Archiving URLs
Archiving the Web, because nothing lasts forever: statistics, online archive services, extracting URLs automatically from browsers, and creating a daemon to regularly back up URLs to multiple sources.
Links on the Internet last forever or a year, whichever inconveniences you more. This is a major problem for anyone serious about writing with good references, as link rot will cripple several percent of all links each year, and compounding.
To deal with link rot, I present my multi-pronged archival strategy using a combination of scripts, daemons, and Internet archival services: URLs are regularly dumped from both my web browser’s daily browsing and my website pages into an archival daemon I wrote, which pre-emptively downloads copies locally and attempts to archive them in the Internet Archive. This ensures a copy will be available indefinitely from one of several sources. Link rot is then detected by regular runs of
linkchecker, and any newly dead links can be immediately checked for alternative locations, or restored from one of the archive sources.As an additional flourish, my local archives are efficiently cryptographically timestamped using Bitcoin in case forgery is a concern, and I demonstrate a simple compression trick for substantially reducing sizes of large web archives such as crawls (particularly useful for repeated crawls such as my DNM archives).
Given my interest in long term content and extensive linking, link rot is an issue of deep concern to me. I need backups not just for my files1, but for the web pages I read and use—they’re all part of my exomind. It’s not much good to have an extensive essay on some topic where half the links are dead and the reader can neither verify my claims nor get context for my claims.
Link Rot
Decay is inherent in all compound things. Work out your own salvation with diligence.
Last words of the Buddha
The dimension of digital decay is dismal and distressing. Wikipedia:
In a 200323ya experiment, Fetterly et al 2003 discovered that about one link out of every 200 disappeared each week from the Internet. McCown et al 2005 discovered that half of the URLs cited in D-Lib Magazine articles were no longer accessible 10 years after publication [the irony!], and other studies have shown link rot in academic literature to be even worse (Spinellis, 2003, Lawrence et al 2001). Nelson & Allen 2002 examined link rot in digital libraries and found that about 3% of the objects were no longer accessible after one year.
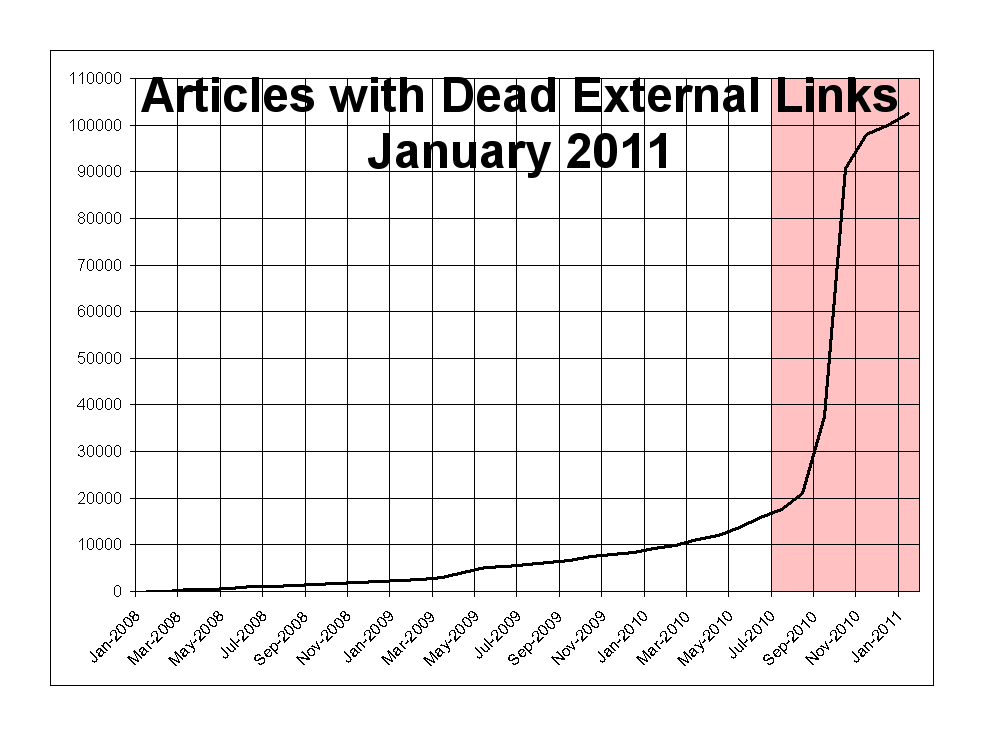
Bruce Schneier remarks that one friend experienced 50% linkrot in one of his pages over less than 9 years (not that the situation was any better in 1998), and that his own blog posts link to news articles that go dead in days2; Vitorio checks bookmarks from 1997, finding that hand-checking indicates a total link rot of 91% with only half of the dead available in sources like the Internet Archive; Ernie Smith found 1 semi-working link in a 199432ya book about the Internet; the Internet Archive itself has estimated the average lifespan of a Web page at 100 days. A Science study looked at articles in prestigious journals; they didn’t use many Internet links, but when they did, 2 years later ~13% were dead3. The French company Linterweb studied external links on the French Wikipedia before setting up their cache of French external links, and found—back in 200818ya—already 5% were dead. (The English Wikipedia has seen a 2010–January 201115ya spike from a few thousand dead links to ~110,000 out of ~17.5m live links.) A followup check of the viral The Million Dollar Homepage, where it cost up to $62.27$382006k to insert a link by the last insertion on January 200620ya, found that a decade later in 2017, at least half the links were dead or squatted.4 Bookmarking website Pinboard, which provides some archiving services, noted in August 2014 that 17% of 3-year-old links & 25% of 5-year-old links were dead. The dismal studies just go on and on and on (and on).
{kind=link}
Even in a highly stable, funded, curated environment, link rot happens anyway. For example, about 11% of Arab Spring-related tweets were gone within a year (even though Twitter is—currently—still around). And sometimes they just get quietly lost, like when MySpace admitted it lost all music worldwide uploaded 2003–12201511ya, euphemistically describing the mass deletion as “We completely rebuilt MySpace and decided to move over some of your content from the old MySpace” (emphasis added; only some of the 2008–201016ya MySpace music could be rescued & put on the IA by “an anonymous academic study”).
Worlds are always ending.
If you get anything out of reading history or anthropology, it should be that: it’s always the apocalypse somewhere for someone. What comes after each apocalypse may be better or worse, but nevertheless, it comes. Everything that is solid will one day melt into thin air, and nothing you value—the things you will miss, the smallest everyday details of life, your secret rituals and private jokes, the odd thoughts that cur and recur, those things of beauty not written in any book—none of that will survive on its own, will be lost and forgotten, and if you don’t preserve it, probably no one else will either.
You may not care about that, and that is your choice. Your time can be well-spent otherwise. But if you do, you should know that: worlds are always ending, and in an important sense, yours already has. It just takes a while.
Linkrot Quantities
My specific target date is 2070, 60 years from now. As of 2011-03-10, Gwern.net has around 6,800 external links (with around 2,200 to non-Wikipedia websites)5. Even at the lowest estimate of 3% annual linkrot, few will survive to 2070. If each link has a 97% chance of surviving each year, then the chance a link will be alive in 2070 is 0.972070 − 2011 ≈ 0.16 (or to put it another way, an 84% chance any given link will die). The 95% confidence interval for such a binomial distribution says that of the 2,200 non-Wikipedia links, ~336–394 will survive to 20706. If we try to predict using a more reasonable estimate of 50% linkrot, then an average of 0 links will survive (0.502070 − 2011 × 2,200 = 1.735 × 10−16 × 2,200 ≈ 0). It would be a good idea to simply assume that no link will survive.
With that in mind, one can consider remedies. (If we lie to ourselves and say it won’t be a problem in the future, then we guarantee that it will be a problem. “People can stand what is true, for they are already enduring it.”)
If you want to pre-emptively archive a specific page, that is easy: go to the IA and archive it, or in your web browser, print a PDF of it, or for more complex pages, use a browser plugin (eg. ScrapBook). But I find I visit and link so many web pages that I rarely think in advance of link rot to save a copy; what I need is a more systematic approach to detect and create links for all web pages I might need.
Detection
With every new spring
the blossoms speak not a word
yet expound the Law—
knowing what is at its heart
by the scattering storm winds.Shōtetsu7
The first remedy is to learn about broken links as soon as they happen, which allows one to react quickly and scrape archives or search engine caches (‘lazy preservation’). I currently use linkchecker to spider Gwern.net looking for broken links. linkchecker is run in a cron job like so:
@monthly linkchecker --check-extern --timeout=35 --no-warnings --file-output=html \
--ignore-url=^mailto --ignore-url=^irc --ignore-url=http://.*\.onion \
--ignore-url=paypal.com --ignore-url=web.archive.org \
https://gwern.netJust this command would turn up many false positives. For example, there would be several hundred warnings on Wikipedia links because I link to redirects; and linkchecker respects robots.txts which forbid it to check liveness, but emits a warning about this. These can be suppressed by editing ~/.linkchecker/linkcheckerrc to say ignorewarnings=http-moved-permanent,http-robots-denied (the available warning classes are listed in linkchecker -h).
The quicker you know about a dead link, the sooner you can look for replacements or its new home.
Prevention
Remote Caching
Anything you post on the internet will be there as long as it’s embarrassing and gone as soon as it would be useful.8
We can ask a third party to keep a cache for us. There are several archive site possibilities:
the Internet Archive
Linterweb’s WikiWix9.
Peeep.us (defunct as of 2018)
There are other options but they are not available like Google11 or various commercial/government archives12
(An example would be bits.blogs.nytimes.com/2010/12/07/palm-is-far-from-game-over-says-former-chief/ being archived at webcitation.org/5ur7ifr12.)
These archives are also good for archiving your own website:
you may be keeping backups of it, but your own website/server backups can be lost (I can speak from personal experience here), so it’s good to have external copies
Another benefit is the reduction in ‘bus-factor’: if you were hit by a bus tomorrow, who would get your archives and be able to maintain the websites and understand the backups etc.? While if archived in IA, people already know how to get copies and there are tools to download entire domains.
A focus on backing up only one’s website can blind one to the need for archiving the external links as well. Many pages are meaningless or less valuable with broken links. A linkchecker script/daemon can also archive all the external links.
So there are several benefits to doing web archiving beyond simple server backups.
My first program in this vein of thought was a bot which fired off WebCite, Internet Archive/Alexa, & Archive.is requests: Wikipedia Archiving Bot, quickly followed up by a RSS version. (Or you could install the Alexa Toolbar to get automatic submission to the Internet Archive, if you have ceased to care about privacy.)
The core code was quickly adapted into a gitit wiki plugin which hooked into the save-page functionality and tried to archive every link in the newly-modified page, Interwiki.hs
Finally, I wrote archiver, a daemon which watches13/reads a text file. Source is available via git clone https://github.com/gwern/archiver-bot.git. (A similar tool is Archiveror; the Python package archivenow does something similar & as of January 2021 is probably better.)
The library half of archiver is a simple wrapper around the appropriate HTTP requests; the executable half reads a specified text file and loops as it (slowly) fires off requests and deletes the appropriate URL.
That is, archiver is a daemon which will process a specified text file, each line of which is a URL, and will one by one request that the URLs be archived or spidered
Usage of archiver might look like archiver ~/.urls.txt gwern@gwern.net. In the past, archiver would sometimes crash for unknown reasons, so I usually wrap it in a while loop like so: while true; do archiver ~/.urls.txt gwern@gwern.net; done. If I wanted to put it in a detached GNU screen session: screen -d -m -S "archiver" sh -c 'while true; do archiver ~/.urls.txt gwern@gwern.net; done'. Finally, rather than start it manually, I use a cron job to start it at boot, for a final invocation of
@reboot sleep 4m && screen -d -m -S "archiver" sh -c 'while true; do archiver ~/.urls.txt \
"cd ~/www && nice --adjustment=20 ionice -c3 wget --unlink --limit-rate=20k --page-requisites --timestamping \
-e robots=off --reject .iso,.exe,.gz,.xz,.rar,.7z,.tar,.bin,.zip,.jar,.flv,.mp4,.avi,.webm \
--user-agent='Firefox/4.9'" 500; done'Local Caching
Remote archiving, while convenient, has a major flaw: the archive services cannot keep up with the growth of the Internet and are woefully incomplete. I experience this regularly, where a link on Gwern.net goes dead and I cannot find it in the Internet Archive or WebCite, and it is a general phenomenon: Ainsworth et al 2012 find <35% of common Web pages ever copied into an archive service, and typically only one copy exists.
Caching Proxy
The most ambitious & total approach to local caching is to set up a proxy to do your browsing through, and record literally all your web traffic; for example, using Live Archiving Proxy (LAP) or WarcProxy which will save as WARC files every page you visit through it. (Zachary Vance explains how to set up a local HTTPS certificate to MITM your HTTPS browsing as well.)
One may be reluctant to go this far, and prefer something lighter-weight, such as periodically extracting a list of visited URLs from one’s web browser and then attempting to archive them.
Batch Job Downloads
For a while, I used a shell script named, imaginatively enough, local-archiver:
#!/bin/sh
set -euo pipefail
cp `find ~/.mozilla/ -name "places.sqlite"` ~/
sqlite3 places.sqlite "SELECT url FROM moz_places, moz_historyvisits \
WHERE moz_places.id = moz_historyvisits.place_id \
and visit_date > strftime('%s','now','-1.5 month')*1000000 ORDER by \
visit_date;" | filter-urls >> ~/.tmp
rm ~/places.sqlite
split -l500 ~/.tmp ~/.tmp-urls
rm ~/.tmp
cd ~/www/
for file in ~/.tmp-urls*;
do (wget --unlink --continue --page-requisites --timestamping --input-file $file && rm $file &);
done
find ~/www -size +4M -deleteThe code is not the prettiest, but it’s fairly straightforward:
the script grabs my Firefox browsing history by extracting it from the history SQL database file14, and feeds the URLs into wget.
wgetis not the best tool for archiving as it will not run JavaScript or Flash or download videos etc. It will download included JS files but the JS will be obsolete when run in the future and any dynamic content will be long gone. To do better would require a headless browser like PhantomJS which saves to MHT/MHTML, but PhantomJS refuses to support it and I’m not aware of an existing package to do this. In practice, static content is what is most important to archive, most JS is of highly questionable value in the first place, and any important YouTube videos can be archived manually withyoutube-dl, sowget’s limitations haven’t been so bad.The script
splits the long list of URLs into a bunch of files and runs that manywgets in parallel becausewgetapparently has no way of simultaneously downloading from multiple domains. There’s also the chance ofwgethanging indefinitely, so parallel downloads continues to make progress.The
filter-urlscommand is another shell script, which removes URLs I don’t want archived. This script is a hack which looks like this:#!/bin/sh set -euo pipefail cat /dev/stdin | sed -e "s/#.*//" | sed -e "s/&sid=.*$//" | sed -e "s/\/$//" | grep -v -e 4chan -e reddit ...delete any particularly large (>4MB) files which might be media files like videos or audios (podcasts are particular offenders)
A local copy is not the best resource—what if a link goes dead in a way your tool cannot detect so you don’t know to put up your copy somewhere? But it solves the problem decisively.
The downside of this script’s batch approach soon became apparent to me:
not automatic: you have to remember to invoke it and it only provides a single local archive, or if you invoke it regularly as a cron job, you may create lots of duplicates.
unreliable:
wgetmay hang, URLs may be archived too late, it may not be invoked frequently enough, >4MB non-video/audio files are increasingly common…I wanted copies in the Internet Archive & elsewhere as well to let other people benefit and provide redundancy to my local archive
It was to fix these problems that I began working on archiver—which would run constantly archiving URLs in the background, archive them into the IA as well, and be smarter about media file downloads. It has been much more satisfactory.
Daemon
archiver has an extra feature where any third argument is treated as an arbitrary sh command to run after each URL is archived, to which is appended said URL. You might use this feature if you wanted to load each URL into Firefox, or append them to a log file, or simply download or archive the URL in some other way.
For example, instead of a big local-archiver run, I have archiver run wget on each individual URL: screen -d -m -S "archiver" sh -c 'while true; do archiver ~/.urls.txt gwern@gwern.net "cd ~/www && wget --unlink --continue --page-requisites --timestamping -e robots=off --reject .iso,.exe,.gz,.xz,.rar,.7z,.tar,.bin,.zip,.jar,.flv,.mp4,.avi,.webm --user-agent='Firefox/3.6' 120"; done'. (For private URLs which require logins, such as darknet markets, wget can still grab them with some help: installing the Firefox extension Export Cookies, logging into the site in Firefox like usual, exporting one’s cookies.txt, and adding the option --load-cookies cookies.txt to give it access to the cookies.)
Alternately, you might use curl or a specialized archive downloader like the Internet Archive’s crawler Heritrix.
Cryptographic Timestamping Local Archives
We may want cryptographic timestamping to prove that we created a file or archive at a particular date and have not since altered it. Using a timestamping service’s API, I’ve written 2 shell scripts which implement downloading (wget-archive) and timestamping strings or files (timestamp). With these scripts, extending the archive bot is as simple as changing the shell command:
@reboot sleep 4m && screen -d -m -S "archiver" sh -c 'while true; do archiver ~/.urls.txt gwern2@gwern.net \
"wget-archive" 200; done'Now every URL we download is automatically cryptographically timestamped with ~1-day resolution for free.
Resource Consumption
The space consumed by such a backup is not that bad; only 30–50 gigabytes for a year of browsing, and less depending on how hard you prune the downloads. (More, of course, if you use linkchecker to archive entire sites and not just the pages you visit.) Storing this is quite viable in the long term; while page sizes have increased 7× between 200323ya and 201115ya and pages average around 400kb15, Kryder’s law has also been operating and has increased disk capacity by ~128×—in 201115ya, $124.2$802011 will buy you at least 2 terabytes, that works out to 4 cents a gigabyte or 80 cents for the low estimate for downloads; that is much better than the annual fee that somewhere like Pinboard charges. Of course, you need to back this up yourself. We’re relatively fortunate here—most Internet documents are ‘born digital’ and easy to migrate to new formats or inspect in the future. We can download them and worry about how to view them only when we need a particular document, and Web browser backwards-compatibility already stretches back to files written in the early 1990s. (Of course, we’re probably screwed if we discover the content we wanted was dynamically presented only in Adobe Flash or as an inaccessible ‘cloud’ service.) In contrast, if we were trying to preserve programs or software libraries instead, we would face a much more formidable task in keeping a working ladder of binary-compatible virtual machines or interpreters16. The situation with digital movie preservation hardly bears thinking on.
There are ways to cut down on the size; if you tar it all up and run 7-Zip with maximum compression options, you could probably compact it to 1⁄5th the size. I found that the uncompressed files could be reduced by around 10% by using fdupes to look for duplicate files and turning the duplicates into a space-saving hard link to the original with a command like fdupes --recurse --hardlink ~/www/. (Apparently there are a lot of bit-identical JavaScript (eg. JQuery) and images out there.)
Good filtering of URL sources can help reduce URL archiving count by a large amount. Examining my manual backups of Firefox browsing history, over the 1153 days from 2014-02-25 to 2017-04-22, I visited 2,370,111 URLs or 2055 URLs per day; after passing through my filtering script, that leaves 171,446 URLs, which after de-duplication yields 39,523 URLs or ~34 unique URLs per day or 12,520 unique URLs per year to archive.
This shrunk my archive by 9GB from 65GB to 56GB, although at the cost of some archiving fidelity by removing many filetypes like CSS or JavaScript or GIF images. As of 2017-04-22, after ~6 years of archiving, between xz compression (at the cost of easy searchability), aggressive filtering, occasional manual deletion of overly bulky domains I feel are probably adequately covered in the IA etc., my full WWW archives weigh 55GB.
URL Sources
Browser History
There are a number of ways to populate the source text file. For example, I have a script firefox-urls:
#!/bin/sh
set -euo pipefail
cp --force `find ~/.mozilla/firefox/ -name "places.sqlite"|sort|head -1` ~/
sqlite3 -batch places.sqlite "SELECT url FROM moz_places, moz_historyvisits \
WHERE moz_places.id = moz_historyvisits.place_id and \
visit_date > strftime('%s','now','-1 day')*1000000 ORDER by \
visit_date;" | filter-urls
rm ~/places.sqlite(filter-urls is the same script as in local-archiver. If I don’t want a domain locally, I’m not going to bother with remote backups either. In fact, because of WebCite’s rate-limiting, archiver is almost perpetually back-logged, and I especially don’t want it wasting time on worthless links like 4chan.)
This is called every hour by cron:
@hourly firefox-urls >> ~/.urls.txtThis gets all visited URLs in the last time period and prints them out to the file for archiver to process. Hence, everything I browse is backed-up through archiver.
Non-Firefox browsers can be supported with similar strategies; for example, Zachary Vance’s Chromium scripts likewise extracts URLs from Chromium’s SQL history & bookmarks.
Document Links
More useful perhaps is a script to extract external links from Markdown files and print them to standard out: linkExtractor.hs
So now I can take find . -name "*.md", pass the 100 or so Markdown files in my wiki as arguments, and add the thousand or so external links to the archiver queue (eg. find . -name "*.md" -type f -print0 | xargs -0 linkExtractor | filter-urls >> ~/.urls.txt); they will eventually be archived/backed up.
Website Spidering
Sometimes a particular website is of long-term interest to one even if one has not visited every page on it; one could manually visit them and rely on the previous Firefox script to dump the URLs into archiver but this isn’t always practical or time-efficient. linkchecker inherently spiders the websites it is turned upon, so it’s not a surprise that it can build a site map or simply spit out all URLs on a domain; unfortunately, while linkchecker has the ability to output in a remarkable variety of formats, it cannot simply output a newline-delimited list of URLs, so we need to post-process the output considerably. The following is the shell one-liner I use when I want to archive an entire site (note that this is a bad command to run on a large or heavily hyper-linked site like the English Wikipedia or LessWrong!); edit the target domain as necessary:
linkchecker --check-extern -odot --complete -v --ignore-url=^mailto --no-warnings http://www.longbets.org
| grep -F http #
| grep -F -v -e "label=" -e "->" -e '" [' -e '" ]' -e "/ "
| sed -e "s/href=\"//" -e "s/\",//" -e "s/ //"
| filter-urls
| sort --unique >> ~/.urls.txtWhen linkchecker does not work, one alternative is to do a wget --mirror and extract the URLs from the filenames—list all the files and prefix with a “http://” etc.
Fixing Redirects
Redirected URLS (primarily HTTP 301) are not hard to fix, and are worth treating as broken links and updating/fixing:
redirects are broken links in disguise:
This is particularly obvious when every URL is redirected to a homepage or error page because they were too lazy to set up the correct redirects and decide to lie by masking the underlying 404 error. Some broken redirects are subtler and use longer URLs, but can be spotted by reading the final URL: often there will be a tell-tale word or parameter like
paywalloraccessDeniedor?cookie=missing. (It would be hard to detect these automatically by any content-based solution because they are site-specific, constantly changing, and in many cases preserve a ‘teaser’ or abstract, and simply hide the rest.)redirects are prelude to link breaking:
Redirects signal changes in a website, and on the Internet, change is usually for the worse. Many domain moves,
www→ naked subdomain, or HTTP → HTTPS migrations will maintain redirects for a time, and then a later change will break them. (I don’t know if the webmasters in question regard the interim as ‘adequate time to fix’ or if later changes make it hard to maintain the redirect.) The ‘new’ webpage may be substantially different (assets like images are frequently broken in migrations) and needs to be checked to see if it is de facto dead. (This is especially true of Wikipedia articles: when a page is ‘redirected’ or ‘merged’, it usually comes out the worse.) Redirects risk bugs when part of a page’s infrastructure: if a resource is supposed to be loaded over HTTP but gets redirected by a site-wide redirect to HTTPS, say, or vice-versa, then a web browser may kill the request for security reasons, permanently breaking whatever that resource does. The new domain may be a spammer domain, who has purchased it to exploit you & your readers’ inbound traffic. Sometimes an old domain will be abandoned entirely and all its redirects break instantly.Redirects cause ambiguous, complex, & redundant names:
If one links a URL and also a redirect to the URL, even stipulating that the redirect never breaks, this causes a wide variety of problems.
Broadly: one will not get the benefits of the browser highlighting an already-visited link, so one may waste time clicking on a known reference. If one searches the corpus for one URL, they will miss the other hits. If one fixes a broken URL, one hasn’t fixed the redirects to that broken URL & they remain broken. It is harder to fix broken URLs in the first place: you might find that it’s not archived under one URL but an archive exists under the other URL, if only you knew to check.17 One (and one’s readers) may check the corpus for a reference & copy an outdated URL elsewhere like a comment, setting that comment up for all these problems down the line.
Redirects interfere with many Gwern.net features: with my local archives & annotations, use of multiple URLs causes glitches: beyond the missing-archives, I might write a high-quality annotation for one URL while the other URL has no annotation or just an automatic (low-quality) annotation, or they might be the same annotation but diverge over time. Redundant entries cause issues with the similar-links recommendations, because of course if one version is similar to some other annotation, then the other versions will be near-identically similar. Use of redundant names also increases the risk of accidentally setting up redirect loops or redirecting to the wrong place. It clutters my link-checking reports, hiding broken links & bugs in other features (eg. there might be a bug where Gwern.net systematically generates the wrong links, which are fixed by redirects, hiding the bug, but remaining visible in link-checking reports—if it’s not buried under a ton of other redirects or errors). It can break tools like
curlwhich by default won’t follow redirects (because that might be dangerous or wrong), and archiving tools may not work. The final URL/domain may act differently from the original (eg. it might set differentX-Frame-Optionsheaders, breaking my live-link functionality, as is especially likely given that newer web software tends to disable as much as possible—‘change is bad’, see #2).None of these are major problems, but each one is a paper-cut which comes up more & more the larger & more complex the Gwern.net corpus & website get. So it helps to squash redirects where I find them and keep URLs as canonical as possible.
Redirects are slower:
Each redirect costs some milliseconds, and if they cross domains, the lookup can take a while. It is not terribly hard for redirects to stack up: on Gwern.net, a link to an old document could easily incur 4+ redirects.18 Given how much one sweats to eliminate even 100ms from load-time, why tolerate redirects which can be fixed with the swipe of a search-and-replace?
Redirects are reported by linkchecker & the W3C linkchecker.
To fix a redirect, one can hand-edit case by case, but redirects are so pervasive that one should use some sort of global search-and-replace.
Gwern.net Redirect Fixing
Because Gwern.net is primarily text-file based and its codebase has unit-tests, I have scripts to heavily automate finding & fixing redirects—no need to edit the source files by hand! (Ain’t no one got time for that.)
For Gwern.net use, I wrote a simple site-wide string search-and-replace gwsed.sh to allow easy updates like gwsed.sh 'URL1' 'URL2'. (It includes a special case for the common scenario of a site-wide HTTP → HTTPS migration, to detect gwsed.sh 'http://DOMAIN/URL1' 'https://DOMAIN/URL2', where the two strings differ solely by a http vs https prefix, and rewrite it to do gwsed.sh 'http://DOMAIN' 'https://DOMAIN' instead to update all links to that domain. It also includes a special-case for the format of the W3C linkchecker: a command like gwsed.sh URL1 redirected to URL2 will be converted to gwsed.sh URL1 URL2 so I can simply copy-paste right into the terminal.) This also makes updates scriptable in bulk; for example, if I want to do a site-wide check instead of a page-by-page check with the linkchecker tools, I can extract the URLs from all site files, process in a loop to see if they have non-zero redirects when downloaded using curl, print out the old/new, review by eye to delete evil or spurious ones, and automatically string-rewrite the rest:
cd ~/wiki/
URLS=$(find ./ -type f -name "*.md" | \
parallel linkExtractor | \
grep -E -e '^http' | head -500 | sort --unique)
for URL in "$URLS"; do
URLNEW=$(curl --write-out '%{url_effective}\n' --head --location --silent --show-error \
"$URL" --output /dev/null);
if [ "$URL" != "$URLNEW" ]; then echo "$URL redirected to $URLNEW"; fi;
doneThe link-icon & live-link features rely heavily on domain name matches, so they are vulnerable to websites changing; fixing redirects can silently break them. However, they include test suites with at least one example per rule and exercising all of the branches or domains that a rule matches, and the search-and-replace modifies those files as well; so if URLs update, the test-suites will show up on a diff, and if they break the rules, the test-suites will error out on the next sync. So I can simply toss off gwsed.sh calls and be sure that they won’t silently break anything.
Preemptive Local Archiving
In 2020-02, because of the increasing difficulty of repairing old links, I switched Gwern.net’s primary linkrot defense to preemptive local archiving: automatically mirroring locally all PDFs & web pages using manually-reviewed (and edited) SingleFile snapshots converted into Gwtar for efficiency.
While it costs more time upfront (and presented some subtle UX problems like the “Arxiv problem”), it reduces total linkrot work.
Around 2019, while working on a linkchecker report, and spending time tracking down one particularly elusive broken link and drumming my fingers waiting on the slow Wayback Machine website, and comparing the mess to the half-minute it’d’ve taken to make & upload a snapshot with SingleFile, I realized: it’s a lot harder to fix dead links than it is to archive live links. And the more you try to update your links, the more problems you run into, like the widespread abuse of adding paywalls or lying redirects. Prevention > cure.
Easier. If you take the linkrot risk estimates seriously (and having watched so many links die on Gwern.net, I believe them), then as long as fixing is >2–3× harder than archiving (it definitely is), you are better off just archiving from the start instead of wasting time on reports & manual fixing one by one.
Higher-quality. Worse, while the preemptive archiving can be refined & improved, the reactive approach is inherently one of “toil”—treading water. Throw in the reality that the archives often fail or are inadequate, and their decreasing efficacy at capturing web pages as pages get ever more baroque and complex, that archives are ‘un-opinionated’ in making no attempt to strip ads/spam19 or optimize the snapshots or work as a ‘live link’ popup (when the full page pops up inside an iframe cf. the screenshot failure), the public-good of providing an independent archive, the greater speed of loading links from Gwern.net instead of a foreign domain (especially the slow IA), and I had to concede that the cost-benefit had long since favored preemptive local archiving.
Ripping off the bandaid. I had hoped this would not be the case because I wanted to limit the number of archives I had to make or host, but the burden was becoming unsustainable when combined with other site maintenance needs. I had no excuse from expensive cloud storage (even 100GB would have near-zero marginal cost after my move to Hetzner dedicated hosting in 2017), rewriting links would be easy using the Pandoc API, SingleFile was working well when I used it manually & had a convenient CLI mode for scripting purposes like this, and working on fixing broken links was annoying me slightly more every time.
Local Snapshots
So after mulling over the design for a while, I pulled the trigger in 2020-02, creating LinkArchive.hs, which maintains a database of URL/archive/status tuples, and calls linkArchive.sh to lookup or generate the snapshots using SingleFile CLI. The snapshots are reviewed by hand to verify that they work & are readable; if they are not, I make a new one, and often invest some time in making a bunch of uBlock Origin rules to clean a page up. It is worthwhile to do so because the rules will make future archiving easier.
Workflow
Database+directories: A simple database of URLs is maintained, with their status: either the first-seen date, or their on-disk path.
The URL’s snapshot lives at
/doc/www/$DOMAIN/SHA1($URL).html; the hash makes it simple to encode the name without escaping issues or incurring the difficulties of imitating the target URL’s directory structure20, and the separate prefixed domain helped compatibility with the link-icon rules.21Compile-time archiving:
When compiling a page, each link is checked to see if it is on the blacklist (because it is a link which cannot or should not be archived). If not, then if it has an archive, it is rewritten to point to the archive instead. (The original URL is stored in an HTML attribute for any other tools that need to know what that was, such as the popups.) If it doesn’t, then the date is checked: if it was first-seen >6022 days ago, then it is time to archive the URL. (I limit the number of archives per site compilation to 12, to spread out the burden.)
The archiving script checks the URL. If the URL returns a PDF MIME type, then it downloads the PDF and (like my manually-hosted PDFs) runs
ocrmypdfon it to ensure that it has decent OCR, is a standard PDF/A archival-quality PDF, and throws in JBIG2 compression which will often save 2–3× space. If it’s a regular HTML URL, it instead runs SingleFile CLI, which opens the URL in a local Chrome installation, loads all the JS and lazy images etc., and writes out a static snapshot. (In theory, this Chrome instance should have all my usual extensions enabled like uBlock & cookies enabling logins23, but in practice I’ve run into problems and I’m not sure what exactly is getting run because it is impossible to debug.)Large snapshots will be rewritten into a multiple-file form using a custom PHP script,
deconstruct_singlefile.php. This helps reduce the bandwidth burden of Gwern.net readers previewing pages, and lets us run optimization on the individual files. (‘Wild’ JPG, PNG, and GIF files on the Internet can often be shrunk a lot, and this also helps expose invalid files.) In other cases, where we prefer a single file, they are rewritten into a custom “Gwtar” format, which is still complete & a single file but preserves browser download efficiency by clever use of JS.Manual review: The URL & its new snapshot (whether PDF or HTML) are then both opened by the archiving script in Firefox for manual review.
A bad snapshot may require me to add the domain or URL to the blacklist. It may also just be broken (in many different ways, from broken media to sudden paywalls to reloading to a nonexistent URL!), in which case I have to find a replacement URL & do a global rewrite (and the replacement URL will eventually be archived).
Alternately, I may need to make a new snapshot manually, after deleting sticky elements with Always Kill Sticky, scrolling the page to load lazy elements, or spending a while with the uBlock element-picker to delete the most obnoxious elements. (I tried initially to edit the raw HTML of the SingleFile snapshot, but the data-URI encoding of images, and the spaghetti architecture of the pages most in need of de-cruddification, meant that it was far harder to edit it in a text editor than to simply use uBlock or the built-in web tool ‘inspector’ to select & delete. This can also be done repeatedly: take a SingleFile snapshot, delete stuff with inspector, and save with SingleFile again.) Sometimes a page will fail in Chromium SingleFile, but then succeed in Firefox SingleFile.
Since SingleFile saves the final DOM, I can edit the live page:
C-Ito open the browser webdev tools, thenC-Shift-cto select an element with the mouse, thenDelto delete it. (One can also do fancier tricks, like opening multiple pages, and then copy-pasting a particular element. This is good for turning multi-page articles into a single page easily and reliably, which makes reading & archiving easier: you just find the ‘content’ node in each page, and copy it into the first ‘master’ page, and save that page.)Taking the time to remove all the ads & bric-a-brac is useful because it makes the page less likely to break in the future, smaller & faster, more readable as a ‘live’ popup, easier to see if anything is missing, and amortizes across future snapshots (so the manual review gets a little easier every time as the blacklist & blocklist expand).
While it did not solve existing broken links or breakage of links where SingleFile can’t make a good snapshot, and it is a bit annoying to curate snapshots, it is a dramatic improvement over the status quo and I expect the benefits to only increase with time as web pages become ever grosser.
Overall, this review process tends to take about 10–60s per page, and I do ~10⧸day to keep up with my writing & bookmarking, which is an acceptable burden.
Metadata/hiding: The local archives are treated mostly like regular files, while trying to minimize search engine or user exposure; this is because various entities might not appreciate the mirrors24, and I don’t want to have to maintain them indefinitely (particularly by setting up redirects to avoid breaking old hash-URLs due to churn). People will still link to them, but there’s only so much one can do.
The Gwern.net web server (nginx) is instructed to set appropriate headers to block indexing (beyond just
noindex):location /doc/www/ { add_header X-Robots-Tag "none, nosnippet, noarchive, nocache"; }And for good measure,
robots.txt:User-agent: * Disallow: /doc/www/*Results: As of 2023-03-09, there are 14,352 targeted links weighing 47GB (including now-unused archives which will be removed at some point), which is no problem.
The Arxiv Problem
One subtlety that came up after a while was the issue of ‘URL transforms’. In some cases, like BioRxiv, it’s best to simply rewrite URLs to the full-text HTML version (just append .full to the URL); this is simple & one can ensure it happens by including a global search-and-replace in the compilation process, and forget about it while linking BioRxiv normally. Unfortunately, sometimes a global search-and-replace is inadequate: there is a set of URLs where you link to one URL, but for archiving purposes, you want to archive an alternative, a transformation of that URL. The motivating example was ‘the Arxiv problem’, one of the most heavily-linked domains on Gwern.net, and a difficult one to solve: I wound up needing 3 separate URLs to handle browsing as conveniently as possible for both desktop & mobile users.
‘The Arxiv problem’ is the difficulty in presenting Arxiv links to both desktop & mobile users which is not (1) slow, (2) redundant, or (3) foisting a PDF on readers (especially mobile readers). It is polite to link to the Arxiv HTML landing page like /abs/$ID rather than its fulltext PDF under /pdf/$ID, but that would be useless to archive because I already extract most of the relevant information to present as the annotation popup. It would be a waste of reader time to hover over an Arxiv annotated link, read the annotation with the title/author/date/abstract, and then hover over the ‘live’ Arxiv link to… read the same thing, presumably wasting their time until they can navigate to the fulltext PDF which they must have decided is worth their time. Obviously, the ‘live’ link should be the PDF, which can then be a local optimized PDF.25 Straightforward, except Arxiv has an additional wrinkle: whether HTML landing page or PDF, it’s bad for mobile readers on smartphones, who really need a responsive dark mode-compatible HTML version of the paper—which often exists, as there is yet a third set of Arxiv URLs located at the experimental LaTeX → HTML service which covers most (but not all) Arxiv papers, ‘Ar5iv’ (ie. https://arxiv.org/html/$ID)!26
Arxiv is the main problem, but there are a few other cases worth handling. The preprint website OpenReview operates similarly to Arxiv, with an HTML landing page & PDF. And Reddit turns out to archive very poorly by default even using the ‘old’ Reddit interface which is good for regular browsing; but I discovered that while the mobile Reddit (i.reddit.com) didn’t look great, it at least preserved the content reliably. (Particularly acute readers may note that LessWrong → GreaterWrong is not mentioned, because that is treated like a Wikipedia popup in that the JS code calls a specialized API.)
Every CS Problem…
What to do? One could bite the bullet & link Arxiv PDFs (ignoring mobile readers), or link to the Ar5iv HTML version (pleasing mobile but annoying desktop), or always link the abstract as a lowest-common-denominator (wasting a bit of everyone’s time but not foisting PDFs on them). However, I came up with a 3-way approach which integrated seamlessly into my existing popup system approach to showing annotation → archive → live.
I chose to add a second layer of indirection to archive rewrites: links will be rewritten silently before archiving (so in the case of an Arxiv /abs/ link, it gets rewritten to the PDF & the PDF becomes the local archive), and the ‘original link’ may be rewritten (so the popups are lied to and told that Ar5iv was the ‘original’ URL and that is what gets shown as the ‘live’ link).
While tricky to get right and requiring some modifications to the JS, this solves the Arxiv problem for Gwern.net readers:
I link the Arxiv
/abs/normally & conveniently.This automatically creates an annotation containing the landing page’s metadata (plus all my additions like tags, excerpts, backlinks, similar-link recommendations, etc.).
This popup/popover will satisfy most readers.
For readers who want to go deeper and read the fulltext: the title of the popup (popover) is an archive link to a local PDF mirror.
This PDF is small & fast, and will pop up in another ‘live’ popup or tab (fine for desktop readers), or to an external PDF reader on mobile (less fine).
But—as an ‘archive’ link, it automatically comes with a
[LIVE]link appended pointing to the original raw URL (which is actually the Ar5iv version).This is for readers who need to link the original, want to consult it, or when the local archive is unfortunately broken (having been grandfathered in back in 2020-02). In the case of an Ar5iv link, however, this instead says
[HTML]: this tells mobile readers where to click for the HTML version they want.
While complicated to explain, it follows our design language of popups/popovers, and satisfies all users with no wasted clicks or mouse movements—aside from users who do want to visit/copy the /abs/ URL specifically, which I consider a minor use-case worth sacrificing for the other readers.
Reacting To Broken Links
For Books are not absolutely dead things, but doe contain a potencie of life in them to be as active as that soule was whose progeny they are; nay they do preserve as in a violl the purest efficacie and extraction of that living intellect that bred them. I know they are as lively, and as vigorously productive, as those fabulous Dragons teeth; and being sown up and down, may chance to spring up armed men. And yet on the other hand, unlesse warinesse be us’d, as good almost kill a Man as kill a good Book; who kills a Man kills a reasonable creature, Gods Image; but hee who destroyes a good Booke, kills reason it selfe, kills the Image of God, as it were in the eye. Many a man lives a burden to the Earth; but a good Booke is the pretious life-blood of a master spirit, imbalm’d and treasur’d up on purpose to a life beyond life. ’Tis true, no age can restore a life, whereof perhaps there is no great losse; and revolutions of ages do not oft recover the losse of a rejected truth, for the want of which whole Nations fare the worse. We should be wary therefore what persecution we raise against the living labours of publick men, how we spill that season’d life of man preserv’d and stor’d up in Books; since we see a kinde of homicide may be thus committed, sometimes a martyrdome, and if it extend to the whole impression, a kinde of massacre, whereof the execution ends not in the slaying of an elementall life, but strikes at that ethereall and fift essence, the breath of reason it selfe, slaies an immortality rather then a life.
archiver combined with a tool like link-checker means that there will rarely be any broken links on Gwern.net since one can either find a live link or use the archived version. In theory, one has multiple options now:
Search for a copy on the live Web
link the Internet Archive copy
link the WebCite copy
link the WikiWix copy
use the
wgetdumpIf it’s been turned into a full local file-based version with
--convert-links --page-requisites, one can easily convert the dump into something like a standalone PDF suitable for public distribution. (A PDF is easier to store and link than the original directory of bits and pieces or other HTML formats like a ZIP archive of said directory.)I used to use
wkhtmltopdfwhich does a good job of making PDFs of HTML pages; an example of a dead webpage with no Internet mirrors ishttp://www.aeiveos.com/~bradbury/MatrioshkaBrains/MatrioshkaBrainsPaper.htmlwhich can be found at1999-bradbury-matrioshkabrains.pdf, or Sternberg et al’s 200125ya review “The Predictive Value of IQ”. I have since switched to SingleFile to make static HTML snapshots, which unlike MAFF/MHTML, are viewable without any problems in mainstream browsers.
Automatic Internet Archive Repairs
The Internet Archive can be queried via an API for available snapshots near a date. If you know that a URL has an acceptable-quality snapshot, you can get it and use some search-and-replace utility to automatically rewrite a broken link.
So we can ask for the nearest URL to an early date like 1990-01-01:
$ curl --silent 'https://archive.org/wayback/available?timestamp=19900101&url=https://eva.onegeek.org/pipermail/oldeva/2001-September/040368.html' | \
jq --raw-output '.'Yielding:
{
"url": "https://eva.onegeek.org/pipermail/oldeva/2001-September/040368.html",
"archived_snapshots": {
"closest": {
"status": "200",
"available": true,
"url": "https://web.archive.org/web/20110726181638/http://eva.onegeek.org/pipermail/oldeva/2001-September/040368.html",
"timestamp": "20110726181638"
}
},
"timestamp": "19900101"
}So our broken link https://eva.onegeek.org/pipermail/oldeva/2001-September/040368.html can be fixed with the closest.url field of the archived_snapshots object, https://web.archive.org/web/20110726181638/http://eva.onegeek.org/pipermail/oldeva/2001-September/040368.html. Straightforward.
Old = better. If we do not specify a timestamp, or if we specify a recent timestamp like 20230101, the IA will return the most recent snapshot instead. For repairing links, this would usually be a bad idea: for most URLs, the first snapshot will be the highest-quality one, as later snapshots will typically be infected by bitrot, linkrot, website design ‘upgrades’, spam, domain squatters, maliciously indiscriminate redirects to a homepage, etc. Still, for some URLs we would want to do this, and it’s good to know that is possible.
If we have a search-and-replace utility, newline-delimited list of broken URLs we’d like to replace, and a list of text files to update, we can easily script all the queries & updates:
for URL in `cat urls.txt`; do
URL_ARCHIVE=$(curl --silent 'https://archive.org/wayback/available?timestamp=19900101&url='"$URL" | \
jq --exit-status --raw-output '.archived_snapshots.closest.url');
if [ "$URL_ARCHIVE" != "null" ]; then
search-and-replace "$URL" "$URL_ARCHIVE" [FILE]...;
fi
doneWhy Not Internet Archive?
The Internet Archive’s archives should be rehosted when you use them, and it should not be relied on as the only host of an archived webpage: because rehosting is a better reader experience, and the IA is a dangerous single-point-of-failure with several factors increasing its risk of failure.
The above trick of automatic-repair is only intended to be temporary and patch broken links until they can be rehosted locally or rewritten to a live host. I discourage use of links to the Internet Archive as a complete solution to linkrot. Even if the IA snapshot is the best available, one should rehost it oneself for several reasons:
Self-hosting features: your hosting is faster (IA servers are always overloaded), more controllable (eg. you can control X-Frame options so you can pop up the page in an iframe), and visible to search engines (IA hides everything in the Wayback Machine) so people looking for it can find it.
Archive quality verification: when you copy it, you will see what parts might be broken or need fixing, before it’s too late.
Blind use of IA links risks discovering, years down the line, that one linked a useless archive—it actually redirected to a spam site, or the site was broken when the snapshot was made, or got blocked by a paywall, or the page relied on some asset dynamically which the IA didn’t load it, or… IA crawlers generally are simple and do not execute JS or deal with laziness, so as the Web becomes increasingly complex, dynamic, & JS-based, IA snapshots are frequently broken.
One case was the Climbing Mount Improbable website: I thought it was a pity the site had disappeared, and that while it was safely in the IA and apparently working, it ought to be visible to search engines; so I rehosted it, only to discover to my horror that the reason it ‘worked’ was that it was still loading everything from the original Amazon AWS S3 buckets! The site dev had not yet completely deleted it. He would at some point, however, when he noticed the bucket was still costing him money or his AWS account lapsed. I hurried to localize all files, and succeeded. Had I not done so, I would have checked in a few years later and discovered the IA version broken—irretrievably.
IA hosting is riskier than it seems: the IA is a centralized single point of failure.
While I love the IA, I regard it as dangerously rickety, and at risk of collapse in the next earthquake. It is more like Library.nu/Libgen/Sci-Hub than one might hope, and just as one should avoid direct links to those, one should avoid direct IA links: you are putting a lot of eggs in one basket. It would be better to make more eggs, and put them in a different basket, for yourself & others to use; if the original basket never breaks any eggs, great, but sometimes baskets break. And IA’s basket is old & the bottom fraying:
IA servers (Wayback & otherwise) appear to have few backups, redundancy, or error-correction. They are grossly underfunded, so how would they afford such fancy things? Sometimes when I look things up, the server is just… offline. How many mirrors are there of the IA as a whole? Are there any? (There was supposedly one established in Egypt back in the 2000s, but given Egypt’s problems and that I have heard nothing about it in the past decade, I suspect that if it still exists, it is either grossly out-of-date, corrupt, or both.)
behind the scenes, IA is chaotic: it seems to be held together by duct tape and lots of legacy code slowly bitrotting away. They are challenged to keep things running and deal with issues like abuse, and cannot invest much in, say, better crawling or backup solutions.
They may seem reliable from the outside, sure, but that’s how other websites appear before they announce that the database was corrupted in a hard drive crash and all the backups were broken, and they are sorry for your data loss (“mistakes were made”); similarly, sites like What.cd or Library.nu, which were miracles of archives, had remarkable uptime until they went down forever. The past is but prologue, and a poor predictor at that. Will a random IA link work in, say, a mere 20 years? I’d rather have a policy of making rehosted copies of IA links for my many dead links & discover it was partially wasted effort (see #1/2) than wake up one day to read the news & find out that half the links on my site are now dead.
IA mismanagement: IA management has many other priorities than the Wayback Machine; some, like the book scanning projects are reasonable even if it’s not entirely obvious that IA ought to be doing them, and some… are highly questionable or outright incompetent, like the quixotic IA credit union and the ongoing disaster of the National Emergency Library:
Credit union: IA dabbles in some odd projects at the behest of its eccentric founder Brewster Kahle. For example, he invested major effort over many years in trying to set up an Internet Archive credit union to apparently help IA employees with housing loans or something which has equally little to do with archiving, however meritorious; those familiar with the immense regulatory burdens of American banks, and regulators’ hatred of small banks which might embarrass them, will correctly predict that Kahle’s effort was futile right from the beginning (even without the regulators telling Brewster to his face that “that is not going to happen”).
National Emergency Library: While the credit union was simply a debacle in terms of resource consumption, it was not an existential threat to the Wayback Machine. But there is another which is: the extraordinary misjudgement in 2020-03-24, under the pretext of COVID-19, of the IA in deciding (unasked, and unforced) to make millions of IA’s scanned/digital e-books available for de facto unlimited download to everyone (dubbing it the “National Emergency Library”). This shattered the standard digital lending practice of ‘lending’ out a fixed number of copies (usually one) for a limited time—a practice not protected by copyright law (except by wishful thinking of ‘fair use’), but which practice had long been informally tolerated by commercial publishers as long as libraries like IA didn’t push it too far & maintained the pretense of replicating the offline experience with physical books, such as by using waitlists for a limited number of ‘copies’ at a time.
Already on thin ice, the Emergency Library pushed way too far and unsurprisingly, they got sued by major publishers, who were now seeking to kill digital lending entirely because the IA was grossly abusing it. You might think that this is as predictable as the sun rising and so the IA’s leadership, being neither senile nor insane (presumably), must have had a really good defense in copyright law, perhaps one of IA’s special loopholes like Last 20? As one lawyer politely put it before the lawsuit, “seems like a stretch” (having little to go on, as the IA didn’t even have an FAQ explaining how it would be legal at all, so poorly planned was the Emergency Library). Nope. Nothing. Not even a fig leaf. The IA just wanted to do it and did it, and then was shocked when publishers were displeased by one of the most blatant & large-scale copyright infringements ever. (I was so shocked that they were shocked that I stopped donating to the IA.)
In a single master stroke, Brewster Kahle & the IA board managed to (1) fail at the Emergency Library’s intended goal by triggering a “incredibly expensive” lawsuit shuttering it early27, (2) embroil the IA in a lawsuit funded by large wealthy opponents with existential stakes for IA due to the scale of its infringement, and (3) threaten the modus vivendi of IA & everyone else’s digital lending by creating a test case on possibly the least sympathetic & shaky grounds possible. Unsurprisingly to everyone with the slightest familiarity with IP law, the IA lost the case on digital lending entirely. I am unaware of any internal reckoning, assignment of responsibility, or firing of the executives & directors who signed off on the National Emergency Library (at a minimum, Brewster Kahle, and the director of the “Open Libraries” division who announced it, Chris Freeland).
The National Emergency Library will, one devoutly hopes, wind up in a settlement which does not damage IA too badly. Perhaps the publishers will be gentle and settle for the IA clamping down on its lending activities—forever curtailing access and setting a disastrous precedent for libraries everywhere because of their grotesque idiocy—but at least limping away to live another day. However, the long-term viability of any institution capable of making, and then learning nothing from it and keeping the responsible decision-makers in power, is in question.
External Links
archivenow(library for submission toarchive.is,archive.st,perma.cc, Megalodon, WebCite, & IA)Memento meta-archive search engine (for checking IA & other archives)
Archive-It -(by the Internet Archive)
“Testing 3 million hyperlinks, lessons learned”, Stack Exchange
“Backup All The Things”, muflax
Software:
webrecorder.io (online service); webrecorder (offline tool; WARC-based & can deal with dynamically-loaded content); Diskernet
ArchiveBox (headless Chrome)
wabarc wayback (similar ‘meta’-archiver to
archiver-bot)
“Indeed, it seems that Google is forgetting the old Web” (HN)
Appendices
filter-urls
A raw dump of URLs, while certainly archivable, will typically result in a very large mirror of questionable value (is it really necessary to archive Google search queries or Wikipedia articles? usually, no) and worse, given the rate-limiting necessary to store URLs in the Internet Archive or other services, may wind up delaying the archiving of the important links & risking their total loss. Disabling the remote archiving is unacceptable, so the best solution is to simply take a little time to manually blacklist various domains or URL patterns.
This blacklisting can be as simple as a command like filter-urls | grep -v en.wikipedia.org, but can be much more elaborate. The following shell script is the skeleton of my own custom blacklist, derived from manually filtering through several years of daily browsing as well as spiders of dozens of websites for various people & purposes, demonstrating a variety of possible techniques: regexps for domains & file-types & query-strings, sed-based rewrites, fixed-string matches (both blacklists and whitelists), etc.:
#!/bin/sh
# USAGE: `filter-urls` accepts on standard input a list of newline-delimited URLs or filenames,
# and emits on standard output a list of newline-delimited URLs or filenames.
#
# This list may be shorter and entries altered. It tries to remove all unwanted entries, where 'unwanted'
# is a highly idiosyncratic list of regexps and fixed-string matches developed over hundreds of thousands
# of URLs/filenames output by my daily browsing, spidering of interesting sites, and requests
# from other people to spider sites for them.
#
# You are advised to test output to make sure it does not remove
# URLs or filenames you want to keep. (An easy way to test what is removed is to use the `comm` utility.)
#
# For performance, it does not sort or remove duplicates from output; both can be done by
# piping `filter-urls` to `sort --unique`.
set -euo pipefail
cat /dev/stdin \
| sed -e "s/#.*//" -e 's/>$//' -e "s/&sid=.*$//" -e "s/\/$//" -e 's/$/\n/' -e 's/\?sort=.*$//' \
-e 's/^[ \t]*//' -e 's/utm_source.*//' -e 's/https:\/\//http:\/\//' -e 's/\?showComment=.*//' \
| grep "\." \
| grep -F -v "*" \
| grep -E -v -e '\/\.rss$' -e "\.tw$" -e "//%20www\." -e "/file-not-found" -e "258..\.com/$" \
-e "3qavdvd" -e "://avdvd" -e "\.avi" -e "\.com\.tw" -e "\.onion" -e "\?fnid\=" -e "\?replytocom=" \
-e "^lesswrong.com/r/discussion/comments$" -e "^lesswrong.com/user/gwern$" \
-e "^webcitation.org/query$" \
-e "ftp.*" -e "6..6\.com" -e "6..9\.com" -e "6??6\.com" -e "7..7\.com" -e "7..8\.com" -e "7..\.com" \
-e "78..\.com" -e "7??7\.com" -e "8..8\.com" -e "8??8\.com" -e "9..9\.com" -e "9??9\.com" \
-e gold.*sell -e vip.*club \
| grep -F -v -e "#!" -e ".bin" -e ".mp4" -e ".swf" -e "/mediawiki/index.php?title=" -e "/search?q=cache:" \
-e "/wiki/Special:Block/" -e "/wiki/Special:WikiActivity" -e "Special%3ASearch" \
-e "Special:Search" -e "__setdomsess?dest="
# ...
# prevent URLs from piling up at the end of the file
echo -e "\n"filter-urls can be used on one’s local archive to save space by deleting files which may be downloaded by wget as dependencies. For example:
find ~/www | sort --unique >> full.txt && \
find ~/www | filter-urls | sort --unique >> trimmed.txt
comm -23 full.txt trimmed.txt | xargs -d "\n" rm
rm full.txt trimmed.txtsort Key Compression Trick
Cryptographic Timestamping
I use
duplicity&rdiff-backupto backup my entire home directory to a cheap 1.5TB hard drive (bought from Newegg usingforre.st’s “Storage Analysis—GB/$ for different sizes and media” price-chart); a limited selection of folders are backed up to Backblaze B2 usingduplicity.I used to semiannually tar up my important folders, add PAR2 redundancy, and burn them to DVD, but that’s no longer really feasible; if I ever get a Blu-ray burner, I’ll resume WORM backups. (Magnetic media doesn’t strike me as reliable over many decades, and it would ease my mind to have optical backups.)↩︎
“When the Internet Is My Hard Drive, Should I Trust Third Parties?”, Wired:
↩︎Bits and pieces of the web disappear all the time. It’s called ‘link rot’, and we’re all used to it. A friend saved 65 links in 199927ya when he planned a trip to Tuscany; only half of them still work today. In my own blog, essays and news articles and websites that I link to regularly disappear—sometimes within a few days of my linking to them.
“Going, Going, Gone: Lost Internet References”; abstract:
↩︎The extent of Internet referencing and Internet reference activity in medical or scientific publications was systematically examined in more than 1000 articles published between 200026ya and 200323ya in the New England Journal of Medicine, The Journal of the American Medical Association, and Science. Internet references accounted for 2.6% of all references (672/25,548) and in articles 27 months old, 13% of Internet references were inactive.
The Million Dollar Homepage still gets a surprising amount of traffic, so one fun thing one could do is buy up expired domains which paid for particularly large links.↩︎
By 2013-01-06, the number has increased to ~12,000 external links, ~7,200 to non-Wikipedia domains.↩︎
If each link has a fixed chance of dying in each time period, such as 3%, then the total risk of death is an exponential distribution; over the time period 2011–592070 the cumulative chance it will beat each of the 3% risks is 0.1658368ya. So in 2070, how many of the 2200 links will have beat the odds? Each link is independent, so they are like flipping a biased coin and form a binomial distribution. The binomial distribution, being discrete, has no easy equation, so we just ask R how many links survive at the 5th percentile/quantile (a lower bound) and how many survive at the 95th percentile (an upper bound):
↩︎qbinom(c(0.05, 0.95), 2200, 0.97^(2070 - 2011)) # [1] 336 394 ## the 50% annual link rot hypothetical: qbinom(c(0.05, 0.50), 2200, 0.50^(2070 - 2011)) # [1] 0 0101, ‘Buddhism related to Blossoms’; Unforgotten Dreams: Poems by the Zen monk Shōtetsu; trans. Steven D. Carter, ISBN 0-231-10576-2↩︎
My variant: “Social media is a machine for selectively bitrotting everything good about you while preserving millions of copies of your worst tweet.”↩︎
Which I suspect is only accidentally ‘general’ and would shut down access if there were some other way to ensure that Wikipedia external links still got archived.↩︎
Since Pinboard is a bookmarking service more than an archive site, I asked in 201214ya whether treating it as such would be acceptable and Maciej said “Your current archive size, growing at 20 GB a year, should not be a problem. I’ll put you on the heavy-duty server where my own stuff lives.”
I ultimately did not take him up on this offer in part because Pinboard’s archives were relatively low-quality. Pinboard started being neglected around 2017 by Maciej, and as of mid-2022, errors are routine. I do not recommend use of Pinboard.↩︎
I’m convinced that Google would never just delete colossal amounts of Internet data—this is Google, after all, the epitome of storing unthinkable amounts of data—and that Google Cache has merely been hidden. Besides its plausibility & long-standing rumors about its existence, the 2024 ad API leak apparently confirmed the existence of the private Google Internet archives going back many snapshots.↩︎
Which would not be publicly accessible or submittable; I know they exist, but because they hide themselves, I know only from random comments online eg. “years ago a friend of mine who I’d lost contact with caught up with me and told me he found a cached copy of a website I’d taken down in his employer’s equivalent to the Wayback Machine. His employer was a branch of the federal government.”.↩︎
Version 0.1 of my
archiverdaemon didn’t simply read the file until it was empty and exit, but actually watched it for modifications with inotify. I removed this functionality when I realized that the required WebCite choking (just one URL every ~25 seconds) meant thatarchiverwould never finish any reasonable workload.↩︎Much easier than it was in the past; Jamie Zawinski records his travails with the previous Mozilla history format in the aptly-named “when the database worms eat into your brain”.↩︎
An older 2010 Google article put the average at 320kb, but that was an average over the entire Web, including all the old content.↩︎
Already one runs old games like the classic LucasArts adventure games in emulators of the DOS operating system like DOSBox; but those emulators will not always be maintained. Who will emulate the emulators? Presumably in 2050, one will instead emulate some ancient but compatible OS—Windows 7 or Debian 6.0, perhaps—and inside that run DOSBox (to run the DOS which can run the game).↩︎
Assiduously updating redirects can cause archive problems when the new URL breaks before archiving, or it was a lying link & you look up archives of a long-dead link. But you can always look through your version-control history for older URLs to try, and you may not be able to check newer URLs if you weren’t updating. So it’s better to update.↩︎
Imagine a link to
http://www.gwern.net/docs/2010-anderson.pdcreated in 201511ya by a user making a common typo; today it might bounce through the following sequence of redirects (I think): HTTP → HTTPS,www→ root,/docs/→/doc/,...pd→...pdf, and/doc/to/doc/statistics/prediction/to reach its current URL ofhttps://gwern.net/doc/statistics/prediction/2010-anderson.pdf. And that’s just for now—thestatistics/predictiontag is overloaded and needs refactoring into sub-tags, so Anderson & Sherman 2010 will at some point probably be relocated to a Fermi estimate tag’s sub-directory, setting up a 6th redirect. If each redirect takes 50ms (optimistic), then that’s 0.3s spent just to get the URL!↩︎A surprisingly large fraction of Gwern.net readers—and readers in general—still do not use ad-blockers, especially on mobile where they need one most.↩︎
It may be tempting to try to mirror a URL’s
/foo/bar/baz.extstructure, but this is not as useful as it seems (since you will typically have relatively few archived URLs so the structure will be sparse, and you want to tag them anyway), and has many edge-cases in simply converting arbitrary URLs to usable on-disk filepaths. The fact is, it is not 199531ya, and a website is not a Unix directory. Contemporary URLs do not map, in any way, onto HTML filepaths: URLs are stuffed with dangerous characters which will should probably be escaped, punycode encoding of Unicode, website directories which are actually files/pages (the ubiquitous trailing slash), subdomains, query arguments, hash anchors (including the loathed and not completely defunct#!design pattern), redirects, and so on. Further, URLs change at the drop of a hat, including any implied ‘directory hierarchy’, rendering updates difficult—many redundant snapshots or contradictory implied paths. No, no, just resist the temptation to pun on URL ↔︎ filepath, and assign it an opaque unique ID and store that.↩︎No longer necessary with the final link-icon implementation, but this was necessary before when using CSS regexp rules, so rules like
href=*"google.com"would match bothhttps://www.google.comand/doc/www/www.google.com/XYZ.html.↩︎Down from 120 days, then 90, as I kept hitting moving paywalls or sites outright dying.↩︎
This turned out to be a major flaw in archives of some websites like Reddit: there are few archives of the /r/DarkNetMarkets subreddit because it was set to over-18/NSFW, which meant that any cookie-less archiver like IA archived nothing but login-walls!↩︎
I have thus far received only 1 DMCA takedown email, from, oddly, a local newspaper used in my DNM arrests census.↩︎
Rehosting Arxiv PDFs is especially helpful because Arxiv PDFs can be very large (eg. the OFA paper is 35MB—most of my book scans are smaller), slow to download (in addition to the extra domain name lookup), and Arxiv is a nonprofit with minimal budget (so if one is encouraging readers to download PDFs profligately the way my popups do, you should rehost them).↩︎
Ar5iv comes with its own caveats: it cannot render all Arxiv papers, sometimes the rendered one is broken, and it attempts renders with approximately a 1 month lag. Fortunately, it is capable of redirecting to the regular Arxiv landing page (append
?fallback=original), so it is safe to link to it—at worst, a mobile reader just winds where they would’ve ended up anyway.↩︎IA describes it as merely ‘closing 2 weeks early’ to save face, but they had originally said “This suspension will run through June 30, 2020, or the end of the US national emergency, whichever is later.”—the ‘US national emergency’, such as the closure of schools which was the primary rationale, was not over by 2020-06-30, needless to say, or that year (or the year after that).↩︎