2017 News
Annual summary of 2017 Gwern.net newsletters, selecting my best writings, the best 2017 links by topic, and the best books/movies/anime I saw in 2017.
This is the 2017 summary edition of the Gwern.net newsletter (archives), summarizing the best of the monthly 2017 newsletters:
Previous annual newsletters: 2016, 2015.
Writings
Posts:
The Kelly Coin-Flipping Problem: Exact Solutions via Decision Trees
Efficiently calculating the average maximum datapoint from a sample of Gaussians
Site traffic (July 2017–January 2018) was up: 326,852 page-views by 155,532 unique users.
Media
Overview
AI/genetics/VR/Bitcoin/general:
AI: as I hoped in 2016, 2017 saw a re-emergence of model-based RL with various deep approaches to learning reasoning, meta-RL, and environment models. Using relational logics and doing planning over internal models and zero/few-shot learning are no longer things “deep learning can’t do”. My selection for the single biggest breakthrough of the year was when AlphaGo racked up a second major intellectual victory with the demonstration by Zero that using a simple expert iteration algorithm (with MCTS as the expert) does not only solve the long-standing problem of NN self-play being wildly unstable (dating back to attempts to failed attempts to extend TD-Gammon to non-backgammon domains in the 1990s), but also allows superior learning to the complicated human-initialized AGs—in both wallclock time & end strength, which is deeply humbling. 200026ya years of study and tens of millions of active players, and that’s all it takes to surpass the best human Go players ever in the supposedly uniquely human domain of subtle global pattern recognition. Not to mention chess. (Silver et al 2017a, Silver et al 2017b.) Expert iteration is an intriguingly general and underused design pattern, which I think may prove useful, especially if people can remember that it is not limited to two-player games but is a general method for solving any MDP. The second most notable would be GAN work: Wasserstein GAN losses (Arjovsky et al 2017) considerably ameliorated the instability issues when using GANs with various architectures, and although WGANs can still diverge or fail to learn, they are not so much of a black art as the original DCGANs tended to be. This probably helped with later GAN work in 2017, such as the invention of the CycleGAN architecture (Zhu et al 2017) which accomplishes magical & bizarre kinds of learning such as learning, using horse and zebra images, to turn an arbitrary horse image into a zebra & vice-versa, or your face into a car or a bowl of ramen soup. “Who ordered that?” I didn’t, but it’s delicious & hilarious anyway, and suggests that GANs really will be important in unsupervised learning because they appear to be learning a lot about their domains. Additional demonstrations like being able to translate between human languages given only monolingual corpuses merely emphasize that lurking power—I still feel that CycleGAN should not work, much less high-quality neural translation without any translation pairs, but it does. The path to larger-scale photorealistic GANs was discovered by Nvidia’s ProGAN paper (Karras et al 2017): essentially StackGAN’s approach of layering several GANs trained incrementally as upscalers does work (as I expected), but you need much more GPU-compute to reach 1024x1024-size photos and it helps if each new upscaling GAN is only gradually blended in to avoid the random initialization destroying everything previously learned (analogous to transfer learning needing low learning rates or to freeze layers). Time will tell if the ProGAN approach is a one-trick pony for GANs limited to photos. Finally, GANs started turning up as useful components in semi-supervised learning in the GAIL paradigm (Ho & Ermon 2016) for deep RL robotics. I expect GANs are still a while off from being productized or truly critical for anything—they remain a solution in search of a problem, but less so than I commented last year. Indeed, from AlphaGo to GANs, 2017 was the year of deep RL (subreddit traffic octupled). Papers tumbled out constantly, accompanied by ambitious commercial moves: Jeff Dean laid out a vision for using NNs/deep RL essentially everywhere inside Google’s software stack, Google began full self-driving services in Phoenix, while noted researchers like Pieter Abbeel founded robotics startups betting that deep RL has finally cracked imitation & few-shot learning. I can only briefly highlight, in deep RL, continued work on meta-RL & neural net architecture search with fast weights, relational reasoning & logic modules, zero/few-shot learning, deep environment models (critical for planning), and robot progress in sample efficiency/imitation learning/model-based & off-policy learning, in addition to the integration of GANs a la GAIL. What will happen if every year from now on sees as much progress in deep reinforcement learning as we saw in 2017? (Suppose deep learning ultimately does lead to a Singularity; how would it look any different than it does now?) One thing missing from 2017 for me was use of very large NNs using expert mixtures, synthetic gradients, or other techniques; in retrospect, this may reflect hardware limitations as non-Googlers increasingly hit the limits of what can be iterated on reasonably quickly using just 1080tis or P100s. So I am intrigued by the increasing availability of Google’s second-generation TPUs (which can do training) and by discussions of multiple maturing NN accelerator startups which might break Nvidia’s costly monopoly and offer 100s of teraflops or petaflops at non-AmaGoogBookSoft researcher/hobbyist budgets.
Genetics in 2017 was a straight-line continuation of 2016: the UKBB dataset came online and is fully armed & operational, with exomes now following (and whole-genomes soon), resulting in the typical flurries of papers on everything which is heritable (which is everything). Genetic engineering had a banner year between CRISPR and older methods in the pipeline—it seemed like every week there was a new mouse or human trial curing something or other, to the point where I lost track and the NYT has begun reporting on clinical trials being delayed by lack of virus manufacturing capacity. (A good problem to have!) Genome synthesis continues to greatly concern me but nothing newsworthy happened in 2017 other than, presumably, continuing to get cheaper on schedule. Intelligence research did not deliver any particularly amazing results as the SSGAC paper has apparently been delayed to 2018 (with a glimpse in Plomin & von Stumm 2018), but we saw two critical methodological improvements which I expect to yield fruit in 2017–2018: first, as genetic correlation researchers have noted for years, genetic correlations should be able to boost power considerably by correcting for measurement error & increasing effective sample size by appropriate combination of polygenic scores, and MTAG demonstrates this works well for intelligence (Hill et al 2017b increases PGS to ~7% & Hill et al 2018 to ~10%); second, Hsu’s lasso predictions were proven true by Lello et al 2017 demonstrating the creation of a polygenic score explaining most SNP heritability/predicting 40% of height variance. The use of these two simultaneously with SSGAC & other datasets ought to boost IQ PGSes to >10% and possibly much more. Perhaps the most notable single development was the resolution of the long-standing dysgenics question using molecular genetics: has the demographic transition in at least some Western countries led to decreases in the genetic potential for intelligence (mean polygenic score), as suggested by most but not all phenotypic analyses of intelligence/education/fertility? Yes, in Iceland/USA/UK, dysgenics has indeed done that on a meaningful scale, as shown by straightforward calculations of mean polygenic score by birth decade & genetic correlations. More interestingly, the increasing availability of ancient DNA allows for preliminary analyses of how polygenic scores change over time: over tens of thousands of years, human intelligence & disease traits appear to have been slowly selected against (consistent with most genetic variants being harmful & under purifying selection) but that trend reversed at some point relatively recent.
For 2016, I noted that the main story of VR was that it hadn’t failed & was modestly successful; 2017 saw the continuation of this trend as it climbs into its “trough of productivity”—the media hype has popped and for 2017, VR just kept succeeding and building up an increasingly large library of games & applications, while the price continued to drop dramatically (as everyone should have realized but didn’t) with the Oculus now ~$404.46$3002017. So much for “motion sickness will kill VR again” or “VR is too expensive for gamers”. Perhaps the major surprise for me was that Sony’s quiet & noncommittal approach to its headset (which made me wonder if it would be launched at all) masked a huge success, as PSVR has sold into the millions of units and is probably the most popular ‘real’ VR solution despite its technical drawbacks compared to Vive/Oculus. There continues to be no killer app, but the many upcoming hardware improvements like 4K displays or wireless headsets or eye tracking+foveated-rendering will continue increasing quality while prices drop and libraries continue to build up; if there is any natural limit to the VR market, I haven’t seen any sign of it yet. So for 2018–2019, I wonder if VR will simply continue to grow gradually with mobile smartphone VR solutions eating the lunch of full headsets, or if there will be a breakout moment where the price, quality, library, and a killer app hit a critical combination?
Bitcoin underwent one of its periodic ‘bubbles’, complete with the classic accusations that this time Bitcoin will surely go to zero, the fee spikes mean Bitcoin will never scale (“nobody goes there anymore, it’s too popular”), people can’t use it to pay for anything, it’s a clear scam because of various peoples’ foolishness like taking out mortgages to gamble on further increases, Coinbase is run by fools & knaves, random other altcoins have bubbled too & will doubtless replace Bitcoin soon, Bitcoin has failed to achieve any libertarian goals and is now a plaything of the rich, people who were wrong about Bitcoin every time from $1.55$12011 in 201115ya to now will claim to be right morally, the PoW security is wasteful, etc.—one could copy-paste most articles or comments from the last bubble (or the one before that, or before that) into this one with no change other than the numbers. As such, while I have benefited from it, there is little worth saying about it other than to note its existence with bemusement, and reflect on how far Bitcoin & cryptocurrencies have come since I first began using them in 201115ya: Even if Bitcoin goes to zero now, it’s unleashed an incredible Cambrian explosion of cryptography applications and economics crossovers. Cryptoeconomists are going to spend decades digesting proof-of-work, proof-of-stake, slashing, Truthcoin/HiveMind/Augur, zk-SNARKs and zk-STARKs, Mimblewimble, TrueBit, scriptless scripts & other applications of Schnorr signatures, Turing-complete contracts, observed cryptomarkets like the DNMs… You can go through Tim May’s Cyphernomicon and each section corresponds to a project made possible only via Bitcoin’s influence. Bitcoin had more influence in its first 5 years than Chaum’s digital cash has had in 30 years. Cryptography will never be the same. The future’s so bright I gotta wear mirrorshades.
A short note on politics: Donald Trump’s presidency and its backlash in the form of Girardian scapegoating (sexual harassment scandals & social-media purges) have received truly disproportionate coverage and have become almost an addiction. They have distracted from important issues and from important facts like 2017 being one of the best years in human history, many scientific & technological improvements and breakthroughs like genetic engineering or AI, or global & US economic growth. Objectively, Trump’s first year has been largely a non-event; a few things were accomplished like packing federal courts and a bizarre tax bill, but overall not much happened, and Trump has not lived up to the apocalyptic predictions & hysteria. If the next 3 years are similar to 2017, one would have to admit that Trump as president turned out better than George W. Bush!
Links
Genetics:
Everything Is Heritable:
“Accurate Genomic Prediction Of Human Height”, Lello et al 2017 (Hsu’s lasso)
“Genomic analysis of family data reveals additional genetic effects on intelligence and personality”, Hill et al 2017a (GREML-KIN/family-GCTA: IQ missing heritability resolved with novel GCTA—most/all of the rest is due to semi-rare additive variants, implying that GWASes and future polygenic scores will do much better)
“GWAS of 78,308 individuals identifies new loci and genes influencing human intelligence”, Sniekers et al 2017
“Multi-trait analysis of genome-wide association summary statistics using MTAG”, Turley et al 2018; “A combined analysis of genetically correlated traits identifies 107 loci associated with intelligence”, Hill et al 2017b (use of multiple genetic correlations to overcome measurement error greatly boosts efficiency of IQ GWAS, and provides best public polygenic score to date: 7% of variance. This illustrates a good way to work around the shortage of high-quality IQ test scores by exploiting multiple more easily-measured phenotypes. Even better: like LD score regression, MTAG only requires public summary statistics; so it may also, like LD score regression, see an explosion in use—since it is usable by everyone & there are so many overlapping phenotypic measurements…)
“Genome-wide genetic data on ~500,000 UK Biobank participants”, Bycroft et al 2017 (The full UK Biobank n = 500k genetics dataset is now available to researchers! UKBB is the gift that keeps on giving—and now it’s going to give even more by tripling the sample size.)
“An atlas of genetic associations in UK Biobank”, Canela-Xandri et al 2017 (at least 559 of 717 UKBB traits have detectable SNP heritability, with pervasive genetic correlations; polygenic scores for all have been made public via Gene ATLAS. See previously: Ge et al 2016)
“Common risk variants identified in autism spectrum disorder”, Grove et al 2017 (ASD, as expected, crosses the sample size threshold for hits. More importantly: the genetic correlations imply that autism is not a single thing & that intelligence genes are not inherently ‘autistic’; hence it will be possible to select for intelligence without selecting for autism. I’ve always had a hard time believing the simple genetic correlations between intelligence and ‘autism spectrum disorder’ since it’s unclear why variants that improve intelligence would decrease social functioning which should require intelligence as much as anything else; if it’s simply that there’s heterogeneity and that, say, ‘systematizing’ is shared between intelligence and autism diagnoses, that would be a credible resolution.)
“Quantifying the impact of rare and ultra-rare coding variation across the phenotypic spectrum”, Ganna et al 2017
The environment is genetic: “The nature of nurture: effects of parental genotypes”, Kong et al 2017; “Estimating heritability without environmental bias”, Young et al 2017 (interesting new method; among other implications, that much of the benefits of embryo selection would be delayed to the next generation, since they will be expressed via better parenting (whatever that is).)
“10 Years of GWAS Discovery: Biology, Function, and Translation”, Visscher et al 2017 (Almost a decade into the human genetic revolution—GCTA was ~2009—where do we stand?)
Engineering:
“CRISPR/Cas9-mediated gene editing in human zygotes using Cas9 protein”, Tang et al 2017 (no off-target mutations and efficiencies of 20/50/100% for various edits. As I predicted, the older papers, Liang et al 201511ya / Kang et al 2016 / Komor et al 2016, were not state-of-the-art and would be improved on considerably); “Correction of a pathogenic gene mutation in human embryos”, et al 2017 (Human CRISPR editing: no observed off-targets, 27.9% efficiency.)
“Beyond editing to writing large genomes”, Chari & Church 2017 (genome synthesis)
“A New Way to Reproduce: Scientists are trying to manufacture eggs and sperm in the laboratory. Will it end reproduction as we know it?” (Rapid progress towards iterated embryo selection; will it become a reality before genome synthesis?)
“China sprints ahead in CRISPR therapy race: Human trials are using the genome-editing technique to treat cancers and other conditions”, Normile 2017-10-06; “China’s embrace of embryo selection raises thorny questions: Fertility centres are making a massive push to increase preimplantation genetic diagnosis in a bid to eradicate certain diseases” (The wind is rising.)
“U.S. attitudes on human genome editing”, Scheufele et al 2017 (increasingly positive public opinion, especially among the most informed)
“Eugenics 2.0: We’re at the Dawn of Choosing Embryos by Health, Height, and More; Will you be among the first to pick your kids’ IQ? As machine learning unlocks predictions from DNA databases, scientists say parents could have choices never before possible.” (Hsu’s embryo selection startup, Genomic Prediction, comes out of stealth)
“A 100-Year Review: Methods and impacts of genetic selection in dairy cattle—From daughter-dam comparisons to deep learning algorithms”, Weigel et al 2017 (A preview of improving genomic prediction & selection.)
Recent Evolution:
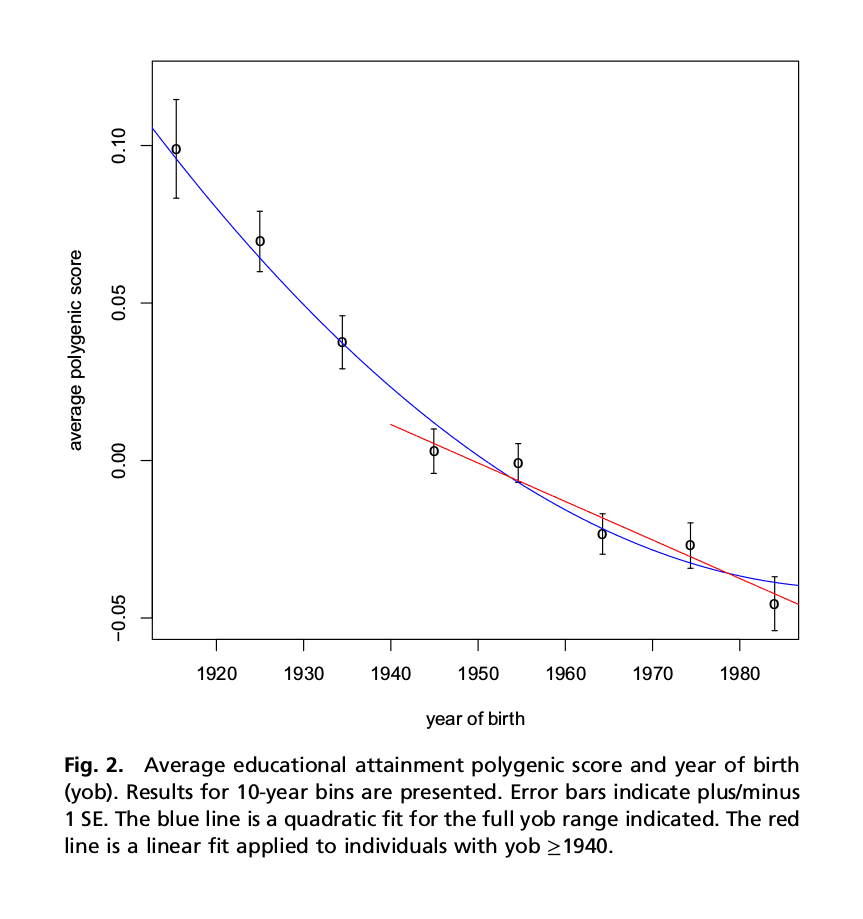
in Iceland: decrease in the education polygenic score 1910–80199036ya, “Selection against variants in the genome associated with educational attainment”, Kong et al 2017 (graph; media)
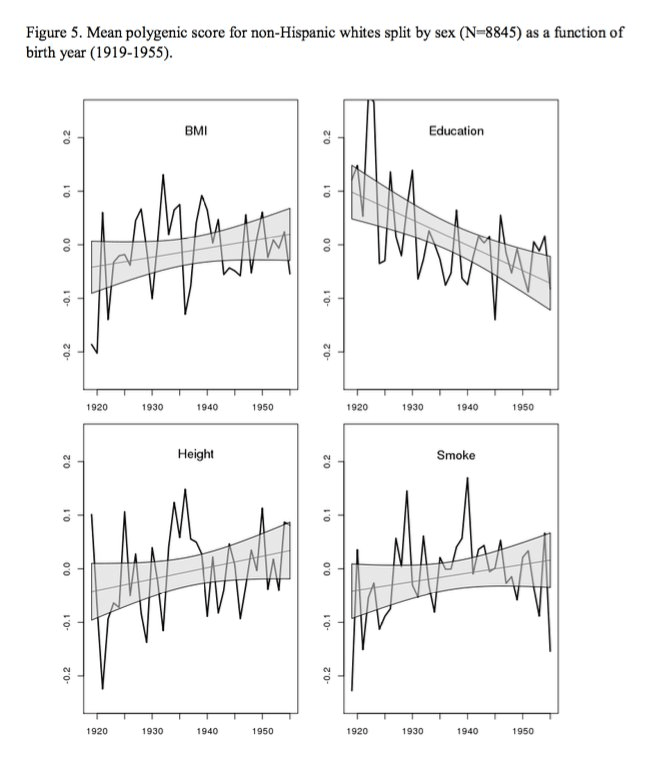
in the US: decrease in the education polygenic score 1920–40196066ya, “Mortality Selection in a Genetic Sample and Implications for Association Studies”, Domingue et al 2016 (graph)
selection against education in the UK: “Signatures of negative selection in the genetic architecture of human complex traits”, Zeng et al 2018
“Patterns of shared signatures of recent positive selection across human populations”, Johnson & Voight 2017
disease mutation load: “The Genomic Health Of Ancient Hominins”, Berens et al 2017 (media; +35% percentile increase in general disease risks over past ~millennia?)
“Detecting polygenic adaptation in admixture graphs”, Racimo et al 2017 (No sign of selection is found for Europeans, but if I understand the method right, it’s only looking at net selection with time steps corresponding to populations branching. So given the European pattern of selection for intelligence at least up until agriculture and then heavy recent dysgenics against education/intelligence, those might mostly cancel compared to an East Asian population like Japan which started later.)
“Soft sweeps are the dominant mode of adaptation in the human genome”, Schrider & Kern 2017 (Detection of 200026ya instances of recent human selection, half of which are specific to individual human populations, and many of which affect the central nervous system. Note this doesn’t cover polygenic selection, so it’s a loose lower bound on how much recent human evolution there has been.)
“Evidence for evolutionary shifts in the fitness landscape of human complex traits”, Uricchio et al 2017 (Recent human evolution <50kya: selection on education/intelligence, schizophrenia, height, BMI, Crohn’s disease)
“Linkage disequilibrium-dependent architecture of human complex traits shows action of negative selection”, Gazal et al 2017 (high mutation load and ongoing purifying/negative selection against variants affecting puberty/anorexia/autism/blood pressure/BMI/celiac disease/Crohn’s disease/breast size/hair curl/heel score/height/gray hair/lung capacity/baldness/cirrhosis/arthritis/schizophrenia/shoe size/unibrow)
“Quantification of frequency-dependent genetic architectures and action of negative selection in 25 UK Biobank traits”, Schoech et al 2017 (mutation load & purifying/negative selection within 25 UKBB traits: larger effects of rarer variants, but rare variants continue to disappoint by not accounting for much variance in total. Traits: puberty/blood pressure/BMI/bone mineral density/lung capacity/height/smoking/waist-hip ratio/allergic eczema/asthma/college education/hypertension/11 blood panel traits)
{kind=link}
{kind=link}
AI:
“CycleGAN: Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks”, Zhu et al 2017; weird and magical, leading to applications like “Unsupervised Machine Translation Using Monolingual Corpora Only”, Lample et al 2017 (but what is it really learning?)
“ProGAN: Progressive Growing of GANs for Improved Quality, Stability, and Variation”, Karras et al 2017 (source; video; GANs generating photorealistic 1024x1024px faces, better than StackGAN++ This jumps right over the uncanny valley to, for many of these, I can no longer tell the difference without focusing hard on the eyes.)
“WGAN: Wasserstein GAN”, Arjovsky et al 2017 (a surprisingly small tweak fixes both mode collapse & divergence, yielding stable GANs which reliably fit datasets like anime faces in my experiments with the code; underfitting/expressiveness seems to remain an issue, though)
GANs start becoming useful: “Generative Adversarial Imitation Learning (GAIL)”, Ho & Ermon 2016; “Learning human behaviors from motion capture by adversarial imitation”, Merel et al 2017 (an unusual applied use of GANs); “Learning from Demonstrations for Real World Reinforcement Learning”, Hester et al 2017
“Inferring and Executing Programs for Visual Reasoning”, Johnson et al 2017
“Hard Mixtures of Experts for Large Scale Weakly Supervised Vision”, Gross et al 2017 (scaling CNNs to 500m+ images by sharding)
“deep learning can’t do logic or reasoning”: “A simple neural network module for relational reasoning”, Santoro et al 2017 (blog)
“Attention Is All You Need” for SOTA machine translation, Vaswani et al 2017
“One Model To Learn Them All”, Kaiser et al 2017 (a single NN for multi-modal tasks: from image classification to image captioning to English parsing to English⟺German⟺French translation)
“2016 in Computer Vision”, Duffy & Flynn (review of primarily DL progress in 2016 on image classification, object detection/tracking, segmentation, upscaling, 3D geometry estimation, and fundamental CNN & dataset R&D)
reinforcement learning research is coming out too frequently to single out more than a few papers; see subscribe to the /r/ReinforcementLearning & /r/DecisionTheory subreddits for updates
AlphaGo Zero: “Mastering The Game of Go without Human Knowledge”, Silver et al 2017a (detailed commentary); “Thinking Fast and Slow with Deep Learning and Tree Search”, Anthony et al 2017 (blog); “Learning Generalized Reactive Policies using Deep Neural Networks”, Groshev et al 2017; “Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm”, Silver et al 2017b (commentary), see also Lagoudakis & Parr 2003
“deep learning can’t do planning”: “Learning model-based planning from scratch”, Pascanu et al 2017; “Imagination-Augmented Agents for Deep Reinforcement Learning”, Weber et al 2017 (blog); “Path Integral Networks: End-to-End Differentiable Optimal Control”, Okada et al 2017; “Value Prediction Network”, Oh et al 2017; “Prediction and Control with Temporal Segment Models”, Mishra et al 2017; “Neural Network Dynamics for Model-Based Deep Reinforcement Learning with Model-Free Fine-Tuning”, Nagabandi et al 2017; “Model-based Adversarial Imitation Learning”, Baram et al 2016; “Learning Generalized Reactive Policies using Deep Neural Networks”, Groshev et al 2017; “Deep Visual Foresight for Planning Robot Motion”, Finn & Levine 2016; “Recurrent Environment Simulators”, Chiappa et al 2017
“Machine Learning for Systems and Systems for Machine Learning”, Jeff Dean, 2017 NIPS slides; “The Case for Learned Index Structures”, Kraska et al 2017
“Deep reinforcement learning from human preferences”, Christiano et al 2017 (blogs: 1, 2)
“SMASH: One-Shot Model Architecture Search through HyperNetworks”, Brock et al 2017
“Bayesian Reinforcement Learning: A Survey”, Ghavamzadeh et al 2016
“TreeQN and ATreeC: Differentiable Tree Planning for Deep Reinforcement Learning”, Farquhar et al 2017 (deep model-based planning; despite GPU VRAM limiting them to depth-2/3 at most, still helpful)
“A Survey of Monte Carlo Tree Search (MCTS) Methods”, Browne et al 201214ya; “A Tutorial on Thompson Sampling”, Russo et al 2017
“Deep Reinforcement Learning that Matters”, Henderson et al 2017
Statistics/meta-science:
“Discontinuation and Nonpublication of Randomized Clinical Trials Conducted in Children”, Pica et al 2016 (>35000 children subjected to useless human experimentation annually in the USA. I’m glad the bioethicists and IRBs are tackling the real problems, like what happens to leftover embryos or whether genetic engineering might insult the disabled or whether enough community meetings have been held & all “stakeholders” properly informed.)
“Is the staggeringly profitable business of scientific publishing bad for science?”
“Proceeding From Observed Correlation to Causal Inference: The Use of Natural Experiments”, Rutter 2007
“A long journey to reproducible results: Replicating our work took four years and 100,000 worms but brought surprising discoveries” (background to Lucanic et al 2017)
“Daryl Bem Proved ESP Is Real—which means science is broken” (Apparently Bem was serious. But one man’s modus ponens is another man’s modus tollens.)
“Reconstruction of a Train Wreck: How Priming Research Went off the Rails”
“‘Peer review’ is younger than you think. Does that mean it can go away?”; “Peer Review: The end of an error?”
“How readers understand causal and correlational expressions used in news headlines”, Adams et al 2017 (people do not understand the difference between correlation and causation)
“A Conceptual Introduction to Hamiltonian Monte Carlo”, Betancourt 2017 (HMC is critical to Bayesian neural networks & Stan)
How Often Does Correlation=Causation? “Bias and high-dimensional adjustment in observational studies of peer effects”, Eckles & Bakshy 2017 (Standard correlational estimate w/controls overestimates effect of Facebook experiment by 320%, requires 3700 additional control variables to approximate the randomized effect.); “Consumer Heterogeneity and Paid Search Effectiveness: A Large Scale Field Experiment”, Blake et al 201412ya (does online advertising actually work?)
Politics/religion:
“Self-Censorship in Public Discourse: A Theory of ‘Political Correctness’ and Related Phenomena”, Loury 1994
“Sparks and Prairie Fires: A Theory of Unanticipated Political Revolution”, Kuran 198937ya (Speaking of information cascades and common knowledge…); “How Stalin Hid Ukraine’s Famine From the World: In 193294ya and 193393ya, millions died across the Soviet Union—and the foreign press corps helped cover up the catastrophe” (A failed information cascade: all the Western journalists knew about Stalin’s genocidal famine and failed economics, but even a front page expose in multiple newspapers based on scores of interviews was not enough to break their censorship.)
“PPE: the Oxford degree that runs Britain”; “The unrecognised simplicities of effective action #2: ‘Systems engineering’ and ‘systems management’—ideas from the Apollo programme for a ‘systems politics’”, Cummings 2017 (what should politics look like in the post-atomic age of existential risk?)
“The Dark Enlightenment”, Nick Land
“Non-Communication at GE: The Impacted Philosophers”, pg111–124, ch7 of Business Adventures: Twelve Classic Tales from the World of Wall Street, Brooks 196957ya (the GE price-fixing scandal: emergent conspiracies from plausible denialability)
“The High Cost of Not Doing Experiments”, Nisbett 2015
66 failed social interventions; “Randomized Controlled Trial of the Metropolitan Police Department Body-Worn Camera Program”/“A Big Test of Police Body Cameras Defies Expectations” (A large pre-registered randomized trial of police bodycams shows tiny effects at best despite extremely promising initial results in other places & experiments. Rossi’s Iron Law of Evaluation: “The expected value of any net impact assessment of any large scale social program is zero”; the Stainless Steel Law: “The better designed the impact assessment of a social program, the more likely is the resulting estimate of net impact to be zero.”)
Psychology:
“Why g Matters: The Complexity of Everyday Life”, Gottfredson 1997
“Does High Self-esteem Cause Better Performance, Interpersonal Success, Happiness, or Healthier Lifestyles?”, Baumeister et al 200323ya; “The Man Who Destroyed America’s Ego: How a rebel psychologist challenged one of the 20th century’s biggest-and most dangerous-idea”; “‘It was quasi-religious’: the great self-esteem con”
“China launches brain-imaging factory: Hub aims to make industrial-scale high-resolution brain mapping a standard tool for neuroscience” (Such data streams could also impact GWASes for intelligence and other cognitive traits: the brains will of course be genotyped and available for GWAS, so the data will be ready and waiting for hierarchical and SEM methods which fractionate intelligence. It is worth noting that the UK Biobank—the gift that keeps on giving—intends to fMRI up to 100,000 of its participants, which would be a good complement to these connectomes, as its current dataset is underpowered eg. Wigmore et al 2017)
“The Effects of Education, Personality, and IQ on Earnings of High-Ability Men”, Gensowski et al 2011
On child psychopathy; “The 1% of the population accountable for 63% of all violent crime convictions”, Falk et al 201313ya; “Common psychiatric disorders [and violent crime] share the same genetic origin: a multivariate sibling study of the Swedish population”, Pettersson et al 2015
“Who Buried Paul?” (A fun retrospective on the “Paul McCartney is actually dead” Beatles conspiracy theory which, if you’re like me, you’ve never heard of before but was apparently quite a thing. Featuring conspiracy theorists literally connecting the dots and seeing stars.)
“Does Far Transfer Exist? Negative Evidence From Chess, Music, and Working Memory Training”, Sala & Gobet 2017
“Practice Does Not Make Perfect: No Causal Effect of Music Practice on Music Ability”, Mosing et al 2014
“Multiplying 10-digit numbers using Flickr: The power of recognition memory”, Drucker 2010
Biology:
“The Fireplace Delusion”; “Wood-smoke health effects: a review”, Naeher et al 200719ya (the Global Burden of Disease estimate for poor countries is that 7.7% of all DALYs lost is due to chronic & ‘lower respiratory infections’, more than either HIV or malaria. Happy holidays.)
“The US President’s Malaria Initiative and under-5 child mortality in sub-Saharan Africa: A difference-in-differences analysis”, Jakubowski et al 2017
“Lithium in Drinking Water and Incidence of Suicide: A Nationwide Individual-Level Cohort Study with 22 Years of Follow-Up”, Knudsen et al 2017; “Lithium in drinking water and the incidence of bipolar disorder: A nation-wide population-based study”, Kessing et al 2017 (Two major blows to the lithium/drinking-water hypothesis)
“Mapping the Human Exposome: It’s now possible to map a person’s lifetime exposure to nutrition, bacteria, viruses, and environmental toxins-which profoundly influence human health”; “Numerous uncharacterized and highly divergent microbes which colonize humans are revealed by circulating cell-free DNA”, Kowarsky et al 2017 (media; towards finding the nonshared-environment component: taking the Gloomy Hypothesis seriously, we are going to need GWAS-scale approaches to measuring pollutants & infections & stressors to find the actual causal agents, instead of the get-rich-quick schemes which dominate epidemiology.)
“Sex Differences In The Adult Human Brain: Evidence From 5,216 UK Biobank Participants”, Ritchie et al 2017
“Why does drug resistance readily evolve but vaccine resistance does not?”, Kennedy & Read 2017
Technology:
“How a Dorm Room Minecraft Scam Brought Down the Internet” (So Mirai was developed to… extort Minecraft servers? 2017 is truly beyond parody. Also, we’re doomed.)
Survey of P=NP results and progress, Aaronson 2016
“Don’t Worry—It Can’t Happen”, Harrington, Scientific American 1940
“TrueBit: A scalable verification solution for blockchains”, Teutsch & Reitwiessner 2017 (Very complex but interesting scheme for safely outsourcing arbitrarily big computations on blockchains)
filfre.net: see June link selection“Cryptology and Physical Security: Rights Amplification in Master-Keyed Mechanical Locks”, Blaze 200323ya (cryptographic attacks offline; see also Blaze 200422yaa “Safecracking for the computer scientist”, Blaze 200422yab)
“When Will The Earth Try to Kill Us Again?” (reviewing the latest work on volcanic cycles and mass-extinction mechanisms)
“Computational Complexity of Air Travel Planning”, De Marcken 200323ya / ITA Software (Airline ticket search is not just NP-hard or worse, but undecidable.)
“Books 1923–18194185ya Now Liberated!”, Internet Archive; “Creating a Last Twenty (L20) Collection: Implementing §108(H) in Libraries, Archives and Museums”, Gard 2017. (A takes an unexpectedly bold step towards ending the orphan copyright deadweight problem by exploiting a copyright provision/loophole I’ve never even heard of before: §108(h) of the 197650ya Copyright Right Act, allowing libraries to legally scan & distribute works in their final 20 years of copyright which are not in “normal commercial exploitation” ie hard to get, to an unspecified degree.)
Economics:
the moral imperative of economic growth:
“How big a deal was the Industrial Revolution?” (the Industrial Revolution—the only important event in the history of human welfare.)
“Stubborn Attachments: A Vision for a Society of Free, Prosperous, and Responsible Individuals” (Tyler Cowen)
“Cornucopia: The Pace of Economic Growth in the Twentieth Century”, DeLong 2000
“99 Reasons 2017 Was A Great Year: If you’re feeling despair about the fate of humanity in the 21st century, you might want to reconsider.” (2017: between the steady improvements across the board on almost all metrics of health and wealth and tech and violence, and population growth, 2017 saw perhaps the greatest increase in utility in the history of the human species—just like 2016 before it, and 201511ya, and 201412ya…)
“Property Is Another Name for Monopoly: Facilitating Efficient Bargaining with Partial Common Ownership of Spectrum, Corporations, and Land”, Posner & Weyl 2016
“Algorithmic Entities”, LoPucki 2017 (Bayern 2016; decentralized autonomous corporations are doable de jure and not just de facto.)
“Amazon’s Antitrust Paradox”, Khan 2017
“Economies of density in e-commerce: a study of Amazon’s fulfillment center network”, Houde et al 2017 (Amazon’s sales tax vs shipping cost tradeoff)
“Are Ideas Getting Harder to Find?”, Bloom et al 2020
“Islam and Economic Performance: Historical and Contemporary Links”, Kuran 2018 (More on perpetuities and the harms of long-term charities)
“Industrial Espionage and Productivity”, Glitz & Meyersson 2017 (Why do countries like East Germany or China engage in so much industrial espionage? Because it works & helps compensate for their own inefficiency.)
“The High-Cost, High-Risk World of Modern Pet Care: A wave of corporatization is hitting the veterinary industry, but does a one-size-fits-all approach work?” (more importantly: why is this model successful in the most free market possible for healthcare?)
“The Common Law Corporation: The Power of the Trust in Anglo-American Business History” (was the limited-liability corporation necessary?)
Philosophy:
“On the Impossibility of Supersized Machines”, Garfinkel et al 2017; “G.K. Chesterton on AI Risk”; “A Thinking Ape’s Critique of Trans-Simianism”
“How To Be Good: An Oxford philosopher thinks he can distill all morality into a formula. Is he right?” (in memory of Derek Parfit)
“Underprotection of Unpredictable Statistical Lives Compared to Predictable Ones”, Lipsitch et al 2016
“What Do Philosophers Believe?”, Bourget & Chalmers 2013
Mike Darwin on animal research, moral cowardice, and reasoning in an uncaring universe
“Wireheading Done Right: Stay Positive Without Going Insane” (Qualia Computing)
“Simon Browne: the soul-murdered theologian”, Berman 199630ya (“The Zombie Preacher of Somerset”)
Misc:
“The Great Moon Hoax” (early science and Natural Theology predicted life was abundant throughout the solar system and universe; instead, we see a Great Silence)
Astronauts after walking on the moon; “This Warrior of a Dead World—Gene Wolfe’s literary portrait of Neil Armstrong”
Fiction:
“Alpha (A translation of Genesis 1)” (
word2vecfor computer-assisted creation of rhyming definitions & Book of Genesis with only words starting with “a”)“The Poet and the Politician: Fujiwara no Teika and the Compilation of the Shinchokusenshu”, Smits 1998
“If You Read Closely: Aoi Hiragi’s Whisper of the Heart on Page and Screen”
Books
Nonfiction:
Site Reliability Engineering: How Google Runs Production Systems (January review)
Artificial Life, Levy
The Grand Strategy of the Roman Empire: From the First Century CE to the Third, Luttwak 2016
Moon Dust: In Search of the Men Who Fell to Earth, Smith 2005
Fiction:
Unsong, Scott Alexander
Unforgotten Dreams: Poems by the Zen monk Shōtetsu, Steven D. Carter
Sunset in a Spiderweb: Sijo Poetry of Ancient Korea, Baron & Kim 1974
TV/movies
Nonfiction movies:
Amy (201511ya; June review)
Fiction:
Anime: