‘low-precision NN’ directory
- See Also
- Links
- “Soulplayer-C64: A Real 25k-Parameter Transformer Running on a Commodore 64!”, gizmo64k 2026
- “EGGROLL: Evolution Strategies at the Hyperscale”, Sarkar et al 2025
- “1 Bit Is All We Need: Binary Normalized Neural Networks”, Cabral et al 2025
- “Compiling a Differentiable Logic Gate Neural Net to C for a 1,744× Speedup”, Clayton 2025
- “Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures”, Zhao et al 2025
- “BitNet B1.58 2B4T Technical Report”, Ma et al 2025
- “MVDRAM: Enabling GeMV Execution in Unmodified DRAM for Low-Bit LLM Acceleration”, Kubo et al 2025
- “Compute-Optimal LLMs Provably Generalize Better With Scale”, Finzi et al 2025
- “μnit Scaling: Simple and Scalable FP8 LLM Training”, Narayan et al 2025
- “2:4 Sparse Llama: Smaller Models for Efficient GPU Inference”, Kurtić et al 2024
- “Model Equality Testing: Which Model Is This API Serving?”, Gao et al 2024
- “Addition Is All You Need for Energy-Efficient Language Models”, Luo & Sun 2024
- “Robust Training of Neural Networks at Arbitrary Precision and Sparsity”, Ye et al 2024
- “A Visual Guide to Quantization”, Grootendorst 2024
- “OpenDiLoCo: An Open-Source Framework for Globally Distributed Low-Communication Training”, Jaghouar et al 2024
- “Probing the Decision Boundaries of In-Context Learning in Large Language Models”, Zhao et al 2024
- “Nemotron-4 340B Technical Report”, Adler et al 2024
- “Scalable Matmul-Free Language Modeling”, Zhu et al 2024
- “BOLD: Boolean Logic Deep Learning”, Nguyen et al 2024
- “Neural Networks (MNIST Inference) on the ‘3¢’ Microcontroller”, cpldcpu 2024
- “How Good Are Low-Bit Quantized LLaMA-3 Models? An Empirical Study”, Huang et al 2024
- “Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws”, Allen-Zhu & Li 2024
- “LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models”, Zheng et al 2024
- “Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression”, Hong et al 2024
- “The Era of 1-Bit LLMs: All Large Language Models Are in 1.58 Bits”, Ma et al 2024
- “FP6-LLM: Efficiently Serving Large Language Models Through FP6-Centric Algorithm-System Co-Design”, Xia et al 2024
- “Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws”, Sardana & Frankle 2023
- “TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones”, Yuan et al 2023
- “LLM-FP4: 4-Bit Floating-Point Quantized Transformers”, Liu et al 2023
- “Training Transformers With 4-Bit Integers”, Xi et al 2023
- “SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression”, Dettmers et al 2023
- “Binary and Ternary Natural Language Generation”, Liu et al 2023
- “AWQ: Activation-Aware Weight Quantization for LLM Compression and Acceleration”, Lin et al 2023
- “Big-PERCIVAL: Exploring the Native Use of 64-Bit Posit Arithmetic in Scientific Computing”, Mallasén et al 2023
- “Int-4 LLaMa Is Not Enough—Int-3 and Beyond: More Compression, Easier to Build Apps on LLMs That Run Locally”, nolano.org 2023
- “SpikeGPT: Generative Pre-Trained Language Model With Spiking Neural Networks”, Zhu et al 2023
- “BMT: Binarized Neural Machine Translation”, Zhang et al 2023
- “Self-Compressing Neural Networks”, Cséfalvay & Imber 2023
- “Who Says Elephants Can’t Run: Bringing Large Scale MoE Models into Cloud Scale Production”, Kim et al 2022
- “SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models”, Xiao et al 2022
- “Efficiently Scaling Transformer Inference”, Pope et al 2022
- “GPTQ: Accurate Post-Training Quantization for Generative Pre-Trained Transformers”, Frantar et al 2022
- “Fast DistilBERT on CPUs”, Shen et al 2022
- “Broken Neural Scaling Laws”, Caballero et al 2022
- “GLM-130B: An Open Bilingual Pre-Trained Model”, Zeng et al 2022
- “FP8 Formats for Deep Learning”, Micikevicius et al 2022
- “
LLM.int8(): 8-Bit Matrix Multiplication for Transformers at Scale”, Dettmers et al 2022 - “Is Integer Arithmetic Enough for Deep Learning Training?”, Ghaffari et al 2022
- “On-Device Training Under 256KB Memory”, Lin et al 2022
- “How to Train Accurate BNNs for Embedded Systems?”, Putter & Corporaal 2022
- “Director: Deep Hierarchical Planning from Pixels”, Hafner et al 2022
- “8-Bit Numerical Formats for Deep Neural Networks”, Noune et al 2022
- “XTC: Extreme Compression for Pre-Trained Transformers Made Simple and Efficient”, Wu et al 2022
- “ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers”, Yao et al 2022
- “Matryoshka Representations for Adaptive Deployment”, Kusupati et al 2022
- “PLAID: An Efficient Engine for Late Interaction Retrieval”, Santhanam et al 2022
- “Maximizing Communication Efficiency for Large-Scale Training via 0/1 Adam”, Lu et al 2022
- “Is Programmable Overhead Worth The Cost? How Much Do We Pay for a System to Be Programmable? It Depends upon Who You Ask”, Bailey 2022
- “Boosted Dense Retriever”, Lewis et al 2021
- “FQ-ViT: Fully Quantized Vision Transformer without Retraining”, Lin et al 2021
- “𝜇NCA: Texture Generation With Ultra-Compact Neural Cellular Automata”, Mordvintsev & Niklasson 2021
- “Prune Once for All: Sparse Pre-Trained Language Models”, Zafrir et al 2021
- “8-Bit Optimizers via Block-Wise Quantization”, Dettmers et al 2021
- “Understanding and Overcoming the Challenges of Efficient Transformer Quantization”, Bondarenko et al 2021
- “Quantization Backdoors to Deep Learning Commercial Frameworks”, Ma et al 2021
- “Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better”, Menghani 2021
- “A Winning Hand: Compressing Deep Networks Can Improve Out-Of-Distribution Robustness”, Diffenderfer et al 2021
- “Ten Lessons From Three Generations Shaped Google’s TPUv4i”, Jouppi et al 2021
- “High-Performance, Distributed Training of Large-Scale Deep Learning Recommendation Models (DLRMs)”, Mudigere et al 2021
- “Deep Residual Learning in Spiking Neural Networks”, Fang et al 2021
- “1-Bit Adam: Communication Efficient Large-Scale Training With Adam’s Convergence Speed”, Tang et al 2021
- “ES-ENAS: Blackbox Optimization over Hybrid Spaces via Combinatorial and Continuous Evolution”, Song et al 2021
- “Switch Transformers: Scaling to Trillion Parameter Models With Simple and Efficient Sparsity”, Fedus et al 2021
- “A Primer in BERTology: What We Know about How BERT Works”, Rogers et al 2020
- “RegDeepDanbooru: Yet Another Deep Danbooru Project”, zyddnys 2020
- “TernaryBERT: Distillation-Aware Ultra-Low Bit BERT”, Zhang et al 2020
- “HOBFLOPS CNNs: Hardware Optimized Bitslice-Parallel Floating-Point Operations for Convolutional Neural Networks”, Garland & Gregg 2020
- “Bayesian Bits: Unifying Quantization and Pruning”, Baalen et al 2020
- “General Purpose Text Embeddings from Pre-Trained Language Models for Scalable Inference”, Du et al 2020
- “Lite Transformer With Long-Short Range Attention”, Wu et al 2020
- “Training With Quantization Noise for Extreme Model Compression”, Fan et al 2020
- “Moniqua: Modulo Quantized Communication in Decentralized SGD”, Lu & Sa 2020
- “Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers”, Li et al 2020
- “L2L: Training Large Neural Networks With Constant Memory Using a New Execution Algorithm”, Pudipeddi et al 2020
- “SWAT: Sparse Weight Activation Training”, Raihan & Aamodt 2020
- “QUARL: Quantized Reinforcement Learning (ActorQ)”, Lam et al 2019
- “SCaNN: Accelerating Large-Scale Inference With Anisotropic Vector Quantization”, Guo et al 2019
- “And the Bit Goes Down: Revisiting the Quantization of Neural Networks”, Stock et al 2019
- “Surrogate Gradient Learning in Spiking Neural Networks”, Neftci et al 2019
- “Rethinking Floating Point for Deep Learning”, Johnson 2018
- “Learning Recurrent Binary/Ternary Weights”, Ardakani et al 2018
- “Rethinking Numerical Representations for Deep Neural Networks”, Hill et al 2018
- “Highly Scalable Deep Learning Training System With Mixed-Precision: Training ImageNet in 4 Minutes”, Jia et al 2018
- “Quantization Mimic: Towards Very Tiny CNN for Object Detection”, Wei et al 2018
- “Training ImageNet in 3 Hours for $25; and CIFAR-10 for $0.26”, Howard 2018
- “High-Accuracy Low-Precision Training”, Sa et al 2018
- “Training Wide Residual Networks for Deployment Using a Single Bit for Each Weight”, McDonnell 2018
- “Universal Deep Neural Network Compression”, Choi et al 2018
- “Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training”, Lin et al 2017
- “Shift: A Zero FLOP, Zero Parameter Alternative to Spatial Convolutions”, Wu et al 2017
- “Training Simplification and Model Simplification for Deep Learning: A Minimal Effort Back Propagation Method”, Sun et al 2017
- “Compressing Word Embeddings via Deep Compositional Code Learning”, Shu & Nakayama 2017
- “Learning Discrete Weights Using the Local Reparameterization Trick”, Shayer et al 2017
- “TensorQuant—A Simulation Toolbox for Deep Neural Network Quantization”, Loroch et al 2017
- “Mixed Precision Training”, Micikevicius et al 2017
- “BitNet: Bit-Regularized Deep Neural Networks”, Raghavan et al 2017
- “Beating Floating Point at Its Own Game: Posit Arithmetic”, Gustafson & Yonemoto 2017
- “Bolt: Accelerated Data Mining With Fast Vector Compression”, Blalock & Guttag 2017
- “Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation”, Wu et al 2016
- “Ternary Neural Networks for Resource-Efficient AI Applications”, Alemdar et al 2016
- “Deep Neural Networks Are Robust to Weight Binarization and Other Non-Linear Distortions”, Merolla et al 2016
- “Convolutional Networks for Fast, Energy-Efficient Neuromorphic Computing”, Esser et al 2016
- “XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks”, Rastegari et al 2016
- “Binarized Neural Networks: Training Deep Neural Networks With Weights and Activations Constrained to +1 or −1”, Courbariaux et al 2016
- “BinaryConnect: Training Deep Neural Networks With Binary Weights during Propagations”, Courbariaux et al 2015
- “Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation”, Bengio et al 2013
- “Efficient Supervised Learning in Networks With Binary Synapses”, Baldassi et al 2007
- “A Self-Optimizing, Non-Symmetrical Neural Net for Content Addressable Memory and Pattern Recognition”, Lapedes & Farber 1986
- “Binary Vector Embeddings Are so Cool”
- “Building a Vector Database in 2GB for 36 Million Wikipedia Passages”
- “Research Log: Monet/PEER Sparse Experts”
- “FlashAttention-3: Fast and Accurate Attention With Asynchrony and Low-Precision”
- Sort By Magic
deep-translationretro-computingstochastic-optimization evolutionary-strategies conditional-computation gradient-estimation hybrid-evolutionary algorithm-optimizationefficient-arithmetic low-bit-acceleration energy-optimization posit-computation model-scalingretrieval-acceleration dense-retrieval vector-compression efficient-inference data-miningfine-tuningscalable-inferencelow-bit-models
- Wikipedia (7)
- Miscellaneous
- Bibliography
See Also
Links
“Soulplayer-C64: A Real 25k-Parameter Transformer Running on a Commodore 64!”, gizmo64k 2026
soulplayer-c64: A real 25k-parameter transformer running on a Commodore 64!
“EGGROLL: Evolution Strategies at the Hyperscale”, Sarkar et al 2025
“1 Bit Is All We Need: Binary Normalized Neural Networks”, Cabral et al 2025
“Compiling a Differentiable Logic Gate Neural Net to C for a 1,744× Speedup”, Clayton 2025
Compiling a Differentiable Logic Gate Neural Net to C for a 1,744× speedup
“Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures”, Zhao et al 2025
Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures
“BitNet B1.58 2B4T Technical Report”, Ma et al 2025
“MVDRAM: Enabling GeMV Execution in Unmodified DRAM for Low-Bit LLM Acceleration”, Kubo et al 2025
MVDRAM: Enabling GeMV Execution in Unmodified DRAM for Low-Bit LLM Acceleration
“Compute-Optimal LLMs Provably Generalize Better With Scale”, Finzi et al 2025
“μnit Scaling: Simple and Scalable FP8 LLM Training”, Narayan et al 2025
“2:4 Sparse Llama: Smaller Models for Efficient GPU Inference”, Kurtić et al 2024
2:4 Sparse Llama: Smaller Models for Efficient GPU Inference
“Model Equality Testing: Which Model Is This API Serving?”, Gao et al 2024
“Addition Is All You Need for Energy-Efficient Language Models”, Luo & Sun 2024
Addition is All You Need for Energy-efficient Language Models
“Robust Training of Neural Networks at Arbitrary Precision and Sparsity”, Ye et al 2024
Robust Training of Neural Networks at Arbitrary Precision and Sparsity
“A Visual Guide to Quantization”, Grootendorst 2024
“OpenDiLoCo: An Open-Source Framework for Globally Distributed Low-Communication Training”, Jaghouar et al 2024
OpenDiLoCo: An Open-Source Framework for Globally Distributed Low-Communication Training
“Probing the Decision Boundaries of In-Context Learning in Large Language Models”, Zhao et al 2024
Probing the Decision Boundaries of In-context Learning in Large Language Models
“Nemotron-4 340B Technical Report”, Adler et al 2024
“Scalable Matmul-Free Language Modeling”, Zhu et al 2024
“BOLD: Boolean Logic Deep Learning”, Nguyen et al 2024
“Neural Networks (MNIST Inference) on the ‘3¢’ Microcontroller”, cpldcpu 2024
Neural Networks (MNIST inference) on the ‘3¢’ Microcontroller
“How Good Are Low-Bit Quantized LLaMA-3 Models? An Empirical Study”, Huang et al 2024
How Good Are Low-bit Quantized LLaMA-3 Models? An Empirical Study
“Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws”, Allen-Zhu & Li 2024
Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws
“LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models”, Zheng et al 2024
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
“Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression”, Hong et al 2024
Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression
“The Era of 1-Bit LLMs: All Large Language Models Are in 1.58 Bits”, Ma et al 2024
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
“FP6-LLM: Efficiently Serving Large Language Models Through FP6-Centric Algorithm-System Co-Design”, Xia et al 2024
FP6-LLM: Efficiently Serving Large Language Models Through FP6-Centric Algorithm-System Co-Design
“Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws”, Sardana & Frankle 2023
Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws
“TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones”, Yuan et al 2023
TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones
“LLM-FP4: 4-Bit Floating-Point Quantized Transformers”, Liu et al 2023
“Training Transformers With 4-Bit Integers”, Xi et al 2023
“SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression”, Dettmers et al 2023
SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression
“Binary and Ternary Natural Language Generation”, Liu et al 2023
“AWQ: Activation-Aware Weight Quantization for LLM Compression and Acceleration”, Lin et al 2023
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
“Big-PERCIVAL: Exploring the Native Use of 64-Bit Posit Arithmetic in Scientific Computing”, Mallasén et al 2023
Big-PERCIVAL: Exploring the Native Use of 64-Bit Posit Arithmetic in Scientific Computing
“Int-4 LLaMa Is Not Enough—Int-3 and Beyond: More Compression, Easier to Build Apps on LLMs That Run Locally”, nolano.org 2023
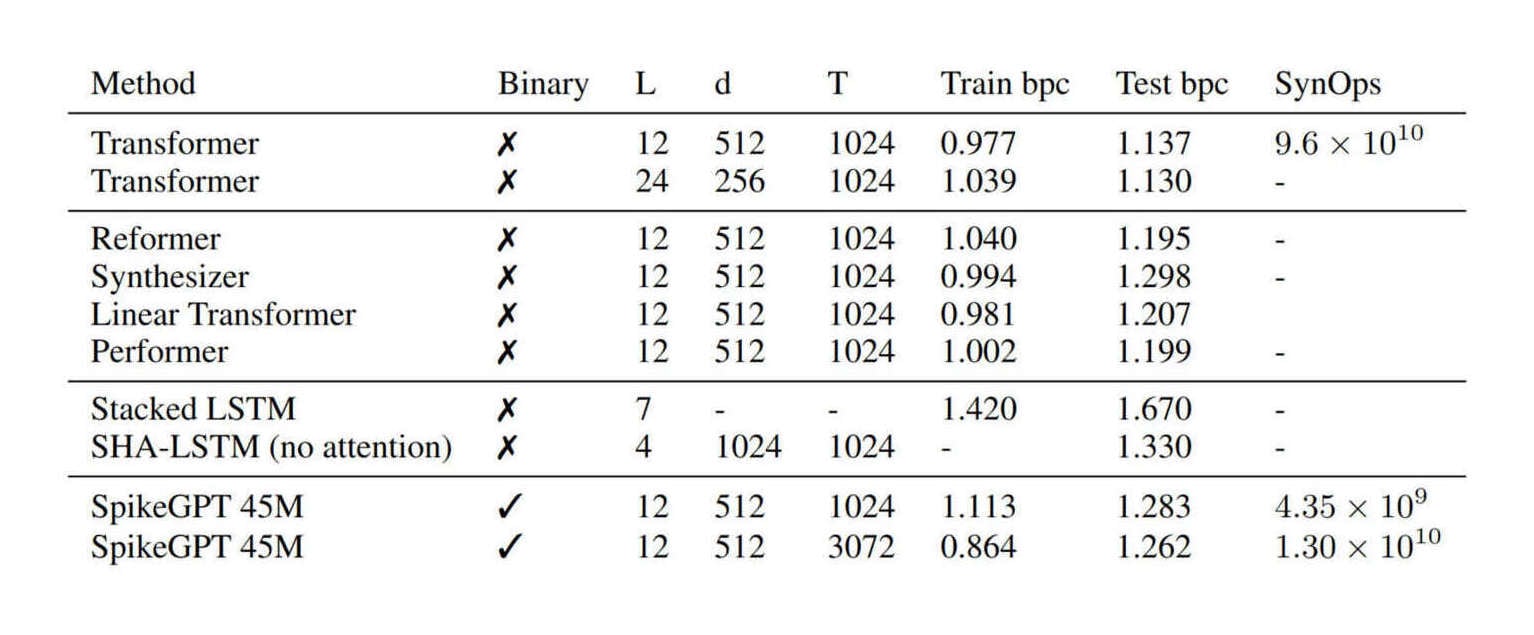
“SpikeGPT: Generative Pre-Trained Language Model With Spiking Neural Networks”, Zhu et al 2023
SpikeGPT: Generative Pre-trained Language Model with Spiking Neural Networks
“BMT: Binarized Neural Machine Translation”, Zhang et al 2023
“Self-Compressing Neural Networks”, Cséfalvay & Imber 2023
“Who Says Elephants Can’t Run: Bringing Large Scale MoE Models into Cloud Scale Production”, Kim et al 2022
Who Says Elephants Can’t Run: Bringing Large Scale MoE Models into Cloud Scale Production
“SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models”, Xiao et al 2022
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
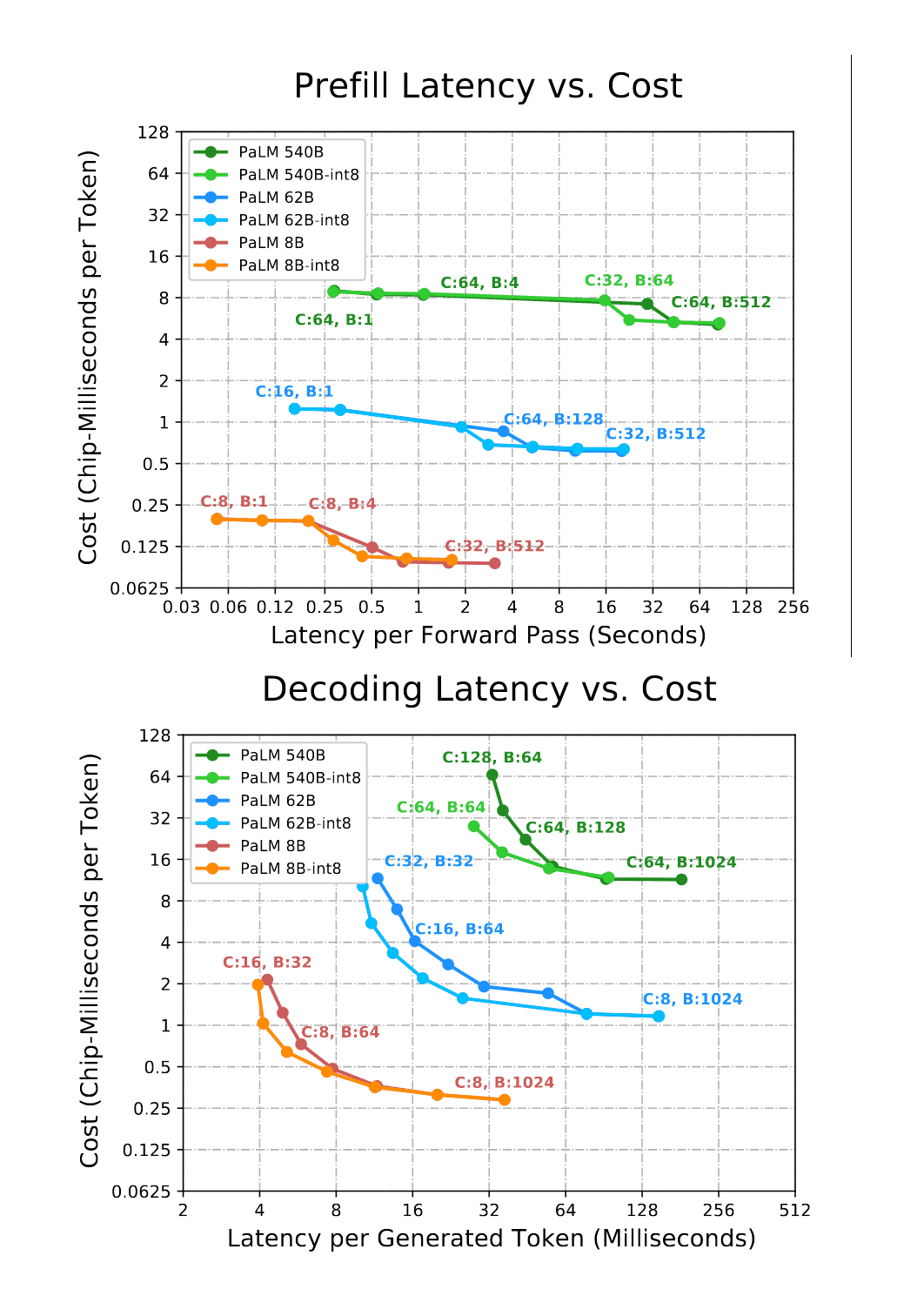
“Efficiently Scaling Transformer Inference”, Pope et al 2022
“GPTQ: Accurate Post-Training Quantization for Generative Pre-Trained Transformers”, Frantar et al 2022
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
“Fast DistilBERT on CPUs”, Shen et al 2022
“Broken Neural Scaling Laws”, Caballero et al 2022
“GLM-130B: An Open Bilingual Pre-Trained Model”, Zeng et al 2022
“FP8 Formats for Deep Learning”, Micikevicius et al 2022
“LLM.int8(): 8-Bit Matrix Multiplication for Transformers at Scale”, Dettmers et al 2022
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
“Is Integer Arithmetic Enough for Deep Learning Training?”, Ghaffari et al 2022
“On-Device Training Under 256KB Memory”, Lin et al 2022
“How to Train Accurate BNNs for Embedded Systems?”, Putter & Corporaal 2022
“Director: Deep Hierarchical Planning from Pixels”, Hafner et al 2022
“8-Bit Numerical Formats for Deep Neural Networks”, Noune et al 2022
“XTC: Extreme Compression for Pre-Trained Transformers Made Simple and Efficient”, Wu et al 2022
XTC: Extreme Compression for Pre-trained Transformers Made Simple and Efficient
“ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers”, Yao et al 2022
ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers
“Matryoshka Representations for Adaptive Deployment”, Kusupati et al 2022
“PLAID: An Efficient Engine for Late Interaction Retrieval”, Santhanam et al 2022
“Maximizing Communication Efficiency for Large-Scale Training via 0/1 Adam”, Lu et al 2022
Maximizing Communication Efficiency for Large-scale Training via 0/1 Adam
“Is Programmable Overhead Worth The Cost? How Much Do We Pay for a System to Be Programmable? It Depends upon Who You Ask”, Bailey 2022
“Boosted Dense Retriever”, Lewis et al 2021
“FQ-ViT: Fully Quantized Vision Transformer without Retraining”, Lin et al 2021
FQ-ViT: Fully Quantized Vision Transformer without Retraining
“𝜇NCA: Texture Generation With Ultra-Compact Neural Cellular Automata”, Mordvintsev & Niklasson 2021
𝜇NCA: Texture Generation with Ultra-Compact Neural Cellular Automata
“Prune Once for All: Sparse Pre-Trained Language Models”, Zafrir et al 2021
“8-Bit Optimizers via Block-Wise Quantization”, Dettmers et al 2021
“Understanding and Overcoming the Challenges of Efficient Transformer Quantization”, Bondarenko et al 2021
Understanding and Overcoming the Challenges of Efficient Transformer Quantization
“Quantization Backdoors to Deep Learning Commercial Frameworks”, Ma et al 2021
Quantization Backdoors to Deep Learning Commercial Frameworks
“Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better”, Menghani 2021
Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better
“A Winning Hand: Compressing Deep Networks Can Improve Out-Of-Distribution Robustness”, Diffenderfer et al 2021
A Winning Hand: Compressing Deep Networks Can Improve Out-Of-Distribution Robustness
“Ten Lessons From Three Generations Shaped Google’s TPUv4i”, Jouppi et al 2021
“High-Performance, Distributed Training of Large-Scale Deep Learning Recommendation Models (DLRMs)”, Mudigere et al 2021
High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models (DLRMs)
“Deep Residual Learning in Spiking Neural Networks”, Fang et al 2021
“1-Bit Adam: Communication Efficient Large-Scale Training With Adam’s Convergence Speed”, Tang et al 2021
1-bit Adam: Communication Efficient Large-Scale Training with Adam’s Convergence Speed
“ES-ENAS: Blackbox Optimization over Hybrid Spaces via Combinatorial and Continuous Evolution”, Song et al 2021
ES-ENAS: Blackbox Optimization over Hybrid Spaces via Combinatorial and Continuous Evolution
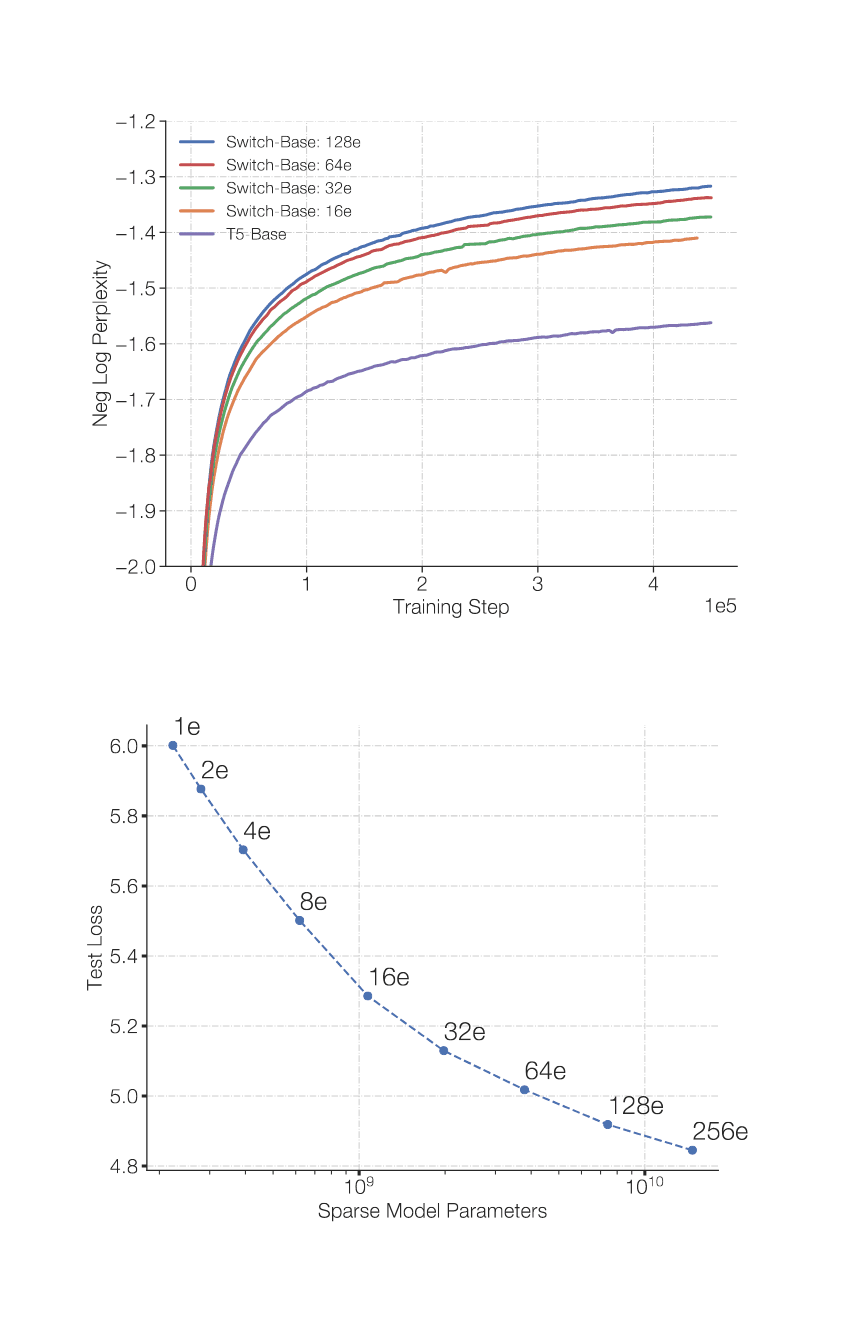
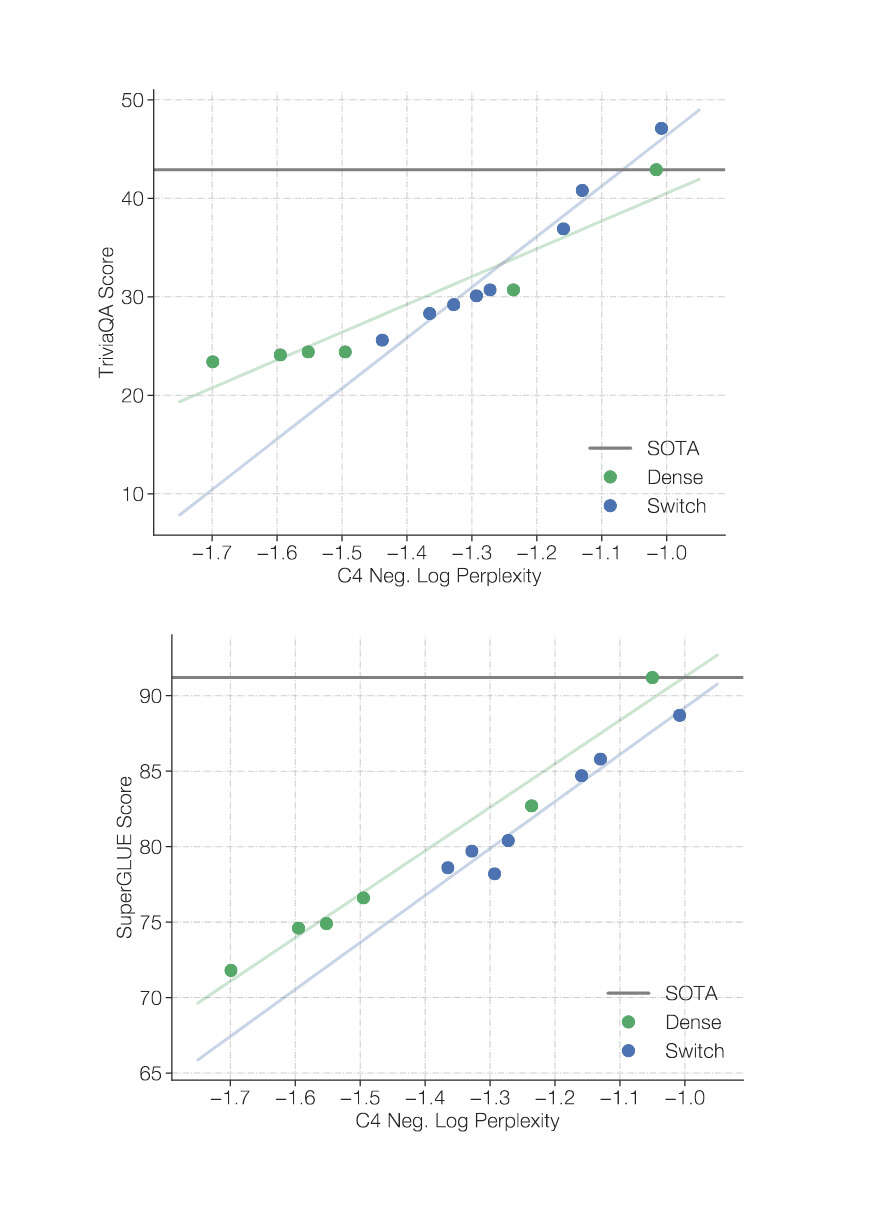
“Switch Transformers: Scaling to Trillion Parameter Models With Simple and Efficient Sparsity”, Fedus et al 2021
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
“A Primer in BERTology: What We Know about How BERT Works”, Rogers et al 2020
“RegDeepDanbooru: Yet Another Deep Danbooru Project”, zyddnys 2020
“TernaryBERT: Distillation-Aware Ultra-Low Bit BERT”, Zhang et al 2020
“HOBFLOPS CNNs: Hardware Optimized Bitslice-Parallel Floating-Point Operations for Convolutional Neural Networks”, Garland & Gregg 2020
“Bayesian Bits: Unifying Quantization and Pruning”, Baalen et al 2020
“General Purpose Text Embeddings from Pre-Trained Language Models for Scalable Inference”, Du et al 2020
General Purpose Text Embeddings from Pre-trained Language Models for Scalable Inference
“Lite Transformer With Long-Short Range Attention”, Wu et al 2020
“Training With Quantization Noise for Extreme Model Compression”, Fan et al 2020
Training with Quantization Noise for Extreme Model Compression
“Moniqua: Modulo Quantized Communication in Decentralized SGD”, Lu & Sa 2020
Moniqua: Modulo Quantized Communication in Decentralized SGD
“Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers”, Li et al 2020
“L2L: Training Large Neural Networks With Constant Memory Using a New Execution Algorithm”, Pudipeddi et al 2020
L2L: Training Large Neural Networks with Constant Memory using a New Execution Algorithm
“SWAT: Sparse Weight Activation Training”, Raihan & Aamodt 2020
“QUARL: Quantized Reinforcement Learning (ActorQ)”, Lam et al 2019
“SCaNN: Accelerating Large-Scale Inference With Anisotropic Vector Quantization”, Guo et al 2019
SCaNN: Accelerating Large-Scale Inference with Anisotropic Vector Quantization
“And the Bit Goes Down: Revisiting the Quantization of Neural Networks”, Stock et al 2019
And the Bit Goes Down: Revisiting the Quantization of Neural Networks
“Surrogate Gradient Learning in Spiking Neural Networks”, Neftci et al 2019
“Rethinking Floating Point for Deep Learning”, Johnson 2018
“Learning Recurrent Binary/Ternary Weights”, Ardakani et al 2018
“Rethinking Numerical Representations for Deep Neural Networks”, Hill et al 2018
Rethinking Numerical Representations for Deep Neural Networks
“Highly Scalable Deep Learning Training System With Mixed-Precision: Training ImageNet in 4 Minutes”, Jia et al 2018
Highly Scalable Deep Learning Training System with Mixed-Precision: Training ImageNet in 4 Minutes
“Quantization Mimic: Towards Very Tiny CNN for Object Detection”, Wei et al 2018
Quantization Mimic: Towards Very Tiny CNN for Object Detection
“Training ImageNet in 3 Hours for $25; and CIFAR-10 for $0.26”, Howard 2018
Training ImageNet in 3 hours for $25; and CIFAR-10 for $0.26
“High-Accuracy Low-Precision Training”, Sa et al 2018
“Training Wide Residual Networks for Deployment Using a Single Bit for Each Weight”, McDonnell 2018
Training wide residual networks for deployment using a single bit for each weight
“Universal Deep Neural Network Compression”, Choi et al 2018
“Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training”, Lin et al 2017
Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training
“Shift: A Zero FLOP, Zero Parameter Alternative to Spatial Convolutions”, Wu et al 2017
Shift: A Zero FLOP, Zero Parameter Alternative to Spatial Convolutions
“Training Simplification and Model Simplification for Deep Learning: A Minimal Effort Back Propagation Method”, Sun et al 2017
“Compressing Word Embeddings via Deep Compositional Code Learning”, Shu & Nakayama 2017
Compressing Word Embeddings via Deep Compositional Code Learning
“Learning Discrete Weights Using the Local Reparameterization Trick”, Shayer et al 2017
Learning Discrete Weights Using the Local Reparameterization Trick
“TensorQuant—A Simulation Toolbox for Deep Neural Network Quantization”, Loroch et al 2017
TensorQuant—A Simulation Toolbox for Deep Neural Network Quantization
“Mixed Precision Training”, Micikevicius et al 2017
“BitNet: Bit-Regularized Deep Neural Networks”, Raghavan et al 2017
“Beating Floating Point at Its Own Game: Posit Arithmetic”, Gustafson & Yonemoto 2017
“Bolt: Accelerated Data Mining With Fast Vector Compression”, Blalock & Guttag 2017
“Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation”, Wu et al 2016
Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
“Ternary Neural Networks for Resource-Efficient AI Applications”, Alemdar et al 2016
Ternary Neural Networks for Resource-Efficient AI Applications
“Deep Neural Networks Are Robust to Weight Binarization and Other Non-Linear Distortions”, Merolla et al 2016
Deep neural networks are robust to weight binarization and other non-linear distortions
“Convolutional Networks for Fast, Energy-Efficient Neuromorphic Computing”, Esser et al 2016
Convolutional Networks for Fast, Energy-Efficient Neuromorphic Computing
“XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks”, Rastegari et al 2016
XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks
“Binarized Neural Networks: Training Deep Neural Networks With Weights and Activations Constrained to +1 or −1”, Courbariaux et al 2016
“BinaryConnect: Training Deep Neural Networks With Binary Weights during Propagations”, Courbariaux et al 2015
BinaryConnect: Training Deep Neural Networks with binary weights during propagations
“Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation”, Bengio et al 2013
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
“Efficient Supervised Learning in Networks With Binary Synapses”, Baldassi et al 2007
Efficient supervised learning in networks with binary synapses
“A Self-Optimizing, Non-Symmetrical Neural Net for Content Addressable Memory and Pattern Recognition”, Lapedes & Farber 1986
A self-optimizing, non-symmetrical neural net for content addressable memory and pattern recognition
“Binary Vector Embeddings Are so Cool”
“Building a Vector Database in 2GB for 36 Million Wikipedia Passages”
Building a vector database in 2GB for 36 million Wikipedia passages
“Research Log: Monet/PEER Sparse Experts”
“FlashAttention-3: Fast and Accurate Attention With Asynchrony and Low-Precision”
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
deep-translation
retro-computing
stochastic-optimization evolutionary-strategies conditional-computation gradient-estimation hybrid-evolutionary algorithm-optimization
efficient-arithmetic low-bit-acceleration energy-optimization posit-computation model-scaling
retrieval-acceleration dense-retrieval vector-compression efficient-inference data-mining
fine-tuning
scalable-inference
low-bit-models
Wikipedia (7)
Miscellaneous
/doc/ai/nn/sparsity/low-precision/2021-fedus-figure1-switchmoetransformerscaling.pnghttps://blog.pgvecto.rs/my-binary-vector-search-is-better-than-your-fp32-vectorshttps://github.com/THUDM/GLM-130B/blob/main/doc/quantization.mdhttps://github.com/vitoplantamura/OnnxStream/tree/846da873570a737b49154e8f835704264864b0fehttps://itnext.io/shrinking-a-language-detection-model-to-under-10-kb-b729bc25fd28https://observablehq.com/@rreusser/half-precision-floating-point-visualizedhttps://www.reddit.com/r/LocalLLaMA/comments/1gsyp7q/humaneval_benchmark_of_exl2_quants_of_popular/https://www.reddit.com/r/mlscaling/comments/146rgq2/chatgpt_is_running_quantized/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2511.16652: “EGGROLL: Evolution Strategies at the Hyperscale”,https://arxiv.org/abs/2505.09343#deepseek: “Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures”,https://arxiv.org/abs/2406.11233: “Probing the Decision Boundaries of In-Context Learning in Large Language Models”,https://arxiv.org/abs/2404.14047: “How Good Are Low-Bit Quantized LLaMA-3 Models? An Empirical Study”,https://arxiv.org/abs/2401.14112#microsoft: “FP6-LLM: Efficiently Serving Large Language Models Through FP6-Centric Algorithm-System Co-Design”,https://arxiv.org/abs/2312.16862: “TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones”,https://arxiv.org/abs/2310.16836: “LLM-FP4: 4-Bit Floating-Point Quantized Transformers”,https://arxiv.org/abs/2305.06946: “Big-PERCIVAL: Exploring the Native Use of 64-Bit Posit Arithmetic in Scientific Computing”,https://nolanoorg.substack.com/p/int-4-llama-is-not-enough-int-3-and: “Int-4 LLaMa Is Not Enough—Int-3 and Beyond: More Compression, Easier to Build Apps on LLMs That Run Locally”,https://arxiv.org/abs/2302.13939: “SpikeGPT: Generative Pre-Trained Language Model With Spiking Neural Networks”,https://arxiv.org/abs/2211.10438: “SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models”,https://arxiv.org/abs/2211.05102#google: “Efficiently Scaling Transformer Inference”,https://arxiv.org/abs/2210.17323: “GPTQ: Accurate Post-Training Quantization for Generative Pre-Trained Transformers”,https://arxiv.org/abs/2210.02414#baai: “GLM-130B: An Open Bilingual Pre-Trained Model”,https://arxiv.org/abs/2206.15472: “On-Device Training Under 256KB Memory”,https://arxiv.org/abs/2206.04114#google: “Director: Deep Hierarchical Planning from Pixels”,https://arxiv.org/abs/2206.01859#microsoft: “XTC: Extreme Compression for Pre-Trained Transformers Made Simple and Efficient”,https://arxiv.org/abs/2206.01861#microsoft: “ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers”,https://arxiv.org/abs/2205.13147: “Matryoshka Representations for Adaptive Deployment”,https://arxiv.org/abs/2202.06009#microsoft: “Maximizing Communication Efficiency for Large-Scale Training via 0/1 Adam”,https://semiengineering.com/is-programmable-overhead-worth-the-cost/: “Is Programmable Overhead Worth The Cost? How Much Do We Pay for a System to Be Programmable? It Depends upon Who You Ask”,https://arxiv.org/abs/2111.13824: “FQ-ViT: Fully Quantized Vision Transformer without Retraining”,https://arxiv.org/abs/2111.05754: “Prune Once for All: Sparse Pre-Trained Language Models”,https://arxiv.org/abs/2110.02861: “8-Bit Optimizers via Block-Wise Quantization”,https://arxiv.org/abs/2109.12948: “Understanding and Overcoming the Challenges of Efficient Transformer Quantization”,2021-jouppi.pdf: “Ten Lessons From Three Generations Shaped Google’s TPUv4i”,https://arxiv.org/abs/2102.04159: “Deep Residual Learning in Spiking Neural Networks”,https://arxiv.org/abs/2102.02888#microsoft: “1-Bit Adam: Communication Efficient Large-Scale Training With Adam’s Convergence Speed”,https://arxiv.org/abs/2101.03961#google: “Switch Transformers: Scaling to Trillion Parameter Models With Simple and Efficient Sparsity”,https://arxiv.org/abs/2004.07320#facebook: “Training With Quantization Noise for Extreme Model Compression”,https://arxiv.org/abs/2001.01969: “SWAT: Sparse Weight Activation Training”,https://arxiv.org/abs/1910.01055#google: “QUARL: Quantized Reinforcement Learning (ActorQ)”,https://www.fast.ai/2018/04/30/dawnbench-fastai/: “Training ImageNet in 3 Hours for $25; and CIFAR-10 for $0.26”,https://arxiv.org/abs/1802.08530: “Training Wide Residual Networks for Deployment Using a Single Bit for Each Weight”,https://arxiv.org/abs/1712.01887: “Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training”,https://arxiv.org/abs/1711.08141: “Shift: A Zero FLOP, Zero Parameter Alternative to Spatial Convolutions”,https://arxiv.org/abs/1603.05279: “XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks”,