‘grokking (NN)’ directory
- See Also
- Gwern
- Links
- “A Simple Method for Accelerating Grokking”, josh 2026
- “Grokking at the Edge of Numerical Stability”, Prieto et al 2025
- “The Complexity Dynamics of Grokking”, DeMoss et al 2024
- “Deep Learning Through A Telescoping Lens: A Simple Model Provides Empirical Insights On Grokking, Gradient Boosting & Beyond”, Jeffares et al 2024
- “The Slingshot Helps With Learning”, Wu 2024
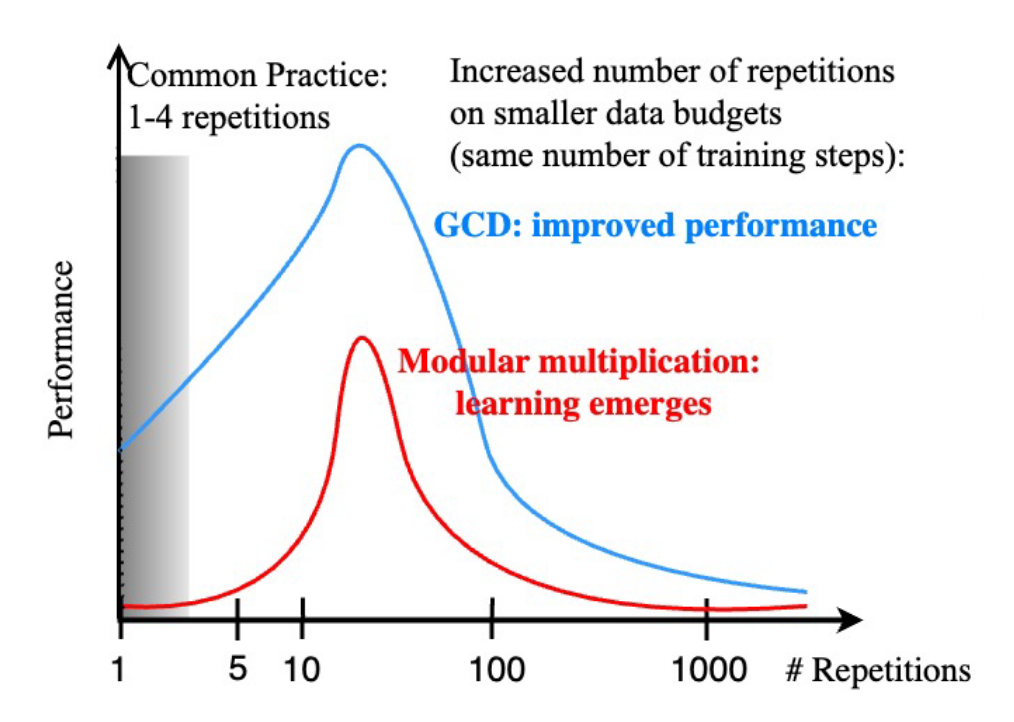
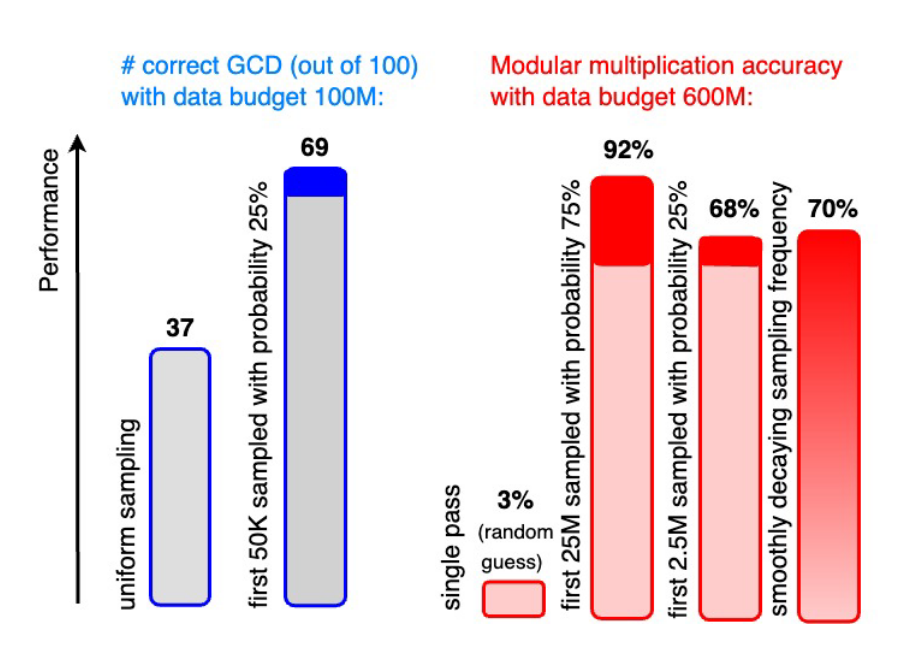
- “Emergent Properties With Repeated Examples”, Charton & Kempe 2024
- “Grokking Modular Polynomials”, Doshi et al 2024
- “Learning to Grok: Emergence of In-Context Learning and Skill Composition in Modular Arithmetic Tasks”, He et al 2024
- “Grokfast: Accelerated Grokking by Amplifying Slow Gradients”, Lee et al 2024
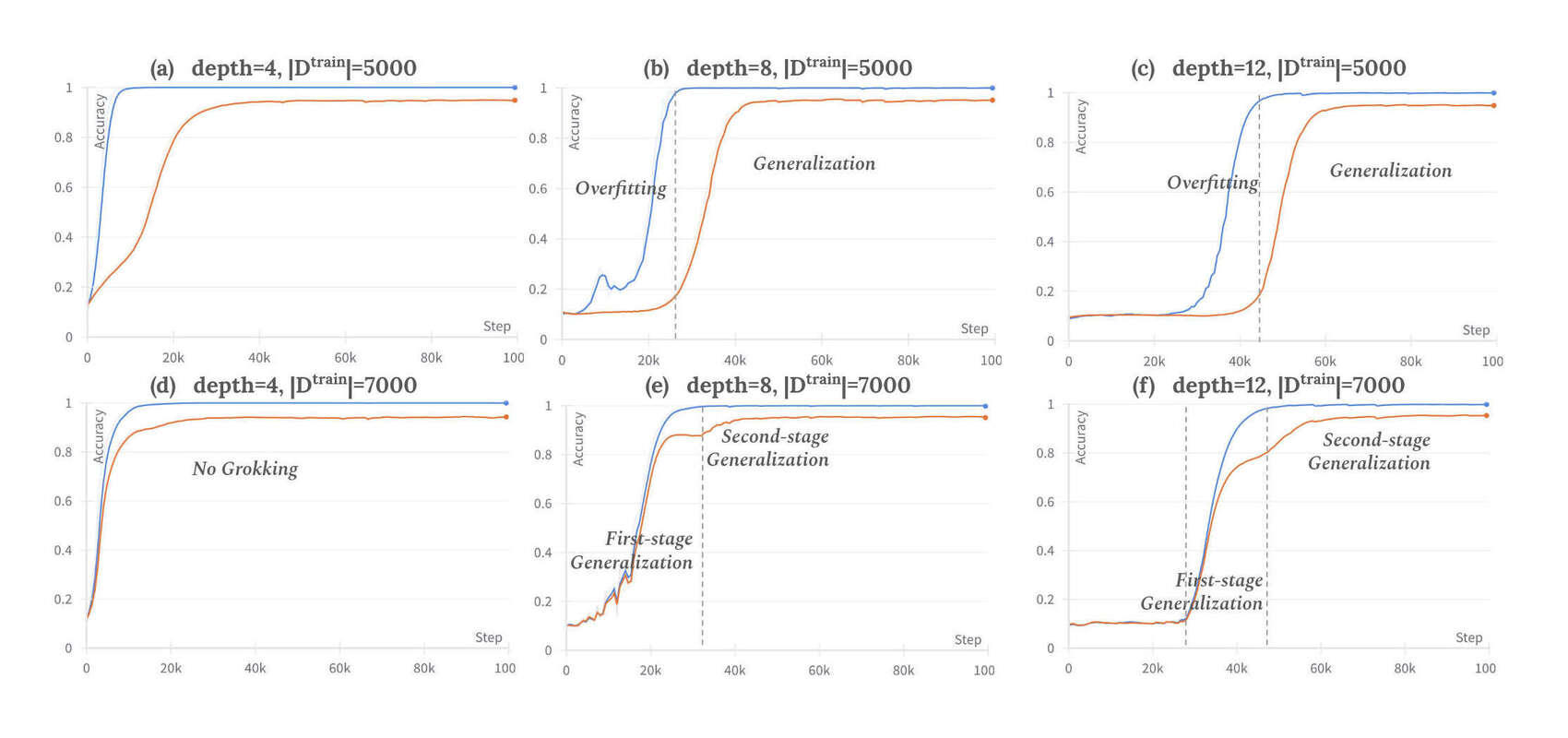
- “Deep Grokking: Would Deep Neural Networks Generalize Better?”, Fan et al 2024
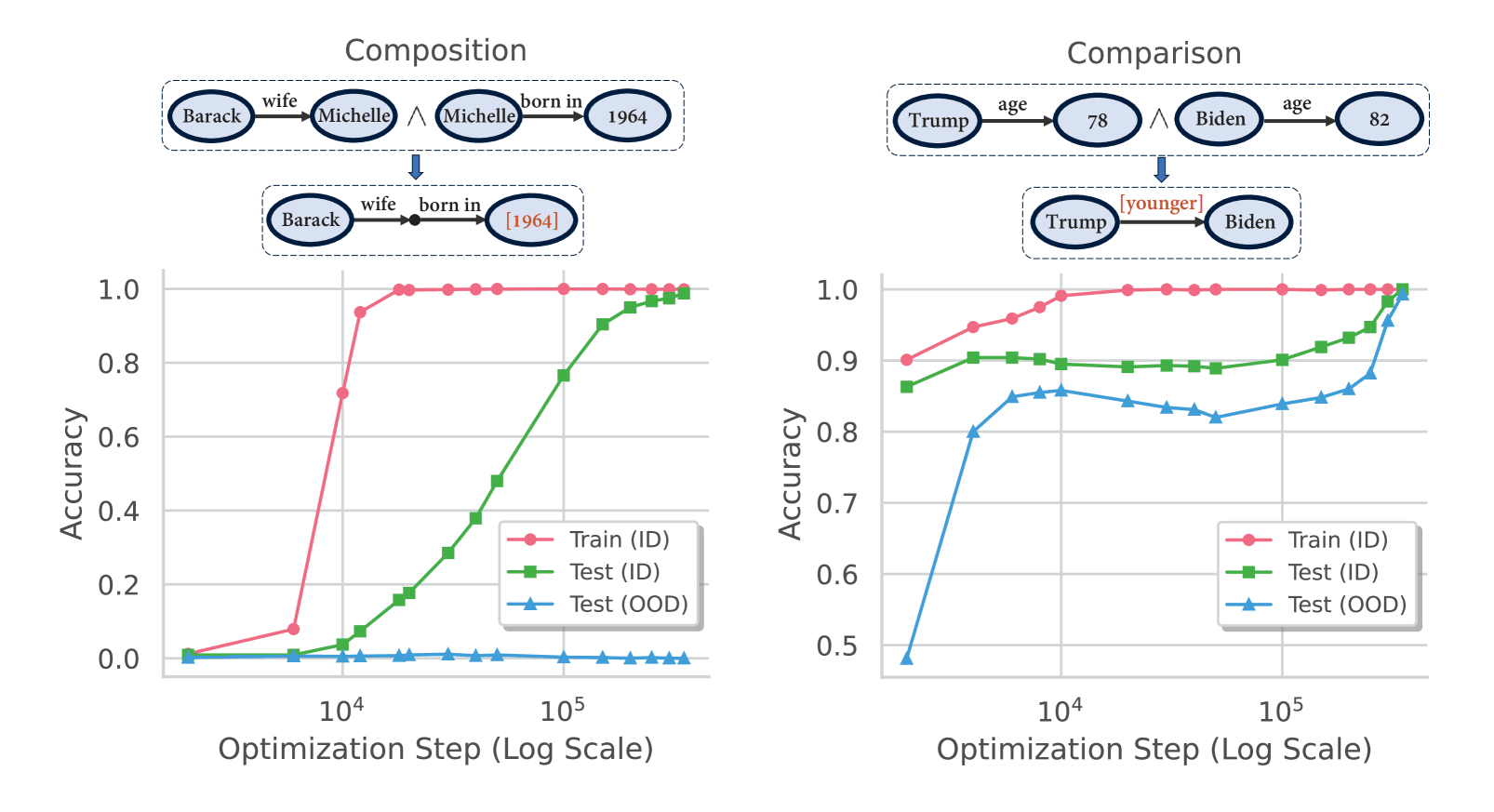
- “Grokked Transformers Are Implicit Reasoners: A Mechanistic Journey to the Edge of Generalization”, Wang et al 2024
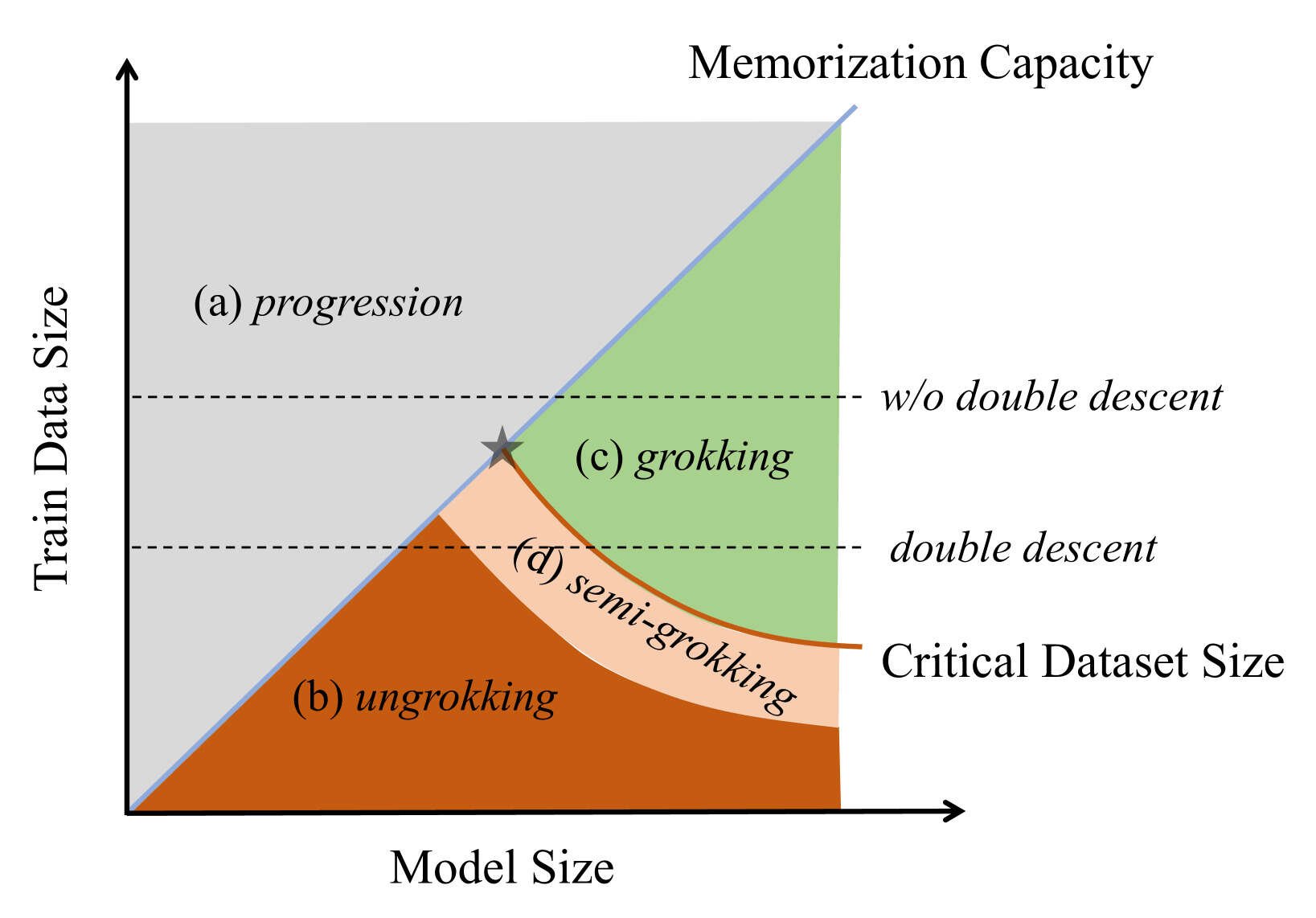
- “Unified View of Grokking, Double Descent and Emergent Abilities: A Perspective from Circuits Competition”, Huang et al 2024
- “A Tale of Tails: Model Collapse As a Change of Scaling Laws”, Dohmatob et al 2024
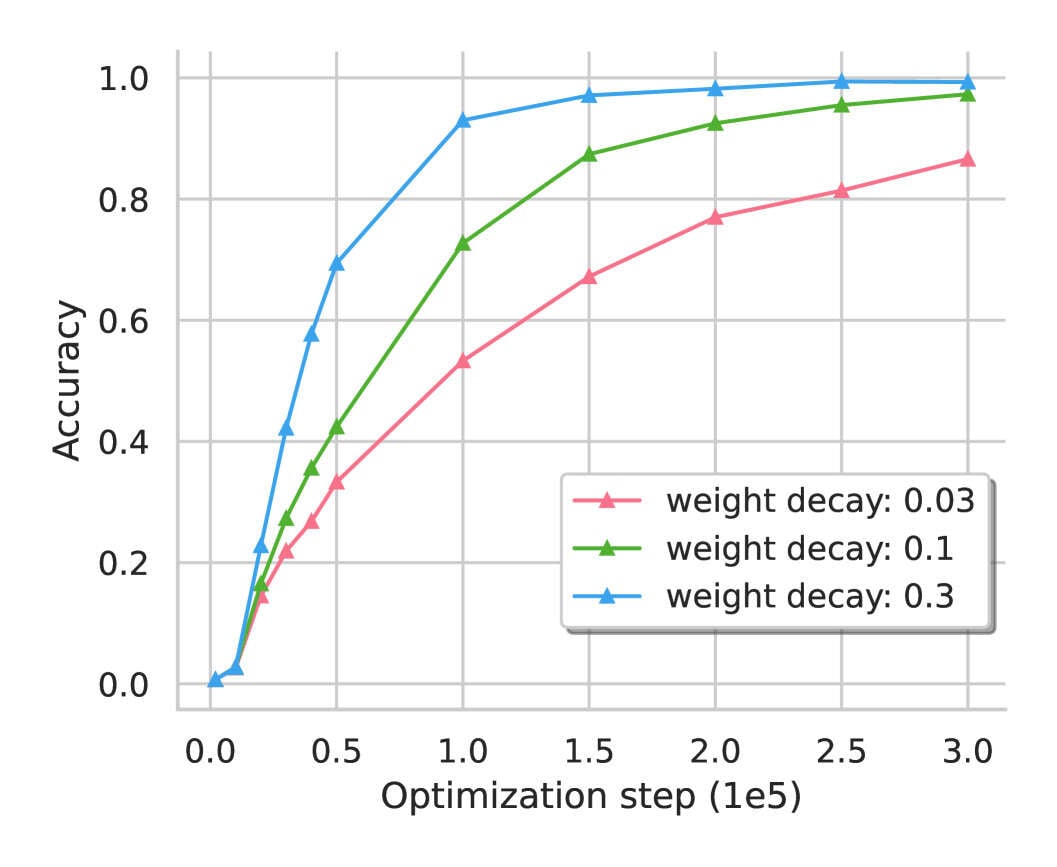
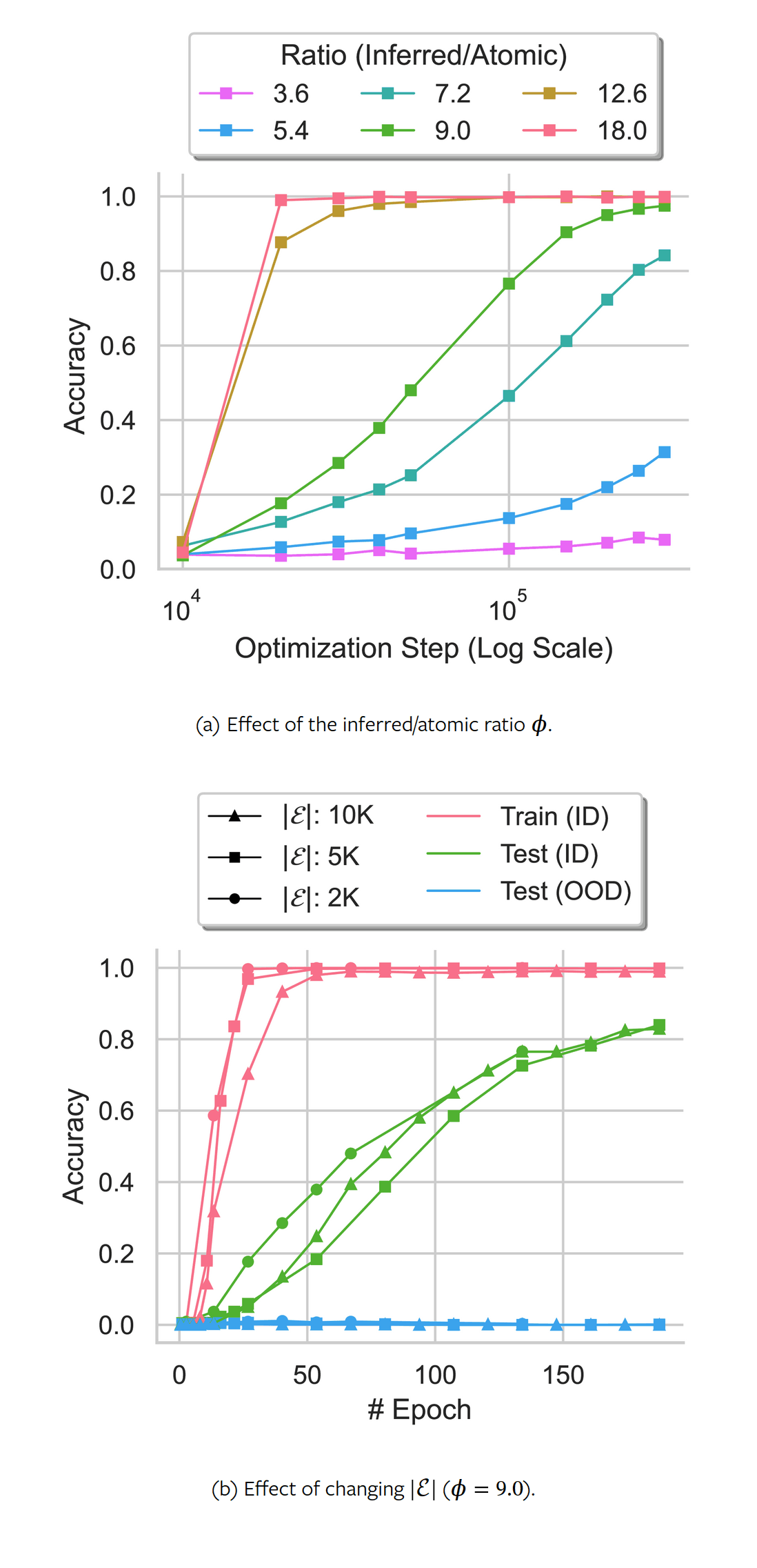
- “Critical Data Size of Language Models from a Grokking Perspective”, Zhu et al 2024
- “Grokking Group Multiplication With Cosets”, Stander et al 2023
- “Dichotomy of Early and Late Phase Implicit Biases Can Provably Induce Grokking”, Lyu et al 2023
- “Outliers With Opposing Signals Have an Outsized Effect on Neural Network Optimization”, Rosenfeld & Risteski 2023
- “Grokking Beyond Neural Networks: An Empirical Exploration With Model Complexity”, Miller et al 2023
- “Grokking in Linear Estimators—A Solvable Model That Groks without Understanding”, Levi et al 2023
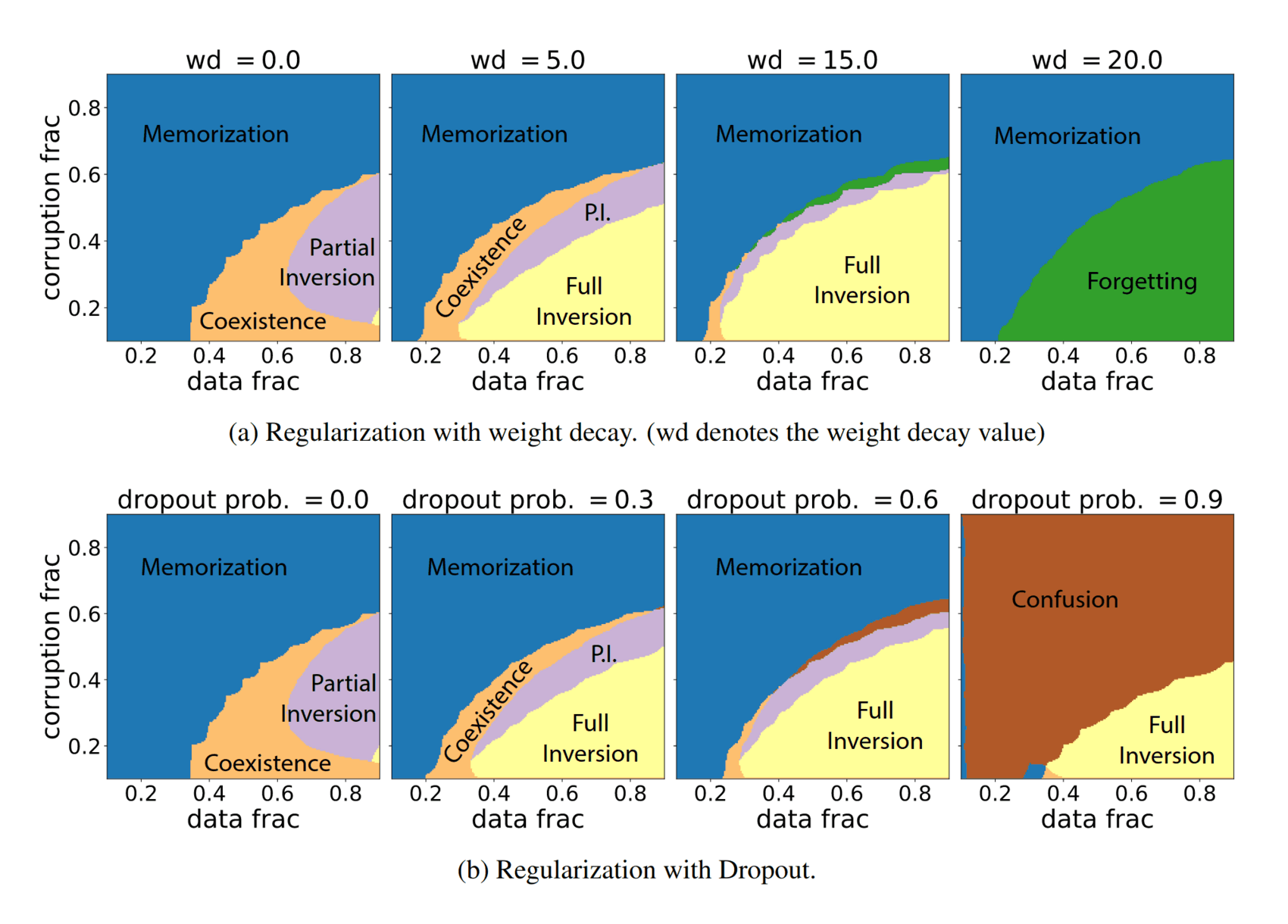
- “To Grok or Not to Grok: Disentangling Generalization and Memorization on Corrupted Algorithmic Datasets”, Doshi et al 2023
- “Grokking As the Transition from Lazy to Rich Training Dynamics”, Kumar et al 2023
- “PassUntil: Predicting Emergent Abilities With Infinite Resolution Evaluation”, Hu et al 2023
- “Explaining Grokking through Circuit Efficiency”, Varma et al 2023
- “Latent State Models of Training Dynamics”, Hu et al 2023
- “The Clock and the Pizza: Two Stories in Mechanistic Explanation of Neural Networks”, Zhong et al 2023
- “Predicting Grokking Long Before It Happens: A Look into the Loss Landscape of Models Which Grok”, Notsawo et al 2023
- “A Toy Model of Universality: Reverse Engineering How Networks Learn Group Operations”, Chughtai et al 2023
- “Progress Measures for Grokking via Mechanistic Interpretability”, Nanda et al 2023
- “Grokking Phase Transitions in Learning Local Rules With Gradient Descent”, Žunkovič & Ilievski 2022
- “Omnigrok: Grokking Beyond Algorithmic Data”, Liu et al 2022
- “The Slingshot Mechanism: An Empirical Study of Adaptive Optimizers and the Grokking Phenomenon”, Thilak et al 2022
- “Towards Understanding Grokking: An Effective Theory of Representation Learning”, Liu et al 2022
- “Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets [Paper]”, Power et al 2022
- “Learning through Atypical "Phase Transitions" in Overparameterized Neural Networks”, Baldassi et al 2021
- “Knowledge Distillation: A Good Teacher Is Patient and Consistent”, Beyer et al 2021
- “Grokking: Generalization Beyond Overfitting On Small Algorithmic Datasets”, Power et al 2021
- “The Large Learning Rate Phase of Deep Learning: the Catapult Mechanism”, Lewkowycz et al 2020
- “A Recipe for Training Neural Networks”, Karpathy 2019
- “The Complexity Dynamics of Grokking [Blog]”, DeMoss et al 2026
- “Sea-Snell/grokking: Unofficial Re-Implementation of ‘Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets’”
- “Openai/grok”
- “Digit-Addition-311p: a Grokked 311-Parameter Transformer for 10-Digit Addition”
- “Teddykoker/grokking: PyTorch Implementation of ‘Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets’”
- “Hypothesis: Gradient Descent Prefers General Circuits”
- “Grokking: Generalization beyond Overfitting on Small Algorithmic Datasets (Paper Explained)”
- Sort By Magic
- Miscellaneous
- Bibliography
See Also
Gwern
“Human-Like Neural Nets by Catapulting”, Gwern 2024
“Hardware Hedging Scaling Risks”, Gwern 2024
Links
“A Simple Method for Accelerating Grokking”, josh 2026
“Grokking at the Edge of Numerical Stability”, Prieto et al 2025
“The Complexity Dynamics of Grokking”, DeMoss et al 2024
“Deep Learning Through A Telescoping Lens: A Simple Model Provides Empirical Insights On Grokking, Gradient Boosting & Beyond”, Jeffares et al 2024
“The Slingshot Helps With Learning”, Wu 2024
“Emergent Properties With Repeated Examples”, Charton & Kempe 2024
“Grokking Modular Polynomials”, Doshi et al 2024
“Learning to Grok: Emergence of In-Context Learning and Skill Composition in Modular Arithmetic Tasks”, He et al 2024
Learning to grok: Emergence of in-context learning and skill composition in modular arithmetic tasks
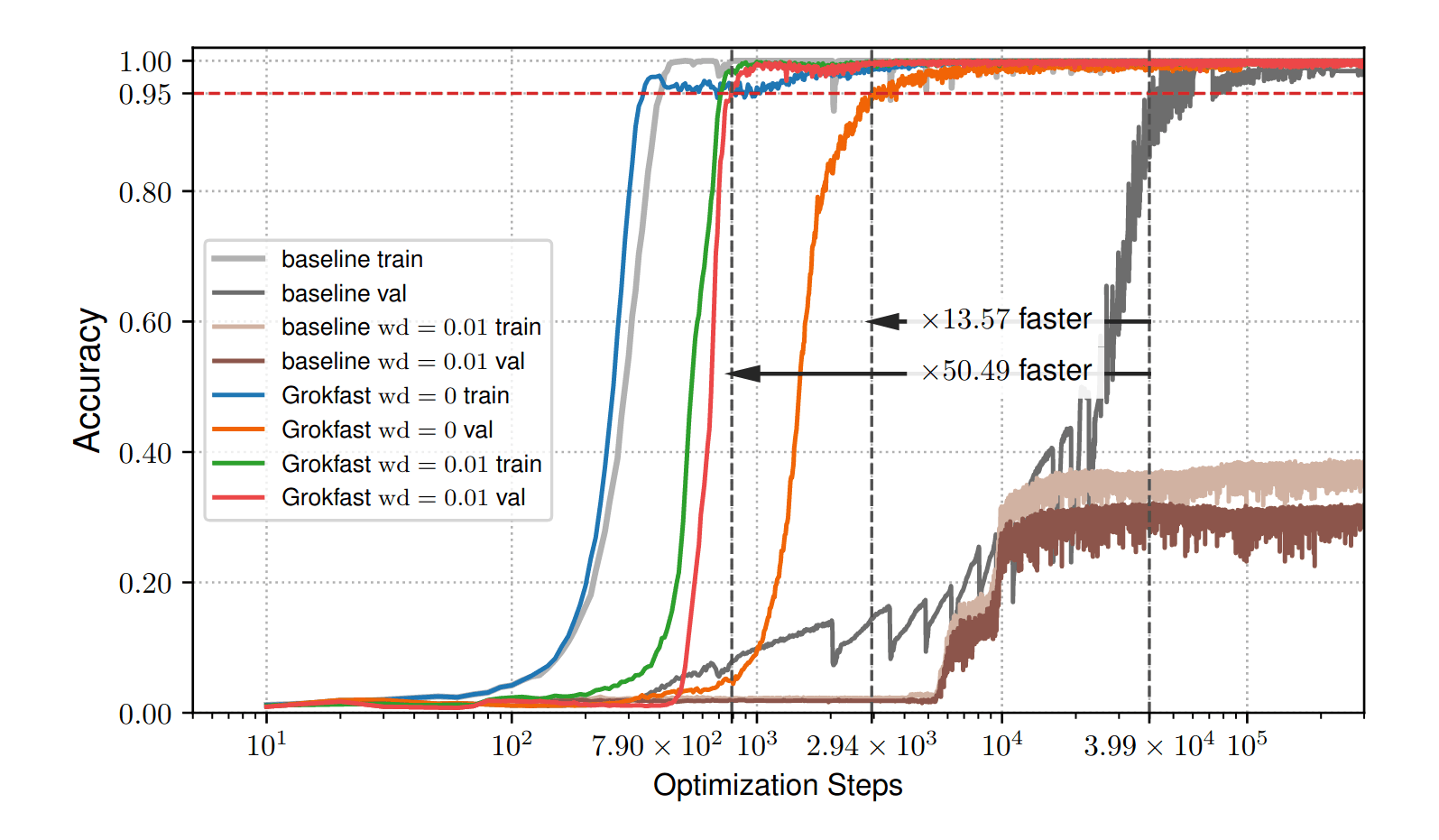
“Grokfast: Accelerated Grokking by Amplifying Slow Gradients”, Lee et al 2024
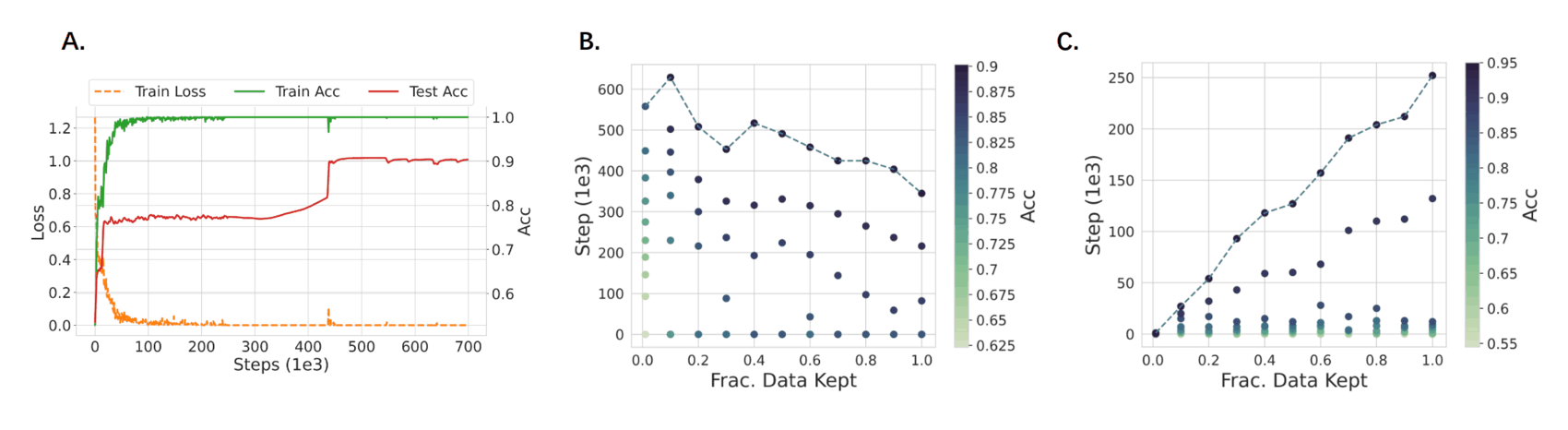
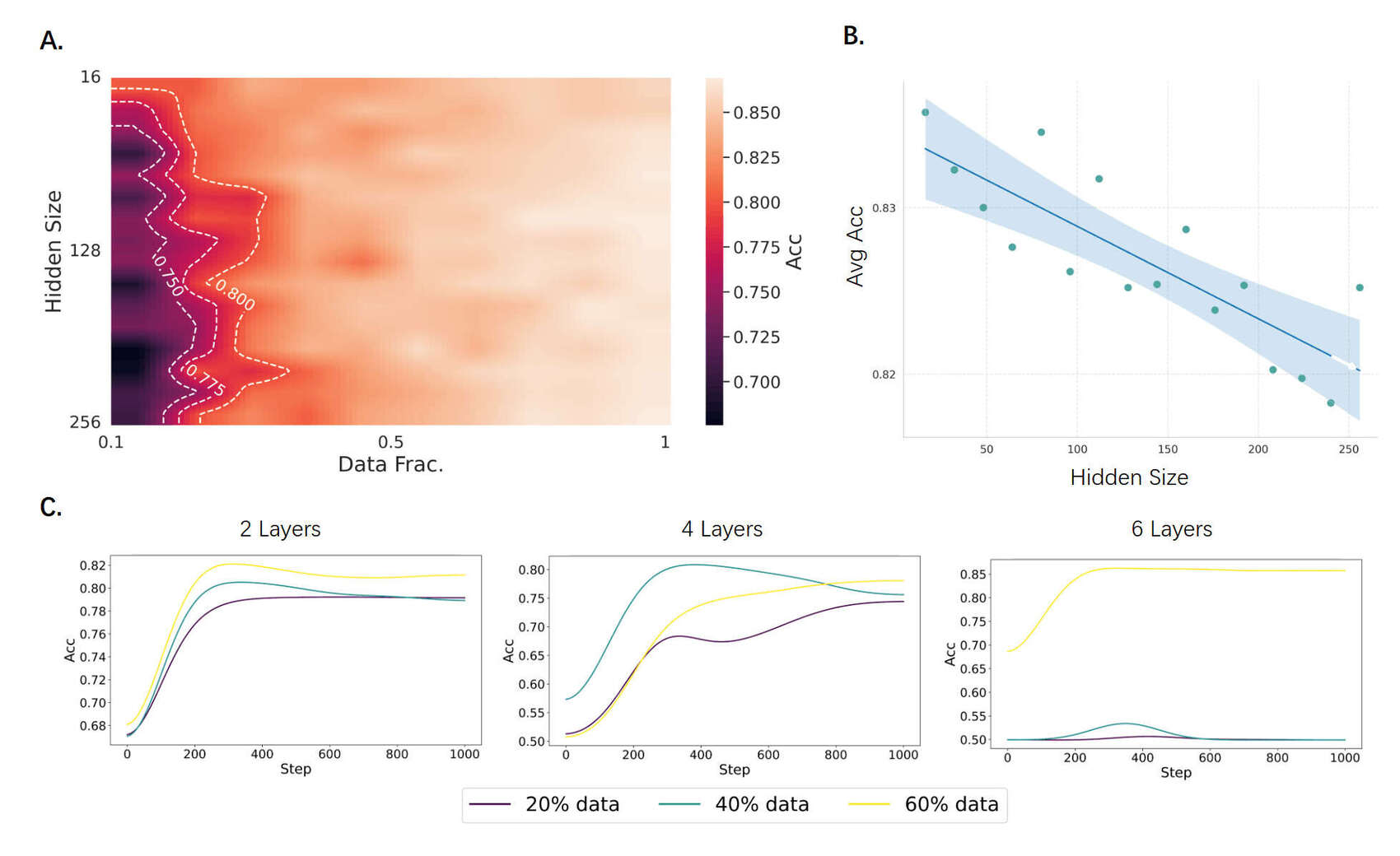
“Deep Grokking: Would Deep Neural Networks Generalize Better?”, Fan et al 2024
Deep Grokking: Would Deep Neural Networks Generalize Better?
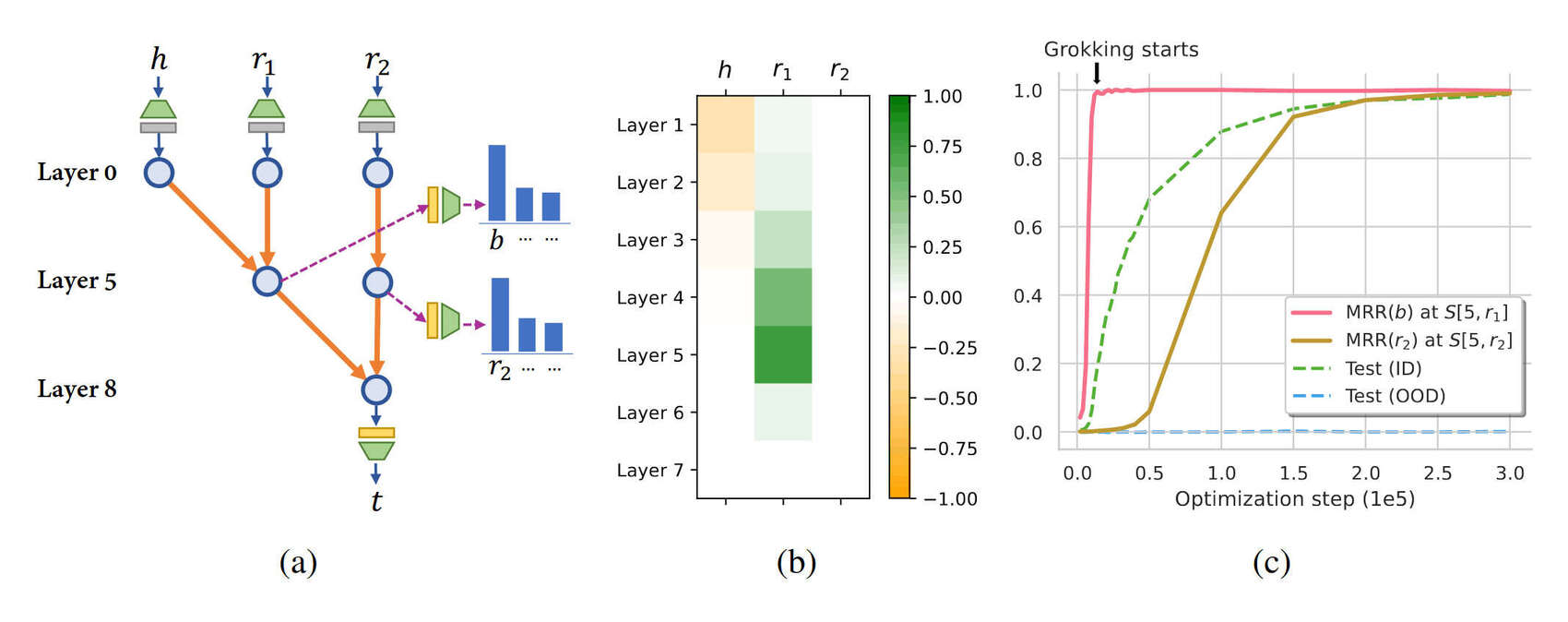
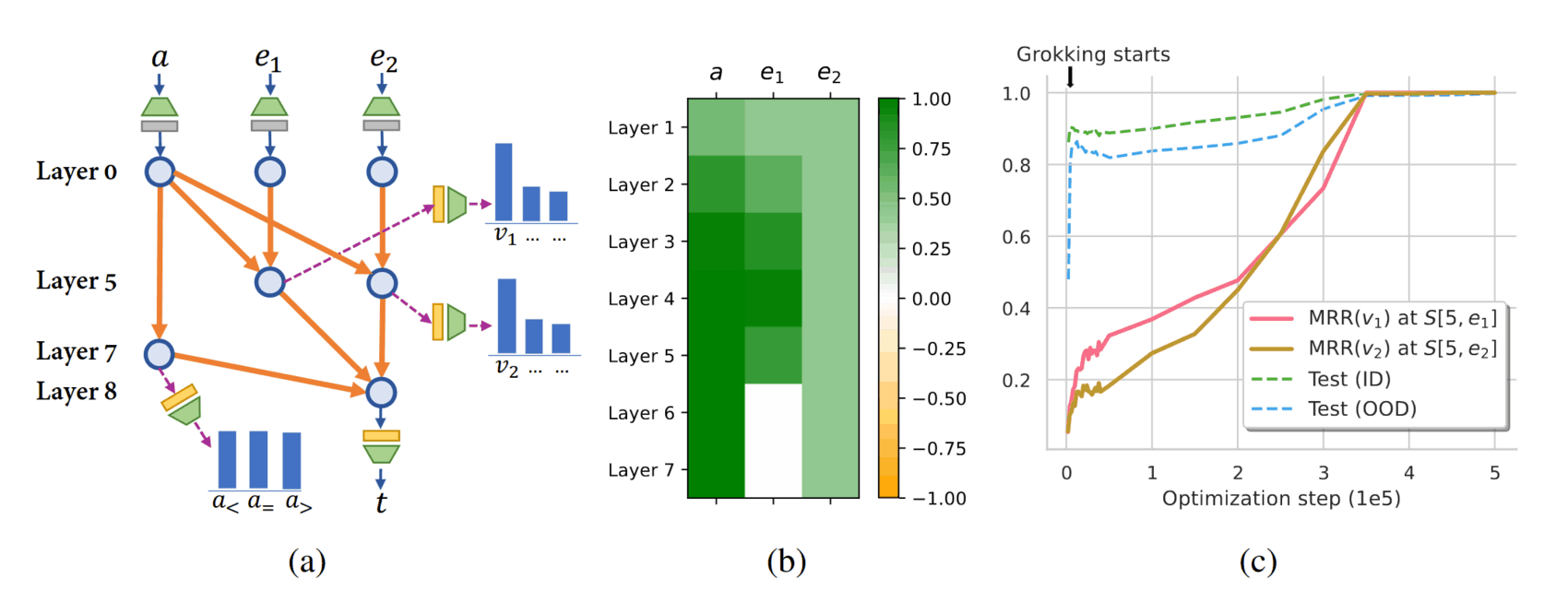
“Grokked Transformers Are Implicit Reasoners: A Mechanistic Journey to the Edge of Generalization”, Wang et al 2024
Grokked Transformers are Implicit Reasoners: A Mechanistic Journey to the Edge of Generalization
“Unified View of Grokking, Double Descent and Emergent Abilities: A Perspective from Circuits Competition”, Huang et al 2024
“A Tale of Tails: Model Collapse As a Change of Scaling Laws”, Dohmatob et al 2024
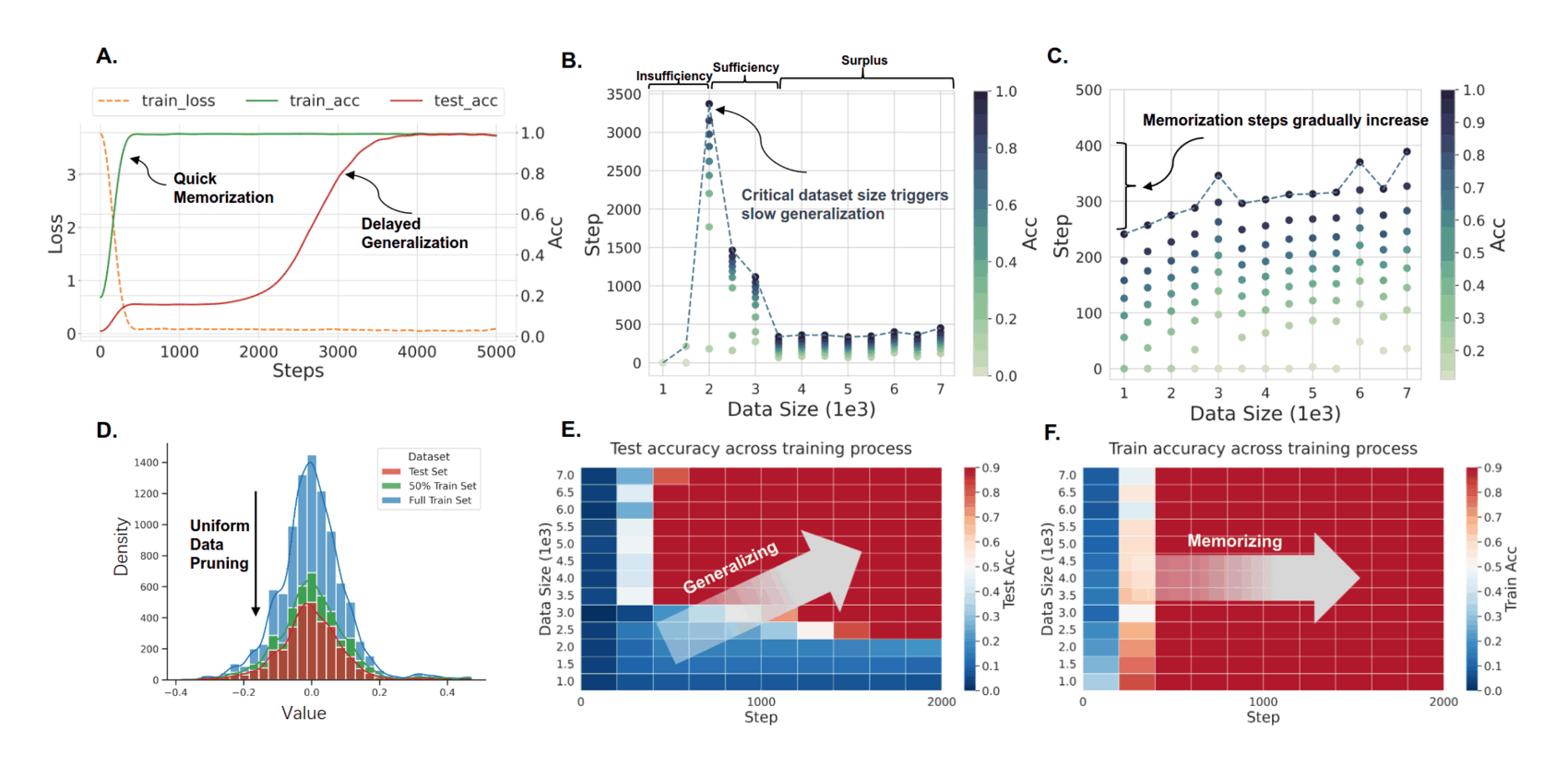
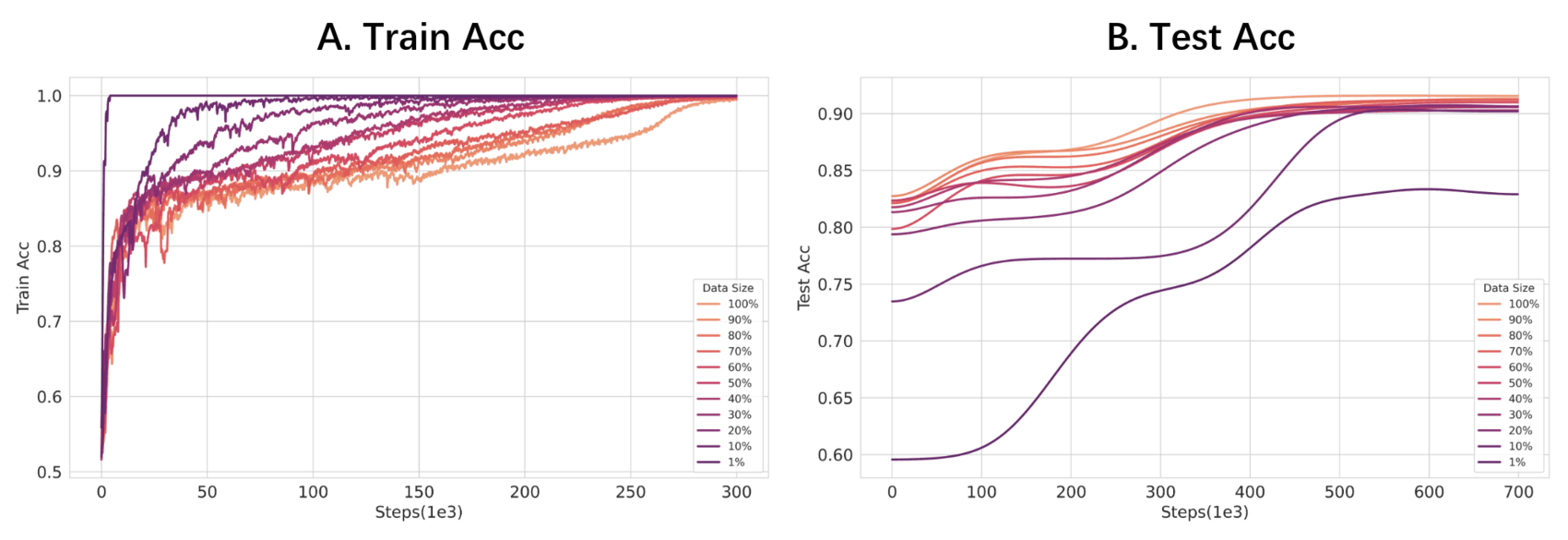
“Critical Data Size of Language Models from a Grokking Perspective”, Zhu et al 2024
Critical Data Size of Language Models from a Grokking Perspective
“Grokking Group Multiplication With Cosets”, Stander et al 2023
“Dichotomy of Early and Late Phase Implicit Biases Can Provably Induce Grokking”, Lyu et al 2023
Dichotomy of Early and Late Phase Implicit Biases Can Provably Induce Grokking
“Outliers With Opposing Signals Have an Outsized Effect on Neural Network Optimization”, Rosenfeld & Risteski 2023
Outliers with Opposing Signals Have an Outsized Effect on Neural Network Optimization
“Grokking Beyond Neural Networks: An Empirical Exploration With Model Complexity”, Miller et al 2023
Grokking Beyond Neural Networks: An Empirical Exploration with Model Complexity
“Grokking in Linear Estimators—A Solvable Model That Groks without Understanding”, Levi et al 2023
Grokking in Linear Estimators—A Solvable Model that Groks without Understanding
“To Grok or Not to Grok: Disentangling Generalization and Memorization on Corrupted Algorithmic Datasets”, Doshi et al 2023
“Grokking As the Transition from Lazy to Rich Training Dynamics”, Kumar et al 2023
Grokking as the Transition from Lazy to Rich Training Dynamics
“PassUntil: Predicting Emergent Abilities With Infinite Resolution Evaluation”, Hu et al 2023
PassUntil: Predicting Emergent Abilities with Infinite Resolution Evaluation
“Explaining Grokking through Circuit Efficiency”, Varma et al 2023
“Latent State Models of Training Dynamics”, Hu et al 2023
“The Clock and the Pizza: Two Stories in Mechanistic Explanation of Neural Networks”, Zhong et al 2023
The Clock and the Pizza: Two Stories in Mechanistic Explanation of Neural Networks
“Predicting Grokking Long Before It Happens: A Look into the Loss Landscape of Models Which Grok”, Notsawo et al 2023
Predicting Grokking Long Before it Happens: A look into the loss landscape of models which grok
“A Toy Model of Universality: Reverse Engineering How Networks Learn Group Operations”, Chughtai et al 2023
A Toy Model of Universality: Reverse Engineering How Networks Learn Group Operations
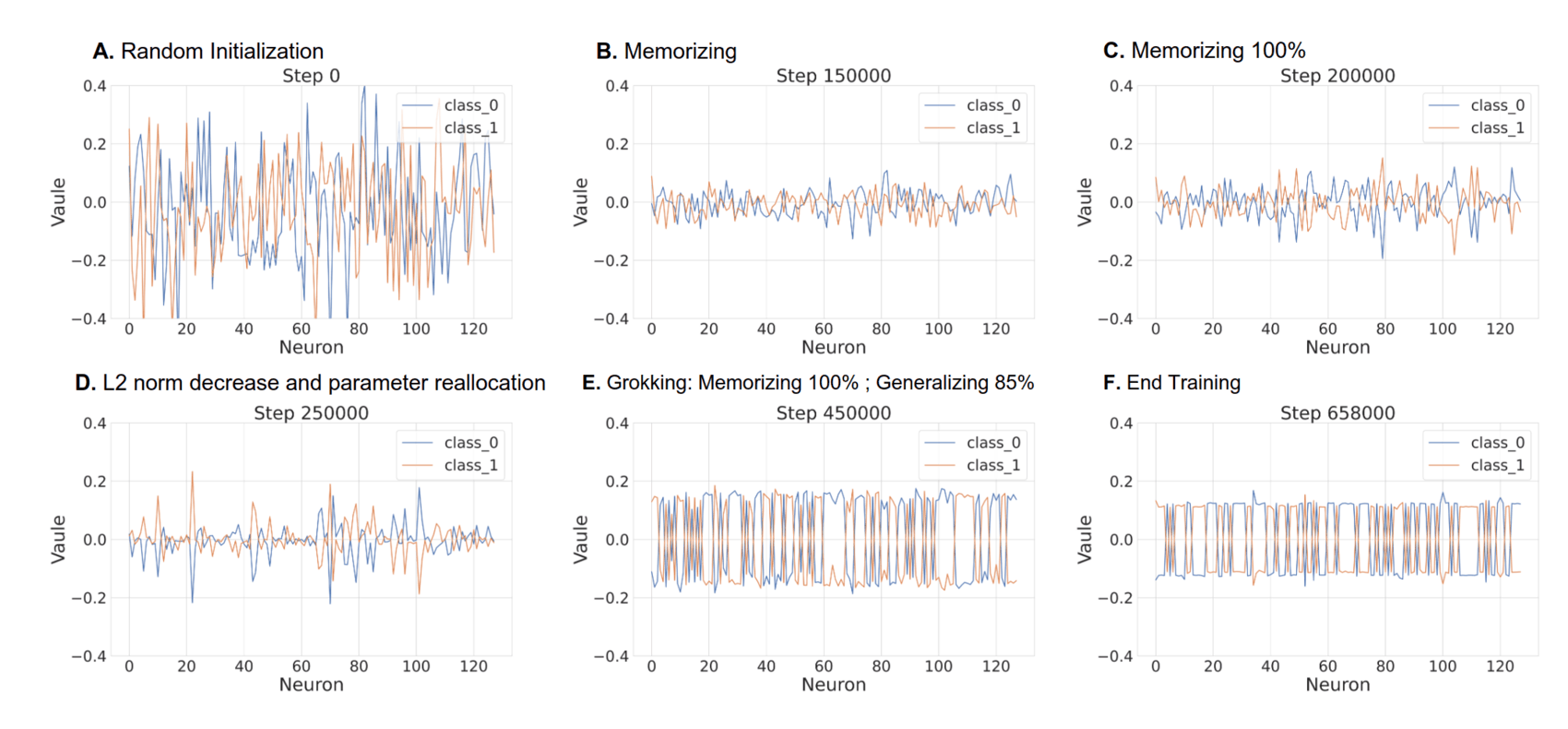
“Progress Measures for Grokking via Mechanistic Interpretability”, Nanda et al 2023
Progress measures for grokking via mechanistic interpretability
“Grokking Phase Transitions in Learning Local Rules With Gradient Descent”, Žunkovič & Ilievski 2022
Grokking phase transitions in learning local rules with gradient descent
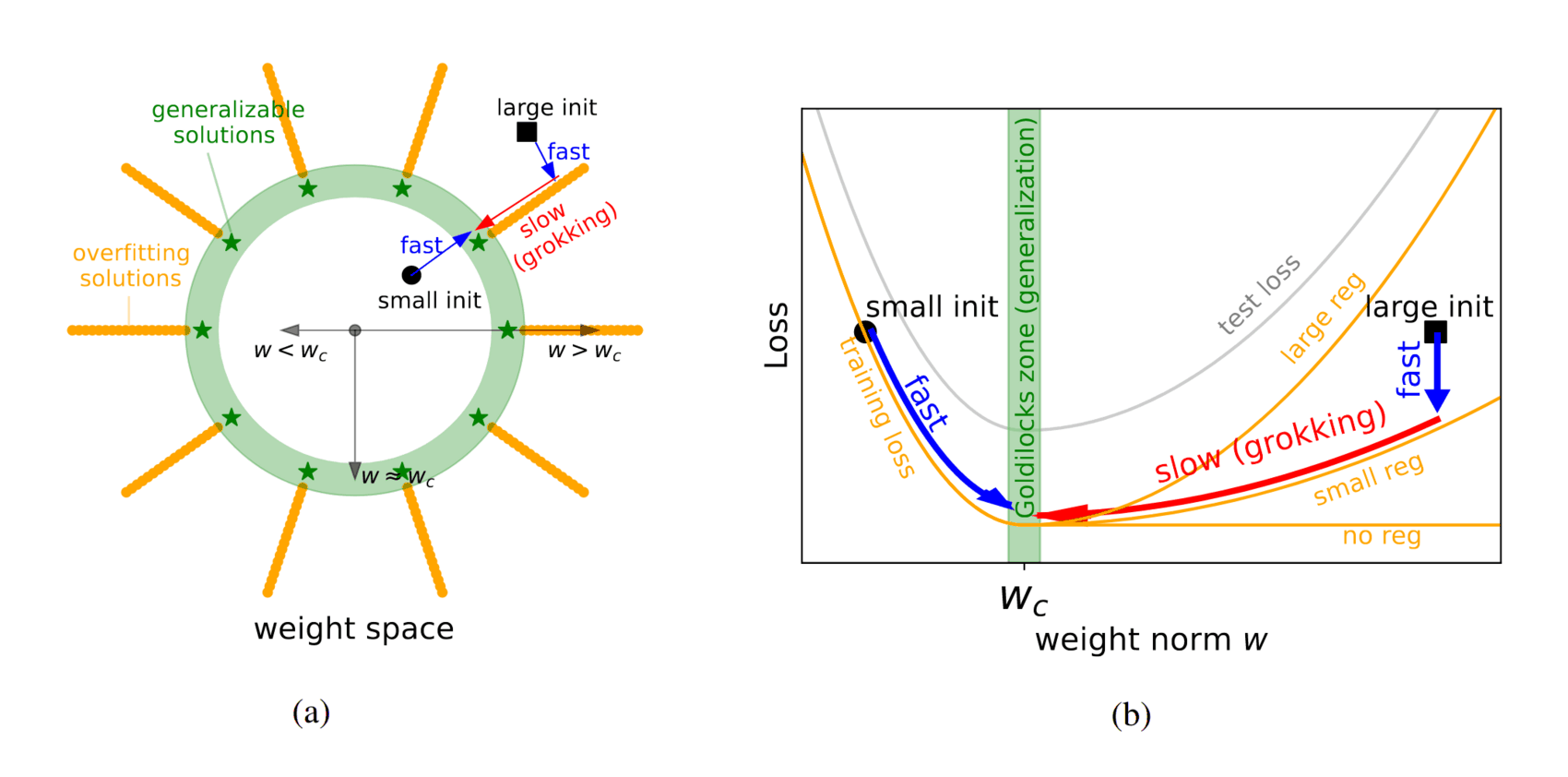
“Omnigrok: Grokking Beyond Algorithmic Data”, Liu et al 2022
“The Slingshot Mechanism: An Empirical Study of Adaptive Optimizers and the Grokking Phenomenon”, Thilak et al 2022
The Slingshot Mechanism: An Empirical Study of Adaptive Optimizers and the Grokking Phenomenon
“Towards Understanding Grokking: An Effective Theory of Representation Learning”, Liu et al 2022
Towards Understanding Grokking: An Effective Theory of Representation Learning
“Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets [Paper]”, Power et al 2022
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets [paper]
“Learning through Atypical "Phase Transitions" in Overparameterized Neural Networks”, Baldassi et al 2021
Learning through atypical "phase transitions" in overparameterized neural networks
“Knowledge Distillation: A Good Teacher Is Patient and Consistent”, Beyer et al 2021
Knowledge distillation: A good teacher is patient and consistent
“Grokking: Generalization Beyond Overfitting On Small Algorithmic Datasets”, Power et al 2021
Grokking: Generalization Beyond Overfitting On Small Algorithmic Datasets
“The Large Learning Rate Phase of Deep Learning: the Catapult Mechanism”, Lewkowycz et al 2020
The large learning rate phase of deep learning: the catapult mechanism
“A Recipe for Training Neural Networks”, Karpathy 2019
“The Complexity Dynamics of Grokking [Blog]”, DeMoss et al 2026
“Sea-Snell/grokking: Unofficial Re-Implementation of ‘Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets’”
“Openai/grok”
“Digit-Addition-311p: a Grokked 311-Parameter Transformer for 10-Digit Addition”
digit-addition-311p: a grokked 311-parameter Transformer for 10-digit addition
“Teddykoker/grokking: PyTorch Implementation of ‘Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets’”
“Hypothesis: Gradient Descent Prefers General Circuits”
“Grokking: Generalization beyond Overfitting on Small Algorithmic Datasets (Paper Explained)”
Grokking: Generalization beyond Overfitting on small algorithmic datasets (Paper Explained)
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
teachers-persistence distillation-concept knowledge-optimization distillation-strategies teacher-student model-relationship
emergent-properties
emergent-abilities
modular-generalization
grokking-theory scaling-grokking dynamic-representation learning-dynamics phase-transition grok-optimization
Miscellaneous
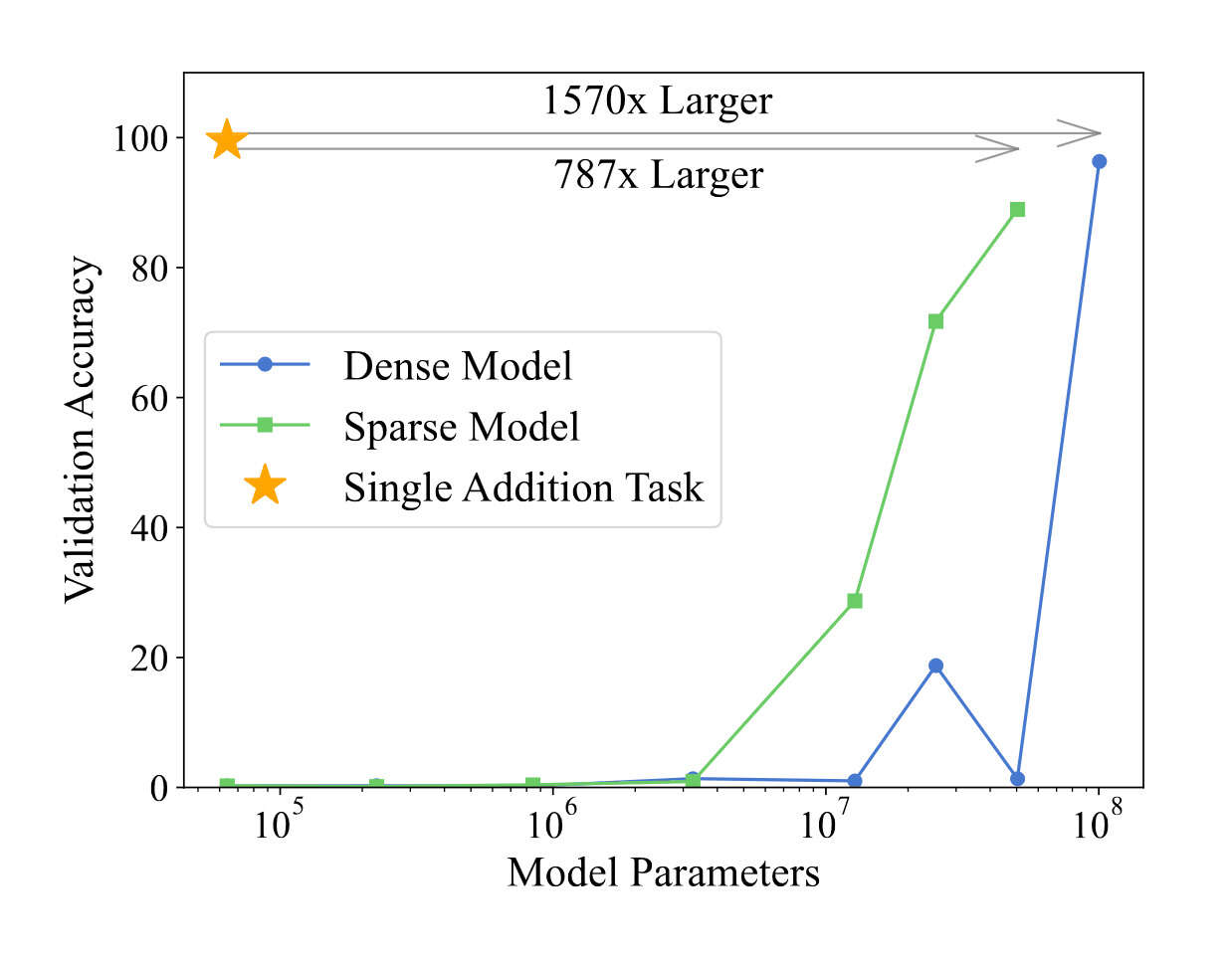
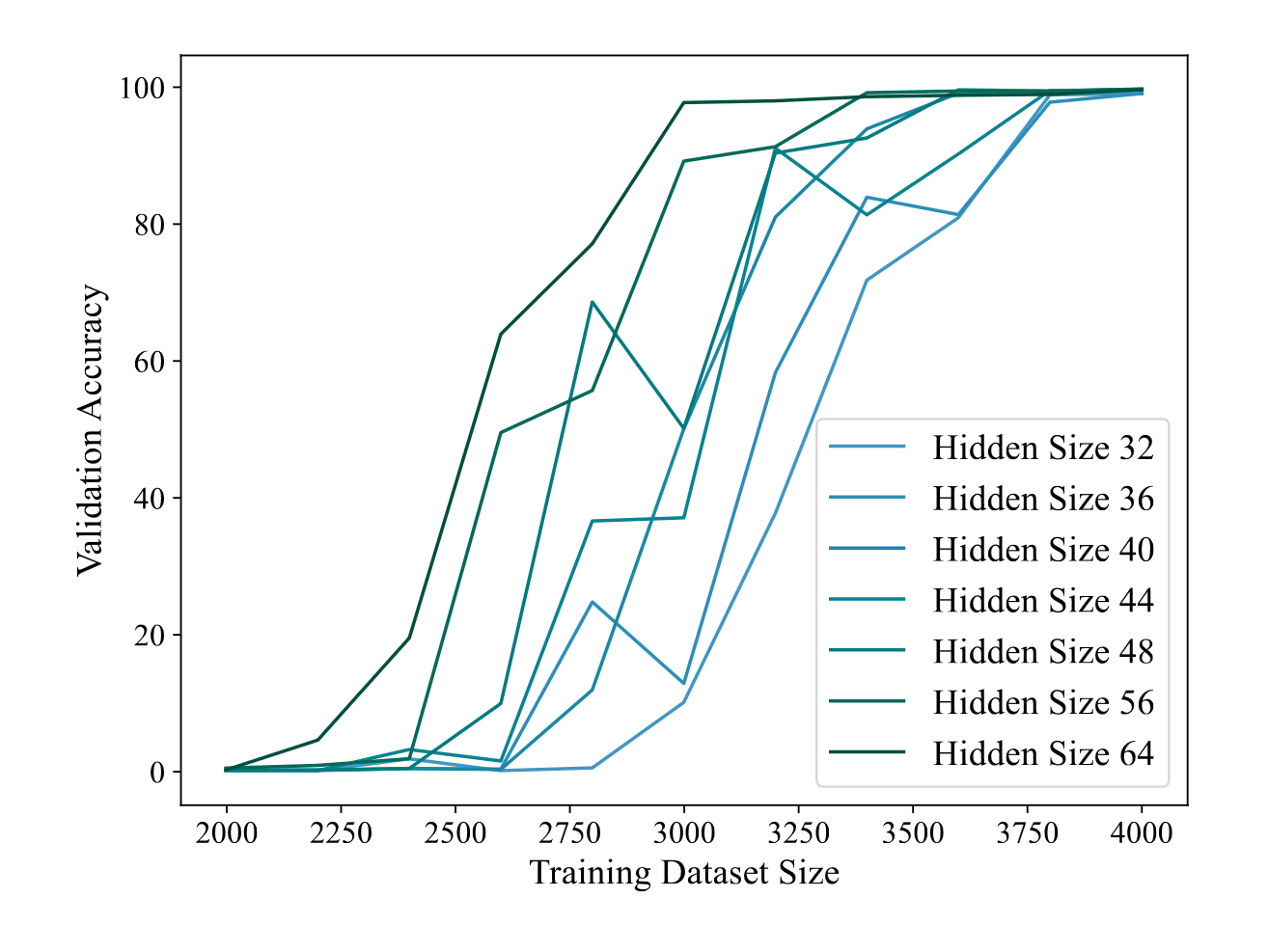
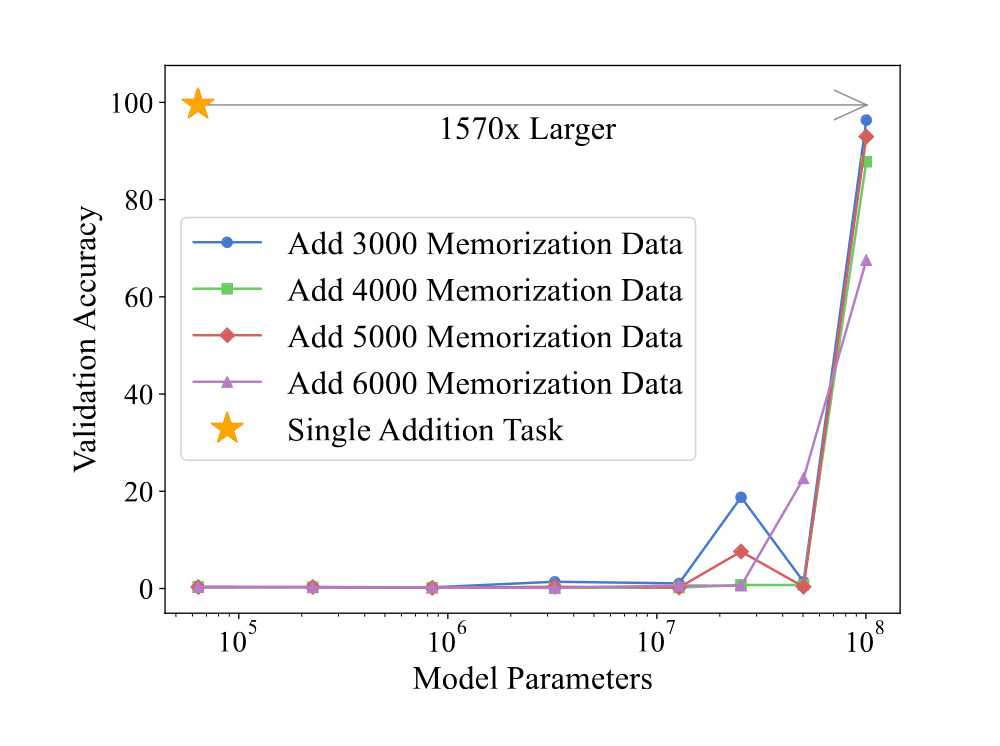
/doc/ai/scaling/emergence/grokking/2024-fan-figure2-grokkingincreaseswithmlpdepth.jpg/doc/ai/scaling/emergence/grokking/2024-huang-figure1-phasediagramofregimesforgrokking.jpg/doc/ai/scaling/emergence/grokking/2024-huang-figure3-modelscalingincreasesgrokking.png/doc/ai/scaling/emergence/grokking/2024-wang-figure1-grokkingforimplicitreasoning.png/doc/ai/scaling/emergence/grokking/2024-zhu-figure11-yelptransformergrokkingshowingdegrokking.png/doc/ai/scaling/emergence/grokking/2024-zhu-figure3-yelpgrokkingresults.png/doc/ai/scaling/emergence/grokking/2022-liu-figure6-phasediagramsofgrokking.png/doc/ai/nn/fully-connected/2021-power-figure1-grokkinglearningcurves.jpghttps://www.lesswrong.com/s/5omSW4wNKbEvYsyje/p/GpSzShaaf8po4rcmAView External Link:
https://www.lesswrong.com/s/5omSW4wNKbEvYsyje/p/GpSzShaaf8po4rcmA
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://www.lesswrong.com/posts/LncYobrn3vRr7qkZW/the-slingshot-helps-with-learning: “The Slingshot Helps With Learning”,https://arxiv.org/abs/2405.20233: “Grokfast: Accelerated Grokking by Amplifying Slow Gradients”,https://arxiv.org/abs/2405.19454: “Deep Grokking: Would Deep Neural Networks Generalize Better?”,https://arxiv.org/abs/2405.15071: “Grokked Transformers Are Implicit Reasoners: A Mechanistic Journey to the Edge of Generalization”,https://arxiv.org/abs/2402.15175: “Unified View of Grokking, Double Descent and Emergent Abilities: A Perspective from Circuits Competition”,https://arxiv.org/abs/2401.10463: “Critical Data Size of Language Models from a Grokking Perspective”,https://arxiv.org/abs/2310.13061: “To Grok or Not to Grok: Disentangling Generalization and Memorization on Corrupted Algorithmic Datasets”,https://arxiv.org/abs/2310.03262: “PassUntil: Predicting Emergent Abilities With Infinite Resolution Evaluation”,https://arxiv.org/abs/2306.13253: “Predicting Grokking Long Before It Happens: A Look into the Loss Landscape of Models Which Grok”,https://arxiv.org/abs/2301.05217: “Progress Measures for Grokking via Mechanistic Interpretability”,https://arxiv.org/abs/2210.15435: “Grokking Phase Transitions in Learning Local Rules With Gradient Descent”,https://arxiv.org/abs/2210.01117: “Omnigrok: Grokking Beyond Algorithmic Data”,https://arxiv.org/abs/2205.10343: “Towards Understanding Grokking: An Effective Theory of Representation Learning”,https://arxiv.org/abs/2110.00683: “Learning through Atypical "Phase Transitions" in Overparameterized Neural Networks”,https://arxiv.org/abs/2106.05237#google: “Knowledge Distillation: A Good Teacher Is Patient and Consistent”,2021-power.pdf#openai: “Grokking: Generalization Beyond Overfitting On Small Algorithmic Datasets”,https://karpathy.github.io/2019/04/25/recipe/: “A Recipe for Training Neural Networks”,