‘RL exploration’ directory
See Also
- Gwern
- “Towards Benchmarking LLM Diversity & Creativity ”, Gwern 2024
- “Can You Unsort Lists for Diversity? ”, Gwern 2019
- “Number Search Engine via NN Embeddings ”, Gwern 2024
- “Novelty Nets: Classifier Anti-Guidance ”, Gwern 2024
- “Free-Play Periods for RL Agents ”, Gwern 2023
- “Candy Japan’s New Box A/
B Test ”, Gwern 2016
- Links
- “Introducing Deep Research: An Agent That Uses Reasoning to Synthesize Large Amounts of Online Information and Complete Multi-Step Research Tasks for You. Available to Pro Users Today, Plus and Team Next ”, OpenAI 2025
- “Diverse Preference Optimization ”, Lanchantin et al 2025
- “Large Language Models Think Too Fast To Explore Effectively ”, Pan et al 2025
- “Multiagent Finetuning: Self Improvement With Diverse Reasoning Chains ”, Subramaniam et al 2025
- “SimpleStrat: Diversifying Language Model Generation With Stratification ”, Wong et al 2024
- “Learning Formal Mathematics From Intrinsic Motivation ”, Poesia et al 2024
- “Intelligent Go-Explore (IGE): Standing on the Shoulders of Giant Foundation Models ”, Lu et al 2024
- “Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts ”, Samvelyan et al 2024
- “Self-Supervised Behavior Cloned Transformers Are Path Crawlers for Text Games ”, Wang & Jansen 2023
- “Zero-Shot Goal-Directed Dialogue via RL on Imagined Conversations ”, Hong et al 2023
- “QDAIF: Quality-Diversity through AI Feedback ”, Bradley et al 2023
- “Beyond Memorization: Violating Privacy Via Inference With Large Language Models ”, Staab et al 2023
- “Let Models Speak Ciphers: Multiagent Debate through Embeddings ”, Pham et al 2023
- “Small Batch Deep Reinforcement Learning ”, Obando-Ceron et al 2023
- “Maximum Diffusion Reinforcement Learning ”, Berrueta et al 2023
- “Language Reward Modulation for Pretraining Reinforcement Learning ”, Adeniji et al 2023
- “Diversifying AI: Towards Creative Chess With AlphaZero (AZdb) ”, Zahavy et al 2023
- “Empowerment Contributes to Exploration Behavior in a Creative Video Game ”, Brändle et al 2023
- “Empowerment Contributes to Exploration Behavior in a Creative Video Game ”, Brändle et al 2023
- “Supervised Pretraining Can Learn In-Context Reinforcement Learning ”, Lee et al 2023
- “Learning to Generate Novel Scientific Directions With Contextualized Literature-Based Discovery ”, Wang et al 2023
- “You And Your Research ”, Hamming 2023
- “Long-Term Value of Exploration: Measurements, Findings and Algorithms ”, Su et al 2023
- “Inducing Anxiety in GPT-3.5 Increases Exploration and Bias ”, Coda-Forno et al 2023
- “Reflexion: Language Agents With Verbal Reinforcement Learning ”, Shinn et al 2023
- “MimicPlay: Long-Horizon Imitation Learning by Watching Human Play ”, Wang et al 2023
- “MarioGPT: Open-Ended Text2Level Generation through Large Language Models ”, Sudhakaran et al 2023
- “DreamerV3: Mastering Diverse Domains through World Models ”, Hafner et al 2023
- “AlphaZe∗∗: AlphaZero-Like Baselines for Imperfect Information Games Are Surprisingly Strong ”, Blüml et al 2023
- “AlphaZe∗∗: AlphaZero-Like Baselines for Imperfect Information Games Are Surprisingly Strong ”, Blüml et al 2023
- “Effect of Lysergic Acid Diethylamide (LSD) on Reinforcement Learning in Humans ”, Kanen et al 2022
- “Curiosity in Hindsight ”, Jarrett et al 2022
- “In-Context Reinforcement Learning With Algorithm Distillation ”, Laskin et al 2022
- “E3B: Exploration via Elliptical Episodic Bonuses ”, Henaff et al 2022
- “Vote-K: Selective Annotation Makes Language Models Better Few-Shot Learners ”, Su et al 2022
- “LGE: Cell-Free Latent Go-Explore ”, Gallouédec & Dellandréa 2022
- “LGE: Cell-Free Latent Go-Explore ”, Gallouédec & Dellandréa 2022
- “A Provably Efficient Model-Free Posterior Sampling Method for Episodic Reinforcement Learning ”, Dann et al 2022
- “Trajectory Autoencoding Planner: Efficient Planning in a Compact Latent Action Space ”, Jiang et al 2022
- “Value-Free Random Exploration Is Linked to Impulsivity ”, Dubois & Hauser 2022
- “Transformer Neural Processes: Uncertainty-Aware Meta Learning Via Sequence Modeling ”, Nguyen & Grover 2022
- “The Cost of Information Acquisition by Natural Selection ”, McGee et al 2022
- “Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos ”, Baker et al 2022
- “BYOL-Explore: Exploration by Bootstrapped Prediction ”, Guo et al 2022
- “Multi-Objective Hyperparameter Optimization—An Overview ”, Karl et al 2022
- “Director: Deep Hierarchical Planning from Pixels ”, Hafner et al 2022
- “Boosting Search Engines With Interactive Agents ”, Ciaramita et al 2022
- “Towards Learning Universal Hyperparameter Optimizers With Transformers ”, Chen et al 2022
- “Cliff Diving: Exploring Reward Surfaces in Reinforcement Learning Environments ”, Sullivan et al 2022
- “Effective Mutation Rate Adaptation through Group Elite Selection ”, Kumar et al 2022
- “Semantic Exploration from Language Abstractions and Pretrained Representations ”, Tam et al 2022
- “Habitat-Web: Learning Embodied Object-Search Strategies from Human Demonstrations at Scale ”, Ramrakhya et al 2022
- “CLIP on Wheels (CoW): Zero-Shot Object Navigation As Object Localization and Exploration ”, Gadre et al 2022
- “Policy Improvement by Planning With Gumbel ”, Danihelka et al 2022
- “Evolving Curricula With Regret-Based Environment Design ”, Parker-Holder et al 2022
- “VAPO: Affordance Learning from Play for Sample-Efficient Policy Learning ”, Borja-Diaz et al 2022
- “Learning Causal Overhypotheses through Exploration in Children and Computational Models ”, Kosoy et al 2022
- “Policy Learning and Evaluation With Randomized Quasi-Monte Carlo ”, Arnold et al 2022
- “NeuPL: Neural Population Learning ”, Liu et al 2022
- “ODT: Online Decision Transformer ”, Zheng et al 2022
- “EvoJAX: Hardware-Accelerated Neuroevolution ”, Tang et al 2022
- “LID: Pre-Trained Language Models for Interactive Decision-Making ”, Li et al 2022
- “Accelerated Quality-Diversity for Robotics through Massive Parallelism ”, Lim et al 2022
- “Rotting Infinitely Many-Armed Bandits ”, Kim et al 2022
- “Don’t Change the Algorithm, Change the Data: Exploratory Data for Offline Reinforcement Learning (ExORL) ”, Yarats et al 2022
- “Any-Play: An Intrinsic Augmentation for Zero-Shot Coordination ”, Lucas & Allen 2022
- “Evolution Gym: A Large-Scale Benchmark for Evolving Soft Robots ”, Bhatia et al 2022
- “Environment Generation for Zero-Shot Compositional Reinforcement Learning ”, Gur et al 2022
- “Safe Deep RL in 3D Environments Using Human Feedback ”, Rahtz et al 2022
- “Automated Reinforcement Learning (AutoRL): A Survey and Open Problems ”, Parker-Holder et al 2022
- “Maximum Entropy Population Based Training for Zero-Shot Human-AI Coordination ”, Zhao et al 2021
- “The Costs and Benefits of Dispersal in Small Populations ”, Polechova 2021
- “The Geometry of Decision-Making in Individuals and Collectives ”, Sridhar et al 2021
- “An Experimental Design Perspective on Model-Based Reinforcement Learning ”, Mehta et al 2021
- “JueWu-MC: Playing Minecraft With Sample-Efficient Hierarchical Reinforcement Learning ”, Lin et al 2021
- “Procedural Generalization by Planning With Self-Supervised World Models ”, Anand et al 2021
- “Correspondence between Neuroevolution and Gradient Descent ”, Whitelam et al 2021
- “URLB: Unsupervised Reinforcement Learning Benchmark ”, Laskin et al 2021
- “Mastering Atari Games With Limited Data ”, Ye et al 2021
- “Discovering and Achieving Goals via World Models ”, Mendonca et al 2021
- “The Structure of Genotype-Phenotype Maps Makes Fitness Landscapes Navigable ”, Greenbury et al 2021
- “Replay-Guided Adversarial Environment Design ”, Jiang et al 2021
- “A Review of the Gumbel-Max Trick and Its Extensions for Discrete Stochasticity in Machine Learning ”, Huijben et al 2021
- “Monkey Plays Pac-Man With Compositional Strategies and Hierarchical Decision-Making ”, Yang et al 2021
- “Neural Autopilot and Context-Sensitivity of Habits ”, Camerer & Li 2021
- “Algorithmic Balancing of Familiarity, Similarity, & Discovery in Music Recommendations ”, Mehrotra 2021
- “TrufLL: Learning Natural Language Generation from Scratch ”, Donati et al 2021
- “Is Curiosity All You Need? On the Utility of Emergent Behaviors from Curious Exploration ”, Groth et al 2021
- “Bootstrapped Meta-Learning ”, Flennerhag et al 2021
- “Open-Ended Learning Leads to Generally Capable Agents ”, Team et al 2021
- “Learning a Large Neighborhood Search Algorithm for Mixed Integer Programs ”, Sonnerat et al 2021
- “Why Generalization in RL Is Difficult: Epistemic POMDPs and Implicit Partial Observability ”, Ghosh et al 2021
- “Imitation-Driven Cultural Collapse ”, Duran-Nebreda & Valverde 2021
- “Multi-Task Curriculum Learning in a Complex, Visual, Hard-Exploration Domain: Minecraft ”, Kanitscheider et al 2021
- “Learning to Hesitate ”, Descamps et al 2021
- “Planning for Novelty: Width-Based Algorithms for Common Problems in Control, Planning and Reinforcement Learning ”, Lipovetzky 2021
- “Trajectory Transformer: Reinforcement Learning As One Big Sequence Modeling Problem ”, Janner et al 2021
- “From Motor Control to Team Play in Simulated Humanoid Football ”, Liu et al 2021
- “Reward Is Enough ”, Silver et al 2021
- “Principled Exploration via Optimistic Bootstrapping and Backward Induction ”, Bai et al 2021
- “Intelligence and Unambitiousness Using Algorithmic Information Theory ”, Cohen et al 2021
- “Deep Bandits Show-Off: Simple and Efficient Exploration With Deep Networks ”, Zhu & Rigotti 2021
- “On Lottery Tickets and Minimal Task Representations in Deep Reinforcement Learning ”, Vischer et al 2021
- “What Are Bayesian Neural Network Posteriors Really Like? ”, Izmailov et al 2021
- “Epistemic Autonomy: Self-Supervised Learning in the Mammalian Hippocampus ”, Santos-Pata et al 2021
- “Bayesian Optimization Is Superior to Random Search for Machine Learning Hyperparameter Tuning: Analysis of the Black-Box Optimization Challenge 2020 ”, Turner et al 2021
- “Flexible Modulation of Sequence Generation in the Entorhinal-Hippocampal System ”, McNamee et al 2021
- “Reinforcement Learning, Bit by Bit ”, Lu et al 2021
- “Asymmetric Self-Play for Automatic Goal Discovery in Robotic Manipulation ”, OpenAI et al 2021
- “Informational Herding, Optimal Experimentation, and Contrarianism ”, Smith et al 2021
- “Go-Explore: First Return, Then Explore ”, Ecoffet et al 2021
- “TacticZero: Learning to Prove Theorems from Scratch With Deep Reinforcement Learning ”, Wu et al 2021
- “Proof Artifact Co-Training for Theorem Proving With Language Models ”, Han et al 2021
- “The MineRL 2020 Competition on Sample Efficient Reinforcement Learning Using Human Priors ”, Guss et al 2021
- “Curriculum Learning: A Survey ”, Soviany et al 2021
- “MAP-Elites Enables Powerful Stepping Stones and Diversity for Modular Robotics ”, Nordmoen et al 2021
- “Is Pessimism Provably Efficient for Offline RL? ”, Jin et al 2020
- “Monte-Carlo Graph Search for AlphaZero ”, Czech et al 2020
- “Imitating Interactive Intelligence ”, Abramson et al 2020
- “Emergent Complexity and Zero-Shot Transfer via Unsupervised Environment Design [UED+PAIRED] ”, Dennis et al 2020
- “Ridge Rider: Finding Diverse Solutions by Following Eigenvectors of the Hessian ”, Parker-Holder et al 2020
- “Meta-Trained Agents Implement Bayes-Optimal Agents ”, Mikulik et al 2020
- “Learning Not to Learn: Nature versus Nurture in Silico ”, Lange & Sprekeler 2020
- “The Child As Hacker ”, Rule et al 2020
- “Assessing Game Balance With AlphaZero: Exploring Alternative Rule Sets in Chess ”, Tomašev et al 2020
- “Assessing Game Balance With AlphaZero: Exploring Alternative Rule Sets in Chess ”, Tomašev et al 2020
- “The Temporal Dynamics of Opportunity Costs: A Normative Account of Cognitive Fatigue and Boredom ”, Agrawal et al 2020
- “The Overfitted Brain: Dreams Evolved to Assist Generalization ”, Hoel 2020
- “The NetHack Learning Environment ”, Küttler et al 2020
- “The NetHack Learning Environment ”, Küttler et al 2020
- “Exploration Strategies in Deep Reinforcement Learning ”, Weng 2020
- “Synthetic Petri Dish: A Novel Surrogate Model for Rapid Architecture Search ”, Rawal et al 2020
- “Automatic Discovery of Interpretable Planning Strategies ”, Skirzyński et al 2020
- “Automatic Discovery of Interpretable Planning Strategies ”, Skirzyński et al 2020
- “IJON: Exploring Deep State Spaces via Fuzzing ”, Aschermann et al 2020
- “Planning to Explore via Self-Supervised World Models ”, Sekar et al 2020
- “Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems ”, Levine et al 2020
- “Pitfalls of Learning a Reward Function Online ”, Armstrong et al 2020
- “First Return, Then Explore ”, Ecoffet et al 2020
- “Real World Games Look Like Spinning Tops ”, Czarnecki et al 2020
- “Approximate Exploitability: Learning a Best Response in Large Games ”, Timbers et al 2020
- “Agent57: Outperforming the Human Atari Benchmark ”, Puigdomènech et al 2020
- “Agent57: Outperforming the Human Atari Benchmark ”, Puigdomènech et al 2020
- “Agent57: Outperforming the Atari Human Benchmark ”, Badia et al 2020
- “Enhanced POET: Open-Ended Reinforcement Learning through Unbounded Invention of Learning Challenges and Their Solutions ”, Wang et al 2020
- “Meta-Learning Curiosity Algorithms ”, Alet et al 2020
- “Curriculum Learning for Reinforcement Learning Domains: A Framework and Survey ”, Narvekar et al 2020
- “AutoML-Zero: Evolving Machine Learning Algorithms From Scratch ”, Real et al 2020
- “Never Give Up: Learning Directed Exploration Strategies ”, Badia et al 2020
- “Effective Diversity in Population Based Reinforcement Learning ”, Parker-Holder et al 2020
- “Near-Perfect Point-Goal Navigation from 2.5 Billion Frames of Experience ”, Wijmans & Kadian 2020
- “MicrobatchGAN: Stimulating Diversity With Multi-Adversarial Discrimination ”, Mordido et al 2020
- “Learning Human Objectives by Evaluating Hypothetical Behavior ”, Reddy et al 2019
- “Optimal Policies Tend to Seek Power ”, Turner et al 2019
- “DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames ”, Wijmans et al 2019
- “Emergent Tool Use From Multi-Agent Autocurricula ”, Baker et al 2019
- “Emergent Tool Use from Multi-Agent Interaction § Surprising Behavior ”, Baker et al 2019
- “Emergent Tool Use from Multi-Agent Interaction § Surprising Behavior ”, Baker et al 2019
- “R2D3: Making Efficient Use of Demonstrations to Solve Hard Exploration Problems ”, Paine et al 2019
- “Benchmarking Bonus-Based Exploration Methods on the Arcade Learning Environment ”, Taïga et al 2019
- “Benchmarking Bonus-Based Exploration Methods on the Arcade Learning Environment ”, Taïga et al 2019
- “A Unified Bellman Optimality Principle Combining Reward Maximization and Empowerment ”, Leibfried et al 2019
- “An Optimistic Perspective on Offline Reinforcement Learning ”, Agarwal et al 2019
- “Meta Reinforcement Learning ”, Weng 2019
- “Search on the Replay Buffer: Bridging Planning and Reinforcement Learning ”, Eysenbach et al 2019
- “ICML 2019 Notes ”, Abel 2019
- “Human-Level Performance in 3D Multiplayer Games With Population-Based Reinforcement Learning ”, Jaderberg et al 2019
- “AI-GAs: AI-Generating Algorithms, an Alternate Paradigm for Producing General Artificial Intelligence ”, Clune 2019
- “Learning to Reason in Large Theories without Imitation ”, Bansal et al 2019
- “Reinforcement Learning, Fast and Slow ”, Botvinick et al 2019
- “Meta Reinforcement Learning As Task Inference ”, Humplik et al 2019
- “Meta-Learning of Sequential Strategies ”, Ortega et al 2019
- “The MineRL 2019 Competition on Sample Efficient Reinforcement Learning Using Human Priors ”, Guss et al 2019
- “Π-IW: Deep Policies for Width-Based Planning in Pixel Domains ”, Junyent et al 2019
- “Learning To Follow Directions in Street View ”, Hermann et al 2019
- “A Generalized Framework for Population Based Training ”, Li et al 2019
- “Go-Explore: a New Approach for Hard-Exploration Problems ”, Ecoffet et al 2019
- “Paired Open-Ended Trailblazer (POET): Endlessly Generating Increasingly Complex and Diverse Learning Environments and Their Solutions ”, Wang et al 2019
- “Is the FDA Too Conservative or Too Aggressive?: A Bayesian Decision Analysis of Clinical Trial Design ”, Isakov et al 2019
- “V-Fuzz: Vulnerability-Oriented Evolutionary Fuzzing ”, Li et al 2019
- “Common Neural Code for Reward and Information Value ”, Kobayashi & Hsu 2019
- “Machine-Learning-Guided Directed Evolution for Protein Engineering ”, Yang et al 2019
- “Enjoy It Again: Repeat Experiences Are Less Repetitive Than People Think ”, O’Brien 2019
- “Evolutionary-Neural Hybrid Agents for Architecture Search ”, Maziarz et al 2018
- “The Bayesian Superorganism III: Externalized Memories Facilitate Distributed Sampling ”, Hunt et al 2018
- “Exploration in the Wild ”, Schulz et al 2018
- “Off-Policy Deep Reinforcement Learning without Exploration ”, Fujimoto et al 2018
- “An Introduction to Deep Reinforcement Learning ”, Francois-Lavet et al 2018
- “The Bayesian Superorganism I: Collective Probability Estimation ”, Hunt et al 2018
- “Exploration by Random Network Distillation ”, Burda et al 2018
- “Computational Noise in Reward-Guided Learning Drives Behavioral Variability in Volatile Environments ”, Findling et al 2018
- “RND: Large-Scale Study of Curiosity-Driven Learning ”, Burda et al 2018
- “Visual Reinforcement Learning With Imagined Goals ”, Nair et al 2018
- “Is Q-Learning Provably Efficient? ”, Jin et al 2018
- “Improving Width-Based Planning With Compact Policies ”, Junyent et al 2018
- “Construction of Arbitrarily Strong Amplifiers of Natural Selection Using Evolutionary Graph Theory ”, Pavlogiannis et al 2018
- “Re-Evaluating Evaluation ”, Balduzzi et al 2018
- “DVRL: Deep Variational Reinforcement Learning for POMDPs ”, Igl et al 2018
- “Mix&Match—Agent Curricula for Reinforcement Learning ”, Czarnecki et al 2018
- “Playing Hard Exploration Games by Watching YouTube ”, Aytar et al 2018
- “Observe and Look Further: Achieving Consistent Performance on Atari ”, Pohlen et al 2018
- “Generalization and Search in Risky Environments ”, Schulz et al 2018
- “Toward Diverse Text Generation With Inverse Reinforcement Learning ”, Shi et al 2018
- “Efficient Multi-Objective Neural Architecture Search via Lamarckian Evolution ”, Elsken et al 2018
- “Learning to Navigate in Cities Without a Map ”, Mirowski et al 2018
- “The Surprising Creativity of Digital Evolution: A Collection of Anecdotes from the Evolutionary Computation and Artificial Life Research Communities ”, Lehman et al 2018
- “Some Considerations on Learning to Explore via Meta-Reinforcement Learning ”, Stadie et al 2018
- “Deep Bayesian Bandits Showdown: An Empirical Comparison of Bayesian Deep Networks for Thompson Sampling ”, Riquelme et al 2018
- “Reinforcement Learning on Web Interfaces Using Workflow-Guided Exploration ”, Liu et al 2018
- “Back to Basics: Benchmarking Canonical Evolution Strategies for Playing Atari ”, Chrabaszcz et al 2018
- “One Big Net For Everything ”, Schmidhuber 2018
- “Learning to Search With MCTSnets ”, Guez et al 2018
- “Learning and Querying Fast Generative Models for Reinforcement Learning ”, Buesing et al 2018
- “Safe Exploration in Continuous Action Spaces ”, Dalal et al 2018
- “Learning to Evade Static PE Machine Learning Malware Models via Reinforcement Learning ”, Anderson et al 2018
- “Deep Reinforcement Fuzzing ”, Böttinger et al 2018
- “Deep Reinforcement Fuzzing ”, Böttinger et al 2018
- “Planning Chemical Syntheses With Deep Neural Networks and Symbolic AI ”, Segler et al 2018
- “Generalization Guides Human Exploration in Vast Decision Spaces ”, Wu et al 2018
- “Innovation and Cumulative Culture through Tweaks and Leaps in Online Programming Contests ”, Miu et al 2018
- “A Flexible Approach to Automated RNN Architecture Generation ”, Schrimpf et al 2017
- “Finding Competitive Network Architectures Within a Day Using UCT ”, Wistuba 2017
- “Improving Exploration in Evolution Strategies for Deep Reinforcement Learning via a Population of Novelty-Seeking Agents ”, Conti et al 2017
- “Deep Neuroevolution: Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning ”, Such et al 2017
- “The Paradoxical Sustainability of Periodic Migration and Habitat Destruction ”, Tan & Cheong 2017
- “Posterior Sampling for Large Scale Reinforcement Learning ”, Theocharous et al 2017
- “Policy Optimization by Genetic Distillation ”, Gangwani & Peng 2017
- “Emergent Complexity via Multi-Agent Competition ”, Bansal et al 2017
- “An Analysis of the Value of Information When Exploring Stochastic, Discrete Multi-Armed Bandits ”, Sledge & Principe 2017
- “The Uncertainty Bellman Equation and Exploration ”, O’Donoghue et al 2017
- “Changing Their Tune: How Consumers’ Adoption of Online Streaming Affects Music Consumption and Discovery ”, Datta et al 2017
- “A Rational Choice Framework for Collective Behavior ”, Krafft 2017
- “Imagination-Augmented Agents for Deep Reinforcement Learning ”, Weber et al 2017
- “Distral: Robust Multitask Reinforcement Learning ”, Teh et al 2017
- “The Intentional Unintentional Agent: Learning to Solve Many Continuous Control Tasks Simultaneously ”, Cabi et al 2017
- “Emergence of Locomotion Behaviors in Rich Environments ”, Heess et al 2017
- “Noisy Networks for Exploration ”, Fortunato et al 2017
- “CAN: Creative Adversarial Networks, Generating "Art" by Learning About Styles and Deviating from Style Norms ”, Elgammal et al 2017
- “Device Placement Optimization With Reinforcement Learning ”, Mirhoseini et al 2017
- “Towards Synthesizing Complex Programs from Input-Output Examples ”, Chen et al 2017
- “Scalable Generalized Linear Bandits: Online Computation and Hashing ”, Jun et al 2017
- “DeepXplore: Automated Whitebox Testing of Deep Learning Systems ”, Pei et al 2017
- “Recurrent Environment Simulators ”, Chiappa et al 2017
- “Learned Optimizers That Scale and Generalize ”, Wichrowska et al 2017
- “Evolution Strategies As a Scalable Alternative to Reinforcement Learning ”, Salimans et al 2017
- “Large-Scale Evolution of Image Classifiers ”, Real et al 2017
- “CoDeepNEAT: Evolving Deep Neural Networks ”, Miikkulainen et al 2017
- “Rotting Bandits ”, Levine et al 2017
- “Neural Combinatorial Optimization With Reinforcement Learning ”, Bello et al 2017
- “Neural Data Filter for Bootstrapping Stochastic Gradient Descent ”, Fan et al 2017
- “Search in Patchy Media: Exploitation-Exploration Tradeoff ”
- “Towards Information-Seeking Agents ”, Bachman et al 2016
- “Exploration and Exploitation of Victorian Science in Darwin’s Reading Notebooks ”, Murdock et al 2016
- “Learning to Learn without Gradient Descent by Gradient Descent ”, Chen et al 2016
- “Learning to Perform Physics Experiments via Deep Reinforcement Learning ”, Denil et al 2016
- “Neural Architecture Search With Reinforcement Learning ”, Zoph & Le 2016
- “Combating Reinforcement Learning’s Sisyphean Curse With Intrinsic Fear ”, Lipton et al 2016
- “Bayesian Reinforcement Learning: A Survey ”, Ghavamzadeh et al 2016
- “Human Collective Intelligence As Distributed Bayesian Inference ”, Krafft et al 2016
- “Some Mechanistic Requirements for Major Transitions ”, Schuster 2016
- “Universal Darwinism As a Process of Bayesian Inference ”, Campbell 2016
- “Unifying Count-Based Exploration and Intrinsic Motivation ”, Bellemare et al 2016
- “D-TS: Double Thompson Sampling for Dueling Bandits ”, Wu & Liu 2016
- “Improving Information Extraction by Acquiring External Evidence With Reinforcement Learning ”, Narasimhan et al 2016
- “Deep Exploration via Bootstrapped DQN ”, Osband et al 2016
- “The Netflix Recommender System ”, Gomez-Uribe & Hunt 2015
- “On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models ”, Schmidhuber 2015
- “Online Batch Selection for Faster Training of Neural Networks ”, Loshchilov & Hutter 2015
- “MAP-Elites: Illuminating Search Spaces by Mapping Elites ”, Mouret & Clune 2015
- “What My Deep Model Doesn’t Know… ”, Gal 2015
- “The Psychology and Neuroscience of Curiosity ”, Kidd & Hayden 2015
- “Thompson Sampling With the Online Bootstrap ”, Eckles & Kaptein 2014
- “On the Complexity of Best Arm Identification in Multi-Armed Bandit Models ”, Kaufmann et al 2014
- “Robots That Can Adapt like Animals ”, Cully et al 2014
- “Freeze-Thaw Bayesian Optimization ”, Swersky et al 2014
- “Search for the Wreckage of Air France Flight AF 447 ”, Stone et al 2014
- “(More) Efficient Reinforcement Learning via Posterior Sampling ”, Osband et al 2013
- “Model-Based Bayesian Exploration ”, Dearden et al 2013
- “PUCT: Continuous Upper Confidence Trees With Polynomial Exploration-Consistency ”, Auger et al 2013
- “(More) Efficient Reinforcement Learning via Posterior Sampling [PSRL] ”, Osband 2013
- “Experimental Design for Partially Observed Markov Decision Processes ”, Thorbergsson & Hooker 2012
- “Learning Is Planning: near Bayes-Optimal Reinforcement Learning via Monte-Carlo Tree Search ”, Asmuth & Littman 2012
- “PILCO: A Model-Based and Data-Efficient Approach to Policy Search ”, Deisenroth & Rasmussen 2011
- “Abandoning Objectives: Evolution Through the Search for Novelty Alone ”, Lehman & Stanley 2011
- “Planning to Be Surprised: Optimal Bayesian Exploration in Dynamic Environments ”, Sun et al 2011
- “Age-Fitness Pareto Optimization ”, Schmidt & Lipson 2010
- “Monte-Carlo Planning in Large POMDPs ”, Silver & Veness 2010
- “Formal Theory of Creativity & Fun & Intrinsic Motivation (1990–2010) ”, Schmidhuber 2010
- “The Epistemic Benefit of Transient Diversity ”, Zollman 2009
- “Specialization Effect and Its Influence on Memory and Problem Solving in Expert Chess Players ”, Bilalić et al 2009
- “Specialization Effect and Its Influence on Memory and Problem Solving in Expert Chess Players ”, Bilalić et al 2009
- “Driven by Compression Progress: A Simple Principle Explains Essential Aspects of Subjective Beauty, Novelty, Surprise, Interestingness, Attention, Curiosity, Creativity, Art, Science, Music, Jokes ”, Schmidhuber 2008
- “Pure Exploration for Multi-Armed Bandit Problems ”, Bubeck et al 2008
- “Exploiting Open-Endedness to Solve Problems Through the Search for Novelty ”, Lehman & Stanley 2008
- “Towards Efficient Evolutionary Design of Autonomous Robots ”, Krčah 2008
- “Towards Efficient Evolutionary Design of Autonomous Robots ”, Krčah 2008
- “Resilient Machines Through Continuous Self-Modeling ”, Bongard et al 2006
- “ALPS: the Age-Layered Population Structure for Reducing the Problem of Premature Convergence ”, Hornby 2006
- “Bayesian Adaptive Exploration ”, Loredo & Chernoff 2003
- “NEAT: Evolving Neural Networks through Augmenting Topologies ”, Stanley & Miikkulainen 2002
- “Self-Verification, The Key to AI ”, Sutton 2001
- “A Bayesian Framework for Reinforcement Learning ”, Strens 2000
- “Case Studies in Evolutionary Experimentation and Computation ”, Rechenberg 2000
- “Efficient Progressive Sampling ”, Provost et al 1999b
- “Evolving 3D Morphology and Behavior by Competition ”, Sims 1994
- “Interactions between Learning and Evolution ”, Ackley & Littman 1992
- “Evolution Strategy: Nature’s Way of Optimization ”, Rechenberg 1989
- “The Ms. Pac-Man Mystery: How 3 Guys from Montana Invented the Ultimate Strategy ”, Stokstad 1984
- “The Analysis of Sequential Experiments With Feedback to Subjects ”, Diaconis & Graham 1981
- “Evolutionsstrategien ”, Rechenberg 1977
- Evolutionsstrategie: Optimierung Technischer Systeme Nach Prinzipien Der Biologischen Evolution, Rechenberg 1973
- “The Usefulness of Useless Knowledge ”, Flexner 1939
- “Curiosity Killed the Mario ”
- “Brian Christian on Computer Science Algorithms That Tackle Fundamental and Universal Problems ”
- “Solving Zelda With the Antithesis SDK ”
- “Goodhart’s Law, Diversity and a Series of Seemingly Unrelated Toy Problems ”
- “Why Generalization in RL Is Difficult: Epistemic POMDPs and Implicit Partial Observability [Blog] ”
- Bayesian Optimization Book
- “Temporal Difference Learning and TD-Gammon ”
- “An Experimental Design Perspective on Model-Based Reinforcement Learning [Blog] ”
- “Safety-First AI for Autonomous Data Center Cooling and Industrial Control ”
- “Pulling JPEGs out of Thin Air ”
- “Curriculum For Reinforcement Learning ”
- “Why Testing Self-Driving Cars in SF Is Challenging but Necessary ”
- “Reinforcement Learning With Prediction-Based Rewards ”
- “Prompting Diverse Ideas: Increasing AI Idea Variance ”
- “Mathematical Discoveries from Program Search With Large Language Models ”
- “You Need a Novelty Budget ”
- “ChatGPT As Muse, Not Oracle ”, Litt 2025
- “Cultivating a State of Mind Where New Ideas Are Born ”, Karlsson 2025
- “Conditions for Mathematical Equivalence of Stochastic Gradient Descent and Natural Selection ”
- “Probable Points and Credible Intervals, Part 2: Decision Theory ”
- “AI Is Learning How to Create Itself ”
- “Montezuma’s Revenge Solved by Go-Explore, a New Algorithm for Hard-Exploration Problems (Sets Records on Pitfall, Too) ”
- “Monkeys Play Pac-Man ”
- “Playing Montezuma’s Revenge With Intrinsic Motivation ”
- Sort By Magic
- Wikipedia (19)
- Miscellaneous
- Bibliography
Gwern
“Towards Benchmarking LLM Diversity & Creativity ”, Gwern 2024
“Can You Unsort Lists for Diversity? ”, Gwern 2019
“Number Search Engine via NN Embeddings ”, Gwern 2024
“Novelty Nets: Classifier Anti-Guidance ”, Gwern 2024
“Free-Play Periods for RL Agents ”, Gwern 2023
“Candy Japan’s New Box A/B Test ”, Gwern 2016
Links
“Introducing Deep Research: An Agent That Uses Reasoning to Synthesize Large Amounts of Online Information and Complete Multi-Step Research Tasks for You. Available to Pro Users Today, Plus and Team Next ”, OpenAI 2025
“Diverse Preference Optimization ”, Lanchantin et al 2025
“Large Language Models Think Too Fast To Explore Effectively ”, Pan et al 2025
“Multiagent Finetuning: Self Improvement With Diverse Reasoning Chains ”, Subramaniam et al 2025
Multiagent Finetuning: Self Improvement with Diverse Reasoning Chains
“SimpleStrat: Diversifying Language Model Generation With Stratification ”, Wong et al 2024
SimpleStrat: Diversifying Language Model Generation with Stratification
“Learning Formal Mathematics From Intrinsic Motivation ”, Poesia et al 2024
“Intelligent Go-Explore (IGE): Standing on the Shoulders of Giant Foundation Models ”, Lu et al 2024
Intelligent Go-Explore (IGE): Standing on the Shoulders of Giant Foundation Models
“Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts ”, Samvelyan et al 2024
Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts
“Self-Supervised Behavior Cloned Transformers Are Path Crawlers for Text Games ”, Wang & Jansen 2023
Self-Supervised Behavior Cloned Transformers are Path Crawlers for Text Games
“Zero-Shot Goal-Directed Dialogue via RL on Imagined Conversations ”, Hong et al 2023
Zero-Shot Goal-Directed Dialogue via RL on Imagined Conversations
“QDAIF: Quality-Diversity through AI Feedback ”, Bradley et al 2023
“Beyond Memorization: Violating Privacy Via Inference With Large Language Models ”, Staab et al 2023
Beyond Memorization: Violating Privacy Via Inference with Large Language Models
“Let Models Speak Ciphers: Multiagent Debate through Embeddings ”, Pham et al 2023
Let Models Speak Ciphers: Multiagent Debate through Embeddings
“Small Batch Deep Reinforcement Learning ”, Obando-Ceron et al 2023
“Maximum Diffusion Reinforcement Learning ”, Berrueta et al 2023
“Language Reward Modulation for Pretraining Reinforcement Learning ”, Adeniji et al 2023
Language Reward Modulation for Pretraining Reinforcement Learning
“Diversifying AI: Towards Creative Chess With AlphaZero (AZdb) ”, Zahavy et al 2023
Diversifying AI: Towards Creative Chess with AlphaZero (AZdb)
“Empowerment Contributes to Exploration Behavior in a Creative Video Game ”, Brändle et al 2023
Empowerment contributes to exploration behavior in a creative video game
“Supervised Pretraining Can Learn In-Context Reinforcement Learning ”, Lee et al 2023
Supervised Pretraining Can Learn In-Context Reinforcement Learning
“Learning to Generate Novel Scientific Directions With Contextualized Literature-Based Discovery ”, Wang et al 2023
Learning to Generate Novel Scientific Directions with Contextualized Literature-based Discovery
“You And Your Research ”, Hamming 2023
“Long-Term Value of Exploration: Measurements, Findings and Algorithms ”, Su et al 2023
Long-Term Value of Exploration: Measurements, Findings and Algorithms
“Inducing Anxiety in GPT-3.5 Increases Exploration and Bias ”, Coda-Forno et al 2023
“Reflexion: Language Agents With Verbal Reinforcement Learning ”, Shinn et al 2023
Reflexion: Language Agents with Verbal Reinforcement Learning
“MimicPlay: Long-Horizon Imitation Learning by Watching Human Play ”, Wang et al 2023
MimicPlay: Long-Horizon Imitation Learning by Watching Human Play
“MarioGPT: Open-Ended Text2Level Generation through Large Language Models ”, Sudhakaran et al 2023
MarioGPT: Open-Ended Text2Level Generation through Large Language Models
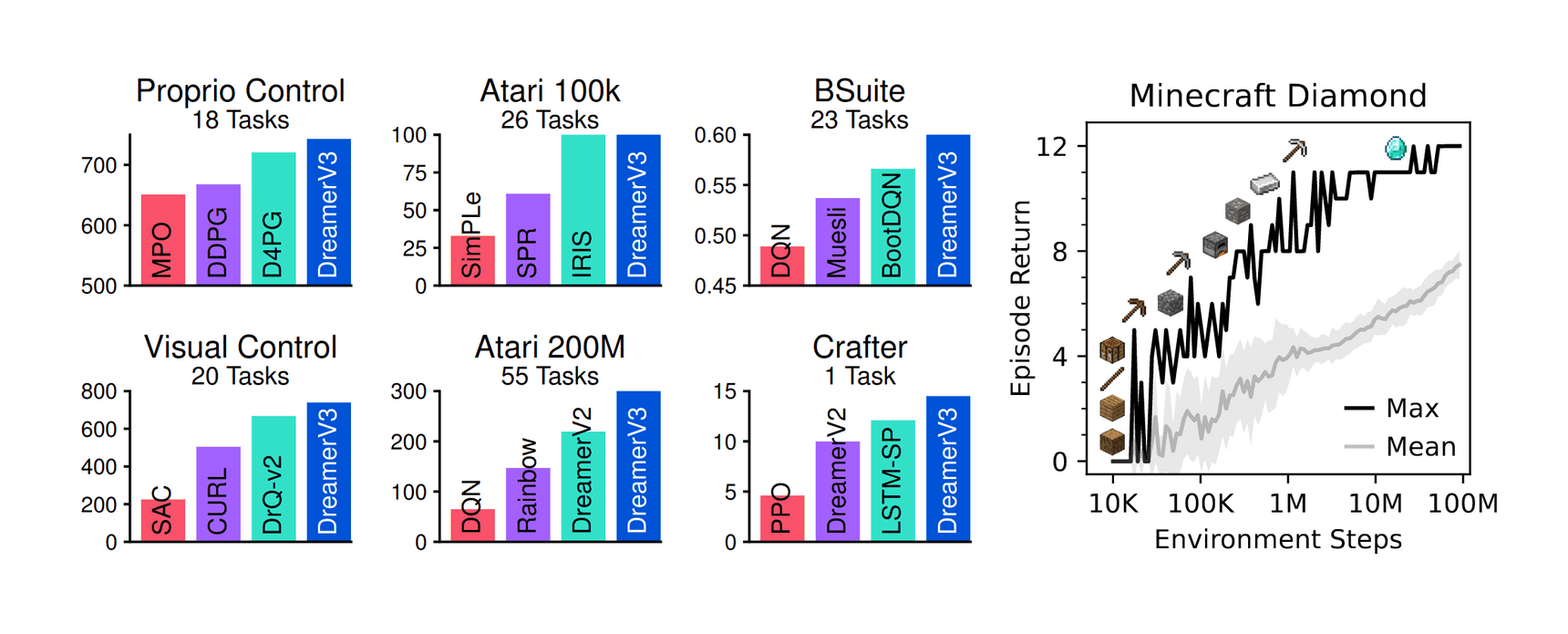
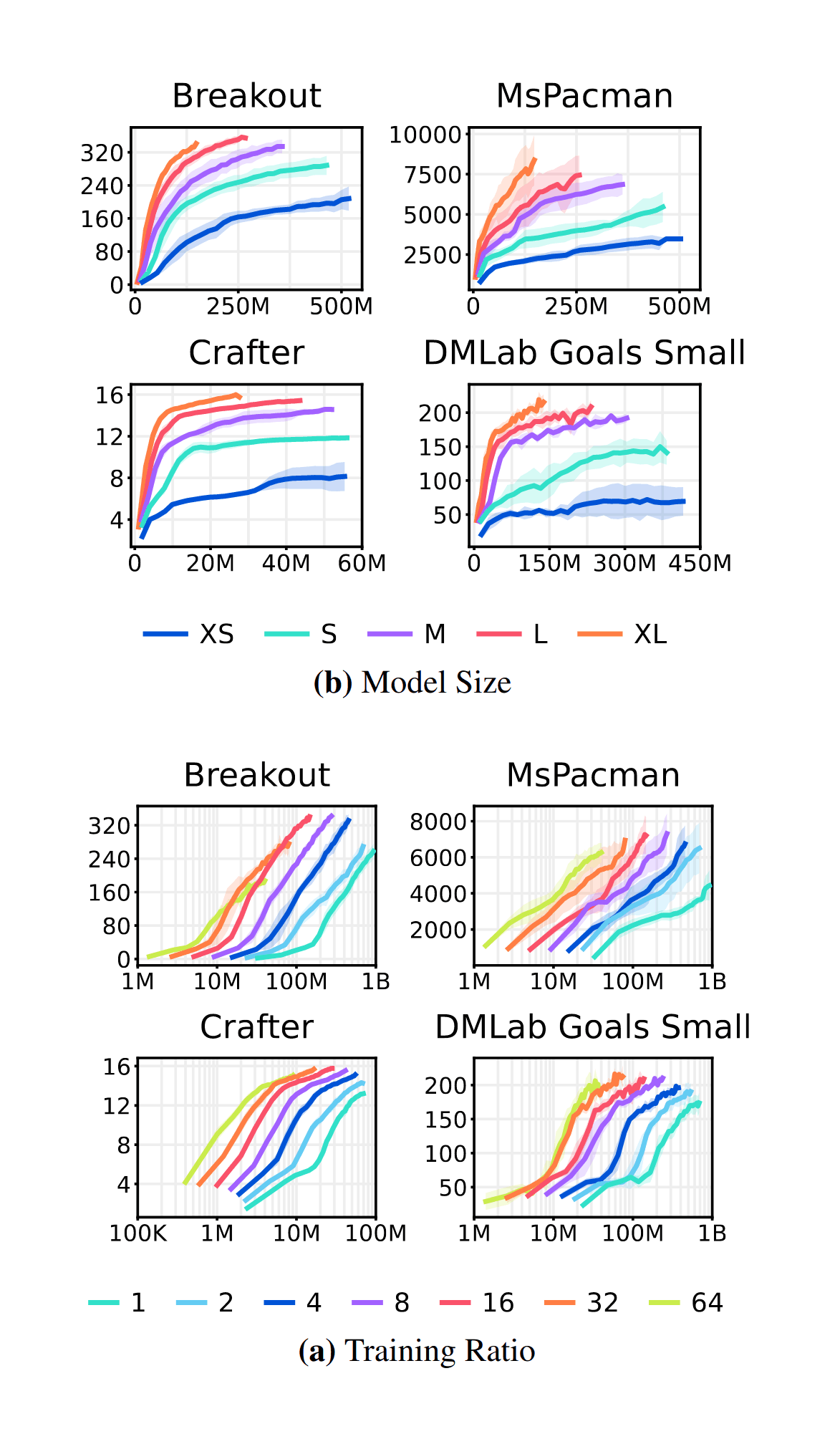
“DreamerV3: Mastering Diverse Domains through World Models ”, Hafner et al 2023
“AlphaZe∗∗: AlphaZero-Like Baselines for Imperfect Information Games Are Surprisingly Strong ”, Blüml et al 2023
AlphaZe∗∗: AlphaZero-like baselines for imperfect information games are surprisingly strong
“Effect of Lysergic Acid Diethylamide (LSD) on Reinforcement Learning in Humans ”, Kanen et al 2022
Effect of lysergic acid diethylamide (LSD) on reinforcement learning in humans
“Curiosity in Hindsight ”, Jarrett et al 2022
“In-Context Reinforcement Learning With Algorithm Distillation ”, Laskin et al 2022
In-context Reinforcement Learning with Algorithm Distillation
“E3B: Exploration via Elliptical Episodic Bonuses ”, Henaff et al 2022
“Vote-K: Selective Annotation Makes Language Models Better Few-Shot Learners ”, Su et al 2022
Vote-K: Selective Annotation Makes Language Models Better Few-Shot Learners
“LGE: Cell-Free Latent Go-Explore ”, Gallouédec & Dellandréa 2022
“A Provably Efficient Model-Free Posterior Sampling Method for Episodic Reinforcement Learning ”, Dann et al 2022
A Provably Efficient Model-Free Posterior Sampling Method for Episodic Reinforcement Learning
“Trajectory Autoencoding Planner: Efficient Planning in a Compact Latent Action Space ”, Jiang et al 2022
Trajectory Autoencoding Planner: Efficient Planning in a Compact Latent Action Space
“Value-Free Random Exploration Is Linked to Impulsivity ”, Dubois & Hauser 2022
“Transformer Neural Processes: Uncertainty-Aware Meta Learning Via Sequence Modeling ”, Nguyen & Grover 2022
Transformer Neural Processes: Uncertainty-Aware Meta Learning Via Sequence Modeling
“The Cost of Information Acquisition by Natural Selection ”, McGee et al 2022
“Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos ”, Baker et al 2022
Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos
“BYOL-Explore: Exploration by Bootstrapped Prediction ”, Guo et al 2022
“Multi-Objective Hyperparameter Optimization—An Overview ”, Karl et al 2022
“Director: Deep Hierarchical Planning from Pixels ”, Hafner et al 2022
“Boosting Search Engines With Interactive Agents ”, Ciaramita et al 2022
“Towards Learning Universal Hyperparameter Optimizers With Transformers ”, Chen et al 2022
Towards Learning Universal Hyperparameter Optimizers with Transformers
“Cliff Diving: Exploring Reward Surfaces in Reinforcement Learning Environments ”, Sullivan et al 2022
Cliff Diving: Exploring Reward Surfaces in Reinforcement Learning Environments
“Effective Mutation Rate Adaptation through Group Elite Selection ”, Kumar et al 2022
Effective Mutation Rate Adaptation through Group Elite Selection
“Semantic Exploration from Language Abstractions and Pretrained Representations ”, Tam et al 2022
Semantic Exploration from Language Abstractions and Pretrained Representations
“Habitat-Web: Learning Embodied Object-Search Strategies from Human Demonstrations at Scale ”, Ramrakhya et al 2022
Habitat-Web: Learning Embodied Object-Search Strategies from Human Demonstrations at Scale
“CLIP on Wheels (CoW): Zero-Shot Object Navigation As Object Localization and Exploration ”, Gadre et al 2022
CLIP on Wheels (CoW): Zero-Shot Object Navigation as Object Localization and Exploration
“Policy Improvement by Planning With Gumbel ”, Danihelka et al 2022
“Evolving Curricula With Regret-Based Environment Design ”, Parker-Holder et al 2022
“VAPO: Affordance Learning from Play for Sample-Efficient Policy Learning ”, Borja-Diaz et al 2022
VAPO: Affordance Learning from Play for Sample-Efficient Policy Learning
“Learning Causal Overhypotheses through Exploration in Children and Computational Models ”, Kosoy et al 2022
Learning Causal Overhypotheses through Exploration in Children and Computational Models
“Policy Learning and Evaluation With Randomized Quasi-Monte Carlo ”, Arnold et al 2022
Policy Learning and Evaluation with Randomized Quasi-Monte Carlo
“NeuPL: Neural Population Learning ”, Liu et al 2022
“ODT: Online Decision Transformer ”, Zheng et al 2022
“EvoJAX: Hardware-Accelerated Neuroevolution ”, Tang et al 2022
“LID: Pre-Trained Language Models for Interactive Decision-Making ”, Li et al 2022
LID: Pre-Trained Language Models for Interactive Decision-Making
“Accelerated Quality-Diversity for Robotics through Massive Parallelism ”, Lim et al 2022
Accelerated Quality-Diversity for Robotics through Massive Parallelism
“Rotting Infinitely Many-Armed Bandits ”, Kim et al 2022
“Don’t Change the Algorithm, Change the Data: Exploratory Data for Offline Reinforcement Learning (ExORL) ”, Yarats et al 2022
“Any-Play: An Intrinsic Augmentation for Zero-Shot Coordination ”, Lucas & Allen 2022
Any-Play: An Intrinsic Augmentation for Zero-Shot Coordination
“Evolution Gym: A Large-Scale Benchmark for Evolving Soft Robots ”, Bhatia et al 2022
Evolution Gym: A Large-Scale Benchmark for Evolving Soft Robots
“Environment Generation for Zero-Shot Compositional Reinforcement Learning ”, Gur et al 2022
Environment Generation for Zero-Shot Compositional Reinforcement Learning
“Safe Deep RL in 3D Environments Using Human Feedback ”, Rahtz et al 2022
“Automated Reinforcement Learning (AutoRL): A Survey and Open Problems ”, Parker-Holder et al 2022
Automated Reinforcement Learning (AutoRL): A Survey and Open Problems
“Maximum Entropy Population Based Training for Zero-Shot Human-AI Coordination ”, Zhao et al 2021
Maximum Entropy Population Based Training for Zero-Shot Human-AI Coordination
“The Costs and Benefits of Dispersal in Small Populations ”, Polechova 2021
“The Geometry of Decision-Making in Individuals and Collectives ”, Sridhar et al 2021
The geometry of decision-making in individuals and collectives
“An Experimental Design Perspective on Model-Based Reinforcement Learning ”, Mehta et al 2021
An Experimental Design Perspective on Model-Based Reinforcement Learning
“JueWu-MC: Playing Minecraft With Sample-Efficient Hierarchical Reinforcement Learning ”, Lin et al 2021
JueWu-MC: Playing Minecraft with Sample-efficient Hierarchical Reinforcement Learning
“Procedural Generalization by Planning With Self-Supervised World Models ”, Anand et al 2021
Procedural Generalization by Planning with Self-Supervised World Models
“Correspondence between Neuroevolution and Gradient Descent ”, Whitelam et al 2021
“URLB: Unsupervised Reinforcement Learning Benchmark ”, Laskin et al 2021
“Mastering Atari Games With Limited Data ”, Ye et al 2021
“Discovering and Achieving Goals via World Models ”, Mendonca et al 2021
“The Structure of Genotype-Phenotype Maps Makes Fitness Landscapes Navigable ”, Greenbury et al 2021
The structure of genotype-phenotype maps makes fitness landscapes navigable
“Replay-Guided Adversarial Environment Design ”, Jiang et al 2021
“A Review of the Gumbel-Max Trick and Its Extensions for Discrete Stochasticity in Machine Learning ”, Huijben et al 2021
A Review of the Gumbel-max Trick and its Extensions for Discrete Stochasticity in Machine Learning
“Monkey Plays Pac-Man With Compositional Strategies and Hierarchical Decision-Making ”, Yang et al 2021
Monkey Plays Pac-Man with Compositional Strategies and Hierarchical Decision-making
“Neural Autopilot and Context-Sensitivity of Habits ”, Camerer & Li 2021
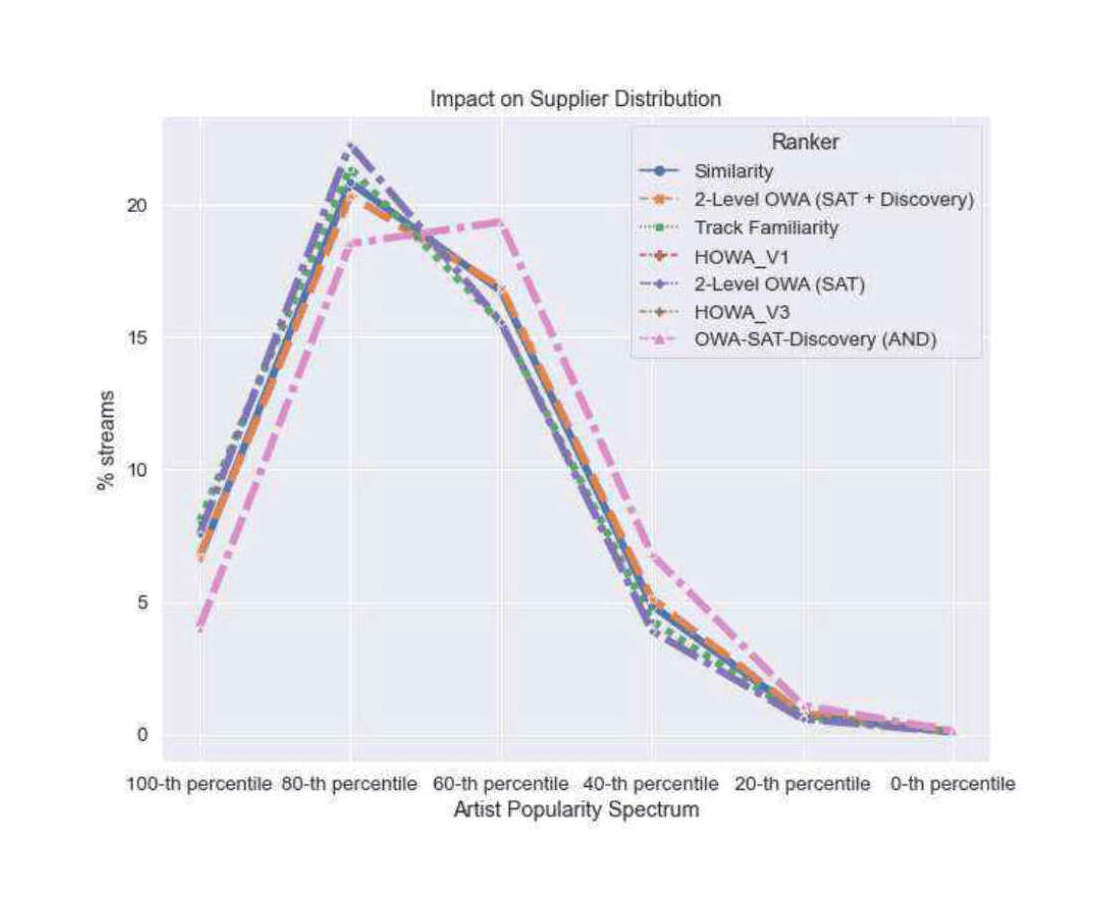
“Algorithmic Balancing of Familiarity, Similarity, & Discovery in Music Recommendations ”, Mehrotra 2021
Algorithmic Balancing of Familiarity, Similarity, & Discovery in Music Recommendations
“TrufLL: Learning Natural Language Generation from Scratch ”, Donati et al 2021
“Is Curiosity All You Need? On the Utility of Emergent Behaviors from Curious Exploration ”, Groth et al 2021
Is Curiosity All You Need? On the Utility of Emergent Behaviors from Curious Exploration
“Bootstrapped Meta-Learning ”, Flennerhag et al 2021
“Open-Ended Learning Leads to Generally Capable Agents ”, Team et al 2021
“Learning a Large Neighborhood Search Algorithm for Mixed Integer Programs ”, Sonnerat et al 2021
Learning a Large Neighborhood Search Algorithm for Mixed Integer Programs
“Why Generalization in RL Is Difficult: Epistemic POMDPs and Implicit Partial Observability ”, Ghosh et al 2021
Why Generalization in RL is Difficult: Epistemic POMDPs and Implicit Partial Observability
“Imitation-Driven Cultural Collapse ”, Duran-Nebreda & Valverde 2021
“Multi-Task Curriculum Learning in a Complex, Visual, Hard-Exploration Domain: Minecraft ”, Kanitscheider et al 2021
Multi-task curriculum learning in a complex, visual, hard-exploration domain: Minecraft
“Learning to Hesitate ”, Descamps et al 2021
“Planning for Novelty: Width-Based Algorithms for Common Problems in Control, Planning and Reinforcement Learning ”, Lipovetzky 2021
“Trajectory Transformer: Reinforcement Learning As One Big Sequence Modeling Problem ”, Janner et al 2021
Trajectory Transformer: Reinforcement Learning as One Big Sequence Modeling Problem
“From Motor Control to Team Play in Simulated Humanoid Football ”, Liu et al 2021
From Motor Control to Team Play in Simulated Humanoid Football
“Reward Is Enough ”, Silver et al 2021
“Principled Exploration via Optimistic Bootstrapping and Backward Induction ”, Bai et al 2021
Principled Exploration via Optimistic Bootstrapping and Backward Induction
“Intelligence and Unambitiousness Using Algorithmic Information Theory ”, Cohen et al 2021
Intelligence and Unambitiousness Using Algorithmic Information Theory
“Deep Bandits Show-Off: Simple and Efficient Exploration With Deep Networks ”, Zhu & Rigotti 2021
Deep Bandits Show-Off: Simple and Efficient Exploration with Deep Networks
“On Lottery Tickets and Minimal Task Representations in Deep Reinforcement Learning ”, Vischer et al 2021
On Lottery Tickets and Minimal Task Representations in Deep Reinforcement Learning
“What Are Bayesian Neural Network Posteriors Really Like? ”, Izmailov et al 2021
“Epistemic Autonomy: Self-Supervised Learning in the Mammalian Hippocampus ”, Santos-Pata et al 2021
Epistemic Autonomy: Self-supervised Learning in the Mammalian Hippocampus
“Bayesian Optimization Is Superior to Random Search for Machine Learning Hyperparameter Tuning: Analysis of the Black-Box Optimization Challenge 2020 ”, Turner et al 2021
“Flexible Modulation of Sequence Generation in the Entorhinal-Hippocampal System ”, McNamee et al 2021
Flexible modulation of sequence generation in the entorhinal-hippocampal system
“Reinforcement Learning, Bit by Bit ”, Lu et al 2021
“Asymmetric Self-Play for Automatic Goal Discovery in Robotic Manipulation ”, OpenAI et al 2021
Asymmetric self-play for automatic goal discovery in robotic manipulation
“Informational Herding, Optimal Experimentation, and Contrarianism ”, Smith et al 2021
Informational Herding, Optimal Experimentation, and Contrarianism
“Go-Explore: First Return, Then Explore ”, Ecoffet et al 2021
“TacticZero: Learning to Prove Theorems from Scratch With Deep Reinforcement Learning ”, Wu et al 2021
TacticZero: Learning to Prove Theorems from Scratch with Deep Reinforcement Learning
“Proof Artifact Co-Training for Theorem Proving With Language Models ”, Han et al 2021
Proof Artifact Co-training for Theorem Proving with Language Models
“The MineRL 2020 Competition on Sample Efficient Reinforcement Learning Using Human Priors ”, Guss et al 2021
The MineRL 2020 Competition on Sample Efficient Reinforcement Learning using Human Priors
“Curriculum Learning: A Survey ”, Soviany et al 2021
“MAP-Elites Enables Powerful Stepping Stones and Diversity for Modular Robotics ”, Nordmoen et al 2021
MAP-Elites Enables Powerful Stepping Stones and Diversity for Modular Robotics
“Is Pessimism Provably Efficient for Offline RL? ”, Jin et al 2020
“Monte-Carlo Graph Search for AlphaZero ”, Czech et al 2020
“Imitating Interactive Intelligence ”, Abramson et al 2020
“Emergent Complexity and Zero-Shot Transfer via Unsupervised Environment Design [UED+PAIRED] ”, Dennis et al 2020
Emergent Complexity and Zero-shot Transfer via Unsupervised Environment Design [UED+PAIRED]
“Ridge Rider: Finding Diverse Solutions by Following Eigenvectors of the Hessian ”, Parker-Holder et al 2020
Ridge Rider: Finding Diverse Solutions by Following Eigenvectors of the Hessian
“Meta-Trained Agents Implement Bayes-Optimal Agents ”, Mikulik et al 2020
“Learning Not to Learn: Nature versus Nurture in Silico ”, Lange & Sprekeler 2020
“The Child As Hacker ”, Rule et al 2020
“Assessing Game Balance With AlphaZero: Exploring Alternative Rule Sets in Chess ”, Tomašev et al 2020
Assessing Game Balance with AlphaZero: Exploring Alternative Rule Sets in Chess
“The Temporal Dynamics of Opportunity Costs: A Normative Account of Cognitive Fatigue and Boredom ”, Agrawal et al 2020
The Temporal Dynamics of Opportunity Costs: A Normative Account of Cognitive Fatigue and Boredom
“The Overfitted Brain: Dreams Evolved to Assist Generalization ”, Hoel 2020
The Overfitted Brain: Dreams evolved to assist generalization
“The NetHack Learning Environment ”, Küttler et al 2020
“Exploration Strategies in Deep Reinforcement Learning ”, Weng 2020
“Synthetic Petri Dish: A Novel Surrogate Model for Rapid Architecture Search ”, Rawal et al 2020
Synthetic Petri Dish: A Novel Surrogate Model for Rapid Architecture Search
“Automatic Discovery of Interpretable Planning Strategies ”, Skirzyński et al 2020
“IJON: Exploring Deep State Spaces via Fuzzing ”, Aschermann et al 2020
“Planning to Explore via Self-Supervised World Models ”, Sekar et al 2020
“Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems ”, Levine et al 2020
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
“Pitfalls of Learning a Reward Function Online ”, Armstrong et al 2020
“First Return, Then Explore ”, Ecoffet et al 2020
“Real World Games Look Like Spinning Tops ”, Czarnecki et al 2020
“Approximate Exploitability: Learning a Best Response in Large Games ”, Timbers et al 2020
Approximate exploitability: Learning a best response in large games
“Agent57: Outperforming the Human Atari Benchmark ”, Puigdomènech et al 2020
“Agent57: Outperforming the Atari Human Benchmark ”, Badia et al 2020
“Enhanced POET: Open-Ended Reinforcement Learning through Unbounded Invention of Learning Challenges and Their Solutions ”, Wang et al 2020
“Meta-Learning Curiosity Algorithms ”, Alet et al 2020
“Curriculum Learning for Reinforcement Learning Domains: A Framework and Survey ”, Narvekar et al 2020
Curriculum Learning for Reinforcement Learning Domains: A Framework and Survey
“AutoML-Zero: Evolving Machine Learning Algorithms From Scratch ”, Real et al 2020
AutoML-Zero: Evolving Machine Learning Algorithms From Scratch
“Never Give Up: Learning Directed Exploration Strategies ”, Badia et al 2020
“Effective Diversity in Population Based Reinforcement Learning ”, Parker-Holder et al 2020
Effective Diversity in Population Based Reinforcement Learning
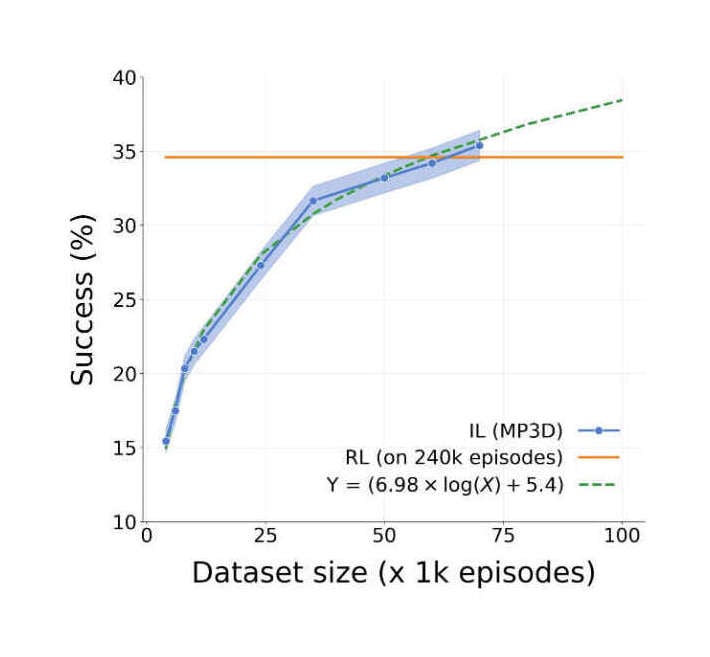
“Near-Perfect Point-Goal Navigation from 2.5 Billion Frames of Experience ”, Wijmans & Kadian 2020
Near-perfect point-goal navigation from 2.5 billion frames of experience
“MicrobatchGAN: Stimulating Diversity With Multi-Adversarial Discrimination ”, Mordido et al 2020
microbatchGAN: Stimulating Diversity with Multi-Adversarial Discrimination
“Learning Human Objectives by Evaluating Hypothetical Behavior ”, Reddy et al 2019
Learning Human Objectives by Evaluating Hypothetical Behavior
“Optimal Policies Tend to Seek Power ”, Turner et al 2019
“DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames ”, Wijmans et al 2019
DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames
“Emergent Tool Use From Multi-Agent Autocurricula ”, Baker et al 2019
“Emergent Tool Use from Multi-Agent Interaction § Surprising Behavior ”, Baker et al 2019
Emergent Tool Use from Multi-Agent Interaction § Surprising behavior
“Emergent Tool Use from Multi-Agent Interaction § Surprising Behavior ”, Baker et al 2019
Emergent Tool Use from Multi-Agent Interaction § Surprising behavior
“R2D3: Making Efficient Use of Demonstrations to Solve Hard Exploration Problems ”, Paine et al 2019
R2D3: Making Efficient Use of Demonstrations to Solve Hard Exploration Problems
“Benchmarking Bonus-Based Exploration Methods on the Arcade Learning Environment ”, Taïga et al 2019
Benchmarking Bonus-Based Exploration Methods on the Arcade Learning Environment
“A Unified Bellman Optimality Principle Combining Reward Maximization and Empowerment ”, Leibfried et al 2019
A Unified Bellman Optimality Principle Combining Reward Maximization and Empowerment
“An Optimistic Perspective on Offline Reinforcement Learning ”, Agarwal et al 2019
“Meta Reinforcement Learning ”, Weng 2019
“Search on the Replay Buffer: Bridging Planning and Reinforcement Learning ”, Eysenbach et al 2019
Search on the Replay Buffer: Bridging Planning and Reinforcement Learning
“ICML 2019 Notes ”, Abel 2019
“Human-Level Performance in 3D Multiplayer Games With Population-Based Reinforcement Learning ”, Jaderberg et al 2019
Human-level performance in 3D multiplayer games with population-based reinforcement learning
“AI-GAs: AI-Generating Algorithms, an Alternate Paradigm for Producing General Artificial Intelligence ”, Clune 2019
“Learning to Reason in Large Theories without Imitation ”, Bansal et al 2019
“Reinforcement Learning, Fast and Slow ”, Botvinick et al 2019
“Meta Reinforcement Learning As Task Inference ”, Humplik et al 2019
“Meta-Learning of Sequential Strategies ”, Ortega et al 2019
“The MineRL 2019 Competition on Sample Efficient Reinforcement Learning Using Human Priors ”, Guss et al 2019
The MineRL 2019 Competition on Sample Efficient Reinforcement Learning using Human Priors
“Π-IW: Deep Policies for Width-Based Planning in Pixel Domains ”, Junyent et al 2019
π-IW: Deep Policies for Width-Based Planning in Pixel Domains
“Learning To Follow Directions in Street View ”, Hermann et al 2019
“A Generalized Framework for Population Based Training ”, Li et al 2019
“Go-Explore: a New Approach for Hard-Exploration Problems ”, Ecoffet et al 2019
“Paired Open-Ended Trailblazer (POET): Endlessly Generating Increasingly Complex and Diverse Learning Environments and Their Solutions ”, Wang et al 2019
“Is the FDA Too Conservative or Too Aggressive?: A Bayesian Decision Analysis of Clinical Trial Design ”, Isakov et al 2019
“V-Fuzz: Vulnerability-Oriented Evolutionary Fuzzing ”, Li et al 2019
“Common Neural Code for Reward and Information Value ”, Kobayashi & Hsu 2019
“Machine-Learning-Guided Directed Evolution for Protein Engineering ”, Yang et al 2019
Machine-learning-guided directed evolution for protein engineering
“Enjoy It Again: Repeat Experiences Are Less Repetitive Than People Think ”, O’Brien 2019
Enjoy it again: Repeat experiences are less repetitive than people think
“Evolutionary-Neural Hybrid Agents for Architecture Search ”, Maziarz et al 2018
“The Bayesian Superorganism III: Externalized Memories Facilitate Distributed Sampling ”, Hunt et al 2018
The Bayesian Superorganism III: externalized memories facilitate distributed sampling
“Exploration in the Wild ”, Schulz et al 2018
“Off-Policy Deep Reinforcement Learning without Exploration ”, Fujimoto et al 2018
“An Introduction to Deep Reinforcement Learning ”, Francois-Lavet et al 2018
“The Bayesian Superorganism I: Collective Probability Estimation ”, Hunt et al 2018
The Bayesian Superorganism I: collective probability estimation
“Exploration by Random Network Distillation ”, Burda et al 2018
“Computational Noise in Reward-Guided Learning Drives Behavioral Variability in Volatile Environments ”, Findling et al 2018
Computational noise in reward-guided learning drives behavioral variability in volatile environments
“RND: Large-Scale Study of Curiosity-Driven Learning ”, Burda et al 2018
“Visual Reinforcement Learning With Imagined Goals ”, Nair et al 2018
“Is Q-Learning Provably Efficient? ”, Jin et al 2018
“Improving Width-Based Planning With Compact Policies ”, Junyent et al 2018
“Construction of Arbitrarily Strong Amplifiers of Natural Selection Using Evolutionary Graph Theory ”, Pavlogiannis et al 2018
Construction of arbitrarily strong amplifiers of natural selection using evolutionary graph theory
“Re-Evaluating Evaluation ”, Balduzzi et al 2018
“DVRL: Deep Variational Reinforcement Learning for POMDPs ”, Igl et al 2018
“Mix&Match—Agent Curricula for Reinforcement Learning ”, Czarnecki et al 2018
“Playing Hard Exploration Games by Watching YouTube ”, Aytar et al 2018
“Observe and Look Further: Achieving Consistent Performance on Atari ”, Pohlen et al 2018
Observe and Look Further: Achieving Consistent Performance on Atari
“Generalization and Search in Risky Environments ”, Schulz et al 2018
“Toward Diverse Text Generation With Inverse Reinforcement Learning ”, Shi et al 2018
Toward Diverse Text Generation with Inverse Reinforcement Learning
“Efficient Multi-Objective Neural Architecture Search via Lamarckian Evolution ”, Elsken et al 2018
Efficient Multi-objective Neural Architecture Search via Lamarckian Evolution
“Learning to Navigate in Cities Without a Map ”, Mirowski et al 2018
“The Surprising Creativity of Digital Evolution: A Collection of Anecdotes from the Evolutionary Computation and Artificial Life Research Communities ”, Lehman et al 2018
“Some Considerations on Learning to Explore via Meta-Reinforcement Learning ”, Stadie et al 2018
Some Considerations on Learning to Explore via Meta-Reinforcement Learning
“Deep Bayesian Bandits Showdown: An Empirical Comparison of Bayesian Deep Networks for Thompson Sampling ”, Riquelme et al 2018
“Reinforcement Learning on Web Interfaces Using Workflow-Guided Exploration ”, Liu et al 2018
Reinforcement Learning on Web Interfaces Using Workflow-Guided Exploration
“Back to Basics: Benchmarking Canonical Evolution Strategies for Playing Atari ”, Chrabaszcz et al 2018
Back to Basics: Benchmarking Canonical Evolution Strategies for Playing Atari
“One Big Net For Everything ”, Schmidhuber 2018
“Learning to Search With MCTSnets ”, Guez et al 2018
“Learning and Querying Fast Generative Models for Reinforcement Learning ”, Buesing et al 2018
Learning and Querying Fast Generative Models for Reinforcement Learning
“Safe Exploration in Continuous Action Spaces ”, Dalal et al 2018
“Learning to Evade Static PE Machine Learning Malware Models via Reinforcement Learning ”, Anderson et al 2018
Learning to Evade Static PE Machine Learning Malware Models via Reinforcement Learning
“Deep Reinforcement Fuzzing ”, Böttinger et al 2018
“Planning Chemical Syntheses With Deep Neural Networks and Symbolic AI ”, Segler et al 2018
Planning chemical syntheses with deep neural networks and symbolic AI
“Generalization Guides Human Exploration in Vast Decision Spaces ”, Wu et al 2018
Generalization guides human exploration in vast decision spaces
“Innovation and Cumulative Culture through Tweaks and Leaps in Online Programming Contests ”, Miu et al 2018
Innovation and cumulative culture through tweaks and leaps in online programming contests
“A Flexible Approach to Automated RNN Architecture Generation ”, Schrimpf et al 2017
A Flexible Approach to Automated RNN Architecture Generation
“Finding Competitive Network Architectures Within a Day Using UCT ”, Wistuba 2017
Finding Competitive Network Architectures Within a Day Using UCT
“Improving Exploration in Evolution Strategies for Deep Reinforcement Learning via a Population of Novelty-Seeking Agents ”, Conti et al 2017
“Deep Neuroevolution: Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning ”, Such et al 2017
“The Paradoxical Sustainability of Periodic Migration and Habitat Destruction ”, Tan & Cheong 2017
The paradoxical sustainability of periodic migration and habitat destruction
“Posterior Sampling for Large Scale Reinforcement Learning ”, Theocharous et al 2017
“Policy Optimization by Genetic Distillation ”, Gangwani & Peng 2017
“Emergent Complexity via Multi-Agent Competition ”, Bansal et al 2017
“An Analysis of the Value of Information When Exploring Stochastic, Discrete Multi-Armed Bandits ”, Sledge & Principe 2017
An Analysis of the Value of Information when Exploring Stochastic, Discrete Multi-Armed Bandits
“The Uncertainty Bellman Equation and Exploration ”, O’Donoghue et al 2017
“Changing Their Tune: How Consumers’ Adoption of Online Streaming Affects Music Consumption and Discovery ”, Datta et al 2017
“A Rational Choice Framework for Collective Behavior ”, Krafft 2017
“Imagination-Augmented Agents for Deep Reinforcement Learning ”, Weber et al 2017
Imagination-Augmented Agents for Deep Reinforcement Learning
“Distral: Robust Multitask Reinforcement Learning ”, Teh et al 2017
“The Intentional Unintentional Agent: Learning to Solve Many Continuous Control Tasks Simultaneously ”, Cabi et al 2017
The Intentional Unintentional Agent: Learning to Solve Many Continuous Control Tasks Simultaneously
“Emergence of Locomotion Behaviors in Rich Environments ”, Heess et al 2017
“Noisy Networks for Exploration ”, Fortunato et al 2017
“CAN: Creative Adversarial Networks, Generating "Art" by Learning About Styles and Deviating from Style Norms ”, Elgammal et al 2017
“Device Placement Optimization With Reinforcement Learning ”, Mirhoseini et al 2017
“Towards Synthesizing Complex Programs from Input-Output Examples ”, Chen et al 2017
Towards Synthesizing Complex Programs from Input-Output Examples
“Scalable Generalized Linear Bandits: Online Computation and Hashing ”, Jun et al 2017
Scalable Generalized Linear Bandits: Online Computation and Hashing
“DeepXplore: Automated Whitebox Testing of Deep Learning Systems ”, Pei et al 2017
DeepXplore: Automated Whitebox Testing of Deep Learning Systems
“Recurrent Environment Simulators ”, Chiappa et al 2017
“Learned Optimizers That Scale and Generalize ”, Wichrowska et al 2017
“Evolution Strategies As a Scalable Alternative to Reinforcement Learning ”, Salimans et al 2017
Evolution Strategies as a Scalable Alternative to Reinforcement Learning
“Large-Scale Evolution of Image Classifiers ”, Real et al 2017
“CoDeepNEAT: Evolving Deep Neural Networks ”, Miikkulainen et al 2017
“Rotting Bandits ”, Levine et al 2017
“Neural Combinatorial Optimization With Reinforcement Learning ”, Bello et al 2017
Neural Combinatorial Optimization with Reinforcement Learning
“Neural Data Filter for Bootstrapping Stochastic Gradient Descent ”, Fan et al 2017
Neural Data Filter for Bootstrapping Stochastic Gradient Descent
“Search in Patchy Media: Exploitation-Exploration Tradeoff ”
“Towards Information-Seeking Agents ”, Bachman et al 2016
“Exploration and Exploitation of Victorian Science in Darwin’s Reading Notebooks ”, Murdock et al 2016
Exploration and exploitation of Victorian science in Darwin’s reading notebooks
“Learning to Learn without Gradient Descent by Gradient Descent ”, Chen et al 2016
Learning to Learn without Gradient Descent by Gradient Descent
“Learning to Perform Physics Experiments via Deep Reinforcement Learning ”, Denil et al 2016
Learning to Perform Physics Experiments via Deep Reinforcement Learning
“Neural Architecture Search With Reinforcement Learning ”, Zoph & Le 2016
“Combating Reinforcement Learning’s Sisyphean Curse With Intrinsic Fear ”, Lipton et al 2016
Combating Reinforcement Learning’s Sisyphean Curse with Intrinsic Fear
“Bayesian Reinforcement Learning: A Survey ”, Ghavamzadeh et al 2016
“Human Collective Intelligence As Distributed Bayesian Inference ”, Krafft et al 2016
Human collective intelligence as distributed Bayesian inference
“Some Mechanistic Requirements for Major Transitions ”, Schuster 2016
“Universal Darwinism As a Process of Bayesian Inference ”, Campbell 2016
“Unifying Count-Based Exploration and Intrinsic Motivation ”, Bellemare et al 2016
“D-TS: Double Thompson Sampling for Dueling Bandits ”, Wu & Liu 2016
“Improving Information Extraction by Acquiring External Evidence With Reinforcement Learning ”, Narasimhan et al 2016
Improving Information Extraction by Acquiring External Evidence with Reinforcement Learning
“Deep Exploration via Bootstrapped DQN ”, Osband et al 2016
“The Netflix Recommender System ”, Gomez-Uribe & Hunt 2015
“On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models ”, Schmidhuber 2015
“Online Batch Selection for Faster Training of Neural Networks ”, Loshchilov & Hutter 2015
Online Batch Selection for Faster Training of Neural Networks
“MAP-Elites: Illuminating Search Spaces by Mapping Elites ”, Mouret & Clune 2015
“What My Deep Model Doesn’t Know… ”, Gal 2015
“The Psychology and Neuroscience of Curiosity ”, Kidd & Hayden 2015
“Thompson Sampling With the Online Bootstrap ”, Eckles & Kaptein 2014
“On the Complexity of Best Arm Identification in Multi-Armed Bandit Models ”, Kaufmann et al 2014
On the Complexity of Best Arm Identification in Multi-Armed Bandit Models
“Robots That Can Adapt like Animals ”, Cully et al 2014
“Freeze-Thaw Bayesian Optimization ”, Swersky et al 2014
“Search for the Wreckage of Air France Flight AF 447 ”, Stone et al 2014
“(More) Efficient Reinforcement Learning via Posterior Sampling ”, Osband et al 2013
(More) Efficient Reinforcement Learning via Posterior Sampling
“Model-Based Bayesian Exploration ”, Dearden et al 2013
“PUCT: Continuous Upper Confidence Trees With Polynomial Exploration-Consistency ”, Auger et al 2013
PUCT: Continuous Upper Confidence Trees with Polynomial Exploration-Consistency
“(More) Efficient Reinforcement Learning via Posterior Sampling [PSRL] ”, Osband 2013
(More) efficient reinforcement learning via posterior sampling [PSRL]
“Experimental Design for Partially Observed Markov Decision Processes ”, Thorbergsson & Hooker 2012
Experimental design for Partially Observed Markov Decision Processes
“Learning Is Planning: near Bayes-Optimal Reinforcement Learning via Monte-Carlo Tree Search ”, Asmuth & Littman 2012
Learning is planning: near Bayes-optimal reinforcement learning via Monte-Carlo tree search
“PILCO: A Model-Based and Data-Efficient Approach to Policy Search ”, Deisenroth & Rasmussen 2011
PILCO: A Model-Based and Data-Efficient Approach to Policy Search
“Abandoning Objectives: Evolution Through the Search for Novelty Alone ”, Lehman & Stanley 2011
Abandoning Objectives: Evolution Through the Search for Novelty Alone
“Planning to Be Surprised: Optimal Bayesian Exploration in Dynamic Environments ”, Sun et al 2011
Planning to Be Surprised: Optimal Bayesian Exploration in Dynamic Environments
“Age-Fitness Pareto Optimization ”, Schmidt & Lipson 2010
“Monte-Carlo Planning in Large POMDPs ”, Silver & Veness 2010
“Formal Theory of Creativity & Fun & Intrinsic Motivation (1990–2010) ”, Schmidhuber 2010
Formal Theory of Creativity & Fun & Intrinsic Motivation (1990–2010)
“The Epistemic Benefit of Transient Diversity ”, Zollman 2009
“Specialization Effect and Its Influence on Memory and Problem Solving in Expert Chess Players ”, Bilalić et al 2009
Specialization Effect and Its Influence on Memory and Problem Solving in Expert Chess Players
“Driven by Compression Progress: A Simple Principle Explains Essential Aspects of Subjective Beauty, Novelty, Surprise, Interestingness, Attention, Curiosity, Creativity, Art, Science, Music, Jokes ”, Schmidhuber 2008
“Pure Exploration for Multi-Armed Bandit Problems ”, Bubeck et al 2008
“Exploiting Open-Endedness to Solve Problems Through the Search for Novelty ”, Lehman & Stanley 2008
Exploiting Open-Endedness to Solve Problems Through the Search for Novelty
“Towards Efficient Evolutionary Design of Autonomous Robots ”, Krčah 2008
“Resilient Machines Through Continuous Self-Modeling ”, Bongard et al 2006
“ALPS: the Age-Layered Population Structure for Reducing the Problem of Premature Convergence ”, Hornby 2006
ALPS: the age-layered population structure for reducing the problem of premature convergence
“Bayesian Adaptive Exploration ”, Loredo & Chernoff 2003
“NEAT: Evolving Neural Networks through Augmenting Topologies ”, Stanley & Miikkulainen 2002
NEAT: Evolving Neural Networks through Augmenting Topologies
“Self-Verification, The Key to AI ”, Sutton 2001
Self-Verification, The Key to AI
“A Bayesian Framework for Reinforcement Learning ”, Strens 2000
“Case Studies in Evolutionary Experimentation and Computation ”, Rechenberg 2000
Case studies in evolutionary experimentation and computation
“Efficient Progressive Sampling ”, Provost et al 1999b
“Evolving 3D Morphology and Behavior by Competition ”, Sims 1994
Evolving 3D Morphology and Behavior by Competition
“Interactions between Learning and Evolution ”, Ackley & Littman 1992
“Evolution Strategy: Nature’s Way of Optimization ”, Rechenberg 1989
“The Ms. Pac-Man Mystery: How 3 Guys from Montana Invented the Ultimate Strategy ”, Stokstad 1984
The Ms. Pac-Man Mystery: How 3 guys from Montana invented the ultimate strategy
“The Analysis of Sequential Experiments With Feedback to Subjects ”, Diaconis & Graham 1981
The Analysis of Sequential Experiments with Feedback to Subjects
“Evolutionsstrategien ”, Rechenberg 1977
Evolutionsstrategie: Optimierung Technischer Systeme Nach Prinzipien Der Biologischen Evolution, Rechenberg 1973
Evolutionsstrategie: Optimierung technischer Systeme nach Prinzipien der biologischen Evolution
“The Usefulness of Useless Knowledge ”, Flexner 1939
The Usefulness of Useless Knowledge
“Curiosity Killed the Mario ”
“Brian Christian on Computer Science Algorithms That Tackle Fundamental and Universal Problems ”
Brian Christian on computer science algorithms that tackle fundamental and universal problems
“Solving Zelda With the Antithesis SDK ”
Solving Zelda with the Antithesis SDK
“Goodhart’s Law, Diversity and a Series of Seemingly Unrelated Toy Problems ”
Goodhart’s Law, Diversity and a Series of Seemingly Unrelated Toy Problems
“Why Generalization in RL Is Difficult: Epistemic POMDPs and Implicit Partial Observability [Blog] ”
Why Generalization in RL is Difficult: Epistemic POMDPs and Implicit Partial Observability [blog]
Bayesian Optimization Book
“Temporal Difference Learning and TD-Gammon ”
“An Experimental Design Perspective on Model-Based Reinforcement Learning [Blog] ”
An Experimental Design Perspective on Model-Based Reinforcement Learning [blog]
“Safety-First AI for Autonomous Data Center Cooling and Industrial Control ”
Safety-first AI for autonomous data center cooling and industrial control
“Pulling JPEGs out of Thin Air ”
Pulling JPEGs out of thin air
“Curriculum For Reinforcement Learning ”
Curriculum For Reinforcement Learning
“Why Testing Self-Driving Cars in SF Is Challenging but Necessary ”
Why testing self-driving cars in SF is challenging but necessary
“Reinforcement Learning With Prediction-Based Rewards ”
“Prompting Diverse Ideas: Increasing AI Idea Variance ”
“Mathematical Discoveries from Program Search With Large Language Models ”
Mathematical discoveries from program search with large language models
“You Need a Novelty Budget ”
“ChatGPT As Muse, Not Oracle ”, Litt 2025
“Cultivating a State of Mind Where New Ideas Are Born ”, Karlsson 2025
“Conditions for Mathematical Equivalence of Stochastic Gradient Descent and Natural Selection ”
Conditions for mathematical equivalence of Stochastic Gradient Descent and Natural Selection
“Probable Points and Credible Intervals, Part 2: Decision Theory ”
Probable Points and Credible Intervals, Part 2: Decision Theory
“AI Is Learning How to Create Itself ”
AI is learning how to create itself
“Montezuma’s Revenge Solved by Go-Explore, a New Algorithm for Hard-Exploration Problems (Sets Records on Pitfall, Too) ”
“Monkeys Play Pac-Man ”
“Playing Montezuma’s Revenge With Intrinsic Motivation ”
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
Miscellaneous
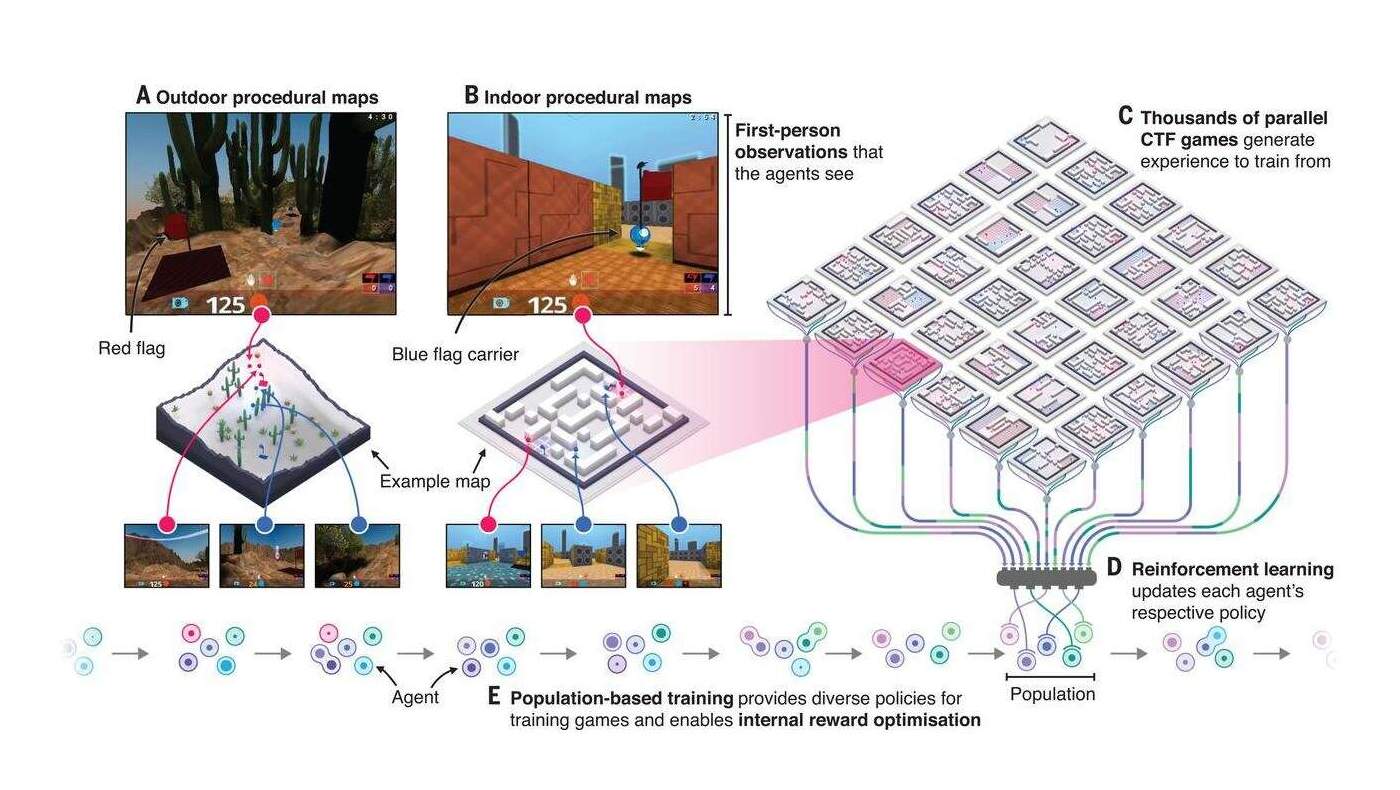
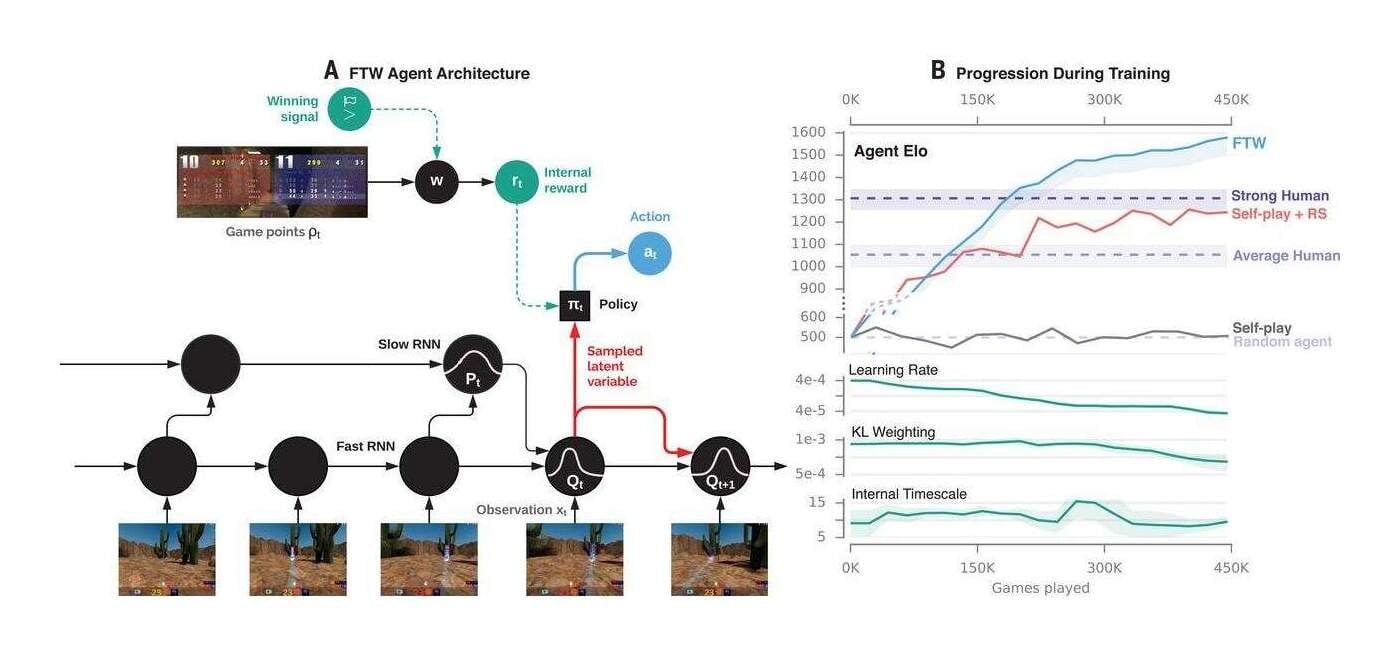
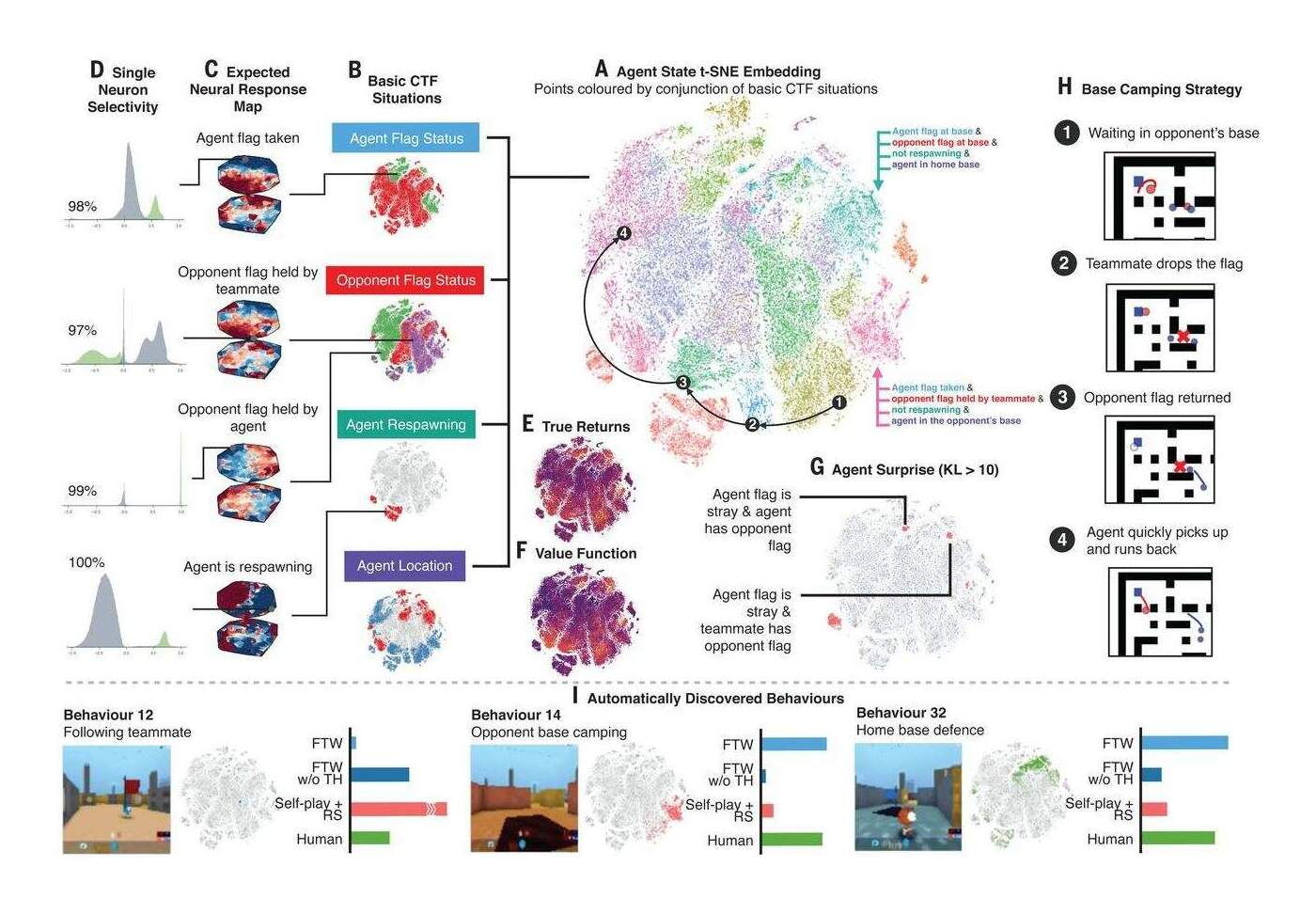
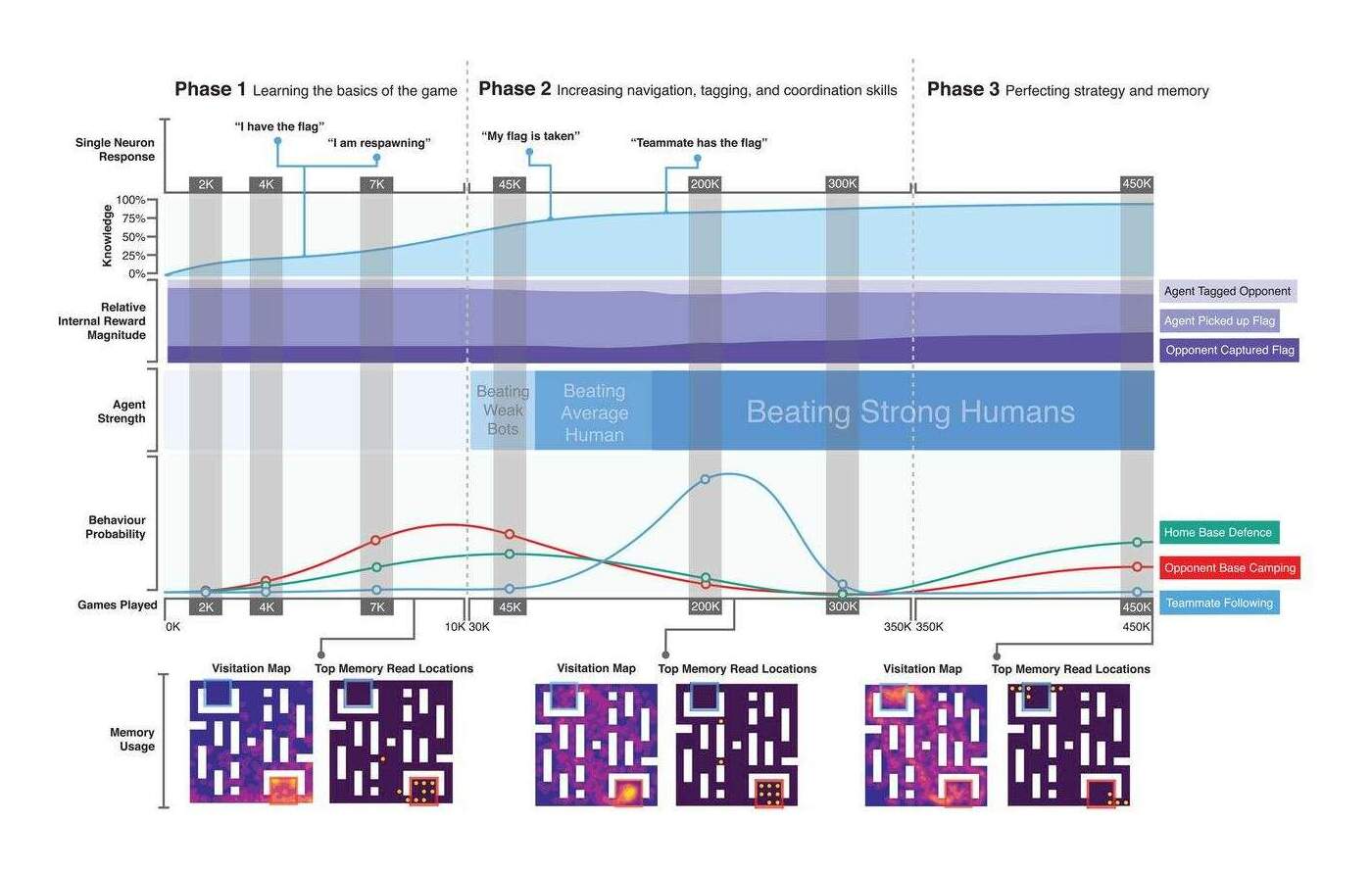
/doc/reinforcement-learning/ exploration/ 2020-interactiveagentsgroup-figure15-scalingandtransfer.jpg : /doc/reinforcement-learning/ exploration/ 2019-jaderberg-figure1-ctftaskandtraining.jpg : /doc/reinforcement-learning/ exploration/ 2019-jaderberg-figure2-agentarchitectureandbenchmarking.jpg : /doc/reinforcement-learning/ exploration/ 2019-jaderberg-figure4-progressionofagentduringtraining.jpg : http://bayesiandeeplearning.org/ 2017/ papers/ 57.pdf : http://incompleteideas.net/ book/ ebook/ node45.html : http://vision.psych.umn.edu/ groups/ schraterlab/ dearden98bayesian.pdf https://engineeringideas.substack.com/ p/ review-of-why-greatness-cannot-be https://nathanieltravis.com/ 2022/ 01/ 17/ is-human-behavior-just-elaborate-running-and-tumbling/ https://openai.com/ blog/ learning-montezumas-revenge-from-a-single-demonstration/ https://patentimages.storage.googleapis.com/ 57/ 53/ 22/ 91b8a6792dbb1e/ US20180204116A1.pdf#deepmind https://people.idsia.ch/ ~juergen/ FKI-126-90_(revised)bw_ocr.pdf : https://tor-lattimore.com/ downloads/ book/ book.pdf#page=412 : https://www.freaktakes.com/ p/ the-past-and-present-of-computer https://www.microsoft.com/ en-us/ research/ blog/ phi-2-the-surprising-power-of-small-language-models/ https://www.quantamagazine.org/ clever-machines-learn-how-to-be-curious-20170919/ : https://www.quantamagazine.org/ random-search-wired-into-animals-may-help-them-hunt-20200611/ :
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://: “Intelligent Go-Explore (IGE): Standing on the Shoulders of Giant Foundation Models ”,arxiv.org/ abs/ 2405.15143 https://: “Small Batch Deep Reinforcement Learning ”,arxiv.org/ abs/ 2310.03882#deepmind https://: “Diversifying AI: Towards Creative Chess With AlphaZero (AZdb) ”,arxiv.org/ abs/ 2308.09175#deepmind https://: “Supervised Pretraining Can Learn In-Context Reinforcement Learning ”,arxiv.org/ abs/ 2306.14892 1986-hamming: “You And Your Research ”,https://: “MarioGPT: Open-Ended Text2Level Generation through Large Language Models ”,arxiv.org/ abs/ 2302.05981 https://: “DreamerV3: Mastering Diverse Domains through World Models ”,arxiv.org/ abs/ 2301.04104#deepmind https://: “Vote-K: Selective Annotation Makes Language Models Better Few-Shot Learners ”,arxiv.org/ abs/ 2209.01975 https://: “Trajectory Autoencoding Planner: Efficient Planning in a Compact Latent Action Space ”,arxiv.org/ abs/ 2208.10291 https://: “Value-Free Random Exploration Is Linked to Impulsivity ”,www.nature.com/ articles/ s41467-022-31918-9 https://: “Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos ”,arxiv.org/ abs/ 2206.11795#openai https://: “Director: Deep Hierarchical Planning from Pixels ”,arxiv.org/ abs/ 2206.04114#google https://: “Boosting Search Engines With Interactive Agents ”,openreview.net/ forum?id=0ZbPmmB61g#google https://: “Towards Learning Universal Hyperparameter Optimizers With Transformers ”,arxiv.org/ abs/ 2205.13320#google https://: “Semantic Exploration from Language Abstractions and Pretrained Representations ”,arxiv.org/ abs/ 2204.05080#deepmind https://: “Habitat-Web: Learning Embodied Object-Search Strategies from Human Demonstrations at Scale ”,arxiv.org/ abs/ 2204.03514#facebook https://: “Policy Improvement by Planning With Gumbel ”,openreview.net/ forum?id=bERaNdoegnO#deepmind https://: “NeuPL: Neural Population Learning ”,arxiv.org/ abs/ 2202.07415#deepmind https://: “EvoJAX: Hardware-Accelerated Neuroevolution ”,arxiv.org/ abs/ 2202.05008#google https://: “Maximum Entropy Population Based Training for Zero-Shot Human-AI Coordination ”,arxiv.org/ abs/ 2112.11701#tencent https://: “Procedural Generalization by Planning With Self-Supervised World Models ”,arxiv.org/ abs/ 2111.01587#deepmind https://: “Mastering Atari Games With Limited Data ”,arxiv.org/ abs/ 2111.00210 2021-mehrotra.pdf#spotify: “Algorithmic Balancing of Familiarity, Similarity, & Discovery in Music Recommendations ”,https://: “Trajectory Transformer: Reinforcement Learning As One Big Sequence Modeling Problem ”,trajectory-transformer.github.io/ https://: “From Motor Control to Team Play in Simulated Humanoid Football ”,arxiv.org/ abs/ 2105.12196#deepmind https://: “Reward Is Enough ”,www.sciencedirect.com/ science/ article/ pii/ S0004370221000862#deepmind 2021-ecoffet.pdf#uber: “Go-Explore: First Return, Then Explore ”,https://: “The MineRL 2020 Competition on Sample Efficient Reinforcement Learning Using Human Priors ”,arxiv.org/ abs/ 2101.11071 https://: “Imitating Interactive Intelligence ”,arxiv.org/ abs/ 2012.05672#deepmind https://: “Assessing Game Balance With AlphaZero: Exploring Alternative Rule Sets in Chess ”,arxiv.org/ abs/ 2009.04374#deepmind https://: “Agent57: Outperforming the Human Atari Benchmark ”,deepmind.google/ discover/ blog/ agent57-outperforming-the-human-atari-benchmark/ https://: “DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames ”,arxiv.org/ abs/ 1911.00357#facebook https://: “Emergent Tool Use from Multi-Agent Interaction § Surprising Behavior ”,openai.com/ research/ emergent-tool-use#surprisingbehaviors https://: “Meta Reinforcement Learning ”,lilianweng.github.io/ lil-log/ 2019/ 06/ 23/ meta-reinforcement-learning.html#openai https://: “ICML 2019 Notes ”,david-abel.github.io/ notes/ icml_2019.pdf 2019-jaderberg.pdf#deepmind: “Human-Level Performance in 3D Multiplayer Games With Population-Based Reinforcement Learning ”,https://: “Improving Width-Based Planning With Compact Policies ”,arxiv.org/ abs/ 1806.05898 https://: “Construction of Arbitrarily Strong Amplifiers of Natural Selection Using Evolutionary Graph Theory ”,www.nature.com/ articles/ s42003-018-0078-7 https://: “Back to Basics: Benchmarking Canonical Evolution Strategies for Playing Atari ”,arxiv.org/ abs/ 1802.08842 https://: “Deep Neuroevolution: Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning ”,arxiv.org/ abs/ 1712.06567#uber 2015-gomezuribe.pdf: “The Netflix Recommender System ”,2010-schmidt.pdf: “Age-Fitness Pareto Optimization ”,2010-silver.pdf: “Monte-Carlo Planning in Large POMDPs ”,https://: “Specialization Effect and Its Influence on Memory and Problem Solving in Expert Chess Players ”,onlinelibrary.wiley.com/ doi/ 10.1111/ j.1551-6709.2009.01030.x 2006-hornby.pdf: “ALPS: the Age-Layered Population Structure for Reducing the Problem of Premature Convergence ”,