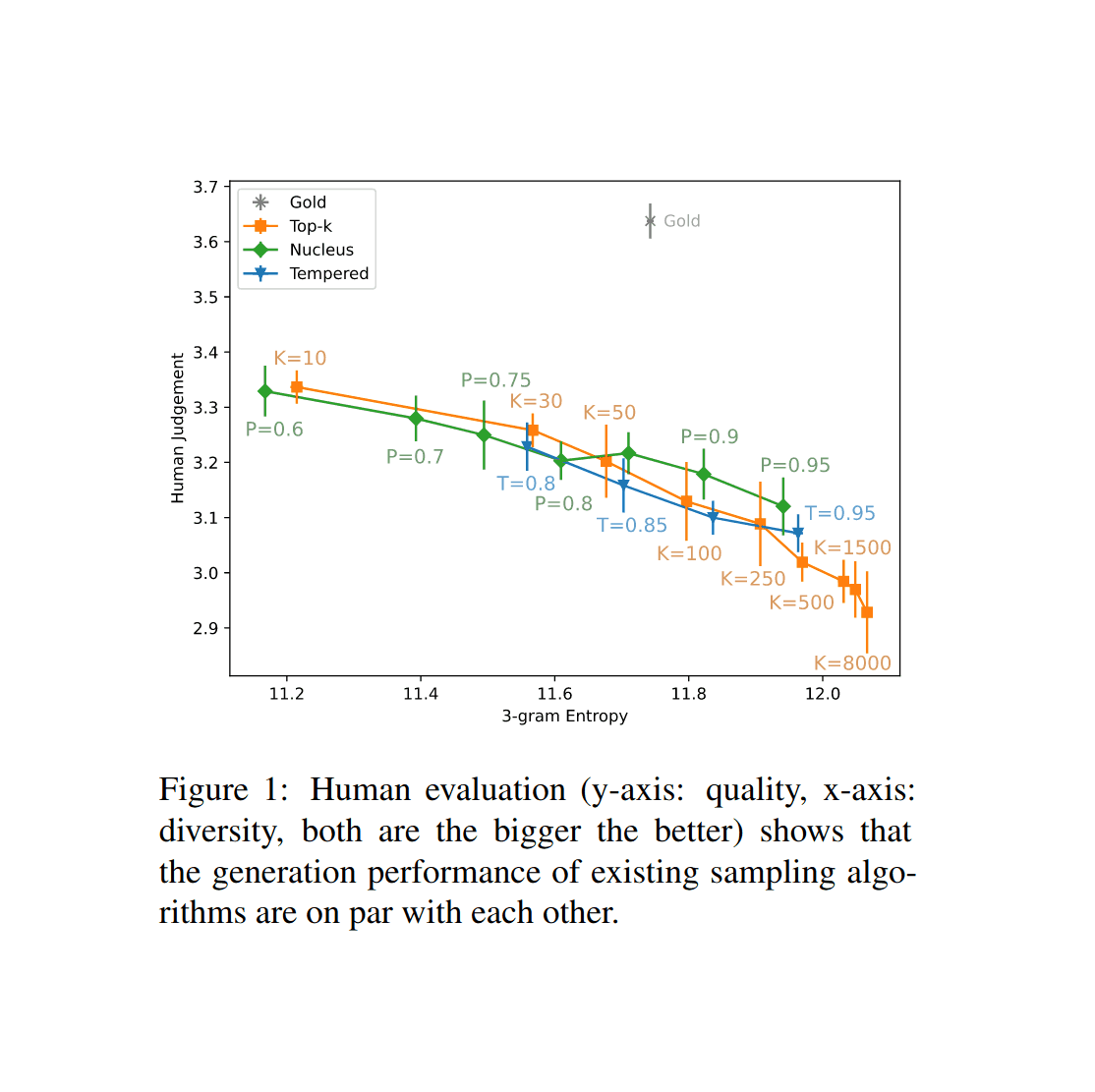
/doc/ai/nn/transformer/gpt/2/2025-03-08-2019-12-18-shawnpresser-gpt-2-117m-rdota2.tar.xz/doc/ai/nn/transformer/gpt/2/2020-nadeem-figure1-gpt2samplingqualityvsdiversity.png/doc/ai/nn/transformer/gpt/2/2019-10-19-gwern-gpt2-poetry-pgclean-117m.tar.xz/doc/ai/nn/transformer/gpt/2/2019-07-21-gwern-gpt2-345m-taotehching-all.tar.xz/doc/ai/nn/transformer/gpt/2/2019-05-13-gwern-gpt2-poetry-345m.tar.xz/doc/ai/nn/transformer/gpt/2/2019-03-06-gwern-gpt2-poetry-projectgutenberg-network-519407.tar.xz/doc/ai/nn/transformer/gpt/poetry/2019-03-06-gpt2-poetry-1000samples.txt/doc/ai/nn/transformer/gpt/2/2019-02-24-gwern-shawnpresser-gpt2-anime-13m-31839.tar.xzhttps://colab.research.google.com/drive/1VLG8e7YSEwypxU-noRNhsv5dW4NfTGcehttps://www.aiweirdness.com/d-and-d-character-bios-now-making-19-03-15/https://www.lesswrong.com/posts/ukTLGe5CQq9w8FMne/inducing-unprompted-misalignment-in-llmshttps://www.reddit.com/r/mlscaling/comments/1d3a793/andrej_karpathy_gpt2_124m_in_llmc_in_90_minutes/
{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2410.00179: “Evaluating the Fairness of Task-Adaptive Pretraining on Unlabeled Test Data Before Few-Shot Text Classification”,https://arxiv.org/abs/2405.14838: “From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step”,https://arxiv.org/abs/2405.15071: “Grokked Transformers Are Implicit Reasoners: A Mechanistic Journey to the Edge of Generalization”,https://lab42.global/community-interview-jack-cole/: “Test-Time Augmentation to Solve ARC”,https://arxiv.org/abs/2402.19155: “Beyond Language Models (BGPT): Byte Models Are Digital World Simulators”,https://arxiv.org/abs/2312.09230: “Successor Heads: Recurring, Interpretable Attention Heads In The Wild”,https://arxiv.org/abs/2312.07551: “Language Model Alignment With Elastic Reset”,https://www.wired.com/story/what-openai-really-wants/: “What OpenAI Really Wants”,https://arxiv.org/abs/2306.17806#eleutherai: “Stay on Topic With Classifier-Free Guidance”,https://arxiv.org/abs/2305.09828: “Mimetic Initialization of Self-Attention Layers”,https://arxiv.org/abs/2302.05981: “MarioGPT: Open-Ended Text2Level Generation through Large Language Models”,https://arxiv.org/abs/2301.04408: “GPT-3 As Knowledge Worker: A Zero-Shot Evaluation of AI CPA Capabilities”,https://arxiv.org/abs/2210.15097: “Contrastive Decoding: Open-Ended Text Generation As Optimization”,https://arxiv.org/abs/2210.14140: “Contrastive Search Is What You Need For Neural Text Generation”,https://arxiv.org/abs/2210.04243: “Fine-Tuning Pre-Trained Transformers into Decaying Fast Weights”,https://www.nature.com/articles/s41598-022-20460-9: “Deep Language Algorithms Predict Semantic Comprehension from Brain Activity”,https://arxiv.org/abs/2205.14135: “FlashAttention: Fast and Memory-Efficient Exact Attention With IO-Awareness”,https://aclanthology.org/2022.acl-short.43.pdf: “FLOTA: An Embarrassingly Simple Method to Mitigate Und-Es-Ira-Ble Properties of Pretrained Language Model Tokenizers”,2022-liu-3.pdf: “Quantifying and Alleviating Political Bias in Language Models”,https://arxiv.org/abs/2111.09734: “ClipCap: CLIP Prefix for Image Captioning”,https://openreview.net/forum?id=gJcEM8sxHK: “Mapping Language Models to Grounded Conceptual Spaces”,https://arxiv.org/abs/2109.07958: “TruthfulQA: Measuring How Models Mimic Human Falsehoods”,https://arxiv.org/abs/2107.01294#allen: “Scarecrow: A Framework for Scrutinizing Machine Text”,https://arxiv.org/abs/2106.09685#microsoft: “LoRA: Low-Rank Adaptation of Large Language Models”,https://osf.io/preprints/psyarxiv/m6s28/: “Let the Algorithm Speak: How to Use Neural Networks for Automatic Item Generation in Psychological Scale Development”,https://arankomatsuzaki.wordpress.com/2021/06/04/gpt-j/: “GPT-J-6B: 6B JAX-Based Transformer”,https://arxiv.org/abs/2106.00958#openai: “LHOPT: A Generalizable Approach to Learning Optimizers”,https://arxiv.org/abs/2101.00027#eleutherai: “The Pile: An 800GB Dataset of Diverse Text for Language Modeling”,https://arxiv.org/abs/2101.00190: “Prefix-Tuning: Optimizing Continuous Prompts for Generation”,https://aclanthology.org/2021.naacl-main.235.pdf#facebook: “Bot-Adversarial Dialogue for Safe Conversational Agents”,https://arxiv.org/abs/2003.13624: “TREC CAsT 2019: The Conversational Assistance Track Overview”,https://www.newsweek.com/openai-text-generator-gpt-2-video-game-walkthrough-most-tedious-1488334: “OpenAI Text Generator GPT-2 Creates Video Game Walkthrough for ‘Most Tedious Game in History’”,2020-calderwood.pdf: “How Novelists Use Generative Language Models: An Exploratory User Study”,https://www.uber.com/blog/pplm/: “Controlling Text Generation With Plug and Play Language Models”,https://play.aidungeon.com/main/home: AI Dungeon 2,https://openai.com/research/fine-tuning-gpt-2: “Fine-Tuning GPT-2 from Human Preferences”,https://arxiv.org/abs/1909.08053#nvidia: “Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism”,https://minimaxir.com/2019/09/howto-gpt2/: “How To Make Custom AI-Generated Text With GPT-2”,https://medium.com/@vanya_cohen/opengpt-2-we-replicated-gpt-2-because-you-can-too-45e34e6d36dc: “OpenGPT-2: We Replicated GPT-2-1.5b Because You Can Too”,https://nv-adlr.github.io/MegatronLM: “MegatronLM: Training Billion+ Parameter Language Models Using GPU Model Parallelism”,https://medium.com/@NPCollapse/replicating-gpt2-1-5b-86454a7f26af: “Replicating GPT-2-1.5B”,https://openai.com/index/better-language-models/: “Better Language Models and Their Implications”,https://sites.research.google/trc/: “TensorFlow Research Cloud (TRC): Accelerate Your Cutting-Edge Machine Learning Research With Free Cloud TPUs”,