Machine Learning Scaling
Bibliography of ML scaling papers showing smooth scaling of neural net performance in general with increasingly large parameters, data, & compute.
“Do Deep Convolutional Nets Really Need to be Deep and Convolutional?”, Urban et al 2016 (negative result, particularly on scaling—wrong, but why?)
“Revisiting Unreasonable Effectiveness of Data in Deep Learning Era”, Sun et al 2017
“Deep Learning Scaling is Predictable, Empirically”, Hestness et al 2017
“Learning Visual Features from Large Weakly Supervised Data”, Joulin et al 201511ya; “Exploring the Limits of Weakly Supervised Pretraining”, Mahajan et al 2018; “Revisiting Weakly Supervised Pre-Training of Visual Perception Models”, Singh et al 2022 (CNNs scale to billions of hashtagged Instagram images)
WebVision: “WebVision Challenge: Visual Learning and Understanding With Web Data”, Li et al 2017a/“WebVision Database: Visual Learning and Understanding from Web Data”, Li et al 2017b/“CurriculumNet: Weakly Supervised Learning from Large-Scale Web Images”, Guo et al 2018
“Measuring the Effects of Data Parallelism on Neural Network Training”, Shallue et al 2018
“Gradient Noise Scale: An Empirical Model of Large-Batch Training”, McCandlish et al 2018
“A Constructive Prediction of the Generalization Error Across Scales”, Rosenfeld et al 2019
“EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks”, Tan & Le 2019
“One Epoch Is All You Need”, Komatsuzaki 2019
“Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers”, Li et al 2020
“Small Data, Big Decisions: Model Selection in the Small-Data Regime”, Bornschein et al 2020
Key GPT papers:
“Scaling Laws for Neural Language Models”, Kaplan et al 2020
“Scaling Laws from the Data Manifold Dimension”, Sharma & Kaplan 2020
“Scaling Laws for Autoregressive Generative Modeling”, Henighan et al 2020 (noise & resolution); “Broken Neural Scaling Laws”, Caballero et al 2022
“GPT-3: Language Models are Few-Shot Learners”, Brown et al 2020
“Measuring Massive Multitask Language Understanding”, Hendrycks et al 2020; “Measuring Mathematical Problem Solving With the MATH Dataset”, Hendrycks et al 2021
“Decoupling the Role of Data, Attention, and Losses in Multimodal Transformers”, Hendricks et al 2021
“Scaling Laws for Transfer”, Hernandez et al 2021; “Scaling Laws for Language Transfer Learning”, Christina Kim (Hernandez et al 2021 followup: smooth scaling for En → De/Es/Zh); “When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method”, Zhang et al 2024; “Scaling Laws for Code: Every Programming Language Matters”, Yang et al 2025
“Scaling Laws for Neural Machine Translation”, Ghorbani et al 2021; “Data and Parameter Scaling Laws for Neural Machine Translation”, Gordon et al 2021; “Unsupervised Neural Machine Translation with Generative Language Models Only”, Han et al 2021; “Data Scaling Laws in NMT: The Effect of Noise and Architecture”, Bansal et al 2022
“How Many Data Points is a Prompt Worth?”, Le Scao & Rush 2021
“Recursively Summarizing Books with Human Feedback”, Wu et al 2021
“Codex: Evaluating Large Language Models Trained on Code”, Chen et al 2021 (small versions of GitHub Copilot, solves simple linear algebra/statistics problems too); “Program Synthesis with Large Language Models”, Austin et al 2021; “Show Your Work: Scratchpads for Intermediate Computation with Language Models”, Anonymous et al 2021; “Few-Shot Self-Rationalization with Natural Language Prompts”, Marasović et al 2021
“Scarecrow: A Framework for Scrutinizing Machine Text”, Dou et al 2021
“A Recipe For Arbitrary Text Style Transfer with Large Language Models”, Reif et al 2021
Instruction tuning/multi-task finetuning
“M6-10T: A Sharing-Delinking Paradigm for Efficient Multi-Trillion Parameter Pretraining”, Lin et al 2021
“Training Verifiers to Solve Math Word Problems”, Cobbe et al 2021
“Symbolic Knowledge Distillation: from General Language Models to Commonsense Models”, West et al 2021
“An Explanation of In-Context Learning as Implicit Bayesian Inference”, Xie et al 2021
“Blender: Recipes for building an open-domain chatbot”, Roller et al 2020
“Big Self-Supervised Models are Strong Semi-Supervised Learners”, Chen et al 2020a
“iGPT: Generative Pretraining from Pixels”, Chen et al 2020b
“GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding”, Lepikhin et al 2020; “Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity”, Fedus et al 2021; “Exploring Sparse Expert Models and Beyond”, Yang et al 2021
“On the Predictability of Pruning Across Scales”, Rosenfeld et al 2020 (scaling laws for sparsity: initially large size reductions are free, then power-law worsening, then plateau at tiny but bad models)
“How big should my language model be?”, Huggingface 2020
“When Do You Need Billions of Words of Pretraining Data?”, Zhang et al 2020; “Learning Which Features Matter: RoBERTa Acquires a Preference forLinguistic Generalizations (Eventually)”, Warstadt et al 2020; “Probing Across Time: What Does RoBERTa Know and When?”, Liu et al 2021
CLIP; “ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision”, Jia et al 2021 (see also CC-12M; EfficientNet trained on 1.8 billion images on a TPUv3-1024); “WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training”, Huo et al 2021; “Multimodal Few-Shot Learning with Frozen Language Models”, Tsimpoukelli et al 2021; “GrokNet: Unified Computer Vision Model Trunk and Embeddings For Commerce”, Bell et al 2020; “Billion-Scale (Pinterest) Pretraining with Vision Transformers for Multi-Task Visual Representations”, Beale et al 2021
“DALL·E 1: Zero-Shot Text-to-Image Generation”, Ramesh et al 2021 (blog); “M6: A Chinese Multimodal Pretrainer”, Lin et al 2021 (Chinese DALL·E 1: 1.9TB images/0.29TB text for 10b-parameter dense/100b-parameter MoE Transformer; shockingly fast Chinese replication of DALL·E 1/CLIP)
“Improved Denoising Diffusion Probabilistic Models”, Nichol & Dhariwal 2021 (DDPM scaling laws for FID & likelihood)
“Automatic Curation of Large-Scale Datasets for Audio-Visual Representation Learning”, Lee et al 2021
“Scaling Laws for Acoustic Models”, Droppo & Elibol 2021
“XLSR: Unsupervised Cross-lingual Representation Learning for Speech Recognition”, Conneau et al 2020
“Scaling End-to-End Models for Large-Scale Multilingual ASR”, Li et al 2021; “Scaling ASR Improves Zero and Few Shot Learning”, Xiao et al 2021
“VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation Learning, Semi-Supervised Learning and Interpretation”, Wang et al 2021; “wav2vec: Large-Scale Self-Supervised and Semi-Supervised Learning for Speech Translation”, Wang et al 2021 (fMRI); “XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale”, Babu et al 2021
“HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units”, Hsu et al 2021
“SEER: Self-supervised Pretraining of Visual Features in the Wild”, Goyal et al 2021; “Vision Models Are More Robust And Fair When Pretrained On Uncurated Images Without Supervision”, Goyal et al 2022
“Fast and Accurate Model Scaling”, Dollár et al 2021; “Revisiting ResNets: Improved Training and Scaling Strategies”, Bello et al 2021
“XLM-R: Unsupervised Cross-lingual Representation Learning at Scale”, Conneau et al 2019; “XLM-R XL/XLM-R XXL: Larger-Scale Transformers for Multilingual Masked Language Modeling”, Goyal et al 2021; “Facebook AI WMT21 News Translation Task Submission”, Tran et al 2021
“ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation”, Sun et al 2021
“LEMON: Scaling Up Vision-Language Pre-training for Image Captioning”, Hu et al 2021
“Flamingo: a Visual Language Model for Few-Shot Learning”, Alayrac et al 2022
“Scaling Vision Transformers”, Zhai et al 2021
“CoAtNet: Marrying Convolution and Attention for All Data Sizes”, Dai et al 2021
“BEiT: BERT Pre-Training of Image Transformers”, Bao et al 2021; “Masked Autoencoders Are Scalable Vision Learners”, He et al 2021
“A Universal Law of Robustness via Isoperimetry”, Bubeck & Sellke 2021; “Exploring the Limits of Out-of-Distribution Detection”, Fort et al 2021; “Partial success in closing the gap between human and machine vision”, Geirhos et al 2021
“Effect of scale on catastrophic forgetting in neural networks”, Anonymous 2021
“On the Opportunities and Risks of Foundation Models”, Bommasani et al 2021 (review)
“Exploring the Limits of Large Scale Pre-training”, Abnar et al 2021
“Scaling Laws for the Few-Shot Adaptation of Pre-trained Image Classifiers”, Prato et al 2021
“E(3)-Equivariant Graph Neural Networks for Data-Efficient and Accurate Interatomic Potentials”, Batzner et al 2021
Face recognition: “WebFace260M: A Benchmark for Million-Scale Deep Face Recognition”, Zhu et al 2022
“Fine-tuned Language Models are Continual Learners”, Scialom at al 2022
Embeddings: “DynamicEmbedding: Extending TensorFlow for Colossal-Scale Applications”, Zeng et al 2020; “DLRM: High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models”, Mudigere et al 2021; “Make Every feature Binary (MEB): A 135b-parameter sparse neural network for massively improved search relevance”; “Persia: A Hybrid System Scaling Deep Learning Based Recommenders up to 100 Trillion Parameters”, Lian et al 2021 (Kuaisho)
“Scaling Law for Recommendation Models: Towards General-purpose User Representations”, Shin et al 2021; “Understanding Scaling Laws for Recommendation Models”, Ardalani et al 2022
MLPs/FCs: from the “Fully-Connected Neural Nets” bibliography: Urban et al 2016; “MLP-Mixer: An all-MLP Architecture for Vision”, Tolstikhin et al 2021; “gMLP: Pay Attention to MLPs”, Liu et al 2021
Reinforcement Learning:
“Fine-Tuning Language Models from Human Preferences”, Ziegler et al 2019; “Learning to summarize from human feedback”, Stiennon et al 2020
“Measuring hardware overhang”, hippke (the curves cross: “with today’s [trained] algorithms, computers would have beat the world chess champion already in 199432ya on a contemporary desk computer”)
“Scaling Scaling Laws with Board Games”, Jones 2021 (AlphaZero/Hex: highly-optimized GPU implementation enables showing smooth scaling across 6 OOM of compute—2× FLOPS = 66% victory; amortization of training → runtime tree-search, where 10× training = 15× runtime)
“MuZero Unplugged: Online and Offline Reinforcement Learning by Planning with a Learned Model”, Schrittwieser et al 2021
“From Motor Control to Team Play in Simulated Humanoid Football”, Liu et al 2021
“Open-Ended Learning Leads to Generally Capable Agents”, Open Ended Learning Team et al 2021; “Procedural Generalization by Planning with Self-Supervised World Models”, Anand et al 2021
“Fictitious Co-Play: Collaborating with Humans without Human Data”, Strouse et al 2021
“Gato: A Generalist Agent”, Reed et al 2022 (small Decision Transformer can learn >500 tasks; scaling smoothly)
“Multi-Game Decision Transformers”, Lee et al 2022 (near-human offline single-checkpoint ALE agent with scaling & rapid transfer)
Theory:
“Does Learning Require Memorization? A Short Tale about a Long Tail”, Feldman 2019
“Generalization bounds for deep learning”, Valle-Pérez & Louis 2020
“The Deep Bootstrap Framework: Good Online Learners are Good Offline Generalizers”, Nakkiran et al 2020
“Explaining Neural Scaling Laws”, Bahri et al 2021
“Learning Curve Theory”, Hutter 2021 (Rohin Shah commentary; more on the manifold hypothesis)
“The Shape of Learning Curves: a Review”, Viering & Loog 2021
“A mathematical theory of semantic development in deep neural networks”, Saxe et al 2019 (are jumps in NN capabilities to be expected when scaling? see also Viering & Loog 2021’s discussion of phase transitions & averaging of exponentials giving power-laws, human “vocabulary spurts”, and “Acquisition of Chess Knowledge in AlphaZero”, McGrath et al 2021 §6 “Rapid increase of basic knowledge”); sequential learning in OpenFold
“A Farewell to the Bias-Variance Tradeoff? An Overview of the Theory of Overparameterized Machine Learning”, Dar et al 2021
Historical:
“Toward A Universal Law Of Generalization For Psychological Science”, Shepard 1987
“Scaling to Very Very Large Corpora for Natural Language Disambiguation”, Banko & Brill 2001
“Large Scale Online Learning”, Bottou & LeCun 200323ya (“We argue that suitably designed online learning algorithms asymptotically outperform any batch learning algorithm.”)
“Tree Induction versus Logistic Regression: A Learning-Curve Analysis”, Perlich et al 2003
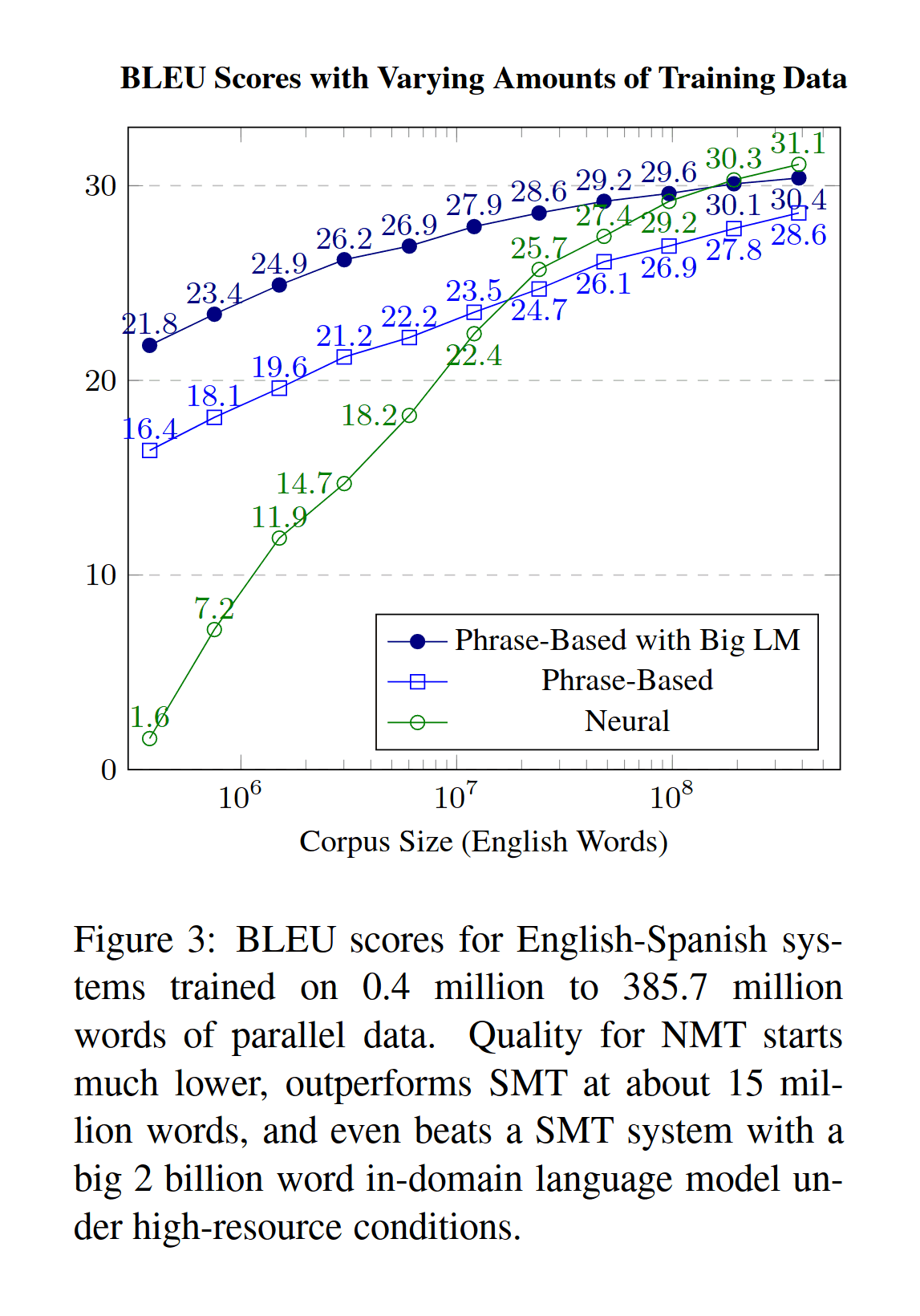
“Large Language Models in Machine Translation”, Brants et al 200719ya; Koehn & Knowles 2017 (Figure 3)
“The Unreasonable Effectiveness of Data”, Halevy et al 2009
“The Tradeoffs of Large-Scale Learning”, Bottou & Bousquet 200719ya/201214ya; “Large-Scale Machine Learning Revisited [slides]”, Bottou 2013
See Also: For more ML scaling research, follow the /r/MLScaling subreddit; “It Looks Like You’re Trying To Take Over The World”
{kind=link}