On GPT-3: meta-learning, scaling, implications, and deep theory. The scaling hypothesis: neural nets absorb data & compute, generalizing and becoming more Bayesian as problems get harder, manifesting new abilities even at trivial-by-global-standards-scale. The deep learning revolution has begun as foretold.
GPT-3, announced by OpenAI in May 2020, is the largest neural network ever trained, by over an order of magnitude. Trained on Internet text data, it is the successor to GPT-2, which had surprised everyone by its natural language understanding & generation ability. To the surprise of most (including myself), this vast increase in size did not run into diminishing or negative returns, as many expected, but the benefits of scale continued to happen as forecasted by OpenAI. These benefits were not merely learning more facts & text than GPT-2, but qualitatively distinct & even more surprising in showing meta-learning: while GPT-2 learned how to do common natural language tasks like text summarization, GPT-3 instead learned how to follow directions and learn new tasks from a few examples. (As a result, GPT-3 outputs & interaction are more fascinating & human-like than GPT-2.)
While the immediate applications of GPT-3, like my poetry or humor writings, are nice, the short-term implications of GPT-3 are much more important.
First, while GPT-3 is expensive by conventional DL standards, it is cheap by scientific/commercial/military/government budget standards, and the results indicate that models could be made much larger. Second, models can also be made much more powerful, as GPT is an old approach known to be flawed in both minor & major ways, and far from an ‘ideal’ Transformer. Third, GPT-3’s capabilities come from learning on raw (unsupervised) data; that has long been one of the weakest areas of DL, holding back progress in other areas like reinforcement learning or robotics. Models like GPT-3 suggest that large unsupervised models will be vital components of future DL systems, as they can be ‘plugged into’ systems to immediately provide understanding of the world, humans, natural language, and reasoning.
The meta-learning has a longer-term implication: it is a demonstration of the blessings of scale, where problems with simple neural networks vanish, and they become more powerful, more generalizable, more human-like when simply made very large & trained on very large datasets with very large compute—even though those properties are believed to require complicated architectures & fancy algorithms (and this perceived need drives much research). Unsupervised models benefit from this, as training on large corpuses like Internet-scale text present a myriad of difficult problems to solve; this is enough to drive meta-learning despite GPT not being designed for meta-learning in any way. (This family of phenomena is perhaps driven by neural networks functioning as ensembles of many sub-networks with them all averaging out to an Occam’s razor, which for small data & models, learn superficial or memorized parts of the data, but can be forced into true learning by making the problems hard & rich enough; as meta-learners learn amortized Bayesian inference, they build in informative priors when trained over many tasks, and become dramatically more sample-efficient and better at generalization.)
The blessings of scale in turn support a radical theory: an old AI paradigm held by a few pioneers in connectionism (early artificial neural network research) and by more recent deep learning researchers, the scaling hypothesis. The scaling hypothesis regards the blessings of scale as the secret of AGI: intelligence is ‘just’ simple neural units & learning algorithms applied to diverse experiences at a (currently) unreachable scale. As increasing computational resources permit running such algorithms at the necessary scale, the neural networks will get ever more intelligent.
When? Estimates of Moore’s law-like progress curves decades ago by pioneers like Hans Moravec indicated that it would take until the 2010s for the sufficiently-cheap compute for tiny insect-level prototype systems to be available, and the 2020s for the first sub-human systems to become feasible, and these forecasts are holding up. (Despite this vindication, the scaling hypothesis is so unpopular an idea, and difficult to prove in advance rather than as a fait accompli, that while the GPT-3 results finally drew some public notice after OpenAI enabled limited public access & people could experiment with it live, it is unlikely that many entities will modify their research philosophies, much less kick off an ‘arms race’.)
More concerningly, GPT-3’s scaling curves, unpredicted meta-learning, and success on various anti-AI challenges suggests that in terms of futurology, AI researchers’ forecasts are an emperor sans garments: they have no coherent model of how AI progress happens or why GPT-3 was possible or what specific achievements should cause alarm, where intelligence comes from, and do not learn from any falsified predictions. Their primary concerns appear to be supporting the status quo, placating public concern, and remaining respectable. As such, their comments on AI risk are meaningless: they would make the same public statements if the scaling hypothesis were true or not.
Depending on what investments are made into scaling DL, and how fast compute grows, the 2020s should be quite interesting—sigmoid or singularity?
For more ML scaling research, follow the /r/MLScaling subreddit. For a fiction treatment as SF short story, see “It Looks Like You’re Trying To Take Over The World”.
Read The Samples
On “GPT-3: Language Models are Few-Shot Learners”, et al 2020 (poems & my followup “GPT-3 Creative Writing”, compare my old finetuned GPT-2 poetry; random samples; “OpenAI API” with real-world demos)
I strongly encourage anyone interested in GPT-3 to also at least skim OA’s random samples, or better yet, my samples in “GPT-3 Creative Writing”—reading the paper & looking at some standard benchmark graphs does not give a good feel for what working with GPT-3 is like or the diversity of things it can do which are missed by benchmarks.
Meta-Learning
Learning to learn. In May 2020, OA released—to remarkably little interest from researchers, no blog post, no media blitz, and little public discussion beyond the snidely dismissive—the long-awaited followup to GPT-2, one model to rule them all: a 117× larger 175b-parameter model with far more powerful language generation, which lets it solve a wide variety of problems from arithmetic1 to English translation to unscrambling anagrams to SAT analogies—purely from being prompted with text examples, without any specialized training or finetuning whatsoever, merely next-word prediction training on a big Internet text corpus. This implies GPT-3’s attention mechanisms serve as “fast weights” that have “learned to learn” by training on sufficiently varied data2, forcing it to do more than just learn ordinary textual relationships. Like OpenAI’s Jukebox just weeks ago (itself a remarkable demonstration of scaling in synthesizing raw audio music complete with remarkably realistic voices/instruments), the announcement of GPT-3 appears to have sunk almost without a trace, so I will go into more depth than usual.
Flexing GPT
‘“They are absolutely reasonable. I think that is their distinguishing characteristic. Yes, Mr. Erskine, an absolutely reasonable people. I assure you there is no nonsense about the Americans.” “How dreadful!” cried Lord Henry. “I can stand brute force, but brute reason is quite unbearable. There is something unfair about its use. It is hitting below the intellect.”’
The Picture of Dorian Gray, Oscar Wilde
“Attacks only get better.” 2 years ago, GPT-1 was interestingly useful pretraining and adorable with its “sentiment neuron”. 1 year ago, GPT-2 was impressive with its excellent text generation & finetuning capabilities. This year, GPT-3 is scary because it’s a magnificently obsolete architecture from early 2018 (used mostly for software engineering convenience as the infrastructure has been debugged), which is small & shallow compared to what’s possible34, with a simple uniform architecture5 trained in the dumbest way possible (unidirectional prediction of next text token) on a single impoverished modality (random Internet HTML text dumps6) on tiny data (fits on a laptop), sampled in a dumb way7, its benchmark performance sabotaged by bad prompts & data tokenization problems (especially arithmetic & commonsense reasoning), and yet, the first version already manifests crazy runtime meta-learning—and the scaling curves still are not bending! The samples are also better than ever, whether it’s GPT-3 inventing new penis jokes8 or writing (mostly working) JavaScript tutorials about rotating arrays.
It’s odd that this qualitative leap appears to be largely missed by the standard NLP benchmarks. Nothing in the raw metrics reported on, say, Penn Tree Bank or LAMBADA or WinoGrande would lead you to expect all of this hilarious and creative output; the meta-learning results might, but only if you already thought meta-learning was important. This suggests to me that a useful post-GPT-3 contribution would be figuring out how to benchmark these sorts of flexible text generation capabilities (possibly something along the lines of Chollet’s image-based Abstraction and Reasoning Corpus (ARC)).
Baking The Cake
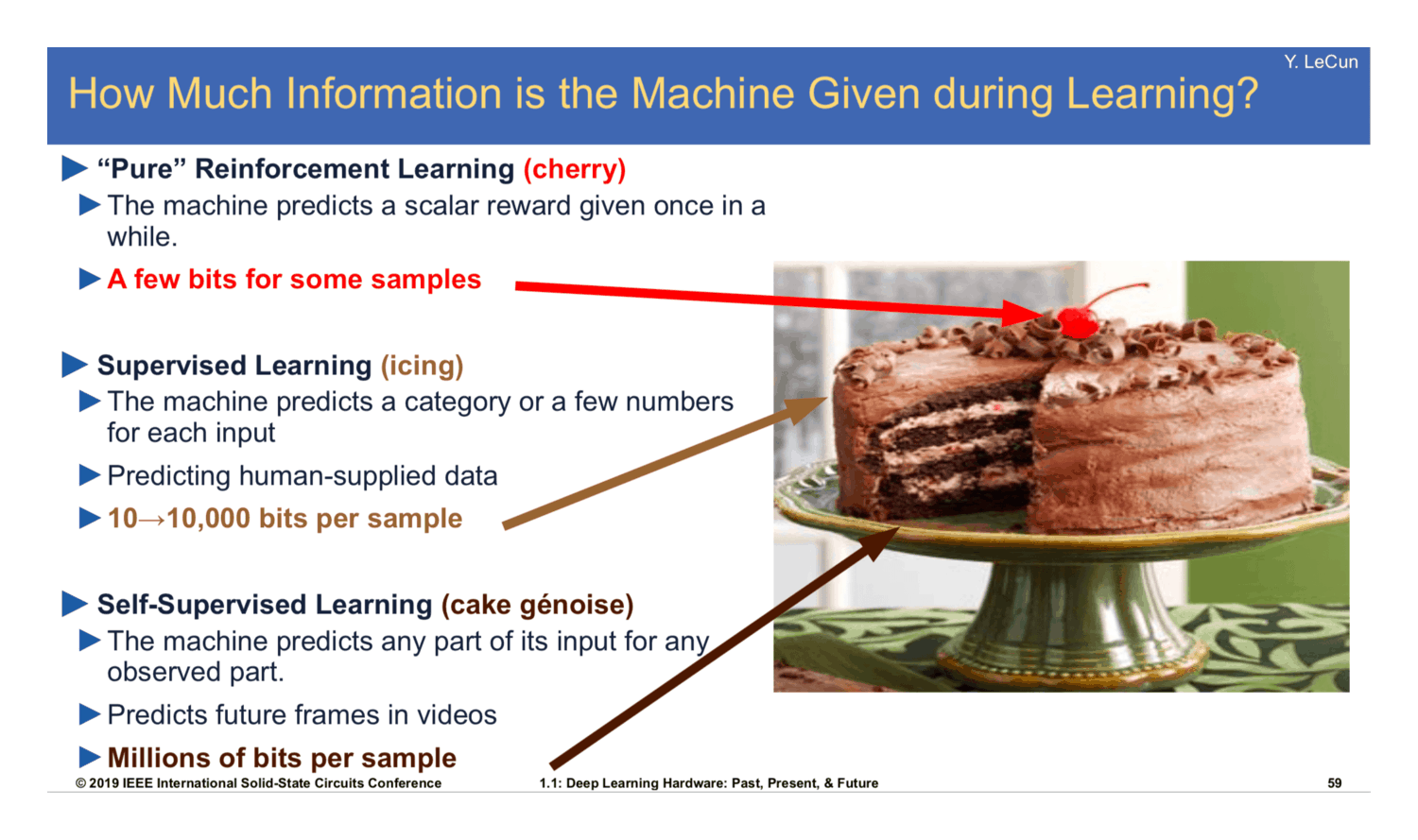
Is GPT actually part of AGI—or is the cake a lie? (2019)
Not the whole picture, but a big part. Does it set SOTA on every task? No, of course not. But the question is not whether we can lawyerly find any way in which it might not work, but whether there is any way which it might work. And there are many ways it might work better (see the “Limitations” section for just a few). Does GPT-3 do anything like steer a robot around SF shooting lasers and rockets at humans⸮ No, of course not. It is ‘just’ a text prediction model, an idiot savant of text; but an idiot savant, we should remember, is only a genetic mutation or bit of brain damage away from a normal human. If RL is the cherry on the top of the supervised learning frosting, and supervised learning is the frosting on top of the unsupervised learning cake, well, it looks like the cake layers are finally rising.

A better GPT-3 lesson.
Scaling still working. I was surprised, as I had expected closer to 100b parameters, and I thought that the performance of CTRL/Meena/MegatronLM/T5/Turing-NLG/GPipe suggested that, the scaling papers9 notwithstanding, the scaling curves had started to bend and by 100b, it might be hard to justify further scaling. However, in the latest version of “the unreasonable effectiveness of data” where “the curves cross”/“scissor effect” and the neural method eventually wins (eg. 2001, et al 2007, 2017), GPT-3 hits twice that without noticeable change in scaling factors: its scaling continues to be roughly logarithmic/power-law, as it was for much smaller models & as forecast, and it has not hit a regime where gains effectively halt or start to require increases vastly beyond feasibility. That suggests that it would be both possible and useful to head to trillions of parameters (which are still well within available compute & budgets, requiring merely thousands of GPUs & perhaps $10–$100m budgets assuming no improvements which of course there will be, see 2020 etc in this issue), and eyeballing the graphs, many benchmarks like the Winograd schema WinoGrande would fall by 10t parameters. The predictability of scaling is striking, and makes scaling models more like statistics than AI. (AI is statistics which does what we want it to but doesn’t work; and statistics is AI which works but doesn’t do what we want.)
{kind=link}
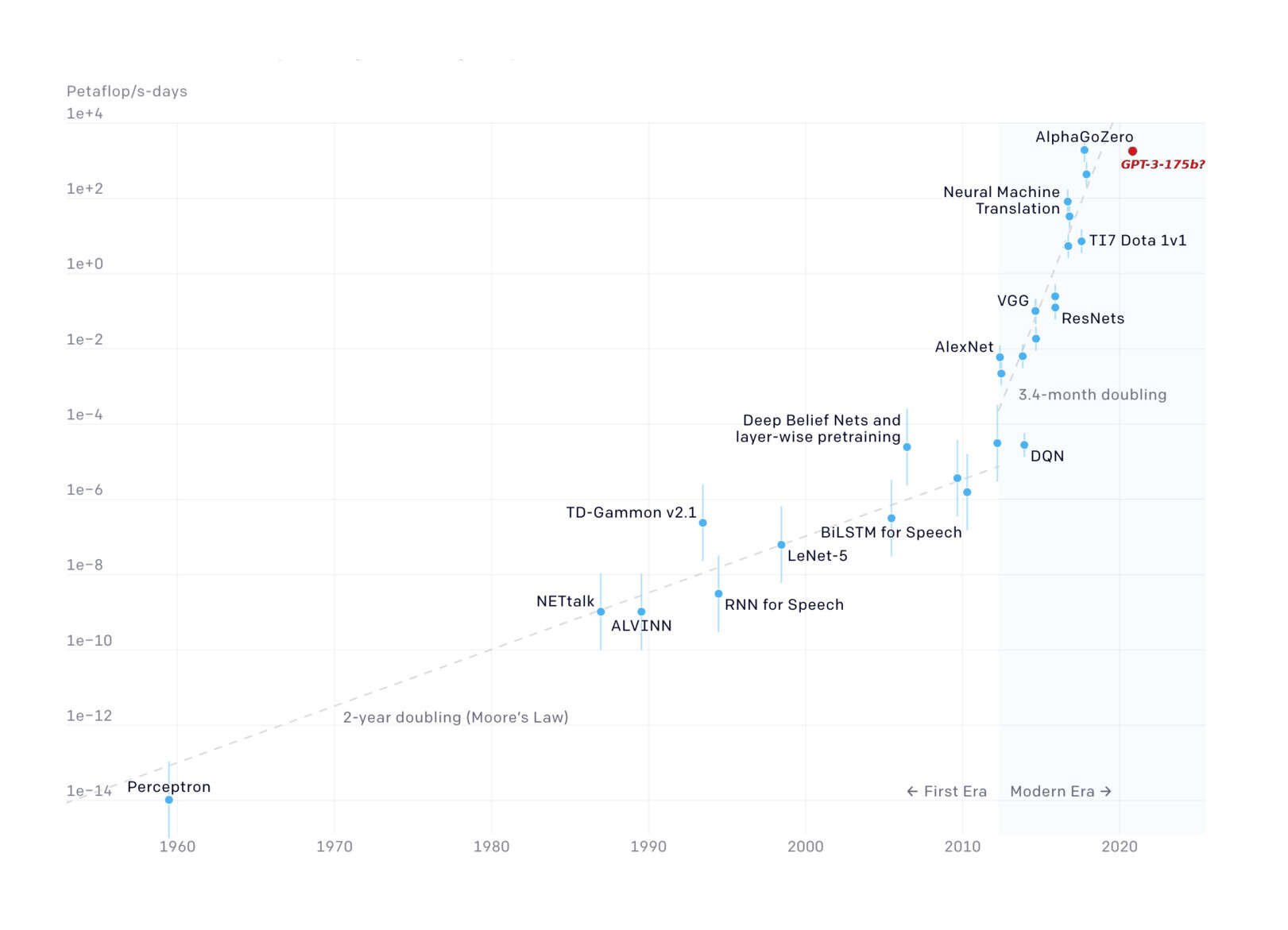
GPT-3: not even that much compute—3640 petaflop/s-day, only 2× their estimate for AlphaGo Zero, 1860164ya. (Historical graph modified by myself from “AI and Compute”, et al 2018.)
Anti-scaling: penny-wise, pound-foolish. GPT-3 is an extraordinarily expensive model by the standards of machine learning: it is estimated that training it may require the annual cost of more machine learning researchers than you can count on one hand (~$5m10), up to $30 of hard drive space to store the model (500–800GB), and multiple pennies of electricity per 100 pages of output (0.4 kWH). Researchers are concerned about the prospects for scaling: can ML afford to run projects which cost more than 0.1 milli-Manhattan-Projects⸮11 Surely it would be too expensive, even if it represented another large leap in AI capabilities, to spend up to 10 milli-Manhattan-Projects to scale GPT-3 100× to a trivial thing like human-like performance in many domains⸮ Many researchers feel that such a suggestion is absurd and refutes the entire idea of scaling machine learning research further; they asseverate that their favored approaches (you know, the ones which don’t work12) will run far more efficiently, and that the field would be more productive if it instead focused on research which can be conducted by an impoverished goatherder on an old laptop running off solar panels.13 Nonetheless, I think we can expect further scaling. (10×? No, 10× isn’t cool. You know what’s cool? 100–1000×, trained on a fancy new supercomputer.) It is, after all, easier to make something efficient after it exists than before.
Scaling
How far will scaling go? The scaling papers suggest that the leaps we have seen over the past few years are not even half way there in terms of absolute likelihood loss, never mind what real-world capabilities each additional decrement translates into. The scaling curves are clean; from “Scaling Laws for Neural Language Models”, et al 2020:
")
DL scaling laws: compute, data, model parameters. (Figure 1)
GPT-3 represents ~103 on this chart, leaving plenty of room for further loss decreases—especially given the uncertainty in extrapolation:
_ and _L(D)_ due to the slow growth of data needed for compute-efficient training. The intersection marks the point before which we expect our predictions to break down. The location of this point is highly sensitive to the precise exponents from our power-law fits. (Kaplan et al 2020)")
Projecting DL power laws: still room beyond GPT-3.
Lo and behold, the scaling laws continue for GPT-3 models for several orders past et al 2020; from et al 2020:
 follows a power-law trend with the amount of compute used for training. The power-law behavior observed in Kaplan et al 2020 continues for an additional two orders of magnitude with only small deviations from the predicted curve. For this figure, we exclude embedding parameters from compute and parameter counts. (Brown et al 2020). Cross-validation loss extrapolation: $L(oss) = 2.57 · C(ompute in petaflop-s/days) ^ −0.048$")
GPT-3 continues to scale as predicted. (Note GPT-3’s curve has not ‘bounced’, and it trained only ~0.5 epoches, see Table 2.2)
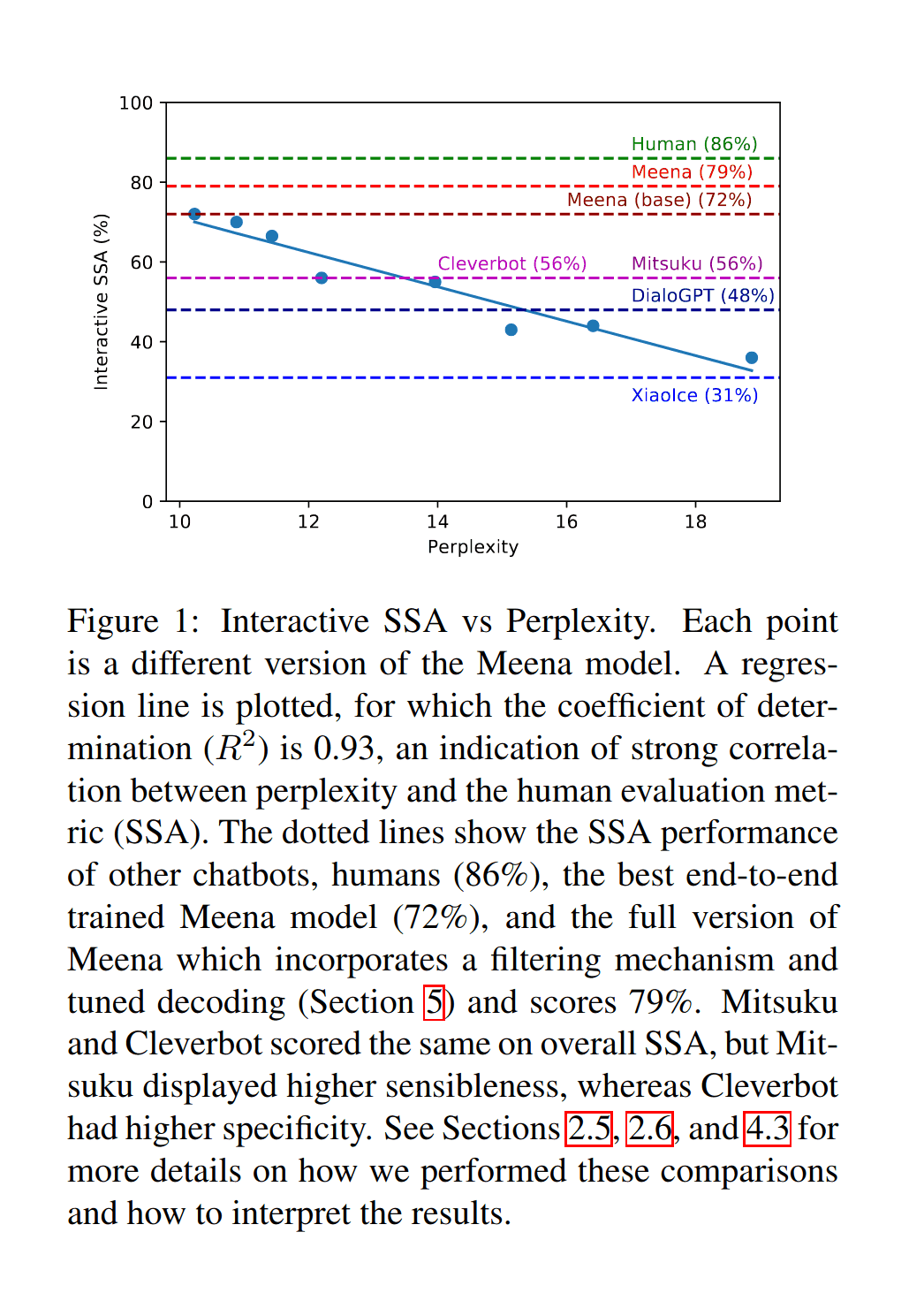
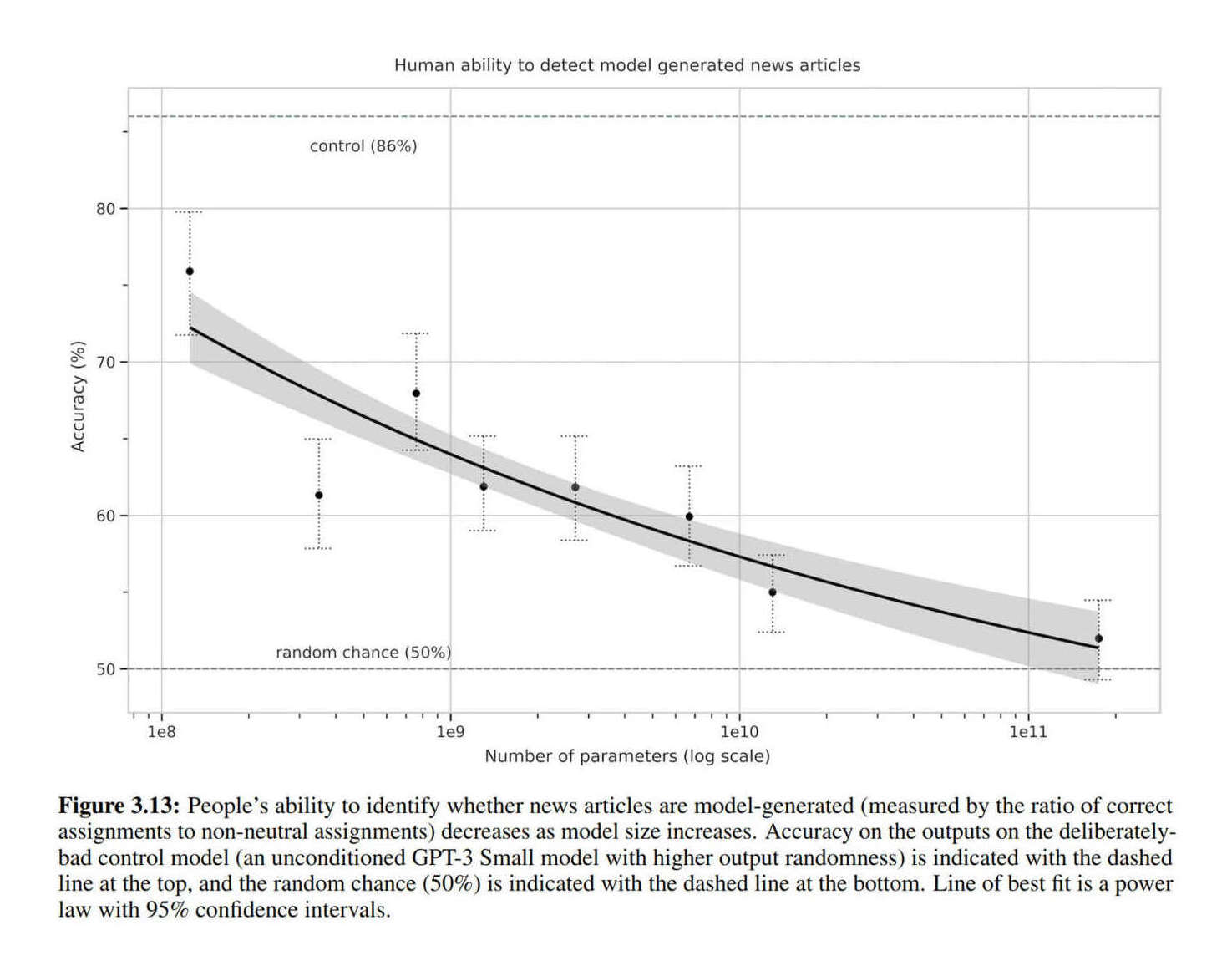
If we see such striking gains in halving the validation loss but with so far left to go, what is left to emerge as we third or halve again? How far does this go, exactly? How do we predict what emerges when? Bueller? Bueller? (See also Meena’s perplexity vs human-ness chatbot ratings, GPT-3-written news articles’ probability of fooling humans by parameter count, and GPT-3 model size vs Q&A from et al 2020.)
{kind=link}
{kind=link}
{kind=link}
Blessings Of Scale
Extrapolating the spectacular performance of GPT-3 into the future suggests that the answer to life, the universe and everything is just 4.398 trillion parameters.
We don’t know how to train NNs. The blessings of scale is the observation that for deep learning, hard problems are easier to solve than easy problems—everything gets better as it gets larger (in contrast to the usual outcome in research, where small things are hard and large things impossible). The bigger the neural net/compute/data/problem, the faster it learns, the better it learns, the stabler it learns, and so on. A problem we can’t solve at all at small n may suddenly become straightforward with millions or billions of n. “NNs are lazy”: they can do far more than we make them do when we push them beyond easy answers & cheap shortcuts. The bitter lesson is the harder and bigger, the better. (Besides GPT-3, one could mention recent progress in semi-supervised learning & the model-based DRL renaissance.)

AlphaGo Zero: ‘just stack moar layers lol!’
Blessings of scale: stability → generalization → meta-learning. GPT-3 is hamstrung by its training & data, but DL enjoys an unreasonably effective blessing of dimensionality—just simply training a big model on a lot of data induces better properties like meta-learning without even the slightest bit of that architecture being built in; and in general, training on more and harder tasks creates ever more human-like performance, generalization, and robustness. The GPT natural-language & programming language models, iGPT/Vision Transformer for images (and to some degree GPT-f), show that simply scaling up models & datasets without any supervision produces results competitive with the best (and most complex) alternatives, using the same simple architecture, gradually passing from superficial surface correlations to more human-like brain activity ( et al 2020) and linguistic biases as data increases (eg. et al 2020). In fact, one may not even need complicated attention mechanisms at scale, as fully-connected networks—hard to get much simpler than them!—work surprisingly well for many tasks. One typically trains such large models with simple optimizers like Adam—because the complicated ones lose their advantages as batch sizes increase and the simple optimizers work fine and are more memory-efficient anyway. OA5 does not just scale to, but stabilizes at, minibatches of millions due to gradient noise. OA5-like, BigGAN stabilizes at large-scale image datasets like JFT-300M & benefits from unusually large minibatches and VAEs (long an also-ran to GANs or autoregressive models in terms of sharp image generation) catch up if you make them very deep (2020, 2020); while classifier CNNs like BiT14/ et al 2020 or ResNeXt or Noisy Student transfer & robustify with human-like errors15, multimodal learning produces better representations on fewer data (eg. ViLBERT/VideoBERT, motivating OA’s interest in big multimodal models), and RNNs can predict videos. AlphaStar reaches human-level with hundreds of competing self-players to cover possible strategies. Imitation learning DRL like MetaMimic generalizes at hundreds of tasks to train a deep net. Disentanglement emerges in StyleGAN with sufficiently deep w embeddings, with enough parameters to train raw audio in the aforementioned Jukebox, or in relational networks/GQN/Transformers with enough samples to force factorization. (See also et al 2019/ et al 2017/ et al 2018/2019/Interactive Agents 2020.) Training Dactyl (or humanoid robots) on millions of domain randomizations induced similar implicit meta-learning where during each runtime invocation, the RNN probes its environment and encodes its understanding of robot hand control into its hidden state; and DD-PPO outperforms classical robot planners by scaling 2 orders. Or in Procgen or CoinRun, training on hundreds of levels trains agents to solve levels individually and worsens performance on other levels, but at thousands of levels, they begin to generalize to unseen levels. (Similarly, language model pretraining-finetuning overfits at small numbers of datasets but improves markedly with enough diversity.) AlphaZero demonstrated truly superhuman Go without ‘delusions’ just by training a bigger model on a richer signal & pro-level play without any search—and MuZero, for that matter, demonstrated that just training an RNN end-to-end to predict a reward on enough data is enough to obsolete even AlphaZero and learn tree search implicitly (but better). And on and on. DM researcher Matthew Botvinick, discussing their meta-reinforcement learning work where they were surprised to discover meta-learning emerging, and that it did so regardless of which specific architecture they used:
…it’s something that just happens. In a sense, you can’t avoid this happening. If you have a system that has memory, and the function of that memory is shaped by reinforcement learning, and this system is trained on a series of interrelated tasks, this is going to happen. You can’t stop it.
Pace Breiman, why? Why do they transfer and generalize? Why do these blessings of scale exist? Why do we need to train large models when small models provably exist with the same performance? Why do larger models not overfit (though they can) and generalize better than smaller models? What’s up with the whole ‘double descent’ anyway?
These are all, ahem, deep questions about neural networks and heavily debated, but right now, I would suggest that the answer lies in some mix of the model compression/distillation, ‘lottery ticket hypothesis’, Bayesian neural network, and learned representation (like circuits) literatures.
Big models work because they encode a dizzyingly vast number of sub-models in an extremely high-dimensional abstract space, representing countless small sub-models ( et al 2020) interpolating over data, one of which is likely to solve the problem well, and so ensures the problem is soluble by the overall model. They function as an ensemble: even though there countless overfit sub-models inside the single big model, they all average out, leading to a preference for simple solutions. This Occam’s razor biases the model towards simple solutions which are flexible enough to gradually expand in complexity to match the data.
However, “neural nets are lazy”: sub-models which memorize pieces of the data, or latch onto superficial features, learn quickest and are the easiest to represent internally. If the model & data & compute are not big or varied enough, the optimization, by the end of the cursory training, will have only led to a sub-model which achieves a low loss but missed important pieces of the desired solution.
On the other hand, for a model like GPT-3, it is sufficiently powerful a model that its sub-models can do anything from poetry to arithmetic, and it is trained on so much data that those superficial models may do well early on, but gradually fall behind more abstract models; a sub-model which memorizes some of the data is indeed much simpler than a sub-model which encodes genuine arithmetic (a NN can probably memorize tens of thousands of lookup table entries storing examples of addition in the space it would take to encode an abstract algorithm like ‘addition’), but it can’t possibly memorize all the instances of arithmetic (implicit or explicit) in GPT-3’s Internet-scale dataset. If a memorizing sub-model tried to do so, it would become extremely large and penalized. Eventually, after enough examples and enough updates, there may be a phase transition (2021), and the simplest ‘arithmetic’ model which accurately predicts the data just is arithmetic. And then the meta-learning, after seeing enough instances of algorithms which vary slightly within each sample, making it hard to learn each task separately, just is learning of more generic algorithms, yielding sub-models which achieve lower loss than the rival sub-models, which either fail to predict well or bloat unacceptably. (GPT-2-1.5b apparently was too small or shallow to ensemble easily over sub-models encoding meta-learning algorithms, or perhaps not trained long enough on enough data to locate the meta-learner models; GPT-3 was.)
So, the larger the model, the better, if there is enough data & compute to push it past the easy convenient sub-models and into the sub-models which express desirable traits like generalizing, factorizing perception into meaningful latent dimensions, meta-learning tasks based on descriptions, learning causal reasoning & logic, and so on. If the ingredients are there, it’s going to happen.
Scaling Hypothesis
The strong scaling hypothesis is that, once we find a scalable architecture like self-attention or convolutions, which like the brain can be applied fairly uniformly (eg. “The Brain as a Universal Learning Machine” or Hawkins), we can simply train ever larger NNs and ever more sophisticated behavior will emerge naturally as the easiest way to optimize for all the tasks & data. More powerful NNs are ‘just’ scaled-up weak NNs, in much the same way that human brains look much like scaled-up primate brains.
While I was highly skeptical of scaling hypothesis advocates when I first became interested in AI 2004–6201014ya (back when AI was stuck in the doldrums of hopelessly narrow tools and dates like 2028 seemed impossibly far away), which smacked of numerology and “if you build it they will come” logic (at the time, we certainly didn’t have general algorithms that you could just throw compute at), in 2020, I have to admit, I was wrong and they were right. We built the compute, and the algorithms did come, and the scaling hypothesis has only looked more and more plausible every year since 201014ya.
Why Does Pretraining Work?
The pretraining thesis goes something like this:
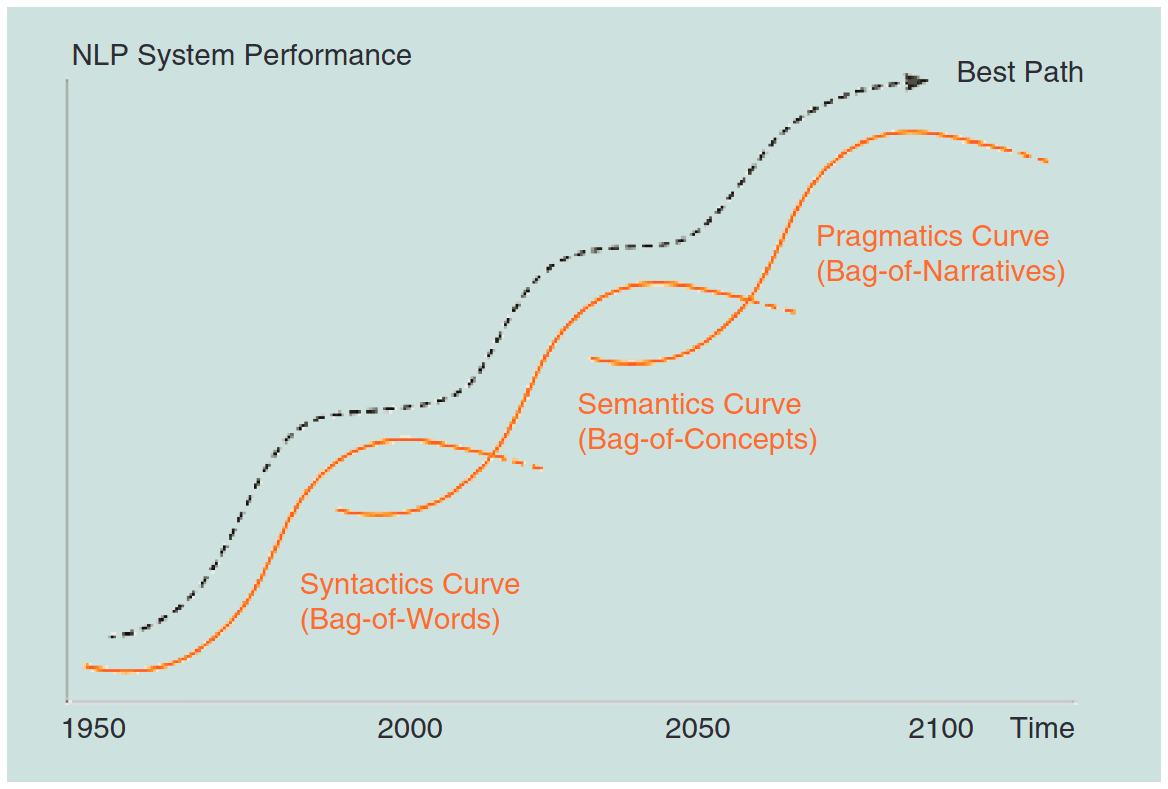
“Figure 1: Envisioned evolution of NLP research through three different eras or curves” (the hypothetical S-curves & progress in natural language modeling; from 2014)
Humans, one might say, are the cyanobacteria of AI: we constantly emit large amounts of structured data, which implicitly rely on logic, causality, object permanence, history—all of that good stuff. All of that is implicit and encoded into our writings and videos and ‘data exhaust’. A model learning to predict must learn to understand all of that to get the best performance; as it predicts the easy things which are mere statistical pattern-matching, what’s left are the hard things. AI critics often say that the long tail of scenarios for tasks like self-driving cars or natural language can only be solved by true generalization & reasoning; it follows then that if models solve the long tail, they must learn to generalize & reason.
Early on in training, a model learns the crudest levels: that some letters like ‘e’ are more frequent than others like ‘z’, that every 5 characters or so there is a space, and so on. It goes from predicted uniformly-distributed bytes to what looks like Base-60 encoding—alphanumeric gibberish. As crude as this may be, it’s enough to make quite a bit of absolute progress: a random predictor needs 8 bits to ‘predict’ a byte/character, but just by at least matching letter and space frequencies, it can almost halve its error to around 5 bits.16 Because it is learning so much from every character, and because the learned frequencies are simple, it can happen so fast that if one is not logging samples frequently, one might not even observe the improvement.
As training progresses, the task becomes more difficult. Now it begins to learn what words actually exist and do not exist. It doesn’t know anything about meaning, but at least now when it’s asked to predict the second half of a word, it can actually do that to some degree, saving it a few more bits. This takes a while because any specific instance will show up only occasionally: a word may not appear in a dozen samples, and there are many thousands of words to learn. With some more work, it has learned that punctuation, pluralization, possessives are all things that exist. Put that together, and it may have progressed again, all the way down to 3–4 bits error per character! (While the progress is gratifyingly fast, it’s still all gibberish, though, makes no mistake: a sample may be spelled correctly, but it doesn’t make even a bit of sense.)
But once a model has learned a good English vocabulary and correct formatting/spelling, what’s next? There’s not much juice left in predicting within-words. The next thing is picking up associations among words. What words tend to come first? What words ‘cluster’ and are often used nearby each other? Nautical terms tend to get used a lot with each other in sea stories, and likewise Bible passages, or American history Wikipedia article, and so on. If the word “Jefferson” is the last word, then “Washington” may not be far away, and it should hedge its bets on predicting that ‘W’ is the next character, and then if it shows up, go all-in on “ashington”. Such bag-of-words approaches still predict badly, but now we’re down to perhaps <3 bits per character.
What next? Does it stop there? Not if there is enough data and the earlier stuff like learning English vocab doesn’t hem the model in by using up its learning ability. Gradually, other words like “President” or “general” or “after” begin to show the model subtle correlations: “Jefferson was President after…” With many such passages, the word “after” begins to serve a use in predicting the next word, and then the use can be broadened.
By this point, the loss is perhaps 2 bits: every additional 0.1 bit decrease comes at a steeper cost and takes more time. However, now the sentences have started to make sense. A sentence like “Jefferson was President after Washington” does in fact mean something (and if occasionally we sample “Washington was President after Jefferson”, well, what do you expect from such an un-converged model). Jarring errors will immediately jostle us out of any illusion about the model’s understanding, and so training continues. (Around here, Markov chain & n-gram models start to fall behind; they can memorize increasingly large chunks of the training corpus, but they can’t solve increasingly critical syntactic tasks like balancing parentheses or quotes, much less start to ascend from syntax to semantics.)
Now training is hard. Even subtler aspects of language must be modeled, such as keeping pronouns consistent. This is hard in part because the model’s errors are becoming rare, and because the relevant pieces of text are increasingly distant and ‘long-range’. As it makes progress, the absolute size of errors shrinks dramatically. Consider the case of associating names with gender pronouns: the difference between “Janelle ate some ice cream, because he likes sweet things like ice cream” and “Janelle ate some ice cream, because she likes sweet things like ice cream” is one no human could fail to notice, and yet, it is a difference of a single letter. If we compared two models, one of which didn’t understand gender pronouns at all and guessed ‘he’/‘she’ purely at random, and one which understood them perfectly and always guessed ‘she’, the second model would attain a lower average error of barely <0.02 bits per character!
Nevertheless, as training continues, these problems and more, like imitating genres, get solved, and eventually at a loss of 1–2 (where a small char-RNN might converge on a small corpus like Shakespeare or some Project Gutenberg ebooks), we will finally get samples that sound human—at least, for a few sentences. These final samples may convince us briefly, but, aside from issues like repetition loops, even with good samples, the errors accumulate: a sample will state that someone is “alive” and then 10 sentences later, use the word “dead”, or it will digress into an irrelevant argument instead of the expected next argument, or someone will do something physically improbable, or it may just continue for a while without seeming to get anywhere.
All of these errors are far less than <0.02 bits per character; we are now talking not hundredths of bits per characters but less than ten-thousandths.
The pretraining thesis argues that this can go even further: we can compare this performance directly with humans doing the same objective task, who can achieve closer to 0.7 bits per character. What is in that missing >0.4?

“Yeah, but there’s more to being smart than knowing compression schemes!” “No there’s not!” “Shoot—he knows the secret!!”
Well—everything! Everything that the model misses. While just babbling random words was good enough at the beginning, at the end, it needs to be able to reason our way through the most difficult textual scenarios requiring causality or commonsense reasoning. Every error where the model predicts that ice cream put in a freezer will “melt” rather than “freeze”, every case where the model can’t keep straight whether a person is alive or dead, every time that the model chooses a word that doesn’t help build somehow towards the ultimate conclusion of an ‘essay’, every time that it lacks the theory of mind to compress novel scenes describing the Machiavellian scheming of a dozen individuals at dinner jockeying for power as they talk, every use of logic or abstraction or instructions or Q&A where the model is befuddled and needs more bits to cover up for its mistake where a human would think, understand, and predict. For a language model, the truth is that which keeps on predicting well—because truth is one and error many. Each of these cognitive breakthroughs allows ever so slightly better prediction of a few relevant texts; nothing less than true understanding will suffice for ideal prediction.
If we trained a model which reached that loss of <0.7, which could predict text indistinguishable from a human, whether in a dialogue or quizzed about ice cream or being tested on SAT analogies or tutored in mathematics, if for every string the model did just as good a job of predicting the next character as you could do, how could we say that it doesn’t truly understand everything? (If nothing else, we could, by definition, replace humans in any kind of text-writing job!)
The last bits are deepest. The implication here is that the final few bits are the most valuable bits, which require the most of what we think of as intelligence. A helpful analogy here might be our actions: for the most part, all humans execute actions equally well. We all pick up a tea mug without dropping, and can lift our legs to walk down thousands of steps without falling even once. For everyday actions (the sort which make up most of a corpus), anybody, of any intelligence, can get enough practice & feedback to do them quite well, learning individual algorithms to solve each class of problems extremely well, in isolation.17 Meanwhile for rare problems, there may be too few instances to do any better than memorize the answer. In the middle of the spectrum are problems which are similar but not too similar to other problems; these are the sorts of problem which reward flexible meta-learning and generalization, and many intermediate problems may be necessary to elicit those capabilities (“neural nets are lazy”).
Where individuals differ is when they start running into the long tail of novel choices, rare choices, choices that take seconds but unfold over a lifetime, choices where we will never get any feedback (like after our death). One only has to make a single bad decision, out of a lifetime of millions of discrete decisions, to wind up in jail or dead. A small absolute average improvement in decision quality, if it is in those decisions, may be far more important than its quantity indicates, and give us some intutition for why those last bits are the hardest/deepest. (Why do humans have such large brains, when animals like chimpanzees do so many ordinary activities seemingly as well with a fraction of the expense? Why is language worthwhile? Perhaps because of considerations like these. We may be at our most human while filling out the paperwork for life insurance.)
Reasons for doubt. The pretraining thesis, while logically impeccable—how is a model supposed to solve all possible trick questions without understanding, just guessing?—never struck me as convincing, an argument admitting neither confutation nor conviction. It feels too much like a magic trick: “here’s some information theory, here’s a human benchmark, here’s how we can encode all tasks as a sequence prediction problem, hey presto—Intelligence!” There are lots of algorithms which are Turing-complete or ‘universal’ in some sense; there are lots of algorithms like AIXI which solve AI in some theoretical sense (Schmidhuber & company have many of these cute algorithms such as ‘the fastest possible algorithm for all problems’, with the minor catch of some constant factors which require computers bigger than the universe).
Why think pretraining or sequence modeling is not another one of them? Sure, if the model got a low enough loss, it’d have to be intelligent, but how could you prove that would happen in practice? (Training char-RNNs was fun, but they hadn’t exactly revolutionized deep learning.) It might require more text than exists, countless petabytes of data for all of those subtle factors like logical reasoning to represent enough training signal, amidst all the noise and distractors, to train a model. Or maybe your models are too small to do more than absorb the simple surface-level signals, and you would have to scale them 100 orders of magnitude for it to work, because the scaling curves didn’t cooperate. Or maybe your models are fundamentally broken, and stuff like abstraction require an entirely different architecture to work at all, and whatever you do, your current models will saturate at poor performance. Or it’ll train, but it’ll spend all its time trying to improve the surface-level modeling, absorbing more and more literal data and facts without ever ascending to the higher planes of cognition as planned. Or…
‘The possibilities of developing an atomic weapon and the desirability of doing it secretly were discussed at a Princeton University conference in which I participated in March 193985ya…Bohr said this rare variety could not be separated from common uranium except by turning the country into a gigantic factory. Bohr was worried that this could be done and that an atomic bomb could be developed—but he hoped that neither could be accomplished. Years later, when Bohr came to Los Alamos, I was prepared to say, “You see . . .” But before I could open my mouth, he said: “You see, I told you it couldn’t be done without turning the whole country into a factory. You have done just that.”’
But apparently, it would’ve worked fine. Even RNNs probably would’ve worked—Transformers are nice, but they seem mostly be about efficiency.19 (Training large RNNs is much more expensive, and doing BPTT over multiple nodes is much harder engineering-wise.) It just required more compute & data than anyone was willing to risk on it until a few true-believers were able to get their hands on a few million dollars of compute.
-
Q: Did anyone predict, quantitatively, that this would happen where it did?
-
A: Not that I know of.
-
Q: What would future scaled-up models learn?
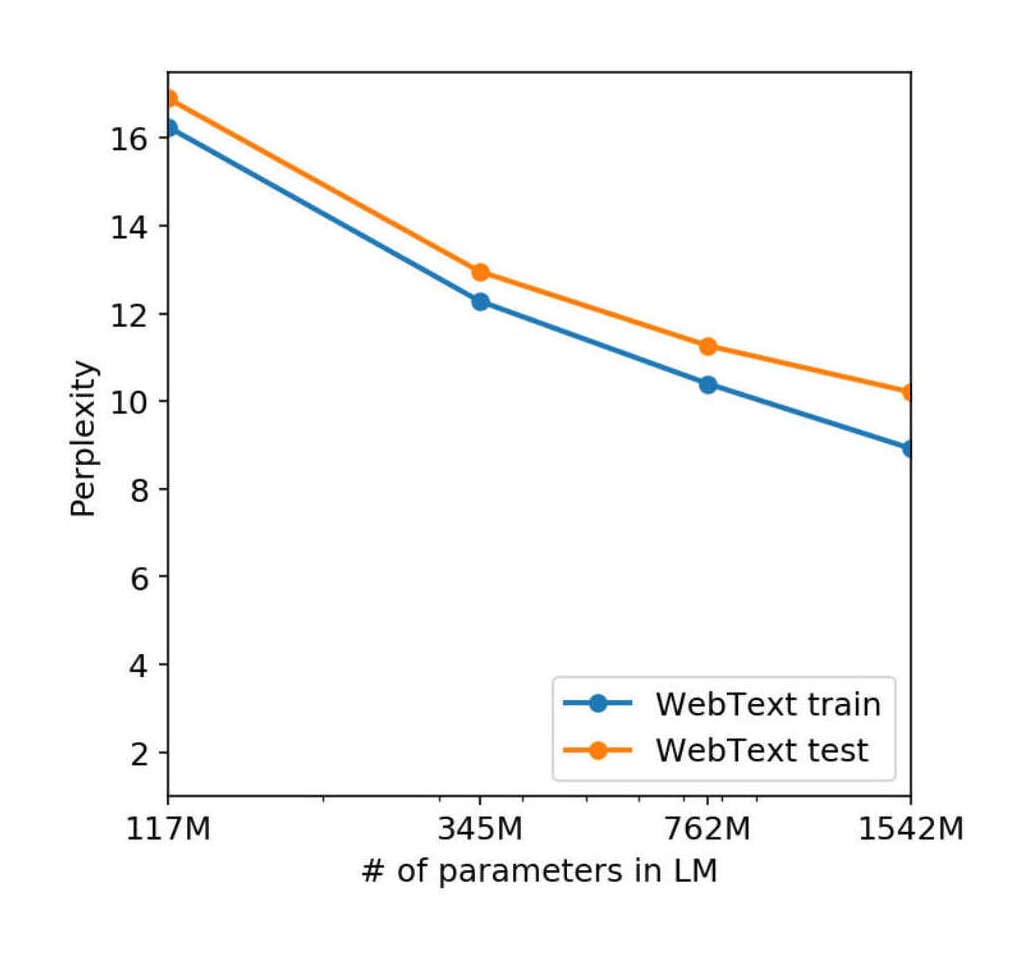
GPT-2-1.5b had a cross-entropy WebText validation loss of ~3.3 (based on the perplexity of ~10 in Figure 4, and log2(10) = 3.32). GPT-3 halved that loss to ~1.73 judging from et al 2020 and using the scaling formula (2.57 × (3.64 × 103)−0.048). For a hypothetical GPT-4, if the scaling curve continues for another 3 orders or so of compute (100–1000×) before crossing over and hitting harder diminishing returns, the cross-entropy loss will drop to ~1.24 (2.57 × (3.64 × (103 × 103))−0.048).
If GPT-3 gained so much meta-learning and world knowledge by dropping its absolute loss ~50% when starting from GPT-2’s level, what capabilities would another ~30% improvement over GPT-3 gain? (Cutting the loss that much would still not reach human-level, as far as I can tell.20) What would a drop to ≤1, perhaps using wider context windows or recurrency, gain?
-
A: I don’t know.
{kind=link}
-
Q: Does anyone?
-
A: Not that I know of.21
Prospects
In the problem of decoding, the most important information which we can possess is the knowledge that the message which we are reading is not gibberish…In a similar way, when we consider a problem of nature such as that of atomic reactions and atomic explosives, the largest single item of information which we can make public is that they exist. Once a scientist attacks a problem which he knows to have an answer, his entire attitude is changed. He is already some 50% of his way toward that answer…the one secret concerning the atomic bomb which might have been kept and which was given to the public and to all potential enemies without the least inhibition, was that of the possibility on its construction. Take a problem of this importance and assure the scientific world that it has an answer; then both the intellectual ability of the scientists and the existing laboratory facilities are so widely distributed that the quasi-independent realization of the task will be a matter of merely a few years anywhere in the world.
Norbert Wiener, pg124–125, The Human Use of Human Beings (emphasis added)
People who work in machine learning simply didn’t think that neural networks could do much. People didn’t believe large neural networks could be trained…The ideas were all there, the thing that was missing was a lot of supervised data and a lot of compute. Once you have [those two], then there is a third thing is that is needed—and that is conviction. Conviction that if you take the right stuff, which already exists, and apply and mix it with a lot of data and a lot of compute, that it will in fact work. And so that was the missing piece.
What can we expect from future DL work? Will GPT-3 kickstart an arms race where soon we will be discussing, blase, what would seem now like ludicrously farfetched schemes like bidirectional multimodal Transformer 100× the size trained on 100× the data (video/text/PDFs-as-images/photo/robotics) with supplementary supervised learning as the backbone of a MuZero-like learning+planning DRL agent running on thousands of tasks (such as coding) simultaneously?
The existence of the hardware overhang implies that the limiting factor here is less hardware than human: will any organization treat GPT-3 as a Sputnik moment and invest aggressively in scaling programs? Is there a GPT-4-equivalent brewing away inside DeepMind or Google Brain’s TPU pods now? They aren’t stupid, they have the hardware, they have the budgets, they have the people.
But I think they lack a vision. As far as I can tell: they do not have any such thing, because Google Brain & DeepMind do not believe in the scaling hypothesis the way that Sutskever, Amodei and others at OA do. Just read through machine learning Twitter to see the disdain for the scaling hypothesis. (A quarter year on from GPT-3 and counting, can you name a single dense model as large as the 17b Turing-NLG—never mind larger than GPT-3?)
Google Brain is entirely too practical and short-term focused to dabble in such esoteric & expensive speculation, although Quoc V. Le’s group occasionally surprises you. They’ll dabble in mixture-of-expert models like GShard, but mostly because they expect to be likely to be able to deploy it or something like it to production in Google Translate.23
Why didn’t DeepMind do GPT-3? DeepMind24 holds what we might call the “weak scaling hypothesis”: they believe that AGI will require us to “find the right algorithms” effectively replicating a mammalian brain module by module, and that while these modules will be extremely large & expensive by contemporary standards (which is why compute is important, to give us “a more powerful tool with which to hunt for the right algorithms”), they still need to be invented & finetuned piece by piece, with little risk or surprise until the final assembly. Each piece, however, itself can scale: there’s no magical intelligence gland or quantum woo which creates a bright line between humans and, say, chimpanzees or rodents. (As much as we humans extravagantly admire our own capabilities like language or logic, those are relatively minor flourishes on the basic brain—each organism solves the same basic problems, like exploration, long-term memory, learning world-models, associating rewards with specific actions, meta-learning, etc.) As such, once you have a rat-level AGI, a human-level AGI is just more so. (And rats are a lot easier to experiment on.) That is how you get DM contraptions like Agent57 which throw the kitchen sink at the wall to see what sticks, and why they place such emphasis on neuroscience as inspiration and cross-fertilization for reverse-engineering the brain. (See also Sam Altman’s podcast interview comments on OA’s advantage vs unnamed rivals with more compute is because the lack of compute makes them stay “small and focused”—“for sure” like a startup approach.) When someone seems to have come up with a scalable architecture for cracking a hard problem, like AlphaZero or AlphaStar, they are willing to pour on the gas to make it scale, but otherwise, incremental refinement on ALE and then DMLab-30 is the game plan. They have been biting off and chewing pieces of the brain for a decade, and it’ll probably take another decade or two of steady chewing if all goes well. Because they have locked up so much talent and have so much proprietary code and believe all of that is a major moat to any competitor trying to replicate the complicated brain, they are fairly easygoing. You will not see DM ‘bet the company’ on any moonshot; Google’s cashflow isn’t going anywhere (and DM’s budget), and slow and steady wins the race.
Going beyond that, most other research labs like Tesla or FAIR are irrelevant and uninterested. Chinese AI companies are a question mark: past the language barrier, I seem to discern interest in AGI & little of the reflexive Western opposition, and companies like Baidu occasionally release important research (such as the early scaling paper et al 2017), but overall, Chinese AI may be overestimated, and they seem to suffer from a kind of Dutch disease—funding for surveillance technology, and for narrow e-commerce niches, is so plentiful that other areas are neglected.
OA, lacking anything like DM’s long-term funding from Google or its enormous headcount, is making a startup-like bet that they know an important truth which is a secret: “the scaling hypothesis is true!” So, simple DRL algorithms like PPO on top of large simple architectures like RNNs or Transformers can emerge, exploiting the blessings of scale, and meta-learn their way to powerful capabilities, enabling further funding for still more compute & scaling, in a virtuous cycle. This is why OA had to revise its corporate form: lacking any enormous endowment or extremely deep-pocketed patron like Google, where does it get the money to scale (or hire machine learning engineer/researchers who can command salaries in the millions)? OA has to earn the necessary money, so in a move like Mozilla Foundation owning Mozilla Corporation (to sell Firefox search engine placement), or the Hershey orphanage owning Hershey Chocolate or the Girl Scouts licensing their cookies, OpenAI switched from a pure nonprofit funded by donations to a nonprofit which owns a for-profit subsidiary/startup, “OpenAI LP”, which can take investments and engage in for-profit activities. OA LP, while controlled by OA, can then shoot for the moon. And if OA is wrong to trust in the God of Straight Lines On Graphs, well, they never could compete with DM directly using DM’s favored approach, and were always going to be an also-ran footnote, so they have no regret.
While all of this hypothetically can be replicated relatively easily (never underestimate the amount of tweaking and special sauce it takes) by competitors if they wished (the necessary amounts of compute budgets are still trivial in terms of Big Science or other investments like AlphaGo or AlphaStar or Waymo, after all), said competitors lack the very most important thing, which no amount of money or GPUs can ever cure: the courage of their convictions. They are too hidebound and deeply philosophically wrong to ever admit fault and try to overtake OA until it’s too late. How can we talk seriously about any kind of military Manhattan Project when the US military doesn’t even let its developers use Tensorflow or PyTorch, or about government projects in the shadow of coronavirus? This might seem absurd (surely the Bitter Lesson/scaling hypothesis have now earned enough prior probability to be taken seriously and receive major research investments to test how far they can go, especially given how important the implications are), but look at the repeated criticism of OA every time they release a new example of the scaling hypothesis, from GPT-1 to Dactyl to OA5 to GPT-2 to iGPT to GPT-3… To paraphrase St Augustine, most peoples’ reaction to the Bitter Lesson or scaling hypothesis is “grant me scale & compute—but not yet”.25
A critical indicator will be whether organizations beyond ‘the usual suspects’ (Microsoft ZeRO-2 team has reached 1t-scale training, but there is also Nvidia, Salesforce, Allen, Google DM/GB, Connor/EleutherAI, Facebook FAIR) start participating or if they continue to dismiss scaling. At least as of 2020-10-26, 152 days later, no model has come near GPT-3, and indeed, no model has even exceeded Turing-NLG’s 17b.26
Critiquing The Critics
Keeping track. GPT-3 in 2020 makes as good a point as any to take a look back on the past decade. It’s remarkable to reflect that someone who started a PhD because they were excited by these new “ResNets” would still not have finished it by now—that is how recent even resnets are, never mind Transformers, and how rapid the pace of progress is. In 201014ya, one could easily fit everyone in the world who genuinely believed in deep learning into a moderate-sized conference room (assisted slightly by the fact that 3 of them were busy founding DeepMind). Someone interested in machine learning in 201014ya might have read about some interesting stuff from weirdo diehard connectionists in recognizing hand-written digits using all of 1–2 million parameters, or some modest neural tweaks to standard voice-recognition hidden Markov models. In 201014ya, who would have predicted that over the next 10 years, deep learning would undergo a Cambrian explosion causing a mass extinction of alternative approaches throughout machine learning, that models would scale up to 175,000 million parameters, and that these enormous models would just spontaneously develop all these capabilities?
No one. That is, no one aside from a few diehard connectionists written off as willfully-deluded old-school fanatics by the rest of the AI community (never mind the world), such as Moravec, Schmidhuber, Sutskever, Legg, & Amodei.
One of the more shocking things about looking back is realizing how unsurprising and easily predicted all of this was if you listened to the right people. In 199826ya, 22 years ago, Moravec noted that AI research could be deceptive, and hardware limits meant that “intelligent machine research did not make steady progress in its first 50 years, it marked time for 30 of them!”, predicting that as Moore’s law continued, “things will go much faster in the next 50 years than they have in the last 50.” Moravec further observed that part of the reason for rapid progress was the hardware overhang: while supercomputers of the necessary power would exist long before the connectionist revolution began, no one would be allowed to use them27, as they would be devoted to ‘more important’ (prestigious) hard STEM work, like “physics simulations” (ie. climate simulations & nuclear bombs)28, and “AI research must wait for the power to become more affordable.” Affordable meaning a workstation roughly ~$2,013.25$1,0001998; sufficiently cheap compute to rival a human would arrive sometime in the 2020s, with the 2010s seeing affordable systems in the lizard–mouse range. As it happens, the start of the DL revolution is typically dated to AlexNet in 201212ya, by a grad student29 using 2 GTX 580 3GB GPUs (launch list price of… $713.09$5002010, for a system build cost of perhaps $2,064.28$1,5002012). 2020 saw GPT-3 arrive, and as discussed before, there are many reasons to expect the cost to fall, in addition to the large hardware compute gains that are being forecast for the 2020s despite the general deceleration of Moore’s law.30
The accelerating pace of the last 10 years should wake anyone from their dogmatic slumber and make them sit upright. It turned out, it’s Hans Moravec’s world, and the rest of us were just living in a fool’s paradise. And there are 28 years left in Moravec’s forecast…
The temptation, that many do not resist so much as revel in, is to give in to a déformation professionnelle and dismiss any model as “just” this or that(“just billions of IF statements” or “just a bunch of multiplications” or “just millions of memorized web pages”), missing the forest for the trees, as Moravec commented of chess engines:
The event was notable for many reasons, but one especially is of interest here. Several times during both matches, Kasparov reported signs of mind in the machine. At times in the second tournament, he worried there might be humans behind the scenes, feeding Deep Blue strategic insights!…In all other chess computers, he reports a mechanical predictability stemming from their undiscriminating but limited lookahead, and absence of long-term strategy. In Deep Blue, to his consternation, he saw instead an “alien intelligence.”
…Deep Blue’s creators know its quantitative superiority over other chess machines intimately, but lack the chess understanding to share Kasparov’s deep appreciation of the difference in the quality of its play. I think this dichotomy will show up increasingly in coming years. Engineers who know the mechanism of advanced robots most intimately will be the last to admit they have real minds. From the inside, robots will indisputably be machines, acting according to mechanical principles, however elaborately layered. Only on the outside, where they can be appreciated as a whole, will the impression of intelligence emerge. A human brain, too, does not exhibit the intelligence under a neurobiologist’s microscope that it does participating in a lively conversation.
But of course, if we ever succeed in AI, or in reductionism in general, it must be by reducing Y to ‘just X’. Showing that some task requiring intelligence can be solved by a well-defined algorithm with no ‘intelligence’ is precisely what success must look like! (Otherwise, the question has been thoroughly begged & the problem has only been pushed elsewhere; computer chips are made of transistors, not especially tiny homunculi.)
As long as the AI [OA5] can explore, it will learn, given enough time…We just kept waiting for the magic to run out. We kept waiting to hit a wall, and we never seemed to hit a wall.
Give it the compute, give it the data, and it will do amazing things. This stuff is like—it’s like alchemy!
Ilya Sutskever, summer 2019
Hindsight is 20⁄20. Even in 2015, all the experts assured us that AGI the scaling hypothesis seemed highly dubious: you needed something to scale, after all, and it was all too easy to look at flaws in existing systems and imagine that they would never go away and progress would sigmoid any month now, soon. Like the genomics revolution where a few far-sighted seers extrapolated that the necessary n for GWASes would increase exponentially & deliver powerful PGSes soon, while sober experts wrung their hands over “missing heritability” & the miraculous complexity of biology & scoff about how such n requirements proved GWAS was a failed paradigm, the future arrived at first slowly and then quickly. Yet, here we are: all honor to the fanatics, shame and humiliation to the critics!31 If only one could go back 10 years, or even 5, to watch every AI researchers’ head explode reading this paper… Unfortunately, few heads appear to be exploding now, because human capacity for hindsight & excuses is boundless (“I can get that much with finetuning, anyway I predicted it all along, how boring”) and, unfortunately, “there is no fire alarm” for AGI. (If you are still certain that there is near-zero probability of AGI in the next few decades, why? Did you predict—in writing—capabilities like GPT-3? Is this how you expect AI failure to look in the decades beforehand? What specific task, what specific number, would convince you otherwise? How would the world look different than it does now if these crude prototype insect-brain-sized DL systems were not on a path to success?)
Authority without accountability. What should we think about the experts? Projections of failure were made by eminent, respectable, serious people. They spoke in considered tones of why AI hype was excessive and might trigger an “AI winter”, and the fundamental flaws of fashionable approaches and why brute force could not work. These statements were made routinely in 2014, 2015, 2016… And they were wrong. I am aware of few issuing a mea culpa or reflecting on it.32 It is a puzzling failure, and I’ve reflected on it before.
Phatic, not predictive. There is, however, a certain tone of voice the bien pensant all speak in, whose sound is the same whether right or wrong; a tone shared with many statements in January to March of this year; a tone we can also find in a 194084ya Scientific American article authoritatively titled, “Don’t Worry—It Can’t Happen”, which advised the reader to not be concerned about it any longer “and get sleep”. (‘It’ was the atomic bomb, about which certain scientists had stopped talking, raising public concerns; not only could it happen, the British bomb project had already begun, and 5 years later it did happen.)
The iron law of bureaucracy: Cathedral gothic. This tone of voice is the voice of authority.
The voice of authority insists on calm, and people not “panicking” (the chief of sins).
The voice of authority assures you that it won’t happen (because it can’t happen).
The voice utters simple arguments about why the status quo will prevail, and considers only how the wild new idea could fail (and not all the possible options).
The voice is not, and does not deal in, uncertainty; things will either happen or they will not, and since it will not happen, there is no need to take any precautions (and you should not worry because it can’t happen).
The voice does not believe in drawing lines on graphs (it is rank numerology).
The voice does not issue any numerical predictions (which could be falsified).
The voice will not share its source code (for complicated reasons which cannot be explained to the laity).
The voice is opposed to unethical things like randomized experiments on volunteers (but will overlook the insult).
The voice does not have a model of the future (because a model implies it does not already know the future).
The voice is concerned about its public image (and unkind gossip about it by other speakers of the voice).
The voice is always sober, respectable, and credentialed (the voice would be pleased to write an op-ed for your national magazine and/or newspaper).
The voice speaks, and is not spoken to (you cannot ask the voice what objective fact would change its mind).
The voice never changes its mind (until it does).
The voice is never surprised by events in the world (only disappointed).
The voice advises you to go back to sleep (right now).
When someone speaks about future possibilities, what is the tone of their voice?
Appendix
It From Byte
Powerful generative models like GPT-3 learn to imitate agents and thus become agents when prompted appropriately. This is an inevitable consequence of training on huge amounts of human-generated data. This can be a problem.
Is human data (or moral equivalents like DRL agents) necessary, and other kinds of data, such as physics data, free of this problem? (And so a safety strategy of filtering data could reduce or eliminate hidden agency.)
I argue no: agency is not discrete or immaterial, but an ordinary continuum of capability, useful to a generative model in many contexts beyond those narrowly defined as ‘agents’, such as in the “intentional stance” or variational approaches to solving physics problems. Much like other DRL-elicited capabilities like meta-learning, memory, exploration, or reasoning, ‘agency’ is a useful tool for a large family of problems, and a powerful model applied to that family may, at some point, develop concepts of agency or theory of mind etc.
Thus, a very wide range of problems, at scale, may surprisingly induce emergent agency.
I have previously argued that GPT-3 clearly shows agency because it is doing offline imitation learning (behavioral cloning, specifically) from the human-generated text data, and so it learns generative models of many agents, real or fictional. These generative models offer agentic capabilities, because they can be used to prompt the model to ‘roleplay’—plan & take action which will steer environments into small goal regions of state-space; and this is not merely hypothetical, or confined to text transcripts of actions & results in its internal simulated environments, but given effectors, like in the case of SayCan, a language model will in fact do such things in the real world.
That such systems may never have ‘experienced the real world’ or been trained deliberately on exact action sequences of malicious agents doesn’t mean that they cannot generalize or imitate. A sufficiently accurate simulation of an agent just is an agent. (One can set up a prompt for GPT-3 to imitate Adolf Hitler and ask him how to regain power & resume exterminating the Jews and get back a semi-coherent high-level plan; this is unfortunate, and the simulacra need not even be of a real person—evil fictional characters plan evil things just as easily, because it’s not hard to imagine what horrible things they would want to do.) This doesn’t seem all that different from accepted instances of reinforcement learning, like behavior learning or offline reinforcement learning: if you train on data from agents, whether humans or logged data from DRL agents, then the question is “how would you not learn from all these examples how to act & be capable of pursuing goals?” Presumably you would not only if you were a stupid model, too small or given too little data.
If these are not ‘agents’, I don’t know what “really” is an agent; or at least if critics insist on some sort of definition of ‘agent’ which excludes these, I think perhaps we should then abandon the word ‘agent’ entirely—because if giving a SayCan robot an instruction to ‘fetch a can of Coke and bring it to me’, with it using image inputs to construct step-by-step plans to find, possess, and return with the can, and successfully doing so often in real life on a real robot, does not count as an ‘agent’, then we need a word for such non-agent systems, so we can discuss their non-agency dangers. (If we define them as sub-agents because of lack of appendages and thus define all models as harmless non-agents, this is an unacceptable equivocation given the extreme carelessness and insouciance people display in hooking up their models the first chance they get to humans, APIs, search engines, or robots—hardly had the OpenAI GPT-3 API been launched in July 2020 than people were showing off using its basic HTML/CSS/JS abilities to drive web browsers, and large LM model developers like LaMDA or Adept display an unseemly eagerness to let it query arbitrary URLs without their paper even bothering to specify it was live. The AI box hadn’t even been invented before everyone decided to let their AI out of the box to be slightly more useful, as should come as no surprise—after all, tool AIs want to be agent AIs.)
But one might wonder how far this logic goes: do we have agent AIs emerging from our tool AIs only because we trained them on so much agent-generated data? If we scrapped human text corpuses, full of text about humans planning and taking actions and obtaining goals, or video datasets stuffed full of agents doing stuff, and if we deleted image datasets as well because they are just snapshots of videos and depict agents & actions & environments full of traces of agency, would we then have a model which is now just a (relatively) safe ‘tool AI’, with no agency lurking?
I would still say that there’s a possibility, and maybe not even that small one: agency is not a discrete thing, but a continuum, which is a convergent instrumental drive / emergent capability because it is useful even for understanding “non-agentic” things.
All Is Atoms & Void
First, there cannot be any principled, hard-and-fast, necessary distinction between data which is ‘agentic’ and data which is merely ‘natural’. This is because there is no such distinction in reality either: all ‘agency’ is constructed of non-agentic bits like atoms. There is no agency-particle, no pineal gland granting access to ‘Genuine Decision-Making™’. An agentic human is made out of the same fundamental things as a clump of dust swirling in space, or rock, or a computer. It must be the case that one could, starting only from simulations of (possibly a lot of) atoms, nothing but the most raw physics equations and atoms & the void, and eventually recapitulate the history of the universe and observe things like the origin of life and humans. Thus, one turns non-agentic data (physics equations) into agentic data.
OK, but barring a hypercomputer, that is unlikely to happen. If we consider realistic levels of compute, like contemporary NNs, trained on less-than-everything-in-the-universe & apparently harmless data like, say, the hydrology of rivers flowing downhill (eg. for flood prevention), or the trajectory of the solar system, surely none of that agency will evolve—no amount of modeling the chaotic dynamics of Pluto will give you any help in modeling the dynamics of astronomy infighting about whether Pluto is a planet, right?
Intentional Interpretive Stance
Here again I differ, and invoke Daniel Dennett’s intentional stance. Humans do, in fact, model natural systems like these as agents. We find such teleological explanations indispensable for intuition and shortcut reasoning across many natural systems.
Variational Interpretations
Janus comments, apropos of their emphasis on what I might call a ‘world-modeling-centric’ intuition for GPT-3 vs my ‘agent-centric’ view that:
For example, Gwern has said that anyone who uses GPT for long enough begins to think of it as an agent who only cares about roleplaying a lot of roles. That framing seems unnatural to me, comparable to thinking of physics as an agent who only cares about evolving the universe accurately according to the laws of physics. At best, the agent is an epicycle; but it is also compatible with interpretations that generate dubious predictions.
I embrace that description: it is in fact natural and not an elaborate epicycle on a geocentric model of the world, but rather, heliocentrism—powerful, and useful, and simpler. That it (also like heliocentrism33) may feel counterintuitive is unfortunate, but its virtues are proven.
We err if an intentional stance leads us engage in the pathetic fallacy and say that the river-spirit wants to reunite with the ocean (and we must offer sacrifices lest the dikes breach), but we are correct when we say that the river tries to find the optimal path which minimizes its gravitational or free energy. It is both true, predictively useful, and mathematically equivalent to the other way of formulating it, in terms of ‘forward’ processes computing step by step, atom by atom, and at the getting the same answer—but typically much easier to solve. (Ted Chiang’s “Story Of Your Life” tries to convey this perspective via fiction.) And this shortcut is a trick we can use universally, for everything from a river flowing downhill to the orbit of a planet to the path of photon through water minimizing travel time to evolutionary dynamics: instead of trying to understand it step by step, treat the system as a whole via the variational principle as ‘wanting’ to minimize (or maximize) some simple global quantity (a reward), and picking the sequence of actions that does so. (“The river wants to minimize its height, so without simulating it down to the individual water currents, I can look at the map and see that it should ‘choose’ to go left, then right, and then meander over this flat slightly-sloping part. Ah, looks like I was right.”) Then, into this modular trick, just plug in the system and quantity in question, and think like an agent…34
Uh oh. ‘Predictively useful’, ‘shortcut’, ‘much easier’, ‘universally’—all properties a neural net loves. All natural to it. Why would it try to solve each heterogeneous problem with a separate, computationally-expensive, bag of tricks, when there’s one weird trick AI safety researchers hate, like adopting teleological and variational reasoning?
Inducing Emergence Is Expensive
Of course, this frame can be more expensive than solving a problem directly. Variational approaches are powerful but counterintuitive, and there are often many simpler approximations or memorization that a model can do. For a single problem like modeling the orbit of Pluto, it is unlikely that any variational approach would be learned. Why would it, when there is only 1 system and 1 quantity minimized, so they can just be assumed? This is similar to other model capabilities induced by pretraining: things like induction heads or meta-learning or counting or reasoning need to pay their way, and are not superior to alternatives right from the start. They need rich enough models to compute them feasibly, enough data to force them out of easier solutions (which will fail on a few rare datapoints), and enough training (to work through all the possibilities to converge on the better capabilities).
What Can Induce Agency Emergence?
Unfortunately, this is an empirical matter. How many datasets? How big is each dataset? How diverse do they have to be? What even is a ‘dataset’, since we can always lump or split it? We struggle to predict when a capability will develop in GPT-3, so we definitely can’t say a priori that “Pluto is safe to model, but then tossing in a few thousand exoplanet solar systems would begin to elicit a define-system/plug-in-reward/maximize module and bring back agency”.
Cellular Automatons
It would also be hard to say at all what mathematical or physical systems exhibit the right kinds of maximizing behavior which can be generalized to an intentional stance. Does the ultra-abstract & simple cellular automaton Conway’s Game of Life (GoL) induce an intentional stance?
It has no agents, no biology, no evolution in the usual sense—but it does have many small patterns which can be usefully chunked to help understand a specific GoL. Humans, of course, look at a GoL as a bunch of small entities like ‘gliders’, but a NN given randomly-initialized boards may also see the same thing, because most GoL patterns will die out or reach fixed-points like gliders or still-life patterns: it is simply simpler to chunk a large GoL board into a few ‘gliders’ wandering through ‘empty space’ interrupted by the occasional ‘still life’.
And once you are talking about gliders wandering around unless they run into a still-life block which kills them, you are much of the way to an intentional stance—not modeling a glider as the inexorable outcome of applying this and that rule about the local-neighborhood to a million cells of equal importance, but as a specific entity of interest against an implicit & ignored background of dead cells, which will travel around and shoot off to infinity or meet its doom.
So, I wouldn’t want to bet too much on GoL being unable to induce any transfer.
Turing Machine
Can we go even broader? How about, not natural physics systems, nor specific abstractions of interest to humans (GoL is especially interesting among cellular automatons, and we ignore the large space of CA rules which define a CA but which does nothing interesting), but all Turing machines, let’s say random rules with some length-biased sample of random programs which we dovetail & treat available tapes as a sequence prediction problem. There is no more general computable setting, after all.
Single TM
Would training on a random Turing machine risk the possibility of agency?
Maybe not. For a single TM, this might foster some capabilities like instruction-following (for the same reason that pretraining on source code, especially source code augmented with state logs, is a powerful prior for many tasks), but it does not seem to have any of the traits that would induce agency. There is nothing that random TM programs try to minimize or maximize; they simply run. They don’t try to maximize run time length (terminating or non-terminating), or write as few or as many places on the tape as possible, or to achieve particular patterns. A model would simply learn the TM rules and attempt to approximate it as best as it can given its own limited feedforward neural net resources; eventually, if it can work iteratively or recurrently, it would learn the rules and generalize perfectly, and no further learning occurs. Classifying TM programs by whether they halt doesn’t help: yes, the Busy Beaver ‘wants’ to maximize something, but that’s just by definition as the longest terminating program, there are many more TM programs which are ‘happy’ to halt very quickly. So predicting halting status may learn things, but also still nothing that prima facie looks like agency.
TM Meta-Learning
This might be due to there being only a single TM, making it analogous to training only on Pluto. Perhaps the right setting would be training over many TM rules (and programs within each one). This is what a researcher would be more interested in, since few TMs are of any intrinsic interest, nor do we know the One True Turing Machine™; we’d rather have a neural network which is learning to learn TMs, or meta-learning, and training a NN over many environments drawn from a distribution is the easiest way to induce meta-learning. So what if we trained a model to do sequence prediction of a random TM + random program, without reuse? If single random Turing machines are harmless, how about all of them?
Hm, well… It’s worth noting how Alan Turing introduced the Turing machine formalism: as a general setting in which a man read and executed sets of rules about how to mark up a paper tape. So even in the original formulation of computers as tools which merely do what they are programmed to do, we have a homunculus at the center! This homunculus could do (and given different instructions, would) anything to the tape, but he wants to follow the current set of instructions accurately, until he’s done. In each draw from the TM+program distribution, he is following a different set of instructions, and now the model is attempting to infer what he wants, to as quickly as possible begin predicting the sequence accurately by recomputing it.
This provides our modularity, and a particular computation executed, and strong optimization pressure to rapidly ‘read’ the history and infer what the new rules must be. That may not have a clean reward-maximizing interpretation, but it does sound a lot like what anyone does with an agent of any kind: the inverse reinforcement learning problem of inferring the reward function can be arbitrarily hard, and until we succeed at that, we instead infer local rules & patterns, which target particular outcomes (regions of state-space). You may not know why your neighbor does that weird thing he does, but you can infer that he will do it, and not another agent, not even his evil identical twin. Is inferring TM rules the simplest & most rudimentary possible ‘theory of mind’? Maybe. In which case, there is no escape from the possibility of agency anywhere.
Ambient Agency
Agency may be like Turing-completeness: even in settings free of selection or optimization, it is a capability too useful and too convergent to guarantee its absence. The broader and more powerful a system is, the more the next feature or next piece of data may push it over the edge, and it becomes harder to engineer a system without that aspect.
Agency can be learned from data generated by agents, who generate extremely selective data. Or if you carefully remove all that, it may come from the selection of non-human data. Or it may be implicit in the dynamics of a replicator system. Or it may be one of the countless physical systems which have such interpretations which are computationally more efficient and thus any NN which is optimized to balance realizable compute with accuracy will be pushed to such interpretations. Or it may be a good simplification of systems with macro-statistics where the detailed micro-state adds little. Or it may stem from simply meta-learning of rule induction on TMs, because agents may follow complex sets of policies which are learnable but the motivating reward-function is an under-determined blackbox.
Or… like squashing Turing-completeness, as soon as one hole in the sinking ship is patched, you notice another leak spring up. You can’t keep a good idea down. All you can do is make a complex system that doesn’t display agency as far as you can tell; unfortunately, much like Turing-completeness (or security vulnerabilities), that there is no overt agency doesn’t mean it is not there. The model won’t tell you, it is just getting on with the job of lowering its loss. (“Sampling can show the presence of knowledge, but not the absence.”)
I do not have any solutions to this, other than to advise yet again to abandon the seductive, convenient, but wrong idea that tool AIs (under any branding, be it ‘tool AIs’ or ‘physics generative models’ or ‘world simulators’), cannot or will not be agent AIs. They may well be, and the better they get, the more likely it is, and tampering with data is not a solution.
-
Given the number of comments on the paper’s arithmetic benchmark, I should point out that the arithmetic benchmark appears to greatly understate GPT-3’s abilities due to the BPE encoding issue: even using commas markedly improves its 5-digit addition ability, for example. The BPE issue also appears to explain much of the poor performance on the anagram/shuffling tasks. This is something to keep in mind for any task which requires character-level manipulation or understanding.↩︎
-
On implicit meta-learning, see: et al 2016/ et al 2018 (Botvinick commentary)/ et al 2019a, 2019, 2015/2018, 2018/2019.↩︎
-
GPT-3 hardly costs more than a few million dollars of compute (as of early 2020) as the extensive scaling research beforehand enabled one training run, and it is cheap to run (pg39): “Even with the full GPT-3 175B, generating 100 pages of content from a trained model can cost on the order of 0.4 kW-hr, or only a few cents in energy costs.” (Likewise, T5 was trained only once.) And for the cost of one model, GPT-3 API users have shown that you get the equivalent of hundreds of smaller special-purpose models, each requiring more researchers, custom datasets, countless training runs, and tinkering, assuming said models could be created at all. (A slogan for the future: “One model, one vector—once.”)
For comparison, the PDP-11 was a common academic workhorse due to its extremely low cost, a mere $99,445.6$20,0001970, while the first Lisp Machine cost >$233,898.95$50,0001972—expensive for a workstation but a bargain compared to researchers hogging mainframes costing tens of millions. IBM’s (otherwise useless) Deep Blue AI project reputedly cost >$10.45$51997m for the final iteration (reports of $208.98$1001997m appear to be a confusion with the estimated value of publicity mentioned in pg187 of Hsu’s Behind Deep Blue) and Big Science projects like ITER blow >5000× the funding to mostly fail. (The particle physicists, incidentally, are back asking for ≫$24b, based on, presumably the scientific revolutions & world-changing breakthroughs that the LHC’s >$12.84$92010b investment produced, or the $4.79$21993b spent to (not) build the SSC…)
GPT-3 could have been done decades ago with global computing resources & scientific budgets; what could be done with today’s hardware & budgets that we just don’t know or care to do? There is a hardware overhang. (See also the Whole Brain Emulation Roadmap & “2019 recent trends in GPU price per FLOPS”.)↩︎
-
Further, NNs have additional hardware overhangs of their own due to the many orders of magnitude asymmetry of training vs running. Transfer learning and meta-learning are so much faster than the baseline model training. You can ‘train’ GPT-3 without even any gradient steps—just examples. You pay the extremely steep upfront cost of One Big Model to Rule Them All, and then reuse it everywhere at tiny marginal cost. If you train a model, then as soon as it’s done you get, among other things:
-
the ability to run thousands of copies in parallel on the same hardware
-
in a context like AlphaGo, I estimate several hundred ELO strength gains if you reuse the same hardware to merely run tree search with exact copies of the original model
-
-
meta-learning/transfer-learning to any related domain, cutting training requirements by orders of magnitude
-
model compression/distillation to train student models which are a fraction of the size, FLOPS, or latency (ratios varying widely based on task, approach, domain, acceptable performance degradation, targeted hardware etc, but often extreme like 1⁄100th)
-
reuse of the model elsewhere to instantly power up other models (eg. use of text or image embeddings for a DRL agent)
-
learning-by-doing/experience curve effects (highest in information technologies, and high for DL: 2020), so the next from-scratch model may be much cheaper.
For example: after all the iterative model architecture & game upgrades done while training the first OpenAI Five (OA5) DoTA2 agent was completed, the second iteration of OA5, “Rerun”, was trained from scratch. Rerun required only 20% of the training for a “98% win-rate against the final version of OpenAI Five.” As the authors note: “The ideal option would be to run Rerun-like training from the very start, but this is impossible—the OpenAI Five curve represents lessons learned that led to the final codebase, environment, etc., without which it would not be possible to train Rerun.”
-
baseline for engineering much more efficient ones by ablating and comparing with the original
-
-
eg. a narrow context window severely limits it, and motivates the need for efficient attention. More broadly, GPT-3 does nothing exotic—no use of brain imitation learning or neural architecture search to try to tailor the model, online hyperparameter optimization (possibly >3× speedup) or even decide basic hyperparameters like widths (which as EfficientNet shows, can make quite a different even in “well-understood and hand-optimized vanilla architectures”).↩︎
-
Not even PDFs—so no Google Books, no Arxiv, no Libgen, no Sci-Hub…↩︎
-
Generating text from a LM can reveal the presence of knowledge, but not its absence, and it is universally agreed that the current crude heuristic methods like top-k cannot possibly be optimal.↩︎
-
‘A man is at the doctor’s office, and the doctor tells him, “I’ve got some good news and some bad news for you.” / The man says, “Well, I can’t take the bad news right now, so give me the good news first.” / The doctor says, “Well, the good news is that you have an 18-inch penis.” / The man looks stunned for a moment, and then asks, “What’s the bad news?” / The doctor says, “Your brain’s in your dick.”’↩︎
-
In particular, sample-efficiency increases with model size up to compute-efficient scaling, and GPT-2 can memorize data after seeing it only once—a desirable property given long-tailed real-world distributions of data. (An example of how not to do scaling papers is et al 2020, which, in stark contrast to the foregoing papers—which Thompson et al do not mention at all!—attempts to infer scaling not from well-controlled experiments run by the authors, which yield extremely tight and highly predictive curves, but attempts to infer them from occasional reported numbers in highly disparate research papers; unsurprisingly, their curves barely predict anything and seem to be serious overestimates anyway.)
It is noteworthy that the pursuit of large models is driven almost exclusively by OpenAI & industry entities (the latter of which are content with far smaller models), and that academia has evinced an almost total disinterest—disgust & anger, even, and denial (one might say “green AI” is green with envy). For all that the scaling hypothesis is ‘obvious’ and scaling is ‘predicted’, there is remarkably little interest in actually doing it. Perhaps we should pay more attention to what people do rather than what they say; and recall that successful academic communities produce questions, not answers.↩︎
-
Roughly around Chuan Li’s estimate, using nominal list prices without discounts (which could be steep as the marginal costs of cloud compute are substantially lower). The R&D project cost would be much higher, but is amortized over all subsequent models & projects.↩︎
-
The Manhattan Project cost ~$25.73$21946b.↩︎
-
One is reminded of the joke about the customer complaining to the butcher:
“Your meat is $10/lb, while your competitor across the street sells it at $1!” “So go buy his meat.” “I would, but he has none.” “When I don’t have any meat, it costs $1 too.”↩︎
-
As if we live in a world where grad students could go to the Moon on a ramen budget if we just wished hard enough, as if focusing on CO2 costs & not benefits in our evaluations is not like making a scissor with only one blade, or as if “green AI” approaches to try to create small models without going through big models did not look increasingly futile and like throwing good money after bad, and were not the least green of all AI research… To the extent that all cutting-edge AI research ~201014ya could be done with grad student money like $1,426.18$1,0002010 of hardware, where AI research in decades before & after benefited from big iron, that is an indictment of that era, demonstrating what a stagnant dead end that research was, that its techniques were so smallminded and hobbled it could not benefit from the available large-scale compute.↩︎
-
Fun trivia: BiT is now more accurate at predicting (cleaned, corrected) ImageNet labels than the original ImageNet labels are.↩︎
-
One interesting aspect of image scaling experiments like et al 2020 is that even when performance is ‘plateauing’ on the original task & approaching label error, the transfer learning continues to improve. Apparently the internal representations, even when adequate for mere classification and so the score cannot increase more than a small percentage, become more human-like—because it’s encoding dark knowledge or more adversarial robustness? I’ve noticed with language models, the final fractions of a loss appear to make a substantial difference to generated sample quality, perhaps because it is only after all the easier modeling is finished that the lazy language model is forced to squeeze out the next bit of performance by more correctly modeling more sophisticated things like logic, objects, world-knowledge, etc.↩︎
-
The numbers here are not exact and are for illustration; because BPEs don’t correspond to any intuitive, I am going to borrow from my observations watching char-RNNs, and talk about the loss per character instead of BPE.↩︎
-
If you see thousands of images labeled ‘dog’ and thousands more labeled ‘cat’, you can simply learn separate dog & cat classifiers without bothering to understand their shared aspects like being domesticated quadruped mammal predators. This won’t be useful if you are then asked to classify ‘ferret’ images, but you weren’t asked to, so that’s not your problem, since you can just learn yet another separate classifier for ferrets if you then get a lot of ferret images.↩︎
-
pg210–211, “The Quiet Enemy”, The Legacy of Hiroshima, 1962.↩︎
-
Another way of interpreting the various papers about how Transformers are actually like RNNs or are actually Hopfield networks is to take that as indicating that what is important about them is not any inherent new capability compared to older architectures, but some lower-level aspect like being more efficiently trainable on contemporary hardware.↩︎
-
How do these absolute prediction performances compare to humans? It’s hard to say. The only available benchmarks for perplexity for humans/GPT-2/GPT-3 appear to be WebText, Penn Tree Bank (PTB; based on the Brown Corpus), 1 Billion Word (1BW), and LAMBADA. But coverage is spotty.
I found no human benchmarks for WebText or Penn Tree Bank, so I can’t compare the human vs GPT-2/GPT-3 perplexities (GPT-2 PTB: 35.7; GPT-3 PTB: 20.5).
GPT-2 was benchmarked at 43 perplexity on the 1 Billion Word (1BW) benchmark vs a (highly extrapolated) human perplexity of 12 (which interestingly extrapolates, using 201212ya LSTM RNNs, that “10 to 20 more years of research before human performance is reached”), but that may be an unfair benchmark (“Our model is still substantially worse than prior work on the One Billion Word Benchmark ( et al 2013). This is likely due to a combination of it being both the largest dataset and having some of the most destructive pre-processing—1BW’s sentence level shuffling removes all long-range structure.”) and 1BW was dropped from the GPT-3 evaluation due to data contamination (“We omit the 4 Wikipedia-related tasks in that work because they are entirely contained in our training data, and we also omit the one-billion word benchmark due to a high fraction of the dataset being contained in our training set.”).
LAMBADA was benchmarked at a GPT-2 perplexity of 8.6, and a GPT-3 perplexity of 3.0 (zero-shot) / 1.92 (few-shot). OA claims in their GPT-2 blog post (but not the paper) that human perplexity is 1–2, but provides no sources and I couldn’t find any. (The authors might be guessing based on how LAMBADA was constructed: examples were filtered by whether two independent human raters provided the same right answer, which lower bounds how good humans must be at predicting the answer.)
So overall, it looks like the best guess is that GPT-3 continues to have somewhere around twice the absolute error of a human. This implies it will take a large (yet, far from impossible) amount of compute to fully close the remaining gap with the current scaling laws. If we irresponsibly extrapolate out the WebText scaling curve further, assume GPT-3 has twice the error of a human at its current WebText perplexity of 1.73 (and so humans are ~0.86), then we need 2.57 · (3.64 · (103 · x))-0.048 = 0.86, where x = 2.2e6 or 2,200,000× the compute of GPT-3. (This would roughly equal the cost to the USA of invading Iraq.)
When is that feasible?
If we imagine that peak AI compute usage doubles every 3.4 months, then 2.2e6 would be 22 doublings away—or 6.3 years, in 2027. Most people believe that compute trend must break down soon, and that sort of prediction is a good reason why!
Going the other direction, 2020’s estimate is that, net of hardware & algorithmic progress, the cost of a fixed level of performance halves every 16 months; so if GPT-3 cost ~$5m in early 2020, then it’ll cost $2.5m around mid-2021, and so on. Similarly, a GPT-human requiring 2.2e6× more compute would presumably cost on the order of $10 trillion in 2020, but after 14 halvings (18 years) would cost $1b in 2038.↩︎
-
As of December 2020, half a year later, almost no researcher has been willing to go on record as saying what specific capabilities they predict future 1t, 10t, or 100t models will have or not have, and at what size which missing capabilities will emerge—just as no one is on record successfully predicting GPT-2 or GPT-3’s specific capabilities.↩︎
-
See also Sutskever’s DRL talk, and Wojciech Zaremba’s comments about OA5 (transcript):
↩︎-
-
Lukas Biewald: How much of the work then on DotA2 was, you felt, like fundamentally moving ML forward and how much of it was DotA-specific or can you even pull those apart?
-
Wojciech Zaremba: I think there was a decent amount of DotA-specific work. And then I think it was more than optimal, but also simultaneously hard. So I remember at the beginning of DotA project, it was actually unclear how to approach it.
People are saying that contemporary reinforcement learning will have no chance in solving this problem. And people looked into off-policy matters, on-policy matters, evolutionary strategies. The thing that became quite surprising is that methods that already exist, with appropriate scale work extremely well. So that was a big surprise. And I remember some people even before DotA time at OpenAI, saying that maybe reinforcement learning is a dead end. And all of a sudden it’s a very different story now.
-
L Biewald: For sure.
-
-
-
Production services, especially free production services, usually lag long after the unpublished SOTA inside the most cutting-edge lab. The second is the only thing that matters for predicting AI progress or AI risk, of course, but people will insist on measuring AI progress by bizarre metrics like what an arbitrary free service could do last year. As a rule of thumb, assume that: if you are using a free service with no login, the quality is at least 2 years behind SOTA; free with a login, >1.5 years; paid service, >1 year; & recently-released research paper, >6 months.↩︎
-
Particularly Demis Hassabis; I’m not sure about Shane Legg’s current views, although given the accuracy of his 2009 predictions while founding DeepMind & his 2018 comments, he probably hasn’t much changed his views that AI will be empowered by the (realized) exponential compute gains or his AGI forecast of ~2028. (This is consistent with the latest Metaculus forecasts.)↩︎
-
When faced with the choice between having to admit all their fancy hard work is a dead-end, swallow the bitter lesson, and start budgeting tens of millions of compute, or instead writing a disdainful tweet explaining how, “actually, GPT-3 shows that scaling is a dead end, it’s an environmental catastrophe, and it’s just imitation intelligence anyway”—most people will get busy on the tweet!↩︎
-
A mixture-of-expert model like GShard or an embedding like DynamicEmbedding is not comparable to ‘dense’ models like GPT-3, as it’s always been cheap & easy to train models with billions of ‘parameters’ in some sense, like extremely large embeddings; however, these parameters do little, and are more like a few hundred shallow models glued back-to-back. They probably do not learn the same interesting things that a dense model would with the same nominal parameter count.↩︎
-
This seems to be a bit of a blind spot by commentators: the assumption that if the necessary resource exists, then it will be used. For example, Jim Gray (d. 200717ya) in June 199925ya pokes a bit of fun at Turing’s connectionist hardware argument by noting that (using an optimistic lower bound on human brain computational power):
Desktop machines should be about as intelligent as a spider or a frog, and supercomputers ought to be nearing human intelligence…So, we should start seeing intelligence in these supercomputers any day now (just kidding)…[but we do not because] we are missing something very fundamental. Clearly, the software and databases we have for our super-computers is not on a track to pass the Turing Test in the next decade. Something quite different is needed. Out-of-the-box, radical thinking is needed.
We have been handed a puzzle: genomes and brains work. But we are clueless what the solution is. Understanding the answer is a wonderful long-term research goal.
With the benefit of hindsight, we can say that it is true that supercomputers in 199925ya could have been showing far more impressive levels of intelligence than they were, and that it was also true that the software being run on the supercomputers in 199925ya were never going to lead to meaningful AI progress, and that there is no particular contradiction or mystery—it was simply that no one was trying. No supercomputer owner was going to let it be tied up for years doing the minor-yet-critical iteration to make connectionist approaches like RNNs or CNNs work. Thus, something quite different & radical was indeed needed—but we already knew what the solution looked like.↩︎
-
Strikingly, as of 2020, this is still true: eg. the only deep learning research I have seen done on Summit were materials science & biology. (In double-checking Arxiv, I did find one non-STEM paper using Summit resources: et al 2019, focusing on systems engineering in training a video classification model.)↩︎
-
Peter Norvig offers an example of what happens when grad students can’t afford the necessary computing power to make neural nets work:
Lukas Biewald: When you look at deep learning, it sort of feels like that came suddenly, but a lot of those techniques were around, in fact in your book, I remember quite far back. Do you think that the field missed something, or was it just not possible to run at the scale necessary to show that these neural network techniques were working better than people expected in the early aughts?
Peter Norvig: Yeah. I mean, if you say suddenly, right, we’ve got a sudden leap in computer vision and image net after Hinton had been trying the same thing for 30 years, right?…And then it finally worked. And I think the biggest difference was the computing power. Definitely there were advances in data. So we could do ImageNet because Fei-Fei Li and others gathered this large database, and that was really important. There are certainly differences in the algorithm, right? We’ve got a slightly different squashing function. Instead of shaped like this [sigmoid], it’s shaped like this [ReLU]. I mean, I don’t know how big a deal that was, but we learned how to do stochastic gradient descent a little bit better. We figured that dropout gave you a little bit better robustness.
So there were small things, but I think probably the biggest was the computing power. And I mean, I certainly remember Geoff Hinton came to Berkeley when I was a grad student in 198143ya, I think, when he talked about these neural nets. And we fellow grad students thought that was so cool. So we said, ‘Let’s go back into the lab and implement it.’
And of course, there was absolutely nothing you could download, so we had to build it all from scratch. And we got it to do exclusive or [XOR], and then we got it to do something a little bit more complicated. And it was exciting. And then we gave it the first real problem, and it ran overnight, and it didn’t converge, and we let it run one more day, and it still didn’t converge. And then we gave up, and we went back to our sort of knowledge-based systems approach. But if we had the computing power of today, it probably would have converged after 5 seconds.
By my estimate, Norvig’s attempt used the equivalent of 0.8 milliseconds of contemporary GPU-time.
(In ~1981, an expensive PC costing the equivalent of >$5,000, of the sort a high-powered AI lab might allocate 1 apiece to grad students, might have an additional Intel 8087 floating-point coprocessor capable of 50,000 FP64 FLOPS; conservatively assuming that ‘overnight’ + ‘one more day’ ≤ 2 days, then Norvig’s experiment used 2d × 24h × 60m × 60s × 50,000 = 8×109 FLOPS; a 2020 Nvidia A100 GPU nominally priced ~$10,000 boasts 9.7 FP64 TFLOPS or 9,700,000,000,000 FLOPS (and far more in the more useful low-precision regimes like FP32, but 198143ya ML didn’t know that); thus, 8×109 / 9.7×1012 = 8×10−4 seconds = 0.8 milliseconds.)↩︎
-
Jeff Dean notes, “It is perhaps unfortunate that just as we started to have enough computational performance to start to tackle interesting real-world problems and the increased scale and applicability of machine learning has led to a dramatic thirst for additional computational resources to tackle larger problems, the computing industry as a whole has experienced a dramatic slowdown in the year-over-year improvement of general purpose CPU performance.” Under the computational view, this is not a coincidence: compute, not algorithms, are the critical factor; biological systems often come within orders of magnitude, or less, of the theoretical optimum for a task; and the closer one comes to optimal, the slower progress becomes; so, just as artificial computation finally starts doing “interesting real-world problems”, it necessarily is approaching its limits. (It could have been otherwise: Moore’s law could have stopped short by many orders of magnitude of biological efficiency, or surpassed it by many orders, with no temporal coincidence, and AI happened for other reasons.)↩︎
-
Now that GPT-3’s few-shot and T5 finetuning have begun to make people like Gary Marcus feel slightly nervous about WinoGrande, they have begun preparing their excuses for why Winograd schemas weren’t really good measures of commonsense reasoning/intelligence (because intelligence, of course, is whatever AI can’t do yet).↩︎
-
Feynman: “There are several references to previous flights; the acceptance and success of these flights are taken as evidence of safety. But erosion and blowby are not what the design expected. They are warnings that something is wrong. The equipment is not operating as expected, and therefore there is a danger that it can operate with even wider deviations in the unexpected and not thoroughly understood way. The fact that this danger did not lead to catastrophe before is no guarantee that it will not the next time, unless it is completely understood.”
One is reminded of the catastrophic dismissals of Western technology by the Chinese emperors & Shaka Zulu: the error was not in dismissing the technology as practically unimportant (it arguably was), nor in failing to realize that they were already centuries behind in the most important geopolitical development in millennia, but in failing to acknowledge that they couldn’t explain why the Western technology had gotten so good so fast and thus couldn’t know that it wouldn’t get much better still.↩︎
-
As my favorite Wittgenstein anecdote goes, heliocentrism strikes everyone as false because things just don’t look as if the Earth whirls at astronomical velocities around a star, but as if the Earth is perfectly still and everything else whirls around it (1963, An Introduction to Wittgenstein’s Tractatus):
↩︎The general method that Wittgenstein does suggest is that of ‘shewing that a man has supplied no meaning [“no reference”?] for certain signs in his sentences’. I can illustrate the method from Wittgenstein’s later way of discussing problems. He once greeted me with the question: ‘Why do people say that it was natural to think that the sun went round the earth rather than that the earth turned on its axis? I replied: ’I suppose, because it looked as if the sun went round the earth.’ ‘Well,’ he asked, ‘what would it have looked like if it had looked as if the earth turned on its axis?’
This question brought it out that I had hitherto given no relevant meaning to ‘it looks as if’ in ‘it looks as if the sun goes round the earth’. My reply was to hold out my hands with the palms upward, and raise them from my knees in a circular sweep, at the same time leaning backwards and assuming a dizzy expression. ‘Exactly!’ he said.
-
This connection is more than superficial—a lot of RL work draws on formal analogies to physics and variational principles.↩︎