‘MLP NN’ directory
- See Also
- Gwern
- Links
- “Neural Networks Learn Bloom Filters”
- “Every Feedforward Neural Network Definable in an O-Minimal Structure Has Finite Sample Complexity”, Kratsios et al 2026
- “Friendship Is All You Need: Subliminal Pony Propagation in Large Language Models, Or, How I Learned to Stop Worrying and Love the Sparkle”, Sparkle et al 2026
- “Shared Sensitivity to Data Distribution during Learning in Humans and Transformer Networks”, Lerousseau & Summerfield 2025
- “Learning without Training: The Implicit Dynamics of In-Context Learning”, Dherin et al 2025
- “Transformers Pretrained on Procedural Data Contain Modular Structures for Algorithmic Reasoning”, Shinnick et al 2025
- “Compiling a Differentiable Logic Gate Neural Net to C for a 1,744× Speedup”, Clayton 2025
- “μPC: Scaling Predictive Coding to 100+ Layer Networks”, Innocenti et al 2025
- “Bigram Subnetworks: Mapping to Next Tokens in Transformer Language Models”, Chang & Bergen 2025
- “Progress Report on a Toy Model Of Memorization”, Brave 2025
- “NeuRaLaTeX: A Machine Learning Library Written in Pure LaTeX”, Gardner et al 2025
- “NeuralSVG: An Implicit Representation for Text-To-Vector Generation”, Polaczek et al 2025
- “Titans: Learning to Memorize at Test Time”, Behrouz et al 2024
- “AUNN: Simple Implementation of Gwern’s AUNN Proposal”, Roland 2024
- “Flexible Task Abstractions Emerge in Linear Networks With Fast and Bounded Units”, Sandbrink et al 2024
- “The Slingshot Helps With Learning”, Wu 2024
- “Arithmetic Without Algorithms: Language Models Solve Math With a Bag of Heuristics”, Nikankin et al 2024
- “SimBa: Simplicity Bias for Scaling Up Parameters in Deep Reinforcement Learning”, Lee et al 2024
- “Bilinear MLPs Enable Weight-Based Mechanistic Interpretability”, Pearce et al 2024
- “NGPT: Normalized Transformer With Representation Learning on the Hypersphere”, Loshchilov et al 2024
- “How Feature Learning Can Improve Neural Scaling Laws”, Bordelon et al 2024
- “Magika: AI-Powered Content-Type Detection”, Fratantonio et al 2024
- “On the Complexity of Neural Computation in Superposition”, Adler & Shavit 2024
- “Masked Mixers for Language Generation and Retrieval”, Badger 2024
- “GSoC 2024: Differentiable Logic for Interactive Systems and Generative Music”
- “Mathematical Models of Computation in Superposition”, Hänni et al 2024
- “PEER: Mixture of A Million Experts”, He 2024
- “What Matters in Transformers? Not All Attention Is Needed”, He et al 2024
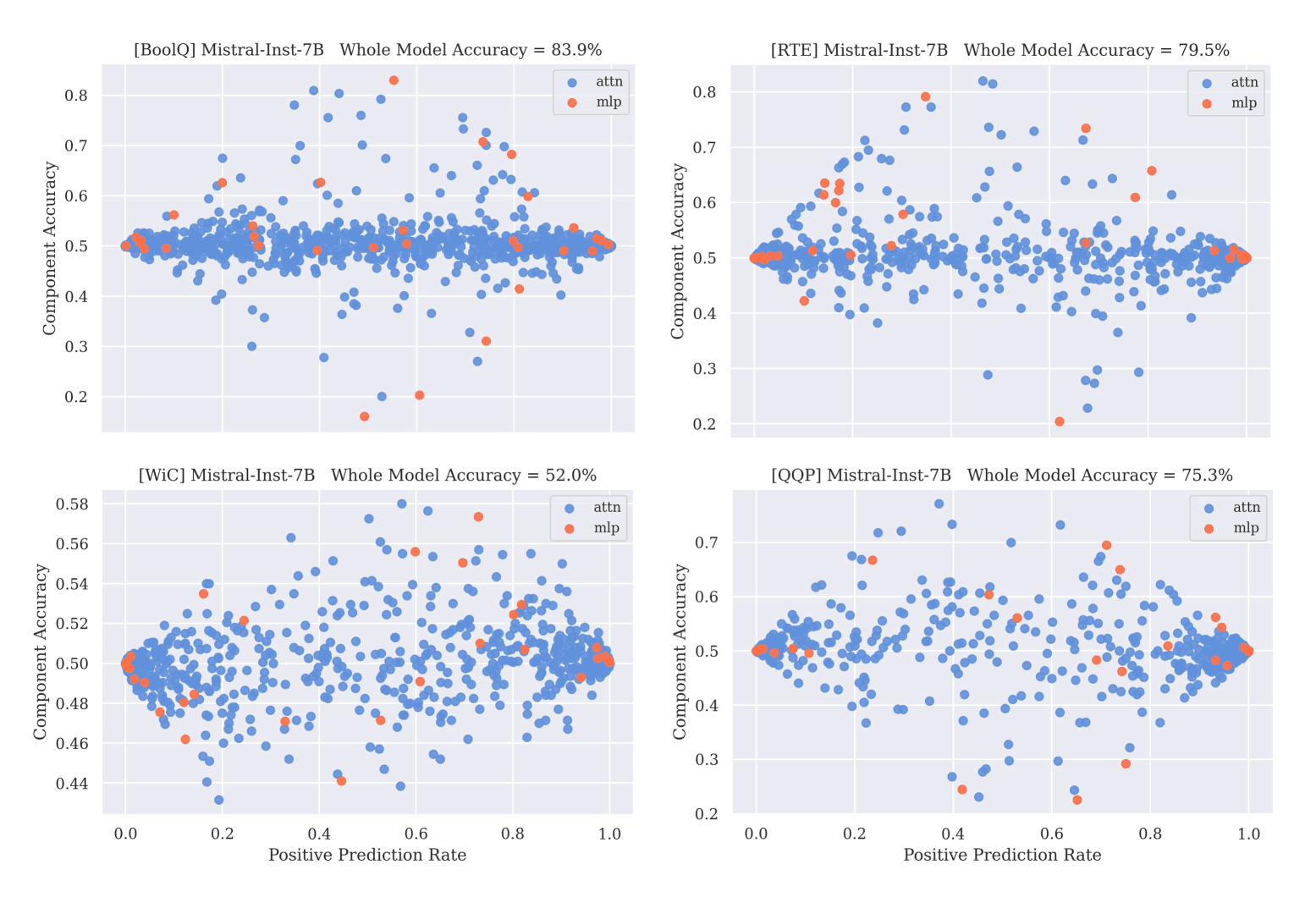
- “When Parts Are Greater Than Sums: Individual LLM Components Can Outperform Full Models”, Chang et al 2024
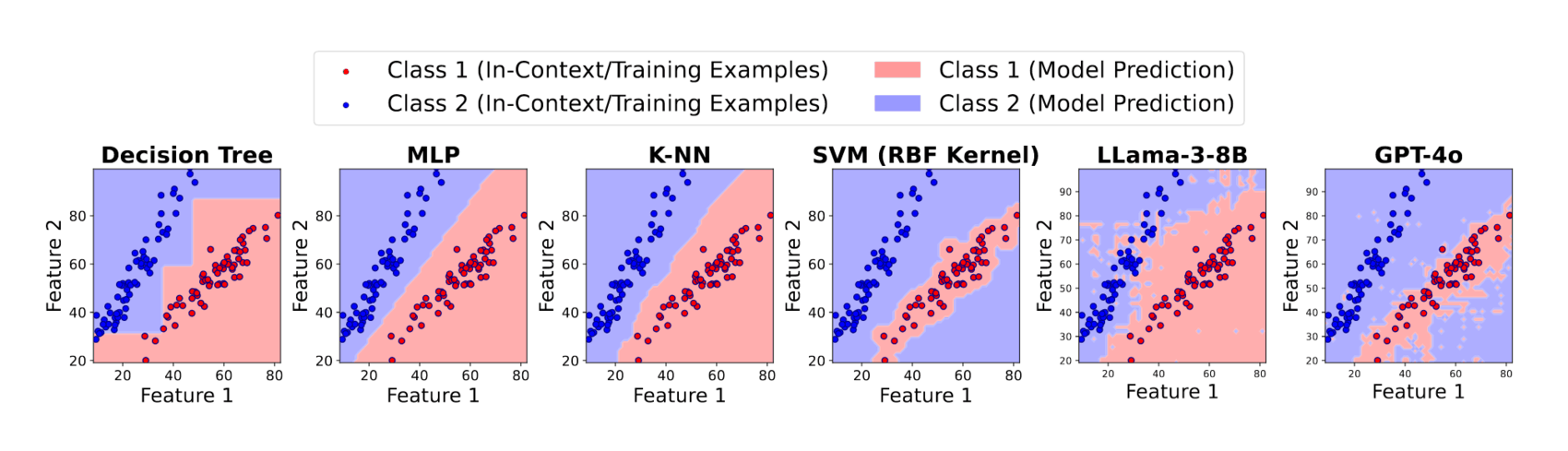
- “Probing the Decision Boundaries of In-Context Learning in Large Language Models”, Zhao et al 2024
- “MAR: Autoregressive Image Generation without Vector Quantization”, Li et al 2024
- “Grokking Modular Polynomials”, Doshi et al 2024
- “Grokfast: Accelerated Grokking by Amplifying Slow Gradients”, Lee et al 2024
- “Lateralization MLP: A Simple Brain-Inspired Architecture for Diffusion”, Hu & Rostami 2024
- “Bigger, Regularized, Optimistic: Scaling for Compute and Sample-Efficient Continuous Control”, Nauman et al 2024
- “MLPs Learn In-Context”, Tong & Pehlevan 2024
- “Verified Neural Compressed Sensing”, Bunel et al 2024
- “An Exactly Solvable Model for Emergence and Scaling Laws in the Multitask Sparse Parity Problem”, Nam et al 2024
- “Neural Redshift: Random Networks Are Not Random Functions”, Teney et al 2024
- “Verifiable Evaluations of Machine Learning Models Using ZkSNARKs”, South et al 2024
- “Surfing the OCEAN: The Machine Learning Psycholexical Approach 2.0 to Detect Personality Traits in Texts”, Giannini et al 2024
- “Neural Spline Fields for Burst Image Fusion and Layer Separation”, Chugunov et al 2023
- “SwitchHead: Accelerating Transformers With Mixture-Of-Experts Attention”, Csordás et al 2023
- “SMERF: Streamable Memory Efficient Radiance Fields for Real-Time Large-Scene Exploration”, Duckworth et al 2023
- “Grokking Group Multiplication With Cosets”, Stander et al 2023
- “Rethinking Attention: Exploring Shallow Feed-Forward Neural Networks As an Alternative to Attention Layers in Transformers”, Bozic et al 2023
- “HyperFields: Towards Zero-Shot Generation of NeRFs from Text”, Babu et al 2023
- “Grokking Beyond Neural Networks: An Empirical Exploration With Model Complexity”, Miller et al 2023
- “To Grok or Not to Grok: Disentangling Generalization and Memorization on Corrupted Algorithmic Datasets”, Doshi et al 2023
- “Polynomial Time Cryptanalytic Extraction of Neural Network Models”, Shamir et al 2023
- “One Wide Feedforward Is All You Need”, Pires et al 2023
- “Does Circuit Analysis Interpretability Scale? Evidence from Multiple Choice Capabilities in Chinchilla”, Lieberum et al 2023
- “Self Expanding Neural Networks”, Mitchell et al 2023
- “The Clock and the Pizza: Two Stories in Mechanistic Explanation of Neural Networks”, Zhong et al 2023
- “Scaling MLPs: A Tale of Inductive Bias”, Bachmann et al 2023
- “Any Deep ReLU Network Is Shallow”, Villani & Schoots 2023
- “Does the First Letter of One’s Name Affect Life Decisions? A Natural Language Processing Examination of Nominative Determinism”, Chatterjee et al 2023
- “Simplicial Hopfield Networks”, Burns & Fukai 2023
- “How Does GPT-2 Compute Greater-Than?: Interpreting Mathematical Abilities in a Pre-Trained Language Model”, Hanna et al 2023
- “Two-Step Training: Adjustable Sketch Colorization via Reference Image and Text Tag”, Yan et al 2023
- “HyperDiffusion: Generating Implicit Neural Fields With Weight-Space Diffusion”, Erkoç et al 2023
- “The Quantization Model of Neural Scaling”, Michaud et al 2023
- “TSMixer: An All-MLP Architecture for Time Series Forecasting”, Chen et al 2023
- “Loss Landscapes Are All You Need: Neural Network Generalization Can Be Explained Without the Implicit Bias of Gradient Descent”, Chiang et al 2023
- “A Toy Model of Universality: Reverse Engineering How Networks Learn Group Operations”, Chughtai et al 2023
- “Looped Transformers As Programmable Computers”, Giannou et al 2023
- “Organic Reaction Mechanism Classification Using Machine Learning”, Burés & Larrosa 2023
- “DataMUX: Data Multiplexing for Neural Networks”, Murahari et al 2023
- “Merging Enzymatic and Synthetic Chemistry With Computational Synthesis Planning”, Levin et al 2022
- “Magic3D: High-Resolution Text-To-3D Content Creation”, Lin et al 2022
- “DINER: Disorder-Invariant Implicit Neural Representation”, Xie et al 2022
- “How Much Does Attention Actually Attend? Questioning the Importance of Attention in Pretrained Transformers”, Hassid et al 2022
- “Compressing Multidimensional Weather and Climate Data into Neural Networks”, Huang & Hoefler 2022
- “Deep Differentiable Logic Gate Networks”, Petersen et al 2022
- “The Lazy Neuron Phenomenon: On Emergence of Activation Sparsity in Transformers”, Li et al 2022
- “Neural Networks Are Decision Trees”, Aytekin 2022
- “The Unreasonable Effectiveness of Fully-Connected Layers for Low-Data Regimes”, Kocsis et al 2022
- “Scaling Forward Gradient With Local Losses”, Ren et al 2022
- “The Lie Derivative for Measuring Learned Equivariance”, Gruver et al 2022
- “Omnigrok: Grokking Beyond Algorithmic Data”, Liu et al 2022
- “DreamFusion: Text-To-3D Using 2D Diffusion”, Poole et al 2022
- “
g.pt: Learning to Learn With Generative Models of Neural Network Checkpoints”, Peebles et al 2022 - “Random Initializations Performing above Chance and How to Find Them”, Benzing et al 2022
- “Scaling Laws vs Model Architectures: How Does Inductive Bias Influence Scaling?”, Tay et al 2022
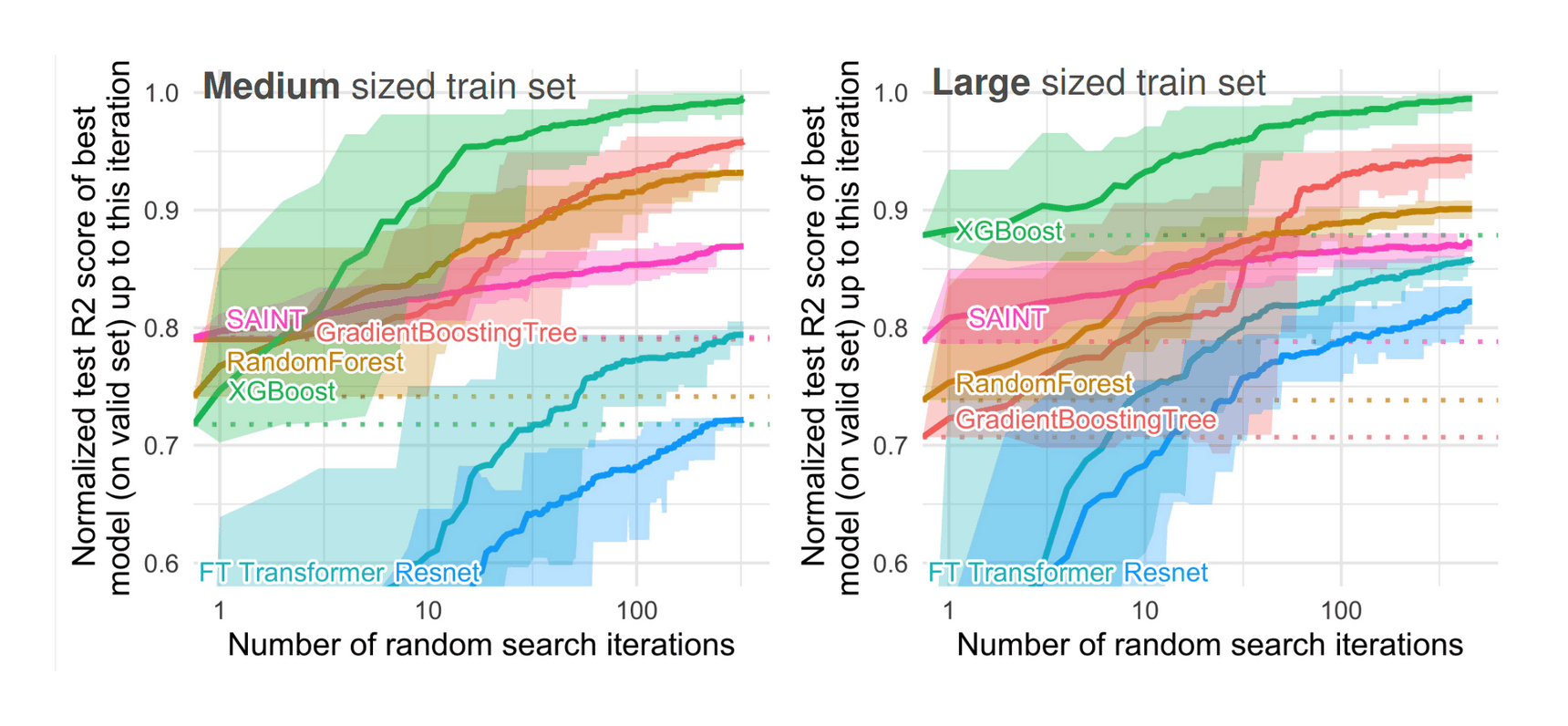
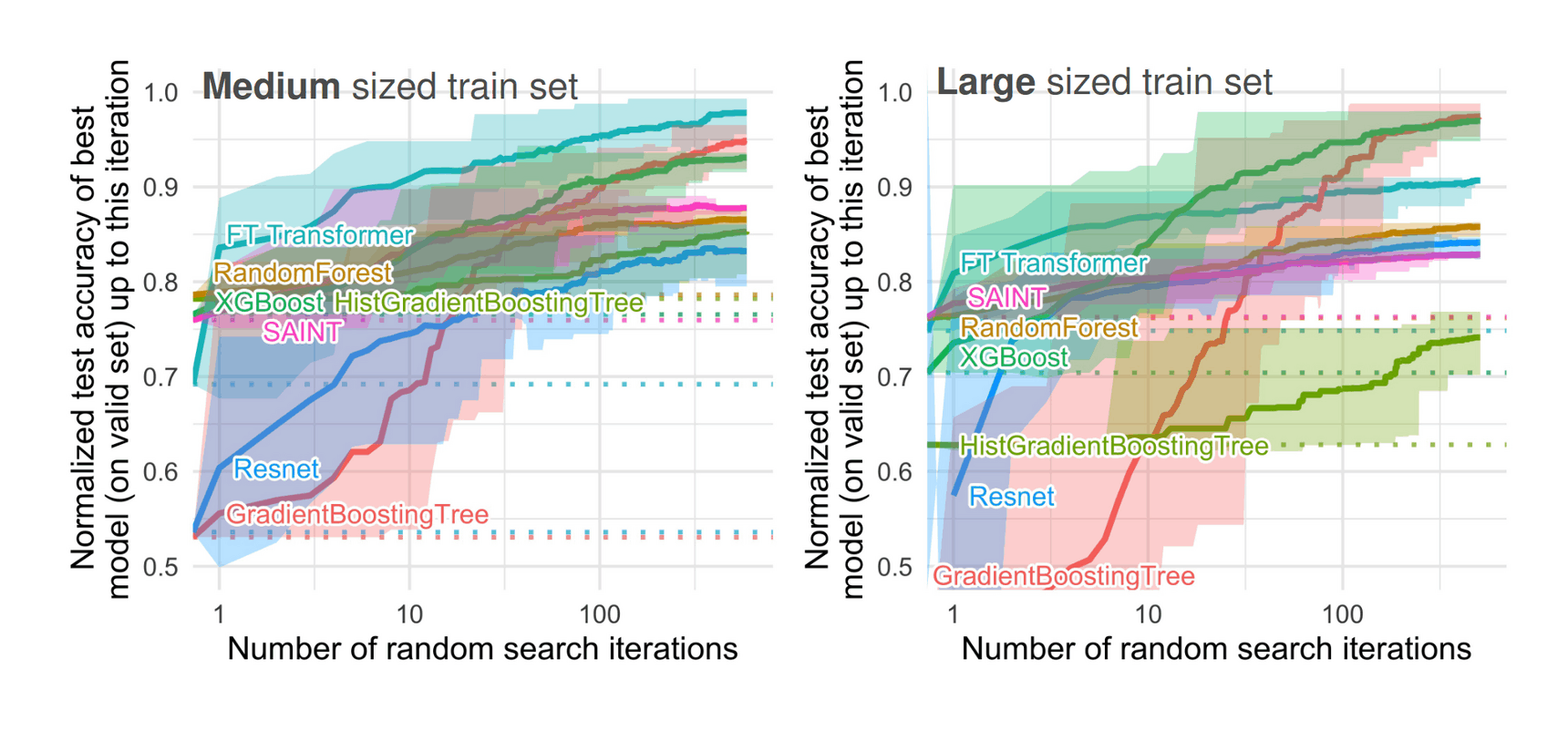
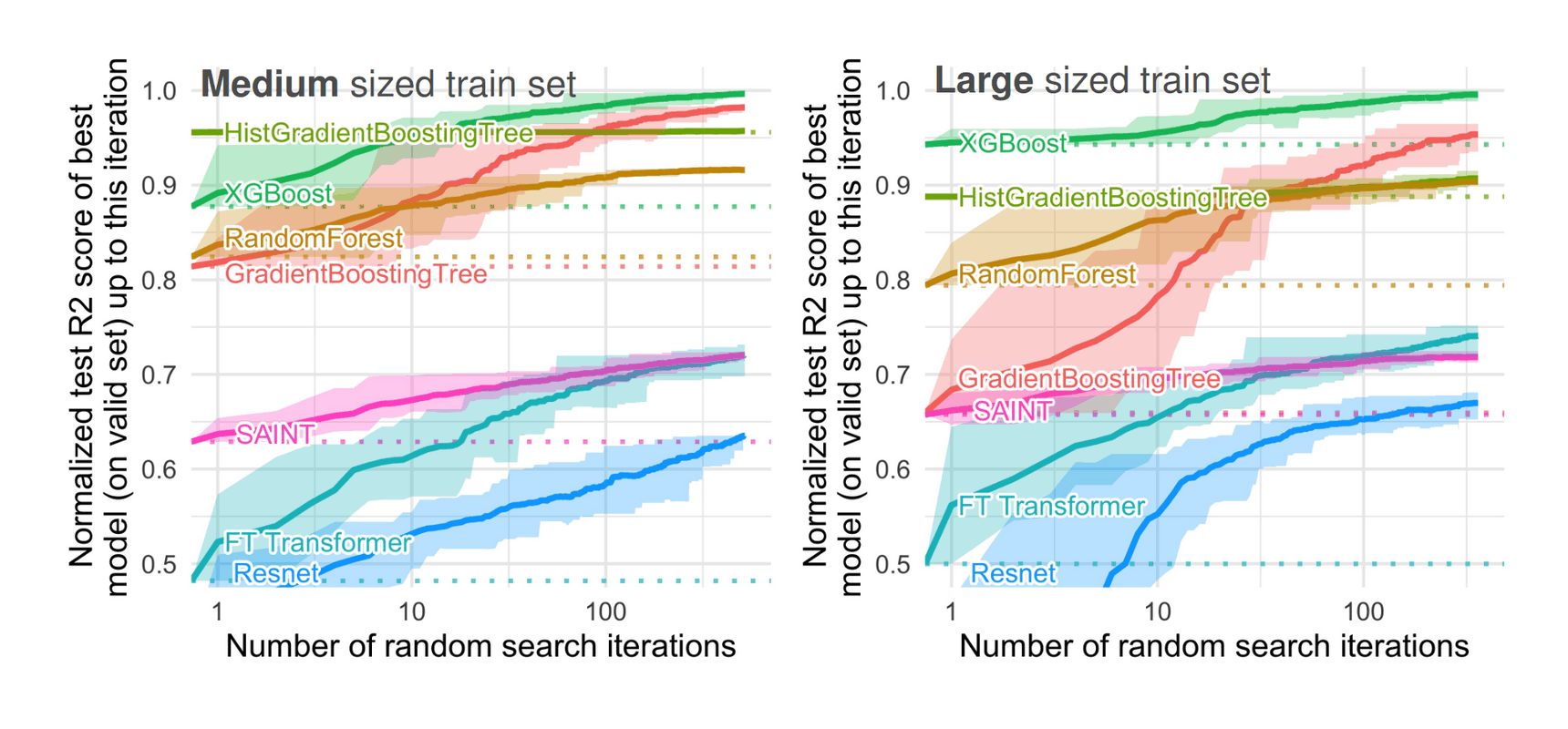
- “Why Do Tree-Based Models Still Outperform Deep Learning on Tabular Data?”, Grinsztajn et al 2022
- “Revisiting Pretraining Objectives for Tabular Deep Learning”, Rubachev et al 2022
- “RHO-LOSS: Prioritized Training on Points That Are Learnable, Worth Learning, and Not Yet Learnt”, Mindermann et al 2022
- “MLP-3D: A MLP-Like 3D Architecture With Grouped Time Mixing”, Qiu et al 2022
- “ChordMixer: A Scalable Neural Attention Model for Sequences With Different Lengths”, Khalitov et al 2022
- “Sparse Mixers: Combining MoE and Mixing to Build a More Efficient BERT”, Lee-Thorp & Ainslie 2022
- “Towards Understanding Grokking: An Effective Theory of Representation Learning”, Liu et al 2022
- “Paramixer: Parameterizing Mixing Links in Sparse Factors Works Better Than Dot-Product Self-Attention”, Yu et al 2022
- “Deep Learning Meets Nonparametric Regression: Are Weight-Decayed DNNs Locally Adaptive?”, Zhang & Wang 2022
- “Efficient Language Modeling With Sparse All-MLP”, Yu et al 2022
- “HyperMixer: An MLP-Based Low Cost Alternative to Transformers”, Mai et al 2022
- “MLP-ASR: Sequence-Length Agnostic All-MLP Architectures for Speech Recognition”, Sakuma et al 2022
- “Mixing and Shifting: Exploiting Global and Local Dependencies in Vision MLPs”, Zheng et al 2022
- “PNLP-Mixer: an Efficient All-MLP Architecture for Language”, Fusco et al 2022
- “Data-Driven Emergence of Convolutional Structure in Neural Networks”, Ingrosso & Goldt 2022
- “When Shift Operation Meets Vision Transformer: An Extremely Simple Alternative to Attention Mechanism (ShiftViT)”, Wang et al 2022
- “ConvMixer: Patches Are All You Need?”, Trockman & Kolter 2022
- “MAXIM: Multi-Axis MLP for Image Processing”, Tu et al 2022
- “Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets [Paper]”, Power et al 2022
- “The GatedTabTransformer: An Enhanced Deep Learning Architecture for Tabular Modeling”, Cholakov & Kolev 2022
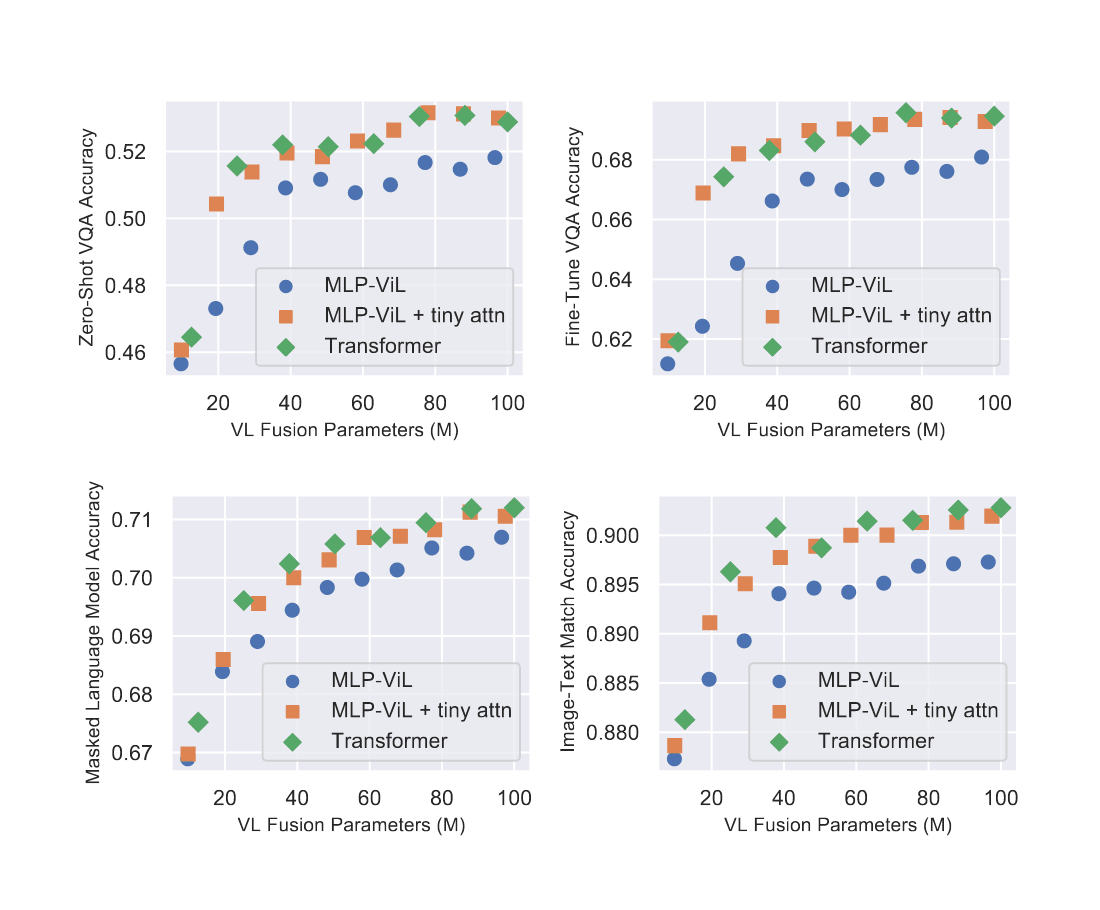
- “MLP Architectures for Vision-And-Language Modeling: An Empirical Study”, Nie et al 2021
- “Noether Networks: Meta-Learning Useful Conserved Quantities”, Alet et al 2021
- “Residual Pathway Priors for Soft Equivariance Constraints”, Finzi et al 2021
- “Zero-Shot Text-Guided Object Generation With Dream Fields”, Jain et al 2021
- “MorphMLP: A Self-Attention Free, MLP-Like Backbone for Image and Video”, Zhang et al 2021
- “PointMixer: MLP-Mixer for Point Cloud Understanding”, Choe et al 2021
- “MetaFormer Is Actually What You Need for Vision”, Yu et al 2021
- “Deep Learning without Shortcuts: Shaping the Kernel With Tailored Rectifiers”, Zhang et al 2021
- “ZerO Initialization: Initializing Residual Networks With Only Zeros and Ones”, Zhao et al 2021
- “Wide Neural Networks Forget Less Catastrophically”, Mirzadeh et al 2021
- “ADOP: Approximate Differentiable One-Pixel Point Rendering”, Rückert et al 2021
- “Rapid Training of Deep Neural Networks without Skip Connections or Normalization Layers Using Deep Kernel Shaping”, Martens et al 2021
- “Exploring the Limits of Large Scale Pre-Training”, Abnar et al 2021
- “Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?”, Tang et al 2021
- “AFT: An Attention Free Transformer”, Zhai et al 2021
- “ConvMLP: Hierarchical Convolutional MLPs for Vision”, Li et al 2021
- “Sparse-MLP: A Fully-MLP Architecture With Conditional Computation”, Lou et al 2021
- “Implicit Behavioral Cloning”, Florence et al 2021
- “A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP”, Zhao et al 2021
- “Hire-MLP: Vision MLP via Hierarchical Rearrangement”, Guo et al 2021
- “RaftMLP: How Much Can Be Done Without Attention and With Less Spatial Locality?”, Tatsunami & Taki 2021
- “S2-MLPv2: Improved Spatial-Shift MLP Architecture for Vision”, Yu et al 2021
- “CycleMLP: A MLP-Like Architecture for Dense Prediction”, Chen et al 2021
- “AS-MLP: An Axial Shifted MLP Architecture for Vision”, Lian et al 2021
- “Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition”, Hou et al 2021
- “Real-Time Neural Radiance Caching for Path Tracing”, Müller et al 2021
- “Towards Biologically Plausible Convolutional Networks”, Pogodin et al 2021
- “Well-Tuned Simple Nets Excel on Tabular Datasets”, Kadra et al 2021
- “MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis”, Tae et al 2021
- “PairConnect: A Compute-Efficient MLP Alternative to Attention”, Xu et al 2021
- “S2-MLP: Spatial-Shift MLP Architecture for Vision”, Yu et al 2021
- “When Vision Transformers Outperform ResNets without Pre-Training or Strong Data Augmentations”, Chen et al 2021
- “Container: Context Aggregation Network”, Gao et al 2021
- “MixerGAN: An MLP-Based Architecture for Unpaired Image-To-Image Translation”, Cazenavette & Guevara 2021
- “One4all User Representation for Recommender Systems in E-Commerce”, Shin et al 2021
- “Pay Attention to MLPs”, Liu et al 2021
- “FNet: Mixing Tokens With Fourier Transforms”, Lee-Thorp et al 2021
- “ResMLP: Feedforward Networks for Image Classification With Data-Efficient Training”, Touvron et al 2021
- “Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet”, Melas-Kyriazi 2021
- “Multi-Scale Inference of Genetic Trait Architecture Using Biologically Annotated Neural Networks”, Demetci et al 2021
- “RepMLP: Re-Parameterizing Convolutions into Fully-Connected Layers for Image Recognition”, Ding et al 2021
- “MLP-Mixer: An All-MLP Architecture for Vision”, Tolstikhin et al 2021
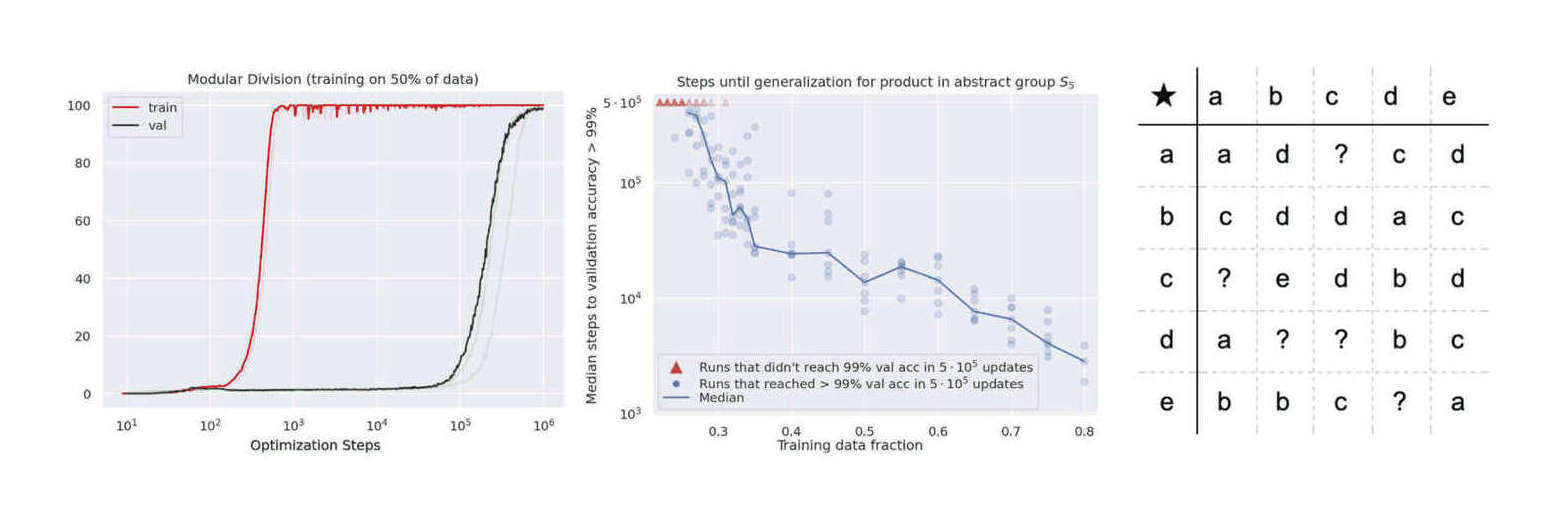
- “Grokking: Generalization Beyond Overfitting On Small Algorithmic Datasets”, Power et al 2021
- “Sifting out the Features by Pruning: Are Convolutional Networks the Winning Lottery Ticket of Fully Connected Ones?”, Pellegrini & Biroli 2021
- “Fully-Connected Neural Nets”, Gwern 2021
- “Revisiting Simple Neural Probabilistic Language Models”, Sun & Iyyer 2021
- “KiloNeRF: Speeding up Neural Radiance Fields With Thousands of Tiny MLPs”, Reiser et al 2021
- “Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows”, Liu et al 2021
- “Attention Is Not All You Need: Pure Attention Loses Rank Doubly Exponentially With Depth”, Dong et al 2021
- “Clusterability in Neural Networks”, Filan et al 2021
- “Training Larger Networks for Deep Reinforcement Learning”, Ota et al 2021
- “Explaining Neural Scaling Laws”, Bahri et al 2021
- “Neural Geometric Level of Detail: Real-Time Rendering With Implicit 3D Shapes”, Takikawa et al 2021
- “Is MLP-Mixer a CNN in Disguise? As Part of This Blog Post, We Look at the MLP Mixer Architecture in Detail and Also Understand Why It Is Not Considered Convolution Free.”
- “Transformer Feed-Forward Layers Are Key-Value Memories”, Pipek et al 2020
- “AdnFM: An Attentive DenseNet Based Factorization Machine for CTR Prediction”, Wang et al 2020
- “TabTransformer: Tabular Data Modeling Using Contextual Embeddings”, Huang et al 2020
- “Scaling down Deep Learning”, Greydanus 2020
- “Image Generators With Conditionally-Independent Pixel Synthesis”, Anokhin et al 2020
- “D2RL: Deep Dense Architectures in Reinforcement Learning”, Sinha et al 2020
- “Fourier Neural Operator for Parametric Partial Differential Equations”, Li et al 2020
- “Intelligent Matrix Exponentiation”, Fischbacher et al 2020
- “Towards Learning Convolutions from Scratch”, Neyshabur 2020
- “Hyperparameter Ensembles for Robustness and Uncertainty Quantification”, Wenzel et al 2020
- “Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains”, Tancik et al 2020
- “SIREN: Implicit Neural Representations With Periodic Activation Functions”, Sitzmann et al 2020
- “Linformer: Self-Attention With Linear Complexity”, Wang et al 2020
- “A Map of Object Space in Primate Inferotemporal Cortex”, Bao et al 2020
- “Synthesizer: Rethinking Self-Attention in Transformer Models”, Tay et al 2020
- “Deep Learning Training in Facebook Data Centers: Design of Scale-Up and Scale-Out Systems”, Naumov et al 2020
- “NeRF: Representing Scenes As Neural Radiance Fields for View Synthesis”, Mildenhall et al 2020
- “Cryptanalytic Extraction of Neural Network Models”, Carlini et al 2020
- “ReZero Is All You Need: Fast Convergence at Large Depth”, Bachlechner et al 2020
- “Train-By-Reconnect: Decoupling Locations of Weights from Their Values (LaPerm)”, Qiu & Suda 2020
- “Can Increasing Input Dimensionality Improve Deep Reinforcement Learning?”, Ota et al 2020
- “Quasi-Equivalence of Width and Depth of Neural Networks”, Fan et al 2020
- “Gesticulator: A Framework for Semantically-Aware Speech-Driven Gesture Generation”, Kucherenko et al 2020
- “What’s Hidden in a Randomly Weighted Neural Network?”, Ramanujan et al 2019
- “Understanding the Generalization of ‘Lottery Tickets’ in Neural Networks”, Morcos & Tian 2019
- “The Bouncer Problem: Challenges to Remote Explainability”, Merrer & Tredan 2019
- “3D Human Pose Estimation via Human Structure-Aware Fully Connected Network”, Zhang et al 2019d
- “Finding the Needle in the Haystack With Convolutions: on the Benefits of Architectural Bias”, d’Ascoli et al 2019
- “Generalization Guarantees for Neural Networks via Harnessing the Low-Rank Structure of the Jacobian”, Oymak et al 2019
- “Implicit Regularization in Deep Matrix Factorization”, Arora et al 2019
- “MoGlow: Probabilistic and Controllable Motion Synthesis Using Normalizing Flows”, Henter et al 2019
- “Fixup Initialization: Residual Learning Without Normalization”, Zhang et al 2019
- “SwitchNet: a Neural Network Model for Forward and Inverse Scattering Problems”, Khoo & Ying 2018
- “A Jamming Transition from Under-Parameterization to Over-Parameterization Affects Loss Landscape and Generalization”, Spigler et al 2018
- “Neural Arithmetic Logic Units”, Trask et al 2018
- “The Goldilocks Zone: Towards Better Understanding of Neural Network Loss Landscapes”, Fort & Scherlis 2018
- “Scalable Training of Artificial Neural Networks With Adaptive Sparse Connectivity Inspired by Network Science”, Mocanu et al 2018
- “Deep Learning Generalizes Because the Parameter-Function Map Is Biased towards Simple Functions”, Valle-Pérez et al 2018
- “Bidirectional Learning for Robust Neural Networks”, Pontes-Filho & Liwicki 2018
- “NAIS-Net: Stable Deep Networks from Non-Autonomous Differential Equations”, Ciccone et al 2018
- “Large Scale Distributed Neural Network Training through Online Distillation”, Anil et al 2018
- “Meta-Learning Update Rules for Unsupervised Representation Learning”, Metz et al 2018
- “Learning and Memorization”, Chatterjee 2018
- “Repurposing High-Throughput Image Assays Enables Biological Activity Prediction for Drug Discovery”, Simm et al 2018
- “Improving Palliative Care With Deep Learning”, An et al 2018
- “Learning to Play Chess With Minimal Lookahead and Deep Value Neural Networks”, Sabatelli 2017 (page 3)
- “Neural Collaborative Filtering”, He et al 2017
- “Sharp Models on Dull Hardware: Fast and Accurate Neural Machine Translation Decoding on the CPU”, Devlin 2017
- “The Shattered Gradients Problem: If Resnets Are the Answer, Then What Is the Question?”, Balduzzi et al 2017
- “Gender-From-Iris or Gender-From-Mascara?”, Kuehlkamp et al 2017
- “Skip Connections Eliminate Singularities”, Orhan & Pitkow 2017
- “Deep Information Propagation”, Schoenholz et al 2016
- “Topology and Geometry of Half-Rectified Network Optimization”, Freeman & Bruna 2016
- “On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima”, Keskar et al 2016
- “Decoupled Neural Interfaces Using Synthetic Gradients”, Jaderberg et al 2016
- “Learning to Optimize”, Li & Malik 2016
- “Do Deep Convolutional Nets Really Need to Be Deep and Convolutional?”, Urban et al 2016
- “Network Morphism”, Wei et al 2016
- “Adding Gradient Noise Improves Learning for Very Deep Networks”, Neelakantan et al 2015
- “How Far Can We Go without Convolution: Improving Fully-Connected Networks”, Lin et al 2015
- “BinaryConnect: Training Deep Neural Networks With Binary Weights during Propagations”, Courbariaux et al 2015
- “Tensorizing Neural Networks”, Novikov et al 2015
- “A Neural Attention Model for Abstractive Sentence Summarization”, Rush et al 2015
- “Deep Neural Networks for Large Vocabulary Handwritten Text Recognition”, Bluche 2015
- “In Search of the Real Inductive Bias: On the Role of Implicit Regularization in Deep Learning”, Neyshabur et al 2014
- “The Loss Surfaces of Multilayer Networks”, Choromanska et al 2014
- “On the Number of Linear Regions of Deep Neural Networks”, Montúfar et al 2014
- “Do Deep Nets Really Need to Be Deep?”, Ba & Caruana 2013
- “On the Number of Response Regions of Deep Feed Forward Networks With Piece-Wise Linear Activations”, Pascanu et al 2013
- “Network In Network”, Lin et al 2013
- “Deep Big Multilayer Perceptrons for Digit Recognition”, Cireşan et al 2012
- “Natural Language Processing (Almost) from Scratch”, Collobert et al 2011
- “Deep Big Simple Neural Nets Excel on Handwritten Digit Recognition”, Ciresan et al 2010
- “Compositional Pattern Producing Networks: A Novel Abstraction of Development”, Stanley 2007
- “Extraction De Séquences Numériques Dans Des Documents Manuscrits Quelconques”, Chatelain 2006
- “Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis”, Simard et al 2003
- “NEAT: Evolving Neural Networks through Augmenting Topologies”, Stanley & Miikkulainen 2002
- “DARPA and the Quest for Machine Intelligence, 1983–1993”, Roland & Shiman 2002
- “Quantitative Analysis of Multivariate Data Using Artificial Neural Networks: A Tutorial Review and Applications to the Deconvolution of Pyrolysis Mass Spectra”, Goodacre et al 1996
- “Statistical Mechanics of Generalization”, Opper & Kinzel 1996
- “On the Ability of the Optimal Perceptron to Generalize”, Opper et al 1990
- “Learning To Tell Two Spirals Apart”, Lang & Witbrock 1988
- “Learning Internal Representations by Error Propagation”, Rumelhart et al 1986
- “Neural Networks and Physical Systems With Emergent Collective Computational Abilities”, Hopfield 1982
- “Can You Reverse Engineer Our Neural Network? [Encoding MD5 into a MLP]”
- “Technion-Cs-Nlp/llm-Arithmetic-Heuristics”
- “Research Log: Monet/PEER Sparse Experts”
- Sort By Magic
- Wikipedia (2)
- Miscellaneous
- Bibliography
See Also
Gwern
“Dat Tail, Dat Flank—Never Forget”, Gwern 2025
{kind=link}
“Absolute Unit NNs: Regression-Based MLPs for Everything”, Gwern 2023
“Research Ideas”, Gwern 2017
“Modular Brain AUNNs for Uploads”, Gwern 2023
“Language-Conditioned Absolute Unit NNs”, Gwern 2022
Links
“Neural Networks Learn Bloom Filters”
“Every Feedforward Neural Network Definable in an O-Minimal Structure Has Finite Sample Complexity”, Kratsios et al 2026
Every Feedforward Neural Network Definable in an o-Minimal Structure Has Finite Sample Complexity
“Friendship Is All You Need: Subliminal Pony Propagation in Large Language Models, Or, How I Learned to Stop Worrying and Love the Sparkle”, Sparkle et al 2026
“Shared Sensitivity to Data Distribution during Learning in Humans and Transformer Networks”, Lerousseau & Summerfield 2025
Shared sensitivity to data distribution during learning in humans and Transformer networks
“Learning without Training: The Implicit Dynamics of In-Context Learning”, Dherin et al 2025
Learning without training: The implicit dynamics of in-context learning
“Transformers Pretrained on Procedural Data Contain Modular Structures for Algorithmic Reasoning”, Shinnick et al 2025
Transformers Pretrained on Procedural Data Contain Modular Structures for Algorithmic Reasoning
“Compiling a Differentiable Logic Gate Neural Net to C for a 1,744× Speedup”, Clayton 2025
Compiling a Differentiable Logic Gate Neural Net to C for a 1,744× speedup
“μPC: Scaling Predictive Coding to 100+ Layer Networks”, Innocenti et al 2025
“Bigram Subnetworks: Mapping to Next Tokens in Transformer Language Models”, Chang & Bergen 2025
Bigram Subnetworks: Mapping to Next Tokens in Transformer Language Models
“Progress Report on a Toy Model Of Memorization”, Brave 2025
“NeuRaLaTeX: A Machine Learning Library Written in Pure LaTeX”, Gardner et al 2025
NeuRaLaTeX: A machine learning library written in pure LaTeX
“NeuralSVG: An Implicit Representation for Text-To-Vector Generation”, Polaczek et al 2025
NeuralSVG: An Implicit Representation for Text-to-Vector Generation
“Titans: Learning to Memorize at Test Time”, Behrouz et al 2024
“AUNN: Simple Implementation of Gwern’s AUNN Proposal”, Roland 2024
“Flexible Task Abstractions Emerge in Linear Networks With Fast and Bounded Units”, Sandbrink et al 2024
Flexible task abstractions emerge in linear networks with fast and bounded units
“The Slingshot Helps With Learning”, Wu 2024
“Arithmetic Without Algorithms: Language Models Solve Math With a Bag of Heuristics”, Nikankin et al 2024
Arithmetic Without Algorithms: Language Models Solve Math With a Bag of Heuristics
“SimBa: Simplicity Bias for Scaling Up Parameters in Deep Reinforcement Learning”, Lee et al 2024
SimBa: Simplicity Bias for Scaling Up Parameters in Deep Reinforcement Learning
“Bilinear MLPs Enable Weight-Based Mechanistic Interpretability”, Pearce et al 2024
Bilinear MLPs enable weight-based mechanistic interpretability
“NGPT: Normalized Transformer With Representation Learning on the Hypersphere”, Loshchilov et al 2024
nGPT: Normalized Transformer with Representation Learning on the Hypersphere
“How Feature Learning Can Improve Neural Scaling Laws”, Bordelon et al 2024
“Magika: AI-Powered Content-Type Detection”, Fratantonio et al 2024
“On the Complexity of Neural Computation in Superposition”, Adler & Shavit 2024
“Masked Mixers for Language Generation and Retrieval”, Badger 2024
“GSoC 2024: Differentiable Logic for Interactive Systems and Generative Music”
GSoC 2024: Differentiable Logic for Interactive Systems and Generative Music
“Mathematical Models of Computation in Superposition”, Hänni et al 2024
“PEER: Mixture of A Million Experts”, He 2024
“What Matters in Transformers? Not All Attention Is Needed”, He et al 2024
“When Parts Are Greater Than Sums: Individual LLM Components Can Outperform Full Models”, Chang et al 2024
When Parts are Greater Than Sums: Individual LLM Components Can Outperform Full Models
“Probing the Decision Boundaries of In-Context Learning in Large Language Models”, Zhao et al 2024
Probing the Decision Boundaries of In-context Learning in Large Language Models
“MAR: Autoregressive Image Generation without Vector Quantization”, Li et al 2024
MAR: Autoregressive Image Generation without Vector Quantization
“Grokking Modular Polynomials”, Doshi et al 2024
“Grokfast: Accelerated Grokking by Amplifying Slow Gradients”, Lee et al 2024
“Lateralization MLP: A Simple Brain-Inspired Architecture for Diffusion”, Hu & Rostami 2024
Lateralization MLP: A Simple Brain-inspired Architecture for Diffusion
“Bigger, Regularized, Optimistic: Scaling for Compute and Sample-Efficient Continuous Control”, Nauman et al 2024
Bigger, Regularized, Optimistic: scaling for compute and sample-efficient continuous control
“MLPs Learn In-Context”, Tong & Pehlevan 2024
“Verified Neural Compressed Sensing”, Bunel et al 2024
“An Exactly Solvable Model for Emergence and Scaling Laws in the Multitask Sparse Parity Problem”, Nam et al 2024
An exactly solvable model for emergence and scaling laws in the multitask sparse parity problem
“Neural Redshift: Random Networks Are Not Random Functions”, Teney et al 2024
“Verifiable Evaluations of Machine Learning Models Using ZkSNARKs”, South et al 2024
Verifiable evaluations of machine learning models using zkSNARKs
“Surfing the OCEAN: The Machine Learning Psycholexical Approach 2.0 to Detect Personality Traits in Texts”, Giannini et al 2024
“Neural Spline Fields for Burst Image Fusion and Layer Separation”, Chugunov et al 2023
Neural Spline Fields for Burst Image Fusion and Layer Separation
“SwitchHead: Accelerating Transformers With Mixture-Of-Experts Attention”, Csordás et al 2023
SwitchHead: Accelerating Transformers with Mixture-of-Experts Attention
“SMERF: Streamable Memory Efficient Radiance Fields for Real-Time Large-Scene Exploration”, Duckworth et al 2023
SMERF: Streamable Memory Efficient Radiance Fields for Real-Time Large-Scene Exploration
“Grokking Group Multiplication With Cosets”, Stander et al 2023
“Rethinking Attention: Exploring Shallow Feed-Forward Neural Networks As an Alternative to Attention Layers in Transformers”, Bozic et al 2023
“HyperFields: Towards Zero-Shot Generation of NeRFs from Text”, Babu et al 2023
HyperFields: Towards Zero-Shot Generation of NeRFs from Text
“Grokking Beyond Neural Networks: An Empirical Exploration With Model Complexity”, Miller et al 2023
Grokking Beyond Neural Networks: An Empirical Exploration with Model Complexity
“To Grok or Not to Grok: Disentangling Generalization and Memorization on Corrupted Algorithmic Datasets”, Doshi et al 2023
“Polynomial Time Cryptanalytic Extraction of Neural Network Models”, Shamir et al 2023
Polynomial Time Cryptanalytic Extraction of Neural Network Models
“One Wide Feedforward Is All You Need”, Pires et al 2023
“Does Circuit Analysis Interpretability Scale? Evidence from Multiple Choice Capabilities in Chinchilla”, Lieberum et al 2023
“Self Expanding Neural Networks”, Mitchell et al 2023
“The Clock and the Pizza: Two Stories in Mechanistic Explanation of Neural Networks”, Zhong et al 2023
The Clock and the Pizza: Two Stories in Mechanistic Explanation of Neural Networks
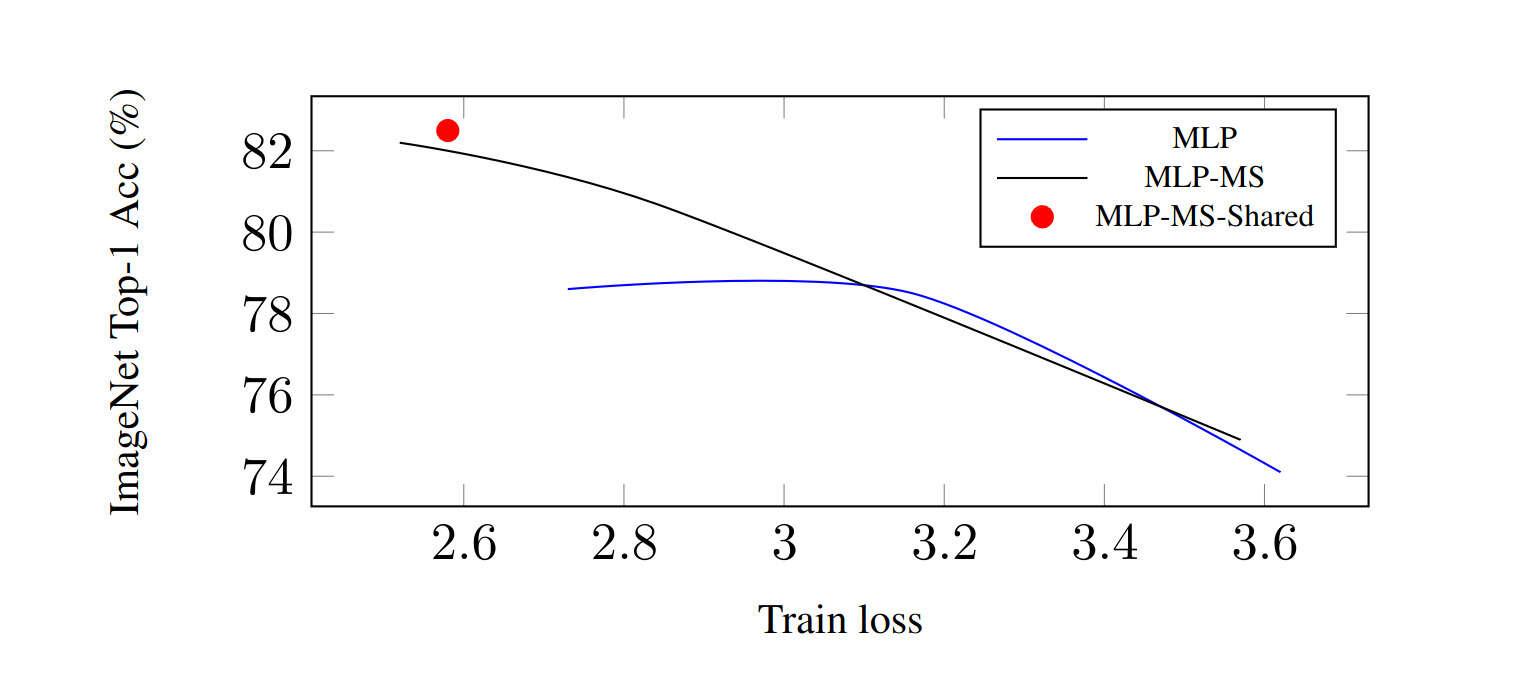
“Scaling MLPs: A Tale of Inductive Bias”, Bachmann et al 2023
“Any Deep ReLU Network Is Shallow”, Villani & Schoots 2023
“Does the First Letter of One’s Name Affect Life Decisions? A Natural Language Processing Examination of Nominative Determinism”, Chatterjee et al 2023
“Simplicial Hopfield Networks”, Burns & Fukai 2023
“How Does GPT-2 Compute Greater-Than?: Interpreting Mathematical Abilities in a Pre-Trained Language Model”, Hanna et al 2023
“Two-Step Training: Adjustable Sketch Colorization via Reference Image and Text Tag”, Yan et al 2023
Two-Step Training: Adjustable Sketch Colorization via Reference Image and Text Tag
“HyperDiffusion: Generating Implicit Neural Fields With Weight-Space Diffusion”, Erkoç et al 2023
HyperDiffusion: Generating Implicit Neural Fields with Weight-Space Diffusion
“The Quantization Model of Neural Scaling”, Michaud et al 2023
“TSMixer: An All-MLP Architecture for Time Series Forecasting”, Chen et al 2023
TSMixer: An All-MLP Architecture for Time Series Forecasting
“Loss Landscapes Are All You Need: Neural Network Generalization Can Be Explained Without the Implicit Bias of Gradient Descent”, Chiang et al 2023
“A Toy Model of Universality: Reverse Engineering How Networks Learn Group Operations”, Chughtai et al 2023
A Toy Model of Universality: Reverse Engineering How Networks Learn Group Operations
“Looped Transformers As Programmable Computers”, Giannou et al 2023
“Organic Reaction Mechanism Classification Using Machine Learning”, Burés & Larrosa 2023
Organic reaction mechanism classification using machine learning
“DataMUX: Data Multiplexing for Neural Networks”, Murahari et al 2023
“Merging Enzymatic and Synthetic Chemistry With Computational Synthesis Planning”, Levin et al 2022
Merging enzymatic and synthetic chemistry with computational synthesis planning
“Magic3D: High-Resolution Text-To-3D Content Creation”, Lin et al 2022
“DINER: Disorder-Invariant Implicit Neural Representation”, Xie et al 2022
“How Much Does Attention Actually Attend? Questioning the Importance of Attention in Pretrained Transformers”, Hassid et al 2022
“Compressing Multidimensional Weather and Climate Data into Neural Networks”, Huang & Hoefler 2022
Compressing multidimensional weather and climate data into neural networks
“Deep Differentiable Logic Gate Networks”, Petersen et al 2022
“The Lazy Neuron Phenomenon: On Emergence of Activation Sparsity in Transformers”, Li et al 2022
The Lazy Neuron Phenomenon: On Emergence of Activation Sparsity in Transformers
“Neural Networks Are Decision Trees”, Aytekin 2022
“The Unreasonable Effectiveness of Fully-Connected Layers for Low-Data Regimes”, Kocsis et al 2022
The Unreasonable Effectiveness of Fully-Connected Layers for Low-Data Regimes
“Scaling Forward Gradient With Local Losses”, Ren et al 2022
“The Lie Derivative for Measuring Learned Equivariance”, Gruver et al 2022
“Omnigrok: Grokking Beyond Algorithmic Data”, Liu et al 2022
“DreamFusion: Text-To-3D Using 2D Diffusion”, Poole et al 2022
“g.pt: Learning to Learn With Generative Models of Neural Network Checkpoints”, Peebles et al 2022
g.pt: Learning to Learn with Generative Models of Neural Network Checkpoints
“Random Initializations Performing above Chance and How to Find Them”, Benzing et al 2022
Random initializations performing above chance and how to find them
“Scaling Laws vs Model Architectures: How Does Inductive Bias Influence Scaling?”, Tay et al 2022
Scaling Laws vs Model Architectures: How does Inductive Bias Influence Scaling?
“Why Do Tree-Based Models Still Outperform Deep Learning on Tabular Data?”, Grinsztajn et al 2022
Why do tree-based models still outperform deep learning on tabular data?
“Revisiting Pretraining Objectives for Tabular Deep Learning”, Rubachev et al 2022
“RHO-LOSS: Prioritized Training on Points That Are Learnable, Worth Learning, and Not Yet Learnt”, Mindermann et al 2022
RHO-LOSS: Prioritized Training on Points that are Learnable, Worth Learning, and Not Yet Learnt
“MLP-3D: A MLP-Like 3D Architecture With Grouped Time Mixing”, Qiu et al 2022
“ChordMixer: A Scalable Neural Attention Model for Sequences With Different Lengths”, Khalitov et al 2022
ChordMixer: A Scalable Neural Attention Model for Sequences with Different Lengths
“Sparse Mixers: Combining MoE and Mixing to Build a More Efficient BERT”, Lee-Thorp & Ainslie 2022
Sparse Mixers: Combining MoE and Mixing to build a more efficient BERT
“Towards Understanding Grokking: An Effective Theory of Representation Learning”, Liu et al 2022
Towards Understanding Grokking: An Effective Theory of Representation Learning
“Paramixer: Parameterizing Mixing Links in Sparse Factors Works Better Than Dot-Product Self-Attention”, Yu et al 2022
“Deep Learning Meets Nonparametric Regression: Are Weight-Decayed DNNs Locally Adaptive?”, Zhang & Wang 2022
Deep Learning meets Nonparametric Regression: Are Weight-Decayed DNNs Locally Adaptive?
“Efficient Language Modeling With Sparse All-MLP”, Yu et al 2022
“HyperMixer: An MLP-Based Low Cost Alternative to Transformers”, Mai et al 2022
HyperMixer: An MLP-based Low Cost Alternative to Transformers
“MLP-ASR: Sequence-Length Agnostic All-MLP Architectures for Speech Recognition”, Sakuma et al 2022
MLP-ASR: Sequence-length agnostic all-MLP architectures for speech recognition
“Mixing and Shifting: Exploiting Global and Local Dependencies in Vision MLPs”, Zheng et al 2022
Mixing and Shifting: Exploiting Global and Local Dependencies in Vision MLPs
“PNLP-Mixer: an Efficient All-MLP Architecture for Language”, Fusco et al 2022
“Data-Driven Emergence of Convolutional Structure in Neural Networks”, Ingrosso & Goldt 2022
Data-driven emergence of convolutional structure in neural networks
“When Shift Operation Meets Vision Transformer: An Extremely Simple Alternative to Attention Mechanism (ShiftViT)”, Wang et al 2022
“ConvMixer: Patches Are All You Need?”, Trockman & Kolter 2022
“MAXIM: Multi-Axis MLP for Image Processing”, Tu et al 2022
“Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets [Paper]”, Power et al 2022
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets [paper]
“The GatedTabTransformer: An Enhanced Deep Learning Architecture for Tabular Modeling”, Cholakov & Kolev 2022
The GatedTabTransformer: An enhanced deep learning architecture for tabular modeling
“MLP Architectures for Vision-And-Language Modeling: An Empirical Study”, Nie et al 2021
MLP Architectures for Vision-and-Language Modeling: An Empirical Study
“Noether Networks: Meta-Learning Useful Conserved Quantities”, Alet et al 2021
“Residual Pathway Priors for Soft Equivariance Constraints”, Finzi et al 2021
“Zero-Shot Text-Guided Object Generation With Dream Fields”, Jain et al 2021
“MorphMLP: A Self-Attention Free, MLP-Like Backbone for Image and Video”, Zhang et al 2021
MorphMLP: A Self-Attention Free, MLP-Like Backbone for Image and Video
“PointMixer: MLP-Mixer for Point Cloud Understanding”, Choe et al 2021
“MetaFormer Is Actually What You Need for Vision”, Yu et al 2021
“Deep Learning without Shortcuts: Shaping the Kernel With Tailored Rectifiers”, Zhang et al 2021
Deep Learning without Shortcuts: Shaping the Kernel with Tailored Rectifiers
“ZerO Initialization: Initializing Residual Networks With Only Zeros and Ones”, Zhao et al 2021
ZerO Initialization: Initializing Residual Networks with only Zeros and Ones
“Wide Neural Networks Forget Less Catastrophically”, Mirzadeh et al 2021
“ADOP: Approximate Differentiable One-Pixel Point Rendering”, Rückert et al 2021
“Rapid Training of Deep Neural Networks without Skip Connections or Normalization Layers Using Deep Kernel Shaping”, Martens et al 2021
“Exploring the Limits of Large Scale Pre-Training”, Abnar et al 2021
“Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?”, Tang et al 2021
Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?
“AFT: An Attention Free Transformer”, Zhai et al 2021
“ConvMLP: Hierarchical Convolutional MLPs for Vision”, Li et al 2021
“Sparse-MLP: A Fully-MLP Architecture With Conditional Computation”, Lou et al 2021
Sparse-MLP: A Fully-MLP Architecture with Conditional Computation
“Implicit Behavioral Cloning”, Florence et al 2021
“A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP”, Zhao et al 2021
A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP
“Hire-MLP: Vision MLP via Hierarchical Rearrangement”, Guo et al 2021
“RaftMLP: How Much Can Be Done Without Attention and With Less Spatial Locality?”, Tatsunami & Taki 2021
RaftMLP: How Much Can Be Done Without Attention and with Less Spatial Locality?
“S2-MLPv2: Improved Spatial-Shift MLP Architecture for Vision”, Yu et al 2021
S2-MLPv2: Improved Spatial-Shift MLP Architecture for Vision
“CycleMLP: A MLP-Like Architecture for Dense Prediction”, Chen et al 2021
“AS-MLP: An Axial Shifted MLP Architecture for Vision”, Lian et al 2021
“Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition”, Hou et al 2021
Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition
“Real-Time Neural Radiance Caching for Path Tracing”, Müller et al 2021
“Towards Biologically Plausible Convolutional Networks”, Pogodin et al 2021
“Well-Tuned Simple Nets Excel on Tabular Datasets”, Kadra et al 2021
“MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis”, Tae et al 2021
MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis
“PairConnect: A Compute-Efficient MLP Alternative to Attention”, Xu et al 2021
PairConnect: A Compute-Efficient MLP Alternative to Attention
“S2-MLP: Spatial-Shift MLP Architecture for Vision”, Yu et al 2021
“When Vision Transformers Outperform ResNets without Pre-Training or Strong Data Augmentations”, Chen et al 2021
When Vision Transformers Outperform ResNets without Pre-training or Strong Data Augmentations
“Container: Context Aggregation Network”, Gao et al 2021
“One4all User Representation for Recommender Systems in E-Commerce”, Shin et al 2021
One4all User Representation for Recommender Systems in E-commerce
“Pay Attention to MLPs”, Liu et al 2021
“FNet: Mixing Tokens With Fourier Transforms”, Lee-Thorp et al 2021
“ResMLP: Feedforward Networks for Image Classification With Data-Efficient Training”, Touvron et al 2021
ResMLP: Feedforward networks for image classification with data-efficient training
“Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet”, Melas-Kyriazi 2021
Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet
“Multi-Scale Inference of Genetic Trait Architecture Using Biologically Annotated Neural Networks”, Demetci et al 2021
Multi-scale Inference of Genetic Trait Architecture using Biologically Annotated Neural Networks
“RepMLP: Re-Parameterizing Convolutions into Fully-Connected Layers for Image Recognition”, Ding et al 2021
RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition
“MLP-Mixer: An All-MLP Architecture for Vision”, Tolstikhin et al 2021
“Grokking: Generalization Beyond Overfitting On Small Algorithmic Datasets”, Power et al 2021
Grokking: Generalization Beyond Overfitting On Small Algorithmic Datasets
“Sifting out the Features by Pruning: Are Convolutional Networks the Winning Lottery Ticket of Fully Connected Ones?”, Pellegrini & Biroli 2021
“Fully-Connected Neural Nets”, Gwern 2021
“Revisiting Simple Neural Probabilistic Language Models”, Sun & Iyyer 2021
“KiloNeRF: Speeding up Neural Radiance Fields With Thousands of Tiny MLPs”, Reiser et al 2021
KiloNeRF: Speeding up Neural Radiance Fields with Thousands of Tiny MLPs
“Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows”, Liu et al 2021
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
“Attention Is Not All You Need: Pure Attention Loses Rank Doubly Exponentially With Depth”, Dong et al 2021
Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth
“Clusterability in Neural Networks”, Filan et al 2021
“Training Larger Networks for Deep Reinforcement Learning”, Ota et al 2021
“Explaining Neural Scaling Laws”, Bahri et al 2021
“Neural Geometric Level of Detail: Real-Time Rendering With Implicit 3D Shapes”, Takikawa et al 2021
Neural Geometric Level of Detail: Real-time Rendering with Implicit 3D Shapes
“Is MLP-Mixer a CNN in Disguise? As Part of This Blog Post, We Look at the MLP Mixer Architecture in Detail and Also Understand Why It Is Not Considered Convolution Free.”
“Transformer Feed-Forward Layers Are Key-Value Memories”, Pipek et al 2020
“AdnFM: An Attentive DenseNet Based Factorization Machine for CTR Prediction”, Wang et al 2020
AdnFM: An Attentive DenseNet based Factorization Machine for CTR Prediction
“TabTransformer: Tabular Data Modeling Using Contextual Embeddings”, Huang et al 2020
TabTransformer: Tabular Data Modeling Using Contextual Embeddings
“Scaling down Deep Learning”, Greydanus 2020
“Image Generators With Conditionally-Independent Pixel Synthesis”, Anokhin et al 2020
Image Generators with Conditionally-Independent Pixel Synthesis
“D2RL: Deep Dense Architectures in Reinforcement Learning”, Sinha et al 2020
“Fourier Neural Operator for Parametric Partial Differential Equations”, Li et al 2020
Fourier Neural Operator for Parametric Partial Differential Equations
“Intelligent Matrix Exponentiation”, Fischbacher et al 2020
“Towards Learning Convolutions from Scratch”, Neyshabur 2020
“Hyperparameter Ensembles for Robustness and Uncertainty Quantification”, Wenzel et al 2020
Hyperparameter Ensembles for Robustness and Uncertainty Quantification
“Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains”, Tancik et al 2020
Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains
“SIREN: Implicit Neural Representations With Periodic Activation Functions”, Sitzmann et al 2020
SIREN: Implicit Neural Representations with Periodic Activation Functions
“Linformer: Self-Attention With Linear Complexity”, Wang et al 2020
“A Map of Object Space in Primate Inferotemporal Cortex”, Bao et al 2020
“Synthesizer: Rethinking Self-Attention in Transformer Models”, Tay et al 2020
Synthesizer: Rethinking Self-Attention in Transformer Models
“Deep Learning Training in Facebook Data Centers: Design of Scale-Up and Scale-Out Systems”, Naumov et al 2020
Deep Learning Training in Facebook Data Centers: Design of Scale-up and Scale-out Systems
“NeRF: Representing Scenes As Neural Radiance Fields for View Synthesis”, Mildenhall et al 2020
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
“Cryptanalytic Extraction of Neural Network Models”, Carlini et al 2020
“ReZero Is All You Need: Fast Convergence at Large Depth”, Bachlechner et al 2020
“Train-By-Reconnect: Decoupling Locations of Weights from Their Values (LaPerm)”, Qiu & Suda 2020
Train-by-Reconnect: Decoupling Locations of Weights from their Values (LaPerm)
“Can Increasing Input Dimensionality Improve Deep Reinforcement Learning?”, Ota et al 2020
Can Increasing Input Dimensionality Improve Deep Reinforcement Learning?
“Quasi-Equivalence of Width and Depth of Neural Networks”, Fan et al 2020
“Gesticulator: A Framework for Semantically-Aware Speech-Driven Gesture Generation”, Kucherenko et al 2020
Gesticulator: A framework for semantically-aware speech-driven gesture generation
“What’s Hidden in a Randomly Weighted Neural Network?”, Ramanujan et al 2019
“Understanding the Generalization of ‘Lottery Tickets’ in Neural Networks”, Morcos & Tian 2019
Understanding the generalization of ‘lottery tickets’ in neural networks
“The Bouncer Problem: Challenges to Remote Explainability”, Merrer & Tredan 2019
“3D Human Pose Estimation via Human Structure-Aware Fully Connected Network”, Zhang et al 2019d
3D human pose estimation via human structure-aware fully connected network
“Finding the Needle in the Haystack With Convolutions: on the Benefits of Architectural Bias”, d’Ascoli et al 2019
Finding the Needle in the Haystack with Convolutions: on the benefits of architectural bias
“Generalization Guarantees for Neural Networks via Harnessing the Low-Rank Structure of the Jacobian”, Oymak et al 2019
Generalization Guarantees for Neural Networks via Harnessing the Low-rank Structure of the Jacobian
“Implicit Regularization in Deep Matrix Factorization”, Arora et al 2019
“MoGlow: Probabilistic and Controllable Motion Synthesis Using Normalizing Flows”, Henter et al 2019
MoGlow: Probabilistic and controllable motion synthesis using normalizing flows
“Fixup Initialization: Residual Learning Without Normalization”, Zhang et al 2019
Fixup Initialization: Residual Learning Without Normalization
“SwitchNet: a Neural Network Model for Forward and Inverse Scattering Problems”, Khoo & Ying 2018
SwitchNet: a neural network model for forward and inverse scattering problems
“A Jamming Transition from Under-Parameterization to Over-Parameterization Affects Loss Landscape and Generalization”, Spigler et al 2018
“Neural Arithmetic Logic Units”, Trask et al 2018
“The Goldilocks Zone: Towards Better Understanding of Neural Network Loss Landscapes”, Fort & Scherlis 2018
The Goldilocks zone: Towards better understanding of neural network loss landscapes
“Scalable Training of Artificial Neural Networks With Adaptive Sparse Connectivity Inspired by Network Science”, Mocanu et al 2018
“Deep Learning Generalizes Because the Parameter-Function Map Is Biased towards Simple Functions”, Valle-Pérez et al 2018
Deep learning generalizes because the parameter-function map is biased towards simple functions
“Bidirectional Learning for Robust Neural Networks”, Pontes-Filho & Liwicki 2018
“NAIS-Net: Stable Deep Networks from Non-Autonomous Differential Equations”, Ciccone et al 2018
NAIS-Net: Stable Deep Networks from Non-Autonomous Differential Equations
“Large Scale Distributed Neural Network Training through Online Distillation”, Anil et al 2018
Large scale distributed neural network training through online distillation
“Meta-Learning Update Rules for Unsupervised Representation Learning”, Metz et al 2018
Meta-Learning Update Rules for Unsupervised Representation Learning
“Learning and Memorization”, Chatterjee 2018
“Repurposing High-Throughput Image Assays Enables Biological Activity Prediction for Drug Discovery”, Simm et al 2018
Repurposing High-Throughput Image Assays Enables Biological Activity Prediction for Drug Discovery
“Improving Palliative Care With Deep Learning”, An et al 2018
“Learning to Play Chess With Minimal Lookahead and Deep Value Neural Networks”, Sabatelli 2017 (page 3)
Learning to Play Chess with Minimal Lookahead and Deep Value Neural Networks
“Neural Collaborative Filtering”, He et al 2017
“Sharp Models on Dull Hardware: Fast and Accurate Neural Machine Translation Decoding on the CPU”, Devlin 2017
Sharp Models on Dull Hardware: Fast and Accurate Neural Machine Translation Decoding on the CPU
“The Shattered Gradients Problem: If Resnets Are the Answer, Then What Is the Question?”, Balduzzi et al 2017
The Shattered Gradients Problem: If resnets are the answer, then what is the question?
“Gender-From-Iris or Gender-From-Mascara?”, Kuehlkamp et al 2017
“Skip Connections Eliminate Singularities”, Orhan & Pitkow 2017
“Deep Information Propagation”, Schoenholz et al 2016
“Topology and Geometry of Half-Rectified Network Optimization”, Freeman & Bruna 2016
Topology and Geometry of Half-Rectified Network Optimization
“On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima”, Keskar et al 2016
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
“Decoupled Neural Interfaces Using Synthetic Gradients”, Jaderberg et al 2016
“Learning to Optimize”, Li & Malik 2016
“Do Deep Convolutional Nets Really Need to Be Deep and Convolutional?”, Urban et al 2016
Do Deep Convolutional Nets Really Need to be Deep and Convolutional?
“Network Morphism”, Wei et al 2016
“Adding Gradient Noise Improves Learning for Very Deep Networks”, Neelakantan et al 2015
Adding Gradient Noise Improves Learning for Very Deep Networks
“How Far Can We Go without Convolution: Improving Fully-Connected Networks”, Lin et al 2015
How far can we go without convolution: Improving fully-connected networks
“BinaryConnect: Training Deep Neural Networks With Binary Weights during Propagations”, Courbariaux et al 2015
BinaryConnect: Training Deep Neural Networks with binary weights during propagations
“Tensorizing Neural Networks”, Novikov et al 2015
“A Neural Attention Model for Abstractive Sentence Summarization”, Rush et al 2015
A Neural Attention Model for Abstractive Sentence Summarization
“Deep Neural Networks for Large Vocabulary Handwritten Text Recognition”, Bluche 2015
Deep Neural Networks for Large Vocabulary Handwritten Text Recognition
“In Search of the Real Inductive Bias: On the Role of Implicit Regularization in Deep Learning”, Neyshabur et al 2014
In Search of the Real Inductive Bias: On the Role of Implicit Regularization in Deep Learning
“The Loss Surfaces of Multilayer Networks”, Choromanska et al 2014
“On the Number of Linear Regions of Deep Neural Networks”, Montúfar et al 2014
“Do Deep Nets Really Need to Be Deep?”, Ba & Caruana 2013
“On the Number of Response Regions of Deep Feed Forward Networks With Piece-Wise Linear Activations”, Pascanu et al 2013
On the number of response regions of deep feed forward networks with piece-wise linear activations
“Network In Network”, Lin et al 2013
“Deep Big Multilayer Perceptrons for Digit Recognition”, Cireşan et al 2012
“Natural Language Processing (Almost) from Scratch”, Collobert et al 2011
“Deep Big Simple Neural Nets Excel on Handwritten Digit Recognition”, Ciresan et al 2010
Deep Big Simple Neural Nets Excel on Handwritten Digit Recognition
“Compositional Pattern Producing Networks: A Novel Abstraction of Development”, Stanley 2007
Compositional pattern producing networks: A novel abstraction of development
“Extraction De Séquences Numériques Dans Des Documents Manuscrits Quelconques”, Chatelain 2006
Extraction de séquences numériques dans des documents manuscrits quelconques
“Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis”, Simard et al 2003
Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis
“NEAT: Evolving Neural Networks through Augmenting Topologies”, Stanley & Miikkulainen 2002
NEAT: Evolving Neural Networks through Augmenting Topologies
“DARPA and the Quest for Machine Intelligence, 1983–1993”, Roland & Shiman 2002
“Quantitative Analysis of Multivariate Data Using Artificial Neural Networks: A Tutorial Review and Applications to the Deconvolution of Pyrolysis Mass Spectra”, Goodacre et al 1996
“Statistical Mechanics of Generalization”, Opper & Kinzel 1996
“On the Ability of the Optimal Perceptron to Generalize”, Opper et al 1990
“Learning To Tell Two Spirals Apart”, Lang & Witbrock 1988
“Learning Internal Representations by Error Propagation”, Rumelhart et al 1986
“Neural Networks and Physical Systems With Emergent Collective Computational Abilities”, Hopfield 1982
Neural networks and physical systems with emergent collective computational abilities
“Can You Reverse Engineer Our Neural Network? [Encoding MD5 into a MLP]”
Can you reverse engineer our neural network? [encoding MD5 into a MLP]
“Technion-Cs-Nlp/llm-Arithmetic-Heuristics”
“Research Log: Monet/PEER Sparse Experts”
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
user-representation
machine-intelligence
human-pose
gender-prediction
neural-architecture neural-library fully-connected nets-ml latex-framework pure-latex neural-framework
language-generation
nominative-determinism
predictive-modeling
evaluation
loss-landscape
Wikipedia (2)
Miscellaneous
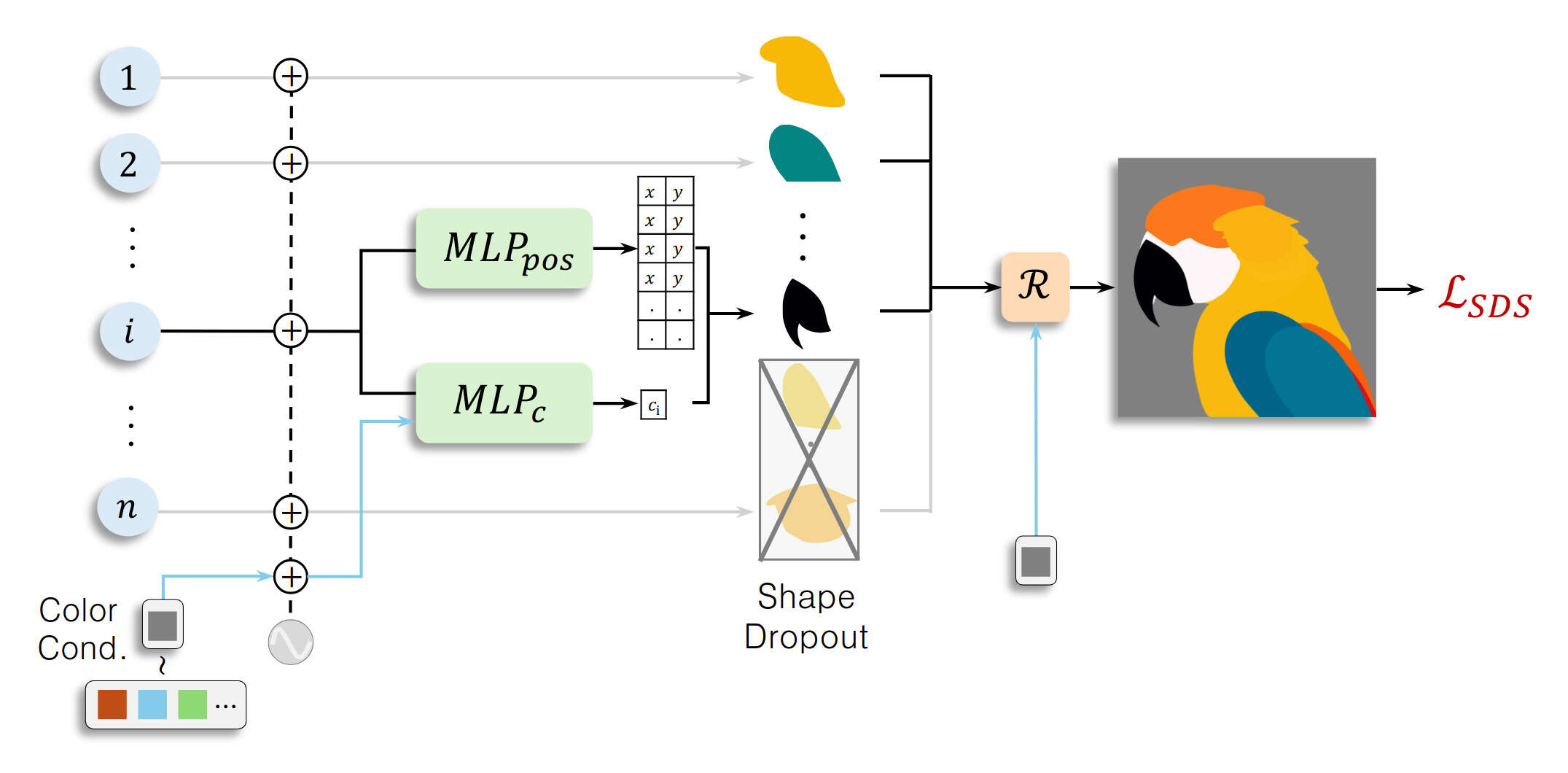
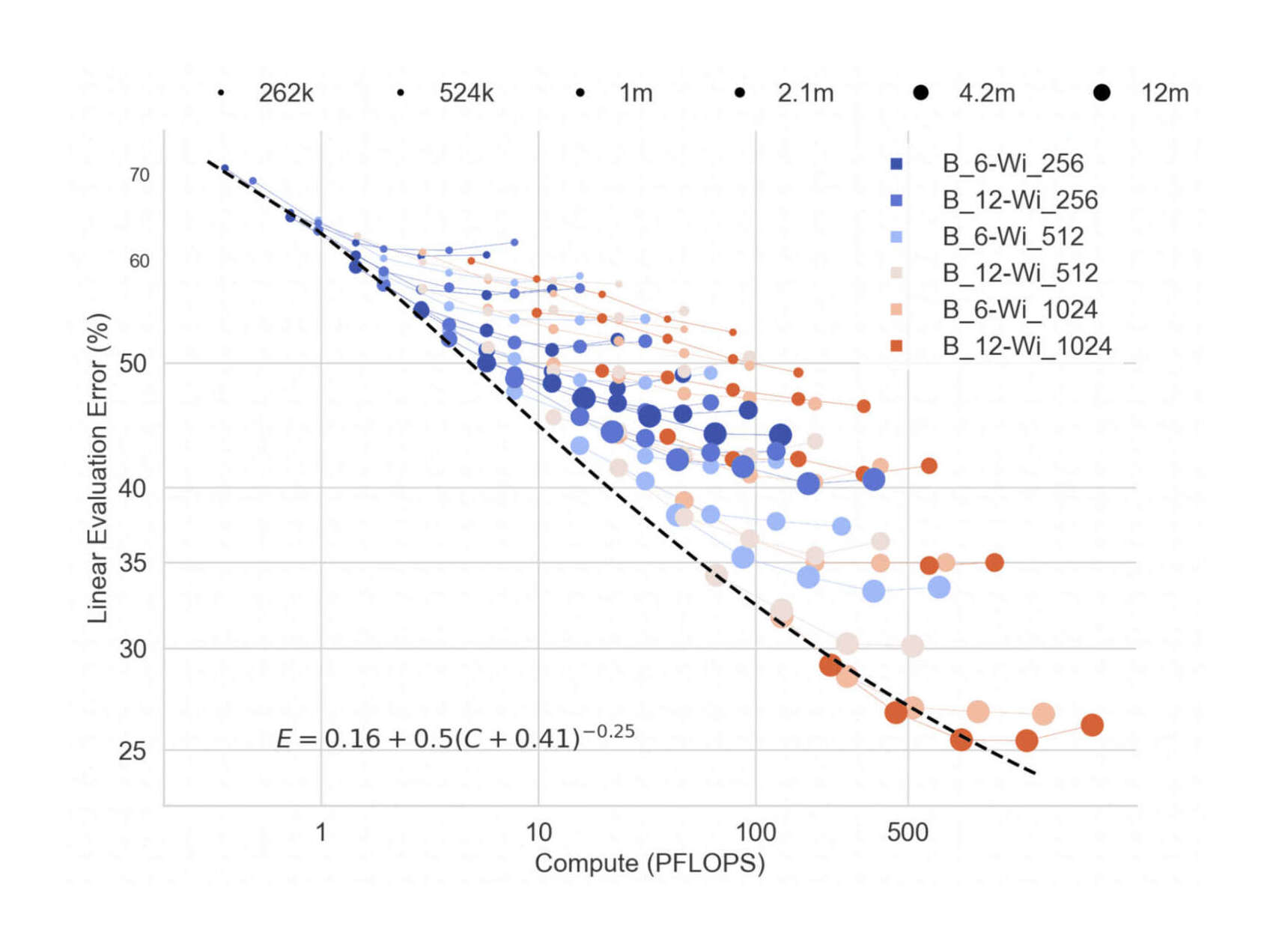
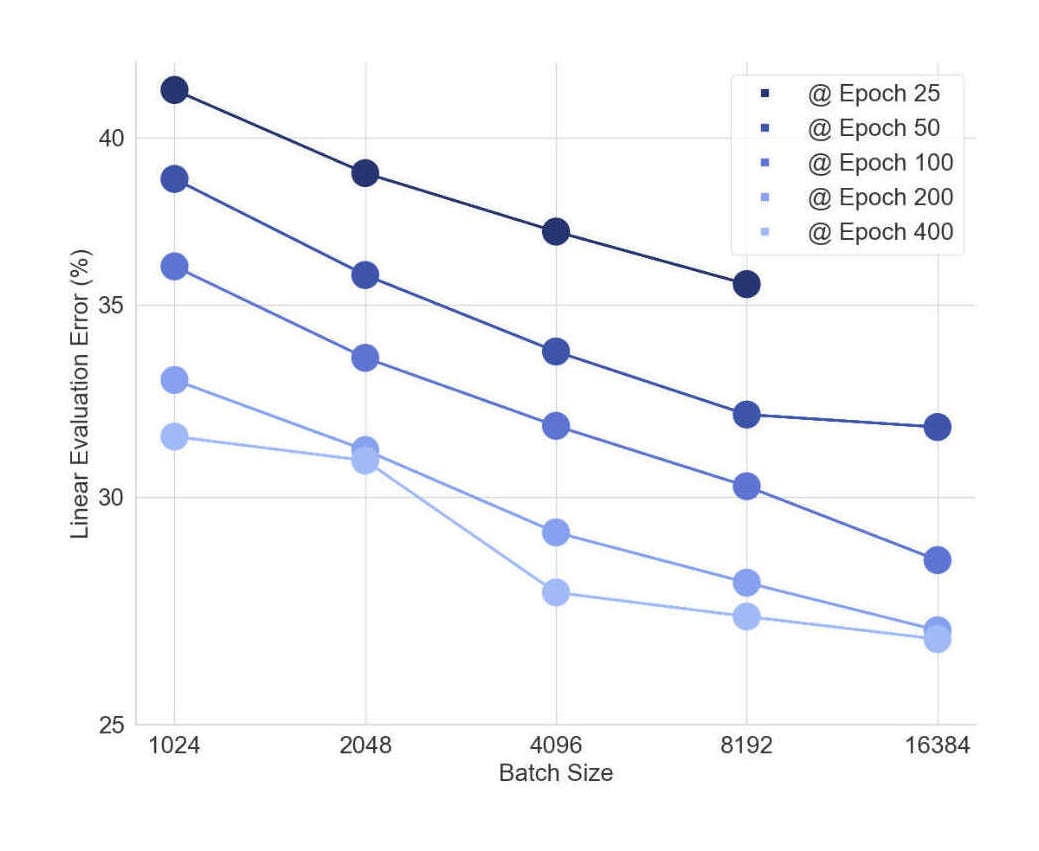
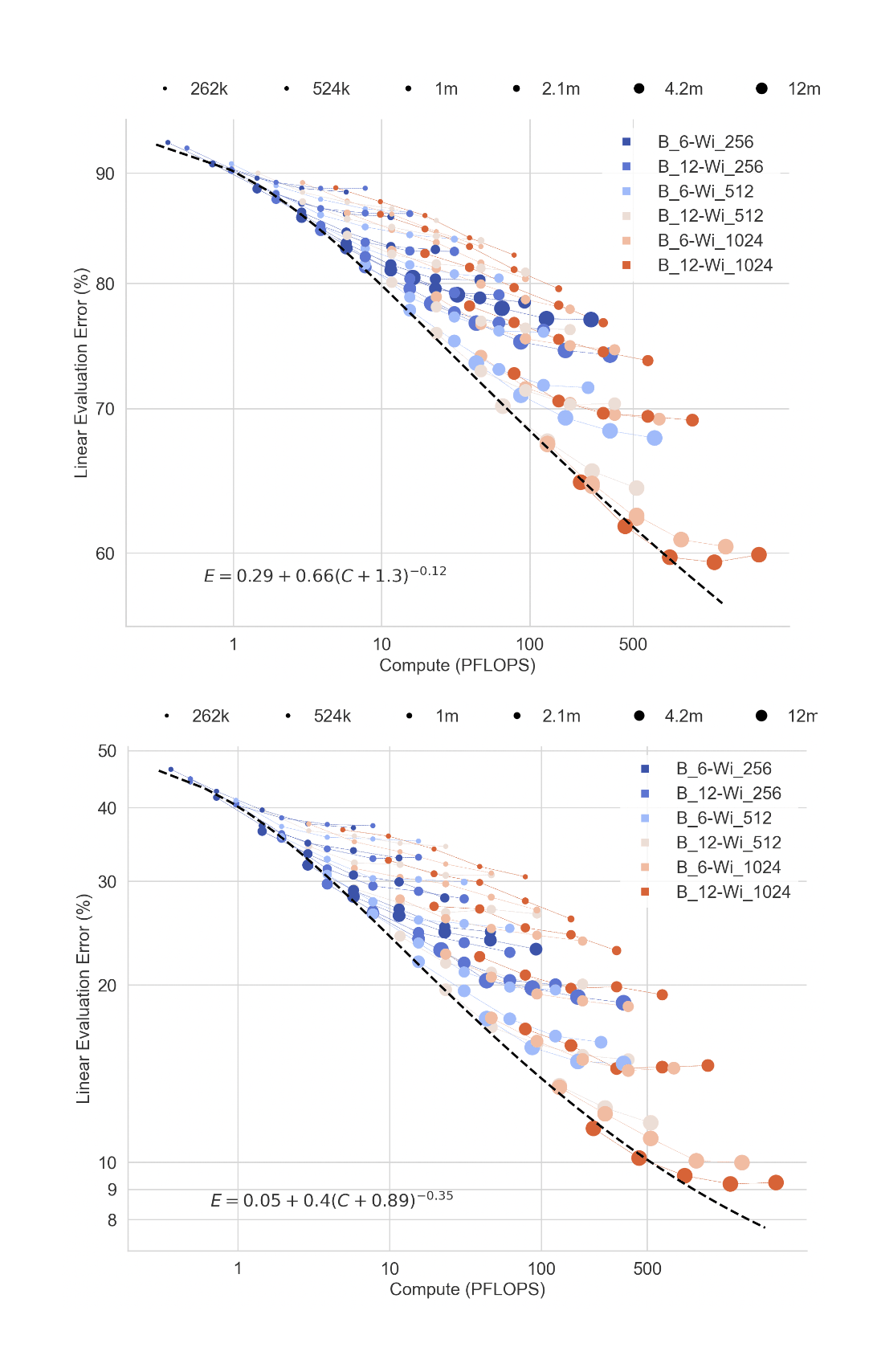
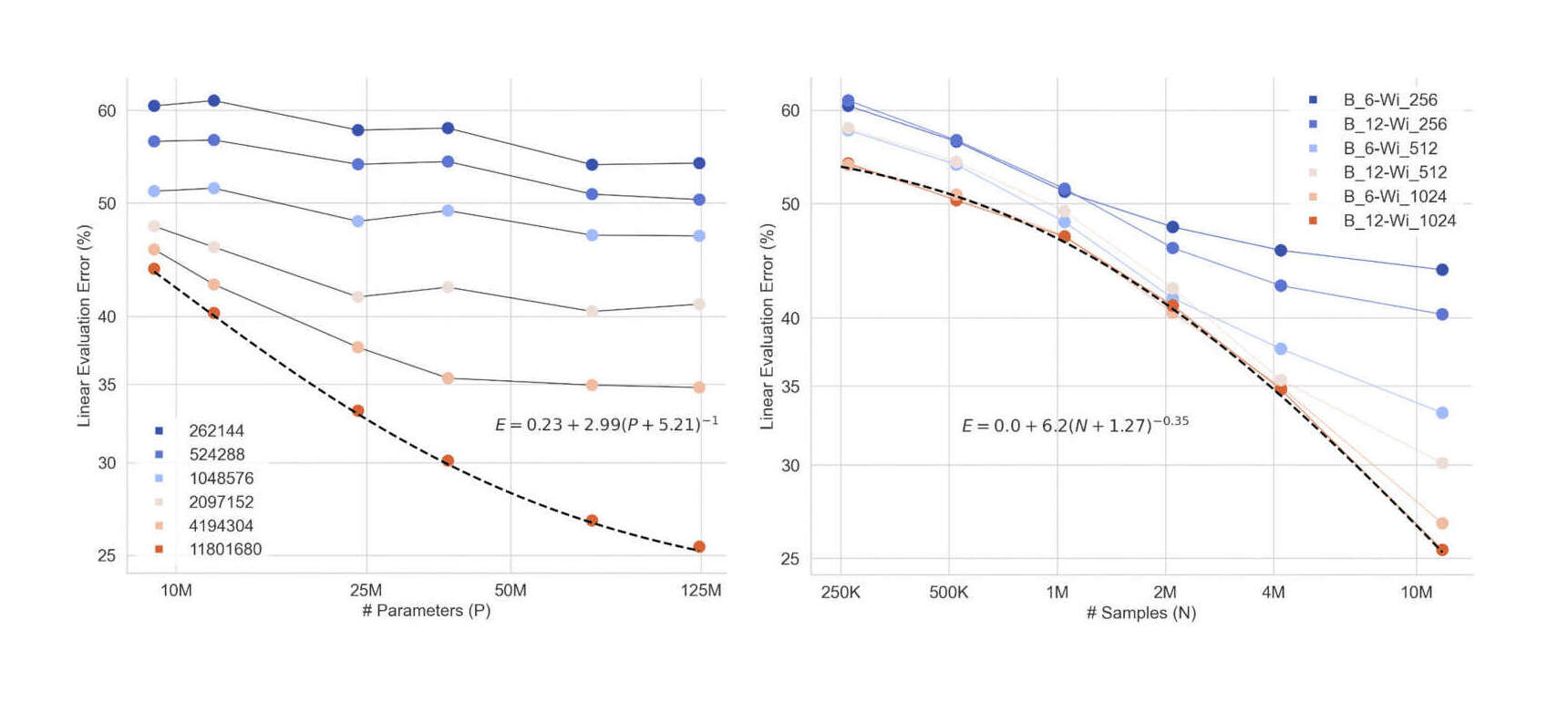
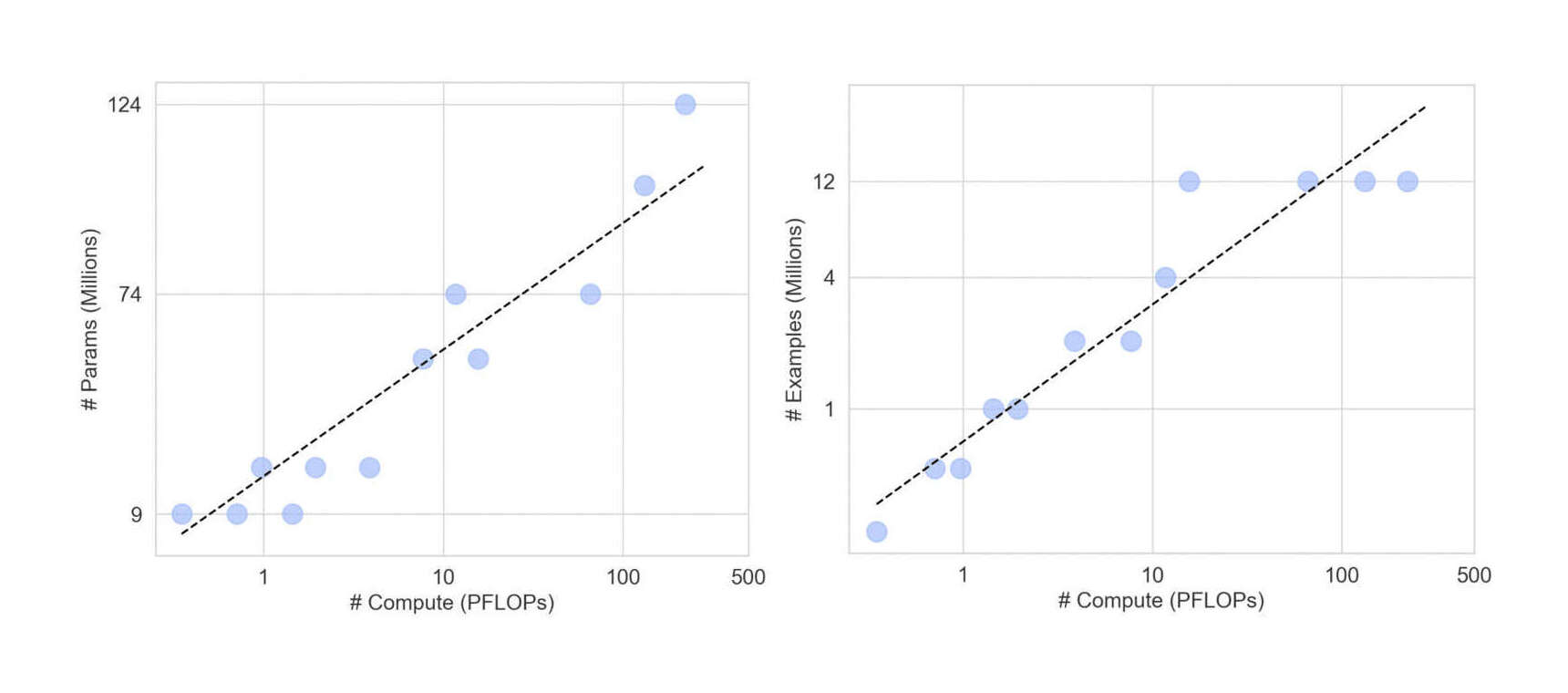
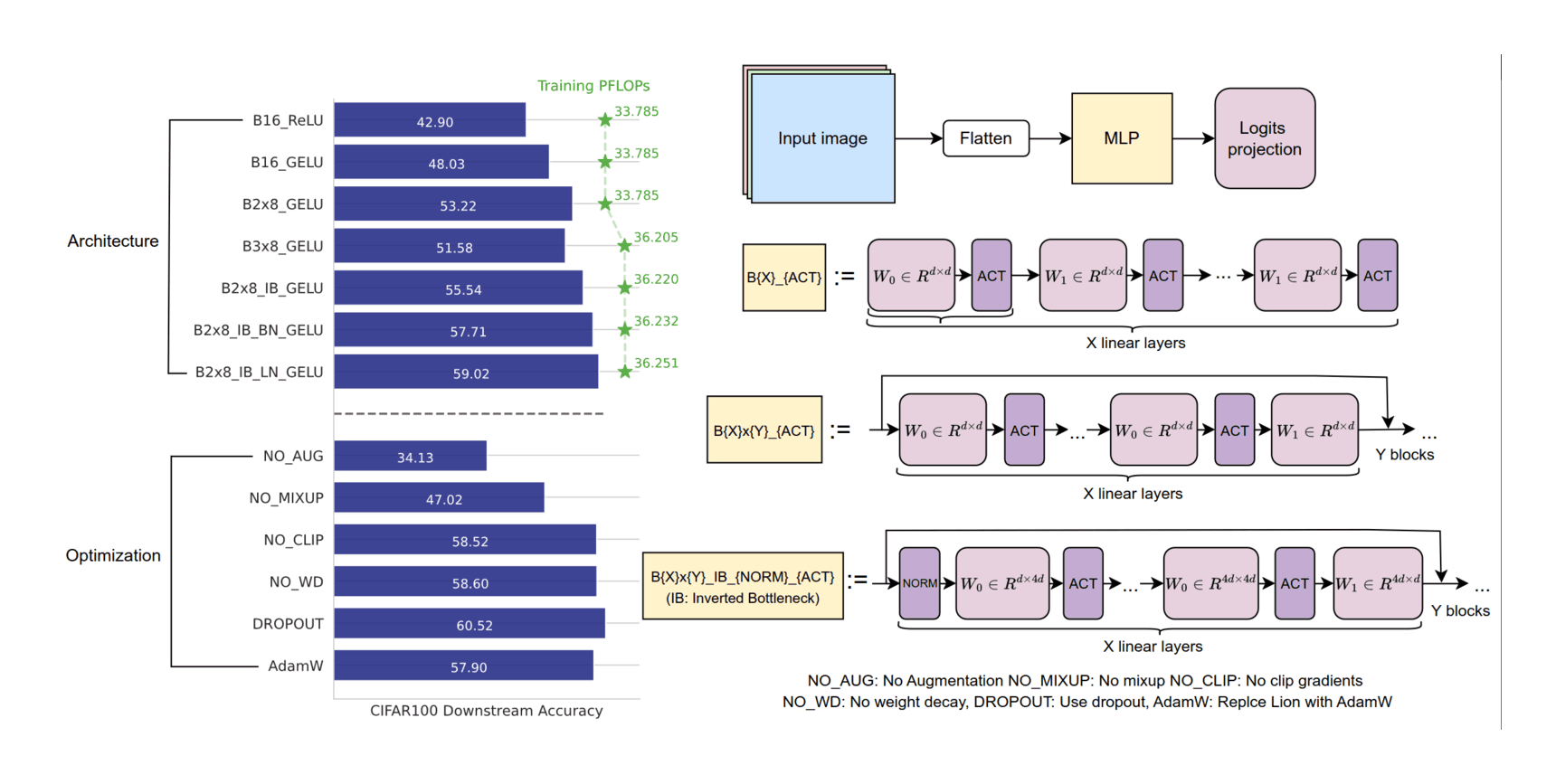
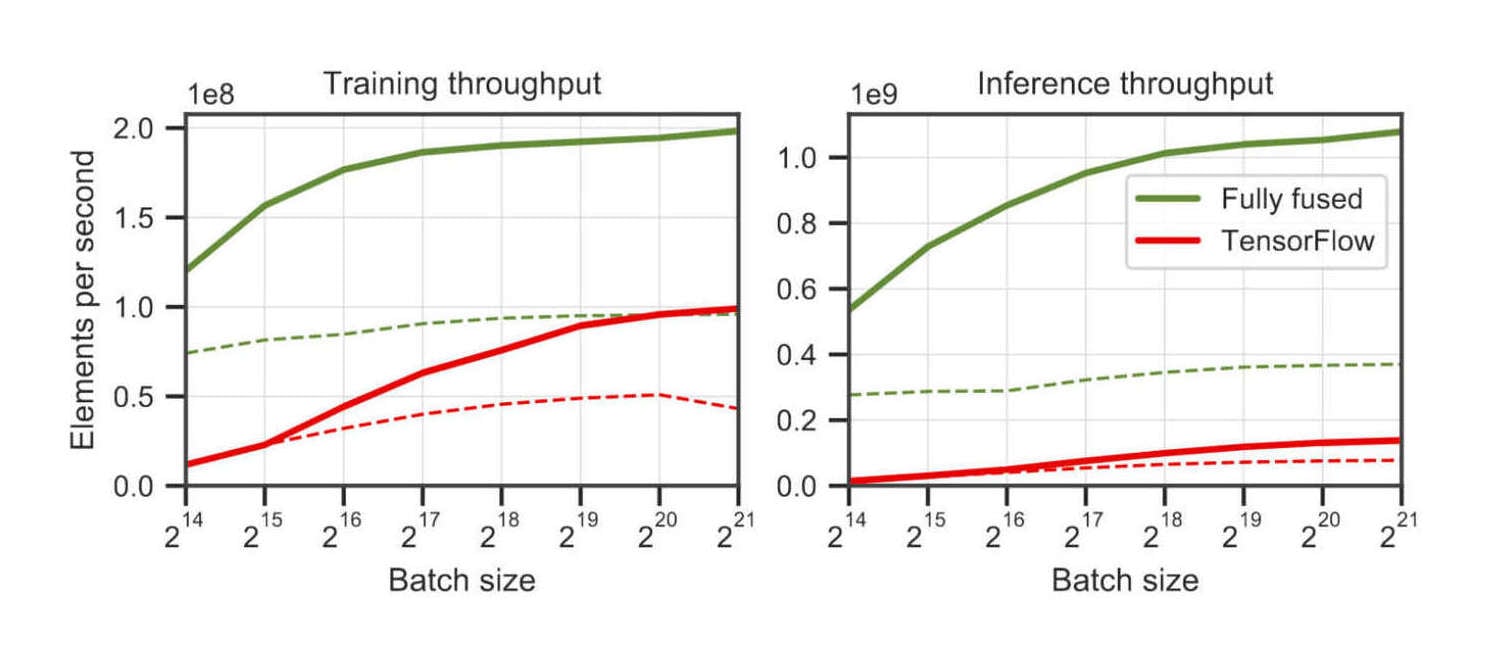
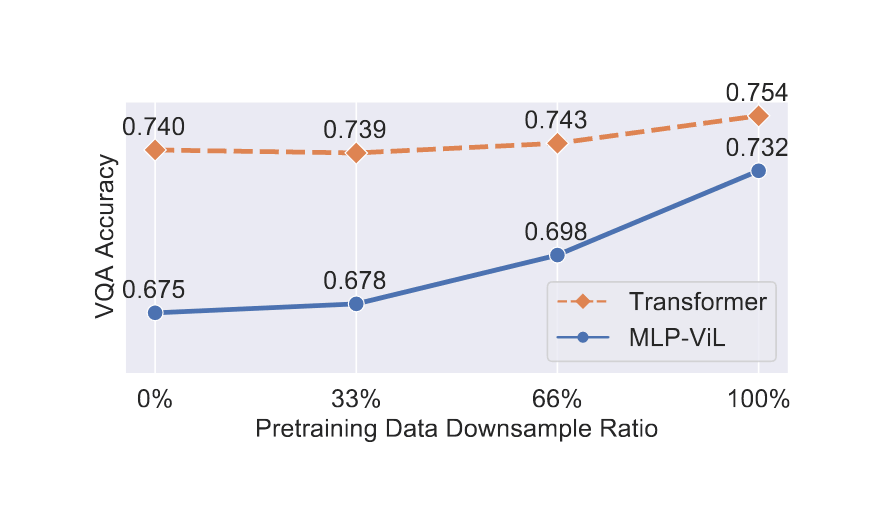
/doc/ai/nn/fully-connected/2025-04-07-gwern-ifnn-architecture.svg/doc/ai/nn/fully-connected/2023-08-17-gwern-aunn-architecture.png/doc/ai/nn/fully-connected/2023-08-17-gwern-aunn-architecture.svg/doc/ai/nn/fully-connected/2023-bachmann-figure1-mlpcomputescalingoncifar100.jpg/doc/ai/nn/fully-connected/2023-bachmann-figure4-mlpsscalewellwithincreasingbatchsize.jpg/doc/ai/nn/fully-connected/2023-bachmann-figure5-scalingofmlpsoncifar10andimagenet1k.png/doc/ai/nn/fully-connected/2023-bachmann-figure7-suprachinchilladatascalingformlpsoncifar100loss.jpg/doc/ai/nn/fully-connected/2023-bachmann-figure8-mlparchitectureablations.png/doc/ai/nn/fully-connected/2021-muller-figure7-fullyfusedfullyconnectednetworkspeedupongpu.jpg/doc/ai/nn/fully-connected/2021-ni-figure2-vilmlpvstransformerbypretrainingdatafraction.png/doc/ai/nn/fully-connected/2021-power-figure1-grokkinglearningcurves.jpg/doc/ai/nn/fully-connected/2020-ota-figure1-densenetmlpschematicarchitecture.jpg/doc/ai/nn/fully-connected/2020-ota-figure2-overallofenetarchitectureshematic.pnghttps://colab.research.google.com/github/murphyka/ml_colabs/blob/main/Simple_MLP_Visualization.ipynbhttps://cprimozic.net/blog/reverse-engineering-a-small-neural-network/https://transformer-circuits.pub/2024/jan-update/index.html#mnist-sparsehttps://www.lesswrong.com/s/5omSW4wNKbEvYsyje/p/GpSzShaaf8po4rcmAView External Link:
https://www.lesswrong.com/s/5omSW4wNKbEvYsyje/p/GpSzShaaf8po4rcmA
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2503.24187: “NeuRaLaTeX: A Machine Learning Library Written in Pure LaTeX”,https://arxiv.org/abs/2501.03992: “NeuralSVG: An Implicit Representation for Text-To-Vector Generation”,https://www.lesswrong.com/posts/LncYobrn3vRr7qkZW/the-slingshot-helps-with-learning: “The Slingshot Helps With Learning”,https://arxiv.org/abs/2406.15786: “What Matters in Transformers? Not All Attention Is Needed”,https://arxiv.org/abs/2406.13131: “When Parts Are Greater Than Sums: Individual LLM Components Can Outperform Full Models”,https://arxiv.org/abs/2406.11233: “Probing the Decision Boundaries of In-Context Learning in Large Language Models”,https://arxiv.org/abs/2405.20233: “Grokfast: Accelerated Grokking by Amplifying Slow Gradients”,https://arxiv.org/abs/2310.13061: “To Grok or Not to Grok: Disentangling Generalization and Memorization on Corrupted Algorithmic Datasets”,https://arxiv.org/abs/2310.08708: “Polynomial Time Cryptanalytic Extraction of Neural Network Models”,https://arxiv.org/abs/2306.13575: “Scaling MLPs: A Tale of Inductive Bias”,https://arxiv.org/abs/2303.13506: “The Quantization Model of Neural Scaling”,https://arxiv.org/abs/2303.06053#google: “TSMixer: An All-MLP Architecture for Time Series Forecasting”,2023-bures.pdf: “Organic Reaction Mechanism Classification Using Machine Learning”,https://www.nature.com/articles/s41467-022-35422-y: “Merging Enzymatic and Synthetic Chemistry With Computational Synthesis Planning”,https://arxiv.org/abs/2211.03495: “How Much Does Attention Actually Attend? Questioning the Importance of Attention in Pretrained Transformers”,https://arxiv.org/abs/2210.06313#google: “The Lazy Neuron Phenomenon: On Emergence of Activation Sparsity in Transformers”,https://arxiv.org/abs/2210.03310#google: “Scaling Forward Gradient With Local Losses”,https://arxiv.org/abs/2210.01117: “Omnigrok: Grokking Beyond Algorithmic Data”,https://arxiv.org/abs/2209.12892: “g.pt: Learning to Learn With Generative Models of Neural Network Checkpoints”,https://arxiv.org/abs/2207.10551#google: “Scaling Laws vs Model Architectures: How Does Inductive Bias Influence Scaling?”,https://arxiv.org/abs/2206.07137: “RHO-LOSS: Prioritized Training on Points That Are Learnable, Worth Learning, and Not Yet Learnt”,https://arxiv.org/abs/2206.05852: “ChordMixer: A Scalable Neural Attention Model for Sequences With Different Lengths”,https://arxiv.org/abs/2205.12399#google: “Sparse Mixers: Combining MoE and Mixing to Build a More Efficient BERT”,https://arxiv.org/abs/2205.10343: “Towards Understanding Grokking: An Effective Theory of Representation Learning”,https://arxiv.org/abs/2204.10670: “Paramixer: Parameterizing Mixing Links in Sparse Factors Works Better Than Dot-Product Self-Attention”,https://arxiv.org/abs/2203.06850: “Efficient Language Modeling With Sparse All-MLP”,https://arxiv.org/abs/2203.03691: “HyperMixer: An MLP-Based Low Cost Alternative to Transformers”,https://arxiv.org/abs/2202.06510#microsoft: “Mixing and Shifting: Exploiting Global and Local Dependencies in Vision MLPs”,https://arxiv.org/abs/2201.10801: “When Shift Operation Meets Vision Transformer: An Extremely Simple Alternative to Attention Mechanism (ShiftViT)”,https://arxiv.org/abs/2201.09792: “ConvMixer: Patches Are All You Need?”,https://arxiv.org/abs/2111.11418: “MetaFormer Is Actually What You Need for Vision”,https://arxiv.org/abs/2110.11526#deepmind: “Wide Neural Networks Forget Less Catastrophically”,https://arxiv.org/abs/2110.02095#google: “Exploring the Limits of Large Scale Pre-Training”,https://arxiv.org/abs/2109.05422: “Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?”,https://arxiv.org/abs/2109.04454: “ConvMLP: Hierarchical Convolutional MLPs for Vision”,https://arxiv.org/abs/2108.13002#microsoft: “A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP”,https://arxiv.org/abs/2108.13341#huawei: “Hire-MLP: Vision MLP via Hierarchical Rearrangement”,https://arxiv.org/abs/2108.04384: “RaftMLP: How Much Can Be Done Without Attention and With Less Spatial Locality?”,https://arxiv.org/abs/2108.01072#baidu: “S2-MLPv2: Improved Spatial-Shift MLP Architecture for Vision”,https://arxiv.org/abs/2107.10224: “CycleMLP: A MLP-Like Architecture for Dense Prediction”,https://arxiv.org/abs/2107.08391: “AS-MLP: An Axial Shifted MLP Architecture for Vision”,https://arxiv.org/abs/2106.12368: “Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition”,https://arxiv.org/abs/2106.12372#nvidia: “Real-Time Neural Radiance Caching for Path Tracing”,https://arxiv.org/abs/2106.07477#baidu: “S2-MLP: Spatial-Shift MLP Architecture for Vision”,https://arxiv.org/abs/2106.01548: “When Vision Transformers Outperform ResNets without Pre-Training or Strong Data Augmentations”,https://arxiv.org/abs/2106.01401: “Container: Context Aggregation Network”,https://arxiv.org/abs/2105.08050#google: “Pay Attention to MLPs”,https://arxiv.org/abs/2105.03824#google: “FNet: Mixing Tokens With Fourier Transforms”,https://arxiv.org/abs/2105.02723: “Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet”,https://arxiv.org/abs/2105.01883: “RepMLP: Re-Parameterizing Convolutions into Fully-Connected Layers for Image Recognition”,https://arxiv.org/abs/2105.01601#google: “MLP-Mixer: An All-MLP Architecture for Vision”,2021-power.pdf#openai: “Grokking: Generalization Beyond Overfitting On Small Algorithmic Datasets”,abstract: “Fully-Connected Neural Nets”,https://arxiv.org/abs/2103.14030: “Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows”,https://arxiv.org/abs/2011.13775: “Image Generators With Conditionally-Independent Pixel Synthesis”,https://arxiv.org/abs/2005.00743#google: “Synthesizer: Rethinking Self-Attention in Transformer Models”,https://arxiv.org/abs/2003.01629: “Can Increasing Input Dimensionality Improve Deep Reinforcement Learning?”,https://arxiv.org/abs/1911.13299: “What’s Hidden in a Randomly Weighted Neural Network?”,https://arxiv.org/abs/1804.00222#google: “Meta-Learning Update Rules for Unsupervised Representation Learning”,2017-sabatelli.pdf#page=3: “Learning to Play Chess With Minimal Lookahead and Deep Value Neural Networks”,https://arxiv.org/abs/1402.1869: “On the Number of Linear Regions of Deep Neural Networks”,2011-collobert.pdf: “Natural Language Processing (Almost) from Scratch”,