‘model-based RL’ directory
- See Also
- Gwern
- Links
- “Advancing Mathematics Research With AI-Driven Formal Proof Search”, Tsoukalas et al 2026
- “Imperfect World Models Are Exploitable”, Bhamidipaty et al 2026
- “The Biggest Trackmania Pathfinding Competition”, Wirtual 2026
- “Optimal Caverna Gameplay via Formal Methods”, Diehl 2026
- “I Spent the Last Month and a Half Building a Model That Visualizes Strategic Golf: A Way to Actually See the Ideas Hidden in Golf Course Architecture”, Schoolfield 2026
- “The Waymo World Model: A New Frontier For Autonomous Driving Simulation”, Waymo 2026
- “The Anticipation of Imminent Events Is Time-Scale Invariant”, Grabenhorst et al 2026
- “How Gemini 3 Pro Beat Pokemon Crystal (And 2.5 Pro Didn’t)”, Zhang 2025
- “TreeGRPO: Tree-Advantage GRPO for Online RL Post-Training of Diffusion Models”, Ding & Ye 2025
- “SIMA 2: A Generalist Embodied Agent for Virtual Worlds”, team et al 2025
- “Effective Harnesses for Long-Running Agents: Agents Still Face Challenges Working across Many Context Windows. We Looked to Human Engineers for Inspiration in Creating a More Effective Harness for Long-Running Agents”, Young 2025
- “Reasoning With Sampling: Your Base Model Is Smarter Than You Think”, Karan & Du 2025
- “Spooky Collusion at a Distance With Superrational AI”, bira 2025
- “Tree-GRPO: Tree Search for LLM Agent Reinforcement Learning”, Ji et al 2025
- “Graph Theory in State-Space [For Klotski Sliding-Block Puzzle]”, 2swap 2025
- “Lost in Latent Space: An Empirical Study of Latent Diffusion Models for Physics Emulation”, Rozet et al 2025
- “Strategic Intelligence in Large Language Models: Evidence from Evolutionary Game Theory”, Payne & Alloui-Cros 2025
- “V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning”, Assran et al 2025
- “Visual Planning: Let’s Think Only With Images”, Xu et al 2025
- “Reinforcement Learning Finetunes Small Subnetworks in Large Language Models”, Mukherjee et al 2025
- “XXt Can Be Faster”, Rybin et al 2025
- “LLMs Get Lost In Multi-Turn Conversation”, Laban et al 2025
- “Reinforcement Learning for Reasoning in Large Language Models With One Training Example”, Wang et al 2025
- “Tina: Tiny Reasoning Models via LoRA”, Wang et al 2025
- “The Geometry of Self-Verification in a Task-Specific Reasoning Model”, Lee et al 2025
- “Is Google Gemini-2.5-Pro Now Better Than Claude at Pokémon? [Probably]”, Bradshaw 2025
- “Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?”, Yue et al 2025
- “Interpreting Emergent Planning in Model-Free Reinforcement Learning”, Bush et al 2025
- “Video-T1: Test-Time Scaling for Video Generation”, Liu et al 2025
- “(How) Do Language Models Track State?”, Li et al 2025
- “NaturalReasoning: Reasoning in the Wild With 2.8M Challenging Questions”, Yuan et al 2025
- “Training Language Models for Social Deduction With Multi-Agent Reinforcement Learning”, Sarkar et al 2025
- “Competitive Programming With Large Reasoning Models”, El-Kishky et al 2025
- “MR.Q: Towards General-Purpose Model-Free Reinforcement Learning”, Fujimoto et al 2025
- “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning”, Guo et al 2025
- “Deployment of an Aerial Multi-Agent System for Automated Task Execution in Large-Scale Underground Mining Environments”, Dahlquist et al 2025
- “Generalized Dijkstra in Haskell”, flupe 2024
- “Proposing and Solving Olympiad Geometry With Guided Tree Search”, Zhang et al 2024
- “Centaur: a Foundation Model of Human Cognition”, Binz et al 2024
- “Embodied Agent Interface: Benchmarking LLMs for Embodied Decision Making”, Li et al 2024
- “Interpretable Contrastive Monte Carlo Tree Search Reasoning”, Gao et al 2024
- “OpenAI Co-Founder Sutskever’s New Safety-Focused AI Startup SSI Raises $1 Billion”, Cai et al 2024
- “The Brain Simulates Actions and Their Consequences during REM Sleep”, Senzai & Scanziani 2024
- “Solving Path of Exile Item Crafting With Value Iteration”, Britz 2024
- “Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models”, Denison et al 2024
- “DT-VIN: Scaling Value Iteration Networks to 5000 Layers for Extreme Long-Term Planning”, Wang et al 2024
- “MCTSr: Accessing GPT-4 Level Mathematical Olympiad Solutions via Monte Carlo Tree Self-Refine With LLaMA-3-8B”, Zhang et al 2024
- “Safety Alignment Should Be Made More Than Just a Few Tokens Deep”, Qi et al 2024
- “Can Language Models Serve As Text-Based World Simulators?”, Wang et al 2024
- “Evaluating the World Model Implicit in a Generative Model”, Vafa et al 2024
- “OmegaPRM: Improve Mathematical Reasoning in Language Models by Automated Process Supervision”, Luo et al 2024
- “Diffusion On Syntax Trees For Program Synthesis”, Kapur et al 2024
- “A Pontryagin Perspective on Reinforcement Learning”, Eberhard et al 2024
- “DeTikZify: Synthesizing Graphics Programs for Scientific Figures and Sketches With TikZ”, Belouadi et al 2024
- “DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data”, Xin et al 2024
- “Amit’s A✱ Pages”, Patel 2024
- “From r to Q✱: Your Language Model Is Secretly a Q-Function”, Rafailov et al 2024
- “Algorithmic Collusion by Large Language Models”, Fish et al 2024
- “Identifying General Reaction Conditions by Bandit Optimization”, Wang et al 2024b
- “Gradient-Based Planning With World Models”, V et al 2023
- “ReCoRe: Regularized Contrastive Representation Learning of World Model”, Poudel et al 2023
- “Can a Transformer Represent a Kalman Filter?”, Goel & Bartlett 2023
- “Self-Supervised Behavior Cloned Transformers Are Path Crawlers for Text Games”, Wang & Jansen 2023
- “Why Won’t OpenAI Say What the Q✱ Algorithm Is? Supposed AI Breakthroughs Are Frequently Veiled in Secrecy, Hindering Scientific Consensus”, Hao 2023
- “Zero-Shot Goal-Directed Dialogue via RL on Imagined Conversations”, Hong et al 2023
- “The Neural Basis of Mental Navigation in Rats: A Brain–machine Interface Demonstrates Volitional Control of Hippocampal Activity”, Coulter & Kemere 2023
- “Volitional Activation of Remote Place Representations With a Hippocampal Brain–machine Interface”, Lai et al 2023
- “Learning Unsupervised World Models for Autonomous Driving via Discrete Diffusion”, Zhang et al 2023
- “Self-AIXI: Self-Predictive Universal AI”, Catt et al 2023
- “Othello Is Solved”, Takizawa 2023
- “Course Correcting Koopman Representations”, Fathi et al 2023
- “Predictive Auxiliary Objectives in Deep RL Mimic Learning in the Brain”, Fang & Stachenfeld 2023
- “Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models”, Zhou et al 2023
- “Comparative Study of Model-Based and Model-Free Reinforcement Learning Control Performance in HVAC Systems”, Gao & Wang 2023
- “Learning to Model the World With Language”, Lin et al 2023
- “Do Models Explain Themselves? Counterfactual Simulatability of Natural Language Explanations”, Chen et al 2023
- “Fighting Uncertainty With Gradients: Offline Reinforcement Learning via Diffusion Score Matching”, Suh et al 2023
- “From Word Models to World Models: Translating from Natural Language to the Probabilistic Language of Thought”, Wong et al 2023
- “Improving Long-Horizon Imitation Through Instruction Prediction”, Hejna et al 2023
- “When to Show a Suggestion? Integrating Human Feedback in AI-Assisted Programming (CDHF)”, Mozannar et al 2023
- “Reasoning With Language Model Is Planning With World Model”, Hao et al 2023
- “Micromouse: The Fastest Maze-Solving Competition On Earth”, Veritasium 2023
- “Long-Term Value of Exploration: Measurements, Findings and Algorithms”, Su et al 2023
- “Emergence of Belief-Like Representations through Reinforcement Learning”, Hennig et al 2023
- “Six Experiments in Action Minimization”, Greydanus 2023
- “Finding Paths of Least Action With Gradient Descent”, Greydanus 2023
- “MimicPlay: Long-Horizon Imitation Learning by Watching Human Play”, Wang et al 2023
- “Graph Schemas As Abstractions for Transfer Learning, Inference, and Planning”, Guntupalli et al 2023
- “John Carmack’s ‘Different Path’ to Artificial General Intelligence”, Carmack 2023
- “DreamerV3: Mastering Diverse Domains through World Models”, Hafner et al 2023
- “Merging Enzymatic and Synthetic Chemistry With Computational Synthesis Planning”, Levin et al 2022
- “PALMER: Perception-Action Loop With Memory for Long-Horizon Planning”, Beker et al 2022
- “Space Is a Latent [CSCG] Sequence: Structured Sequence Learning As a Unified Theory of Representation in the Hippocampus”, Raju et al 2022
- “CICERO: Human-Level Play in the Game of Diplomacy by Combining Language Models With Strategic Reasoning”, Bakhtin et al 2022
- “Online Learning and Bandits With Queried Hints”, Bhaskara et al 2022
- “E3B: Exploration via Elliptical Episodic Bonuses”, Henaff et al 2022
- “Creating a Dynamic Quadrupedal Robotic Goalkeeper With Reinforcement Learning”, Huang et al 2022
- “Top-Down Design of Protein Nanomaterials With Reinforcement Learning”, Lutz et al 2022
- “Simplifying Model-Based RL: Learning Representations, Latent-Space Models, and Policies With One Objective (ALM)”, Ghugare et al 2022
- “IRIS: Transformers Are Sample-Efficient World Models”, Micheli et al 2022
- “LGE: Cell-Free Latent Go-Explore”, Gallouédec & Dellandréa 2022
- “LaTTe: Language Trajectory TransformEr”, Bucker et al 2022
- “PI-ARS: Accelerating Evolution-Learned Visual-Locomotion With Predictive Information Representations”, Lee et al 2022
- “Learning With Combinatorial Optimization Layers: a Probabilistic Approach”, Dalle et al 2022
- “Spatial Representation by Ramping Activity of Neurons in the Retrohippocampal Cortex”, Tennant et al 2022
- “Inner Monologue: Embodied Reasoning through Planning With Language Models”, Huang et al 2022
- “LM-Nav: Robotic Navigation With Large Pre-Trained Models of Language, Vision, and Action”, Shah et al 2022
- “DayDreamer: World Models for Physical Robot Learning”, Wu et al 2022
- “Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos”, Baker et al 2022
- “GODEL: Large-Scale Pre-Training for Goal-Directed Dialog”, Peng et al 2022
- “BYOL-Explore: Exploration by Bootstrapped Prediction”, Guo et al 2022
- “Director: Deep Hierarchical Planning from Pixels”, Hafner et al 2022
- “Flexible Diffusion Modeling of Long Videos”, Harvey et al 2022
- “Housekeep: Tidying Virtual Households Using Commonsense Reasoning”, Kant et al 2022
- “Semantic Exploration from Language Abstractions and Pretrained Representations”, Tam et al 2022
- “Demonstrate Once, Imitate Immediately (DOME): Learning Visual Servoing for One-Shot Imitation Learning”, Valassakis et al 2022
- “Do As I Can, Not As I Say (SayCan): Grounding Language in Robotic Affordances”, Ahn et al 2022
- “Reinforcement Learning With Action-Free Pre-Training from Videos”, Seo et al 2022
- “On-The-Fly Strategy Adaptation for Ad-Hoc Agent Coordination”, Zand et al 2022
- “VAPO: Affordance Learning from Play for Sample-Efficient Policy Learning”, Borja-Diaz et al 2022
- “Learning Synthetic Environments and Reward Networks for Reinforcement Learning”, Ferreira et al 2022
- “How to Build a Cognitive Map: Insights from Models of the Hippocampal Formation”, Whittington et al 2022
- “LID: Pre-Trained Language Models for Interactive Decision-Making”, Li et al 2022
- “Rotting Infinitely Many-Armed Bandits”, Kim et al 2022
- “Language Models As Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents”, Huang et al 2022
- “What Is the Point of Computers? A Question for Pure Mathematicians”, Buzzard 2021
- “An Experimental Design Perspective on Model-Based Reinforcement Learning”, Mehta et al 2021
- “Residual Pathway Priors for Soft Equivariance Constraints”, Finzi et al 2021
- “Reinforcement Learning on Human Decision Models for Uniquely Collaborative AI Teammates”, Kantack 2021
- “Learning Representations for Pixel-Based Control: What Matters and Why?”, Tomar et al 2021
- “Learning Behaviors through Physics-Driven Latent Imagination”, Richard et al 2021
- “Is Bang-Bang Control All You Need? Solving Continuous Control With Bernoulli Policies”, Seyde et al 2021
- “Skill Induction and Planning With Latent Language”, Sharma et al 2021
- “Example-Driven Model-Based Reinforcement Learning for Solving Long-Horizon Visuomotor Tasks”, Wu et al 2021
- “TrufLL: Learning Natural Language Generation from Scratch”, Donati et al 2021
- “Dropout’s Dream Land: Generalization from Learned Simulators to Reality”, Wellmer & Kwok 2021
- “Human-Level Reinforcement Learning through Theory-Based Modeling, Exploration, and Planning [EMPA]”, Tsividis et al 2021
- “FitVid: Overfitting in Pixel-Level Video Prediction”, Babaeizadeh et al 2021
- “Brax—A Differentiable Physics Engine for Large Scale Rigid Body Simulation”, Freeman et al 2021
- “A Graph Placement Methodology for Fast Chip Design”, Mirhoseini et al 2021
- “Planning for Novelty: Width-Based Algorithms for Common Problems in Control, Planning and Reinforcement Learning”, Lipovetzky 2021
- “The Whole Prefrontal Cortex Is Premotor Cortex”, Fine & Hayden 2021
- “PIGLeT: Language Grounding Through Neuro-Symbolic Interaction in a 3D World”, Zellers et al 2021
- “Constructions in Combinatorics via Neural Networks”, Wagner 2021
- “Machine Translation Decoding beyond Beam Search”, Leblond et al 2021
- “Learning What To Do by Simulating the Past”, Lindner et al 2021
- “Waymo Simulated Driving Behavior in Reconstructed Fatal Crashes within an Autonomous Vehicle Operating Domain”, Scanlon et al 2021
- “Latent Imagination Facilitates Zero-Shot Transfer in Autonomous Racing”, Brunnbauer et al 2021
- “Replaying Real Life: How the Waymo Driver Avoids Fatal Human Crashes”, Waymo 2021
- “Learning Chess Blindfolded: Evaluating Language Models on State Tracking”, Toshniwal et al 2021
- “COMBO: Conservative Offline Model-Based Policy Optimization”, Yu et al 2021
- “A✱ Search Without Expansions: Learning Heuristic Functions With Deep Q-Networks”, Agostinelli et al 2021
- “ViNG: Learning Open-World Navigation With Visual Goals”, Shah et al 2020
- “Inductive Biases for Deep Learning of Higher-Level Cognition”, Goyal & Bengio 2020
- “Multimodal Dynamics Modeling for Off-Road Autonomous Vehicles”, Tremblay et al 2020
- “Targeting for Long-Term Outcomes”, Yang et al 2020
- “What Are the Statistical Limits of Offline RL With Linear Function Approximation?”, Wang et al 2020
- “A Time Leap Challenge for SAT Solving”, Fichte et al 2020
- “The Overfitted Brain: Dreams Evolved to Assist Generalization”, Hoel 2020
- “RL Unplugged: A Suite of Benchmarks for Offline Reinforcement Learning”, Gulcehre et al 2020
- “Mathematical Reasoning via Self-Supervised Skip-Tree Training”, Rabe et al 2020
- “MOPO: Model-Based Offline Policy Optimization”, Yu et al 2020
- “Learning to Simulate Dynamic Environments With GameGAN”, Kim et al 2020
- “Planning to Explore via Self-Supervised World Models”, Sekar et al 2020
- “Learning to Simulate Dynamic Environments With GameGAN [Homepage]”, Kim et al 2020
- “Reinforcement Learning With Augmented Data”, Laskin et al 2020
- “Learning to Fly via Deep Model-Based Reinforcement Learning”, Becker-Ehmck et al 2020
- “Introducing Dreamer: Scalable Reinforcement Learning Using World Models”, Hafner 2020
- “Reinforcement Learning for Combinatorial Optimization: A Survey”, Mazyavkina et al 2020
- “Learning to Prove Theorems by Learning to Generate Theorems”, Wang & Deng 2020
- “The Gambler’s Problem and Beyond”, Wang et al 2019
- “Combining Q-Learning and Search With Amortized Value Estimates”, Hamrick et al 2019
- “Dream to Control: Learning Behaviors by Latent Imagination”, Hafner et al 2019
- “Approximate Inference in Discrete Distributions With Monte Carlo Tree Search and Value Functions”, Buesing et al 2019
- “Is a Good Representation Sufficient for Sample Efficient Reinforcement Learning?”, Du et al 2019
- “Designing Agent Incentives to Avoid Reward Tampering”, Everitt et al 2019
- “An Application of Reinforcement Learning to Aerobatic Helicopter Flight”, Abbeel et al 2019
- “When to Trust Your Model: Model-Based Policy Optimization (MOPO)”, Janner et al 2019
- “VISR: Fast Task Inference With Variational Intrinsic Successor Features”, Hansen et al 2019
- “Write, Execute, Assess: Program Synthesis With a REPL”, Ellis et al 2019
- “Learning to Reason in Large Theories without Imitation”, Bansal et al 2019
- “Biasing MCTS With Features for General Games”, Soemers et al 2019
- “DRC: An Investigation of Model-Free Planning”, Guez et al 2019
- “The Credit Assignment Problem”, Demski 2019
- “Bayesian Layers: A Module for Neural Network Uncertainty”, Tran et al 2018
- “PlaNet: Learning Latent Dynamics for Planning from Pixels”, Hafner et al 2018
- “Bayesian Action Decoder for Deep Multi-Agent Reinforcement Learning”, Foerster et al 2018
- “Human-Like Playtesting With Deep Learning”, Gudmundsson et al 2018
- “General Value Function Networks”, Schlegel et al 2018
- “Towards Automated Deep Learning: Efficient Joint Neural Architecture and Hyperparameter Search”, Zela et al 2018
- “The Alignment Problem for Bayesian History-Based Reinforcement Learners”, Everitt & Hutter 2018
- “Neural Scene Representation and Rendering”, Eslami et al 2018
- “Deep Reinforcement Learning in a Handful of Trials Using Probabilistic Dynamics Models”, Kurtl et al 2018
- “Mining Gold from Implicit Models to Improve Likelihood-Free Inference”, Brehmer et al 2018
- “Learning to Optimize Tensor Programs”, Chen et al 2018
- “Reinforcement Learning and Control As Probabilistic Inference: Tutorial and Review”, Levine 2018
- “Estimate and Replace: A Novel Approach to Integrating Deep Neural Networks With Existing Applications”, Hadash et al 2018
- “World Models”, Ha & Schmidhuber 2018
- “Deep Bayesian Bandits Showdown: An Empirical Comparison of Bayesian Deep Networks for Thompson Sampling”, Riquelme et al 2018
- “Differentiable Dynamic Programming for Structured Prediction and Attention”, Mensch & Blondel 2018
- “Planning With Pixels in (Almost) Real Time”, Bandres et al 2018
- “How to Explore Chemical Space Using Algorithms and Automation”, Gromski et al 2018
- “Planning Chemical Syntheses With Deep Neural Networks and Symbolic AI”, Segler et al 2018
- “Generalization Guides Human Exploration in Vast Decision Spaces”, Wu et al 2018
- “Safe Policy Search With Gaussian Process Models”, Polymenakos et al 2017
- “Using Parameterized Black-Box Priors to Scale Up Model-Based Policy Search for Robotics”, Chatzilygeroudis & Mouret 2017
- “Analogical-Based Bayesian Optimization”, Le et al 2017
- “A Game-Theoretic Analysis of the Off-Switch Game”, Wängberg et al 2017
- “Neural Network Dynamics for Model-Based Deep Reinforcement Learning With Model-Free Fine-Tuning”, Nagabandi et al 2017
- “Learning Transferable Architectures for Scalable Image Recognition”, Zoph et al 2017
- “Learning Model-Based Planning from Scratch”, Pascanu et al 2017
- “Value Prediction Network”, Oh et al 2017
- “Path Integral Networks: End-To-End Differentiable Optimal Control”, Okada et al 2017
- “Visual Semantic Planning Using Deep Successor Representations”, Zhu et al 2017
- “AIXIjs: A Software Demo for General Reinforcement Learning”, Aslanides 2017
- “Metacontrol for Adaptive Imagination-Based Optimization”, Hamrick et al 2017
- “DeepArchitect: Automatically Designing and Training Deep Architectures”, Negrinho & Gordon 2017
- “Stochastic Constraint Programming As Reinforcement Learning”, Prestwich et al 2017
- “Recurrent Environment Simulators”, Chiappa et al 2017
- “Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World”, Tobin et al 2017
- “Prediction and Control With Temporal Segment Models”, Mishra et al 2017
- “Rotting Bandits”, Levine et al 2017
- “The Hippocampus As a Predictive Map”, Stachenfeld et al 2017
- “The Predictron: End-To-End Learning and Planning”, Silver et al 2016
- “Model-Based Adversarial Imitation Learning”, Baram et al 2016
- “DeepMath: Deep Sequence Models for Premise Selection”, Alemi et al 2016
- “Death and Suicide in Universal Artificial Intelligence”, Martin et al 2016
- “Value Iteration Networks”, Tamar et al 2016
- “On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models”, Schmidhuber 2015
- “Classical Planning Algorithms on the Atari Video Games”, Lipovetzky et al 2015
- “Optimal Regret Analysis of Thompson Sampling in Stochastic Multi-Armed Bandit Problem With Multiple Plays”, Komiyama et al 2015
- “Compress and Control”, Veness et al 2014
- “Learning to Win by Reading Manuals in a Monte-Carlo Framework”, Branavan et al 2014
- “Whatever Next? Predictive Brains, Situated Agents, and the Future of Cognitive Science”, Clark 2013
- “Model-Based Bayesian Exploration”, Dearden et al 2013
- “PUCT: Continuous Upper Confidence Trees With Polynomial Exploration-Consistency”, Auger et al 2013
- “Planning As Satisfiability: Heuristics”, Rintanen 2012
- “Width and Serialization of Classical Planning Problems”, Lipovetzky & Geffner 2012
- “An Empirical Evaluation of Thompson Sampling”, Chapelle & Li 2011
- “POMCP: Monte-Carlo Planning in Large POMDPs”, Silver & Veness 2010
- “A Monte Carlo AIXI Approximation”, Veness et al 2009
- “The Neural Processes Underpinning Episodic Memory”, Hassabis 2009
- “Evolution And Episodic Memory: An Analysis And Demonstration Of A Social Function Of Episodic Recollection”, Klein et al 2009
- “Resilient Machines Through Continuous Self-Modeling”, Bongard et al 2006
- “Gödel Machines: Self-Referential Universal Problem Solvers Making Provably Optimal Self-Improvements”, Schmidhuber 2003
- “Policy Mining: Learning Decision Policies from Fixed Sets of Data”, Zadrozny 2003
- “The Speed Prior: A New Simplicity Measure Yielding Near-Optimal Computable Predictions”, Schmidhuber 2002
- “Iterative Widening”, Cazenave 2001
- “Abstract Proof Search”, Cazenave 2000
- “Paul J. Werbos Interview”, Werbos 1998
- “A Critique of Pure Reason”, McDermott 1987
- “Human Window on the World”, Michie 1985
- “Why the Law of Effect Will Not Go Away”, Dennett 1974
- “First Place in Tetris 99 Using Computer Vision, Classical AI, and a Whole Lot of Free Time”
- “Getting the World Record in HATETRIS”
- “Solving Probabilistic Tic-Tac-Toe”, Abraham 2026
- “Approximate Bayes Optimal Policy Search Using Neural Networks”
- “Embodying Addiction: A Predictive Processing Account”
- “Joel Veness”
- “Introducing ‘Computer Use’, a New Claude-3.5-Sonnet, and Claude 3.5 Haiku”, Anthropic 2026
- “Developing a Computer Use Model”, Anthropic 2026
- “AIXIjs: General Reinforcement Learning in the Browser”
- “Why Rationalists Get Depressed”
- “Best-Of-n With Misaligned Reward Models for Math Reasoning”
- “Did Claude 3 Opus Align Itself via Gradient Hacking?”
- “A Year Late, Claude Finally Beats Pokémon”
- “Claude Plays Pokemon”
- Sort By Magic
- Wikipedia (9)
- Miscellaneous
- Bibliography
See Also
Gwern
“‘Try, Score, Change’: Reinforcement Learning for Children”, Pro et al 2026
“The Kelly Coin-Flipping Game: Exact Solutions”, Gwern et al 2017
“Resorting Media Ratings”, Gwern 2015
Links
“Advancing Mathematics Research With AI-Driven Formal Proof Search”, Tsoukalas et al 2026
Advancing Mathematics Research with AI-Driven Formal Proof Search
“Imperfect World Models Are Exploitable”, Bhamidipaty et al 2026
“The Biggest Trackmania Pathfinding Competition”, Wirtual 2026
“Optimal Caverna Gameplay via Formal Methods”, Diehl 2026
“I Spent the Last Month and a Half Building a Model That Visualizes Strategic Golf: A Way to Actually See the Ideas Hidden in Golf Course Architecture”, Schoolfield 2026
“The Waymo World Model: A New Frontier For Autonomous Driving Simulation”, Waymo 2026
The Waymo World Model: A New Frontier For Autonomous Driving Simulation
“The Anticipation of Imminent Events Is Time-Scale Invariant”, Grabenhorst et al 2026
“How Gemini 3 Pro Beat Pokemon Crystal (And 2.5 Pro Didn’t)”, Zhang 2025
“TreeGRPO: Tree-Advantage GRPO for Online RL Post-Training of Diffusion Models”, Ding & Ye 2025
TreeGRPO: Tree-Advantage GRPO for Online RL Post-Training of Diffusion Models
“SIMA 2: A Generalist Embodied Agent for Virtual Worlds”, team et al 2025
“Effective Harnesses for Long-Running Agents: Agents Still Face Challenges Working across Many Context Windows. We Looked to Human Engineers for Inspiration in Creating a More Effective Harness for Long-Running Agents”, Young 2025
“Reasoning With Sampling: Your Base Model Is Smarter Than You Think”, Karan & Du 2025
Reasoning with Sampling: Your Base Model is Smarter Than You Think
“Spooky Collusion at a Distance With Superrational AI”, bira 2025
“Tree-GRPO: Tree Search for LLM Agent Reinforcement Learning”, Ji et al 2025
“Graph Theory in State-Space [For Klotski Sliding-Block Puzzle]”, 2swap 2025
Graph Theory in State-Space [for Klotski sliding-block puzzle]
“Lost in Latent Space: An Empirical Study of Latent Diffusion Models for Physics Emulation”, Rozet et al 2025
Lost in Latent Space: An Empirical Study of Latent Diffusion Models for Physics Emulation
“Strategic Intelligence in Large Language Models: Evidence from Evolutionary Game Theory”, Payne & Alloui-Cros 2025
Strategic Intelligence in Large Language Models: Evidence from evolutionary Game Theory
“V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning”, Assran et al 2025
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
“Visual Planning: Let’s Think Only With Images”, Xu et al 2025
“Reinforcement Learning Finetunes Small Subnetworks in Large Language Models”, Mukherjee et al 2025
Reinforcement Learning Finetunes Small Subnetworks in Large Language Models
“XXt Can Be Faster”, Rybin et al 2025
“LLMs Get Lost In Multi-Turn Conversation”, Laban et al 2025
“Reinforcement Learning for Reasoning in Large Language Models With One Training Example”, Wang et al 2025
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
“Tina: Tiny Reasoning Models via LoRA”, Wang et al 2025
“The Geometry of Self-Verification in a Task-Specific Reasoning Model”, Lee et al 2025
The Geometry of Self-Verification in a Task-Specific Reasoning Model
“Is Google Gemini-2.5-Pro Now Better Than Claude at Pokémon? [Probably]”, Bradshaw 2025
Is Google Gemini-2.5-pro now better than Claude at Pokémon? [probably]
“Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?”, Yue et al 2025
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
“Interpreting Emergent Planning in Model-Free Reinforcement Learning”, Bush et al 2025
Interpreting Emergent Planning in Model-Free Reinforcement Learning
“Video-T1: Test-Time Scaling for Video Generation”, Liu et al 2025
“(How) Do Language Models Track State?”, Li et al 2025
“NaturalReasoning: Reasoning in the Wild With 2.8M Challenging Questions”, Yuan et al 2025
NaturalReasoning: Reasoning in the Wild with 2.8M Challenging Questions
“Training Language Models for Social Deduction With Multi-Agent Reinforcement Learning”, Sarkar et al 2025
Training Language Models for Social Deduction with Multi-Agent Reinforcement Learning
“Competitive Programming With Large Reasoning Models”, El-Kishky et al 2025
“MR.Q: Towards General-Purpose Model-Free Reinforcement Learning”, Fujimoto et al 2025
MR.Q: Towards General-Purpose Model-Free Reinforcement Learning
“DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning”, Guo et al 2025
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
“Deployment of an Aerial Multi-Agent System for Automated Task Execution in Large-Scale Underground Mining Environments”, Dahlquist et al 2025
“Generalized Dijkstra in Haskell”, flupe 2024
“Proposing and Solving Olympiad Geometry With Guided Tree Search”, Zhang et al 2024
Proposing and solving olympiad geometry with guided tree search
“Centaur: a Foundation Model of Human Cognition”, Binz et al 2024
“Embodied Agent Interface: Benchmarking LLMs for Embodied Decision Making”, Li et al 2024
Embodied Agent Interface: Benchmarking LLMs for Embodied Decision Making
“Interpretable Contrastive Monte Carlo Tree Search Reasoning”, Gao et al 2024
“OpenAI Co-Founder Sutskever’s New Safety-Focused AI Startup SSI Raises $1 Billion”, Cai et al 2024
OpenAI co-founder Sutskever’s new safety-focused AI startup SSI raises $1 billion
“The Brain Simulates Actions and Their Consequences during REM Sleep”, Senzai & Scanziani 2024
The brain simulates actions and their consequences during REM sleep
“Solving Path of Exile Item Crafting With Value Iteration”, Britz 2024
“Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models”, Denison et al 2024
Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models
“DT-VIN: Scaling Value Iteration Networks to 5000 Layers for Extreme Long-Term Planning”, Wang et al 2024
DT-VIN: Scaling Value Iteration Networks to 5000 Layers for Extreme Long-Term Planning
“MCTSr: Accessing GPT-4 Level Mathematical Olympiad Solutions via Monte Carlo Tree Self-Refine With LLaMA-3-8B”, Zhang et al 2024
“Safety Alignment Should Be Made More Than Just a Few Tokens Deep”, Qi et al 2024
Safety Alignment Should Be Made More Than Just a Few Tokens Deep
“Can Language Models Serve As Text-Based World Simulators?”, Wang et al 2024
“Evaluating the World Model Implicit in a Generative Model”, Vafa et al 2024
“OmegaPRM: Improve Mathematical Reasoning in Language Models by Automated Process Supervision”, Luo et al 2024
OmegaPRM: Improve Mathematical Reasoning in Language Models by Automated Process Supervision
“Diffusion On Syntax Trees For Program Synthesis”, Kapur et al 2024
“A Pontryagin Perspective on Reinforcement Learning”, Eberhard et al 2024
“DeTikZify: Synthesizing Graphics Programs for Scientific Figures and Sketches With TikZ”, Belouadi et al 2024
DeTikZify: Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ
“DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data”, Xin et al 2024
DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data
“Amit’s A✱ Pages”, Patel 2024
“From r to Q✱: Your Language Model Is Secretly a Q-Function”, Rafailov et al 2024
“Algorithmic Collusion by Large Language Models”, Fish et al 2024
“Identifying General Reaction Conditions by Bandit Optimization”, Wang et al 2024b
Identifying general reaction conditions by bandit optimization
“Gradient-Based Planning With World Models”, V et al 2023
“ReCoRe: Regularized Contrastive Representation Learning of World Model”, Poudel et al 2023
ReCoRe: Regularized Contrastive Representation Learning of World Model
“Can a Transformer Represent a Kalman Filter?”, Goel & Bartlett 2023
“Self-Supervised Behavior Cloned Transformers Are Path Crawlers for Text Games”, Wang & Jansen 2023
Self-Supervised Behavior Cloned Transformers are Path Crawlers for Text Games
“Why Won’t OpenAI Say What the Q✱ Algorithm Is? Supposed AI Breakthroughs Are Frequently Veiled in Secrecy, Hindering Scientific Consensus”, Hao 2023
“Zero-Shot Goal-Directed Dialogue via RL on Imagined Conversations”, Hong et al 2023
Zero-Shot Goal-Directed Dialogue via RL on Imagined Conversations
“The Neural Basis of Mental Navigation in Rats: A Brain–machine Interface Demonstrates Volitional Control of Hippocampal Activity”, Coulter & Kemere 2023
“Volitional Activation of Remote Place Representations With a Hippocampal Brain–machine Interface”, Lai et al 2023
Volitional activation of remote place representations with a hippocampal brain–machine interface
“Learning Unsupervised World Models for Autonomous Driving via Discrete Diffusion”, Zhang et al 2023
Learning Unsupervised World Models for Autonomous Driving via Discrete Diffusion
“Self-AIXI: Self-Predictive Universal AI”, Catt et al 2023
“Othello Is Solved”, Takizawa 2023
“Course Correcting Koopman Representations”, Fathi et al 2023
“Predictive Auxiliary Objectives in Deep RL Mimic Learning in the Brain”, Fang & Stachenfeld 2023
Predictive auxiliary objectives in deep RL mimic learning in the brain
“Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models”, Zhou et al 2023
Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
“Comparative Study of Model-Based and Model-Free Reinforcement Learning Control Performance in HVAC Systems”, Gao & Wang 2023
“Learning to Model the World With Language”, Lin et al 2023
“Do Models Explain Themselves? Counterfactual Simulatability of Natural Language Explanations”, Chen et al 2023
Do Models Explain Themselves? Counterfactual Simulatability of Natural Language Explanations
“Fighting Uncertainty With Gradients: Offline Reinforcement Learning via Diffusion Score Matching”, Suh et al 2023
Fighting Uncertainty with Gradients: Offline Reinforcement Learning via Diffusion Score Matching
“From Word Models to World Models: Translating from Natural Language to the Probabilistic Language of Thought”, Wong et al 2023
“Improving Long-Horizon Imitation Through Instruction Prediction”, Hejna et al 2023
Improving Long-Horizon Imitation Through Instruction Prediction
“When to Show a Suggestion? Integrating Human Feedback in AI-Assisted Programming (CDHF)”, Mozannar et al 2023
When to Show a Suggestion? Integrating Human Feedback in AI-Assisted Programming (CDHF)
“Reasoning With Language Model Is Planning With World Model”, Hao et al 2023
“Micromouse: The Fastest Maze-Solving Competition On Earth”, Veritasium 2023
“Long-Term Value of Exploration: Measurements, Findings and Algorithms”, Su et al 2023
Long-Term Value of Exploration: Measurements, Findings and Algorithms
“Emergence of Belief-Like Representations through Reinforcement Learning”, Hennig et al 2023
Emergence of belief-like representations through reinforcement learning
“Six Experiments in Action Minimization”, Greydanus 2023
Six Experiments in Action Minimization
View External Link:
“Finding Paths of Least Action With Gradient Descent”, Greydanus 2023
Finding Paths of Least Action with Gradient Descent
View External Link:
“MimicPlay: Long-Horizon Imitation Learning by Watching Human Play”, Wang et al 2023
MimicPlay: Long-Horizon Imitation Learning by Watching Human Play
“Graph Schemas As Abstractions for Transfer Learning, Inference, and Planning”, Guntupalli et al 2023
Graph schemas as abstractions for transfer learning, inference, and planning
“John Carmack’s ‘Different Path’ to Artificial General Intelligence”, Carmack 2023
John Carmack’s ‘Different Path’ to Artificial General Intelligence
“DreamerV3: Mastering Diverse Domains through World Models”, Hafner et al 2023
“Merging Enzymatic and Synthetic Chemistry With Computational Synthesis Planning”, Levin et al 2022
Merging enzymatic and synthetic chemistry with computational synthesis planning
“PALMER: Perception-Action Loop With Memory for Long-Horizon Planning”, Beker et al 2022
PALMER: Perception-Action Loop with Memory for Long-Horizon Planning
“Space Is a Latent [CSCG] Sequence: Structured Sequence Learning As a Unified Theory of Representation in the Hippocampus”, Raju et al 2022
“CICERO: Human-Level Play in the Game of Diplomacy by Combining Language Models With Strategic Reasoning”, Bakhtin et al 2022
“Online Learning and Bandits With Queried Hints”, Bhaskara et al 2022
“E3B: Exploration via Elliptical Episodic Bonuses”, Henaff et al 2022
“Creating a Dynamic Quadrupedal Robotic Goalkeeper With Reinforcement Learning”, Huang et al 2022
Creating a Dynamic Quadrupedal Robotic Goalkeeper with Reinforcement Learning
“Top-Down Design of Protein Nanomaterials With Reinforcement Learning”, Lutz et al 2022
Top-down design of protein nanomaterials with reinforcement learning
“Simplifying Model-Based RL: Learning Representations, Latent-Space Models, and Policies With One Objective (ALM)”, Ghugare et al 2022
“IRIS: Transformers Are Sample-Efficient World Models”, Micheli et al 2022
“LGE: Cell-Free Latent Go-Explore”, Gallouédec & Dellandréa 2022
“LaTTe: Language Trajectory TransformEr”, Bucker et al 2022
“PI-ARS: Accelerating Evolution-Learned Visual-Locomotion With Predictive Information Representations”, Lee et al 2022
PI-ARS: Accelerating Evolution-Learned Visual-Locomotion with Predictive Information Representations
“Learning With Combinatorial Optimization Layers: a Probabilistic Approach”, Dalle et al 2022
Learning with Combinatorial Optimization Layers: a Probabilistic Approach
“Spatial Representation by Ramping Activity of Neurons in the Retrohippocampal Cortex”, Tennant et al 2022
Spatial representation by ramping activity of neurons in the retrohippocampal cortex
“Inner Monologue: Embodied Reasoning through Planning With Language Models”, Huang et al 2022
Inner Monologue: Embodied Reasoning through Planning with Language Models
“LM-Nav: Robotic Navigation With Large Pre-Trained Models of Language, Vision, and Action”, Shah et al 2022
LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action
“DayDreamer: World Models for Physical Robot Learning”, Wu et al 2022
“Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos”, Baker et al 2022
Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos
“GODEL: Large-Scale Pre-Training for Goal-Directed Dialog”, Peng et al 2022
“BYOL-Explore: Exploration by Bootstrapped Prediction”, Guo et al 2022
“Director: Deep Hierarchical Planning from Pixels”, Hafner et al 2022
“Flexible Diffusion Modeling of Long Videos”, Harvey et al 2022
“Housekeep: Tidying Virtual Households Using Commonsense Reasoning”, Kant et al 2022
Housekeep: Tidying Virtual Households using Commonsense Reasoning
“Semantic Exploration from Language Abstractions and Pretrained Representations”, Tam et al 2022
Semantic Exploration from Language Abstractions and Pretrained Representations
“Demonstrate Once, Imitate Immediately (DOME): Learning Visual Servoing for One-Shot Imitation Learning”, Valassakis et al 2022
“Do As I Can, Not As I Say (SayCan): Grounding Language in Robotic Affordances”, Ahn et al 2022
Do As I Can, Not As I Say (SayCan): Grounding Language in Robotic Affordances
“Reinforcement Learning With Action-Free Pre-Training from Videos”, Seo et al 2022
Reinforcement Learning with Action-Free Pre-Training from Videos
“On-The-Fly Strategy Adaptation for Ad-Hoc Agent Coordination”, Zand et al 2022
On-the-fly Strategy Adaptation for ad-hoc Agent Coordination
“VAPO: Affordance Learning from Play for Sample-Efficient Policy Learning”, Borja-Diaz et al 2022
VAPO: Affordance Learning from Play for Sample-Efficient Policy Learning
“Learning Synthetic Environments and Reward Networks for Reinforcement Learning”, Ferreira et al 2022
Learning Synthetic Environments and Reward Networks for Reinforcement Learning
“How to Build a Cognitive Map: Insights from Models of the Hippocampal Formation”, Whittington et al 2022
How to build a cognitive map: insights from models of the hippocampal formation
“LID: Pre-Trained Language Models for Interactive Decision-Making”, Li et al 2022
LID: Pre-Trained Language Models for Interactive Decision-Making
“Rotting Infinitely Many-Armed Bandits”, Kim et al 2022
“Language Models As Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents”, Huang et al 2022
Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents
“What Is the Point of Computers? A Question for Pure Mathematicians”, Buzzard 2021
What is the point of computers? A question for pure mathematicians
“An Experimental Design Perspective on Model-Based Reinforcement Learning”, Mehta et al 2021
An Experimental Design Perspective on Model-Based Reinforcement Learning
“Residual Pathway Priors for Soft Equivariance Constraints”, Finzi et al 2021
“Reinforcement Learning on Human Decision Models for Uniquely Collaborative AI Teammates”, Kantack 2021
Reinforcement Learning on Human Decision Models for Uniquely Collaborative AI Teammates
“Learning Representations for Pixel-Based Control: What Matters and Why?”, Tomar et al 2021
Learning Representations for Pixel-based Control: What Matters and Why?
“Learning Behaviors through Physics-Driven Latent Imagination”, Richard et al 2021
Learning Behaviors through Physics-driven Latent Imagination
“Is Bang-Bang Control All You Need? Solving Continuous Control With Bernoulli Policies”, Seyde et al 2021
Is Bang-Bang Control All You Need? Solving Continuous Control with Bernoulli Policies
“Example-Driven Model-Based Reinforcement Learning for Solving Long-Horizon Visuomotor Tasks”, Wu et al 2021
Example-Driven Model-Based Reinforcement Learning for Solving Long-Horizon Visuomotor Tasks
“TrufLL: Learning Natural Language Generation from Scratch”, Donati et al 2021
“Dropout’s Dream Land: Generalization from Learned Simulators to Reality”, Wellmer & Kwok 2021
Dropout’s Dream Land: Generalization from Learned Simulators to Reality
“Human-Level Reinforcement Learning through Theory-Based Modeling, Exploration, and Planning [EMPA]”, Tsividis et al 2021
Human-Level Reinforcement Learning through Theory-Based Modeling, Exploration, and Planning [EMPA]
“FitVid: Overfitting in Pixel-Level Video Prediction”, Babaeizadeh et al 2021
“Brax—A Differentiable Physics Engine for Large Scale Rigid Body Simulation”, Freeman et al 2021
Brax—A Differentiable Physics Engine for Large Scale Rigid Body Simulation
“A Graph Placement Methodology for Fast Chip Design”, Mirhoseini et al 2021
“Planning for Novelty: Width-Based Algorithms for Common Problems in Control, Planning and Reinforcement Learning”, Lipovetzky 2021
“The Whole Prefrontal Cortex Is Premotor Cortex”, Fine & Hayden 2021
“PIGLeT: Language Grounding Through Neuro-Symbolic Interaction in a 3D World”, Zellers et al 2021
PIGLeT: Language Grounding Through Neuro-Symbolic Interaction in a 3D World
“Constructions in Combinatorics via Neural Networks”, Wagner 2021
“Machine Translation Decoding beyond Beam Search”, Leblond et al 2021
“Learning What To Do by Simulating the Past”, Lindner et al 2021
“Waymo Simulated Driving Behavior in Reconstructed Fatal Crashes within an Autonomous Vehicle Operating Domain”, Scanlon et al 2021
“Latent Imagination Facilitates Zero-Shot Transfer in Autonomous Racing”, Brunnbauer et al 2021
Latent Imagination Facilitates Zero-Shot Transfer in Autonomous Racing
“Replaying Real Life: How the Waymo Driver Avoids Fatal Human Crashes”, Waymo 2021
Replaying real life: how the Waymo Driver avoids fatal human crashes
“Learning Chess Blindfolded: Evaluating Language Models on State Tracking”, Toshniwal et al 2021
Learning Chess Blindfolded: Evaluating Language Models on State Tracking
“COMBO: Conservative Offline Model-Based Policy Optimization”, Yu et al 2021
“A✱ Search Without Expansions: Learning Heuristic Functions With Deep Q-Networks”, Agostinelli et al 2021
A✱ Search Without Expansions: Learning Heuristic Functions with Deep Q-Networks
“ViNG: Learning Open-World Navigation With Visual Goals”, Shah et al 2020
“Inductive Biases for Deep Learning of Higher-Level Cognition”, Goyal & Bengio 2020
Inductive Biases for Deep Learning of Higher-Level Cognition
“Multimodal Dynamics Modeling for Off-Road Autonomous Vehicles”, Tremblay et al 2020
Multimodal dynamics modeling for off-road autonomous vehicles
“Targeting for Long-Term Outcomes”, Yang et al 2020
“What Are the Statistical Limits of Offline RL With Linear Function Approximation?”, Wang et al 2020
What are the Statistical Limits of Offline RL with Linear Function Approximation?
“A Time Leap Challenge for SAT Solving”, Fichte et al 2020
“The Overfitted Brain: Dreams Evolved to Assist Generalization”, Hoel 2020
The Overfitted Brain: Dreams evolved to assist generalization
“RL Unplugged: A Suite of Benchmarks for Offline Reinforcement Learning”, Gulcehre et al 2020
RL Unplugged: A Suite of Benchmarks for Offline Reinforcement Learning
“Mathematical Reasoning via Self-Supervised Skip-Tree Training”, Rabe et al 2020
Mathematical Reasoning via Self-supervised Skip-tree Training
“MOPO: Model-Based Offline Policy Optimization”, Yu et al 2020
“Learning to Simulate Dynamic Environments With GameGAN”, Kim et al 2020
“Planning to Explore via Self-Supervised World Models”, Sekar et al 2020
“Learning to Simulate Dynamic Environments With GameGAN [Homepage]”, Kim et al 2020
Learning to Simulate Dynamic Environments with GameGAN [homepage]
“Reinforcement Learning With Augmented Data”, Laskin et al 2020
“Learning to Fly via Deep Model-Based Reinforcement Learning”, Becker-Ehmck et al 2020
“Introducing Dreamer: Scalable Reinforcement Learning Using World Models”, Hafner 2020
Introducing Dreamer: Scalable Reinforcement Learning Using World Models
“Reinforcement Learning for Combinatorial Optimization: A Survey”, Mazyavkina et al 2020
Reinforcement Learning for Combinatorial Optimization: A Survey
“Learning to Prove Theorems by Learning to Generate Theorems”, Wang & Deng 2020
“The Gambler’s Problem and Beyond”, Wang et al 2019
“Combining Q-Learning and Search With Amortized Value Estimates”, Hamrick et al 2019
Combining Q-Learning and Search with Amortized Value Estimates
“Dream to Control: Learning Behaviors by Latent Imagination”, Hafner et al 2019
“Approximate Inference in Discrete Distributions With Monte Carlo Tree Search and Value Functions”, Buesing et al 2019
Approximate Inference in Discrete Distributions with Monte Carlo Tree Search and Value Functions
“Is a Good Representation Sufficient for Sample Efficient Reinforcement Learning?”, Du et al 2019
Is a Good Representation Sufficient for Sample Efficient Reinforcement Learning?
“Designing Agent Incentives to Avoid Reward Tampering”, Everitt et al 2019
“An Application of Reinforcement Learning to Aerobatic Helicopter Flight”, Abbeel et al 2019
An Application of Reinforcement Learning to Aerobatic Helicopter Flight
“When to Trust Your Model: Model-Based Policy Optimization (MOPO)”, Janner et al 2019
When to Trust Your Model: Model-Based Policy Optimization (MOPO)
“VISR: Fast Task Inference With Variational Intrinsic Successor Features”, Hansen et al 2019
VISR: Fast Task Inference with Variational Intrinsic Successor Features
“Write, Execute, Assess: Program Synthesis With a REPL”, Ellis et al 2019
“Learning to Reason in Large Theories without Imitation”, Bansal et al 2019
“Biasing MCTS With Features for General Games”, Soemers et al 2019
“DRC: An Investigation of Model-Free Planning”, Guez et al 2019
“The Credit Assignment Problem”, Demski 2019
“Bayesian Layers: A Module for Neural Network Uncertainty”, Tran et al 2018
“PlaNet: Learning Latent Dynamics for Planning from Pixels”, Hafner et al 2018
“Bayesian Action Decoder for Deep Multi-Agent Reinforcement Learning”, Foerster et al 2018
Bayesian Action Decoder for Deep Multi-Agent Reinforcement Learning
“Human-Like Playtesting With Deep Learning”, Gudmundsson et al 2018
“General Value Function Networks”, Schlegel et al 2018
“Towards Automated Deep Learning: Efficient Joint Neural Architecture and Hyperparameter Search”, Zela et al 2018
Towards Automated Deep Learning: Efficient Joint Neural Architecture and Hyperparameter Search
“The Alignment Problem for Bayesian History-Based Reinforcement Learners”, Everitt & Hutter 2018
The Alignment Problem for Bayesian History-Based Reinforcement Learners
“Neural Scene Representation and Rendering”, Eslami et al 2018
“Deep Reinforcement Learning in a Handful of Trials Using Probabilistic Dynamics Models”, Kurtl et al 2018
Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models
“Mining Gold from Implicit Models to Improve Likelihood-Free Inference”, Brehmer et al 2018
Mining gold from implicit models to improve likelihood-free inference
“Learning to Optimize Tensor Programs”, Chen et al 2018
“Reinforcement Learning and Control As Probabilistic Inference: Tutorial and Review”, Levine 2018
Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review
“Estimate and Replace: A Novel Approach to Integrating Deep Neural Networks With Existing Applications”, Hadash et al 2018
“World Models”, Ha & Schmidhuber 2018
“Deep Bayesian Bandits Showdown: An Empirical Comparison of Bayesian Deep Networks for Thompson Sampling”, Riquelme et al 2018
“Differentiable Dynamic Programming for Structured Prediction and Attention”, Mensch & Blondel 2018
Differentiable Dynamic Programming for Structured Prediction and Attention
“Planning With Pixels in (Almost) Real Time”, Bandres et al 2018
“How to Explore Chemical Space Using Algorithms and Automation”, Gromski et al 2018
How to explore chemical space using algorithms and automation
“Planning Chemical Syntheses With Deep Neural Networks and Symbolic AI”, Segler et al 2018
Planning chemical syntheses with deep neural networks and symbolic AI
“Generalization Guides Human Exploration in Vast Decision Spaces”, Wu et al 2018
Generalization guides human exploration in vast decision spaces
“Safe Policy Search With Gaussian Process Models”, Polymenakos et al 2017
“Using Parameterized Black-Box Priors to Scale Up Model-Based Policy Search for Robotics”, Chatzilygeroudis & Mouret 2017
Using Parameterized Black-Box Priors to Scale Up Model-Based Policy Search for Robotics
“Analogical-Based Bayesian Optimization”, Le et al 2017
“A Game-Theoretic Analysis of the Off-Switch Game”, Wängberg et al 2017
“Neural Network Dynamics for Model-Based Deep Reinforcement Learning With Model-Free Fine-Tuning”, Nagabandi et al 2017
Neural Network Dynamics for Model-Based Deep Reinforcement Learning with Model-Free Fine-Tuning
“Learning Transferable Architectures for Scalable Image Recognition”, Zoph et al 2017
Learning Transferable Architectures for Scalable Image Recognition
“Learning Model-Based Planning from Scratch”, Pascanu et al 2017
“Value Prediction Network”, Oh et al 2017
“Path Integral Networks: End-To-End Differentiable Optimal Control”, Okada et al 2017
Path Integral Networks: End-to-End Differentiable Optimal Control
“Visual Semantic Planning Using Deep Successor Representations”, Zhu et al 2017
Visual Semantic Planning using Deep Successor Representations
“AIXIjs: A Software Demo for General Reinforcement Learning”, Aslanides 2017
“Metacontrol for Adaptive Imagination-Based Optimization”, Hamrick et al 2017
“DeepArchitect: Automatically Designing and Training Deep Architectures”, Negrinho & Gordon 2017
DeepArchitect: Automatically Designing and Training Deep Architectures
“Stochastic Constraint Programming As Reinforcement Learning”, Prestwich et al 2017
“Recurrent Environment Simulators”, Chiappa et al 2017
“Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World”, Tobin et al 2017
Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World
“Prediction and Control With Temporal Segment Models”, Mishra et al 2017
“Rotting Bandits”, Levine et al 2017
“The Hippocampus As a Predictive Map”, Stachenfeld et al 2017
“The Predictron: End-To-End Learning and Planning”, Silver et al 2016
“Model-Based Adversarial Imitation Learning”, Baram et al 2016
“DeepMath: Deep Sequence Models for Premise Selection”, Alemi et al 2016
“Death and Suicide in Universal Artificial Intelligence”, Martin et al 2016
“Value Iteration Networks”, Tamar et al 2016
“On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models”, Schmidhuber 2015
“Classical Planning Algorithms on the Atari Video Games”, Lipovetzky et al 2015
“Optimal Regret Analysis of Thompson Sampling in Stochastic Multi-Armed Bandit Problem With Multiple Plays”, Komiyama et al 2015
“Compress and Control”, Veness et al 2014
“Whatever Next? Predictive Brains, Situated Agents, and the Future of Cognitive Science”, Clark 2013
Whatever next? Predictive brains, situated agents, and the future of cognitive science
“Model-Based Bayesian Exploration”, Dearden et al 2013
“PUCT: Continuous Upper Confidence Trees With Polynomial Exploration-Consistency”, Auger et al 2013
PUCT: Continuous Upper Confidence Trees with Polynomial Exploration-Consistency
“Planning As Satisfiability: Heuristics”, Rintanen 2012
“Width and Serialization of Classical Planning Problems”, Lipovetzky & Geffner 2012
“An Empirical Evaluation of Thompson Sampling”, Chapelle & Li 2011
“POMCP: Monte-Carlo Planning in Large POMDPs”, Silver & Veness 2010
“A Monte Carlo AIXI Approximation”, Veness et al 2009
“The Neural Processes Underpinning Episodic Memory”, Hassabis 2009
“Evolution And Episodic Memory: An Analysis And Demonstration Of A Social Function Of Episodic Recollection”, Klein et al 2009
“Resilient Machines Through Continuous Self-Modeling”, Bongard et al 2006
“Gödel Machines: Self-Referential Universal Problem Solvers Making Provably Optimal Self-Improvements”, Schmidhuber 2003
Gödel Machines: Self-Referential Universal Problem Solvers Making Provably Optimal Self-Improvements
“Policy Mining: Learning Decision Policies from Fixed Sets of Data”, Zadrozny 2003
Policy Mining: Learning Decision Policies from Fixed Sets of Data
“The Speed Prior: A New Simplicity Measure Yielding Near-Optimal Computable Predictions”, Schmidhuber 2002
The Speed Prior: A New Simplicity Measure Yielding Near-Optimal Computable Predictions
“Paul J. Werbos Interview”, Werbos 1998
“A Critique of Pure Reason”, McDermott 1987
“Human Window on the World”, Michie 1985
“Why the Law of Effect Will Not Go Away”, Dennett 1974
“First Place in Tetris 99 Using Computer Vision, Classical AI, and a Whole Lot of Free Time”
First place in Tetris 99 using computer vision, classical AI, and a whole lot of free time
“Getting the World Record in HATETRIS”
“Solving Probabilistic Tic-Tac-Toe”, Abraham 2026
Solving Probabilistic Tic-Tac-Toe
View External Link:
https://louisabraham.github.io/articles/probabilistic-tic-tac-toe
“Approximate Bayes Optimal Policy Search Using Neural Networks”
Approximate Bayes Optimal Policy Search using Neural Networks
“Embodying Addiction: A Predictive Processing Account”
“Joel Veness”
“Introducing ‘Computer Use’, a New Claude-3.5-Sonnet, and Claude 3.5 Haiku”, Anthropic 2026
Introducing ‘computer use’, a new Claude-3.5-sonnet, and Claude 3.5 Haiku
“Developing a Computer Use Model”, Anthropic 2026
“AIXIjs: General Reinforcement Learning in the Browser”
“Why Rationalists Get Depressed”
“Best-Of-n With Misaligned Reward Models for Math Reasoning”
“Did Claude 3 Opus Align Itself via Gradient Hacking?”
“A Year Late, Claude Finally Beats Pokémon”
“Claude Plays Pokemon”
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
episodic-memory
neuroscience
differentiable-physics
satisfaction-heuristics
bayesian-uncertainty
human-feedback
ai-ethics
automation-mining
transfer-learning
protein-design
model-based-control
Wikipedia (9)
Miscellaneous
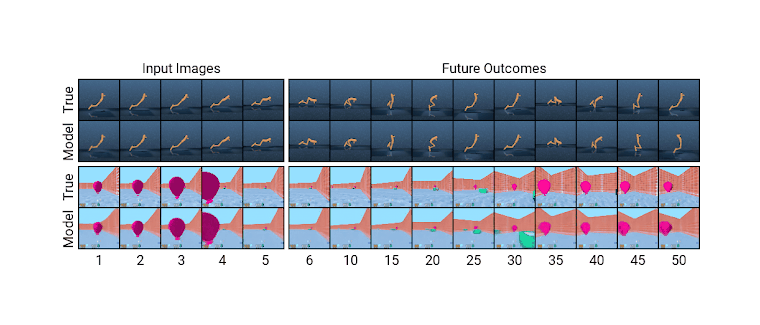
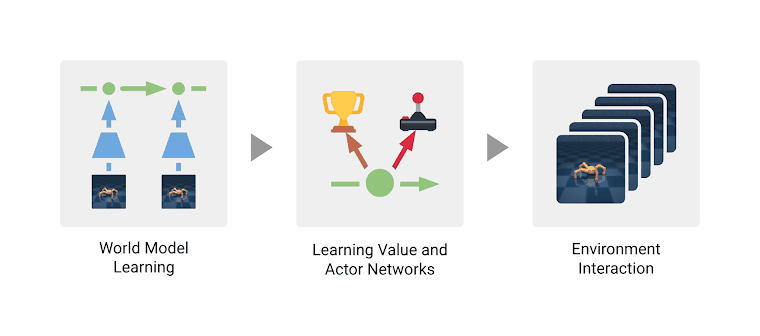
/doc/reinforcement-learning/model/2020-hafner-dreamer-learninganimation.mp4/doc/reinforcement-learning/model/2020-hafner-dreamer-modelpredictions.png/doc/reinforcement-learning/model/2020-hafner-dreamer-threephasearchitecture.png/doc/reinforcement-learning/model/2010-silver-figure1-illustrationofpomcpmctssearchoverapomdp.jpghttps://github.com/KeeyanGhoreshi/PokemonFireredSingleSequencehttps://if50.substack.com/p/christopher-strachey-and-the-dawnhttps://netflixtechblog.com/artwork-personalization-c589f074ad76https://www.bkgm.com/articles/Berliner/ComputerBackgammon/index.htmlhttps://www.freepatentsonline.com/y2024/0104353.html#deepmindhttps://www.lesswrong.com/posts/S54HKhxQyttNLATKu/deconfusing-direct-vs-amortised-optimizationhttps://www.lesswrong.com/posts/ZwshvqiqCvXPsZEct/the-learning-theoretic-agenda-status-2023https://www.lesswrong.com/posts/nmxzr2zsjNtjaHh7x/actually-othello-gpt-has-a-linear-emergent-world
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2512.08153: “TreeGRPO: Tree-Advantage GRPO for Online RL Post-Training of Diffusion Models”,https://arxiv.org/abs/2512.04797#deepmind: “SIMA 2: A Generalist Embodied Agent for Virtual Worlds”,https://arxiv.org/abs/2506.09985#facebook: “V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning”,https://arxiv.org/abs/2505.11711: “Reinforcement Learning Finetunes Small Subnetworks in Large Language Models”,https://arxiv.org/abs/2504.20571: “Reinforcement Learning for Reasoning in Large Language Models With One Training Example”,https://arxiv.org/abs/2504.14379: “The Geometry of Self-Verification in a Task-Specific Reasoning Model”,https://arxiv.org/abs/2502.06807#openai: “Competitive Programming With Large Reasoning Models”,https://arxiv.org/abs/2410.01707: “Interpretable Contrastive Monte Carlo Tree Search Reasoning”,https://www.reuters.com/technology/artificial-intelligence/openai-co-founder-sutskevers-new-safety-focused-ai-startup-ssi-raises-1-billion-2024-09-04/: “OpenAI Co-Founder Sutskever’s New Safety-Focused AI Startup SSI Raises $1 Billion”,https://arxiv.org/abs/2406.08404#schmidhuber: “DT-VIN: Scaling Value Iteration Networks to 5000 Layers for Extreme Long-Term Planning”,https://arxiv.org/abs/2406.07394: “MCTSr: Accessing GPT-4 Level Mathematical Olympiad Solutions via Monte Carlo Tree Self-Refine With LLaMA-3-8B”,https://arxiv.org/abs/2406.03689: “Evaluating the World Model Implicit in a Generative Model”,https://arxiv.org/abs/2405.15306: “DeTikZify: Synthesizing Graphics Programs for Scientific Figures and Sketches With TikZ”,https://arxiv.org/abs/2404.12358: “From r to Q✱: Your Language Model Is Secretly a Q-Function”,2024-wang-2.pdf: “Identifying General Reaction Conditions by Bandit Optimization”,https://arxiv.org/abs/2311.01017: “Learning Unsupervised World Models for Autonomous Driving via Discrete Diffusion”,https://openreview.net/forum?id=psXVkKO9No#deepmind: “Self-AIXI: Self-Predictive Universal AI”,https://arxiv.org/abs/2310.04406: “Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models”,2023-gao.pdf: “Comparative Study of Model-Based and Model-Free Reinforcement Learning Control Performance in HVAC Systems”,https://arxiv.org/abs/2306.04930#microsoft: “When to Show a Suggestion? Integrating Human Feedback in AI-Assisted Programming (CDHF)”,https://arxiv.org/abs/2302.12422#nvidia: “MimicPlay: Long-Horizon Imitation Learning by Watching Human Play”,https://arxiv.org/abs/2301.04104#deepmind: “DreamerV3: Mastering Diverse Domains through World Models”,https://www.nature.com/articles/s41467-022-35422-y: “Merging Enzymatic and Synthetic Chemistry With Computational Synthesis Planning”,2022-bakhtin.pdf: “CICERO: Human-Level Play in the Game of Diplomacy by Combining Language Models With Strategic Reasoning”,https://arxiv.org/abs/2209.08466: “Simplifying Model-Based RL: Learning Representations, Latent-Space Models, and Policies With One Objective (ALM)”,https://arxiv.org/abs/2209.00588: “IRIS: Transformers Are Sample-Efficient World Models”,https://arxiv.org/abs/2207.05608#google: “Inner Monologue: Embodied Reasoning through Planning With Language Models”,https://arxiv.org/abs/2207.04429: “LM-Nav: Robotic Navigation With Large Pre-Trained Models of Language, Vision, and Action”,https://arxiv.org/abs/2206.14176: “DayDreamer: World Models for Physical Robot Learning”,https://arxiv.org/abs/2206.11795#openai: “Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos”,https://arxiv.org/abs/2206.11309#microsoft: “GODEL: Large-Scale Pre-Training for Goal-Directed Dialog”,https://arxiv.org/abs/2206.04114#google: “Director: Deep Hierarchical Planning from Pixels”,https://arxiv.org/abs/2204.05080#deepmind: “Semantic Exploration from Language Abstractions and Pretrained Representations”,https://arxiv.org/abs/2204.01691#google: “Do As I Can, Not As I Say (SayCan): Grounding Language in Robotic Affordances”,https://arxiv.org/abs/2106.13281#google: “Brax—A Differentiable Physics Engine for Large Scale Rigid Body Simulation”,https://waymo.com/blog/2021/03/replaying-real-life/: “Replaying Real Life: How the Waymo Driver Avoids Fatal Human Crashes”,https://research.google/blog/introducing-dreamer-scalable-reinforcement-learning-using-world-models/: “Introducing Dreamer: Scalable Reinforcement Learning Using World Models”,https://arxiv.org/abs/1901.03559#deepmind: “DRC: An Investigation of Model-Free Planning”,2018-gudmundsson.pdf: “Human-Like Playtesting With Deep Learning”,2018-everitt.pdf: “The Alignment Problem for Bayesian History-Based Reinforcement Learners”,https://arxiv.org/abs/1705.07615: “AIXIjs: A Software Demo for General Reinforcement Learning”,2010-silver.pdf: “POMCP: Monte-Carlo Planning in Large POMDPs”,2001-cazenave.pdf: “Iterative Widening”,