‘NN pruning’ directory
- See Also
- Links
- “Weight-Sparse Circuits May Be Interpretable Yet Unfaithful”, Drori 2026
- “I Solved Cartpole-V1 Using Only Bitwise Ops With Differentiable Logic Synthesis”, kiockete 2026
- “Differentiable Logic Synthesis: Spectral Coefficient Selection via Sinkhorn-Constrained Composition”, Pavlov 2026
- “Gogipav14/spectral-Llm: Differentiable Logic Synthesis: Spectral Coefficient Selection via Sinkhorn-Constrained Composition”, Pavlov 2026
- “Weight-Sparse Transformers Have Interpretable Circuits”, Gao et al 2025
- “Compiling a Differentiable Logic Gate Neural Net to C for a 1,744× Speedup”, Clayton 2025
- “On the Creation of Narrow AI: Hierarchy and Nonlocality of Neural Network Skills”, Michaud et al 2025
- “Bigram Subnetworks: Mapping to Next Tokens in Transformer Language Models”, Chang & Bergen 2025
- “2:4 Sparse Llama: Smaller Models for Efficient GPU Inference”, Kurtić et al 2024
- “The Super Weight in Large Language Models”, Yu et al 2024
- “What Matters in Transformers? Not All Attention Is Needed”, He et al 2024
- “When Parts Are Greater Than Sums: Individual LLM Components Can Outperform Full Models”, Chang et al 2024
- “Pre-Training Small Base LMs With Fewer Tokens”, Sanyal et al 2024
- “Streamlining Redundant Layers to Compress Large Language Models”, Chen et al 2024
- “The Unreasonable Ineffectiveness of the Deeper Layers”, Gromov et al 2024
- “Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression”, Hong et al 2024
- “SliceGPT: Compress Large Language Models by Deleting Rows and Columns”, Ashkboos et al 2024
- “Weight Subcloning: Direct Initialization of Transformers Using Larger Pretrained Ones”, Samragh et al 2023
- “To Grok or Not to Grok: Disentangling Generalization and Memorization on Corrupted Algorithmic Datasets”, Doshi et al 2023
- “Sheared LLaMA: Accelerating Language Model Pre-Training via Structured Pruning”, Xia et al 2023
- “One Wide Feedforward Is All You Need”, Pires et al 2023
- “A Comparative Study between Full-Parameter and LoRA-Based Fine-Tuning on Chinese Instruction Data for Instruction Following Large Language Model”, Sun et al 2023
- “Fast As CHITA: Neural Network Pruning With Combinatorial Optimization”, Benbaki et al 2023
- “Self-Compressing Neural Networks”, Cséfalvay & Imber 2023
- “Pruning Compact ConvNets for Efficient Inference”, Ghosh et al 2023
- “Rethinking the Role of Scale for In-Context Learning: An Interpretability-Based Case Study at 66 Billion Scale”, Bansal et al 2022
- “Lottery Tickets on a Data Diet: Finding Initializations With Sparse Trainable Networks”, Paul et al 2022
- “Heavy-Tailed Neuronal Connectivity Arises from Hebbian Self–organization”, Lynn et al 2022
- “PPCD-GAN: Progressive Pruning and Class-Aware Distillation for Large-Scale Conditional GANs Compression”, Vo et al 2022
- “The Combinatorial Brain Surgeon: Pruning Weights That Cancel One Another in Neural Networks”, Yu et al 2022
- “Data-Efficient Structured Pruning via Submodular Optimization”, Halabi et al 2022
- “Sparsity Winning Twice: Better Robust Generalization from More Efficient Training”, Chen et al 2022
- “Fortuitous Forgetting in Connectionist Networks”, Zhou et al 2022
- “How Many Degrees of Freedom Do We Need to Train Deep Networks: a Loss Landscape Perspective”, Larsen et al 2021
- “Prune Once for All: Sparse Pre-Trained Language Models”, Zafrir et al 2021
- “DSEE: Dually Sparsity-Embedded Efficient Tuning of Pre-Trained Language Models”, Chen et al 2021
- “HALP: Hardware-Aware Latency Pruning”, Shen et al 2021
- “On the Interplay Between Sparsity, Naturalness, Intelligibility, and Prosody in Speech Synthesis”, Lai et al 2021
- “Block Pruning For Faster Transformers”, Lagunas et al 2021
- “Scaling Laws for Deep Learning”, Rosenfeld 2021
- “A Winning Hand: Compressing Deep Networks Can Improve Out-Of-Distribution Robustness”, Diffenderfer et al 2021
- “Chasing Sparsity in Vision Transformers: An End-To-End Exploration”, Chen et al 2021
- “On Lottery Tickets and Minimal Task Representations in Deep Reinforcement Learning”, Vischer et al 2021
- “Sifting out the Features by Pruning: Are Convolutional Networks the Winning Lottery Ticket of Fully Connected Ones?”, Pellegrini & Biroli 2021
- “Learning N:M Fine-Grained Structured Sparse Neural Networks From Scratch”, Zhou et al 2021
- “ES-ENAS: Blackbox Optimization over Hybrid Spaces via Combinatorial and Continuous Evolution”, Song et al 2021
- “Postnatal Connectomic Development of Inhibition in Mouse Barrel Cortex”, Gour et al 2020
- “Progressively Stacking 2.0: A Multi-Stage Layerwise Training Method for BERT Training Speedup”, Yang et al 2020
- “A Primer in BERTology: What We Know about How BERT Works”, Rogers et al 2020
- “Bort: Optimal Subarchitecture Extraction For BERT”, Wynter & Perry 2020
- “Pruning Neural Networks at Initialization: Why Are We Missing the Mark?”, Frankle et al 2020
- “Logarithmic Pruning Is All You Need”, Orseau et al 2020
- “On the Predictability of Pruning Across Scales”, Rosenfeld et al 2020
- “Progressive Skeletonization: Trimming More Fat from a Network at Initialization”, Jorge et al 2020
- “Pruning Neural Networks without Any Data by Iteratively Conserving Synaptic Flow”, Tanaka et al 2020
- “Movement Pruning: Adaptive Sparsity by Fine-Tuning”, Sanh et al 2020
- “Bayesian Bits: Unifying Quantization and Pruning”, Baalen et al 2020
- “Lite Transformer With Long-Short Range Attention”, Wu et al 2020
- “On the Effect of Dropping Layers of Pre-Trained Transformer Models”, Sajjad et al 2020
- “Train-By-Reconnect: Decoupling Locations of Weights from Their Values (LaPerm)”, Qiu & Suda 2020
- “Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers”, Li et al 2020
- “What’s Hidden in a Randomly Weighted Neural Network?”, Ramanujan et al 2019
- “Sparse Networks from Scratch: Faster Training without Losing Performance”, Dettmers & Zettlemoyer 2019
- “Playing the Lottery With Rewards and Multiple Languages: Lottery Tickets in RL and NLP”, Yu et al 2019
- “SpArSe: Sparse Architecture Search for CNNs on Resource-Constrained Microcontrollers”, Fedorov et al 2019
- “Are 16 Heads Really Better Than One?”, Michel et al 2019
- “Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned”, Voita et al 2019
- “Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask”, Zhou et al 2019
- “Stabilizing the Lottery Ticket Hypothesis”, Frankle et al 2019
- “The State of Sparsity in Deep Neural Networks”, Gale et al 2019
- “Differential Contribution of Cortical Thickness, Surface Area, and Gyrification to Fluid and Crystallized Intelligence”, Tadayon et al 2019
- “Efficient Training of BERT by Progressively Stacking”, Gong et al 2019
- “A Closer Look at Structured Pruning for Neural Network Compression”, Crowley et al 2018
- “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks”, Frankle & Carbin 2018
- “Efficient Neural Audio Synthesis”, Kalchbrenner et al 2018
- “Recovering from Random Pruning: On the Plasticity of Deep Convolutional Neural Networks”, Mittal et al 2018
- “Learning to Prune Filters in Convolutional Neural Networks”, Huang et al 2018
- “Faster Gaze Prediction With Dense Networks and Fisher Pruning”, Theis et al 2018
- “Automated Pruning for Deep Neural Network Compression”, Manessi et al 2017
- “Training Simplification and Model Simplification for Deep Learning: A Minimal Effort Back Propagation Method”, Sun et al 2017
- “NeST: A Neural Network Synthesis Tool Based on a Grow-And-Prune Paradigm”, Dai et al 2017
- “To Prune, or Not to Prune: Exploring the Efficacy of Pruning for Model Compression”, Zhu & Gupta 2017
- “Bayesian Sparsification of Recurrent Neural Networks”, Lobacheva et al 2017
- “Structured Bayesian Pruning via Log-Normal Multiplicative Noise”, Neklyudov et al 2017
- “Exploring Sparsity in Recurrent Neural Networks”, Narang et al 2017
- “Variational Dropout Sparsifies Deep Neural Networks”, Molchanov et al 2017
- “Iterative Magnitude Pruning: Learning Both Weights and Connections for Efficient Neural Networks”, Han et al 2015
- “It Takes Two Neurons To Ride a Bicycle”, Cook 2004
- “Flat Minima”, Hochreiter & Schmidhuber 1997
- “Optimal Brain Surgeon and General Network Pruning”, Hassibi et al 1993
- “Fault Tolerance of Pruned Multilayer Networks”, Segee & Carter 1991
- “Using Relevance to Reduce Network Size Automatically”, Mozer & Smolensky 1989
- “Optimal Brain Damage”, LeCun et al 1989
- “Trading Off Compute in Training and Inference § Pruning”
- Sort By Magic
differentiable-synthesisvisual-predictionconnectomic-development neuronal-connectivity development-inhibition self-organization heavy-tailednetwork-reduction flat-minima fault-tolerance narrow-ai pruning-techniquesbert-optimization bert-training efficiency-boosting architecture-extraction progressive-learning training-methodsmodel-compressionmodel-pruning
- Wikipedia (1)
- Miscellaneous
- Bibliography
See Also
Links
“Weight-Sparse Circuits May Be Interpretable Yet Unfaithful”, Drori 2026
“I Solved Cartpole-V1 Using Only Bitwise Ops With Differentiable Logic Synthesis”, kiockete 2026
I solved Cartpole-v1 using only bitwise ops with Differentiable Logic Synthesis
“Differentiable Logic Synthesis: Spectral Coefficient Selection via Sinkhorn-Constrained Composition”, Pavlov 2026
Differentiable Logic Synthesis: Spectral Coefficient Selection via Sinkhorn-Constrained Composition
“Gogipav14/spectral-Llm: Differentiable Logic Synthesis: Spectral Coefficient Selection via Sinkhorn-Constrained Composition”, Pavlov 2026
“Weight-Sparse Transformers Have Interpretable Circuits”, Gao et al 2025
“Compiling a Differentiable Logic Gate Neural Net to C for a 1,744× Speedup”, Clayton 2025
Compiling a Differentiable Logic Gate Neural Net to C for a 1,744× speedup
“On the Creation of Narrow AI: Hierarchy and Nonlocality of Neural Network Skills”, Michaud et al 2025
On the creation of narrow AI: hierarchy and nonlocality of neural network skills
“Bigram Subnetworks: Mapping to Next Tokens in Transformer Language Models”, Chang & Bergen 2025
Bigram Subnetworks: Mapping to Next Tokens in Transformer Language Models
“2:4 Sparse Llama: Smaller Models for Efficient GPU Inference”, Kurtić et al 2024
2:4 Sparse Llama: Smaller Models for Efficient GPU Inference
“The Super Weight in Large Language Models”, Yu et al 2024
“What Matters in Transformers? Not All Attention Is Needed”, He et al 2024
“When Parts Are Greater Than Sums: Individual LLM Components Can Outperform Full Models”, Chang et al 2024
When Parts are Greater Than Sums: Individual LLM Components Can Outperform Full Models
“Pre-Training Small Base LMs With Fewer Tokens”, Sanyal et al 2024
“Streamlining Redundant Layers to Compress Large Language Models”, Chen et al 2024
Streamlining Redundant Layers to Compress Large Language Models
“The Unreasonable Ineffectiveness of the Deeper Layers”, Gromov et al 2024
“Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression”, Hong et al 2024
Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression
“SliceGPT: Compress Large Language Models by Deleting Rows and Columns”, Ashkboos et al 2024
SliceGPT: Compress Large Language Models by Deleting Rows and Columns
“Weight Subcloning: Direct Initialization of Transformers Using Larger Pretrained Ones”, Samragh et al 2023
Weight subcloning: direct initialization of transformers using larger pretrained ones
“To Grok or Not to Grok: Disentangling Generalization and Memorization on Corrupted Algorithmic Datasets”, Doshi et al 2023
“Sheared LLaMA: Accelerating Language Model Pre-Training via Structured Pruning”, Xia et al 2023
Sheared LLaMA: Accelerating Language Model Pre-training via Structured Pruning
“One Wide Feedforward Is All You Need”, Pires et al 2023
“A Comparative Study between Full-Parameter and LoRA-Based Fine-Tuning on Chinese Instruction Data for Instruction Following Large Language Model”, Sun et al 2023
“Fast As CHITA: Neural Network Pruning With Combinatorial Optimization”, Benbaki et al 2023
Fast as CHITA: Neural Network Pruning with Combinatorial Optimization
“Self-Compressing Neural Networks”, Cséfalvay & Imber 2023
“Pruning Compact ConvNets for Efficient Inference”, Ghosh et al 2023
“Rethinking the Role of Scale for In-Context Learning: An Interpretability-Based Case Study at 66 Billion Scale”, Bansal et al 2022
“Lottery Tickets on a Data Diet: Finding Initializations With Sparse Trainable Networks”, Paul et al 2022
Lottery Tickets on a Data Diet: Finding Initializations with Sparse Trainable Networks
“Heavy-Tailed Neuronal Connectivity Arises from Hebbian Self–organization”, Lynn et al 2022
Heavy-tailed neuronal connectivity arises from Hebbian self–organization
“PPCD-GAN: Progressive Pruning and Class-Aware Distillation for Large-Scale Conditional GANs Compression”, Vo et al 2022
“The Combinatorial Brain Surgeon: Pruning Weights That Cancel One Another in Neural Networks”, Yu et al 2022
The Combinatorial Brain Surgeon: Pruning Weights That Cancel One Another in Neural Networks
“Data-Efficient Structured Pruning via Submodular Optimization”, Halabi et al 2022
Data-Efficient Structured Pruning via Submodular Optimization
“Sparsity Winning Twice: Better Robust Generalization from More Efficient Training”, Chen et al 2022
Sparsity Winning Twice: Better Robust Generalization from More Efficient Training
“Fortuitous Forgetting in Connectionist Networks”, Zhou et al 2022
“How Many Degrees of Freedom Do We Need to Train Deep Networks: a Loss Landscape Perspective”, Larsen et al 2021
How many degrees of freedom do we need to train deep networks: a loss landscape perspective
“Prune Once for All: Sparse Pre-Trained Language Models”, Zafrir et al 2021
“DSEE: Dually Sparsity-Embedded Efficient Tuning of Pre-Trained Language Models”, Chen et al 2021
DSEE: Dually Sparsity-embedded Efficient Tuning of Pre-trained Language Models
“HALP: Hardware-Aware Latency Pruning”, Shen et al 2021
“On the Interplay Between Sparsity, Naturalness, Intelligibility, and Prosody in Speech Synthesis”, Lai et al 2021
On the Interplay Between Sparsity, Naturalness, Intelligibility, and Prosody in Speech Synthesis
“Block Pruning For Faster Transformers”, Lagunas et al 2021
“Scaling Laws for Deep Learning”, Rosenfeld 2021
“A Winning Hand: Compressing Deep Networks Can Improve Out-Of-Distribution Robustness”, Diffenderfer et al 2021
A Winning Hand: Compressing Deep Networks Can Improve Out-Of-Distribution Robustness
“Chasing Sparsity in Vision Transformers: An End-To-End Exploration”, Chen et al 2021
Chasing Sparsity in Vision Transformers: An End-to-End Exploration
“On Lottery Tickets and Minimal Task Representations in Deep Reinforcement Learning”, Vischer et al 2021
On Lottery Tickets and Minimal Task Representations in Deep Reinforcement Learning
“Sifting out the Features by Pruning: Are Convolutional Networks the Winning Lottery Ticket of Fully Connected Ones?”, Pellegrini & Biroli 2021
“Learning N:M Fine-Grained Structured Sparse Neural Networks From Scratch”, Zhou et al 2021
Learning N:M Fine-grained Structured Sparse Neural Networks From Scratch
“ES-ENAS: Blackbox Optimization over Hybrid Spaces via Combinatorial and Continuous Evolution”, Song et al 2021
ES-ENAS: Blackbox Optimization over Hybrid Spaces via Combinatorial and Continuous Evolution
“Postnatal Connectomic Development of Inhibition in Mouse Barrel Cortex”, Gour et al 2020
Postnatal connectomic development of inhibition in mouse barrel cortex
“Progressively Stacking 2.0: A Multi-Stage Layerwise Training Method for BERT Training Speedup”, Yang et al 2020
Progressively Stacking 2.0: A Multi-stage Layerwise Training Method for BERT Training Speedup
“A Primer in BERTology: What We Know about How BERT Works”, Rogers et al 2020
“Bort: Optimal Subarchitecture Extraction For BERT”, Wynter & Perry 2020
“Pruning Neural Networks at Initialization: Why Are We Missing the Mark?”, Frankle et al 2020
Pruning Neural Networks at Initialization: Why are We Missing the Mark?
“Logarithmic Pruning Is All You Need”, Orseau et al 2020
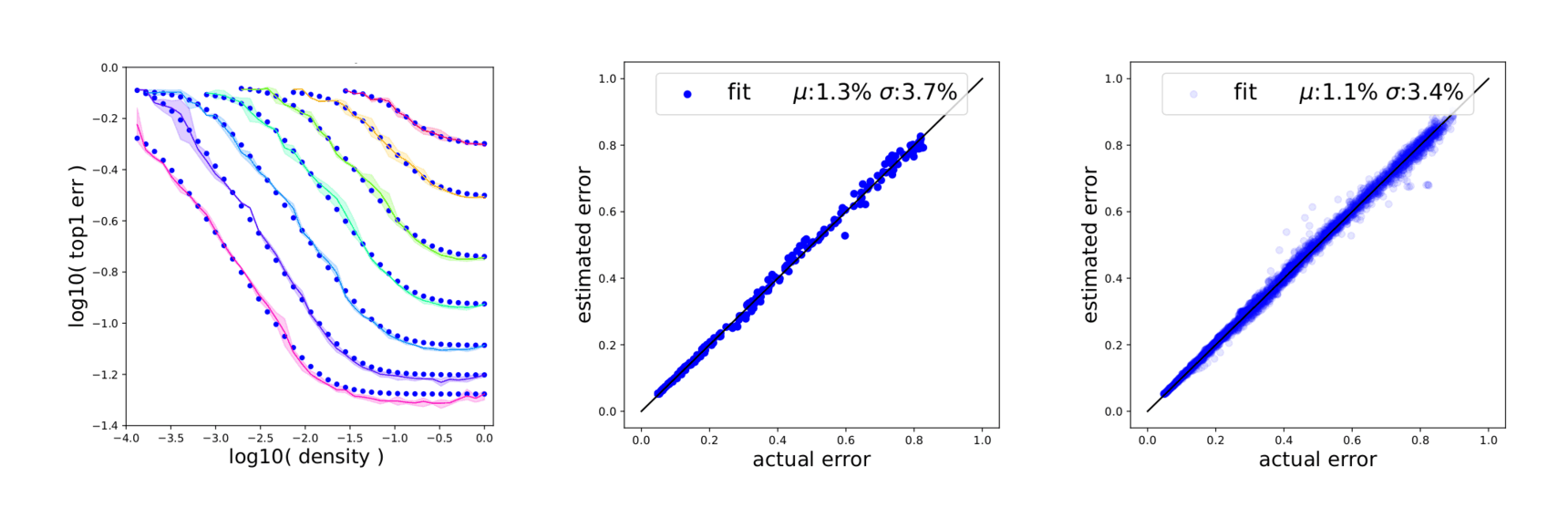
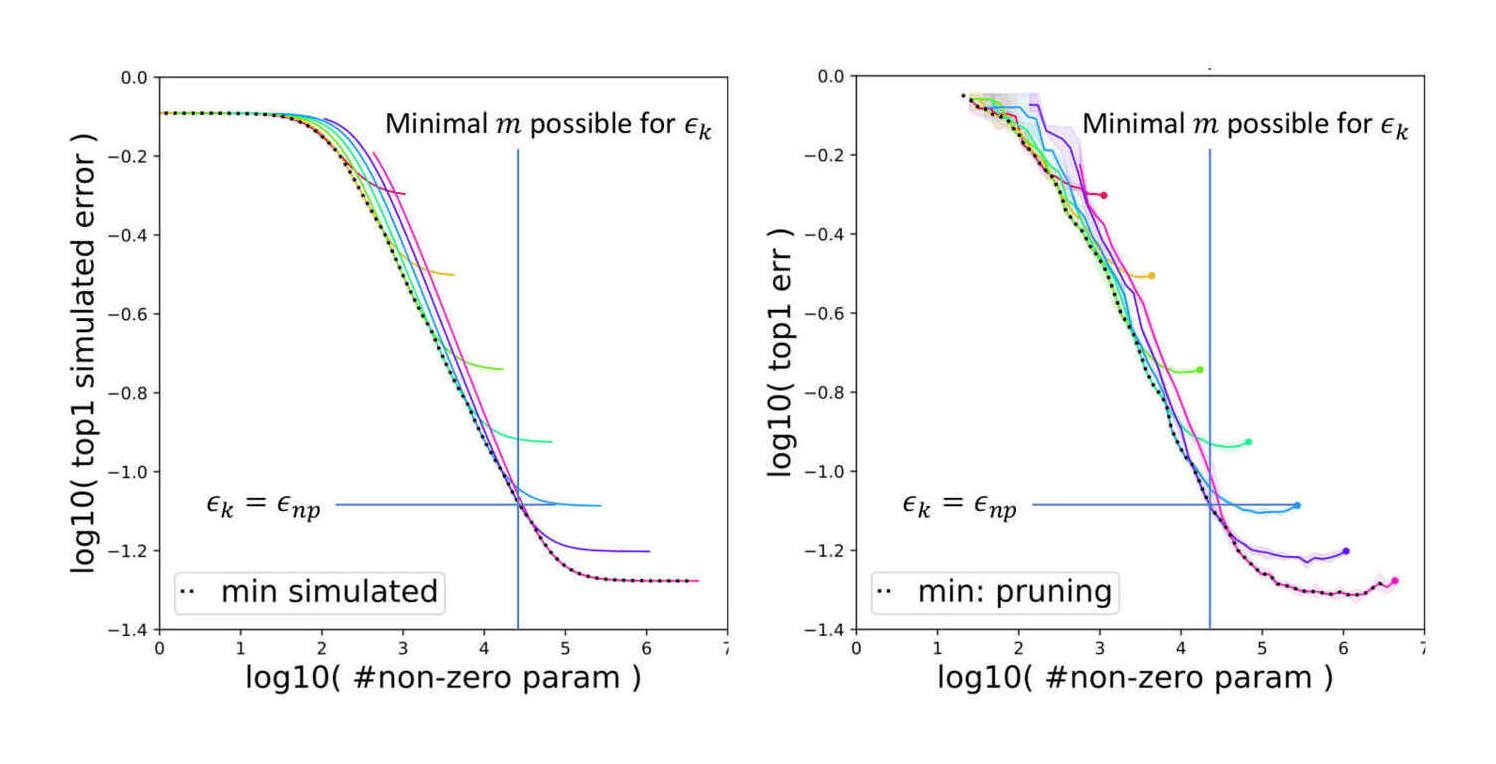
“On the Predictability of Pruning Across Scales”, Rosenfeld et al 2020
“Progressive Skeletonization: Trimming More Fat from a Network at Initialization”, Jorge et al 2020
Progressive Skeletonization: Trimming more fat from a network at initialization
“Pruning Neural Networks without Any Data by Iteratively Conserving Synaptic Flow”, Tanaka et al 2020
Pruning neural networks without any data by iteratively conserving synaptic flow
“Movement Pruning: Adaptive Sparsity by Fine-Tuning”, Sanh et al 2020
“Bayesian Bits: Unifying Quantization and Pruning”, Baalen et al 2020
“Lite Transformer With Long-Short Range Attention”, Wu et al 2020
“On the Effect of Dropping Layers of Pre-Trained Transformer Models”, Sajjad et al 2020
On the Effect of Dropping Layers of Pre-trained Transformer Models
“Train-By-Reconnect: Decoupling Locations of Weights from Their Values (LaPerm)”, Qiu & Suda 2020
Train-by-Reconnect: Decoupling Locations of Weights from their Values (LaPerm)
“Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers”, Li et al 2020
“What’s Hidden in a Randomly Weighted Neural Network?”, Ramanujan et al 2019
“Sparse Networks from Scratch: Faster Training without Losing Performance”, Dettmers & Zettlemoyer 2019
Sparse Networks from Scratch: Faster Training without Losing Performance
“Playing the Lottery With Rewards and Multiple Languages: Lottery Tickets in RL and NLP”, Yu et al 2019
Playing the lottery with rewards and multiple languages: lottery tickets in RL and NLP
“SpArSe: Sparse Architecture Search for CNNs on Resource-Constrained Microcontrollers”, Fedorov et al 2019
SpArSe: Sparse Architecture Search for CNNs on Resource-Constrained Microcontrollers
“Are 16 Heads Really Better Than One?”, Michel et al 2019
“Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned”, Voita et al 2019
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned
“Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask”, Zhou et al 2019
Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask
“Stabilizing the Lottery Ticket Hypothesis”, Frankle et al 2019
“The State of Sparsity in Deep Neural Networks”, Gale et al 2019
“Differential Contribution of Cortical Thickness, Surface Area, and Gyrification to Fluid and Crystallized Intelligence”, Tadayon et al 2019
“Efficient Training of BERT by Progressively Stacking”, Gong et al 2019
“A Closer Look at Structured Pruning for Neural Network Compression”, Crowley et al 2018
A Closer Look at Structured Pruning for Neural Network Compression
“The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks”, Frankle & Carbin 2018
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
“Efficient Neural Audio Synthesis”, Kalchbrenner et al 2018
“Recovering from Random Pruning: On the Plasticity of Deep Convolutional Neural Networks”, Mittal et al 2018
Recovering from Random Pruning: On the Plasticity of Deep Convolutional Neural Networks
“Learning to Prune Filters in Convolutional Neural Networks”, Huang et al 2018
“Faster Gaze Prediction With Dense Networks and Fisher Pruning”, Theis et al 2018
Faster gaze prediction with dense networks and Fisher pruning
“Automated Pruning for Deep Neural Network Compression”, Manessi et al 2017
“Training Simplification and Model Simplification for Deep Learning: A Minimal Effort Back Propagation Method”, Sun et al 2017
“NeST: A Neural Network Synthesis Tool Based on a Grow-And-Prune Paradigm”, Dai et al 2017
NeST: A Neural Network Synthesis Tool Based on a Grow-and-Prune Paradigm
“To Prune, or Not to Prune: Exploring the Efficacy of Pruning for Model Compression”, Zhu & Gupta 2017
To prune, or not to prune: exploring the efficacy of pruning for model compression
“Bayesian Sparsification of Recurrent Neural Networks”, Lobacheva et al 2017
“Structured Bayesian Pruning via Log-Normal Multiplicative Noise”, Neklyudov et al 2017
Structured Bayesian Pruning via Log-Normal Multiplicative Noise
“Exploring Sparsity in Recurrent Neural Networks”, Narang et al 2017
“Variational Dropout Sparsifies Deep Neural Networks”, Molchanov et al 2017
“Iterative Magnitude Pruning: Learning Both Weights and Connections for Efficient Neural Networks”, Han et al 2015
Iterative Magnitude Pruning: Learning both Weights and Connections for Efficient Neural Networks
“It Takes Two Neurons To Ride a Bicycle”, Cook 2004
“Flat Minima”, Hochreiter & Schmidhuber 1997
“Optimal Brain Surgeon and General Network Pruning”, Hassibi et al 1993
“Fault Tolerance of Pruned Multilayer Networks”, Segee & Carter 1991
“Using Relevance to Reduce Network Size Automatically”, Mozer & Smolensky 1989
“Optimal Brain Damage”, LeCun et al 1989
“Trading Off Compute in Training and Inference § Pruning”
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
differentiable-synthesis
visual-prediction
connectomic-development neuronal-connectivity development-inhibition self-organization heavy-tailed
network-reduction flat-minima fault-tolerance narrow-ai pruning-techniques
bert-optimization bert-training efficiency-boosting architecture-extraction progressive-learning training-methods
model-compression
model-pruning
Wikipedia (1)
Miscellaneous
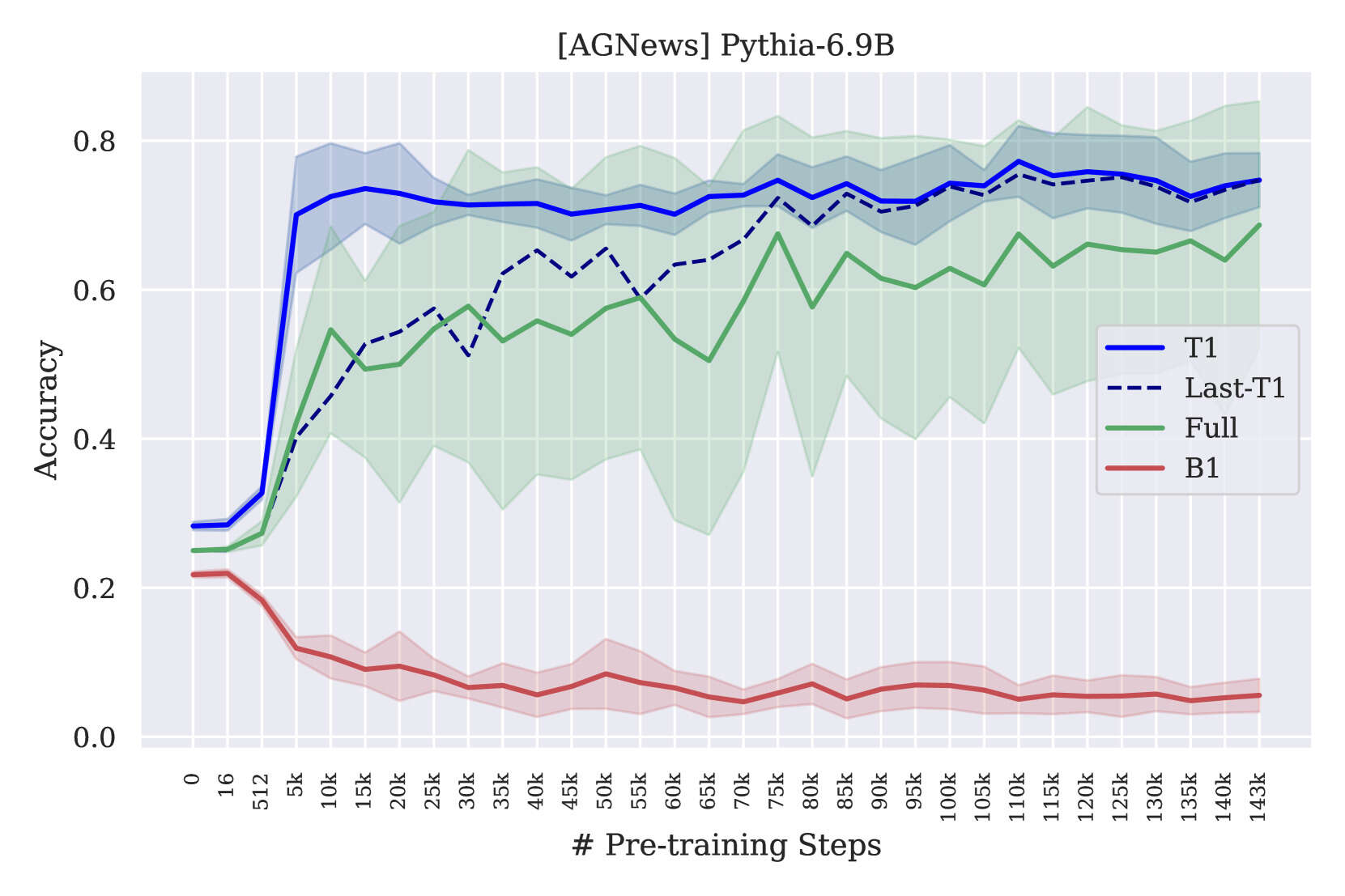
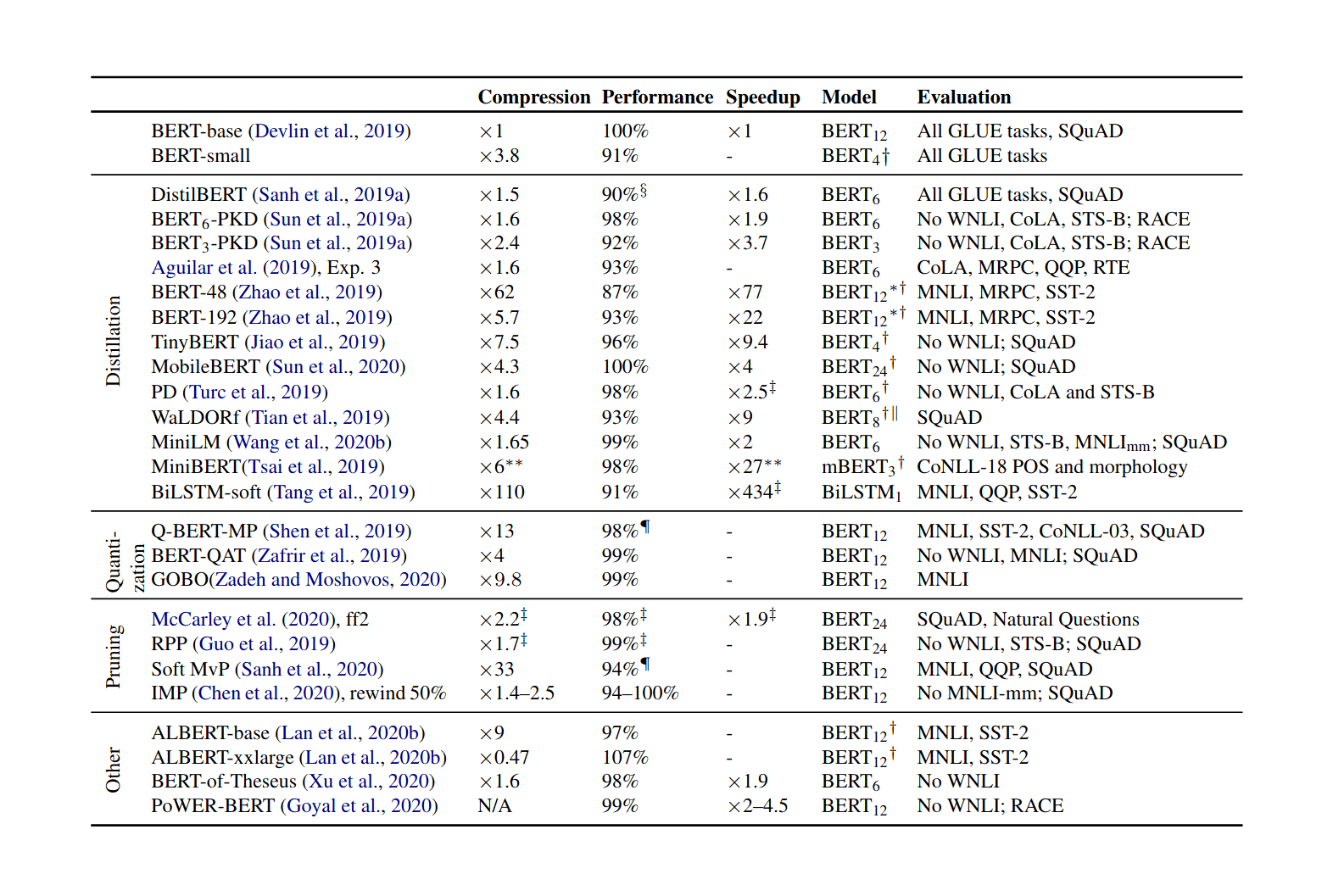
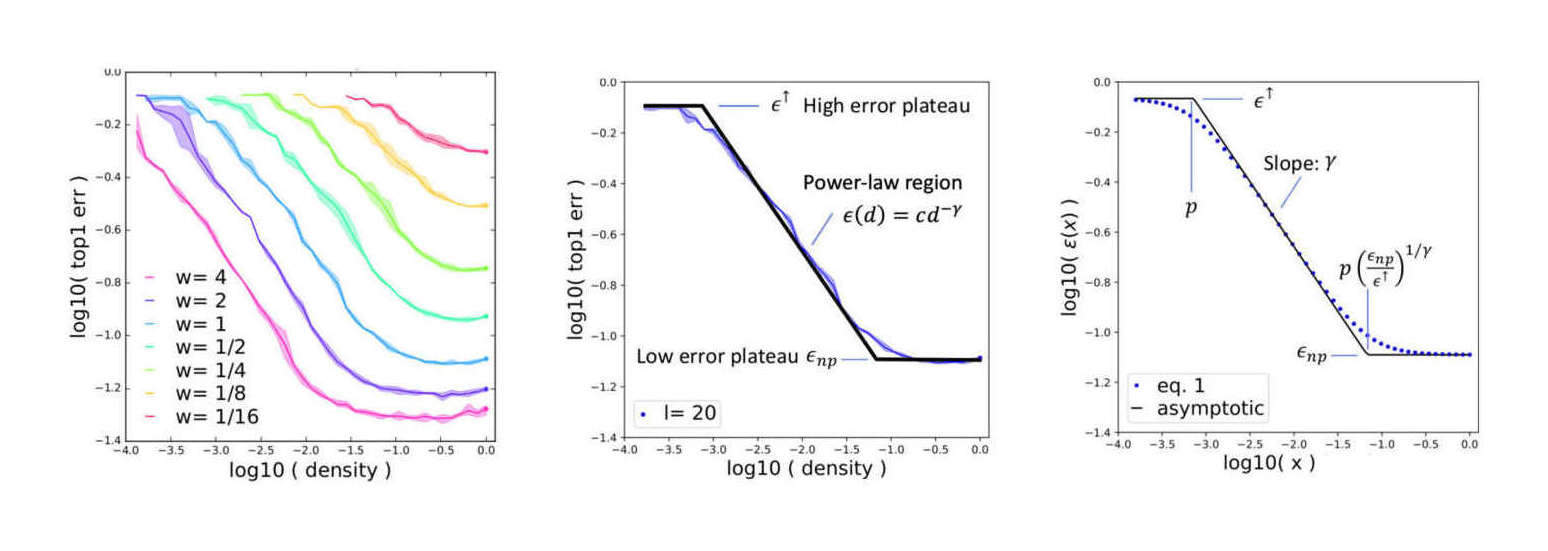
/doc/ai/nn/sparsity/pruning/2020-rogers-table1-bertcompression.png/doc/ai/nn/sparsity/pruning/2020-rosenfeld-equation1-functionalformofdlscalingpruninglaw.pnghttps://cprimozic.net/blog/reverse-engineering-a-small-neural-network/https://magazine.sebastianraschka.com/p/practical-tips-for-finetuning-llms
{kind=link}
{kind=link}
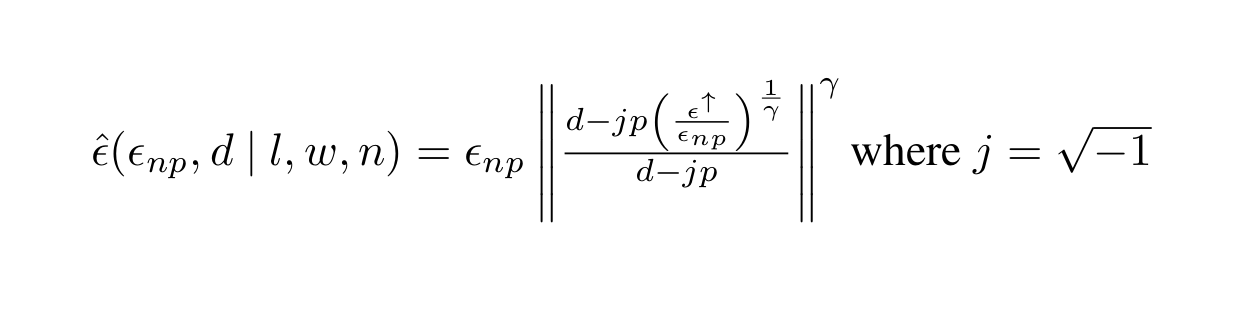{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2406.15786: “What Matters in Transformers? Not All Attention Is Needed”,https://arxiv.org/abs/2406.13131: “When Parts Are Greater Than Sums: Individual LLM Components Can Outperform Full Models”,https://arxiv.org/abs/2404.08634: “Pre-Training Small Base LMs With Fewer Tokens”,https://arxiv.org/abs/2403.17887#facebook: “The Unreasonable Ineffectiveness of the Deeper Layers”,https://arxiv.org/abs/2401.15024#microsoft: “SliceGPT: Compress Large Language Models by Deleting Rows and Columns”,https://arxiv.org/abs/2310.13061: “To Grok or Not to Grok: Disentangling Generalization and Memorization on Corrupted Algorithmic Datasets”,https://arxiv.org/abs/2310.06694: “Sheared LLaMA: Accelerating Language Model Pre-Training via Structured Pruning”,https://arxiv.org/abs/2202.09844: “Sparsity Winning Twice: Better Robust Generalization from More Efficient Training”,https://arxiv.org/abs/2111.05754: “Prune Once for All: Sparse Pre-Trained Language Models”,https://arxiv.org/abs/2111.00160: “DSEE: Dually Sparsity-Embedded Efficient Tuning of Pre-Trained Language Models”,https://arxiv.org/abs/2108.07686: “Scaling Laws for Deep Learning”,https://arxiv.org/abs/2106.04533: “Chasing Sparsity in Vision Transformers: An End-To-End Exploration”,https://arxiv.org/abs/2009.08576: “Pruning Neural Networks at Initialization: Why Are We Missing the Mark?”,https://arxiv.org/abs/2006.10621: “On the Predictability of Pruning Across Scales”,https://arxiv.org/abs/2006.05467: “Pruning Neural Networks without Any Data by Iteratively Conserving Synaptic Flow”,https://arxiv.org/abs/2004.03844: “On the Effect of Dropping Layers of Pre-Trained Transformer Models”,https://arxiv.org/abs/1911.13299: “What’s Hidden in a Randomly Weighted Neural Network?”,https://arxiv.org/abs/1903.01611: “Stabilizing the Lottery Ticket Hypothesis”,https://arxiv.org/abs/1902.09574: “The State of Sparsity in Deep Neural Networks”,https://arxiv.org/abs/1810.04622: “A Closer Look at Structured Pruning for Neural Network Compression”,https://arxiv.org/abs/1801.10447: “Recovering from Random Pruning: On the Plasticity of Deep Convolutional Neural Networks”,2004-cook.pdf: “It Takes Two Neurons To Ride a Bicycle”,1993-hassibi.pdf: “Optimal Brain Surgeon and General Network Pruning”,