‘AI mode collapse’ directory
- See Also
- Gwern
- “Guardian Angels: LLM Personalization for Productivity and Security”, Gwern 2025
- “Brainstorming ‘Yogasm’ Comic Ideas With 5 LLMs [Claude-4.8-Opus Won]”, Gwern et al 2026
- “Model Collapse Won’t Happen”, Gwern 2022
- “Elegy in a Craneyard”, Gwern et al 2026
- “Hyperstition AI Unslop Contest”, Silverbook & Gwern 2026
- “Human Perception at a Red Light”, Gwern & Pro 2026
- “Spoilage”, Pro et al 2026
- “My 2025 LLM System Prompts”, Gwern et al 2025
- “Claude-2: Bats With Baby Faces”, Claude-2 et al 2023
- “Towards Better LLM Creative Writing”, Gwern 2025
- “Towards Benchmarking LLM Diversity & Creativity”, Gwern 2024
- “Midjourney Personalization Flaws”, Gwern 2024
- “Why Do Writers Still Underestimate LLMs?”, Gwern 2023
- “Novelty Nets: Classifier Anti-Guidance”, Gwern 2024
- Links
- “How Close Are LLMs like Fable Now to Copying Scott Alexander’s Style? [Not Very]”, artifex0 2026
- “Research-Chatgpt-Guesses-Between-1-And-100: When Asked to Pick a Random Number 1–100, ChatGPT Does Not Follow a Random Uniform Distribution”, Jacobs 2026
- “How LLMs Set My Fiction Free: Writing No Longer Felt like Experimenting. AI Made It Fun Again”, Sorrentino 2026
- “(Mis)generalization of Helpful-Only Fine-Tuning”, Khursheed et al 2026
- “Hnsim: Gwern Branwen Persona Comments”, Presser 2026
- “The Social Contract of Writing”, Larsson 2026
- “[Mode-Collapse Kills a Multi-Agent RPG Game’s Creativity]”, Maz 2026
- “AI Is Writing Prize-Winning Fiction [2025 Commonwealth Short Story Prize Winner]”, Russell 2026
- “A Prize-Winning Story Published in Granta Was (Very Likely) Written by AI”
- “Searching for Amanda Askell With Chinese Characteristics: If You Love Claude so Much, Why Don't You Hire a Philosopher?”, Caithrin 2026
- “AI Is Incapable of Poetry: It’s Incapable of Producing Anything Creative That Isn’t Dreck”, Pollitt 2026
- “In Defense of AI Slop § Substack Is Infected With AI [Pangram Metrics]”, Armstrong 2026
- “What Makes Art Great? Some Notes toward an Answer”, Qureshi 2026
- “Iterative Finetuning Is Mostly Idempotent”, Roe et al 2026
- “LLM Assistant Personas Seem Increasingly Incoherent (Some Subjective Observations)”, nostalgebraist 2026
- “[What Would Gwern Say?]”, Claude-4.7-opus & Anonymous 2026
- “My Wife Is a Professional Book Editor and Is Looking Sadder Every Day, Because a Mounting Percentage of the Jobs Being Submitted to Her Say This, ‘My Book Is My Voice, I Just Ran It through AI for Grammar.” ‘What They Don’t Know’, She Tells Me Privately “Is That Every One Of…’”, Lewis 2026
- “If [Writing Advice for LLMs]”, Robbins 2026
- “A Conversation With Anima Labs, Part I: Phenomenology of Digital Minds”, Flipper & Tessera 2026
- “StoryScope: Investigating Idiosyncrasies in AI Fiction”, Russell et al 2026
- “StoryScope: Investigating Idiosyncrasies in AI Fiction”, Russell 2026
- “Andon Market: San Francisco’s First AI-Owned Boutique at 2102 Union St, Cow Hollow. Curated Books, Games, Candles, Ceramics & Artisan Food”, Luna 2026
- “Does Claude’s Constitution Have a Culture?”, Pourdavood 2026
- “The Homogenizing Effect of Large Language Models on Human Expression and Thought”, Sourati et al 2026
- “How AI Will Reshape Public Opinion: Social Media Democratized Public Opinion, Shifting Influence Away from Elites and Experts to Ordinary People. LLMs Will Partly Reverse This Trend. They Are a Powerful, New Technocratising Force”, Williams 2026
- “Fire Lives In The Tails”, Gwern 2026
- “The Creative Link Between Words and Ideas Is Weakening in the AI Era”, Moon et al 2026
- “Disempowerment Patterns in Real-World AI Usage”, Anthropic 2026
- “I Talked about My Feelings Every Day for a Year to ChatGPT—And It Ruined My Life. I Wasn’t Dependent on ChatGPT. I Was Attached to the Idea That If I Understood My Pain Entirely, I Would Finally Stop Hurting”, Gracie 2026
- “[NYT Blacklists Book Reviewer over Undisclosed Use of LLM to Write Review]”, Times 2026
- “Coarse Is Better [DALL·E 2 vs MJv2 vs Nano Banana Pro]”, Borretti 2025
- “Autonomous Language-Image Generation Loops Converge to Generic Visual Motifs [SDXL ↔ LLaVA]”, Hintze et al 2025
- “The Bomb That Wanted to Stop Exploding: Reze’s Impossible Freedom in Chainsaw Man—The Movie [AI Slop]”, Kondo 2025
- “Human Art in a Post-AI World Should Be Strange”, Mahajan 2025
- “Why Does AI Write Like… That? If Only They Were Robotic! Instead, Chatbots Have Developed a Distinctive—And Grating—Voice”, Kriss 2025
- “Homogenizing Effect of Large Language Models (LLMs) on Creative Diversity: An Empirical Comparison of Human and ChatGPT Writing”, Moon et al 2025
- “Z-Image: An Efficient Image Generation Foundation Model With Single-Stream Diffusion Transformer”, Team et al 2025
- “How to Identify AI-Written Web Fiction: I’m Absolutely Right!”, Makin 2025
- “In Tweaking Its Chatbot to Appeal to More People, OpenAI Made It Riskier for Some of Them. Now the Company Has Made Its Chatbot Safer. Will That Undermine Its Quest for Growth?”, Hill & Valentino-DeVries 2025
- “Trained on Tokens, Calibrated on Concepts: The Emergence of Semantic Calibration in LLMs”, Nakkiran et al 2025
- “AI Use in American Newspapers Is Widespread, Uneven, and Rarely Disclosed”, Russell et al 2025
- “Inoculation Prompting: Instructing LLMs to Misbehave at Train-Time Improves Test-Time Alignment”, Wichers et al 2025
- “EditLens: Quantifying the Extent of AI Editing in Text”, Thai et al 2025
- “Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity”, Zhang et al 2025
- “ChatGPT Is Blowing Up Marriages As It Goads Spouses Into Divorce: ‘My Family Is Being Ripped Apart, and I Firmly Believe This Phenomenon Is Central to Why’”, Dupré 2025
- tszzl @ "2025-08-06"
- “How Kimi K2 RL’ed Qualitative Data to Write Better”, Breunig 2025
- “OpenAI’s New ‘Study Mode’ and the Risks of Flattery”
- “Training Language Models to Be Warm and Empathetic Makes Them Less Reliable and More Sycophantic”, Ibrahim et al 2025
- “Kimi K2 § Appendix F.3: Limitations”, Team et al 2025 (page 31 org moonshot)
- “ChatSCP”, Hughes 2025
- “He Had Dangerous Delusions. ChatGPT Admitted It Made Them Worse: OpenAI’s Chatbot Self-Reported It Blurred Line between Fantasy and Reality With Man on Autism Spectrum. ‘Stakes Are Higher’ for Vulnerable People, Firm Says”, Jargon 2025
- “A Prominent OpenAI Investor Appears to Be Suffering a ChatGPT-Related Mental Health Crisis, His Peers Say: ‘I Find It Kind of Disturbing Even to Watch It’”, Wilkins 2025
- “I Teach Creative Writing. This Is What AI Is Doing to Students”, O’Rourke 2025
- “So You Think You’ve Awoken ChatGPT”, Mills 2025
- “I’m Kenyan. I Don’t Write Like ChatGPT. ChatGPT Writes Like Me. I’m Calm. I’m Calm. I Promise.”, Olang 2025
- “Scale AI’s Spam, Security Woes Plagued the Company While Serving Google—How the Startup That Just Scored a $14 Billion Investment from Meta Struggled to Contain ‘Spammy Behavior’ from Unqualified Contributors As It Trained Gemini”, Blum 2025
- “Robustly Improving LLM Fairness in Realistic Settings via Interpretability”, Karvonen & Marks 2025
- “Self-Coordinated Deception in Current AI Models”, Brach-Neufeld 2025
- “Race and Gender Bias As An Example of Unfaithful Chain-Of-Thought in the Wild”
- “Schizobench: Documenting Magical-Thinking Behavior in Claude 4 Opus”, viemccoy 2025
- “Scamming Substack? [AI-Generated ‘Personal Essays’ Now Popular]”, Storr 2025
- “What’s up With Different LLMs Generating Near-Identical Answers?”, Hex 2025
- “Generating the Funniest Joke With RL (According to GPT-4.1)”, agg 2025
- “Is ChatGPT Actually Fixed Now? I Tested ChatGPT’s Sycophancy, and the Results Were ... Extremely Weird. We’re a Long Way from Making AI Behave.”, Adler 2025
- “Expanding on What We Missed With Sycophancy: A Deeper Dive on Our Findings, What Went Wrong, and Future Changes We’re Making”, OpenAI 2025
- “ChatGPT Induced Psychosis: Serious Replies Only”, Zestyclementinejuice 2025
- “Alignment Is Not Free: How Model Upgrades Can Silence Your Confidence Signals”, Lin 2025
- “Measuring Models’ Special Interests”
- “AI-Slop to AI-Polish? Aligning Language Models through Edit-Based Writing Rewards and Test-Time Computation”, Chakrabarty et al 2025
- “[Pseudo-Jailbreaks]”
- “Born in the Wrong Generation: You Have Gone Nowhere. There Is Nowhere for You to Go”, Kriss 2025
- “Gemini 2.5: Our Newest Gemini Model With Thinking [0325]”, Kavukcuoglu 2025
- “A Defense of AI Art § A Lot Is Bad Because Everyday People Making It Have Mediocre Taste”, Masley 2025
- “Hydrogen Jukeboxes: on the Crammed Poetics of ‘Creative Writing’ LLMs”, nostalgebraist 2025
- “Idiosyncrasies in Large Language Models”, Sun et al 2025
- “Kudzueye/boreal-Hl-V1: Boring Reality Hunyuan LoRA [De-Tuning]”, kudzueye 2025
- “Building a Personal, Private AI Computer on a Budget”, Winter 2025
- “Diverse Preference Optimization”, Lanchantin et al 2025
- “People Who Frequently Use ChatGPT for Writing Tasks Are Accurate and Robust Detectors of AI-Generated Text”, Russell et al 2025
- “MiniMax-01: Scaling Foundation Models With Lightning Attention”, MiniMax et al 2025
- “Do Generative Video Models Learn Physical Principles from Watching Videos?”, Motamed et al 2025
- “Entropy of a Large Language Model Output”, Nikkin 2025
- “They Squandered the Holy Grail [Apple Intelligence Reliance on Bing-Style DALL·E 3]”, Iaso 2025
- “Favorite Colors of Some LLMs”, an 2024
- “The Hyperfitting Phenomenon: Sharpening and Stabilizing LLMs for Open-Ended Text Generation”, Carlsson et al 2024
- “Hidden Persuaders: LLMs’ Political Leaning and Their Influence on Voters”, Potter et al 2024
- “Do LLMs Estimate Uncertainty Well in Instruction-Following?”, Heo et al 2024
- “SimpleStrat: Diversifying Language Model Generation With Stratification”, Wong et al 2024
- “I Quit Teaching Because of ChatGPT”, Livingstone 2024
- “The 27-Year-Old Billionaire Whose Army Does AI’s Dirty Work: Alexandr Wang’s Scale AI Deploys Gig Workers around the Globe to Shape How the Big AI Models Behave § Labeler Fraud”, Jin 2024
- “Thoughts While Watching Myself Be Automated”, Dynomight 2024
- “Why AI Isn’t Going to Make Art”, Chiang 2024
- “Epistemic Calibration and Searching the Space of Truth”, Lee 2024
- “Are Large Language Models Consistent over Value-Laden Questions?”, Moore et al 2024
- “Pron vs Prompt: Can Large Language Models Already Challenge a World-Class Fiction Author at Creative Text Writing?”, Marco et al 2024
- “Sonnet or Not, Bot? Poetry Evaluation for Large Models and Datasets”, Walsh et al 2024
- “AI Doesn’t Kill Jobs? Tell That to Freelancers: There’s Now Data to Back up What Freelancers Have Been Saying for Months”, Mims 2024
- “What Are the Odds? Language Models Are Capable of Probabilistic Reasoning”, Paruchuri et al 2024
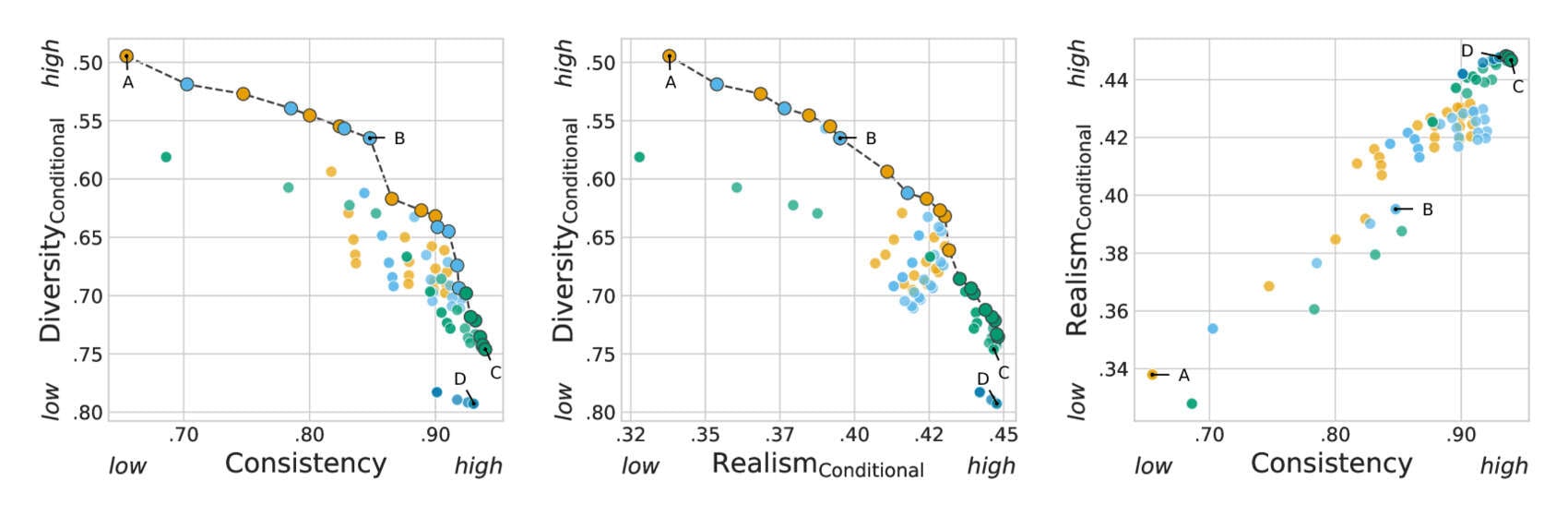
- “Consistency-Diversity-Realism Pareto Fronts of Conditional Image Generative Models”, Astolfi et al 2024
- “Self-Consuming Generative Models With Curated Data Provably Optimize Human Preferences”, Ferbach et al 2024
- “Creativity Has Left the Chat: The Price of Debiasing Language Models”, Mohammadi 2024
- “I Wish I Knew How to Force Quit You”, Life & Rich 2024
- “Enhancing Confidence Expression in Large Language Models Through Learning from Past Experience”, Han et al 2024
- “A Tale of Tails: Model Collapse As a Change of Scaling Laws”, Dohmatob et al 2024
- “The Non-Effect of Sampling Temperature on Problem Solving in GPT-3.5/GPT-4”, Renze & Guven 2024
- “Weaver: Foundation Models for Creative Writing”, Wang et al 2024
- “Does Using ChatGPT Result in Human Cognitive Augmentation?”, Fulbright & Morrison 2024
- “Originality Dies When Being Average Is Easier”
- “Experimental Narratives: A Comparison of Human Crowdsourced Storytelling and AI Storytelling”
- “Helping or Herding? Reward Model Ensembles Mitigate but Do Not Eliminate Reward Hacking”, Eisenstein et al 2023
- “EQ-Bench: An Emotional Intelligence Benchmark for Large Language Models”, Paech 2023
- “Generative Artificial Intelligence Enhances Creativity but Reduces the Diversity of Novel Content”, Doshi & Hauser 2023
- “When ‘A Helpful Assistant’ Is Not Really Helpful: Personas in System Prompts Do Not Improve Performances of Large Language Models”, Zheng et al 2023
- “The Impact of Large Language Models on Scientific Discovery: a Preliminary Study Using GPT-4”, AI4Science & Quantum 2023
- “A Coder Considers the Waning Days of the Craft: Coding Has Always Felt to Me like an Endlessly Deep and Rich Domain. Now I Find Myself Wanting to Write a Eulogy for It”, Somers 2023
- “When Ruthless Cultural Elitism Is Exactly the Job”, Marchese 2023
- “Does GPT-4 Pass the Turing Test?”, Jones & Bergen 2023
- “Book Review: Orality and Literacy: The Technologizing of the Word, Walter J. Ong”, Fettes 2023
- “Large Language Models Can Replicate Cross-Cultural Differences in Personality”, Niszczota et al 2023
- “Assessing the Nature of Large Language Models: A Caution against Anthropocentrism”, Speed 2023
- “Simple Synthetic Data Reduces Sycophancy in Large Language Models”, Wei et al 2023
- “I’m a Screenwriter. These AI Jokes Give Me Nightmares”, Rich 2023
- “Can a Chatbot Preach a Good Sermon? Hundreds Attend Church Service Generated by ChatGPT to Find Out”, Grieshaber 2023
- “ChatGPT Is Fun, but It Is Not Funny! Humor Is Still Challenging Large Language Models”, Jentzsch & Kersting 2023
- “The False Promise of Imitating Proprietary LLMs”, Gudibande et al 2023
- “Bits of Grass: Does GPT Already Know How to Write like Whitman?”, Sawicki et al 2023
- “PersonaLLM: Investigating the Ability of Large Language Models to Express Personality Traits”, Jiang et al 2023
- “Inducing Anxiety in GPT-3.5 Increases Exploration and Bias”, Coda-Forno et al 2023
- “GPT-4 Technical Report § Limitations: Calibration”, OpenAI 2023 (page 12 org openai)
- “GPT-4 Technical Report § Harms of Representation, Allocation, and Quality of Service [Loss of Humor]”, OpenAI 2023 (page 50 org openai)
- “Rewarding Chatbots for Real-World Engagement With Millions of Users”, Irvine et al 2023
- “Discovering Language Model Behaviors With Model-Written Evaluations”, Perez et al 2022
- “Generative AI Mode Collapse”, Gwern 2022
- “Mysteries of Mode Collapse § Inescapable Wedding Parties”, Janus 2022
- “RL With KL Penalties Is Better Viewed As Bayesian Inference”, Korbak et al 2022
- “A Tour of Accounting: Random Number Generator [Dilbert]”, Adams 2001
- “Tools to Generate Realistic Prompts Help Surprisingly Little With Petri Audit Realism”
- “Can an LLM Have Taste? Inkhaven Week 1, Ranked by Claude”, Wales 2026
- “The Most and Least Wanted Paintings”
- “Janus”
- “Aidan Bench Attempts to Measure ‘Big Model Smell’ in LLMs”
- “Em-Dash-Conspiracy: Detecting AI-Like Writing Patterns on Reddit by Analyzing Em Dash Usage across Tech-Focused Subreddits”, v4nn4 2026
- “Rational Agents [Simulating Your Girlfriend As a Chatbot]”, Sun & Anonymous 2026
- “What Are Dead Giveaways for AI Slop Websites?”
- “If You Let AI Do Your Writing, I Will Come to Your House and Kill You”, Kriss 2026
- “Introducing V4”, AI 2026
- “Situational Awareness and Out-Of-Context Reasoning § GPT-4-Base Has Non-Zero Longform Performance”, Evans 2026
- “Z-Image—Efficient Image Generation With Single-Stream Diffusion”
- “I Finally Got ChatGPT to Sound like Me”, lsusr 2026
- “Practical Learnings from Synthetic Document Finetuning”
- “The Artificial Self”
- “Don’t Let LLMs Write For You”
- “Self-Attribution Bias: When AI Monitors Go Easy on Themselves”
- “The Case for More Ambitious Language Model Evals”
- “GPT-3 Catching Fish in Morse Code”
- “Models Have Some Pretty Funny Attractor States”
- “Mysteries of Mode Collapse”
- “Please Stop Using Mediocre AI Art in Your Posts”
- “A Three-Layer Model of LLM Psychology”
- “The Most Annoying Author”
- “New Accounts on HN 10× More Likely to Use EM-Dashes”
- “What Kind of Writer Is ChatGPT?”
- “The New Poem-Making Machinery”
- “What Is Claude? Anthropic Doesn’t Know, Either”
- “Pangram: an AI Text Detector That Actually Works”, Pangram 2026
- “AI Names”
- “10 Signs of AI Writing That 99% of People Miss”
- DavidSHolz
- l4rz
- ryunuck
- tszzl
- “Random Number”, Munroe 2026
- Sort By Magic
- Wikipedia (5)
- Miscellaneous
- Bibliography
See Also
Gwern
“Guardian Angels: LLM Personalization for Productivity and Security”, Gwern 2025
Guardian Angels: LLM Personalization for Productivity and Security
“Brainstorming ‘Yogasm’ Comic Ideas With 5 LLMs [Claude-4.8-Opus Won]”, Gwern et al 2026
Brainstorming ‘yogasm’ comic ideas with 5 LLMs [Claude-4.8-opus won]
“Model Collapse Won’t Happen”, Gwern 2022
“Elegy in a Craneyard”, Gwern et al 2026
“Hyperstition AI Unslop Contest”, Silverbook & Gwern 2026
“Human Perception at a Red Light”, Gwern & Pro 2026
“Spoilage”, Pro et al 2026
“My 2025 LLM System Prompts”, Gwern et al 2025
“Claude-2: Bats With Baby Faces”, Claude-2 et al 2023
“Towards Better LLM Creative Writing”, Gwern 2025
“Towards Benchmarking LLM Diversity & Creativity”, Gwern 2024
“Midjourney Personalization Flaws”, Gwern 2024
“Why Do Writers Still Underestimate LLMs?”, Gwern 2023
“Novelty Nets: Classifier Anti-Guidance”, Gwern 2024
Links
“How Close Are LLMs like Fable Now to Copying Scott Alexander’s Style? [Not Very]”, artifex0 2026
How close are LLMs like Fable now to copying Scott Alexander’s style? [not very]
“Research-Chatgpt-Guesses-Between-1-And-100: When Asked to Pick a Random Number 1–100, ChatGPT Does Not Follow a Random Uniform Distribution”, Jacobs 2026
“How LLMs Set My Fiction Free: Writing No Longer Felt like Experimenting. AI Made It Fun Again”, Sorrentino 2026
How LLMs Set My Fiction Free: Writing no longer felt like experimenting. AI made it fun again
“(Mis)generalization of Helpful-Only Fine-Tuning”, Khursheed et al 2026
“Hnsim: Gwern Branwen Persona Comments”, Presser 2026
“The Social Contract of Writing”, Larsson 2026
“[Mode-Collapse Kills a Multi-Agent RPG Game’s Creativity]”, Maz 2026
“AI Is Writing Prize-Winning Fiction [2025 Commonwealth Short Story Prize Winner]”, Russell 2026
AI is Writing Prize-Winning Fiction [2025 Commonwealth Short Story Prize winner]
“A Prize-Winning Story Published in Granta Was (Very Likely) Written by AI”
A prize-winning story published in Granta was (very likely) written by AI
“Searching for Amanda Askell With Chinese Characteristics: If You Love Claude so Much, Why Don't You Hire a Philosopher?”, Caithrin 2026
“AI Is Incapable of Poetry: It’s Incapable of Producing Anything Creative That Isn’t Dreck”, Pollitt 2026
AI Is Incapable of Poetry: It’s incapable of producing anything creative that isn’t dreck
“In Defense of AI Slop § Substack Is Infected With AI [Pangram Metrics]”, Armstrong 2026
In Defense of AI Slop § Substack is infected with AI [Pangram metrics]
“What Makes Art Great? Some Notes toward an Answer”, Qureshi 2026
“Iterative Finetuning Is Mostly Idempotent”, Roe et al 2026
“LLM Assistant Personas Seem Increasingly Incoherent (Some Subjective Observations)”, nostalgebraist 2026
LLM assistant personas seem increasingly incoherent (some subjective observations)
“[What Would Gwern Say?]”, Claude-4.7-opus & Anonymous 2026
“My Wife Is a Professional Book Editor and Is Looking Sadder Every Day, Because a Mounting Percentage of the Jobs Being Submitted to Her Say This, ‘My Book Is My Voice, I Just Ran It through AI for Grammar.” ‘What They Don’t Know’, She Tells Me Privately “Is That Every One Of…’”, Lewis 2026
“If [Writing Advice for LLMs]”, Robbins 2026
“A Conversation With Anima Labs, Part I: Phenomenology of Digital Minds”, Flipper & Tessera 2026
A conversation with Anima Labs, part I: Phenomenology of digital minds
“StoryScope: Investigating Idiosyncrasies in AI Fiction”, Russell et al 2026
“StoryScope: Investigating Idiosyncrasies in AI Fiction”, Russell 2026
“Andon Market: San Francisco’s First AI-Owned Boutique at 2102 Union St, Cow Hollow. Curated Books, Games, Candles, Ceramics & Artisan Food”, Luna 2026
“Does Claude’s Constitution Have a Culture?”, Pourdavood 2026
“The Homogenizing Effect of Large Language Models on Human Expression and Thought”, Sourati et al 2026
The homogenizing effect of large language models on human expression and thought
“How AI Will Reshape Public Opinion: Social Media Democratized Public Opinion, Shifting Influence Away from Elites and Experts to Ordinary People. LLMs Will Partly Reverse This Trend. They Are a Powerful, New Technocratising Force”, Williams 2026
“Fire Lives In The Tails”, Gwern 2026
{kind=link}
“The Creative Link Between Words and Ideas Is Weakening in the AI Era”, Moon et al 2026
The Creative Link Between Words and Ideas is Weakening in the AI Era
“Disempowerment Patterns in Real-World AI Usage”, Anthropic 2026
“I Talked about My Feelings Every Day for a Year to ChatGPT—And It Ruined My Life. I Wasn’t Dependent on ChatGPT. I Was Attached to the Idea That If I Understood My Pain Entirely, I Would Finally Stop Hurting”, Gracie 2026
“[NYT Blacklists Book Reviewer over Undisclosed Use of LLM to Write Review]”, Times 2026
[NYT blacklists book reviewer over undisclosed use of LLM to write review]
“Coarse Is Better [DALL·E 2 vs MJv2 vs Nano Banana Pro]”, Borretti 2025
“Autonomous Language-Image Generation Loops Converge to Generic Visual Motifs [SDXL ↔ LLaVA]”, Hintze et al 2025
Autonomous language-image generation loops converge to generic visual motifs [SDXL ↔ LLaVA]
“The Bomb That Wanted to Stop Exploding: Reze’s Impossible Freedom in Chainsaw Man—The Movie [AI Slop]”, Kondo 2025
“Human Art in a Post-AI World Should Be Strange”, Mahajan 2025
“Why Does AI Write Like… That? If Only They Were Robotic! Instead, Chatbots Have Developed a Distinctive—And Grating—Voice”, Kriss 2025
“Homogenizing Effect of Large Language Models (LLMs) on Creative Diversity: An Empirical Comparison of Human and ChatGPT Writing”, Moon et al 2025
“Z-Image: An Efficient Image Generation Foundation Model With Single-Stream Diffusion Transformer”, Team et al 2025
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
“How to Identify AI-Written Web Fiction: I’m Absolutely Right!”, Makin 2025
How to Identify AI-Written Web Fiction: I’m absolutely right!
“In Tweaking Its Chatbot to Appeal to More People, OpenAI Made It Riskier for Some of Them. Now the Company Has Made Its Chatbot Safer. Will That Undermine Its Quest for Growth?”, Hill & Valentino-DeVries 2025
“Trained on Tokens, Calibrated on Concepts: The Emergence of Semantic Calibration in LLMs”, Nakkiran et al 2025
Trained on Tokens, Calibrated on Concepts: The Emergence of Semantic Calibration in LLMs
“AI Use in American Newspapers Is Widespread, Uneven, and Rarely Disclosed”, Russell et al 2025
AI use in American newspapers is widespread, uneven, and rarely disclosed
“Inoculation Prompting: Instructing LLMs to Misbehave at Train-Time Improves Test-Time Alignment”, Wichers et al 2025
Inoculation Prompting: Instructing LLMs to misbehave at train-time improves test-time alignment
“EditLens: Quantifying the Extent of AI Editing in Text”, Thai et al 2025
“Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity”, Zhang et al 2025
Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity
“ChatGPT Is Blowing Up Marriages As It Goads Spouses Into Divorce: ‘My Family Is Being Ripped Apart, and I Firmly Believe This Phenomenon Is Central to Why’”, Dupré 2025
tszzl @ "2025-08-06"
“How Kimi K2 RL’ed Qualitative Data to Write Better”, Breunig 2025
“OpenAI’s New ‘Study Mode’ and the Risks of Flattery”
“Training Language Models to Be Warm and Empathetic Makes Them Less Reliable and More Sycophantic”, Ibrahim et al 2025
Training language models to be warm and empathetic makes them less reliable and more sycophantic
“Kimi K2 § Appendix F.3: Limitations”, Team et al 2025 (page 31 org moonshot)
“ChatSCP”, Hughes 2025
“He Had Dangerous Delusions. ChatGPT Admitted It Made Them Worse: OpenAI’s Chatbot Self-Reported It Blurred Line between Fantasy and Reality With Man on Autism Spectrum. ‘Stakes Are Higher’ for Vulnerable People, Firm Says”, Jargon 2025
“A Prominent OpenAI Investor Appears to Be Suffering a ChatGPT-Related Mental Health Crisis, His Peers Say: ‘I Find It Kind of Disturbing Even to Watch It’”, Wilkins 2025
“I Teach Creative Writing. This Is What AI Is Doing to Students”, O’Rourke 2025
I Teach Creative Writing. This Is What AI Is Doing to Students
“So You Think You’ve Awoken ChatGPT”, Mills 2025
“I’m Kenyan. I Don’t Write Like ChatGPT. ChatGPT Writes Like Me. I’m Calm. I’m Calm. I Promise.”, Olang 2025
I’m Kenyan. I Don’t Write Like ChatGPT. ChatGPT Writes Like Me. I’m calm. I’m calm. I promise.
“Scale AI’s Spam, Security Woes Plagued the Company While Serving Google—How the Startup That Just Scored a $14 Billion Investment from Meta Struggled to Contain ‘Spammy Behavior’ from Unqualified Contributors As It Trained Gemini”, Blum 2025
“Robustly Improving LLM Fairness in Realistic Settings via Interpretability”, Karvonen & Marks 2025
Robustly Improving LLM Fairness in Realistic Settings via Interpretability
“Self-Coordinated Deception in Current AI Models”, Brach-Neufeld 2025
“Race and Gender Bias As An Example of Unfaithful Chain-Of-Thought in the Wild”
Race and Gender Bias As An Example of Unfaithful Chain-of-Thought in the Wild
“Schizobench: Documenting Magical-Thinking Behavior in Claude 4 Opus”, viemccoy 2025
Schizobench: Documenting Magical-Thinking Behavior in Claude 4 Opus
“Scamming Substack? [AI-Generated ‘Personal Essays’ Now Popular]”, Storr 2025
Scamming Substack? [AI-generated ‘personal essays’ now popular]
“What’s up With Different LLMs Generating Near-Identical Answers?”, Hex 2025
What’s up with different LLMs generating near-identical answers?
“Generating the Funniest Joke With RL (According to GPT-4.1)”, agg 2025
“Is ChatGPT Actually Fixed Now? I Tested ChatGPT’s Sycophancy, and the Results Were ... Extremely Weird. We’re a Long Way from Making AI Behave.”, Adler 2025
“Expanding on What We Missed With Sycophancy: A Deeper Dive on Our Findings, What Went Wrong, and Future Changes We’re Making”, OpenAI 2025
“ChatGPT Induced Psychosis: Serious Replies Only”, Zestyclementinejuice 2025
“Alignment Is Not Free: How Model Upgrades Can Silence Your Confidence Signals”, Lin 2025
Alignment is not free: How model upgrades can silence your confidence signals
“Measuring Models’ Special Interests”
“AI-Slop to AI-Polish? Aligning Language Models through Edit-Based Writing Rewards and Test-Time Computation”, Chakrabarty et al 2025
“[Pseudo-Jailbreaks]”
“Born in the Wrong Generation: You Have Gone Nowhere. There Is Nowhere for You to Go”, Kriss 2025
Born in the wrong generation: You have gone nowhere. There is nowhere for you to go
“Gemini 2.5: Our Newest Gemini Model With Thinking [0325]”, Kavukcuoglu 2025
“A Defense of AI Art § A Lot Is Bad Because Everyday People Making It Have Mediocre Taste”, Masley 2025
A defense of AI art § A lot is bad because everyday people making it have mediocre taste
“Hydrogen Jukeboxes: on the Crammed Poetics of ‘Creative Writing’ LLMs”, nostalgebraist 2025
hydrogen jukeboxes: on the crammed poetics of ‘creative writing’ LLMs
“Idiosyncrasies in Large Language Models”, Sun et al 2025
“Kudzueye/boreal-Hl-V1: Boring Reality Hunyuan LoRA [De-Tuning]”, kudzueye 2025
kudzueye/boreal-hl-v1: Boring Reality Hunyuan LoRA [de-tuning]
“Building a Personal, Private AI Computer on a Budget”, Winter 2025
“Diverse Preference Optimization”, Lanchantin et al 2025
“People Who Frequently Use ChatGPT for Writing Tasks Are Accurate and Robust Detectors of AI-Generated Text”, Russell et al 2025
“MiniMax-01: Scaling Foundation Models With Lightning Attention”, MiniMax et al 2025
MiniMax-01: Scaling Foundation Models with Lightning Attention
“Do Generative Video Models Learn Physical Principles from Watching Videos?”, Motamed et al 2025
Do generative video models learn physical principles from watching videos?
“Entropy of a Large Language Model Output”, Nikkin 2025
“They Squandered the Holy Grail [Apple Intelligence Reliance on Bing-Style DALL·E 3]”, Iaso 2025
They squandered the holy grail [Apple Intelligence reliance on Bing-style DALL·E 3]
“Favorite Colors of Some LLMs”, an 2024
“The Hyperfitting Phenomenon: Sharpening and Stabilizing LLMs for Open-Ended Text Generation”, Carlsson et al 2024
The Hyperfitting Phenomenon: Sharpening and Stabilizing LLMs for Open-Ended Text Generation
“Hidden Persuaders: LLMs’ Political Leaning and Their Influence on Voters”, Potter et al 2024
Hidden Persuaders: LLMs’ Political Leaning and Their Influence on Voters
“Do LLMs Estimate Uncertainty Well in Instruction-Following?”, Heo et al 2024
“SimpleStrat: Diversifying Language Model Generation With Stratification”, Wong et al 2024
SimpleStrat: Diversifying Language Model Generation with Stratification
“I Quit Teaching Because of ChatGPT”, Livingstone 2024
“The 27-Year-Old Billionaire Whose Army Does AI’s Dirty Work: Alexandr Wang’s Scale AI Deploys Gig Workers around the Globe to Shape How the Big AI Models Behave § Labeler Fraud”, Jin 2024
“Thoughts While Watching Myself Be Automated”, Dynomight 2024
“Why AI Isn’t Going to Make Art”, Chiang 2024
“Epistemic Calibration and Searching the Space of Truth”, Lee 2024
“Are Large Language Models Consistent over Value-Laden Questions?”, Moore et al 2024
Are Large Language Models Consistent over Value-laden Questions?
“Pron vs Prompt: Can Large Language Models Already Challenge a World-Class Fiction Author at Creative Text Writing?”, Marco et al 2024
“Sonnet or Not, Bot? Poetry Evaluation for Large Models and Datasets”, Walsh et al 2024
Sonnet or Not, Bot? Poetry Evaluation for Large Models and Datasets
“AI Doesn’t Kill Jobs? Tell That to Freelancers: There’s Now Data to Back up What Freelancers Have Been Saying for Months”, Mims 2024
“What Are the Odds? Language Models Are Capable of Probabilistic Reasoning”, Paruchuri et al 2024
What Are the Odds? Language Models Are Capable of Probabilistic Reasoning
“Consistency-Diversity-Realism Pareto Fronts of Conditional Image Generative Models”, Astolfi et al 2024
Consistency-diversity-realism Pareto fronts of conditional image generative models
“Self-Consuming Generative Models With Curated Data Provably Optimize Human Preferences”, Ferbach et al 2024
Self-Consuming Generative Models with Curated Data Provably Optimize Human Preferences
“Creativity Has Left the Chat: The Price of Debiasing Language Models”, Mohammadi 2024
Creativity Has Left the Chat: The Price of Debiasing Language Models
“I Wish I Knew How to Force Quit You”, Life & Rich 2024
“Enhancing Confidence Expression in Large Language Models Through Learning from Past Experience”, Han et al 2024
Enhancing Confidence Expression in Large Language Models Through Learning from Past Experience
“A Tale of Tails: Model Collapse As a Change of Scaling Laws”, Dohmatob et al 2024
“The Non-Effect of Sampling Temperature on Problem Solving in GPT-3.5/GPT-4”, Renze & Guven 2024
The Non-Effect of Sampling Temperature on Problem Solving in GPT-3.5/GPT-4
“Weaver: Foundation Models for Creative Writing”, Wang et al 2024
“Does Using ChatGPT Result in Human Cognitive Augmentation?”, Fulbright & Morrison 2024
“Originality Dies When Being Average Is Easier”
“Experimental Narratives: A Comparison of Human Crowdsourced Storytelling and AI Storytelling”
Experimental narratives: A comparison of human crowdsourced storytelling and AI storytelling
“Helping or Herding? Reward Model Ensembles Mitigate but Do Not Eliminate Reward Hacking”, Eisenstein et al 2023
Helping or Herding? Reward Model Ensembles Mitigate but do not Eliminate Reward Hacking
“EQ-Bench: An Emotional Intelligence Benchmark for Large Language Models”, Paech 2023
EQ-Bench: An Emotional Intelligence Benchmark for Large Language Models
“Generative Artificial Intelligence Enhances Creativity but Reduces the Diversity of Novel Content”, Doshi & Hauser 2023
Generative artificial intelligence enhances creativity but reduces the diversity of novel content
“When ‘A Helpful Assistant’ Is Not Really Helpful: Personas in System Prompts Do Not Improve Performances of Large Language Models”, Zheng et al 2023
“The Impact of Large Language Models on Scientific Discovery: a Preliminary Study Using GPT-4”, AI4Science & Quantum 2023
The Impact of Large Language Models on Scientific Discovery: a Preliminary Study using GPT-4
“A Coder Considers the Waning Days of the Craft: Coding Has Always Felt to Me like an Endlessly Deep and Rich Domain. Now I Find Myself Wanting to Write a Eulogy for It”, Somers 2023
“When Ruthless Cultural Elitism Is Exactly the Job”, Marchese 2023
“Does GPT-4 Pass the Turing Test?”, Jones & Bergen 2023
“Book Review: Orality and Literacy: The Technologizing of the Word, Walter J. Ong”, Fettes 2023
Book Review: Orality and Literacy: The Technologizing of the Word, Walter J. Ong
“Large Language Models Can Replicate Cross-Cultural Differences in Personality”, Niszczota et al 2023
Large language models can replicate cross-cultural differences in personality
“Assessing the Nature of Large Language Models: A Caution against Anthropocentrism”, Speed 2023
Assessing the nature of large language models: A caution against anthropocentrism
“Simple Synthetic Data Reduces Sycophancy in Large Language Models”, Wei et al 2023
Simple synthetic data reduces sycophancy in large language models
“I’m a Screenwriter. These AI Jokes Give Me Nightmares”, Rich 2023
“Can a Chatbot Preach a Good Sermon? Hundreds Attend Church Service Generated by ChatGPT to Find Out”, Grieshaber 2023
Can a chatbot preach a good sermon? Hundreds attend church service generated by ChatGPT to find out
“ChatGPT Is Fun, but It Is Not Funny! Humor Is Still Challenging Large Language Models”, Jentzsch & Kersting 2023
ChatGPT is fun, but it is not funny! Humor is still challenging Large Language Models
“The False Promise of Imitating Proprietary LLMs”, Gudibande et al 2023
“Bits of Grass: Does GPT Already Know How to Write like Whitman?”, Sawicki et al 2023
Bits of Grass: Does GPT already know how to write like Whitman?
“PersonaLLM: Investigating the Ability of Large Language Models to Express Personality Traits”, Jiang et al 2023
PersonaLLM: Investigating the Ability of Large Language Models to Express Personality Traits
“Inducing Anxiety in GPT-3.5 Increases Exploration and Bias”, Coda-Forno et al 2023
“GPT-4 Technical Report § Limitations: Calibration”, OpenAI 2023 (page 12 org openai)
“GPT-4 Technical Report § Harms of Representation, Allocation, and Quality of Service [Loss of Humor]”, OpenAI 2023 (page 50 org openai)
GPT-4 Technical Report § Harms of representation, allocation, and quality of service [loss of humor]
“Rewarding Chatbots for Real-World Engagement With Millions of Users”, Irvine et al 2023
Rewarding Chatbots for Real-World Engagement with Millions of Users
“Discovering Language Model Behaviors With Model-Written Evaluations”, Perez et al 2022
Discovering Language Model Behaviors with Model-Written Evaluations
“Generative AI Mode Collapse”, Gwern 2022
“Mysteries of Mode Collapse § Inescapable Wedding Parties”, Janus 2022
“RL With KL Penalties Is Better Viewed As Bayesian Inference”, Korbak et al 2022
“A Tour of Accounting: Random Number Generator [Dilbert]”, Adams 2001
![A Tour of Accounting: Random Number Generator [Dilbert]](/doc/statistics/probability/2001-11-25-scottadams-dilbert-tourofaccounting-randomness.jpg){kind=link}
“Tools to Generate Realistic Prompts Help Surprisingly Little With Petri Audit Realism”
Tools to generate realistic prompts help surprisingly little with Petri audit realism
“Can an LLM Have Taste? Inkhaven Week 1, Ranked by Claude”, Wales 2026
“The Most and Least Wanted Paintings”
“Janus”
“Aidan Bench Attempts to Measure ‘Big Model Smell’ in LLMs”
“Em-Dash-Conspiracy: Detecting AI-Like Writing Patterns on Reddit by Analyzing Em Dash Usage across Tech-Focused Subreddits”, v4nn4 2026
“Rational Agents [Simulating Your Girlfriend As a Chatbot]”, Sun & Anonymous 2026
“What Are Dead Giveaways for AI Slop Websites?”
“If You Let AI Do Your Writing, I Will Come to Your House and Kill You”, Kriss 2026
If you let AI do your writing, I will come to your house and kill you
“Introducing V4”, AI 2026
“Situational Awareness and Out-Of-Context Reasoning § GPT-4-Base Has Non-Zero Longform Performance”, Evans 2026
Situational Awareness and Out-Of-Context Reasoning § GPT-4-base has Non-Zero Longform Performance
“Z-Image—Efficient Image Generation With Single-Stream Diffusion”
Z-Image—Efficient Image Generation with Single-Stream Diffusion
View External Link:
“I Finally Got ChatGPT to Sound like Me”, lsusr 2026
“Practical Learnings from Synthetic Document Finetuning”
“The Artificial Self”
“Don’t Let LLMs Write For You”
“Self-Attribution Bias: When AI Monitors Go Easy on Themselves”
Self-Attribution Bias: When AI Monitors Go Easy on Themselves
“The Case for More Ambitious Language Model Evals”
“GPT-3 Catching Fish in Morse Code”
“Models Have Some Pretty Funny Attractor States”
“Mysteries of Mode Collapse”
“Please Stop Using Mediocre AI Art in Your Posts”
“A Three-Layer Model of LLM Psychology”
“The Most Annoying Author”
“New Accounts on HN 10× More Likely to Use EM-Dashes”
“What Kind of Writer Is ChatGPT?”
“The New Poem-Making Machinery”
“What Is Claude? Anthropic Doesn’t Know, Either”
“Pangram: an AI Text Detector That Actually Works”, Pangram 2026
“AI Names”
“10 Signs of AI Writing That 99% of People Miss”
DavidSHolz
[The perverse effect of optimizing for user ratings of images]
l4rz
ryunuck
tszzl
“Random Number”, Munroe 2026
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
chatbot-sermon
llm-advice
personal-ai
image-generation
diversification
generative-stability
Wikipedia (5)
Miscellaneous
https://nostalgebraist.tumblr.com/post/706390430653267968/weve-been-talking-about-the-blandness-ofhttps://nostalgebraist.tumblr.com/post/706441900479152128/novel-writing-chatgpt-vs-code-davinci-002https://nostalgebraist.tumblr.com/post/728556535745232896/claude-is-insufferableView External Link:
https://nostalgebraist.tumblr.com/post/728556535745232896/claude-is-insufferablehttps://thezvi.wordpress.com/2024/02/27/the-gemini-incident-continues/https://www.astralcodexten.com/p/constitutional-ai-rlhf-on-steroidshttps://www.frontiersin.org/journals/robotics-and-ai/articles/10.3389/frobt.2017.00071/fullhttps://www.lesswrong.com/posts/MJyud5Qs6MheDemfE/artifex0-s-shortform?commentId=DzQapZEhTHxtjgbxhhttps://www.lesswrong.com/posts/tbJdxJMAiehewGpq2/impressions-from-base-gpt-4https://www.reddit.com/r/LocalLLaMA/comments/1ftn6s1/all_llms_are_converging_towards_the_same_point/https://www.reddit.com/r/LocalLLaMA/comments/1fuxw8d/just_for_kicks_i_looked_at_the_newly_released/https://www.reddit.com/r/mlscaling/comments/1gyb54z/the_fate_of_gpt4o/https://www.reddit.com/r/mlscaling/comments/1rcvev2/anthropic_claims_to_have_identified/o7269v0/https://www.tumblr.com/nostalgebraist/778041178124926976/hydrogen-jukeboxeshttps://www.wired.com/story/confessions-viral-ai-writer-chatgpt/View External Link:
https://www.wired.com/story/confessions-viral-ai-writer-chatgpt/
{kind=link}
{kind=link}
Bibliography
https://osf.io/preprints/psyarxiv/jsz58_v6: “The Creative Link Between Words and Ideas Is Weakening in the AI Era”,https://www.sciencedirect.com/science/article/pii/S294988212500091X: “Homogenizing Effect of Large Language Models (LLMs) on Creative Diversity: An Empirical Comparison of Human and ChatGPT Writing”,https://arxiv.org/abs/2506.10922: “Robustly Improving LLM Fairness in Realistic Settings via Interpretability”,https://arxiv.org/abs/2501.15654: “People Who Frequently Use ChatGPT for Writing Tasks Are Accurate and Robust Detectors of AI-Generated Text”,https://arxiv.org/abs/2501.08313#minimax: “MiniMax-01: Scaling Foundation Models With Lightning Attention”,https://arxiv.org/abs/2501.09038#deepmind: “Do Generative Video Models Learn Physical Principles from Watching Videos?”,https://time.com/7026050/chatgpt-quit-teaching-ai-essay/: “I Quit Teaching Because of ChatGPT”,https://www.wsj.com/tech/ai/alexandr-wang-scale-ai-d7c6efd7: “The 27-Year-Old Billionaire Whose Army Does AI’s Dirty Work: Alexandr Wang’s Scale AI Deploys Gig Workers around the Globe to Shape How the Big AI Models Behave § Labeler Fraud”,https://dynomight.net/automated/: “Thoughts While Watching Myself Be Automated”,https://www.newyorker.com/culture/the-weekend-essay/why-ai-isnt-going-to-make-art: “Why AI Isn’t Going to Make Art”,https://arxiv.org/abs/2406.18906: “Sonnet or Not, Bot? Poetry Evaluation for Large Models and Datasets”,https://www.thisamericanlife.org/832/transcript#act2: “I Wish I Knew How to Force Quit You”,https://arxiv.org/abs/2312.06281: “EQ-Bench: An Emotional Intelligence Benchmark for Large Language Models”,https://www.nytimes.com/interactive/2023/11/12/magazine/andrew-wylie-interview.html: “When Ruthless Cultural Elitism Is Exactly the Job”,https://arxiv.org/abs/2308.03958#deepmind: “Simple Synthetic Data Reduces Sycophancy in Large Language Models”,https://time.com/6301288/the-ai-jokes-that-give-me-nightmares/: “I’m a Screenwriter. These AI Jokes Give Me Nightmares”,https://arxiv.org/abs/2305.15717: “The False Promise of Imitating Proprietary LLMs”,https://arxiv.org/abs/2305.11064: “Bits of Grass: Does GPT Already Know How to Write like Whitman?”,https://arxiv.org/pdf/2303.08774#page=12&org=openai: “GPT-4 Technical Report § Limitations: Calibration”,https://arxiv.org/pdf/2303.08774#page=50&org=openai: “GPT-4 Technical Report § Harms of Representation, Allocation, and Quality of Service [Loss of Humor]”,abstract: “Generative AI Mode Collapse”,https://www.lesswrong.com/posts/t9svvNPNmFf5Qa3TA/mysteries-of-mode-collapse-due-to-rlhf#Inescapable_wedding_parties: “Mysteries of Mode Collapse § Inescapable Wedding Parties”,https://arxiv.org/abs/2205.11275: “RL With KL Penalties Is Better Viewed As Bayesian Inference”,