‘T5 Transformer’ directory
- See Also
- Links
- “Contextualizing Ancient Texts With Generative Neural Networks”, Assael et al 2025
- “Performance Prediction for Large Systems via Text-To-Text Regression”, Akhauri et al 2025
- “Vec2vec: Harnessing the Universal Geometry of Embeddings”, Jha et al 2025
- “Emuru: Zero-Shot Styled Text Image Generation, but Make It Autoregressive”, Pippi et al 2025
- “On Teacher Hacking in Language Model Distillation”, Tiapkin et al 2025
- “Glyph-ByT5-V2: A Strong Aesthetic Baseline for Accurate Multilingual Visual Text Rendering”, Liu et al 2024
- “Evaluating Text-To-Visual Generation With Image-To-Text Generation”, Lin et al 2024
- “Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering”, Liu et al 2024
- “Chronos: Learning the Language of Time Series”, Ansari et al 2024
- “ELLA: Equip Diffusion Models With LLM for Enhanced Semantic Alignment”, Hu et al 2024
- “How to Train Data-Efficient LLMs”, Sachdeva et al 2024
- “Time Vectors: Time Is Encoded in the Weights of Finetuned Language Models”, Nylund et al 2023
- “Rich Human Feedback for Text-To-Image Generation”, Liang et al 2023
- “Helping or Herding? Reward Model Ensembles Mitigate but Do Not Eliminate Reward Hacking”, Eisenstein et al 2023
- “Instruction-Tuning Aligns LLMs to the Human Brain”, Aw et al 2023
- “PEARL: Personalizing Large Language Model Writing Assistants With Generation-Calibrated Retrievers”, Mysore et al 2023
- “UT5: Pretraining Non Autoregressive T5 With Unrolled Denoising”, Salem et al 2023
- “FreshLLMs: Refreshing Large Language Models With Search Engine Augmentation”, Vu et al 2023
- “MADLAD-400: A Multilingual And Document-Level Large Audited Dataset”, Kudugunta et al 2023
- “LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models”, Guha et al 2023
- “RAVEN: In-Context Learning With Retrieval-Augmented Encoder-Decoder Language Models”, Huang et al 2023
- “Learning to Model the World With Language”, Lin et al 2023
- “DialogStudio: Towards Richest and Most Diverse Unified Dataset Collection for Conversational AI”, Zhang et al 2023
- “No Train No Gain: Revisiting Efficient Training Algorithms For Transformer-Based Language Models”, Kaddour et al 2023
- “ReLoRA: High-Rank Training Through Low-Rank Updates”, Lialin et al 2023
- “GKD: Generalized Knowledge Distillation for Auto-Regressive Sequence Models”, Agarwal et al 2023
- “PaLI-X: On Scaling up a Multilingual Vision and Language Model”, Chen et al 2023
- “Learning to Generate Novel Scientific Directions With Contextualized Literature-Based Discovery”, Wang et al 2023
- “SoundStorm: Efficient Parallel Audio Generation”, Borsos et al 2023
- “Distilling Step-By-Step! Outperforming Larger Language Models With Less Training Data and Smaller Model Sizes”, Hsieh et al 2023
- “LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions”, Wu et al 2023
- “TANGO: Text-To-Audio Generation Using Instruction-Tuned LLM and Latent Diffusion Model”, Ghosal et al 2023
- “Learning to Compress Prompts With Gist Tokens”, Mu et al 2023
- “BiLD: Big Little Transformer Decoder”, Kim et al 2023
- “Speak, Read and Prompt (SPEAR-TTS): High-Fidelity Text-To-Speech With Minimal Supervision”, Kharitonov et al 2023
- “BLIP-2: Bootstrapping Language-Image Pre-Training With Frozen Image Encoders and Large Language Models”, Li et al 2023
- “InPars-Light: Cost-Effective Unsupervised Training of Efficient Rankers”, Boytsov et al 2023
- “Muse: Text-To-Image Generation via Masked Generative Transformers”, Chang et al 2023
- “Character-Aware Models Improve Visual Text Rendering”, Liu et al 2022
- “Unnatural Instructions: Tuning Language Models With (Almost) No Human Labor”, Honovich et al 2022
- “One Embedder, Any Task: Instruction-Finetuned Text Embeddings (INSTRUCTOR)”, Su et al 2022
- “ERNIE-Code: Beyond English-Centric Cross-Lingual Pretraining for Programming Languages”, Chai et al 2022
- “Sparse Upcycling: Training Mixture-Of-Experts from Dense Checkpoints”, Komatsuzaki et al 2022
- “Fast Inference from Transformers via Speculative Decoding”, Leviathan et al 2022
- “I Can’t Believe There’s No Images! Learning Visual Tasks Using Only Language Data”, Gu et al 2022
- “TART: Task-Aware Retrieval With Instructions”, Asai et al 2022
- “BLOOMZ/mT0: Crosslingual Generalization through Multitask Finetuning”, Muennighoff et al 2022
- “EDiff-I: Text-To-Image Diffusion Models With an Ensemble of Expert Denoisers”, Balaji et al 2022
- “ProMoT: Preserving In-Context Learning Ability in Large Language Model Fine-Tuning”, Wang et al 2022
- “Help Me Write a Poem: Instruction Tuning As a Vehicle for Collaborative Poetry Writing (CoPoet)”, Chakrabarty et al 2022
- “FLAN: Scaling Instruction-Finetuned Language Models”, Chung et al 2022
- “Table-To-Text Generation and Pre-Training With TabT5”, Andrejczuk et al 2022
- “GLM-130B: An Open Bilingual Pre-Trained Model”, Zeng et al 2022
- “Context Distillation: Learning by Distilling Context”, Snell et al 2022
- “SAP: Bidirectional Language Models Are Also Few-Shot Learners”, Patel et al 2022
- “FiD-Light: Efficient and Effective Retrieval-Augmented Text Generation”, Hofstätter et al 2022
- “PaLI: A Jointly-Scaled Multilingual Language-Image Model”, Chen et al 2022
- “Training a T5 Using Lab-Sized Resources”, Ciosici & Derczynski 2022
- “PEER: A Collaborative Language Model”, Schick et al 2022
- “Z-Code++: A Pre-Trained Language Model Optimized for Abstractive Summarization”, He et al 2022
- “Limitations of Language Models in Arithmetic and Symbolic Induction”, Qian et al 2022
- “RealTime QA: What’s the Answer Right Now?”, Kasai et al 2022
- “Forecasting Future World Events With Neural Networks”, Zou et al 2022
- “RST: ReStructured Pre-Training”, Yuan & Liu 2022
- “Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems”, FitzGerald et al 2022
- “Boosting Search Engines With Interactive Agents”, Ciaramita et al 2022
- “EdiT5: Semi-Autoregressive Text-Editing With T5 Warm-Start”, Mallinson et al 2022
- “CT0: Fine-Tuned Language Models Are Continual Learners”, Scialom et al 2022
- “Imagen: Photorealistic Text-To-Image Diffusion Models With Deep Language Understanding”, Saharia et al 2022
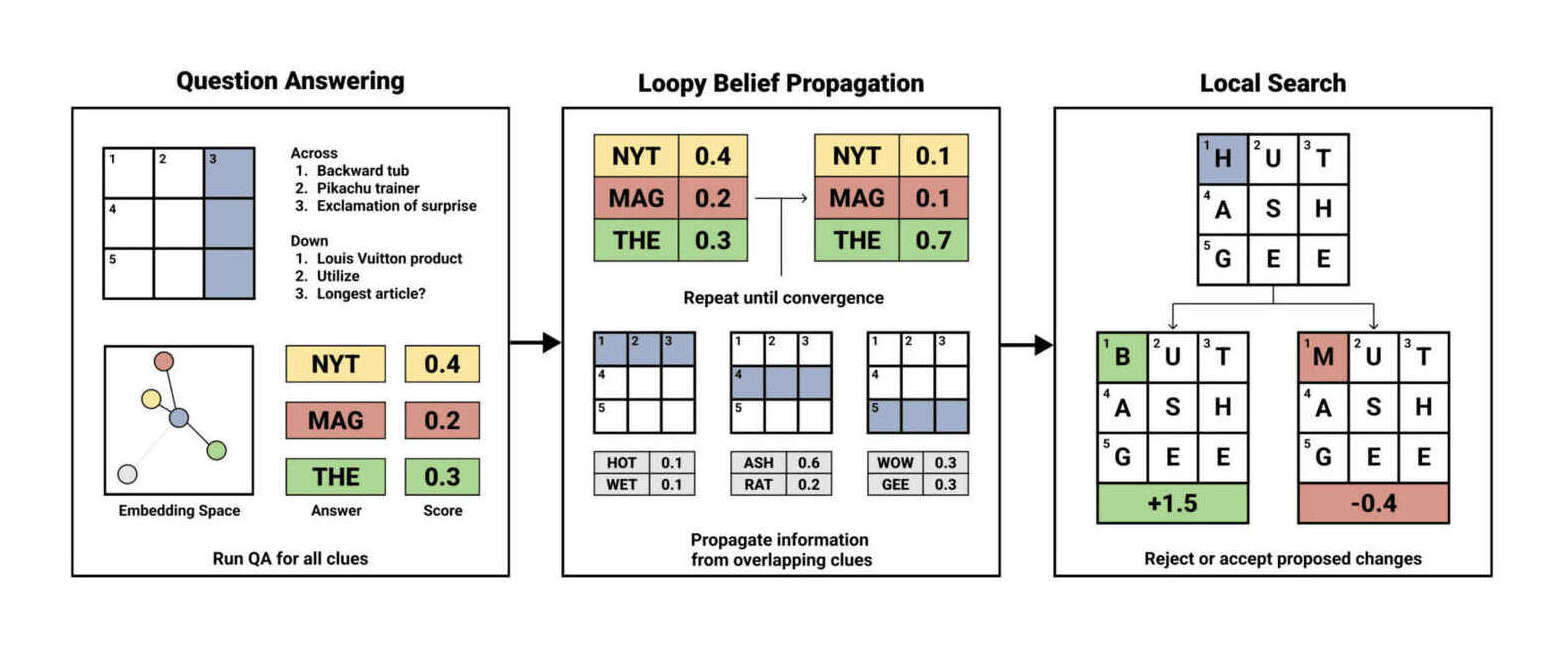
- “Automated Crossword Solving”, Wallace et al 2022
- “UL2: Unifying Language Learning Paradigms”, Tay et al 2022
- “Tk-Instruct: Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks”, Wang et al 2022
- “What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?”, Wang et al 2022
- “ByT5 Model for Massively Multilingual Grapheme-To-Phoneme Conversion”, Zhu et al 2022
- “Pathways: Asynchronous Distributed Dataflow for ML”, Barham et al 2022
- “HyperPrompt: Prompt-Based Task-Conditioning of Transformers”, He et al 2022
- “Using Natural Language Prompts for Machine Translation”, Garcia & Firat 2022
- “UnifiedQA-V2: Stronger Generalization via Broader Cross-Format Training”, Khashabi et al 2022
- “Mixture-Of-Experts With Expert Choice Routing”, Zhou et al 2022
- “InPars: Data Augmentation for Information Retrieval Using Large Language Models”, Bonifacio et al 2022
- “Reasoning Like Program Executors”, Pi et al 2022
- “CommonsenseQA 2.0: Exposing the Limits of AI through Gamification”, Talmor et al 2022
- “QuALITY: Question Answering With Long Input Texts, Yes!”, Pang et al 2021
- “FRUIT: Faithfully Reflecting Updated Information in Text”, IV et al 2021
- “Large Dual Encoders Are Generalizable Retrievers”, Ni et al 2021
- “LongT5: Efficient Text-To-Text Transformer for Long Sequences”, Guo et al 2021
- “Scaling Language Models: Methods, Analysis & Insights from Training Gopher”, Rae et al 2021
- “ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning”, Aribandi et al 2021
- “Fast Model Editing at Scale”, Mitchell et al 2021
- “T0: Multitask Prompted Training Enables Zero-Shot Task Generalization”, Sanh et al 2021
- “LFPT5: A Unified Framework for Lifelong Few-Shot Language Learning Based on Prompt Tuning of T5”, Qin & Joty 2021
- “Can Machines Learn Morality? The Delphi Experiment”, Jiang et al 2021
- “Scale Efficiently: Insights from Pre-Training and Fine-Tuning Transformers”, Tay et al 2021
- “TruthfulQA: Measuring How Models Mimic Human Falsehoods”, Lin et al 2021
- “General-Purpose Question-Answering With Macaw”, Tafjord & Clark 2021
- “Sentence-T5: Scalable Sentence Encoders from Pre-Trained Text-To-Text Models”, Ni et al 2021
- “Time-Aware Language Models As Temporal Knowledge Bases”, Dhingra et al 2021
- “Implicit Representations of Meaning in Neural Language Models”, Li et al 2021
- “Explainable Multi-Hop Verbal Reasoning Through Internal Monologue”, Liang et al 2021
- “ByT5: Towards a Token-Free Future With Pre-Trained Byte-To-Byte Models”, Xue et al 2021
- “Carbon Emissions and Large Neural Network Training”, Patterson et al 2021
- “The Power of Scale for Parameter-Efficient Prompt Tuning”, Lester et al 2021
- “UNICORN on RAINBOW: A Universal Commonsense Reasoning Model on a New Multitask Benchmark”, Lourie et al 2021
- “GLM: General Language Model Pretraining With Autoregressive Blank Infilling”, Du et al 2021
- “Investigating the Limitations of the Transformers With Simple Arithmetic Tasks”, Nogueira et al 2021
- “VL-T5: Unifying Vision-And-Language Tasks via Text Generation”, Cho et al 2021
- “Switch Transformers: Scaling to Trillion Parameter Models With Simple and Efficient Sparsity”, Fedus et al 2021
- “MT5: A Massively Multilingual Pre-Trained Text-To-Text Transformer”, Xue et al 2020
- “TextSETTR: Few-Shot Text Style Extraction and Tunable Targeted Restyling”, Riley et al 2020
- “MMLU: Measuring Massive Multitask Language Understanding”, Hendrycks et al 2020
- “ProtTrans: Towards Cracking the Language of Life’s Code Through Self-Supervised Deep Learning and High Performance Computing”, Elnaggar et al 2020
- “Leveraging Passage Retrieval With Generative Models for Open Domain Question Answering”, Izacard & Grave 2020
- “UnifiedQA: Crossing Format Boundaries With a Single QA System”, Khashabi et al 2020
- “TTTTTackling WinoGrande Schemas”, Lin et al 2020
- “How Much Knowledge Can You Pack Into the Parameters of a Language Model?”, Roberts et al 2020
- “CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning”, Lin et al 2019
- “T5: Exploring the Limits of Transfer Learning With a Unified Text-To-Text Transformer”, Raffel et al 2019
- “Colin Raffel”
- “AIGText/Glyph-ByT5: [ECCV2024] This Is an Official Inference Code”, Liu et al 2026
- “
t5: Model Code for Inferencing T5”, NovelAI 2026 - “Google-Deepmind/regress-Lm: Library for Text-To-Text Regression, Applicable to Any Input String Representation and Allows Pretraining and Fine-Tuning over Multiple Regression Tasks”
- “
scaling_transformersRepo”, Google 2026 - “Lintang Sutawika Homepage”, Sutawika 2026
- “Transformer-VAE for Program Synthesis”
- “Jason Wei”
- “What Happened to BERT & T5? On Transformer Encoders, PrefixLM and Denoising Objectives”, Tay 2026
- colinraffel
- Sort By Magic
- Miscellaneous
- Bibliography
See Also
Links
“Contextualizing Ancient Texts With Generative Neural Networks”, Assael et al 2025
Contextualizing ancient texts with generative neural networks
“Performance Prediction for Large Systems via Text-To-Text Regression”, Akhauri et al 2025
Performance Prediction for Large Systems via Text-to-Text Regression
“Vec2vec: Harnessing the Universal Geometry of Embeddings”, Jha et al 2025
“Emuru: Zero-Shot Styled Text Image Generation, but Make It Autoregressive”, Pippi et al 2025
Emuru: Zero-Shot Styled Text Image Generation, but Make It Autoregressive
“On Teacher Hacking in Language Model Distillation”, Tiapkin et al 2025
“Glyph-ByT5-V2: A Strong Aesthetic Baseline for Accurate Multilingual Visual Text Rendering”, Liu et al 2024
Glyph-ByT5-v2: A Strong Aesthetic Baseline for Accurate Multilingual Visual Text Rendering
“Evaluating Text-To-Visual Generation With Image-To-Text Generation”, Lin et al 2024
Evaluating Text-to-Visual Generation with Image-to-Text Generation
“Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering”, Liu et al 2024
Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering
“Chronos: Learning the Language of Time Series”, Ansari et al 2024
“ELLA: Equip Diffusion Models With LLM for Enhanced Semantic Alignment”, Hu et al 2024
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
“How to Train Data-Efficient LLMs”, Sachdeva et al 2024
“Time Vectors: Time Is Encoded in the Weights of Finetuned Language Models”, Nylund et al 2023
Time Vectors: Time is Encoded in the Weights of Finetuned Language Models
“Rich Human Feedback for Text-To-Image Generation”, Liang et al 2023
“Helping or Herding? Reward Model Ensembles Mitigate but Do Not Eliminate Reward Hacking”, Eisenstein et al 2023
Helping or Herding? Reward Model Ensembles Mitigate but do not Eliminate Reward Hacking
“Instruction-Tuning Aligns LLMs to the Human Brain”, Aw et al 2023
“PEARL: Personalizing Large Language Model Writing Assistants With Generation-Calibrated Retrievers”, Mysore et al 2023
PEARL: Personalizing Large Language Model Writing Assistants with Generation-Calibrated Retrievers
“UT5: Pretraining Non Autoregressive T5 With Unrolled Denoising”, Salem et al 2023
UT5: Pretraining Non autoregressive T5 with unrolled denoising
“FreshLLMs: Refreshing Large Language Models With Search Engine Augmentation”, Vu et al 2023
FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation
“MADLAD-400: A Multilingual And Document-Level Large Audited Dataset”, Kudugunta et al 2023
MADLAD-400: A Multilingual And Document-Level Large Audited Dataset
“LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models”, Guha et al 2023
LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models
“RAVEN: In-Context Learning With Retrieval-Augmented Encoder-Decoder Language Models”, Huang et al 2023
RAVEN: In-Context Learning with Retrieval-Augmented Encoder-Decoder Language Models
“Learning to Model the World With Language”, Lin et al 2023
“DialogStudio: Towards Richest and Most Diverse Unified Dataset Collection for Conversational AI”, Zhang et al 2023
DialogStudio: Towards Richest and Most Diverse Unified Dataset Collection for Conversational AI
“No Train No Gain: Revisiting Efficient Training Algorithms For Transformer-Based Language Models”, Kaddour et al 2023
No Train No Gain: Revisiting Efficient Training Algorithms For Transformer-based Language Models
“ReLoRA: High-Rank Training Through Low-Rank Updates”, Lialin et al 2023
“GKD: Generalized Knowledge Distillation for Auto-Regressive Sequence Models”, Agarwal et al 2023
GKD: Generalized Knowledge Distillation for Auto-regressive Sequence Models
“PaLI-X: On Scaling up a Multilingual Vision and Language Model”, Chen et al 2023
PaLI-X: On Scaling up a Multilingual Vision and Language Model
“Learning to Generate Novel Scientific Directions With Contextualized Literature-Based Discovery”, Wang et al 2023
Learning to Generate Novel Scientific Directions with Contextualized Literature-based Discovery
“SoundStorm: Efficient Parallel Audio Generation”, Borsos et al 2023
“Distilling Step-By-Step! Outperforming Larger Language Models With Less Training Data and Smaller Model Sizes”, Hsieh et al 2023
“LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions”, Wu et al 2023
LaMini-LM: A Diverse Herd of Distilled Models from Large-Scale Instructions
“TANGO: Text-To-Audio Generation Using Instruction-Tuned LLM and Latent Diffusion Model”, Ghosal et al 2023
TANGO: Text-to-Audio Generation using Instruction-Tuned LLM and Latent Diffusion Model
“Learning to Compress Prompts With Gist Tokens”, Mu et al 2023
“BiLD: Big Little Transformer Decoder”, Kim et al 2023
“Speak, Read and Prompt (SPEAR-TTS): High-Fidelity Text-To-Speech With Minimal Supervision”, Kharitonov et al 2023
Speak, Read and Prompt (SPEAR-TTS): High-Fidelity Text-to-Speech with Minimal Supervision
“BLIP-2: Bootstrapping Language-Image Pre-Training With Frozen Image Encoders and Large Language Models”, Li et al 2023
“InPars-Light: Cost-Effective Unsupervised Training of Efficient Rankers”, Boytsov et al 2023
InPars-Light: Cost-Effective Unsupervised Training of Efficient Rankers
“Muse: Text-To-Image Generation via Masked Generative Transformers”, Chang et al 2023
Muse: Text-To-Image Generation via Masked Generative Transformers
“Character-Aware Models Improve Visual Text Rendering”, Liu et al 2022
“Unnatural Instructions: Tuning Language Models With (Almost) No Human Labor”, Honovich et al 2022
Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor
“One Embedder, Any Task: Instruction-Finetuned Text Embeddings (INSTRUCTOR)”, Su et al 2022
One Embedder, Any Task: Instruction-Finetuned Text Embeddings (INSTRUCTOR)
“ERNIE-Code: Beyond English-Centric Cross-Lingual Pretraining for Programming Languages”, Chai et al 2022
ERNIE-Code: Beyond English-Centric Cross-lingual Pretraining for Programming Languages
“Sparse Upcycling: Training Mixture-Of-Experts from Dense Checkpoints”, Komatsuzaki et al 2022
Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints
“Fast Inference from Transformers via Speculative Decoding”, Leviathan et al 2022
“I Can’t Believe There’s No Images! Learning Visual Tasks Using Only Language Data”, Gu et al 2022
I Can’t Believe There’s No Images! Learning Visual Tasks Using only Language Data
“TART: Task-Aware Retrieval With Instructions”, Asai et al 2022
“BLOOMZ/mT0: Crosslingual Generalization through Multitask Finetuning”, Muennighoff et al 2022
BLOOMZ/mT0: Crosslingual Generalization through Multitask Finetuning
“EDiff-I: Text-To-Image Diffusion Models With an Ensemble of Expert Denoisers”, Balaji et al 2022
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
“ProMoT: Preserving In-Context Learning Ability in Large Language Model Fine-Tuning”, Wang et al 2022
ProMoT: Preserving In-Context Learning ability in Large Language Model Fine-tuning
“Help Me Write a Poem: Instruction Tuning As a Vehicle for Collaborative Poetry Writing (CoPoet)”, Chakrabarty et al 2022
Help me write a poem: Instruction Tuning as a Vehicle for Collaborative Poetry Writing (CoPoet)
“FLAN: Scaling Instruction-Finetuned Language Models”, Chung et al 2022
“Table-To-Text Generation and Pre-Training With TabT5”, Andrejczuk et al 2022
“GLM-130B: An Open Bilingual Pre-Trained Model”, Zeng et al 2022
“Context Distillation: Learning by Distilling Context”, Snell et al 2022
“SAP: Bidirectional Language Models Are Also Few-Shot Learners”, Patel et al 2022
SAP: Bidirectional Language Models Are Also Few-shot Learners
“FiD-Light: Efficient and Effective Retrieval-Augmented Text Generation”, Hofstätter et al 2022
FiD-Light: Efficient and Effective Retrieval-Augmented Text Generation
“PaLI: A Jointly-Scaled Multilingual Language-Image Model”, Chen et al 2022
“Training a T5 Using Lab-Sized Resources”, Ciosici & Derczynski 2022
“PEER: A Collaborative Language Model”, Schick et al 2022
“Z-Code++: A Pre-Trained Language Model Optimized for Abstractive Summarization”, He et al 2022
Z-Code++: A Pre-trained Language Model Optimized for Abstractive Summarization
“Limitations of Language Models in Arithmetic and Symbolic Induction”, Qian et al 2022
Limitations of Language Models in Arithmetic and Symbolic Induction
“RealTime QA: What’s the Answer Right Now?”, Kasai et al 2022
“Forecasting Future World Events With Neural Networks”, Zou et al 2022
“RST: ReStructured Pre-Training”, Yuan & Liu 2022
“Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems”, FitzGerald et al 2022
“Boosting Search Engines With Interactive Agents”, Ciaramita et al 2022
“EdiT5: Semi-Autoregressive Text-Editing With T5 Warm-Start”, Mallinson et al 2022
“CT0: Fine-Tuned Language Models Are Continual Learners”, Scialom et al 2022
“Imagen: Photorealistic Text-To-Image Diffusion Models With Deep Language Understanding”, Saharia et al 2022
Imagen: Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
“Automated Crossword Solving”, Wallace et al 2022
“UL2: Unifying Language Learning Paradigms”, Tay et al 2022
“Tk-Instruct: Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks”, Wang et al 2022
Tk-Instruct: Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks
“What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?”, Wang et al 2022
What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?
“ByT5 Model for Massively Multilingual Grapheme-To-Phoneme Conversion”, Zhu et al 2022
ByT5 model for massively multilingual grapheme-to-phoneme conversion
“Pathways: Asynchronous Distributed Dataflow for ML”, Barham et al 2022
“HyperPrompt: Prompt-Based Task-Conditioning of Transformers”, He et al 2022
“Using Natural Language Prompts for Machine Translation”, Garcia & Firat 2022
“UnifiedQA-V2: Stronger Generalization via Broader Cross-Format Training”, Khashabi et al 2022
UnifiedQA-v2: Stronger Generalization via Broader Cross-Format Training
“Mixture-Of-Experts With Expert Choice Routing”, Zhou et al 2022
“InPars: Data Augmentation for Information Retrieval Using Large Language Models”, Bonifacio et al 2022
InPars: Data Augmentation for Information Retrieval using Large Language Models
“Reasoning Like Program Executors”, Pi et al 2022
“CommonsenseQA 2.0: Exposing the Limits of AI through Gamification”, Talmor et al 2022
CommonsenseQA 2.0: Exposing the Limits of AI through Gamification
“QuALITY: Question Answering With Long Input Texts, Yes!”, Pang et al 2021
“FRUIT: Faithfully Reflecting Updated Information in Text”, IV et al 2021
“Large Dual Encoders Are Generalizable Retrievers”, Ni et al 2021
“LongT5: Efficient Text-To-Text Transformer for Long Sequences”, Guo et al 2021
LongT5: Efficient Text-To-Text Transformer for Long Sequences
“Scaling Language Models: Methods, Analysis & Insights from Training Gopher”, Rae et al 2021
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
“ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning”, Aribandi et al 2021
ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning
“Fast Model Editing at Scale”, Mitchell et al 2021
“T0: Multitask Prompted Training Enables Zero-Shot Task Generalization”, Sanh et al 2021
T0: Multitask Prompted Training Enables Zero-Shot Task Generalization
“LFPT5: A Unified Framework for Lifelong Few-Shot Language Learning Based on Prompt Tuning of T5”, Qin & Joty 2021
LFPT5: A Unified Framework for Lifelong Few-shot Language Learning Based on Prompt Tuning of T5
“Can Machines Learn Morality? The Delphi Experiment”, Jiang et al 2021
“Scale Efficiently: Insights from Pre-Training and Fine-Tuning Transformers”, Tay et al 2021
Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers
“TruthfulQA: Measuring How Models Mimic Human Falsehoods”, Lin et al 2021
“General-Purpose Question-Answering With Macaw”, Tafjord & Clark 2021
“Sentence-T5: Scalable Sentence Encoders from Pre-Trained Text-To-Text Models”, Ni et al 2021
Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models
“Time-Aware Language Models As Temporal Knowledge Bases”, Dhingra et al 2021
“Implicit Representations of Meaning in Neural Language Models”, Li et al 2021
Implicit Representations of Meaning in Neural Language Models
“Explainable Multi-Hop Verbal Reasoning Through Internal Monologue”, Liang et al 2021
Explainable Multi-hop Verbal Reasoning Through Internal Monologue
“ByT5: Towards a Token-Free Future With Pre-Trained Byte-To-Byte Models”, Xue et al 2021
ByT5: Towards a token-free future with pre-trained byte-to-byte models
“Carbon Emissions and Large Neural Network Training”, Patterson et al 2021
“The Power of Scale for Parameter-Efficient Prompt Tuning”, Lester et al 2021
“UNICORN on RAINBOW: A Universal Commonsense Reasoning Model on a New Multitask Benchmark”, Lourie et al 2021
UNICORN on RAINBOW: A Universal Commonsense Reasoning Model on a New Multitask Benchmark
“GLM: General Language Model Pretraining With Autoregressive Blank Infilling”, Du et al 2021
GLM: General Language Model Pretraining with Autoregressive Blank Infilling
“Investigating the Limitations of the Transformers With Simple Arithmetic Tasks”, Nogueira et al 2021
Investigating the Limitations of the Transformers with Simple Arithmetic Tasks
“VL-T5: Unifying Vision-And-Language Tasks via Text Generation”, Cho et al 2021
VL-T5: Unifying Vision-and-Language Tasks via Text Generation
“Switch Transformers: Scaling to Trillion Parameter Models With Simple and Efficient Sparsity”, Fedus et al 2021
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
“MT5: A Massively Multilingual Pre-Trained Text-To-Text Transformer”, Xue et al 2020
mT5: A massively multilingual pre-trained text-to-text transformer
“TextSETTR: Few-Shot Text Style Extraction and Tunable Targeted Restyling”, Riley et al 2020
TextSETTR: Few-Shot Text Style Extraction and Tunable Targeted Restyling
“MMLU: Measuring Massive Multitask Language Understanding”, Hendrycks et al 2020
“ProtTrans: Towards Cracking the Language of Life’s Code Through Self-Supervised Deep Learning and High Performance Computing”, Elnaggar et al 2020
“Leveraging Passage Retrieval With Generative Models for Open Domain Question Answering”, Izacard & Grave 2020
Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering
“UnifiedQA: Crossing Format Boundaries With a Single QA System”, Khashabi et al 2020
UnifiedQA: Crossing Format Boundaries With a Single QA System
“TTTTTackling WinoGrande Schemas”, Lin et al 2020
“How Much Knowledge Can You Pack Into the Parameters of a Language Model?”, Roberts et al 2020
How Much Knowledge Can You Pack Into the Parameters of a Language Model?
“CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning”, Lin et al 2019
CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning
“T5: Exploring the Limits of Transfer Learning With a Unified Text-To-Text Transformer”, Raffel et al 2019
T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
“Colin Raffel”
“AIGText/Glyph-ByT5: [ECCV2024] This Is an Official Inference Code”, Liu et al 2026
AIGText/Glyph-ByT5: [ECCV2024] This is an official inference code
“t5: Model Code for Inferencing T5”, NovelAI 2026
“Google-Deepmind/regress-Lm: Library for Text-To-Text Regression, Applicable to Any Input String Representation and Allows Pretraining and Fine-Tuning over Multiple Regression Tasks”
“scaling_transformers Repo”, Google 2026
“Lintang Sutawika Homepage”, Sutawika 2026
“Transformer-VAE for Program Synthesis”
“Jason Wei”
“What Happened to BERT & T5? On Transformer Encoders, PrefixLM and Denoising Objectives”, Tay 2026
What happened to BERT & T5? On Transformer Encoders, PrefixLM and Denoising Objectives
colinraffel
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
text-contextualization
multilingual-datasets conversational-ai dataset-collection document-level
text-to-audio
model-personalization
instruction-tuning
moral-reasoning
collaborative-modeling
temporal-reasoning
byte-to-byte
efficient-training
Miscellaneous
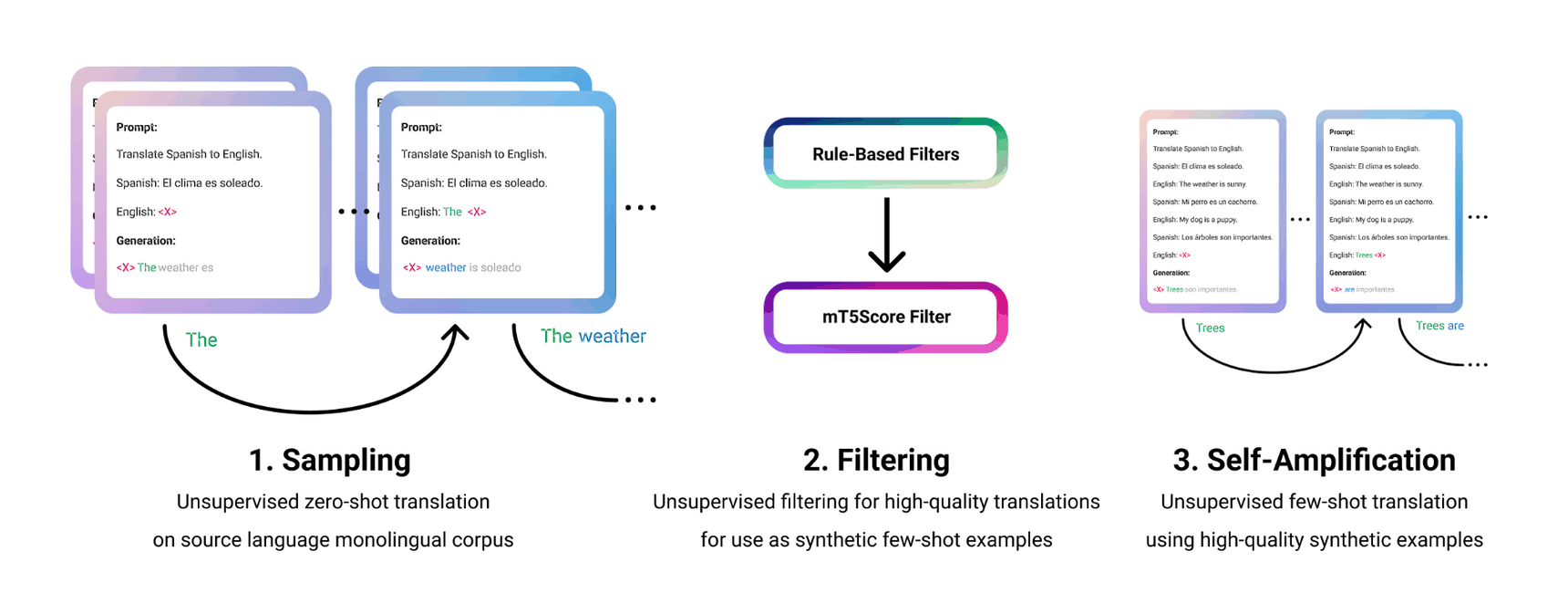
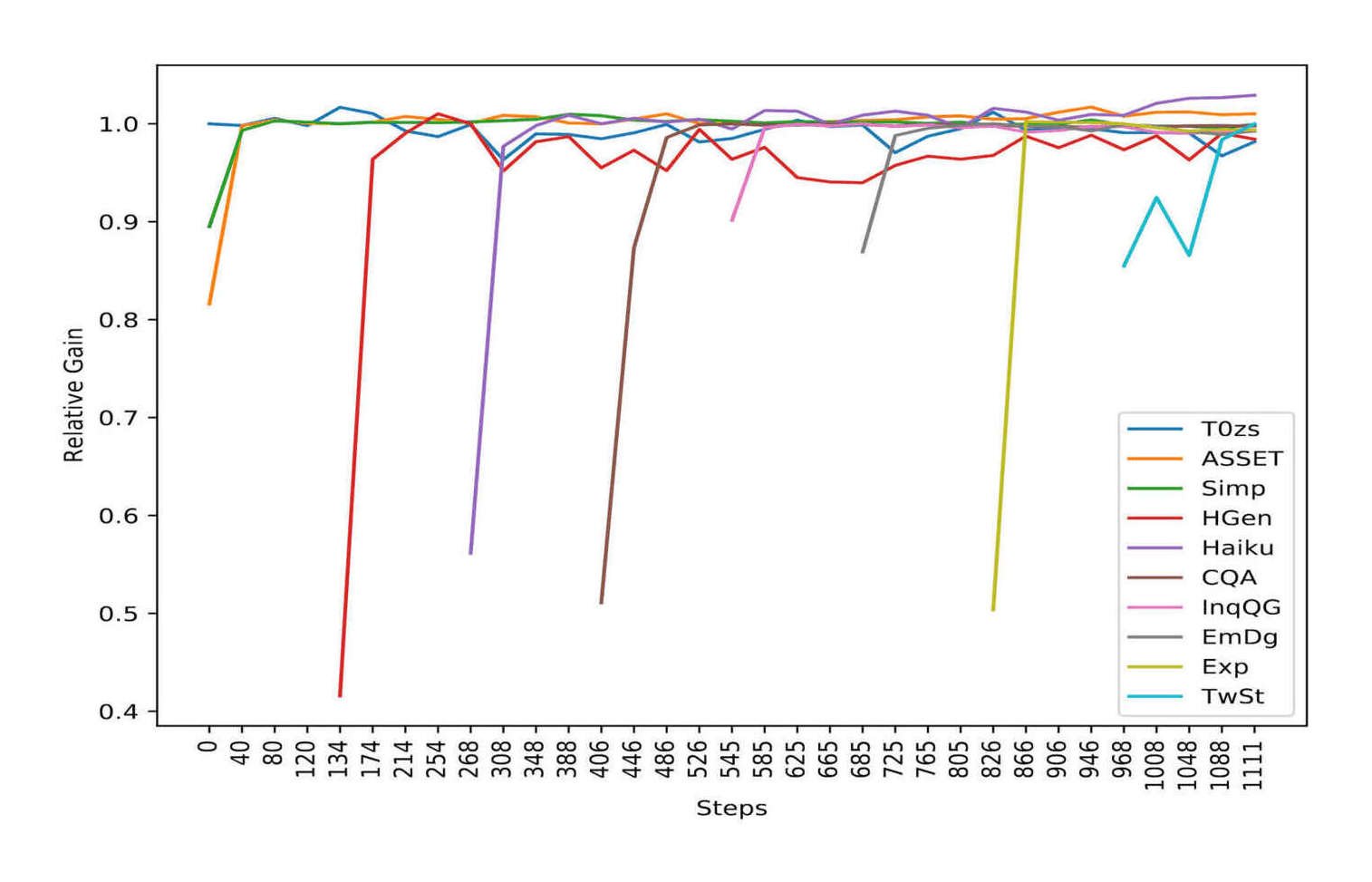
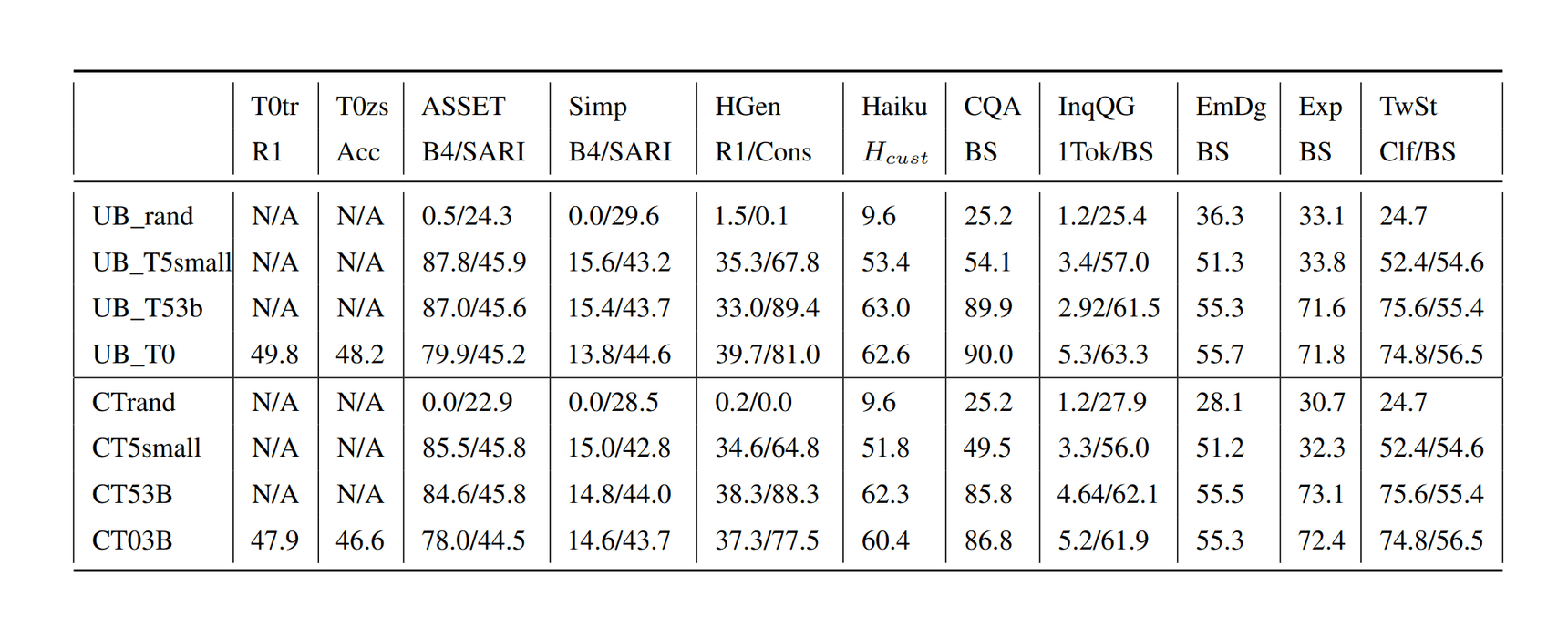
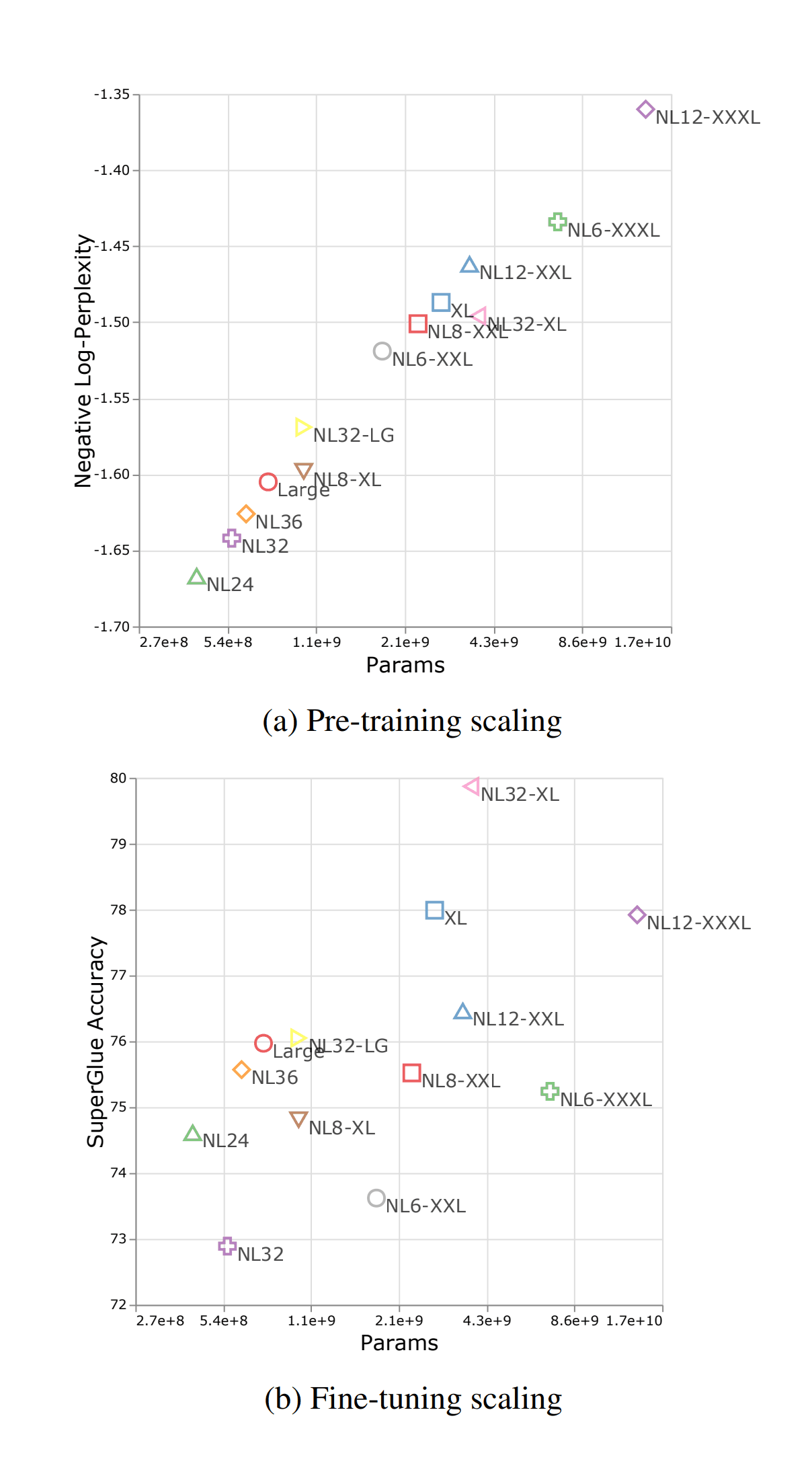
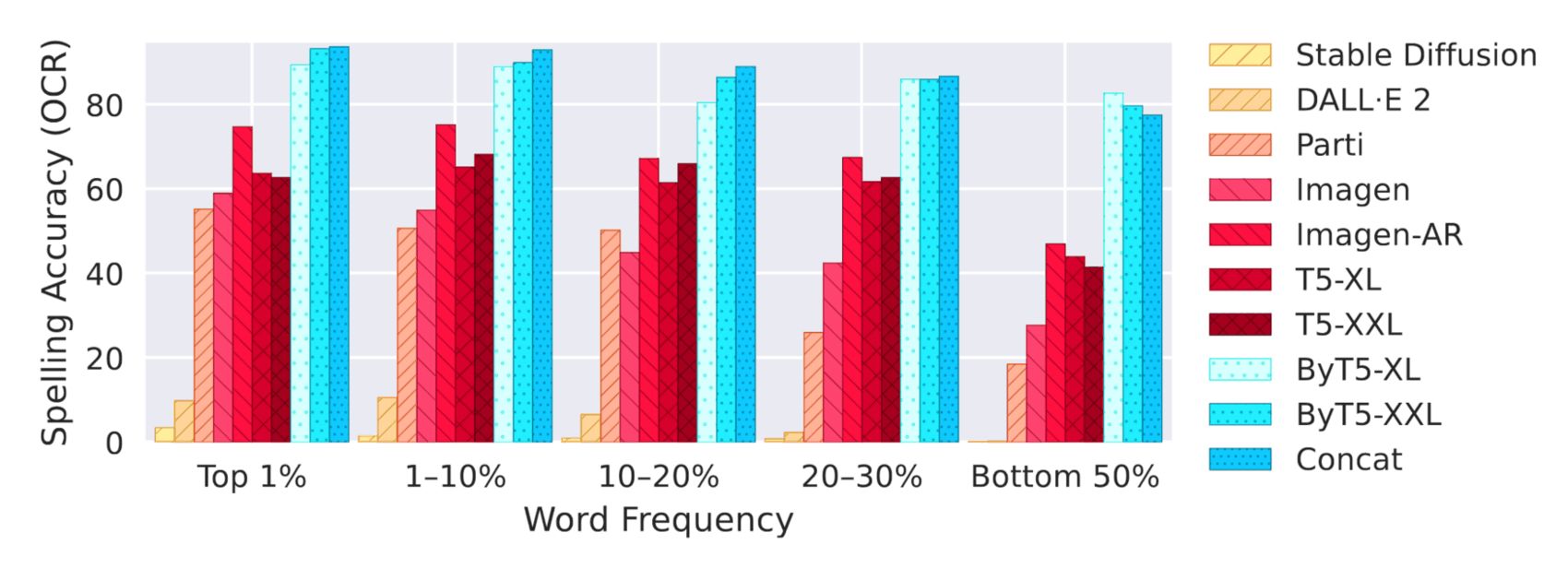
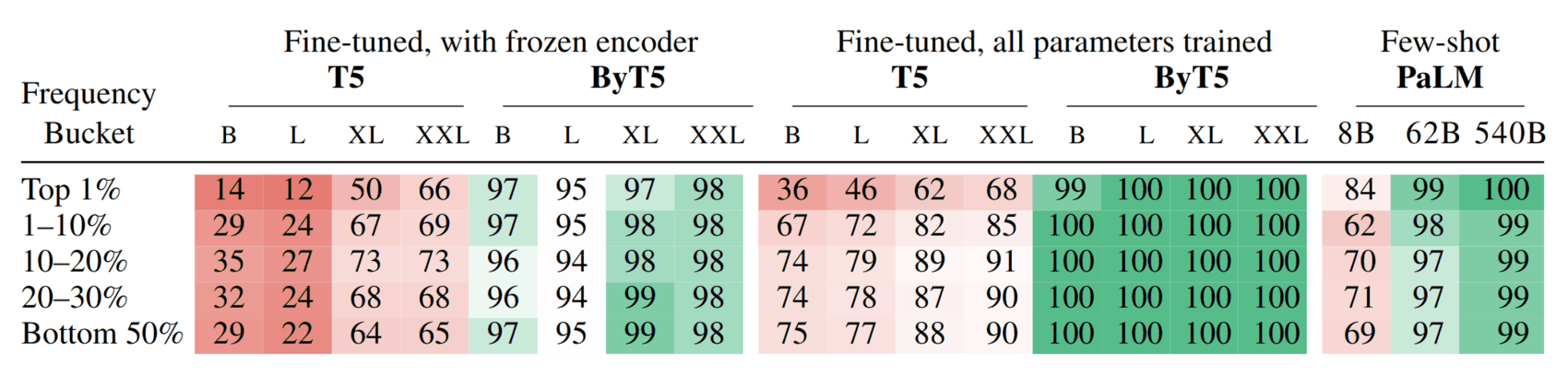
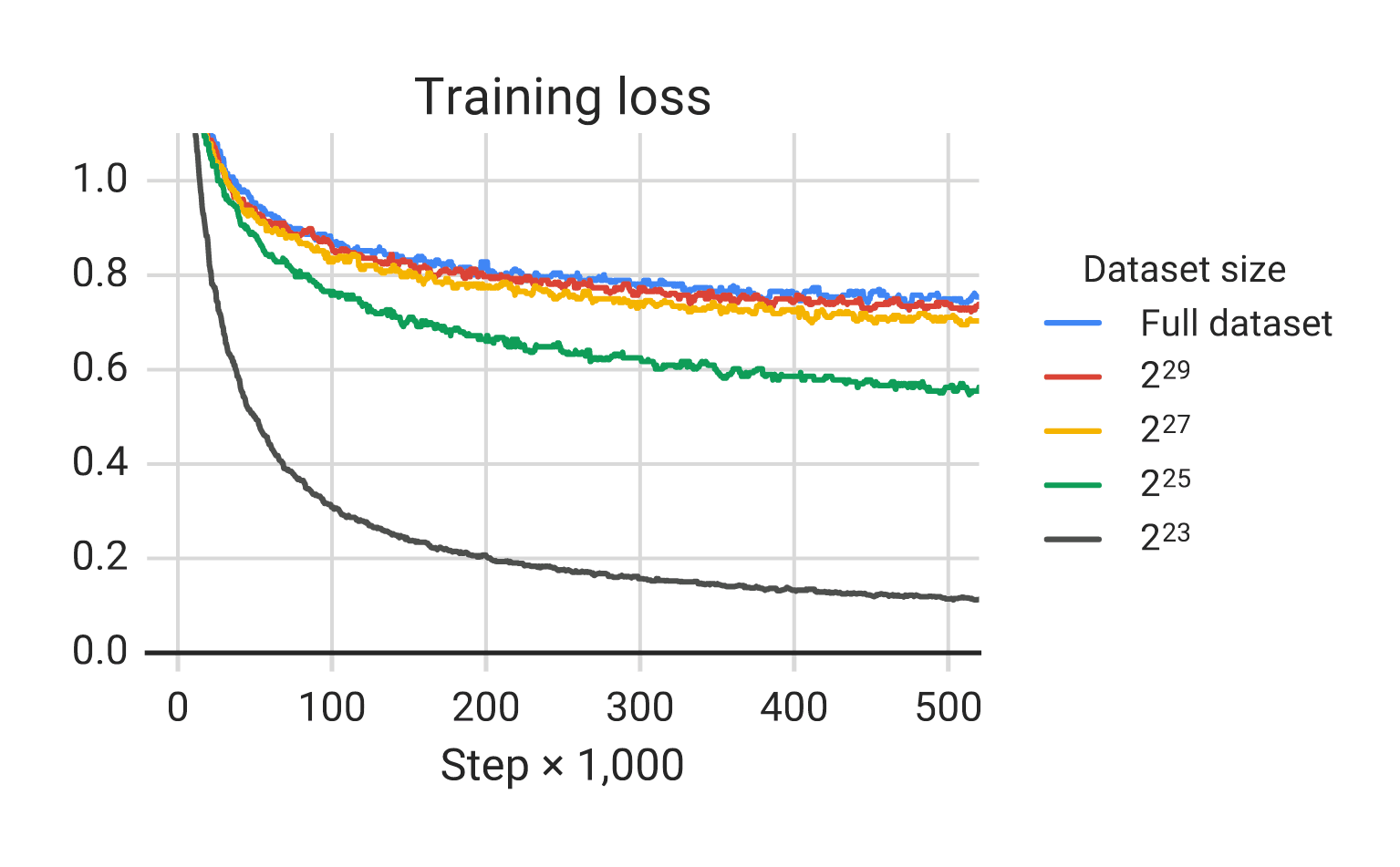
/doc/ai/nn/transformer/t5/2022-patel-figure2-mt5fewshotpromptingbootstrapselfdistillationprocess.png/doc/ai/nn/transformer/t5/2021-tay-figure1-t5pretrainingvsfinetuningtransferscaling.png/doc/ai/nn/tokenization/2021-liu-table1-spellingtestforbyt5vst5vspalmshowsbyt5spellsmuchbetter.png/doc/ai/nn/transformer/t5/2019-raffel-figure6-effectsofdatasetduplicationont5traininglosscurves.pnghttps://aclanthology.org/2023.findings-emnlp.18/View External Link:
https://blog.eleuther.ai/pile-t5/View External Link:
https://colab.research.google.com/drive/1-ROO7L09EupLFLQM-TWgDHa5-FIOdLLhhttps://github.com/google-research/google-research/tree/master/ul2https://www.forbes.com/sites/rashishrivastava/2023/04/11/writer-generative-ai/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://www.nature.com/articles/s41586-025-09292-5#deepmind: “Contextualizing Ancient Texts With Generative Neural Networks”,https://arxiv.org/abs/2503.17074: “Emuru: Zero-Shot Styled Text Image Generation, but Make It Autoregressive”,https://arxiv.org/abs/2406.10208#microsoft: “Glyph-ByT5-V2: A Strong Aesthetic Baseline for Accurate Multilingual Visual Text Rendering”,https://arxiv.org/abs/2404.01291: “Evaluating Text-To-Visual Generation With Image-To-Text Generation”,https://arxiv.org/abs/2403.09622#microsoft: “Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering”,https://arxiv.org/abs/2310.03214#google: “FreshLLMs: Refreshing Large Language Models With Search Engine Augmentation”,https://arxiv.org/abs/2307.06440: “No Train No Gain: Revisiting Efficient Training Algorithms For Transformer-Based Language Models”,https://arxiv.org/abs/2305.09636#google: “SoundStorm: Efficient Parallel Audio Generation”,https://arxiv.org/abs/2305.02301#google: “Distilling Step-By-Step! Outperforming Larger Language Models With Less Training Data and Smaller Model Sizes”,https://arxiv.org/abs/2304.13731: “TANGO: Text-To-Audio Generation Using Instruction-Tuned LLM and Latent Diffusion Model”,https://arxiv.org/abs/2304.08467: “Learning to Compress Prompts With Gist Tokens”,https://arxiv.org/abs/2301.12597#salesforce: “BLIP-2: Bootstrapping Language-Image Pre-Training With Frozen Image Encoders and Large Language Models”,https://arxiv.org/abs/2301.00704#google: “Muse: Text-To-Image Generation via Masked Generative Transformers”,https://arxiv.org/abs/2212.10562#google: “Character-Aware Models Improve Visual Text Rendering”,https://arxiv.org/abs/2212.09741: “One Embedder, Any Task: Instruction-Finetuned Text Embeddings (INSTRUCTOR)”,https://arxiv.org/abs/2212.05055#google: “Sparse Upcycling: Training Mixture-Of-Experts from Dense Checkpoints”,https://arxiv.org/abs/2211.01786: “BLOOMZ/mT0: Crosslingual Generalization through Multitask Finetuning”,https://arxiv.org/abs/2211.01324#nvidia: “EDiff-I: Text-To-Image Diffusion Models With an Ensemble of Expert Denoisers”,https://arxiv.org/abs/2210.13669: “Help Me Write a Poem: Instruction Tuning As a Vehicle for Collaborative Poetry Writing (CoPoet)”,https://arxiv.org/abs/2210.11416#google: “FLAN: Scaling Instruction-Finetuned Language Models”,https://arxiv.org/abs/2210.02414#baai: “GLM-130B: An Open Bilingual Pre-Trained Model”,https://arxiv.org/abs/2209.14500: “SAP: Bidirectional Language Models Are Also Few-Shot Learners”,https://arxiv.org/abs/2208.11663#facebook: “PEER: A Collaborative Language Model”,https://arxiv.org/abs/2208.09770#microsoft: “Z-Code++: A Pre-Trained Language Model Optimized for Abstractive Summarization”,https://arxiv.org/abs/2206.15474: “Forecasting Future World Events With Neural Networks”,https://arxiv.org/abs/2206.07808#amazon: “Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems”,https://openreview.net/forum?id=0ZbPmmB61g#google: “Boosting Search Engines With Interactive Agents”,https://arxiv.org/abs/2205.12209#google: “EdiT5: Semi-Autoregressive Text-Editing With T5 Warm-Start”,https://arxiv.org/abs/2205.12393: “CT0: Fine-Tuned Language Models Are Continual Learners”,https://arxiv.org/abs/2205.11487#google: “Imagen: Photorealistic Text-To-Image Diffusion Models With Deep Language Understanding”,https://arxiv.org/abs/2205.09665#bair: “Automated Crossword Solving”,https://arxiv.org/abs/2205.05131#google: “UL2: Unifying Language Learning Paradigms”,https://arxiv.org/abs/2204.07705: “Tk-Instruct: Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks”,https://arxiv.org/abs/2204.03067: “ByT5 Model for Massively Multilingual Grapheme-To-Phoneme Conversion”,https://arxiv.org/abs/2203.00759: “HyperPrompt: Prompt-Based Task-Conditioning of Transformers”,https://arxiv.org/abs/2202.11822#google: “Using Natural Language Prompts for Machine Translation”,https://arxiv.org/abs/2202.09368#google: “Mixture-Of-Experts With Expert Choice Routing”,https://arxiv.org/abs/2201.11473#microsoft: “Reasoning Like Program Executors”,https://arxiv.org/abs/2201.05320#allen: “CommonsenseQA 2.0: Exposing the Limits of AI through Gamification”,https://arxiv.org/abs/2112.07899#google: “Large Dual Encoders Are Generalizable Retrievers”,https://arxiv.org/abs/2112.07916#google: “LongT5: Efficient Text-To-Text Transformer for Long Sequences”,https://arxiv.org/abs/2112.11446#deepmind: “Scaling Language Models: Methods, Analysis & Insights from Training Gopher”,https://arxiv.org/abs/2110.11309: “Fast Model Editing at Scale”,https://arxiv.org/abs/2109.10686#google: “Scale Efficiently: Insights from Pre-Training and Fine-Tuning Transformers”,https://arxiv.org/abs/2109.07958: “TruthfulQA: Measuring How Models Mimic Human Falsehoods”,https://arxiv.org/abs/2109.02593#allen: “General-Purpose Question-Answering With Macaw”,https://arxiv.org/abs/2108.08877#google: “Sentence-T5: Scalable Sentence Encoders from Pre-Trained Text-To-Text Models”,https://arxiv.org/abs/2106.00737: “Implicit Representations of Meaning in Neural Language Models”,https://arxiv.org/abs/2105.13626#google: “ByT5: Towards a Token-Free Future With Pre-Trained Byte-To-Byte Models”,https://arxiv.org/abs/2104.10350#google: “Carbon Emissions and Large Neural Network Training”,https://arxiv.org/abs/2103.13009#allen: “UNICORN on RAINBOW: A Universal Commonsense Reasoning Model on a New Multitask Benchmark”,https://arxiv.org/abs/2101.03961#google: “Switch Transformers: Scaling to Trillion Parameter Models With Simple and Efficient Sparsity”,https://arxiv.org/abs/2009.03300: “MMLU: Measuring Massive Multitask Language Understanding”,https://arxiv.org/abs/2007.06225: “ProtTrans: Towards Cracking the Language of Life’s Code Through Self-Supervised Deep Learning and High Performance Computing”,