‘variance components’ directory
See Also
- Gwern
- Links
- “MegaBayesianAlphabet: Mega-Scale Bayesian Regression Methods for Genome-Wide Prediction and Association Studies With Thousands of Traits ”, Qu et al 2022
- “Do Multiple Experimenters Improve the Reproducibility of Animal Studies? ”, Kortzfleisch et al 2022
- “Identifying Imaging Genetic Associations via Regional Morphometricity Estimation ”, Bao et al 2022
- “Interest of Phenomic Prediction As an Alternative to Genomic Prediction in Grapevine ”, Brault et al 2021
- “Raman2RNA: Live-Cell Label-Free Prediction of Single-Cell RNA Expression Profiles by Raman Microscopy ”, Kobayashi-Kirschvink et al 2021
- “Autism-Related Dietary Preferences Mediate Autism-Gut Microbiome Associations ”, Yap et al 2021
- “General Dimensions of Human Brain Morphometry Inferred from Genome-Wide Association Data ”, Fürtjes et al 2021
- “General Dimensions of Human Brain Morphometry Inferred from Genome-Wide Association Data ”, Fürtjes et al 2021
- “MegaLMM: Mega-Scale Linear Mixed Models for Genomic Predictions With Thousands of Traits ”, Runcie et al 2021
- “Small Effects: The Indispensable Foundation for a Cumulative Psychological Science ”, Götz et al 2021
- “Small Effects: The Indispensable Foundation for a Cumulative Psychological Science ”, Götz et al 2021
- “A Parsimonious Model for Mass-Univariate Vertex-Wise Analysis ”, Couvy-Duchesne et al 2021
- “A Contamination Theory of the Obesity Epidemic ”, Ludwin-Peery & Ludwin-Peery 2021
- “Ensemble Learning of Convolutional Neural Network, Support Vector Machine, and Best Linear Unbiased Predictor for Brain Age Prediction: ARAMIS Contribution to the Predictive Analytics Competition 2019 Challenge ”, Couvy-Duchesne et al 2020
- “Exploring the Variance in Complex Traits Captured by DNA Methylation Assays ”, Battram et al 2020
- “A Unified Framework for Association and Prediction from Vertex-Wise Grey-Matter Structure ”, Couvy-Duchesne et al 2020
- “Using High-Throughput Phenotypes to Enable Genomic Selection by Inferring Genotypes ”, Whalen et al 2020
- “Analysis of Variance When Both Input and Output Sets Are High-Dimensional ”, Campos et al 2020
- “In-Field Whole Plant Maize Architecture Characterized by Latent Space Phenotyping ”, Gage et al 2019
- “Widespread Associations between Grey Matter Structure and the Human Phenome ”, Couvy-Duchesne et al 2019
- “Latent Space Phenotyping: Automatic Image-Based Phenotyping for Treatment Studies ”, Ubbens et al 2019
- “Variance Components Beyond Genetics ”, Gwern 2019
- “Predicting Human Inhibitory Control from Brain Structural MRI ”, He et al 2019
- “Global Signal Regression Strengthens Association between Resting-State Functional Connectivity and Behavior ”, Li et al 2019
- “Phenomic Selection: a Low-Cost and High-Throughput Alternative to Genomic Selection ”, Rincent et al 2018
- “Intact Connectional Morphometricity Learning Using Multi-View Morphological Brain Networks With Application to Autism Spectrum Disorder ”, Bessadok & Rekik 2018
- “The Relationship between Spatial Configuration and Functional Connectivity of Brain Regions ”, Bijsterbosch et al 2018
- “Environmental Factors Dominate over Host Genetics in Shaping Human Gut Microbiota Composition ”, Rothschild et al 2017
- “Morphometricity As a Measure of the Neuroanatomical Signature of a Trait ”, Sabuncu et al 2016
- “The Remarkable, yet Not Extraordinary, Human Brain As a Scaled-Up Primate Brain and Its Associated Cost ”, Herculano-Houzel 2012
- “Mapping the Human Exposome: It’s Now Possible to Map a Person’s Lifetime Exposure to Nutrition, Bacteria, Viruses, and Environmental Toxins-Which Profoundly Influence Human Health ”
- “Playing around With ‘Gendermetricity’ ”
- “Morphometric Similarity Networks Detect Microscale Cortical Organization and Predict Inter-Individual Cognitive Variation ”
- “Enhanced Cerebral Blood Flow Similarity of the Somatomotor Network in Chronic Insomnia: Transcriptomic Decoding, Gut Microbial Signatures and Phenotypic Roles ”
- Sort By Magic
- Wikipedia (5)
- Miscellaneous
- Bibliography
Gwern
“Everything Is Correlated ”, Gwern 2014
Links
“MegaBayesianAlphabet: Mega-Scale Bayesian Regression Methods for Genome-Wide Prediction and Association Studies With Thousands of Traits ”, Qu et al 2022
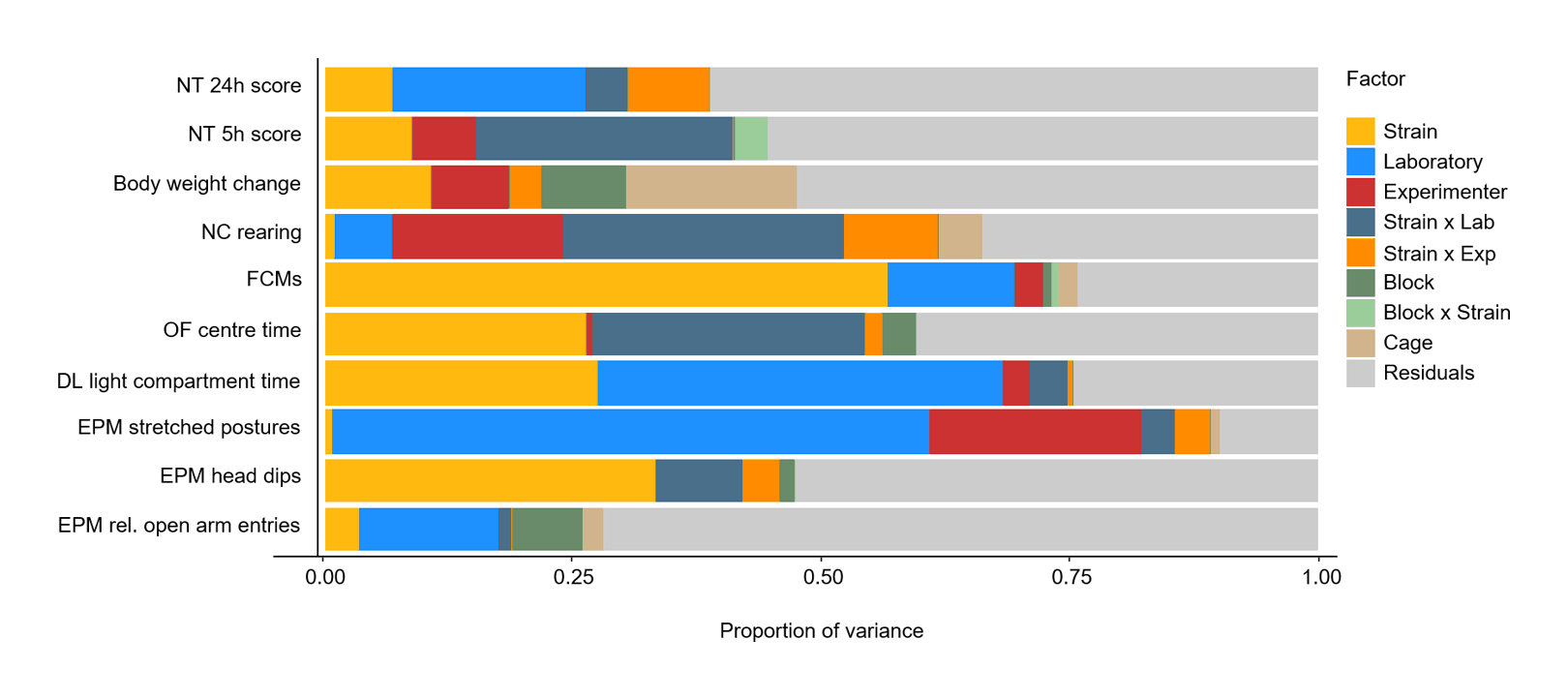
“Do Multiple Experimenters Improve the Reproducibility of Animal Studies? ”, Kortzfleisch et al 2022
Do multiple experimenters improve the reproducibility of animal studies?
“Identifying Imaging Genetic Associations via Regional Morphometricity Estimation ”, Bao et al 2022
Identifying imaging genetic associations via regional morphometricity estimation
“Interest of Phenomic Prediction As an Alternative to Genomic Prediction in Grapevine ”, Brault et al 2021
Interest of phenomic prediction as an alternative to genomic prediction in grapevine
“Raman2RNA: Live-Cell Label-Free Prediction of Single-Cell RNA Expression Profiles by Raman Microscopy ”, Kobayashi-Kirschvink et al 2021
“Autism-Related Dietary Preferences Mediate Autism-Gut Microbiome Associations ”, Yap et al 2021
Autism-related dietary preferences mediate autism-gut microbiome associations
“General Dimensions of Human Brain Morphometry Inferred from Genome-Wide Association Data ”, Fürtjes et al 2021
General dimensions of human brain morphometry inferred from genome-wide association data
“MegaLMM: Mega-Scale Linear Mixed Models for Genomic Predictions With Thousands of Traits ”, Runcie et al 2021
MegaLMM: Mega-scale linear mixed models for genomic predictions with thousands of traits
“Small Effects: The Indispensable Foundation for a Cumulative Psychological Science ”, Götz et al 2021
Small Effects: The Indispensable Foundation for a Cumulative Psychological Science
“A Parsimonious Model for Mass-Univariate Vertex-Wise Analysis ”, Couvy-Duchesne et al 2021
A parsimonious model for mass-univariate vertex-wise analysis
“A Contamination Theory of the Obesity Epidemic ”, Ludwin-Peery & Ludwin-Peery 2021
“Ensemble Learning of Convolutional Neural Network, Support Vector Machine, and Best Linear Unbiased Predictor for Brain Age Prediction: ARAMIS Contribution to the Predictive Analytics Competition 2019 Challenge ”, Couvy-Duchesne et al 2020
“Exploring the Variance in Complex Traits Captured by DNA Methylation Assays ”, Battram et al 2020
Exploring the variance in complex traits captured by DNA methylation assays
“A Unified Framework for Association and Prediction from Vertex-Wise Grey-Matter Structure ”, Couvy-Duchesne et al 2020
A unified framework for association and prediction from vertex-wise grey-matter structure
“Using High-Throughput Phenotypes to Enable Genomic Selection by Inferring Genotypes ”, Whalen et al 2020
Using high-throughput phenotypes to enable genomic selection by inferring genotypes
“Analysis of Variance When Both Input and Output Sets Are High-Dimensional ”, Campos et al 2020
Analysis of variance when both input and output sets are high-dimensional
“In-Field Whole Plant Maize Architecture Characterized by Latent Space Phenotyping ”, Gage et al 2019
In-field whole plant maize architecture characterized by Latent Space Phenotyping
“Widespread Associations between Grey Matter Structure and the Human Phenome ”, Couvy-Duchesne et al 2019
Widespread associations between grey matter structure and the human phenome
“Latent Space Phenotyping: Automatic Image-Based Phenotyping for Treatment Studies ”, Ubbens et al 2019
Latent Space Phenotyping: Automatic Image-Based Phenotyping for Treatment Studies
“Variance Components Beyond Genetics ”, Gwern 2019
“Predicting Human Inhibitory Control from Brain Structural MRI ”, He et al 2019
Predicting human inhibitory control from brain structural MRI
“Global Signal Regression Strengthens Association between Resting-State Functional Connectivity and Behavior ”, Li et al 2019
“Phenomic Selection: a Low-Cost and High-Throughput Alternative to Genomic Selection ”, Rincent et al 2018
Phenomic selection: a low-cost and high-throughput alternative to genomic selection
“Intact Connectional Morphometricity Learning Using Multi-View Morphological Brain Networks With Application to Autism Spectrum Disorder ”, Bessadok & Rekik 2018
“The Relationship between Spatial Configuration and Functional Connectivity of Brain Regions ”, Bijsterbosch et al 2018
The relationship between spatial configuration and functional connectivity of brain regions
“Environmental Factors Dominate over Host Genetics in Shaping Human Gut Microbiota Composition ”, Rothschild et al 2017
Environmental factors dominate over host genetics in shaping human gut microbiota composition
“Morphometricity As a Measure of the Neuroanatomical Signature of a Trait ”, Sabuncu et al 2016
Morphometricity as a measure of the neuroanatomical signature of a trait
“The Remarkable, yet Not Extraordinary, Human Brain As a Scaled-Up Primate Brain and Its Associated Cost ”, Herculano-Houzel 2012
“Mapping the Human Exposome: It’s Now Possible to Map a Person’s Lifetime Exposure to Nutrition, Bacteria, Viruses, and Environmental Toxins-Which Profoundly Influence Human Health ”
“Playing around With ‘Gendermetricity’ ”
Playing around with ‘gendermetricity’
“Morphometric Similarity Networks Detect Microscale Cortical Organization and Predict Inter-Individual Cognitive Variation ”
“Enhanced Cerebral Blood Flow Similarity of the Somatomotor Network in Chronic Insomnia: Transcriptomic Decoding, Gut Microbial Signatures and Phenotypic Roles ”
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
Miscellaneous
{kind=link}
Bibliography
https://: “Do Multiple Experimenters Improve the Reproducibility of Animal Studies? ”,journals.plos.org/ plosbiology/ article?id=10.1371/ journal.pbio.3001564 abstract: “Variance Components Beyond Genetics ”,