Timothy Falcon’s quantitative-finance interview problem #14 asks for the optimal stopping strategy when playing a card-drawing game of l cards where red = +$1 & black = −$1; the value approaches 0.5 × √l. I re-solve it with dynamic programming in R, and others in Neat, Haskell & C, with increasing efficiency.
Problem 14 is a probability question about optimal stopping in a card game where one draws from a finite deck of good & bad cards; the goal is to stop when the random walk has fluctuated to as a high good value as likely; what is the expected payoff given optimal play? This question has some counterintuitive aspects and has been used as an interview question.
It can be treated as a multi-stage decision problem and solved by top-down & bottom-up dynamic programming, to estimate the value of optimal play (and thus provide the actual optimal strategy). The value of a game with a standard deck of 52 (26 good vs 26 bad) cards is ~$2.62; the value increases as the square root of cards.
Naive implementations which take hours or error out can be optimized down to milliseconds. We build on the original spreadsheet answer by providing a top-down DP (naive memoization) implementation in R (verified in simulation), Neat implementations (naive & optimized to use arrays), and an optimized C version; these have 𝒪(l2) time/space computational complexity, limiting their range. Then we provide the more efficient bottom-up solution in Haskell & C, which need 𝒪(l2) time but only 𝒪(l) space.
While it’s not easy to change the 𝒪(l2) complexity without problem-specific analysis or approximation, modern computers are so powerful that by improving the constant factors, we can still calculate shockingly high card counts. The efficient C bottom-up can be made faster by careful use of parallelism at the CPU-core level using vector instructions, and then by breaking the problem up into individual DP problems which can be solved independently in different CPU threads or processes.
This final version lets us calculate values of Problem 14 from the original 52 cards up to 133.7 million cards (value of $6,038.32), and fit approximations which confirm the conjecture that it increases as a square-root. (An approximation yields <0.002% relative error at 133.7m card count.)
You have 52 playing cards (26 red, 26 black). You draw cards one by one. A red card pays you a dollar. A black one fines you a dollar. You can stop any time you want. Cards are not returned to the deck after being drawn. What is the optimal stopping rule in terms of maximizing expected payoff?
Also, what is the expected payoff following this optimal rule?
This is a fun problem because the sampling-without-replacement makes it counterintuitive—you are so used to sampling-with-replacement that the changing probabilities and the 0-EV-by-construction throws you for a loop. First, you think that it has to be 0 EV because the payoffs neutralize each other and so you shouldn’t play at all; then you think that you ought to quit as soon as you are negative to cut your losses; both are wrong, and optimal play can go quite negative before quitting, because it ‘knows’ that the good cards are still in the deck and must then be coming up and it still has a chance to exploit a random walk up to >$0 to eke out a profit.
And this problem is not as artificial as it might sound, as Stas Volkov points out that it corresponds to some scenarios in quantitative finance. The fact that it starts & ends at 0 makes it a special case of a “Brownian bridge” process, which is a Brownian random walk which is required to start & end at specific values; such processes cover things like financial bonds (eg. a zero-coupon bond), whose prices may walk up & down but must end at a specific redemption value, or stock share prices if they are affected by stock pinning which drives their price to a specific value (set by options on them). The ability to quit the game at any time then corresponds to selling or to exercising an “American” option (which can be exercised at any time). Optimal stopping, then, is simply how to trade so as to make as much money as possible. General solutions to this problem of optimal stopping on a Brownian bridge are given in Ekström & Wanntorp2009.
Coldwell gives a spreadsheet by a Han Zheng which concludes the expected return is $2.624475549.
The spread sheet below does this calculation, the value in each cell is the maximum of either what we are currently holding or the expected return of a gamble. If the former is the maximum then we quit…For the avoidance of doubt, each cell shows the expected return from the position represented by that cell. So at the beginning of the game the expected return is $2.624475549.1
Good #
26
25
24
23
22
21
20
19
18
17
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
26
2.624
2.322
2.061
1.834
1.637
1.464
1.311
1.176
1.056
0.9479
0.8509
0.7632
0.6835
0.6107
0.5439
0.4824
0.4254
0.3724
0.3228
0.2762
0.2322
0.1903
0.1503
0.1117
0.07407
0.03704
0
25
2.927
2.573
2.27
2.009
1.783
1.587
1.415
1.264
1.13
1.011
0.9049
0.8091
0.7227
0.6441
0.5723
0.5065
0.4458
0.3895
0.3371
0.288
0.2418
0.198
0.1562
0.116
0.07692
0.03846
0
24
3.296
2.876
2.52
2.217
1.956
1.731
1.536
1.366
1.216
1.084
0.9661
0.861
0.7667
0.6814
0.6039
0.5332
0.4683
0.4084
0.3528
0.301
0.2523
0.2064
0.1626
0.1207
0.08
0.04
0
23
3.751
3.246
2.824
2.466
2.162
1.902
1.678
1.484
1.315
1.167
1.036
0.92
0.8164
0.7233
0.6393
0.563
0.4933
0.4292
0.3701
0.3152
0.2638
0.2155
0.1696
0.1258
0.08333
0.04167
0
22
4.322
3.706
3.196
2.771
2.411
2.106
1.846
1.624
1.431
1.264
1.117
0.9876
0.873
0.7708
0.6791
0.5963
0.5211
0.4524
0.3892
0.3308
0.2764
0.2254
0.1773
0.1313
0.08696
0.04348
0
21
5.051
4.284
3.661
3.146
2.716
2.354
2.049
1.79
1.568
1.377
1.211
1.066
0.9381
0.825
0.7243
0.6339
0.5523
0.4782
0.4105
0.3481
0.2903
0.2364
0.1856
0.1374
0.09091
0.04545
0
20
6
5.027
4.249
3.618
3.095
2.659
2.296
1.99
1.732
1.511
1.322
1.157
1.013
0.8874
0.7759
0.6767
0.5876
0.5072
0.4342
0.3674
0.3058
0.2485
0.1948
0.144
0.09524
0.04762
0
19
7
6
5.006
4.219
3.574
3.041
2.601
2.236
1.931
1.673
1.453
1.265
1.102
0.9598
0.8355
0.7256
0.6278
0.5401
0.4609
0.3889
0.3229
0.2619
0.205
0.1513
0.1
0.05
0
18
8
7
6
5
4.19
3.528
2.986
2.541
2.175
1.869
1.612
1.393
1.206
1.045
0.9049
0.7823
0.674
0.5776
0.4913
0.4133
0.3422
0.2769
0.2163
0.1594
0.1053
0.05263
0
17
9
8
7
6
5
4.16
3.479
2.928
2.48
2.112
1.806
1.549
1.332
1.146
0.9866
0.8484
0.7275
0.6208
0.5259
0.4409
0.364
0.2937
0.2289
0.1684
0.1111
0.05556
0
16
10
9
8
7
6
5
4.127
3.429
2.87
2.418
2.048
1.741
1.484
1.268
1.084
0.9267
0.7903
0.671
0.5659
0.4726
0.3888
0.3128
0.2431
0.1785
0.1176
0.05882
0
15
11
10
9
8
7
6
5
4.094
3.378
2.811
2.355
1.982
1.674
1.417
1.202
1.02
0.8648
0.7301
0.6126
0.5092
0.4173
0.3346
0.2593
0.19
0.125
0.0625
0
14
12
11
10
9
8
7
6
5
4.059
3.328
2.753
2.291
1.913
1.603
1.348
1.135
0.9546
0.8006
0.6678
0.5521
0.4504
0.3596
0.2778
0.2029
0.1333
0.06667
0
13
13
12
11
10
9
8
7
6
5
4.026
3.28
2.696
2.223
1.841
1.531
1.276
1.065
0.886
0.7338
0.603
0.4892
0.3889
0.2992
0.2179
0.1429
0.07143
0
12
14
13
12
11
10
9
8
7
6
5
4
3.241
2.635
2.151
1.765
1.455
1.202
0.9914
0.8143
0.6643
0.5356
0.4234
0.3242
0.2352
0.1538
0.07692
0
11
15
14
13
12
11
10
9
8
7
6
5
4
3.199
2.569
2.076
1.687
1.377
1.124
0.9144
0.7394
0.5916
0.4647
0.3538
0.2555
0.1667
0.08333
0
10
16
15
14
13
12
11
10
9
8
7
6
5
4
3.152
2.499
1.998
1.607
1.296
1.042
0.8334
0.6608
0.5152
0.3896
0.2797
0.1818
0.09091
0
9
17
16
15
14
13
12
11
10
9
8
7
6
5
4
3.101
2.427
1.919
1.525
1.208
0.9542
0.7483
0.5779
0.4336
0.3091
0.2
0.1
0
8
18
17
16
15
14
13
12
11
10
9
8
7
6
5
4
3.048
2.356
1.841
1.434
1.114
0.8618
0.6581
0.4889
0.3455
0.2222
0.1111
0
7
19
18
17
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2.299
1.754
1.335
1.015
0.7639
0.5606
0.3917
0.25
0.125
0
6
20
19
18
17
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2.232
1.656
1.229
0.9091
0.6571
0.4524
0.2857
0.1429
0
5
21
20
19
18
17
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2.154
1.55
1.119
0.7937
0.5357
0.3333
0.1667
0
4
22
21
20
19
18
17
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2.067
1.444
1
0.6571
0.4
0.2
0
3
23
22
21
20
19
18
17
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1.343
0.85
0.5
0.25
0
2
24
23
22
21
20
19
18
17
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1.2
0.6667
0.3333
0
1
25
24
23
22
21
20
19
18
17
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0.5
0
0
26
25
24
23
22
21
20
19
18
17
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
0
The value grows slowly. A good guess is that it is growing as a square-root and not a logarithm, because random walks often involve square-roots. Plotting an approximation shows that a square-root approximation fits far better than a log, even ignoring the issues with the initial values.
The reasoning is a bit opaque, the dynamic programming is buried in the spreadsheet, and it’s not clear how you’d construct your own spreadsheet or how it would scale to much larger deck sizes like 100,000. Is there a computational approach which trades arithmetic for analysis?
Yes: we can brute-force it, in a smart way, using dynamic programming. While ‘play optimally every possible sequence of 52 cards’ may sound combinatorially infeasible (52! = 8 × 1067), that is an illusory complexity: as soon as you reduce it to ‘red’ vs ‘black’, it immediately looks like it has sub-problems which can be solved independently & reused in the solution of harder problems. Thus, this is a perfect dynamic programming example because the choice must depend only on 2 variables, the counts of good (red) & bad (black) cards, and your choices at the base-case boundaries like (0,0) or (good,0) or (0,bad) are forced.
Borrowing from Kelly Coin-Flip, we simply define the dynamics & choices, set up the top-down recursion on a 𝑆(good,bad,winnings) 3-tuple, memoise using a hashmap, and ask for the value of a (26,26,0) game. This will run in something like 𝒪(l2) time+space in cards, where 26 is small enough that it will be near-instant.
The tricky part here—which tripped me up initially & yielded a value of $2.86 by accidentally leaving the probability of good/bad cards fixed at P = 0.50 the entire game—is that the P of good/bad is itself dependent on the state: the more of the good cards that get used up, the higher the probability of a bad draw and vice-versa, so the probabilities are constantly changing to push back towards the middle. (The EV being higher than the correct EV is a hint as to the error: if the P remains at 0.5 the entire game, perhaps because we were sampling with replacement instead, then the value will be higher because there will be no ‘reversion’ from using up the good cards—we can always ride good luck still higher.)
This is an easy enough problem that with no further optimization, the code runs near-instantly (all the way up to 143 cards, worth $6.21519192, where it hits a stack limit) & we confirm that Han Zheng’s value $2.62 is correct.
The value function lets us play an optimal game by simply comparing the value of the two possible choices—‘quit’, and ‘keep playing’—and doing the choice with the larger value.
This means we can double-check with a simulation that the optimal policy does in fact attain the claimed value of the specified game (26,26,0):
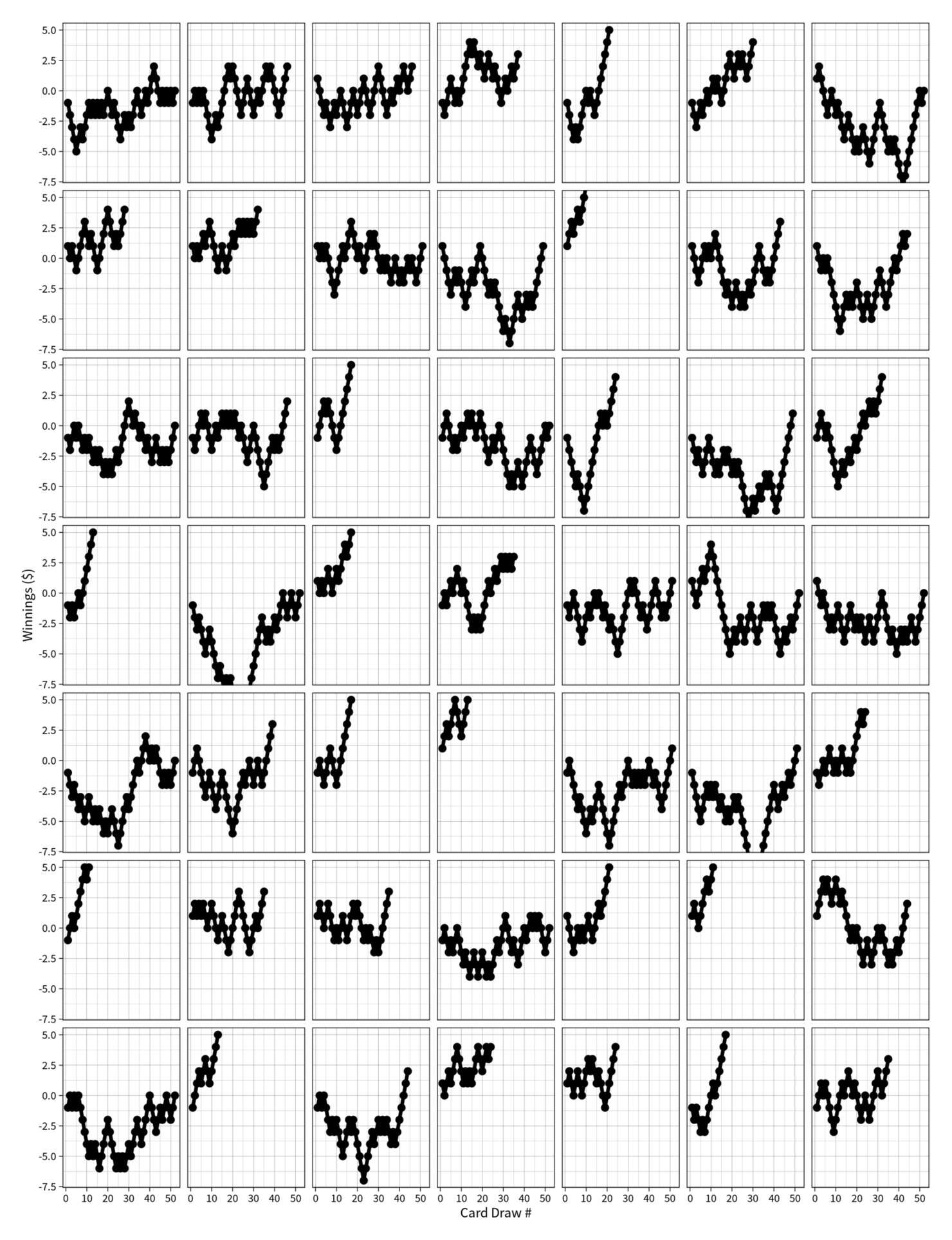
Simulating 49 sample games, we can see how while the optimal strategy looks fairly risky, it usually wins in the end:
Simulation of winnings over a sample of 49 games of (26,26) using the optimal-stopping strategy. (One can see the implicit decision boundary where trajectories stop.)
FeepingCreature notes that this is slower than it needs to be, and can be converted from the hashmap memoization to a faster flat array, especially if, like Zheng’s spreadsheet, one stops tracking winnings and only tracks (good,bad) so the value function is reporting the marginal value of the state. FeepingCreature’s faster, winnings-free, array-based version with a Monte Carlo simulation to double-check results:
The top-down dynamic programming is the simplest & easiest to understand: one just sets up the logical dependency, enables memoization, and requests the desired value. It comes with a performance drawback of taking 𝒪(l2) time/space, because it must define, evaluate, and store every possible state 𝑆 tuple value as it might be requested at any time. So even a close-to-the-metal implementation will struggle if you ask for the value of games with thousands of cards: it will take a long time to run and use possibly tens of gigabytes of memory.
But like in the Kelly Coin-Flip problem, we can note that most 𝑆 will not be requested ever again (at least, if the user isn’t requesting a bunch of values eg. at a REPL), because the game has a continually-shrinking (as cards get used up) ‘tree’ structure, and that evaluation follows a sort of ‘wave’ or ‘ripple’ back from the root final states like (0,0) or (10,0) to the initial (26,26). Since the evaluation won’t revisit them, they can be discarded immediately if we start at the root final states, then evaluate the set of states ‘before’ them (now that we know the ‘next’ state), throw out the roots, and move back 1 level to evaluate the state of states before those, and so on and so forth.
This bottom-up evaluation will still be 𝒪(l2) time (the constant factor can be optimized by further changing the evaluation pattern), but only 𝒪(l) linear space. So, if one was patient, one could evaluate up to millions of cards, probably, in a reasonable time like a few days. I have evaluated up to l = 22,974, available as a text file.
importData.DecimalimportData.RatioimportData.VectorimportqualifiedData.VectorasVsolve :: (Fractional a, Ord a) =>Int->Int-> asolve r b = go r bwhere tab = V.generate 27 (\r -> V.generate 27 (\b -> go r b)) look r b = tab V.! r V.! b go 0 b =0-- stop when there's only black cards go r 0=fromIntegral r -- take all the remaining red cards go r b =max0 (fromIntegral r/fromIntegral (r+b) * (look (r -1) b +1) +fromIntegral b/fromIntegral (r+b) * (look r (b -1) -1))-- > solve 26 26 :: Rational-- 41984711742427 % 15997372030584---- > 41984711742427 / 15997372030584-- 2.624475548993925
module fourteen2;import std.math;float solve(){auto tab =newfloat[](27*27);auto look =(r, b)=> tab[r *27+ b];auto go =(r, b)=>0if r ==0else r if b ==0else max(0.0f, r*1.0f/(r+b)*(look(r -1, b)+1)+ b*1.0f/(r+b)*(look(r, b -1)-1));for(r in 0..27)for(b in 0..27) tab[r *27+ b]= go(r, b);return look(26,26);}void main(){ print("$(solve)");}
The need to calculate all the possible states makes it hard to get around the asymptotic in bottom-up evaluation. But the constant factors can still be improved.
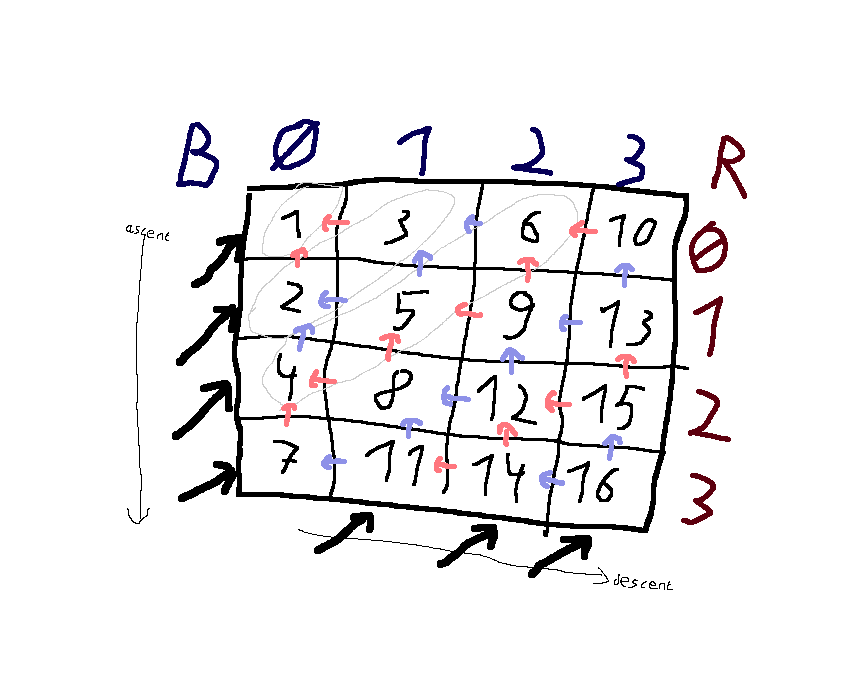
Diagonal traversal pattern illustration, by FeepingCreature.
In particular, the evaluation is single-threaded with every calculation depending on the previous one. This means that the CPU cannot run the arithmetic in parallel, nor can the compiler SIMDvectorize it to use AVX instructions like VMAXP; we forfeit much of the performance of our CPU core. This is despite the problem looking reasonably parallel—lots of states are ‘distant’ and don’t seem like they ought to depend on each other. What they actually depend on are just a few prior states, which we might call ‘diagonal’ states. So because the loops to only refer to ‘up and left’ states, many of the later states can be computed independently of each other, in one big parallel batch, as long as the right subset of later states is chosen, moving on the diagonal.
FeepingCreature’s diagonal evaluation:
#include <stdbool.h>#include <stdio.h>#include <stdlib.h>#include <math.h>#define FP doubleFP calc(int cards,int r,int b,int dia,bool ascent, FP *prevDia);int main(){int cards =200000; FP *prevDia = malloc(sizeof(FP)*(cards+1)); FP *curDia = malloc(sizeof(FP)*(cards+1));/** * visualization aid * B 0 | 1 | 2 * R-+---+---+-- * 0 | 0 | 1 | 2 * 1 | 0 | 1 | 1 * 2 | 0 | 0 | 0 */// ascentfor(int row =0; row <= cards; row++){for(int dia =0; dia <= row; dia++){int r = row - dia;int b = dia; curDia[dia]= calc(cards, r, b, dia,true, prevDia);} FP *tmp = curDia; curDia = prevDia; prevDia = tmp;}// descentfor(int col =1; col <= cards; col++){for(int dia =0; dia <= cards - col; dia++){int r = cards - dia;int b = col + dia; curDia[dia]= calc(cards, r, b, dia,false, prevDia);} FP *tmp = curDia; curDia = prevDia; prevDia = tmp;} printf("expected value is %f\n", prevDia[0]);return0;}FP calc(int cards,int r,int b,int dia,bool ascent, FP *prevDia){if(r ==0)return0;elseif(b ==0)return r;else{// red drawnint upIndex = ascent ? dia :(dia +1);// black drawnint leftIndex = ascent ?(dia -1): dia; FP pRed =(FP) r /(r + b); FP pBlack =1- pRed; FP payoff = pRed*(prevDia[upIndex]+1)+ pBlack*(prevDia[leftIndex]-1);if(payoff >0)return payoff;return0;}}
The initial version ran substantially faster when compiled with Clang (clang -Ofast -march=native fourteen.c -lm -o fourteen) rather than GCC (FeepingCreature’s laptop got 6s vs 17s for evaluating (100,000, 100,000)), due to poor GCC auto-vectorization (as reported by -fopt-info-vec-all). This second version should vectorize on both Clang & GCC (4.6s vs 5.8s), and can calculate into the millions without a problem. Probably it would be even faster on a CPU with AVX-512, as it could vectorize more.
The difference in performance between the simplest easiest R version, which took a bad programmer (myself) minutes to write the first version but takes seconds to evaluate & tops out at 143, and this optimized C implementation, which took multiple versions & hours to write by good programmers (FeepingCreature with advice from Khoth & nshepperd), but runs in milliseconds & tops out at somewhere between ‘millions’ and ‘however long you care to wait’, illustrates how much potential for optimization there can be—your computer may be faster than you think.
Further parallelization would require threads or processes, and has the problem that the overhead of creating & communicating is vastly greater than the actual calculations here of some addition/division/multiplication operations. (Anything involving IPC or synchronization on a modern multi-core computer can be safely assumed to cost the equivalent of thousands or hundreds of thousands of arithmetic operations.) For card counts like 52, I don’t think any parallelism above the CPU-core level is worthwhile; it would only work on far larger problems.
A spinlock is one way to lock for synchronization, and for large card counts like l = 100,000, there may be enough work when split up to keep CPU cores busy: a spinlock for one thread, when it hits a value it needs but which hasn’t been computed yet, will check constantly, and as soon as the other thread finishes computing the necessary value, will grab it and resume its own computation with as little delay as possible. FeepingCreature provides a parallelized version of the diagonal code, which tries to split the pending diagonal of 100,000 into separate parts (like 4 parts for the 4 cores of his laptop), evaluate them separately on a thread for each core, and spin until all 4 finish, at which point it moves up to the next 100,001 and starts again. This reduces to the same approach as before when only 1 thread is used.
Efficiency-wise, on my 16-core AMDRyzen Threadripper1950X CPU, the optimal thread count appears to be ~12, and I get a GCC2 speedup of 6.1s → 2.9s to calculate the 100k value of $165.075847.
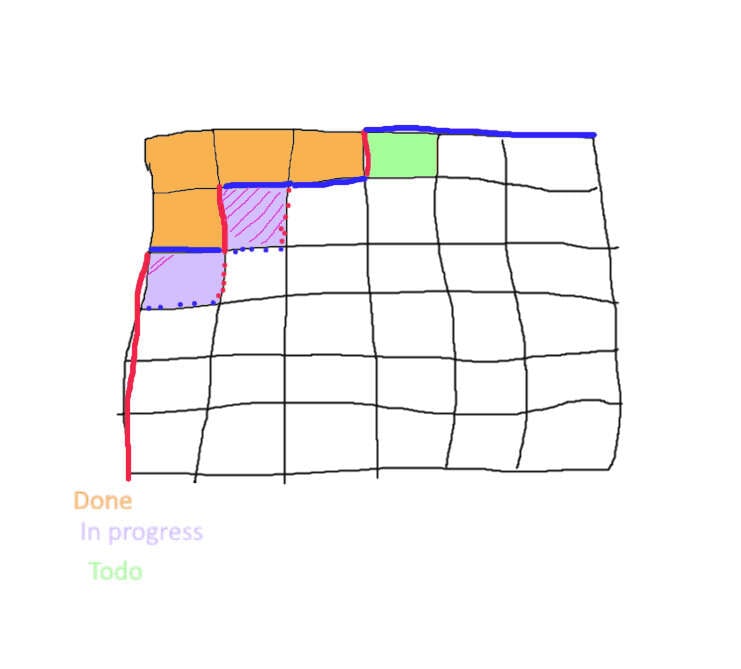
Diagram by Khoth of the block-level dependencies as a large problem evaluates.
One could expose enough parallelism to make it profitable by breaking up the problem into large blocks, which can be evaluated independently, such as 10,000×10,000 blocks (also improves locality), and assigns each block to a different CPU core. Nested within each block, the core evaluates diagonally as before. The optimal size of the blocks will depend on how many blocks there are available at each phase: the bigger the card count, the more blocks will become available after the initial setup: too big and there will only be a few ‘intermediate’ blocks that size, moderately too small and it doesn’t help, and too small (like size = 10) and the overhead becomes so severe it may take minutes to finish instead of <1s. On my Threadripper, for l = 100,000 cards some manual tweaking suggested a block size = 400.
Khoth’s bottom-up+diagonalized+blocks version in C (clang -Wall -Ofast -march=native -pthread -o Khoth -lm Khoth.c):
#include <pthread.h>#include <stdio.h>#include <stdint.h>#include <stdbool.h>#include <semaphore.h>// NUM_CARDS must be a multiple of BLOCK_SIZE because I'm lazy#define NUM_CARDS 100000#define BLOCK_SIZE 400#define NUM_THREADS 15#define DIV_ROUND_UP(x, y)(((x)+(y)-1)/(y))#define NUM_BLOCKS DIV_ROUND_UP(NUM_CARDS, BLOCK_SIZE)#define FP double#define MAX(x,y)((x)>(y)?(x):(y))#define MIN(x,y)((x)<(y)?(x):(y))typedefstruct{int r;int b;} work_item_t;int head;int tail;sem_t work_sem;sem_t done_sem;pthread_mutex_t put_work_mutex = PTHREAD_MUTEX_INITIALIZER;pthread_mutex_t grab_work_mutex = PTHREAD_MUTEX_INITIALIZER;#define WORK_QUEUE_LEN NUM_BLOCKSwork_item_t work_queue[WORK_QUEUE_LEN];pthread_t workers[NUM_THREADS];FP r0_edge[NUM_BLOCKS*BLOCK_SIZE +1];FP b0_edge[NUM_BLOCKS*BLOCK_SIZE +1];FP diag_arr[NUM_THREADS][2][BLOCK_SIZE+1];int b_progress[NUM_BLOCKS];int r_progress[NUM_BLOCKS];work_item_t get_work(void){ sem_wait(&work_sem); pthread_mutex_lock(&grab_work_mutex); work_item_t ret = work_queue[tail]; tail++;if(tail == WORK_QUEUE_LEN) tail =0; pthread_mutex_unlock(&grab_work_mutex);return ret;}// Meh: nasty get/put asymmetry with the locking, can't be arsed making it nicevoid put_work(work_item_t work){ work_queue[head]= work; head++;if(head == WORK_QUEUE_LEN) head =0; sem_post(&work_sem);}void handle_work_done(work_item_t work){ pthread_mutex_lock(&put_work_mutex); b_progress[work.r]= work.b+1; r_progress[work.b]= work.r+1;if(work.r +1< NUM_BLOCKS && b_progress[work.r +1]== work.b){ put_work((work_item_t){.b = work.b,.r = work.r +1});}if(work.b +1< NUM_BLOCKS && r_progress[work.b +1]== work.r){ put_work((work_item_t){.b = work.b +1,.r = work.r});}if(work.b +1== NUM_BLOCKS && work.r +1== NUM_BLOCKS){ sem_post(&done_sem);} pthread_mutex_unlock(&put_work_mutex);}int cash(int rem_black,int rem_red){return rem_red - rem_black;}void do_block(int thread,int block_r,int block_b){ count = BLOCK_SIZE;int base_b =1+ BLOCK_SIZE*block_b;int base_r =1+ BLOCK_SIZE*block_r;int cur =0; FP * cur_dia; FP * prev_dia;for(int dia =1; dia <= count; dia++){ cur_dia = diag_arr[thread][cur]; prev_dia = diag_arr[thread][!cur]; cur =!cur; prev_dia[0]= b0_edge[base_r+dia -1]; prev_dia[dia]= r0_edge[base_b+dia -1];for(int ix =0; ix < dia; ix++){int b_ix = ix;int r_ix = dia - ix -1;int b = base_b + b_ix;int r = base_r + r_ix; FP p =(FP)b /(FP)(b + r); FP value_if_stop = cash(b, r); FP value_if_go = p*prev_dia[ix]+(1-p)*prev_dia[ix+1]; cur_dia[ix+1]= MAX(value_if_stop, value_if_go);}}for(int dia = count -1; dia >0; dia--){ cur_dia = diag_arr[thread][cur]; prev_dia = diag_arr[thread][!cur]; cur =!cur; r0_edge[base_b + count - dia -1]= prev_dia[1]; b0_edge[base_r + count - dia -1]= prev_dia[dia+1];for(int ix =0; ix < dia; ix++){int b_ix = count - dia + ix;int r_ix = count -1- ix;int b = base_b + b_ix;int r = base_r + r_ix; FP p =(FP)b /(FP)(b + r); FP value_if_stop = cash(b, r); FP get_black_val = prev_dia[ix+1]; FP get_red_val = prev_dia[ix+2]; FP value_if_go = p*get_black_val +(1-p)*get_red_val; cur_dia[ix+1]= MAX(value_if_stop, value_if_go);}} r0_edge[base_b + count -1]= cur_dia[1]; b0_edge[base_r + count -1]= cur_dia[1];}void*worker_thread(void* arg){int thread_id =(intptr_t)arg;while(true){ work_item_t work = get_work(); do_block(thread_id, work.r, work.b); handle_work_done(work);}return NULL;}int main(){for(int i =0; i <= NUM_CARDS; i++){ b0_edge[i]= i;} sem_init(&work_sem,0,0); sem_init(&done_sem,0,0); put_work((work_item_t){.r =0,.b =0});for(int i =0; i < NUM_THREADS; i++){ pthread_create(&workers[i], NULL, worker_thread,(void*)(uintptr_t)i);} sem_wait(&done_sem); printf("value=%g\n", r0_edge[NUM_CARDS]);return0;}
This gives a total runtime under Clang of ~0.85s (GCC: 1.3s).
Can it be faster? Of course. The fastest code is the code that doesn’t run, and looking at the work the code does, much of it seems to be wasted.
If you look at the spreadsheet solution, the whole bottom left of the spreadsheet is simple: if you know you should stop when there are x good cards and y bad cards remaining, you don’t need to do all the calculations to know you should stop when there x good cards and >y bad cards remaining—it can only be worse, never better. This skipping of most of the bottom triangle cuts off almost half the state space (because it’s the lower triangle) and thus, skips half the computations, and since we are compute-bound, almost doubles speed:
#include <pthread.h>#include <stdio.h>#include <stdbool.h>#include <semaphore.h>#include <stdint.h>// NUM_CARDS must be a multiple of BLOCK_SIZE because I'm lazy#define NUM_CARDS 133787000#define BLOCK_SIZE 1000#define NUM_THREADS 15#define DIV_ROUND_UP(x, y)(((x)+(y)-1)/(y))#define NUM_BLOCKS DIV_ROUND_UP(NUM_CARDS, BLOCK_SIZE)#define FP double#define MAX(x,y)((x)>(y)?(x):(y))#define MIN(x,y)((x)<(y)?(x):(y))typedefstruct{int r;int b;} work_item_t;int head;int tail;sem_t work_sem;sem_t done_sem;pthread_mutex_t put_work_mutex = PTHREAD_MUTEX_INITIALIZER;pthread_mutex_t grab_work_mutex = PTHREAD_MUTEX_INITIALIZER;#define WORK_QUEUE_LEN NUM_BLOCKSwork_item_t work_queue[WORK_QUEUE_LEN];pthread_t workers[NUM_THREADS];FP r0_edge[NUM_BLOCKS*BLOCK_SIZE +1];FP b0_edge[NUM_BLOCKS*BLOCK_SIZE +1];FP diag_arr[NUM_THREADS][2][BLOCK_SIZE+1];int b_progress[NUM_BLOCKS];int r_progress[NUM_BLOCKS];int skipped[NUM_BLOCKS];work_item_t get_work(void){ sem_wait(&work_sem); pthread_mutex_lock(&grab_work_mutex); work_item_t ret = work_queue[tail]; tail++;if(tail == WORK_QUEUE_LEN) tail =0; pthread_mutex_unlock(&grab_work_mutex);return ret;}// Meh: nasty get/put asymmetry with the locking, can't be arsed making it nicevoid put_work(work_item_t work){ work_queue[head]= work; head++;if(head == WORK_QUEUE_LEN) head =0; sem_post(&work_sem);}int cash(int rem_black,int rem_red){return rem_red - rem_black;}void handle_work_done(work_item_t work){ pthread_mutex_lock(&put_work_mutex); b_progress[work.r]= work.b+1; r_progress[work.b]= work.r+1;if(work.b +1< NUM_BLOCKS && work.r +1< NUM_BLOCKS && cash((work.b+1)*BLOCK_SIZE,(work.r+1)*BLOCK_SIZE)== r0_edge[(work.b+1)*BLOCK_SIZE]){ r_progress[work.b]= NUM_BLOCKS; skipped[work.b +1]= work.r+1;}elseif(work.r +1< NUM_BLOCKS &&(b_progress[work.r +1]>= work.b || skipped[work.b])){ put_work((work_item_t){.b = work.b,.r = work.r +1});}if(work.b +1< NUM_BLOCKS && r_progress[work.b +1]>= work.r){ put_work((work_item_t){.b = work.b +1,.r = work.r});}if(work.b +1== NUM_BLOCKS && work.r +1== NUM_BLOCKS){ sem_post(&done_sem);} pthread_mutex_unlock(&put_work_mutex);}void do_block(int thread,int block_r,int block_b){int count = BLOCK_SIZE;int base_b =1+ BLOCK_SIZE*block_b;int base_r =1+ BLOCK_SIZE*block_r;if(skipped[block_b]&& skipped[block_b]<= block_r){for(int i =0; i < BLOCK_SIZE; i++){ b0_edge[base_r + i]= cash(base_b -1, base_r + i);}}int cur =0; FP * cur_dia; FP * prev_dia;for(int dia =1; dia <= count; dia++){ cur_dia = diag_arr[thread][cur]; prev_dia = diag_arr[thread][!cur]; cur =!cur; prev_dia[0]= b0_edge[base_r+dia -1]; prev_dia[dia]= r0_edge[base_b+dia -1];for(int ix =0; ix < dia; ix++){int b_ix = ix;int r_ix = dia - ix -1;int b = base_b + b_ix;int r = base_r + r_ix; FP p =(FP)b /(FP)(b + r); FP value_if_stop = cash(b, r); FP value_if_go = p*prev_dia[ix]+(1-p)*prev_dia[ix+1]; cur_dia[ix+1]= MAX(value_if_stop, value_if_go);}}for(int dia = count -1; dia >0; dia--){ cur_dia = diag_arr[thread][cur]; prev_dia = diag_arr[thread][!cur]; cur =!cur; r0_edge[base_b + count - dia -1]= prev_dia[1]; b0_edge[base_r + count - dia -1]= prev_dia[dia+1];for(int ix =0; ix < dia; ix++){int b_ix = count - dia + ix;int r_ix = count -1- ix;int b = base_b + b_ix;int r = base_r + r_ix; FP p =(FP)b /(FP)(b + r); FP value_if_stop = cash(b, r); FP get_black_val = prev_dia[ix+1]; FP get_red_val = prev_dia[ix+2]; FP value_if_go = p*get_black_val +(1-p)*get_red_val; cur_dia[ix+1]= MAX(value_if_stop, value_if_go);}} r0_edge[base_b + count -1]= cur_dia[1]; b0_edge[base_r + count -1]= cur_dia[1];}void*worker_thread(void* arg){int thread_id =(intptr_t)arg;while(true){ work_item_t work = get_work(); do_block(thread_id, work.r, work.b); handle_work_done(work);}return NULL;}int main(){for(int i =0; i <= NUM_CARDS; i++){ b0_edge[i]= i;} sem_init(&work_sem,0,0); sem_init(&done_sem,0,0); put_work((work_item_t){.r =0,.b =0});for(int i =0; i < NUM_THREADS; i++){ pthread_create(&workers[i], NULL, worker_thread,(void*)(uintptr_t)i);} sem_wait(&done_sem); printf("value=%g\n", r0_edge[NUM_CARDS]);return0;}
For kicks, I thought I’d calculate the largest l possible. This turns out to be l = 133,787,000; higher values require static arrays so large that the linker balks—presumably there’s a way around that but 133m seems big enough. I messed with the block size some more on l = 2m ($818.1, ~2m10s), and found that a block size closer to 1,000 seems better than 400, so for a 133m run, I bumped it to 1,000 to be safe, since as the card count gets bigger, the optimal block size presumably also slowly gets bigger.
After 9 days on my Threadripper (8–17 October 2022) & 51 CPU-core-days (184,331 CPU-core-minutes), the exact value of l = 133,787,000 turns out to be $6,038.22. Comparing this to my original square root approximation of -0.0186936 + 0.522088* sqrt(133787000) → $6,038.78162, the approximation has an error of 0.009%. If we include that into the square-root approximation, the finetuned approximation then yields -0.0146229 + 0.522048 * sqrt(133787000) → $6,038.32303, which has a better error of 0.0017%.
Where could one go from the final block+skip version (short of analytical expressions or approximations)? A few possibilities:
exact calculation:
caching: begin storing pre-computed values in the algorithm, such as every power of 10.
After all, now that values like l = 133m have been calculated, why should they ever be calculated again? They provide a shortcut to all intermediate values, and a speedup for larger values.
GPUs: small local arithmetic calculations done in parallel with minimal control-flow or long-range dependencies scream for a GPU implementation (might require low-level CUDA programming to ensure that the calculations stay in the GPU thread they should)
cluster parallelization: for larger problems, network overhead/latency becomes less of an issue and parallelizing across multiple computers becomes useful
approximation:
ε probability truncation: as the card count increases, more of the state-space is devoted to increasingly astronomically-unlikely scenarios, which contribute ever tinier values to the final value of the game, because there are no massive payoffs or penalties lurking, only the same old ±$1.
Thus, one could truncating value estimates at some small fixed value ε to avoid full rollouts. I suspect that such an approximation would turn it into 𝒪(1) space + 𝒪(l) time, because one is now just calculating a wide diagonal ‘beam’ of fixed-width down through the square of all possible states
ε value truncation (perhaps sub-machine precision—the exact calculation is not exact here once something falls below double-precision floating-point format’s ability to represent a number, so compute spent on that is wasted)
It is hard to know if the value < ε before you spend the compute, of course, so one needs to figure out a way to bound it or have a good heuristic to guess it.
values <-read.table("https://gwern.net/doc/statistics/decision/2022-10-03-feepingcreature-problem14-bottomup-values0to22974.txt")df <-rbind(data.frame(Cards=seq(0,22974), Value=values$V1, Type="exact"),data.frame(Cards=c(100000),Value=165.076, Type="exact"))df <- df[-1,] # delete 0 card entry to make things easier with the logsllog <-lm(Value ~log(Cards), data=df); summary(llog)# ...Residuals:# Min 1Q Median 3Q Max# −6.62279 −4.98638 −1.00526 3.96333 107.14550## Coefficients:# Estimate Std. Error t value Pr(>|t|)# (Intercept) −106.6454973 0.3724555 −286.331 < 2.22e-16# log(Cards) 17.6267169 0.0409405 430.545 < 2.22e-16## Residual standard error: 6.19828 on 22973 degrees of freedom# Multiple R-squared: 0.889734, Adjusted R-squared: 0.889729# F-statistic: 185369 on 1 and 22973 DF, p-value: < 2.22e-16lsqrt <-lm(Value ~sqrt(Cards), data=df); summary(lsqrt)# ...Residuals:# Min 1Q Median 3Q Max# −0.05298383 −0.00071444 0.00047093 0.00121099 0.01869362## Coefficients:# Estimate Std. Error t value Pr(>|t|)# (Intercept) −1.86936e-02 3.70052e-05 −505.163 < 2.22e-16# sqrt(Cards) 5.22088e-01 3.45212e-07 1512369.327 < 2.22e-16## Residual standard error: 0.00187101 on 22974 degrees of freedom# Multiple R-squared: 1, Adjusted R-squared: 1# F-statistic: 2.28726e+12 on 1 and 22974 DF, p-value: < 2.22e-16### The fit:#### v = −0.0186936 + 0.522088 * √(cards)#### so 100k = 165.080028 (not quite 165.076), 1m = 522.0, 10m = 1650.96,## 100m = 5220.86, 1b = 16509.85, 10b = 52208.78, 100b = 165098.70 etcllogsqrt <-lm(Value ~log(Cards) +sqrt(Cards), data=df); summary(llogsqrt)# ...Residuals:# Min 1Q Median 3Q Max# −80.34388 −1.34909 −0.15215 1.34937 26.80501## Coefficients:# Estimate Std. Error t value Pr(>|t|)# (Intercept) −2.66931e+01 1.72306e-01 −154.917 < 2.22e-16# log(Cards) 4.40946e+00 2.66876e-02 165.225 < 2.22e-16# sqrt(Cards) 3.91493e-01 7.45612e-04 525.063 < 2.22e-16## Residual standard error: 2.68411 on 91897 degrees of freedom# Multiple R-squared: 0.978735, Adjusted R-squared: 0.978735# F-statistic: 2.11482e+06 on 2 and 91897 DF, p-value: < 2.22e-16df <-rbind(df,data.frame(Cards=df$Cards, Value=predict(llog), Type="log"),data.frame(Cards=df$Cards, Value=predict(lsqrt), Type="√"),data.frame(Cards=df$Cards, Value=predict(llogsqrt), Type="log+√"))p <-qplot(x=Cards, y=Value, color=Type, data=df) +theme_bw(base_size =50)p +geom_line(aes(x=Cards, y=Value), linetype ="dashed", size =5) +scale_color_manual(values=c("#999999", "#5b6b6b", "#313131", "#000000")) +xlab("Card Draw (#)") +ylab("Winnings ($)") +theme(legend.position ="none") +ggtitle(" √ vs Log approximation of Problem 14 value") +geom_point(size=8) +theme(strip.background =element_blank(), strip.text.x =element_blank())
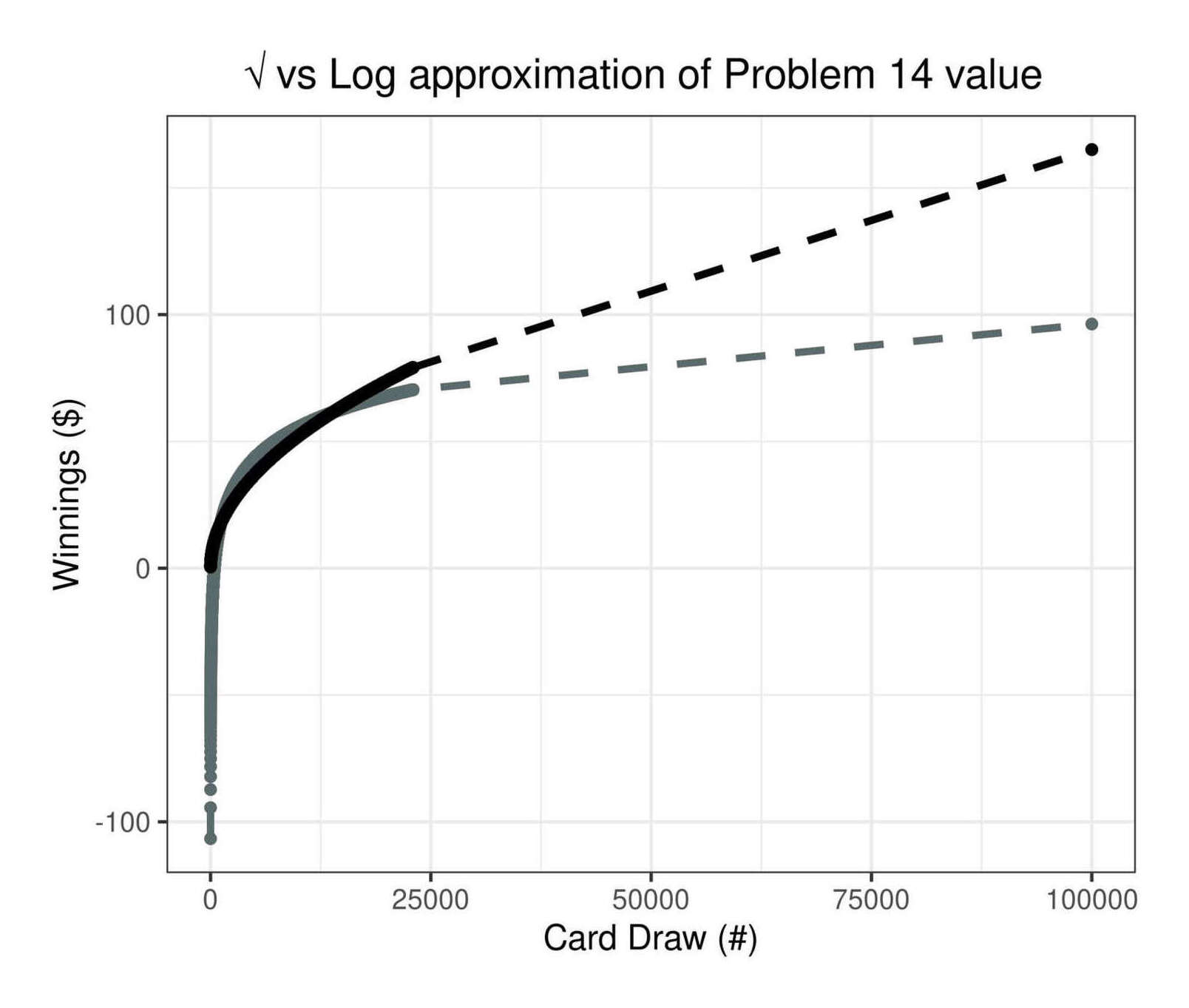
The square-root fits well enough that adding additional terms seems unnecessary, while the residual values indicate that the log fit has some serious issues somewhere. Plotting reveals that the log is wildly inaccurate early on, hitting negative values; ignoring that, it grows too slowly compared to the true value, while the square root fits perfectly:
Plotting the square root & logarithmic approximations for the Problem 14 value of card counts = 1–22,294 & 100,000: the square root fits so well that the exact points are hidden, while the log is erroneous almost everywhere.
The square-root fit looks suspiciously like it is just the initial expected value of 1 card (0.5) along with a tiny near-zero misfit term that vanishes as the card value asymptotically increases; I wonder if the limit is just 0.5 × √l?
The largest available exact value, l = 133m, changes the approximation consistent with that:
## compare with the final available exact value of 𝑙 = 133,787,000df <-rbind(df, data.frame(Cards=c(133787000),Value=6038.22, Type="exact"))lsqrt <-lm(Value ~sqrt(Cards), data=df); summary(lsqrt)# Residuals:# Min 1Q Median 3Q Max# −0.10346355 0.00010533 0.00071383 0.00105519 0.00453808## Coefficients:# Estimate Std. Error t value Pr(>|t|)# (Intercept) −1.46229e-02 2.54948e-05 −573.563 < 2.22e-16# sqrt(Cards) 5.22048e-01 1.93756e-07 2694354.736 < 2.22e-16## Residual standard error: 0.00245711 on 22974 degrees of freedom# Multiple R-squared: 1, Adjusted R-squared: 1# F-statistic: 7.25955e+12 on 1 and 22974 DF, p-value: < 2.22e-16
It adjusts the coefficients a bit, and then the relative error drops; the 0.5 multiplier gets slightly smaller, but the offset/intercept gets slightly bigger. So it looks like it does converge to 0.5 × √l with, for small numbers, an intercept as a constant to help soak up the zig-zag staircase discretization one often sees in probability problems.
Howe2014 further calculates that an omniscient player who knew the deck order could expect to win $4.04.
It doesn’t compile as-is with Clang, for some reason. Replacing the volatile bool declarations with _Atomic(bool) compiles, but is ~0.1s slower for both GCC & Clang (2.9s → 3s).
As a last optimization trick, can sometimes squeeze out another few % of performance (like it did with “Kelly Coin Flip”), but in this case, Clang PGO actually makes it slower by ~0.03s:
While one would think PGO would never hurt, we apparently are so close to the machine & optimal performance by parallelism that PGO isn’t smart enough to help given the complexity.