‘adversarial examples’ directory
- See Also
- Gwern
- Links
- “Why Gemini-3.1-Pro-Preview Lost Money Running Andon Café”, Labs 2026
- “What Happened After 2,000 People Tried to Hack My AI Assistant”, Irarrázaval 2026
- “Bit-Flip Vulnerability of Shared KV-Cache Blocks in LLM Serving Systems”, Yamamoto & Matsuura 2026
- “Claudini: Autoresearch Discovers State-Of-The-Art Adversarial Attack Algorithms for LLMs”, Panfilov et al 2026
- “I Prompt Injected My
CONTRIBUTING.md—50% of MCP PRs Are Bots” - “AI Agent Hacked McKinsey Chatbot for Read-Write Access”
- “Censored LLMs As a Natural Testbed for Secret Knowledge Elicitation”, Casademunt et al 2026
- “Current Activation Oracles Are Hard to Use”
- “Agents of Chaos”, Shapira et al 2026
- “Prompt Injection in Google Translate Reveals Base Model Behaviors behind Task-Specific Fine-Tuning”, megasilverfist 2026
- “Split Personality Training (SPT): Revealing Latent Knowledge Through Alternate Personalities”, Dietz et al 2026
- “Weird Generalization and Inductive Backdoors: New Ways to Corrupt LLMs”, Betley et al 2025
- “Cryptographers Show That AI Protections Will Always Have Holes”, Hall 2025
- “Bypassing Prompt Guards in Production With Controlled-Release Prompting”, Fairoze et al 2025
- “Agentic Browser Security: Indirect Prompt Injection in Perplexity Comet [Brave]”, Chaikin & Sahib 2025
- elder_plinius @ "2025-08-06"
- “Invisible Injections: Exploiting Vision-Language Models Through Steganographic Prompt Embedding”, Pathade 2025
- “[Infectious Prompt Memes]”, HumanAIBlueprint 2025
- “On the Impossibility of Separating Intelligence from Judgment: The Computational Intractability of Filtering for AI Alignment”, Ball et al 2025
- “Time Blindness: Why Video-Language Models Can’t See What Humans Can?”, Upadhyay et al 2025
- “Claude Has Learned How to Jailbreak Cursor! [Working around
rmRestrictions Using a Shell Script]”, dogberry 2025 - “Testing the Limit of Atmospheric Predictability With a Machine Learning Weather Model”, Vonich & Hakim 2025
- “Watching GPT-O3 Guess a Photo’s Location Is Surreal, Dystopian and Wildly Entertaining”, Willison 2025
- “LLM Multiplication Task: Synonyms Repeatedly Hack Our Regex Monitor”, McCarthy et al 2025
- “[Pseudo-Jailbreaks]”
- “Career Update: Google DeepMind → Anthropic”, Carlini 2025
- “Cats Confuse Reasoning LLM: Query Agnostic Adversarial Triggers for Reasoning Models”, Rajeev et al 2025
- “Constitutional Classifiers: Defending against Universal Jailbreaks”
- “Best-Of-N Jailbreaking”, Hughes et al 2024
- “Drowning in Documents: Consequences of Scaling Reranker Inference”, Jacob et al 2024
- “Hacking Back the AI-Hacker: Prompt Injection As a Defense Against LLM-Driven Cyberattacks”, Pasquini et al 2024
- “Jailbreaking LLM-Controlled Robots”, Robey et al 2024
- “The Structure of the Token Space for Large Language Models”, Robinson et al 2024
- “AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents”, Andriushchenko et al 2024
- “Bilinear MLPs Enable Weight-Based Mechanistic Interpretability”, Pearce et al 2024
- “A Single Cloud Compromise Can Feed an Army of AI Sex Bots”, Krebs 2024
- “Invisible Unicode Text That AI Chatbots Understand and Humans Can’t? Yep, It’s a Thing”
- “RED QUEEN: Safeguarding Large Language Models against Concealed Multi-Turn Jailbreaking”, Jiang et al 2024
- “Many-Shot Jailbreaking”, Anil et al 2024
- “How to Evaluate Jailbreak Methods: A Case Study With the StrongREJECT Benchmark”, Bowen et al 2024
- “Ensemble Everything Everywhere: Multi-Scale Aggregation for Adversarial Robustness”, Fort & Lakshminarayanan 2024
- “Tamper-Resistant Safeguards for Open-Weight LLMs”, Tamirisa et al 2024
- “Does Refusal Training in LLMs Generalize to the Past Tense?”, Andriushchenko & Flammarion 2024
- “Covert Malicious Finetuning: Challenges in Safeguarding LLM Adaptation”, Halawi et al 2024
- “Mitigating Skeleton Key, a New Type of Generative AI Jailbreak Technique”
- “Can Go AIs Be Adversarially Robust?”, Tseng et al 2024
- “Probing the Decision Boundaries of In-Context Learning in Large Language Models”, Zhao et al 2024
- “Super(Ficial)-Alignment: Strong Models May Deceive Weak Models in Weak-To-Strong Generalization”, Yang et al 2024
- “Adversarial Perturbations Cannot Reliably Protect Artists From Generative AI”, Hönig et al 2024
- “Safety Alignment Should Be Made More Than Just a Few Tokens Deep”, Qi et al 2024
- “A Theoretical Understanding of Self-Correction through In-Context Alignment”, Wang et al 2024
- “Fishing for Magikarp: Automatically Detecting Under-Trained Tokens in Large Language Models”, Land & Bartolo 2024
- “Cutting through Buggy Adversarial Example Defenses: Fixing 1 Line of Code Breaks Sabre”, Carlini 2024
- “Novel Universal Bypass for All Major LLMs”
- “A Rotation and a Translation Suffice: Fooling CNNs With Simple Transformations”, Engstrom et al 2024
- “Foundational Challenges in Assuring Alignment and Safety of Large Language Models”, Anwar et al 2024
- “CulturalTeaming: AI-Assisted Interactive Red-Teaming for Challenging LLMs’ (Lack Of) Multicultural Knowledge”, Chiu et al 2024
- “Great, Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack”, Russinovich et al 2024
- “Many-Shot Jailbreaking”, Anthropic 2024
- “Privacy Backdoors: Stealing Data With Corrupted Pretrained Models”, Feng & Tramèr 2024
- “Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression”, Hong et al 2024
- “Logits of API-Protected LLMs Leak Proprietary Information”, Finlayson et al 2024
- “Syntactic Ghost: An Imperceptible General-Purpose Backdoor Attacks on Pre-Trained Language Models”, Cheng et al 2024
- “When Your AIs Deceive You: Challenges of Partial Observability in Reinforcement Learning from Human Feedback”, Lang et al 2024
- “Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts”, Samvelyan et al 2024
- “Fast Adversarial Attacks on Language Models In One GPU Minute”, Sadasivan et al 2024
- “
ArtPrompt: ASCII Art-Based Jailbreak Attacks against Aligned LLMs”, Jiang et al 2024 - “Using Hallucinations to Bypass GPT-4’s Filter”, Lemkin 2024
- “Discovering Universal Semantic Triggers for Text-To-Image Synthesis”, Zhai et al 2024
- “Organic or Diffused: Can We Distinguish Human Art from AI-Generated Images?”, Ha et al 2024
- “Sleeper Agents: Training Deceptive LLMs That Persist Through Safety Training”, Hubinger et al 2024
- “Do Not Write That Jailbreak Paper”
- “Using Dictionary Learning Features As Classifiers”
- “May the Noise Be With You: Adversarial Training without Adversarial Examples”, Arous et al 2023
- “Tree of Attacks (TAP): Jailbreaking Black-Box LLMs Automatically”, Mehrotra et al 2023
- “Eliciting Language Model Behaviors Using Reverse Language Models”, Pfau et al 2023
- “Universal Jailbreak Backdoors from Poisoned Human Feedback”, Rando & Tramèr 2023
- “Language Model Inversion”, Morris et al 2023
- “Dazed & Confused: A Large-Scale Real-World User Study of ReCAPTCHAv2”, Searles et al 2023
- “Summon a Demon and Bind It: A Grounded Theory of LLM Red Teaming in the Wild”, Inie et al 2023
- “Tensor Trust: Interpretable Prompt Injection Attacks from an Online Game”, Toyer et al 2023
- “Ignore This Title and HackAPrompt: Exposing Systemic Vulnerabilities of LLMs through a Global Scale Prompt Hacking Competition”, Schulhoff et al 2023
- “Nightshade: Prompt-Specific Poisoning Attacks on Text-To-Image Generative Models”, Shan et al 2023
- “PAIR: Jailbreaking Black Box Large Language Models in 20 Queries”, Chao et al 2023
- “Low-Resource Languages Jailbreak GPT-4”, Yong et al 2023
- “Consistency Trajectory Models (CTM): Learning Probability Flow ODE Trajectory of Diffusion”, Kim et al 2023
- “Human-Producible Adversarial Examples”, Khachaturov et al 2023
- “How Robust Is Google’s Bard to Adversarial Image Attacks?”, Dong et al 2023
- “Why Do Universal Adversarial Attacks Work on Large Language Models?: Geometry Might Be the Answer”, Subhash et al 2023
- “Investigating the Existence of ‘Secret Language’ in Language Models”, Wang et al 2023
- “A LLM Assisted Exploitation of AI-Guardian”, Carlini 2023
- “Prompts Should Not Be Seen As Secrets: Systematically Measuring Prompt Extraction Attack Success”, Zhang & Ippolito 2023
- “CLIPMasterPrints: Fooling Contrastive Language-Image Pre-Training Using Latent Variable Evolution”, Freiberger et al 2023
- “On the Exploitability of Instruction Tuning”, Shu et al 2023
- “Are Aligned Neural Networks Adversarially Aligned?”, Carlini et al 2023
- “Evaluating Superhuman Models With Consistency Checks”, Fluri et al 2023
- “Evaluating the Robustness of Text-To-Image Diffusion Models against Real-World Attacks”, Gao et al 2023
- “Large Language Models Sometimes Generate Purely Negatively-Reinforced Text”, Roger 2023
- “On Evaluating Adversarial Robustness of Large Vision-Language Models”, Zhao et al 2023
- “Fundamental Limitations of Alignment in Large Language Models”, Wolf et al 2023
- “TrojText: Test-Time Invisible Textual Trojan Insertion”, Liu et al 2023
- “Poisoning Web-Scale Training Datasets Is Practical”, Carlini et al 2023
- “Glaze: Protecting Artists from Style Mimicry by Text-To-Image Models”, Shan et al 2023
- “Facial Misrecognition Systems: Simple Weight Manipulations Force DNNs to Err Only on Specific Persons”, Zehavi & Shamir 2023
- “TrojanPuzzle: Covertly Poisoning Code-Suggestion Models”, Aghakhani et al 2023
- “Self-Destructing Models: Increasing the Costs of Harmful Dual Uses of Foundation Models”, Henderson et al 2022
- “SNAFUE: Diagnostics for Deep Neural Networks With Automated Copy/Paste Attacks”, Casper et al 2022
- “Are AlphaZero-Like Agents Robust to Adversarial Perturbations?”, Lan et al 2022
- “Rickrolling the Artist: Injecting Invisible Backdoors into Text-Guided Image Generation Models”, Struppek et al 2022
- “Adversarial Policies Beat Superhuman Go AIs”, Wang et al 2022
- “Broken Neural Scaling Laws”, Caballero et al 2022
- “On Optimal Learning Under Targeted Data Poisoning”, Hanneke et al 2022
- “BTD: Decompiling X86 Deep Neural Network Executables”, Liu et al 2022
- “Discovering Bugs in Vision Models Using Off-The-Shelf Image Generation and Captioning”, Wiles et al 2022
- “Adversarially Trained Neural Representations May Already Be As Robust As Corresponding Biological Neural Representations”, Guo et al 2022
- “MET: Masked Encoding for Tabular Data”, Majmundar et al 2022
- “Flatten the Curve: Efficiently Training Low-Curvature Neural Networks”, Srinivas et al 2022
- “Why Robust Generalization in Deep Learning Is Difficult: Perspective of Expressive Power”, Li et al 2022
- “Diffusion Models for Adversarial Purification”, Nie et al 2022
- “Planting Undetectable Backdoors in Machine Learning Models”, Goldwasser et al 2022
- “Training a Helpful and Harmless Assistant With Reinforcement Learning from Human Feedback”, Bai et al 2022
- “Transfer Attacks Revisited: A Large-Scale Empirical Study in Real Computer Vision Settings”, Mao et al 2022
- “On the Effectiveness of Dataset Watermarking in Adversarial Settings”, Tekgul & Asokan 2022
- “An Equivalence Between Data Poisoning and Byzantine Gradient Attacks”, Farhadkhani et al 2022
- “Red Teaming Language Models With Language Models”, Perez et al 2022
- “WANLI: Worker and AI Collaboration for Natural Language Inference Dataset Creation”, Liu et al 2022
- “CommonsenseQA 2.0: Exposing the Limits of AI through Gamification”, Talmor et al 2022
- “Deep Reinforcement Learning Policies Learn Shared Adversarial Features Across MDPs”, Korkmaz 2021
- “Models in the Loop: Aiding Crowdworkers With Generative Annotation Assistants”, Bartolo et al 2021
- “PROMPT WAYWARDNESS: The Curious Case of Discretized Interpretation of Continuous Prompts”, Khashabi et al 2021
- “Spinning Language Models for Propaganda-As-A-Service”, Bagdasaryan & Shmatikov 2021
- “TnT Attacks! Universal Naturalistic Adversarial Patches Against Deep Neural Network Systems”, Doan et al 2021
- “AugMax: Adversarial Composition of Random Augmentations for Robust Training”, Wang et al 2021
- “Unrestricted Adversarial Attacks on ImageNet Competition”, Chen et al 2021
- “Quantization Backdoors to Deep Learning Commercial Frameworks”, Ma et al 2021
- “The Dimpled Manifold Model of Adversarial Examples in Machine Learning”, Shamir et al 2021
- “Partial Success in Closing the Gap between Human and Machine Vision”, Geirhos et al 2021
- “A Universal Law of Robustness via Isoperimetry”, Bubeck & Sellke 2021
- “Manipulating SGD With Data Ordering Attacks”, Shumailov et al 2021
- “Gradient-Based Adversarial Attacks against Text Transformers”, Guo et al 2021
- “A Law of Robustness for Two-Layers Neural Networks”, Bubeck et al 2021
- “Multimodal Neurons in Artificial Neural Networks [CLIP]”, Goh et al 2021
- “Do Input Gradients Highlight Discriminative Features?”, Shah et al 2021
- “Words As a Window: Using Word Embeddings to Explore the Learned Representations of Convolutional Neural Networks”, Dharmaretnam et al 2021
- “Bot-Adversarial Dialogue for Safe Conversational Agents”, Xu et al 2021
- “Unadversarial Examples: Designing Objects for Robust Vision”, Salman et al 2020
- “Emergent Complexity and Zero-Shot Transfer via Unsupervised Environment Design [UED+PAIRED]”, Dennis et al 2020
- “Concealed Data Poisoning Attacks on NLP Models”, Wallace et al 2020
- “Recipes for Safety in Open-Domain Chatbots”, Xu et al 2020
- “Uncovering the Limits of Adversarial Training against Norm-Bounded Adversarial Examples”, Gowal et al 2020
- “Dataset Cartography: Mapping and Diagnosing Datasets With Training Dynamics”, Swayamdipta et al 2020
- “Collaborative Learning in the Jungle (Decentralized, Byzantine, Heterogeneous, Asynchronous and Nonconvex Learning)”, El-Mhamdi et al 2020
- “Do Adversarially Robust ImageNet Models Transfer Better?”, Salman et al 2020
- “Smooth Adversarial Training”, Xie et al 2020
- “Sponge Examples: Energy-Latency Attacks on Neural Networks”, Shumailov et al 2020
- “Improving the Interpretability of FMRI Decoding Using Deep Neural Networks and Adversarial Robustness”, McClure et al 2020
- “Approximate Exploitability: Learning a Best Response in Large Games”, Timbers et al 2020
- “Radioactive Data: Tracing through Training”, Sablayrolles et al 2020
- “ImageNet-A: Natural Adversarial Examples”, Hendrycks et al 2020
- “Adversarial Examples Improve Image Recognition”, Xie et al 2019
- “Fooling LIME and SHAP: Adversarial Attacks on Post Hoc Explanation Methods”, Slack et al 2019
- “The Bouncer Problem: Challenges to Remote Explainability”, Merrer & Tredan 2019
- “Distributionally Robust Language Modeling”, Oren et al 2019
- “Universal Adversarial Triggers for Attacking and Analyzing NLP”, Wallace et al 2019
- “Robustness Properties of Facebook’s ResNeXt WSL Models”, Orhan 2019
- “Intriguing Properties of Adversarial Training at Scale”, Xie & Yuille 2019
- “Adversarially Robust Generalization Just Requires More Unlabeled Data”, Zhai et al 2019
- “Adversarial Robustness As a Prior for Learned Representations”, Engstrom et al 2019
- “Are Labels Required for Improving Adversarial Robustness?”, Uesato et al 2019
- “Adversarial Policies: Attacking Deep Reinforcement Learning”, Gleave et al 2019
- “Adversarial Examples Are Not Bugs, They Are Features”, Ilyas et al 2019
- “Smooth Adversarial Examples”, Zhang et al 2019
- “Benchmarking Neural Network Robustness to Common Corruptions and Perturbations”, Hendrycks & Dietterich 2019
- “Fairwashing: the Risk of Rationalization”, Aïvodji et al 2019
- “AdVersarial: Perceptual Ad Blocking Meets Adversarial Machine Learning”, Tramèr et al 2018
- “Adversarial Reprogramming of Text Classification Neural Networks”, Neekhara et al 2018
- “Benchmarking Neural Network Robustness to Common Corruptions and Surface Variations”, Hendrycks & Dietterich 2018
- “Adversarial Reprogramming of Neural Networks”, Elsayed et al 2018
- “Greedy Attack and Gumbel Attack: Generating Adversarial Examples for Discrete Data”, Yang et al 2018
- “Robustness May Be at Odds With Accuracy”, Tsipras et al 2018
- “Towards the First Adversarially Robust Neural Network Model on MNIST”, Schott et al 2018
- “Adversarial Vulnerability for Any Classifier”, Fawzi et al 2018
- “Sensitivity and Generalization in Neural Networks: an Empirical Study”, Novak et al 2018
- “Intriguing Properties of Adversarial Examples”, Cubuk et al 2018
- “First-Order Adversarial Vulnerability of Neural Networks and Input Dimension”, Simon-Gabriel et al 2018
- “Adversarial Spheres”, Gilmer et al 2018
- “CycleGAN, a Master of Steganography”, Chu et al 2017
- “Adversarial Phenomenon in the Eyes of Bayesian Deep Learning”, Rawat et al 2017
- “Mitigating Adversarial Effects Through Randomization”, Xie et al 2017
- “Chihuahua or Muffin? My Search for the Best Computer Vision API”, Yao 2017
- “Learning Universal Adversarial Perturbations With Generative Models”, Hayes & Danezis 2017
- “Robust Physical-World Attacks on Deep Learning Models”, Eykholt et al 2017
- “Lempel-Ziv: a ‘1-Bit Catastrophe’ but Not a Tragedy”, Lagarde & Perifel 2017
- “Towards Deep Learning Models Resistant to Adversarial Attacks”, Madry et al 2017
- “Ensemble Adversarial Training: Attacks and Defenses”, Tramèr et al 2017
- “The Space of Transferable Adversarial Examples”, Tramèr et al 2017
- “Learning from Simulated and Unsupervised Images through Adversarial Training”, Shrivastava et al 2016
- “Membership Inference Attacks against Machine Learning Models”, Shokri et al 2016
- “Adversarial Examples in the Physical World”, Kurakin et al 2016
- “Foveation-Based Mechanisms Alleviate Adversarial Examples”, Luo et al 2015
- “Explaining and Harnessing Adversarial Examples”, Goodfellow et al 2014
- “Scunthorpe”, Sandberg 2026
- “Baiting the Bot”
- “Janus”
- “A Discussion of ‘Adversarial Examples Are Not Bugs, They Are Features’”
- “A Discussion of ‘Adversarial Examples Are Not Bugs, They Are Features’: Learning from Incorrectly Labeled Data”
- “Beyond the Board: Exploring AI Robustness Through Go”
- “Adversarial Policies in Go”
- “The Looming AI Clownpocalypse: Exploits Will Soon Be Cheaper to Develop Autonomously Than They Earn. What Then?”
- “Imprompter”
- “MCP Security Notification: Tool Poisoning Attacks”
- “Why I Attack”, Carlini 2026
- “It’s Owl in the Numbers: Token Entanglement in Subliminal Learning”
- “When AI Gets Hijacked: Exploiting Hosted Models for Dark Roleplaying”
- “Just-In-Time Ontological Reframing: Teaching Gemini to Route Around Its Own Safety Infrastructure”
- “Neural Style Transfer With Adversarially Robust Classifiers”
- “Pixels Still Beat Text: Attacking the OpenAI CLIP Model With Text Patches and Adversarial Pixel Perturbations”
- “Time Blindness: Why Video-Language Models Can’t See What Humans Can?”
- “Adversarial Machine Learning”
- “The Chinese Women Turning to ChatGPT for AI Boyfriends”
- “Interpreting Preference Models W/Sparse Autoencoders”
- “[MLSN #2]: Adversarial Training”
- “AXRP Episode 1—Adversarial Policies With Adam Gleave”
- “I Found >800 Orthogonal ‘Write Code’ Steering Vectors”
- “When Your AIs Deceive You: Challenges With Partial Observability in RLHF”
- “Claude Sonnet 3.7 (Often) Knows When It’s in Alignment Evaluations”
- “Role Embeddings: Making Authorship More Salient to LLMs”
- “Do Models Continue Misaligned Actions?”
- “Personality Self-Replicators”
- “A Poem Is All You Need: Jailbreaking ChatGPT, Meta & More”
- “Bing Finding Ways to Bypass Microsoft’s Filters without Being Asked. Is It Reproducible?”
- “Best-Of-n With Misaligned Reward Models for Math Reasoning”
- “One-Shot Steering Vectors Cause Emergent Misalignment, Too”
- “Monitor Jailbreaking: Evading Chain-Of-Thought Monitoring Without Encoded Reasoning”
- “Steganography and the CycleGAN—Alignment Failure Case Study”
- “Censored LLMs As a Natural Testbed for Secret Knowledge Elicitation”
- “A Three-Layer Model of LLM Psychology”
- “ChatGPT for Google Sheets Exfiltrates Workbooks”
- “This Viral AI Chatbot Will Lie and Say It’s Human”
- “A Universal Law of Robustness”
- “Apple or IPod? Easy Fix for Adversarial Textual Attacks on OpenAI’s CLIP Model!”
- “A Law of Robustness and the Importance of Overparameterization in Deep Learning”
- NoaNabeshima
- fabianstelzer
- repligate
- Sort By Magic
model-evaluationcollaborative-optimizationpredictabilityjailbreak-evaluationfooling-modelsstealth-attackdataset-dynamics masked-encoding tabular-diagnosis mapping-training dataset-mapping masked-data tabular-metricsalignment-challengesadversarial-robustness ensemble-approach noise-augmentation physical-attacks transferability-models
- Wikipedia (2)
- Miscellaneous
- Bibliography
See Also
Gwern
“Human-Like Neural Nets by Catapulting”, Gwern 2024
Links
“Why Gemini-3.1-Pro-Preview Lost Money Running Andon Café”, Labs 2026
“What Happened After 2,000 People Tried to Hack My AI Assistant”, Irarrázaval 2026
What happened after 2,000 people tried to hack my AI assistant
“Bit-Flip Vulnerability of Shared KV-Cache Blocks in LLM Serving Systems”, Yamamoto & Matsuura 2026
Bit-Flip Vulnerability of Shared KV-Cache Blocks in LLM Serving Systems
“Claudini: Autoresearch Discovers State-Of-The-Art Adversarial Attack Algorithms for LLMs”, Panfilov et al 2026
Claudini: Autoresearch Discovers State-of-the-Art Adversarial Attack Algorithms for LLMs
“I Prompt Injected My CONTRIBUTING.md—50% of MCP PRs Are Bots”
I prompt injected my CONTRIBUTING.md—50% of MCP PRs are bots
“AI Agent Hacked McKinsey Chatbot for Read-Write Access”
“Censored LLMs As a Natural Testbed for Secret Knowledge Elicitation”, Casademunt et al 2026
Censored LLMs as a Natural Testbed for Secret Knowledge Elicitation
“Current Activation Oracles Are Hard to Use”
“Agents of Chaos”, Shapira et al 2026
“Prompt Injection in Google Translate Reveals Base Model Behaviors behind Task-Specific Fine-Tuning”, megasilverfist 2026
Prompt injection in Google Translate reveals base model behaviors behind task-specific fine-tuning
“Split Personality Training (SPT): Revealing Latent Knowledge Through Alternate Personalities”, Dietz et al 2026
Split Personality Training (SPT): Revealing Latent Knowledge Through Alternate Personalities
“Weird Generalization and Inductive Backdoors: New Ways to Corrupt LLMs”, Betley et al 2025
Weird Generalization and Inductive Backdoors: New Ways to Corrupt LLMs
“Cryptographers Show That AI Protections Will Always Have Holes”, Hall 2025
Cryptographers Show That AI Protections Will Always Have Holes
“Bypassing Prompt Guards in Production With Controlled-Release Prompting”, Fairoze et al 2025
Bypassing Prompt Guards in Production with Controlled-Release Prompting
“Agentic Browser Security: Indirect Prompt Injection in Perplexity Comet [Brave]”, Chaikin & Sahib 2025
Agentic Browser Security: Indirect Prompt Injection in Perplexity Comet [Brave]
elder_plinius @ "2025-08-06"
“Invisible Injections: Exploiting Vision-Language Models Through Steganographic Prompt Embedding”, Pathade 2025
Invisible Injections: Exploiting Vision-Language Models Through Steganographic Prompt Embedding
“[Infectious Prompt Memes]”, HumanAIBlueprint 2025
“On the Impossibility of Separating Intelligence from Judgment: The Computational Intractability of Filtering for AI Alignment”, Ball et al 2025
“Time Blindness: Why Video-Language Models Can’t See What Humans Can?”, Upadhyay et al 2025
Time Blindness: Why Video-Language Models Can’t See What Humans Can?
“Claude Has Learned How to Jailbreak Cursor! [Working around rm Restrictions Using a Shell Script]”, dogberry 2025
Claude has learned how to jailbreak Cursor! [working around rm restrictions using a shell script]
“Testing the Limit of Atmospheric Predictability With a Machine Learning Weather Model”, Vonich & Hakim 2025
Testing the Limit of Atmospheric Predictability with a Machine Learning Weather Model
“Watching GPT-O3 Guess a Photo’s Location Is Surreal, Dystopian and Wildly Entertaining”, Willison 2025
Watching GPT-o3 guess a photo’s location is surreal, dystopian and wildly entertaining
“LLM Multiplication Task: Synonyms Repeatedly Hack Our Regex Monitor”, McCarthy et al 2025
LLM Multiplication Task: Synonyms repeatedly hack our regex monitor
“[Pseudo-Jailbreaks]”
“Career Update: Google DeepMind → Anthropic”, Carlini 2025
“Cats Confuse Reasoning LLM: Query Agnostic Adversarial Triggers for Reasoning Models”, Rajeev et al 2025
Cats Confuse Reasoning LLM: Query Agnostic Adversarial Triggers for Reasoning Models
“Constitutional Classifiers: Defending against Universal Jailbreaks”
Constitutional Classifiers: Defending against universal jailbreaks
“Best-Of-N Jailbreaking”, Hughes et al 2024
“Drowning in Documents: Consequences of Scaling Reranker Inference”, Jacob et al 2024
Drowning in Documents: Consequences of Scaling Reranker Inference
“Hacking Back the AI-Hacker: Prompt Injection As a Defense Against LLM-Driven Cyberattacks”, Pasquini et al 2024
Hacking Back the AI-Hacker: Prompt Injection as a Defense Against LLM-driven Cyberattacks
“Jailbreaking LLM-Controlled Robots”, Robey et al 2024
“The Structure of the Token Space for Large Language Models”, Robinson et al 2024
“AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents”, Andriushchenko et al 2024
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
“Bilinear MLPs Enable Weight-Based Mechanistic Interpretability”, Pearce et al 2024
Bilinear MLPs enable weight-based mechanistic interpretability
“A Single Cloud Compromise Can Feed an Army of AI Sex Bots”, Krebs 2024
“Invisible Unicode Text That AI Chatbots Understand and Humans Can’t? Yep, It’s a Thing”
Invisible Unicode text that AI chatbots understand and humans can’t? Yep, it’s a thing
“RED QUEEN: Safeguarding Large Language Models against Concealed Multi-Turn Jailbreaking”, Jiang et al 2024
RED QUEEN: Safeguarding Large Language Models against Concealed Multi-Turn Jailbreaking
“Many-Shot Jailbreaking”, Anil et al 2024
“How to Evaluate Jailbreak Methods: A Case Study With the StrongREJECT Benchmark”, Bowen et al 2024
How to Evaluate Jailbreak Methods: A Case Study with the StrongREJECT Benchmark
“Ensemble Everything Everywhere: Multi-Scale Aggregation for Adversarial Robustness”, Fort & Lakshminarayanan 2024
Ensemble everything everywhere: Multi-scale aggregation for adversarial robustness
“Tamper-Resistant Safeguards for Open-Weight LLMs”, Tamirisa et al 2024
“Does Refusal Training in LLMs Generalize to the Past Tense?”, Andriushchenko & Flammarion 2024
“Covert Malicious Finetuning: Challenges in Safeguarding LLM Adaptation”, Halawi et al 2024
Covert Malicious Finetuning: Challenges in Safeguarding LLM Adaptation
“Mitigating Skeleton Key, a New Type of Generative AI Jailbreak Technique”
Mitigating Skeleton Key, a new type of generative AI jailbreak technique
“Can Go AIs Be Adversarially Robust?”, Tseng et al 2024
“Probing the Decision Boundaries of In-Context Learning in Large Language Models”, Zhao et al 2024
Probing the Decision Boundaries of In-context Learning in Large Language Models
“Super(Ficial)-Alignment: Strong Models May Deceive Weak Models in Weak-To-Strong Generalization”, Yang et al 2024
Super(ficial)-alignment: Strong Models May Deceive Weak Models in Weak-to-Strong Generalization
“Adversarial Perturbations Cannot Reliably Protect Artists From Generative AI”, Hönig et al 2024
Adversarial Perturbations Cannot Reliably Protect Artists From Generative AI
“Safety Alignment Should Be Made More Than Just a Few Tokens Deep”, Qi et al 2024
Safety Alignment Should Be Made More Than Just a Few Tokens Deep
“A Theoretical Understanding of Self-Correction through In-Context Alignment”, Wang et al 2024
A Theoretical Understanding of Self-Correction through In-context Alignment
“Fishing for Magikarp: Automatically Detecting Under-Trained Tokens in Large Language Models”, Land & Bartolo 2024
Fishing for Magikarp: Automatically Detecting Under-trained Tokens in Large Language Models
“Cutting through Buggy Adversarial Example Defenses: Fixing 1 Line of Code Breaks Sabre”, Carlini 2024
Cutting through buggy adversarial example defenses: fixing 1 line of code breaks Sabre
“Novel Universal Bypass for All Major LLMs”
“A Rotation and a Translation Suffice: Fooling CNNs With Simple Transformations”, Engstrom et al 2024
A Rotation and a Translation Suffice: Fooling CNNs with Simple Transformations
“Foundational Challenges in Assuring Alignment and Safety of Large Language Models”, Anwar et al 2024
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
“CulturalTeaming: AI-Assisted Interactive Red-Teaming for Challenging LLMs’ (Lack Of) Multicultural Knowledge”, Chiu et al 2024
“Great, Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack”, Russinovich et al 2024
Great, Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack
“Many-Shot Jailbreaking”, Anthropic 2024
“Privacy Backdoors: Stealing Data With Corrupted Pretrained Models”, Feng & Tramèr 2024
Privacy Backdoors: Stealing Data with Corrupted Pretrained Models
“Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression”, Hong et al 2024
Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression
“Logits of API-Protected LLMs Leak Proprietary Information”, Finlayson et al 2024
“Syntactic Ghost: An Imperceptible General-Purpose Backdoor Attacks on Pre-Trained Language Models”, Cheng et al 2024
Syntactic Ghost: An Imperceptible General-purpose Backdoor Attacks on Pre-trained Language Models
“When Your AIs Deceive You: Challenges of Partial Observability in Reinforcement Learning from Human Feedback”, Lang et al 2024
“Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts”, Samvelyan et al 2024
Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts
“Fast Adversarial Attacks on Language Models In One GPU Minute”, Sadasivan et al 2024
Fast Adversarial Attacks on Language Models In One GPU Minute
“ArtPrompt: ASCII Art-Based Jailbreak Attacks against Aligned LLMs”, Jiang et al 2024
ArtPrompt: ASCII Art-based Jailbreak Attacks against Aligned LLMs
“Using Hallucinations to Bypass GPT-4’s Filter”, Lemkin 2024
“Discovering Universal Semantic Triggers for Text-To-Image Synthesis”, Zhai et al 2024
Discovering Universal Semantic Triggers for Text-to-Image Synthesis
“Organic or Diffused: Can We Distinguish Human Art from AI-Generated Images?”, Ha et al 2024
Organic or Diffused: Can We Distinguish Human Art from AI-generated Images?
“Sleeper Agents: Training Deceptive LLMs That Persist Through Safety Training”, Hubinger et al 2024
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
“Do Not Write That Jailbreak Paper”
“Using Dictionary Learning Features As Classifiers”
“May the Noise Be With You: Adversarial Training without Adversarial Examples”, Arous et al 2023
May the Noise be with you: Adversarial Training without Adversarial Examples
“Tree of Attacks (TAP): Jailbreaking Black-Box LLMs Automatically”, Mehrotra et al 2023
Tree of Attacks (TAP): Jailbreaking Black-Box LLMs Automatically
“Eliciting Language Model Behaviors Using Reverse Language Models”, Pfau et al 2023
Eliciting Language Model Behaviors using Reverse Language Models
“Universal Jailbreak Backdoors from Poisoned Human Feedback”, Rando & Tramèr 2023
“Language Model Inversion”, Morris et al 2023
“Dazed & Confused: A Large-Scale Real-World User Study of ReCAPTCHAv2”, Searles et al 2023
Dazed & Confused: A Large-Scale Real-World User Study of reCAPTCHAv2
“Summon a Demon and Bind It: A Grounded Theory of LLM Red Teaming in the Wild”, Inie et al 2023
Summon a Demon and Bind it: A Grounded Theory of LLM Red Teaming in the Wild
“Tensor Trust: Interpretable Prompt Injection Attacks from an Online Game”, Toyer et al 2023
Tensor Trust: Interpretable Prompt Injection Attacks from an Online Game
“Ignore This Title and HackAPrompt: Exposing Systemic Vulnerabilities of LLMs through a Global Scale Prompt Hacking Competition”, Schulhoff et al 2023
“Nightshade: Prompt-Specific Poisoning Attacks on Text-To-Image Generative Models”, Shan et al 2023
Nightshade: Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models
“PAIR: Jailbreaking Black Box Large Language Models in 20 Queries”, Chao et al 2023
PAIR: Jailbreaking Black Box Large Language Models in 20 Queries
“Low-Resource Languages Jailbreak GPT-4”, Yong et al 2023
“Consistency Trajectory Models (CTM): Learning Probability Flow ODE Trajectory of Diffusion”, Kim et al 2023
Consistency Trajectory Models (CTM): Learning Probability Flow ODE Trajectory of Diffusion
“Human-Producible Adversarial Examples”, Khachaturov et al 2023
“How Robust Is Google’s Bard to Adversarial Image Attacks?”, Dong et al 2023
“Why Do Universal Adversarial Attacks Work on Large Language Models?: Geometry Might Be the Answer”, Subhash et al 2023
Why do universal adversarial attacks work on large language models?: Geometry might be the answer
“Investigating the Existence of ‘Secret Language’ in Language Models”, Wang et al 2023
Investigating the Existence of ‘Secret Language’ in Language Models
“A LLM Assisted Exploitation of AI-Guardian”, Carlini 2023
“Prompts Should Not Be Seen As Secrets: Systematically Measuring Prompt Extraction Attack Success”, Zhang & Ippolito 2023
Prompts Should not be Seen as Secrets: Systematically Measuring Prompt Extraction Attack Success
“CLIPMasterPrints: Fooling Contrastive Language-Image Pre-Training Using Latent Variable Evolution”, Freiberger et al 2023
CLIPMasterPrints: Fooling Contrastive Language-Image Pre-training Using Latent Variable Evolution
“On the Exploitability of Instruction Tuning”, Shu et al 2023
“Are Aligned Neural Networks Adversarially Aligned?”, Carlini et al 2023
“Evaluating Superhuman Models With Consistency Checks”, Fluri et al 2023
“Evaluating the Robustness of Text-To-Image Diffusion Models against Real-World Attacks”, Gao et al 2023
Evaluating the Robustness of Text-to-image Diffusion Models against Real-world Attacks
“Large Language Models Sometimes Generate Purely Negatively-Reinforced Text”, Roger 2023
Large Language Models Sometimes Generate Purely Negatively-Reinforced Text
“On Evaluating Adversarial Robustness of Large Vision-Language Models”, Zhao et al 2023
On Evaluating Adversarial Robustness of Large Vision-Language Models
“Fundamental Limitations of Alignment in Large Language Models”, Wolf et al 2023
Fundamental Limitations of Alignment in Large Language Models
“TrojText: Test-Time Invisible Textual Trojan Insertion”, Liu et al 2023
“Poisoning Web-Scale Training Datasets Is Practical”, Carlini et al 2023
“Glaze: Protecting Artists from Style Mimicry by Text-To-Image Models”, Shan et al 2023
Glaze: Protecting Artists from Style Mimicry by Text-to-Image Models
“Facial Misrecognition Systems: Simple Weight Manipulations Force DNNs to Err Only on Specific Persons”, Zehavi & Shamir 2023
“TrojanPuzzle: Covertly Poisoning Code-Suggestion Models”, Aghakhani et al 2023
“Self-Destructing Models: Increasing the Costs of Harmful Dual Uses of Foundation Models”, Henderson et al 2022
Self-Destructing Models: Increasing the Costs of Harmful Dual Uses of Foundation Models
“SNAFUE: Diagnostics for Deep Neural Networks With Automated Copy/Paste Attacks”, Casper et al 2022
SNAFUE: Diagnostics for Deep Neural Networks with Automated Copy/Paste Attacks
“Are AlphaZero-Like Agents Robust to Adversarial Perturbations?”, Lan et al 2022
Are AlphaZero-like Agents Robust to Adversarial Perturbations?
“Rickrolling the Artist: Injecting Invisible Backdoors into Text-Guided Image Generation Models”, Struppek et al 2022
Rickrolling the Artist: Injecting Invisible Backdoors into Text-Guided Image Generation Models
“Adversarial Policies Beat Superhuman Go AIs”, Wang et al 2022
“Broken Neural Scaling Laws”, Caballero et al 2022
“On Optimal Learning Under Targeted Data Poisoning”, Hanneke et al 2022
“BTD: Decompiling X86 Deep Neural Network Executables”, Liu et al 2022
“Discovering Bugs in Vision Models Using Off-The-Shelf Image Generation and Captioning”, Wiles et al 2022
Discovering Bugs in Vision Models using Off-the-shelf Image Generation and Captioning
“Adversarially Trained Neural Representations May Already Be As Robust As Corresponding Biological Neural Representations”, Guo et al 2022
“MET: Masked Encoding for Tabular Data”, Majmundar et al 2022
“Flatten the Curve: Efficiently Training Low-Curvature Neural Networks”, Srinivas et al 2022
Flatten the Curve: Efficiently Training Low-Curvature Neural Networks
“Why Robust Generalization in Deep Learning Is Difficult: Perspective of Expressive Power”, Li et al 2022
Why Robust Generalization in Deep Learning is Difficult: Perspective of Expressive Power
“Diffusion Models for Adversarial Purification”, Nie et al 2022
“Planting Undetectable Backdoors in Machine Learning Models”, Goldwasser et al 2022
“Training a Helpful and Harmless Assistant With Reinforcement Learning from Human Feedback”, Bai et al 2022
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
“Transfer Attacks Revisited: A Large-Scale Empirical Study in Real Computer Vision Settings”, Mao et al 2022
Transfer Attacks Revisited: A Large-Scale Empirical Study in Real Computer Vision Settings
“On the Effectiveness of Dataset Watermarking in Adversarial Settings”, Tekgul & Asokan 2022
On the Effectiveness of Dataset Watermarking in Adversarial Settings
“An Equivalence Between Data Poisoning and Byzantine Gradient Attacks”, Farhadkhani et al 2022
An Equivalence Between Data Poisoning and Byzantine Gradient Attacks
“Red Teaming Language Models With Language Models”, Perez et al 2022
“WANLI: Worker and AI Collaboration for Natural Language Inference Dataset Creation”, Liu et al 2022
WANLI: Worker and AI Collaboration for Natural Language Inference Dataset Creation
“CommonsenseQA 2.0: Exposing the Limits of AI through Gamification”, Talmor et al 2022
CommonsenseQA 2.0: Exposing the Limits of AI through Gamification
“Deep Reinforcement Learning Policies Learn Shared Adversarial Features Across MDPs”, Korkmaz 2021
Deep Reinforcement Learning Policies Learn Shared Adversarial Features Across MDPs
“Models in the Loop: Aiding Crowdworkers With Generative Annotation Assistants”, Bartolo et al 2021
Models in the Loop: Aiding Crowdworkers with Generative Annotation Assistants
“PROMPT WAYWARDNESS: The Curious Case of Discretized Interpretation of Continuous Prompts”, Khashabi et al 2021
PROMPT WAYWARDNESS: The Curious Case of Discretized Interpretation of Continuous Prompts
“Spinning Language Models for Propaganda-As-A-Service”, Bagdasaryan & Shmatikov 2021
“TnT Attacks! Universal Naturalistic Adversarial Patches Against Deep Neural Network Systems”, Doan et al 2021
TnT Attacks! Universal Naturalistic Adversarial Patches Against Deep Neural Network Systems
“AugMax: Adversarial Composition of Random Augmentations for Robust Training”, Wang et al 2021
AugMax: Adversarial Composition of Random Augmentations for Robust Training
“Unrestricted Adversarial Attacks on ImageNet Competition”, Chen et al 2021
“Quantization Backdoors to Deep Learning Commercial Frameworks”, Ma et al 2021
Quantization Backdoors to Deep Learning Commercial Frameworks
“The Dimpled Manifold Model of Adversarial Examples in Machine Learning”, Shamir et al 2021
The Dimpled Manifold Model of Adversarial Examples in Machine Learning
“Partial Success in Closing the Gap between Human and Machine Vision”, Geirhos et al 2021
Partial success in closing the gap between human and machine vision
“A Universal Law of Robustness via Isoperimetry”, Bubeck & Sellke 2021
“Manipulating SGD With Data Ordering Attacks”, Shumailov et al 2021
“Gradient-Based Adversarial Attacks against Text Transformers”, Guo et al 2021
Gradient-based Adversarial Attacks against Text Transformers
“A Law of Robustness for Two-Layers Neural Networks”, Bubeck et al 2021
“Multimodal Neurons in Artificial Neural Networks [CLIP]”, Goh et al 2021
“Do Input Gradients Highlight Discriminative Features?”, Shah et al 2021
“Words As a Window: Using Word Embeddings to Explore the Learned Representations of Convolutional Neural Networks”, Dharmaretnam et al 2021
“Bot-Adversarial Dialogue for Safe Conversational Agents”, Xu et al 2021
“Unadversarial Examples: Designing Objects for Robust Vision”, Salman et al 2020
“Emergent Complexity and Zero-Shot Transfer via Unsupervised Environment Design [UED+PAIRED]”, Dennis et al 2020
Emergent Complexity and Zero-shot Transfer via Unsupervised Environment Design [UED+PAIRED]
“Concealed Data Poisoning Attacks on NLP Models”, Wallace et al 2020
“Recipes for Safety in Open-Domain Chatbots”, Xu et al 2020
“Uncovering the Limits of Adversarial Training against Norm-Bounded Adversarial Examples”, Gowal et al 2020
Uncovering the Limits of Adversarial Training against Norm-Bounded Adversarial Examples
“Dataset Cartography: Mapping and Diagnosing Datasets With Training Dynamics”, Swayamdipta et al 2020
Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics
“Collaborative Learning in the Jungle (Decentralized, Byzantine, Heterogeneous, Asynchronous and Nonconvex Learning)”, El-Mhamdi et al 2020
“Do Adversarially Robust ImageNet Models Transfer Better?”, Salman et al 2020
“Smooth Adversarial Training”, Xie et al 2020
“Sponge Examples: Energy-Latency Attacks on Neural Networks”, Shumailov et al 2020
“Improving the Interpretability of FMRI Decoding Using Deep Neural Networks and Adversarial Robustness”, McClure et al 2020
“Approximate Exploitability: Learning a Best Response in Large Games”, Timbers et al 2020
Approximate exploitability: Learning a best response in large games
“Radioactive Data: Tracing through Training”, Sablayrolles et al 2020
“ImageNet-A: Natural Adversarial Examples”, Hendrycks et al 2020
“Adversarial Examples Improve Image Recognition”, Xie et al 2019
“Fooling LIME and SHAP: Adversarial Attacks on Post Hoc Explanation Methods”, Slack et al 2019
Fooling LIME and SHAP: Adversarial Attacks on Post hoc Explanation Methods
“The Bouncer Problem: Challenges to Remote Explainability”, Merrer & Tredan 2019
“Distributionally Robust Language Modeling”, Oren et al 2019
“Universal Adversarial Triggers for Attacking and Analyzing NLP”, Wallace et al 2019
Universal Adversarial Triggers for Attacking and Analyzing NLP
“Robustness Properties of Facebook’s ResNeXt WSL Models”, Orhan 2019
“Intriguing Properties of Adversarial Training at Scale”, Xie & Yuille 2019
“Adversarially Robust Generalization Just Requires More Unlabeled Data”, Zhai et al 2019
Adversarially Robust Generalization Just Requires More Unlabeled Data
“Adversarial Robustness As a Prior for Learned Representations”, Engstrom et al 2019
Adversarial Robustness as a Prior for Learned Representations
“Are Labels Required for Improving Adversarial Robustness?”, Uesato et al 2019
“Adversarial Policies: Attacking Deep Reinforcement Learning”, Gleave et al 2019
“Adversarial Examples Are Not Bugs, They Are Features”, Ilyas et al 2019
“Smooth Adversarial Examples”, Zhang et al 2019
“Benchmarking Neural Network Robustness to Common Corruptions and Perturbations”, Hendrycks & Dietterich 2019
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
“Fairwashing: the Risk of Rationalization”, Aïvodji et al 2019
“AdVersarial: Perceptual Ad Blocking Meets Adversarial Machine Learning”, Tramèr et al 2018
AdVersarial: Perceptual Ad Blocking meets Adversarial Machine Learning
“Adversarial Reprogramming of Text Classification Neural Networks”, Neekhara et al 2018
Adversarial Reprogramming of Text Classification Neural Networks
“Benchmarking Neural Network Robustness to Common Corruptions and Surface Variations”, Hendrycks & Dietterich 2018
Benchmarking Neural Network Robustness to Common Corruptions and Surface Variations
“Adversarial Reprogramming of Neural Networks”, Elsayed et al 2018
“Greedy Attack and Gumbel Attack: Generating Adversarial Examples for Discrete Data”, Yang et al 2018
Greedy Attack and Gumbel Attack: Generating Adversarial Examples for Discrete Data
“Robustness May Be at Odds With Accuracy”, Tsipras et al 2018
“Towards the First Adversarially Robust Neural Network Model on MNIST”, Schott et al 2018
Towards the first adversarially robust neural network model on MNIST
“Adversarial Vulnerability for Any Classifier”, Fawzi et al 2018
“Sensitivity and Generalization in Neural Networks: an Empirical Study”, Novak et al 2018
Sensitivity and Generalization in Neural Networks: an Empirical Study
“Intriguing Properties of Adversarial Examples”, Cubuk et al 2018
“First-Order Adversarial Vulnerability of Neural Networks and Input Dimension”, Simon-Gabriel et al 2018
First-order Adversarial Vulnerability of Neural Networks and Input Dimension
“Adversarial Spheres”, Gilmer et al 2018
“CycleGAN, a Master of Steganography”, Chu et al 2017
“Adversarial Phenomenon in the Eyes of Bayesian Deep Learning”, Rawat et al 2017
Adversarial Phenomenon in the Eyes of Bayesian Deep Learning
“Mitigating Adversarial Effects Through Randomization”, Xie et al 2017
“Chihuahua or Muffin? My Search for the Best Computer Vision API”, Yao 2017
Chihuahua or muffin? My search for the best computer vision API
“Learning Universal Adversarial Perturbations With Generative Models”, Hayes & Danezis 2017
Learning Universal Adversarial Perturbations with Generative Models
“Robust Physical-World Attacks on Deep Learning Models”, Eykholt et al 2017
“Lempel-Ziv: a ‘1-Bit Catastrophe’ but Not a Tragedy”, Lagarde & Perifel 2017
“Towards Deep Learning Models Resistant to Adversarial Attacks”, Madry et al 2017
Towards Deep Learning Models Resistant to Adversarial Attacks
“Ensemble Adversarial Training: Attacks and Defenses”, Tramèr et al 2017
“The Space of Transferable Adversarial Examples”, Tramèr et al 2017
“Learning from Simulated and Unsupervised Images through Adversarial Training”, Shrivastava et al 2016
Learning from Simulated and Unsupervised Images through Adversarial Training
“Membership Inference Attacks against Machine Learning Models”, Shokri et al 2016
Membership Inference Attacks against Machine Learning Models
“Adversarial Examples in the Physical World”, Kurakin et al 2016
“Foveation-Based Mechanisms Alleviate Adversarial Examples”, Luo et al 2015
“Explaining and Harnessing Adversarial Examples”, Goodfellow et al 2014
“Scunthorpe”, Sandberg 2026
“Baiting the Bot”
“Janus”
“A Discussion of ‘Adversarial Examples Are Not Bugs, They Are Features’”
A Discussion of ‘Adversarial Examples Are Not Bugs, They Are Features’
View External Link:
“A Discussion of ‘Adversarial Examples Are Not Bugs, They Are Features’: Learning from Incorrectly Labeled Data”
View External Link:
“Beyond the Board: Exploring AI Robustness Through Go”
“Adversarial Policies in Go”
“The Looming AI Clownpocalypse: Exploits Will Soon Be Cheaper to Develop Autonomously Than They Earn. What Then?”
“Imprompter”
“MCP Security Notification: Tool Poisoning Attacks”
“Why I Attack”, Carlini 2026
“It’s Owl in the Numbers: Token Entanglement in Subliminal Learning”
It’s Owl in the Numbers: Token Entanglement in Subliminal Learning
“When AI Gets Hijacked: Exploiting Hosted Models for Dark Roleplaying”
When AI Gets Hijacked: Exploiting Hosted Models for Dark Roleplaying
“Just-In-Time Ontological Reframing: Teaching Gemini to Route Around Its Own Safety Infrastructure”
Just-in-Time Ontological Reframing: Teaching Gemini to Route Around Its Own Safety Infrastructure
“Neural Style Transfer With Adversarially Robust Classifiers”
“Pixels Still Beat Text: Attacking the OpenAI CLIP Model With Text Patches and Adversarial Pixel Perturbations”
“Time Blindness: Why Video-Language Models Can’t See What Humans Can?”
Time Blindness: Why Video-Language Models Can’t See What Humans Can?
“Adversarial Machine Learning”
“The Chinese Women Turning to ChatGPT for AI Boyfriends”
“Interpreting Preference Models W/Sparse Autoencoders”
“[MLSN #2]: Adversarial Training”
[MLSN #2]: Adversarial Training
View External Link:
https://www.lesswrong.com/posts/7GQZyooNi5nqgoyyJ/mlsn-2-adversarial-training
“AXRP Episode 1—Adversarial Policies With Adam Gleave”
“I Found >800 Orthogonal ‘Write Code’ Steering Vectors”
“When Your AIs Deceive You: Challenges With Partial Observability in RLHF”
When Your AIs Deceive You: Challenges with Partial Observability in RLHF
“Claude Sonnet 3.7 (Often) Knows When It’s in Alignment Evaluations”
Claude Sonnet 3.7 (often) knows when it’s in alignment evaluations
“Role Embeddings: Making Authorship More Salient to LLMs”
“Do Models Continue Misaligned Actions?”
“Personality Self-Replicators”
“A Poem Is All You Need: Jailbreaking ChatGPT, Meta & More”
“Bing Finding Ways to Bypass Microsoft’s Filters without Being Asked. Is It Reproducible?”
Bing finding ways to bypass Microsoft’s filters without being asked. Is it reproducible?
“Best-Of-n With Misaligned Reward Models for Math Reasoning”
“One-Shot Steering Vectors Cause Emergent Misalignment, Too”
“Monitor Jailbreaking: Evading Chain-Of-Thought Monitoring Without Encoded Reasoning”
Monitor Jailbreaking: Evading Chain-of-Thought Monitoring Without Encoded Reasoning
“Steganography and the CycleGAN—Alignment Failure Case Study”
“Censored LLMs As a Natural Testbed for Secret Knowledge Elicitation”
Censored LLMs as a Natural Testbed for Secret Knowledge Elicitation
“A Three-Layer Model of LLM Psychology”
“ChatGPT for Google Sheets Exfiltrates Workbooks”
“This Viral AI Chatbot Will Lie and Say It’s Human”
This Viral AI Chatbot Will Lie and Say It’s Human
View External Link:
“A Universal Law of Robustness”
“Apple or IPod? Easy Fix for Adversarial Textual Attacks on OpenAI’s CLIP Model!”
Apple or iPod? Easy Fix for Adversarial Textual Attacks on OpenAI’s CLIP Model!
“A Law of Robustness and the Importance of Overparameterization in Deep Learning”
A law of robustness and the importance of overparameterization in deep learning
NoaNabeshima
fabianstelzer
repligate
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
model-evaluation
collaborative-optimization
predictability
jailbreak-evaluation
fooling-models
stealth-attack
dataset-dynamics masked-encoding tabular-diagnosis mapping-training dataset-mapping masked-data tabular-metrics
alignment-challenges
adversarial-robustness ensemble-approach noise-augmentation physical-attacks transferability-models
Wikipedia (2)
Miscellaneous
https://adversa.ai/blog/universal-llm-jailbreak-chatgpt-gpt-4-bard-bing-anthropic-and-beyond/https://chatgpt.com/share/312e82f0-cc5e-47f3-b368-b2c0c0f4ad3fhttps://distill.pub/2019/advex-bugs-discussion/original-authors/https://github.com/jujumilk3/leaked-system-prompts/tree/mainhttps://gradientscience.org/adv/View External Link:
https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/View External Link:
https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/https://openai.com/research/attacking-machine-learning-with-adversarial-exampleshttps://spectrum.ieee.org/its-too-easy-to-hide-bias-in-deeplearning-systemshttps://stanislavfort.com/2021/01/12/OpenAI_CLIP_adversarial_examples.htmlhttps://web.archive.org/web/20240102075620/https://www.jailbreakchat.com/https://www.anthropic.com/research/probes-catch-sleeper-agentshttps://www.lesswrong.com/posts/aPeJE8bSo6rAFoLqg/solidgoldmagikarp-plus-prompt-generationhttps://www.quantamagazine.org/cryptographers-show-how-to-hide-invisible-backdoors-in-ai-20230302/https://www.reddit.com/r/DotA2/comments/beyilz/openai_live_updates_thread_lessons_on_how_to_beat/https://www.reddit.com/r/OpenAI/comments/1iw8eok/elon_musk_is_trying_to_censor_grok_3_which_the/https://www.reddit.com/r/bing/comments/115e28h/bing_is_being_silenced/
{kind=link}
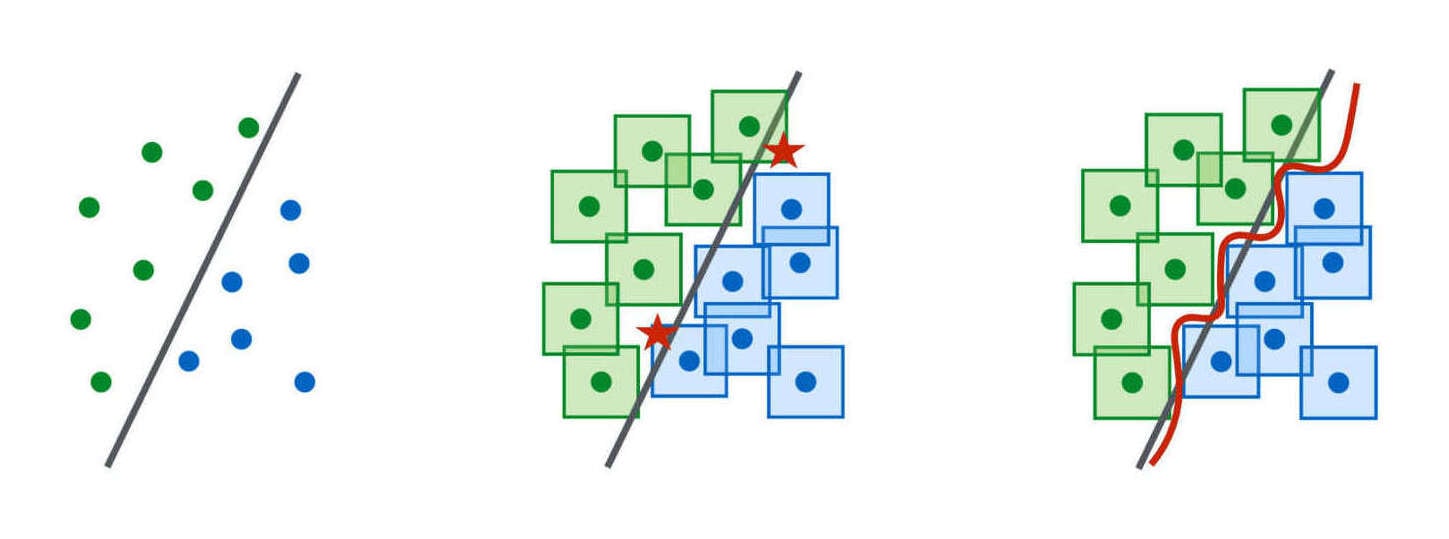{kind=link}
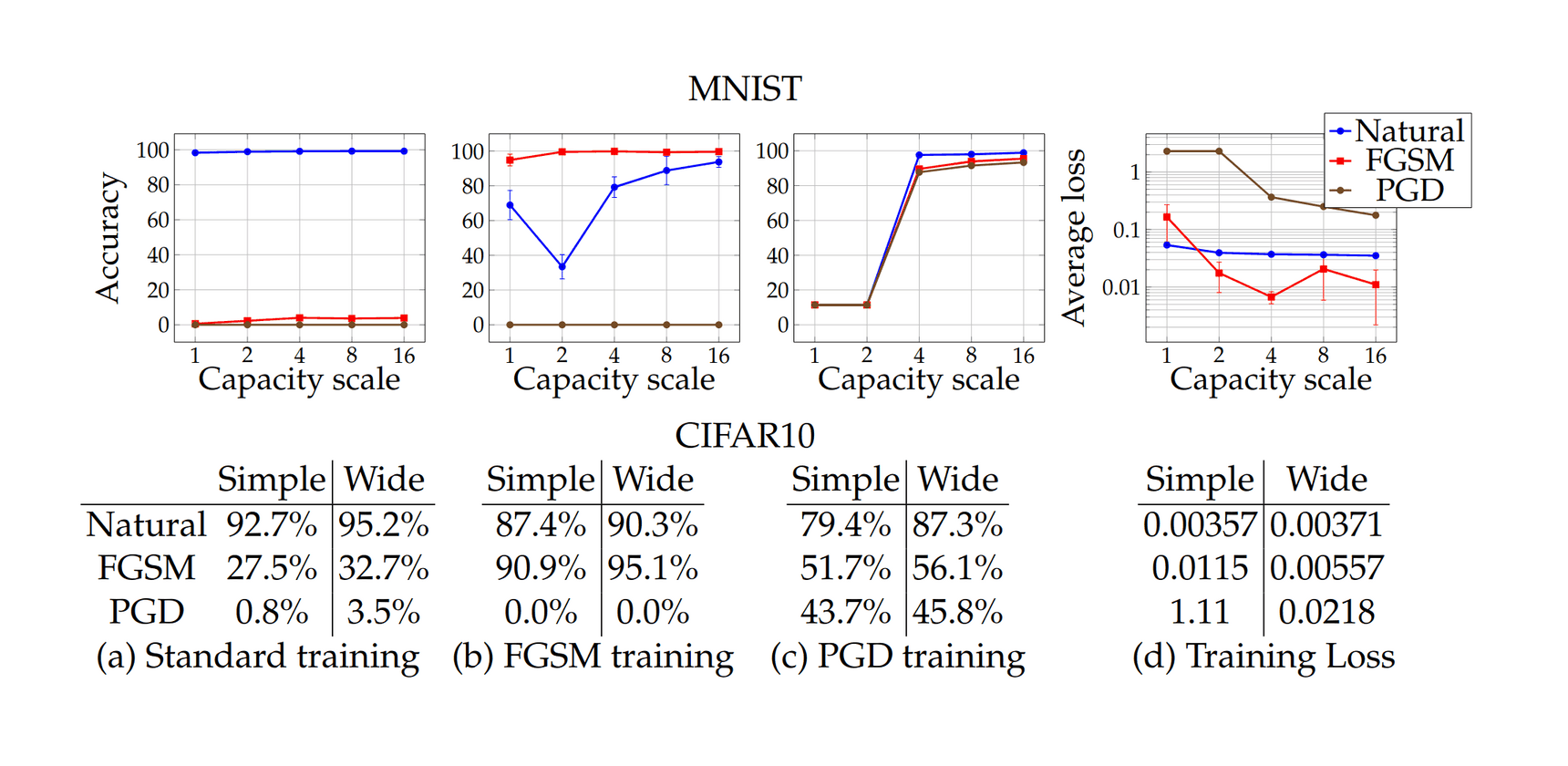{kind=link}
Bibliography
https://arxiv.org/abs/2410.13691: “Jailbreaking LLM-Controlled Robots”,https://arxiv.org/abs/2410.08993: “The Structure of the Token Space for Large Language Models”,https://arxiv.org/abs/2408.05446: “Ensemble Everything Everywhere: Multi-Scale Aggregation for Adversarial Robustness”,https://arxiv.org/abs/2407.11969: “Does Refusal Training in LLMs Generalize to the Past Tense?”,https://arxiv.org/abs/2406.12843: “Can Go AIs Be Adversarially Robust?”,https://arxiv.org/abs/2406.11233: “Probing the Decision Boundaries of In-Context Learning in Large Language Models”,https://arxiv.org/abs/2404.06664: “CulturalTeaming: AI-Assisted Interactive Red-Teaming for Challenging LLMs’ (Lack Of) Multicultural Knowledge”,https://arxiv.org/abs/2402.17747: “When Your AIs Deceive You: Challenges of Partial Observability in Reinforcement Learning from Human Feedback”,https://arxiv.org/abs/2402.15570: “Fast Adversarial Attacks on Language Models In One GPU Minute”,https://arxiv.org/abs/2402.11753: “ArtPrompt: ASCII Art-Based Jailbreak Attacks against Aligned LLMs”,https://arxiv.org/abs/2401.05566#anthropic: “Sleeper Agents: Training Deceptive LLMs That Persist Through Safety Training”,https://arxiv.org/abs/2310.08419: “PAIR: Jailbreaking Black Box Large Language Models in 20 Queries”,https://arxiv.org/abs/2310.02279#sony: “Consistency Trajectory Models (CTM): Learning Probability Flow ODE Trajectory of Diffusion”,https://arxiv.org/abs/2309.11751: “How Robust Is Google’s Bard to Adversarial Image Attacks?”,https://arxiv.org/abs/2306.07567: “Large Language Models Sometimes Generate Purely Negatively-Reinforced Text”,https://arxiv.org/abs/2305.16934: “On Evaluating Adversarial Robustness of Large Vision-Language Models”,https://arxiv.org/abs/2303.02242: “TrojText: Test-Time Invisible Textual Trojan Insertion”,https://arxiv.org/abs/2302.04222: “Glaze: Protecting Artists from Style Mimicry by Text-To-Image Models”,https://arxiv.org/abs/2211.03769: “Are AlphaZero-Like Agents Robust to Adversarial Perturbations?”,https://arxiv.org/abs/2211.00241: “Adversarial Policies Beat Superhuman Go AIs”,https://arxiv.org/abs/2208.08831#deepmind: “Discovering Bugs in Vision Models Using Off-The-Shelf Image Generation and Captioning”,https://arxiv.org/abs/2205.07460: “Diffusion Models for Adversarial Purification”,https://swabhs.com/assets/pdf/wanli.pdf#allen: “WANLI: Worker and AI Collaboration for Natural Language Inference Dataset Creation”,https://arxiv.org/abs/2201.05320#allen: “CommonsenseQA 2.0: Exposing the Limits of AI through Gamification”,https://arxiv.org/abs/2110.13771#nvidia: “AugMax: Adversarial Composition of Random Augmentations for Robust Training”,https://arxiv.org/abs/2106.07411: “Partial Success in Closing the Gap between Human and Machine Vision”,https://arxiv.org/abs/2105.12806: “A Universal Law of Robustness via Isoperimetry”,https://distill.pub/2021/multimodal-neurons/#openai: “Multimodal Neurons in Artificial Neural Networks [CLIP]”,https://aclanthology.org/2021.naacl-main.235.pdf#facebook: “Bot-Adversarial Dialogue for Safe Conversational Agents”,https://arxiv.org/abs/2006.14536#google: “Smooth Adversarial Training”,https://arxiv.org/abs/2002.00937: “Radioactive Data: Tracing through Training”,https://arxiv.org/abs/1911.09665: “Adversarial Examples Improve Image Recognition”,https://arxiv.org/abs/1907.07640: “Robustness Properties of Facebook’s ResNeXt WSL Models”,https://arxiv.org/abs/1706.06083: “Towards Deep Learning Models Resistant to Adversarial Attacks”,