‘Google Imagen’ directory
- See Also
- Gwern
- “Sleepcat Purrkit”, Gwern et al 2026
- “Gazing Into the Abyssinian”, Claude-5-Fable et al 2026
- “The Fractal Rug Shop”, Gwern & Pro 2026
- “Parting Shot”, Pro et al 2026
- “The Cure for the Barren Goat”, Gwern et al 2026
- “Happy New Year”, Gwern & Pro 2026
- “Melancholy [Sample Grid]”, Gwern et al 2026
- “Accountant Who Owns a Rabbit”, Pro et al 2026
- “Eau De Windowsill”, Claude-4.6-opus et al 2026
- “The Catsby”, Gemini-3.1-pro-preview et al 2026
- “Oh, This Old Thing?”, Gwern et al 2026
- “Cream of Can”, Gwern et al 2026
- “Rhesus Pieces”, Gwern et al 2026
- “Spoilage”, Gwern & Pro 2026
- “Death’s Dating Problems”, Gwern 2026
- “I’d Show All My Online Friends, but I Now Worry They Wouldn’t Get It”, Gwern 2026
- Links
- Habeas Corpus, Gwern & Pro 2026
- “The Repugnant Conclusion”, Gwern & 2 2026
- “Panda Express”, Gwern et al 2026
- “The Zen of Instant Coffee”, Gwern & Pro 2026
- “King Pin”, Gwern et al 2026
- “Commoditize Your Complement: The Salt Deserts of Profitability”, Gwern et al 2026
- “The Necrology Clinic”, Gwern & Pro 2026
- “The Sound of One Pocky”, Thinking et al 2026
- “Forget It, Jake”, Gwern et al 2026
- “Cat Walking”, Gwern & Pro 2026
- “Commitment”, Gwern & Pro 2026
- “Soylent Mocktail”, Gwern & Pro 2026
- “Our Uncertain Times”, Gwern et al 2026
- “Down To Fund”, Gwern & Pro 2026
- “Celeryman”, Gwern & Pro 2026
- “The Job Interview”, Gwern et al 2026
- “M. Bison”, Gwern et al 2026
- “Bison versus Byson”, Gwern & Pro 2026
- “Just When He Thought He Was Out...”, Gwern & Pro 2026
- “Melancholy”, Gwern et al 2026
- “Early IRA Withdrawals”, Gwern & Pro 2026
- “Executetion”, Gwern & Pro 2026
- “Parkour”, Gwern et al 2026
- “Shih Tzu Massage”, Gwern & Pro 2026
- “Trace of the True Self”, Gwern et al 2026
- “What Does The Fox Say?”, Gwern & Pro 2026
- Reductio Ad Ursum, Gwern & Pro 2026
- “Hug Dealer”, Gwern & Pro 2026
- “Cannibalism”, Gwern & Pro 2026
- “The Golden Loaf”, Gwern & Pro 2026
- “Currying Favor”, Gwern et al 2026
- “Houston, We Have Landed”, Gwern et al 2026
- “Apawcalypse Meow”, Gwern et al 2026
- “Death Is Always An Option”, Gwern 2026
- “The Roomba Dance”, Gwern 2026
- “Bee Not Afraid”, Gwern 2026
- “Fine Art versus Fiiine Art”, Gwern 2026
- “It Was an Ominous Sign”, Gwern & Gemini-3.1-pro-preview 2026
- “Apparently, He’s Been ‘Manifesting’”, Gwern & Gemini-3.1-pro-preview 2026
- “The Children Yearn for the Mimes”, Gwern 2026
- “Nano Banana 2: Google’s Latest AI Image Generation Model; Advanced World Knowledge, Production-Ready Specs, Subject Consistency & More, at Flash Speed”, Raisinghani 2026
- “The Fall”, Gwern 2026
- “He Looks Just Like You!”, Gwern 2026
- “Our Noble Zettelkasten...”, Gwern 2026
- “Local Wikis vs Cloud Wikis”, Gwern 2026
- “What Frightens Us In A Madman Is His Sanity”, Gwern & Pro 2026
- “It’s A Living”, Gwern & Pro 2026
- “We Just Fixed That Wall”, Gwern & Pro 2026
- “With Sheila, It Was Always Mixed Signals”, Pro & Gwern 2026
- “PaperBanana: Automating Academic Illustration for AI Scientists”, Zhu et al 2026
- “‘It’s So Beautiful’ § Being Eaten”, Gwern & Pro 2026
- “‘It’s So Beautiful’ § Burnt”, Gwern 2026
- “‘It’s So Beautiful’ § Shooting Star”, Gwern & Gemini-3-pro-preview 2026
- “On the Internet, Everyone Knows You’re a Dog!”, Gwern 2026
- “Cool, Cool, Cool”, Gwern 2026
- “Seed Round”, Gwern & Gemini-3-pro-preview 2026
- “Well, Well... Lookit Mister Fancy Pants Here”, Gwern 2026
- “Coarse Is Better [DALL·E 2 vs MJv2 vs Nano Banana Pro]”, Borretti 2025
- “Research vs Development”, Gwern & Pro 2025
- “Nano Banana Pro: Gemini 3 Pro Image Model from Google DeepMind; Turn Your Visions into Studio-Quality Designs With Unprecedented Control, Improved Text Rendering and Enhanced World Knowledge”, Raisinghani 2025
- “Nano Banana: Image Editing in Google Gemini Gets a Major Upgrade; Transform Images in Amazing New Ways With Updated Native Image Editing in the Gemini App”, Sharon & Brichtova 2025
- “Announcing Imagen 4 Fast, and the General Availability of the Imagen 4 Family in the Gemini API”, Google 2025
- “Introducing Veo 3 and Imagen 4, and a New Tool for Filmmaking Called Flow”, Collins 2025
- “Traffic Lights: Yes, Maybe, No—Can You Please Repeat The Question?”, Gwern 2025
- “Imagen 3”, Baldridge et al 2024
- “Intriguing Properties of Generative Classifiers”, Jaini et al 2023
- “Dreamix: Video Diffusion Models Are General Video Editors”, Molad et al 2023
- “Character-Aware Models Improve Visual Text Rendering”, Liu et al 2022
- “Imagen Video: High Definition Video Generation With Diffusion Models”, Ho et al 2022
- “DreamBooth: Fine Tuning Text-To-Image Diffusion Models for Subject-Driven Generation”, Ruiz et al 2022
- “Prompt-To-Prompt Image Editing With Cross Attention Control”, Hertz et al 2022
- “Imagen: Photorealistic Text-To-Image Diffusion Models With Deep Language Understanding”, Saharia et al 2022
- “Imagen”, DeepMind 2026
- “PaperBanana: Automating Academic Illustration for AI Scientists”
- “Imagen Video”
- “Imagen Video”
- “Checking in on Scott’s Composition Image Bet With Imagen 3”
- Sort By Magic
- Miscellaneous
- Bibliography
See Also
Gwern
“Sleepcat Purrkit”, Gwern et al 2026
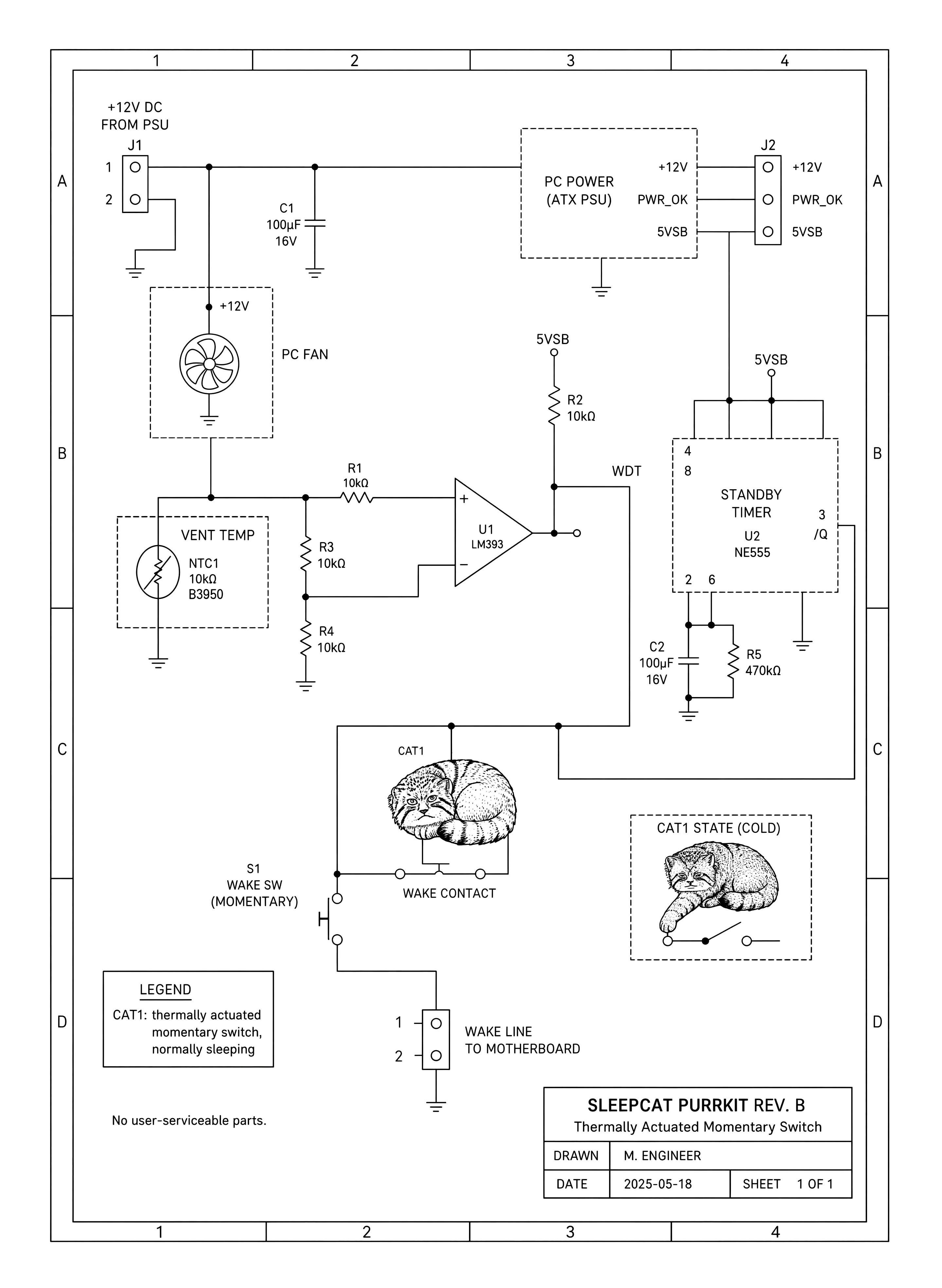{kind=link}
“Gazing Into the Abyssinian”, Claude-5-Fable et al 2026
{kind=link}
“The Fractal Rug Shop”, Gwern & Pro 2026
{kind=link}
“Parting Shot”, Pro et al 2026
{kind=link}
“The Cure for the Barren Goat”, Gwern et al 2026
{kind=link}
“Happy New Year”, Gwern & Pro 2026
{kind=link}
“Melancholy [Sample Grid]”, Gwern et al 2026
![Melancholy [sample grid]](/doc/dog/2026-04-12-gwern-gemini31propreview-nanobananapro-melancholy-meloncollieimageideas-samples-2x5.jpg){kind=link}
“Accountant Who Owns a Rabbit”, Pro et al 2026
{kind=link}
“Eau De Windowsill”, Claude-4.6-opus et al 2026
{kind=link}
“The Catsby”, Gemini-3.1-pro-preview et al 2026
{kind=link}
“Oh, This Old Thing?”, Gwern et al 2026
{kind=link}
“Cream of Can”, Gwern et al 2026
{kind=link}
“Rhesus Pieces”, Gwern et al 2026
{kind=link}
“Spoilage”, Gwern & Pro 2026
{kind=link}
“Death’s Dating Problems”, Gwern 2026
{kind=link}
“I’d Show All My Online Friends, but I Now Worry They Wouldn’t Get It”, Gwern 2026
I’d show all my online friends, but I now worry they wouldn’t get it
{kind=link}
Links
Habeas Corpus, Gwern & Pro 2026
{kind=link}
“The Repugnant Conclusion”, Gwern & 2 2026
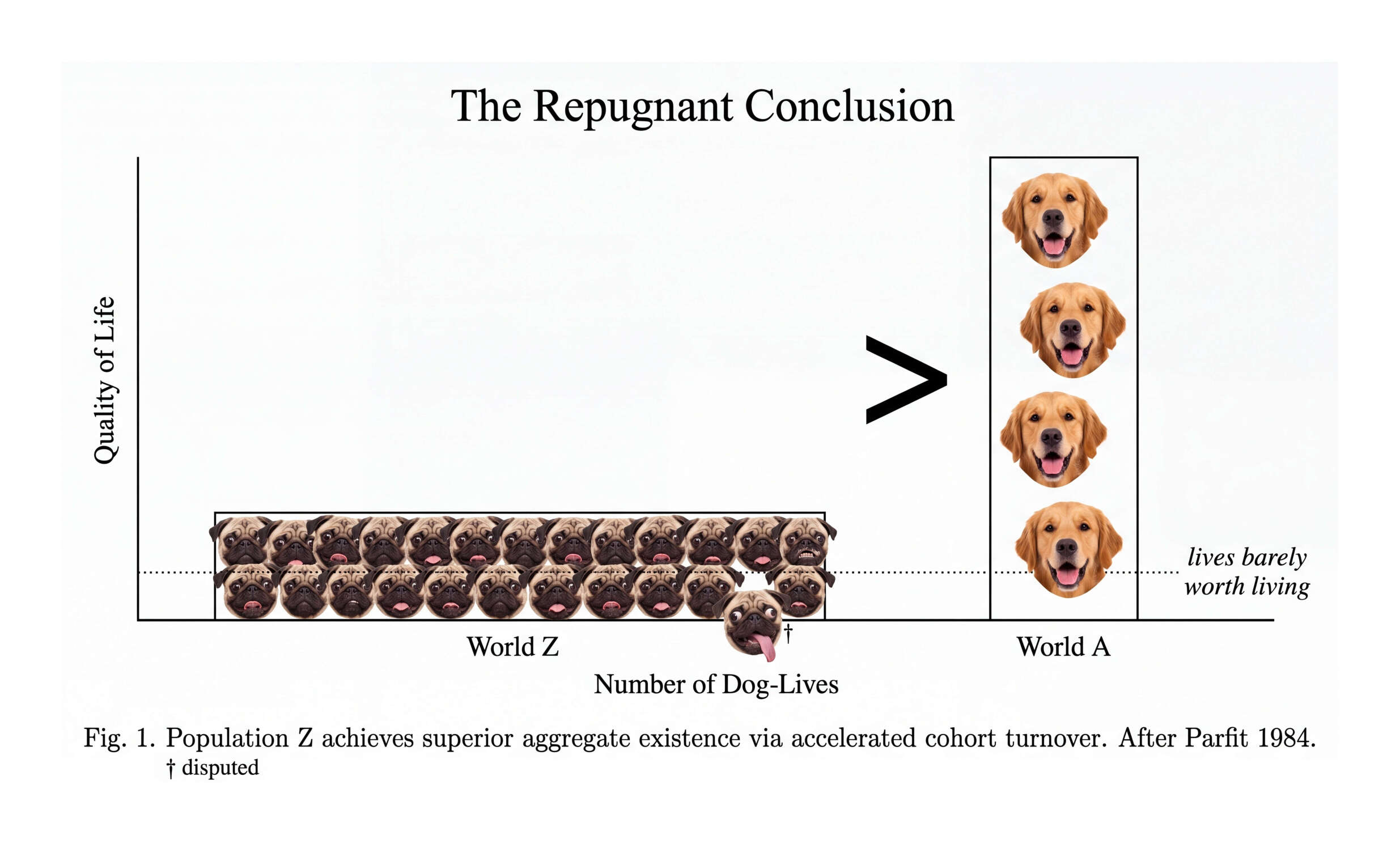{kind=link}
“Panda Express”, Gwern et al 2026
{kind=link}
“The Zen of Instant Coffee”, Gwern & Pro 2026
{kind=link}
“King Pin”, Gwern et al 2026
{kind=link}
“Commoditize Your Complement: The Salt Deserts of Profitability”, Gwern et al 2026
Commoditize Your Complement: The Salt Deserts of Profitability
{kind=link}
“The Necrology Clinic”, Gwern & Pro 2026
{kind=link}
“The Sound of One Pocky”, Thinking et al 2026
{kind=link}
“Forget It, Jake”, Gwern et al 2026
{kind=link}
“Cat Walking”, Gwern & Pro 2026
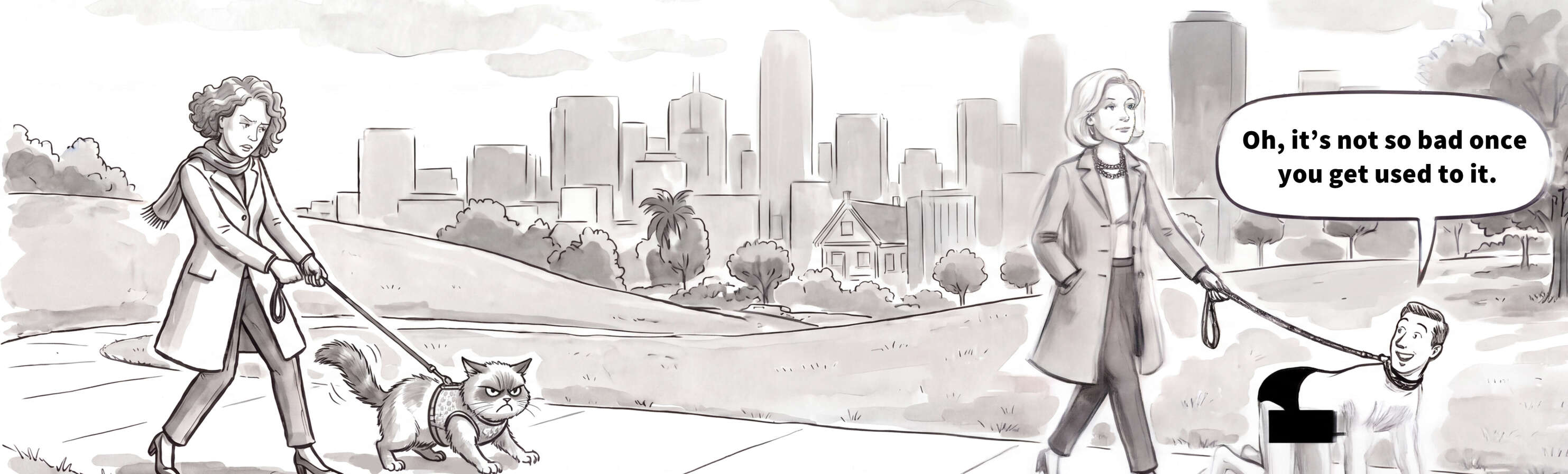{kind=link}
“Commitment”, Gwern & Pro 2026
{kind=link}
“Soylent Mocktail”, Gwern & Pro 2026
{kind=link}
“Our Uncertain Times”, Gwern et al 2026
{kind=link}
“Down To Fund”, Gwern & Pro 2026
{kind=link}
“Celeryman”, Gwern & Pro 2026
{kind=link}
“The Job Interview”, Gwern et al 2026
{kind=link}
“M. Bison”, Gwern et al 2026
{kind=link}
“Bison versus Byson”, Gwern & Pro 2026
{kind=link}
“Just When He Thought He Was Out...”, Gwern & Pro 2026
{kind=link}
“Melancholy”, Gwern et al 2026
{kind=link}
“Early IRA Withdrawals”, Gwern & Pro 2026
{kind=link}
“Executetion”, Gwern & Pro 2026
{kind=link}
“Parkour”, Gwern et al 2026
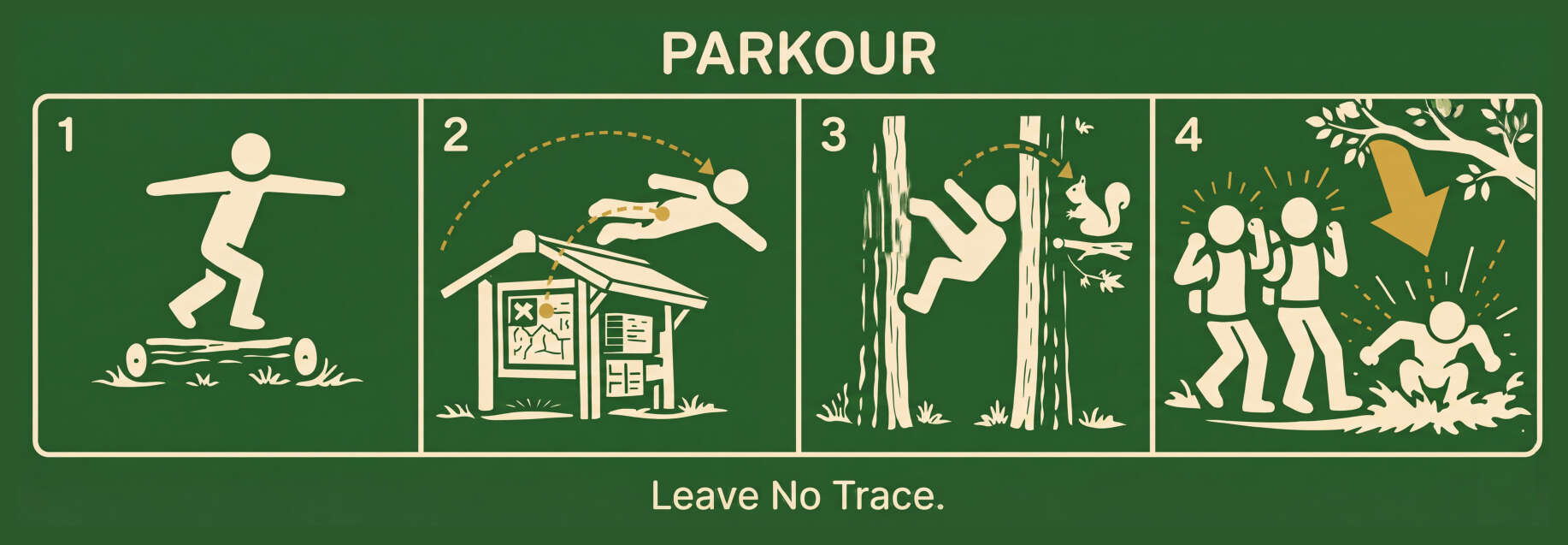{kind=link}
“Shih Tzu Massage”, Gwern & Pro 2026
{kind=link}
“Trace of the True Self”, Gwern et al 2026
{kind=link}
“What Does The Fox Say?”, Gwern & Pro 2026
{kind=link}
Reductio Ad Ursum, Gwern & Pro 2026
{kind=link}
“Hug Dealer”, Gwern & Pro 2026
{kind=link}
“Cannibalism”, Gwern & Pro 2026
{kind=link}
“The Golden Loaf”, Gwern & Pro 2026
{kind=link}
“Currying Favor”, Gwern et al 2026
{kind=link}
“Houston, We Have Landed”, Gwern et al 2026
{kind=link}
“Apawcalypse Meow”, Gwern et al 2026
{kind=link}
“Death Is Always An Option”, Gwern 2026
{kind=link}
“The Roomba Dance”, Gwern 2026
{kind=link}
“Bee Not Afraid”, Gwern 2026
{kind=link}
“Fine Art versus Fiiine Art”, Gwern 2026
{kind=link}
“It Was an Ominous Sign”, Gwern & Gemini-3.1-pro-preview 2026
{kind=link}
“Apparently, He’s Been ‘Manifesting’”, Gwern & Gemini-3.1-pro-preview 2026
{kind=link}
“The Children Yearn for the Mimes”, Gwern 2026
{kind=link}
“Nano Banana 2: Google’s Latest AI Image Generation Model; Advanced World Knowledge, Production-Ready Specs, Subject Consistency & More, at Flash Speed”, Raisinghani 2026
“The Fall”, Gwern 2026
{kind=link}
“He Looks Just Like You!”, Gwern 2026
{kind=link}
“Our Noble Zettelkasten...”, Gwern 2026
{kind=link}
“Local Wikis vs Cloud Wikis”, Gwern 2026
{kind=link}
“What Frightens Us In A Madman Is His Sanity”, Gwern & Pro 2026
{kind=link}
“It’s A Living”, Gwern & Pro 2026
{kind=link}
“We Just Fixed That Wall”, Gwern & Pro 2026
{kind=link}
“With Sheila, It Was Always Mixed Signals”, Pro & Gwern 2026
{kind=link}
“PaperBanana: Automating Academic Illustration for AI Scientists”, Zhu et al 2026
PaperBanana: Automating Academic Illustration for AI Scientists
“‘It’s So Beautiful’ § Being Eaten”, Gwern & Pro 2026
{kind=link}
“‘It’s So Beautiful’ § Burnt”, Gwern 2026
{kind=link}
“‘It’s So Beautiful’ § Shooting Star”, Gwern & Gemini-3-pro-preview 2026
{kind=link}
“On the Internet, Everyone Knows You’re a Dog!”, Gwern 2026
{kind=link}
“Cool, Cool, Cool”, Gwern 2026
{kind=link}
“Seed Round”, Gwern & Gemini-3-pro-preview 2026
{kind=link}
“Well, Well... Lookit Mister Fancy Pants Here”, Gwern 2026
{kind=link}
“Coarse Is Better [DALL·E 2 vs MJv2 vs Nano Banana Pro]”, Borretti 2025
“Research vs Development”, Gwern & Pro 2025
{kind=link}
“Nano Banana Pro: Gemini 3 Pro Image Model from Google DeepMind; Turn Your Visions into Studio-Quality Designs With Unprecedented Control, Improved Text Rendering and Enhanced World Knowledge”, Raisinghani 2025
View External Link:
https://blog.google/innovation-and-ai/products/nano-banana-pro/
“Announcing Imagen 4 Fast, and the General Availability of the Imagen 4 Family in the Gemini API”, Google 2025
Announcing Imagen 4 Fast, and the general availability of the Imagen 4 family in the Gemini API
“Introducing Veo 3 and Imagen 4, and a New Tool for Filmmaking Called Flow”, Collins 2025
Introducing Veo 3 and Imagen 4, and a new tool for filmmaking called Flow
View External Link:
https://blog.google/technology/ai/generative-media-models-io-2025/
“Traffic Lights: Yes, Maybe, No—Can You Please Repeat The Question?”, Gwern 2025
Traffic Lights: Yes, Maybe, No—Can You Please Repeat The Question?
{kind=link}
“Imagen 3”, Baldridge et al 2024
“Intriguing Properties of Generative Classifiers”, Jaini et al 2023
“Dreamix: Video Diffusion Models Are General Video Editors”, Molad et al 2023
“Character-Aware Models Improve Visual Text Rendering”, Liu et al 2022
“Imagen Video: High Definition Video Generation With Diffusion Models”, Ho et al 2022
Imagen Video: High Definition Video Generation with Diffusion Models
“DreamBooth: Fine Tuning Text-To-Image Diffusion Models for Subject-Driven Generation”, Ruiz et al 2022
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
“Prompt-To-Prompt Image Editing With Cross Attention Control”, Hertz et al 2022
“Imagen: Photorealistic Text-To-Image Diffusion Models With Deep Language Understanding”, Saharia et al 2022
Imagen: Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
“Imagen”, DeepMind 2026
“PaperBanana: Automating Academic Illustration for AI Scientists”
PaperBanana: Automating Academic Illustration for AI Scientists
“Imagen Video”
“Imagen Video”
“Checking in on Scott’s Composition Image Bet With Imagen 3”
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
generative-classifiers
madness-analysis
video-editing
Miscellaneous
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2302.01329#google: “Dreamix: Video Diffusion Models Are General Video Editors”,https://arxiv.org/abs/2212.10562#google: “Character-Aware Models Improve Visual Text Rendering”,https://arxiv.org/abs/2208.12242#google: “DreamBooth: Fine Tuning Text-To-Image Diffusion Models for Subject-Driven Generation”,https://arxiv.org/abs/2205.11487#google: “Imagen: Photorealistic Text-To-Image Diffusion Models With Deep Language Understanding”,