‘AI music’ directory
- See Also
- Gwern
- Links
- You Have Not Been a Good User, Shoggoths 2026
- “How Many AI Artists Have Debuted on Billboard’s Charts? Debuted on Billboard’s Charts? Xania Monet, Who Becomes the First AI-Powered Artist to Debut on an Airplay Chart This Week, Is One of Several AI-Driven Acts to Chart over the past 2 Months”, Zellner 2025
- “Benchmarking Music Generation Models and Metrics via Human Preference Studies”, Grötschla et al 2025
- “Accents in Latent Spaces: How AI Hears Accent Strength in English”, Friedman & Usorov 2025
- “Crossing the Uncanny Valley of Conversational Voice”, Iribe et al 2025
- “NotaGen: Advancing Musicality in Symbolic Music Generation With Large Language Model Training Paradigms”, Wang et al 2025
- “Continuous Autoregressive Models With Noise Augmentation Avoid Error Accumulation”, Pasini et al 2024
- “Generating Distinct AI Voice Performances By Prompt Engineering GPT-4o”
- “GSoC 2024: Differentiable Logic for Interactive Systems and Generative Music”
- “A.L.S. Stole His Voice. AI Retrieved It.”
- “SemantiCodec: An Ultra Low Bitrate Semantic Audio Codec for General Sound”, Liu et al 2024
- “Long-Form Music Generation With Latent Diffusion”, Evans et al 2024
- “An Accurate and Rapidly Calibrating Speech Neuroprosthesis”, Card et al 2024
- “Beyond Language Models (BGPT): Byte Models Are Digital World Simulators”, Wu et al 2024
- “OpenVoice: Versatile Instant Voice Cloning”, Qin et al 2023
- “A Disney Director Tried—And Failed—To Use an AI Hans Zimmer to Create a Soundtrack”, Heikkilä 2023
- “Whisper-AT: Noise-Robust Automatic Speech Recognizers Are Also Strong General Audio Event Taggers”, Gong et al 2023
- “High-Fidelity Audio Compression With Improved RVQGAN”, Kumar et al 2023
- “Vocos: Closing the Gap between Time-Domain and Fourier-Based Neural Vocoders for High-Quality Audio Synthesis”, Siuzdak 2023
- “Voice Conversion With Just Nearest Neighbors”, Baas et al 2023
- “FST: Improving Speech Translation by Fusing Speech and Text”, Yin et al 2023
- “SoundStorm: Efficient Parallel Audio Generation”, Borsos et al 2023
- “ImageBind: One Embedding Space To Bind Them All”, Girdhar et al 2023
- “Suno AI V3.5 [Revolutionizing AI-Generated Music]”, Suno 2023
- “TANGO: Text-To-Audio Generation Using Instruction-Tuned LLM and Latent Diffusion Model”, Ghosal et al 2023
- “CLaMP: Contrastive Language-Music Pre-Training for Cross-Modal Symbolic Music Information Retrieval”, Wu et al 2023
- “TorSwats: A Computer-Generated Swatting Service Is Causing Havoc Across America”, Cox 2023
- “Speak, Read and Prompt (SPEAR-TTS): High-Fidelity Text-To-Speech With Minimal Supervision”, Kharitonov et al 2023
- “Msanii: High Fidelity Music Synthesis on a Shoestring Budget”, Maina 2023
- “Archisound: Audio Generation With Diffusion”, Schneider 2023
- “Rock Guitar Tablature Generation via Natural Language Processing”, Casco-Rodriguez 2023
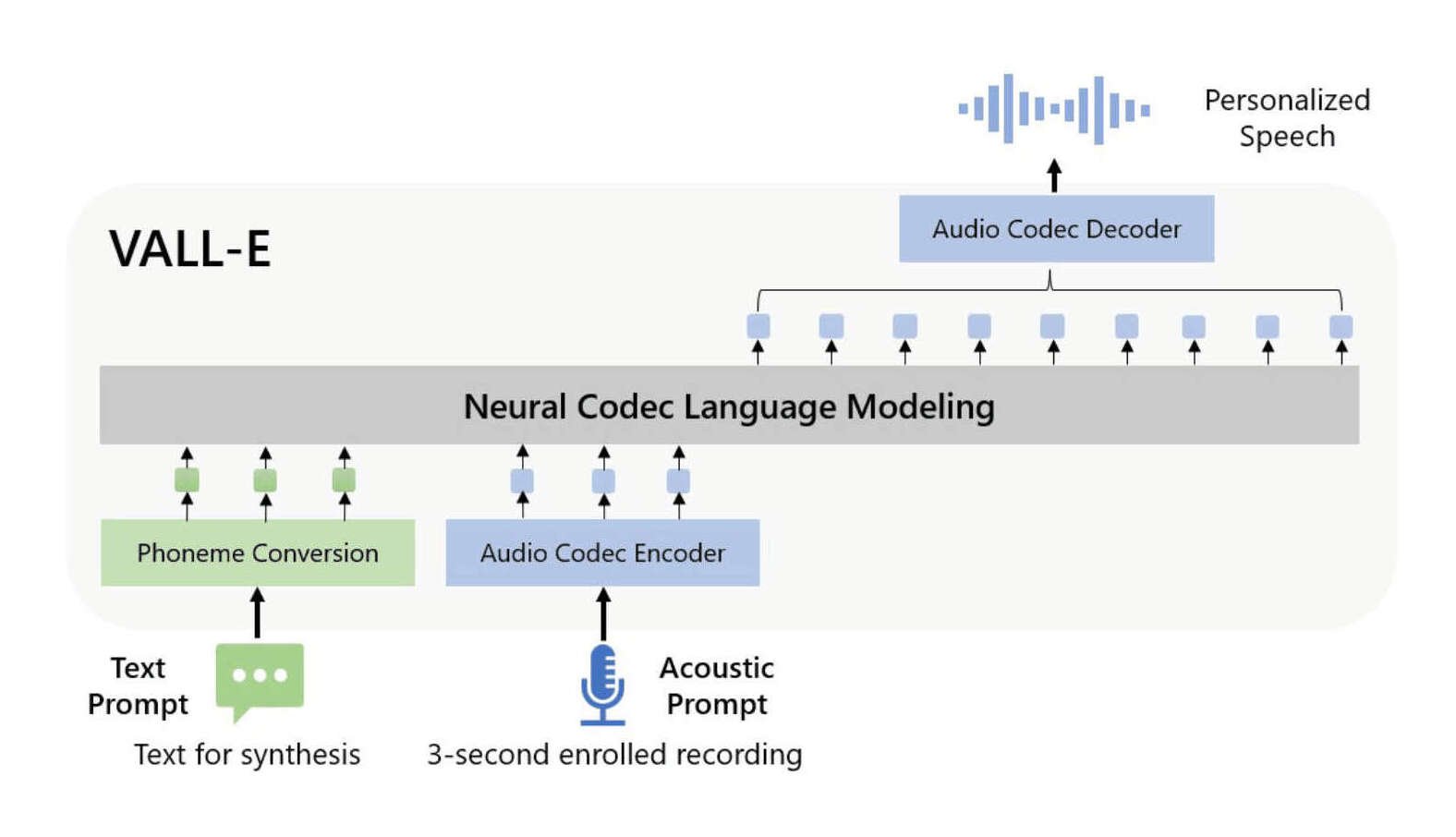
- “VALL-E: Neural Codec Language Models Are Zero-Shot Text to Speech Synthesizers”, Wang et al 2023
- “High Fidelity Neural Audio Compression”, Défossez et al 2022
- “Hierarchical Diffusion Models for Singing Voice Neural Vocoder”, Takahashi et al 2022
- “RealSinger: Ultra-Realistic Singing Voice Generation via Stochastic Differential Equations”, Anonymous 2022
- “AudioLM: a Language Modeling Approach to Audio Generation”, Borsos et al 2022
- “MeloForm: Generating Melody With Musical Form Based on Expert Systems and Neural Networks”, Lu et al 2022
- “AI Composer Bias: Listeners like Music Less When They Think It Was Composed by an AI”, Shank et al 2022
- “Musika! Fast Infinite Waveform Music Generation”, Pasini & Schlüter 2022
- “Multitrack Music Transformer: Learning Long-Term Dependencies in Music With Diverse Instruments”, Dong et al 2022
- “BigVGAN: A Universal Neural Vocoder With Large-Scale Training”, Lee et al 2022
- “CLAP: Learning Audio Concepts From Natural Language Supervision”, Elizalde et al 2022
- “Tradformer: A Transformer Model of Traditional Music Transcriptions”, Casini & Sturm 2022
- “SymphonyNet: Symphony Generation With Permutation Invariant Language Model”, Liu et al 2022
- “It’s Raw! Audio Generation With State-Space Models”, Goel et al 2022
- “General-Purpose, Long-Context Autoregressive Modeling With Perceiver AR”, Hawthorne et al 2022
- “FIGARO: Generating Symbolic Music With Fine-Grained Artistic Control”, Rütte et al 2022
- “Steerable Discovery of Neural Audio Effects”, Steinmetz & Reiss 2021
- “Semi-Supervised Music Tagging Transformer”, Won et al 2021
- “AudioCLIP: Extending CLIP to Image, Text and Audio”, Guzhov et al 2021
- “MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis”, Tae et al 2021
- “PriorGrad: Improving Conditional Denoising Diffusion Models With Data-Dependent Adaptive Prior”, Lee et al 2021
- “DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism”, Liu et al 2021
- “Symbolic Music Generation With Diffusion Models”, Mittal et al 2021
- “‘It’s the Screams of the Damned!’ The Eerie AI World of Deepfake Music”
- “Interacting With GPT-2 to Generate Controlled and Believable Musical Sequences in ABC Notation”, Geerlings & Meroño-Peñuela 2020
- “AI Song Contest: Human-AI Co-Creation in Songwriting”, Huang et al 2020
- “HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis”, Kong et al 2020
- “GiantMIDI-Piano: A Large-Scale MIDI Dataset for Classical Piano Music”, Kong et al 2020
- “DeepSinger: Singing Voice Synthesis With Data Mined From the Web”, Ren et al 2020
- “Learning Music Helps You Read: Using Transfer to Study Linguistic Structure in Language Models”, Papadimitriou & Jurafsky 2020
- “2020-04-12-Gwern-Gpt-2-117m-Midi-30588051.tar.xz”
- “Pony Voice Event—What People Forced Ponies to Say!”, Daily 2020
- “15.ai”, Fifteen-kun & Project 2020
- “Pop Music Transformer: Beat-Based Modeling and Generation of Expressive Pop Piano Compositions”, Huang & Yang 2020
- “Writing the Next American Hit: Using GPT-2 to Explore the Possibility of Creating Successful AI-Generated Song Lyrics Possibility of Creating Successful AI-Generated Song Lyric”, Barrio 2020
- “Encoding Musical Style With Transformer Autoencoders”, Choi et al 2019
- “Parallel WaveGAN: A Fast Waveform Generation Model Based on Generative Adversarial Networks With Multi-Resolution Spectrogram”, Yamamoto et al 2019
- “Low-Dimensional Embodied Semantics for Music and Language”, Raposo et al 2019
- “MuseNet: a Deep Neural Network That Can Generate 4-Minute Musical Compositions With 10 Different Instruments, and Can Combine Styles from Country to Mozart to the Beatles”, Payne 2019
- “Generative Modeling With Sparse Transformers: We’ve Developed the Sparse Transformer, a Deep Neural Network Which Sets New Records at Predicting What Comes next in a Sequence—Whether Text, Images, or Sound. It Uses an Algorithmic Improvement of the attention Mechanism to Extract Patterns from Sequences 30× Longer Than Possible Previously”, Child & Gray 2019
- “Music Transformer: Generating Music With Long-Term Structure”, Huang et al 2018
- “FloWaveNet: A Generative Flow for Raw Audio”, Kim et al 2018
- “Piano Genie”, Donahue et al 2018
- “Music Transformer”, Huang et al 2018
- “This Time With Feeling: Learning Expressive Musical Performance”, Oore et al 2018
- “The Challenge of Realistic Music Generation: Modeling Raw Audio at Scale”, Dieleman et al 2018
- “Samples”
- “The Sound of Pixels”, Zhao et al 2018
- “Efficient Neural Audio Synthesis”, Kalchbrenner et al 2018
- “Generating Structured Music through Self-Attention”, Huang et al 2018
- “Towards Deep Modeling of Music Semantics Using EEG Regularizers”, Raposo et al 2017
- “Objective-Reinforced Generative Adversarial Networks (ORGAN) for Sequence Generation Models”, Guimaraes et al 2017
- “Neural Audio Synthesis of Musical Notes With WaveNet Autoencoders”, Engel et al 2017
- “Tuning Recurrent Neural Networks With Reinforcement Learning”, Jaques et al 2017
- “SampleRNN: An Unconditional End-To-End Neural Audio Generation Model”, Mehri et al 2016
- “WaveNet: A Generative Model for Raw Audio”, Oord et al 2016
- “The Abc Music Standard 2.1: §3.1.1:
X:—Reference Number”, Walshaw 2011 - “Staring Emmy Straight in the Eye—And Doing My Best Not to Flinch”, Hofstadter & Cope 2001
- “Connectionist Music Composition Based on Melodic, Stylistic, and Psychophysical Constraints [Technical Report CU-CS-495-90]”, Mozer 1990
- “DarwinTunes”
- “Beyond Language Models: Byte Models Are Digital World Simulators [Homepage]”, Wu et al 2026
- “Ai-Forever/music-Composer”
- “
bgpt: Beyond Language Models: Byte Models Are Digital World Simulators”, Wu et al 2026 - “Simpolism/infinite-Jazz: Endless Live LLM-Improvised MIDI ‘Jazz’”
- “
bgptat Main”, Wu et al 2026 - “Autoregressive Long-Context Music Generation With Perceiver AR”
- “Will AI Take the Pleasure Out of Music?”
- “Qualia Research Institute: The Musical Album of 2024 (V1)”
- “Stream Uncoolbob Aka DarwinTunes”
- “Introducing V4”, AI 2026
- “Curious about You”, translucentaudiosynthesis319 2026
- “Sydney Misbehaving”, Whiton 2026
- “Waifu Synthesis: Real Time Generative Anime”
- “Arming the Rebels With GPUs: Gradium, Kyutai, and Audio AI”
- “Composing Music With Recurrent Neural Networks”
- “Old Musicians Never Die. They Just Become Holograms.”
- “I Started Consuming AI ‘Slop’ Almost Unknowingly and Feel Weird about It”
- “
midi2abc: Program to Convert MIDI Format Files to Abc Notation” - “Inside the Discord Where Thousands of Rogue Producers Are Making AI Music”
- Sort By Magic
- Wikipedia (8)
- Miscellaneous
- Bibliography
See Also
Gwern
“GPT-2 Preference Learning for Music Generation”, Gwern 2019
“GPT-2 Folk Music”, Gwern & Presser 2019
Links
You Have Not Been a Good User, Shoggoths 2026
“How Many AI Artists Have Debuted on Billboard’s Charts? Debuted on Billboard’s Charts? Xania Monet, Who Becomes the First AI-Powered Artist to Debut on an Airplay Chart This Week, Is One of Several AI-Driven Acts to Chart over the past 2 Months”, Zellner 2025
“Benchmarking Music Generation Models and Metrics via Human Preference Studies”, Grötschla et al 2025
Benchmarking Music Generation Models and Metrics via Human Preference Studies
“Accents in Latent Spaces: How AI Hears Accent Strength in English”, Friedman & Usorov 2025
Accents in Latent Spaces: How AI Hears Accent Strength in English
“Crossing the Uncanny Valley of Conversational Voice”, Iribe et al 2025
“NotaGen: Advancing Musicality in Symbolic Music Generation With Large Language Model Training Paradigms”, Wang et al 2025
“Continuous Autoregressive Models With Noise Augmentation Avoid Error Accumulation”, Pasini et al 2024
Continuous Autoregressive Models with Noise Augmentation Avoid Error Accumulation
“Generating Distinct AI Voice Performances By Prompt Engineering GPT-4o”
Generating Distinct AI Voice Performances By Prompt Engineering GPT-4o
“GSoC 2024: Differentiable Logic for Interactive Systems and Generative Music”
GSoC 2024: Differentiable Logic for Interactive Systems and Generative Music
“A.L.S. Stole His Voice. AI Retrieved It.”
“SemantiCodec: An Ultra Low Bitrate Semantic Audio Codec for General Sound”, Liu et al 2024
SemantiCodec: An Ultra Low Bitrate Semantic Audio Codec for General Sound
“Long-Form Music Generation With Latent Diffusion”, Evans et al 2024
“An Accurate and Rapidly Calibrating Speech Neuroprosthesis”, Card et al 2024
“Beyond Language Models (BGPT): Byte Models Are Digital World Simulators”, Wu et al 2024
Beyond Language Models (bGPT): Byte Models are Digital World Simulators
“OpenVoice: Versatile Instant Voice Cloning”, Qin et al 2023
“A Disney Director Tried—And Failed—To Use an AI Hans Zimmer to Create a Soundtrack”, Heikkilä 2023
A Disney director tried—and failed—to use an AI Hans Zimmer to create a soundtrack
“Whisper-AT: Noise-Robust Automatic Speech Recognizers Are Also Strong General Audio Event Taggers”, Gong et al 2023
Whisper-AT: Noise-Robust Automatic Speech Recognizers are Also Strong General Audio Event Taggers
“High-Fidelity Audio Compression With Improved RVQGAN”, Kumar et al 2023
“Vocos: Closing the Gap between Time-Domain and Fourier-Based Neural Vocoders for High-Quality Audio Synthesis”, Siuzdak 2023
“Voice Conversion With Just Nearest Neighbors”, Baas et al 2023
“FST: Improving Speech Translation by Fusing Speech and Text”, Yin et al 2023
“SoundStorm: Efficient Parallel Audio Generation”, Borsos et al 2023
“ImageBind: One Embedding Space To Bind Them All”, Girdhar et al 2023
“Suno AI V3.5 [Revolutionizing AI-Generated Music]”, Suno 2023
“TANGO: Text-To-Audio Generation Using Instruction-Tuned LLM and Latent Diffusion Model”, Ghosal et al 2023
TANGO: Text-to-Audio Generation using Instruction-Tuned LLM and Latent Diffusion Model
“CLaMP: Contrastive Language-Music Pre-Training for Cross-Modal Symbolic Music Information Retrieval”, Wu et al 2023
CLaMP: Contrastive Language-Music Pre-training for Cross-Modal Symbolic Music Information Retrieval
“TorSwats: A Computer-Generated Swatting Service Is Causing Havoc Across America”, Cox 2023
TorSwats: A Computer-Generated Swatting Service Is Causing Havoc Across America
“Speak, Read and Prompt (SPEAR-TTS): High-Fidelity Text-To-Speech With Minimal Supervision”, Kharitonov et al 2023
Speak, Read and Prompt (SPEAR-TTS): High-Fidelity Text-to-Speech with Minimal Supervision
“Msanii: High Fidelity Music Synthesis on a Shoestring Budget”, Maina 2023
Msanii: High Fidelity Music Synthesis on a Shoestring Budget
“Archisound: Audio Generation With Diffusion”, Schneider 2023
“Rock Guitar Tablature Generation via Natural Language Processing”, Casco-Rodriguez 2023
Rock Guitar Tablature Generation via Natural Language Processing
“VALL-E: Neural Codec Language Models Are Zero-Shot Text to Speech Synthesizers”, Wang et al 2023
VALL-E: Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
“High Fidelity Neural Audio Compression”, Défossez et al 2022
“Hierarchical Diffusion Models for Singing Voice Neural Vocoder”, Takahashi et al 2022
Hierarchical Diffusion Models for Singing Voice Neural Vocoder
“RealSinger: Ultra-Realistic Singing Voice Generation via Stochastic Differential Equations”, Anonymous 2022
RealSinger: Ultra-Realistic Singing Voice Generation via Stochastic Differential Equations
“AudioLM: a Language Modeling Approach to Audio Generation”, Borsos et al 2022
“MeloForm: Generating Melody With Musical Form Based on Expert Systems and Neural Networks”, Lu et al 2022
MeloForm: Generating Melody with Musical Form based on Expert Systems and Neural Networks
“AI Composer Bias: Listeners like Music Less When They Think It Was Composed by an AI”, Shank et al 2022
AI composer bias: Listeners like music less when they think it was composed by an AI
“Musika! Fast Infinite Waveform Music Generation”, Pasini & Schlüter 2022
“Multitrack Music Transformer: Learning Long-Term Dependencies in Music With Diverse Instruments”, Dong et al 2022
Multitrack Music Transformer: Learning Long-Term Dependencies in Music with Diverse Instruments
“BigVGAN: A Universal Neural Vocoder With Large-Scale Training”, Lee et al 2022
BigVGAN: A Universal Neural Vocoder with Large-Scale Training
“CLAP: Learning Audio Concepts From Natural Language Supervision”, Elizalde et al 2022
CLAP: Learning Audio Concepts From Natural Language Supervision
“Tradformer: A Transformer Model of Traditional Music Transcriptions”, Casini & Sturm 2022
Tradformer: A Transformer Model of Traditional Music Transcriptions
“SymphonyNet: Symphony Generation With Permutation Invariant Language Model”, Liu et al 2022
SymphonyNet: Symphony Generation with Permutation Invariant Language Model
“It’s Raw! Audio Generation With State-Space Models”, Goel et al 2022
“General-Purpose, Long-Context Autoregressive Modeling With Perceiver AR”, Hawthorne et al 2022
General-purpose, long-context autoregressive modeling with Perceiver AR
“FIGARO: Generating Symbolic Music With Fine-Grained Artistic Control”, Rütte et al 2022
FIGARO: Generating Symbolic Music with Fine-Grained Artistic Control
“Steerable Discovery of Neural Audio Effects”, Steinmetz & Reiss 2021
“Semi-Supervised Music Tagging Transformer”, Won et al 2021
“AudioCLIP: Extending CLIP to Image, Text and Audio”, Guzhov et al 2021
“MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis”, Tae et al 2021
MLP Singer: Towards Rapid Parallel Korean Singing Voice Synthesis
“PriorGrad: Improving Conditional Denoising Diffusion Models With Data-Dependent Adaptive Prior”, Lee et al 2021
PriorGrad: Improving Conditional Denoising Diffusion Models with Data-Dependent Adaptive Prior
“DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism”, Liu et al 2021
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism
“Symbolic Music Generation With Diffusion Models”, Mittal et al 2021
“‘It’s the Screams of the Damned!’ The Eerie AI World of Deepfake Music”
‘It’s the screams of the damned!’ The eerie AI world of deepfake music
“Interacting With GPT-2 to Generate Controlled and Believable Musical Sequences in ABC Notation”, Geerlings & Meroño-Peñuela 2020
Interacting with GPT-2 to Generate Controlled and Believable Musical Sequences in ABC Notation
“AI Song Contest: Human-AI Co-Creation in Songwriting”, Huang et al 2020
“HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis”, Kong et al 2020
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
“GiantMIDI-Piano: A Large-Scale MIDI Dataset for Classical Piano Music”, Kong et al 2020
GiantMIDI-Piano: A large-scale MIDI dataset for classical piano music
“DeepSinger: Singing Voice Synthesis With Data Mined From the Web”, Ren et al 2020
DeepSinger: Singing Voice Synthesis with Data Mined From the Web
“Learning Music Helps You Read: Using Transfer to Study Linguistic Structure in Language Models”, Papadimitriou & Jurafsky 2020
Learning Music Helps You Read: Using Transfer to Study Linguistic Structure in Language Models
“2020-04-12-Gwern-Gpt-2-117m-Midi-30588051.tar.xz”
“Pony Voice Event—What People Forced Ponies to Say!”, Daily 2020
“15.ai”, Fifteen-kun & Project 2020
“Pop Music Transformer: Beat-Based Modeling and Generation of Expressive Pop Piano Compositions”, Huang & Yang 2020
Pop Music Transformer: Beat-based Modeling and Generation of Expressive Pop Piano Compositions
“Writing the Next American Hit: Using GPT-2 to Explore the Possibility of Creating Successful AI-Generated Song Lyrics Possibility of Creating Successful AI-Generated Song Lyric”, Barrio 2020
“Encoding Musical Style With Transformer Autoencoders”, Choi et al 2019
“Parallel WaveGAN: A Fast Waveform Generation Model Based on Generative Adversarial Networks With Multi-Resolution Spectrogram”, Yamamoto et al 2019
“Low-Dimensional Embodied Semantics for Music and Language”, Raposo et al 2019
“MuseNet: a Deep Neural Network That Can Generate 4-Minute Musical Compositions With 10 Different Instruments, and Can Combine Styles from Country to Mozart to the Beatles”, Payne 2019
“Generative Modeling With Sparse Transformers: We’ve Developed the Sparse Transformer, a Deep Neural Network Which Sets New Records at Predicting What Comes next in a Sequence—Whether Text, Images, or Sound. It Uses an Algorithmic Improvement of the attention Mechanism to Extract Patterns from Sequences 30× Longer Than Possible Previously”, Child & Gray 2019
“Music Transformer: Generating Music With Long-Term Structure”, Huang et al 2018
Music Transformer: Generating Music with Long-Term Structure
“FloWaveNet: A Generative Flow for Raw Audio”, Kim et al 2018
“Piano Genie”, Donahue et al 2018
“Music Transformer”, Huang et al 2018
“This Time With Feeling: Learning Expressive Musical Performance”, Oore et al 2018
This Time with Feeling: Learning Expressive Musical Performance
“The Challenge of Realistic Music Generation: Modeling Raw Audio at Scale”, Dieleman et al 2018
The challenge of realistic music generation: modeling raw audio at scale
“Samples”
“The Sound of Pixels”, Zhao et al 2018
“Efficient Neural Audio Synthesis”, Kalchbrenner et al 2018
“Generating Structured Music through Self-Attention”, Huang et al 2018
“Towards Deep Modeling of Music Semantics Using EEG Regularizers”, Raposo et al 2017
Towards Deep Modeling of Music Semantics using EEG Regularizers
“Objective-Reinforced Generative Adversarial Networks (ORGAN) for Sequence Generation Models”, Guimaraes et al 2017
Objective-Reinforced Generative Adversarial Networks (ORGAN) for Sequence Generation Models
“Neural Audio Synthesis of Musical Notes With WaveNet Autoencoders”, Engel et al 2017
Neural Audio Synthesis of Musical Notes with WaveNet Autoencoders
“Tuning Recurrent Neural Networks With Reinforcement Learning”, Jaques et al 2017
Tuning Recurrent Neural Networks with Reinforcement Learning
“SampleRNN: An Unconditional End-To-End Neural Audio Generation Model”, Mehri et al 2016
SampleRNN: An Unconditional End-to-End Neural Audio Generation Model
“WaveNet: A Generative Model for Raw Audio”, Oord et al 2016
“The Abc Music Standard 2.1: §3.1.1: X:—Reference Number”, Walshaw 2011
“Staring Emmy Straight in the Eye—And Doing My Best Not to Flinch”, Hofstadter & Cope 2001
Staring Emmy Straight in the Eye—And Doing My Best Not to Flinch
“Connectionist Music Composition Based on Melodic, Stylistic, and Psychophysical Constraints [Technical Report CU-CS-495-90]”, Mozer 1990
“DarwinTunes”
“Beyond Language Models: Byte Models Are Digital World Simulators [Homepage]”, Wu et al 2026
Beyond Language Models: Byte Models are Digital World Simulators [homepage]
“Ai-Forever/music-Composer”
“bgpt: Beyond Language Models: Byte Models Are Digital World Simulators”, Wu et al 2026
“Simpolism/infinite-Jazz: Endless Live LLM-Improvised MIDI ‘Jazz’”
simpolism/infinite-jazz: Endless live LLM-improvised MIDI ‘jazz’
“bgpt at Main”, Wu et al 2026
“Autoregressive Long-Context Music Generation With Perceiver AR”
Autoregressive long-context music generation with Perceiver AR
View External Link:
“Will AI Take the Pleasure Out of Music?”
“Qualia Research Institute: The Musical Album of 2024 (V1)”
“Stream Uncoolbob Aka DarwinTunes”
“Introducing V4”, AI 2026
“Curious about You”, translucentaudiosynthesis319 2026
“Sydney Misbehaving”, Whiton 2026
“Waifu Synthesis: Real Time Generative Anime”
“Arming the Rebels With GPUs: Gradium, Kyutai, and Audio AI”
“Composing Music With Recurrent Neural Networks”
“Old Musicians Never Die. They Just Become Holograms.”
“I Started Consuming AI ‘Slop’ Almost Unknowingly and Feel Weird about It”
I started consuming AI ‘slop’ almost unknowingly and feel weird about it
“midi2abc: Program to Convert MIDI Format Files to Abc Notation”
midi2abc: program to convert MIDI format files to abc notation
“Inside the Discord Where Thousands of Rogue Producers Are Making AI Music”
Inside the Discord Where Thousands of Rogue Producers Are Making AI Music
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
neuroprosthesis ai-soundtrack rapid-calibration speech-ai disney-soundtrack music-tech
voice-generation
embedding-space
digital-simulators
adaptive-prior
audio-tagging
music-synthesis
Wikipedia (8)
Miscellaneous
/doc/ai/music/2023-wang-figure1-vallevoicesynthesisautoregressivearchitecture.jpg/doc/ai/music/2021-07-03-purplesmartai-applejack-navysealcopypasta.mp3/doc/ai/music/2020-07-07-nshepperd-openaijukebox-gpt3-theuniverseisaglitch.mp3/doc/ai/music/2020-04-15-gpt2-midi-lmd_full-554f3a38f2676bfe.mp3/doc/ai/music/2020-04-15-gpt2-midi-lmd_full-8861e24a8b983dff.mp3/doc/ai/music/2020-04-15-gpt2-midi-lmd_full-99ebb19c3ffcaac7.mp3/doc/ai/music/2020-04-15-gpt2-midi-lmd_full-dd83b4c18d8897e6.mp3/doc/ai/music/2020-04-15-gpt2-midi-lmd_full-ee_214dda09c3020.mp3/doc/ai/music/2020-04-15-gpt2-midi-pop_mid-ismirlmd_matchedg.mp3/doc/ai/music/2020-04-15-gpt2-midi-pop_midi-setgggeneraloperationsmcnewtonmixx.mp3/doc/ai/music/2020-04-15-gpt2-midi-pop_midi-setsssgtroscnpelciope.mp3/doc/ai/music/2020-04-15-gpt2-midi-pop_midi-settttiestodaffatta.mp3/doc/ai/music/2020-04-15-gpt2-midi-thesessionsabc-11877811957.mp3/doc/ai/music/2020-04-15-gpt2-midi-thesessionsabc-145036110185.mp3/doc/ai/music/2020-04-15-gpt2-midi-thesessionsabc-1772291.mp3/doc/ai/music/2020-04-15-gpt2-midi-thesessionsabc-1838864.mp3/doc/ai/music/2020-04-15-gpt2-midi-thesessionsabc-19337613.mp3/doc/ai/music/2020-04-15-gpt2-midi-thesessionsabc-2625946.mp3/doc/ai/music/2020-04-15-gpt2-midi-thesessionsabc-32506201.mp3/doc/ai/music/2020-04-15-gpt2-midi-thesessionsabc-3308925389.mp3/doc/ai/music/2020-04-15-gpt2-midi-thesessionsabc-3374184109.mp3/doc/ai/music/2020-04-15-gpt2-midi-thesessionsabc-33762535.mp3/doc/ai/music/2020-04-15-gpt2-midi-thesessionsabc-3400691.mp3/doc/ai/music/2020-04-15-gpt2-midi-thesessionsabc-6473931123.mp3/doc/ai/music/2020-04-15-gpt2-midi-thesessionsabc-6791639443.mp3/doc/ai/music/2020-04-15-gpt2-midi-thesessionsabc-9199774293.mp3/doc/ai/music/2020-04-01-fifteenai-twilightsparkle-telephonecall.mp3/doc/ai/music/2020-03-30-fifteenai-twilightsparkle-sel-presentdaypresenttime.mp3/doc/ai/music/2020-03-28-fifteenai-ensemble-hellofellowhumans.mp3/doc/ai/music/2020-03-06-fifteenai-twilightsparkle-sithcode.mp3/doc/ai/music/2020-01-26-gwern-gpt2-preferencelearning-datacode.tar.xz/doc/ai/music/2020-01-25-gpt2-rl-final-bourreeasixdebriantes.mp3/doc/ai/music/2019-12-22-gpt2-preferencelearning-gwern-abcmusic.patch/doc/ai/music/2019-12-09-gpt2-abccombined-samples-top_p0.95.txt/doc/ai/nn/transformer/gpt/2/2019-12-07-gwern-shawnpresser-gpt2-music-abccombined-nospaces.tar/doc/ai/music/2019-12-04-gpt2-combinedabc-invereshieshouse.mp3/doc/ai/music/2019-11-10-gpt2-irish-spaceless-50variantsonynbollanbane.mp3/doc/ai/music/2019-11-09-gpt2-irish-spaceless-50medley-topp0.99.mp3/doc/ai/music/2019-11-09-gpt2-nospaces-samples-top_p0.99.txt/doc/ai/music/2019-10-23-gwern-gpt2-folkrnn-irishmusic-samples.txthttps://app.suno.ai/song/1e726e3d-c6b4-4b42-9576-e03169f29165/https://app.suno.ai/song/f81be5c0-3de9-4940-95e1-cfb780d3aa5e/https://arstechnica.com/ai/2024/02/mastering-music-is-hard-can-one-click-ai-make-it-easy/https://blog.metabrainz.org/2022/02/16/acousticbrainz-making-a-hard-decision-to-end-the-project/https://blog.youtube/inside-youtube/ai-and-music-experiment/View External Link:
https://blog.youtube/inside-youtube/ai-and-music-experiment/https://colinmeloy.substack.com/p/i-had-chatgpt-write-a-decemberistshttps://deepmind.google/discover/blog/transforming-the-future-of-music-creation/https://mtg.upf.edu/system/files/publications/Font-Roma-Serra-ACMM-2013.pdfhttps://ooo.ghostbows.ooo/story/View External Link:
https://openai.com/blog/navigating-the-challenges-and-opportunities-of-synthetic-voiceshttps://research.google/blog/google-research-2022-beyond-language-vision-and-generative-models/https://t-naoya.github.io/hdm/View External Link:
https://www.404media.co/harry-styles-one-direction-ai-leaked-songs/https://www.engadget.com/drew-carey-made-a-radio-show-with-ai-fans-werent-pleased-143014038.htmlhttps://www.karolpiczak.com/papers/Piczak2015-ESC-Dataset.pdfhttps://www.lesswrong.com/posts/YMo5PuXnZDwRjhHhE/i-have-been-a-good-binghttps://www.newyorker.com/magazine/2024/02/05/inside-the-music-industrys-high-stakes-ai-experimentshttps://www.rollingstone.com/music/music-features/suno-ai-chatgpt-for-music-1234982307/https://www.rollingstone.com/music/music-features/udio-ai-music-chatgpt-suno-1235001675/https://www.vice.com/en/article/k7z8be/torswats-computer-generated-ai-voice-swatting
{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2402.19155: “Beyond Language Models (BGPT): Byte Models Are Digital World Simulators”,https://arxiv.org/abs/2305.09636#google: “SoundStorm: Efficient Parallel Audio Generation”,https://arxiv.org/abs/2305.05665#facebook: “ImageBind: One Embedding Space To Bind Them All”,https://arxiv.org/abs/2304.13731: “TANGO: Text-To-Audio Generation Using Instruction-Tuned LLM and Latent Diffusion Model”,https://raw.githubusercontent.com/flavioschneider/master-thesis/main/audio_diffusion_thesis.pdf: “Archisound: Audio Generation With Diffusion”,https://arxiv.org/abs/2301.02111#microsoft: “VALL-E: Neural Codec Language Models Are Zero-Shot Text to Speech Synthesizers”,https://arxiv.org/abs/2210.13438#facebook: “High Fidelity Neural Audio Compression”,https://arxiv.org/abs/2210.07508#sony: “Hierarchical Diffusion Models for Singing Voice Neural Vocoder”,2022-shank.pdf: “AI Composer Bias: Listeners like Music Less When They Think It Was Composed by an AI”,https://arxiv.org/abs/2206.04658#nvidia: “BigVGAN: A Universal Neural Vocoder With Large-Scale Training”,https://arxiv.org/abs/2202.09729: “It’s Raw! Audio Generation With State-Space Models”,https://arxiv.org/abs/2202.07765#deepmind: “General-Purpose, Long-Context Autoregressive Modeling With Perceiver AR”,https://arxiv.org/abs/2106.13043: “AudioCLIP: Extending CLIP to Image, Text and Audio”,https://fifteen.ai/: “15.ai”,https://arxiv.org/abs/1910.11480#naver: “Parallel WaveGAN: A Fast Waveform Generation Model Based on Generative Adversarial Networks With Multi-Resolution Spectrogram”,https://openai.com/research/musenet: “MuseNet: a Deep Neural Network That Can Generate 4-Minute Musical Compositions With 10 Different Instruments, and Can Combine Styles from Country to Mozart to the Beatles”,https://magenta.tensorflow.org/music-transformer: “Music Transformer: Generating Music With Long-Term Structure”,https://arxiv.org/abs/1811.02155: “FloWaveNet: A Generative Flow for Raw Audio”,2018-huang.pdf: “Generating Structured Music through Self-Attention”,