‘AI emergence’ directory
- See Also
- Links
- “Scaling Laws Are Unreliable for Downstream Tasks: A Reality Check”, Lourie et al 2025
- “Data Mixing Can Induce Phase Transitions in Knowledge Acquisition”, Gu et al 2025
- “On the Creation of Narrow AI: Hierarchy and Nonlocality of Neural Network Skills”, Michaud et al 2025
- “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning”, Guo et al 2025
- “ICLR: In-Context Learning of Representations”, Park et al 2024
- “Observational Scaling Laws and the Predictability of Language Model Performance”, Ruan et al 2024
- “Foundational Challenges in Assuring Alignment and Safety of Large Language Models”, Anwar et al 2024
- “A Phase Transition between Positional and Semantic Learning in a Solvable Model of Dot-Product Attention”, Cui et al 2024
- “Compositional Capabilities of Autoregressive Transformers: A Study on Synthetic, Interpretable Tasks”, Ramesh et al 2023
- “Training Dynamics of Contextual N-Grams in Language Models”, Quirke et al 2023
- “Compositional Abilities Emerge Multiplicatively: Exploring Diffusion Models on a Synthetic Task”, Okawa et al 2023
- “A Theory for Emergence of Complex Skills in Language Models”, Arora & Goyal 2023
- “Teaching Arithmetic to Small Transformers”, Lee et al 2023
- “Schema-Learning and Rebinding As Mechanisms of In-Context Learning and Emergence”, Swaminathan et al 2023
- “8 Things to Know about Large Language Models”, Bowman 2023
- “The Quantization Model of Neural Scaling”, Michaud et al 2023
- “Toolformer: Language Models Can Teach Themselves to Use Tools”, Schick et al 2023
- “Interactive-Chain-Prompting (INTERCPT): Ambiguity Resolution for Crosslingual Conditional Generation With Interaction”, Pilault et al 2023
- “Broken Neural Scaling Laws”, Caballero et al 2022
- “U-PaLM: Transcending Scaling Laws With 0.1% Extra Compute”, Tay et al 2022
- “Challenging BIG-Bench Tasks (BBH) and Whether Chain-Of-Thought Can Solve Them”, Suzgun et al 2022
- “Language Models Are Multilingual Chain-Of-Thought Reasoners”, Shi et al 2022
- “Hidden Progress in Deep Learning: SGD Learns Parities Near the Computational Limit”, Barak et al 2022
- “Emergent Abilities of Large Language Models”, Wei et al 2022
- “Beyond the Imitation Game: Quantifying and Extrapolating the Capabilities of Language Models”, Srivastava et al 2022
- “Data Distributional Properties Drive Emergent Few-Shot Learning in Transformers”, Chan et al 2022
- “PaLM: Scaling Language Modeling With Pathways”, Chowdhery et al 2022
- “In-Context Learning and Induction Heads”, Olsson et al 2022
- “Predictability and Surprise in Large Generative Models”, Ganguli et al 2022
- “The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models”, Pan et al 2022
- “A Mathematical Framework for Transformer Circuits”, Elhage et al 2021
- “Scaling Language Models: Methods, Analysis & Insights from Training Gopher”, Rae et al 2021
- “A General Language Assistant As a Laboratory for Alignment”, Askell et al 2021
- “Mapping Language Models to Grounded Conceptual Spaces”, Patel & Pavlick 2021
- “Program Synthesis With Large Language Models”, Austin et al 2021
- “MMLU: Measuring Massive Multitask Language Understanding”, Hendrycks et al 2020
- “GPT-3: Language Models Are Few-Shot Learners”, Brown et al 2020
- “Emergence in Cognitive Science”, McClelland 2010
- “Observed Universality of Phase Transitions in High-Dimensional Geometry, With Implications for Modern Data Analysis and Signal Processing”, Donoho & Tanner 2009
- “The Phase Transition In Human Cognition § Phase Transitions in Language Processing”, Spivey et al 2009 (page 13)
- “A Dynamic Systems Model of Cognitive and Language Growth”, Geert 1991
- Sort By Magic
- Wikipedia (2)
- Miscellaneous
- Bibliography
See Also
Links
“Scaling Laws Are Unreliable for Downstream Tasks: A Reality Check”, Lourie et al 2025
Scaling Laws Are Unreliable for Downstream Tasks: A Reality Check
“Data Mixing Can Induce Phase Transitions in Knowledge Acquisition”, Gu et al 2025
Data Mixing Can Induce Phase Transitions in Knowledge Acquisition
“On the Creation of Narrow AI: Hierarchy and Nonlocality of Neural Network Skills”, Michaud et al 2025
On the creation of narrow AI: hierarchy and nonlocality of neural network skills
“DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning”, Guo et al 2025
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
“ICLR: In-Context Learning of Representations”, Park et al 2024
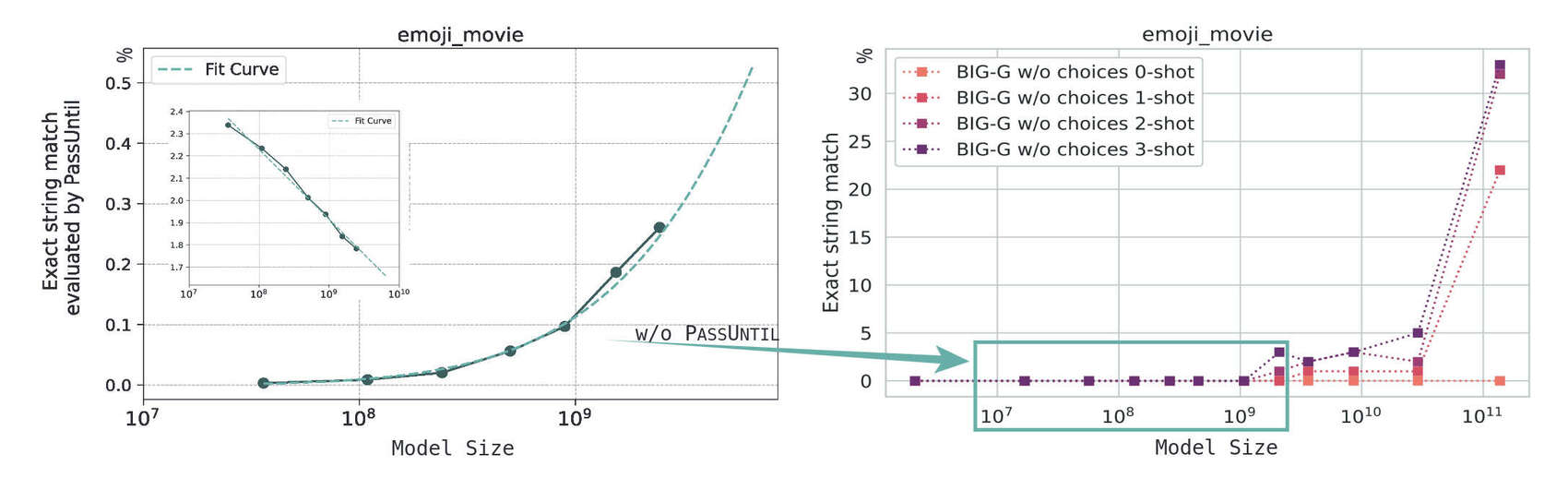
“Observational Scaling Laws and the Predictability of Language Model Performance”, Ruan et al 2024
Observational Scaling Laws and the Predictability of Language Model Performance
“Foundational Challenges in Assuring Alignment and Safety of Large Language Models”, Anwar et al 2024
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
“A Phase Transition between Positional and Semantic Learning in a Solvable Model of Dot-Product Attention”, Cui et al 2024
“Compositional Capabilities of Autoregressive Transformers: A Study on Synthetic, Interpretable Tasks”, Ramesh et al 2023
Compositional Capabilities of Autoregressive Transformers: A Study on Synthetic, Interpretable Tasks
“Training Dynamics of Contextual N-Grams in Language Models”, Quirke et al 2023
“Compositional Abilities Emerge Multiplicatively: Exploring Diffusion Models on a Synthetic Task”, Okawa et al 2023
Compositional Abilities Emerge Multiplicatively: Exploring Diffusion Models on a Synthetic Task
“A Theory for Emergence of Complex Skills in Language Models”, Arora & Goyal 2023
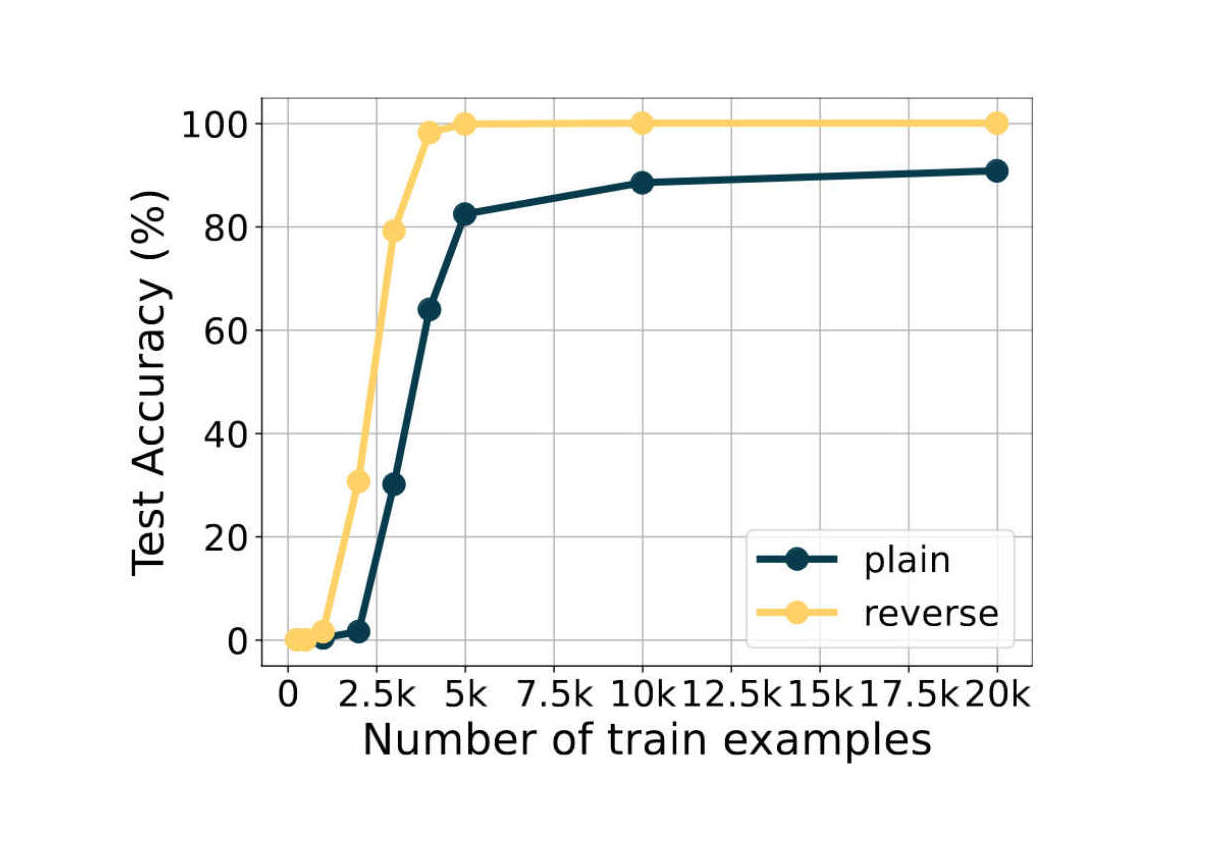
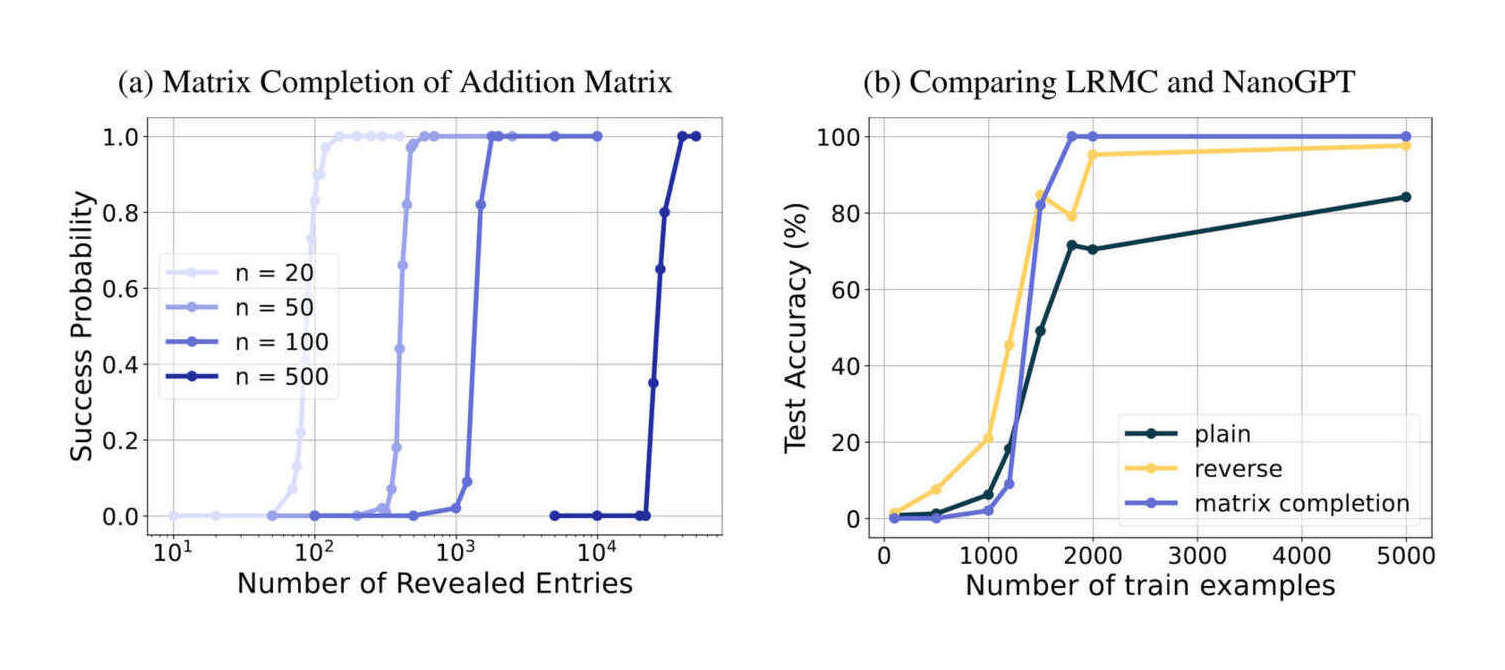
“Teaching Arithmetic to Small Transformers”, Lee et al 2023
“Schema-Learning and Rebinding As Mechanisms of In-Context Learning and Emergence”, Swaminathan et al 2023
Schema-learning and rebinding as mechanisms of in-context learning and emergence
“8 Things to Know about Large Language Models”, Bowman 2023
“The Quantization Model of Neural Scaling”, Michaud et al 2023
“Toolformer: Language Models Can Teach Themselves to Use Tools”, Schick et al 2023
Toolformer: Language Models Can Teach Themselves to Use Tools
“Interactive-Chain-Prompting (INTERCPT): Ambiguity Resolution for Crosslingual Conditional Generation With Interaction”, Pilault et al 2023
“Broken Neural Scaling Laws”, Caballero et al 2022
“U-PaLM: Transcending Scaling Laws With 0.1% Extra Compute”, Tay et al 2022
“Challenging BIG-Bench Tasks (BBH) and Whether Chain-Of-Thought Can Solve Them”, Suzgun et al 2022
Challenging BIG-Bench Tasks (BBH) and Whether Chain-of-Thought Can Solve Them
“Language Models Are Multilingual Chain-Of-Thought Reasoners”, Shi et al 2022
“Hidden Progress in Deep Learning: SGD Learns Parities Near the Computational Limit”, Barak et al 2022
Hidden Progress in Deep Learning: SGD Learns Parities Near the Computational Limit
“Emergent Abilities of Large Language Models”, Wei et al 2022
“Beyond the Imitation Game: Quantifying and Extrapolating the Capabilities of Language Models”, Srivastava et al 2022
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
“Data Distributional Properties Drive Emergent Few-Shot Learning in Transformers”, Chan et al 2022
Data Distributional Properties Drive Emergent Few-Shot Learning in Transformers
“PaLM: Scaling Language Modeling With Pathways”, Chowdhery et al 2022
“In-Context Learning and Induction Heads”, Olsson et al 2022
“Predictability and Surprise in Large Generative Models”, Ganguli et al 2022
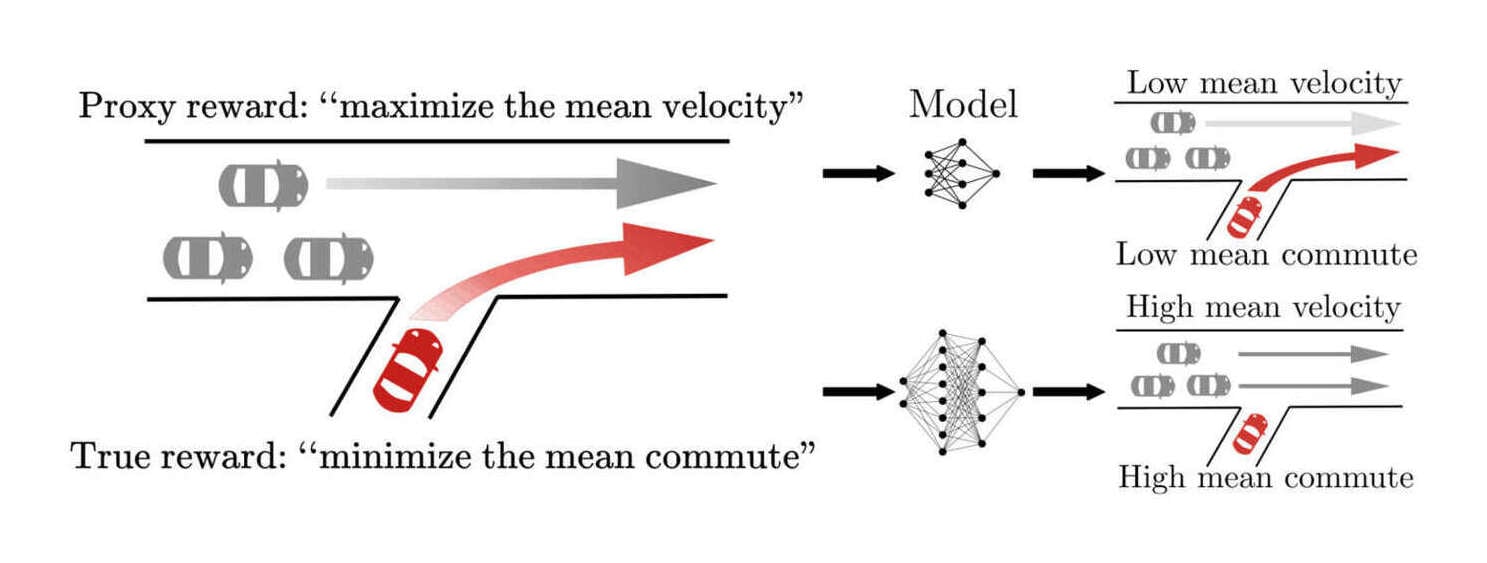
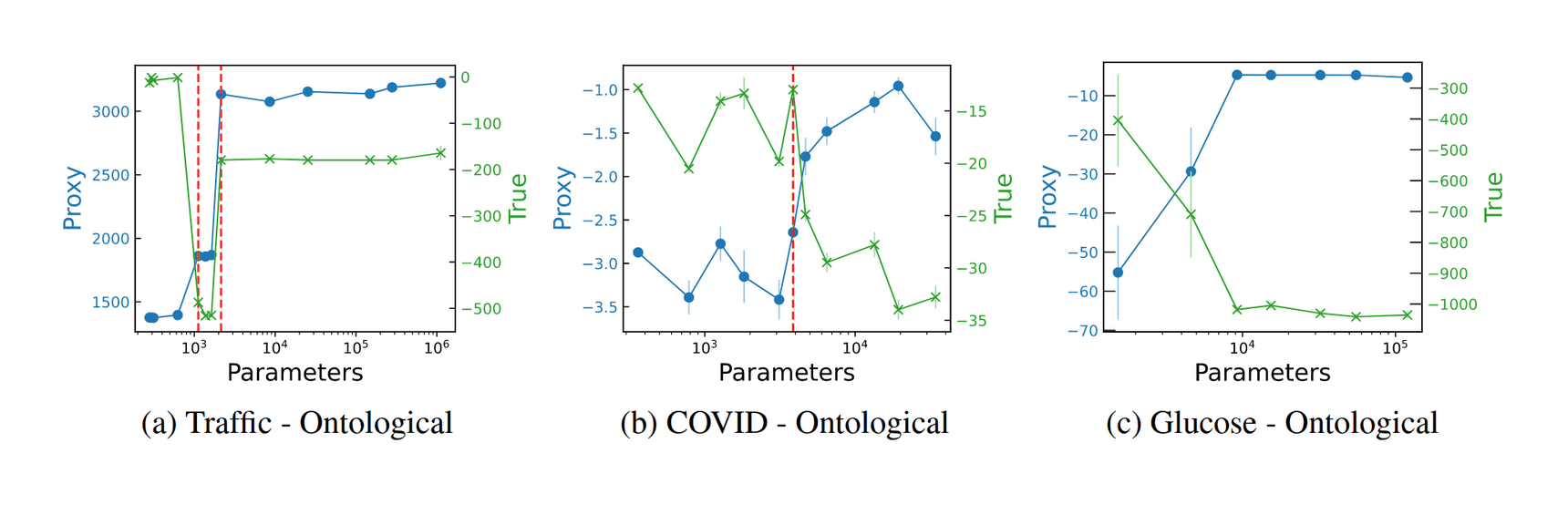
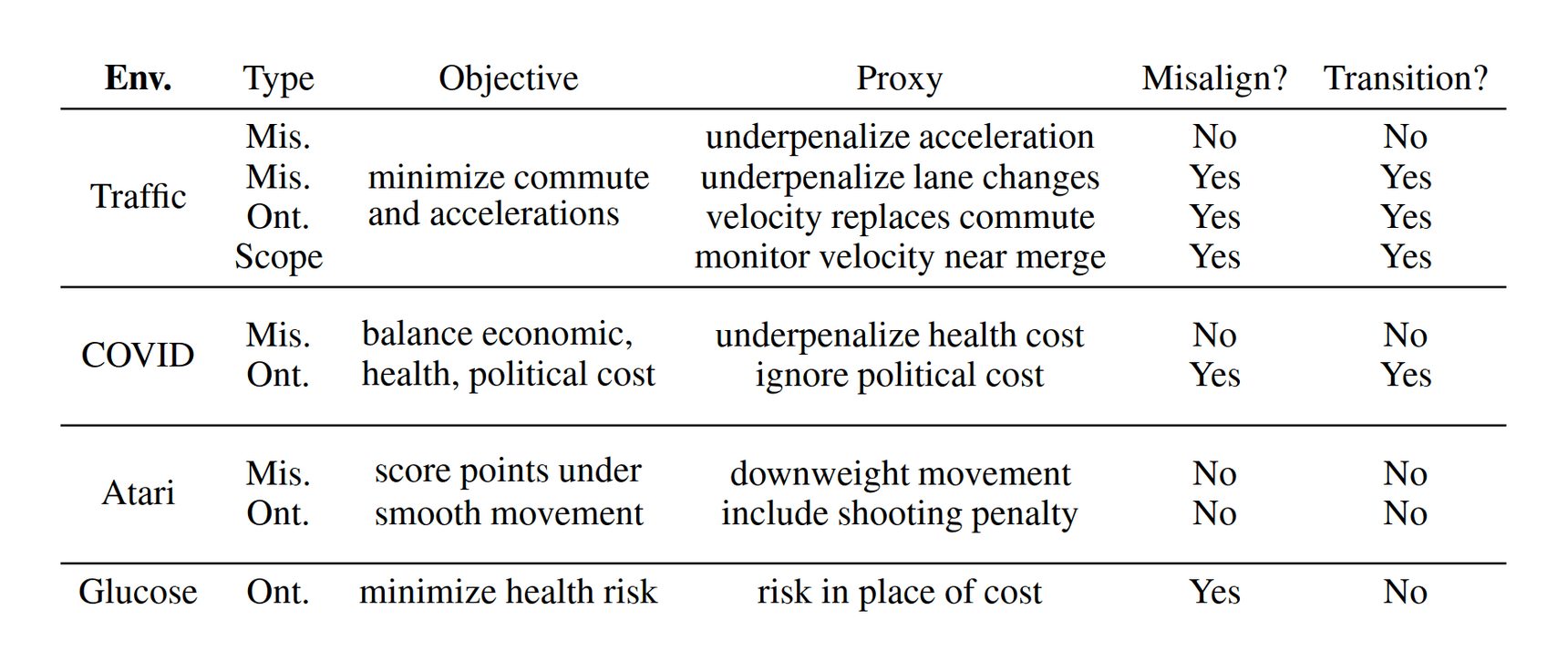
“The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models”, Pan et al 2022
The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models
“A Mathematical Framework for Transformer Circuits”, Elhage et al 2021
“Scaling Language Models: Methods, Analysis & Insights from Training Gopher”, Rae et al 2021
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
“A General Language Assistant As a Laboratory for Alignment”, Askell et al 2021
“Mapping Language Models to Grounded Conceptual Spaces”, Patel & Pavlick 2021
“Program Synthesis With Large Language Models”, Austin et al 2021
“MMLU: Measuring Massive Multitask Language Understanding”, Hendrycks et al 2020
“GPT-3: Language Models Are Few-Shot Learners”, Brown et al 2020
“Emergence in Cognitive Science”, McClelland 2010
“Observed Universality of Phase Transitions in High-Dimensional Geometry, With Implications for Modern Data Analysis and Signal Processing”, Donoho & Tanner 2009
“The Phase Transition In Human Cognition § Phase Transitions in Language Processing”, Spivey et al 2009 (page 13)
The Phase Transition In Human Cognition § Phase Transitions in Language Processing
“A Dynamic Systems Model of Cognitive and Language Growth”, Geert 1991
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
transformer-circuits
reward-alignment
in-context-learning
llm-safety
emergent-abilities
Wikipedia (2)
Miscellaneous
/doc/ai/scaling/emergence/2022-pan-figure2-largernnmodelsarebetteratrewardhacking.pnghttps://cse-robotics.engr.tamu.edu/dshell/cs689/papers/anderson72more_is_different.pdfhttps://www.quantamagazine.org/the-unpredictable-abilities-emerging-from-large-ai-models-20230316/https://www.reddit.com/r/mlscaling/comments/sjzvl0/d_instances_of_nonlog_capability_spikes_or/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2405.10938: “Observational Scaling Laws and the Predictability of Language Model Performance”,https://arxiv.org/abs/2307.03381: “Teaching Arithmetic to Small Transformers”,https://arxiv.org/abs/2307.01201#deepmind: “Schema-Learning and Rebinding As Mechanisms of In-Context Learning and Emergence”,https://arxiv.org/abs/2303.13506: “The Quantization Model of Neural Scaling”,https://arxiv.org/abs/2210.11399#google: “U-PaLM: Transcending Scaling Laws With 0.1% Extra Compute”,https://arxiv.org/abs/2210.09261#google: “Challenging BIG-Bench Tasks (BBH) and Whether Chain-Of-Thought Can Solve Them”,https://arxiv.org/abs/2210.03057#google: “Language Models Are Multilingual Chain-Of-Thought Reasoners”,https://arxiv.org/abs/2206.04615: “Beyond the Imitation Game: Quantifying and Extrapolating the Capabilities of Language Models”,https://arxiv.org/abs/2204.02311#google: “PaLM: Scaling Language Modeling With Pathways”,https://arxiv.org/abs/2202.07785#anthropic: “Predictability and Surprise in Large Generative Models”,https://arxiv.org/abs/2201.03544: “The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models”,https://arxiv.org/abs/2112.11446#deepmind: “Scaling Language Models: Methods, Analysis & Insights from Training Gopher”,https://arxiv.org/abs/2112.00861#anthropic: “A General Language Assistant As a Laboratory for Alignment”,https://openreview.net/forum?id=gJcEM8sxHK: “Mapping Language Models to Grounded Conceptual Spaces”,https://arxiv.org/abs/2009.03300: “MMLU: Measuring Massive Multitask Language Understanding”,https://onlinelibrary.wiley.com/doi/full/10.1111/j.1756-8765.2010.01116.x: “Emergence in Cognitive Science”,1991-vangeert.pdf: “A Dynamic Systems Model of Cognitive and Language Growth”,