‘compression’ directory
- See Also
- Gwern
- Links
- “Neural Networks Learn Bloom Filters”
- “When AI Writes the World’s Software, Who Verifies It? § Zlib Autoformalization”, Moura 2026
- “Dictionary Compression Is Finally Here, and It’s Ridiculously Good”, Perry 2026
- “Large Language Models and the Entropy of English”, Scheibner et al 2025
- “Cognitive Tech from Algorithmic Information Theory [Heuristics]”, Wyeth 2025
- “Linguistic Structure from a Bottleneck on Sequential Information Processing”, Futrell & Hahn 2025
- “OpenZL: A Graph-Based Model for Compression”, Collet et al 2025
- “LSTM or Transformer As ‘Malware Packer’”, Bednarskiwsieci 2025
- “OpenAI Charges by the Minute, So Make the Minutes Shorter”, Mandis 2025
- “The JPEG XL Image Coding System: History, Features, Coding Tools, Design Rationale, and Future”, Sneyers et al 2025
- “Hypernym Mercury: Token Optimization Through Semantic Field Constriction And Reconstruction From Hypernyms. A New Text Compression Method”, Forrester & Sulea 2025
- “Generative Modeling in Latent Space [Why VAEs Etc. Work]”, Dieleman 2025
- “SuperBPE: Space Travel for Language Models”, Liu et al 2025
- “Deep Learning Is Not So Mysterious or Different”, Wilson 2025
- “PtrHash: Minimal Perfect Hashing at RAM Throughput”, Koerkamp 2025
- “How Unix
spellRan in 64kB RAM: How Do You Fit a Dictionary in 64kb RAM? Unix Engineers Solved It With Clever Data Structures and Compression Tricks”, Upadhyay 2025 - “Optimal Bounds for Open Addressing Without Reordering”, Farach-Colton et al 2025
- “The Complexity Dynamics of Grokking”, DeMoss et al 2024
- “FineZip: Pushing the Limits of Large Language Models for Practical Lossless Text Compression”, Mittu et al 2024
- “WebP: The WebPage Compression Format”, Sireneva 2024
- “Investigating Learning-Independent Abstract Reasoning in Artificial Neural Networks”, Barak & Loewenstein 2024
- “Uncheatable_eval: Evaluating LLMs With Dynamic Data”, Jellyfish042 2024
- “SemantiCodec: An Ultra Low Bitrate Semantic Audio Codec for General Sound”, Liu et al 2024
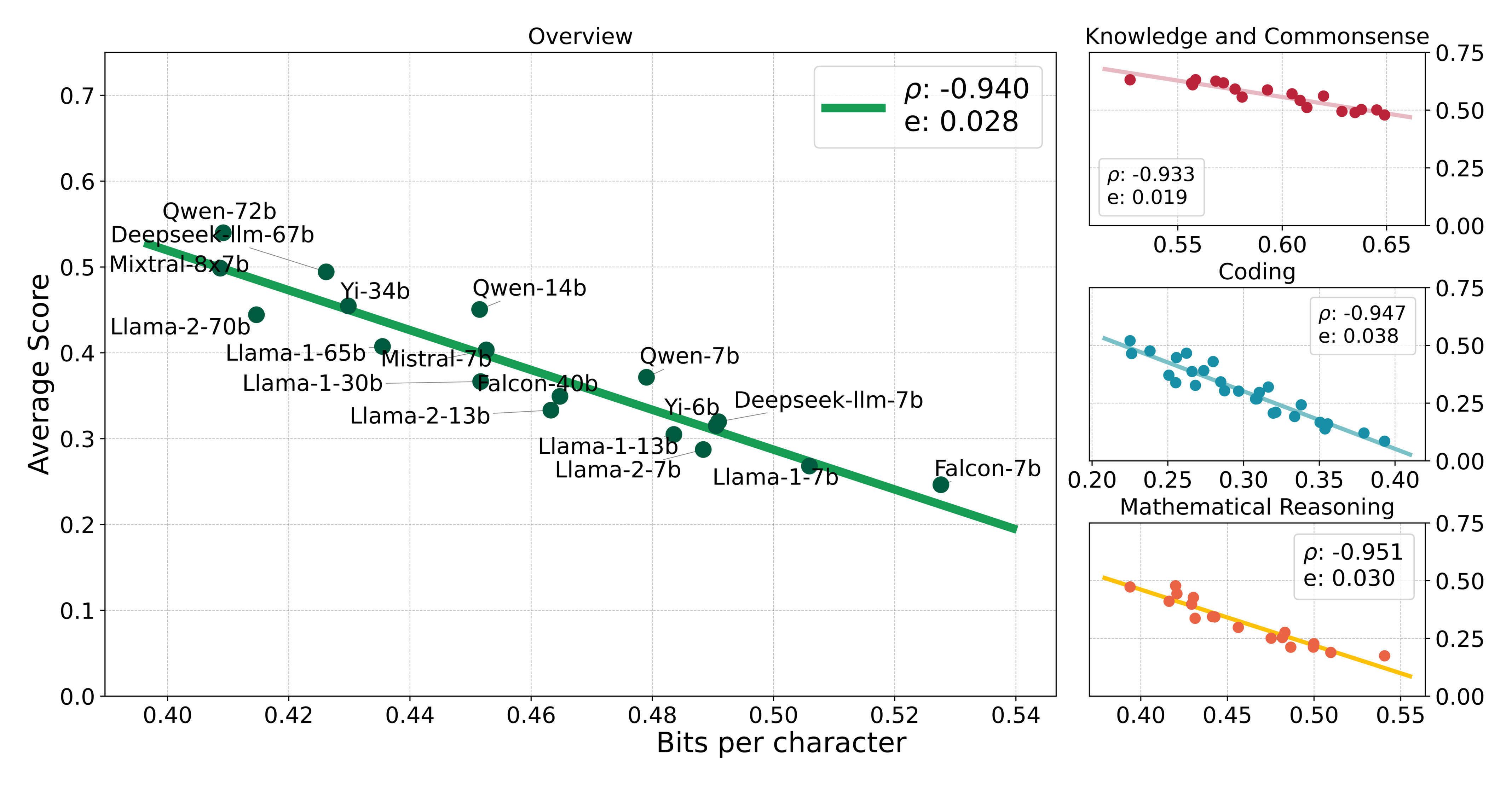
- “Compression Represents Intelligence Linearly”, Huang et al 2024
- “Training LLMs over Neurally Compressed Text”, Lester et al 2024
- “Tokenization Is More Than Compression”, Schmidt et al 2024
- “Infini-Gram: Scaling Unbounded n-Gram Language Models to a Trillion Tokens”, Liu et al 2024
- “Language Modeling Is Compression”, Delétang et al 2023
- “UltraLogLog: A Practical and More Space-Efficient Alternative to HyperLogLog for Approximate Distinct Counting”, Ertl 2023
- “Bayesian Flow Networks”, Graves et al 2023
- “
ts_zip: Text Compression Using Large Language Models [RWKV 169M V4]”, Bellard 2023 - “Gzip versus Bag-Of-Words for Text Classification With k-NN”, Opitz 2023
- “LLMZip: Lossless Text Compression Using Large Language Models”, Valmeekam et al 2023
- “Should You Marginalize over Possible Tokenizations?”, Chirkova et al 2023
- “High-Fidelity Audio Compression With Improved RVQGAN”, Kumar et al 2023
- “White-Box Transformers via Sparse Rate Reduction”, Yu et al 2023
- “How to Enumerate Trees from a Context-Free Grammar”, Piantadosi 2023
- “DIRAC: Neural Image Compression With a Diffusion-Based Decoder”, Goose et al 2023
- “Less Is More: Parameter-Free Text Classification With Gzip”, Jiang et al 2022
- “Low-Bitrate Redundancy Coding of Speech Using a Rate-Distortion-Optimized Variational Autoencoder”, Valin et al 2022
- “RGB No More: Minimally-Decoded JPEG Vision Transformers”, Park & Johnson 2022
- “High Fidelity Neural Audio Compression”, Défossez et al 2022
- “Compressing Multidimensional Weather and Climate Data into Neural Networks”, Huang & Hoefler 2022
- “T2CI-GAN: Text to Compressed Image Generation Using Generative Adversarial Network”, Rajesh et al 2022
- “DiffC: Lossy Compression With Gaussian Diffusion”, Theis et al 2022
- “What Is a Succinct Rank Data Structure? How Does It Work?”, templatetypedef 2022
- “MuZero With Self-Competition for Rate Control in VP9 Video Compression”, Mandhane et al 2022
- “A Deep Dive into an NSO Zero-Click IMessage Exploit: Remote Code Execution”, Beer & Groß 2021
- “Tiny Pointers”, Bender et al 2021
- “SZ3: A Modular Framework for Composing Prediction-Based Error-Bounded Lossy Compressors”, Liang et al 2021
- “Palette: Image-To-Image Diffusion Models”, Saharia et al 2021
- “Autoregressive Diffusion Models”, Hoogeboom et al 2021
- “Variational Diffusion Models”, Kingma et al 2021
- “JPEG XL Would Be Turing-Complete”, Bohdan 2021
- “Rip Van Winkle’s Razor, a Simple New Estimate for Adaptive Data Analysis”, Arora & Zhang 2021
- “Why Are Tar.xz Files 15× Smaller When Using Python’s Tar Library Compared to MacOS Tar?”, Lindestøkke 2021
- “Generating Images With Sparse Representations”, Nash et al 2021
- “Rip Van Winkle’s Razor: A Simple Estimate of Overfit to Test Data”, Arora & Zhang 2021
- “Generative Speech Coding With Predictive Variance Regularization”, Kleijn et al 2021
- “1-Bit Adam: Communication Efficient Large-Scale Training With Adam’s Convergence Speed”, Tang et al 2021
- “NNCP V2: Lossless Data Compression With Transformer § Pg4”, Bellard 2021 (page 4)
- “Scaling Laws for Autoregressive Generative Modeling”, Henighan et al 2020
- “Password Similarity Using Probabilistic Data Structures”, Berardi et al 2020
- “Not-So-BigGAN: Generating High-Fidelity Images on Small Compute With Wavelet-Based Super-Resolution”, Han et al 2020
- “A Tutorial on VAEs: From Bayes’ Rule to Lossless Compression”, Yu 2020
- “Zip Files: History, Explanation and Implementation”, Wennborg 2020
- “The 1-Bit Instrument: The Fundamentals of 1-Bit Synthesis, Their Implementational Implications, and Instrumental Possibilities”, Troise 2020
- “People Prefer Simpler Content When There Are More Choices: A Time Series Analysis of Lyrical Complexity in Six Decades of American Popular Music”, Varnum et al 2019
- “Bit-Swap: Recursive Bits-Back Coding for Lossless Compression With Hierarchical Latent Variables”, Kingma et al 2019
- “Unraveling the JPEG: JPEG Images Are Everywhere in Our Digital Lives, but behind the Veil of Familiarity Lie Algorithms That Remove Details That Are Imperceptible to the Human Eye. This Produces the Highest Visual Quality With the Smallest File Size—But What Does That Look Like? Let’s See What Our Eyes Can’t See!”, Shehata 2019
- “Practical Lossless Compression With Latent Variables Using Bits Back Coding”, Townsend et al 2019
- “Associative Compression Networks for Representation Learning”, Graves et al 2018
- “The Description Length of Deep Learning Models”, Blier & Ollivier 2018
- “SignSGD: Compressed Optimization for Non-Convex Problems”, Bernstein et al 2018
- “Hans Peter Luhn and the Birth of the Hashing Algorithm: The IBM Engineer’s Hashing Algorithm Gave Computers a Way to Quickly Search Documents, DNA, and Databases”, Stevens 2018
- “Introduction to Locality-Sensitive Hashing”, Neylon 2018
- “Lempel-Ziv: a ‘1-Bit Catastrophe’ but Not a Tragedy”, Lagarde & Perifel 2017
- A Mind Is Born, Akesson 2017
- “A Mind Is Born Video [256 Byte Demo]”, Akesson 2017
- “BBhash: Fast and Scalable Minimal Perfect Hashing for Massive Key Sets”, Limasset et al 2017
- “Estimation of Gap Between Current Language Models and Human Performance”, Shen et al 2017
- “Wuffs: Wrangling Untrusted File Formats Safely”, Tao 2017
- “Full Resolution Image Compression With Recurrent Neural Networks”, Toderici et al 2016
- “On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models”, Schmidhuber 2015
- “Compress and Control”, Veness et al 2014
- “A Really Simple Approximation of Smallest Grammar”, Jeż 2014
- “One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling”, Chelba et al 2013
- “The Thermodynamics of Prediction”, Still et al 2012
- “Looks Like It [A Simple Image Perceptual Hash]”, Krawetz 2011
- “Notes on a New Philosophy of Empirical Science”, Burfoot 2011
- “Universal Entropy of Word Ordering Across Linguistic Families”, Montemurro & Zanette 2011
- “Google-Wide Profiling: A Continuous Profiling Infrastructure for Data Centers”, Ren et al 2010
- “New Strategy of Lossy Text Compression”, Al-Dubaee & Ahmad 2010
- “A Monte Carlo AIXI Approximation”, Veness et al 2009
- “A Machine Learning Perspective on Predictive Coding With PAQ8 and New Applications”, Knoll 2009
- “Seam Carving for Content-Aware Image Resizing”, Avidan & Shamir 2007
- “The Bayesian Brain: the Role of Uncertainty in Neural Coding and Computation”, Knill & Pouget 2004
- “Clustering by Compression”, Cilibrasi & Vitanyi 2003
- “Data Compression and Entropy Estimates by Non-Sequential Recursive Pair Substitution”, Grassberger 2002
- “Compression and Information Leakage of Plaintext”, Kelsey 2002
- “Estimating and Comparing Entropy across Written Natural Languages Using PPM Compression”, Behr et al 2002
- “The Similarity Metric”, Li et al 2001
- “Language Trees and Zipping”, Benedetto et al 2001
- “Redundancy Reduction Revisited”, Barlow 2001
- “Optimization Is Easy and Learning Is Hard in the Typical Function”, English 2000
- “Fast Text Compression With Neural Networks”, Mahoney 2000
- “Text Compression As a Test for Artificial Intelligence”, Mahoney 1999
- “An Information-Theoretic Model for Steganography”, Cachin 1998
- “The Art of Computer Programming, Volume 3: Sorting & Searching § Chapter 6, Searching: Hashing: History”, Knuth 1998
- “Low-Complexity Art”, Schmidhuber 1997
- “The Entropy Of English Using Ppm-Based Models”, Teahan 1996
- “Measuring the Complexity of Writing Systems”, Bosch et al 1994
- “Entropy of Natural Languages: Theory and Experiment”, Levitin & Reingold 1994
- “Space-Efficient Static Trees and Graphs”, Jacobson 1989
- “Succinct Static Data Structures”, Jacobson 1988
- “The Alice and Bob After Dinner Speech”, Gordon 1984
- “Development of a Spelling List”, McIlroy 1982
- “Possible Principles Underlying the Transformations of Sensory Messages”, Barlow 1961
- “Prediction and Entropy of Printed English”, Shannon 1951
- “About the Test Data”
- “Human Knowledge Compression Contest: FAQ”, Prize 2026
- “Human Knowledge Compression Contest: FAQ”, Prize 2026
- “Human Knowledge Compression Contest: Detailed Rules”, Prize 2026
- “Timm S. Mueller”
- “An Estimate of an Upper Bound for the Entropy of English”
- “Codec2: a Whole Podcast on a Floppy Disk”
- “Finding Near-Duplicates With Jaccard Similarity and MinHash”
- “How We Shrank Our Trip Planner till It Didn’t Need Data.”
- “The Complexity Dynamics of Grokking [Blog]”, DeMoss et al 2026
- “Cole Wyeth’s Personal Website”, Wyeth 2026
- “Statistical Inference Through Data Compression”
- “A Proposal for Common Crawl to Consider Moving Compression from Gzip to Zstandard”
- “Compression Represents Intelligence Linearly [Code]”
- “XWRT (XML-WRT) Is an Efficient XML/HTML/text Compressor”
- “ChessPositionRanking/img/2389704906374985477664262349386869232706664089.png at Main • Tromp/ChessPositionRanking”
- “Llm-Compression Data”
- “King James Programming”
- “LZ4—Extremely Fast Compression”
- “T-Rex As: ‘The Computer Scientist’”, North 2026
- “Relation of Word Order and Compression Ratio and Degree of Structure”
- “That Alien Message”, Yudkowsky 2026
- Sort By Magic
archive-optimizationdata-profiling security-exploit continuous-monitoring zero-click vulnerability data-analysisbit-synthesislyrical-analysisdictionary-optimization dictionary-structure spell-checking spell-similarity memory-efficient spelling-techniquesdata-optimization image-compression neural-models steganography algorithm-analysis efficient-hashingcompression-theory
- Wikipedia (50)
- Miscellaneous
- Bibliography
See Also
Gwern
“Towards a Better Hutter Prize”, Gwern 2026
“Gwtar: a Static Efficient Single-File HTML Format”, Gwern 2026
“Quantifying Truesight With SAEs”, Gwern 2025
“Research Ideas”, Gwern 2017
“𝑈𝑚𝑖𝑛𝑒𝑘𝑜: The Hopium Of The Magics”, Gwern 2018
“The 𝚜𝚘𝚛𝚝 –𝚔𝚎𝚢 Trick”, Gwern 2014
“Against Copyright”, Gwern 2008
Links
“Neural Networks Learn Bloom Filters”
“When AI Writes the World’s Software, Who Verifies It? § Zlib Autoformalization”, Moura 2026
When AI Writes the World’s Software, Who Verifies It? § zlib autoformalization
“Dictionary Compression Is Finally Here, and It’s Ridiculously Good”, Perry 2026
Dictionary Compression is finally here, and it’s ridiculously good
“Large Language Models and the Entropy of English”, Scheibner et al 2025
“Cognitive Tech from Algorithmic Information Theory [Heuristics]”, Wyeth 2025
Cognitive Tech from Algorithmic Information Theory [heuristics]
“Linguistic Structure from a Bottleneck on Sequential Information Processing”, Futrell & Hahn 2025
Linguistic structure from a bottleneck on sequential information processing
“OpenZL: A Graph-Based Model for Compression”, Collet et al 2025
“LSTM or Transformer As ‘Malware Packer’”, Bednarskiwsieci 2025
“OpenAI Charges by the Minute, So Make the Minutes Shorter”, Mandis 2025
“The JPEG XL Image Coding System: History, Features, Coding Tools, Design Rationale, and Future”, Sneyers et al 2025
The JPEG XL Image Coding System: History, Features, Coding Tools, Design Rationale, and Future
“Hypernym Mercury: Token Optimization Through Semantic Field Constriction And Reconstruction From Hypernyms. A New Text Compression Method”, Forrester & Sulea 2025
“Generative Modeling in Latent Space [Why VAEs Etc. Work]”, Dieleman 2025
“SuperBPE: Space Travel for Language Models”, Liu et al 2025
“Deep Learning Is Not So Mysterious or Different”, Wilson 2025
“PtrHash: Minimal Perfect Hashing at RAM Throughput”, Koerkamp 2025
“How Unix spell Ran in 64kB RAM: How Do You Fit a Dictionary in 64kb RAM? Unix Engineers Solved It With Clever Data Structures and Compression Tricks”, Upadhyay 2025
“Optimal Bounds for Open Addressing Without Reordering”, Farach-Colton et al 2025
“The Complexity Dynamics of Grokking”, DeMoss et al 2024
“FineZip: Pushing the Limits of Large Language Models for Practical Lossless Text Compression”, Mittu et al 2024
FineZip: Pushing the Limits of Large Language Models for Practical Lossless Text Compression
“WebP: The WebPage Compression Format”, Sireneva 2024
“Investigating Learning-Independent Abstract Reasoning in Artificial Neural Networks”, Barak & Loewenstein 2024
Investigating learning-independent abstract reasoning in artificial neural networks
“Uncheatable_eval: Evaluating LLMs With Dynamic Data”, Jellyfish042 2024
“SemantiCodec: An Ultra Low Bitrate Semantic Audio Codec for General Sound”, Liu et al 2024
SemantiCodec: An Ultra Low Bitrate Semantic Audio Codec for General Sound
“Compression Represents Intelligence Linearly”, Huang et al 2024
“Training LLMs over Neurally Compressed Text”, Lester et al 2024
“Tokenization Is More Than Compression”, Schmidt et al 2024
“Infini-Gram: Scaling Unbounded n-Gram Language Models to a Trillion Tokens”, Liu et al 2024
Infini-gram: Scaling Unbounded n-gram Language Models to a Trillion Tokens
“Language Modeling Is Compression”, Delétang et al 2023
“UltraLogLog: A Practical and More Space-Efficient Alternative to HyperLogLog for Approximate Distinct Counting”, Ertl 2023
“Bayesian Flow Networks”, Graves et al 2023
“ts_zip: Text Compression Using Large Language Models [RWKV 169M V4]”, Bellard 2023
ts_zip: Text Compression using Large Language Models [RWKV 169M v4]
“Gzip versus Bag-Of-Words for Text Classification With k-NN”, Opitz 2023
“LLMZip: Lossless Text Compression Using Large Language Models”, Valmeekam et al 2023
LLMZip: Lossless Text Compression using Large Language Models
“Should You Marginalize over Possible Tokenizations?”, Chirkova et al 2023
“High-Fidelity Audio Compression With Improved RVQGAN”, Kumar et al 2023
“White-Box Transformers via Sparse Rate Reduction”, Yu et al 2023
“How to Enumerate Trees from a Context-Free Grammar”, Piantadosi 2023
“DIRAC: Neural Image Compression With a Diffusion-Based Decoder”, Goose et al 2023
DIRAC: Neural Image Compression with a Diffusion-Based Decoder
“Less Is More: Parameter-Free Text Classification With Gzip”, Jiang et al 2022
“Low-Bitrate Redundancy Coding of Speech Using a Rate-Distortion-Optimized Variational Autoencoder”, Valin et al 2022
Low-Bitrate Redundancy Coding of Speech Using a Rate-Distortion-Optimized Variational Autoencoder
“RGB No More: Minimally-Decoded JPEG Vision Transformers”, Park & Johnson 2022
“High Fidelity Neural Audio Compression”, Défossez et al 2022
“Compressing Multidimensional Weather and Climate Data into Neural Networks”, Huang & Hoefler 2022
Compressing multidimensional weather and climate data into neural networks
“T2CI-GAN: Text to Compressed Image Generation Using Generative Adversarial Network”, Rajesh et al 2022
T2CI-GAN: Text to Compressed Image generation using Generative Adversarial Network
“DiffC: Lossy Compression With Gaussian Diffusion”, Theis et al 2022
“What Is a Succinct Rank Data Structure? How Does It Work?”, templatetypedef 2022
“MuZero With Self-Competition for Rate Control in VP9 Video Compression”, Mandhane et al 2022
MuZero with Self-competition for Rate Control in VP9 Video Compression
“A Deep Dive into an NSO Zero-Click IMessage Exploit: Remote Code Execution”, Beer & Groß 2021
A deep dive into an NSO zero-click iMessage exploit: Remote Code Execution
“Tiny Pointers”, Bender et al 2021
“SZ3: A Modular Framework for Composing Prediction-Based Error-Bounded Lossy Compressors”, Liang et al 2021
SZ3: A Modular Framework for Composing Prediction-Based Error-Bounded Lossy Compressors
“Palette: Image-To-Image Diffusion Models”, Saharia et al 2021
“Autoregressive Diffusion Models”, Hoogeboom et al 2021
“Variational Diffusion Models”, Kingma et al 2021
“JPEG XL Would Be Turing-Complete”, Bohdan 2021
“Rip Van Winkle’s Razor, a Simple New Estimate for Adaptive Data Analysis”, Arora & Zhang 2021
Rip van Winkle’s Razor, a Simple New Estimate for Adaptive Data Analysis
“Why Are Tar.xz Files 15× Smaller When Using Python’s Tar Library Compared to MacOS Tar?”, Lindestøkke 2021
Why are tar.xz files 15× smaller when using Python’s tar library compared to macOS tar?
“Generating Images With Sparse Representations”, Nash et al 2021
“Rip Van Winkle’s Razor: A Simple Estimate of Overfit to Test Data”, Arora & Zhang 2021
Rip van Winkle’s Razor: A Simple Estimate of Overfit to Test Data
“Generative Speech Coding With Predictive Variance Regularization”, Kleijn et al 2021
Generative Speech Coding with Predictive Variance Regularization
“1-Bit Adam: Communication Efficient Large-Scale Training With Adam’s Convergence Speed”, Tang et al 2021
1-bit Adam: Communication Efficient Large-Scale Training with Adam’s Convergence Speed
“NNCP V2: Lossless Data Compression With Transformer § Pg4”, Bellard 2021 (page 4)
“Scaling Laws for Autoregressive Generative Modeling”, Henighan et al 2020
“Password Similarity Using Probabilistic Data Structures”, Berardi et al 2020
“Not-So-BigGAN: Generating High-Fidelity Images on Small Compute With Wavelet-Based Super-Resolution”, Han et al 2020
not-so-BigGAN: Generating High-Fidelity Images on Small Compute with Wavelet-based Super-Resolution
“A Tutorial on VAEs: From Bayes’ Rule to Lossless Compression”, Yu 2020
A Tutorial on VAEs: From Bayes’ Rule to Lossless Compression
“Zip Files: History, Explanation and Implementation”, Wennborg 2020
“The 1-Bit Instrument: The Fundamentals of 1-Bit Synthesis, Their Implementational Implications, and Instrumental Possibilities”, Troise 2020
“People Prefer Simpler Content When There Are More Choices: A Time Series Analysis of Lyrical Complexity in Six Decades of American Popular Music”, Varnum et al 2019
“Bit-Swap: Recursive Bits-Back Coding for Lossless Compression With Hierarchical Latent Variables”, Kingma et al 2019
Bit-Swap: Recursive Bits-Back Coding for Lossless Compression with Hierarchical Latent Variables
“Unraveling the JPEG: JPEG Images Are Everywhere in Our Digital Lives, but behind the Veil of Familiarity Lie Algorithms That Remove Details That Are Imperceptible to the Human Eye. This Produces the Highest Visual Quality With the Smallest File Size—But What Does That Look Like? Let’s See What Our Eyes Can’t See!”, Shehata 2019
“Practical Lossless Compression With Latent Variables Using Bits Back Coding”, Townsend et al 2019
Practical Lossless Compression with Latent Variables using Bits Back Coding
“Associative Compression Networks for Representation Learning”, Graves et al 2018
Associative Compression Networks for Representation Learning
“The Description Length of Deep Learning Models”, Blier & Ollivier 2018
“SignSGD: Compressed Optimization for Non-Convex Problems”, Bernstein et al 2018
“Hans Peter Luhn and the Birth of the Hashing Algorithm: The IBM Engineer’s Hashing Algorithm Gave Computers a Way to Quickly Search Documents, DNA, and Databases”, Stevens 2018
“Introduction to Locality-Sensitive Hashing”, Neylon 2018
“Lempel-Ziv: a ‘1-Bit Catastrophe’ but Not a Tragedy”, Lagarde & Perifel 2017
A Mind Is Born, Akesson 2017
“A Mind Is Born Video [256 Byte Demo]”, Akesson 2017
“BBhash: Fast and Scalable Minimal Perfect Hashing for Massive Key Sets”, Limasset et al 2017
BBhash: Fast and scalable minimal perfect hashing for massive key sets
“Estimation of Gap Between Current Language Models and Human Performance”, Shen et al 2017
Estimation of Gap Between Current Language Models and Human Performance
“Wuffs: Wrangling Untrusted File Formats Safely”, Tao 2017
“Full Resolution Image Compression With Recurrent Neural Networks”, Toderici et al 2016
Full Resolution Image Compression with Recurrent Neural Networks
“On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models”, Schmidhuber 2015
“Compress and Control”, Veness et al 2014
“A Really Simple Approximation of Smallest Grammar”, Jeż 2014
“One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling”, Chelba et al 2013
One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling
“The Thermodynamics of Prediction”, Still et al 2012
“Looks Like It [A Simple Image Perceptual Hash]”, Krawetz 2011
“Notes on a New Philosophy of Empirical Science”, Burfoot 2011
“Universal Entropy of Word Ordering Across Linguistic Families”, Montemurro & Zanette 2011
Universal Entropy of Word Ordering Across Linguistic Families
“Google-Wide Profiling: A Continuous Profiling Infrastructure for Data Centers”, Ren et al 2010
Google-Wide Profiling: A Continuous Profiling Infrastructure for Data Centers
“New Strategy of Lossy Text Compression”, Al-Dubaee & Ahmad 2010
“A Monte Carlo AIXI Approximation”, Veness et al 2009
“A Machine Learning Perspective on Predictive Coding With PAQ8 and New Applications”, Knoll 2009
A Machine Learning Perspective on Predictive Coding with PAQ8 and New Applications
“Seam Carving for Content-Aware Image Resizing”, Avidan & Shamir 2007
“The Bayesian Brain: the Role of Uncertainty in Neural Coding and Computation”, Knill & Pouget 2004
The Bayesian brain: the role of uncertainty in neural coding and computation
“Clustering by Compression”, Cilibrasi & Vitanyi 2003
“Data Compression and Entropy Estimates by Non-Sequential Recursive Pair Substitution”, Grassberger 2002
Data Compression and Entropy Estimates by Non-sequential Recursive Pair Substitution
“Compression and Information Leakage of Plaintext”, Kelsey 2002
“Estimating and Comparing Entropy across Written Natural Languages Using PPM Compression”, Behr et al 2002
Estimating and Comparing Entropy across Written Natural Languages Using PPM Compression
“The Similarity Metric”, Li et al 2001
“Language Trees and Zipping”, Benedetto et al 2001
“Redundancy Reduction Revisited”, Barlow 2001
“Optimization Is Easy and Learning Is Hard in the Typical Function”, English 2000
Optimization is easy and learning is hard in the typical function
“Fast Text Compression With Neural Networks”, Mahoney 2000
“Text Compression As a Test for Artificial Intelligence”, Mahoney 1999
“An Information-Theoretic Model for Steganography”, Cachin 1998
“The Art of Computer Programming, Volume 3: Sorting & Searching § Chapter 6, Searching: Hashing: History”, Knuth 1998
“Low-Complexity Art”, Schmidhuber 1997
“The Entropy Of English Using Ppm-Based Models”, Teahan 1996
“Measuring the Complexity of Writing Systems”, Bosch et al 1994
“Entropy of Natural Languages: Theory and Experiment”, Levitin & Reingold 1994
“Space-Efficient Static Trees and Graphs”, Jacobson 1989
“Succinct Static Data Structures”, Jacobson 1988
“The Alice and Bob After Dinner Speech”, Gordon 1984
“Development of a Spelling List”, McIlroy 1982
“Possible Principles Underlying the Transformations of Sensory Messages”, Barlow 1961
Possible Principles Underlying the Transformations of Sensory Messages
“Prediction and Entropy of Printed English”, Shannon 1951
“About the Test Data”
“Human Knowledge Compression Contest: FAQ”, Prize 2026
“Human Knowledge Compression Contest: FAQ”, Prize 2026
“Human Knowledge Compression Contest: Detailed Rules”, Prize 2026
“Timm S. Mueller”
“An Estimate of an Upper Bound for the Entropy of English”
“Codec2: a Whole Podcast on a Floppy Disk”
“Finding Near-Duplicates With Jaccard Similarity and MinHash”
“How We Shrank Our Trip Planner till It Didn’t Need Data.”
“The Complexity Dynamics of Grokking [Blog]”, DeMoss et al 2026
“Cole Wyeth’s Personal Website”, Wyeth 2026
“Statistical Inference Through Data Compression”
“A Proposal for Common Crawl to Consider Moving Compression from Gzip to Zstandard”
A Proposal for Common Crawl to Consider Moving Compression from Gzip to Zstandard
“Compression Represents Intelligence Linearly [Code]”
“XWRT (XML-WRT) Is an Efficient XML/HTML/text Compressor”
“ChessPositionRanking/img/2389704906374985477664262349386869232706664089.png at Main • Tromp/ChessPositionRanking”
{kind=link}
“Llm-Compression Data”
“King James Programming”
“LZ4—Extremely Fast Compression”
“T-Rex As: ‘The Computer Scientist’”, North 2026
“Relation of Word Order and Compression Ratio and Degree of Structure”
Relation of Word Order and Compression Ratio and Degree of Structure
“That Alien Message”, Yudkowsky 2026
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
archive-optimization
data-profiling security-exploit continuous-monitoring zero-click vulnerability data-analysis
bit-synthesis
lyrical-analysis
dictionary-optimization dictionary-structure spell-checking spell-similarity memory-efficient spelling-techniques
data-optimization image-compression neural-models steganography algorithm-analysis efficient-hashing
compression-theory
Wikipedia (50)
Miscellaneous
/doc/cs/algorithm/information/compression/2026-01-23-dbohdan-gpt5imagemini-gwtarlogo-guitar.png/doc/cs/algorithm/information/compression/2026-01-23-dbohdan-gpt5imagemini-gwtarlogo-guitar.svg/doc/cs/algorithm/information/compression/2010-stevesouder-forcinggzipcompression.html/doc/cs/algorithm/information/compression/2004-ryannorth-dinosaurcomics-391.pnghttp://brokenbytes.blogspot.com/2015/04/the-making-of-p0-snake-part-3-audio.htmlhttp://slightlynew.blogspot.com/2011/05/who-writes-wikipedia-information.htmlhttp://thevirtuosi.blogspot.com/2011/08/tweet-is-worth-at-least-140-words.htmlhttps://ai.meta.com/blog/deepfovea-using-deep-learning-for-foveated-reconstruction-in-ar-vrhttps://blog.andrewcantino.com/blog/2012/06/15/compressing-code/https://blog.cloudflare.com/brotli-compression-using-a-reduced-dictionary/https://blog.cloudflare.com/improving-compression-with-preset-deflate-dictionary/https://blog.jcoglan.com/2017/02/12/the-myers-diff-algorithm-part-1/https://clemenswinter.com/2024/04/07/the-simple-beauty-of-xor-floating-point-compression/https://cloudinary.com/blog/a_one_color_image_is_worth_two_thousand_words#the_most_predictable_imagehttps://code.flickr.net/2015/09/25/perceptual-image-compression-at-flickr/https://code4k.blogspot.com/2010/12/crinkler-secrets-4k-intro-executable.htmlhttps://fastcompression.blogspot.com/2018/02/when-to-use-dictionary-compression.htmlhttps://frankforce.com/city-in-a-bottle-a-256-byte-raycasting-system/https://gist.github.com/munificent/b1bcd969063da3e6c298be070a22b604https://github.com/facebook/zstd#the-case-for-small-data-compressionhttps://killedbyapixel.github.io/TinyCode/games/CrossMyHeart/View External Link:
https://killedbyapixel.github.io/TinyCode/games/CrossMyHeart/https://kylehovey.github.io/blog/automata-nebulaView External Link:
https://lichess.org/@/lichess/blog/developer-update-275-improved-game-compression/Wqa7GiAAhttps://mailinator.blogspot.com/2012/02/how-mailinator-compresses-email-by-90.htmlhttps://mattmahoney.net/dc/dce.htmlView HTML:
https://maxhalford.github.io/blog/text-classification-by-compression/View External Link:
https://maxhalford.github.io/blog/text-classification-by-compression/https://research.google/blog/lyra-a-new-very-low-bitrate-codec-for-speech-compression/https://shkspr.mobi/blog/2024/01/compressing-text-into-images/https://terrytao.wordpress.com/2007/04/13/compressed-sensing-and-single-pixel-cameras/https://timepedia.blogspot.com/2009/08/on-reducing-size-of-compressed.htmlhttps://timepedia.blogspot.com/2009/11/traveling-salesman-problem-and.htmlhttps://triplehappy.wordpress.com/2015/10/26/chess-move-compression/https://wrap.warwick.ac.uk/61087/7/WRAP_cs-rr-360.pdf#page=2https://www.antoniomallia.it/sorted-integers-compression-with-elias-fano-encoding.htmlhttps://www.chromium.org/developers/design-documents/software-updates-courgette/https://www.lesswrong.com/posts/soQX8yXLbKy7cFvy8/entropy-and-short-codesView External Link:
https://www.lesswrong.com/posts/soQX8yXLbKy7cFvy8/entropy-and-short-codeshttps://www.stavros.io/posts/compressing-images-with-stable-diffusion/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://www.nature.com/articles/s41562-025-02336-w: “Linguistic Structure from a Bottleneck on Sequential Information Processing”,https://arxiv.org/abs/2503.13423: “SuperBPE: Space Travel for Language Models”,https://arxiv.org/abs/2409.17141: “FineZip: Pushing the Limits of Large Language Models for Practical Lossless Text Compression”,https://arxiv.org/abs/2404.09937: “Compression Represents Intelligence Linearly”,https://arxiv.org/abs/2306.04050: “LLMZip: Lossless Text Compression Using Large Language Models”,https://arxiv.org/abs/2212.09410: “Less Is More: Parameter-Free Text Classification With Gzip”,https://arxiv.org/abs/2210.13438#facebook: “High Fidelity Neural Audio Compression”,https://www.offconvex.org/2021/04/07/ripvanwinkle/: “Rip Van Winkle’s Razor, a Simple New Estimate for Adaptive Data Analysis”,https://arxiv.org/abs/2102.02888#microsoft: “1-Bit Adam: Communication Efficient Large-Scale Training With Adam’s Convergence Speed”,https://arxiv.org/abs/2010.14701#openai: “Scaling Laws for Autoregressive Generative Modeling”,https://arxiv.org/abs/2009.04433: “Not-So-BigGAN: Generating High-Fidelity Images on Small Compute With Wavelet-Based Super-Resolution”,https://arxiv.org/abs/1804.02476#deepmind: “Associative Compression Networks for Representation Learning”,1997-schmidhuber.pdf: “Low-Complexity Art”,1994-vandenbosch.pdf: “Measuring the Complexity of Writing Systems”,1961-barlow.pdf: “Possible Principles Underlying the Transformations of Sensory Messages”,