LW anchoring experiment
Do mindless positive/negative comments skew article quality ratings up and down?
I do an informal experiment testing whether LessWrong karma scores are susceptible to a form of anchoring based on the first comment posted; a medium-large effect size is found. Although the data does not fit the assumed normal distribution so there may or may not be any actual anchoring effect.
Do social media websites suffer from Matthew effects or anchoring, where an early intervention can have substantial effects? Most studies or analyses suggest the effects are small.
Problem
2012-02-27 IRC:
Grognor> I've been reading the highest-scoring articles, and I have noticed a pattern
a MUCH HIGHER PROPORTION of top-scoring articles have "upvoted" in the first two words in the
first comment
(standard disclaimer: correlation is not causation blah blah)
https://www.lesswrong.com/r/lesswrong/lw/6r6/tendencies_in_reflective_equilibrium/ then I see this,
one of the follow-ups to one of the top-scoring articles like this. the first comment
says "not upvoted"
and it has a much lower score
while reading it, I was wondering "why is this at only 23? this is one of the best articles
I've ever oh look at that comment"
I'm definitely hitting on a real phenomenon here, probably some social thing that says
"hey if he upvoted, I should too" and it seems to be incredibly
strongly related to the first comment
the proportion is really quite astounding
https://www.lesswrong.com/lw/5n6/i_know_im_biased_but/ compare this to the
Tendencies in Reflective Equilibrium post. Compared to that, it's awful, but it has
nearly the same score. Note the distinct lack of a first comment saying "not upvoted"
(side note: I thought my article, "on saying the obvious", would have a much lower score than
it did. note the first comment: "good points, all of them.")
it seems like it's having more of an effect than I would naively predict
...
gwern> Grognor: hm. maybe I should register a sockpuppet and on every future article I write flip a coin
and write either upvoted or downvoted
quanticle> gwern: Aren't you afraid you'll incur Goodhart's wrath?
gwern> quanticle: no, that would be if I only put in 'upvoted' comments
gwern> Grognor: do these comments tend to include any reasons?
Grognor> gwern: yes
Boxo> you suggesting that the comments cause the upvotes? I'd rather say that the post is just the kind
of post that makes lots people think as their first reaction
"hell yeah imma upvote this", makes upvoting salient to them, and then some of that bubbles up to
the comments
Grognor> Boxo: I'm not suggesting it's entirely that simple, no, but I do think it's obvious now that a
first comment that says "upvoted for reasons x, y, and z"
will cause more people to upvote than otherwise would have, and vice versa
Boxo> (ie. you saw X and Y and though X caused Y, but I think there's a Z that causes both X and Y)
ksotala> Every now and then, I catch myself wanting to upvote something because others have upvoted it
already. It sounds reasonable that having an explicit comment
declaring "I upvoted" might have an even stronger effect.
ksotala> On the other hand, I usually decide to up/downvote before reading the comments.
gwern> ksotala: you should turn on anti-kibitzing then
rmmh> gwern: maybe karma blinding like HN would help
Boxo> I guess any comment about voting could remind people to vote, in whatever direction. Could test this
if you had the total number of votes per post.
Grognor> that too. the effect here is multifarious and complicated and the intricate details could not
possibly be worked out, which is exactly why this proportion of first comments with an 'upvoted'
note surprises meSuch an anchoring or social proof effect resulting in a first-mover advantage seems plausible to me. At least one experiment found something similar online: “Social Influence Bias: A Randomized Experiment”:
Our society is increasingly relying on the digitized, aggregated opinions of others to make decisions. We therefore designed and analyzed a large-scale randomized experiment on a social news aggregation Web site to investigate whether knowledge of such aggregates distorts decision-making. Prior ratings created significant bias in individual rating behavior, and positive and negative social influences created asymmetric herding effects. Whereas negative social influence inspired users to correct manipulated ratings, positive social influence increased the likelihood of positive ratings by 32% and created accumulating positive herding that increased final ratings by 25% on average. This positive herding was topic-dependent and affected by whether individuals were viewing the opinions of friends or enemies. A mixture of changing opinion and greater turnout under both manipulations together with a natural tendency to up-vote on the site combined to create the herding effects. Such findings will help interpret collective judgment accurately and avoid social influence bias in collective intelligence in the future.
Design
So on the 27th, I registered the account “Rhwawn”1. I made some quality comments and upvotes to seed the account as a legitimate active account.
Thereafter, whenever I wrote an Article or Discussion, after making it public, I flipped a coin and if Heads, I posted a comment as Rhwawn saying “Upvoted” or if Tails, a comment saying “Downvoted” with some additional text (see next section). Needless to say, no actual vote was made. I then made a number of quality comments and votes on other Articles/Discussions to camouflage the experimental intervention. (In no case did I upvote or downvote someone I had already replied to or voted on with my ‘Gwern’ account.) Finally, I scheduled a reminder on my calendar for 30 days later to record the karma on that Article/Discussion. I don’t post that often, so I decided to stop after 1 year, on 2013-02-27. I wound up breaking this decision since by September 201214ya I had ceased to find it an interesting question, it was an unfinished task that was burdening my mind, and the necessity of making some genuine contributions as Rhwawn to cloak an anchoring comment was a not-so-trivial inconvenience that was stopping me from posting.
To enlarge the sample, I passed Recent Posts through xclip -o | grep '^by ' | cut -d ' ' -f 2 | sort | uniq -c | sort -g and picking everyone with >=6 posts (8 people excluding me), and I messaged them with a short message explaining my desire for a large sample and the burden of participation (“It would require perhaps half a minute to a minute of your time every time you post an Article or Discussion for the next year, which is for most of you no more than once a week or month.”)
For those who replied, I sent a copy of this writeup and explained their procedure would be as follows: every time they posted they would flip a coin and post likewise (the Rhwawn account password having been shared with them); however, as a convenience to them, I would take care of recording the karma a month later. (I subscribed to participants’ post RSS feeds; this would not guarantee that I would learn of their posts in time to add a randomized sock comment - hence the need for their active participation - but I could at least handle the scheduling & karma-checking for them.)
Questions
I will have to do some contemplation of values before I accept or reject. I like getting honest feedback on my posts, I like accumulating karma, and I also like performing experiments.
Randomization suggests that your expected-karma-value would be 0, unless you expect asymmetry between positive and negative.
What do you anticipate doing with the data accumulated over the course of the experiment?
Oh, it’d be simple enough. Sort articles into one group of karma scores for the positive anchors, the other group for the negative anchors; feed into a two-sample t-test to see if the means differ and if the difference is significant. I can probably copy the R code straight from my various Zeo-related R sessions.
If I can hit p < 0.10 or p < 0.05 or so, post an Article triumphantly announcing the finding of bias and an object lesson of why one shouldn’t take karma too seriously; if I don’t, post a Discussion article discussing it and why I thought the results didn’t reach significance. (Not enough articles? Too weak assumptions in my t-test?)
And the ethics?
The post authors are volunteers, and as already pointed out, the expected karma benefit is 0. So no one is harmed, and as for the deception, it does not seem to me to be a big deal. We are already nudged by countless primes and stimuli and biases, so another one, designed to be neutral in total effect, seems harmless to me.
What comes before determines what comes after…The thoughts of all men arise from the darkness. If you are the movement of your soul, and the cause of that movement precedes you, then how could you ever call your thoughts your own? How could you be anything other than a slave to the darkness that comes before?…History. Language. Passion. Custom. All these things determine what men say, think, and do. These are the hidden puppet-strings from which all men hang…all men are deceived…So long as what comes before remains shrouded, so long as men are already deceived, what does [deceiving men] matter?
Data
The results:
Post |
Author |
Date |
Anchor |
Post karma |
Comment karma |
|---|---|---|---|---|---|
02 March |
0 |
11 |
-4 |
||
02 March |
0 |
19 |
-6 |
||
Kaj_Sotala |
08 March |
1 |
50 |
0 |
|
05 March |
0 |
9 |
-2 |
||
gwern |
10 March |
1 |
19 |
-3 |
|
gwern |
11 March |
0 |
11 |
-7 |
|
13 March |
1 |
62 |
0 |
||
16 March |
1 |
120 |
1 |
||
Kaj_Sotala |
18 March |
1 |
49 |
0 |
|
orthonormal |
24 March |
1 |
20 |
-1 |
|
orthonormal |
06 April |
0 |
16 |
-13 |
|
Kaj_Sotala |
23 April |
0 |
20 |
4 |
|
gwern |
23 April |
1 |
10 |
0 |
|
gwern |
18 May |
0 |
45 |
-8 |
|
gwern |
01 July |
1 |
22 |
0 |
|
gwern |
07 July |
0 |
23 |
-11 |
|
gwern |
02 Sep |
0 |
33 |
-9 |
Analysis
For the analysis, I have 2 questions:
Is there a difference in karma between posts that received a negative initial comment and those that received a positive initial comment? (Any difference suggests that one or both are having an effect.)
Is there a difference in karma between the two kinds of initial comments (as I began to suspect during the experiment)?
Article Effect
Some Bayesian inference using BEST:
lw <- data.frame(Anchor = c( 0, 0, 1, 0, 1, 0, 1, 1, 1, 1, 0, 0, 1, 0, 1, 0, 0),
Post.karma = c(11,19,50, 9,19,11,62,120,49,20,16,20,10,45,22,23,33))
source("BEST.R")
neg <- lw[lw$Anchor==0,]$Post.karma
pos <- lw[lw$Anchor==1,]$Post.karma
mcmc = BESTmcmc(neg, pos)
BESTplot(neg, pos, mcmcChain=mcmc)
#
# SUMMARY.INFO
# PARAMETER mean median mode HDIlow HDIhigh pcgtZero
# mu1 20.1792 20.104 20.0392 10.7631 29.9835 NA
# mu2 41.9474 41.640 40.4661 11.0307 75.1056 NA
# muDiff -21.7682 -21.519 -22.6345 -55.3222 11.2283 8.143
# sigma1 13.1212 12.264 10.9018 5.8229 22.4381 NA
# sigma2 40.9768 37.835 33.8565 16.5560 72.6948 NA
# sigmaDiff -27.8556 -24.995 -21.7802 -60.9420 -0.9855 0.838
# nu 30.0681 21.230 5.6449 1.0001 86.5698 NA
# nuLog10 1.2896 1.327 1.4332 0.4332 2.0671 NA
# effSz -0.7718 -0.765 -0.7632 -1.8555 0.3322 8.143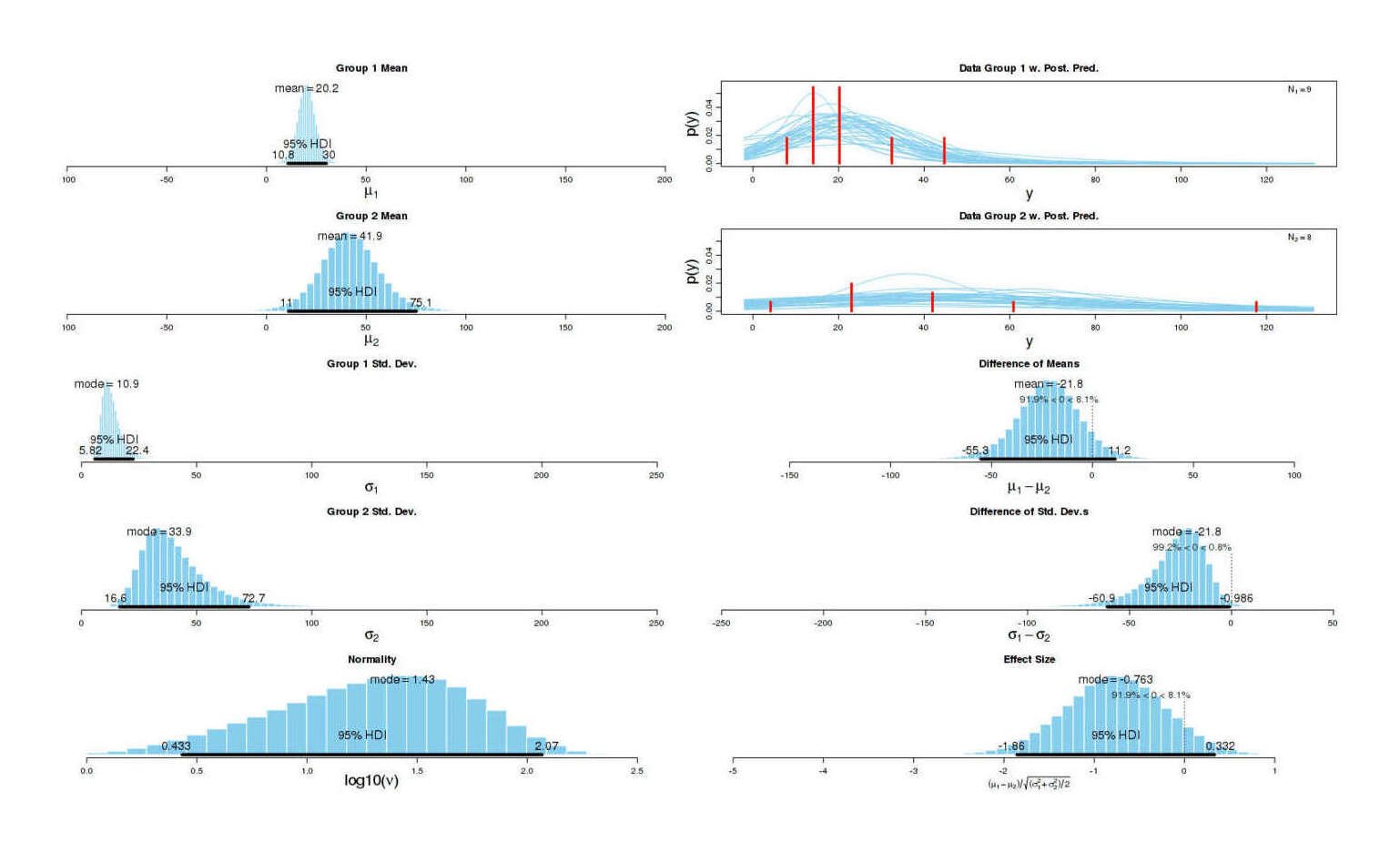
Graphical summary of BEST results for full dataset
The results are heavily skewed by Yvain’s very popular post; we can’t trust any results based on such a high scoring post. Let’s try omitting Yvain’s datapoint. BEST actually crashes displaying the result, perhaps due to making an assumption about there being at least 8 datapoints or something; and it’s question whether we should be using a normal-based test like BEST in the first place: just from graphing we can see it’s definitely not a normal distribution. So we’ll fall back to a distribution-free Mann-Whitney U two-sample test (rather than a t-test):
# wilcox.test(Post.karma ~ Anchor, data=lw)
#
# Wilcoxon rank sum test with continuity correction
#
# data: Post.karma by Anchor
# W = 19, p-value = 0.1117
# ...
wilcox.test(Post.karma ~ Anchor, data=(lw[lw$Post.karma<100,]))
#
# Wilcoxon rank sum test with continuity correction
#
# data: Post.karma by Anchor
# W = 19, p-value = 0.203Reasonable. To work around the bug, let’s replace Yvain by the mean for that group without him, 33; the new results:
# SUMMARY.INFO
# PARAMETER mean median mode HDIlow HDIhigh pcgtZero
# mu1 20.2877 20.2002 20.1374 10.863 29.9532 NA
# mu2 32.7912 32.7664 32.8370 15.609 50.4410 NA
# muDiff -12.5035 -12.4802 -12.2682 -32.098 7.3301 9.396
# sigma1 13.2561 12.3968 10.9385 6.044 22.3085 NA
# sigma2 22.4574 20.6784 18.3106 10.449 38.5859 NA
# sigmaDiff -9.2013 -8.1031 -7.1115 -28.725 7.6973 11.685
# nu 33.2258 24.5819 8.6726 1.143 91.3693 NA
# nuLog10 1.3575 1.3906 1.4516 0.555 2.0837 NA
# effSz -0.7139 -0.7066 -0.7053 -1.779 0.3607 9.396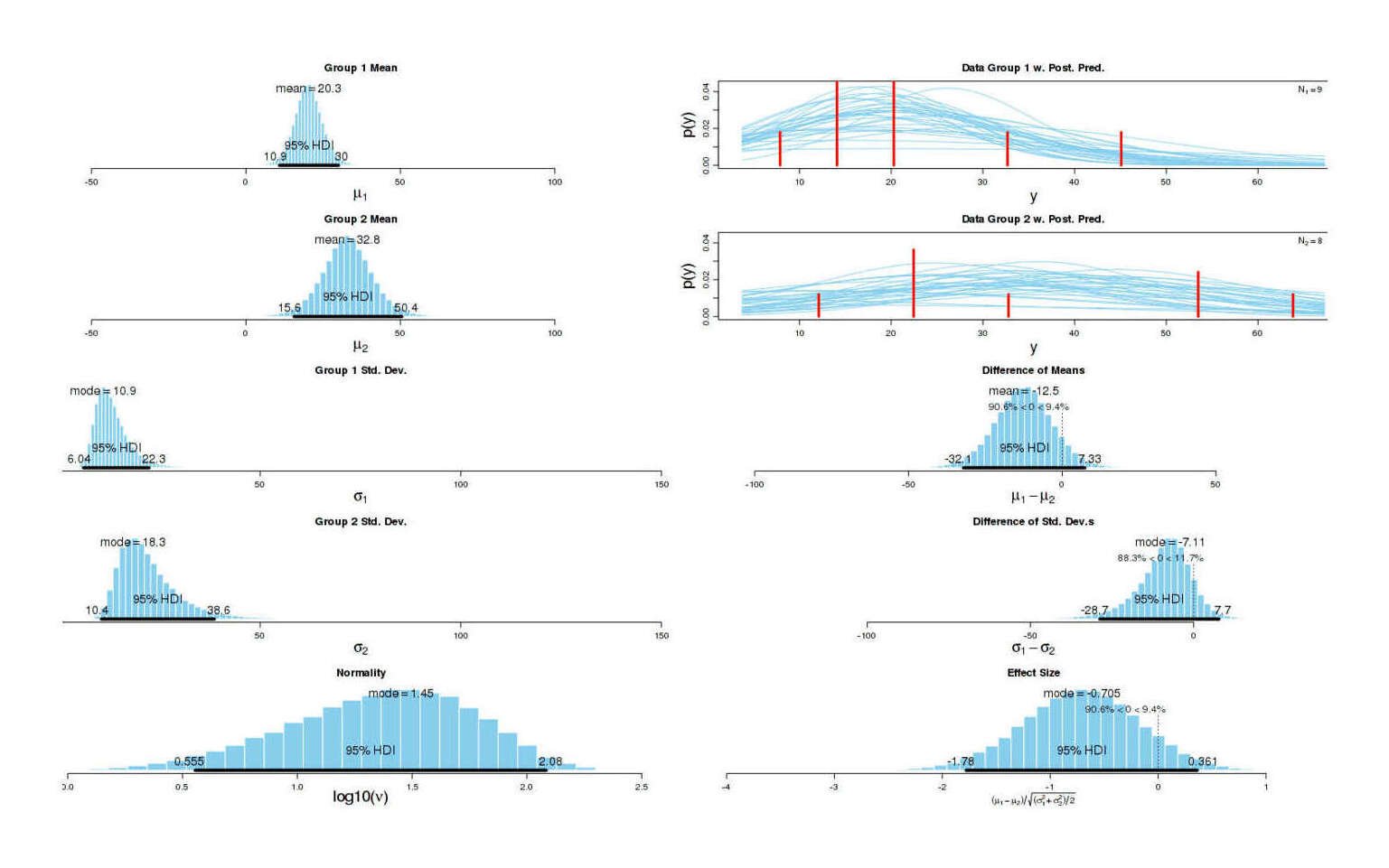
Graphical summary of BEST results for dataset with Yvain replaced by a mean
The difference in means has shrunk but not gone away; it’s large enough that 10% of the possible effect sizes (of “a negative initial comment rather than positive”) may be zero or actually be positive (increase karma) instead. This is a little concerning, but I don’t take this too seriously:
this is not a lot of data
as we’ve seen there are extreme outliers suggesting that the assumption that karma scores are Gaussian/normal may be badly wrong
even at face value, 10 karma points doesn’t seem like it’s large enough to have any important real-world consequences (like make people leave LW who should’ve stayed)
Pursuing point number two, there’s two main options for dealing with the normal distribution assumption of BEST/t-tests being violated: either switch to a test which assumes a distribution more like what we actually see & hope that this new distribution is close enough to true, or use a test which doesn’t rely on distributions at all.
For example, we could try to model it as a Poisson distribution and see if the anchoring variable is an important predictor of the mean of the process sum, which it seems to be:
summary(glm(Post.karma ~ Anchor, data=lw, family=poisson))
# ...
# Deviance Residuals:
# Min 1Q Median 3Q Max
# -6.194 -2.915 -0.396 0.885 9.423
#
# Coefficients:
# Estimate Std. Error z value Pr(>|z|)
# (Intercept) 3.0339 0.0731 41.49 <2e-16
# Anchor 0.7503 0.0905 8.29 <2e-16
# ...
summary(glm(Post.karma ~ Anchor, data=(lw[lw$Post.karma<100,]), family=poisson))
# ...
# Deviance Residuals:
# Min 1Q Median 3Q Max
# -4.724 -2.386 -0.744 2.493 4.594
#
# Coefficients:
# Estimate Std. Error z value Pr(>|z|)
# (Intercept) 3.0339 0.0731 41.49 <2e-16
# Anchor 0.4669 0.0983 4.75 2e-06(On a side note, I regard these p-values as evidence for an effect even thought they don’t fall under 0.05 or another alpha I defined in advance: with this small sample size and hence low statistical power, to reach p < 0.05, each anchoring comment would have to have a grotesquely large effect on article karma - but anchoring comments having such an effect is highly unlikely! Anchoring, in psychology, isn’t that omnipotent: it’s relatively subtle. So we have a similar problem as with the 2013 Lewis meditation results - they’re the sort of situations where it’d be nicer to be talking in more relative terms like Bayes factors.)
Comment Treatment
How did these mindless unsubstantiated comments either praising or criticizing an article get treated by the community? Let’s look at the anchoring comment’s karma:
neg <- lw[lw$Anchor==0,]$Comment.karma
pos <- lw[lw$Anchor==1,]$Comment.karma
mcmc = BESTmcmc(neg, pos)
BESTplot(neg, pos, mcmcChain=mcmc)
# SUMMARY.INFO
# PARAMETER mean median mode HDIlow HDIhigh pcgtZero
# mu1 -6.4278 -6.4535 -6.55032 -10.5214 -2.2350 NA
# mu2 -0.2755 -0.2455 -0.01863 -1.3180 0.7239 NA
# muDiff -6.1523 -6.1809 -6.25451 -10.3706 -1.8571 0.569
# sigma1 5.6508 5.2895 4.70143 2.3262 9.7424 NA
# sigma2 1.2614 1.1822 1.07138 0.2241 2.4755 NA
# sigmaDiff 4.3893 4.0347 3.53457 1.1012 8.5941 99.836
# nu 27.4160 18.1596 4.04827 1.0001 83.9648 NA
# nuLog10 1.2060 1.2591 1.41437 0.2017 2.0491 NA
# effSz -1.6750 -1.5931 -1.48805 -3.2757 -0.1889 0.569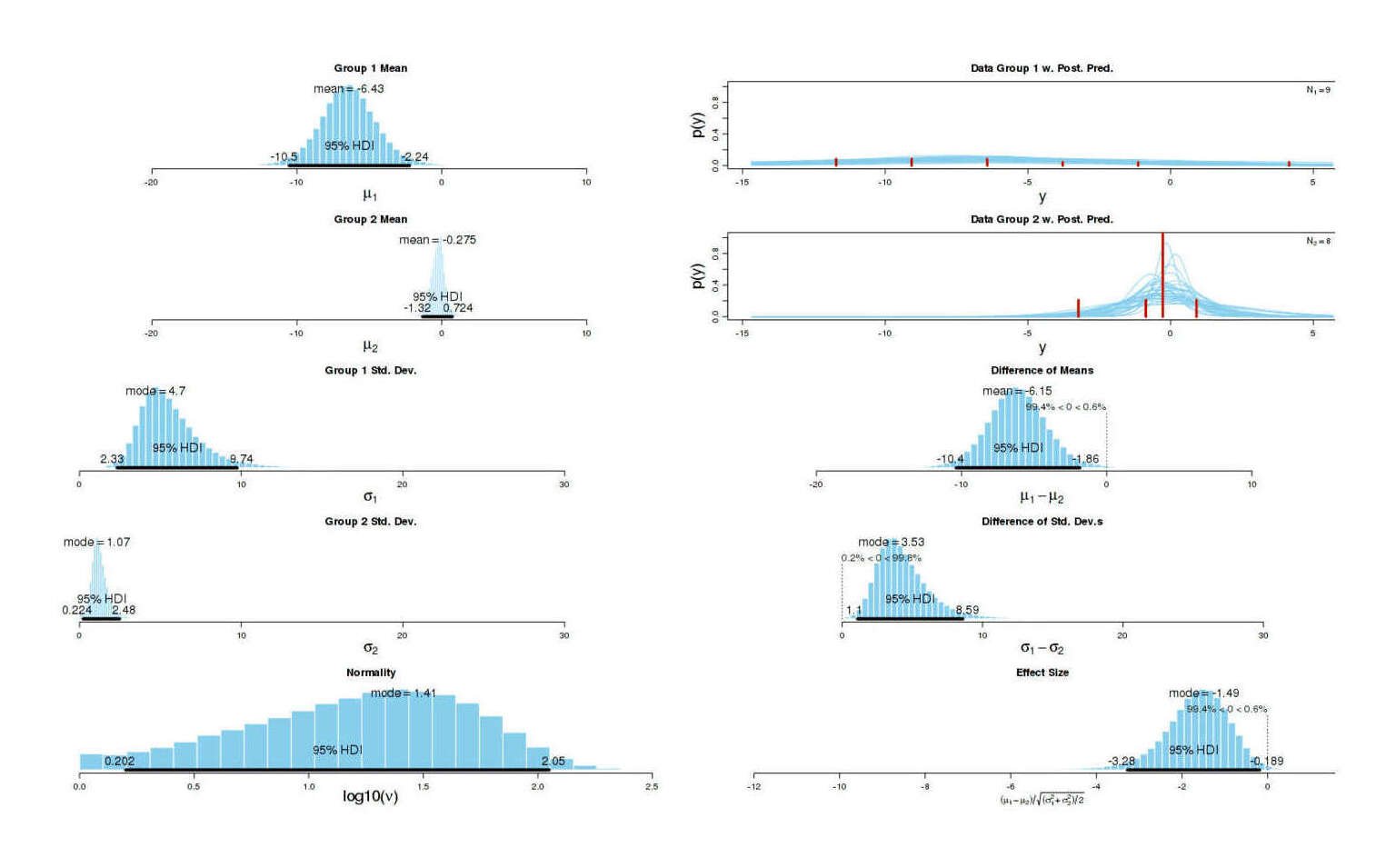
Graphical summary of BEST results for full dataset of how the positive/negative comments were treated
As one would hope, neither group of comments ends up with net positive mean score, but they’re clearly being treated very differently: the negative comments get downvoted far more than the positive comments. I take this as perhaps implying that LW’s reputation for being negative & hostile is a bit overblown: we’re negative and hostile to poorly thought out criticisms and arguments, not fluffy praise.
See Also
External Links
“Field experiments of success-breeds-success dynamics”, van de Rijt et al 201412ya (small ‘Matthe effects’ in popularity dynamics on Kickstarter/WP/Change.org/Epinions: randomness, not manipulability)
If you were wondering about the account name: both ‘Rhwawn’ and ‘Gwern’ are character names from the Welsh collection Mabinogion. They share the distinctions of being short, nearly unique, and obviously pseudonymous to anyone who Googles them, which is why I also used that name as an alternate account on Wikipedia.↩︎
Comment Variation
Grognor pointed that the original comments came with reasons, but unfortunately if I came up with reasons for either comment, some criticisms or praise would be better than others and this would be another source of variability; so I added generic reasons.
I know from watching them plummet into oblivion that comments which are just “Upvoted” or “Downvoted” are not a good idea for any anchoring question - they’ll quickly be hidden, so any effect size will be a lot smaller than usual, and it’s possible that hidden comments themselves anchor (my guess: negatively, by making people think “why is this attracting stupid comments?”).
While if you go with more carefully rationalized comments, that’s sort of like the XKCD cartoon: quality comments start to draw on the experimenter’s own strengths & weaknesses (I’m sure I could make both quality criticisms and praises of psychology-related articles, but not so much technical decision theory articles).
It’s a “damned if you do, damned if you don’t” sort of dilemma.
I hoped my strategy would be a golden mean of not too trivial to be downvoted into oblivion, but not so high-quality and individualized that comparability was lost. I think I came close, since as we see in the analysis section, the positive anchoring comments saw only a small negative net downvote, indicating LWers may not have regarded it as good enough to upvote but also not so obviously bad as to merit a downvote.
(Of course, I didn’t expect the positive and negative comments to be treated differently - they’re pretty much the same thing, with a negation. I’m not sure how I would have designed it differently if I had known about the double-standard in advance.)
To avoid issues with some criticisms being accurate and others poor, a fixed list of reasons was used with minor variation to make them fit in:
Negative; “Downvoted; …”
“too much weight on n studies”
“too many studies cited”
“too reliant on personal anecdote”
“too heavy on math”
“not enough math”
“rather obvious”
“not very interesting”
Positive; “Upvoted; …”
“good use of n studies”
“thorough citation of claims”
“enjoyable anecdotes”
“rigorous use of math”
“just enough math”
“not at all obvious”
“very interesting”