https://openai.com/index/whisper/
https://github.com/openai/whisper
https://github.com/openai/whisper/blob/main/model-card.md
https://cookbook.openai.com/examples/whisper_prompting_guide
https://github.com/alphacep/whisper-prompts
https://www.lesswrong.com/posts/thePw6qdyabD8XR4y/interpreting-openai-s-whisper
https://www.lesswrong.com/posts/thePw6qdyabD8XR4y/interpreting-openai-s-whisper#3_1__Whisper_learns_language_modelling_bigrams
Distil-Whisper: Robust Knowledge Distillation via Large-Scale Pseudo Labelling
ESB: A Benchmark For Multi-Domain End-to-End Speech Recognition
Why YouTube Could Give Google an Edge in AI
How Tech Giants Cut Corners to Harvest Data for AI: OpenAI, Google and Meta ignored corporate policies, altered their own rules and discussed skirting copyright law as they sought online information to train their newest artificial intelligence systems
VoxLingua107: a Dataset for Spoken Language Recognition
Attention Is All You Need
Using the Output Embedding to Improve Language Models
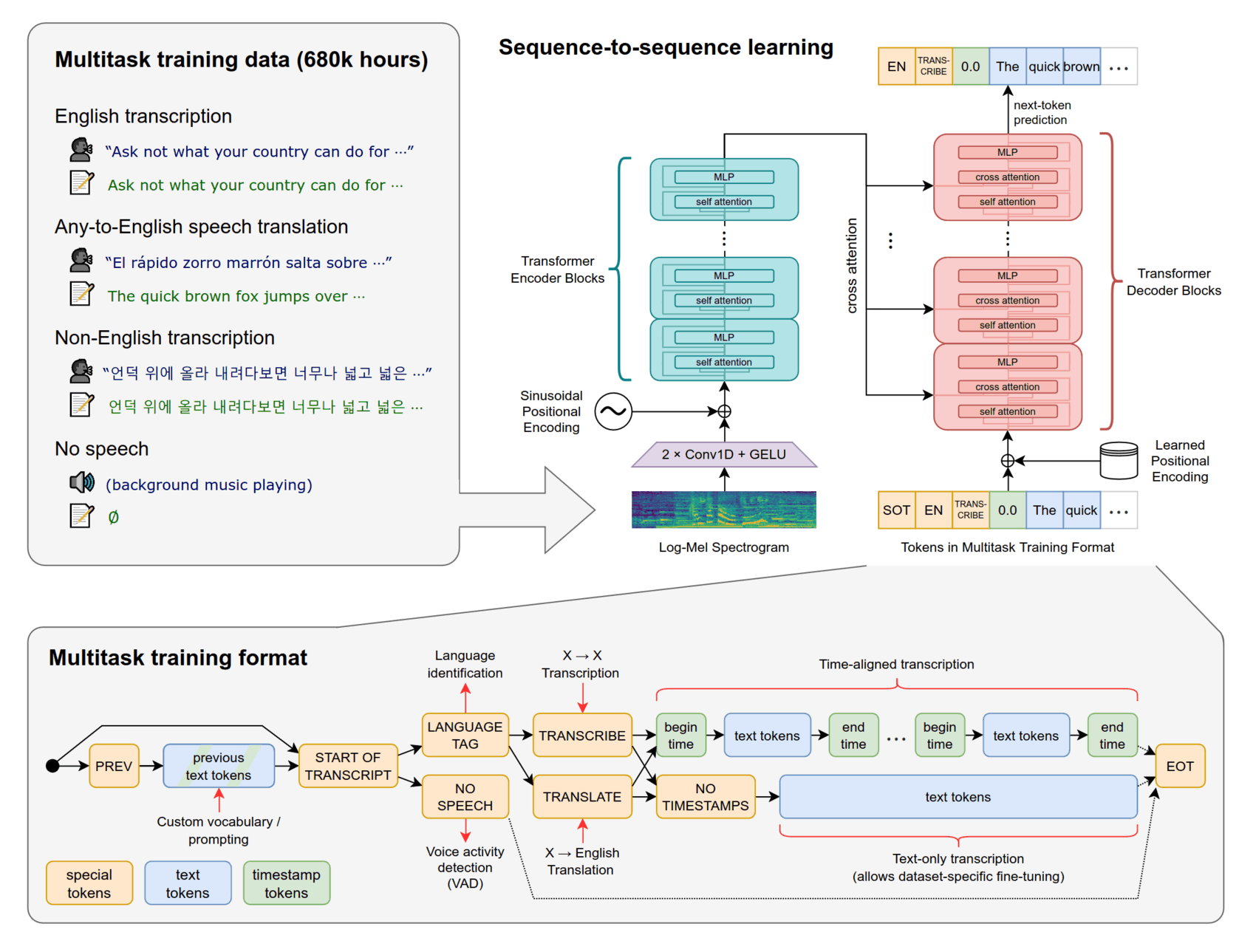
2022-radford-figure1-overviewofwhispertransformerarchitecture.png
BPEs: Neural Machine Translation of Rare Words with Subword Units
Language Models are Unsupervised Multitask Learners
https://arxiv.org/pdf/2212.04356#page=4&org=openai
‘dynamic evaluation (NN)’ directory
https://arxiv.org/pdf/2212.04356#page=28&org=openai
FLEURS: Few-shot Learning Evaluation of Universal Representations of Speech
CoVoST 2 and Massively Multilingual Speech-to-Text Translation
XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale
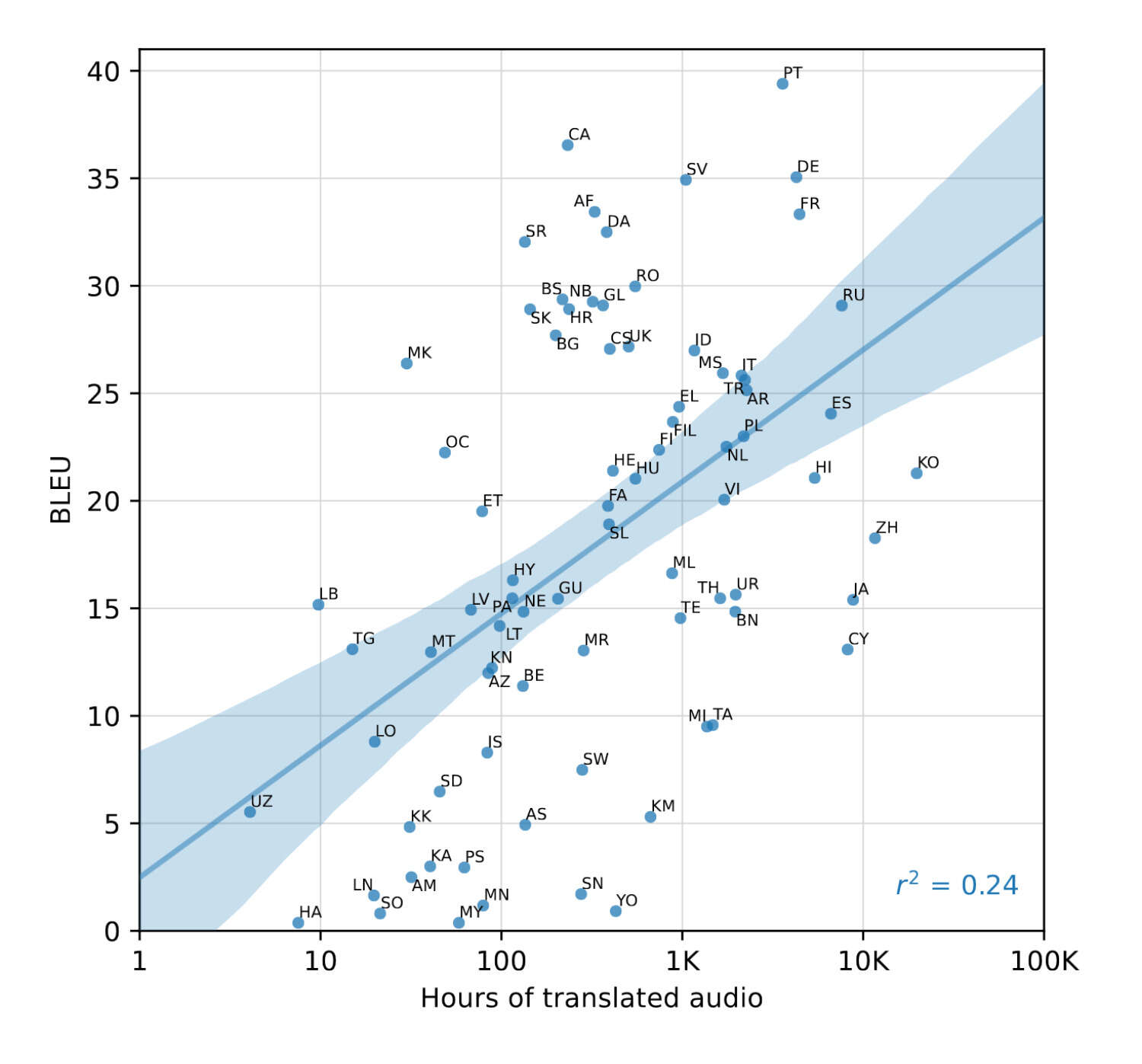
2022-radford-figure4-correlationofpretraininglanguagedatawithtranslationperformance.jpg
https://catalog.ngc.nvidia.com/orgs/nvidia/teams/nemo/models/stt_en_conformer_ctc_large
Conformer: Convolution-augmented Transformer for Speech Recognition
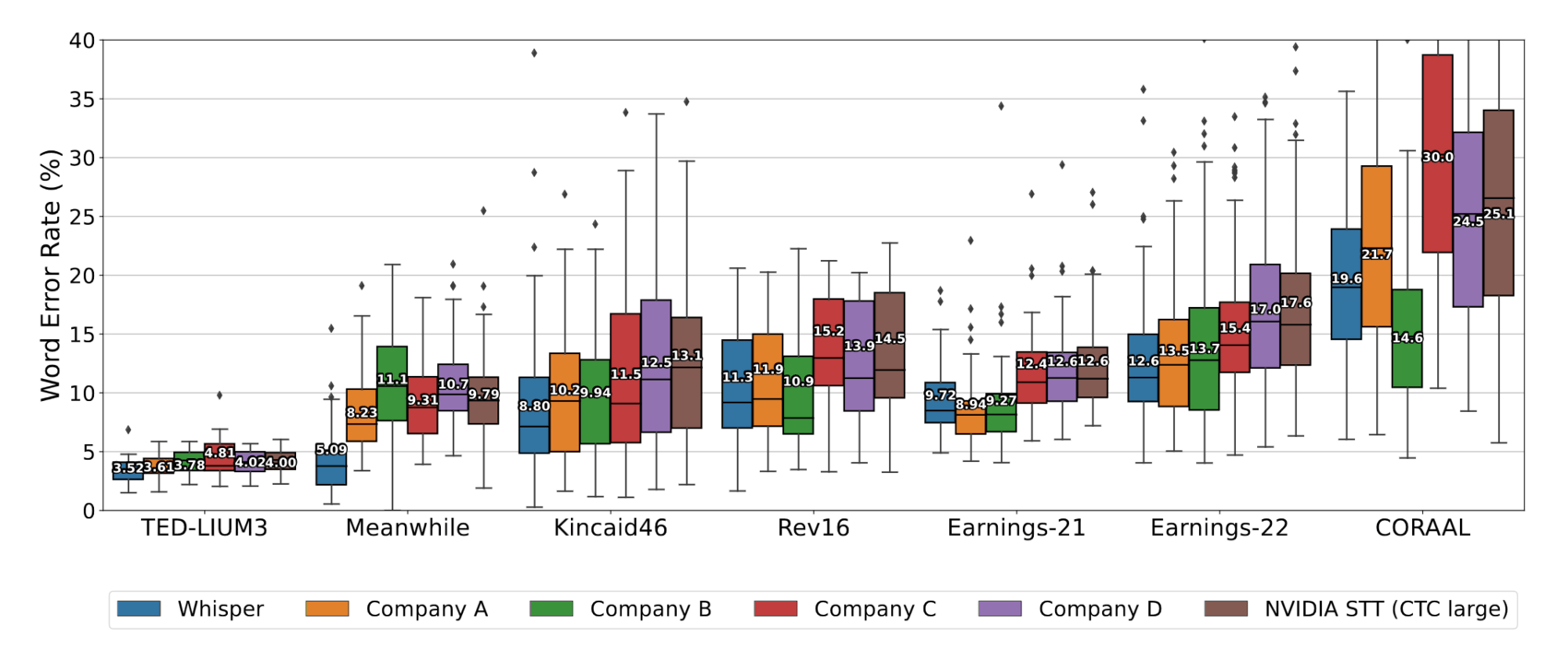
2022-radford-figure6-whisperbenchmarksagainstrivalsacrossotherdatasets.png
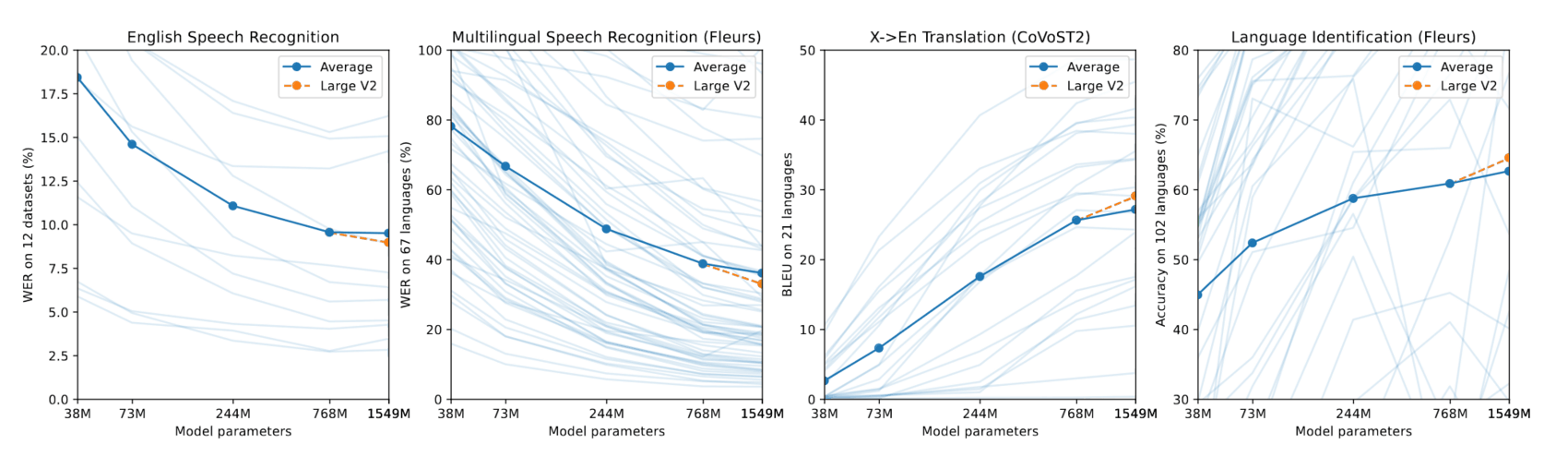
2022-radford-figure8-whisperscalingbymodelsize.png
Chinchilla: Training Compute-Optimal Large Language Models
{kind=link}
{kind=link}
{kind=link}
{kind=link}