Description of 3 anime datasets for machine learning based on Danbooru: cropped anime faces, whole-single-character crops, and hand crops (with hand detection model).
Documentation of 3 anime datasets for machine learning based on Danbooru: 300k cropped anime faces (primarily used for StyleGAN/This Waifu Does Not Exist), 855k whole-single-character figure crops (extracted from Danbooru using AniSeg), and 58k hand crops (based on a dataset of 14k hand-annotated bounding boxes used to train a YOLOv3 hand detection model).
These datasets can be used for machine learning directly, or included as data augmentation: faces, figures, and hands are some of the most noticeable features of anime images, and by cropping images down to just those 3 features, they can enhance modeling of those by eliminating distracting context, zooming in, and increasing the weight during training.
Danbooru2019 Portraits
Danbooru2019 Portraits is a dataset of n = 302,652 (16GB) 512px anime faces.
The faces were cropped from solo SFW Danbooru2019 images in a relatively broad ‘portrait’ style encompassing necklines/ears/hats/etc rather than tightly focused on the face, upscaled to 512px as necessary, and low-quality images deleted by manual review using ‘Discriminator ranking’.
It has been used for creating TWDNE.
The Portraits dataset was constructed to train StyleGAN anime face models for creating ThisWaifuDoesNotExist.net.
Faces → Portraits Motivation
The main issues I saw for the faces based on TWDNE feedback were:
-
Sexually-Suggestive Faces: because I had not expected StyleGAN to work or to wind up making something like TWDNE, I had not taken the effort to crop faces solely from the SFW subset (since no GAN had proven to be good enough to pick up any embarrassing details and I was more concerned with maximizing the dataset size).
Danbooru is divided into 3 ratings, “safe”/“questionable”/“explicit”, with “questionable” bordering on softcore. The explicitly-NSFW images make up only ~9% of Danbooru but between the SFW-but-suggestive images and the explicit ones, and StyleGAN’s learning capabilities, this proved to be enough to make some of the faces quite naughty-looking. Naturally, everyone insisted on joking about this. This could be fixed simply by filtering in “safe”-only rather than merely filtering-out “explicit”.
-
Head Crops: Nagadomi’s face-cropper is a face cropper, not a head-cropper or a portrait-cropper.
The face-cropper centers its crops on the center of a face (like the nose) and, given the original bounding box, will necessarily cut off all the additional details associated with anime heads such as the ‘ahoge’ or bunny ears or twin-tails, since those are not faces. Similarly, I had left Nagadomi’s face-cropper on the default settings instead of bothering to tweak it to produce more head-shot-like crops—since if GANs couldn’t master the faces there was no point in making the problem even harder & worrying about details of the hair.
This was not good for characters with distinctive hats or hair or animal ears (such as Holo’s wolf ears). This could be fixed by playing with scaling the bounding box around the face by different x/y multipliers to see what picks up the rest of the head. (Another approach would be to use AniSeg to detect face & whole-character-figure simultaneously, and crop the figure from its top to the bottom of the face.)
-
Messy Background/Bodies: I suspected that the tightness of the crops also made it hard for StyleGAN to learn things in the edges, like backgrounds or shoulders, because they would always be partial if the face-cropper was doing its job.
With bigger crops, there would be more variation and more opportunity to see whole shoulders or large unobstructed backgrounds, and this might lead to more convincing overall images.
-
Holo/Asuka Overrepresentation: to my surprise, TWDNE viewers seemed quite annoyed by the overrepresentation of Holo/Asuka-like (but mostly Holo) samples.
For the same reason as not filtering to SFW, I had thrown in 2 earlier datasets I had made of Holo & Asuka faces—I had made the at 512px, and cleaned them fairly thoroughly, and they would increase the dataset size, so why not? Being overrepresented, and well-represented in Danbooru (a major part of why I had chosen them in the first place to make prototype datasets with), of course StyleGAN was more likely to generate samples looking like them than other popular anime characters.1 Why this annoyed people, I don’t understand, but it might as well be fixed.
-
Persistent Global Artifacts: despite the generally excellent results, there are still occasional bizarre anomalous images which are scarce faces at all, even with 𝜓 = 0.7; I suspect that this may be due to the small percentage of non-faces, cut-off faces, or just poorly/weirdly drawn faces and that more stringent data cleaning would help polish the model.
Portraits Improvements
Issues #1–3 can be fixed by transfer-learning StyleGAN on a new dataset made of faces from the SFW subset and cropped with much larger margins to produce more ‘portrait’-style face crops. (There would still be many errors or suboptimal crops but I am not sure there is any full solution short of training a face-localization CNN just for anime images.)
For this, I needed to edit lbpcascade_animeface’s crop.py and adjust the margins. Experimenting, I changed the cropping line to:
for (x, y, w, h) in faces:
cropped = image[int(y*0.25): y + h, int(x*0.90): x + int(w*1.25)]These margins seemed to deliver acceptable results which generally show the entire head while leaving enough room for extra background or hats/ears (although there is still the occasional error like a 4-koma comic or image with multiple faces or heads still partially cropped):
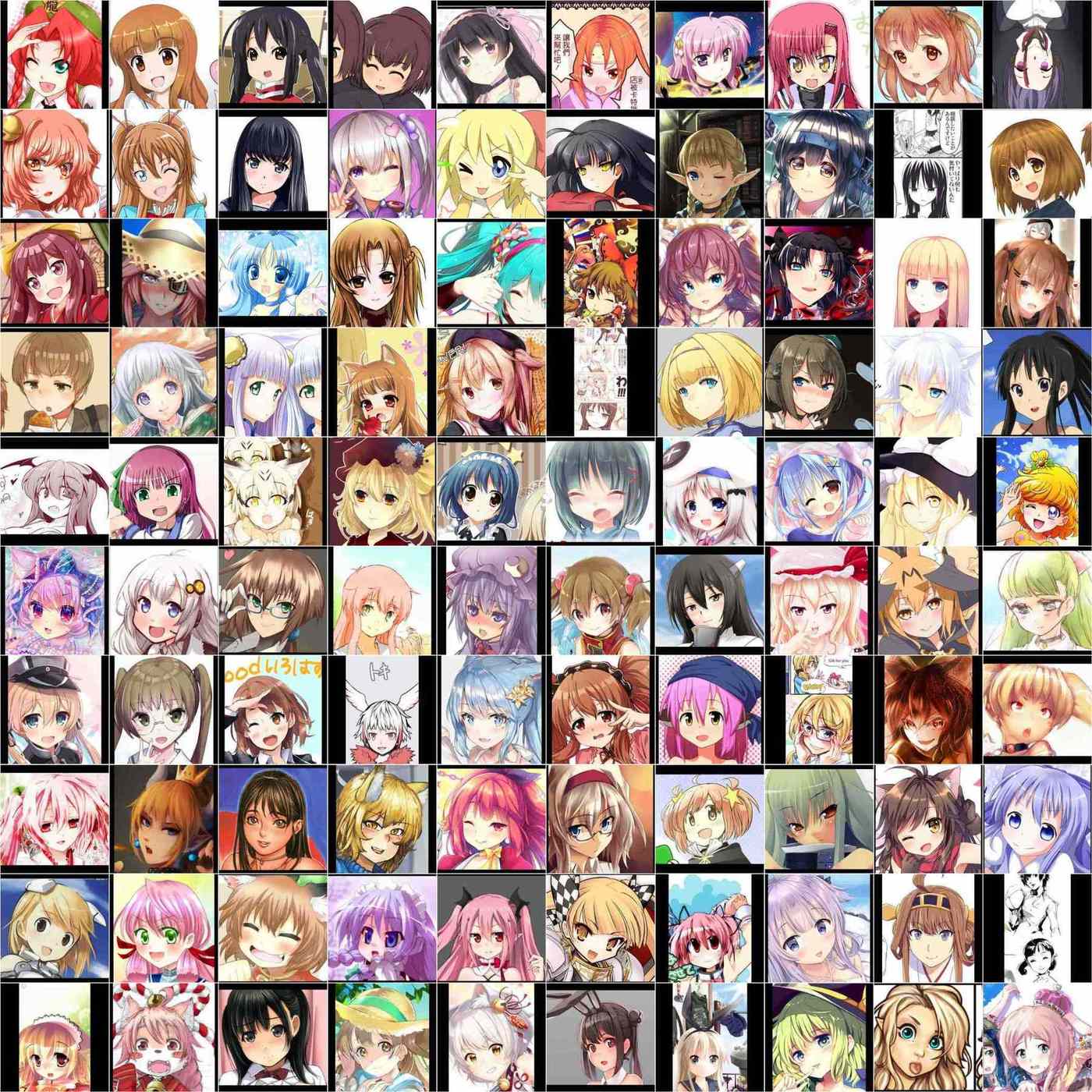
100 real faces from the ‘portrait’ dataset (SFW Danbooru2018 cropped with expanded margins) in a 10
After cropping all ~2.8m SFW Danbooru2018 full-resolution images (as demonstrated in the cropping section), I was left with ~700k faces. This was a large dataset, but the disadvantage was that many heads/faces overlapped, so after a few weeks of training, I had decent portraits marred by strange hydra-like heads jutting in from the side. So I redid the cropping process using the solo tag to eliminate images which might have multiple faces in them.
Issue #4 is solved by just not adding the Asuka/Holo datasets.
Finally, issue #5 is harder to deal with: pruning 200k+ images by hand is infeasible, there’s no easy way to improve the face cropping script, and I don’t have the budget to Mechanical-Turk review all the faces like et al 2018 did for FFHQ to remove their false positives (like statues).
One way I do have to improve it is to exploit the Discriminator of a pretrained face GAN. The anime face StyleGAN D would be ideal since it clearly works so well already, so I wrote a ranker.py script (see previous section) to use a StyleGAN checkpoint and rank specified images on disk, and then rebuilt the .tfrecords with troublesome images removed. (This process can be reiterated as the StyleGAN model improves and the D improves its ability to spot anomalies.) I engaged in 5 cycles of ranker.py cleaning over April 2019, deleting 14k images; it seemed to reduce some of the artifacting related to hands.
Portraits Dataset
The final 512px portrait dataset (with portrait crops, improved filtering via solo, & discriminator ranking for cleaning) is available for download via rsync (16GB, n = 302,652):
rsync --verbose --recursive rsync://176.9.41.242:873/biggan/portraits/ ./portraits/Identies/labels are not provided by default, but the filename is $ID.jpg; the identity of a face can be retrieved from the Danbooru metadata (a JSON export is included in Danbooru20xx) by looking up the character-category tags for the given ID number, and because they were cropped from solo-tagged images, there should be only one character tag.
IDs Malformed?
Despite my intent, the ID in many Portraits filenames does not seem to actually match the respective Danbooru metadata. I have not figured out why.
Portraits Citing
Please cite this dataset as:
-
Gwern Branwen, Anonymous, & The Danbooru Community; “Danbooru2019 Portraits: A Large-Scale Anime Head Illustration Dataset”, 2019-03-12. Web. Accessed [DATE]
https://gwern.net/crop#danbooru2019-portraits@misc{danbooru2019Portraits, author = {Gwern Branwen and Anonymous and Danbooru Community}, title = {Danbooru2019 Portraits: A Large-Scale Anime Head Illustration Dataset}, howpublished = {\url{https://gwern.net/crop#danbooru2019-portraits}}, url = {https://gwern.net/crop#danbooru2019-portraits}, type = {dataset}, year = {2019}, month = {March}, timestamp = {2019-03-12}, note = {Accessed: DATE} }
Danbooru2019 Figures
The Danbooru2019 Figures dataset is a large-scale character anime illustration dataset of n = 855,880 images (248GB; minimum width 512px).
They were cropped from Danbooru2019 using the AniSeg anime character detection model. The images are cropped to focus on a single character’s entire visible body, extending ‘portrait’ crops to ‘figure’ crops.
This is useful for tasks focusing on individual characters, such as character classification or for generative tasks (a corpus for weak models like StyleGAN, or data augmentation for BigGAN).

40 random figure crops from Danbooru2019 (4
Focus on just the hard parts. I created this dataset to assist our BigGAN training by data augmentation of difficult object classes: by providing a large set of images cropped to just the character (as opposed to the usual random crops), BigGAN should better learn body structure and reuse that knowledge elsewhere. This is a ML trick which we have used for faces/portraits in BigGAN and l4rz in StyleGAN, and will use for hands as well. This could also be useful for StyleGAN, by greatly restricting the variation in images to single centered objects (StyleGAN falls apart when it needs to model multiple objects in a variation of positions). Other applications might be using it as a starting dataset for using object localizers to crop out things like faces where images with multiple instances would be ambiguous or too occluded (multiple faces overlapping) or too low-quality (eg. backgrounds), so the whole Danbooru2019 dataset wouldn’t be as useful.
Figures Download
To download the cropped images:
rsync --verbose --recursive rsync://176.9.41.242:873/biggan/danbooru2019-figures ./danbooru2019-figures/Identies/labels are not provided by default, but the filename is $ID_crop.jpg; the identity of a face can be retrieved from the Danbooru metadata (a JSON export is included in Danbooru20xx) by looking up the character-category tags for the given ID number, and because they were cropped from solo-tagged images, there should be only one character tag.
Figures Construction
Details of getting AniSeg running & cropping. Danbooru2019 Figures was constructed by filtering images from Danbooru2019 by solo & SFW status (~1,538,723 images of ~65,783 characters illustrated by ~133,856 artists), and then cropping using Jerry Li’s AniSeg model (a TensorFlow Object Detection API-based faster-rcnn Python model for anime character face detection & portrait segmentation), which Li constructed by annotating images from Danbooru20182.
Before running AniSeg, I had to make 3 changes. AniSeg had two bugs (SciPy dependency & model loading code) and the provided script for detecting faces/figures does not include any functionality for cropping images. The bugs have been fixed & the detection code now supports cropping with the options --output_cropped_image/--only_output_cropped_single_object. At the time, I modified the script to do cropping without those options, and I ran the figure cropper (slowly) over Danbooru2019 like thus:
python3 infer_from_image.py --inference_graph=./2019-04-29-jerryli27-aniseg-models-figurefacecrop/figuresegmentation.pb \
--input_images='/media/gwern/Data2/danbooru2019/original-sfw-solo/*/*' \
--output_path=/media/gwern/Data/danbooru2019-datasets/danbooru2019-figuresFilter & upscale. After cropping out figures, I followed the image processing described in my StyleGAN faces writeup: I converted the images to JPG, deleted images <50kb, deleted images <256px in width, used waifu2x to 2× upscale images <512px in width to >512px in width, and deleted monochrome images (images with <255 unique colors). Note that unlike the portraits dataset, these images are not resized with 512×512px squares with black backgrounds as necessary. This allows random crops if the user wants, and they can be downscaled as necessary (eg. mogrify -resize 512x512\> -extent 512x512\> -gravity center -background black). This gave a final dataset of n = 855,880 JPGS (248GB).
Figures Citing
Please cite this dataset as:
-
Gwern Branwen, Anonymous, & The Danbooru Community; “Danbooru2019 Figures: A Large-Scale Anime Character Illustration Dataset”, 2020-01-13. Web. Accessed [DATE]
https://gwern.net/crop#figures@misc{danbooru2019Figures, author = {Gwern Branwen and Anonymous and Danbooru Community}, title = {Danbooru2019: A Large-Scale Anime Character Illustration Dataset}, howpublished = {\url{https://gwern.net/crop#figures}}, url = {https://gwern.net/crop#figures}, type = {dataset}, year = {2020}, month = {May}, timestamp = {2020-05-31}, note = {Accessed: DATE} }
Hands
We create & release PALM: the PALM Anime Locator Model. PALM is a pretrained anime hand detector/localization neural network, and 3 sets of accompanying anime hand datasets:
A dataset of 5,382 anime-style Danbooru2019 images annotated with the locations of 14,394 hands.
This labeled dataset is used to train a YOLOv3 model to detect hands in anime.
A second dataset of 96,534 hands cropped from the Danbooru2019 SFW dataset using the PALM YOLO model.
A cleaned version of #2, consisting of 58,536 hand crops upscaled to ≥512px.
Hand detection can be used to clean images (eg. remove face images with any hands in the way), or to generate datasets of just hands (as a form of data augmentation for GANs), to generate reference datasets for artists, or for other purposes. (For human hands, see the “11K Hands” dataset.)
Likely Obsolete
The PALM cropped dataset is probably obsoleted by aspect-ratio training, and one would get better results using the PALM detection model to prioritize training on crops generated during training.
Human artists beginning the drawing-hands art class.
After faces & whole bodies, the next most glaring source of artifacts in GAN anime samples like TWDNE is drawing hands. Common GAN failure: hands. Hands are notorious among human artists for being difficult and easily breaking suspension of disbelief, and it’s worth noting that aside from the face, the hands are the biggest part of a cortical homunculus, suggesting the attention we pay to them while failing to realize it; no wonder that so many illustrations carefully crop the subject to avoid hands, or tuck hands into dresses or sleeves, among the impressive variety of tricks artists use to avoid depicting hands. (Even with these tricks, it is not uncommon to find high quality art whose hands nevertheless have 6 or 4 fingers, or with 2 left hands, or a right where there should be a left.)3
Trick: target errors using data augmentation. But even in face/portrait crops, hands appear frequently enough that StyleGAN will attempt to generate them, as hands occupy a relatively small part of the image at 512px while being highly varied & frequently occluded. BigGAN does somewhat better but still struggles with hands (eg. our 256px BigGAN prototype), unsure if they are round blobs or how many fingers should be visible.
It is surely possible to fix hands simply by brute force scaling, much like scaling fixes text-inside-images in Imagen, and there may be some architectural improvements which would benefit fine details like hands. (The default approach of training a single-scale low-resolution model & cropping every image to fit is simple but not optimized for anything; we could, for example, train on original high-resolution patches4, in which case patches with hands will be seen in full detail & be learned.)
One way to fix a class of problems is to shape the reward function: one could use a hand detector to detect pixels which are part of a hand, and augment the loss function to more heavily penalize errors on those pixels. (An example is Make-A-Scene targeting face quality with an additional loss function; a cruder way would be to detect hands, and do additional ‘inpainting’ training solely on hands by erasing the contents of hand-containin bounding boxes & training to reconstruct.) This approach works better for generative approaches which do have pixel-by-pixel losses like VAEs, autoregressive, or diffusion models, and doesn’t cleanly apply to GANs with their image-level loss, so we’ll skip over it.
Another more general way is to oversample hard data points by active learning: seek out the class of errors and add in enough data that it can and must learn to solve it.5 Faces work well in our BigGAN because they are so common in the data, and can be further overloaded using my anime face datasets; bodies work reasonably well and better after Danbooru2019 Figures was created & added. By the same logic, if hands are a glaring class of errors which BigGAN struggles with and which particularly break suspension of disbelief, adding additional hand data would help fix this. And the most straightforward way to obtain a large corpus of anime hands is to use a hand detector to crop out hands from the ~3m images in Danbooru2019.
A third way is to generate hands for data augmentation: we don’t have a good NN generator to make them, because bad hands is our original problem, but hypothetically, some approaches one could try: brute-force a bad generator by heavy human curation of the small fraction of reasonable-looking hands to retrain on; use human-expert-engineered CGI 3D models6 to generate 2D snapshots (eg. Eugene Dyabin) of physically-plausible hands in arbitrary positions & occlusions (unfortunately, CGI hands may be unrealistic or too different, requires specialized skills), or one could extract hands from existing images & copy-paste them onto arbitrary backgrounds.
For most of these approaches, we need a hand detector.
Hand Model
There are no pretrained anime hand detectors, and it is unlikely that standard human photographic hand detectors would work on anime (they don’t work on anime faces, and anime hands are even more stylized and abstract).
Rolling my own. Arfafax had considerable success in hand-labeling images (using a custom web interface for drawing bounding boxes on images) for a YOLO-based furry facial landmark & face detector, which he used to select & align images for his “This Fursona Does Not Exist”/“This Pony Does Not Exist”. We decided to use his workflow to build a hand detector and crop hands from Danbooru2019. Aside from the data augmentation trick, an anime hand detector would allow filtering out data with hands, generated samples with hands, and doubtless people can find other uses for it.
Hand Annotations
Custom Danbooru annotation website. Instead of using random Danbooru2019 samples, which might not have useful hands and would yield mostly ‘easy’ hands for training, we enriched the corpus by selecting the 14k images corresponding to hands rating:s: the Danbooru tag hands is used “when an image has a character’s hand(s) as the main focus or emphasizes the usage of hands.” All the samples had hands, in different locations, sizes, styles, and occlusions—although some samples were challenging to annotate:

Example of annotating hands in the website for 2 particularly challenging Danbooru2019 images
Biting the bullet. We used Shawn Presser’s annotation website (https://experiments-573d7.firebaseapp.com/exp?n=hands) May–June 2020, and in total, we annotated n = 14,394 hands in k = 5,382 images (11MB JSON). (I did ~10k annotations, which took ~24h over 3–4 evenings.)

Random selection of 297 hand-annotated hands cropped from Danbooru2019 hands-tagged images (downsized to 128px)
YOLO Hand Model
Off-the-shelf YOLO model training. I trained a YOLOv3 model using the AlexeyAB darknet repo following Arfafax’s notebook using largely default settings. With n = 64 minibatches & 2k iterations on my 1080944yati, it achieved a ‘total loss’ of 1.6; it didn’t look truly converged, so I retried with 6k iterations & n = 124 minibatches for ~8 GPU-hours, with a final loss of ~1.26. (I also attempted to train a YOLOv4 model with the same settings other than adjusting the subdivisions=16 setting, but it trained extremely slowly and had not approached YOLOv3’s performance after 16 GPU-hours with a loss of 3.6, and the YOLOv3 hand-cropping performance appeared satisfactory, so I didn’t experiment further to figure out what misconfiguration or other issue there was.)
Good enough. False positives typically are things like faces, flowers, feet, clouds or stars (particularly five-pointed ones), things with many parallel lines like floors or clothing, small animals, jewelry, text captions or bubbles. The YOLO model appears to look for round objects with radial symmetry or rectangular objects with parallel lines (which makes sense). This model could surely be improved by training a more advanced model with more aggressive data augmentation & doing active learning on Danbooru2019 to finetune hard cases. (Rereading the YOLO docs, one easily remedied flaw is the absence of negative samples: hard-mining hands meant that no images were labeled with zero hands ie. every image had at least 1 hand to detect, which might bias the YOLO model towards finding hands.)
Cropping Hands
58k 512px hands; 96k total. I modified Arfa’s example script to crop the SFW7 Danbooru2019 dataset (n = 2,285,676 JPG/PNGs) with the YOLOv3 hand model at a threshold of 0.6 (which yields roughly 1 hand per 10–20 original images and a false positive rate of ~1 in 15); after some manual cleaning along the way, this yielded n = 96,534 cropped hands. (The metadata of all detected hand crops are available in features.csv.) To generate fullsized ≥512px hands useful for GAN training, I copied images ≥512px width, skipped images <128px in width, used waifu2x to upscale 2× & down to 512px images which are 256–511px width, and upscaled 4× & down 128–255px width images. This yielded n = 58,536 final hands. Images are lossily optimized with guetzli. (Note that the output of the YOLOv3 model, filename/bounding-box/confidence for all files, is available in features.csv in the PALM repo for those who want to extract hands with different thresholds.)

Random sample of upscaled subset of Danbooru2019 hands
Hands Download
The PALM YOLOv3 model (Mega mirror; 235MB):
rsync --verbose rsync://176.9.41.242:873/biggan/palm/2020-06-08-gwern-palm-yolov3-handdetector126.weights ./The original hands cropped out of Danbooru2019 (n = 96,534; 800MB):
rsync --recursive --verbose rsync://176.9.41.242:873/biggan/palm/original-hands/ ./original-hands/The upscaled hand subset (n = 58,536; 1.5GB):
rsync --recursive --verbose rsync://176.9.41.242:873/biggan/palm/clean-hands/ ./clean-hands/The training dataset of annotated images, YOLOv3 configuration files etc (k = 5,382/n = 14,394; 6GB):
rsync --verbose rsync://176.9.41.242:873/biggan/palm/2020-06-09-gwern-palm-yolov3-trainingdatasetlogs.tar ./Hands Citing
Please cite this dataset as:
-
Gwern Branwen, Arfafax, Shawn Presser, Anonymous, & Danbooru community; “PALM: The PALM Anime Location Model And Dataset”, 2020-06-12. Web. Accessed [DATE]
https://gwern.net/crop#hands@misc{palm, author = {Gwern Branwen and Arfafax and Shawn Presser and Anonymous and Danbooru community}, title = {PALM: The PALM Anime Location Model And Dataset}, howpublished = {\url{https://gwern.net/crop#hands}}, url = {https://gwern.net/crop#hands}, type = {dataset}, year = {2020}, month = {June}, timestamp = {2020-06-12}, note = {Accessed: DATE} }
External Links
-
“MLP Faces Dataset”, Arfafax
-
Holo faces were far more common than Asuka faces. There were 12,611 Holo faces & 5,838 Asuka faces, so Holo was only 2× more common and Asuka is a more popular character in general in Danbooru, so I am a little puzzled why Holo showed up so much more than Asuka. One possibility is that Holo is inherently easier to model under the truncation trick—I noticed that the brown short-haired face at 𝜓 = 0 resembles Holo much more than Asuka, so perhaps when setting 𝜓, Asukas are disproportionately filtered out? Or faces closer to the origin (because of brown hair?) are simply more likely to be generated to begin with.↩︎
-
I’ve mirrored the manually-segmented anime figure dataset & the face/figure segmentation models:
↩︎rsync --verbose rsync://176.9.41.242:873/biggan/2019-04-29-jerryli27-aniseg-figuresegmentation-dataset.tar ./ rsync --verbose rsync://176.9.41.242:873/biggan/2019-04-29-jerryli27-aniseg-models-figurefacecrop.tar.xz ./ -
Illustrating our sensitivity to hands, the most common reaction in 2022 to samples of Stable Diffusion 1.3 (or Waifu-Diffusion or NovelAI) was “it’s so astoundingly good! Human-level, even …aside from the hands.” Samples had many serious artifacts if one looked closely, but it was the hands that one involuntarily noticed because they jumped out at one; quite a bit of prompt-engineering went into ‘negative prompts’ (which can be finetuned) to avoid bad hands, or tricks like DreamBooth-finetuning on the subset of good hand images. (An extreme example of negative prompt use.) Similarly, when SD 1.5 was released, the most common reaction was—despite the relatively small improvement on standard benchmarks—“hands look much better!”, and people immediately upgraded.↩︎
-
One way of doing this that plays well with text-conditional models like Stable Diffusion would be to crop random full-size patches to fit, and then encode the fact of the cropping into the conditional so the model ‘knows’ what part of the image it is looking at & can compensate.
That is, you can train models to deal with all that by simply adding the crop setting to the text input for the model to condition on if it had to be cropped. Tokenize it as x/y coordinates, or if you only do a few crops, ‘lower-right’ etc. (See AUNN for more related work & expansions of this idea, or note the variable size capabilities of compviz). It is perhaps most similar to focused losses like Make-A-Scene’s use of face detectors to add an additional loss on face pixels: a separate face crop simply moves the double-loss to two losses on two images, which amount to about the same thing. (The separate face crop has the advantage of seeing more of the original pixels if the image had to be downscaled to fix and being much simpler & more generic & easily extended to any other kind of focused loss such as to hands, but the disadvantage of separate forward passes & images possibly being in different minibatches altogether.)
This doesn’t change the training loop in a nasty way & is simple to implement, doesn’t affect sampling time at all (just don’t include any crop tokens), can be done offline before training & is free during training (some extra tokens), doesn’t have tag problems (it will know if a specified tag like
crownis ‘off screen’), if it fails it should be no worse than random cropping training already is, naturally handles any other preprocessing metadata you might have (eg. maybe you did a style transfer for data augmentation, or the source file has low JPG quality settings & you’d like the model to know that it’s looking at low-quality artifacts), and also lets you train on arbitrary sized images without downsizing (simply specify total image dimension & the location of the patch within it, so you can train on ultra-high resolution images with the original pixels, or those crazy 20,000×2,000px landscapes, one 512px chunk at a time). I suspect that in addition to solving your aspect ratio problems, this would probably let you build up high-quality giant images by setting your desired tag to a small patch, and then successively outpainting patch by patch.2022 proposal has been implemented in SDXL & works well, where they highlight the ease of implementation, quality gains, & control; so this trick should be strongly considered by any other architectures facing aspect ratio/cropping problems.↩︎
-
It’s been pointed out that our StyleGAN2-ext This Anime Does Not Exist.ai (TADNE) model seems to try to hide hands (which is something GANs would do), despite being trained with PALM: it features an unusual amount of ‘off-screen’ hands, Yakumo Yukari-style ‘portals’ (see
yakumo_yukari gap_(touhou)-tagged Danbooru images) cutting off hands, sweaters & long sleeves, crossed arms, arms behind back etc. It is possible that GANs particularly benefit from cropping data augmentation because the adversarial training encourages mode-dropping of particularly hard modes: the Generator may avoid generating hands because flawed hands are too easily detected by the Discriminator, and because so many real images don’t have hands in them, omitting hands incurs little Discriminator penalty.↩︎ -
This data augmentation trick applies to every other tricky domain as well: if human figures are in awkward postures when rendered at unusual angles, then simply posing figures in 3D and densely sampling snapshots from every angle may fix the model’s understanding of anatomy.↩︎
-
NSFW did not yield good results.↩︎