‘diffusion NN’ directory
- See Also
- Gwern
- Links
- “Anime-2026: A Large-Scale Anime Character Dataset for Anime-Related AI Tasks”, Xuyang et al 2026
- “Learnings from Paying Artists Royalties for AI-Generated Art: A Retrospective on Tess.Design, Our Attempt to Make an Ethical, Artist-Friendly AI Marketplace. We Launched Tess in May 2024 and Shut It down in January 2026”, Enthoven 2026
- “The 1 Million Dollar RPG Maps Bundle Scam”, Botter 2026
- “Autonomous Language-Image Generation Loops Converge to Generic Visual Motifs [SDXL ↔ LLaVA]”, Hintze et al 2025
- “TreeGRPO: Tree-Advantage GRPO for Online RL Post-Training of Diffusion Models”, Ding & Ye 2025
- “Foundations of Diffusion Models in General State Spaces: A Self-Contained Introduction”, Pauline et al 2025
- “Z-Image: An Efficient Image Generation Foundation Model With Single-Stream Diffusion Transformer”, Team et al 2025
- “Wan 2.2 Human Image Generation Is Very Good. This Open Model Has a Great Future.Workflow Included [Video Generation → Image Generation]”, yomasexbomb 2025
- “Lost in Latent Space: An Empirical Study of Latent Diffusion Models for Physics Emulation”, Rozet et al 2025
- “Generative Thermodynamic Computing”, Whitelam 2025
- “SSIMBaD: Sigma Scaling With SSIM-Guided Balanced Diffusion for AnimeFace Colorization”, Seo et al 2025
- “Instance-Guided Anime Editing With a Curated Large-Scale Dataset”, Lin et al 2025
- “Gen2seg: Generative Models Enable Generalizable Instance Segmentation”, Khangaonkar & Pirsiavash 2025
- “FramePack: Packing Input Frame Context in Next-Frame Prediction Models for Video Generation”, Zhang & Agrawala 2025
- “AnimeDL-2M: Million-Scale AI-Generated Anime Image Detection and Localization in Diffusion Era”, Zhu et al 2025
- “Generative Modeling in Latent Space [Why VAEs Etc. Work]”, Dieleman 2025
- “GenEAva: Generating Cartoon Avatars With Fine-Grained Facial Expressions from Realistic Diffusion-Based Faces”, Yu et al 2025
- “ColorizeDiffusion V2: Enhancing Reference-Based Sketch Colorization Through Separating Utilities”, Yan et al 2025
- “NoProp: Training Neural Networks without Backpropagation or Forward-Propagation”, Li et al 2025
- “Image Referenced Sketch Colorization Based on Animation Creation Workflow”, Yan et al 2025
- “ColorizeDiffusion: Improving Reference-Based Sketch Colorization With Latent Diffusion Model”, Yan et al 2025
- “Step-Video-T2V Technical Report: The Practice, Challenges, and Future of Video Foundation Model”, Ma et al 2025
- “InstaNovo Enables Diffusion-Powered de Novo Peptide Sequencing in Large-Scale Proteomics Experiments”, Eloff et al 2025
- “Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps”, Ma et al 2025
- “MangaNinja: Line Art Colorization With Precise Reference Following”, Liu et al 2025
- “Do Generative Video Models Learn Physical Principles from Watching Videos?”, Motamed et al 2025
- “An Analytic Theory of Creativity in Convolutional Diffusion Models”, Kamb & Ganguli 2024
- “Exploring Denoising Diffusion Models for Realistic Anime Character Generation”, Kumari & Bhadoria 2024
- “AniDoc: Animation Creation Made Easier”, Meng et al 2024
- “AniSora: Exploring the Frontiers of Animation Video Generation in the Sora Era”, Jiang et al 2024
- “Proactive Agents for Multi-Turn Text-To-Image Generation Under Uncertainty”, Hahn et al 2024
- “Probabilistic Weather Forecasting With Machine Learning”, Price et al 2024
- “Art-Free Generative Models: Art Creation Without Graphic Art Knowledge”, Ren et al 2024
- “Revisiting Your Memory: Reconstruction of Affect-Contextualized Memory via EEG-Guided Audiovisual Generation”, Kwon et al 2024
- “How Far Is Video Generation from World Model: A Physical Law Perspective”, Kang et al 2024
- “Data Scaling Laws in Imitation Learning for Robotic Manipulation”, Lin et al 2024
- “One Step Diffusion via Shortcut Models”, Frans et al 2024
- “SANA: Efficient High-Resolution Image Synthesis With Linear Diffusion Transformers”, Xie et al 2024
- “Denoising With a Joint-Embedding Predictive Architecture”, Chen et al 2024
- “Copying Style, Extracting Value: Illustrators’ Perception of AI Style Transfer and Its Impact on Creative Labor”, Porquet et al 2024
- “Improvements to SDXL in NovelAI Diffusion V3”, Ossa et al 2024
- “[Taylor Swift Endorses Kamala Harris due to Deepfakes]”, Swift 2024
- “Diffusion Is Spectral Autoregression”, Dieleman 2024
- “My Dead Father Is ‘Writing’ Me Notes Again”
- “Computational Design of Serine Hydrolases”, Lauko et al 2024
- “The Rise of Terminator Zero With Writer Mattson Tomlin & Director Masashi Kudo”, Baron 2024
- “NovelAI Diffusion V1 Weights Release”, NovelAI 2024
- “Transfusion: Predict the Next Token and Diffuse Images With One Multi-Modal Model”, Zhou et al 2024
- “Stretching Each Dollar: Diffusion Training from Scratch on a Micro-Budget”, Sehwag et al 2024
- “Diffusion Forcing: Next-Token Prediction Meets Full-Sequence Diffusion”, Chen et al 2024
- “4lph4bet_processor: This Script Processes a Grid Image Generated With the 4lph4bet Family of LoRAs for Stable Diffusion 1.5 for Font Creation Using Calligraphr”, 414design 2024
- “MAR: Autoregressive Image Generation without Vector Quantization”, Li et al 2024
- “Adversarial Perturbations Cannot Reliably Protect Artists From Generative AI”, Hönig et al 2024
- “Glyph-ByT5-V2: A Strong Aesthetic Baseline for Accurate Multilingual Visual Text Rendering”, Liu et al 2024
- “Consistency-Diversity-Realism Pareto Fronts of Conditional Image Generative Models”, Astolfi et al 2024
- “Interpreting the Weight Space of Customized Diffusion Models”, Dravid et al 2024
- “SF-V: Single Forward Video Generation Model”, Zhang et al 2024
- “Diffusion On Syntax Trees For Program Synthesis”, Kapur et al 2024
- “ToonCrafter: Generative Cartoon Interpolation”, Xing et al 2024
- “Lateralization MLP: A Simple Brain-Inspired Architecture for Diffusion”, Hu & Rostami 2024
- “DiM: Scaling Diffusion Mamba With Bidirectional SSMs for Efficient Image and Video Generation”, Mo & Tian 2024
- “Dynamic Typography: Bringing Text to Life via Video Diffusion Prior”, Liu et al 2024
- “Long-Form Music Generation With Latent Diffusion”, Evans et al 2024
- “VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time”, Xu et al 2024
- “ControlNet++: Improving Conditional Controls With Efficient Consistency Feedback”, Li et al 2024
- “Evaluating Text-To-Visual Generation With Image-To-Text Generation”, Lin et al 2024
- “Measuring Style Similarity in Diffusion Models”, Somepalli et al 2024
- “Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data”, Gerstgrasser et al 2024
- “TextCraftor: Your Text Encoder Can Be Image Quality Controller”, Li et al 2024
- “Improving Text-To-Image Consistency via Automatic Prompt Optimization”, Mañas et al 2024
- “SDXS: Real-Time One-Step Latent Diffusion Models With Image Conditions”, Song et al 2024
- “Stability AI Announcement”, Stability 2024
- “CMD: Efficient Video Diffusion Models via Content-Frame Motion-Latent Decomposition”, Yu et al 2024
- “ZigMa: Zigzag Mamba Diffusion Model”, Hu et al 2024
- “Atomically Accurate de Novo Design of Single-Domain Antibodies”, Bennett et al 2024
- “Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering”, Liu et al 2024
- “Sketch2Manga: Shaded Manga Screening from Sketch With Diffusion Models”, Lin et al 2024
- “ELLA: Equip Diffusion Models With LLM for Enhanced Semantic Alignment”, Hu et al 2024
- “Transparent Image Layer Diffusion Using Latent Transparency”, Zhang & Agrawala 2024
- “Neural Network Parameter Diffusion”, Wang et al 2024
- “CartoonizeDiff: Diffusion-Based Photo Cartoonization Scheme”, Jeon et al 2024
- “Discovering Universal Semantic Triggers for Text-To-Image Synthesis”, Zhai et al 2024
- “Annotated Hands for Generative Models”, Yang et al 2024
- “AnimeDiffusion: Anime Diffusion Colorization”, Cao et al 2024
- “Benchmarking Robustness of Multimodal Image-Text Models under Distribution Shift”, Qiu et al 2024
- “Fixed Point Diffusion Models”, Bai & Melas-Kyriazi 2024
- “Why a Chinese Court’s Landmark Decision Recognising the Copyright for an AI-Generated Image Benefits Creators in This Nascent Field”, Shen 2024
- “Bridging the Gap: Sketch to Color Diffusion Model With Semantic Prompt Learning”, Wang et al 2024
- “Applying Conditional Information in Guiding Diffusion-Based Method for Anime-Style Face Drawing”, Bảo 2024
- “FramePack Homepage”
- “GenCast: Diffusion-Based Ensemble Forecasting for Medium-Range Weather”, Price et al 2023
- “Training Stable Diffusion from Scratch Costs <$160k”, Stephenson & Seguin 2023
- “Generative AI Beyond LLMs: System Implications of Multi-Modal Generation”, Golden et al 2023
- “DreamTuner: Single Image Is Enough for Subject-Driven Generation”, Hua et al 2023
- “FontDiffuser: One-Shot Font Generation via Denoising Diffusion With Multi-Scale Content Aggregation and Style Contrastive Learning”, Yang et al 2023
- “Rich Human Feedback for Text-To-Image Generation”, Liang et al 2023
- “ECLIPSE: A Resource-Efficient Text-To-Image Prior for Image Generations”, Patel et al 2023
- “Self-Conditioned Image Generation via Generating Representations”, Li et al 2023
- “Diffusion Illusions: Hiding Images in Plain Sight”, Burgert et al 2023
- “Diffusion Illusions: Hiding Images in Plain Sight”, Burgert et al 2023
- “RyannDaGreat/Diffusion-Illusions: Diffusion Illusions: Hiding Images in Plain Sight”, Burgert et al 2023
- “Retrieving Conditions from Reference Images for Diffusion Models”, Tang et al 2023
- “Analyzing and Improving the Training Dynamics of Diffusion Models”, Karras et al 2023
- “DiffiT: Diffusion Vision Transformers for Image Generation”, Hatamizadeh et al 2023
- “Diffusion Models Without Attention”, Yan et al 2023
- “MicroCinema: A Divide-And-Conquer Approach for Text-To-Video Generation”, Wang et al 2023
- “AnyLens: A Generative Diffusion Model With Any Rendering Lens”, Voynov et al 2023
- “Visual Anagrams: Generating Multi-View Optical Illusions With Diffusion Models”, Geng et al 2023
- “Stability AI Explores Sale As Investor Urges CEO to Resign: Move Follows Letter from Investor Coatue Calling for Changes; Coatue Concerned about Stability AI’s Financial Position”, Bergen & Metz 2023
- “TextDiffuser-2: Unleashing the Power of Language Models for Text Rendering”, Chen et al 2023
- “MobileDiffusion: Subsecond Text-To-Image Generation on Mobile Devices”, Zhao et al 2023
- “Adversarial Diffusion Distillation”, Sauer et al 2023
- “Generative Models: What Do They Know? Do They Know Things? Let’s Find Out!”, Du et al 2023
- “Shadows Don’t Lie and Lines Can’t Bend! Generative Models Don’t Know Projective Geometry…for Now”, Sarkar et al 2023
- “Diffusion Illusions”, Burgert et al 2023
- “Test-Time Adaptation of Discriminative Models via Diffusion Generative Feedback”, Prabhudesai et al 2023
- “Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets”, Blattmann et al 2023
- “Diffusion Model Alignment Using Direct Preference Optimization”, Wallace et al 2023
- “Concept Sliders: LoRA Adaptors for Precise Control in Diffusion Models”, Gandikota et al 2023
- “Introducing NovelAI Diffusion Anime V3”, NovelAI 2023
- “UFOGen: You Forward Once Large Scale Text-To-Image Generation via Diffusion GANs”, Xu et al 2023
- “I2VGen-XL: High-Quality Image-To-Video Synthesis via Cascaded Diffusion Models”, Zhang et al 2023
- “AnyText: Multilingual Visual Text Generation And Editing”, Tuo et al 2023
- “Idempotent Generative Network”, Shocher et al 2023
- “Beyond U: Making Diffusion Models Faster & Lighter”, Calvo-Ordonez et al 2023
- “CADS: Unleashing the Diversity of Diffusion Models through Condition-Annealed Sampling”, Sadat et al 2023
- “CommonCanvas: An Open Diffusion Model Trained With Creative-Commons Images”, Gokaslan et al 2023
- “Nightshade: Prompt-Specific Poisoning Attacks on Text-To-Image Generative Models”, Shan et al 2023
- “Compositional Abilities Emerge Multiplicatively: Exploring Diffusion Models on a Synthetic Task”, Okawa et al 2023
- “Text Embeddings Reveal (Almost) As Much As Text”, Morris et al 2023
- “Generalization in Diffusion Models Arises from Geometry-Adaptive Harmonic Representation”, Kadkhodaie et al 2023
- “Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack”, Dai et al 2023
- “Maximum Diffusion Reinforcement Learning”, Berrueta et al 2023
- “Generating and Imputing Tabular Data via Diffusion and Flow-Based Gradient-Boosted Trees”, Jolicoeur-Martineau et al 2023
- “InstaFlow: One Step Is Enough for High-Quality Diffusion-Based Text-To-Image Generation”, Liu et al 2023
- “Generating Tabular Datasets under Differential Privacy”, Truda 2023
- “Anime Rock, Paper, Scissors 2”, Digital 2023
- “MetaDiff: Meta-Learning With Conditional Diffusion for Few-Shot Learning”, Zhang & Yu 2023
- “Provable Guarantees for Generative Behavior Cloning: Bridging Low-Level Stability and High-Level Behavior”, Block et al 2023
- “FABRIC: Personalizing Diffusion Models With Iterative Feedback”, Rütte et al 2023
- “Synthetic Lagrangian Turbulence by Generative Diffusion Models”, Li et al 2023
- “Diffusion Models Beat GANs on Image Classification”, Mukhopadhyay et al 2023
- “SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis”, Podell et al 2023
- “SDXL § Micro-Conditioning: Conditioning the Model on Image Size”, Podell et al 2023 (page 3 org stability)
- “DiffSketcher: Text Guided Vector Sketch Synthesis through Latent Diffusion Models”, Xing et al 2023
- “Fighting Uncertainty With Gradients: Offline Reinforcement Learning via Diffusion Score Matching”, Suh et al 2023
- “Semi-Implicit Denoising Diffusion Models (SIDDMs)”, Xu et al 2023
- “Evaluating the Robustness of Text-To-Image Diffusion Models against Real-World Attacks”, Gao et al 2023
- “StyleTTS 2: Towards Human-Level Text-To-Speech through Style Diffusion and Adversarial Training With Large Speech Language Models”, Li et al 2023
- “Beyond Surface Statistics: Scene Representations in a Latent Diffusion Model”, Chen et al 2023
- “Exposing Flaws of Generative Model Evaluation Metrics and Their Unfair Treatment of Diffusion Models”, Stein et al 2023
- “StyleDrop: Text-To-Image Generation in Any Style”, Sohn et al 2023
- “Artificial Intelligence and Art: Identifying the Esthetic Judgment Factors That Distinguish Human & Machine-Generated Artwork”, Samo & Highhouse 2023
- “Spontaneous Symmetry Breaking in Generative Diffusion Models”, Raya & Ambrogioni 2023
- “Tree-Ring Watermarks: Fingerprints for Diffusion Images That Are Invisible and Robust”, Wen et al 2023
- “UDPM: Upsampling Diffusion Probabilistic Models”, Abu-Hussein & Giryes 2023
- “Generalizable Synthetic Image Detection via Language-Guided Contrastive Learning”, Wu et al 2023
- “Common Diffusion Noise Schedules and Sample Steps Are Flawed”, Lin et al 2023
- “Diffusart: Enhancing Line Art Colorization With Conditional Diffusion Models”, Carrillo et al 2023
- “Continual Diffusion: Continual Customization of Text-To-Image Diffusion With C-LoRA”, Smith et al 2023
- “Reference-Based Image Composition With Sketch via Structure-Aware Diffusion Model”, Kim et al 2023
- “HyperDiffusion: Generating Implicit Neural Fields With Weight-Space Diffusion”, Erkoç et al 2023
- “Masked Diffusion Transformer Is a Strong Image Synthesizer”, Gao et al 2023
- “Prompting AI Art: An Investigation into the Creative Skill of Prompt Engineering”, Oppenlaender et al 2023
- “Animators React 11: Mulan, Aladdin, ‘Anime Rock Paper Scissors’”, Digital 2023
- “Animators React 11: Mulan, Aladdin, ‘Anime Rock Paper Scissors’”, Digital 2023
- “TRACT: Denoising Diffusion Models With Transitive Closure Time-Distillation”, Berthelot et al 2023
- “Consistency Models”, Song et al 2023
- “Understanding the Diffusion Objective As a Weighted Integral of ELBOs”, Kingma & Gao 2023
- “Anime Rock, Paper, Scissors”, Digital 2023
- “Did We Just Change Animation Forever? § Making Of”, Digital 2023
- “Unsupervised Discovery of Semantic Latent Directions in Diffusion Models”, Park et al 2023
- “Adding Conditional Control to Text-To-Image Diffusion Models”, Zhang et al 2023
- “Glaze: Protecting Artists from Style Mimicry by Text-To-Image Models”, Shan et al 2023
- “Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning and Discovery”, Wen et al 2023
- “Imitating Human Behavior With Diffusion Models”, Pearce et al 2023
- “Msanii: High Fidelity Music Synthesis on a Shoestring Budget”, Maina 2023
- “Archisound: Audio Generation With Diffusion”, Schneider 2023
- “DIRAC: Neural Image Compression With a Diffusion-Based Decoder”, Goose et al 2023
- “Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-To-Video Generation”, Wu et al 2022
- “Scalable Adaptive Computation for Iterative Generation”, Jabri et al 2022
- “Diffusion Transformers (DiTs): Scalable Diffusion Models With Transformers”, Peebles & Xie 2022
- “Point·E: A System for Generating 3D Point Clouds from Complex Prompts”, Nichol et al 2022
- “Broadly Applicable and Accurate Protein Design by Integrating Structure Prediction Networks and Diffusion Generative Models”, Watson et al 2022
- “The Stable Artist: Steering Semantics in Diffusion Latent Space”, Brack et al 2022
- “Multi-Concept Customization of Text-To-Image Diffusion”, Kumari et al 2022
- “Multi-Resolution Textual Inversion”, Daras & Dimakis 2022
- “Latent Video Diffusion Models for High-Fidelity Video Generation With Arbitrary Lengths”, He et al 2022
- “VectorFusion: Text-To-SVG by Abstracting Pixel-Based Diffusion Models”, Jain et al 2022
- “DreamArtist: Towards Controllable One-Shot Text-To-Image Generation via Contrastive Prompt-Tuning”, Dong et al 2022
- “DiffusionDet: Diffusion Model for Object Detection”, Chen et al 2022
- “Null-Text Inversion for Editing Real Images Using Guided Diffusion Models”, Mokady et al 2022
- “InstructPix2Pix: Learning to Follow Image Editing Instructions”, Brooks et al 2022
- “Versatile Diffusion: Text, Images and Variations All in One Diffusion Model”, Xu et al 2022
- “Rickrolling the Artist: Injecting Invisible Backdoors into Text-Guided Image Generation Models”, Struppek et al 2022
- “EDiff-I: Text-To-Image Diffusion Models With an Ensemble of Expert Denoisers”, Balaji et al 2022
- “DiffusionDB: A Large-Scale Prompt Gallery Dataset for Text-To-Image Generative Models”, Wang et al 2022
- “Imagic: Text-Based Real Image Editing With Diffusion Models”, Kawar et al 2022
- “Hierarchical Diffusion Models for Singing Voice Neural Vocoder”, Takahashi et al 2022
- “Flow Matching for Generative Modeling”, Lipman et al 2022
- “On Distillation of Guided Diffusion Models”, Meng et al 2022
- “Improving Sample Quality of Diffusion Models Using Self-Attention Guidance”, Hong et al 2022
- “Rectified Flow: A Marginal Preserving Approach to Optimal Transport”, Liu 2022
- “DreamFusion: Text-To-3D Using 2D Diffusion”, Poole et al 2022
- “RealSinger: Ultra-Realistic Singing Voice Generation via Stochastic Differential Equations”, Anonymous 2022
- “
g.pt: Learning to Learn With Generative Models of Neural Network Checkpoints”, Peebles et al 2022 - “PFGM: Poisson Flow Generative Models”, Xu et al 2022
- “This Artist Is Dominating AI-Generated Art. And He’s Not Happy about It. Greg Rutkowski Is a More Popular Prompt Than Picasso”, Heikkilä 2022
- “Brain Imaging Generation With Latent Diffusion Models”, Pinaya et al 2022
- “Soft Diffusion: Score Matching for General Corruptions”, Daras et al 2022
- “Flow Straight and Fast: Learning to Generate and Transfer Data With Rectified Flow”, Liu et al 2022
- “Frido: Feature Pyramid Diffusion for Complex Scene Image Synthesis”, Fan et al 2022
- “Understanding Diffusion Models: A Unified Perspective”, Luo 2022
- “Cold Diffusion: Inverting Arbitrary Image Transforms Without Noise”, Bansal et al 2022
- “Diffusion-QL: Diffusion Policies As an Expressive Policy Class for Offline Reinforcement Learning”, Wang et al 2022
- “An Image Is Worth One Word: Personalizing Text-To-Image Generation Using Textual Inversion”, Gal et al 2022
- “Text-Guided Synthesis of Artistic Images With Retrieval-Augmented Diffusion Models”, Rombach et al 2022
- “NUWA-∞: Autoregressive over Autoregressive Generation for Infinite Visual Synthesis”, Wu et al 2022
- “IHDM: Generative Modeling With Inverse Heat Dissipation”, Rissanen et al 2022
- “DiffC: Lossy Compression With Gaussian Diffusion”, Theis et al 2022
- “Diffusion-GAN: Training GANs With Diffusion”, Wang et al 2022
- “Compositional Visual Generation With Composable Diffusion Models”, Liu et al 2022
- “DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps”, Lu et al 2022
- “Score-Based Generative Models Detect Manifolds”, Pidstrigach 2022
- “Elucidating the Design Space of Diffusion-Based Generative Models”, Karras et al 2022
- “Text2Human: Text-Driven Controllable Human Image Generation”, Jiang et al 2022
- “Improved Vector Quantized Diffusion Models”, Tang et al 2022
- “Maximum Likelihood Training of Implicit Nonlinear Diffusion Models”, Kim et al 2022
- “Flexible Diffusion Modeling of Long Videos”, Harvey et al 2022
- “Planning With Diffusion for Flexible Behavior Synthesis”, Janner et al 2022
- “Diffusion Models for Adversarial Purification”, Nie et al 2022
- “Retrieval-Augmented Diffusion Models: Semi-Parametric Neural Image Synthesis”, Blattmann et al 2022
- “Video Diffusion Models”, Ho et al 2022
- “KNN-Diffusion: Image Generation via Large-Scale Retrieval”, Ashual et al 2022
- “Perception Prioritized Training of Diffusion Models”, Choi et al 2022
- “Diffusion Probabilistic Modeling for Video Generation”, Yang et al 2022
- “Diffusion Causal Models for Counterfactual Estimation”, Sanchez & Tsaftaris 2022
- “Truncated Diffusion Probabilistic Models and Diffusion-Based Adversarial Autoencoders”, Zheng et al 2022
- “Learning Fast Samplers for Diffusion Models by Differentiating Through Sample Quality”, Watson et al 2022
- “From Data to Functa: Your Data Point Is a Function and You Should Treat It like One”, Dupont et al 2022
- “Denoising Diffusion Restoration Models”, Kawar et al 2022
- “DiffuseVAE: Efficient, Controllable and High-Fidelity Generation from Low-Dimensional Latents”, Pandey et al 2022
- “Itô-Taylor Sampling Scheme for Denoising Diffusion Probabilistic Models Using Ideal Derivatives”, Tachibana et al 2021
- “High-Resolution Image Synthesis With Latent Diffusion Models”, Rombach et al 2021
- “High Fidelity Visualization of What Your Self-Supervised Representation Knows About”, Bordes et al 2021
- “More Control for Free! Image Synthesis With Semantic Diffusion Guidance”, Liu et al 2021
- “Come-Closer-Diffuse-Faster: Accelerating Conditional Diffusion Models for Inverse Problems through Stochastic Contraction”, Chung et al 2021
- “VQ-DDM: Global Context With Discrete Diffusion in Vector Quantized Modeling for Image Generation”, Hu et al 2021
- “Diffusion Autoencoders: Toward a Meaningful and Decodable Representation”, Preechakul et al 2021
- “Blended Diffusion for Text-Driven Editing of Natural Images”, Avrahami et al 2021
- “Vector Quantized Diffusion Model for Text-To-Image Synthesis”, Gu et al 2021
- “Classifier-Free Diffusion Guidance”, Ho & Salimans 2021
- “Unleashing Transformers: Parallel Token Prediction With Discrete Absorbing Diffusion for Fast High-Resolution Image Generation from Vector-Quantized Codes”, Bond-Taylor et al 2021
- “Restormer: Efficient Transformer for High-Resolution Image Restoration”, Zamir et al 2021
- “Tackling the Generative Learning Trilemma With Denoising Diffusion GANs”, Xiao et al 2021
- “Diffusion Normalizing Flow”, Zhang & Chen 2021
- “Palette: Image-To-Image Diffusion Models”, Saharia et al 2021
- “Progressive Distillation for Fast Sampling of Diffusion Models”, Salimans & Ho 2021
- “DiffusionCLIP: Text-Guided Image Manipulation Using Diffusion Models”, Kim & Ye 2021
- “Unconditional Diffusion Guidance”, Ho & Salimans 2021
- “Generative Probabilistic Image Colorization”, Furusawa et al 2021
- “Bilateral Denoising Diffusion Models”, Lam et al 2021
- “ImageBART: Bidirectional Context With Multinomial Diffusion for Autoregressive Image Synthesis”, Esser et al 2021
- “Variational Diffusion Models”, Kingma et al 2021
- “LoRA: Low-Rank Adaptation of Large Language Models”, Hu et al 2021
- “PriorGrad: Improving Conditional Denoising Diffusion Models With Data-Dependent Adaptive Prior”, Lee et al 2021
- “Score-Based Generative Modeling in Latent Space”, Vahdat et al 2021
- “CDM: Cascaded Diffusion Models for High Fidelity Image Generation”, Ho et al 2021
- “Learning to Efficiently Sample from Diffusion Probabilistic Models”, Watson et al 2021
- “Gotta Go Fast When Generating Data With Score-Based Models”, Jolicoeur-Martineau et al 2021
- “Diffusion Models Beat GANs on Image Synthesis”, Dhariwal & Nichol 2021
- “DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism”, Liu et al 2021
- “Image Super-Resolution via Iterative Refinement”, Saharia et al 2021
- “Learning Energy-Based Models by Diffusion Recovery Likelihood”, Gao et al 2021
- “Improved Denoising Diffusion Probabilistic Models”, Nichol & Dhariwal 2021
- “Denoising Diffusion Implicit Models”, Song et al 2021
- “Maximum Likelihood Training of Score-Based Diffusion Models”, Song et al 2021
- “Score-Based Generative Modeling through Stochastic Differential Equations”, Song et al 2020
- “Denoising Diffusion Probabilistic Models”, Ho et al 2020
- “NoGAN: Decrappification, DeOldification, and Super Resolution”, Antic et al 2019
- “Conceptual Captions: A Cleaned, Hypernymed, Image Alt-Text Dataset For Automatic Image Captioning”, Sharma et al 2018
- “Improving Sampling from Generative Autoencoders With Markov Chains”, Creswell et al 2016
- “Deep Unsupervised Learning Using Nonequilibrium Thermodynamics”, Sohl-Dickstein et al 2015
- “A Connection Between Score Matching and Denoising Autoencoders”, Vincent 2011
- “Optimal Approximation of Signal Priors”, Hyvarinen 2008
- “Estimation of Non-Normalized Statistical Models by Score Matching”, Hyvarinen 2005
- “The AI Art Apocalypse”
- “Towards Pony Diffusion V7, Going With the Flow.”, AstraliteHeart 2026
- “QR Code Monster SDXL—V1.0 [Stable Diffusion XL Controlnet]”
- “Image Synthesis Style Studies Database (The List)”
- “AnimeDL-2M: Million-Scale AI-Generated Anime Image Detection and Localization in Diffusion Era”
- “AIGText/Glyph-ByT5: [ECCV2024] This Is an Official Inference Code”, Liu et al 2026
- “Negative Prompt”
- “Combination of OpenAI GLIDE and Latent Diffusion”
- “KaliYuga-Ai/Textile-Diffusion”
- “V Objective Diffusion Inference Code for PyTorch”
- “High-Resolution Image Synthesis With Latent Diffusion Models”
- “Neonbjb/tortoise-Tts: A Multi-Voice TTS System Trained With an Emphasis on Quality”
- “Code for Reproducing Results ‘Glow: Generative Flow With Invertible 1×1 Convolutions’”
- “Openai/guided-Diffusion”
- “The Annotated Diffusion Model”
- “Ideogram Homepage”, Ideogram 2026
- “PaintsUndo: A Base Model of Drawing Behaviors in Digital Paintings”
- “Keypoint Based Anime Generation With Additional CLIP Guided Tuning”
- “Rethinking The Danbooru 2021 Dataset”
- “A Closer Look Into The Latent-Diffusion Repo, Do Better Than Just Looking”
- “Model Comparison Study for Disco Diffusion v. 5”
- “Model Comparison Study for Disco Diffusion v. 5---PLMS Sampling Edition”
- “Flexible Diffusion Modeling of Long Videos”
- “Guidance: a Cheat Code for Diffusion Models”
- “Stability AI CEO Resigns Because You Can’t Beat Centralized AI With More Centralized AI”
- “Z-Image—Efficient Image Generation With Single-Stream Diffusion”
- “ControlNet Game of Life”
- “Case Study: Interpreting, Manipulating, and Controlling CLIP With Sparse Autoencoders”
- “The AI Animal Letters of the Alphabet”
- “Generative Modeling by Estimating Gradients of the Data Distribution”
- Sort By Magic
- Wikipedia (7)
- Miscellaneous
- Bibliography
See Also
Gwern
“Research Ideas”, Gwern 2017
Links
“Anime-2026: A Large-Scale Anime Character Dataset for Anime-Related AI Tasks”, Xuyang et al 2026
Anime-2026: A Large-scale Anime Character Dataset for Anime-related AI Tasks
“Learnings from Paying Artists Royalties for AI-Generated Art: A Retrospective on Tess.Design, Our Attempt to Make an Ethical, Artist-Friendly AI Marketplace. We Launched Tess in May 2024 and Shut It down in January 2026”, Enthoven 2026
“The 1 Million Dollar RPG Maps Bundle Scam”, Botter 2026
“Autonomous Language-Image Generation Loops Converge to Generic Visual Motifs [SDXL ↔ LLaVA]”, Hintze et al 2025
Autonomous language-image generation loops converge to generic visual motifs [SDXL ↔ LLaVA]
“TreeGRPO: Tree-Advantage GRPO for Online RL Post-Training of Diffusion Models”, Ding & Ye 2025
TreeGRPO: Tree-Advantage GRPO for Online RL Post-Training of Diffusion Models
“Foundations of Diffusion Models in General State Spaces: A Self-Contained Introduction”, Pauline et al 2025
Foundations of Diffusion Models in General State Spaces: A Self-Contained Introduction
“Z-Image: An Efficient Image Generation Foundation Model With Single-Stream Diffusion Transformer”, Team et al 2025
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
“Wan 2.2 Human Image Generation Is Very Good. This Open Model Has a Great Future.Workflow Included [Video Generation → Image Generation]”, yomasexbomb 2025
“Lost in Latent Space: An Empirical Study of Latent Diffusion Models for Physics Emulation”, Rozet et al 2025
Lost in Latent Space: An Empirical Study of Latent Diffusion Models for Physics Emulation
“Generative Thermodynamic Computing”, Whitelam 2025
“SSIMBaD: Sigma Scaling With SSIM-Guided Balanced Diffusion for AnimeFace Colorization”, Seo et al 2025
SSIMBaD: Sigma Scaling with SSIM-Guided Balanced Diffusion for AnimeFace Colorization
“Instance-Guided Anime Editing With a Curated Large-Scale Dataset”, Lin et al 2025
Instance-guided anime editing with a curated large-scale dataset
“Gen2seg: Generative Models Enable Generalizable Instance Segmentation”, Khangaonkar & Pirsiavash 2025
gen2seg: Generative Models Enable Generalizable Instance Segmentation
“FramePack: Packing Input Frame Context in Next-Frame Prediction Models for Video Generation”, Zhang & Agrawala 2025
FramePack: Packing Input Frame Context in Next-Frame Prediction Models for Video Generation
“AnimeDL-2M: Million-Scale AI-Generated Anime Image Detection and Localization in Diffusion Era”, Zhu et al 2025
AnimeDL-2M: Million-Scale AI-Generated Anime Image Detection and Localization in Diffusion Era
“Generative Modeling in Latent Space [Why VAEs Etc. Work]”, Dieleman 2025
“GenEAva: Generating Cartoon Avatars With Fine-Grained Facial Expressions from Realistic Diffusion-Based Faces”, Yu et al 2025
“ColorizeDiffusion V2: Enhancing Reference-Based Sketch Colorization Through Separating Utilities”, Yan et al 2025
ColorizeDiffusion v2: Enhancing Reference-based Sketch Colorization Through Separating Utilities
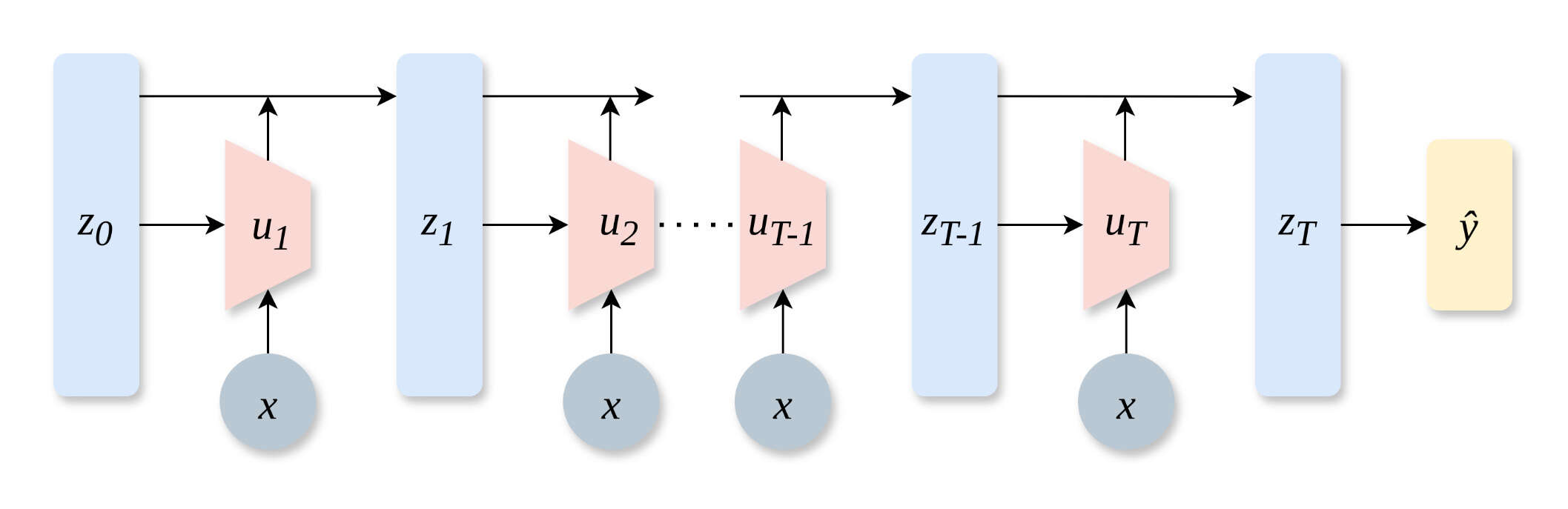
“NoProp: Training Neural Networks without Backpropagation or Forward-Propagation”, Li et al 2025
NoProp: Training Neural Networks without backpropagation or Forward-propagation
“Image Referenced Sketch Colorization Based on Animation Creation Workflow”, Yan et al 2025
Image Referenced Sketch Colorization Based on Animation Creation Workflow
“ColorizeDiffusion: Improving Reference-Based Sketch Colorization With Latent Diffusion Model”, Yan et al 2025
ColorizeDiffusion: Improving Reference-Based Sketch Colorization with Latent Diffusion Model
“Step-Video-T2V Technical Report: The Practice, Challenges, and Future of Video Foundation Model”, Ma et al 2025
Step-Video-T2V Technical Report: The Practice, Challenges, and Future of Video Foundation Model
“InstaNovo Enables Diffusion-Powered de Novo Peptide Sequencing in Large-Scale Proteomics Experiments”, Eloff et al 2025
InstaNovo enables diffusion-powered de novo peptide sequencing in large-scale proteomics experiments
“Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps”, Ma et al 2025
Inference-Time Scaling for Diffusion Models beyond Scaling Denoising Steps
“MangaNinja: Line Art Colorization With Precise Reference Following”, Liu et al 2025
MangaNinja: Line Art Colorization with Precise Reference Following
“Do Generative Video Models Learn Physical Principles from Watching Videos?”, Motamed et al 2025
Do generative video models learn physical principles from watching videos?
“An Analytic Theory of Creativity in Convolutional Diffusion Models”, Kamb & Ganguli 2024
An analytic theory of creativity in convolutional diffusion models
“Exploring Denoising Diffusion Models for Realistic Anime Character Generation”, Kumari & Bhadoria 2024
Exploring Denoising Diffusion Models for Realistic Anime Character Generation
“AniDoc: Animation Creation Made Easier”, Meng et al 2024
“AniSora: Exploring the Frontiers of Animation Video Generation in the Sora Era”, Jiang et al 2024
AniSora: Exploring the Frontiers of Animation Video Generation in the Sora Era
“Proactive Agents for Multi-Turn Text-To-Image Generation Under Uncertainty”, Hahn et al 2024
Proactive Agents for Multi-Turn Text-to-Image Generation Under Uncertainty
“Probabilistic Weather Forecasting With Machine Learning”, Price et al 2024
“Art-Free Generative Models: Art Creation Without Graphic Art Knowledge”, Ren et al 2024
Art-Free Generative Models: Art Creation Without Graphic Art Knowledge
“Revisiting Your Memory: Reconstruction of Affect-Contextualized Memory via EEG-Guided Audiovisual Generation”, Kwon et al 2024
“How Far Is Video Generation from World Model: A Physical Law Perspective”, Kang et al 2024
How Far is Video Generation from World Model: A Physical Law Perspective
“Data Scaling Laws in Imitation Learning for Robotic Manipulation”, Lin et al 2024
Data Scaling Laws in Imitation Learning for Robotic Manipulation
“One Step Diffusion via Shortcut Models”, Frans et al 2024
“SANA: Efficient High-Resolution Image Synthesis With Linear Diffusion Transformers”, Xie et al 2024
SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
“Denoising With a Joint-Embedding Predictive Architecture”, Chen et al 2024
“Copying Style, Extracting Value: Illustrators’ Perception of AI Style Transfer and Its Impact on Creative Labor”, Porquet et al 2024
“Improvements to SDXL in NovelAI Diffusion V3”, Ossa et al 2024
“[Taylor Swift Endorses Kamala Harris due to Deepfakes]”, Swift 2024
“Diffusion Is Spectral Autoregression”, Dieleman 2024
“My Dead Father Is ‘Writing’ Me Notes Again”
“Computational Design of Serine Hydrolases”, Lauko et al 2024
“The Rise of Terminator Zero With Writer Mattson Tomlin & Director Masashi Kudo”, Baron 2024
The Rise of Terminator Zero with Writer Mattson Tomlin & Director Masashi Kudo
“NovelAI Diffusion V1 Weights Release”, NovelAI 2024
“Transfusion: Predict the Next Token and Diffuse Images With One Multi-Modal Model”, Zhou et al 2024
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
“Stretching Each Dollar: Diffusion Training from Scratch on a Micro-Budget”, Sehwag et al 2024
Stretching Each Dollar: Diffusion Training from Scratch on a Micro-Budget
“Diffusion Forcing: Next-Token Prediction Meets Full-Sequence Diffusion”, Chen et al 2024
Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion
“4lph4bet_processor: This Script Processes a Grid Image Generated With the 4lph4bet Family of LoRAs for Stable Diffusion 1.5 for Font Creation Using Calligraphr”, 414design 2024
“MAR: Autoregressive Image Generation without Vector Quantization”, Li et al 2024
MAR: Autoregressive Image Generation without Vector Quantization
“Adversarial Perturbations Cannot Reliably Protect Artists From Generative AI”, Hönig et al 2024
Adversarial Perturbations Cannot Reliably Protect Artists From Generative AI
“Glyph-ByT5-V2: A Strong Aesthetic Baseline for Accurate Multilingual Visual Text Rendering”, Liu et al 2024
Glyph-ByT5-v2: A Strong Aesthetic Baseline for Accurate Multilingual Visual Text Rendering
“Consistency-Diversity-Realism Pareto Fronts of Conditional Image Generative Models”, Astolfi et al 2024
Consistency-diversity-realism Pareto fronts of conditional image generative models
“Interpreting the Weight Space of Customized Diffusion Models”, Dravid et al 2024
Interpreting the Weight Space of Customized Diffusion Models
“SF-V: Single Forward Video Generation Model”, Zhang et al 2024
“Diffusion On Syntax Trees For Program Synthesis”, Kapur et al 2024
“ToonCrafter: Generative Cartoon Interpolation”, Xing et al 2024
“Lateralization MLP: A Simple Brain-Inspired Architecture for Diffusion”, Hu & Rostami 2024
Lateralization MLP: A Simple Brain-inspired Architecture for Diffusion
“DiM: Scaling Diffusion Mamba With Bidirectional SSMs for Efficient Image and Video Generation”, Mo & Tian 2024
DiM: Scaling Diffusion Mamba with Bidirectional SSMs for Efficient Image and Video Generation
“Dynamic Typography: Bringing Text to Life via Video Diffusion Prior”, Liu et al 2024
Dynamic Typography: Bringing Text to Life via Video Diffusion Prior
“Long-Form Music Generation With Latent Diffusion”, Evans et al 2024
“VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time”, Xu et al 2024
VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time
“ControlNet++: Improving Conditional Controls With Efficient Consistency Feedback”, Li et al 2024
ControlNet++: Improving Conditional Controls with Efficient Consistency Feedback
“Evaluating Text-To-Visual Generation With Image-To-Text Generation”, Lin et al 2024
Evaluating Text-to-Visual Generation with Image-to-Text Generation
“Measuring Style Similarity in Diffusion Models”, Somepalli et al 2024
“Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data”, Gerstgrasser et al 2024
“TextCraftor: Your Text Encoder Can Be Image Quality Controller”, Li et al 2024
TextCraftor: Your Text Encoder Can be Image Quality Controller
“Improving Text-To-Image Consistency via Automatic Prompt Optimization”, Mañas et al 2024
Improving Text-to-Image Consistency via Automatic Prompt Optimization
“SDXS: Real-Time One-Step Latent Diffusion Models With Image Conditions”, Song et al 2024
SDXS: Real-Time One-Step Latent Diffusion Models with Image Conditions
“Stability AI Announcement”, Stability 2024
“CMD: Efficient Video Diffusion Models via Content-Frame Motion-Latent Decomposition”, Yu et al 2024
CMD: Efficient Video Diffusion Models via Content-Frame Motion-Latent Decomposition
“ZigMa: Zigzag Mamba Diffusion Model”, Hu et al 2024
“Atomically Accurate de Novo Design of Single-Domain Antibodies”, Bennett et al 2024
Atomically accurate de novo design of single-domain antibodies
“Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering”, Liu et al 2024
Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering
“Sketch2Manga: Shaded Manga Screening from Sketch With Diffusion Models”, Lin et al 2024
Sketch2Manga: Shaded Manga Screening from Sketch with Diffusion Models
“ELLA: Equip Diffusion Models With LLM for Enhanced Semantic Alignment”, Hu et al 2024
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
“Transparent Image Layer Diffusion Using Latent Transparency”, Zhang & Agrawala 2024
“Neural Network Parameter Diffusion”, Wang et al 2024
“CartoonizeDiff: Diffusion-Based Photo Cartoonization Scheme”, Jeon et al 2024
“Discovering Universal Semantic Triggers for Text-To-Image Synthesis”, Zhai et al 2024
Discovering Universal Semantic Triggers for Text-to-Image Synthesis
“Annotated Hands for Generative Models”, Yang et al 2024
“AnimeDiffusion: Anime Diffusion Colorization”, Cao et al 2024
“Benchmarking Robustness of Multimodal Image-Text Models under Distribution Shift”, Qiu et al 2024
Benchmarking Robustness of Multimodal Image-Text Models under Distribution Shift
“Fixed Point Diffusion Models”, Bai & Melas-Kyriazi 2024
“Why a Chinese Court’s Landmark Decision Recognising the Copyright for an AI-Generated Image Benefits Creators in This Nascent Field”, Shen 2024
“Bridging the Gap: Sketch to Color Diffusion Model With Semantic Prompt Learning”, Wang et al 2024
Bridging the Gap: Sketch to Color Diffusion Model with Semantic Prompt Learning
“Applying Conditional Information in Guiding Diffusion-Based Method for Anime-Style Face Drawing”, Bảo 2024
Applying Conditional Information in Guiding Diffusion-Based method for Anime-Style Face Drawing
“FramePack Homepage”
View External Link:
“GenCast: Diffusion-Based Ensemble Forecasting for Medium-Range Weather”, Price et al 2023
GenCast: Diffusion-based ensemble forecasting for medium-range weather
“Training Stable Diffusion from Scratch Costs <$160k”, Stephenson & Seguin 2023
“Generative AI Beyond LLMs: System Implications of Multi-Modal Generation”, Golden et al 2023
Generative AI Beyond LLMs: System Implications of Multi-Modal Generation
“DreamTuner: Single Image Is Enough for Subject-Driven Generation”, Hua et al 2023
DreamTuner: Single Image is Enough for Subject-Driven Generation
“FontDiffuser: One-Shot Font Generation via Denoising Diffusion With Multi-Scale Content Aggregation and Style Contrastive Learning”, Yang et al 2023
“Rich Human Feedback for Text-To-Image Generation”, Liang et al 2023
“ECLIPSE: A Resource-Efficient Text-To-Image Prior for Image Generations”, Patel et al 2023
ECLIPSE: A Resource-Efficient Text-to-Image Prior for Image Generations
“Self-Conditioned Image Generation via Generating Representations”, Li et al 2023
Self-conditioned Image Generation via Generating Representations
“Diffusion Illusions: Hiding Images in Plain Sight”, Burgert et al 2023
“Diffusion Illusions: Hiding Images in Plain Sight”, Burgert et al 2023
“RyannDaGreat/Diffusion-Illusions: Diffusion Illusions: Hiding Images in Plain Sight”, Burgert et al 2023
RyannDaGreat/Diffusion-Illusions: Diffusion Illusions: Hiding Images in Plain Sight
“Retrieving Conditions from Reference Images for Diffusion Models”, Tang et al 2023
Retrieving Conditions from Reference Images for Diffusion Models
“Analyzing and Improving the Training Dynamics of Diffusion Models”, Karras et al 2023
Analyzing and Improving the Training Dynamics of Diffusion Models
“DiffiT: Diffusion Vision Transformers for Image Generation”, Hatamizadeh et al 2023
“Diffusion Models Without Attention”, Yan et al 2023
“MicroCinema: A Divide-And-Conquer Approach for Text-To-Video Generation”, Wang et al 2023
MicroCinema: A Divide-and-Conquer Approach for Text-to-Video Generation
“AnyLens: A Generative Diffusion Model With Any Rendering Lens”, Voynov et al 2023
AnyLens: A Generative Diffusion Model with Any Rendering Lens
“Visual Anagrams: Generating Multi-View Optical Illusions With Diffusion Models”, Geng et al 2023
Visual Anagrams: Generating Multi-View Optical Illusions with Diffusion Models
“Stability AI Explores Sale As Investor Urges CEO to Resign: Move Follows Letter from Investor Coatue Calling for Changes; Coatue Concerned about Stability AI’s Financial Position”, Bergen & Metz 2023
“TextDiffuser-2: Unleashing the Power of Language Models for Text Rendering”, Chen et al 2023
TextDiffuser-2: Unleashing the Power of Language Models for Text Rendering
“MobileDiffusion: Subsecond Text-To-Image Generation on Mobile Devices”, Zhao et al 2023
MobileDiffusion: Subsecond Text-to-Image Generation on Mobile Devices
“Adversarial Diffusion Distillation”, Sauer et al 2023
“Generative Models: What Do They Know? Do They Know Things? Let’s Find Out!”, Du et al 2023
Generative Models: What do they know? Do they know things? Let’s find out!
“Shadows Don’t Lie and Lines Can’t Bend! Generative Models Don’t Know Projective Geometry…for Now”, Sarkar et al 2023
Shadows Don’t Lie and Lines Can’t Bend! Generative Models don’t know Projective Geometry…for now
“Diffusion Illusions”, Burgert et al 2023
“Test-Time Adaptation of Discriminative Models via Diffusion Generative Feedback”, Prabhudesai et al 2023
Test-time Adaptation of Discriminative Models via Diffusion Generative Feedback
“Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets”, Blattmann et al 2023
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
“Diffusion Model Alignment Using Direct Preference Optimization”, Wallace et al 2023
Diffusion Model Alignment Using Direct Preference Optimization
“Concept Sliders: LoRA Adaptors for Precise Control in Diffusion Models”, Gandikota et al 2023
Concept Sliders: LoRA Adaptors for Precise Control in Diffusion Models
“Introducing NovelAI Diffusion Anime V3”, NovelAI 2023
“UFOGen: You Forward Once Large Scale Text-To-Image Generation via Diffusion GANs”, Xu et al 2023
UFOGen: You Forward Once Large Scale Text-to-Image Generation via Diffusion GANs
“I2VGen-XL: High-Quality Image-To-Video Synthesis via Cascaded Diffusion Models”, Zhang et al 2023
I2VGen-XL: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models
“AnyText: Multilingual Visual Text Generation And Editing”, Tuo et al 2023
“Idempotent Generative Network”, Shocher et al 2023
“Beyond U: Making Diffusion Models Faster & Lighter”, Calvo-Ordonez et al 2023
“CADS: Unleashing the Diversity of Diffusion Models through Condition-Annealed Sampling”, Sadat et al 2023
CADS: Unleashing the Diversity of Diffusion Models through Condition-Annealed Sampling
“CommonCanvas: An Open Diffusion Model Trained With Creative-Commons Images”, Gokaslan et al 2023
CommonCanvas: An Open Diffusion Model Trained with Creative-Commons Images
“Nightshade: Prompt-Specific Poisoning Attacks on Text-To-Image Generative Models”, Shan et al 2023
Nightshade: Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models
“Compositional Abilities Emerge Multiplicatively: Exploring Diffusion Models on a Synthetic Task”, Okawa et al 2023
Compositional Abilities Emerge Multiplicatively: Exploring Diffusion Models on a Synthetic Task
“Text Embeddings Reveal (Almost) As Much As Text”, Morris et al 2023
“Generalization in Diffusion Models Arises from Geometry-Adaptive Harmonic Representation”, Kadkhodaie et al 2023
Generalization in diffusion models arises from geometry-adaptive harmonic representation
“Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack”, Dai et al 2023
Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack
“Maximum Diffusion Reinforcement Learning”, Berrueta et al 2023
“Generating and Imputing Tabular Data via Diffusion and Flow-Based Gradient-Boosted Trees”, Jolicoeur-Martineau et al 2023
Generating and Imputing Tabular Data via Diffusion and Flow-based Gradient-Boosted Trees
“InstaFlow: One Step Is Enough for High-Quality Diffusion-Based Text-To-Image Generation”, Liu et al 2023
InstaFlow: One Step is Enough for High-Quality Diffusion-Based Text-to-Image Generation
“Generating Tabular Datasets under Differential Privacy”, Truda 2023
“Anime Rock, Paper, Scissors 2”, Digital 2023
“MetaDiff: Meta-Learning With Conditional Diffusion for Few-Shot Learning”, Zhang & Yu 2023
MetaDiff: Meta-Learning with Conditional Diffusion for Few-Shot Learning
“Provable Guarantees for Generative Behavior Cloning: Bridging Low-Level Stability and High-Level Behavior”, Block et al 2023
“FABRIC: Personalizing Diffusion Models With Iterative Feedback”, Rütte et al 2023
FABRIC: Personalizing Diffusion Models with Iterative Feedback
“Synthetic Lagrangian Turbulence by Generative Diffusion Models”, Li et al 2023
Synthetic Lagrangian Turbulence by Generative Diffusion Models
“Diffusion Models Beat GANs on Image Classification”, Mukhopadhyay et al 2023
“SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis”, Podell et al 2023
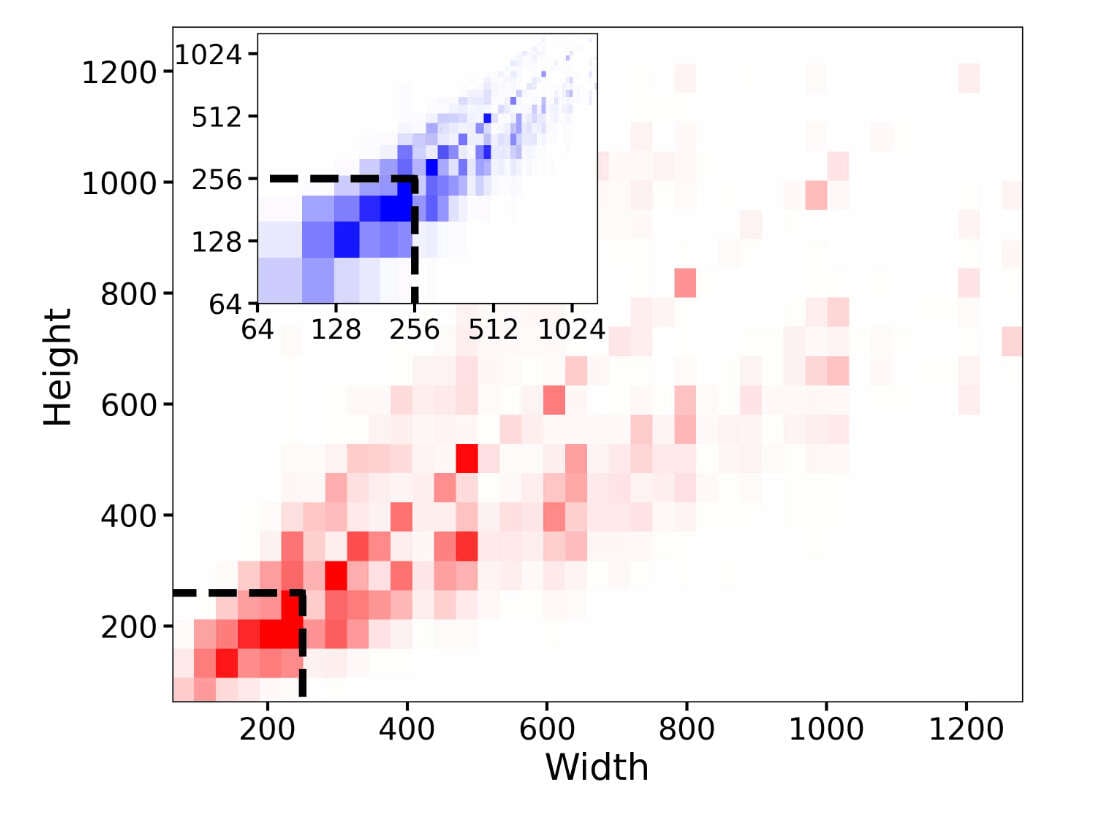
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
“SDXL § Micro-Conditioning: Conditioning the Model on Image Size”, Podell et al 2023 (page 3 org stability)
SDXL § Micro-Conditioning: Conditioning the Model on Image Size
“DiffSketcher: Text Guided Vector Sketch Synthesis through Latent Diffusion Models”, Xing et al 2023
DiffSketcher: Text Guided Vector Sketch Synthesis through Latent Diffusion Models
“Fighting Uncertainty With Gradients: Offline Reinforcement Learning via Diffusion Score Matching”, Suh et al 2023
Fighting Uncertainty with Gradients: Offline Reinforcement Learning via Diffusion Score Matching
“Semi-Implicit Denoising Diffusion Models (SIDDMs)”, Xu et al 2023
“Evaluating the Robustness of Text-To-Image Diffusion Models against Real-World Attacks”, Gao et al 2023
Evaluating the Robustness of Text-to-image Diffusion Models against Real-world Attacks
“StyleTTS 2: Towards Human-Level Text-To-Speech through Style Diffusion and Adversarial Training With Large Speech Language Models”, Li et al 2023
“Beyond Surface Statistics: Scene Representations in a Latent Diffusion Model”, Chen et al 2023
Beyond Surface Statistics: Scene Representations in a Latent Diffusion Model
“Exposing Flaws of Generative Model Evaluation Metrics and Their Unfair Treatment of Diffusion Models”, Stein et al 2023
Exposing flaws of generative model evaluation metrics and their unfair treatment of diffusion models
“StyleDrop: Text-To-Image Generation in Any Style”, Sohn et al 2023
“Artificial Intelligence and Art: Identifying the Esthetic Judgment Factors That Distinguish Human & Machine-Generated Artwork”, Samo & Highhouse 2023
“Spontaneous Symmetry Breaking in Generative Diffusion Models”, Raya & Ambrogioni 2023
Spontaneous symmetry breaking in generative diffusion models
“Tree-Ring Watermarks: Fingerprints for Diffusion Images That Are Invisible and Robust”, Wen et al 2023
Tree-Ring Watermarks: Fingerprints for Diffusion Images that are Invisible and Robust
“UDPM: Upsampling Diffusion Probabilistic Models”, Abu-Hussein & Giryes 2023
“Generalizable Synthetic Image Detection via Language-Guided Contrastive Learning”, Wu et al 2023
Generalizable Synthetic Image Detection via Language-guided Contrastive Learning
“Common Diffusion Noise Schedules and Sample Steps Are Flawed”, Lin et al 2023
Common Diffusion Noise Schedules and Sample Steps are Flawed
“Diffusart: Enhancing Line Art Colorization With Conditional Diffusion Models”, Carrillo et al 2023
Diffusart: Enhancing Line Art Colorization with Conditional Diffusion Models
“Continual Diffusion: Continual Customization of Text-To-Image Diffusion With C-LoRA”, Smith et al 2023
Continual Diffusion: Continual Customization of Text-to-Image Diffusion with C-LoRA
“Reference-Based Image Composition With Sketch via Structure-Aware Diffusion Model”, Kim et al 2023
Reference-based Image Composition with Sketch via Structure-aware Diffusion Model
“HyperDiffusion: Generating Implicit Neural Fields With Weight-Space Diffusion”, Erkoç et al 2023
HyperDiffusion: Generating Implicit Neural Fields with Weight-Space Diffusion
“Masked Diffusion Transformer Is a Strong Image Synthesizer”, Gao et al 2023
“Prompting AI Art: An Investigation into the Creative Skill of Prompt Engineering”, Oppenlaender et al 2023
Prompting AI Art: An Investigation into the Creative Skill of Prompt Engineering
“Animators React 11: Mulan, Aladdin, ‘Anime Rock Paper Scissors’”, Digital 2023
Animators React 11: Mulan, Aladdin, ‘Anime Rock Paper Scissors’
“Animators React 11: Mulan, Aladdin, ‘Anime Rock Paper Scissors’”, Digital 2023
Animators React 11: Mulan, Aladdin, ‘Anime Rock Paper Scissors’
“TRACT: Denoising Diffusion Models With Transitive Closure Time-Distillation”, Berthelot et al 2023
TRACT: Denoising Diffusion Models with Transitive Closure Time-Distillation
“Consistency Models”, Song et al 2023
“Understanding the Diffusion Objective As a Weighted Integral of ELBOs”, Kingma & Gao 2023
Understanding the Diffusion Objective as a Weighted Integral of ELBOs
“Anime Rock, Paper, Scissors”, Digital 2023
“Did We Just Change Animation Forever? § Making Of”, Digital 2023
“Unsupervised Discovery of Semantic Latent Directions in Diffusion Models”, Park et al 2023
Unsupervised Discovery of Semantic Latent Directions in Diffusion Models
“Adding Conditional Control to Text-To-Image Diffusion Models”, Zhang et al 2023
Adding Conditional Control to Text-to-Image Diffusion Models
“Glaze: Protecting Artists from Style Mimicry by Text-To-Image Models”, Shan et al 2023
Glaze: Protecting Artists from Style Mimicry by Text-to-Image Models
“Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning and Discovery”, Wen et al 2023
Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning and Discovery
“Imitating Human Behavior With Diffusion Models”, Pearce et al 2023
“Msanii: High Fidelity Music Synthesis on a Shoestring Budget”, Maina 2023
Msanii: High Fidelity Music Synthesis on a Shoestring Budget
“Archisound: Audio Generation With Diffusion”, Schneider 2023
“DIRAC: Neural Image Compression With a Diffusion-Based Decoder”, Goose et al 2023
DIRAC: Neural Image Compression with a Diffusion-Based Decoder
“Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-To-Video Generation”, Wu et al 2022
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
“Scalable Adaptive Computation for Iterative Generation”, Jabri et al 2022
“Diffusion Transformers (DiTs): Scalable Diffusion Models With Transformers”, Peebles & Xie 2022
Diffusion Transformers (DiTs): Scalable Diffusion Models with Transformers
“Point·E: A System for Generating 3D Point Clouds from Complex Prompts”, Nichol et al 2022
Point·E: A System for Generating 3D Point Clouds from Complex Prompts
“Broadly Applicable and Accurate Protein Design by Integrating Structure Prediction Networks and Diffusion Generative Models”, Watson et al 2022
“The Stable Artist: Steering Semantics in Diffusion Latent Space”, Brack et al 2022
The Stable Artist: Steering Semantics in Diffusion Latent Space
“Multi-Concept Customization of Text-To-Image Diffusion”, Kumari et al 2022
“Multi-Resolution Textual Inversion”, Daras & Dimakis 2022
“Latent Video Diffusion Models for High-Fidelity Video Generation With Arbitrary Lengths”, He et al 2022
Latent Video Diffusion Models for High-Fidelity Video Generation with Arbitrary Lengths
“VectorFusion: Text-To-SVG by Abstracting Pixel-Based Diffusion Models”, Jain et al 2022
VectorFusion: Text-to-SVG by Abstracting Pixel-Based Diffusion Models
“DreamArtist: Towards Controllable One-Shot Text-To-Image Generation via Contrastive Prompt-Tuning”, Dong et al 2022
DreamArtist: Towards Controllable One-Shot Text-to-Image Generation via Contrastive Prompt-Tuning
“DiffusionDet: Diffusion Model for Object Detection”, Chen et al 2022
“Null-Text Inversion for Editing Real Images Using Guided Diffusion Models”, Mokady et al 2022
Null-text Inversion for Editing Real Images using Guided Diffusion Models
“InstructPix2Pix: Learning to Follow Image Editing Instructions”, Brooks et al 2022
InstructPix2Pix: Learning to Follow Image Editing Instructions
“Versatile Diffusion: Text, Images and Variations All in One Diffusion Model”, Xu et al 2022
Versatile Diffusion: Text, Images and Variations All in One Diffusion Model
“Rickrolling the Artist: Injecting Invisible Backdoors into Text-Guided Image Generation Models”, Struppek et al 2022
Rickrolling the Artist: Injecting Invisible Backdoors into Text-Guided Image Generation Models
“EDiff-I: Text-To-Image Diffusion Models With an Ensemble of Expert Denoisers”, Balaji et al 2022
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
“DiffusionDB: A Large-Scale Prompt Gallery Dataset for Text-To-Image Generative Models”, Wang et al 2022
DiffusionDB: A Large-scale Prompt Gallery Dataset for Text-to-Image Generative Models
“Imagic: Text-Based Real Image Editing With Diffusion Models”, Kawar et al 2022
“Hierarchical Diffusion Models for Singing Voice Neural Vocoder”, Takahashi et al 2022
Hierarchical Diffusion Models for Singing Voice Neural Vocoder
“Flow Matching for Generative Modeling”, Lipman et al 2022
“On Distillation of Guided Diffusion Models”, Meng et al 2022
“Improving Sample Quality of Diffusion Models Using Self-Attention Guidance”, Hong et al 2022
Improving Sample Quality of Diffusion Models Using Self-Attention Guidance
“Rectified Flow: A Marginal Preserving Approach to Optimal Transport”, Liu 2022
Rectified Flow: A Marginal Preserving Approach to Optimal Transport
“DreamFusion: Text-To-3D Using 2D Diffusion”, Poole et al 2022
“RealSinger: Ultra-Realistic Singing Voice Generation via Stochastic Differential Equations”, Anonymous 2022
RealSinger: Ultra-Realistic Singing Voice Generation via Stochastic Differential Equations
“g.pt: Learning to Learn With Generative Models of Neural Network Checkpoints”, Peebles et al 2022
g.pt: Learning to Learn with Generative Models of Neural Network Checkpoints
“PFGM: Poisson Flow Generative Models”, Xu et al 2022
“This Artist Is Dominating AI-Generated Art. And He’s Not Happy about It. Greg Rutkowski Is a More Popular Prompt Than Picasso”, Heikkilä 2022
“Brain Imaging Generation With Latent Diffusion Models”, Pinaya et al 2022
“Soft Diffusion: Score Matching for General Corruptions”, Daras et al 2022
“Flow Straight and Fast: Learning to Generate and Transfer Data With Rectified Flow”, Liu et al 2022
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
“Frido: Feature Pyramid Diffusion for Complex Scene Image Synthesis”, Fan et al 2022
Frido: Feature Pyramid Diffusion for Complex Scene Image Synthesis
“Understanding Diffusion Models: A Unified Perspective”, Luo 2022
“Cold Diffusion: Inverting Arbitrary Image Transforms Without Noise”, Bansal et al 2022
Cold Diffusion: Inverting Arbitrary Image Transforms Without Noise
“Diffusion-QL: Diffusion Policies As an Expressive Policy Class for Offline Reinforcement Learning”, Wang et al 2022
Diffusion-QL: Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning
“An Image Is Worth One Word: Personalizing Text-To-Image Generation Using Textual Inversion”, Gal et al 2022
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
“Text-Guided Synthesis of Artistic Images With Retrieval-Augmented Diffusion Models”, Rombach et al 2022
Text-Guided Synthesis of Artistic Images with Retrieval-Augmented Diffusion Models
“NUWA-∞: Autoregressive over Autoregressive Generation for Infinite Visual Synthesis”, Wu et al 2022
NUWA-∞: Autoregressive over Autoregressive Generation for Infinite Visual Synthesis
“IHDM: Generative Modeling With Inverse Heat Dissipation”, Rissanen et al 2022
“DiffC: Lossy Compression With Gaussian Diffusion”, Theis et al 2022
“Diffusion-GAN: Training GANs With Diffusion”, Wang et al 2022
“Compositional Visual Generation With Composable Diffusion Models”, Liu et al 2022
Compositional Visual Generation with Composable Diffusion Models
“DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps”, Lu et al 2022
DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps
“Score-Based Generative Models Detect Manifolds”, Pidstrigach 2022
“Elucidating the Design Space of Diffusion-Based Generative Models”, Karras et al 2022
Elucidating the Design Space of Diffusion-Based Generative Models
“Text2Human: Text-Driven Controllable Human Image Generation”, Jiang et al 2022
“Improved Vector Quantized Diffusion Models”, Tang et al 2022
“Maximum Likelihood Training of Implicit Nonlinear Diffusion Models”, Kim et al 2022
Maximum Likelihood Training of Implicit Nonlinear Diffusion Models
“Flexible Diffusion Modeling of Long Videos”, Harvey et al 2022
“Planning With Diffusion for Flexible Behavior Synthesis”, Janner et al 2022
“Diffusion Models for Adversarial Purification”, Nie et al 2022
“Retrieval-Augmented Diffusion Models: Semi-Parametric Neural Image Synthesis”, Blattmann et al 2022
Retrieval-Augmented Diffusion Models: Semi-Parametric Neural Image Synthesis
“Video Diffusion Models”, Ho et al 2022
“KNN-Diffusion: Image Generation via Large-Scale Retrieval”, Ashual et al 2022
“Perception Prioritized Training of Diffusion Models”, Choi et al 2022
“Diffusion Probabilistic Modeling for Video Generation”, Yang et al 2022
“Diffusion Causal Models for Counterfactual Estimation”, Sanchez & Tsaftaris 2022
“Truncated Diffusion Probabilistic Models and Diffusion-Based Adversarial Autoencoders”, Zheng et al 2022
Truncated Diffusion Probabilistic Models and Diffusion-based Adversarial Autoencoders
“Learning Fast Samplers for Diffusion Models by Differentiating Through Sample Quality”, Watson et al 2022
Learning Fast Samplers for Diffusion Models by Differentiating Through Sample Quality
“From Data to Functa: Your Data Point Is a Function and You Should Treat It like One”, Dupont et al 2022
From data to functa: Your data point is a function and you should treat it like one
“Denoising Diffusion Restoration Models”, Kawar et al 2022
“DiffuseVAE: Efficient, Controllable and High-Fidelity Generation from Low-Dimensional Latents”, Pandey et al 2022
DiffuseVAE: Efficient, Controllable and High-Fidelity Generation from Low-Dimensional Latents
“Itô-Taylor Sampling Scheme for Denoising Diffusion Probabilistic Models Using Ideal Derivatives”, Tachibana et al 2021
Itô-Taylor Sampling Scheme for Denoising Diffusion Probabilistic Models using Ideal Derivatives
“High-Resolution Image Synthesis With Latent Diffusion Models”, Rombach et al 2021
High-Resolution Image Synthesis with Latent Diffusion Models
“High Fidelity Visualization of What Your Self-Supervised Representation Knows About”, Bordes et al 2021
High Fidelity Visualization of What Your Self-Supervised Representation Knows About
“More Control for Free! Image Synthesis With Semantic Diffusion Guidance”, Liu et al 2021
More Control for Free! Image Synthesis with Semantic Diffusion Guidance
“Come-Closer-Diffuse-Faster: Accelerating Conditional Diffusion Models for Inverse Problems through Stochastic Contraction”, Chung et al 2021
“VQ-DDM: Global Context With Discrete Diffusion in Vector Quantized Modeling for Image Generation”, Hu et al 2021
VQ-DDM: Global Context with Discrete Diffusion in Vector Quantized Modeling for Image Generation
“Diffusion Autoencoders: Toward a Meaningful and Decodable Representation”, Preechakul et al 2021
Diffusion Autoencoders: Toward a Meaningful and Decodable Representation
“Blended Diffusion for Text-Driven Editing of Natural Images”, Avrahami et al 2021
“Vector Quantized Diffusion Model for Text-To-Image Synthesis”, Gu et al 2021
Vector Quantized Diffusion Model for Text-to-Image Synthesis
“Classifier-Free Diffusion Guidance”, Ho & Salimans 2021
“Unleashing Transformers: Parallel Token Prediction With Discrete Absorbing Diffusion for Fast High-Resolution Image Generation from Vector-Quantized Codes”, Bond-Taylor et al 2021
“Restormer: Efficient Transformer for High-Resolution Image Restoration”, Zamir et al 2021
Restormer: Efficient Transformer for High-Resolution Image Restoration
“Tackling the Generative Learning Trilemma With Denoising Diffusion GANs”, Xiao et al 2021
Tackling the Generative Learning Trilemma with Denoising Diffusion GANs
“Diffusion Normalizing Flow”, Zhang & Chen 2021
“Palette: Image-To-Image Diffusion Models”, Saharia et al 2021
“Progressive Distillation for Fast Sampling of Diffusion Models”, Salimans & Ho 2021
Progressive Distillation for Fast Sampling of Diffusion Models
“DiffusionCLIP: Text-Guided Image Manipulation Using Diffusion Models”, Kim & Ye 2021
DiffusionCLIP: Text-guided Image Manipulation Using Diffusion Models
“Unconditional Diffusion Guidance”, Ho & Salimans 2021
“Generative Probabilistic Image Colorization”, Furusawa et al 2021
“Bilateral Denoising Diffusion Models”, Lam et al 2021
“ImageBART: Bidirectional Context With Multinomial Diffusion for Autoregressive Image Synthesis”, Esser et al 2021
ImageBART: Bidirectional Context with Multinomial Diffusion for Autoregressive Image Synthesis
“Variational Diffusion Models”, Kingma et al 2021
“LoRA: Low-Rank Adaptation of Large Language Models”, Hu et al 2021
“PriorGrad: Improving Conditional Denoising Diffusion Models With Data-Dependent Adaptive Prior”, Lee et al 2021
PriorGrad: Improving Conditional Denoising Diffusion Models with Data-Dependent Adaptive Prior
“Score-Based Generative Modeling in Latent Space”, Vahdat et al 2021
“CDM: Cascaded Diffusion Models for High Fidelity Image Generation”, Ho et al 2021
CDM: Cascaded Diffusion Models for High Fidelity Image Generation
“Learning to Efficiently Sample from Diffusion Probabilistic Models”, Watson et al 2021
Learning to Efficiently Sample from Diffusion Probabilistic Models
“Gotta Go Fast When Generating Data With Score-Based Models”, Jolicoeur-Martineau et al 2021
“Diffusion Models Beat GANs on Image Synthesis”, Dhariwal & Nichol 2021
“DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism”, Liu et al 2021
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism
“Image Super-Resolution via Iterative Refinement”, Saharia et al 2021
“Learning Energy-Based Models by Diffusion Recovery Likelihood”, Gao et al 2021
Learning Energy-Based Models by Diffusion Recovery Likelihood
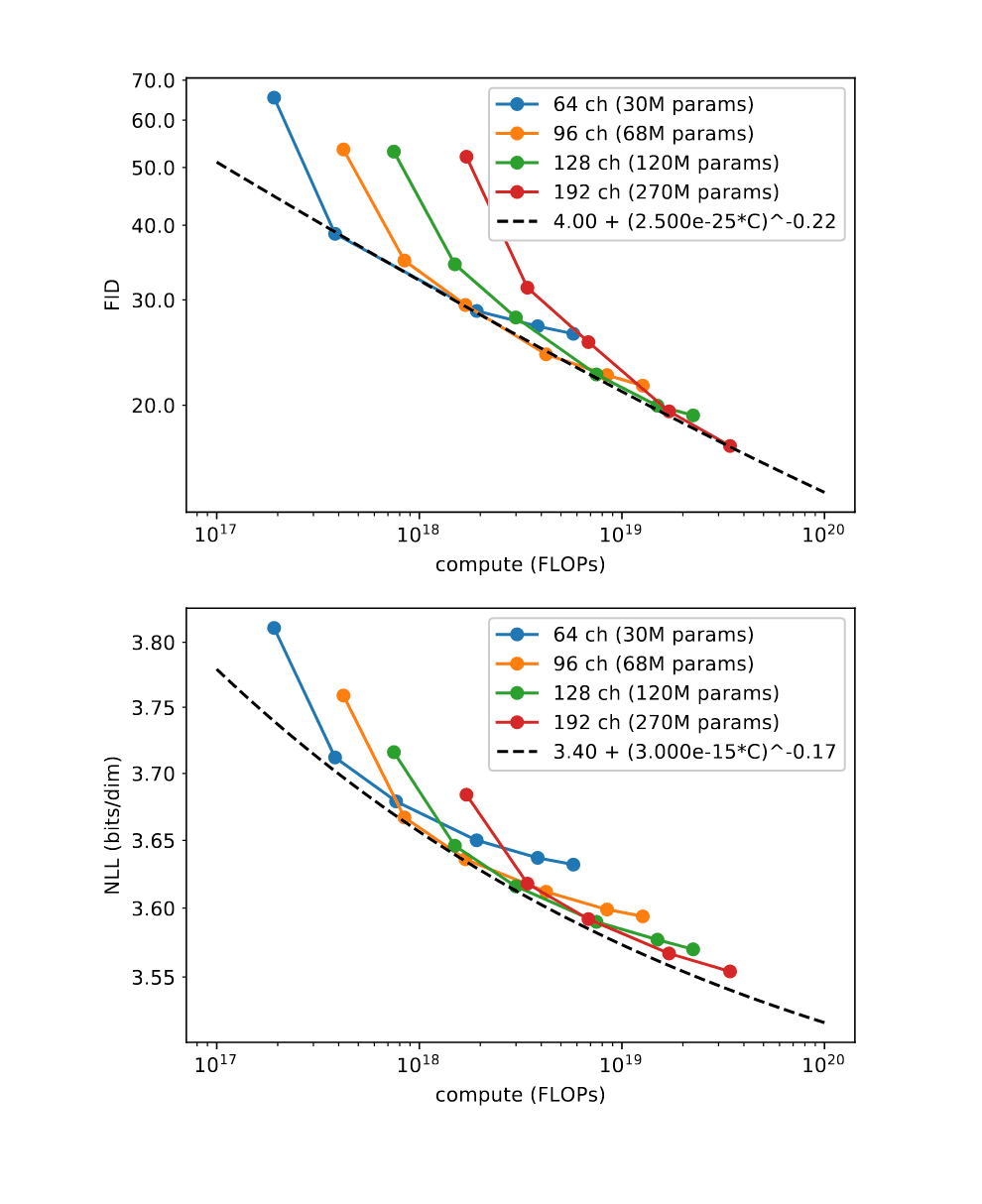
“Improved Denoising Diffusion Probabilistic Models”, Nichol & Dhariwal 2021
“Denoising Diffusion Implicit Models”, Song et al 2021
“Maximum Likelihood Training of Score-Based Diffusion Models”, Song et al 2021
“Score-Based Generative Modeling through Stochastic Differential Equations”, Song et al 2020
Score-Based Generative Modeling through Stochastic Differential Equations
“Denoising Diffusion Probabilistic Models”, Ho et al 2020
“NoGAN: Decrappification, DeOldification, and Super Resolution”, Antic et al 2019
NoGAN: Decrappification, DeOldification, and Super Resolution
“Improving Sampling from Generative Autoencoders With Markov Chains”, Creswell et al 2016
Improving Sampling from Generative Autoencoders with Markov Chains
“Deep Unsupervised Learning Using Nonequilibrium Thermodynamics”, Sohl-Dickstein et al 2015
Deep Unsupervised Learning using Nonequilibrium Thermodynamics
“A Connection Between Score Matching and Denoising Autoencoders”, Vincent 2011
A Connection Between Score Matching and Denoising Autoencoders
“Optimal Approximation of Signal Priors”, Hyvarinen 2008
“Estimation of Non-Normalized Statistical Models by Score Matching”, Hyvarinen 2005
Estimation of Non-Normalized Statistical Models by Score Matching
“The AI Art Apocalypse”
“Towards Pony Diffusion V7, Going With the Flow.”, AstraliteHeart 2026
“QR Code Monster SDXL—V1.0 [Stable Diffusion XL Controlnet]”
“Image Synthesis Style Studies Database (The List)”
“AnimeDL-2M: Million-Scale AI-Generated Anime Image Detection and Localization in Diffusion Era”
AnimeDL-2M: Million-Scale AI-Generated Anime Image Detection and Localization in Diffusion Era
“AIGText/Glyph-ByT5: [ECCV2024] This Is an Official Inference Code”, Liu et al 2026
AIGText/Glyph-ByT5: [ECCV2024] This is an official inference code
“Negative Prompt”
“Combination of OpenAI GLIDE and Latent Diffusion”
“KaliYuga-Ai/Textile-Diffusion”
“V Objective Diffusion Inference Code for PyTorch”
“High-Resolution Image Synthesis With Latent Diffusion Models”
High-Resolution Image Synthesis with Latent Diffusion Models
“Neonbjb/tortoise-Tts: A Multi-Voice TTS System Trained With an Emphasis on Quality”
neonbjb/tortoise-tts: A multi-voice TTS system trained with an emphasis on quality
“Code for Reproducing Results ‘Glow: Generative Flow With Invertible 1×1 Convolutions’”
Code for reproducing results ‘Glow: Generative Flow with Invertible 1×1 Convolutions’
“Openai/guided-Diffusion”
“The Annotated Diffusion Model”
“Ideogram Homepage”, Ideogram 2026
“PaintsUndo: A Base Model of Drawing Behaviors in Digital Paintings”
PaintsUndo: A Base Model of Drawing Behaviors in Digital Paintings
“Keypoint Based Anime Generation With Additional CLIP Guided Tuning”
Keypoint Based Anime Generation With Additional CLIP Guided Tuning
“Rethinking The Danbooru 2021 Dataset”
“A Closer Look Into The Latent-Diffusion Repo, Do Better Than Just Looking”
A Closer Look Into The latent-diffusion Repo, Do Better Than Just Looking
“Model Comparison Study for Disco Diffusion v. 5”
“Model Comparison Study for Disco Diffusion v. 5---PLMS Sampling Edition”
Model Comparison Study for Disco Diffusion v. 5---PLMS Sampling Edition
“Flexible Diffusion Modeling of Long Videos”
“Guidance: a Cheat Code for Diffusion Models”
“Stability AI CEO Resigns Because You Can’t Beat Centralized AI With More Centralized AI”
Stability AI CEO resigns because you can’t beat centralized AI with more centralized AI
“Z-Image—Efficient Image Generation With Single-Stream Diffusion”
Z-Image—Efficient Image Generation with Single-Stream Diffusion
View External Link:
“ControlNet Game of Life”
“Case Study: Interpreting, Manipulating, and Controlling CLIP With Sparse Autoencoders”
Case Study: Interpreting, Manipulating, and Controlling CLIP With Sparse Autoencoders
“The AI Animal Letters of the Alphabet”
“Generative Modeling by Estimating Gradients of the Data Distribution”
Generative Modeling by Estimating Gradients of the Data Distribution
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
media-manipulation
storytelling
memory-reconstruction
caption-retrieval
data-function
video-generation
ai-artistry copyright-issues creative-labor aesthetic-judgment ethics-in-art ai-marketplace
de-novo
diffusion-models
anime-diffusion
Wikipedia (7)
Miscellaneous
/doc/ai/nn/diffusion/2025-li-figure1-architectureofnoprop.jpg/doc/ai/nn/diffusion/2025-li-figure2-noproplearnedimageprototypesforcifar10classification.png/doc/ai/nn/diffusion/2024-12-23-gwern-recraft-wombat-monochromeface.svg/doc/ai/nn/diffusion/2023-10-24-gwern-sdxl-ssd1b-capitallettertprompts.png/doc/ai/nn/diffusion/2023-podell-figure2-datalossduetononsquareimageaspectratios.jpg/doc/ai/nn/diffusion/2022-09-21-gwern-stablediffusionv14-circulardropcapinitialsamples.png/doc/ai/nn/diffusion/2022-09-20-novelai-kurumuz-animestablediffusion-asukasamples.png/doc/ai/nn/diffusion/2022-ashual-figure5-knnretrievalimageediting.png/doc/ai/nn/diffusion/2022-balaji-figure1-samplesoftexttoimagefromediffi.png/doc/ai/nn/diffusion/2021-nichol-figure10-scalinglawsforddpmincomputevsnllfid.pnghttps://blog.metaphysic.ai/the-road-to-realistic-full-body-deepfakes/https://blog.novelai.net/novelai-improvements-on-stable-diffusion-e10d38db82achttps://bonfx.com/how-to-use-dreamstudio-stablediffusion-to-create-a-traditional-illustration/https://colab.research.google.com/drive/1dlgggNa5Mz8sEAGU0wFCHhGLFooW_pf1https://discuss.huggingface.co/t/decoding-latents-to-rgb-without-upscaling/23204/4https://fortune.com/2023/11/29/stability-ai-sale-intel-ceo-resign/https://generalrobots.substack.com/p/dimension-hopper-part-1https://github.com/curiousjp/toy_sd_genetics?tab=readme-ov-file#toy_sd_geneticshttps://github.com/marqo-ai/marqo/blob/mainline/examples/StableDiffusion/hot-dog-100k.mdhttps://github.com/vitoplantamura/OnnxStream/tree/846da873570a737b49154e8f835704264864b0fehttps://globalcomix.com/c/paintings-photographs/chapters/en/1/1https://hforsten.com/identifying-stable-diffusion-xl-10-images-from-vae-artifacts.htmlhttps://huggingface.co/Gustavosta/MagicPrompt-Stable-Diffusionhttps://huggingface.co/Onodofthenorth/SD_PixelArt_SpriteSheet_Generatorhttps://huggingface.co/Ryukijano/CatCon-Controlnet-WD-1-5-b2Rhttps://jxmo.notion.site/The-Weird-and-Wonderful-World-of-AI-Art-b9615a2e7278435b98380ff81ae1cf09https://keras.io/examples/generative/random_walks_with_stable_diffusion/View External Link:
https://keras.io/examples/generative/random_walks_with_stable_diffusion/https://lambdalabs.com/blog/inference-benchmark-stable-diffusionhttps://medium.com/@enryu9000/anifusion-diffusion-models-for-anime-pictures-138cf1af2cbehttps://minimaxir.com/2022/11/stable-diffusion-negative-prompt/View External Link:
https://minimaxir.com/2022/11/stable-diffusion-negative-prompt/https://nostalgebraist.tumblr.com/post/672300992964050944/franks-image-generation-model-explainedhttps://old.reddit.com/r/StableDiffusion/comments/y91pp7/stable_diffusion_v15/https://paperswithcode.com/sota/text-to-image-generation-on-cocohttps://pub.towardsai.net/stable-diffusion-based-image-compresssion-6f1f0a399202https://research.google/blog/google-research-2022-beyond-language-vision-and-generative-models/https://research.google/blog/mobilediffusion-rapid-text-to-image-generation-on-device/https://saltacc.notion.site/saltacc/WD-1-5-Beta-3-Release-Notes-1e35a0ed1bb24c5b93ec79c45c217f63https://sander.ai/2024/02/28/paradox.htmlView HTML:
https://t-naoya.github.io/hdm/View External Link:
https://talesofsyn.com/posts/creating-isometric-rpg-game-backgroundshttps://www.facebook.com/marcello.herreshoff/posts/10160262954262798https://www.hollywoodreporter.com/tv/tv-news/secret-invasion-ai-opening-1235521299/https://www.reddit.com/r/Bard/comments/1795exq/google_sge_image_generation_is_so_good_at/https://www.reddit.com/r/StableDiffusion/comments/11f4zgt/remixing_memes_with_multi_controlnet_is/https://www.reddit.com/r/StableDiffusion/comments/15aapcb/sdxl_10_is_out/https://www.reddit.com/r/StableDiffusion/comments/18r7mqf/top_online_nsfw_creators_updated/https://www.reddit.com/r/StableDiffusion/comments/1bsi2xs/the_experiment/https://www.reddit.com/r/StableDiffusion/comments/ys434h/animating_generated_face_test/https://www.reddit.com/r/StableDiffusion/comments/z0xyk2/dreambooth_model_for_cutting_machines/https://www.reddit.com/r/aigamedev/comments/142j3yt/valve_is_not_willing_to_publish_games_with_ai/https://www.reddit.com/r/sdnsfw/comments/ylo4eh/huge_list_of_sexy_tested_photorealism_keywords/https://www.samdickie.me/writing/experiment-1-creating-a-landing-page-using-ai-tools-no-codehttps://www.stavros.io/posts/compressing-images-with-stable-diffusion/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2512.08153: “TreeGRPO: Tree-Advantage GRPO for Online RL Post-Training of Diffusion Models”,https://arxiv.org/abs/2502.10248#stepfun: “Step-Video-T2V Technical Report: The Practice, Challenges, and Future of Video Foundation Model”,https://arxiv.org/abs/2501.08332#bytedance: “MangaNinja: Line Art Colorization With Precise Reference Following”,https://arxiv.org/abs/2501.09038#deepmind: “Do Generative Video Models Learn Physical Principles from Watching Videos?”,https://arxiv.org/abs/2412.20292: “An Analytic Theory of Creativity in Convolutional Diffusion Models”,2024-kumari.pdf: “Exploring Denoising Diffusion Models for Realistic Anime Character Generation”,https://arxiv.org/abs/2412.06771#deepmind: “Proactive Agents for Multi-Turn Text-To-Image Generation Under Uncertainty”,https://arxiv.org/abs/2410.10629#nvidia: “SANA: Efficient High-Resolution Image Synthesis With Linear Diffusion Transformers”,https://arxiv.org/abs/2410.03755#meituan: “Denoising With a Joint-Embedding Predictive Architecture”,https://arxiv.org/abs/2409.17410: “Copying Style, Extracting Value: Illustrators’ Perception of AI Style Transfer and Its Impact on Creative Labor”,https://arxiv.org/abs/2409.15997#novelai: “Improvements to SDXL in NovelAI Diffusion V3”,https://arxiv.org/abs/2406.10208#microsoft: “Glyph-ByT5-V2: A Strong Aesthetic Baseline for Accurate Multilingual Visual Text Rendering”,https://arxiv.org/abs/2404.01291: “Evaluating Text-To-Visual Generation With Image-To-Text Generation”,https://arxiv.org/abs/2403.13802: “ZigMa: Zigzag Mamba Diffusion Model”,https://arxiv.org/abs/2403.09622#microsoft: “Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering”,https://arxiv.org/abs/2401.08741: “Fixed Point Diffusion Models”,https://arxiv.org/abs/2312.12142: “FontDiffuser: One-Shot Font Generation via Denoising Diffusion With Multi-Scale Content Aggregation and Style Contrastive Learning”,https://arxiv.org/abs/2312.02139: “DiffiT: Diffusion Vision Transformers for Image Generation”,https://arxiv.org/abs/2311.18829#microsoft: “MicroCinema: A Divide-And-Conquer Approach for Text-To-Video Generation”,https://arxiv.org/abs/2311.16465: “TextDiffuser-2: Unleashing the Power of Language Models for Text Rendering”,https://arxiv.org/abs/2311.17042#stability: “Adversarial Diffusion Distillation”,https://arxiv.org/abs/2311.12092: “Concept Sliders: LoRA Adaptors for Precise Control in Diffusion Models”,https://arxiv.org/abs/2311.09257#google: “UFOGen: You Forward Once Large Scale Text-To-Image Generation via Diffusion GANs”,https://arxiv.org/abs/2311.04145#alibaba: “I2VGen-XL: High-Quality Image-To-Video Synthesis via Cascaded Diffusion Models”,https://arxiv.org/abs/2310.16825: “CommonCanvas: An Open Diffusion Model Trained With Creative-Commons Images”,https://arxiv.org/abs/2309.15807#facebook: “Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack”,https://arxiv.org/abs/2309.09968: “Generating and Imputing Tabular Data via Diffusion and Flow-Based Gradient-Boosted Trees”,https://arxiv.org/abs/2309.06380: “InstaFlow: One Step Is Enough for High-Quality Diffusion-Based Text-To-Image Generation”,https://arxiv.org/abs/2307.01952#stability: “SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis”,https://arxiv.org/pdf/2307.01952#page=3&org=stability: “SDXL § Micro-Conditioning: Conditioning the Model on Image Size”,https://arxiv.org/abs/2306.07691: “StyleTTS 2: Towards Human-Level Text-To-Speech through Style Diffusion and Adversarial Training With Large Speech Language Models”,https://arxiv.org/abs/2306.04675#layer6ai: “Exposing Flaws of Generative Model Evaluation Metrics and Their Unfair Treatment of Diffusion Models”,2023-samo.pdf: “Artificial Intelligence and Art: Identifying the Esthetic Judgment Factors That Distinguish Human & Machine-Generated Artwork”,https://arxiv.org/abs/2305.16269: “UDPM: Upsampling Diffusion Probabilistic Models”,https://arxiv.org/abs/2303.14389: “Masked Diffusion Transformer Is a Strong Image Synthesizer”,https://arxiv.org/abs/2303.01469#openai: “Consistency Models”,https://arxiv.org/abs/2302.04222: “Glaze: Protecting Artists from Style Mimicry by Text-To-Image Models”,https://raw.githubusercontent.com/flavioschneider/master-thesis/main/audio_diffusion_thesis.pdf: “Archisound: Audio Generation With Diffusion”,https://arxiv.org/abs/2212.08751#openai: “Point·E: A System for Generating 3D Point Clouds from Complex Prompts”,https://arxiv.org/abs/2211.09788: “DiffusionDet: Diffusion Model for Object Detection”,https://arxiv.org/abs/2211.09800: “InstructPix2Pix: Learning to Follow Image Editing Instructions”,https://arxiv.org/abs/2211.01324#nvidia: “EDiff-I: Text-To-Image Diffusion Models With an Ensemble of Expert Denoisers”,https://arxiv.org/abs/2210.07508#sony: “Hierarchical Diffusion Models for Singing Voice Neural Vocoder”,https://arxiv.org/abs/2210.03142#google: “On Distillation of Guided Diffusion Models”,https://arxiv.org/abs/2209.12892: “g.pt: Learning to Learn With Generative Models of Neural Network Checkpoints”,https://arxiv.org/abs/2208.09392: “Cold Diffusion: Inverting Arbitrary Image Transforms Without Noise”,https://arxiv.org/abs/2208.01618: “An Image Is Worth One Word: Personalizing Text-To-Image Generation Using Textual Inversion”,https://arxiv.org/abs/2207.09814#microsoft: “NUWA-∞: Autoregressive over Autoregressive Generation for Infinite Visual Synthesis”,https://arxiv.org/abs/2205.16007#microsoft: “Improved Vector Quantized Diffusion Models”,https://arxiv.org/abs/2205.07460: “Diffusion Models for Adversarial Purification”,https://arxiv.org/abs/2112.10752: “High-Resolution Image Synthesis With Latent Diffusion Models”,https://arxiv.org/abs/2112.05744: “More Control for Free! Image Synthesis With Semantic Diffusion Guidance”,https://arxiv.org/abs/2106.09685#microsoft: “LoRA: Low-Rank Adaptation of Large Language Models”,https://cascaded-diffusion.github.io/: “CDM: Cascaded Diffusion Models for High Fidelity Image Generation”,https://arxiv.org/abs/2105.05233#openai: “Diffusion Models Beat GANs on Image Synthesis”,https://arxiv.org/abs/2104.07636#google: “Image Super-Resolution via Iterative Refinement”,https://arxiv.org/abs/2102.09672#openai: “Improved Denoising Diffusion Probabilistic Models”,2018-sharma.pdf#google: “Conceptual Captions: A Cleaned, Hypernymed, Image Alt-Text Dataset For Automatic Image Captioning”,2011-vincent.pdf: “A Connection Between Score Matching and Denoising Autoencoders”,https://www.jmlr.org/papers/volume6/hyvarinen05a/hyvarinen05a.pdf: “Estimation of Non-Normalized Statistical Models by Score Matching”,