https://github.com/gregorbachmann/scaling_mlps
Pay Attention to MLPs
MLP Architectures for Vision-and-Language Modeling: An Empirical Study
https://www.kaggle.com/c/tiny-imagenet
‘MLP NN’ directory
ImageNet Large Scale Visual Recognition Challenge
Attention Is All You Need
MLP-Mixer: An all-MLP Architecture for Vision
scaling-hypothesis#blessings-of-scale
[Transclude the forward-link's
context]
Layer Normalization
How far can we go without convolution: Improving fully-connected networks
A Downsampled Variant of ImageNet as an Alternative to the CIFAR datasets
Symbolic Discovery of Optimization Algorithms
https://arxiv.org/pdf/2306.13575.pdf#page=5
mixup: Beyond Empirical Risk Minimization
Deep Residual Learning for Image Recognition
https://arxiv.org/pdf/2306.13575.pdf#page=16
https://arxiv.org/pdf/2306.13575.pdf#page=6
Scaling Laws for Neural Language Models
LLaMa-1: Open and Efficient Foundation Language Models
https://arxiv.org/pdf/2306.13575.pdf#page=17
index#convolution-learning
[Transclude the forward-link's
context]
https://arxiv.org/pdf/2306.13575.pdf#page=7
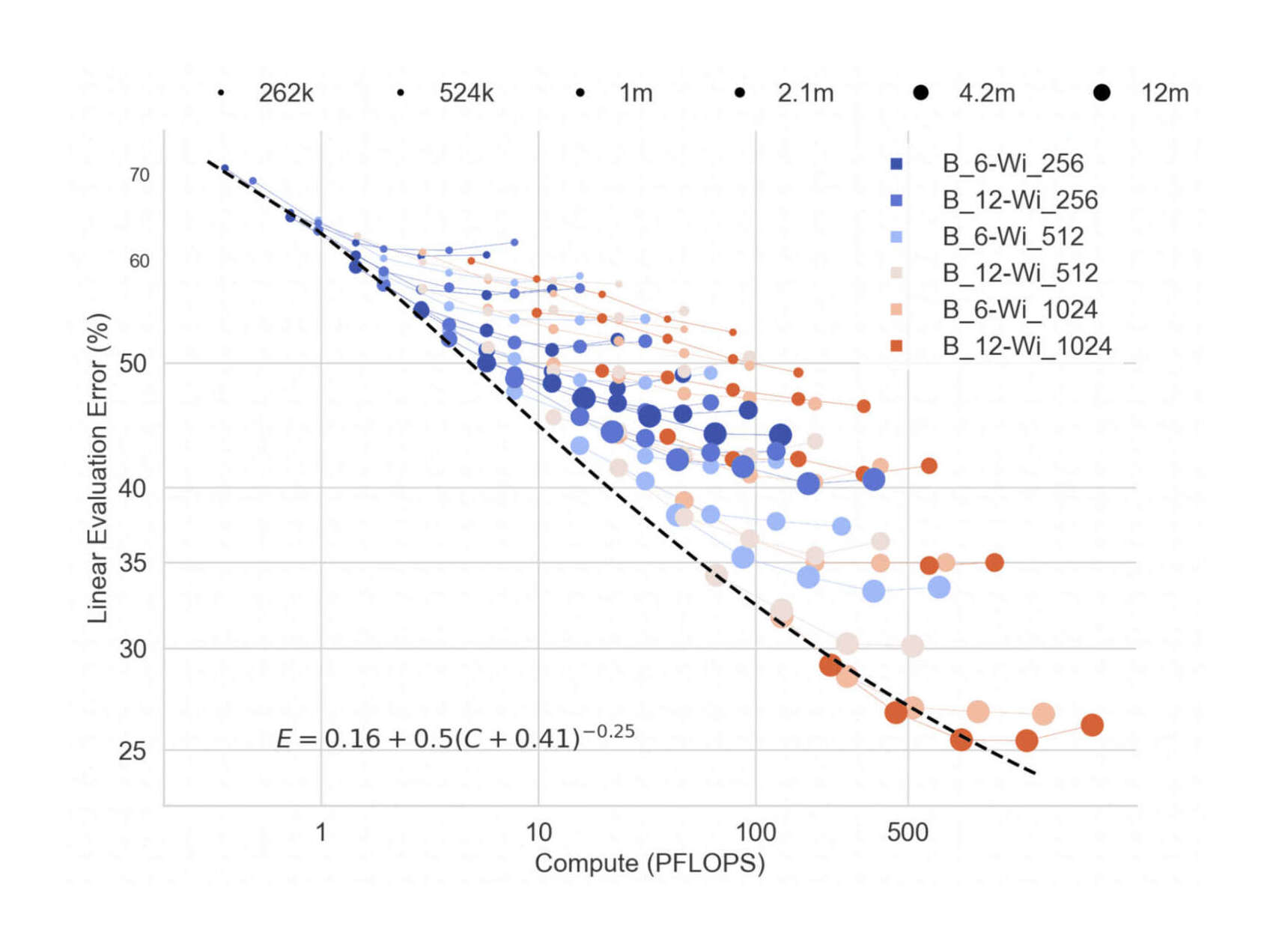
2023-bachmann-figure1-mlpcomputescalingoncifar100.jpg
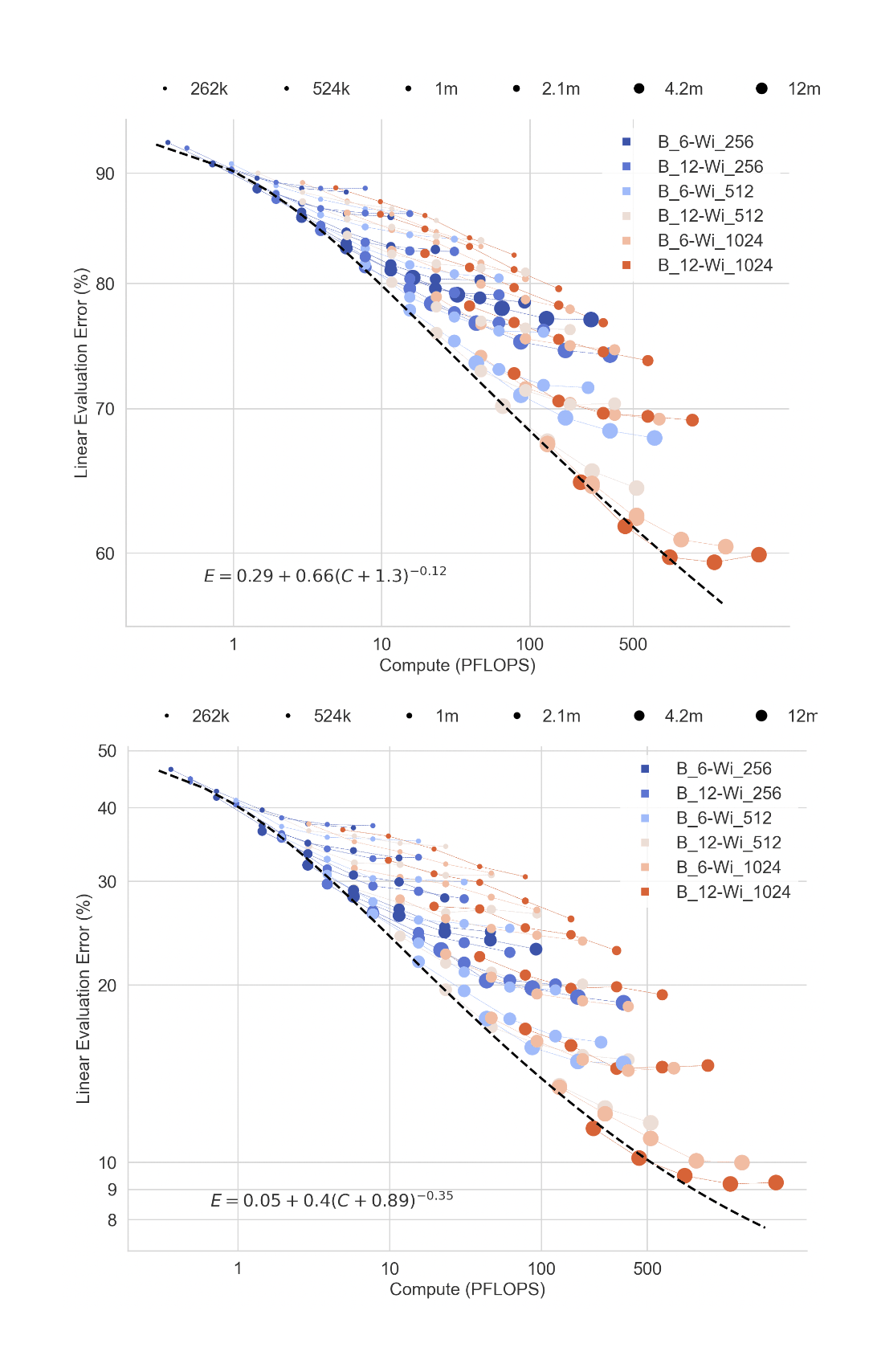
2023-bachmann-figure5-scalingofmlpsoncifar10andimagenet1k.png
https://arxiv.org/pdf/2306.13575.pdf#page=8
Chinchilla: Training Compute-Optimal Large Language Models
https://arxiv.org/abs/2306.12517
Vision Transformer: An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale
Faster SGD training by minibatch persistency
ConvNeXt: A ConvNet for the 2020s
ImageNet: A Large-Scale Hierarchical Image Database
{kind=link}
{kind=link}