backstop#deep-bayes
[Transclude the forward-link's
context]
ML Scaling subreddit
It Looks Like You’re Trying To Take Over The World
GPT-3: Language Models are Few-Shot Learners
GPT-3 paper § Figure F.1: Four uncurated completions from a context suggesting the model compose a poem in the style of Wallace Stevens with the title ‘Shadows on the Way’
GPT-3 Creative Fiction
GPT-2 Neural Network Poetry
GPT-3 Github JSON Dump Reformatted to Readable HTML
OpenAI API
Better Language Models and Their Implications
GPT-3 Creative Fiction § BPEs
Using Fast Weights to Attend to the Recent Past
https://www.reddit.com/r/reinforcementlearning/search/?q=flair%3AMetaRL&include_over_18=on&restrict_sr=on&sort=top
One-shot Learning with Memory-Augmented Neural Networks
Prefrontal cortex as a meta-reinforcement learning system
Matt Botvinick on the spontaneous emergence of learning algorithms
Reinforcement Learning, Fast and Slow
AI-GAs: AI-generating algorithms, an alternate paradigm for producing general artificial intelligence
On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models
One Big Net For Everything
Meta-Learning: Learning to Learn Fast
Meta Reinforcement Learning
Jukebox: We’re introducing Jukebox, a neural net that generates music, including rudimentary singing, as raw audio in a variety of genres and artist styles. We’re releasing the model weights and code, along with a tool to explore the generated samples.
GPT-1: Improving Language Understanding with Unsupervised Learning
I Recently Came across Https://arxiv.org/abs/2004.08900, Which ‘Assumes 2-3 Runs’ of T5-11B. In Fact, We Trained T5-11B once. That’s Why We Spend 35 Pages Figuring out How We Should Train Before We Start Training. You Don’t Want to Mess up a Training Run That Big.
CERN makes bold push to build €21-billion supercollider: European particle-physics lab will pursue a 100-kilometre machine to uncover the Higgs boson’s secrets—but it doesn’t yet have the funds
Whole Brain Emulation: A Roadmap
2019 recent trends in GPU price per FLOPS
Measuring the Algorithmic Efficiency of Neural Networks
Dota 2 With Large Scale Deep Reinforcement Learning § Pg11
D.5: Context Dependence
‘self-attention’ directory
WBE & DRL: a Middle Way of imitation learning on brains
LHOPT: A Generalizable Approach to Learning Optimizers
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
GPT-3 random sample dump: JavaScript tutorial
On the Measure of Intelligence
Deep Learning Hardware: Past, Present, & Future § Pg60
Technology Forecasting: The Garden of Forking Paths
GPT-3: Language Models Are Few-Shot Learners: 5. Limitations
CTRL: A Conditional Transformer Language Model For Controllable Generation
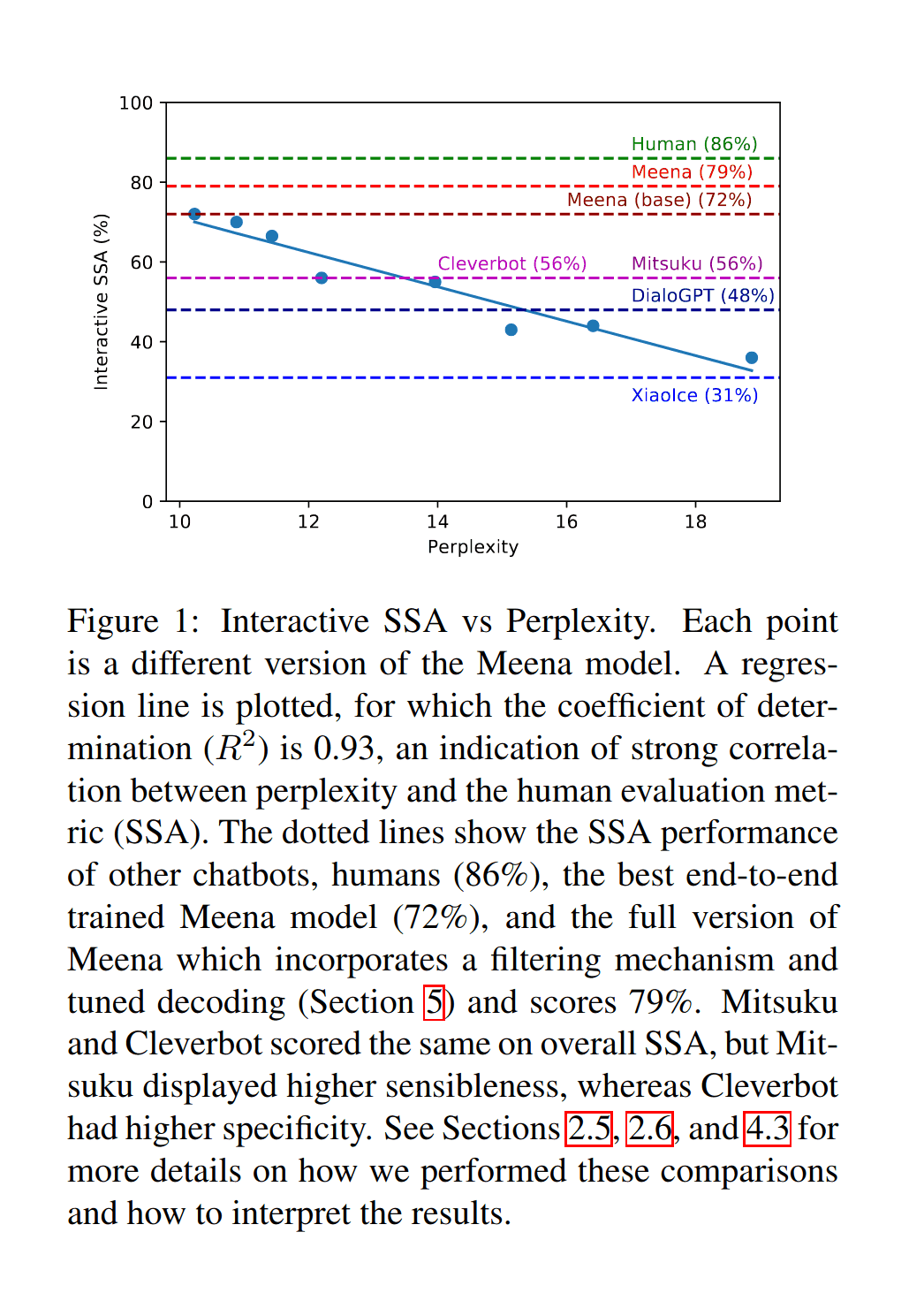
Towards a Human-like Open-Domain Chatbot
MegatronLM: Training Billion+ Parameter Language Models Using GPU Model Parallelism
T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Turing-NLG: A 17-billion-parameter language model by Microsoft
GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
Extracting Training Data from Large Language Models
Does Learning Require Memorization? A Short Tale about a Long Tail
The Computational Limits of Deep Learning
The Unreasonable Effectiveness of Data
Scaling to Very Very Large Corpora for Natural Language Disambiguation
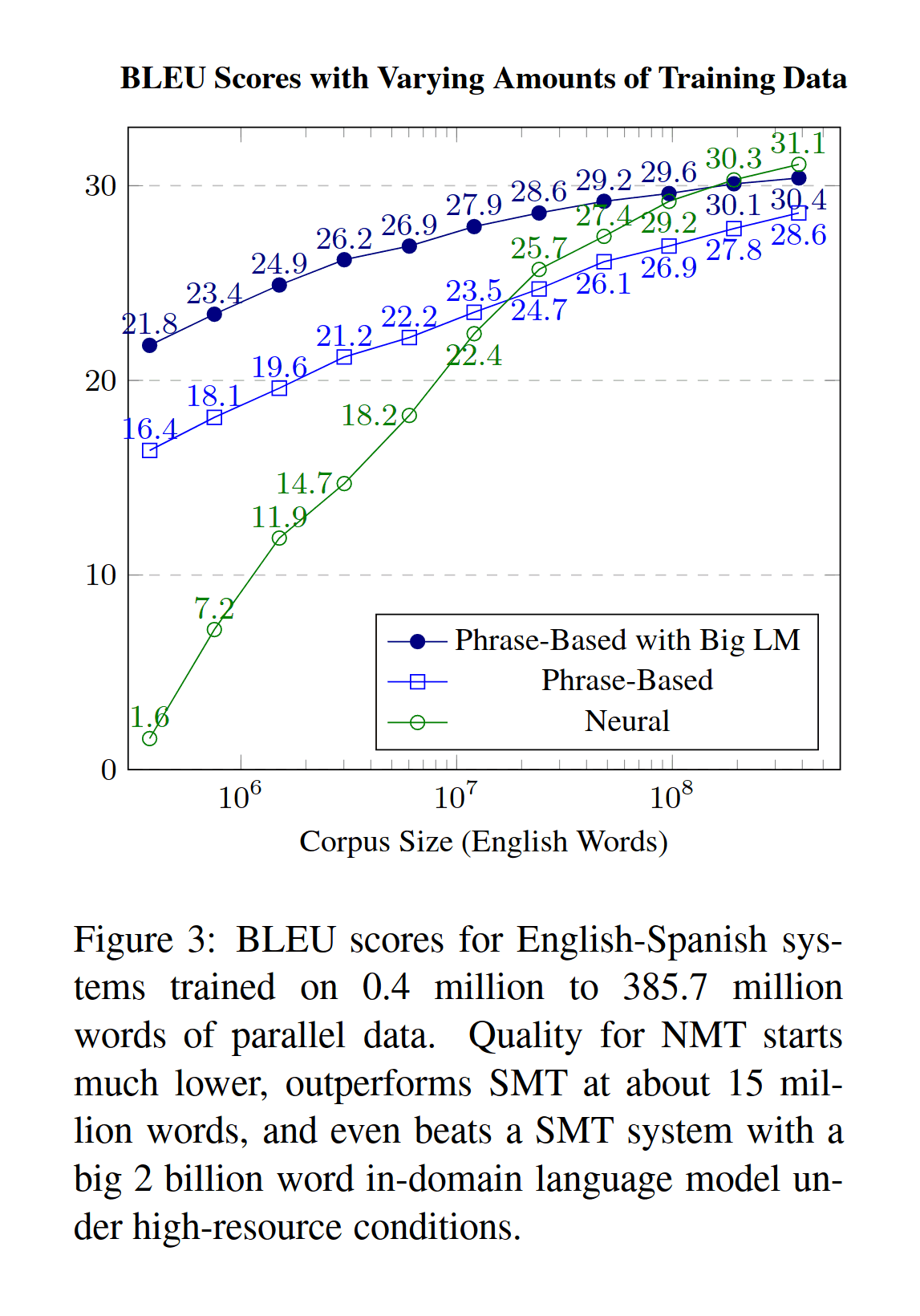
Large Language Models in Machine Translation
2017-koehn-figure3-bleuscoreswithvaryingamountsoftrainingdata.png
WinoGrande: An Adversarial Winograd Schema Challenge at Scale
Total Compute Used to Train Language Model: Table D.1
AI and Compute
OpenAI's GPT-3 Language Model: A Technical Overview
People I Know at OpenAI Say V4 Is around the Corner and Easily Doable, And...will Be Here Soon (Not Months but Year or So). And They Are Confident It Will Scale and Be around 100--1000×.
Microsoft announces new supercomputer, lays out vision for future AI work
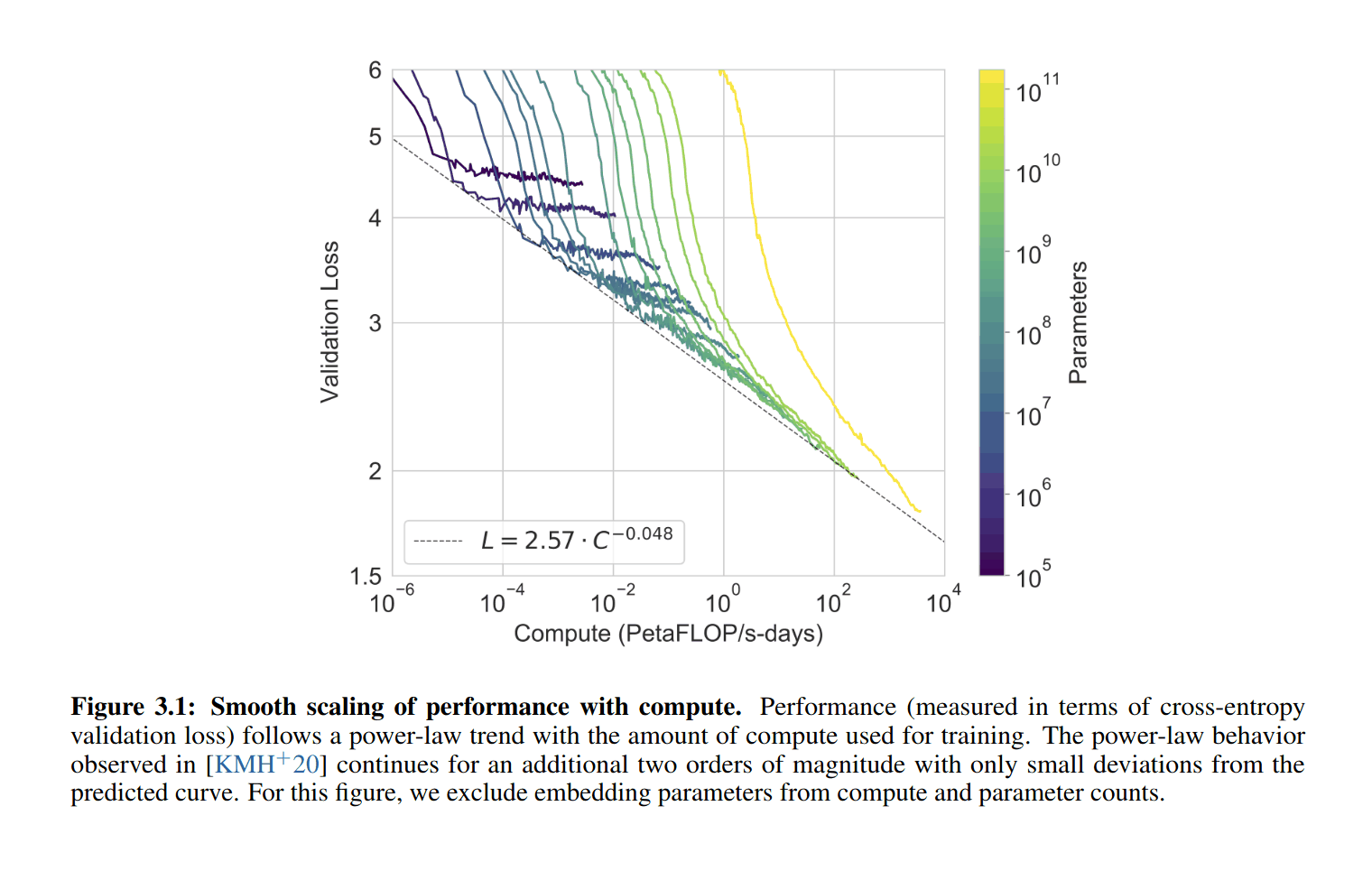
Scaling Laws for Neural Language Models
Scaling Laws for Neural Language Models: Figure 1: Language Modeling Performance Improves Smoothly As We Increase the Model Size, Dataset Size, and Amount of Compute Used for Training.
Scaling Laws for Neural Language Models: Figure 15: Far beyond the Model Sizes We Study Empirically, We Find a Contradiction between Our Equations § Pg17
https://arxiv.org/pdf/2005.14165.pdf#page=11&org=openai
Table 2.2: Datasets Used to Train GPT-3. ‘Weight in Training Mix’ Refers to the Fraction of Examples during Training That Are Drawn from a given Dataset, Which We Intentionally Do Not Make Proportional to the Size of the Dataset. As a Result, When We Train for 300 Billion Tokens, Some Datasets Are Seen up to 3.4 times during Training While Other Datasets Are Seen Less Than Once.
2020-adiwardana-meena-figure1-humanratingsvslikelihood.png
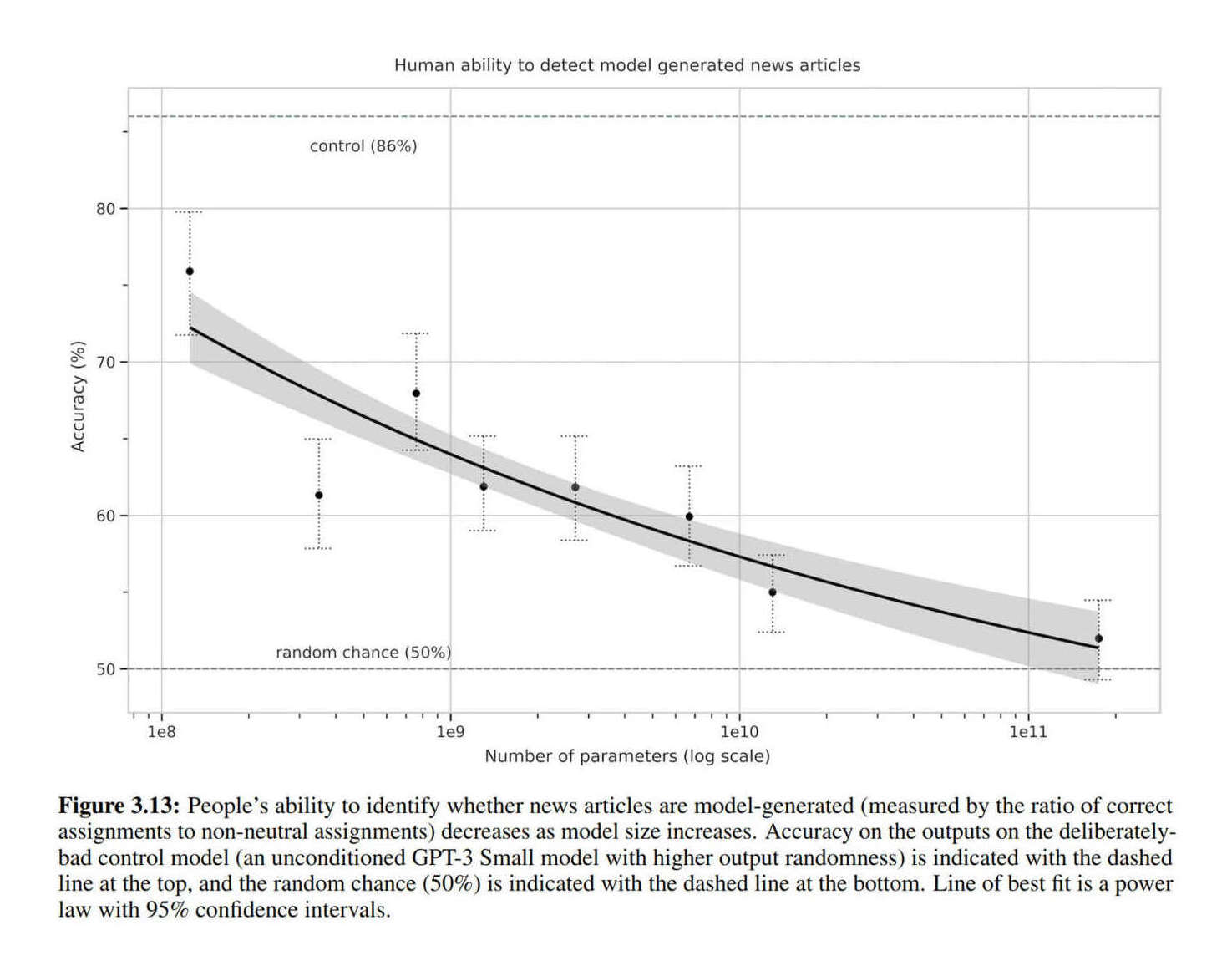
2020-brown-figure313-humanabilitytodetectmodelgeneratednewsstories.jpg
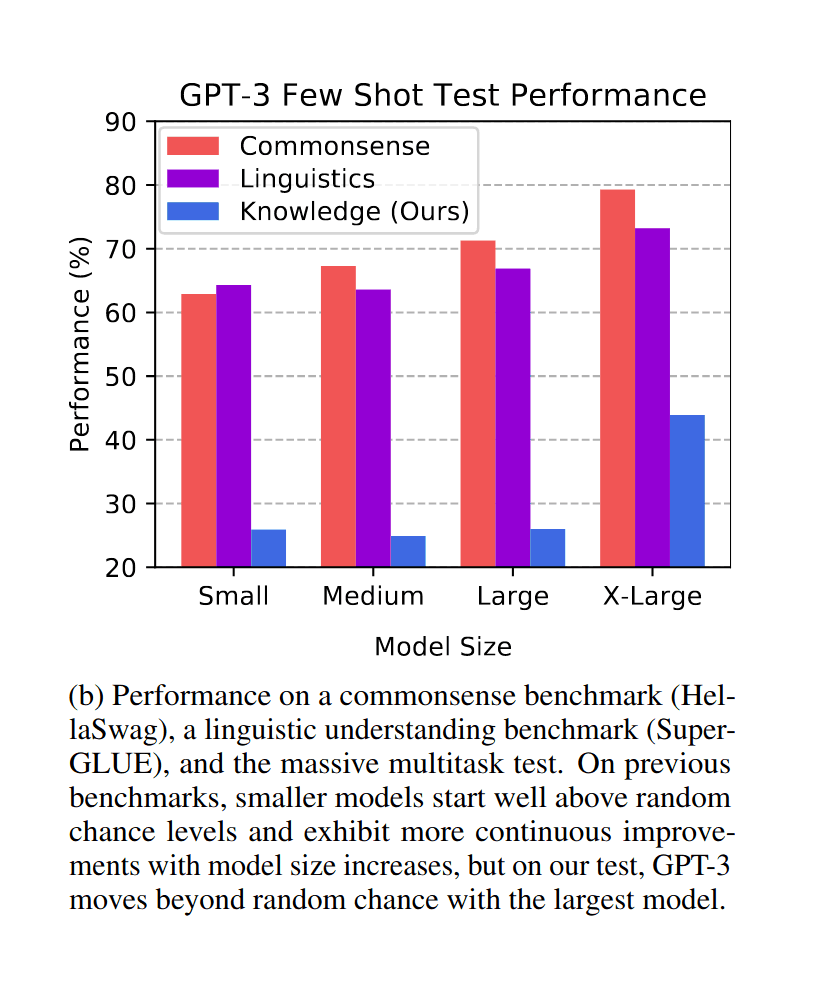
2020-hendrycks-figure1b-gpt3-qascaling.png
MMLU: Measuring Massive Multitask Language Understanding
https://x.com/geoffreyhinton/status/1270814602931187715
The Bitter Lesson
Image GPT (iGPT): We find that, just as a large transformer model trained on language can generate coherent text, the same exact model trained on pixel sequences can generate coherent image completions and samples
Vision Transformer: An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale
Generative Language Modeling for Automated Theorem Proving
The neural architecture of language: Integrative reverse-engineering converges on a model for predictive processing
Learning Which Features Matter: RoBERTa Acquires a Preference for Linguistic Generalizations (Eventually)
‘MLP NN’ directory
A Large Batch Optimizer Reality Check: Traditional, Generic Optimizers Suffice Across Batch Sizes
Dota 2 With Large Scale Deep Reinforcement Learning: §4.3: Batch Size
How AI Training Scales
BigGAN: Large Scale GAN Training For High Fidelity Natural Image Synthesis § 5.2 Additional Evaluation On JFT-300M
Very Deep VAEs Generalize Autoregressive Models and Can Outperform Them on Images
NVAE: A Deep Hierarchical Variational Autoencoder
Big Transfer (BiT): General Visual Representation Learning
Are we done with ImageNet?
On Robustness and Transferability of Convolutional Neural Networks
Robustness properties of Facebook’s ResNeXt WSL models
Self-training with Noisy Student improves ImageNet classification
Measuring Robustness to Natural Distribution Shifts in Image Classification
Understanding Robustness of Transformers for Image Classification
Distilling the Knowledge in a Neural Network
Smooth Adversarial Training
12-in-1: Multi-Task Vision and Language Representation Learning
VideoBERT: A Joint Model for Video and Language Representation Learning
The messy, secretive reality behind OpenAI’s bid to save the world: The AI moonshot was founded in the spirit of transparency. This is the inside story of how competitive pressure eroded that idealism
High Fidelity Video Prediction with Large Stochastic Recurrent Neural Networks
Grandmaster level in StarCraft II using multi-agent reinforcement learning
One-Shot High-Fidelity Imitation: Training Large-Scale Deep Nets with RL
A Style-Based Generator Architecture for Generative Adversarial Networks
A simple neural network module for relational reasoning
Neural scene representation and rendering
Transformers as Soft Reasoners over Language
Environmental drivers of systematicity and generalization in a situated agent
Gated-Attention Architectures for Task-Oriented Language Grounding
Interactive Grounded Language Acquisition and Generalization in a 2D World
Compositional generalization through meta sequence-to-sequence learning
Imitating Interactive Intelligence
Solving Rubik’s Cube with a Robot Hand
Learning Agile Soccer Skills for a Bipedal Robot with Deep Reinforcement Learning
DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames
Procgen Benchmark: We’re releasing Procgen Benchmark, 16 simple-to-use procedurally-generated environments which provide a direct measure of how quickly a reinforcement learning agent learns generalizable skills
Understanding RL Vision: With diverse environments, we can analyze, diagnose and edit deep reinforcement learning models using attribution
Muppet: Massive Multi-task Representations with Pre-Finetuning
A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
MuZero: Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model
Reflections After Refereeing Papers for NIPS
Understanding deep learning requires rethinking generalization
Deep Double Descent: We show that the double descent phenomenon occurs in CNNs, ResNets, and transformers: performance first improves, then gets worse, and then improves again with increasing model size, data size, or training time
Understanding the generalization of ‘lottery tickets’ in neural networks
Bayesian Deep Learning and a Probabilistic Perspective of Generalization
On Linear Identifiability of Learned Representations
Zoom In: An Introduction to Circuits—By studying the connections between neurons, we can find meaningful algorithms in the weights of neural networks
Neural Networks, Manifolds, and Topology
Logarithmic Pruning is All You Need
Direct Fit to Nature: An Evolutionary Perspective on Biological and Artificial Neural Networks
The Shape of Learning Curves: a Review: 6. Ill-Behaved Learning Curves: 6.1. Phase Transitions
The Brain as a Universal Learning Machine
The remarkable, yet not extraordinary, human brain as a scaled-up primate brain and its associated cost
Jumping NLP Curves: A Review of Natural Language Processing Research [Review Article]
difference#efficient-natural-languages
[Transclude the forward-link's
context]
Data Distributional Properties Drive Emergent Few-Shot Learning in Transformers
The Legacy of Hiroshima
Hopfield Networks is All You Need
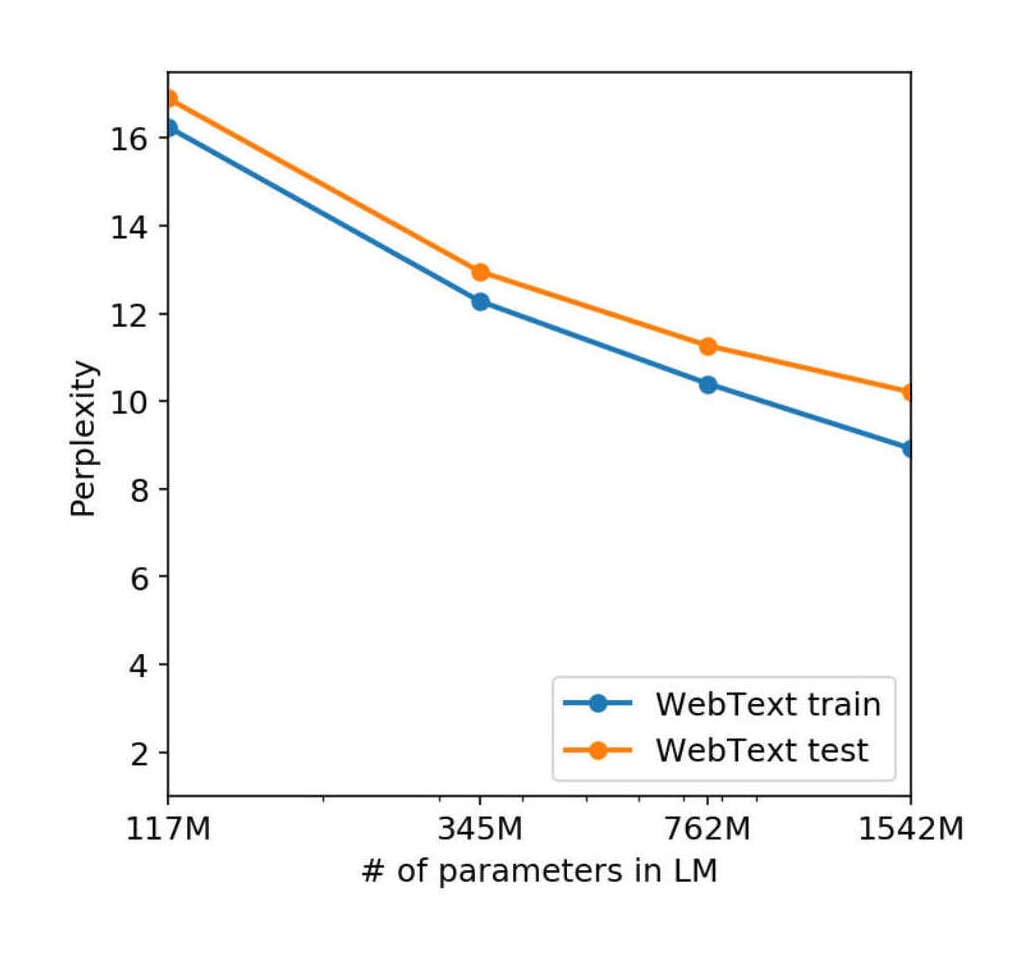
2019-radford-figure4-gpt2validationloss.jpg
2020-brown-figure31-gpt3scaling.png
Building a Large Annotated Corpus of English: The Penn Treebank
One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling
The LAMBADA dataset: Word prediction requiring a broad discourse context
https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf#page=5
Estimation of Gap Between Current Language Models and Human Performance
https://arxiv.org/pdf/2005.14165.pdf&org=openai#page=12
Ilya Sutskever: Deep Learning
If You Want to Solve a Hard Problem in Reinforcement Learning, You Just Scale. It’s Just Gonna Work Just like Supervised Learning. It’s the Same, the Same Story Exactly. It Was Kind of Hard to Believe That Supervised Learning Can Do All Those Things, but It’s Not Just Vision, It’s Everything and the Same Thing Seems to Hold for Reinforcement Learning Provided You Have a Lot of Experience.
What Could Make AI Conscious?
https://wandb.ai/wandb_fc/gradient-dissent/reports/What-could-make-AI-conscious-with-Wojciech-Zaremba-co-founder-of-OpenAI--Vmlldzo3NDk3MDI
Evolution Strategies as a Scalable Alternative to Reinforcement Learning
Proximal Policy Optimization Algorithms
Are we in an AI overhang?
‘MoE NN’ directory
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Why didn’t DeepMind build GPT-3?
Tick, tock, tick, tock… BING
The Teenies
Google DeepMind founder and leader in artificial intelligence returns to Hamilton
Goodbye 2010
When Will the First Artificial General Intelligence System Be Devised, Tested, and Publicly Known Of?
Will AI Progress Surprise Us?
Agent57: Outperforming the human Atari benchmark
‘How GPT-3 Is Shaping Our AI Future’ With Sam Altman/Azeem Azhar (The Exponential View), Wednesday 7 October 2020
DeepMind Lab
June 2020 News § Companies House
[Transclude the forward-link's
context]
Deep Learning Scaling is Predictable, Empirically
Is Science Slowing Down?
Trust Algorithms? The Army Doesn’t Even Trust Its Own AI Developers
ZeRO-2 & DeepSpeed: Shattering barriers of deep learning speed & scale
DeepSpeed: Extreme-scale model training for everyone
When will computer hardware match the human brain?
Ilya Sutskever: Deep Learning | AI Podcast #94 With Lex Fridman
What Next? A Dozen Information-Technology Research Goals: 3. Turing’s Vision of Machine Intelligence
Exascale Deep Learning for Scientific Inverse Problems
Pushing the limit of molecular dynamics with ab initio accuracy to 100 million atoms with machine learning
ProtTrans: Towards Cracking the Language of Life’s Code Through Self-Supervised Deep Learning and High Performance Computing
Training Kinetics in 15 Minutes: Large-scale Distributed Training on Videos
Peter Norvig, Google’s Director of Research—Singularity Is in the Eye of the Beholder: We'Re Thrilled to Have Peter Norvig Who Join Us to Talk about the Evolution of Deep Learning, His Industry-Defining Book, His Work at Google, and What He Thinks the Future Holds for Machine Learning Research (2020-11-20)
The Deep Learning Revolution and Its Implications for Computer Architecture and Chip Design
OpenAI Built Gaming Bots That Can Work As a Team With Inhuman Precision
Can a Machine Learn to Write for The New Yorker? Extraordinary Advances in Machine Learning in Recent Years Have Resulted in AIs That Can Write for You.
https://news.ycombinator.com/item?id=9109140
TTTTTackling WinoGrande Schemas
A Review of Winograd Schema Challenge Datasets and Approaches
The Defeat of the Winograd Schema Challenge
One Man’s Modus Ponens
There’s No Fire Alarm for Artificial General Intelligence
Appendix F: Personal Observations on the Reliability of the Shuttle
2019 News § What Progress?
[Transclude the forward-link's
context]
Don’t Worry—It Can’t Happen
Ra
Reward is enough
gpt-3#roleplaying
[Transclude the forward-link's
context]
Do As I Can, Not As I Say (SayCan): Grounding Language in Robotic Affordances
Why Tool AIs Want to Be Agent AIs
Simulators
Here’s Another Stabilized Sky Timelapse, This Time at Crater Lake, Oregon. The Water Was Still for Most of It, Which Created a Nice Mirror for the Stars. I Also Got My Astro-Modified Camera Working, Which Provides More Vibrancy in the Nebulae in the Milky Way. #EppurSiMuove
Star Timelapse Revealing the Earth’s Rotation
‘Story Of Your Life’ Is Not A Time-Travel Story
Surprisingly Turing-Complete
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}