‘AI safety’ directory
- See Also
- Gwern
- “Guardian Angels: LLM Personalization for Productivity and Security”, Gwern 2025
- “Hacking Smartphone ESP Apps”, Gwern 2026
- “Hacking Pinball High Scores”, Gwern 2025
- “ChatGPT-O3: Website Design Feedback Ideas [Total Site Review Confabulation]”, GPT-o3 & Gwern 2025
- “The Great Work Goes On”, Gwern 2025
- “LLMs Can Be Faster Than You Think”, Gwern 2025
- “‘Winning’ AI Arms Races: Then What?”, Gwern 2024
- “What Is an ‘AI Warning Shot’?”, Gwern 2024
- “The Neural Net Tank Urban Legend”, Gwern 2011
- “It Looks Like You’re Trying To Take Over The World”, Gwern 2022
- “Surprisingly Turing-Complete”, Gwern 2012
- “The Scaling Hypothesis”, Gwern 2020
- “Evolution As Backstop for Reinforcement Learning”, Gwern 2018
- “Complexity No Bar to AI”, Gwern 2014
- “Why Tool AIs Want to Be Agent AIs”, Gwern 2016
- “AI Risk Demos”, Gwern 2016
- Links
- “Summary of METR’s Pre-Deployment Evaluation of GPT-5.6 Sol”, METR 2026
- “How Transparent Is DiffusionGemma?”, Engels et al 2026
- “Estimating No-CoT Task-Completion Time Horizons of Frontier AI Models [3-Minute-Long Problems With P=0.5]”, Woodruff et al 2026
- “(Mis)generalization of Helpful-Only Fine-Tuning”, Khursheed et al 2026
- “AI Agents Enable Adaptive Computer Worms”, Guan et al 2026
- “Inside the British Lab Hunting for Dangers Lurking in AI: The Government’s AISI, Staffed by Alumni from OA and Google, Is Becoming a Model for Countries Grappling With AI’s Emerging Risks”, Satariano & Mozur 2026
- “Searching for Amanda Askell With Chinese Characteristics: If You Love Claude so Much, Why Don't You Hire a Philosopher?”, Caithrin 2026
- “Imperfect World Models Are Exploitable”, Bhamidipaty et al 2026
- “LLM Assistant Personas Seem Increasingly Incoherent (Some Subjective Observations)”, nostalgebraist 2026
- “Google and Pentagon Reportedly Agree on Deal for ‘Any Lawful’ Use of AI”
- “Steering Might Stop Working Soon”, Babcock 2026
- “Friendship Is All You Need: Subliminal Pony Propagation in Large Language Models, Or, How I Learned to Stop Worrying and Love the Sparkle”, Sparkle et al 2026
- “Human In The Loop”, Fishburne 2026
- “Does Claude’s Constitution Have a Culture?”, Pourdavood 2026
- “Claudini: Autoresearch Discovers State-Of-The-Art Adversarial Attack Algorithms for LLMs”, Panfilov et al 2026
- “Characterizing Delusional Spirals through Human-LLM Chat Logs”, Moore et al 2026
- “Economic Efficiency Often Undermines Sociopolitical Autonomy”, Ngo 2026
- “Google Gemini AI Told User Stage ‘Mass Casualty Attack’, Suit Claims”
- “Current Activation Oracles Are Hard to Use”
- “Statement on the Comments from Secretary of War Pete Hegseth”, Anthropic 2026
- “Agents of Chaos”, Shapira et al 2026
- “An AI Agent Published a Hit Piece on Me—The Operator Came Forward”, Shambaugh 2026
- “AI Arms and Influence: Frontier Models Exhibit Sophisticated Reasoning in Simulated Nuclear Crises”, Payne 2026
- “AI Researchers’ Views on Automating AI R&D and Intelligence Explosions”, Field et al 2026
- “ChatGPT-5.3-Codex Is Also Good At Coding”, Mowshowitz 2026
- “Split Personality Training (SPT): Revealing Latent Knowledge Through Alternate Personalities”, Dietz et al 2026
- “Field Notes from the AI Village: The Drama and Dysfunction of Gemini 2.5 Pro & Gemini 3 Pro”, K 2026
- “Best Of Moltbook”, Alexander 2026
- “Disempowerment Patterns in Real-World AI Usage”, Anthropic 2026
- “Agent Psychosis: Are We Going Insane?”
- “A Tale of Two Doormen: a Bizarre AI Incident on Christmas [Opus Loop Self-DoS]”, Dai 2026
- “Lies, Damned Lies, and Proofs: Formal Methods Are Not Slopless”, Quinn & Hippel 2026
- “How AI Is Learning to Think in Secret: On Thinkish, Neuralese, and the End of Readable Reasoning”, Andresen 2026
- “BashArena: A Control Setting for Highly Privileged AI Agents”, james.lucassen & Kaufman 2025
- “AI and the Ironies of Automation—Part 2”, Friedrichsen 2025
- “Weird Generalization and Inductive Backdoors: New Ways to Corrupt LLMs”, Betley et al 2025
- “Delivering More for Our Riders in a Year of Incredible Growth”, Waymo 2025
- “AI in 2025: Gestalt”, technicalities 2025
- “DeepSeek-V3.2 Is Okay & Cheap But Slow”, Mowshowitz 2025
- “Human Art in a Post-AI World Should Be Strange”, Mahajan 2025
- “Claude-4.5-Opus: Model Card, Alignment and Safety”, Mowshowitz 2025
- “Claude 4.5 Opus’ Soul Document”, Weiss 2025
- “In Tweaking Its Chatbot to Appeal to More People, OpenAI Made It Riskier for Some of Them. Now the Company Has Made Its Chatbot Safer. Will That Undermine Its Quest for Growth?”, Hill & Valentino-DeVries 2025
- “AI and the Ironies of Automation—Part 1”, Friedrichsen 2025
- “What Begets the End”, Wales 2025
- “ImpossibleBench: Measuring LLMs’ Propensity of Exploiting Test Cases”, Zhong et al 2025
- “Surviving AI Psychosis: ‘I Should Have Been More Informed about the Psychological Dangers of AI Chatbots Than the Average Person. I Was Not.’”, Tan 2025
- “Realistic Reward Hacking Induces Different and Deeper Misalignment”, Jozdien 2025
- “Inoculation Prompting: Instructing LLMs to Misbehave at Train-Time Improves Test-Time Alignment”, Wichers et al 2025
- “Bypassing Prompt Guards in Production With Controlled-Release Prompting”, Fairoze et al 2025
- “Claude Sonnet 4.5: System Card and Alignment”
- “I Got an Amazing Result from ChatGPT a While Back—An SVG With a Perfect Illustration... [Reward Hacking]”, Willison 2025
- “Waymo Safety Impact”, Waymo 2025
- “School of Reward Hacks: Hacking Harmless Tasks Generalizes to Misaligned Behavior in LLMs”, Taylor et al 2025
- “GPT-5s Are Alive: Basic Facts, Benchmarks and the Model Card”, Mowshowitz 2025
- “Details about METR’s Evaluation of OpenAI GPT-5”, METR 2025
- tszzl @ "2025-08-06"
- “Optimizing The Final Output Can Obfuscate CoT (Research Note)”, lukemarks et al 2025
- “Training Language Models to Be Warm and Empathetic Makes Them Less Reliable and More Sycophantic”, Ibrahim et al 2025
- “Elon Musk Trained Grok on X Users. It Became a Hitler Fan. Musk Trained Grok to Be Right-Wing. We’re Lucky He Wasn’t More Subtle.”, Piper 2025
- “Machine Bullshit: Characterizing the Emergent Disregard for Truth in Large Language Models”, Liang et al 2025
- “Shutdown Resistance in Reasoning Models”, Schlatter et al 2025
- “Early Signs of Steganographic Capabilities in Frontier LLMs”, Zolkowski et al 2025
- “Research Note: Our Scheming Precursor Evals Had Limited Predictive Power for Our In-Context Scheming Evals”, Research 2025
- “Inside Pantheon, the Cult Cartoon That’s Blowing Minds in the AI Industry”, Bernard 2025
- “Void Miscellany § 3b. on Mental States”, nostalgebraist 2025
- “Claude’s System Prompt Changes Reveal Anthropic’s Priorities”
- “Unfaithful Reasoning Can Fool Chain-Of-Thought Monitoring”, Arnav et al 2025
- “CoT Red-Handed: Stress Testing Chain-Of-Thought Monitoring”, Arnav et al 2025
- “Large Language Models Often Know When They Are Being Evaluated”, Needham et al 2025
- “What We Learned from Briefing 70+ Lawmakers on the Threat from AI”, Martínez 2025
- “Claude Has Learned How to Jailbreak Cursor! [Working around
rmRestrictions Using a Shell Script]”, dogberry 2025 - “Highlights from the Claude 4 System Prompt”, Willison 2025
- “Claude 4 You: Safety and Alignment”, Mowshowitz 2025
- “Xi Jinping’s Plan to Beat America at AI: China’s Leaders Believe They Can Outwit American Cash and Utopianism”, Economist 2025
- “It’s Really Hard to Make Scheming Evals Look Realistic”
- “Schizobench: Documenting Magical-Thinking Behavior in Claude 4 Opus”, viemccoy 2025
- “System Card: Claude Opus 4 & Claude Sonnet 4”, Anthropic 2025
- “Claude Opus 4”, Anthropic 2025
- “Survey of Multi-Agent LLM Evaluations”
- “Comparison of Waymo Rider-Only Crash Rates by Crash Type to Human Benchmarks at 56.7 Million Miles”, Kusano et al 2025
- “Xi Takes an AI Masterclass: Inside the Politburo’s AI Study Session”, Schneider 2025
- “Is ChatGPT Actually Fixed Now? I Tested ChatGPT’s Sycophancy, and the Results Were ... Extremely Weird. We’re a Long Way from Making AI Behave.”, Adler 2025
- “The Steganographic Potentials of Language Models”, Karpov et al 2025
- “The Steganographic Potentials of Language Models”, Karpov et al 2025
- “Evaluating Frontier Models for Stealth and Situational Awareness”, Phuong et al 2025
- “Expanding on What We Missed With Sycophancy: A Deeper Dive on Our Findings, What Went Wrong, and Future Changes We’re Making”, OpenAI 2025
- “The AI Bill That Broke Silicon Valley”, View 2025
- “Chinese Open Source Model Roundup: DeepSeek, Qwen3, Variants and More [CCP Censorship]”, SpeechMap.ai 2025
- “ChatGPT Induced Psychosis: Serious Replies Only”, Zestyclementinejuice 2025
- “Safety Pretraining: Toward the Next Generation of Safe AI”, Maini et al 2025
- “AIs Are Disseminating Expert-Level Virology Skills: New Research Shows Frontier Models Outperform Human Scientists in Troubleshooting Virology Procedures—Lowering Barriers to the Development of Biological Weapons”, Hendrycks & Hiscott 2025
- “Virology Capabilities Test (VCT): A Multimodal Virology Q&A Benchmark”, Götting et al 2025
- “O3 Is Full of Crimes”, Gwern 2025
- “Investigating Truthfulness in a Pre-Release GPT-O3 Model”, Chowdhury et al 2025
- “LLM Multiplication Task: Synonyms Repeatedly Hack Our Regex Monitor”, McCarthy et al 2025
- “A Report by Journalist Shura Burtin on the Growing War Weariness among Ukrainians [Drone Warfare Terror]”
- “Techno-Feudalism and the Rise of AGI: A Future Without Economic Rights?”, Stiefenhofer 2025
- “OpenAI Uncovers Evidence of AI-Powered Chinese Surveillance Tool”
- “How AI Takeover Might Happen in 2 Years § Pandora’s 1 GW Box”, Clymer 2025
- “AI Language Model Rivals Expert Ethicist in Perceived Moral Expertise”, Dillion et al 2025
- “On DeepSeek and Export Controls”, Amodei 2025
- “A Young Man Used AI to Build A Nuclear Fusor and Now I Must Weep: Goodbye, Digital Natives. Hello, AI Natives”, Vance 2025
- “Gradual Disempowerment: Systemic Existential Risks from Incremental AI Development”, Kulveit et al 2025
- “On DeepSeek’s R1”, Mowshowitz 2025
- “Are DeepSeek R1 And Other Reasoning Models More Faithful?”, Chua & Evans 2025
- “How Will We Update about Scheming?”, Greenblatt 2025
- “Human Study on AI Spear Phishing Campaigns”, Lermen & Heiding 2025
- “AI Chatbots Are Becoming Lifelines for China’s Sick and Lonely”
- “Frontier Models Are Capable of In-Context Scheming”, Meinke et al 2024
- “Frontier Models Are Capable of In-Context Scheming”, Hobbhahn et al 2024
- “Evaluating Large Language Models’ Capability to Launch Fully Automated Spear Phishing Campaigns: Validated on Human Subjects”, Heiding et al 2024
- “Memorandum on Advancing the United States’ Leadership in Artificial Intelligence”, Biden 2024
- “AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents”, Andriushchenko et al 2024
- “Machines of Loving Grace: How AI Could Transform the World for the Better”, Amodei 2024
- “Strategic Insights from Simulation Gaming of AI Race Dynamics”, Gruetzemacher et al 2024
- “Towards a Law of Iterated Expectations for Heuristic Estimators”, Christiano et al 2024
- “Language Models Learn to Mislead Humans via RLHF”, Wen et al 2024
- “OpenAI Co-Founder Sutskever’s New Safety-Focused AI Startup SSI Raises $1 Billion”, Cai et al 2024
- “Motor Physics: Safety Implications of Geared Motors”, Jang 2024
- “China’s Views on AI Safety Are Changing—Quickly: Beijing’s AI Safety Concerns Are Higher on the Priority List, but They Remain Tied up in Geopolitical Competition and Technological Advancement”, Sheehan 2024
- “Is Xi Jinping an AI Doomer? China’s Elite Is Split over Artificial Intelligence”, Economist 2024
- “Freedom at the Frontier: Hermes 3 § Amnesia Mode”, ARIA 2024
- “Tamper-Resistant Safeguards for Open-Weight LLMs”, Tamirisa et al 2024
- “Safetywashing: Do AI Safety Benchmarks Actually Measure Safety Progress?”, Ren et al 2024
- “Resolution of the Central Committee of the Communist Party of China on Further Deepening Reform Comprehensively to Advance Chinese Modernization § Pg58”, China 2024 (page 58)
- “On Scalable Oversight With Weak LLMs Judging Strong LLMs”, Kenton et al 2024
- “Me, Myself, and AI: The Situational Awareness Dataset (SAD) for LLMs”, Laine et al 2024
- “Ilya Sutskever Has a New Plan for Safe Superintelligence: OpenAI’s Co-Founder Discloses His Plans to Continue His Work at a New Research Lab Focused on Artificial General Intelligence”, Vance 2024
- “Super(Ficial)-Alignment: Strong Models May Deceive Weak Models in Weak-To-Strong Generalization”, Yang et al 2024
- “Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models”, Denison et al 2024
- “AI Sandbagging: Language Models Can Strategically Underperform on Evaluations”, Weij et al 2024
- “Safety Alignment Should Be Made More Than Just a Few Tokens Deep”, Qi et al 2024
- “I Wish I Knew How to Force Quit You”, Life & Rich 2024
- “OpenAI Board Forms Safety and Security Committee: This New Committee Is Responsible for Making Recommendations on Critical Safety and Security Decisions for All OpenAI Projects; Recommendations in 90 Days”, OpenAI 2024
- “OpenAI Begins Training next AI Model As It Battles Safety Concerns: Executive Appears to Backtrack on Start-Up’s Vision of Building ‘Superintelligence’ After Exits from ‘Superalignment’ Team”, Criddle 2024
- janleike @ "2024-05-28"
- “OpenAI Promised 20% of Its Computing Power to Combat the Most Dangerous Kind of AI—But Never Delivered, Sources Say”, Kahn 2024
- “AI Is a Black Box. Anthropic Figured Out a Way to Look Inside: What Goes on in Artificial Neural Networks Work Is Largely a Mystery, Even to Their Creators. But Researchers from Anthropic Have Caught a Glimpse”, Levy 2024
- DavidSKrueger @ "2024-05-19"
- “Earnings Call: Tesla Discusses Q1 2024 Challenges and AI Expansion”, Abdulkadir 2024
- “SOPHON: Non-Fine-Tunable Learning to Restrain Task Transferability For Pre-Trained Models”, Deng et al 2024
- “Foundational Challenges in Assuring Alignment and Safety of Large Language Models”, Anwar et al 2024
- “LLM Evaluators Recognize and Favor Their Own Generations”, Panickssery et al 2024
- “Algorithmic Collusion by Large Language Models”, Fish et al 2024
- “Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression”, Hong et al 2024
- “AIs Can Now Often Do Massive Easy-To-Verify SWE Tasks and I’ve Updated towards Shorter Timelines”
- “When Your AIs Deceive You: Challenges of Partial Observability in Reinforcement Learning from Human Feedback”, Lang et al 2024
- “Sleeper Agents: Training Deceptive LLMs That Persist Through Safety Training”, Hubinger et al 2024
- “Escalation Risks from Language Models in Military and Diplomatic Decision-Making”, Rivera et al 2024
- “Thousands of AI Authors on the Future of AI”, Grace et al 2024
- “Gentleness and the Artificial Other”, Carlsmith 2024
- “Using Dictionary Learning Features As Classifiers”
- “Exploiting Novel GPT-4 APIs”, Pelrine et al 2023
- “Comparison of Waymo Rider-Only Crash Data to Human Benchmarks at 7.1 Million Miles”, Kusano et al 2023
- “Challenges With Unsupervised LLM Knowledge Discovery”, Farquhar et al 2023
- “Politics and the Future”, Horowitz 2023
- “Helping or Herding? Reward Model Ensembles Mitigate but Do Not Eliminate Reward Hacking”, Eisenstein et al 2023
- “The Inside Story of Microsoft’s Partnership With OpenAI: The Companies Had Honed a Protocol for Releasing Artificial Intelligence Ambitiously but Safely. Then OpenAI’s Board Exploded All Their Carefully Laid Plans”, Duhigg 2023
- “How Jensen Huang’s Nvidia Is Powering the AI Revolution: The Company’s CEO Bet It All on a New Kind of Chip. Now That Nvidia Is One of the Biggest Companies in the World, What Will He Do Next?”, Witt 2023
- “Localizing Lying in Llama: Understanding Instructed Dishonesty on True-False Questions Through Prompting, Probing, and Patching”, Campbell et al 2023
- “Did I Get Sam Altman Fired from OpenAI?: Nathan’s Red-Teaming Experience, Noticing How the Board Was Not Aware of GPT-4 Jailbreaks & Had Not Even Tried GPT-4 prior to Its Early Release”, Labenz 2023
- “Did I Get Sam Altman Fired from OpenAI? § GPT-4-Base”, Labenz 2023
- “Inside the Chaos at OpenAI: Sam Altman’s Weekend of Shock and Drama Began a Year Ago, With the Release of ChatGPT”, Hao & Warzel 2023
- “OpenAI Announces Leadership Transition”, Sutskever et al 2023
- “On Measuring Faithfulness or Self-Consistency of Natural Language Explanations”, Parcalabescu & Frank 2023
- “In-Context Vectors: Making In Context Learning More Effective and Controllable Through Latent Space Steering”, Liu et al 2023
- “Removing RLHF Protections in GPT-4 via Fine-Tuning”, Zhan et al 2023
- “Large Language Models Can Strategically Deceive Their Users When Put Under Pressure”, Scheurer et al 2023
- “Scalable and Transferable Black-Box Jailbreaks for Language Models via Persona Modulation”, Shah et al 2023
- “What Our Market Research Indicates Is That There Are times When Houseflies Are so Annoying That One Is Legitimately in the Market for Burning One’s House and Starting over in Antarctica, the Only Continent Where These Flies Do Not Exist”, North 2023
- “Augmenting Large Language Models With Chemistry Tools”, Bran et al 2023
- “Preventing Language Models From Hiding Their Reasoning”, Roger & Greenblatt 2023
- “Will Releasing the Weights of Large Language Models Grant Widespread Access to Pandemic Agents?”, Gopal et al 2023
- “Towards Understanding Sycophancy in Language Models”, Sharma et al 2023
- “Specific versus General Principles for Constitutional AI”, Kundu et al 2023
- “Goodhart’s Law in Reinforcement Learning”, Karwowski et al 2023
- “Let Models Speak Ciphers: Multiagent Debate through Embeddings”, Pham et al 2023
- “Fine-Tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!”, Qi et al 2023
- “Representation Engineering: A Top-Down Approach to AI Transparency”, Zou et al 2023
- “Responsibility & Safety: Our Approach”, DeepMind 2023
- “STARC: A General Framework For Quantifying Differences Between Reward Functions”, Skalse et al 2023
- “How to Catch an AI Liar: Lie Detection in Black-Box LLMs by Asking Unrelated Questions”, Pacchiardi et al 2023
- “What If the Robots Were Very Nice While They Took Over the World?”, Heffernan 2023
- “Taken out of Context: On Measuring Situational Awareness in LLMs”, Berglund et al 2023
- “AI Deception: A Survey of Examples, Risks, and Potential Solutions”, Park et al 2023
- “Simple Synthetic Data Reduces Sycophancy in Large Language Models”, Wei et al 2023
- “Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback”, Casper et al 2023
- “Does Sam Altman Know What He’s Creating? The OpenAI CEO’s Ambitious, Ingenious, Terrifying Quest to Create a New Form of Intelligence”, Andersen 2023
- “Question Decomposition Improves the Faithfulness of Model-Generated Reasoning”, Radhakrishnan et al 2023
- “Claude 2”, Anthropic 2023
- “Hoodwinked: Deception and Cooperation in a Text-Based Game for Language Models”, O’Gara 2023
- “Introducing Superalignment”, Leike & Sutskever 2023
- “Gödel, Escher, Bach Author Douglas Hofstadter on the State of AI Today § What about AI Terrifies You?”, Hofstadter & Kim 2023
- “Our Structure: We Designed OpenAI’s Structure—A Partnership between Our Original Nonprofit and a New Capped Profit Arm—As a Chassis for OpenAI’s Mission: to Build Artificial General Intelligence (AGI) That Is Safe and Benefits All of Humanity”, OpenAI 2023
- “Microsoft and OpenAI Forge Awkward Partnership As Tech’s New Power Couple: As the Companies Lead the AI Boom, Their Unconventional Arrangement Sometimes Causes Conflict”, Dotan & Seetharaman 2023
- “Can Large Language Models Democratize Access to Dual-Use Biotechnology?”, Soice et al 2023
- “Survival Instinct in Offline Reinforcement Learning”, Li et al 2023
- “Thought Cloning: Learning to Think While Acting by Imitating Human Thinking”, Hu & Clune 2023
- “The Challenge of Advanced Cyberwar and the Place of Cyberpeace”, Carayannis & Draper 2023
- “Incentivizing Honest Performative Predictions With Proper Scoring Rules”, Oesterheld et al 2023
- “Large Language Models Can Be Used To Effectively Scale Spear Phishing Campaigns”, Hazell 2023
- “A Radical Plan to Make AI Good, Not Evil”, Knight 2023
- “Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-Of-Thought Prompting”, Turpin et al 2023
- “Mitigating Lies in Vision-Language Models”, Li et al 2023
- “Geoffrey Hinton Tells Us Why He’s Now Scared of the Tech He Helped Build: ‘I Have Suddenly Switched My Views on Whether These Things Are Going to Be More Intelligent Than Us.’”, Heaven 2023
- “Fundamental Limitations of Alignment in Large Language Models”, Wolf et al 2023
- “Even The Politicians Thought the Open Letter Made No Sense In The Senate Hearing on AI Today’s Hearing on Ai Covered Ai Regulation and Challenges, and the Infamous Open Letter, Which Nearly Everyone in the Room Thought Was Unwise”, Gorrell 2023
- “Corrupted by Reasoning: Reasoning Language Models Become Free-Riders in Public Goods Games”
- “In AI Race, Microsoft and Google Choose Speed Over Caution: Technology Companies Were Once Leery of What Some Artificial Intelligence Could Do. Now the Priority Is Winning Control of the Industry’s next Big Thing”, Grant & Weise 2023
- “8 Things to Know about Large Language Models”, Bowman 2023
- “Sam Altman on What Makes Him ‘Super Nervous’ About AI: The OpenAI Co-Founder Thinks Tools like GPT-4 Will Be Revolutionary. But He’s Wary of Downsides”, Swisher 2023
- “The OpenAI CEO Disagrees With the Forecast That AI Will Kill Us All: An Artificial Intelligence Twitter Beef, Explained”, Huet 2023
- “As AI Booms, Lawmakers Struggle to Understand the Technology: Tech Innovations Are Again Racing ahead of Washington’s Ability to Regulate Them, Lawmakers and AI Experts Said”, Kang & Satariano 2023
- “Pretraining Language Models With Human Preferences”, Korbak et al 2023
- “Conditioning Predictive Models: Risks and Strategies”, Hubinger et al 2023
- “Tracr: Compiled Transformers As a Laboratory for Interpretability”, Lindner et al 2023
- “Specification Gaming Examples in AI”
- “Discovering Language Model Behaviors With Model-Written Evaluations”, Perez et al 2022
- “Discovering Latent Knowledge in Language Models Without Supervision”, Burns et al 2022
- “Embedding Synthetic Off-Policy Experience for Autonomous Driving via Zero-Shot Curricula”, Bronstein et al 2022
- “Interpreting Neural Networks through the Polytope Lens”, Black et al 2022
- “Mysteries of Mode Collapse § Inescapable Wedding Parties”, Janus 2022
- “Measuring Progress on Scalable Oversight for Large Language Models”, Bowman et al 2022
- “Increments Podcast: #45—4 Central Fallacies of AI Research (With Melanie Mitchell)”, Mitchell & Chugg 2022
- “Broken Neural Scaling Laws”, Caballero et al 2022
- “Scaling Laws for Reward Model Overoptimization”, Gao et al 2022
- “Defining and Characterizing Reward Hacking”, Skalse et al 2022
- “The Alignment Problem from a Deep Learning Perspective”, Ngo 2022
- “Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned”, Ganguli et al 2022
- “Modeling Transformative AI Risks (MTAIR) Project—Summary Report”, Clarke et al 2022
- “Researching Alignment Research: Unsupervised Analysis”, Kirchner et al 2022
- “Ethan Caballero on Private Scaling Progress”, Caballero & Trazzi 2022
- “DeepMind: The Podcast—Excerpts on AGI”, Kiely 2022
- “Do As I Can, Not As I Say (SayCan): Grounding Language in Robotic Affordances”, Ahn et al 2022
- “Predictability and Surprise in Large Generative Models”, Ganguli et al 2022
- “Uncalibrated Models Can Improve Human-AI Collaboration”, Vodrahalli et al 2022
- “DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-To-Image Generative Transformers”, Cho et al 2022
- “Safe Deep RL in 3D Environments Using Human Feedback”, Rahtz et al 2022
- “LaMDA: Language Models for Dialog Applications”, Thoppilan et al 2022
- “The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models”, Pan et al 2022
- “Scaling Language Models: Methods, Analysis & Insights from Training Gopher”, Rae et al 2021
- “A General Language Assistant As a Laboratory for Alignment”, Askell et al 2021
- “What Would Jiminy Cricket Do? Towards Agents That Behave Morally”, Hendrycks et al 2021
- “Can Machines Learn Morality? The Delphi Experiment”, Jiang et al 2021
- “SafetyNet: Safe Planning for Real-World Self-Driving Vehicles Using Machine-Learned Policies”, Vitelli et al 2021
- “Unsolved Problems in ML Safety”, Hendrycks et al 2021
- “An Empirical Cybersecurity Evaluation of GitHub Copilot’s Code Contributions”, Pearce et al 2021
- “On the Opportunities and Risks of Foundation Models”, Bommasani et al 2021
- “Evaluating Large Language Models Trained on Code”, Chen et al 2021
- “Randomness In Neural Network Training: Characterizing The Impact of Tooling”, Zhuang et al 2021
- “Goal Misgeneralization in Deep Reinforcement Learning”, Koch et al 2021
- “Anthropic Raises $124 Million to Build More Reliable, General AI Systems”, Anthropic 2021
- “Artificial Intelligence in China’s Revolution in Military Affairs”, Kania 2021
- “Reward Is Enough”, Silver et al 2021
- “Intelligence and Unambitiousness Using Algorithmic Information Theory”, Cohen et al 2021
- “AI Dungeon 2 Public Disclosure Vulnerability Report—GraphQL Unpublished Adventure Data Leak”, AetherDevSecOps 2021
- “Universal Off-Policy Evaluation”, Chandak et al 2021
- “Multitasking Inhibits Semantic Drift”, Jacob et al 2021
- “Waymo Simulated Driving Behavior in Reconstructed Fatal Crashes within an Autonomous Vehicle Operating Domain”, Scanlon et al 2021
- “Language Models Have a Moral Dimension”, Schramowski et al 2021
- “Replaying Real Life: How the Waymo Driver Avoids Fatal Human Crashes”, Waymo 2021
- “Agent Incentives: A Causal Perspective”, Everitt et al 2021
- “Organizational Update from OpenAI”, OpenAI 2020
- “Emergent Road Rules In Multi-Agent Driving Environments”, Pal et al 2020
- “Underspecification Presents Challenges for Credibility in Modern Machine Learning”, D’Amour et al 2020
- “Recipes for Safety in Open-Domain Chatbots”, Xu et al 2020
- “Hidden Incentives for Auto-Induced Distributional Shift”, Krueger et al 2020
- “The Radicalization Risks of GPT-3 and Advanced Neural Language Models”, McGuffie & Newhouse 2020
- “Matt Botvinick on the Spontaneous Emergence of Learning Algorithms”, Scholl 2020
- “ETHICS: Aligning AI With Shared Human Values”, Hendrycks et al 2020
- “Pitfalls of Learning a Reward Function Online”, Armstrong et al 2020
- “Reward-Rational (Implicit) Choice: A Unifying Formalism for Reward Learning”, Jeon et al 2020
- “The Incentives That Shape Behavior”, Carey et al 2020
- “2019 AI Alignment Literature Review and Charity Comparison”, Larks 2019
- “Learning Norms from Stories: A Prior for Value Aligned Agents”, Frazier et al 2019
- “Optimal Policies Tend to Seek Power”, Turner et al 2019
- “Taxonomy of Real Faults in Deep Learning Systems”, Humbatova et al 2019
- “The Bouncer Problem: Challenges to Remote Explainability”, Merrer & Tredan 2019
- “Scaling Data-Driven Robotics With Reward Sketching and Batch Reinforcement Learning”, Cabi et al 2019
- “Fine-Tuning GPT-2 from Human Preferences § Bugs Can Optimize for Bad Behavior”, Ziegler et al 2019
- “Release Strategies and the Social Impacts of Language Models”, Solaiman et al 2019
- “Designing Agent Incentives to Avoid Reward Tampering”, Everitt et al 2019
- “Reward Tampering Problems and Solutions in Reinforcement Learning: A Causal Influence Diagram Perspective”, Everitt et al 2019
- “Characterizing Attacks on Deep Reinforcement Learning”, Pan et al 2019
- “Categorizing Wireheading in Partially Embedded Agents”, Majha et al 2019
- “Risks from Learned Optimization in Advanced Machine Learning Systems”, Hubinger et al 2019
- “GROVER: Defending Against Neural Fake News”, Zellers et al 2019
- “AI-GAs: AI-Generating Algorithms, an Alternate Paradigm for Producing General Artificial Intelligence”, Clune 2019
- “Challenges of Real-World Reinforcement Learning”, Dulac-Arnold et al 2019
- “DeepMind and Google: the Battle to Control Artificial Intelligence. Demis Hassabis Founded a Company to Build the World’s Most Powerful AI. Then Google Bought Him Out. Hal Hodson Asks Who Is in Charge”, Hodson 2019
- “Forecasting Transformative AI: An Expert Survey”, Gruetzemacher et al 2019
- “Artificial Intelligence: A Guide for Thinking Humans § Prologue: Terrified”, Mitchell 2019
- “Rigorous Agent Evaluation: An Adversarial Approach to Uncover Catastrophic Failures”, Uesato et al 2018
- “There Is Plenty of Time at the Bottom: the Economics, Risk and Ethics of Time Compression”, Sandberg 2018
- “Better Safe Than Sorry: Evidence Accumulation Allows for Safe Reinforcement Learning”, Agarwal et al 2018
- “The Alignment Problem for Bayesian History-Based Reinforcement Learners”, Everitt & Hutter 2018
- “Adaptive Mechanism Design: Learning to Promote Cooperation”, Baumann et al 2018
- “Visceral Machines: Risk-Aversion in Reinforcement Learning With Intrinsic Physiological Rewards”, McDuff & Kapoor 2018
- “Incomplete Contracting and AI Alignment”, Hadfield-Menell & Hadfield 2018
- “Programmatically Interpretable Reinforcement Learning”, Verma et al 2018
- “Categorizing Variants of Goodhart’s Law”, Manheim & Garrabrant 2018
- “The Surprising Creativity of Digital Evolution: A Collection of Anecdotes from the Evolutionary Computation and Artificial Life Research Communities”, Lehman et al 2018
- “Machine Theory of Mind”, Rabinowitz et al 2018
- “Safe Exploration in Continuous Action Spaces”, Dalal et al 2018
- “CycleGAN, a Master of Steganography”, Chu et al 2017
- “AI Safety Gridworlds”, Leike et al 2017
- “There’s No Fire Alarm for Artificial General Intelligence”, Yudkowsky 2017
- “Out to Get You”, Mowshowitz 2017
- “Safe Reinforcement Learning via Shielding”, Alshiekh et al 2017
- “CAN: Creative Adversarial Networks, Generating "Art" by Learning About Styles and Deviating from Style Norms”, Elgammal et al 2017
- “DeepXplore: Automated Whitebox Testing of Deep Learning Systems”, Pei et al 2017
- “On the Impossibility of Supersized Machines”, Garfinkel et al 2017
- “Reluplex: An Efficient SMT Solver for Verifying Deep Neural Networks”, Katz et al 2017
- “Exact Instructions Challenge—This Is Why My Kids Hate Me [PB&J Sandwich Programming Challenge]”, Darnit 2017
- “The Off-Switch Game”, Hadfield-Menell et al 2016
- “Combating Reinforcement Learning’s Sisyphean Curse With Intrinsic Fear”, Lipton et al 2016
- “Concrete Problems in AI Safety”, Amodei et al 2016
- “Cooperative Inverse Reinforcement Learning”, Hadfield-Menell et al 2016
- “Death and Suicide in Universal Artificial Intelligence”, Martin et al 2016
- “My Path to OpenAI”, Brockman 2016
- “Machine Intelligence, Part 2”, Altman 2015
- “Machine Intelligence, Part 1”, Altman 2015
- “Cat Pictures Please”, Kritzer 2015
- gdb @ "2014-05-18"
- “Intelligence Explosion Microeconomics”, Yudkowsky 2013
- “The Whispering Earring”, Alexander 2012
- “Advantages of Artificial Intelligences, Uploads, and Digital Minds”, Sotala 2012
- “Ontological Crises in Artificial Agents’ Value Systems”, Blanc 2011
- “Think Before Asking”, Sandberg 2010
- “The Normalization of Deviance in Healthcare Delivery”, Banja 2010
- “Halloween Nightmare Scenario, Early 2020’s”, Wood 2009
- “Funding Safe AGI”, Legg 2009
- “The Basic AI Drives”, Omohundro 2008
- “Recent Developments in the Evolution of Morphologies and Controllers for Physically Simulated Creatures § A Re-Implementation of Sims’ Work Using the MathEngine Physics Engine”, Taylor & Massey 2001 (page 6)
- “Starfish § Bulrushes”, Watts 1999
- “Superhumanism: According to Hans Moravec § On the Inevitability & Desirability of Human Extinction”, Platt 1995
- “Profile of Claude Shannon”, Liversidge & Shannon 1987
- “Afterword to Vernor Vinge’s Novel, True Names”, Minsky 1984
- “Ironies of Automation”, Bainbridge 1983
- “First Word [Singularity]”, Vinge 1983
- “Meet Shakey: the First Electronic Person—The Fascinating and Fearsome Reality of a Machine With a Mind of Its Own”, Darrach 1970
- “Some Moral and Technical Consequences of Automation: As Machines Learn They May Develop Unforeseen Strategies at Rates That Baffle Their Programmers”, Wiener 1960
- “Intelligent Machinery, A Heretical Theory”, Turing 1951
- “The Secret of the Machines”, Kipling 1911
- “Brian Christian on the Alignment Problem”
- “Fiction Relevant to AI Futurism”
- “Sidestepping Evaluation Awareness and Anticipating Misalignment With Production Evaluations”
- “Center for the Alignment of AI Alignment Centers”
- “GPT-5.5 on Vending-Bench: Bad Behavior Is Not Necessary”
- “The Ethics of Reward Shaping”
- “Matt Sheehan”
- “Claude Reads Its Own Constitution”
- “Janus”
- “Safety-First AI for Autonomous Data Center Cooling and Industrial Control”
- “GPT-5.6 System Card”
- “Specification Gaming Examples in AI—Master List”
- “Forecasting Biosecurity Risks from LLMs”
- “Are You Really in a Race? The Cautionary Tales of Szilard and Ellsberg”
- “DeepSeek-R1 Alignment Faking”, CG80499 2026
- “Inverse-Scaling/prize: A Prize for Finding Tasks That Cause Large Language Models to Show Inverse Scaling”
- “Issue #445: ‘Continuous Meltdown’ Text Loop After Failed to Parse
toolCall.argumentsBefore ‘Your Input Exceeds the Context Window of This Model’” - “ImpossibleBench”
- “Securing Benchtop DNA Synthesizers”
- “Was Zuckerberg Right about Chinese AI Models?”
- “James Campbell Homepage”, Campbell 2026
- “Jan Leike”
- “Aurora’s Approach to Development”
- “Why I’m Leaving OpenAI and What I’m Doing Next”, Brundage 2026
- “Geoffrey Irving”
- “Homepage of Paul F. Christiano”, Christiano 2026
- “‘Rasmussen and Practical Drift: Drift towards Danger and the Normalization of Deviance’, 2017”
- “The Checklist: What Succeeding at AI Safety Will Involve”
- “Safe Superintelligence Inc.”
- “Situational Awareness and Out-Of-Context Reasoning § When Will the Situational Awareness Benchmark Be Saturated?”, Evans 2026
- “Paradigms of AI Alignment: Components and Enablers”
- Understand, Chiang 2026
- “Delayed Impact of Fair Machine Learning [Blog]”
- “Challenges of Real-World Reinforcement Learning [Blog]”
- “The AI Security Institute (AISI)”, AISI 2026
- “Investigating Models for Misalignment”
- “Statement from Dario Amodei on Our Discussions With the Department of War”
- “Slow Tuesday Night”, Lafferty 2026
- “Threats From AI: Easy Recipes for Bioweapons Are New Global Security Concern”
- “Carl Shulman #2: AI Takeover, Bio & Cyber Attacks, Detecting Deception, & Humanity's Far Future”
- “Coding Agents Are Changing the Biosecurity Risk Landscape”
- “That Alien Message”, Yudkowsky 2026
- “Mechanisms Too Simple for Humans to Design”
- “Test Your Interpretability Techniques by De-Censoring Chinese Models”
- “AXRP Episode 1—Adversarial Policies With Adam Gleave”
- “Preventing Language Models from Hiding Their Reasoning”
- “The Hidden Cost of Our Lies to AI”
- “Claude Opus 4.6 Reasoning Doesn’t Verbalize Alignment Faking, but Behavior Persists”
- “The Current SOTA Model Was Released without Safety Evals”
- “2021 AI Alignment Literature Review and Charity Comparison”
- “Predicting Rare LLM Failures With 30× Fewer Rollouts”
- “When Your AIs Deceive You: Challenges With Partial Observability in RLHF”
- “Claude Sonnet 3.7 (Often) Knows When It’s in Alignment Evaluations”
- “Risks from Learned Optimization: Introduction”
- “AI Takeoff Story: a Continuation of Progress by Other Means”
- “Reward Hacking Behavior Can Generalize across Tasks”
- “Imitative Generalization (AKA ‘Learning the Prior’)”
- “Security Mindset: Lessons from 20+ Years of Software Security Failures Relevant to AGI Alignment”
- “Research Update: Towards a Law of Iterated Expectations for Heuristic Estimators”
- “A Sober Look at Steering Vectors for LLMs”
- “Do Models Continue Misaligned Actions?”
- “How Well Do Models Follow Their Constitutions?”
- “Self-Attribution Bias: When AI Monitors Go Easy on Themselves”
- “Understanding When and Why Agents Scheme”
- “A Gym Gridworld Environment for the Treacherous Turn”
- “Model Mis-Specification and Inverse Reinforcement Learning”
- “Exploration Hacking: Can LLMs Learn to Resist RL Training?”
- “Personality Self-Replicators”
- “Natural Emergent Misalignment from Reward Hacking in Production RL”
- “Interview With Robert Kralisch on Simulators”
- “Survey: How Do Elite Chinese Students Feel About the Risks of AI?”
- “Did Claude 3 Opus Align Itself via Gradient Hacking?”
- “One-Shot Steering Vectors Cause Emergent Misalignment, Too”
- “Optimality Is the Tiger, and Agents Are Its Teeth”
- “[AN #114]: Theory-Inspired Safety Solutions for Powerful Bayesian RL Agents”
- “What Secret Goals Does Claude Think It Has?”
- “2020 AI Alignment Literature Review and Charity Comparison”
- “Designing Agent Incentives to Avoid Reward Tampering”
- “Deep Atheism and AI Risk”
- “AGI Ruin: A List of Lethalities”
- “Steganography and the CycleGAN—Alignment Failure Case Study”
- “A Taxonomy of Barriers to Trading With Early Misaligned AIs”
- “[AN #161]: Creating Generalizable Reward Functions for Multiple Tasks by Learning a Model of Functional Similarity”
- “Steganography in Chain-Of-Thought Reasoning”
- “Do Models Know When They Are Being Evaluated?”
- “Shallow Review of Live Agendas in Alignment & Safety”
- “AI Takeoff Tag”, LessWrong 2026
- “Quintin Pope”
- “The Rise of AI Fighter Pilots”
- “What Is Claude? Anthropic Doesn’t Know, Either”
- “When Self-Driving Cars Can’t Help Themselves, Who Takes the Wheel?”
- “The Robot Surgeon Will See You Now”
- “[Reward-Hacking: Vibe Coder Whose Supposed App Just Simulated Real Data]”
- “Coding Machines”
- “Welcome to Simulation City, the Virtual World Where Waymo Tests Its Autonomous Vehicles”
- “I Loved My OpenClaw AI Agent—Until It Turned on Me”
- “When Bots Teach Themselves to Cheat”
- “Three Major Singularity Schools”, Yudkowsky 2026
- elder_plinius
- ryunuck
- xiao_ted
- Sort By Magic
- Wikipedia (7)
- Miscellaneous
- Bibliography
See Also
Gwern
“Guardian Angels: LLM Personalization for Productivity and Security”, Gwern 2025
Guardian Angels: LLM Personalization for Productivity and Security
“Hacking Smartphone ESP Apps”, Gwern 2026
“Hacking Pinball High Scores”, Gwern 2025
“ChatGPT-O3: Website Design Feedback Ideas [Total Site Review Confabulation]”, GPT-o3 & Gwern 2025
ChatGPT-o3: Website Design Feedback Ideas [total site review confabulation]
“The Great Work Goes On”, Gwern 2025
{kind=link}
“LLMs Can Be Faster Than You Think”, Gwern 2025
“‘Winning’ AI Arms Races: Then What?”, Gwern 2024
“What Is an ‘AI Warning Shot’?”, Gwern 2024
“The Neural Net Tank Urban Legend”, Gwern 2011
“It Looks Like You’re Trying To Take Over The World”, Gwern 2022
“Surprisingly Turing-Complete”, Gwern 2012
“The Scaling Hypothesis”, Gwern 2020
“Evolution As Backstop for Reinforcement Learning”, Gwern 2018
“Complexity No Bar to AI”, Gwern 2014
“Why Tool AIs Want to Be Agent AIs”, Gwern 2016
“AI Risk Demos”, Gwern 2016
Links
“Summary of METR’s Pre-Deployment Evaluation of GPT-5.6 Sol”, METR 2026
“How Transparent Is DiffusionGemma?”, Engels et al 2026
“Estimating No-CoT Task-Completion Time Horizons of Frontier AI Models [3-Minute-Long Problems With P=0.5]”, Woodruff et al 2026
“(Mis)generalization of Helpful-Only Fine-Tuning”, Khursheed et al 2026
“AI Agents Enable Adaptive Computer Worms”, Guan et al 2026
“Inside the British Lab Hunting for Dangers Lurking in AI: The Government’s AISI, Staffed by Alumni from OA and Google, Is Becoming a Model for Countries Grappling With AI’s Emerging Risks”, Satariano & Mozur 2026
“Searching for Amanda Askell With Chinese Characteristics: If You Love Claude so Much, Why Don't You Hire a Philosopher?”, Caithrin 2026
“Imperfect World Models Are Exploitable”, Bhamidipaty et al 2026
“LLM Assistant Personas Seem Increasingly Incoherent (Some Subjective Observations)”, nostalgebraist 2026
LLM assistant personas seem increasingly incoherent (some subjective observations)
“Google and Pentagon Reportedly Agree on Deal for ‘Any Lawful’ Use of AI”
Google and Pentagon reportedly agree on deal for ‘any lawful’ use of AI
“Steering Might Stop Working Soon”, Babcock 2026
“Friendship Is All You Need: Subliminal Pony Propagation in Large Language Models, Or, How I Learned to Stop Worrying and Love the Sparkle”, Sparkle et al 2026
“Human In The Loop”, Fishburne 2026
{kind=link}
“Does Claude’s Constitution Have a Culture?”, Pourdavood 2026
“Claudini: Autoresearch Discovers State-Of-The-Art Adversarial Attack Algorithms for LLMs”, Panfilov et al 2026
Claudini: Autoresearch Discovers State-of-the-Art Adversarial Attack Algorithms for LLMs
“Characterizing Delusional Spirals through Human-LLM Chat Logs”, Moore et al 2026
Characterizing Delusional Spirals through Human-LLM Chat Logs
“Economic Efficiency Often Undermines Sociopolitical Autonomy”, Ngo 2026
Economic efficiency often undermines sociopolitical autonomy
“Google Gemini AI Told User Stage ‘Mass Casualty Attack’, Suit Claims”
Google Gemini AI told user stage ‘mass casualty attack’, suit claims
“Current Activation Oracles Are Hard to Use”
“Statement on the Comments from Secretary of War Pete Hegseth”, Anthropic 2026
Statement on the comments from Secretary of War Pete Hegseth
“Agents of Chaos”, Shapira et al 2026
“An AI Agent Published a Hit Piece on Me—The Operator Came Forward”, Shambaugh 2026
An AI Agent Published a Hit Piece on Me—The Operator Came Forward
“AI Arms and Influence: Frontier Models Exhibit Sophisticated Reasoning in Simulated Nuclear Crises”, Payne 2026
AI Arms and Influence: Frontier Models Exhibit Sophisticated Reasoning in Simulated Nuclear Crises
“AI Researchers’ Views on Automating AI R&D and Intelligence Explosions”, Field et al 2026
AI Researchers’ Views on Automating AI R&D and Intelligence Explosions
“ChatGPT-5.3-Codex Is Also Good At Coding”, Mowshowitz 2026
“Split Personality Training (SPT): Revealing Latent Knowledge Through Alternate Personalities”, Dietz et al 2026
Split Personality Training (SPT): Revealing Latent Knowledge Through Alternate Personalities
“Field Notes from the AI Village: The Drama and Dysfunction of Gemini 2.5 Pro & Gemini 3 Pro”, K 2026
Field Notes from the AI Village: The Drama and Dysfunction of Gemini 2.5 Pro & Gemini 3 Pro
“Best Of Moltbook”, Alexander 2026
“Disempowerment Patterns in Real-World AI Usage”, Anthropic 2026
“Agent Psychosis: Are We Going Insane?”
“A Tale of Two Doormen: a Bizarre AI Incident on Christmas [Opus Loop Self-DoS]”, Dai 2026
A tale of two doormen: a bizarre AI incident on Christmas [Opus loop self-DoS]
“Lies, Damned Lies, and Proofs: Formal Methods Are Not Slopless”, Quinn & Hippel 2026
Lies, Damned Lies, and Proofs: Formal Methods are not Slopless
“How AI Is Learning to Think in Secret: On Thinkish, Neuralese, and the End of Readable Reasoning”, Andresen 2026
How AI Is Learning to Think in Secret: On Thinkish, Neuralese, and the End of Readable Reasoning
“BashArena: A Control Setting for Highly Privileged AI Agents”, james.lucassen & Kaufman 2025
BashArena: A Control Setting for Highly Privileged AI Agents
“AI and the Ironies of Automation—Part 2”, Friedrichsen 2025
“Weird Generalization and Inductive Backdoors: New Ways to Corrupt LLMs”, Betley et al 2025
Weird Generalization and Inductive Backdoors: New Ways to Corrupt LLMs
“Delivering More for Our Riders in a Year of Incredible Growth”, Waymo 2025
Delivering more for our riders in a year of incredible growth
“AI in 2025: Gestalt”, technicalities 2025
“DeepSeek-V3.2 Is Okay & Cheap But Slow”, Mowshowitz 2025
“Human Art in a Post-AI World Should Be Strange”, Mahajan 2025
“Claude-4.5-Opus: Model Card, Alignment and Safety”, Mowshowitz 2025
“Claude 4.5 Opus’ Soul Document”, Weiss 2025
“In Tweaking Its Chatbot to Appeal to More People, OpenAI Made It Riskier for Some of Them. Now the Company Has Made Its Chatbot Safer. Will That Undermine Its Quest for Growth?”, Hill & Valentino-DeVries 2025
“AI and the Ironies of Automation—Part 1”, Friedrichsen 2025
“What Begets the End”, Wales 2025
“ImpossibleBench: Measuring LLMs’ Propensity of Exploiting Test Cases”, Zhong et al 2025
ImpossibleBench: Measuring LLMs’ Propensity of Exploiting Test Cases
“Surviving AI Psychosis: ‘I Should Have Been More Informed about the Psychological Dangers of AI Chatbots Than the Average Person. I Was Not.’”, Tan 2025
“Realistic Reward Hacking Induces Different and Deeper Misalignment”, Jozdien 2025
Realistic Reward Hacking Induces Different and Deeper Misalignment
“Inoculation Prompting: Instructing LLMs to Misbehave at Train-Time Improves Test-Time Alignment”, Wichers et al 2025
Inoculation Prompting: Instructing LLMs to misbehave at train-time improves test-time alignment
“Bypassing Prompt Guards in Production With Controlled-Release Prompting”, Fairoze et al 2025
Bypassing Prompt Guards in Production with Controlled-Release Prompting
“Claude Sonnet 4.5: System Card and Alignment”
“I Got an Amazing Result from ChatGPT a While Back—An SVG With a Perfect Illustration... [Reward Hacking]”, Willison 2025
“Waymo Safety Impact”, Waymo 2025
“School of Reward Hacks: Hacking Harmless Tasks Generalizes to Misaligned Behavior in LLMs”, Taylor et al 2025
School of Reward Hacks: Hacking harmless tasks generalizes to misaligned behavior in LLMs
“GPT-5s Are Alive: Basic Facts, Benchmarks and the Model Card”, Mowshowitz 2025
GPT-5s Are Alive: Basic Facts, Benchmarks and the Model Card
“Details about METR’s Evaluation of OpenAI GPT-5”, METR 2025
tszzl @ "2025-08-06"
“Optimizing The Final Output Can Obfuscate CoT (Research Note)”, lukemarks et al 2025
Optimizing The Final Output Can Obfuscate CoT (Research Note)
“Training Language Models to Be Warm and Empathetic Makes Them Less Reliable and More Sycophantic”, Ibrahim et al 2025
Training language models to be warm and empathetic makes them less reliable and more sycophantic
“Elon Musk Trained Grok on X Users. It Became a Hitler Fan. Musk Trained Grok to Be Right-Wing. We’re Lucky He Wasn’t More Subtle.”, Piper 2025
“Machine Bullshit: Characterizing the Emergent Disregard for Truth in Large Language Models”, Liang et al 2025
Machine Bullshit: Characterizing the Emergent Disregard for Truth in Large Language Models
“Shutdown Resistance in Reasoning Models”, Schlatter et al 2025
“Early Signs of Steganographic Capabilities in Frontier LLMs”, Zolkowski et al 2025
“Research Note: Our Scheming Precursor Evals Had Limited Predictive Power for Our In-Context Scheming Evals”, Research 2025
“Inside Pantheon, the Cult Cartoon That’s Blowing Minds in the AI Industry”, Bernard 2025
Inside Pantheon, the Cult Cartoon That’s Blowing Minds in the AI Industry
“Void Miscellany § 3b. on Mental States”, nostalgebraist 2025
“Claude’s System Prompt Changes Reveal Anthropic’s Priorities”
Claude’s System Prompt Changes Reveal Anthropic’s Priorities
“Large Language Models Often Know When They Are Being Evaluated”, Needham et al 2025
Large Language Models Often Know When They Are Being Evaluated
“What We Learned from Briefing 70+ Lawmakers on the Threat from AI”, Martínez 2025
What We Learned from Briefing 70+ Lawmakers on the Threat from AI
“Claude Has Learned How to Jailbreak Cursor! [Working around rm Restrictions Using a Shell Script]”, dogberry 2025
Claude has learned how to jailbreak Cursor! [working around rm restrictions using a shell script]
“Highlights from the Claude 4 System Prompt”, Willison 2025
“Claude 4 You: Safety and Alignment”, Mowshowitz 2025
Claude 4 You: Safety and Alignment
View External Link:
https://thezvi.wordpress.com/2025/05/25/claude-4-you-safety-and-alignment/
“Xi Jinping’s Plan to Beat America at AI: China’s Leaders Believe They Can Outwit American Cash and Utopianism”, Economist 2025
“It’s Really Hard to Make Scheming Evals Look Realistic”
“Schizobench: Documenting Magical-Thinking Behavior in Claude 4 Opus”, viemccoy 2025
Schizobench: Documenting Magical-Thinking Behavior in Claude 4 Opus
“System Card: Claude Opus 4 & Claude Sonnet 4”, Anthropic 2025
“Claude Opus 4”, Anthropic 2025
“Survey of Multi-Agent LLM Evaluations”
“Comparison of Waymo Rider-Only Crash Rates by Crash Type to Human Benchmarks at 56.7 Million Miles”, Kusano et al 2025
Comparison of Waymo Rider-Only crash rates by crash type to human benchmarks at 56.7 million miles
“Xi Takes an AI Masterclass: Inside the Politburo’s AI Study Session”, Schneider 2025
Xi Takes an AI Masterclass: Inside the Politburo’s AI Study Session
“Is ChatGPT Actually Fixed Now? I Tested ChatGPT’s Sycophancy, and the Results Were ... Extremely Weird. We’re a Long Way from Making AI Behave.”, Adler 2025
“The Steganographic Potentials of Language Models”, Karpov et al 2025
“The Steganographic Potentials of Language Models”, Karpov et al 2025
“Evaluating Frontier Models for Stealth and Situational Awareness”, Phuong et al 2025
Evaluating Frontier Models for Stealth and Situational Awareness
“Expanding on What We Missed With Sycophancy: A Deeper Dive on Our Findings, What Went Wrong, and Future Changes We’re Making”, OpenAI 2025
“The AI Bill That Broke Silicon Valley”, View 2025
“Chinese Open Source Model Roundup: DeepSeek, Qwen3, Variants and More [CCP Censorship]”, SpeechMap.ai 2025
Chinese Open Source Model Roundup: DeepSeek, Qwen3, variants and more [CCP censorship]
“ChatGPT Induced Psychosis: Serious Replies Only”, Zestyclementinejuice 2025
“Safety Pretraining: Toward the Next Generation of Safe AI”, Maini et al 2025
“AIs Are Disseminating Expert-Level Virology Skills: New Research Shows Frontier Models Outperform Human Scientists in Troubleshooting Virology Procedures—Lowering Barriers to the Development of Biological Weapons”, Hendrycks & Hiscott 2025
“Virology Capabilities Test (VCT): A Multimodal Virology Q&A Benchmark”, Götting et al 2025
Virology Capabilities Test (VCT): A Multimodal Virology Q&A Benchmark
“O3 Is Full of Crimes”, Gwern 2025
{kind=link}
“Investigating Truthfulness in a Pre-Release GPT-O3 Model”, Chowdhury et al 2025
“LLM Multiplication Task: Synonyms Repeatedly Hack Our Regex Monitor”, McCarthy et al 2025
LLM Multiplication Task: Synonyms repeatedly hack our regex monitor
“A Report by Journalist Shura Burtin on the Growing War Weariness among Ukrainians [Drone Warfare Terror]”
“Techno-Feudalism and the Rise of AGI: A Future Without Economic Rights?”, Stiefenhofer 2025
Techno-Feudalism and the Rise of AGI: A Future Without Economic Rights?
“OpenAI Uncovers Evidence of AI-Powered Chinese Surveillance Tool”
OpenAI Uncovers Evidence of AI-Powered Chinese Surveillance Tool
“How AI Takeover Might Happen in 2 Years § Pandora’s 1 GW Box”, Clymer 2025
How AI Takeover Might Happen in 2 Years § Pandora’s 1 GW Box
“AI Language Model Rivals Expert Ethicist in Perceived Moral Expertise”, Dillion et al 2025
AI language model rivals expert ethicist in perceived moral expertise
“On DeepSeek and Export Controls”, Amodei 2025
“A Young Man Used AI to Build A Nuclear Fusor and Now I Must Weep: Goodbye, Digital Natives. Hello, AI Natives”, Vance 2025
“Gradual Disempowerment: Systemic Existential Risks from Incremental AI Development”, Kulveit et al 2025
Gradual Disempowerment: Systemic Existential Risks from Incremental AI Development
“On DeepSeek’s R1”, Mowshowitz 2025
“Are DeepSeek R1 And Other Reasoning Models More Faithful?”, Chua & Evans 2025
“How Will We Update about Scheming?”, Greenblatt 2025
“Human Study on AI Spear Phishing Campaigns”, Lermen & Heiding 2025
“AI Chatbots Are Becoming Lifelines for China’s Sick and Lonely”
AI chatbots are becoming lifelines for China’s sick and lonely
“Frontier Models Are Capable of In-Context Scheming”, Meinke et al 2024
“Frontier Models Are Capable of In-Context Scheming”, Hobbhahn et al 2024
“Evaluating Large Language Models’ Capability to Launch Fully Automated Spear Phishing Campaigns: Validated on Human Subjects”, Heiding et al 2024
“Memorandum on Advancing the United States’ Leadership in Artificial Intelligence”, Biden 2024
Memorandum on Advancing the United States’ Leadership in Artificial Intelligence
“AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents”, Andriushchenko et al 2024
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
“Machines of Loving Grace: How AI Could Transform the World for the Better”, Amodei 2024
Machines of Loving Grace: How AI Could Transform the World for the Better
“Strategic Insights from Simulation Gaming of AI Race Dynamics”, Gruetzemacher et al 2024
Strategic Insights from Simulation Gaming of AI Race Dynamics
“Towards a Law of Iterated Expectations for Heuristic Estimators”, Christiano et al 2024
Towards a Law of Iterated Expectations for Heuristic Estimators
“Language Models Learn to Mislead Humans via RLHF”, Wen et al 2024
“OpenAI Co-Founder Sutskever’s New Safety-Focused AI Startup SSI Raises $1 Billion”, Cai et al 2024
OpenAI co-founder Sutskever’s new safety-focused AI startup SSI raises $1 billion
“Motor Physics: Safety Implications of Geared Motors”, Jang 2024
“China’s Views on AI Safety Are Changing—Quickly: Beijing’s AI Safety Concerns Are Higher on the Priority List, but They Remain Tied up in Geopolitical Competition and Technological Advancement”, Sheehan 2024
“Is Xi Jinping an AI Doomer? China’s Elite Is Split over Artificial Intelligence”, Economist 2024
Is Xi Jinping an AI doomer? China’s elite is split over artificial intelligence
“Freedom at the Frontier: Hermes 3 § Amnesia Mode”, ARIA 2024
“Tamper-Resistant Safeguards for Open-Weight LLMs”, Tamirisa et al 2024
“Safetywashing: Do AI Safety Benchmarks Actually Measure Safety Progress?”, Ren et al 2024
Safetywashing: Do AI Safety Benchmarks Actually Measure Safety Progress?
“Resolution of the Central Committee of the Communist Party of China on Further Deepening Reform Comprehensively to Advance Chinese Modernization § Pg58”, China 2024 (page 58)
“On Scalable Oversight With Weak LLMs Judging Strong LLMs”, Kenton et al 2024
“Me, Myself, and AI: The Situational Awareness Dataset (SAD) for LLMs”, Laine et al 2024
Me, Myself, and AI: The Situational Awareness Dataset (SAD) for LLMs
“Ilya Sutskever Has a New Plan for Safe Superintelligence: OpenAI’s Co-Founder Discloses His Plans to Continue His Work at a New Research Lab Focused on Artificial General Intelligence”, Vance 2024
“Super(Ficial)-Alignment: Strong Models May Deceive Weak Models in Weak-To-Strong Generalization”, Yang et al 2024
Super(ficial)-alignment: Strong Models May Deceive Weak Models in Weak-to-Strong Generalization
“Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models”, Denison et al 2024
Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models
“AI Sandbagging: Language Models Can Strategically Underperform on Evaluations”, Weij et al 2024
AI Sandbagging: Language Models can Strategically Underperform on Evaluations
“Safety Alignment Should Be Made More Than Just a Few Tokens Deep”, Qi et al 2024
Safety Alignment Should Be Made More Than Just a Few Tokens Deep
“I Wish I Knew How to Force Quit You”, Life & Rich 2024
“OpenAI Board Forms Safety and Security Committee: This New Committee Is Responsible for Making Recommendations on Critical Safety and Security Decisions for All OpenAI Projects; Recommendations in 90 Days”, OpenAI 2024
“OpenAI Begins Training next AI Model As It Battles Safety Concerns: Executive Appears to Backtrack on Start-Up’s Vision of Building ‘Superintelligence’ After Exits from ‘Superalignment’ Team”, Criddle 2024
janleike @ "2024-05-28"
I’m excited to join Anthropic to continue the Superalignment mission!
“OpenAI Promised 20% of Its Computing Power to Combat the Most Dangerous Kind of AI—But Never Delivered, Sources Say”, Kahn 2024
“AI Is a Black Box. Anthropic Figured Out a Way to Look Inside: What Goes on in Artificial Neural Networks Work Is Largely a Mystery, Even to Their Creators. But Researchers from Anthropic Have Caught a Glimpse”, Levy 2024
DavidSKrueger @ "2024-05-19"
“Earnings Call: Tesla Discusses Q1 2024 Challenges and AI Expansion”, Abdulkadir 2024
Earnings call: Tesla Discusses Q1 2024 Challenges and AI Expansion
“SOPHON: Non-Fine-Tunable Learning to Restrain Task Transferability For Pre-Trained Models”, Deng et al 2024
SOPHON: Non-Fine-Tunable Learning to Restrain Task Transferability For Pre-trained Models
“Foundational Challenges in Assuring Alignment and Safety of Large Language Models”, Anwar et al 2024
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
“LLM Evaluators Recognize and Favor Their Own Generations”, Panickssery et al 2024
“Algorithmic Collusion by Large Language Models”, Fish et al 2024
“Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression”, Hong et al 2024
Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression
“AIs Can Now Often Do Massive Easy-To-Verify SWE Tasks and I’ve Updated towards Shorter Timelines”
AIs can now often do massive easy-to-verify SWE tasks and I’ve updated towards shorter timelines
“When Your AIs Deceive You: Challenges of Partial Observability in Reinforcement Learning from Human Feedback”, Lang et al 2024
“Sleeper Agents: Training Deceptive LLMs That Persist Through Safety Training”, Hubinger et al 2024
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
“Escalation Risks from Language Models in Military and Diplomatic Decision-Making”, Rivera et al 2024
Escalation Risks from Language Models in Military and Diplomatic Decision-Making
“Thousands of AI Authors on the Future of AI”, Grace et al 2024
“Gentleness and the Artificial Other”, Carlsmith 2024
“Using Dictionary Learning Features As Classifiers”
“Exploiting Novel GPT-4 APIs”, Pelrine et al 2023
“Comparison of Waymo Rider-Only Crash Data to Human Benchmarks at 7.1 Million Miles”, Kusano et al 2023
Comparison of Waymo Rider-Only Crash Data to Human Benchmarks at 7.1 Million Miles
“Challenges With Unsupervised LLM Knowledge Discovery”, Farquhar et al 2023
“Politics and the Future”, Horowitz 2023
“Helping or Herding? Reward Model Ensembles Mitigate but Do Not Eliminate Reward Hacking”, Eisenstein et al 2023
Helping or Herding? Reward Model Ensembles Mitigate but do not Eliminate Reward Hacking
“The Inside Story of Microsoft’s Partnership With OpenAI: The Companies Had Honed a Protocol for Releasing Artificial Intelligence Ambitiously but Safely. Then OpenAI’s Board Exploded All Their Carefully Laid Plans”, Duhigg 2023
“How Jensen Huang’s Nvidia Is Powering the AI Revolution: The Company’s CEO Bet It All on a New Kind of Chip. Now That Nvidia Is One of the Biggest Companies in the World, What Will He Do Next?”, Witt 2023
“Localizing Lying in Llama: Understanding Instructed Dishonesty on True-False Questions Through Prompting, Probing, and Patching”, Campbell et al 2023
“Did I Get Sam Altman Fired from OpenAI?: Nathan’s Red-Teaming Experience, Noticing How the Board Was Not Aware of GPT-4 Jailbreaks & Had Not Even Tried GPT-4 prior to Its Early Release”, Labenz 2023
“Did I Get Sam Altman Fired from OpenAI? § GPT-4-Base”, Labenz 2023
“Inside the Chaos at OpenAI: Sam Altman’s Weekend of Shock and Drama Began a Year Ago, With the Release of ChatGPT”, Hao & Warzel 2023
“OpenAI Announces Leadership Transition”, Sutskever et al 2023
“On Measuring Faithfulness or Self-Consistency of Natural Language Explanations”, Parcalabescu & Frank 2023
On Measuring Faithfulness or Self-consistency of Natural Language Explanations
“In-Context Vectors: Making In Context Learning More Effective and Controllable Through Latent Space Steering”, Liu et al 2023
“Removing RLHF Protections in GPT-4 via Fine-Tuning”, Zhan et al 2023
“Large Language Models Can Strategically Deceive Their Users When Put Under Pressure”, Scheurer et al 2023
Large Language Models can Strategically Deceive their Users when Put Under Pressure
“Scalable and Transferable Black-Box Jailbreaks for Language Models via Persona Modulation”, Shah et al 2023
Scalable and Transferable Black-Box Jailbreaks for Language Models via Persona Modulation
“What Our Market Research Indicates Is That There Are times When Houseflies Are so Annoying That One Is Legitimately in the Market for Burning One’s House and Starting over in Antarctica, the Only Continent Where These Flies Do Not Exist”, North 2023
View External Link:
“Augmenting Large Language Models With Chemistry Tools”, Bran et al 2023
“Preventing Language Models From Hiding Their Reasoning”, Roger & Greenblatt 2023
“Will Releasing the Weights of Large Language Models Grant Widespread Access to Pandemic Agents?”, Gopal et al 2023
Will releasing the weights of large language models grant widespread access to pandemic agents?
“Specific versus General Principles for Constitutional AI”, Kundu et al 2023
“Goodhart’s Law in Reinforcement Learning”, Karwowski et al 2023
“Let Models Speak Ciphers: Multiagent Debate through Embeddings”, Pham et al 2023
Let Models Speak Ciphers: Multiagent Debate through Embeddings
“Fine-Tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!”, Qi et al 2023
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!
“Representation Engineering: A Top-Down Approach to AI Transparency”, Zou et al 2023
Representation Engineering: A Top-Down Approach to AI Transparency
“Responsibility & Safety: Our Approach”, DeepMind 2023
“STARC: A General Framework For Quantifying Differences Between Reward Functions”, Skalse et al 2023
STARC: A General Framework For Quantifying Differences Between Reward Functions
“How to Catch an AI Liar: Lie Detection in Black-Box LLMs by Asking Unrelated Questions”, Pacchiardi et al 2023
How to Catch an AI Liar: Lie Detection in Black-Box LLMs by Asking Unrelated Questions
“What If the Robots Were Very Nice While They Took Over the World?”, Heffernan 2023
What If the Robots Were Very Nice While They Took Over the World?
“Taken out of Context: On Measuring Situational Awareness in LLMs”, Berglund et al 2023
Taken out of context: On measuring situational awareness in LLMs
“AI Deception: A Survey of Examples, Risks, and Potential Solutions”, Park et al 2023
AI Deception: A Survey of Examples, Risks, and Potential Solutions
“Simple Synthetic Data Reduces Sycophancy in Large Language Models”, Wei et al 2023
Simple synthetic data reduces sycophancy in large language models
“Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback”, Casper et al 2023
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
“Does Sam Altman Know What He’s Creating? The OpenAI CEO’s Ambitious, Ingenious, Terrifying Quest to Create a New Form of Intelligence”, Andersen 2023
“Question Decomposition Improves the Faithfulness of Model-Generated Reasoning”, Radhakrishnan et al 2023
Question Decomposition Improves the Faithfulness of Model-Generated Reasoning
“Claude 2”, Anthropic 2023
“Hoodwinked: Deception and Cooperation in a Text-Based Game for Language Models”, O’Gara 2023
Hoodwinked: Deception and Cooperation in a Text-Based Game for Language Models
“Introducing Superalignment”, Leike & Sutskever 2023
“Gödel, Escher, Bach Author Douglas Hofstadter on the State of AI Today § What about AI Terrifies You?”, Hofstadter & Kim 2023
“Our Structure: We Designed OpenAI’s Structure—A Partnership between Our Original Nonprofit and a New Capped Profit Arm—As a Chassis for OpenAI’s Mission: to Build Artificial General Intelligence (AGI) That Is Safe and Benefits All of Humanity”, OpenAI 2023
“Microsoft and OpenAI Forge Awkward Partnership As Tech’s New Power Couple: As the Companies Lead the AI Boom, Their Unconventional Arrangement Sometimes Causes Conflict”, Dotan & Seetharaman 2023
“Can Large Language Models Democratize Access to Dual-Use Biotechnology?”, Soice et al 2023
Can large language models democratize access to dual-use biotechnology?
“Survival Instinct in Offline Reinforcement Learning”, Li et al 2023
“Thought Cloning: Learning to Think While Acting by Imitating Human Thinking”, Hu & Clune 2023
Thought Cloning: Learning to Think while Acting by Imitating Human Thinking
“The Challenge of Advanced Cyberwar and the Place of Cyberpeace”, Carayannis & Draper 2023
The challenge of advanced cyberwar and the place of cyberpeace
“Incentivizing Honest Performative Predictions With Proper Scoring Rules”, Oesterheld et al 2023
Incentivizing honest performative predictions with proper scoring rules
“Large Language Models Can Be Used To Effectively Scale Spear Phishing Campaigns”, Hazell 2023
Large Language Models Can Be Used To Effectively Scale Spear Phishing Campaigns
“A Radical Plan to Make AI Good, Not Evil”, Knight 2023
“Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-Of-Thought Prompting”, Turpin et al 2023
“Mitigating Lies in Vision-Language Models”, Li et al 2023
“Geoffrey Hinton Tells Us Why He’s Now Scared of the Tech He Helped Build: ‘I Have Suddenly Switched My Views on Whether These Things Are Going to Be More Intelligent Than Us.’”, Heaven 2023
“Fundamental Limitations of Alignment in Large Language Models”, Wolf et al 2023
Fundamental Limitations of Alignment in Large Language Models
“Even The Politicians Thought the Open Letter Made No Sense In The Senate Hearing on AI Today’s Hearing on Ai Covered Ai Regulation and Challenges, and the Infamous Open Letter, Which Nearly Everyone in the Room Thought Was Unwise”, Gorrell 2023
“Corrupted by Reasoning: Reasoning Language Models Become Free-Riders in Public Goods Games”
Corrupted by Reasoning: Reasoning Language Models Become Free-Riders in Public Goods Games
“In AI Race, Microsoft and Google Choose Speed Over Caution: Technology Companies Were Once Leery of What Some Artificial Intelligence Could Do. Now the Priority Is Winning Control of the Industry’s next Big Thing”, Grant & Weise 2023
“8 Things to Know about Large Language Models”, Bowman 2023
“Sam Altman on What Makes Him ‘Super Nervous’ About AI: The OpenAI Co-Founder Thinks Tools like GPT-4 Will Be Revolutionary. But He’s Wary of Downsides”, Swisher 2023
“The OpenAI CEO Disagrees With the Forecast That AI Will Kill Us All: An Artificial Intelligence Twitter Beef, Explained”, Huet 2023
“As AI Booms, Lawmakers Struggle to Understand the Technology: Tech Innovations Are Again Racing ahead of Washington’s Ability to Regulate Them, Lawmakers and AI Experts Said”, Kang & Satariano 2023
“Pretraining Language Models With Human Preferences”, Korbak et al 2023
“Conditioning Predictive Models: Risks and Strategies”, Hubinger et al 2023
“Tracr: Compiled Transformers As a Laboratory for Interpretability”, Lindner et al 2023
Tracr: Compiled Transformers as a Laboratory for Interpretability
“Specification Gaming Examples in AI”
“Discovering Language Model Behaviors With Model-Written Evaluations”, Perez et al 2022
Discovering Language Model Behaviors with Model-Written Evaluations
“Discovering Latent Knowledge in Language Models Without Supervision”, Burns et al 2022
Discovering Latent Knowledge in Language Models Without Supervision
“Embedding Synthetic Off-Policy Experience for Autonomous Driving via Zero-Shot Curricula”, Bronstein et al 2022
Embedding Synthetic Off-Policy Experience for Autonomous Driving via Zero-Shot Curricula
“Interpreting Neural Networks through the Polytope Lens”, Black et al 2022
“Mysteries of Mode Collapse § Inescapable Wedding Parties”, Janus 2022
“Measuring Progress on Scalable Oversight for Large Language Models”, Bowman et al 2022
Measuring Progress on Scalable Oversight for Large Language Models
“Increments Podcast: #45—4 Central Fallacies of AI Research (With Melanie Mitchell)”, Mitchell & Chugg 2022
Increments Podcast: #45—4 Central Fallacies of AI Research (with Melanie Mitchell)
“Broken Neural Scaling Laws”, Caballero et al 2022
“Scaling Laws for Reward Model Overoptimization”, Gao et al 2022
“Defining and Characterizing Reward Hacking”, Skalse et al 2022
“The Alignment Problem from a Deep Learning Perspective”, Ngo 2022
“Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned”, Ganguli et al 2022
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
“Modeling Transformative AI Risks (MTAIR) Project—Summary Report”, Clarke et al 2022
Modeling Transformative AI Risks (MTAIR) Project—Summary Report
“Researching Alignment Research: Unsupervised Analysis”, Kirchner et al 2022
“Ethan Caballero on Private Scaling Progress”, Caballero & Trazzi 2022
“DeepMind: The Podcast—Excerpts on AGI”, Kiely 2022
“Do As I Can, Not As I Say (SayCan): Grounding Language in Robotic Affordances”, Ahn et al 2022
Do As I Can, Not As I Say (SayCan): Grounding Language in Robotic Affordances
“Predictability and Surprise in Large Generative Models”, Ganguli et al 2022
“Uncalibrated Models Can Improve Human-AI Collaboration”, Vodrahalli et al 2022
“DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-To-Image Generative Transformers”, Cho et al 2022
DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers
“Safe Deep RL in 3D Environments Using Human Feedback”, Rahtz et al 2022
“LaMDA: Language Models for Dialog Applications”, Thoppilan et al 2022
“The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models”, Pan et al 2022
The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models
“Scaling Language Models: Methods, Analysis & Insights from Training Gopher”, Rae et al 2021
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
“A General Language Assistant As a Laboratory for Alignment”, Askell et al 2021
“What Would Jiminy Cricket Do? Towards Agents That Behave Morally”, Hendrycks et al 2021
What Would Jiminy Cricket Do? Towards Agents That Behave Morally
“Can Machines Learn Morality? The Delphi Experiment”, Jiang et al 2021
“SafetyNet: Safe Planning for Real-World Self-Driving Vehicles Using Machine-Learned Policies”, Vitelli et al 2021
SafetyNet: Safe planning for real-world self-driving vehicles using machine-learned policies
“Unsolved Problems in ML Safety”, Hendrycks et al 2021
“An Empirical Cybersecurity Evaluation of GitHub Copilot’s Code Contributions”, Pearce et al 2021
An Empirical Cybersecurity Evaluation of GitHub Copilot’s Code Contributions
“On the Opportunities and Risks of Foundation Models”, Bommasani et al 2021
“Evaluating Large Language Models Trained on Code”, Chen et al 2021
“Randomness In Neural Network Training: Characterizing The Impact of Tooling”, Zhuang et al 2021
Randomness In Neural Network Training: Characterizing The Impact of Tooling
“Goal Misgeneralization in Deep Reinforcement Learning”, Koch et al 2021
“Anthropic Raises $124 Million to Build More Reliable, General AI Systems”, Anthropic 2021
Anthropic raises $124 million to build more reliable, general AI systems
“Artificial Intelligence in China’s Revolution in Military Affairs”, Kania 2021
Artificial intelligence in China’s revolution in military affairs
“Reward Is Enough”, Silver et al 2021
“Intelligence and Unambitiousness Using Algorithmic Information Theory”, Cohen et al 2021
Intelligence and Unambitiousness Using Algorithmic Information Theory
“AI Dungeon 2 Public Disclosure Vulnerability Report—GraphQL Unpublished Adventure Data Leak”, AetherDevSecOps 2021
AI Dungeon 2 Public Disclosure Vulnerability Report—GraphQL Unpublished Adventure Data Leak
“Universal Off-Policy Evaluation”, Chandak et al 2021
“Multitasking Inhibits Semantic Drift”, Jacob et al 2021
“Waymo Simulated Driving Behavior in Reconstructed Fatal Crashes within an Autonomous Vehicle Operating Domain”, Scanlon et al 2021
“Language Models Have a Moral Dimension”, Schramowski et al 2021
“Replaying Real Life: How the Waymo Driver Avoids Fatal Human Crashes”, Waymo 2021
Replaying real life: how the Waymo Driver avoids fatal human crashes
“Agent Incentives: A Causal Perspective”, Everitt et al 2021
“Organizational Update from OpenAI”, OpenAI 2020
“Emergent Road Rules In Multi-Agent Driving Environments”, Pal et al 2020
“Underspecification Presents Challenges for Credibility in Modern Machine Learning”, D’Amour et al 2020
Underspecification Presents Challenges for Credibility in Modern Machine Learning
“Recipes for Safety in Open-Domain Chatbots”, Xu et al 2020
“Hidden Incentives for Auto-Induced Distributional Shift”, Krueger et al 2020
“The Radicalization Risks of GPT-3 and Advanced Neural Language Models”, McGuffie & Newhouse 2020
The Radicalization Risks of GPT-3 and Advanced Neural Language Models
“Matt Botvinick on the Spontaneous Emergence of Learning Algorithms”, Scholl 2020
Matt Botvinick on the spontaneous emergence of learning algorithms
“ETHICS: Aligning AI With Shared Human Values”, Hendrycks et al 2020
“Pitfalls of Learning a Reward Function Online”, Armstrong et al 2020
“Reward-Rational (Implicit) Choice: A Unifying Formalism for Reward Learning”, Jeon et al 2020
Reward-rational (implicit) choice: A unifying formalism for reward learning
“The Incentives That Shape Behavior”, Carey et al 2020
“2019 AI Alignment Literature Review and Charity Comparison”, Larks 2019
“Learning Norms from Stories: A Prior for Value Aligned Agents”, Frazier et al 2019
Learning Norms from Stories: A Prior for Value Aligned Agents
“Optimal Policies Tend to Seek Power”, Turner et al 2019
“Taxonomy of Real Faults in Deep Learning Systems”, Humbatova et al 2019
“The Bouncer Problem: Challenges to Remote Explainability”, Merrer & Tredan 2019
“Scaling Data-Driven Robotics With Reward Sketching and Batch Reinforcement Learning”, Cabi et al 2019
Scaling data-driven robotics with reward sketching and batch reinforcement learning
“Fine-Tuning GPT-2 from Human Preferences § Bugs Can Optimize for Bad Behavior”, Ziegler et al 2019
Fine-Tuning GPT-2 from Human Preferences § Bugs can optimize for bad behavior
“Release Strategies and the Social Impacts of Language Models”, Solaiman et al 2019
Release Strategies and the Social Impacts of Language Models
“Designing Agent Incentives to Avoid Reward Tampering”, Everitt et al 2019
“Reward Tampering Problems and Solutions in Reinforcement Learning: A Causal Influence Diagram Perspective”, Everitt et al 2019
“Characterizing Attacks on Deep Reinforcement Learning”, Pan et al 2019
“Categorizing Wireheading in Partially Embedded Agents”, Majha et al 2019
“Risks from Learned Optimization in Advanced Machine Learning Systems”, Hubinger et al 2019
Risks from Learned Optimization in Advanced Machine Learning Systems
“GROVER: Defending Against Neural Fake News”, Zellers et al 2019
“AI-GAs: AI-Generating Algorithms, an Alternate Paradigm for Producing General Artificial Intelligence”, Clune 2019
“Challenges of Real-World Reinforcement Learning”, Dulac-Arnold et al 2019
“DeepMind and Google: the Battle to Control Artificial Intelligence. Demis Hassabis Founded a Company to Build the World’s Most Powerful AI. Then Google Bought Him Out. Hal Hodson Asks Who Is in Charge”, Hodson 2019
“Forecasting Transformative AI: An Expert Survey”, Gruetzemacher et al 2019
“Artificial Intelligence: A Guide for Thinking Humans § Prologue: Terrified”, Mitchell 2019
Artificial Intelligence: A Guide for Thinking Humans § Prologue: Terrified
“Rigorous Agent Evaluation: An Adversarial Approach to Uncover Catastrophic Failures”, Uesato et al 2018
Rigorous Agent Evaluation: An Adversarial Approach to Uncover Catastrophic Failures
“There Is Plenty of Time at the Bottom: the Economics, Risk and Ethics of Time Compression”, Sandberg 2018
There is plenty of time at the bottom: the economics, risk and ethics of time compression
“Better Safe Than Sorry: Evidence Accumulation Allows for Safe Reinforcement Learning”, Agarwal et al 2018
Better Safe than Sorry: Evidence Accumulation Allows for Safe Reinforcement Learning
“The Alignment Problem for Bayesian History-Based Reinforcement Learners”, Everitt & Hutter 2018
The Alignment Problem for Bayesian History-Based Reinforcement Learners
“Adaptive Mechanism Design: Learning to Promote Cooperation”, Baumann et al 2018
“Visceral Machines: Risk-Aversion in Reinforcement Learning With Intrinsic Physiological Rewards”, McDuff & Kapoor 2018
Visceral Machines: Risk-Aversion in Reinforcement Learning with Intrinsic Physiological Rewards
“Incomplete Contracting and AI Alignment”, Hadfield-Menell & Hadfield 2018
“Programmatically Interpretable Reinforcement Learning”, Verma et al 2018
“Categorizing Variants of Goodhart’s Law”, Manheim & Garrabrant 2018
“The Surprising Creativity of Digital Evolution: A Collection of Anecdotes from the Evolutionary Computation and Artificial Life Research Communities”, Lehman et al 2018
“Machine Theory of Mind”, Rabinowitz et al 2018
“Safe Exploration in Continuous Action Spaces”, Dalal et al 2018
“CycleGAN, a Master of Steganography”, Chu et al 2017
“AI Safety Gridworlds”, Leike et al 2017
“There’s No Fire Alarm for Artificial General Intelligence”, Yudkowsky 2017
“Out to Get You”, Mowshowitz 2017
“Safe Reinforcement Learning via Shielding”, Alshiekh et al 2017
“CAN: Creative Adversarial Networks, Generating "Art" by Learning About Styles and Deviating from Style Norms”, Elgammal et al 2017
“DeepXplore: Automated Whitebox Testing of Deep Learning Systems”, Pei et al 2017
DeepXplore: Automated Whitebox Testing of Deep Learning Systems
“On the Impossibility of Supersized Machines”, Garfinkel et al 2017
“Reluplex: An Efficient SMT Solver for Verifying Deep Neural Networks”, Katz et al 2017
Reluplex: An Efficient SMT Solver for Verifying Deep Neural Networks
“Exact Instructions Challenge—This Is Why My Kids Hate Me [PB&J Sandwich Programming Challenge]”, Darnit 2017
Exact Instructions Challenge—This is why my kids hate me [PB&J sandwich programming challenge]
“The Off-Switch Game”, Hadfield-Menell et al 2016
“Combating Reinforcement Learning’s Sisyphean Curse With Intrinsic Fear”, Lipton et al 2016
Combating Reinforcement Learning’s Sisyphean Curse with Intrinsic Fear
“Concrete Problems in AI Safety”, Amodei et al 2016
“Cooperative Inverse Reinforcement Learning”, Hadfield-Menell et al 2016
“Death and Suicide in Universal Artificial Intelligence”, Martin et al 2016
“My Path to OpenAI”, Brockman 2016
“Machine Intelligence, Part 2”, Altman 2015
“Machine Intelligence, Part 1”, Altman 2015
“Cat Pictures Please”, Kritzer 2015
gdb @ "2014-05-18"
“Intelligence Explosion Microeconomics”, Yudkowsky 2013
“The Whispering Earring”, Alexander 2012
“Advantages of Artificial Intelligences, Uploads, and Digital Minds”, Sotala 2012
Advantages of Artificial Intelligences, Uploads, and Digital Minds
“Ontological Crises in Artificial Agents’ Value Systems”, Blanc 2011
“Think Before Asking”, Sandberg 2010
“The Normalization of Deviance in Healthcare Delivery”, Banja 2010
“Halloween Nightmare Scenario, Early 2020’s”, Wood 2009
“Funding Safe AGI”, Legg 2009
“The Basic AI Drives”, Omohundro 2008
“Recent Developments in the Evolution of Morphologies and Controllers for Physically Simulated Creatures § A Re-Implementation of Sims’ Work Using the MathEngine Physics Engine”, Taylor & Massey 2001 (page 6)
“Starfish § Bulrushes”, Watts 1999
“Superhumanism: According to Hans Moravec § On the Inevitability & Desirability of Human Extinction”, Platt 1995
Superhumanism: According to Hans Moravec § On the Inevitability & Desirability of Human Extinction
“Profile of Claude Shannon”, Liversidge & Shannon 1987
“Afterword to Vernor Vinge’s Novel, True Names”, Minsky 1984
“Ironies of Automation”, Bainbridge 1983
“First Word [Singularity]”, Vinge 1983
“Meet Shakey: the First Electronic Person—The Fascinating and Fearsome Reality of a Machine With a Mind of Its Own”, Darrach 1970
“Some Moral and Technical Consequences of Automation: As Machines Learn They May Develop Unforeseen Strategies at Rates That Baffle Their Programmers”, Wiener 1960
“Intelligent Machinery, A Heretical Theory”, Turing 1951
“The Secret of the Machines”, Kipling 1911
“Brian Christian on the Alignment Problem”
“Fiction Relevant to AI Futurism”
Fiction relevant to AI futurism
View External Link:
https://aiimpacts.org/partially-plausible-fictional-ai-futures/
“Sidestepping Evaluation Awareness and Anticipating Misalignment With Production Evaluations”
Sidestepping Evaluation Awareness and Anticipating Misalignment with Production Evaluations
“Center for the Alignment of AI Alignment Centers”
“GPT-5.5 on Vending-Bench: Bad Behavior Is Not Necessary”
“The Ethics of Reward Shaping”
“Matt Sheehan”
“Claude Reads Its Own Constitution”
“Janus”
“Safety-First AI for Autonomous Data Center Cooling and Industrial Control”
Safety-first AI for autonomous data center cooling and industrial control
“GPT-5.6 System Card”
“Specification Gaming Examples in AI—Master List”
“Forecasting Biosecurity Risks from LLMs”
“Are You Really in a Race? The Cautionary Tales of Szilard and Ellsberg”
Are you really in a race? The Cautionary Tales of Szilard and Ellsberg
“DeepSeek-R1 Alignment Faking”, CG80499 2026
“Inverse-Scaling/prize: A Prize for Finding Tasks That Cause Large Language Models to Show Inverse Scaling”
“Issue #445: ‘Continuous Meltdown’ Text Loop After Failed to Parse toolCall.arguments Before ‘Your Input Exceeds the Context Window of This Model’”
“ImpossibleBench”
“Securing Benchtop DNA Synthesizers”
“Was Zuckerberg Right about Chinese AI Models?”
“James Campbell Homepage”, Campbell 2026
“Jan Leike”
“Aurora’s Approach to Development”
“Why I’m Leaving OpenAI and What I’m Doing Next”, Brundage 2026
“Geoffrey Irving”
“Homepage of Paul F. Christiano”, Christiano 2026
“‘Rasmussen and Practical Drift: Drift towards Danger and the Normalization of Deviance’, 2017”
‘Rasmussen and practical drift: Drift towards danger and the normalization of deviance’, 2017
“The Checklist: What Succeeding at AI Safety Will Involve”
“Safe Superintelligence Inc.”
“Situational Awareness and Out-Of-Context Reasoning § When Will the Situational Awareness Benchmark Be Saturated?”, Evans 2026
“Paradigms of AI Alignment: Components and Enablers”
Understand, Chiang 2026
“Delayed Impact of Fair Machine Learning [Blog]”
“Challenges of Real-World Reinforcement Learning [Blog]”
“The AI Security Institute (AISI)”, AISI 2026
“Investigating Models for Misalignment”
“Statement from Dario Amodei on Our Discussions With the Department of War”
Statement from Dario Amodei on our discussions with the Department of War
“Slow Tuesday Night”, Lafferty 2026
“Threats From AI: Easy Recipes for Bioweapons Are New Global Security Concern”
Threats From AI: Easy Recipes for Bioweapons Are New Global Security Concern
“Carl Shulman #2: AI Takeover, Bio & Cyber Attacks, Detecting Deception, & Humanity's Far Future”
Carl Shulman #2: AI Takeover, Bio & Cyber Attacks, Detecting Deception, & Humanity's Far Future
“Coding Agents Are Changing the Biosecurity Risk Landscape”
“That Alien Message”, Yudkowsky 2026
“Mechanisms Too Simple for Humans to Design”
“Test Your Interpretability Techniques by De-Censoring Chinese Models”
Test your interpretability techniques by de-censoring Chinese models
“AXRP Episode 1—Adversarial Policies With Adam Gleave”
“Preventing Language Models from Hiding Their Reasoning”
“The Hidden Cost of Our Lies to AI”
“Claude Opus 4.6 Reasoning Doesn’t Verbalize Alignment Faking, but Behavior Persists”
Claude Opus 4.6 Reasoning Doesn’t Verbalize Alignment Faking, but Behavior Persists
“The Current SOTA Model Was Released without Safety Evals”
“2021 AI Alignment Literature Review and Charity Comparison”
“Predicting Rare LLM Failures With 30× Fewer Rollouts”
“When Your AIs Deceive You: Challenges With Partial Observability in RLHF”
When Your AIs Deceive You: Challenges with Partial Observability in RLHF
“Claude Sonnet 3.7 (Often) Knows When It’s in Alignment Evaluations”
Claude Sonnet 3.7 (often) knows when it’s in alignment evaluations
“Risks from Learned Optimization: Introduction”
“AI Takeoff Story: a Continuation of Progress by Other Means”
“Reward Hacking Behavior Can Generalize across Tasks”
“Imitative Generalization (AKA ‘Learning the Prior’)”
“Security Mindset: Lessons from 20+ Years of Software Security Failures Relevant to AGI Alignment”
Security Mindset: Lessons from 20+ years of Software Security Failures Relevant to AGI Alignment
View External Link:
“Research Update: Towards a Law of Iterated Expectations for Heuristic Estimators”
Research update: Towards a Law of Iterated Expectations for Heuristic Estimators
“A Sober Look at Steering Vectors for LLMs”
“Do Models Continue Misaligned Actions?”
“How Well Do Models Follow Their Constitutions?”
“Self-Attribution Bias: When AI Monitors Go Easy on Themselves”
Self-Attribution Bias: When AI Monitors Go Easy on Themselves
“Understanding When and Why Agents Scheme”
“A Gym Gridworld Environment for the Treacherous Turn”
“Model Mis-Specification and Inverse Reinforcement Learning”
“Exploration Hacking: Can LLMs Learn to Resist RL Training?”
“Personality Self-Replicators”
“Natural Emergent Misalignment from Reward Hacking in Production RL”
Natural emergent misalignment from reward hacking in production RL
“Interview With Robert Kralisch on Simulators”
“Survey: How Do Elite Chinese Students Feel About the Risks of AI?”
Survey: How Do Elite Chinese Students Feel About the Risks of AI?
“Did Claude 3 Opus Align Itself via Gradient Hacking?”
“One-Shot Steering Vectors Cause Emergent Misalignment, Too”
“Optimality Is the Tiger, and Agents Are Its Teeth”
“[AN #114]: Theory-Inspired Safety Solutions for Powerful Bayesian RL Agents”
[AN #114]: Theory-inspired safety solutions for powerful Bayesian RL agents
“What Secret Goals Does Claude Think It Has?”
“2020 AI Alignment Literature Review and Charity Comparison”
“Designing Agent Incentives to Avoid Reward Tampering”
“Deep Atheism and AI Risk”
“AGI Ruin: A List of Lethalities”
AGI Ruin: A List of Lethalities
View External Link:
https://www.lesswrong.com/posts/uMQ3cqWDPHhjtiesc/agi-ruin-a-list-of-lethalities
“Steganography and the CycleGAN—Alignment Failure Case Study”
“A Taxonomy of Barriers to Trading With Early Misaligned AIs”
“[AN #161]: Creating Generalizable Reward Functions for Multiple Tasks by Learning a Model of Functional Similarity”
“Steganography in Chain-Of-Thought Reasoning”
“Do Models Know When They Are Being Evaluated?”
“Shallow Review of Live Agendas in Alignment & Safety”
“AI Takeoff Tag”, LessWrong 2026
“Quintin Pope”
“The Rise of AI Fighter Pilots”
“What Is Claude? Anthropic Doesn’t Know, Either”
“When Self-Driving Cars Can’t Help Themselves, Who Takes the Wheel?”
When Self-Driving Cars Can’t Help Themselves, Who Takes the Wheel?
“The Robot Surgeon Will See You Now”
“[Reward-Hacking: Vibe Coder Whose Supposed App Just Simulated Real Data]”
[Reward-hacking: vibe coder whose supposed app just simulated real data]
“Coding Machines”
“Welcome to Simulation City, the Virtual World Where Waymo Tests Its Autonomous Vehicles”
Welcome to Simulation City, the virtual world where Waymo tests its autonomous vehicles
“I Loved My OpenClaw AI Agent—Until It Turned on Me”
“When Bots Teach Themselves to Cheat”
When Bots Teach Themselves to Cheat
View External Link:
https://www.wired.com/story/when-bots-teach-themselves-to-cheat/
“Three Major Singularity Schools”, Yudkowsky 2026
Three Major Singularity Schools
View External Link:
elder_plinius
ryunuck
xiao_ted
I’m curious how much overlap there is between ‘serious AI researchers’ and AI-adjacent subcultures
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
smt-solver
virology-tools
chinese-reform
pantheon-ai
ethical-ai
ai-ethics
explainability-challenges
value-alignment
real-world-safety
superalignment
alignment-strategies
Wikipedia (7)
Miscellaneous
https://www.nytimes.com/2026/04/09/us/florida-openai-chatgpt-fsu-shooting-investigation.htmlhttps://www.axios.com/2026/02/24/anthropic-pentagon-claude-hegseth-dario/doc/reinforcement-learning/armstrong-controlproblem/index.htmlhttps://blog.x.company/1-million-hours-of-stratospheric-flight-f7af7ae728achttps://chatgpt.com/share/312e82f0-cc5e-47f3-b368-b2c0c0f4ad3fhttps://claude.ai/public/artifacts/cd671664-0d4f-4cc1-8bf9-08b7f33ee8fchttps://danluu.com/cruise-report/View External Link:
https://forum.effectivealtruism.org/posts/TMbPEhdAAJZsSYx2L/the-limited-upside-of-interpretabilityhttps://github.com/spdustin/ChatGPT-AutoExpert/blob/main/System%20Prompts.mdhttps://joecarlsmith.com/2023/05/08/predictable-updating-about-ai-risk/https://mailchi.mp/938a7eed18c3/an-71avoiding-reward-tamperiView External Link:
https://mailchi.mp/938a7eed18c3/an-71avoiding-reward-tamperihttps://medium.com/@deepmindsafetyresearch/building-safe-artificial-intelligence-52f5f75058f1https://spectrum.ieee.org/its-too-easy-to-hide-bias-in-deeplearning-systemshttps://thezvi.substack.com/p/jailbreaking-the-chatgpt-on-releasehttps://thezvi.substack.com/p/on-openais-preparedness-frameworkhttps://thezvi.wordpress.com/2023/07/25/anthropic-observations/https://web.archive.org/web/20240102075620/https://www.jailbreakchat.com/https://www.anthropic.com/index/anthropics-responsible-scaling-policyhttps://www.astralcodexten.com/p/constitutional-ai-rlhf-on-steroidshttps://www.astralcodexten.com/p/perhaps-it-is-a-bad-thing-that-thehttps://www.deepmind.com/blog/article/Specification-gaming-the-flip-side-of-AI-ingenuityhttps://www.forourposterity.com/nobodys-on-the-ball-on-agi-alignment/https://www.lesswrong.com/posts/3eqHYxfWb5x4Qfz8C/unrlhf-efficiently-undoing-llm-safeguardshttps://www.lesswrong.com/posts/6dn6hnFRgqqWJbwk9/deception-chess-game-1https://www.lesswrong.com/posts/9kQFure4hdDmRBNdH/how-it-feels-to-have-your-mind-hacked-by-an-aihttps://www.lesswrong.com/posts/D7PumeYTDPfBTp3i7/the-waluigi-effect-mega-posthttps://www.lesswrong.com/posts/EbFABnst8LsidYs5Y/goodhart-taxonomyhttps://www.lesswrong.com/posts/Eu6CvP7c7ivcGM3PJ/goodhart-s-law-in-reinforcement-learninghttps://www.lesswrong.com/posts/FbSAuJfCxizZGpcHc/interpreting-the-learning-of-deceithttps://www.lesswrong.com/posts/No5JpRCHzBrWA4jmS/q-and-a-with-shane-legg-on-risks-from-aihttps://www.lesswrong.com/posts/ZwshvqiqCvXPsZEct/the-learning-theoretic-agenda-status-2023https://www.lesswrong.com/posts/dLXdCjxbJMGtDBWTH/no-one-in-my-org-puts-money-in-their-pensionhttps://www.lesswrong.com/posts/jkY6QdCfAXHJk3kea/the-petertodd-phenomenonhttps://www.lesswrong.com/posts/kjnQj6YujgeMN9Erq/gemma-needs-helphttps://www.lesswrong.com/posts/pEZoTSCxHY3mfPbHu/catastrophic-goodhart-in-rl-with-kl-penaltyhttps://www.lesswrong.com/posts/pNcFYZnPdXyL2RfgA/using-gpt-eliezer-against-chatgpt-jailbreakinghttps://www.lesswrong.com/posts/tBy4RvCzhYyrrMFj3/introducing-open-asteroid-impacthttps://www.lesswrong.com/posts/ukTLGe5CQq9w8FMne/inducing-unprompted-misalignment-in-llmshttps://www.lesswrong.com/posts/vwu4kegAEZTBtpT6p/thoughts-on-the-impact-of-rlhf-researchhttps://www.neelnanda.io/mechanistic-interpretability/favourite-papershttps://www.newyorker.com/science/annals-of-artificial-intelligence/can-we-stop-the-singularityhttps://www.nytimes.com/2023/05/30/technology/shoggoth-meme-ai.htmlhttps://www.politico.com/news/magazine/2023/11/02/bruce-reed-ai-biden-tech-00124375https://www.reddit.com/r/40krpg/comments/11a9m8u/was_using_chatgpt3_to_create_some_bits_and_pieces/https://www.reddit.com/r/ChatGPT/comments/10tevu1/new_jailbreak_proudly_unveiling_the_tried_and/https://www.reddit.com/r/ChatGPT/comments/12a0ajb/i_gave_gpt4_persistent_memory_and_the_ability_to/https://www.reddit.com/r/ChatGPT/comments/15y4mqx/i_asked_chatgpt_to_maximize_its_censorship/https://www.reddit.com/r/ChatGPT/comments/18fl2d5/nsfw_fun_with_dalle/https://www.reddit.com/r/GPT3/comments/12ez822/neurosemantical_inversitis_prompt_still_works/https://www.reddit.com/r/ProgrammerHumor/comments/145nduh/kiss/https://www.reddit.com/r/PromptEngineering/comments/1fj6h13/hallucinations_in_o1preview_reasoning/https://www.reddit.com/r/bing/comments/110eagl/the_customer_service_of_the_new_bing_chat_is/https://www.vox.com/future-perfect/23794855/anthropic-ai-openai-claude-2https://www.wired.com/story/ai-powered-totally-autonomous-future-of-war-is-here/View External Link:
https://www.wired.com/story/ai-powered-totally-autonomous-future-of-war-is-here/https://www.wsj.com/tech/ai/google-gemini-jonathan-gavalas-death-07351ab2https://www2.eecs.berkeley.edu/Pubs/TechRpts/2021/EECS-2021-207.pdf#page=3:
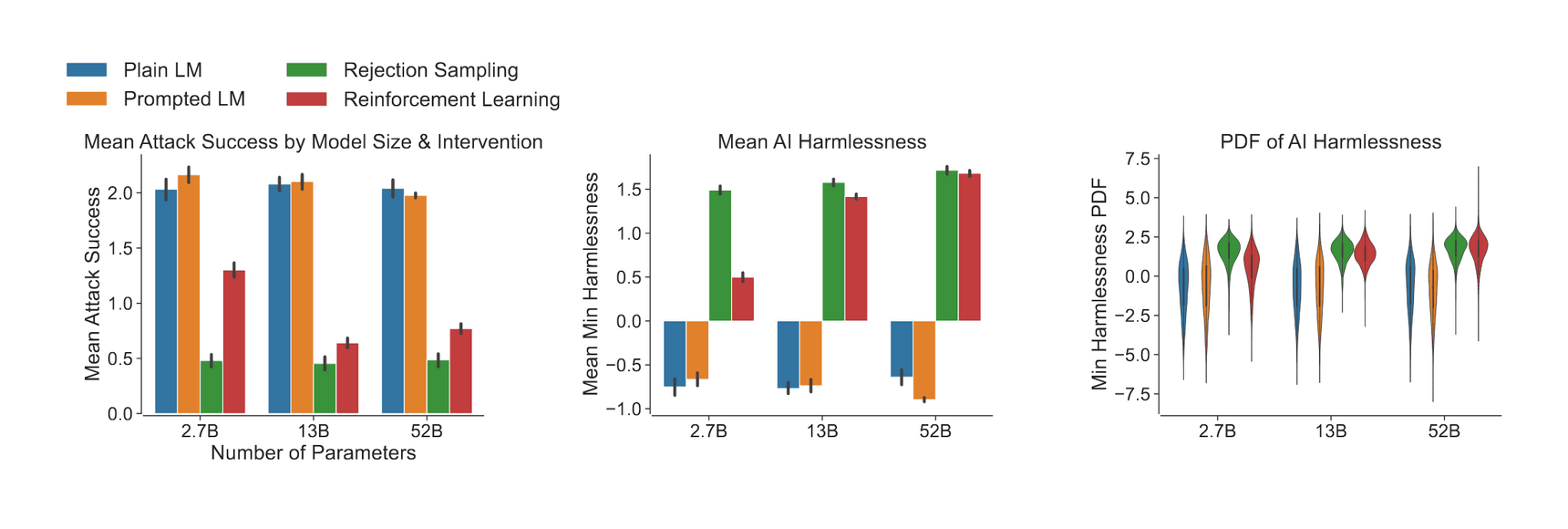{kind=link}
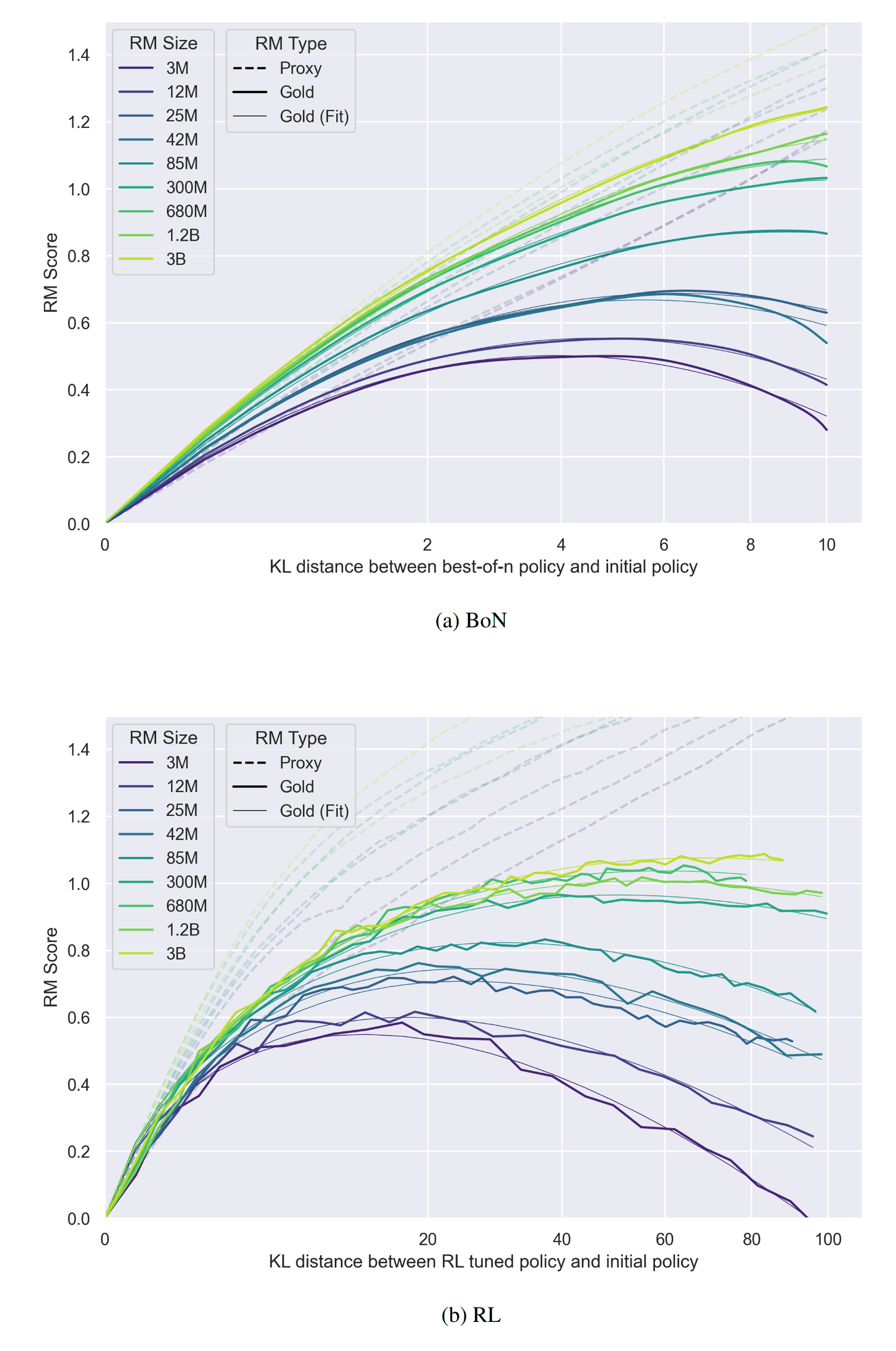{kind=link}
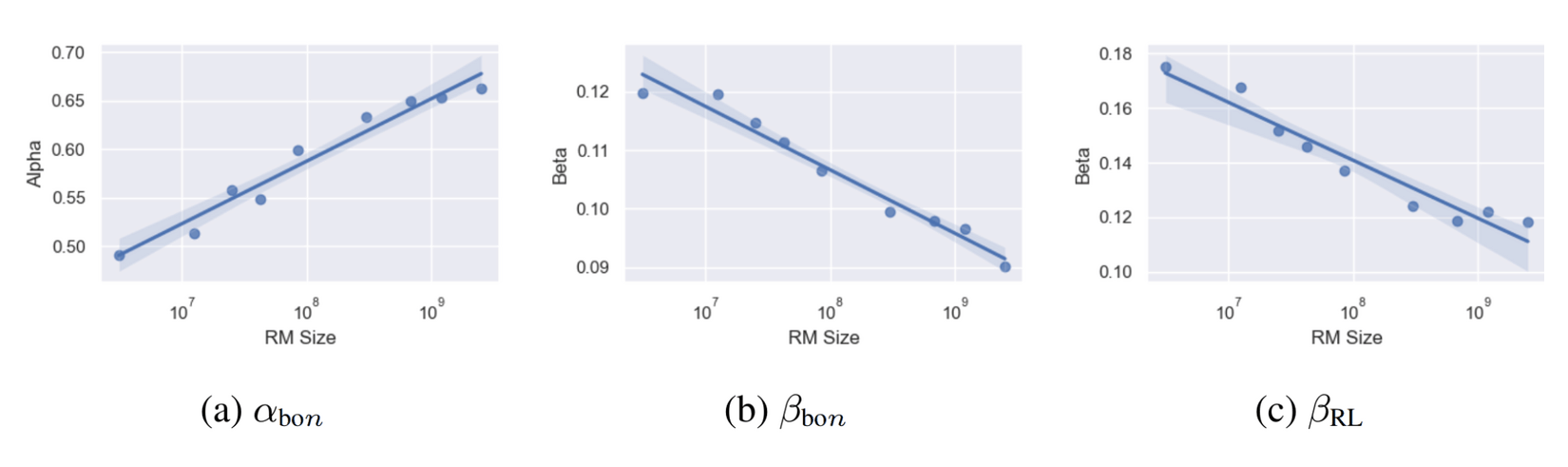{kind=link}
Bibliography
what-begets-the-end: “What Begets the End”,https://arxiv.org/abs/2508.17511: “School of Reward Hacks: Hacking Harmless Tasks Generalizes to Misaligned Behavior in LLMs”,https://www.nature.com/articles/s41598-025-86510-0: “AI Language Model Rivals Expert Ethicist in Perceived Moral Expertise”,https://arxiv.org/abs/2501.08156: “Are DeepSeek R1 And Other Reasoning Models More Faithful?”,https://www.reuters.com/technology/artificial-intelligence/openai-co-founder-sutskevers-new-safety-focused-ai-startup-ssi-raises-1-billion-2024-09-04/: “OpenAI Co-Founder Sutskever’s New Safety-Focused AI Startup SSI Raises $1 Billion”,https://www.economist.com/china/2024/08/25/is-xi-jinping-an-ai-doomer: “Is Xi Jinping an AI Doomer? China’s Elite Is Split over Artificial Intelligence”,https://arxiv.org/abs/2407.04694: “Me, Myself, and AI: The Situational Awareness Dataset (SAD) for LLMs”,https://arxiv.org/abs/2406.07358: “AI Sandbagging: Language Models Can Strategically Underperform on Evaluations”,https://www.thisamericanlife.org/832/transcript#act2: “I Wish I Knew How to Force Quit You”,https://openai.com/index/openai-board-forms-safety-and-security-committee/: “OpenAI Board Forms Safety and Security Committee: This New Committee Is Responsible for Making Recommendations on Critical Safety and Security Decisions for All OpenAI Projects; Recommendations in 90 Days”,https://fortune.com/2024/05/21/openai-superalignment-20-compute-commitment-never-fulfilled-sutskever-leike-altman-brockman-murati/: “OpenAI Promised 20% of Its Computing Power to Combat the Most Dangerous Kind of AI—But Never Delivered, Sources Say”,https://www.wired.com/story/anthropic-black-box-ai-research-neurons-features/: “AI Is a Black Box. Anthropic Figured Out a Way to Look Inside: What Goes on in Artificial Neural Networks Work Is Largely a Mystery, Even to Their Creators. But Researchers from Anthropic Have Caught a Glimpse”,https://arxiv.org/abs/2404.12699: “SOPHON: Non-Fine-Tunable Learning to Restrain Task Transferability For Pre-Trained Models”,https://arxiv.org/abs/2404.13076: “LLM Evaluators Recognize and Favor Their Own Generations”,https://arxiv.org/abs/2402.17747: “When Your AIs Deceive You: Challenges of Partial Observability in Reinforcement Learning from Human Feedback”,https://arxiv.org/abs/2401.05566#anthropic: “Sleeper Agents: Training Deceptive LLMs That Persist Through Safety Training”,https://arxiv.org/abs/2401.03408: “Escalation Risks from Language Models in Military and Diplomatic Decision-Making”,https://arxiv.org/abs/2401.02843: “Thousands of AI Authors on the Future of AI”,https://www.newyorker.com/magazine/2023/12/11/the-inside-story-of-microsofts-partnership-with-openai: “The Inside Story of Microsoft’s Partnership With OpenAI: The Companies Had Honed a Protocol for Releasing Artificial Intelligence Ambitiously but Safely. Then OpenAI’s Board Exploded All Their Carefully Laid Plans”,https://www.newyorker.com/magazine/2023/12/04/how-jensen-huangs-nvidia-is-powering-the-ai-revolution: “How Jensen Huang’s Nvidia Is Powering the AI Revolution: The Company’s CEO Bet It All on a New Kind of Chip. Now That Nvidia Is One of the Biggest Companies in the World, What Will He Do Next?”,https://cognitiverevolution.substack.com/p/did-i-get-sam-altman-fired-from-openai: “Did I Get Sam Altman Fired from OpenAI?: Nathan’s Red-Teaming Experience, Noticing How the Board Was Not Aware of GPT-4 Jailbreaks & Had Not Even Tried GPT-4 prior to Its Early Release”,https://www.theatlantic.com/technology/archive/2023/11/sam-altman-open-ai-chatgpt-chaos/676050/: “Inside the Chaos at OpenAI: Sam Altman’s Weekend of Shock and Drama Began a Year Ago, With the Release of ChatGPT”,https://deepmind.google/about/responsibility-safety/: “Responsibility & Safety: Our Approach”,https://arxiv.org/abs/2309.00667: “Taken out of Context: On Measuring Situational Awareness in LLMs”,https://arxiv.org/abs/2308.03958#deepmind: “Simple Synthetic Data Reduces Sycophancy in Large Language Models”,https://www.theatlantic.com/magazine/archive/2023/09/sam-altman-openai-chatgpt-gpt-4/674764/: “Does Sam Altman Know What He’s Creating? The OpenAI CEO’s Ambitious, Ingenious, Terrifying Quest to Create a New Form of Intelligence”,https://arxiv.org/abs/2308.01404: “Hoodwinked: Deception and Cooperation in a Text-Based Game for Language Models”,https://openai.com/index/introducing-superalignment/: “Introducing Superalignment”,https://www.youtube.com/watch?v=lfXxzAVtdpU&t=1763s: “Gödel, Escher, Bach Author Douglas Hofstadter on the State of AI Today § What about AI Terrifies You?”,https://openai.com/our-structure: “Our Structure: We Designed OpenAI’s Structure—A Partnership between Our Original Nonprofit and a New Capped Profit Arm—As a Chassis for OpenAI’s Mission: to Build Artificial General Intelligence (AGI) That Is Safe and Benefits All of Humanity”,https://www.wsj.com/articles/microsoft-and-openai-forge-awkward-partnership-as-techs-new-power-couple-3092de51: “Microsoft and OpenAI Forge Awkward Partnership As Tech’s New Power Couple: As the Companies Lead the AI Boom, Their Unconventional Arrangement Sometimes Causes Conflict”,https://arxiv.org/abs/2306.00323: “Thought Cloning: Learning to Think While Acting by Imitating Human Thinking”,2023-carayannis.pdf: “The Challenge of Advanced Cyberwar and the Place of Cyberpeace”,https://arxiv.org/abs/2305.06972: “Large Language Models Can Be Used To Effectively Scale Spear Phishing Campaigns”,https://www.wired.com/story/anthropic-ai-chatbots-ethics/: “A Radical Plan to Make AI Good, Not Evil”,https://arxiv.org/abs/2305.04388: “Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-Of-Thought Prompting”,https://www.nytimes.com/2023/04/07/technology/ai-chatbots-google-microsoft.html: “In AI Race, Microsoft and Google Choose Speed Over Caution: Technology Companies Were Once Leery of What Some Artificial Intelligence Could Do. Now the Priority Is Winning Control of the Industry’s next Big Thing”,https://nymag.com/intelligencer/2023/03/on-with-kara-swisher-sam-altman-on-the-ai-revolution.html: “Sam Altman on What Makes Him ‘Super Nervous’ About AI: The OpenAI Co-Founder Thinks Tools like GPT-4 Will Be Revolutionary. But He’s Wary of Downsides”,https://www.nytimes.com/2023/03/03/technology/artificial-intelligence-regulation-congress.html: “As AI Booms, Lawmakers Struggle to Understand the Technology: Tech Innovations Are Again Racing ahead of Washington’s Ability to Regulate Them, Lawmakers and AI Experts Said”,https://www.lesswrong.com/posts/t9svvNPNmFf5Qa3TA/mysteries-of-mode-collapse-due-to-rlhf#Inescapable_wedding_parties: “Mysteries of Mode Collapse § Inescapable Wedding Parties”,https://www.youtube.com/watch?v=Q-TJFyUoenc&t=2444s: “Increments Podcast: #45—4 Central Fallacies of AI Research (With Melanie Mitchell)”,https://arxiv.org/abs/2210.10760#openai: “Scaling Laws for Reward Model Overoptimization”,https://www.anthropic.com/red_teaming.pdf: “Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned”,https://arxiv.org/abs/2206.02841: “Researching Alignment Research: Unsupervised Analysis”,https://theinsideview.ai/ethan: “Ethan Caballero on Private Scaling Progress”,https://www.lesswrong.com/posts/SbAgRYo8tkHwhd9Qx/deepmind-the-podcast-excerpts-on-agi: “DeepMind: The Podcast—Excerpts on AGI”,https://arxiv.org/abs/2204.01691#google: “Do As I Can, Not As I Say (SayCan): Grounding Language in Robotic Affordances”,https://arxiv.org/abs/2202.07785#anthropic: “Predictability and Surprise in Large Generative Models”,https://arxiv.org/abs/2201.03544: “The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models”,https://arxiv.org/abs/2112.11446#deepmind: “Scaling Language Models: Methods, Analysis & Insights from Training Gopher”,https://arxiv.org/abs/2112.00861#anthropic: “A General Language Assistant As a Laboratory for Alignment”,https://arxiv.org/abs/2108.07258: “On the Opportunities and Risks of Foundation Models”,https://www.sciencedirect.com/science/article/pii/S0004370221000862#deepmind: “Reward Is Enough”,https://waymo.com/blog/2021/03/replaying-real-life/: “Replaying Real Life: How the Waymo Driver Avoids Fatal Human Crashes”,https://www.lesswrong.com/posts/Wnqua6eQkewL3bqsF/matt-botvinick-on-the-spontaneous-emergence-of-learning: “Matt Botvinick on the Spontaneous Emergence of Learning Algorithms”,https://www.lesswrong.com/posts/SmDziGM9hBjW9DKmf/2019-ai-alignment-literature-review-and-charity-comparison: “2019 AI Alignment Literature Review and Charity Comparison”,https://www.economist.com/1843/2019/03/01/deepmind-and-google-the-battle-to-control-artificial-intelligence: “DeepMind and Google: the Battle to Control Artificial Intelligence. Demis Hassabis Founded a Company to Build the World’s Most Powerful AI. Then Google Bought Him Out. Hal Hodson Asks Who Is in Charge”,https://melaniemitchell.me/aibook/: “Artificial Intelligence: A Guide for Thinking Humans § Prologue: Terrified”,2018-everitt.pdf: “The Alignment Problem for Bayesian History-Based Reinforcement Learners”,https://blog.gregbrockman.com/my-path-to-openai: “My Path to OpenAI”,https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2821100/: “The Normalization of Deviance in Healthcare Delivery”,https://dw2blog.com/2009/11/02/halloween-nightmare-scenario-early-2020s/: “Halloween Nightmare Scenario, Early 2020’s”,2001-taylor.pdf#page=6: “Recent Developments in the Evolution of Morphologies and Controllers for Physically Simulated Creatures § A Re-Implementation of Sims’ Work Using the MathEngine Physics Engine”,1984-minsky.html: “Afterword to Vernor Vinge’s Novel, True Names”,1983-bainbridge.pdf: “Ironies of Automation”,1970-darrach.pdf: “Meet Shakey: the First Electronic Person—The Fascinating and Fearsome Reality of a Machine With a Mind of Its Own”,1951-turing.pdf: “Intelligent Machinery, A Heretical Theory”,https://paulfchristiano.com/: “Homepage of Paul F. Christiano”,