Fully-Connected Neural Nets
Bibliography of ML papers related to multi-layer perceptrons (fully-connected neural nets), often showing surprising efficacy despite their reputation for being too general to be usable (representing a possible future Bitter Lesson).
“A Neural Probabilistic Language Model”, Bengio et al 200323ya; “Revisiting Simple Neural Probabilistic Language Models”, Sun & Iyyer 2021; “PairConnect: A Compute-Efficient MLP Alternative to Attention”, Xu et al 2021
“Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis”, Simard et al 2003
“Extraction de séquences numériques dans des documents manuscrits quelconques”, Chatelain 2006
“Deep big multilayer perceptrons for digit recognition”, Cireşan 2012
“NIN: Network In Network”, Lin et al 2013
“How far can we go without convolution: Improving fully-connected networks”, Lin et al 2015
“Deep Neural Networks for Large Vocabulary Handwritten Text Recognition”, Bluche 2015
“Tensorizing Neural Networks”, Novikov et al 2015
“Do Deep Convolutional Nets Really Need to be Deep and Convolutional?”, Urban et al 2016 (negative result, particularly on scaling—wrong, but why?); “The Deep Bootstrap Framework: Good Online Learners are Good Offline Generalizers”, Nakkiran et al 2020
“Sharp Models on Dull Hardware: Fast and Accurate Neural Machine Translation Decoding on the CPU”, Devlin 2017
Initialization enlightenment: “The Shattered Gradients Problem: If resnets are the answer, then what is the question?”, Balduzzi et al 2017 (see also “NFNets: High-performance large-scale image recognition without normalization”, Brock et al 2021; Fixup/T-Fixup; Deep Kernel Shaping; ZerO; RepMLPNet; Trockman et al 2022/Trockman & Kolter 2023; partial Dirac initializations in CNNs; Goldilocks zone)
“Skip Connections Eliminate Singularities”, Orhan & Pitkow 2017
“Dynamical Isometry and a Mean Field Theory of CNNs: How to Train 10,000-Layer Vanilla Convolutional Neural Networks”, Xiao et al 2018
“NAIS-Net: Stable Deep Networks from Non-Autonomous Differential Equations”, Ciccone et al 2018
“SwitchNet: a neural network model for forward and inverse scattering problems”, Khoo & Ying 2018
“Scalable training of artificial neural networks with adaptive sparse connectivity inspired by network science”, Mocanu et al 2018
“Finding the Needle in the Haystack with Convolutions: on the benefits of architectural bias”, d’Ascoli et al 2019
“ReZero is All You Need: Fast Convergence at Large Depth”, Bachlechner et al 2020
“β-LASSO: Towards Learning Convolutions from Scratch”, Neyshabur 2020; input-permutation invariance, Tang & 2021; “Sifting out the features by pruning: Are convolutional networks the winning lottery ticket of fully connected ones?”, Pellegrini & Biroli 2021; “Towards Biologically Plausible Convolutional Networks”, Pogodin et al 2021; “Adapting the Function Approximation Architecture in Online Reinforcement Learning”, Martin & Modayil 2021; “Data-driven emergence of convolutional structure in neural networks”, Ingrosso & Goldt 2022; “Noise Transforms Feed-Forward Networks into Sparse Coding Networks”, Anonymous et al 2022; “A Battle of Network Structures: An Empirical Study of CNN, Transformer, and MLP”, Zhao et al 2021; “Scaling MLPs: A Tale of Inductive Bias”, Bachmann et al 2023
“Gesticulator: A framework for semantically-aware speech-driven gesture generation”, Kucherenko et al 2020
“RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition”, Ding et al 2021
“Less is More: Pay Less Attention in Vision Transformers”, Pan et al 2021; “SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers”, Xie et al 2021
“Regularization is all you Need: Simple Neural Nets can Excel on Tabular Data”, Kadra et al 2021
“How Much Does Attention Actually Attend? Questioning the Importance of Attention in Pretrained Transformers”, Hassid et al 2022
“MLPs Learn In-Context”, Tong & Pehlevan 2024 (good MLP scaling for meta-learning vs Transformers)
MLP-Mixer1:
“MLP-Mixer: An all-MLP Architecture for Vision”, Tolstikhin et al 2021; “When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations”, Chen et al 2021; “MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis”, Tae et al 2021; “S2-MLP: Spatial-Shift MLP Architecture for Vision”, Yu et al 2021a/“S2-MLPv2: Improved Spatial-Shift MLP Architecture for Vision”, Yu et al 2021b; “When Shift Operation Meets Vision Transformer (ShiftViT): An Extremely Simple Alternative to Attention Mechanism”, Wang et al 2022
“Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet”, Melas-Kyriazi 2021
“ResMLP: Feedforward networks for image classification with data-efficient training”, Touvron et al 2021
“gMLP: Pay Attention to MLPs”, Liu et al 2021; “MLP-ASR: Sequence-length agnostic all-MLP architectures for speech recognition”, Sakuma et al 2022
“Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition”, Hou et al 2021
“Container: Context Aggregation Network”, Gao et al 2021
“CycleMLP: A MLP-like Architecture for Dense Prediction”, Chen et al 2021
“PointMixer: MLP-Mixer for Point Cloud Understanding”, Choe et al 2021
“RaftMLP: Do MLP-based Models Dream of Winning Over Computer Vision?”, Tatsunami & Taki 2021
“AS-MLP: An Axial Shifted MLP Architecture for Vision”, Lian et al 2021
“Hire-MLP: Vision MLP via Hierarchical Rearrangement”, Guo et al 2021
“Sparse-MLP: A Fully-MLP Architecture with Conditional Computation”, Lou et al 2021
“ConvMLP: Hierarchical Convolutional MLPs for Vision”, Li et al 2021
“Sparse MLP for Image Recognition (sMLPNet): Is Self-Attention Really Necessary?”, Tang et al 2021
“ConvMixer: Patches Are All You Need?”, Trockman & Kolter 2021
“Exploring the Limits of Large Scale Pre-training”, Abnar et al 2021
“MLP Architectures for Vision-and-Language Modeling (MLP-VIL): An Empirical Study”, Ni et al 2021; “pNLP-Mixer: an Efficient all-MLP Architecture for Language”, Fusco et al 2022; “Masked Mixers for Language Generation and Retrieval”, Badger 2024
“MorphMLP: A Self-Attention Free, MLP-Like Backbone for Image and Video”, Zhang et al 2021
“Mixing and Shifting (Mix-Shift-MLP / MS-MLP): Exploiting Global and Local Dependencies in Vision MLPs”, Zheng et al 2022
“Transformer” Variants (typically motivated by efficiency):
“AFT: An Attention Free Transformer”, Zhai et al 2021
“Synthesizer: Rethinking Self-Attention in Transformer Models”, Tay et al 2020 (ResMLP-like)
“Linformer: Self-Attention with Linear Complexity”, Wang et al 2020; “Luna: Linear Unified Nested Attention”, et al 2021; “Beyond Self-attention (EAMLP): External Attention using Two Linear Layers for Visual Tasks”, Guo et al 2021
“MetaFormer is Actually What You Need for Vision”, Yu et al 2021
Image Generation:
“MoGlow: Probabilistic and controllable motion synthesis using normalising flows”, Henter et al 2019
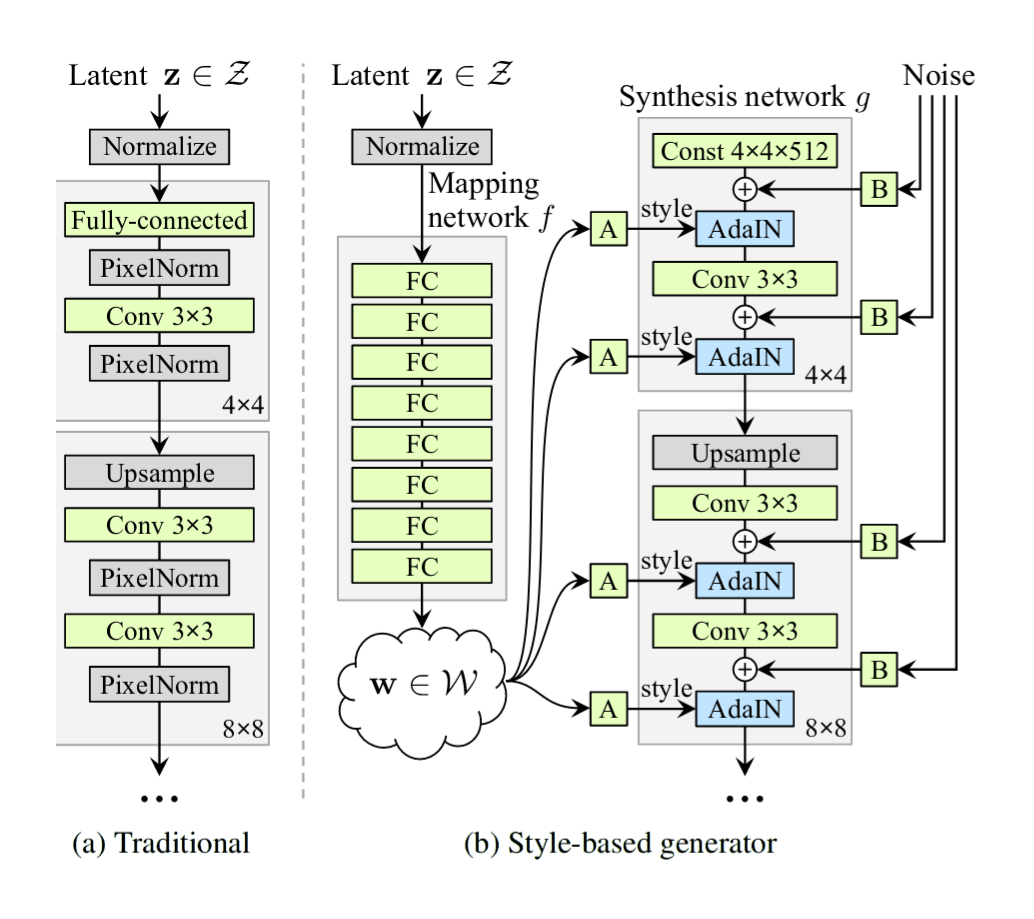
“StyleGAN: A Style-Based Generator Architecture for Generative Adversarial Networks”, Karras et al 2018 (architecture)
“Image Generators with Conditionally-Independent Pixel Synthesis”, Anokhin et al 2020
“Fourier Neural Operator for Parametric Partial Differential Equations”, Li et al 2020
“SIREN: Implicit Neural Representations with Periodic Activation Functions”, Sitzmann et al 2020
“Neural Geometric Level of Detail: Real-time Rendering with Implicit 3D Shapes”, Takikawa et al 2021
“NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis”, Mildenhall et al 2020; “KiloNeRF: Speeding up Neural Radiance Fields with Thousands of Tiny MLPs”, Reiser et al 2021
“MixerGAN: An MLP-Based Architecture for Unpaired Image-to-Image Translation”, Cazenavette & De Guevara 2021
{kind=link}
Why now, if MLPs were always roughly data & compute-competitive with Transformers, and thus, CNNs?
My current theory is that the critical ingredient is normalization and/or gating (to enable signal propagation, like residual layers for CNNs or self-attention over history for Transformers): MLPs, while always acknowledged as extremely powerful, underperform in practice or are highly unstable. Normalization & gating are relatively recent, typically post-2015, and they stabilize MLPs to the point where they Just Work.
If you look at the current crop of MLP papers, what they all seem to have in common is normalization/gating (sometimes hidden or dismissed as an ‘Affine’ layer), and if you remove those ingredient, your loss may go from a perplexity of ~4 to >100, eg; and ones which don’t use these tricks, like many NeRF papers, are also extremely shallow.
Combined with the great success of resnet CNNs & then Transformers, and it’s unsurprising if MLPs were not trial-and-errored enough post-2015 to discover that they worked until the cost of self-attention in Transformers drove interest in removing as much self-attention as possible—eventually leading to the discover that you can remove all of it with surprisingly little damage.↩︎